
On the Gap between Domestic Robotic Applications and Computational Intelligence





Abstract
:1. Introduction
- to give an analysis about the functions of the current state-of-the-art domestic robots and their technologies behind;
- to identify the potential technologies in computational intelligence to be used in the domestic robots and its gap to the state-of-the-art CI models;
- to further foresee the development path of the domestic robotics.
2. Taxonomy of Domestic Robots
2.1. Virtual Robots
2.2. Physical Robots
2.2.1. IoT Robots
2.2.2. Interactive Robots
2.2.3. Service Robots
2.2.4. Boundaries between Categories
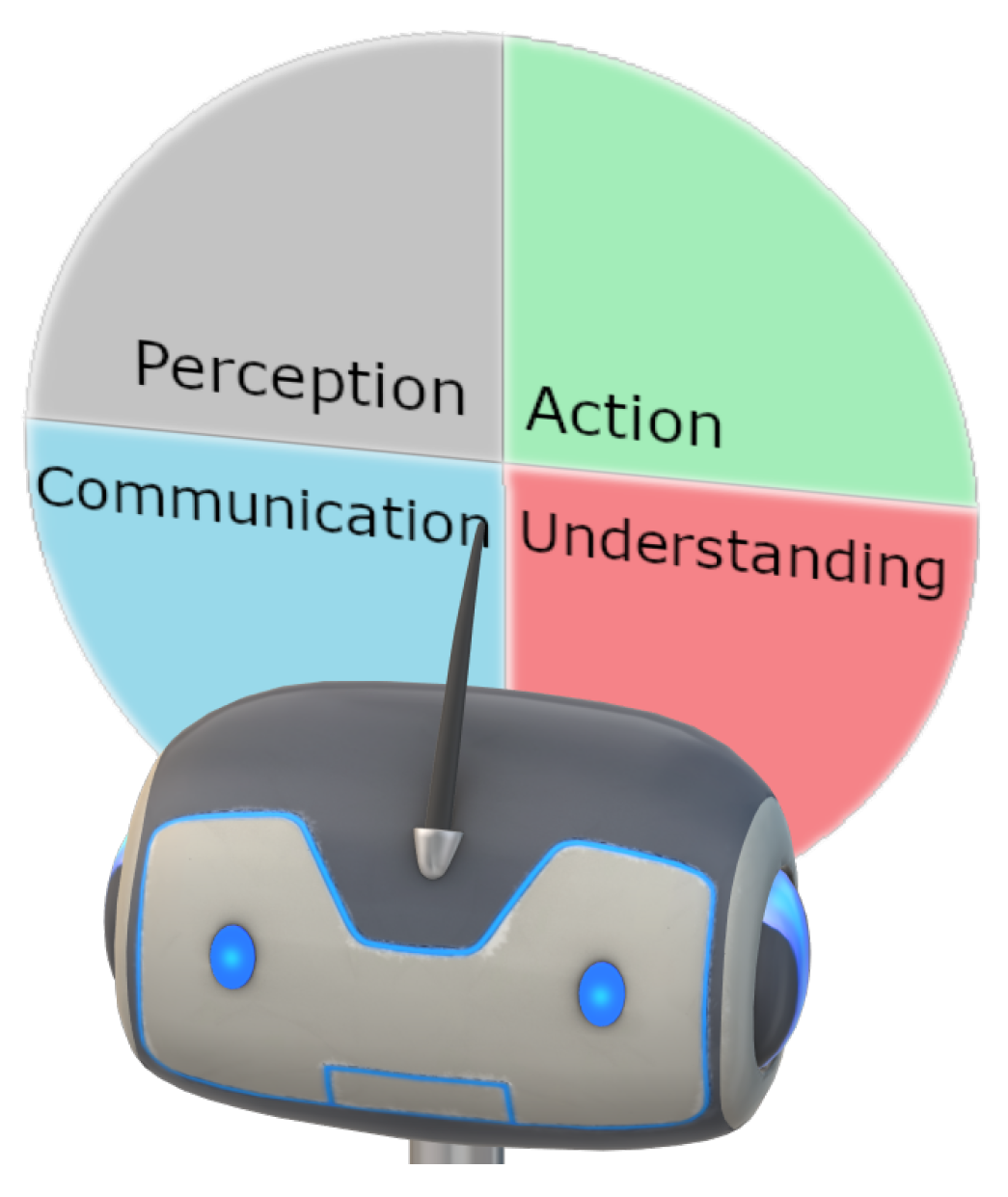
2.3. Multipurpose Domestic Robots and the Core Functions
- Perception: A robot should be able to perceive its surrounding environment, including audio and vision. In addition to being able to recognize audio and vision signals, in the computational intelligence domain, these abilities correspond to automatic speech recognition, face detection and recognition, object detection, action recognition and emotion recognition.
