For the Agent in a Box to be useful for the development of a variety of mobile robots, there are a number of requirements that must be considered. The Agent in a Box must provide useful behaviours for controlling a variety of mobile robots. The Agent in a Box must also provide the means for the reasoner to appropriately select which behaviours to set as intentions while balancing the concerns for safety, health, and the agent’s domain-specific mission. Last, the Agent in a Box needs a generic method for connecting to the environment, enabling it to be used with a variety of sensors and actuators for controlling a variety of mobile robots. The Agent in a Box should also use tools that are familiar to developers. In this case, Agent in a Box uses Jason, a popular BDI reasoning system which uses AgentSpeak. It also uses ROS, a popular framework for the development of distributed robotics.
4.1. Agent in a Box: Connecting to the Environment
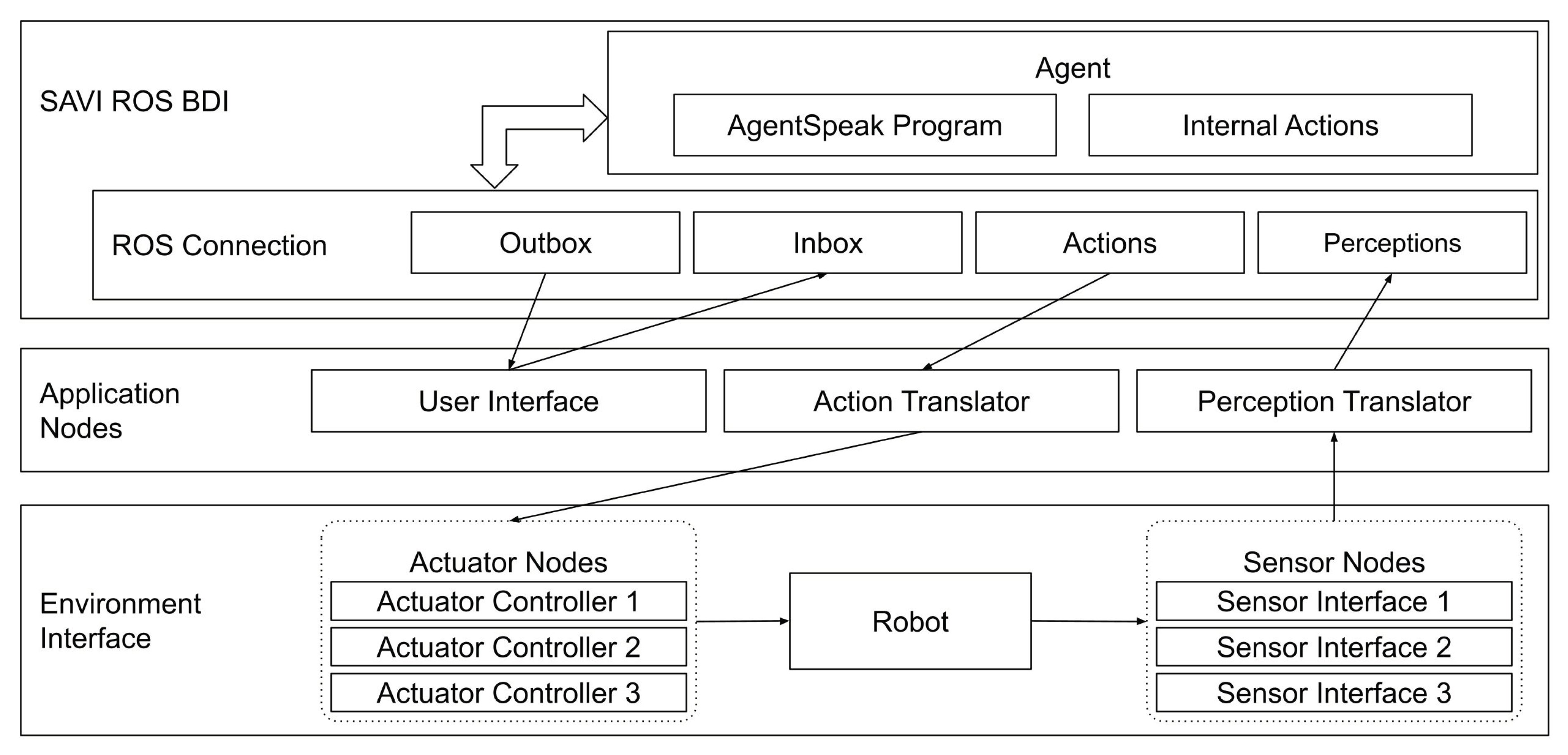
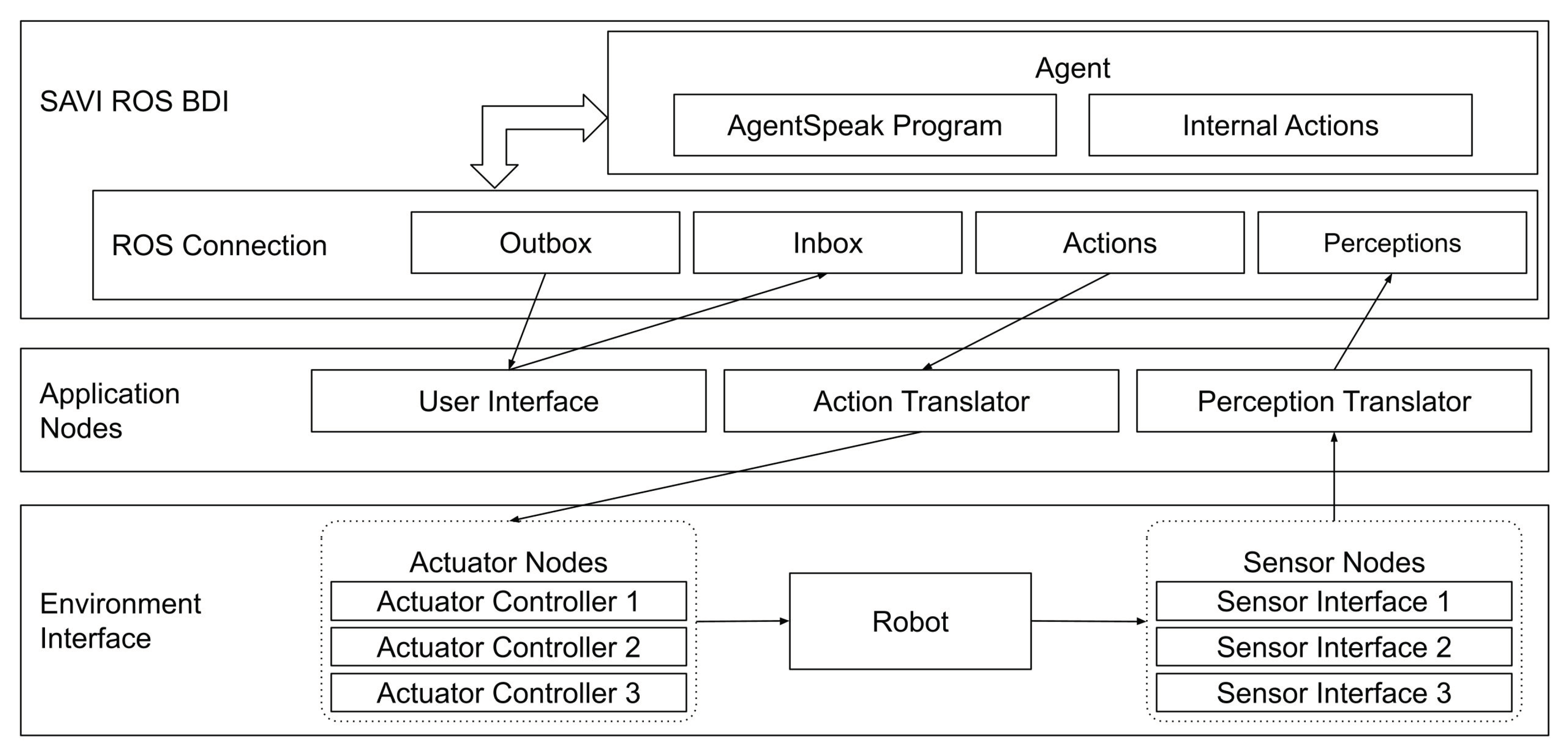
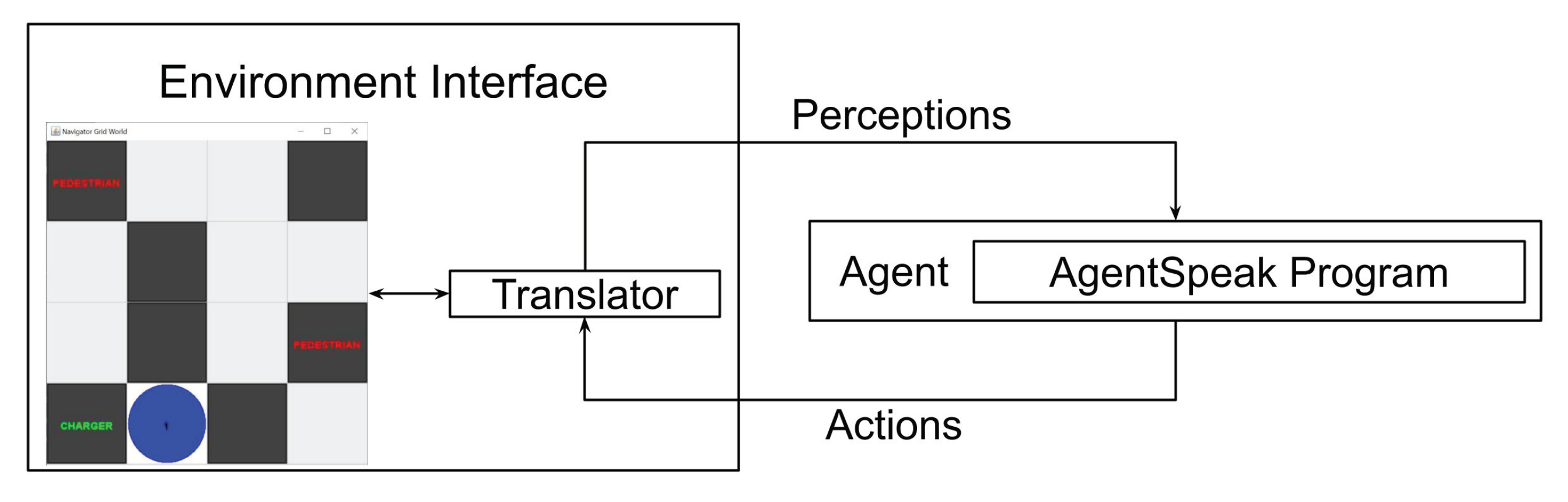
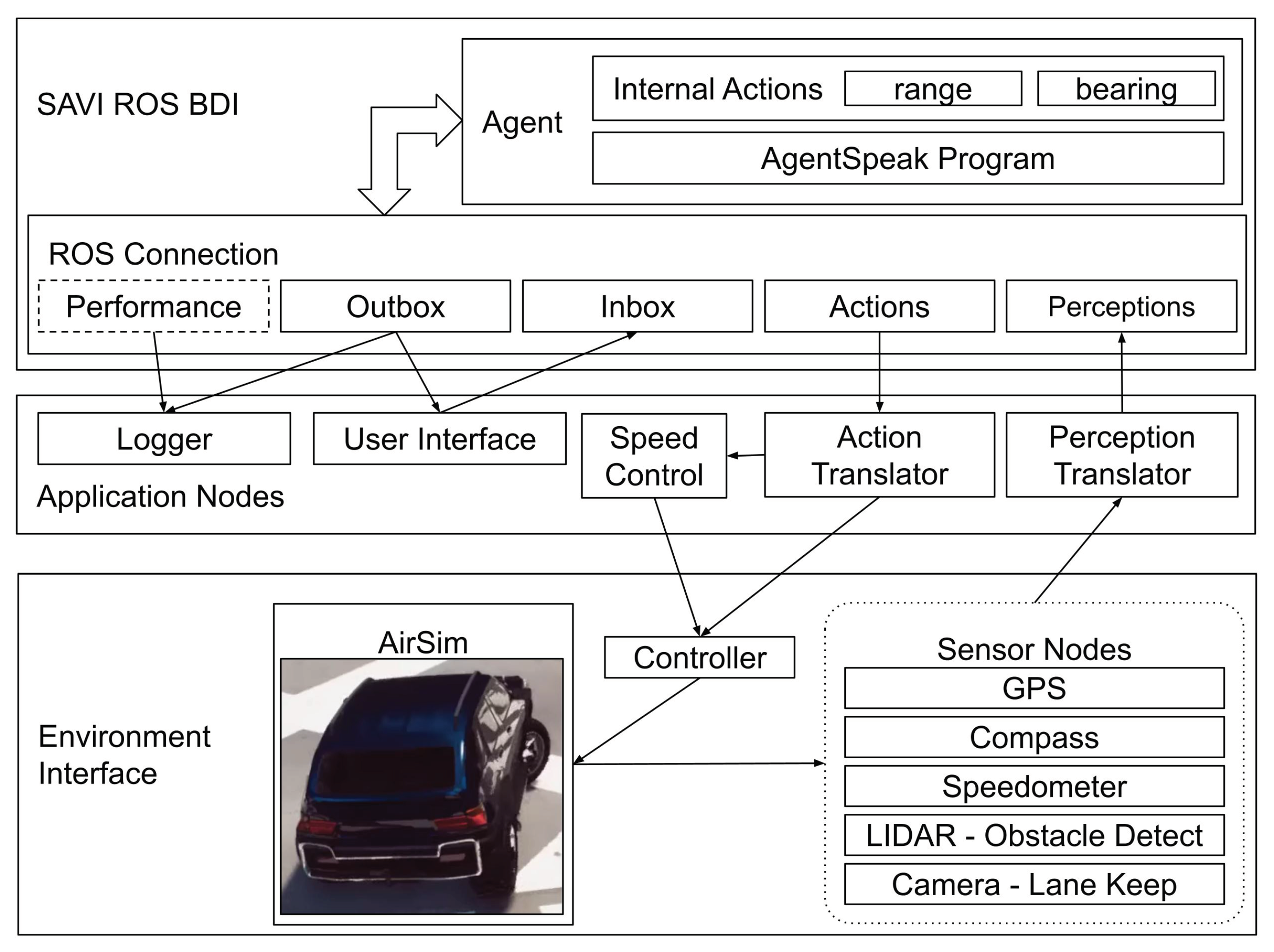
The Agent in a Box provides a means for connecting a BDI agent using Jason and the AgentSpeak language to mobile robots. The goal is to provide the agent with a generic method of connecting to the environment using a method that is familiar in the field of mobile robotics. Given its popularity, and the availability of a variety of modules that may be useful to developers, the Agent in a Box uses ROS for connecting the reasoner to the environment. The architecture for connecting the agent to the environment is shown in
Figure 1. At a high level, this architecture includes an environment interface, containing the nodes connected to the sensors and actuators; application nodes, which include the user interface and translators for the agent. It also includes the agent reasoner. The details of these components are provided in the following paragraphs.
