
Quantitative Analysis and Performance Evaluation of Target-Oriented Replication Strategies in Cloud Computing

 ,
,
Abstract
:1. Introduction
1.1. Background
1.1.1. Data Replication in Clouds
1.1.2. The Need for Data Replication
1.1.3. Research Motivation
1.1.4. Paper Organization
2. Research Methodology Used
2.1. Research Questions
2.2. Sources of Information
2.3. Search Criteria
2.4. Quality Assessment
- Clearly describes target objectives of replication strategies for cloud computing.
- Peer-reviewed articles in the English language.
- Articles published in reputable journals, conferences, and magazines.
- Articles published from 2011 to 2019.
- Does not focus on dynamic replication strategies in the cloud.
- Articles that are not related to the research questions.
- Articles whose full text is not available.
- Articles that have common challenges and references.
2.5. Review Phases
- First of all, the articles were searched based on defined keywords (mentioned in search criteria) and were initially found to be 109 articles in total.
- Then, articles were excluded that do not meet inclusion, exclusion criteria. This criterion minimizes our article search to 53 articles.
- Then, research question objectives were used for further filtration of articles. This criterion also minimizes our article search to 28.
- Finally, articles were evaluated based on full paper reading and the total papers finalized for this research were 22.
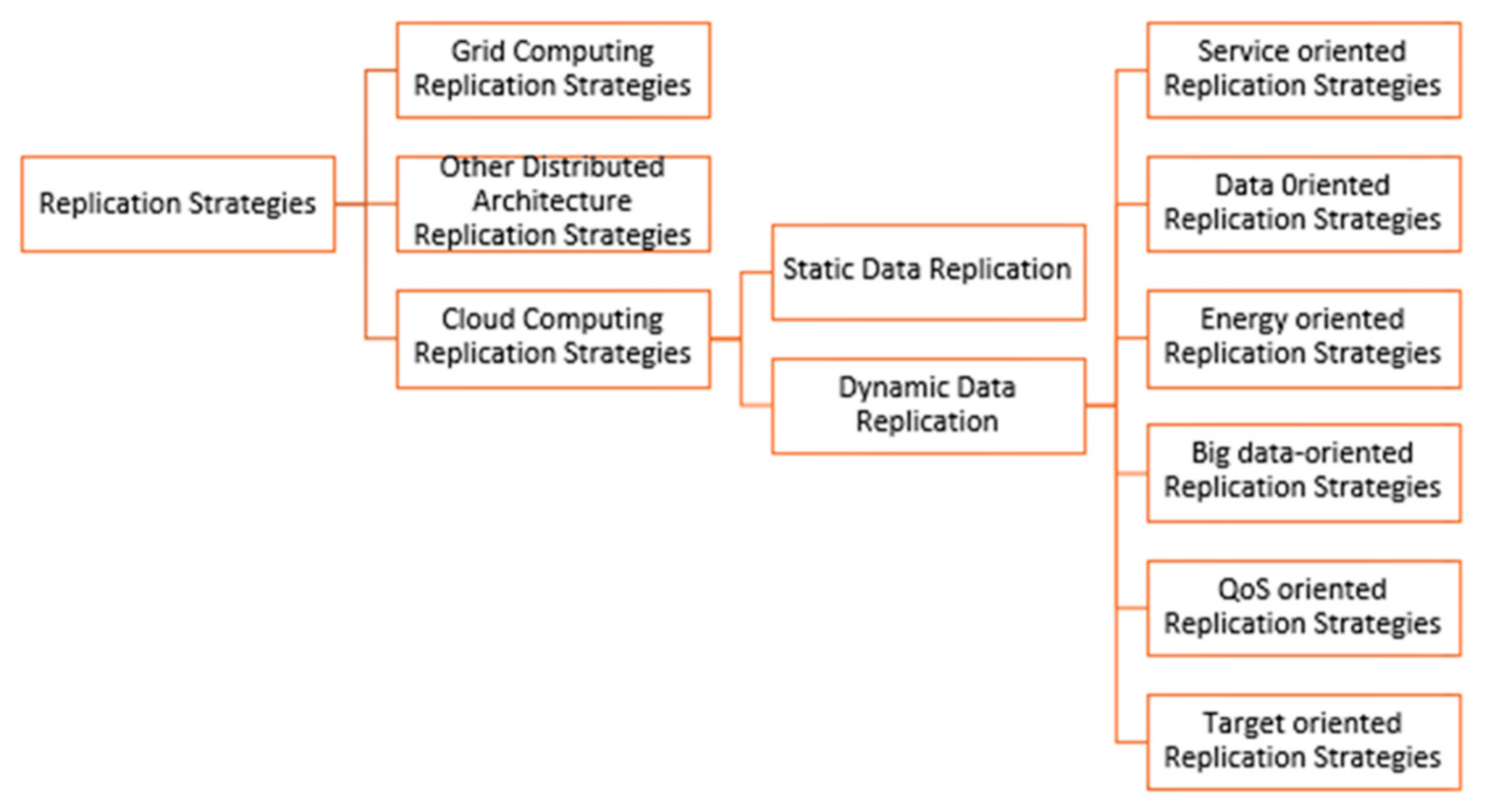
3. Data Replication Strategies
3.1. Grid Computing Replication Strategies
Related Surveys
3.2. Other Distributed Architecture-Based Replication Strategies
Related Surveys
3.3. Cloud Computing Replication Strategies
Related Surveys
4. Dynamic Cloud Computing Replication Strategies Taxonomy
- Service-oriented replication strategies;
- Data-oriented replication strategies;
- Energy-oriented replication strategies;
- Big data-oriented replication strategies;
- Quality of service (QoS)-oriented replication strategies; and
- Target-oriented replication strategies.
4.1. Service-Oriented Replication Strategies
Related Surveys
4.2. Data-Oriented Replication Strategies
Related Surveys
4.3. Energy-Oriented Replication Strategies
Related Surveys
4.4. Big Data-Oriented Replication Strategies
Related Surveys
4.5. QoS-Oriented Replication Strategies
Related Surveys
4.6. Target-Oriented Replication Strategies
4.6.1. Taxonomy of Target Oriented Replication Strategies
4.6.2. Target Objectives of Target-Oriented Replication Strategies
Availability
Reliability
Performance
Fault Tolerance
Load Balancing
Scalability
Elasticity
Consistency
Cost
4.6.3. Target Objectives and Their Relationship with Parameters
4.6.4. Quantitative Analysis of Target-Oriented Replication Strategies
5. Performance Evaluation of Target-Oriented Replication Strategies: Comparison and Evaluation
5.1. Features of Target Objectives for Target-Oriented Replication Strategies in Cloud
5.2. Performance Evaluation Understanding
6. Challenges for Replication Strategies in Clouds
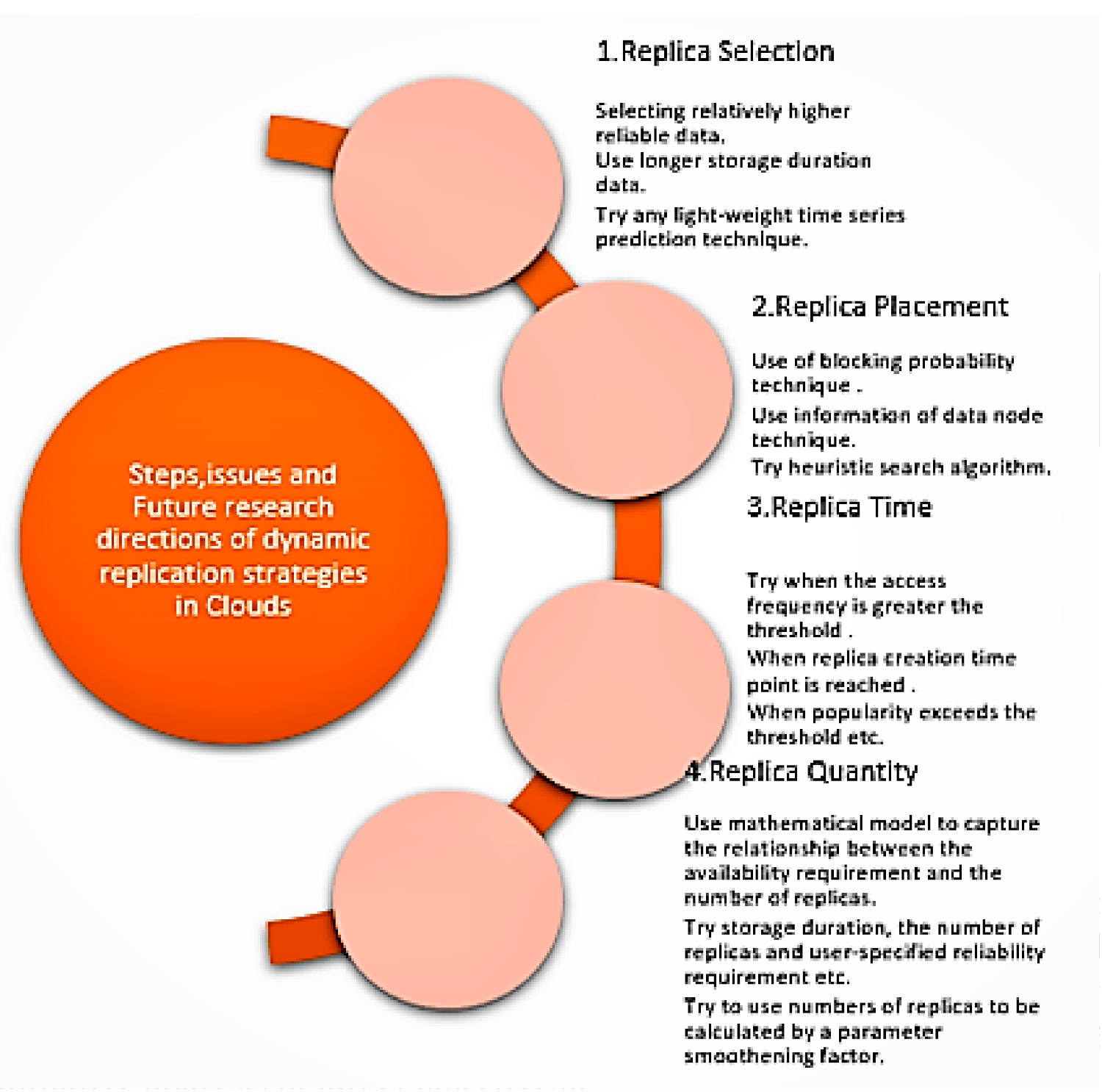
6.1. Challenges of Dynamic Replication Strategies in Clouds
6.1.1. Replica Selection
6.1.2. Replica Placement
6.1.3. Replica Time
6.1.4. Replica Quantity
7. Least Addressed Target Objective of Target-Oriented Replication Strategies in Clouds, Their Challenges, Issues, and Future Research Directions
7.1. Scalability: Challenges and Issues
Future Research Directions for Scalability
7.2. Elasticity: Challenges and Issues
Future Research Directions for Elasticity
7.3. Consistency: Challenges and Issues
Future Research Directions for Consistency
7.4. Cost: Challenges and Issues
8. Discussion
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hameed, A.; Khoshkbarforoushha, A.; Ranjan, R.; Jayaraman, P.P.; Kolodziej, J.; Balaji, P.; Zeadally, S.; Malluhi, Q.M.; Tziritas, N.; Vishnu, A.; et al. A survey and taxonomy on energy efficient resource allocation techniques for cloud computing systems. Computing 2014, 98, 751–774. [Google Scholar] [CrossRef]
- Yavari, M.; Rahbar, A.G.; Fathi, M.H. Temperature and energy-aware consolidation algorithms in cloud computing. J. Cloud Comput. 2019, 8, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Mansouri, N.; Rafsanjani, M.K.; Javidi, M. DPRS: A dynamic popularity aware replication strategy with parallel download scheme in cloud environments. Simul. Model. Pract. Theory 2017, 77, 177–196. [Google Scholar] [CrossRef]
- Ebadi, Y.; Navimipour, N.J. An energy-aware method for data replication in the cloud environments using a Tabu search and particle swarm optimization algorithm. Concurr. Comput. Pract. Exp. 2019, 31, e4757. [Google Scholar] [CrossRef] [Green Version]
- Milani, B.A.; Nima, J.N. A comprehensive review of the data replication techniques in the cloud environments: Major trends and future directions. J. Netw. Comput. Appl. 2016, 64, 229–238. [Google Scholar] [CrossRef]
- Zhao, L.; Sakr, S.; Liu, A.; Bouguettaya, A. SLA-Driven Database Replication on Virtualized Database Servers. In Cloud Data Management; Springer: Cham, Swizterland, 2014; pp. 97–118. [Google Scholar]
- Malik, S.U.R.; Khan, S.U.; Ewen, S.J.; Tziritas, N.; Kolodziej, J.; Zomaya, A.Y.; Li, H. Performance analysis of data intensive cloud systems based on data management and replication: A survey. Distrib. Parallel Databases 2016, 34, 179–215. [Google Scholar] [CrossRef]
- Ikeda, T.; Ohara, M.; Fukumoto, S.; Arai, M.; Iwasaki, K. A Distributed Data Replication Protocol for File Versioning with Optimal Node Assignments. In Proceedings of the 2010 IEEE 16th Pacific Rim International Symposium on Dependable Computing, Tokyo, Japan, 13–15 December 2010; pp. 117–124. [Google Scholar]
- Lin, J.-W.; Chen, C.-H.; Chang, J.M. QoS-aware data replication for data-intensive applications in cloud computing systems. IEEE Trans. Cloud Comput. 2013, 1, 101–115. [Google Scholar]
- Fazilina, A.; Latip, R.; Ibrahim, H.; Abdullah, A. A Review: Replication Strategies for Big Data in Cloud Environment. Int. J. Eng. Technol. 2018, 7, 357–362. [Google Scholar]
- Tomar, D.; Tomar, P. Integration of Cloud Computing and Big Data Technology for Smart Generation. In Proceedings of the 2018 8th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 11–12 January 2018; pp. 1–6. [Google Scholar]
- Xia, Q.; Liang, W.; Xu, Z. QoS-Aware data replications and placements for query evaluation of big data analytics. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar]
- Gopinath, S.; Sherly, E. A Weighted Dynamic Data Replication Management for Cloud Data Storage Systems. Int. J. Appl. Eng. Res. 2017, 12, 15517–15524. [Google Scholar]
- Li, Y.; Yu, M.; Xu, M.; Yang, J.; Sha, D.; Liu, Q.; Yang, C. Big Data and Cloud Computing. In Manual of Digital Earth; Guo, H., Goodchild, M.F., Annoni, A., Eds.; Springer: Singapore, 2020. [Google Scholar]
- Das, M.; Dash, R. Role of Cloud Computing for Big Data: A Review. In Intelligent and Cloud Computing. Smart Innovation, Systems and Technologies; Mishra, D., Buyya, R., Mohapatra, P., Patnaik, S., Eds.; Springer: Singapore, 2021. [Google Scholar]
- Khan, S.; Shakil, K.A.; Alam, M.; Aggarwal, V.B.; Bhatnagar, V.; Mishra, D.K. Cloud-Based Big Data Analytics—A Survey of Current Research and Future Directions. Adv. Intell. Syst. Comput. 2017, 595–604. [Google Scholar] [CrossRef] [Green Version]
- Kobusińska, A.; Leung, C.; Hsu, C.-H.; Raghavendra, S.; Chang, V. Emerging trends, issues and challenges in Internet of Things, Big Data and cloud computing. Futur. Gener. Comput. Syst. 2018, 87, 416–419. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big Data and cloud computing: Innovation opportunities and challenges. Int. J. Digit. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef] [Green Version]
- Rao, T.R.; Mitra, P.; Bhatt, R.; Goswami, A. The big data system, components, tools, and technologies: A survey. Knowl. Inf. Syst. 2019, 60, 1165–1245. [Google Scholar] [CrossRef]
- Nachiappan, R.; Javadi, B.; Calheiros, R.N.; Matawie, K.M. Cloud storage reliability for Big Data applications: A state of the art survey. J. Netw. Comput. Appl. 2017, 97, 35–47. [Google Scholar] [CrossRef]
- Hashem IA, T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Aceto, G.; Persico, V.; Pescapé, A. Industry 4.0 and Health: Internet of Things, Big Data, and Cloud Computing for Healthcare 4.0. J. Ind. Inf. Integr. 2020, 18, 100129. [Google Scholar] [CrossRef]
- Tahir, A.; Chen, F.; Khan, H.U.; Ming, Z.; Ahmad, A.; Nazir, S.; Shafiq, M. A Systematic Review on Cloud Storage Mechanisms Concerning e-Healthcare Systems. Sensors 2020, 20, 5392. [Google Scholar] [CrossRef] [PubMed]
- Shorfuzzaman, M.; Masud, M. Leveraging A Multi-Objective Approach to Data Replication in Cloud Computing Environment to Support Big Data Applications. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef]
- Gopinath, S.; Sherly, E. A Comprehensive Survey on Data Replication Techniques in Cloud Storage Systems. Int. J. Appl. Eng. Res. 2018, 13, 15926–15932. [Google Scholar]
- Chihoub, H.-E.; Ibrahim, S.; Antoniu, G.; Pérez, M.S. Harmony: Towards Automated Self-Adaptive Consistency in Cloud Storage. In Proceedings of the 2012 IEEE International Conference on Cluster Computing, Beijing, China, 24–28 September 2012; pp. 293–301. [Google Scholar]
- Azimi, k.S. A Bee Colony (Beehive) based approach for data replication in cloud environments. In Fundamental Research in Electrical Engineering: The Selected Papers of The First International Conference on Fundamental Research in Electrical Engineering; Springer: Singapore, 2019; pp. 1039–1052. [Google Scholar]
- Boru, D.; Kliazovich, D.; Granelli, F.; Bouvry, P.; Zomaya, A.Y. Energy-efficient data replication in cloud computing datacenters. Clust. Comput. 2015, 18, 385–402. [Google Scholar] [CrossRef]
- Abadi, D.J. Data management in the cloud: Limitations and opportunities. IEEE Data Eng. Bull. 2009, 32, 3–12. [Google Scholar]
- Amjad, T.; Sher, M.; Daud, A. A survey of dynamic replication strategies for improving data availability in data grids. Futur. Gener. Comput. Syst. 2012, 28, 337–349. [Google Scholar] [CrossRef]
- Karandikar, R.; Manish, G. Analytical Survey of Dynamic Replication Strategies in Cloud. In Proceedings of the IJCA-National Conference on Recent Trends in Computer Science and Information Technology, Nagpur, India, 1–5 June 2016. [Google Scholar]