- Action: After perceiving and understanding, a robot should be able to react accordingly, including vacuuming floor after receiving commands, making scheduled movements and doing multi-modal conversations including gestures. The action function can be further formulated into low-level actions, such as movements on wheels, median-level actions, such as pre-defined or adaptive behaviors and high-level actions, such as movements under planning.
- Understanding: In addition to perceiving, the robots should be able to understand what the signals mean. That is, to recognize what humans talk about via speech signals, to navigate itself via seeing the environment through cameras, to recognize human emotions and so on. These abilities correspond to natural language/commands understanding, scene understanding and so on.
- Communication: The communication function is one important element to make the robot “human-like”. It can be used two-fold: firstly, the successful communication skills could be fundamental when the robots are involved in interacting with users, especially during the some tasks in the domestic domain can be too complicated to be finished with one or two commands. Therefore, it is often to converse with human users to achieve common ground understanding, especially the robots are involved in providing entertaining and cognitive services. Both verbal and non-verbal communications are often involved in such interactions.
3. Computational Intelligence in Robotics
3.1. Perception: Speech Recognition, Face Detection and Recognition, Object Detection
3.1.1. Automatic Speech Recognition (ASR)
3.1.2. Object Detection and Recognition
3.1.3. Face Detection and Recognition
- in most cases, a person to be detected may not be included in the training set, while most of the objects recognized are within the training set, which we state the facial recognition is an open-set problem.
- since the labelled objects already exist in the training datasets, we usually employ a discriminative model which produces the labels as outputs given the input signals to solve the object recognition problem. This can be achieved by incorporating a discriminative classifier (e.g., soft-max) at the end of the model. In the case of facial detection, since the output labels of facial detection are only binary, the features can either be pre-defined or data-driven.