Davoust et al. [
46] identified an
impedance mismatch problem [
47] stemming from the differences in how BDI frameworks connect to their environments, and software simulators that lack the sophistication for modeling BDI agents.
Impedance mismatch refers to the “conceptual and technical issues faced when integrating components defined using different methodologies, formalisms or tools” [
46]. To resolve this problem, Davoust et al. proposed the Simulated Autonomous Vehicle Infrastructure (SAVI) architecture, which connected Jason agents to a custom simulation by decoupling the agent reasoning cycle from the simulation cycle [
46]. Recognising that a similar challenge exists for connecting BDI agents to robotic systems, this Agent in a Box architecture uses the SAVI ROS BDI, which built on the solution proposed by the SAVI project, for connecting a Jason BDI agent to ROS. This software is available open source on GitHub [
48].
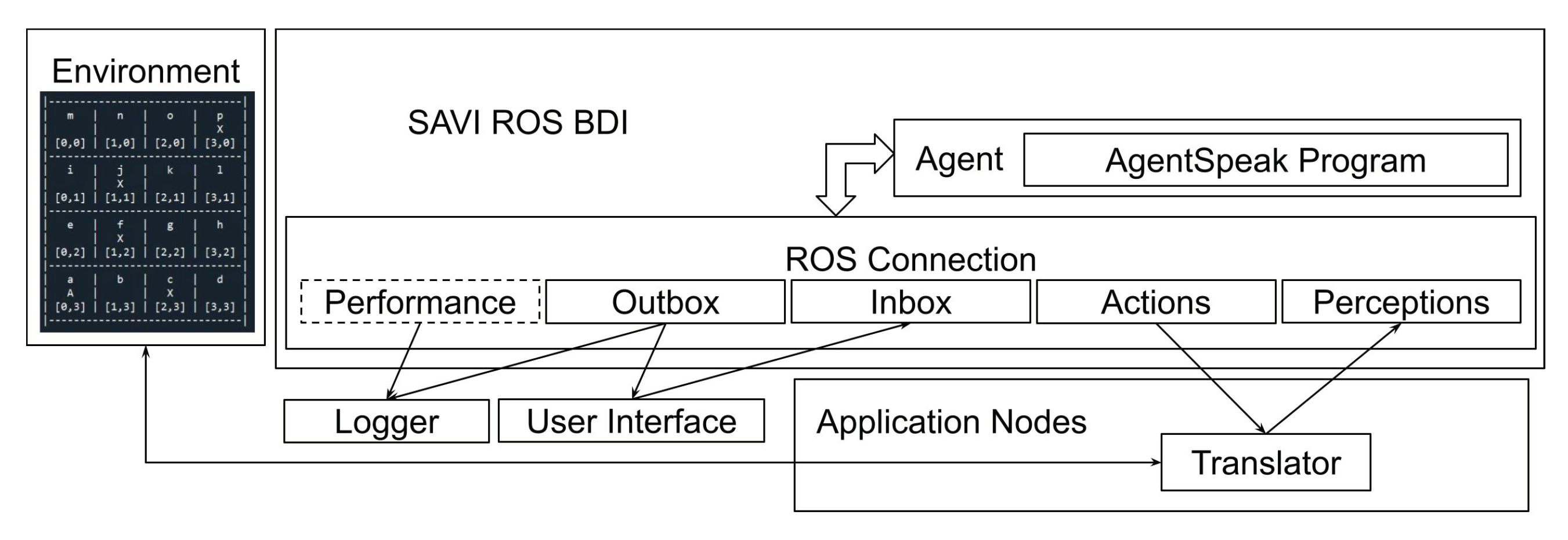
The component of the architecture responsible for connecting the Jason reasoner to ROS is the SAVI ROS BDI node. It provides the necessary abstraction that a BDI agent requires to be suitable for connecting any variety of sensors and actuators. This framework makes the agent available for multiple platforms. SAVI ROS BDI decouples the agent’s reasoning cycle from the implementation of the sensor and actuator interfaces. This ROS node subscribes to the perceptions and inbox topics and publishes to the actions and outbox topics. The recommended method for the developer to provide the sensor perceptions and monitor for actions is discussed below in the explanation of the environment nodes and the application nodes.
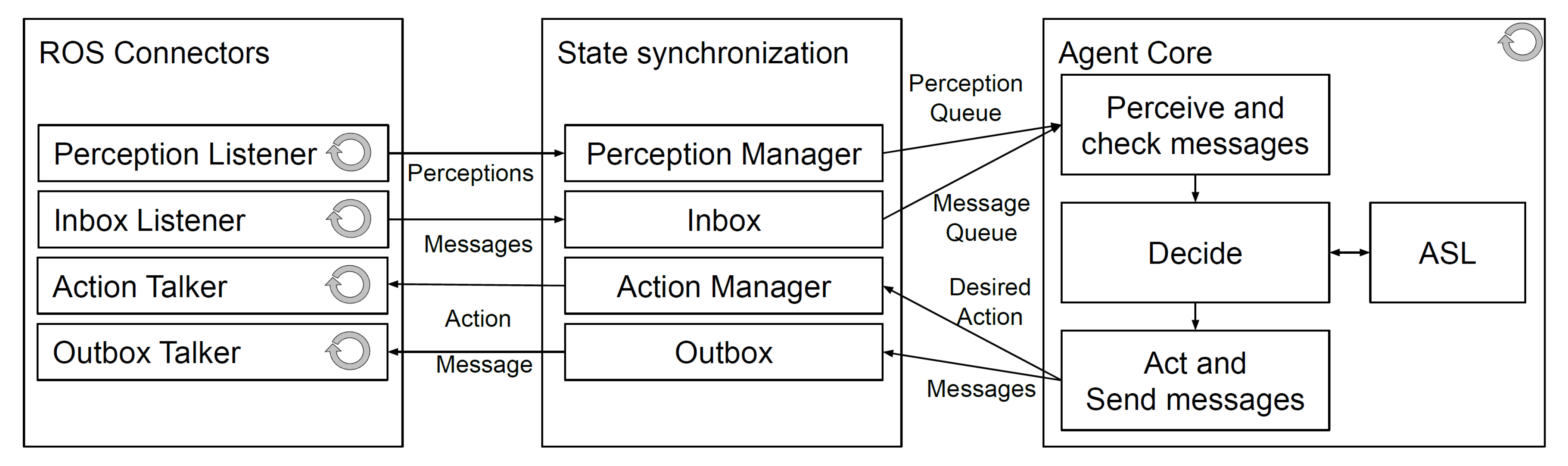
The agent behaviour is implemented as an AgentSpeak program. This program, containing both the framework provided behaviour and the mapping to the application specific behaviour, is interpreted by the Jason reasoner. The agent also has access to a variety of internal actions, primarily used for performing more complex calculations. The internal architecture of this node is shown in
Figure 2. It consists of three main components: the agent core, which contains the Jason reasoner; the ROS connectors, separate threads that are responsible for publishing and subscribing to the ROS topics; and the state synchronisation module, which is the mechanism for data sharing between the ROS connectors and the agent core. Running the Agent Core and the ROS connectors in separate threads decouples the communication with ROS from the agent’s reasoning cycle. The perception and inbox listeners receive data from their respective ROS topics and provide these data to the state synchronisation module’s perception manager and inbox. There, the messages are validated and made available to the agent core, which checks for perceptions and messages at the beginning of each reasoning cycle. Any actions or messages that the agent generates are provided to the action manager and the outbox, in the state synchronisation module. The action and outbox talkers each monitor the state synchronisation module, publishing data on their topics when it becomes available.
The role of the environment interface is to connect the robot’s sensors and actuators to ROS so that the agent can perceive the sensor data and control the actuators. This can involve the use of third-party nodes, perhaps available for specific hardware, or they could be custom-built nodes. This approach to the environment interface bears some similarity to the approach provided by the “Abstraction Engines” project discussed in the state-of-the-art section [
44,
45]. In the Agent in a Box, the sensors are encapsulated in a set of individual nodes which publish their data to relevant ROS topics. The reverse was done for the actuators, encapsulating their controllers as ROS nodes which subscribe to relevant topics for their commands and settings. Each of these nodes is intended to be designed for simplicity, abstracting any underlying implementation details of these components from the broader architecture. This design allows sensor and actuator nodes to be used in a plug-and-play fashion, allowing the flexibility to use unique domain-specific sensors and actuators for different applications.
The application nodes are domain-specific nodes which include a user interface and translators for the agent’s perceptions and actions. The user interface uses agent communication for providing the agent with goals, by publishing to the inbox topic, and monitoring the agent’s progress, by subscribing to the agent’s updates on the outbox topic. The perception translator subscribes to the various sensor data topics and translates the data into a set of predicates. These predicates are the perceptions that will be provided to the agent. The perception translator collects these perceptions and publishes them to the perceptions topic. The perceptions for all the sensors are provided in a single message. This is important as the agent may have plans which use data from multiple sensors in their context checks. If these perceptions are not provided together, there is a possibility that these plans may never be applicable. Last, the action translator subscribes to the actions topic. Similar to the perceptions, the agent’s actions are provided in the form of first-order predicates, containing the name of the action and any relevant parameters. The action translator identifies the provided action and extracts the parameters, publishing them to the appropriate actuator topicfor the relevant actuator node.
4.2. Agent in a Box: Prioritisation of Behaviour
With the architecture for the agent to connect to the robot’s sensors and actuators defined, the focus shifts to how the agent selects which plan will be set as intentions. As was discussed at the beginning of this section, mobile robotic agents are expected to manage a mission of some sort, navigate to a destination, and move through the environment. While doing this, the agent is expected to maintain the safety of itself and others around it by avoiding obstacles. It also needs to maintain its health by managing its consumable resources. In the event that an agent finds an inconsistency between its map and its observations of the environment, it needs to be able to update its map.