- Hamrouni, T.; Sarra, S.; Charrada, F.B. A survey of dynamic replication and replica selection strategies based on data mining techniques in data grids. Eng. Appl. Artif. Intell. 2016, 48, 140–158. [Google Scholar] [CrossRef]
- Pan, S.; Xiong, L.; Xu, Z.; Chong, Y.; Meng, Q. A dynamic replication management strategy in distributed GIS. Comput. Geosci. 2018, 112, 1–8. [Google Scholar] [CrossRef]
- Goel, S.; Rajkumar, B. Data replication strategies in wide-area distributed systems. In Enterprise Service Computing: From Concept to Deployment; IGI Global: Hershey, PA, USA, 2007; pp. 211–241. [Google Scholar]
- Milani, B.A.; Navimipour, N.J. A Systematic Literature Review of the Data Replication Techniques in the Cloud Environments. Big Data Res. 2017, 10, 1–7. [Google Scholar] [CrossRef]
- Warhade, S.; Dahiwale, P.; Raghuwanshi, M. A Dynamic Data Replication in Grid System. Procedia Comput. Sci. 2016, 78, 537–543. [Google Scholar] [CrossRef] [Green Version]
- Naseera, S. A survey on data replication strategies in a Data Grid environment. Multiagent Grid Syst. 2017, 12, 253–269. [Google Scholar] [CrossRef]
- Vashisht, P.; Anju, S.; Rajesh, K. Strategies for replica consistency in data grid–A comprehensive survey. Concurr. Comput. Pract. Exp. 2017, 29, e3907. [Google Scholar] [CrossRef]
- Tos, U.; Mokadem, R.; Hameurlain, A.; Ayav, T.; Bora, S. Dynamic replication strategies in data grid systems: A survey. J. Supercomput. 2015, 71, 4116–4140. [Google Scholar] [CrossRef] [Green Version]
- Hamrouni, T.; Slimani, S.; Ben Charrada, F. A Critical Survey of Data Grid Replication Strategies Based on Data Mining Techniques. Procedia Comput. Sci. 2015, 51, 2779–2788. [Google Scholar] [CrossRef] [Green Version]
- Mansouri, N.; Javidi, M.M. A Survey of Dynamic Replication Strategies for Improving Response Time in Data Grid Environment. Amirkabir Int. J. ModelingIdentif. Simul. Control 2017, 49, 239–264. [Google Scholar]
- Souravlas, S.; Sifaleras, A. Trends in data replication strategies: A survey. Int. J. Parallel Emergent Distrib. Syst. 2019, 34, 222–239. [Google Scholar] [CrossRef]
- Vashisht, P.; Kumar, V.; Kumar, R.; Sharma, A. Optimizing Replica Creation using Agents in Data Grids. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 542–547. [Google Scholar]
- Hamrouni, T.; Hamdeni, C.; Ben Charrada, F. Objective assessment of the performance of data grid replication strategies based on distribution quality. Int. J. Web Eng. Technol. 2016, 11, 3–28. [Google Scholar] [CrossRef]
- Hamrouni, T. Replication in Data Grids: Metrics and Strategies. arXiv 2019, arXiv:1912.10171. [Google Scholar]
- Lwin, T.K.; Alexander, B. Real time analysis of data grid processing for future technology. In Proceedings of the International Conference on Computer Science and Information Technologies, Yerevan, Armenia, 23–27 September 2019; pp. 53–54. [Google Scholar]
- Salah, T.; Zemerly, M.J.; Yeun, C.Y.; Al-Qutayri, M.; Al-Hammadi, Y. The evolution of distributed systems towards microservices architecture. In Proceedings of the 2016 11th International Conference for Internet Technology and Secured Transactions (ICITST), Barcelona, Spain, 22 April 2016; pp. 318–325. [Google Scholar]
- Mokadem, R.; Hameurlain, A. Data replication strategies with performance objective in data grid systems: A survey. Int. J. Grid Util. Comput. 2015, 6, 30. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Clarke, K.; Shekhar, S.; Tao, C.V. Big Spatiotemporal Data Analytics: A research and innovation frontier. Int. J. Geogr. Inf. Sci. 2019, 34, 1075–1088. [Google Scholar] [CrossRef] [Green Version]
- Spaho, E.; Barolli, L.; Xhafa, F. Data Replication Strategies in P2P Systems: A Survey. In Proceedings of the 2014 17th International Conference on Network-Based Information Systems, Salerno, Italy, 10–12 September 2014; pp. 302–309. [Google Scholar]
- Sun, S.; Yao, W.; Qiao, B.; Zong, M.; He, X.; Li, X. RRSD: A file replication method for ensuring data reliability and reducing storage consumption in a dynamic Cloud-P2P environment. Futur. Gener. Comput. Syst. 2019, 100, 844–858. [Google Scholar] [CrossRef]
- Tabet, K.; Mokadem, R.; Laouar, M.R. A data replication strategy for document-oriented NoSQL systems. Int. J. Grid Util. Comput. 2019, 10, 53–62. [Google Scholar] [CrossRef]
- Wang, S.; Batiha, K. A metaheuristic-based method for replica selection in the Internet of Things. Int. J. Commun. Syst. 2020, 33, e4458. [Google Scholar] [CrossRef]
- Lazeb, A.; Mokadem, R.; Belalem, G. Towards a New Data Replication Management in Cloud Systems. Int. J. Strat. Inf. Technol. Appl. 2019, 10, 1–20. [Google Scholar] [CrossRef]
- Abdollahi, N.A.; Rajabion, L. Data replication techniques in the mobile ad hoc networks: A systematic and comprehensive review. Int. J. Pervasive Comput. Commun. 2019, 15, 174–198. [Google Scholar] [CrossRef]
- Nassif, A.B.; Abu Talib, M.; Nasir, Q.; Albadani, H.; Dakalbab, F.M. Machine Learning for Cloud Security: A Systematic Review. IEEE Access 2021, 9, 20717–20735. [Google Scholar] [CrossRef]
- Pan, Q.; Wu, J.; Zheng, X.; Li, J.; Li, S.; Vasilakos, A.V. Leveraging AI and Intelligent Reflecting Surface for Energy-Efficient Communication in 6G IoT. arXiv 2020, arXiv:2012.14716. [Google Scholar]
- Hasenburg, J.; Grambow, M.; Bermbach, D. Towards a replication service for data-intensive fog applications. In Proceedings of the 35th Annual ACM Symposium on Applied Computing; Association for Computing Machinery (ACM), Brno, Czech Republic, 30 March–3 April 2019; pp. 267–270. [Google Scholar]
- Liu, X.; Xie, L.; Wang, Y.; Zou, J.; Xiong, J.; Ying, Z.; Vasilakos, A.V. Privacy and Security Issues in Deep Learning: A Survey. IEEE Access 2021, 9, 4566–4593. [Google Scholar] [CrossRef]
- Hamdan, M.; Hassan, E.; Abdelaziz, A.; Elhigazi, A.; Mohammed, B.; Khan, S.; Vasilakos, A.V.; Marsono, M. A comprehensive survey of load balancing techniques in software-defined network. J. Netw. Comput. Appl. 2021, 174, 102856. [Google Scholar] [CrossRef]
- Ni, J.; Zhang, K.; Vasilakos, A.V. Security and Privacy for Mobile Edge Caching: Challenges and Solutions. IEEE Wirel. Commun. 2020, 1–7. [Google Scholar] [CrossRef]
- Mansouri, N.; Javidi, M.M.; Zade, B.M.H. A CSO-based approach for secure data replication in cloud computing environment. J. Supercomput. 2020, 1–52. [Google Scholar] [CrossRef]
- Alam, M.; Mazliham, M.; Yeakub, M. A Survey of Machine Learning Algorithms in Cloud Computing. In The Perspective of Network Data Replication Decision; UniKL Postgraduate Symposium: Kuala Lumpur, Malaysia, 2013. [Google Scholar]
- Kale, R.V.; Veeravalli, B.; Wang, X. A Practicable Machine Learning Solution for Security-Cognizant Data Placement on Cloud Platforms. In Handbook of Computer Networks and Cyber Security; Springer: Cham, Switzerland, 2020; pp. 111–131. [Google Scholar]
- Tabet, K.; Mokadem, R.; Laouar, M.R.; Eom, S. Data replication in cloud systems: A survey. Int. J. Inf. Syst. Soc. Chang. 2017, 8, 17–33. [Google Scholar] [CrossRef]
- Bhuvaneswari, R.; Ravi, T. A Review of Static and Dynamic Data Replication Mechanisms for Distributed Systems. Int. J. Comput. Sci. Eng. 2018, 6, 953–964. [Google Scholar] [CrossRef]
- Edwin, E.B.; Umamaheswari, P.; Thanka, M.R. An efficient and improved multi-objective optimized replication management with dynamic and cost aware strategies in cloud computing data center. Clust. Comput. 2017, 22, 11119–11128. [Google Scholar] [CrossRef]
- Mealha, D.; Preguiça, N.; Gomes, M.C.; Leitão, J. Data Replication on the Cloud/Edge. In Proceedings of the 6th Workshop on Principles and Practice of Consistency for Distributed Data—PaPoC’19, Dresden Germany, 28–25 March 2019; pp. 1–7. [Google Scholar]
- Saranya, N.; Geetha, K.; Rajan, C. Data Replication in Mobile Edge Computing Systems to Reduce Latency in Internet of Things. Wirel. Pers. Commun. 2020, 112, 2643–2662. [Google Scholar] [CrossRef]
- Atrey, A.; Van Seghbroeck, G.; Mora, H.; De Turck, F.; Volckaert, B. Unifying Data and Replica Placement for Data-intensive Services in Geographically Distributed Clouds. In Proceedings of the Proceedings of the 9th International Conference on Cloud Computing and Services Science, Heraklion, Greece, 2–4 May 2019; pp. 25–36. [Google Scholar]
- Lazeb, A.; Mokadem, R.; Belalem, G. Economic Data Replication Management in the Cloud. In JERI; Saida, Algeria, 27 April 2019. Available online: https://www.semanticscholar.org/paper/Economic-Data-Replication-Management-in-the-Cloud-Lazeb-Mokadem/49a10747912ff82f69d5685ed4181751e92aa9a8 (accessed on 9 March 2021).
- Slimani, S.; Hamrouni, T.; Ben Charrada, F.; Magoules, F. DDSoR: A Dependency Aware Dynamic Service Replication Strategy for Efficient Execution of Service-Oriented Applications in the Cloud. In Proceedings of the 2017 International Conference on High Performance Computing & Simulation (HPCS), Genoa, Italy, 17–21 July 2017; pp. 603–610. [Google Scholar]
- Slimani, S.; Hamrouni, T.; Ben Charrada, F. Service-oriented replication strategies for improving quality-of-service in cloud computing: A survey. Clust. Comput. 2021, 24, 361–392. [Google Scholar] [CrossRef]
- Mohamed, M.F. Service replication taxonomy in distributed environments. Serv. Oriented Comput. Appl. 2016, 10, 317–336. [Google Scholar] [CrossRef]
- Björkqvist, M.F.; Chen, L.Y.; Binder, W. Dynamic Replication in Service-Oriented Systems. In Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (Ccgrid 2012), Ottawa, ON, Canada, 13–16 May 2012; pp. 531–538. [Google Scholar]
- Wu, J.; Zhang, B.; Yang, L.; Wang, P.; Zhang, C. A replicas placement approach of component services for service-based cloud application. Clust. Comput. 2016, 19, 709–721. [Google Scholar] [CrossRef]
- Chen, T.; Bahsoon, R.; Tawil, A.-R.H. Scalable service-oriented replication with flexible consistency guarantee in the cloud. Inf. Sci. 2014, 264, 349–370. [Google Scholar] [CrossRef] [Green Version]
- Tos, U.; Mokadem, R.; Hameurlain, A.; Ayav, T.; Bora, S. A Performance and Profit Oriented Data Replication Strategy for Cloud Systems. In Proceedings of the 2016 International IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016; pp. 780–787. [Google Scholar]
- Mesbahi, M.; Rahmani, A.M. Load Balancing in Cloud Computing: A State of the Art Survey. Int. J. Mod. Educ. Comput. Sci. 2016, 8, 64–78. [Google Scholar] [CrossRef] [Green Version]