- The state-of-art facial recognition methods are evaluated with the standard datasets. In the practical robotic applications, the perceived information usually contains a lot of noise and environmental factors vary, which results in the negative effects in the recognition accuracy.
- Most of the facial recognition methods embedded in robotic systems require the users to stand in the receptive fields of the camera (assuming they are also at a reasonable distance from the camera), which might be inconvenient/unfriendly feeling to the users.
3.2. Action: SLAM, Obstacle Avoidance, and Path Planning
3.2.1. SLAM
3.2.2. Obstacle Avoidance
3.2.3. Path Planning
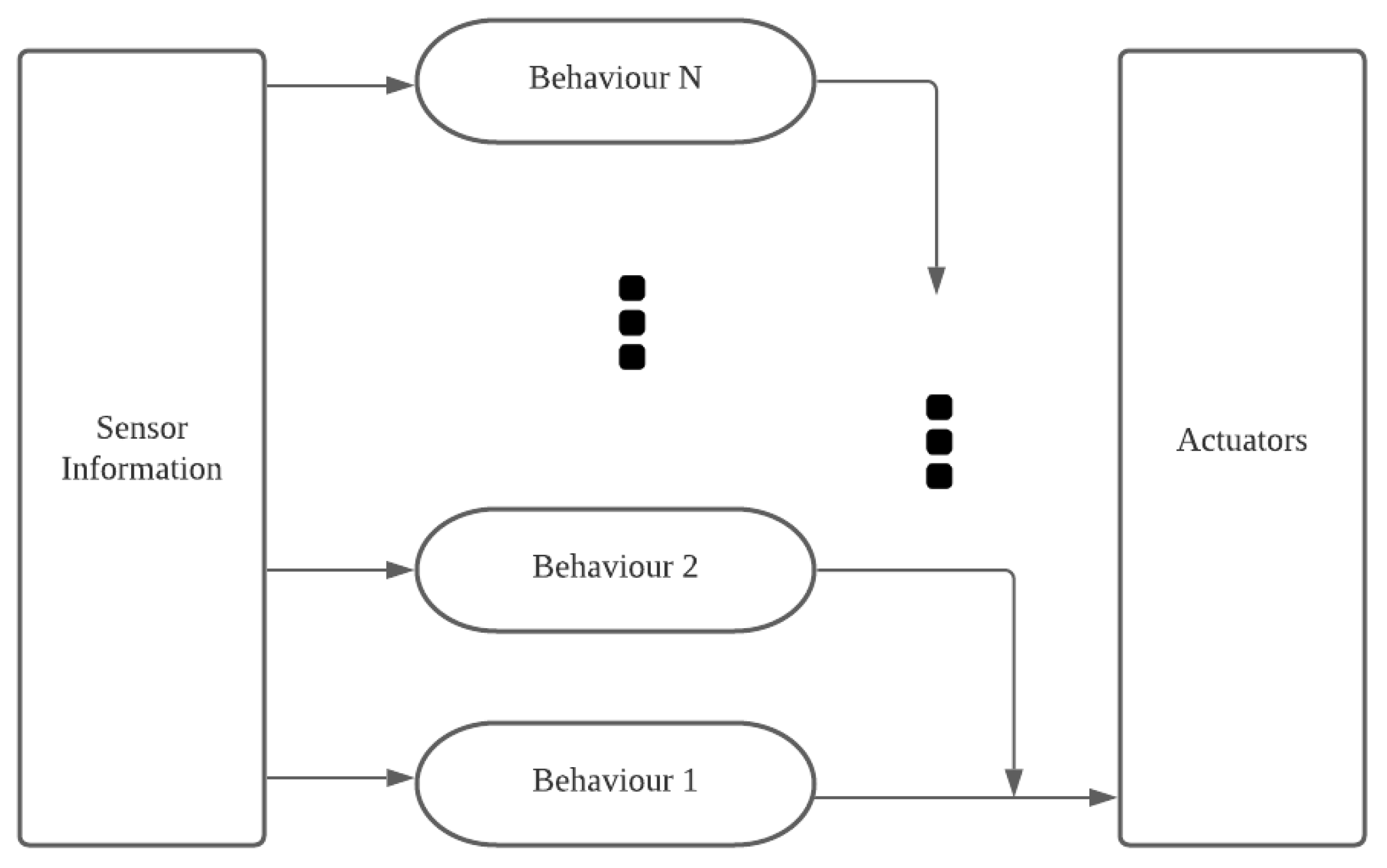
3.2.4. Robotic Action, Behaviors and Their Selections
3.3. Understanding: Action, Intention and Emotion
3.3.1. Action Recognition
3.3.2. Emotion Recognition
- 1
- Computing-wise: How to efficiently utilize the multi-modal sensor signals to identify the emotional status of users? To solve this, we may consider the multi-modal machine learning methods [104].
- 2
- Interaction-wise: During usual interaction, all the social contexts (e.g., wording in the conversation) and common knowledge can also be considered as cues for recognizing emotion. Can we also utilize such knowledge on a robot?
- 3
- Robot-wise: What kind of sensor signals can we choose to jointly estimate the emotion by reducing the noise and placing them together to work robustly?
3.4. Communication: Speech, Dialog and Conversation
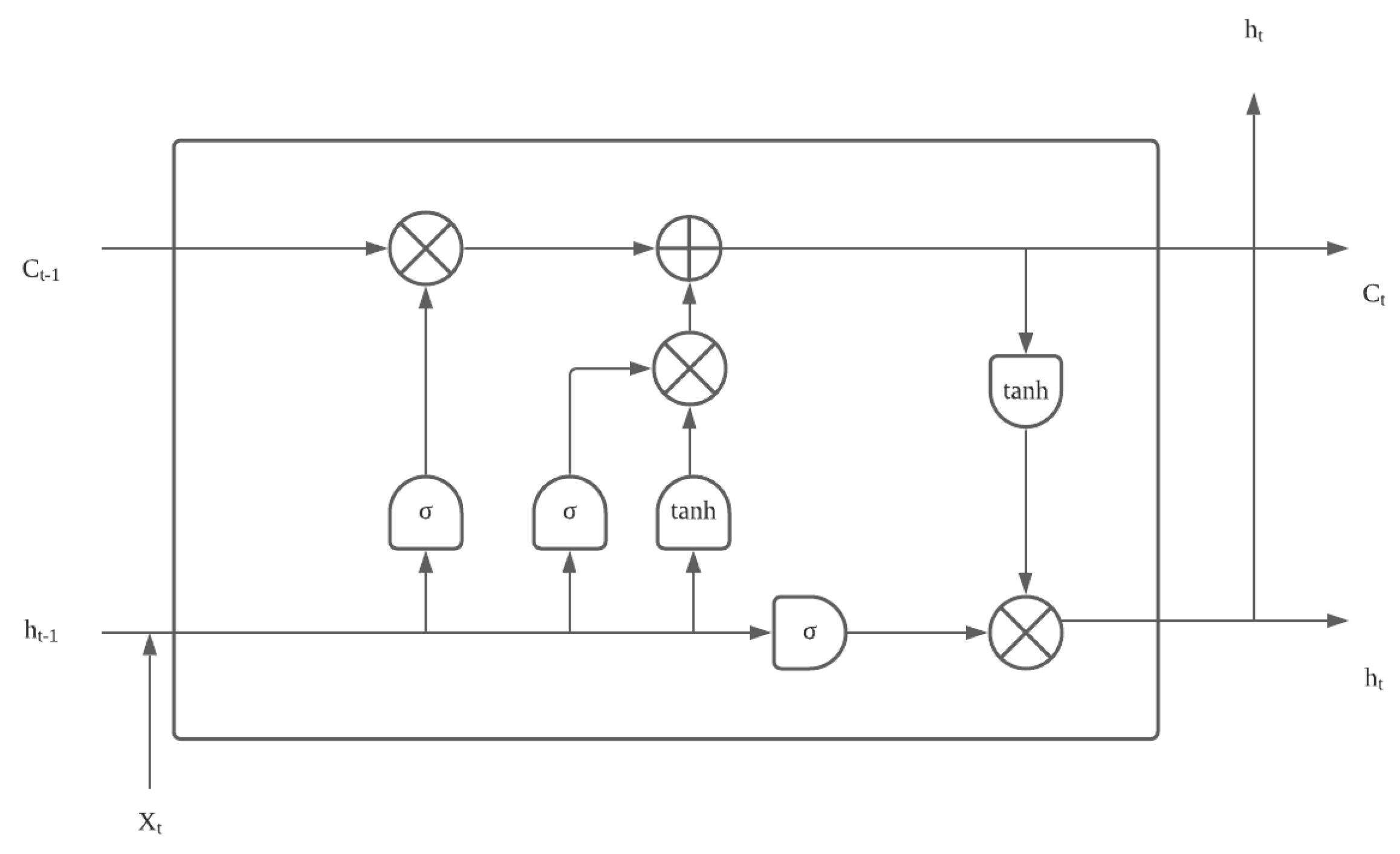
3.4.1. Generation: Speech Synthesis, Inverse Kinematics
3.4.2. Language Models and Language Understanding
3.4.3. Dialogue Systems
4. Domestic Robots in Real Life: Where We Can Fill the Gaps
4.1. Conversational System

- The long-term memory and learning: For the users, the long-term memory of a robot is essential for them to feel like the robot is a continuous being which is co-living with them. Social robots also need long-term memories in order to keep the knowledge acquired from learning to establish long-term relationships with humans and other robots.Since the learning world is open and the users have individual differences, household objects and household tasks as well as the human’s behaviors differ. In order to endow the long-term memory, the ability of continuous learning [124], active learning [125] or learning via human-in-the-loop [126] could be implemented on the robots.