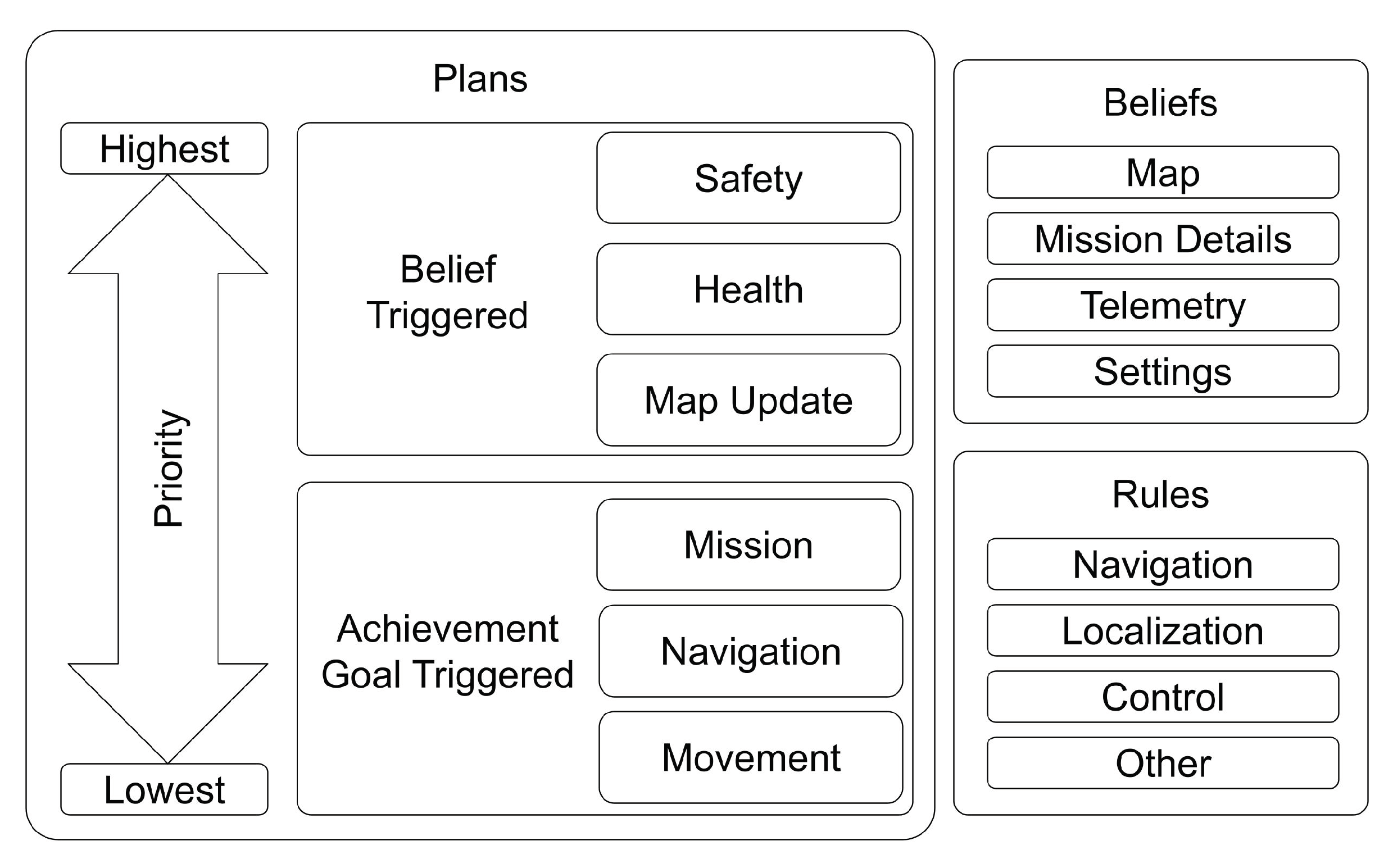
In considering these types of activities, it is proposed that the agent’s plans have a relative priority. For example, the agent should, as its top priority, maintain safety by avoiding obstacles before executing any other behaviour. Inspired by the Subsumption Architecture, which was discussed in
Section 2.4, the Agent in a Box’s agent architecture uses a prioritisation scheme with respect to the selection of which applicable plan will be added to the agent’s intentions. As AgentSpeak provides a full programming language, subsumption behaviours can be implemented, but also other behaviours if needed. The provided prioritisation scheme for the framework is provided in
Figure 3. The prioritisation focuses on having belief-triggered plans for safety, such as for obstacle avoidance, as the highest priority. This is followed by plans which maintain the health of the agent, such as the resource management behaviours, and map update behaviours. Lower priorities are the achievement-triggered plans for mission management, navigation, and movement of the agent. This relative prioritisation is implemented in a method that can be overridden by a developer if necessary.
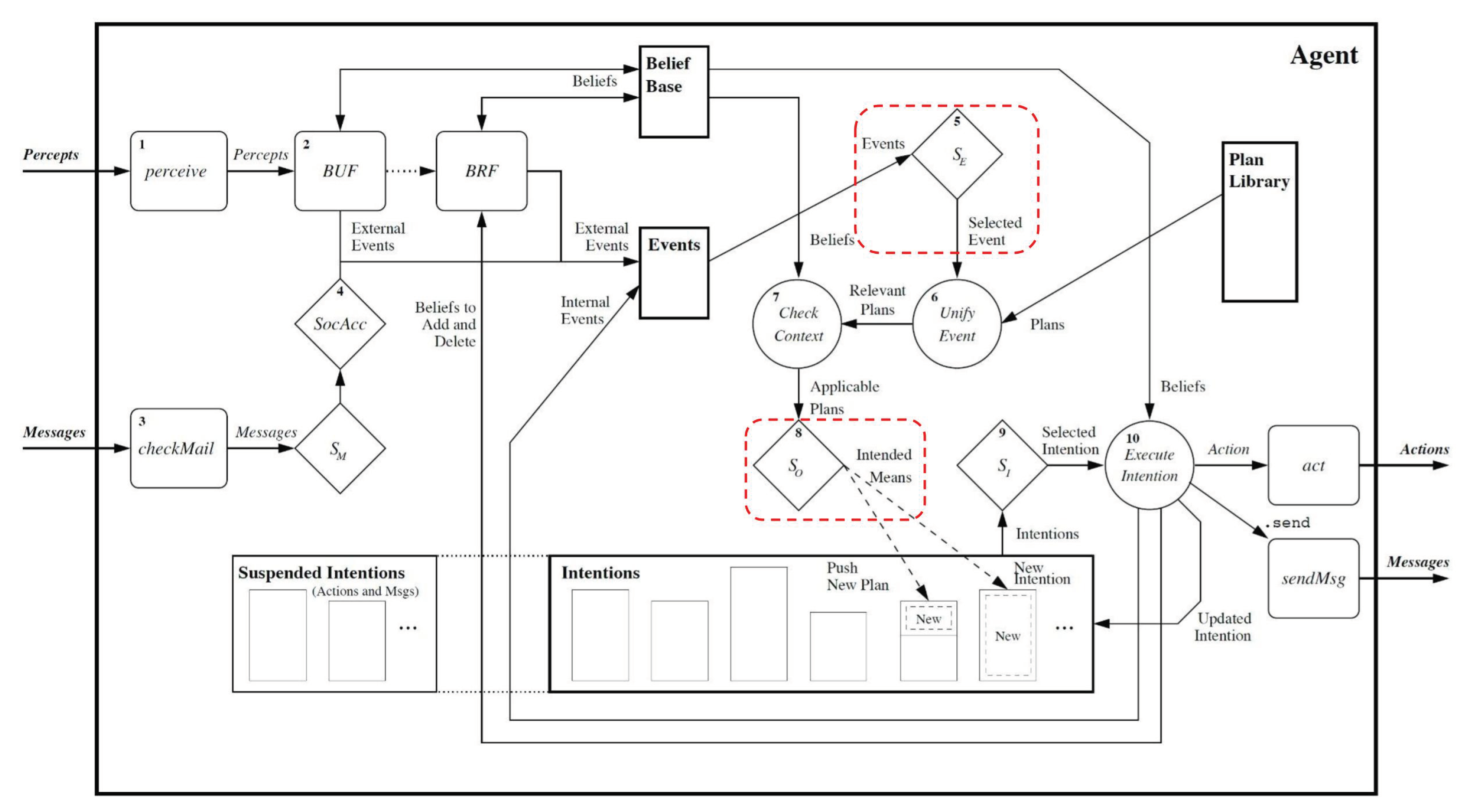
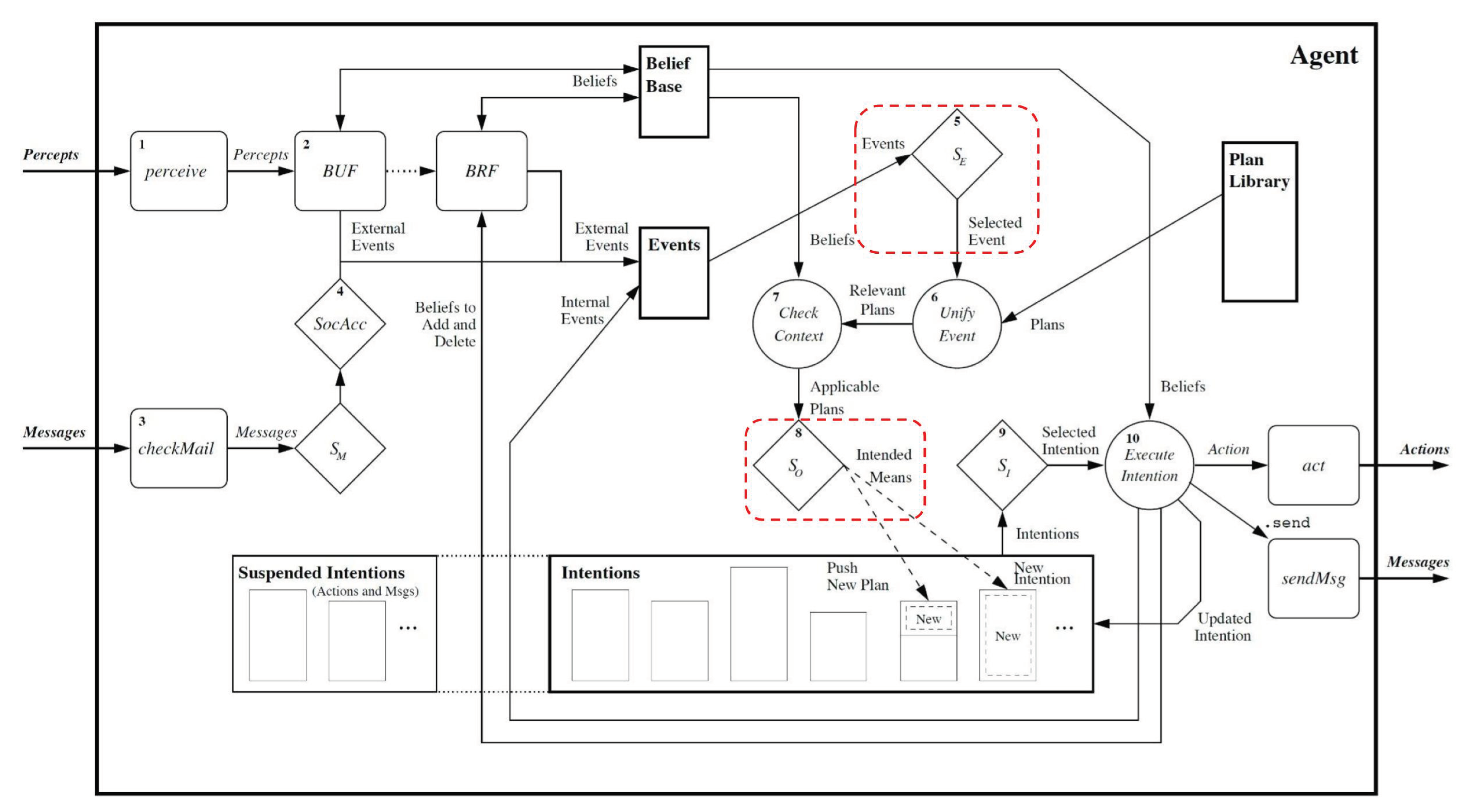
In considering how to incorporate the behaviour prioritisation into Jason’s reasoning framework, it is first necessary to revisit Jason’s reasoning cycle in more detail. Shown in
Figure 4, the focus is on how the reasoner determines what plans should be set as intentions. When an event occurs, which can be a change in goals or beliefs, these events are passed to an event selection function
SE, shown in diamond 5 in the figure, highlighted with a red marking. This function selects which event will receive the attention of the reasoner for that cycle. Similar to the event selection function, Jason’s default event selection function is to select the first event in the queue. With the event selected, all plans associated with this event are unified and their contexts are checked so that the applicable plans can be identified. Applicable plans are then loaded to the option selection function
SO, shown in diamond 8 in the figure, again highlighted with red. Jason’s default option selection is to select the first applicable plan in the queue of applicable plans. This applicable plan is then loaded to the top of the intention stack. [
1]
In the case of relatively simple behaviour designs, Jason’s default event and option selection functions, which choose the first event and option available, may be sufficient. In the case of the Agent in a Box, however, where there are behaviours provided by the framework as well as by the developer of the agent for a specific application domain, there is no guarantee that the order of the behaviours in the plan base will properly reflect the relative priority of these plans. This is further complicated by the possibility that a developer may add new behaviours to the agent in subsequent releases of the agent software. Therefore, there is a risk that the developer may inadvertently modify the ordering of the plans in the agent’s plan base, causing a dramatic change in the agent’s behaviour. To reduce this risk, the Agent in a Box provides the overridden event and option selection functions which prioritise the agent’s behaviour. The event selection function must first select the highest priority triggering event, and the option selection function must select the most appropriate plan triggered by that event.
In order for the event selection function to select the highest priority event, it is necessary for this function to have a means of identifying the type of behaviour the event can trigger. One approach could be to provide annotated event triggers. This approach could be used by the event selection function for prioritising and then selecting the event. These annotations could use categories, such as
health or
mission, to specify the type of behaviour associated with each event. Unfortunately, there is still a significant downside to this approach: the triggering events need to be annotated, not the plans, meaning that the triggering events for achievement goals and for belief-triggered plans need to be annotated at the source. This could be particularly troubling with respect to the belief triggered plans which use perception-generated beliefs. The perception translator, which was discussed in
Section 4.1, would need to generate perceptions with annotations which reflected how the agent would use them. It also means that any achievement goals needed to be annotated when the goal was adopted, which was often in the plan body of other plans. This could mean that some event triggers could be missed in the process of refactoring. Ultimately, the use of trigger annotations was rejected for these reasons.
Instead of using event annotations, the proposed solution is to have a set of beliefs that the agent has with respect to which event triggers are used for which kind of behaviours. This provides a mechanism for the developer of a domain-specific agent to specify what event triggers are associated with what type of behaviour. A sample of these beliefs are shown in Listing 3. In Listing 3, the trigger names for different types of behaviours are identified. These can then be prioritised by the event selection function so that the appropriate event trigger is selected. The terms coloured in blue are Agent in a Box provided beliefs or event triggers and the terms coloured in green are expected or used by the Agent in a Box.