- You, X.; Li, Y.; Zheng, M.; Zhu, C.; Yu, L. A Survey and Taxonomy of Energy Efficiency Relevant Surveys in Cloud-Related Environments. IEEE Access 2017, 5, 14066–14078. [Google Scholar] [CrossRef]
- Ali, S.A.; Affan, M.; Alam, M. A study of efficient energy management techniques for cloud computing environment. arXiv 2018, arXiv:1810.07458. [Google Scholar]
- Huang, H.; Hung, W.; Shin, K.G. FS2: Dynamic data replication in free disk space for improving disk performance and energy consumption. Acm Sigops Oper. Syst. Rev. 2005, 39, 263–276. [Google Scholar] [CrossRef]
- Singh, L.; Malhotra, J. A Survey on Data Placement Strategies for Cloud based Scientific Workflows. Int. J. Comput. Appl. 2016, 141, 30–33. [Google Scholar] [CrossRef]
- Wei, Q.; Veeravalli, B.; Gong, B.; Zeng, L.; Feng, D. CDRM: A Cost-Effective Dynamic Replication Management Scheme for Cloud Storage Cluster. In Proceedings of the 2010 IEEE International Conference on Cluster Computing; Institute of Electrical and Electronics Engineers (IEEE), Heraklion, Greece, 20–24 September 2010; pp. 188–196. [Google Scholar]
- Mansouri, N.; Javidi, M.M. A review of data replication based on meta-heuristics approach in cloud computing and data grid. Soft Comput. 2020, 24, 1–28. [Google Scholar] [CrossRef]
- Cheng, Z.; Luan, Z.; Meng, Y.; Xu, Y.; Qian, D.; Roy, A.; Zhang, N.; Guan, G. ERMS: An Elastic Replication Management System for HDFS. In Proceedings of the 2012 IEEE International Conference on Cluster Computing Workshops, Beijing, China, 24–28 September 2012; pp. 32–40. [Google Scholar]
- Bui, D.-M.; Hussain, S.; Huh, E.-N.; Lee, S. Adaptive Replication Management in HDFS Based on Supervised Learning. IEEE Trans. Knowl. Data Eng. 2016, 28, 1369–1382. [Google Scholar] [CrossRef]
- Qu, K.; Meng, L.; Yang, Y. A dynamic replica strategy based on Markov model for hadoop distributed file system (HDFS). In Proceedings of the 2016 4th International Conference on Cloud Computing and Intelligence Systems (CCIS), Beijing, China, 17–19 August 2016; pp. 337–342. [Google Scholar]
- Kousiouris, G.; Vafiadis, G.; Varvarigou, T. Enabling Proactive Data Management in Virtualized Hadoop Clusters Based on Predicted Data Activity Patterns. In Proceedings of the 2013 Eighth International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, Compiegne, France, 28–30 October 2013; pp. 1–8. [Google Scholar]
- Rimal, B.P.; Jukan, A.; Katsaros, D.; Goeleven, Y. Architectural Requirements for Cloud Computing Systems: An Enterprise Cloud Approach. J. Grid Comput. 2011, 9, 3–26. [Google Scholar] [CrossRef]
- Zhang, T. A QoS-enhanced data replication service in virtualised cloud environments. Int. J. Netw. Virtual Organ. 2020, 22, 1–16. [Google Scholar] [CrossRef]
- Faraidoon, H.; Nagesh, K. A brief survey on dynamic strategies of data replication in cloud environment: Last five year study. Int. J. Eng. Dev. Res. 2017, 5, 342–345. [Google Scholar]
- Zia, A.; Khan, M.N.A. Identifying Key Challenges in Performance Issues in Cloud Computing. Int. J. Mod. Educ. Comput. Sci. 2012, 4, 59–68. [Google Scholar] [CrossRef] [Green Version]
- Xia, Q.; Bai, L.; Liang, W.; Xu, Z.; Yao, L.; Wang, L. Qos-aware proactive data replication for big data analytics in edge clouds. In Proceedings of the 48th International Conference on Parallel Processing: Workshops, Kyoto, Japan, 5–8 August 2019; pp. 1–10. [Google Scholar]
- Xia, Q.; Xu, Z.; Liang, W.; Yu, S.; Guo, S.; Zomaya, A.Y. Efficient Data Placement and Replication for QoS-Aware Approximate Query Evaluation of Big Data Analytics. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2677–2691. [Google Scholar] [CrossRef]
- Kumar, P.J.; Ilango, P. BMAQR: Balanced multi attribute QoS aware replication in HDFS. Int. J. Internet Technol. Secur. Trans. 2018, 8, 195–208. [Google Scholar] [CrossRef]
- Chauhan, N.; Tripathi, S.P. QoS Aware Replica Control Strategies for Distributed Real Time Database Management System. Wirel. Pers. Commun. 2018, 104, 739–752. [Google Scholar] [CrossRef]
- Long, S.-Q.; Zhao, Y.-L.; Chen, W. MORM: A Multi-objective Optimized Replication Management strategy for cloud storage cluster. J. Syst. Arch. 2014, 60, 234–244. [Google Scholar] [CrossRef]
- Xie, F.; Yan, J.; Shen, J. Towards Cost Reduction in Cloud-Based Workflow Management through Data Replication. In Proceedings of the 2017 Fifth International Conference on Advanced Cloud and Big Data (CBD), Shanghai, China, 13–14 August 2017; pp. 94–99. [Google Scholar]
- Li, W.; Yang, Y.; Yuan, D. A Novel Cost-Effective Dynamic Data Replication Strategy for Reliability in Cloud Data Centres. In Proceedings of the 2011 IEEE Ninth International Conference on Dependable, Autonomic and Secure, Sydney, NSW, Australia, 12–14 December 2011; pp. 496–502. [Google Scholar]
- Sun, D.-W.; Chang, G.-R.; Gao, S.; Jin, L.-Z.; Wang, X.-W. Modeling a Dynamic Data Replication Strategy to Increase System Availability in Cloud Computing Environments. J. Comput. Sci. Technol. 2012, 27, 256–272. [Google Scholar] [CrossRef]
- Li, W.; Yang, Y.; Yuan, D. Ensuring Cloud Data Reliability with Minimum Replication by Proactive Replica Checking. IEEE Trans. Comput. 2015, 65, 1494–1506. [Google Scholar] [CrossRef]
- Chihoub, H.-E.; Ibrahim, S.; Antoniu, G.; Perez, M.S. Consistency in the Cloud: When Money Does Matter! In Proceedings of the 2013 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing, Delft, The Netherlands, 13–16 May 2013; pp. 352–359. [Google Scholar]
- Hussein, M.-K.; Mousa, M. A light-weight data replication for cloud data centers environment. Int. J. Eng. Innov. Technol. 2012, 1, 169–175. [Google Scholar]
- Radi, M. Runtime Replica Consistency Mechanism for Cloud Data Storage. In Proceedings of the International Conference on Information & Communication Technology: Application & Techniques (ICICT 2012), Ramallah, Palestine, 16–17 April 2012. [Google Scholar]
- Phansalkar, S.P.; Dani, A.R. Tunable consistency guarantees of selective data consistency model. J. Cloud Comput. 2015, 4, 13. [Google Scholar] [CrossRef] [Green Version]
- Gill, N.K.; Singh, S. A dynamic, cost-aware, optimized data replication strategy for heterogeneous cloud data centers. Futur. Gener. Comput. Syst. 2016, 65, 10–32. [Google Scholar] [CrossRef]
- Bai, X.; Jin, H.; Liao, X.; Shi, X.; Shao, Z. RTRM: A Response Time-Based Replica Management Strategy for Cloud Storage System. In Proceedings of the Constructive Side-Channel Analysis and Secure Design, Paris, France, 6–8 March 2013; pp. 124–133. [Google Scholar]
- Kirubakaran, S.; Valarmathy, S.; Kamalanathan, C. Data replication using modified D2RS in cloud computing for performance improvement. J. Theor. Appl. Inf. Technol. 2013, pp, 460–470. [Google Scholar]
- Rajalakshmi, A.; Vijayakumar, D.; Srinivasagan, K.G. An improved dynamic data replica selection and placement in cloud. In Proceedings of the 2014 International Conference on Recent Trends in Information Technology, Chennai, India, 10–12 April 2014; pp. 1–6. [Google Scholar]
- Xue, M.; Jing, S.J.; Feng, G.X. Replica Placement in Cloud Storage based on Minimal Blocking Probability. In Proceedings of the The 5th International Conference on Computer Engineering and Networks, Shanghai, China, 12–13 September 2015. [Google Scholar]
- Sousa, F.R.C.; Moreira, L.O.; Filho, J.S.C.; Machado, J.C. Predictive elastic replication for multi-tenant databases in the cloud. Concurr. Comput. Pr. Exp. 2018, 30, e4437. [Google Scholar] [CrossRef]
- Mansouri, N. Adaptive data replication strategy in cloud computing for performance improvement. Front. Comput. Sci. 2016, 10, 925–935. [Google Scholar] [CrossRef]
- Sun, S.; Yao, W.; Li, X. DARS: A dynamic adaptive replica strategy under high load Cloud-P2P. Futur. Gener. Comput. Syst. 2018, 78, 31–40. [Google Scholar] [CrossRef]
- Mokadem, R.; Hameurlain, A. A data replication strategy with tenant performance and provider economic profit guarantees in Cloud data centers. J. Syst. Softw. 2020, 159, 110447. [Google Scholar] [CrossRef]
- Limam, S.; Mokadem, R.; Belalem, G. Data replication strategy with satisfaction of availability, performance and tenant budget requirements. Clust. Comput. 2019, 22, 1199–1210. [Google Scholar] [CrossRef]
- Tos, U.; Mokadem, R.; Hameurlain, A.; Ayav, T.; Bora, S. Ensuring performance and provider profit through data replication in cloud systems. Clust. Comput. 2017, 21, 1479–1492. [Google Scholar] [CrossRef] [Green Version]
- Tu, M.; Xiao, L.; Xu, D. Maximizing the Availability of Replicated Services in Widely Distributed Systems Considering Network Availability. In Proceedings of the 2013 IEEE 7th International Conference on Software Security and Reliability, Gaithersburg, MD, USA, 18–20 June 2013; pp. 178–187. [Google Scholar]
- Bachwani, R.; Gryz, L.; Bianchini, R.; Dubnicki, C. Dynamically Quantifying and Improving the Reliability of Distributed Storage Systems. In Proceedings of the 2008 Symposium on Reliable Distributed Systems, Naples, Italy, 6–8 October 2008; pp. 85–94. [Google Scholar]
- Yang, J.-P. Efficient Load Balancing Using Active Replica Management in a Storage System. Math. Probl. Eng. 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Oo, M.; Soe, T.T.; Thida, A. Fault tolerance by replication of distributed database in P2P system using agent approach. Int. J. Comput. 2010, 4, 9–18. [Google Scholar]
- Amoon, M. Adaptive Framework for Reliable Cloud Computing Environment. IEEE Access 2016, 4, 9469–9478. [Google Scholar] [CrossRef]
- Amiri, M.J.; Maiyya, S.; Agrawal, D.; El Abbadi, A. SeeMoRe: A Fault-Tolerant Protocol for Hybrid Cloud Environments. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1345–1356. [Google Scholar]
- Kumar, P.; Kumar, R. Issues and challenges of load balancing techniques in cloud computing: A survey. Acm Comput. Surv. 2019, 51, 1–35. [Google Scholar] [CrossRef]
- Thakur, A.; Goraya, M.S. A taxonomic survey on load balancing in cloud. J. Netw. Comput. Appl. 2017, 98, 43–57. [Google Scholar] [CrossRef]
- Lehrig, S.; Sanders, R.; Brataas, G.; Cecowski, M.; Ivanšek, S.; Polutnik, J. CloudStore—Towards scalability, elasticity, and efficiency benchmarking and analysis in Cloud computing. Futur. Gener. Comput. Syst. 2018, 78, 115–126. [Google Scholar] [CrossRef]