- Multi-modal language processing, understanding and grounding: As we have already discussed, the state-of-the-art language processing is the first step for a robot to possess languages. At present, various data-driven conversation systems have been proposed based on reinforcement learning [127], Attention [128] or the hybrid model of various techniques. If the methods could integrate the continuous learning, they could be possible methods which could avoid the curse of dimensionality in reinforcement learning and result in an open-ended training conversation system. Furthermore, we also anticipate that the language understanding ability of robots is achieved after the language grounding problem for robots, which we will discuss in the next Section 5.1.3 .
- Communitive gestures: As we have mentioned, humans naturally communicate with speech and gestures [109]. Despite the continuous effort on building multi-modal interfaces, current robots can only understand a limited and pre-defined set of gestures from humans, which mostly fall into the category of symbolic gestures. However, most common gestures in daily communication are iconic gestures (e.g., drawing in the space to describe the shape of a stone), which have no particular form and bear close semantic and temporal relation to accompanied speech [129,130]. Without understanding iconic gestures, robots rely on natural language to understand humans. Hence, users must articulate themselves via language, making it less convenient and natural than interacting with humans.
- Other techniques involved object tracking and recognition and object manipulation.
4.2. Affective Communication

- Affective computing: Affective computing [131] is a broader field of emotion recognition, which also includes interpret, process and simulate human affects. Personal or domestic robots are nature embedding platforms to implement and test affective computing models since they have human-like appearances. Various robotic platforms, for instance, Kismet [132,133], have been used to test the affective models as well as tools for human–robot interaction.The affective computing is still an emerging subject, and its theoretical foundation in cognitive sciences is still open to discussion [134]. Most of its applications used in robotic systems have focused on emotion recognition and interpretation based on speech [135], facial [136] and bodily expression [95]. The simulation of emotion and the its synergy [137] to bodily expression, speech and facial expression.
