
An L2 Cache Architecture Supporting Bypassing for Low Energy and High Performance



Abstract
:1. Introduction
2. Related Work
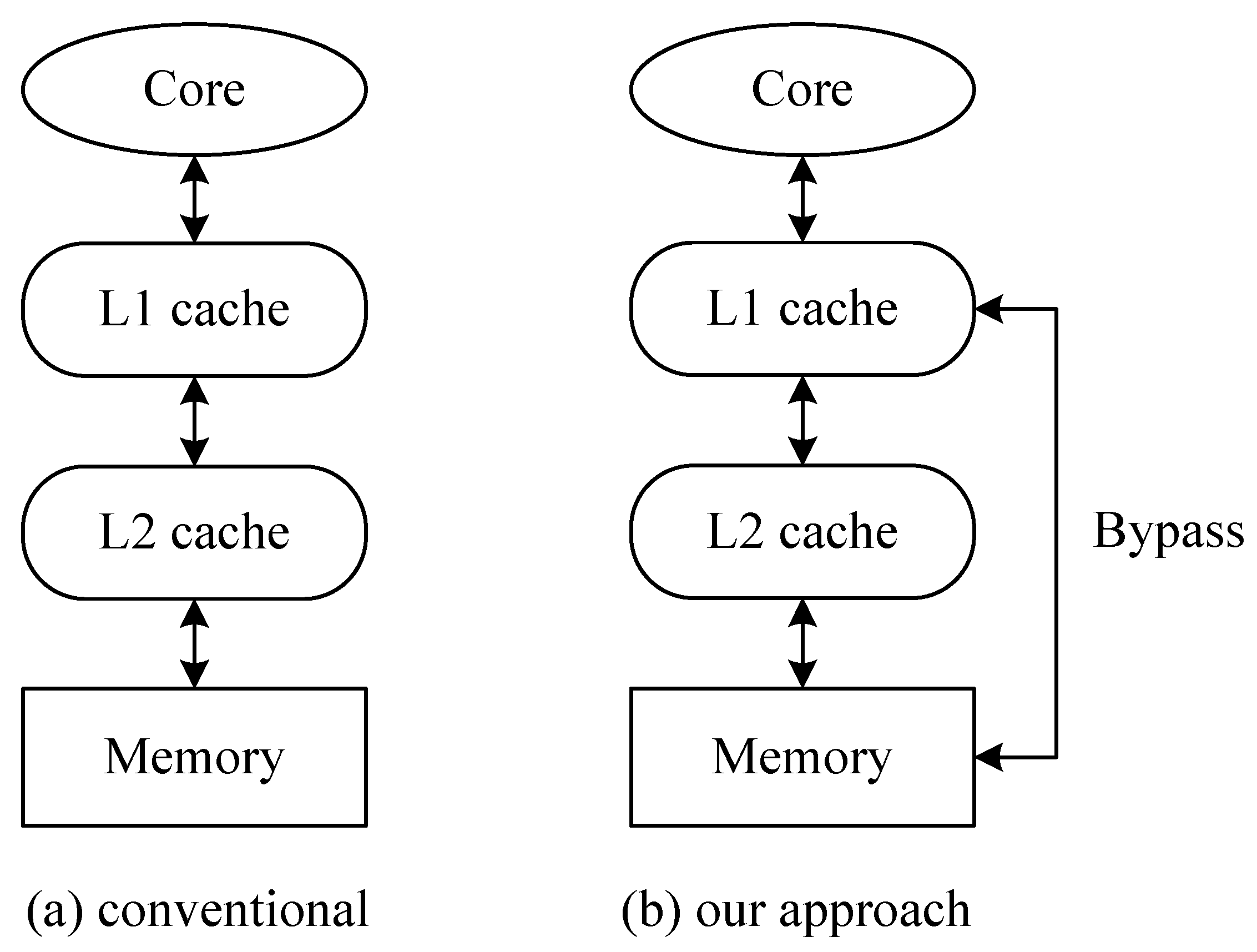
3. Proposed L2 Cache Bypassing
3.1. Bypassing
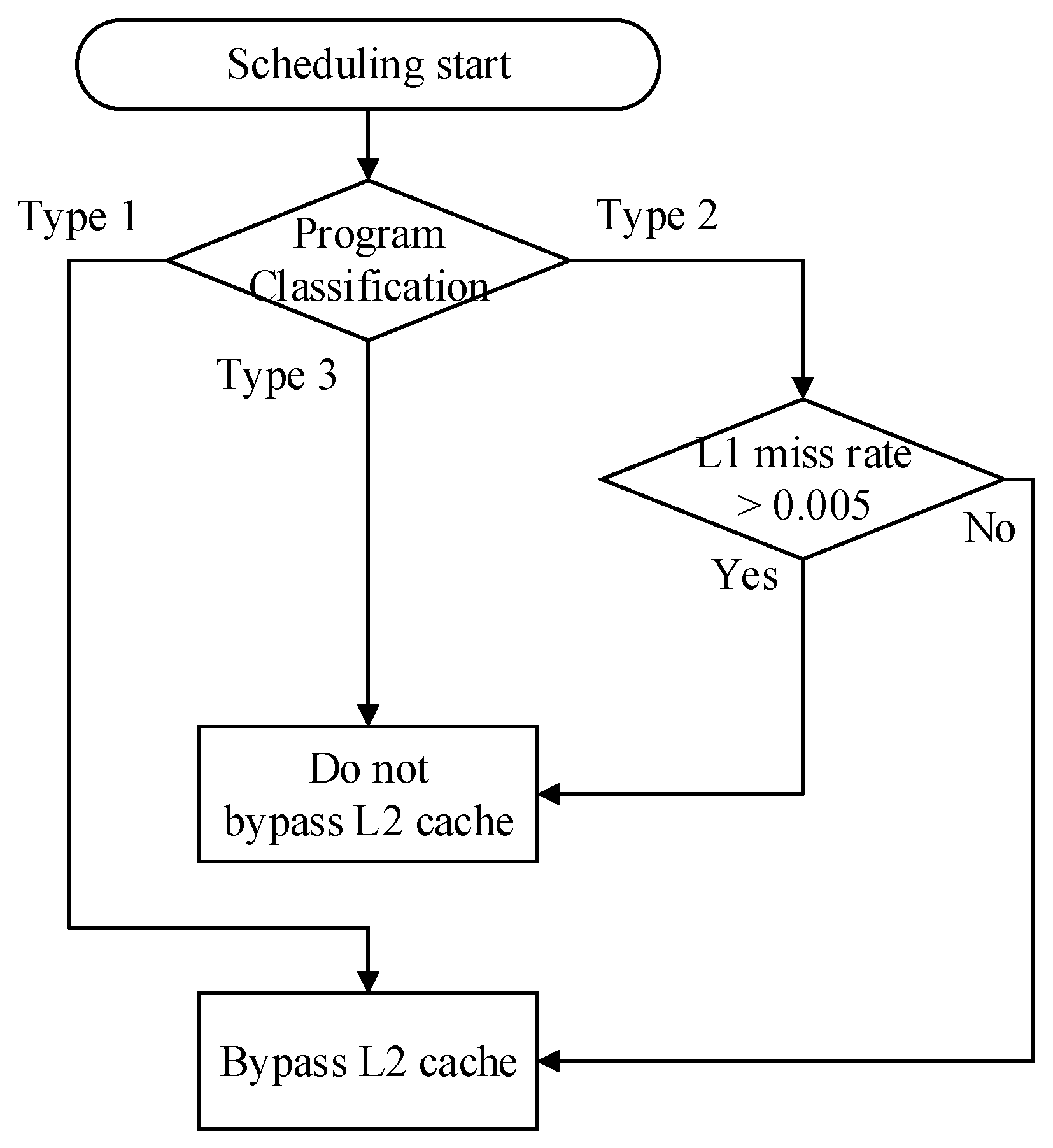
3.2. Program Classification
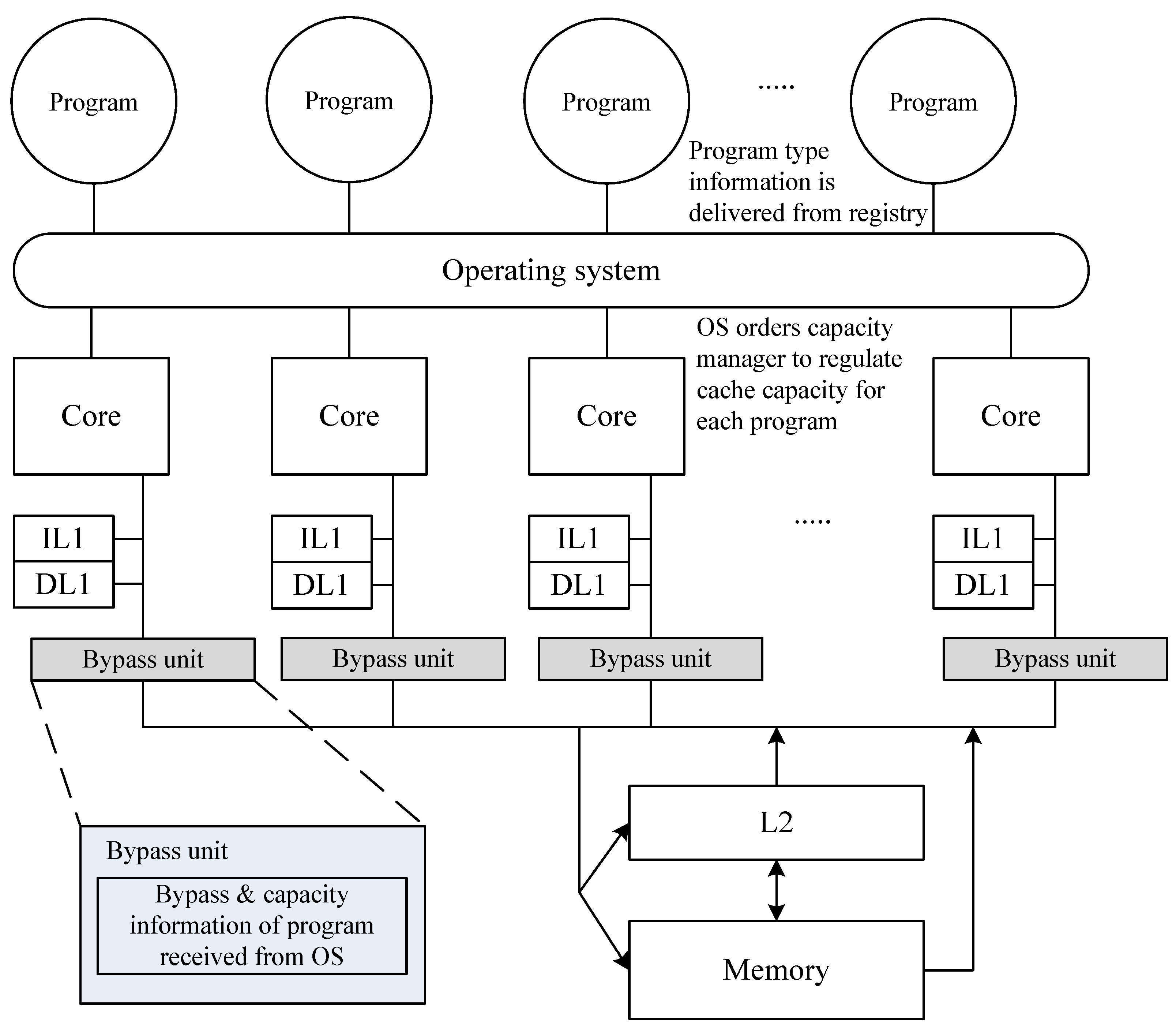
3.3. Proposed Cache Architecture
3.4. Multicore Scheduling
4. Experimental Methodology
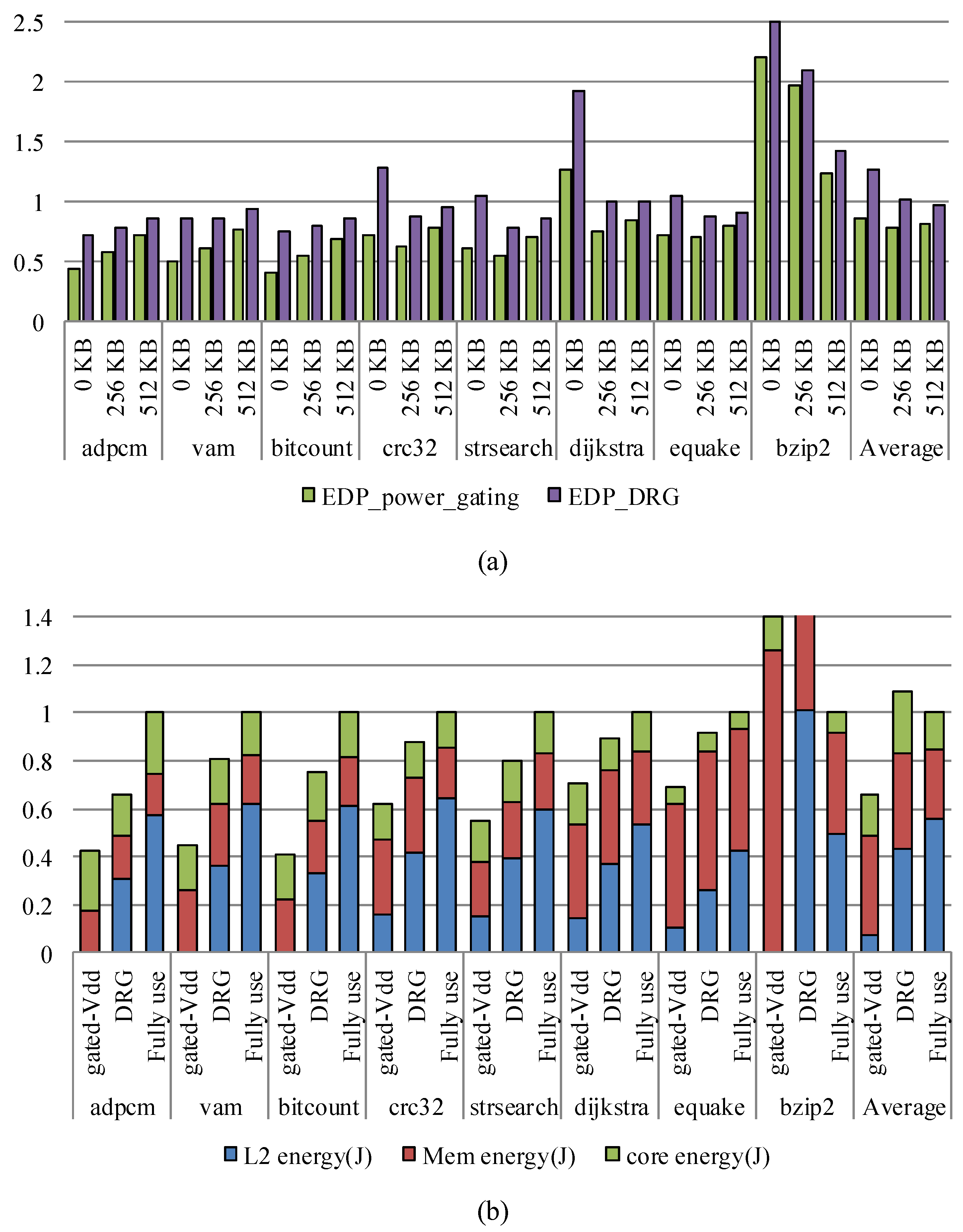
5. Results and Analysis