- Patibandla, R.S.M.L.; Kurra, S.S.; Mundukur, N.B. A Study on Scalability of Services and Privacy Issues in Cloud Computing. Distributed Computing and Internet Technology. ICDCIT 2012. Lecture Notes in Computer Science; Ramanujam, R., Ramaswamy, S., Eds.; Springer: Berlin, Heidelberg, Geramny, 2012; 7154, pp. 212–230. [Google Scholar] [CrossRef]
- Campêlo, R.A.; Casanova, M.A.; Guedes, D.O.; Laender, A.H.F. A brief survey on replica consistency in cloud environments. J. Internet Serv. Appl. 2020, 11, 1–13. [Google Scholar] [CrossRef]
- Hassan, O.A.-H.; Ramaswamy, L.; Miller, J.; Rasheed, K.; Canfield, E.R. Replication in Overlay Networks: A Multi-objective Optimization Approach. In Proceedings of the International Conference on Collaborative Computing: Networking, Applications and Worksharing; Springer: Berlin, Heidelberg, Germany, 2008; pp. 512–528. [Google Scholar]
- Perez-Sorrosal, F.; Patiño-Martínez, M.; Jimenez-Peris, R.; Kemme, B. Elastic SI-Cache: Consistent and scalable caching in multi-tier architectures. VLDB J. 2011, 20, 841–865. [Google Scholar] [CrossRef]
- Qu, C.; Calheiros, R.N.; Buyya, R. Auto-scaling web applications in clouds: A taxonomy and survey. ACM Comput. Surv. 2018, 51, 1–33. [Google Scholar] [CrossRef]
- Khelaifa, A.; Benharzallah, S.; Kahloul, L.; Euler, R.; Laouid, A.; Bounceur, A. A comparative analysis of adaptive consistency approaches in cloud storage. J. Parallel Distrib. Comput. 2019, 129, 36–49. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Wang, W.; Fang, X.; Junzhou, L.; Vasilakos, A.V. Electricity Price-aware Consolidation Algorithms for Time-sensitive VM Services in Cloud Systems. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef] [Green Version]
- Zeng, L.; Xu, S.; Wang, Y.; Kent, K.B.; Bremner, D.; Xu, C. Toward cost-effective replica placements in cloud storage systems with QoS-awareness. Softw. Pract. Exp. 2017, 47, 813–829. [Google Scholar] [CrossRef]
- Casas, I.; Taheri, J.; Ranjan, R.; Wang, L.; Zomaya, A.Y. A balanced scheduler with data reuse and replication for scientific workflows in cloud computing systems. Futur. Gener. Comput. Syst. 2017, 74, 168–178. [Google Scholar] [CrossRef]
- Statovci-Halimi, B.; Halimi, A. QoS management through service level agreements: A short overview. Elektrotechnik Inf. 2004, 121, 243–246. [Google Scholar] [CrossRef]
- Ardagna, D.; Casale, G.; Ciavotta, M.; Pérez, J.F.; Wang, W. Quality-of-service in cloud computing: Modeling techniques and their applications. J. Internet Serv. Appl. 2014, 5, 11. [Google Scholar] [CrossRef] [Green Version]
- Abad, C.L.; Lu, Y.; Campbell, R.H. DARE: Adaptive Data Replication for Efficient Cluster Scheduling. In Proceedings of the 2011 IEEE International Conference on Cluster Computing, Austin, TX, USA, 26–30 September 2011; pp. 159–168. [Google Scholar]
- Chang, W.-C.; Wang, P.-C. Write-Aware Replica Placement for Cloud Computing. IEEE J. Sel. Areas Commun. 2019, 37, 656–667. [Google Scholar] [CrossRef]
- Vobugari, S.; Somayajulu, D.V.L.N.; Subaraya, B.M. Dynamic Replication Algorithm for Data Replication to Improve System Availability: A Performance Engineering Approach. IETE J. Res. 2015, 61, 132–141. [Google Scholar] [CrossRef]
- Wei, J.; Liu, J.; Zhang, R.; Niu, X. Efficient Dynamic Replicated Data Possession Checking in Distributed Cloud Storage Systems. Int. J. Distrib. Sens. Netw. 2016, 12, 1894713. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.; Qin, S.; Lu, J.; Gao, F.; Jin, Z.; Wen, Q. Improved Proofs of Retrievability And Replication For Data Availability In Cloud Storage. Comput. J. 2020, 63, 1216–1230. [Google Scholar] [CrossRef]
- Tos, U.; Mokadem, R.; Hameurlain, A.; Ayav, T. Achieving query performance in the cloud via a cost-effective data replication strategy. Soft Comput. 2021, 1–18. [Google Scholar] [CrossRef]
- John, S.N.; Mirnalinee, T.T. A novel dynamic data replication strategy to improve access efficiency of cloud storage. Inf. Syst. E-Bus. Manag. 2020, 18, 405–426. [Google Scholar] [CrossRef]
- Karandikar, R.R.; Gudadhe, M. B Comparative analysis of dynamic replication strategies in cloud. Int. J. Comput. Appl. 2016, 975, 8887. [Google Scholar]
- Miloudi, I.E.; Yagoubi, B.; Bellounar, F.Z. Dynamic Replication Based on a Data Classification Model in Cloud Computing. In International Symposium on Modelling and Implementation of Complex Systems; Springer: Cham, Switzerland, 24 October 2020; pp. 3–17. [Google Scholar]
- Abbes, H.; Louati, T.; Cérin, C. Dynamic replication factor model for Linux containers-based cloud systems. J. Supercomput. 2020, 76, 7219–7241. [Google Scholar] [CrossRef]
- Karuppusamy, S.; Muthaiyan, M. An Efficient Placement Algorithm for Data Replication and To Improve System Availability in Cloud Environment. Int. J. Intell. Eng. Syst. 2016, 9, 88–97. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J. An Optimized Replica Distribution Method in Cloud Storage System. J. Control. Sci. Eng. 2017, 2017, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Mansouri, N.; Javidi, M.M.; Zade, B.M.H. Using data mining techniques to improve replica management in cloud environment. Soft Comput. 2020, 24, 7335–7360. [Google Scholar] [CrossRef]
- Kaur, A.; Gupta, P.; Singh, M.; Nayyar, A. Data Placement in Era of Cloud Computing: A Survey, Taxonomy and Open Research Issues. Scalable Comput. Pract. Exp. 2019, 20, 377–398. [Google Scholar] [CrossRef]
- Kumar, K.A.; Quamar, A.; Deshpande, A.; Khuller, S. Sword: Workload-aware data placement and replica selection for cloud data management systems. Vldb J. 2014, 23, 845–870. [Google Scholar] [CrossRef]
- Bonvin, N.; Papaioannou, T.G.; Aberer, K. A self-organized, fault-tolerant and scalable replication scheme for cloud storage. In Proceedings of the 1st ACM symposium on Cloud computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 205–216. [Google Scholar]
- Ascó, A.; Leeds, T. Adaptive Strength Geo–Replication Strategy. In Proceedings of the PaPoC ’15 Proceedings of the First Workshop on Principles and Practice of Consistency for Distributed Data, Bordeaux, France, 21 April 2015; Volume 155, p. 161. [Google Scholar]
- Mansouri, Y.; Babar, M.A. The Impact of Distance on Performance and Scalability of Distributed Database Systems in Hybrid Clouds. arXiv 2020, arXiv:2007.15826. [Google Scholar]
- Aslanpour, M.S.; Toosi, A.N.; Taheri, J.; Gaire, R. AutoScaleSim: A simulation toolkit for auto-scaling Web applications in clouds. Simul. Model. Pract. Theory 2021, 108, 102245. [Google Scholar] [CrossRef]
- Sousa, F.R.; Machado, J.C. Towards Elastic Multi-Tenant Database Replication with Quality of Service. In Proceedings of the 2012 IEEE Fifth International Conference on Utility and Cloud Computing, Chicago, IL, USA, 5–8 November 2012; pp. 168–175. [Google Scholar]
- Sharma, U.; Shenoy, P.; Sahu, S.; Shaikh, A. A Cost-Aware Elasticity Provisioning System for the Cloud. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems, Minneapolis, MN, USA, 20–24 June 2011; pp. 559–570. [Google Scholar]
- Maghsoudloo, M.; Khoshavi, N. Elastic HDFS: Interconnected distributed architecture for availability–scalability enhancement of large-scale cloud storages. J. Supercomput. 2019, 76, 174–203. [Google Scholar] [CrossRef]
- Stauffer, J.M.; Megahed, A.; Sriskandarajah, C. Elasticity management for capacity planning in software as a service cloud computing. IISE Trans. 2021, 53, 407–424. [Google Scholar] [CrossRef]
- Mahmood, T.; Narayanan, S.P.; Rao, S.; Vijaykumar, T.N.; Thottethodi, M. Karma: Cost-Effective Geo-Replicated Cloud Storage with Dynamic Enforcement of Causal Consistency. IEEE Trans. Cloud Comput. 2021, 9, 197–211. [Google Scholar] [CrossRef] [Green Version]
- Vignesh, R.; Deepa, D.; Anitha, P.; Divya, S.; Roobini, S. Dynamic Enforcement of Causal Consistency for a Geo-replicated Cloud Storage System. Int. J. Electr. Eng. Technol. 2020, 11. [Google Scholar]
- Seguela, M.; Mokadem, R.; Pierson, J.-M. Comparing energy-aware vs. In cost-aware data replication strategy. In Proceedings of the 2019 Tenth International Green and Sustainable Computing Conference (IGSC), Alexandria, VA, USA, 21–24 October 2019; pp. 1–8. [Google Scholar]
- Khalajzadeh, H.; Yuan, D.; Zhou, B.B.; Grundy, J.; Yang, Y. Cost effective dynamic data placement for efficient access of social networks. J. Parallel Distrib. Comput. 2020, 141, 82–98. [Google Scholar] [CrossRef]
- Liu, J.; Shen, H.; Chi, H.; Narman, H.S.; Yang, Y.; Cheng, L.; Chung, W. A Low-Cost Multi-Failure Resilient Replication Scheme for High-Data Availability in Cloud Storage. IEEE ACM Trans. Netw. 2020, 1–16. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Research Questions (RQ) | Motivation behind Each Research Question |
|---|---|---|
| 1 | RQ1 What are the main areas of research related to replication techniques especially in cloud computing? | Mainly, the aim is to identify and evaluate the various data replication strategies related to articles/studies based on various replication strategies of previously published and mention their importance in cloud computing environments. |
| 2 | RQ2 What are the main target objectives, a replication strategy should possess? | Here, we discuss various dynamic replication strategies based on different categories especially the target-based dynamic replication strategies to understand the need for each replication strategy. |
| 3 | RQ3 What are the most used research replication strategies and how are they applied in the cloud replication area? | |
| 4 | RQ4 What attributes a replication strategy might consider meeting the target objectives? | This research will aim to provide different target-based objectives of dynamic replication strategies and their dependent attributes for best optimization. The relationship will help to understand the utilization of different algorithms for the best performance. |
| 5 | RQ5 What is the relationship between target objectives with their concern parameters? | |
| 6 | RQ6 What is the relationship between different parameters and what are their metrics? | Various research papers need to be identified from different replication strategy categories to reveal vital research problems. The research will display the quantitative analysis for performance evaluations of target-oriented replication strategies in cloud computing. There is a need to develop a technique that will address all attributes (Target Objectives) effectively in one replication strategy. |