- Artificial empathy: Robots built with artificial empathy are able to detect and respond to human emotions in an empathetic way. The constructing of empathy on a robot should also be included in the affective computing. The level of empathy may be calculated by the theory of simulation [138] in empathy.Although these can be also rooted from the emotion recognition techniques, various other cognitive theories—inspired artificially built empathy theories—have be also developed. For instance, from the developmental point of view, the empathy of robots can be developed by the common embodiment to achieve [139], such as artificial pain [140] obtained from the tactile sensors.
- Other techniques involved language understanding and facial Recognition.
4.3. IoT Robots

- Interconnected with other robots and the internet: It seems not difficult for a robot to connect with other devices via internet. With the connections, there are still open questions such as the accessibility of different devices, the trade-off between efficiency in interaction and the completeness of information searching.
- Personalized recommender system: The commercial recommender system usually uses collaborative filtering which collects information or patterns by the collaboration among multiple agents, viewpoints, data sources, etc. This technique is particularly useful for the recommendation of commercial products or common interests among different groups of people. Nevertheless, when the recommendation is about something not common among different people, for instance, a user A at home likes eating fish, while another user B in another home may follow a diet. This recommender problem should be addressed with other algorithms.
- Other techniques involved robotic behaviors, e.g., cooking.

- Scheduler based on psychological and physiological advice: Some personal scheduler should also refer to the psychological and physiological advice from the doctors. These may also need the robot to search the relevant knowledge base for the recommendation for certain individual conditions. A relevant knowledge database should be built and constantly updated online.
- Other techniques involved interconnected with other robots and internet.
5. Future Directions: Trends, Challenges and Solutions
5.1. Cognition
5.1.1. Multi-Modal Learning
- The inference ability which learns the causal relationship;
- the meta-learning ability;
- the self-awareness ability.
5.1.2. Meta-Cognition
Meta-cognitive experiences are any conscious cognitive or affective experiences that accompany and pertain to any intellectual enterprise. An example would be the sudden feeling that you do not understand something another person just said.
- A human–robot interaction (HRI) by implementing theory of mind (ToM). ToM is referred to a meta-cognitive process that an agent could think of and understand other thoughts and decisions made by its counterpart. Therefore, in the domestic robotic scenario, the robots can take into account (monitor) others’ mental state and use that knowledge to predict others’ behavior.
- A safety-lock based on an implementation of self-regulation. This self-regulation mechanism can be close to immediate awareness and body awareness. Therefore, this mechanism can control any non-safe decision making processes when the sensorimotor imagination of the own body is hurt.
5.1.3. Language Grounding
5.1.4. Solutions
- 1
- Knowledge acquisition. The structure of knowledge may be acquired by embodiment. Therefore, the aforementioned multi-modal learning and a symbolic grounding may be necessary.
- 2
- Behavioral learning. Such learning can be conducted via learning by curriculum or human demonstration.
- 3
- Social interaction based on mutual understanding and theory of mind (ToM) [151]. The ToM ability, if it is successfully implemented, is able to allow the robot to dynamically switch the roles during the interaction. It also allows the robot to endow abilities of empathy to assist as a more practical robot assistant.
5.2. Data Safety and Ethics
5.2.1. Data Safety and Ethics in NLP
5.2.2. Data Safety, Ethics and Explainability in Domestic Robots
5.2.3. Solution
- 1
- Sensor-wise: sensors that use bio-metric information, such as cameras, sometimes can be replaced with other sensors such as LiDAR and infrared sensors [159,160,161]. If the bio-metric details of users must be captured, such details should be processed locally at the edge and should not be sent online.
- 2
- Software-wise: it is crucial to ensure its reliability, adaptivity and ubiquity with the advancement of software technology in the network design. To fit the requirements of the ultra-fast network and computing, a designated middle-ware for the safety feature of the network is needed to be further investigated.
6. Summary
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cavallo, F.; Esposito, R.; Limosani, R.; Manzi, A.; Bevilacqua, R.; Felici, E.; Di Nuovo, A.; Cangelosi, A.; Lattanzio, F.; Dario, P. Robotic services acceptance in smart environments with older adults: User satisfaction and acceptability study. J. Med. Internet Res. 2018, 20, e264. [Google Scholar] [CrossRef]
- Zhong, L.; Verma, R. “Robot Rooms”: How Guests Use and Perceive Hotel Robots. Cornell Hosp. Rep. 2019, 19, 1–8. [Google Scholar]
- Pyae, A.; Joelsson, T.N. Investigating the usability and user experiences of voice user interface: A case of Google home smart speaker. In Proceedings of the 20th International Conference on Human-Computer Interaction with Mobile Devices and Services Adjunct, Barcelona, Spain, 3–6 September 2018; pp. 127–131. [Google Scholar]
- Shibata, T.; Inoue, K.; Irie, R. Emotional robot for intelligent system-artificial emotional creature project. In Proceedings of the 5th IEEE International Workshop on Robot and Human Communication (RO-MAN’96 TSUKUBA), Tsukuba, Japan, 11–14 November 1996; pp. 466–471. [Google Scholar]
- Yamamoto, T.; Terada, K.; Ochiai, A.; Saito, F.; Asahara, Y.; Murase, K. Development of human support robot as the research platform of a domestic mobile manipulator. ROBOMECH J. 2019, 6, 1–15. [Google Scholar] [CrossRef]
- Abubshait, A.; Wiese, E. You look human, but act like a machine: Agent appearance and behavior modulate different aspects of human—Robot interaction. Front. Psychol. 2017, 8, 1393. [Google Scholar] [CrossRef]
- Holloway, J. Owners Really Like Their Robot Vacuums, Survey Says. 4 September 2018. Available online: https://newatlas.com/robot-vacuum-market/56200/ (accessed on 4 September 2018).