Section 4.3 discusses the behaviour associated with the triggers defined by the Agent in a Box or by the developer of an agent for a specific domain.
Listing 3: Behaviour Prioritization Beliefs.
![Electronics 10 02136 l003]()
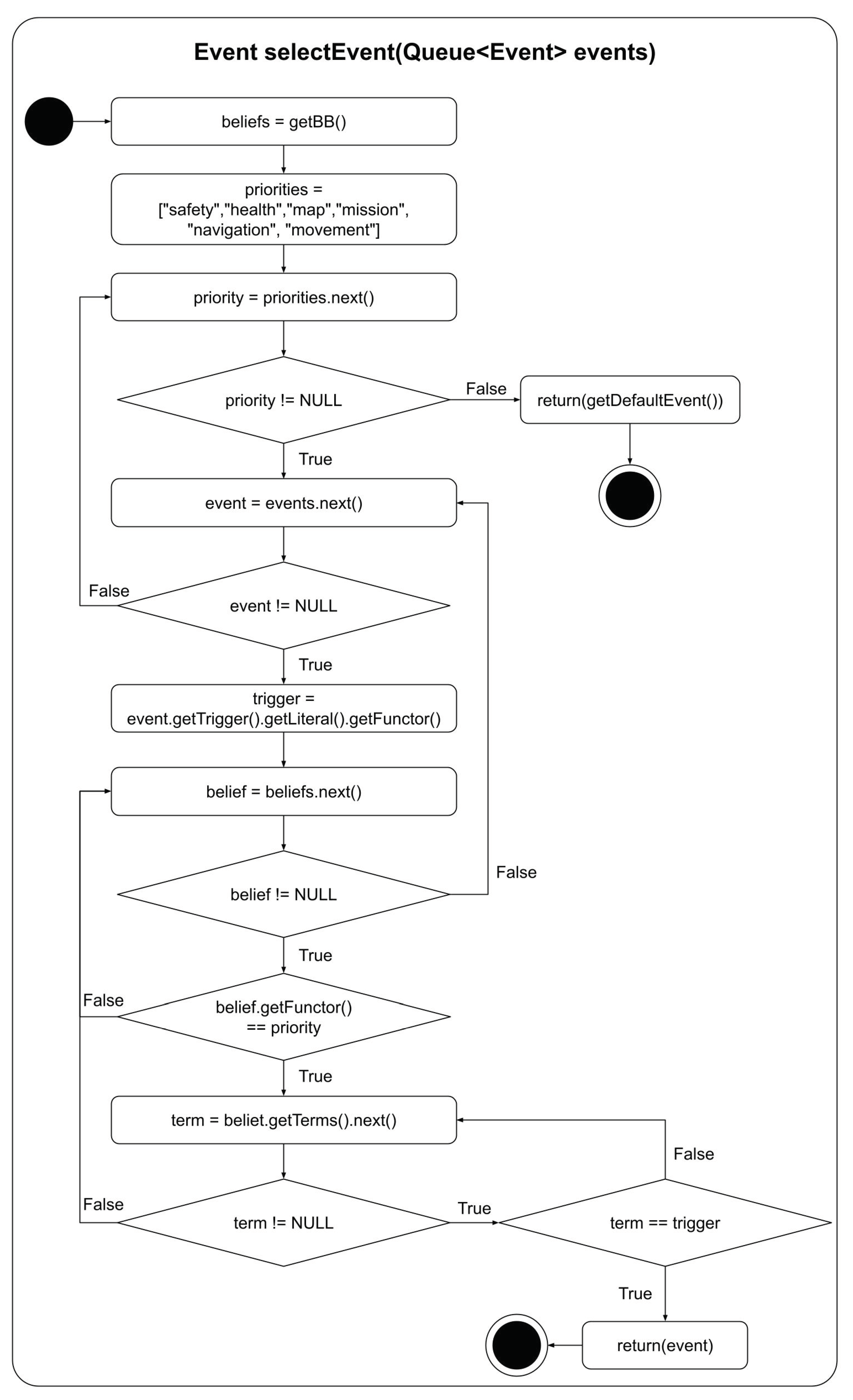
Now that the agent has knowledge of the types of behaviour each event can trigger, the reasoner’s event selection function can use these beliefs for selecting the highest priority triggering event for the agent’s current circumstance. The implementation of this prioritisation is illustrated in
Figure 5. This function is called by the Jason reasoner to select which event to use from a list of events in the agent’s current circumstance. It uses a list of
eventPriorities which specifies the relative priority of the different types of behaviours with their highest priority behaviours listed first. The function uses a set of nested loops to find the highest priority event. The outer loop iterates through the list of priority behaviour types. The next loop level iterates through the event queue, specifically the event functors (the term before the first bracket in a predicate). The following loop level iterates through the belief base looking for beliefs with functors that match the particular behaviour priority level. The function then checks any matching beliefs for terms that match the event trigger. If there is a match, the event is returned, as this is guaranteed to be the highest priority event. If there is not a match, the nested loops continue. If the loops finish without finding an event to return, Jason’s default event selection function is used to select the event, protecting this function from failure.
With the highest priority event having been chosen, it is necessary for the reasoner to select the best option for the intention queue. Once the reasoner has selected which event to use, as discussed above, the reasoner checks the context of all plans triggered by the selected event. The plans that pass this context check become the list of options that the agent can set as intentions. The reasoner then calls the option selection function to select which option should be set as the next intention for the agent. This is necessary as there could be more than one plan applicable to the selected event. For example, default plans, which provide the agent with behaviour in the event that no other plan is applicable, are by definition always applicable. Even though these plans are always applicable, they only provide useful behaviour if it is the only plan applicable to the agent’s context at that time. If there is another applicable plan, it should be selected instead. This leads to a dilemma: how should the option selection function identify the highest priority option?
Ideally, the selected option should be the most applicable or most specific plan. In practice, making this determination can be difficult. Is the most specific plan the one with the most terms in the context? Perhaps yes, however it may not always be the case. That said, one must wonder, how often are there multiple applicable plans for the highest priority event? In examining the contexts of the plans in the Agent in a Box, it was noted that there were generally no more than two options available to the option selection function, one of which was a default plan. This observation provides a simple means for selecting the most appropriate option: a default plan should not be selected if a non-default plan is available. The implementation of the option selection function is illustrated in
Figure 6. This function iterates through the options and checks the length of the plan context. If the context is not null, the plan is not a default plan, and the option is selected. Otherwise, the next plan is checked. If the only available plan is a the default plan, this option is selected.
With the overridden event and option selection functions complete, the Agent in a Box has a method for selecting the highest priority event and an applicable plan option for the agent to add to its intention queue. The agent now needs a set of plans which define the agent’s behaviour. The behaviour framework for the Agent in a Box is discussed in the next section.
4.3. Agent in a Box: Behaviour Framework
The Agent in a Box provides a generic behaviour that is useful for a variety of mobile robotic agents. This includes a set of plans which provide the agent with the ability to navigate, update its map, and manage consumable resources. The Agent in a Box also provides support for agent movement, obstacle avoidance, and mission management. As was discussed in the previous section, there is also a mechanism for the developer to specify the type of behaviour that is associated with each event trigger, enabling the reasoner’s behaviour prioritisation to select the highest priority plan for any given context. Developers of domain-specific agents are not required to use every type of behaviour provided by the Agent in a Box, if they are not all necessary.
This section describes the behaviour framework provided by the Agent in a Box. It also outlines how the developer of an agent for a specific application domain must refine, specialise, or customise the generic behaviours for their domain. This includes providing the agent with specific beliefs, plans, and rules for the agent to use. For example, the developer must provide a definition of the map, the implementation of plans for moving the agent and performing obstacle avoidance appropriate for their domain, and defining the agent’s mission in a way that the generic plans can use. In this section, a variety of AgentSpeak listings are provided. These listings detail the implementation of various agent behaviours. The listings are colour-coded, showing the beliefs and event triggers that are provided by the Agent in a Box in blue, and the beliefs and event triggers that a developer must provide when developing for their specific domain are coloured green.
4.3.1. Navigation
No matter the application domain, all mobile robotic agents need the ability to plan a route to a destination location. The Agent in a Box provides this behaviour, including how the route is generated as well as how the map is defined, using a BDI agent navigation framework [
49]. The navigation framework provides the implementation of the plan for the
!navigate(Destination) achievement goal, which is shown in Listing 4. This plan uses Jason’s A* implementation [
50] to fetch the route from the agent’s perceived position to the destination. It also includes the behaviour belief
navigation(navigate), which specifies the event trigger associated with navigation, used by the behaviour prioritisation methods. The generated path is a list of location waypoints for the agent to follow. These are adopted as as sequence of
!waypoint(NextPosition) achievement goals. In order for the agent to move, the developer for the specific domain must provide an appropriate implementation of the
!waypoint(_) achievement goal. Example implementations of this are provided in the case studies section,
Section 4.4.
Listing 4: Navigation Plan [
49].
![Electronics 10 02136 l004]()
The navigation plan requires several domain-specific parameters to work. This includes a map, written in AgentSpeak which includes predicates that specify the names and coordinates of the points of interest, using the
locationName(Name,[X,Y]) predicate, and possible paths that an agent can navigate between the locations, using the
possible(A,B) predicate. The navigation plan also requires successor state predicates, of the form
suc(CurrentState,NewState,Cost,Operation), which provides A* the cost of moving between any two nodes, and a heuristic predicate, which provides the estimated cost for moving from any given node to the destiation. The heuristic takes the form of
h(CurrentState,Goal,H) [
49]. Last, the developer must provide plans for how the agent should achieve the
!waypoint(_) goal in the specific application domain. This depends on the actions that are available to the agent based on the specific actuators available. Example map definitions, successor state predicates, heuristic predicates, and movement plans are provided in
Section 4.4.
By specifying an application domain-specific map, successor state predicates, heuristic predicate, and movement plans as discussed above, a developer can make use of the navigation achievement goal !navigate(_) to send the agent to a location on the map. Now that the agent has the ability to navigate to a destination, how the agent’s mission should be defined will be discussed next.