| 7 | RQ7 What are the main metrics used for performance evaluation purposes? | |
| 8 | RQ8 What are the key results obtained? | This research also aims to identify the main issues and challenges of existing target-oriented replication strategies along with future directions to ensure optimal services. Various questions discussed here will help in the identification of future research areas. |
| 9 | RQ9 What are the main challenges and open issues of replication in cloud computing? |
| Static Data Replication | Dynamic Data Replication | ||
|---|---|---|---|
| Brief Description | In static data replication, a predefined set of replicas and host nodes are the key factor to achieve the data distribution at multiple sites. It determines the replica node locations at design phase. | Brief Description | In dynamic data replication, the key factor to achieve the data distribution at multiple sites is its automatic/adaptive nature of creating and omitting the replicas, based on user behavior and network topology. It determines the locations of replicas nodes at a run time. |
| Key Features | The static replication strategy accompanies deterministic policies in which the host nodes, the replica numbers are pre-decided and very much characterized. | Key Features | The dynamic strategies by default built and removes the replicas based on storage capacity changes, bandwidth and user access patterns (adaptive in nature). |
| The static replication strategies are always simple to implement because number of replicas is constant. | These strategies are not easy to implement because number of replicas is variable (based on heterogenous workload). | ||
| There is a need to support the random policy to keep the number of active service replicas at the maximum. | Being intelligent in nature, dynamic data replication is developed to make smart choices to choose the location of the data based on current available information. | ||
| Drawbacks | They are used less in real scenarios because of their predetermined nature. | Drawbacks | It is very difficult to control and accumulate the runtime information of all the data nodes in a complex cloud setup. |
| The more active service replicas guarantee more performance, but performance cannot be obtained at a high operation cost. | It takes a lot of effort to maintain the data file consistency effectively. | ||
| Replication Strategy Basic Details | Replication Strategy | Advantage and Disadvantages |
|---|---|---|
| [100] Year 2011 | Description: A cost-effective dynamic data replication strategy, namely (CIR), which is based on an incremental replication method with the aim to reduce the storage cost while maintaining the data reliability requirement. The approach calculating the replica creation to mention the storage duration. | Advantages: High data reliability, High availability, Low replication cost, and Low energy consumption. |
| Disadvantages: High response time and Low load balancing. | ||
| [101] Year 2012 | Description: A novel dynamic data replication strategy, namely (D2RS), which calculates a suitable number of copies based on evaluation and identification of popular data. Moreover, it also analyses and models various relationships accordingly. | Advantages: High availability, Low bandwidth consumption, and Low replication cost. |
| Disadvantages: High user waiting time, Low speed data access, and Low load balancing. | ||
| [102] Year 2015 | Description: A cost-effective data reliability mechanism, namely (PRCR), which is based on a generalized data reliability model. It works on a proactive replica checking approach to ensure the reliability of the data while maintaining the minimum number of replicas. | Advantages: Cost effective reliability, Less failure rates, Reduced storage space, and storage cost. |
| Disadvantages: No reduction in response time and Low load balancing. | ||
| [26] Year 2012 | Description: A replication, namely (Harmony), which handles the key issue in data management and provides the solution to deal with duplicate copies. The basic steps of the technique include determining the files for replication, time of replication, and deciding the final data location for replication. | Advantages: High availability and High performance. |
| Disadvantages: High Downtown and High transactional cost. | ||
| [103] Year 2013 | Description: A replication method, namely (Bismar), which adaptively tunes the consistency level at run-time. The main aim is to reduce the monetary cost (storage, network, and other related costs), along with a low fraction of stale reads. | Advantages: Cost Effective (Reduces Instances cost, Storage cost, and Network cost. |
| Disadvantages: Average Consistency cost efficiency. | ||
| [104] Year 2012 | Description: An adaptive replication strategy that redeploys dynamically large-scale various file replicas on different data nodes and selects the data files which require replication based on minimal cost in order to improve the system availability. | Advantages: Cost effective, Low response time, Low bandwidth consumption, reduced waiting time, and High data access speeding up. |
| Disadvantages: Less data availability. | ||
| [105] Year 2015 | Description: A runtime-based replica consistency mechanism, namely (RBRC), which is mainly used for cloud storage systems. The mechanism achieves a dynamic balance between performance and consistency using read frequency. This method is based on access frequency and its access time. | Advantages: Decreased average file access time, Low replication delay time. |
| Disadvantages: Average load balancing. | ||
| [106] Year 2015 | Description: An adaptive consistency guarantee model that probes the consistency index of an observed replicated data object in an online application. The main aim is to reduce response time. | Advantages: Maintained response time and Time delay. |
| Disadvantages: Assumed Load balancing setting for the Implementation. | ||
| [99] Year 2017 | Description: A novel replication strategy which is used to reduce data storage cost in workflow applications. The strategy considers various parameters for the cost-related effectiveness, which include access frequency, data center storage capacity, the constraints of dataset dependency, and size of datasets in the build-time stage. | Advantages: Reduced cost of data management, decreased data movement, and decreased data transfer cost. |
| Disadvantages: Increased response time. | ||
| [107] Year 2016 | Description: A dynamic cost-aware replication strategy, which optimizes and identifies the least number of replicas that are required to maintain desired availability along with data reliability. | Advantages: Low replication cost, High reliability, and High availability. |
| Disadvantages: Low consistency rates, Low load balancing, and High response time. | ||
| [108] Year 2013 | Description: A response time-based replica strategy, namely RTRM, consisting of replica creation methods. The aim is to automatically increase the number of replicas based on average response time while maintaining the performance. | Advantages: High performance, Low response time, High rapid data download, Low energy consumption, and High data availability. |
| Disadvantages: Low reliability, Low load balancing, and High replication cost. | ||
| [109] Year 2013 | Description: A modified dynamic data replication strategy with synchronous and asynchronous updating. The work is based on the decision of a reasonable number of replicas, along with the right location of replicas, while keeping in mind the execution time. | Advantages: Execution time, High availability, and Performance. |
| Disadvantages: Low speed data access and Low load balancing. | ||
| [110] Year 2014 | Description: A dynamic replica selection and placement strategy which is used for cloud replica management. A replica creation is adapted continuously by changing network connectivity and users. It designs an algorithm for suitable optimal replica selection and placement with a target to increase data availability. | Advantages: Low access time, Low response time, low access cost, Shared bandwidth consumption, and delay time. |
| Disadvantages: Low Load balancing. | ||
| [111] Year 2015 | Description: An effective dynamic replica placement algorithm, namely BPRA, which is based on minimal blocking probability. The main intention is to improve the load balancing using user access information. | Advantages: Improved load balance, Reduced access skew, and file access latency. |
| Disadvantages: Ignored QoS | ||
| [52] Year 2019 | Description: A data replication strategy for MongoDB. The main aim is to provide the performance requirement for the tenants, while the provider’s profit is not ignored. | Advantages: Decreased response time, Resource consumption, and number of replications. |
| Disadvantages: Low load balancing. | ||
| [112] Year 2018 | Description: A predictive approach, namely (PredRep), which is used to characterize the cloud database system workload and automatically provide or reduce resources based on the cost factor and SLA agreement. | Advantages: Reduced cost and SLA violations. |
| Disadvantages: Average load balancing. | ||
| [3] Year 2017 | Description: A data replication strategy for cloud systems, namely (DPRS), which uses the number of requests and free storage space to determine the number of replicas along with a suitable placement site. | Advantages: Low response time, Enhanced storage space, and Effective network usage. |
| Disadvantages: Low reliability. | ||
| [113] Year 2016 | Description: A replica replacement strategy that considers the data file availability, the last time the replica was accessed, access number, and the replica size. The replication not only provides load balancing but also maintained the performance. | Advantages: Increased Performance and Load balancing, less storage usage. |
| Disadvantages: Missing real time Implementation. | ||
| [114] Year 2018 | Description: A dynamic adaptive replica strategy, namely (DARS), which uses node’s overheating similarity to provide the replica creation time, the replica creation opportune moment and locate optimal replica placement node. | Advantages: Superior performance and Better load balance. |
| Disadvantages: Lower access delay. | ||