- Chestnutt, J.; Lau, M.; Cheung, G.; Kuffner, J.; Hodgins, J.; Kanade, T. Footstep planning for the honda asimo humanoid. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 629–634. [Google Scholar]
- Deng, L.; Abdel-Hamid, O.; Yu, D. A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6669–6673. [Google Scholar]
- Povey, D.; Burget, L.; Agarwal, M.; Akyazi, P.; Feng, K.; Ghoshal, A.; Glembek, O.; Goel, N.K.; Karafiát, M.; Rastrow, A.; et al. Subspace Gaussian mixture models for speech recognition. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4330–4333. [Google Scholar]
- Juang, B.H.; Rabiner, L.R. Hidden Markov models for speech recognition. Technometrics 1991, 33, 251–272. [Google Scholar] [CrossRef]
- Sercu, T.; Puhrsch, C.; Kingsbury, B.; LeCun, Y. Very deep multilingual convolutional neural networks for LVCSR. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4955–4959. [Google Scholar]
- Yu, D.; Xiong, W.; Droppo, J.; Stolcke, A.; Ye, G.; Li, J.; Zweig, G. Deep Convolutional Neural Networks with Layer-Wise Context Expansion and Attention. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 17–21. [Google Scholar]
- Sak, H.; Senior, A.W.; Beaufays, F. Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling. In Proceedings of the INTERSPEECH 2014 15th Annual Conference of the International Speech Communication Association, Singapore, Singapore, 14–18 September 2014. [Google Scholar]
- Pundak, G.; Sainath, T. Highway-LSTM and Recurrent Highway Networks for Speech Recognition. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Chorowski, J.K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. arXiv 2015, arXiv:1506.07503. [Google Scholar]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-art speech recognition with sequence-to-sequence models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Wu, J.W.; Cai, W.; Yu, S.M.; Xu, Z.L.; He, X.Y. Optimized visual recognition algorithm in service robots. Int. J. Adv. Robot. Syst. 2020, 17. [Google Scholar] [CrossRef]
- Quan, L.; Pei, D.; Wang, B.; Ruan, W. Research on Human Target Recognition Algorithm of Home Service Robot Based on Fast-RCNN. In Proceedings of the 2017 10th International Conference on Intelligent Computation Technology and Automation (ICICTA), Changsha, China, 9–10 October 2017; pp. 369–373. [Google Scholar]
- Li, P.; Chen, X.; Shen, S. Stereo r-cnn based 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7644–7652. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Schwarz, M.; Milan, A.; Periyasamy, A.S.; Behnke, S. RGB-D object detection and semantic segmentation for autonomous manipulation in clutter. Int. J. Robot. Res. 2018, 37, 437–451. [Google Scholar] [CrossRef] [Green Version]
- Martinez-Martin, E.; Del Pobil, A.P. Object detection and recognition for assistive robots: Experimentation and implementation. IEEE Robot. Autom. Mag. 2017, 24, 123–138. [Google Scholar] [CrossRef]
- Trigueros, D.S.; Meng, L.; Hartnett, M. Face Recognition: From Traditional to Deep Learning Methods. arXiv 2018, arXiv:1811.00116. [Google Scholar]
- Wang, M.; Deng, W. Deep face recognition: A survey. arXiv 2018, arXiv:1804.06655. [Google Scholar]
- Learned-Miller, E.; Huang, G.B.; RoyChowdhury, A.; Li, H.; Hua, G. Labeled faces in the wild: A survey. In Advances in Face Detection and Facial Image Analysis; Springer: Cham, Switzerland, 2016; pp. 189–248. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Closing the gap to human-level performance in face verification. deepface. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; Volume 5, p. 6. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. Deepid3: Face recognition with very deep neural networks. arXiv 2015, arXiv:1502.00873. [Google Scholar]
- Zheng, Y.; Pal, D.K.; Savvides, M. Ring loss: Convex feature normalization for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5089–5097. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Goswami, G.; Bharadwaj, S.; Vatsa, M.; Singh, R. On RGB-D face recognition using Kinect. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–6. [Google Scholar]