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Powell, M.; Yang, S.-H.; Falsafi, B.; Roy, K.; Vijaykumar, T.N. Gated-Vdd: A circuit technique to reduce leakage in deep-submicron cache memories. In Proceedings of the 2000 International Symposium on Low Power Electronics and Design, Rapallo, Italy, 25–27 July 2000. [Google Scholar]
- Agarwal, A.; Li, H.; Roy, K. Drg-Cache: A Data Retention Gated-Ground Cache for Low Power. In Proceedings of the 2002 Design Automation Conference (IEEE Cat. No.02CH37324), New Orleans, LA, USA, 10–14 June 2002. [Google Scholar]
- Lee, S.; Lee, J.Y.; Cho, J.; Lee, H.-J.; Cho, D.; Heo, J.; Cho, S.; Shin, Y.; Yun, S.; Kim, E.; et al. A 32 nm High-k Metal Gate Application Processor with GHz Multi-CORE CPU. In Proceedings of the 2012 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 19–23 February 2012. [Google Scholar]
- Loh, G.H.; Subramaniam, S.; Xie, Y. Zesto: A cycle-level simulator for highly detailed microarchitecture exploration. In Proceedings of the 2009 IEEE International Symposium on Performance Analysis of Systems and Software, Boston, MA, USA, 26–28 April 2009. [Google Scholar]
- Guthaus, M.R.; Ringenberg, J.S.; Ernst, D.; Austin, T.M.; Mudge, T.; Brown, R.B. Mibench: A Free, Commercially Representative Embedded Benchmark Suite. In Proceedings of the Fourth Annual IEEE International Workshop on Workload Characterization. WWC-4 (Cat. No.01EX538), Austin, TX, USA, 2 December 2001. [Google Scholar]
- Csibe: Gcc Code-Size Benchmark Environment. Available online: http://www.inf.u-szeged.hu/csibe/ (accessed on 31 May 2021).