| [115] Year 2020 | Description: A data Replication Strategy (RSPC) that satisfies both performance and minimum availability tenant objectives while ensuring an economic profit for the provider in Cloud datacenters. | Advantages: Reduced resource consumption, Reduced Costs of provider (penalty and data transfer costs) |
| Disadvantages: Missing real-time cloud implementation and consistency consideration. | ||
| [116] Year 2019 | Description: A cost-based dynamic replication strategy (DRAPP) that uses the least number of replicas for simultaneous availability of data and performance tenant requirements in regard while considering the tenant budget along with a profit of provider. While dealing with tenant budget, query scheduling is done in such a way that replicas effectively obey load balancing. | Advantages: Reduced query response time and increased availability. |
| Disadvantages: Missing real-time cloud implementation and energy consumption consideration. | ||
| [117] Year 2018 | Description: A cost-based data replication strategy (PEPRv2) for cloud-based systems that effectively satisfies the response time objective (RTO) for executing queries while simultaneously benefiting the provider to return a profit from each execution. It simultaneously satisfies both the SLA terms and profit of the provider. The SLA includes the availability and performance along with maintaining the query load as per the provider’s profit. | Advantages: Reduced response time, bandwidth consumption, and monetary expenditure. |
| Disadvantages: Missing real-time cloud implementation. |
| Replication Strategy | Target Objectives (Priority Based) | Attributes (Parameters)-Metrics |
|---|---|---|
| [100] Year 2011 | 1. Reliability (Primary Target Objective) 2. Fault Tolerance | The storage space and the storage cost are the reliability-related attributes. Both attributes are reduced and are based on the need basis of replicas. It initially stores only one replica and is incremental in nature. The failure rates of storage units are the fault tolerance related attribute, which directly affects the fault tolerance. Hence, lower the probability of the failure, the higher will be the reliability. Note: The key investigating parameters are Data Reliability, Storage Space, Storage Cost, and Failure Rates. |
| [101] Year 2012 | 1. Availability (Primary Target Objective) 2. Performance (Response Time) 3. Load Balance | The replica no. is the availability related attribute, which is based on a mathematical model to maintain the number of replicas and availability requirement accordingly. The execution rate, response time and bandwidth consumption are the performance-related attributes, and they are reduced because of balanced replica placement. The replica placement is the load balance-related attribute, which is achieved by placing the most popular data files based on access history (access information of data centers). Note: The key investigating parameters are Data Availability, Number of Replicas, Response Time, Execution Rate, and Bandwidth. |
| [102] Year 2015 | 1. Reliability (Primary Target Objective) 2. Performance (Cost) 3. Fault Tolerance | The replica no. is the reliability-related attribute, which initially stores only one replica (original copy of the data). The storage space is the performance-related attribute, which is reduced and, hence, reduces the storage cost of the data. It provides cost-effective reliability based on cost and failure rates of storage units (fault tolerance). The failure rates of storage units are the fault tolerance related attribute. Fewer failure rates of storage increase reliability. Note: The key investigating parameters are Data Reliability, Number of Replicas, Disc Failure Rates, storage space, storage cost. |
| [26] Year 2012 | 1. Performance (Primary Target Objective) 2. Availability | The stale reads rate is the performance-related attribute, which defines the consistency requirements of the application and affects the performance. The replica no. is the availability related attribute, and it dynamically adjusts the number of the replicas used in operation according to the run time based estimated stale read rate and network latency. Note: The key investigating parameters are Data Availability, Number of Replicas, and Stale Read Rates. |
| [103] Year 2013 | 1. Consistency (Primary Target Objective) 2. Performance (Cost) | The stale reads rate and relative cost of the application are the consistency-related attributes, which are estimated based on a probabilistic model using the current read/write rate and network latency. Stale reads are the output of access patterns exhibited by the applications. A low fraction of stale reads is maintained. The consistency cost is the performance-related attribute, consistency is chosen based on operations and is presented by the number of replicas in the quorum (a subset of all the replicas). Note: The key investigating parameters are Stale Reads, Consistency, and Cost. |
| [104] Year 2012 | 1. Reliability (Primary Target Objective) 2. Availability 3. Performance (Cost) | The replica no. is the reliability-related attribute. It improves the data reliability of files based on prediction of the past data access user requests using (Holt’s Linear and Exponential Smoothing (HLES)) time series technique. The optimal replica no. is the availability related attribute. It chooses the best optimal replica selection and placement for the availability purpose. Low replication cost and average response time are the performance-related attributes. It particularly minimizes the bandwidth consumption of the data and increase the load balancing. Note: The key investigating parameters are Data Availability, Number of Replicas, Bandwidth, and Load Balancing. |
| [105] Year 2015 | 1. Consistency (Primary Target Objective) 2. Performance | Replica read frequency is the consistency related attribute. The replicas with high read frequency are updated aggressively, and low read frequency replicas are updated in a lazy way. The other parameters include average file access time, percentage of requesting up-to-date data and number of replications. File access delay time is the performance-related attribute. It lowers the number of replications without wasting network bandwidth, and, because of its shorter replication time, the file access delay time is also reduced. Note: The key investigating parameters are Replica Read Frequency, no. of Replicas, and File access delay time. |
| [106] Year 2015 | 1. Consistency (Primary Target Objective) 2. Performance | Time gap and consistency tuner (consistency index-based protocol-which is the number of correct reads over the total reads are the performance-related attributes. The other parameters include the number of replicas and the threshold of a time gap, which is a minimum value of time gap between a succeeding read request and an update. Note: The key investigating parameters are Time Gap and no. of Reads. |
| [99] Year 2017 | 1. Cost (Primary Target Objective) | The storage cost is the performance-related attribute. The other parameters which play an important role and affect the performance directly include access frequency, storage usage or capacity of data centers, dataset size, and data dependency. Note: The key investigating parameters are Performance, Cost, and Data Size. |
| [107] Year 2016 | 1. Cost (Primary Target Objective) 2. Availability | The storage cost is the performance-related attribute, which is based on the least number of replicas required for a proper availability, the data file is selected on the basis of access intensity, the higher SBER, better response time, and cost of replication. The system byte effective rate, bandwidth consumption, and the response time are the availability related attributes. Note: The key investigating parameters are data file availability, Average File Probability, cost of replication, data file availability, system byte effective rate, and the cost of the replication. |
| [108] Year 2013 | 1. Performance (Primary Target Objective) | The response time is the performance-related attribute. When the response time is longer than the threshold, the replica number will increase; hence, the system will create a new replica. In addition, other related attributes are network utilization, average job time high rapid download and low energy consumption. Based on the new request, the bandwidth is predicted for replica selection. Note: The key investigating parameters are replica creation, Replica selection, and Replica placement. |
| [109] Year 2013 | 1. Availability (Primary Target Objective) 2. Performance | The replica no. is the availability related attribute. The number of replicas is considered as system byte effective rate and is calculated as the number of bytes available to total bytes requested by all tasks. The system byte effective rate is performed in the second stage of the Modified D2RS algorithm stage which is best suited for varied periods. The execution time is the performance related attribute, which increases the performance. Execution time is increased by creating a replica of the data in the data center. The popularity degree is the access frequency based on time factor and user activity. Note: The key investigating parameters are Data Availability, Number of Replicas, Execution Time, and Access Frequency. |
| [110] Year 2014 | 1. Availability (Primary Target Objective) | The replica no. is the availability-related attribute, which is based on the demands of the users and the availability of storage. It chooses the optimal replica selection and placement for the availability purpose based on response time and access time. Note: The key investigating parameters are Data Availability, Access Time, and Response Time. |
| [111] Year 2015 | 1. Reliability (Primary Target Objective) | The replica placement is the reliability-related attribute, which improves reliability and reduces access skew. The reliability is achieved through access latency (decreased file access latency). Note: The key investigating parameters are Data Availability, Access Latency, and Replica Placement. |