4.3.2. Mission Definition
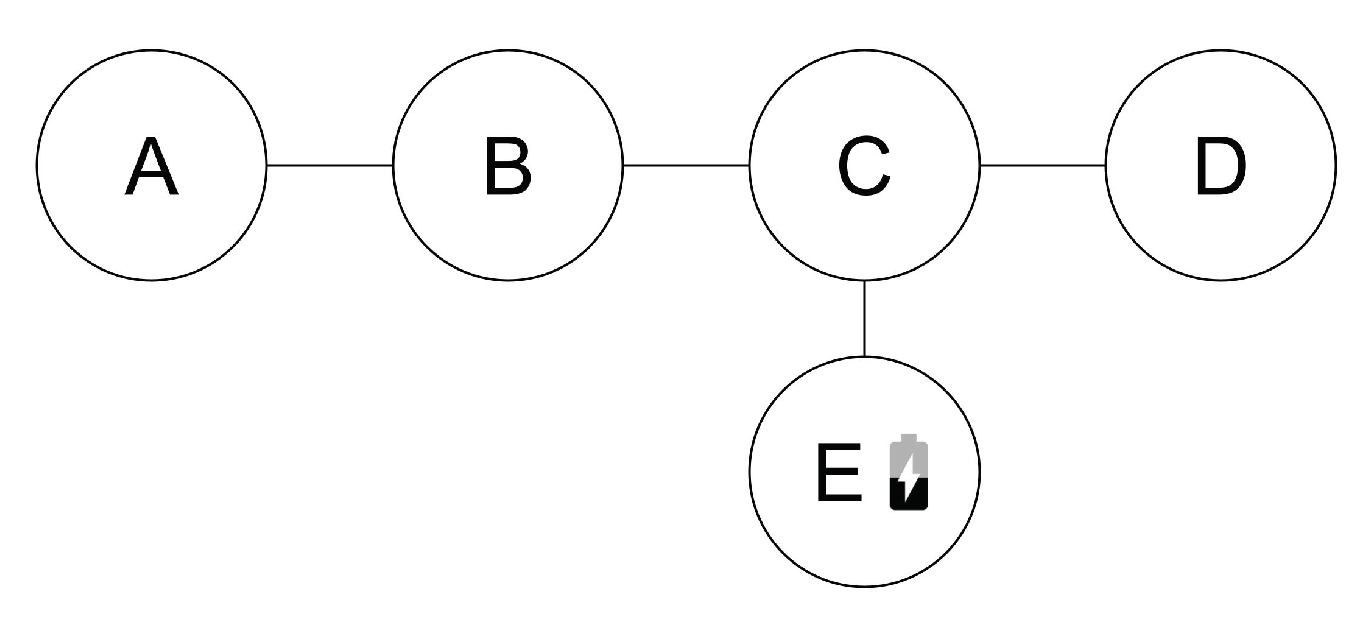
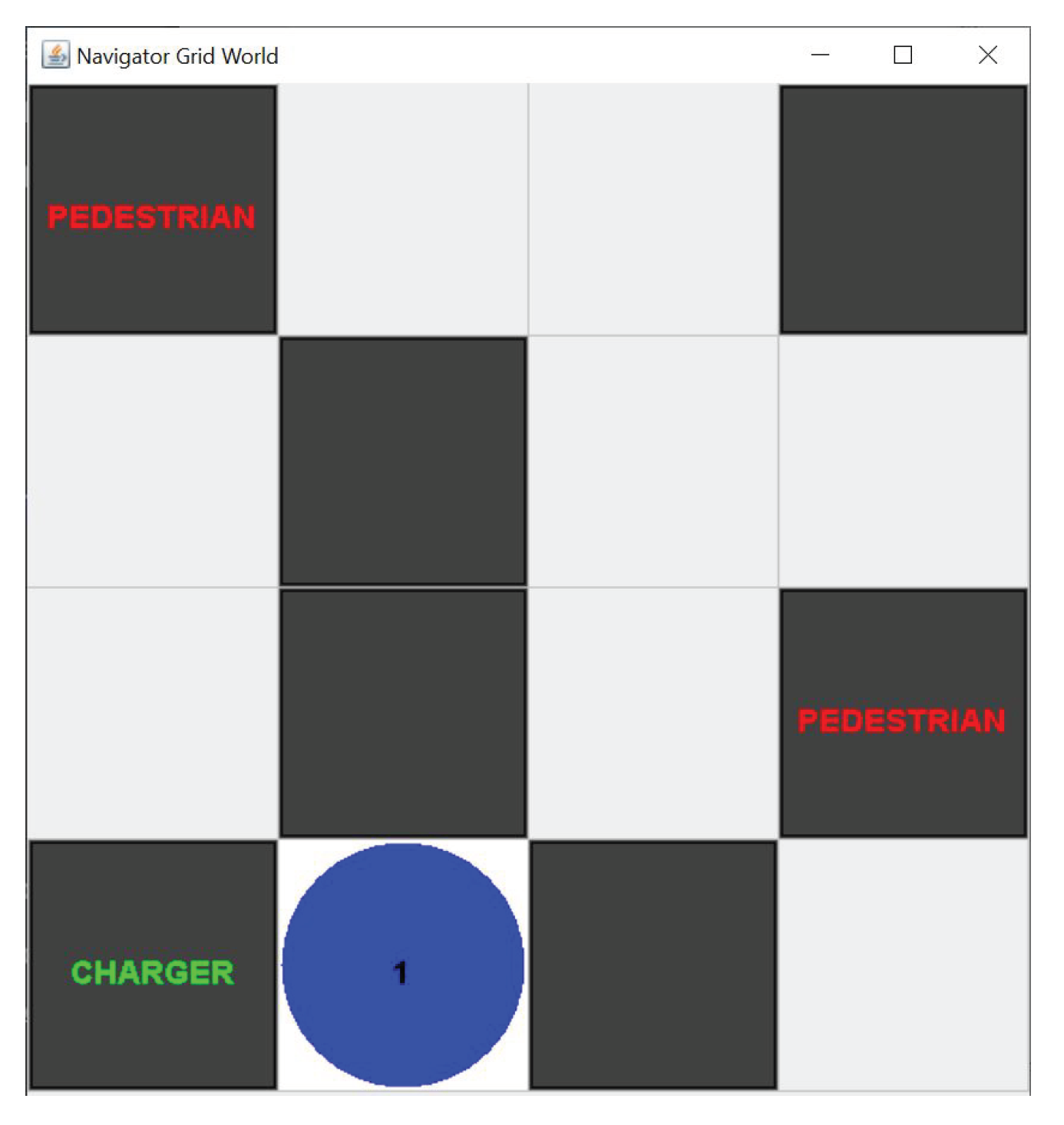
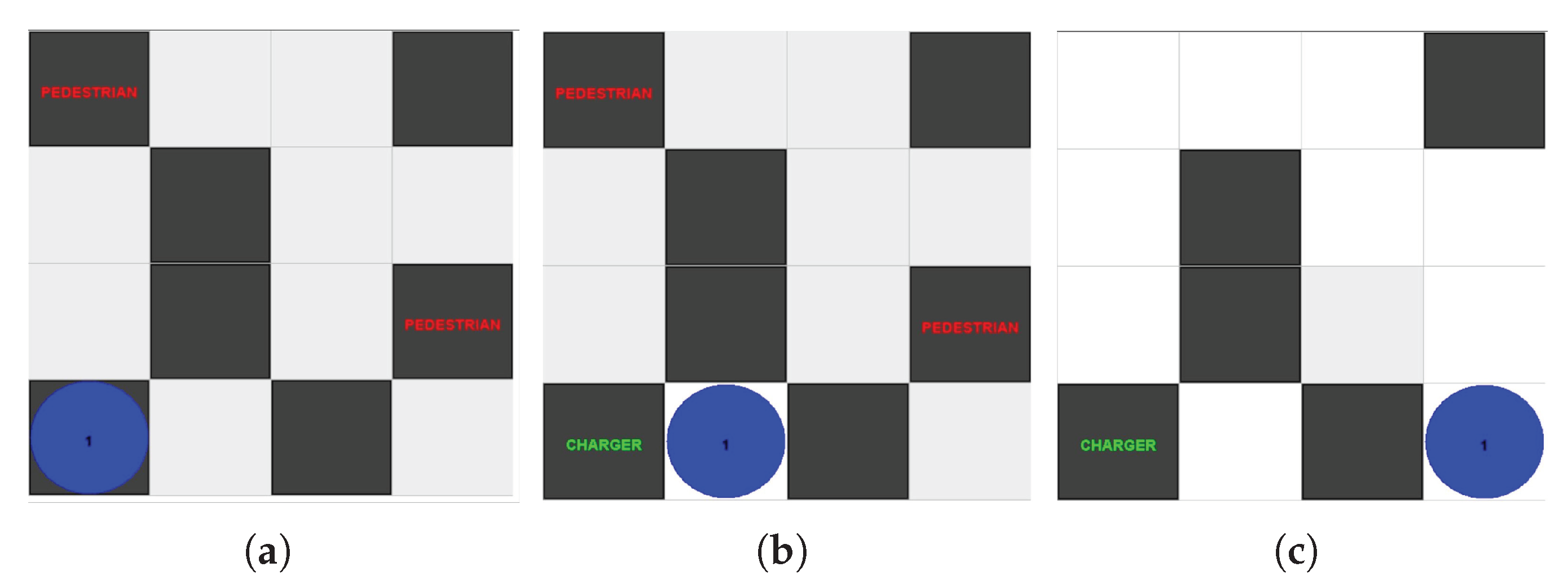
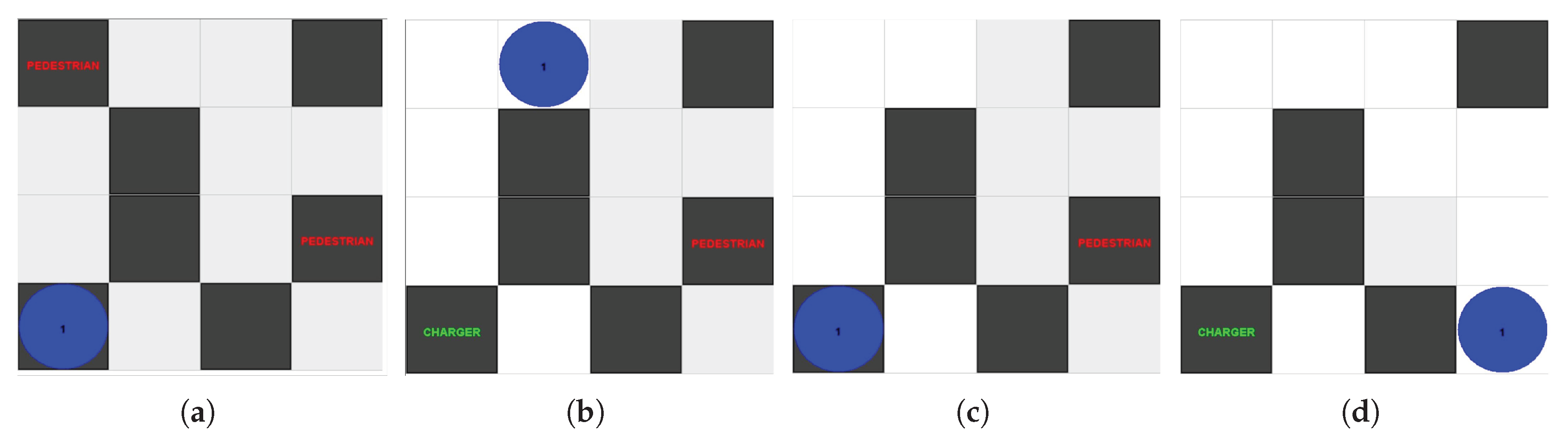
For the Agent in a Box to be useful to users, it needs to be able to complete domain-specific missions. These missions need to be implemented so that they can be interrupted and resumed by other plans in the framework as needed. To illustrate this point, consider a simple example. Assume that an agent is at location
A in the environment shown in
Figure 7 and has been given the goal of moving to location
D. This is easily achieved using the navigation plan discussed in the previous section by adopting the goal of
!navigate(D). To achieve
!navigate(D), the agent adopts achievement goals for
!waypoint(B), followed by
!waypoint(C), and
!waypoint(D). What if the mission is complicated by adding an additional challenge to this scenario, such as the agent realising that it needs to charge its battery at a station located at
E after having already adopted its waypoint goals? Fortunately, the behaviour framework provided by the Agent in a Box includes resource management behaviour. Although the details of this behaviour will be discussed in more detail later, in
Section 4.3.4, one can presume that the agent should navigate to location
E to charge its battery before moving to location
D. The issue is that, once the battery has been recharged, the agent’s intention queue will still contain the waypoint goals for moving the agent from location
A to location
B, and so on, however the agent is now at location
E; the agent’s mission context has changed. This means that the agent needs to regenerate these goals based on this new starting location.
In the case of this simple example, the agent could drop these outdated intentions and readopt the navigation goal, in effect regenerating the waypoint goals. The challenge here is that the mission may be a domain-specific mission that has been specified using achievement goals and parameters not known at the time that the framework was developed. This means that the framework’s battery recharging plan needs to readopt an unknown, domain-specific achievement goal from its generic, framework provided plan. Therefore, a generic mission-level achievement goal is needed so that other framework provided plans can adopt them.
Now that the need for a generic mission-level achievement goal has been established, consideration will be placed on what this goal needs to accomplish. It needs to specify a specific mission, possibly among many possible missions that the agent is capable of, and it also needs to specify any needed parameters that are relevant to that mission. This needs to be accomplished using a generic achievement goal that can be adopted by other plans in the framework. This mission also needs to be implemented so that it can be interrupted, suspended, and readopted. Therefore, the agent will need to set a belief with the mission parameters as well as beliefs on the details of the agent’s progress through the mission, so that the agent doesn’t needlessly repeat any parts of the mission that have already been completed.
Listing 5 shows an implementation of the mission management behaviour for a navigation mission using the generic !mission(Goal,Parameters) goal. This achievement goal allows for the specification of a specific mission goal with the first parameter. The second parameter is a list of parameters that need to be provided to this mission. The context checks for the mission type, allowing the plan body to be used for setting a mission level mental note with the mission parameters, useful for readopting the mission if necessary, adopting the mission specific achievement goal, and then finally dropping the mental note once the mission has been completed. The navigation mission shown in this listing is included with the Agent in a Box, as any mobile agent could be expected to complete a simple navigation mission. A developer of an agent for a specific domain can add additional domain-specific missions for their custom application by providing other plans that achieve the !mission(_,_) in this way. As long missions are implemented using this type of plan they can be interrupted and resumed seamlessly by the plans provided by the Agent in a Box.
Listing 5: Mission Management.
![Electronics 10 02136 l005]()
Now that the Agent in a Box has the ability to navigate through the environment, and can be provided with domain-specific missions, the Agent in a Box needs to be able to avoid obstacles.
4.3.3. Obstacle Avoidance and Map Update
As the agent moves through the environment, there is a possibility that the agent may need to avoid obstacles. There are generally two types of obstacle avoidance scenarios. In the first scenario, the obstacle can be avoided without a significant impact on the mission, for example, stopping to wait for a pedestrian that has wandered into the agent’s path. Once the pedestrian has moved out of the way, the agent can continue its mission without issue. In the second type of obstacle avoidance scenario, the obstacle causes a significant change in the agent’s mission context and the presence of the obstacle has invalidated the agents intentions in some way. For example, if the agent is navigating to a destination and finds that a road on its path has been closed unexpectedly, the agent’s waypoint goals will no longer be valid. Avoiding this second type of obstacle will require a change to these goals.
A sample of the first obstacle avoidance scenario is provided in Listing 6. Assume that the agent has a perception associated with the type of obstacle, in this case pedestrian(blocking). A further assumption is that the agent has an action which stops the robot: drive(stop). Using this perception-generated belief and avoidance action, the obstacle avoidance plan is a simple belief-triggered plan: stop the robot when there is a pedestrian blocking the way. To ensure that this plan is executed to its completion, without any interruption, this plan is implemented with the [atomic] annotation. The event trigger must also be provided using safety(pedestrian) in order for this event to be prioritised by the reasoner. By providing this belief, the developer can add any needed obstacle avoidance behaviour using the sensors and actuators available for their application.
Listing 6: Simple Obstacle Avoidance.
![Electronics 10 02136 l006]()
This first type of obstacle avoidance works well for obstacles that can be easily avoided without any significant impact on the mission, or obstacles that only provide a short disruption. By contrast, for longer term obstacles which interrupt the mission, as described in in obstacle avoidance scenario two above, the agent needs to update its map to reflect the obstacle and regenerate the waypoint achievement goals that are in its intention queue.