- Spec cpu2000. Available online: http://www.spec.org/cpu2000/ (accessed on 31 May 2021).
- Abella, J.; Gonzalez, A.; Vera, X.; O’Boyle, M.F.P. Iatac: A Smart Predictor to Turn-off l2 Cache Lines. Acm Trans. Archit. Code Optim. (TACO) 2005, 2, 55–77. [Google Scholar] [CrossRef]
- Kaxiras, S.; Hu, Z.; Martonosi, M. Cache Decay: Exploiting Generational Behavior to Reduce Cache Leakage Power. In Proceedings of the 28th Annual International Symposium on Computer Architecture, Gothenburg, Sweden, 30 June–4 July 2001. [Google Scholar]
- Sato, M.; Egawa, R.; Takizawa, H.; Kobayasi, H. A voting-based working set assessment scheme for dynamic cache resizing mechanisms. In Proceedings of the 2010 IEEE International Conference on Computer Design, Amsterdam, The Netherlands, 3–6 October 2010. [Google Scholar]
- Flautner, K.; Kim, N.S.; Martin, S.; Blaauw, D.; Mudge, T. Drowsy Caches: Simple Techniques for Reducing Leakage Power. ACM Sigarch Comput. Archit. News 2002, 30, 148–157. [Google Scholar] [CrossRef]
- Liu, H.; Ferdman, M.; Huh, J.; Burger, D. Cache Bursts: A New Approach for Eliminating Dead Blocks and Increasing Cache Efficiency. In Proceedings of the 2008 41st IEEE/ACM International Symposium on Microarchitecture, Como, Italy, 8–12 November 2008. [Google Scholar]
- Kim, S.; Vijaykrishnan, N.; Irwin, J.; John, L.K. On Load Latency in Low-Power Caches. In Proceedings of the 2003 International Symposium on Low Power Electronics and Design, Seoul, Korea, 25–27 August 2003. [Google Scholar]
- Albonesi, D.H. Selective Cache Ways: On-Demand Cache Resource Allocation. In Proceedings of the 32nd Annual ACM/IEEE International Symposium on Microarchitecture, Haifa, Israel, 16–18 November 1999. [Google Scholar]
- Wang, W.; Mishra, P.; Ranka, S. Dynamic cache reconfiguration and partitioning for energy optimization in real-time multi-core systems. In Proceedings of the 2011 48th ACM/EDAC/IEEE Design Automation Conference (DAC), San Diego, CA, USA, 5–9 June 2011. [Google Scholar]
- Fu, X.; Kabir, K.; Wang, X. Cache-Aware Utilization Control for Energy Efficiency in Multi-Core Real-Time Systems. In Proceedings of the 2011 23rd Euromicro Conference on Real-Time Systems, Porto, Portugal, 5–8 July 2011. [Google Scholar]
- Hardy, D.; Piquet, T.; Puaut, I. Using Bypass to Tighten WCET Estimates for Multi-Core Processors with Shared Instruction Caches. In Proceedings of the 2009 30th IEEE Real-Time Systems Symposium, Washington, DC, USA, 1–4 December 2009. [Google Scholar]
- Kgil, T.; Saidi, A.; Binkert, N.; Reinhardt, S.; Flautner, K.; Mudge, T. Picoserver: Using 3D Stacking Technology to Build Energy Efficient Servers. ACM J. Emerg. Technol. Comput. Syst. JETC 2008, 4, 1–34. [Google Scholar] [CrossRef]
- Tandon, P.; Chang, J.; Dreslinski, R.G.; Ranganathan, P.; Mudge, T.; Wenisch, T.F. Picoserver Revisited: On the Profitability of Eliminating Intermediate Cache Levels. WDDD, June 2012. Available online: https://web.eecs.umich.edu/~twenisch/papers/wddd12.pdf (accessed on 31 May 2021).