| [52] Year 2019 | 1. Performance (Cost) (Primary Target Objective) 2. Load balancing 3. Fault tolerance | The response time of query and no. of replicas are the performance-related attributes. The former includes the data size, number of shards, I/O, and network bandwidth. The latter is responsible for data placement based on the estimated threshold, access frequency, and response time. The network bandwidth and least resource consumption reduce the communication costs respectively. The high access frequency is load balancing related attribute, which selects only the most popular data for replication. The sharding is the process of parallelizing the data by splitting the data uniformly across clusters. Hence, sharding is the fault tolerance related attribute. Note: The key investigating parameters are Data Reliability, Storage Space, Storage Cost, and Failure Rates. |
| [112] Year 2018 | 1. Elasticity (Primary Target Objective) 2. SLA (Service Level Agreement) | The variation of the response time and satisfaction function/SLA is the elasticity related attributes. The former is based on the SLA metric which is the value of maximum time response, and the latter is directly based on SLA compliance. Note: The key investigating parameters are Tenant size and Databases (size, queries, and response time). |
| [3] Year 2017 | 1. Performance (Cost) (Primary Target Objective) 2. Fault Tolerance | The number of replicas is the performance-related attribute, which is minimized and the appropriate sites for data placement are dependent on the number of used requests, site centrality, and storage. The knapsack provides the cost optimization of the replication. The other performance-related attribute includes better response time and less cost of replication, decrease user-waiting time, and improve data access. Data access popularity and parallel download are the fault tolerance related attributes. The effective network usage mean response time, storage usage, replication frequency, and hit ratio with respect to the others are also considered as an enhancement achievement. Note: The key investigating parameters are Response time, Storage usage Effective network usage, Replication frequency, and Hit ratio. |
| [113] Year 2016 | 1. Performance (Cost) (Primary Target Objective) 2. Load balancing | The replacement strategy is the performance-related attribute, which is based on the availability of the file, the last time the replica was requested, the number of access, and the size of the replica. Other performance-related attributes include cost, which relies on as storage size of each site, which is kept limited by just keeping the important data only. The replica placement policy is the load balancing related attribute, which allows storing replicas in the relevant sites based on five parameters (failure probability, storage usage, mean service time, latency, and load variance). Both Performance and Load Balancing related attribute target to increase the response time and cost-effective availability. Note: The key investigating parameters are mean Response time, Load balancing, Effective network usage, Replication frequency, and Storage usage. |
| [114] Year 2018 | 1. Performance (Primary Target Objective) 2. Load balancing | The replica creation time and opportune moment are the performance related attribute, which is based on the node’s overheating similarity. They find the optimal placement node using the fuzzy clustering analysis method, and then the replicas are created by node using a decentralized self-adaptive manner. The optimal placement node is the load balancing related attribute, which is found from the neighborhood. The optimal placement node improves the probability of replica to be accessed, relieves the overloaded high node degree, possess low node load, reduces the access delay, and boosts the load balance. Low access delay and acceptable load balance are achieved by reducing the node response latency. Hence, low access delay is based on operation time and the ratio of request versus response. Note: The key investigating parameters are Low access delay, Ratio of average load, Node response latency, and Accessing pressure. |
| [115] Year 2019 | 1. Cost (Primary Target Objective) | The response time of the query is the cost-related attribute, which is responsible for data placement based on the critical threshold achieved. The replica factor is dynamically adjusted to reduce resource consumption. Replica creation relies on the minimum availability objective and Response time (RT)objective. The Strategy always keeps the minimum number of replicas. RSPC satisfies the response time requirement under high loads, complex queries, and strict response time thresholds. Note: The key investigating parameters are Response Time and Replication Cost. |
| [116] Year 2019 | 1. Cost (Primary Target Objective) | The number of replicas is the cost-related attribute, which is responsible for effective load balancing based on query scheduling. The other replication attribute includes response time and SLA agreements. The former is dependent on the threshold. The availability should be less, or response time should be greater than a threshold for effective replication, and the latter minimizes the SLA violations. Note: The key investigating parameters are Load balancing, Response Time, Bandwidth Consumption, and Cost. |
| [117] Year 2018 | 1. Cost (Primary Target Objective) | The response time of the query is the cost-related attribute. The execution of any particular query is estimated and compared with service level objectives (service quality) that the tenant expects from the provider along with profit estimation. It also decreased the number of replicas for a given availability. Note: The key investigating parameters are Response Time, storage usage Network bandwidth consumption, and Cost. |
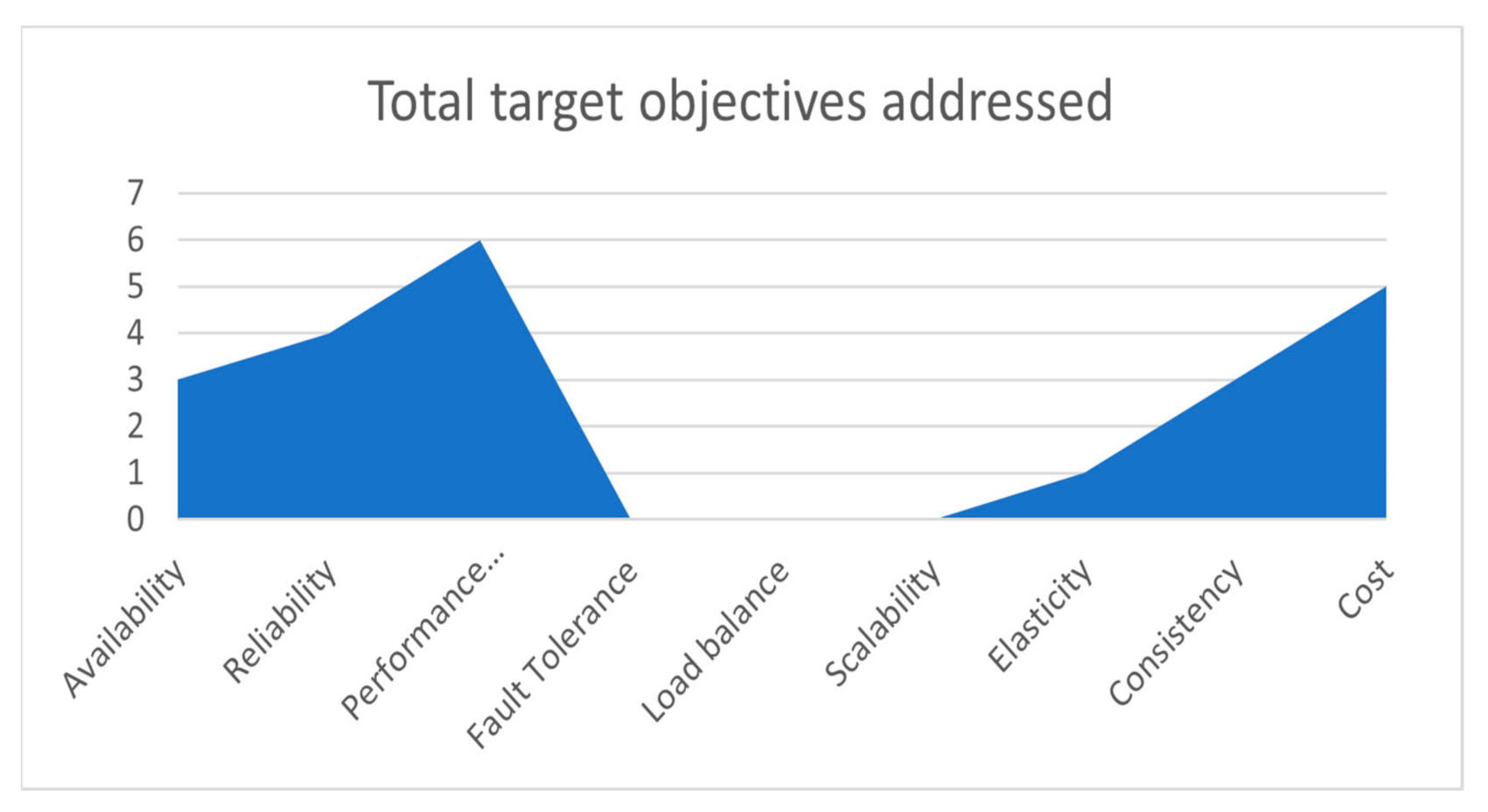
| Most Addressed Target Objective | Average Addressed Target Objective | Least Addressed Target Objective | |||
|---|---|---|---|---|---|
| Availability | [101,109,110] | Fault Tolerance | [3,52,100,102] | Scalability | [112] |
| Reliability | [100,102,104,108,111] | Load Balance | [52,101,113,114] | Elasticity | [112] |
| Performance | [3,26,52,108,113,114] | Consistency | [103,105,106] | ||
| Cost | [99,107,115,116,117] | ||||
| Attribute | Target-Oriented Replication Strategies for Cloud Computing | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| [3] | [26] | [52] | [102] | [100] | [101] | [103] | [104] | [105] | [106] | [99] | |
| Availability | Achieved by decreasing replication frequency and maintaining the rational replicas during changing workloads | Increased | Achieved | Increased | Not Addressed | Increased | Increased by maintaining a low fraction of stale reads | Increased | Addressed | Increased | Not Addressed |
| Reliability | Not Addressed | Not Addressed | Not Addressed | Increased with least replication using proactive replica checking | Increased by predicting and dynamically generating an additional replica when needed | Not Addressed | Not Addressed | Increased by the lightweight time-series prediction algorithm | Not Addressed | Not Addressed | Not Addressed |
| Storage Space | Reduced by breaking the data file into different parts for best storage | Not Addressed | Maintained the storage through popularity degree based on least popular data files are removed and most popular accessed data are replicated | Reduced (limited) | Reduced | Not Addressed | Reduced | Not Addressed | Not Addressed | Not Addressed | Not Addressed |
| Storage Cost | Achieved through least resource utilization | Not Addressed | Reduced because it places the new replicas closer to data consumers and hence reduce the communication costs | Reduced | Reduced | Not addressed | Reduced | Reduced | Not addressed | Not addressed | Reduced due to parameter changes in data set dependency, access frequency, and by partitioning storage space |
| Bandwidth Consumption | Reduced by maintaining the rational replicas during the change environment sessions. Hence, decreases the unnecessary replication which effects directly to bandwidth | Not Addressed | Reduced because of removing the unnecessary replications | No Reduction | Not Addressed | Reduced due to balanced placement of replicas | Not Addressed | Reduced | Reduced because low read frequency replicas are updated in a lazy way | Not addressed | Not Addressed |
| Optimal Number of Replicas | Achieved because it determines the no. of replicas and suitable sites for replica placement based on the number of free spaces, requests and site centrality | Achieved | Maintained because the number of replicas is adjusted dynamically to reduce the resource consumption | Achieved | Not Addressed | Achieved | Achieved | Achieved | Achieved | Achieved | Not Addressed |
| Response Time | Reduced by decreasing the user-waiting time | Reduced by using both the application requirements and the storage system state to handle the consistency at run time and also by using the stale read rate of the application | Response time is decreased, and its estimation is based on parameters that impact the query execution and threshold criteria | No Reduction | No Reduction | Reduced due to placement of replicas | Reduced due to maintenance of an acceptable rate of fresh reads | Reduced | Reduced due to higher percentage of reads, latest data average file access and delay time | No Reduction | Increased response time because of high network usage |
| Load Balancing | Achieved due to reduced replication frequency | Achieved through stale reads estimation | Maintained because only popular data, i.e., having a high access frequency are replicated | High | No Load Balancing | Achieved by placing the Replicas based on access history of data nodes | Achieved by selecting the highest consistency-cost efficiency level to adapt to workload dynamically | Achieved by placing replicas based on Heuristic search Algorithm | Not Addressed | Achieved by using round-robin policy, nearest replica, or heuristic-based replica selection | Not Addressed |
| Fault Tolerance | Achieved by using data access popularity | Not Addressed | Achieved by splitting the data uniformly across various clusters | Achieved | Achieved | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed |
| Consistency | Future Work | Increased | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Increased | Not Addressed | Increased due to replica read frequency | Increased due to time gap effect and consistency index factor | Not Addressed |