The implementation of this map update is provided in Listing 7. Here, the agent has observed an obstruction that was not on the map by perceiving obstacle(Next). This belief needs to be generated by the perception translator based on the robot’s sensor data. With the obstacle observed, the agent may need to update the map. The context check verifies if this obstacle contradicts any belief that the agent can move from its current location to the location of the obstacle. If it does, the agent needs to update the map and suspend and readopt any mission that the agent was working on. The first line in the listing provides the agent with a belief of what type of behaviour is triggered by obstacle. The plan body then checks if the agent was on a mission, which would require the agent drop any invalidated intentions before readopting them. This is done with a simple conditional statement.
Listing 7: Map Update.
![Electronics 10 02136 l007]()
Obstacle avoidance is not the only type of issue that can interrupt the agent’s progress on a mission, the Agent in a Box must also manage its resources, such as the charge of a battery, while working on its mission.
4.3.4. Management of Resources
A common aspect for mobile robots is the need for resource management. This could be to replenish some consumable resource, such as fuel, battery state, or even to seek a maintenance garage for more significant maintenance. Resource management behaviour requires the agent to stop whatever it may have been doing and then navigate to a maintenance station to either refuel, recharge, or seek some other type of maintenance. Once this maintenance is complete, the agent can continue its interrupted mission, however the agent will not be where it was when the mission was interrupted. Therefore, the agent’s context will have changed significantly. This means that the management of resources requires that the agent be able to drop out-of-date intentions and then readopt mission goals once the maintenance has been completed.
Listing 8 provides the Agent in a Box’s mechanism for replenishing a depleted resource. The first plan in the listing triggers on the addition of the resource(State) belief, generated by the perception translator node based on the data from a sensor monitoring the resource. In order for the agent to properly prioritise this event, the agent needs to be provided the health(resource) belief so that the event selection function can identify this trigger as being associated with a health-related behaviour. The plan contexts limit the plans to being applicable only when the resource has been depleted using the lowResource(State) rule, also provided in the example, and if the agent is not already replenishing the resource. The plan body contains a check for any mission that may have been running when the resource was depleted. If there was, the intentions are dropped before adopting the goal of !replenishResource and then readopting the mission goal. If there was no mission in progress, the agent adopts !replenishResource without issue.
There are three plans responsible for replenishing the resource: The first is for moving the agent to the maintenance station, using !navigate(Station), and then docking with the station. This plan then readopts the achievement of the !replenishResource goal so that the progress can be monitored. The second plan is responsible for undocking from the station once the resource has been fully replenished, using the fullResource(State) rule, also defined in the listing. The last of the plans is a default plan which ensures that the goal of replenishing the resource is readopted while the agent works on replenishing the resource.
Listing 8: Resource Management Plans and Rules.
![Electronics 10 02136 l008]()
In order for the agent to properly use the resource management behaviours provided by the Agent in a Box, a number of things are needed. First, any mission that can be interrupted should have an associated mission level mental note on any relevant mission parameters. This way, the mission can be readopted once the resource management process has been completed. Additionally, the agent needs to perceive the status of the resource using the resource(State) perception, which specifies the state of the resource; also needed are perceptions of whether or not the agent is docked at the station using both docked(true) and docked(false). The agent also needs to know the location of the station, using the stationLocation(Station) belief, and the maximum and minimum acceptable state of the resource, using resourceMin(Min) and resourceMax(Max). Last, the action for docking and undocking the agent with the station, station(dock) and station(undock) is needed.
4.3.5. Summary of the Behaviour Framework
This section has detailed Agent in a Box’s behaviour framework, including the generic behaviour that is provided by the framework and what needs to be done to use the framework for a specific application domain. The Agent in a Box can be applied to a variety of mobile robotic agents, providing the needed skeleton for the agent to perform missions, navigate, move, update its map, avoid obstacles, and manage its resources. Additionally, the Agent in a Box depends on elements that the developer of an agent for specific application domains need to provide. For example, the navigation behaviour requires a map, written in AgentSpeak, as well as domain-specific plans for the waypoint(_) goal. Also needed are specific perceptions, actions, and beliefs that the agent needs in order to work. These include perceptions of the agent’s position, resource state, docking station status, and an action for docking the robot at the maintenance station.
Now that the Agent in a Box has been provided, it is time to demonstrate its use for controlling agents in different application domains. The behaviour of the agent in these domains will be used for evaluating the behaviour and usefulness of this approach.
4.4. Case Studies
To validate the usefulness of the Agent in a Box, it has been used to implement mobile robots in three application domains. The domains were chosen to expose how agents implemented with the Agent in a Box work under different scenarios. This ensures that the results observed in the experiments were not tied to the properties of any specific environment, but rather demonstrate the usefulenss of the Agent in a Box for mobile robots in general. Additionally, the domains highlight the level of effort needed for an agent to be developed for different application domains while leveraging the features of the Agent in a Box framework. The first application domain explored is a grid-based domain, discussed in
Section 4.4.1. Building on this environment, an autonomous car, simulated in AirSim, was driven through a neighbourhood environment, discussed in
Section 4.4.2. Lastly, a prototype mail delivery robot is discussed in
Section 4.4.3.
4.4.1. Grid Environment
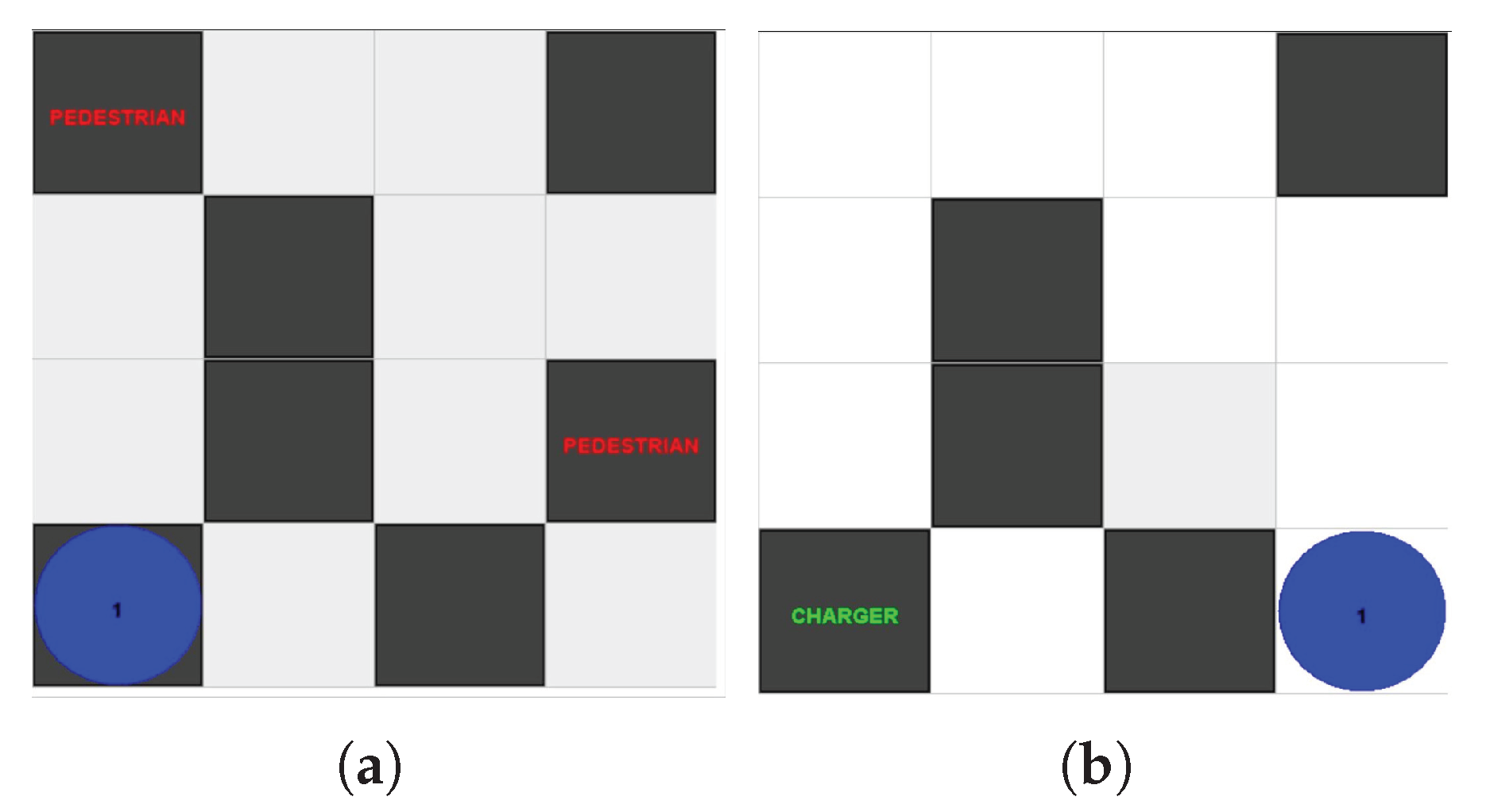
The simplest environment that the Agent in a Box was applied to was a grid environment. Shown in
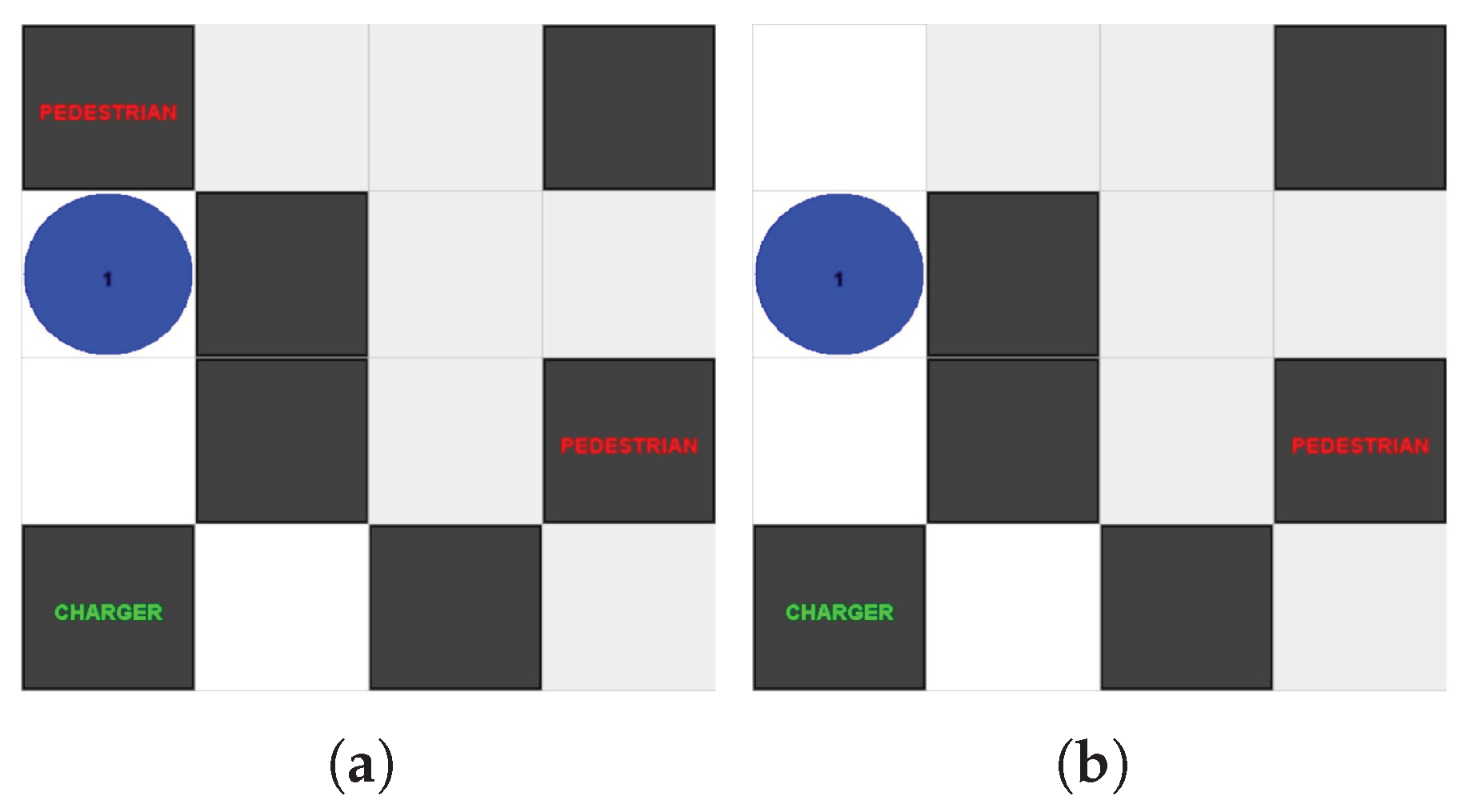
Figure 8, this four by four grid was used for testing the basic principles of the Agent in a Box. In this environment, the agent was situated at a starting location and given the task of moving to a destination location. The agent was given a map showing the possible paths between the locations on the map, however this map did not include the locations of all of the obstacles. Therefore, the agent needed to update its map as it ran. The agent was also equipped with a simulated battery which reduced in charge over time, causing the agent to recharge the battery at a charging station located on the map. There were also pedestrians on the map, obstacles which would block the agent’s path until the agent honked a horn at them. The agent perceived the environment with perceptions of the battery state, map locations, obstacles, and pedestrians adjacent to the agent. The agent was given the ability to honk a horn, connect and disconnect from the charging station, and move to adjacent grid locations. There were two versions of this environment: a synchronised and an asynchronised version.