- Min, R.; Kose, N.; Dugelay, J.L. Kinectfacedb: A kinect database for face recognition. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 1534–1548. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.; Durrant-Whyte, H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef] [Green Version]
- Montemerlo, M.; Thrun, S.; Koller, D.; Wegbreit, B. FastSLAM: A Factored Solution to the Simultaneous Localization and Mapping Problem. In Proceedings of the Eighteenth National Conference on Artificial Intelligence, Menlo Park, CA, USA, 28 July–1 August 2002; pp. 1–6. [Google Scholar]
- Montemerlo, M.; Thrun, S.; Koller, D.; Wegbreit, B. FastSLAM 2.0: An improved particle filtering algorithm for simultaneous localization and mapping that provably converges. IJCAI 2003, 3, 1151–1156. [Google Scholar]
- Zhong, J.; Fung, Y.F. Case study and proofs of ant colony optimisation improved particle filter algorithm. IET Control Theory Appl. 2012, 6, 689–697. [Google Scholar] [CrossRef]
- Liu, Y.; Thrun, S. Results for outdoor-SLAM using sparse extended information filters. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation (Cat. No. 03CH37422), Taipei, Taiwan, 14–19 September 2003; Volume 1, pp. 1227–1233. [Google Scholar]
- Bohren, J.; Rusu, R.B.; Jones, E.G.; Marder-Eppstein, E.; Pantofaru, C.; Wise, M.; Mösenlechner, L.; Meeussen, W.; Holzer, S. Towards autonomous robotic butlers: Lessons learned with the PR2. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 5568–5575. [Google Scholar]
- Hornung, A.; Wurm, K.M.; Bennewitz, M. Humanoid robot localization in complex indoor environments. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 1690–1695. [Google Scholar]
- Jamiruddin, R.; Sari, A.O.; Shabbir, J.; Anwer, T. RGB-depth SLAM review. arXiv 2018, arXiv:1805.07696. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Ackerman, E.; Guizzo, E. iRobot Brings Visual Mapping and Navigation to the Roomba 980. 16 September 2015. Available online: https://spectrum.ieee.org/automaton/robotics/home-robots/irobot-brings-visual-mapping-and-navigation-to-the-roomba-980 (accessed on 16 September 2015).
- Karlsson, N.; Di Bernardo, E.; Ostrowski, J.; Goncalves, L.; Pirjanian, P.; Munich, M.E. The vSLAM algorithm for robust localization and mapping. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 24–29. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohli, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A.W. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; Volume 11, pp. 127–136. [Google Scholar]
- Whelan, T.; Kaess, M.; Fallon, M.; Johannsson, H.; Leonard, J.J.; McDonald, J. Kintinuous: Spatially Extended KinectFusion. In Proceedings of the RSS Workshop on RGB-D: Advanced Reasoning with Depth Cameras, Sydney, Australia, 9–10 July 2012; pp. 1–8. [Google Scholar]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 343–352. [Google Scholar]
- Alajlan, A.M.; Almasri, M.M.; Elleithy, K.M. Multi-sensor based collision avoidance algorithm for mobile robot. In Proceedings of the 2015 Long Island Systems, Applications and Technology, Farmingdale, NY, USA, 1 May 2015; pp. 1–6. [Google Scholar]
- Amditis, A.; Polychronopoulos, A.; Karaseitanidis, I.; Katsoulis, G.; Bekiaris, E. Multiple sensor collision avoidance system for automotive applications using an IMM approach for obstacle tracking. In Proceedings of the Fifth International Conference on Information Fusion, Annapolis, MD, USA, 8–11 July 2002; Volume 2, pp. 812–817. [Google Scholar]
- Borenstein, J.; Koren, Y. Real-time obstacle avoidance for fast mobile robots. IEEE Trans. Syst. Man Cybern. 1989, 19, 1179–1187. [Google Scholar] [CrossRef] [Green Version]
- Borenstein, J.; Koren, Y. The vector field histogram-fast obstacle avoidance for mobile robots. IEEE Trans. Robot. Autom. 1991, 7, 278–288. [Google Scholar] [CrossRef] [Green Version]