| Scalability | Not Addressed | Increased | Scalability is achieved through auto-sharding | Not Addressed | Not Addressed | Not Addressed | Increased | Not Addressed | Increased | Increased | Not Addressed |
| Elasticity | Not Addressed | Increased | Achieved because it removes all unrequired resources/replicas | Not Addressed | Not Addressed | Not Addressed | Increased | Not Addressed | Not Addressed | Not Addressed | Not Addressed |
| SLA | Achieved as QoS requirements are fulfilled | Not Addressed | Achieved and gets triggered only when the response time of a tenant query is more than a response time threshold | Not Addressed | Not Addressed | Not Addressed | Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed |
| [107] | [108] | [109] | [110] | [111] | [112] | [113] | [114] | [125] | [126] | [127] | |
| Availability | Maintained | Not Addressed | Increased due to replication of more recently accessed file | Increased | Increased | Achieved | Increased due to addressing of five parameters in load balancing strategy | Not Addressed | Addressed | Maintain minimum number of replicas for high availability along with performance | Achieved by maintaining minimum availability level |
| Reliability | Maintained | Not Addressed | Not Addressed | Not Addressed | Increased due to decreased file access latency | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed |
| Storage Space | Reduced by deleting the additional replicas long term unassessed data files, or having least access rate compared to other data files | Not Addressed | Not Addressed | Not Addressed | Reduced due to reduced storage redundancy | Reduced by reducing the tenant storage size | Reduced due to the placement of data files in data nodes with low storage utilization to minimize the waiting time | Not Addressed | Reduced search space due to less creation of replicas | Reduced search area because of the known local budget of sub-region which determines the number of replicas | Reduced because from a selected subregion, a node with acceptable storage space is selected for a placement |
| Storage Cost | Reduced because knapsack algorithm is used to invoke to optimize the cost of replication | Not Addressed | Not Addressed | Not Addressed | Reduced due to replica factor, hence reduce the cost of data management | Reduced | Reduced because replicas are dynamically created in advance. Files can be stored in a specific, hence reducing the storage usage (storage elements usage (SEU)) | Not Addressed | Reduced penalty and data transfer costs because most replications are performed per set of queries and also uses fewer storage resources due to fewer replicas creation | Reduced because replicas are only created if the providers profit goes higher than the replication cost | Reduced because it is estimated as the cost of storage I/O performed by any particular query |
| Bandwidth Consumption | Reduced | Reduced because it predicts the bandwidth among the replica servers | Not Addressed | Reduced because during selection and placement of replica, it needs minimum bandwidth consumption | Maintained the bandwidth consumption which does not exceed the bandwidth despite various file request arrival data nodes | Reduced by provisioning | Reduced to reduce the reduced latency | Reduced because of increasing the service node overload | Reduced bandwidth consumption due to Network Bandwidth (NB) locality i.e., a replica of a required remote data is placed at a node having a larger NB toward the node requiring remote data | Reduced bandwidth consumption because the replicas are closer, which target less data transfer | Reduced due to better replica placement by evaluating each subregion for the profit satisfaction and response time and comparison |
| Optimal Number of Replicas | Achieved | Achieved because if the response time is longer than the threshold, the new replicas are created | Achieved | Achieved because optimal replica selection and replica placement rely on response time and access time | Maintained because through BPRA algorithm, the minimal number of replicas are calculated according to available requirement and also replica factor is dynamically adjusted based on file access frequency | Achieved based on forecast approach. Additionally, It provides the estimated time to create a replica, the replica size and information on each tenant | Maintained through data placement | Uses the fuzzy set model for the optimal node | Due to the majority of in region replicas creation, lesser number of replicas are generated, and a remarkable data transfer saving is achieved | Not addressed because search area is reduced | Achieved as it is always associated with each query being executed at a particular time and follow the near-optimal placement |
| Response Time | Reduced even after replication cost equals to the budget | Reduced because during concurrent requests to file, it maintains the average service response time | Reduced | Reduced because response time rely on bandwidth utilization of each random file | Maintained | Reduced | Reduced through increasing the total number of local accesses and avoiding the unnecessary replication | Reduced because of lowest access delay (lowest nonresponse ratio) | Satisfies the response time requirement under high loads (Acceptable Response Time) along with providers profit, especially during high loads. Average response time is reduced due to less Virtual machines overload | Reduced because it uses query number and if providers gain is real, then only a new replica is created | Reduced and checked if it satisfies the service quality expectations from the tenants |
| Load Balancing | Not Addressed | Achieved by maintaining replica placement location | Achieved because it selects the optimal data node with the minimal blocking probability | Maintained | Achieved through the data placement | Increased due to fuzzy clustering analysis method used to select the optimal placement node for stored replicas | Achieved because it does not replicate data when response time objective is satisfied | Achieved because data replication and scheduling of queries are coupled using tenant budget using node load criterion | Reduced because, from a selected subregion, a node with an acceptable load is chosen for the data placement | ||
| Fault Tolerance | Not Addressed | Not Addressed | Not Addressed | Achieved automated fault tolerance | Not Addressed | Achieved by using write-ahead logging scheme | Achieved by improved response time, which generates the new replicas and storing them to the less-load sites | Not Addressed | Not Addressed | Not Addressed | Not Addressed |
| Consistency | Future Work | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Future Work | Not Addressed | Not Addressed | Not Addressed | |
| Scalability | Not Addressed | Not Addressed | Not Addressed | Achieved because the utility computing is based on scaling and scaling is based on optimal replica selection | Not Addressed | Achieved by using Scale tenant | Not Addressed | Increased because of a self-adaptive feature which can handle overload on time and reduces the access delay and hence increase the scalability | Not Addressed | Not Addressed | Not Addressed |
| Elasticity | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Achieved by using the predictive elastic replication strategy which utilizes process decision, based on satisfaction function and the variation of response time | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed |
| SLA | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Not Addressed | Achieved by using the forecast service to assist the decrease of SLA violations. | Not Addressed | Not Addressed | Maintained, addressing both tenant and providers benefits | Due to its dynamic nature, the number of SLA violations are low (Very Less) | Maintained while considering SLA violation count as a measure of response time satisfaction |
| [3] | [26] | [52] | [102] | [100] | [101] | [103] | [104] | [105] | [106] | [99] | |
| Availability | YS | IN | YS | IN | NA | IN | IN | IN | YES | IN | NA |
| Response Time | LW | LW | LW | NC | NA | LW | LW | LW | LW | NC | IN |
| Reliability | NA | NA | NA | HG | HG | NA | NA | HG | NA | NA | NA |
| Bandwidth Consumption | LW | NA | LW | NC | NA | LW | NA | LW | LW | NA | NA |
| Load Balancing | YS | HG | YS | HG | NA | HG | HG | HG | NA | HG | NA |
| Storage Cost | YS | NA | LW | LW | LW | NA | LW | LW | NA | NA | LW |
| Consistency | YS | HG | LW | NA | NA | NA | HG | NA | HG | HG | NA |
| Fault Tolerance | YS | NA | YS | YS | YS | NA | NA | NA | NA | NA | NA |
| Optimal no. of replicas | YS | YS | YS | YS | NA | YS | YS | NA | YS | YS | NA |
| [107] | [108] | [109] | [110] | [111] | [112] | [113] | [114] | [115] | [116] | [117] | |
| Availability | NC | NA | IN | IN | IN | YS | IN | NA | YS | YS | YS |
| Response Time | LW | LW | LW | LW | NC | LW | LW | LW | LW | LW | LW |
| Reliability | NC | NA | NA | NA | IN | NA | NA | NA | NA | NA | NA |
| Bandwidth Consumption | LW | LW | NA | LW | NC | LW | LW | LW | LW | LW | LW |
| Load Balancing | NA | YS | NA | NA | YS | YS | YS | IN | YS | YS | LW |
| Storage Cost | LW | NA | NA | LW | LW | LW | NA | LW | LW | LW | |
| Consistency | NA | NA | NA | NA | NA | LW | YS | NA | NA | NA | NA |
| Fault Tolerance | NA | NA | NA | YS | NA | YS | YS | NA | NA | NA | NA |
| Optimal no. of replicas | YS | YS | YS | YS | NC | YS | YS | YS | YS | NA | YS |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waseem, Q.; Wan Din, W.I.S.; Alshamrani, S.S.; Alharbi, A.; Nazir, A. Quantitative Analysis and Performance Evaluation of Target-Oriented Replication Strategies in Cloud Computing. Electronics 2021, 10, 672. https://doi.org/10.3390/electronics10060672
Waseem Q, Wan Din WIS, Alshamrani SS, Alharbi A, Nazir A. Quantitative Analysis and Performance Evaluation of Target-Oriented Replication Strategies in Cloud Computing. Electronics. 2021; 10(6):672. https://doi.org/10.3390/electronics10060672
Chicago/Turabian StyleWaseem, Quadri, Wan Isni Sofiah Wan Din, Sultan S. Alshamrani, Abdullah Alharbi, and Amril Nazir. 2021. "Quantitative Analysis and Performance Evaluation of Target-Oriented Replication Strategies in Cloud Computing" Electronics 10, no. 6: 672. https://doi.org/10.3390/electronics10060672