- Bao, P.; Pierce, J.; Whittaker, S.; Zhai, S. Smart Phone Use by Non-Mobile Business Users. In Proceedings of the 13th International Conference on Human Computer Interaction with Mobile Devices and Services, Stockholm, Sweden, 30 August—2 September 2011. [Google Scholar]
- 7-Zip LZMA Benchmark. Available online: http://www.7-cpu.com/cpu/Cortex-A9.html (accessed on 31 May 2021).
- The gem5 Simulator System: A Modular Platform for Computer System Architecture Research. Available online: http://www.m5sim.org/Main_Page (accessed on 31 May 2021).
- Li, S.; Ahn, J.H.; Strong, R.D.; Brockman, J.B.; Tullsen, D.M.; Jouppi, N.P. Mcpat: An Integrated Power, Area, and Timing Modeling Framework for Multi-Core and Manycore Architectures. In Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, New York, NY, USA, 12–16 December 2009. [Google Scholar]
- Kanev, S.; Wei, G.-Y.; Brooks, D. Xiosim: Power-Performance Modeling of Mobile x86 Cores. In Proceedings of the 2012 ACM/IEEE International Symposium on Low Power Electronics and Design, Redondo Beach, CA, USA, 30 July–1 August 2012. [Google Scholar]
- Muralimanohar, N. Cacti 6.0: A Tool to Model Large Caches; HP Laboratories: Palo Alto, CA, USA, 2009; pp. 1–24. [Google Scholar]
- Rosenfeld, P.; Cooper-Balis, E.; Jacob, B. Dramsim2: A cycle accurate memory system simulator. Comput. Archit. Lett. 2011, 10, 16–19. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Core | 3-Way out of Order, 1 GHz |
|---|---|
| L1 I-cache | 32 KB, 64 bytes per line, |
| 2-way associativity, 2 cycles | |
| L1 D-cache | 32 KB, 64 bytes per line, |
| 8-way associativity, 3 cycles | |
| Unified L2 cache | 1 MB, 64 bytes per line, |
| 16-way associativity, 12 cycles | |
| Main memory | 1 GB x16 DDR3-667 |
| L2 Usage | Time | Data Request per ins. | L1 Miss Rate | Global Miss Rate | L2 Energy | Memory Energy | Core Energy | Total Energy | |
|---|---|---|---|---|---|---|---|---|---|
| adpcm (type 1) | Bypass | 1.00 | 0.40 | 0.00% | 0.00% | 0.00 | 87.58 | 125.61 | 213.19 |
| 256 KB | 1.00 | 0.00% | 70.65 | 87.63 | 125.61 | 283.90 | |||
| 512 KB | 1.00 | 0.00% | 141.29 | 87.63 | 125.61 | 354.53 | |||
| 1024 KB | 1 | 0.00% | 284.62 | 87.63 | 125.61 | 497.86 | |||
| dijkstra (type 2) | Bypass | 1.55 | 0.38 | 1.27% | 1.27% | 0.00 | 8.49 | 3.69 | 12.18 |
| 256 KB | 1.07 | 0.09% | 2.11 | 5.86 | 2.54 | 10.52 | |||
| 512 KB | 1.05 | 0.09% | 4.14 | 5.43 | 2.49 | 12.05 | |||
| 1024 KB | 1 | 0.09% | 7.97 | 4.63 | 2.38 | 14.98 | |||
| bzip2 (type 3) | Bypass | 2.48 | 0.97 | 0.79% | 0.79% | 0.00 | 211.84 | 22.83 | 234.67 |
| 256 KB | 1.59 | 0.41% | 21.77 | 101.81 | 14.68 | 138.26 | |||
| 512 KB | 1.22 | 0.24% | 33.47 | 68.98 | 11.26 | 113.71 | |||
| 1024 KB | 1 | 0.14% | 55.34 | 47.67 | 9.21 | 112.24 |