The synchronised version of the environment used a single thread of control, meaning that the environment update was tied to the reasoning cycle. The environment would update, then provide perceptions to the agent. The agent would then reason about those perceptions and provide an action, which would then be used to update the environment, then repeating the process. The synchronised version of the grid environment architecture is shown in
Figure 9. The software, implemented using Jason’s agent architecture and environment tools, is available on GitHub [
51].
In contrast to the synchronous environment, the asynchronous version used a separate ROS node for the environment, which updated in its own time. The agent perceived the environment via a set of sensors which periodically monitored the environment and published their data to ROS topics. The agent was connected using SAVI ROS BDI, the Agent in a Box connection scheme discussed in
Section 4.1 and shown in
Figure 1. In this case, a single translator was used for connecting to the environment and passing symbolic perceptions to the agent while also passing actions back to the environment. The software for this version is available on GitHub [
52]. The asynchronous version of the architecture is shown in
Figure 10.
The grid agent made good use of the Agent in a Box, using all of the provided behaviour features and priority levels. Its primary mission was navigation, provided by the Agent in a Box. It also used the resource management behaviour provided by the Agent in a Box for maintaining the charge of its battery and the map update behaviour to maintain the map used by the navigation plan. These methods all worked by ensuring that the translator node responsible for generating the perceptions and interpreting the actions used the same perception and action names used by the Agent in a Box. Some additional work was needed, however, in order for the agent to navigate, move, and avoid pedestrians. This involved providing the map, movement plans, and pedestrian avoidance behaviour.
The navigation behaviour provided by the Agent in a Box requires a map written in AgentSpeak, successor state predicates, and a heuristic predicate. An excerpt of the map is provided in Listing 9, specifying the coordinates of each grid location as well as the possible paths between locations.
Listing 9: Partial Grid Agent Map.
![Electronics 10 02136 l009]()
A sample successor state predicate, which uses a supporting rule, along with the heuristic predicate are provided in Listing 10. The successor state predicate provides the cost to the agent for moving to an adjacent grid square. The example shown provides the rule definition for this predicate for grid squares in the up direction. This uses a rule for getting the location coordinates from the belief base. Last is the heuristic predicate, defined by the last rule in the listing. This rule calculates the Euclidean distance between a given location on the grid and the goal location. This is a cost estimate used by the A* search algorithm which is then used by the navigation plan.
Listing 10: Grid Agent Successor State and Heuristic Definitions.
![Electronics 10 02136 l010]()
With the map defined, the agent needs plans for achieving the !waypoint(_) goal, which the navigation plan will adopt to move the agent along the route that has been generated. The movement plans are responsible for moving the agent to the specified location using the domain-specific actions available to the agent. The grid agent’s movement was designed as shown in Listing 11. The first line in the listing provides the behaviour type for the reasoner to properly prioritise this trigger as being related to movement behaviour. This is followed by the plan for moving the agent. The agent perceives its position with the position(X,Y) predicate and moves using the move(Direction) action which moves the agent in the desired direction. The plan context makes use of the locationName(Current,[X,Y]) and possible(Current,Next) predicates which are map related predicates. It also uses rules for determining the direction that the agent needs to move using simple arithmetic. In this case, the grid is assumed that the X value increases as the agent moves to the right and that the Y value increases as the agent moves down. Note that this plan is only responsible for moving the agent, it is not concerned with health and safety related concerns, such as if there is an obstacle in the path.
Listing 11: Example Movement Plan and Rules.
![Electronics 10 02136 l011]()
With the robot able to navigate and move through the environment, the last needed piece of this implementation is to provide the pedestrian avoidance behaviour. The Agent in a Box provides a mechanism for prioritising safety-related behaviour. The agent perceives the presence of pedestrians through the pedestrian(_) belief. The desired obstacle avoidance action in this environment is for the agent to honk a horn to signal the pedestrian to get out of the way. This can be easily implemented as a belief triggered plan, as shown in Listing 12. First, the behaviour belief was provided, identifying to the reasoner that a safety related behaviour will be triggered by pedestrian events. Next, the plan name was specified as pedestrianAvoidance, further specified to be an atomic plan, meaning that it must be run to completion, without interruption. Last, the belief-triggered plan is provided. By using this design approach, the implementation of the other movement-related plans do not need to be concerned with obstacle avoidance as the agent’s prioritisation method will select this plan as the highest priority.
Listing 12: Grid Agent Obstacle Avoidance.
![Electronics 10 02136 l012]()
A video of the grid behaviour is available on YouTube [
53]. With the grid agent complete, it is time to apply the Agent in a Box to a more realistic environment: a simulated autonomous car.
4.4.2. Simulated Autonomous Car Environment
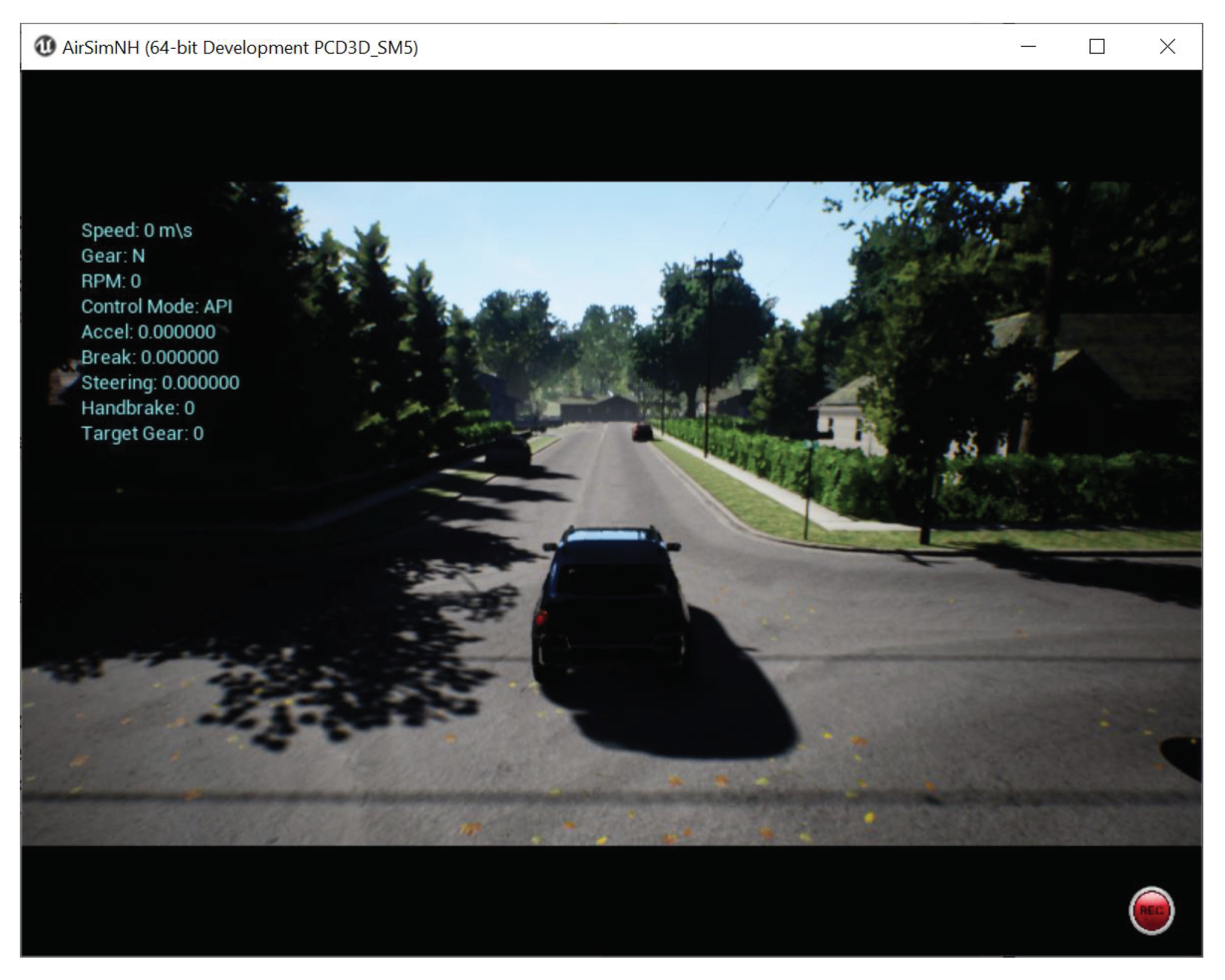
Although the grid agents provided an opportunity to demonstrate all features of the Agent in a Box, it was an overly simplistic environment. If the Agent in a Box is to be useful, it needs to work in an environment more representative of the real world. The Agent in a Box was therefore used to drive a simulated autonomous car.
AirSim is a simulator maintained by Microsoft and available open source [
54,
55]. Originally developed using the Unreal Engine, but now also available using the Unity Engine, it was developed to provide a realistic outdoor environment for the development of UAVs, although it is also useful for the development of autonomous cars [
56]. The development focus was to drive the car in AirSim’s neighborhood environment, in
Figure 11. This environment provides an enclosed suburban neighbourhood, with roads and parked cars that need to be avoided. There are several intersections for the car to navigate. In this environment, the agent’s mission was to drive the car to a specified destination in the environment. The car has a variety of sensors and actuators, including a speedometer, Global Positioning System (GPS), magnetometer (useful as a compass), camera, LIDAR, throttle, brakes, and steering. The software for the agent in this environment is also available on GitHub [
57].
The architecture of the car agent using the Agent in a Box, is shown in
Figure 12. The car was configured with a variety of sensors, including a GPS sensor, a magnetometer, a speedometer, a LIDAR, and a camera. Each of these sensors was monitored by a set of nodes. The GPS node provided the latitude and longitude coordinates of the car, the magnetometer was used for calculating the compass heading of the car, and the speedometer provided the car’s speed in meters per second. The LIDAR sensor was used as an obstacle detection sensor and the camera was used for a lane-keep assist module which provided the recommended steering for the car to follow the road. The topics published by these sensor nodes were subscribed to by the perception translator, which assembled this data into predicates and published to the
perceptions topic for the reasoner. The agent’s control of the car was through setting the desired speed of the car and providing a steering setting. The speed setting was passed to a speed controller which controlled the accelerator and brake of the car. The steering, accelerator, and brake settings were all subscribed by a controller node, which commanded the car in AirSim. There were also modules for logging the behaviour of the reasoning performance and a user interface used for commanding the destination of the car. Within the agent were a number of internal actions, Java functions that the AgentSpeak program could call. These included actions for calculating the range and bearing to specified locations using latitude and longitude coordinates.
Although the behaviour implementation for the car required a number of domain-specific implementations, the mission behaviour for navigation was used as the main behaviour for the agent. Otherwise, the car needed a map of latitude and longitude coordinates for the navigation plan to use, plans for achieving the waypoint goal by controlling the car’s steering and speed, and collision avoidance behaviour for avoiding parked cars.
The map definition for this environment followed the structure defined for the Agent in a Box’s navigation framework. Shown in Listing 13, the main difference was that the coordinate locations used latitude and longitude instead of simple grid locations.
Listing 13: Excerpt of the AirSim Car Map Definition.
![Electronics 10 02136 l013]()
The successor state rule and the heuristic rule needed to be specialised to work with latitude and longitude. The definition of these rules is shown in Listing 14. The successor state rule was simplified, only specifying that it was possible for the car to drive between the specified locations. The heuristic rule required an internal action for calculating the range between the coordinate locations.
Listing 14: AirSim Car Navigation Successor State and Heuristic Definitions.
![Electronics 10 02136 l014]()
The agent has a collision avoidance capability, using the obstacle detection feature with the LIDAR sensor. This functionality was implemented using a belief triggered atomic plan, shown in Listing 15. First, the behaviour triggered by the obstacle was identified as being for safety behaviour. This belief is used by the reasoner to prioritise this event trigger as the agent’s top priority. Next, the plan was annotated as an atomic plan meaning it must run to completion. Finally, the collision avoidance behaviour is provided. The behaviour steers the car away from the parked car obstacles along the side of the road when the distance to an obstacle is less than 5 m.
Listing 15: AirSim Car Obstacle Avoidance Behaviour.
![Electronics 10 02136 l015]()
With navigation and obstacle avoidance handled, it is time to provide plans for driving the car. These are provided in Listing 16. The plans for the !waypoint(Location) achievement goal are responsible for moving the car toward locations on the map specified with latitude and longitude coordinates. These plans are implemented recursively, meaning that the only plan which does not readopt this achievement goal is for the context where the car has arrived at the location. The first plan in the listing stops the car when it has arrived at the location by adopting the achievement goals for setting the speed to zero and setting the steering to zero with the lane-keep assist turned off. Next is the plan responsible for slowing the car as it approaches a location. Here, the car slows to 3 m/s, and the steering is set to the direct bearing to the location with the lane-keep disabled, as the vehicle is close the the location before readopting the goal. The third plan is applicable when the car is not near the location and needs to drive toward it. In this case, the lane-keep assist is enabled, and the vehicle speed is set to 8 m/s, the desired cruising speed for the car. Again, the goal is readopted so that the car continues driving toward the location. Last is a default plan which keeps the car driving toward the location using recursion.
Listing 16: AirSim Car Driving Behaviours.