| Benchmark Combinations | Bench. L2 Cache Using | HM IPC | MEM acc. | Core en. | L2$ en. | Core 0 Progress | Core 1 Progress | Core 2 Progress | Core 3 Progress |
|---|---|---|---|---|---|---|---|---|---|
| bzip2 & bitcount | bzip2 | ||||||||
| bzip2 adpcm | bzip2 | ||||||||
| mcf & bitcount | mcf | 1.12 | 1.18 | 1.01 | 1.02 | 1.15 | 1 | ||
| mcf & adpcm | mcf | 1.13 | 1.14 | 1 | 1 | 1.14 | 1 | ||
| bzip2 & adpcm & dijkstra | bzip2 | 0.98 | 1 | 1 | 1 | 0.93 | 1.84 | 0.46 | |
| bzip2 & adpcm | 1 | 1 | 1 | 1 | 0.93 | 1.84 | 0.48 | ||
| bzip2 & dijkstra | 1.28 | 0.7 | 1.09 | 1 | 1.05 | 1.91 | 0.98 | ||
| adpcm & bitcount & equake & crc32 | equake | 1.31 | 0.56 | 1.02 | 1.01 | 1 | 0.95 | 1.74 | 0.99 |
| adpcm & equake | 1.31 | 0.56 | 1.02 | 1.01 | 1 | 0.96 | 1.75 | 0.99 | |
| bitcount & equake | 1.32 | 0.56 | 1.03 | 1.01 | 1 | 0.99 | 1.76 | 0.99 | |
| equake & crc32 | 1.31 | 0.56 | 1 | 1.01 | 1 | 0.96 | 1.75 | 0.99 | |
| adpcm & equake & crc32 | 1.31 | 0.56 | 1.02 | 1.01 | 1 | 0.94 | 1.74 | 0.99 | |
| adpcm & bitcount & equake | 1.32 | 0.56 | 1.02 | 1.01 | 1 | 0.99 | 1.76 | 0.99 | |
| bitcount & equake & crc32 | 1.41 | 0.56 | 1.03 | 1.01 | 1 | 1 | 1.76 | 0.99 | |
| bzip2 & adpcm & bitcount & equake | bzip2 | 1.02 | 1.03 | 0.99 | 1 | 0.96 | 1 | 0.93 | 1.05 |
| bzip2 & adpcm | 1.02 | 1.03 | 0.99 | 1 | 0.96 | 1 | 0.94 | 1.05 | |
| bzip2 & bitcount | 1.03 | 1.03 | 1 | 1 | 0.96 | 1 | 1 | 1.07 | |
| bzip2 & equake | 1.3 | 0.73 | 1 | 1 | 0.75 | 1 | 0.93 | 2.03 | |
| bzip2 & adpcm & bitcount | 1.03 | 1.03 | 1 | 1 | 0.96 | 1 | 1.01 | 1.07 | |
| bzip2 & adpcm & equake | 1.29 | 0.73 | 0.99 | 1 | 0.75 | 1 | 0.9 | 2.02 | |
| bzip2 & bitcount & equake | 1.31 | 0.72 | 1.01 | 1 | 0.76 | 1 | 0.99 | 2.05 | |
| mcf & bitcount & adpcm | mcf | 0.99 | 1.01 | 0.97 | 1 | 0.99 | 0.98 | 1 | |
| mcf & bitcount | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| mcf & adpcm | 0.99 | 1.01 | 0.99 | 1 | 0.99 | 0.98 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Kim, S.; Hou, J.-U. An L2 Cache Architecture Supporting Bypassing for Low Energy and High Performance. Electronics 2021, 10, 1328. https://doi.org/10.3390/electronics10111328
Park J, Kim S, Hou J-U. An L2 Cache Architecture Supporting Bypassing for Low Energy and High Performance. Electronics. 2021; 10(11):1328. https://doi.org/10.3390/electronics10111328
Chicago/Turabian StylePark, Jungwoo, Soontae Kim, and Jong-Uk Hou. 2021. "An L2 Cache Architecture Supporting Bypassing for Low Energy and High Performance" Electronics 10, no. 11: 1328. https://doi.org/10.3390/electronics10111328
APA StylePark, J., Kim, S., & Hou, J.-U. (2021). An L2 Cache Architecture Supporting Bypassing for Low Energy and High Performance. Electronics, 10(11), 1328. https://doi.org/10.3390/electronics10111328