![Electronics 10 02136 l016]()
These plans are rule supported, using a set of rules, shown in Listing 17, for assessing if the car is near or at a location. There is also a rule for finding the nearest location to the car, which searches the map beliefs for the location with the smallest range to the current location of the car. There are also rules for calculating the destination range and the destination bearing. All of these rules use internal actions for calculating the range and bearing between locations.
Listing 17: AirSim Car Localization Rules.
![Electronics 10 02136 l017]()
Listing 18 provides the implementation of the speed controlling behaviours. First, the mental note of the speed setting is provided for when the agent starts and the car is not moving. This mental note allows the agent to remember the speed setting so that the cruise controller does not need to be reset needlessly. The behaviour belief identifies the behaviour type for the reasoner’s event selection function. Next is a plan for updating the speed setting if the speed needs to be changed. A plan is also provided for setting a speed setting in the event that one has not yet been specified or in case the mental note has been lost for some reason. The setSpeed(_) action is received by a cruise controller module which controls the accelerator and brake to maintain the speed of the car. The last plan in Listing 18 is the default plan, which is only applicable if the speed setting does not need to be changed.
Listing 18: AirSim Speed Control Behaviours.
![Electronics 10 02136 l018]()
Listing 19 provides the rules and plans for controlling the car’s steering. The first item in the listing is a belief with respect to magnetic declination, needed for converting a magnetic bearing to a true bearing. This course correction is used to calculate a steering setting using the rules which define the steering setting rules. The format of this predicate is steeringSetting(TargetBearing, SteeringSetting). These rules set the steering setting to the maximum magnitude when the course correction is greater than 20. If the magnitude is smaller, the steering setting is dampened by dividing it by 180, a crude but effective way of controlling the car’s steering. This is followed by a rule for using the lane-keep assist for steering the car. The lane-keep assist node provides a perception with a steering recommendation for the car, as well as parameters representing the slope and intercept points of the curbs on the road. If the lane is detected, these slopes are nonzero. If the lane is not detected, then this predicate is not available to the agent.
There are three steering plans in Listing 19, triggered on the addition of !control Steering(_,_). First, the behaviour belief identifying that these plans are movement-related, enabling the reasoner to properly prioritise this behaviour, is provided. The first steering plan is used for steering the car with magnetic bearing angles only. This is the case when the lane-keep assist is either disabled or the lane has not been detected by the lane-keep assist module. The second plan uses the lane-keep assist to follow the road. Lastly, there is a default plan, which is provided for completeness.
Listing 19: AirSim Car Steering Behaviours.
![Electronics 10 02136 l019]()
The Agent in a Box was successfully used for controlling the car simulated with AirSim. This was accomplished by steering the car using a combination of a lane-keep assist module and a magnetic bearing to the destination. The agent was also able to perform collision avoidance. The car agent made good use of the Agent in a Box, which enabled the development of the sensor and actuator nodes to be completed in isolation from the scope of the rest of the agent. A video of a navigation scenario is available on YouTube in [
58] along with another focusing on the lane-keep and collision avoidance behaviour is available in [
59].
4.4.3. Mail Delivery Robot
With the features of the Agent in a Box demonstrated in simulated environments, a third case study was completed with a prototype mail delivery robot for delivering mail in institutional settings. A prototype of this robot, building on previously published work [
60,
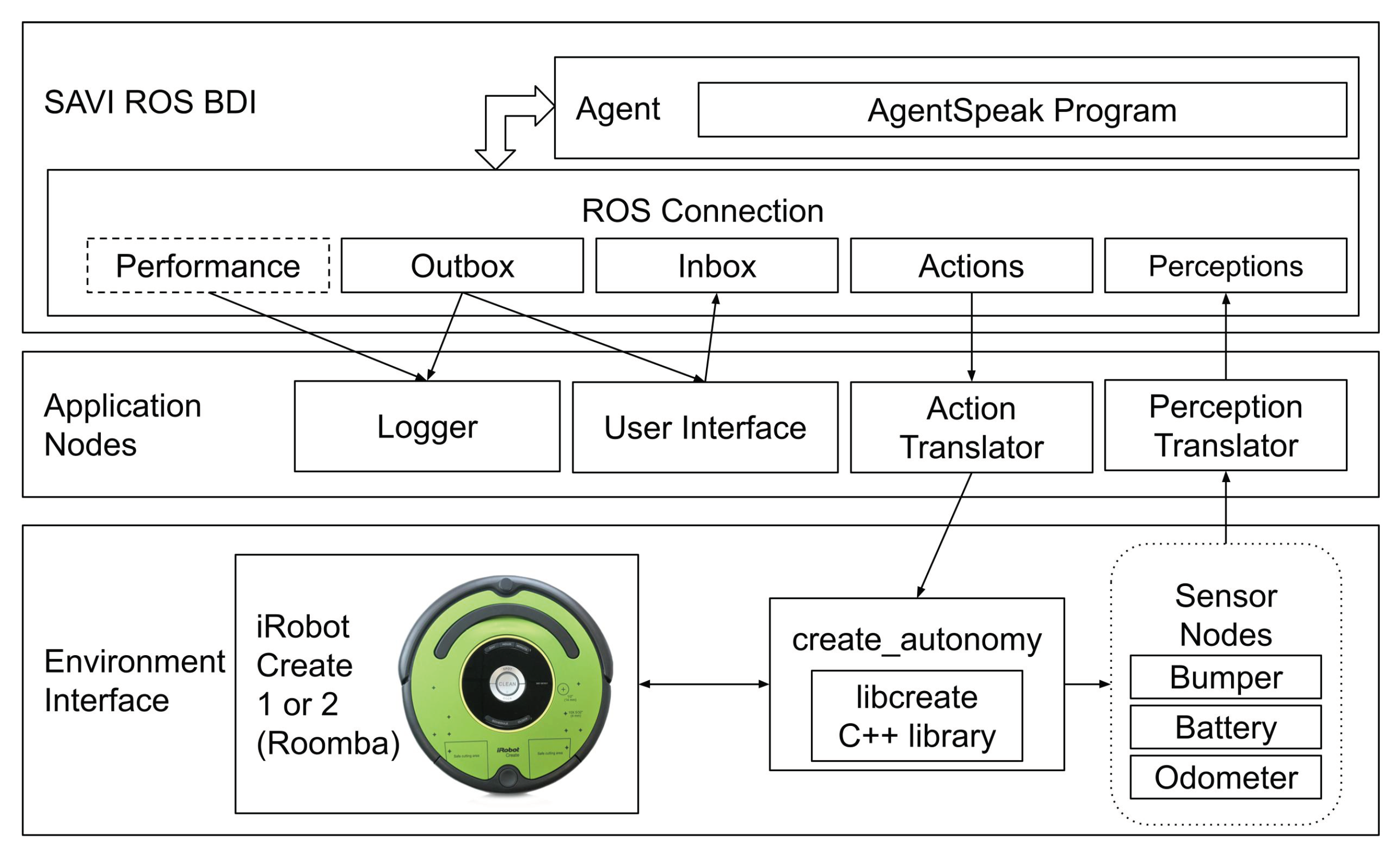
61], was implemented with an iRobot Create and a Raspberry Pi 4 computer, as shown in
Figure 13, and tested in a lab environment. The robot was controlled using the
create_autonomy node [
62], which acts as a connector for the robot to ROS, providing a variety of publishers of the robots various sensors, and a subscriber for its actuators. This work used the bumper sensor for collision detection, battery charge ratio, and the odometer for the robot’s wheels. The robot is controlled by sending parameters for the robot’s wheels, specifically the desired linear and rotational speed. The sensor data were provided to the reasoner in the form of perception predicates, formatted by the perception translator. The action translator generated the appropriate commands for the robot’s wheels from the action predicates provided by the agent. A user interface node provided the means for a user to command the robot to complete mail missions by specifying the locations of the sender and receiver on a predefined map. The software implantation of the mail delivery agent, used for controlling the robot, is available on GitHub [
63].
The mission for the agent controlling the mail robot is provided in Listing 20. This listing provides the implementation of the !mission(_,_) goal for mail missions that can be commanded by a user. The parameters specify the sender and receiver locations on the map. This plan adopts a mission related mental note and achieves the mail mission using the !collectAndDeliverMail(_,_) goal, which in turn uses the !collectMail(_) and !deliverMail(_) goals, also defined in the listing. There are two plans for collecting mail and two more plans for delivering mail using the !navigate(_) goal provided by the Agent in a Box. The first plan sends the robot to the sender’s location to collect the mail if the robot has not already collected it and the second is a default plan provided for the scenario where the robot already has the mail. Third is the plan for delivering mail that the robot has collected by moving to the receiver’s location. Last is another default plan for the scenario where there was no mail for the agent to deliver.
Listing 20: Mail Robot Mission Definition.
![Electronics 10 02136 l020]()
The map used by the mail robot was defined using a set of grid coordinates for various locations in the lab environment. These locations were defined in the same manner as the locations were defined for the grid agents, as shown in Listing 9. In addition to the definition of the map locations and possible movements between these locations, the map includes the successor state and heuristic rules used by the navigation plans, a rule for calculating the range between locations using Euclidean distance, and a rule for determining the location of the robot using the agent’s beliefs about the grid position and map location names. These are provided in Listing 21.
Listing 21: Mail Robot Map Rules.
![Electronics 10 02136 l021]()
With the mission and map defined, the agent needs the ability to move the robot. The Agent in a Box provides the !navigate(_) goal, which moves the agent to a specified destination location using a route obtained with A* search. The plans that achieve this goal move the agent between the locations using the domain-specific !waypoint(_) goal. The plans which implement this goal are provided in Listing 22. The listing provides three plans, one for stopping the agent with the drive(stop) action when the robot is at the location, a second for driving the robot toward the location using several subgoals and position belief updates, and finally a default plan.
Listing 22: Mail Robot Movement -Waypoint.
![Electronics 10 02136 l022]()
The subgoals used for moving the robot include the
!faceNext(_) goal, used for turning the robot to face the next location it will be moving to, and the
!drive(_) goal, which drives the robot linearly forward or backward. Excerpts of the plans and rules which implement these goals are provided in Listing 23. First, the listing provides the initial location of the robot and the direction that it is facing. This is followed by a plan which implements the achievement of the
!faceNext(_) goal using the
direction(_) belief and the
directionTonext(_) rule, which provides the direction that the agent needs to face to move to the next destination. A sample of this rule is provided for the scenario where the agent needs to face
e. The rules for the
w,
n, and
s directions have not been included in the listing to save space, however they are available on Github [
63]. The
!faceNext(_) triggered plan also uses a rule to determine the turn action parameter for turning the robot to face the required direction. The provided rule is for the case where the agent needs to turn to the left, although there are other rules needed for defining if the agent needs to turn to the right, turn around, or if there is no turn needed.
Listing 23: Mail Robot Movement - Excerpts of FaceNext.
![Electronics 10 02136 l023]()
There are two subgoals used for actually moving the robot: !turn(_) and !drive(_). The implementations of these are provided in Listing 24. The goal for turning the robot takes the direction of the turn as a parameter, either left, right, or around. These use the turnRate(X,Y) belief, which specifies the linear and rotational parameters for turning the robot approximately 45. To execute the turn, the agent adopts the !move(X,Y,N) goal, which sends the movement command to the robot N times. The plans for !drive(_) drives the robot forward or backward using the movement parameters specified in the driveRate(_,_) belief, also using the !move(_,_,N) goal, which is the last provided plan in the listing. The plan for this goal is implemented using recursion, using the movement action to control the robot and repeating the goal with a reduced counter after each iteration.
Listing 24: Mail Robot Movement - Turn, Drive, and Move.
![Electronics 10 02136 l024]()
With the plans for supporting the agent’s movement defined, there is a need to provide the agent with the plans needed for obstacle avoidance and for maintenance of the robot’s battery. The Agent in a Box provides support for this functionality by prioritising it over the agent’s other activities. The obstacle avoidance for this agent is provided in Listing 25. The obstacle avoidance is a reactive behaviour implemented using a belief-triggered plan. This is triggered when the the robot’s bumper sensor is activated. The resulting actions are to turn the robot to the left and attempt to the move the robot in an arc around the obstacle before turning to its original direction. As this is implemented as an atomic plan, the agent runs this plan to completion before moving to other activities.
Listing 25: Mail Robot Obstacle Avoidance.
![Electronics 10 02136 l025]()
The final aspect of the agent’s behaviour is the need for the agent to recharge the robot when it runs low on power. This was accomplished by providing the agent with the resource perceptions and actions for docking and undocking the robot that are expected by the Agent in a Box. By doing so, the agent can send the robot to the charging station when the battery needs to be recharged.
The Agent in a Box was successful at controlling the prototype mail delivery robot. Videos of the robot are available on Youtube [
64,
65,
66].
4.4.4. Implementation Summary
The details of how the Agent in a Box can be used to control mobile robots in three environments have been provided. These environments included a grid-based environment, an autonomous car using AirSim, and a prototype mail delivery robot implemented with an iRobot Create and a Raspberry Pi. Using the framework’s provided behaviours for mission management, navigation, map update, and resource management, all that was needed to complete the agent behaviour was to add domain-specific plans for movement and obstacle avoidance. For connecting the agent to the environment, the asynchronous grid environment, the car, and the mail robot all used ROS and the Agent in a Box approach, with sensor nodes, actuator nodes, and translator nodes. This design provided a consistent design for connecting the agent to the environment.




















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}