- Heinla, A.; Reinpõld, R.; Korjus, K. Mobile Robot Having Collision Avoidance System for Crossing a Road from a Pedestrian Pathway. U.S. Patent 10/282,995, 14 March 2019. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Stentz, A. Optimal and efficient path planning for partially known environments. In Intelligent Unmanned Ground Vehicles; Springer: Cham, Switzerland, 1997; pp. 203–220. [Google Scholar]
- Stentz, A. The focussed D^* algorithm for real-time replanning. IJCAI 1995, 95, 1652–1659. [Google Scholar]
- Elbanhawi, M.; Simic, M. Sampling-based robot motion planning: A review. IEEE Access 2014, 2, 56–77. [Google Scholar] [CrossRef]
- Kavraki, L.; Latombe, J.C. Randomized preprocessing of configuration for fast path planning. In Proceedings of the 1994 IEEE International Conference on Robotics and Automation, San Diego, CA, USA, 8–13 May 1994; pp. 2138–2145. [Google Scholar]
- Siciliano, B.; Sciavicco, L.; Villani, L.; Oriolo, G. Robotics: Modelling, Planning and Control; Springer: London, UK, 2009. [Google Scholar]
- Brooks, R. A robust layered control system for a mobile robot. IEEE J. Robot. Autom. 1986, 2, 14–23. [Google Scholar] [CrossRef] [Green Version]
- Brooks, R.A.; Connell, J.H. Asynchronous distributed control system for a mobile robot. In Proceedings of the Cambridge Symposium Intelligent Robotics Systems, Cambridge, MA, USA, 28–31 October 1986. [Google Scholar]
- Maes, P. How to do the right thing. Connect. Sci. 1989, 1, 291–323. [Google Scholar] [CrossRef]
- Maes, P. Situated agents can have goals. Robot. Auton. Syst. 1990, 6, 49–70. [Google Scholar] [CrossRef]
- Arkin, R. Motor schema based navigation for a mobile robot: An approach to programming by behavior. In Proceedings of the 1987 IEEE International Conference on Robotics and Automation, Raleigh, NC, USA, 31 March–3 April 1987; Volume 4, pp. 264–271. [Google Scholar]
- Rusu, P.; Petriu, E.M.; Whalen, T.E.; Cornell, A.; Spoelder, H.J. Behavior-based neuro-fuzzy controller for mobile robot navigation. IEEE Trans. Instrum. Meas. 2003, 52, 1335–1340. [Google Scholar] [CrossRef]
- Aguirre, E.; González, A. Fuzzy behaviors for mobile robot navigation: Design, coordination and fusion. Int. J. Approx. Reason. 2000, 25, 255–289. [Google Scholar] [CrossRef] [Green Version]
- Nattharith, P.; Güzel, M.S. Machine vision and fuzzy logic-based navigation control of a goal-oriented mobile robot. Adapt. Behav. 2016, 24, 168–180. [Google Scholar] [CrossRef]
- Kim, J.; Mishra, A.K.; Limosani, R.; Scafuro, M.; Cauli, N.; Santos-Victor, J.; Mazzolai, B.; Cavallo, F. Control strategies for cleaning robots in domestic applications: A comprehensive review. Int. J. Adv. Robot. Syst. 2019, 16. [Google Scholar] [CrossRef] [Green Version]
- Grigorescu, S.M.; Lüth, T.; Fragkopoulos, C.; Cyriacks, M.; Gräser, A. A BCI-controlled robotic assistant for quadriplegic people in domestic and professional life. Robotica 2012, 30, 419–431. [Google Scholar] [CrossRef] [Green Version]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 4489–4497. [Google Scholar]
- Goodale, M.A.; Milner, A.D. Separate visual pathways for perception and action. Trends Neurosci. 1992, 15, 20–25. [Google Scholar] [CrossRef]
- Bayat, A.; Pomplun, M.; Tran, D.A. A study on human activity recognition using accelerometer data from smartphones. Procedia Comput. Sci. 2014, 34, 450–457. [Google Scholar] [CrossRef] [Green Version]
- Florentino-Liano, B.; O’Mahony, N.; Artés-Rodríguez, A. Human activity recognition using inertial sensors with invariance to sensor orientation. In Proceedings of the 2012 3rd International Workshop on Cognitive Information Processing (CIP), Baiona, Spain, 28–30 May 2012; pp. 1–6. [Google Scholar]
- Stork, J.A.; Spinello, L.; Silva, J.; Arras, K.O. Audio-based human activity recognition using non-markovian ensemble voting. In Proceedings of the 2012 IEEE RO-MAN: The 21st IEEE International Symposium on Robot and Human Interactive Communication, Paris, France, 9–13 September 2012; pp. 509–514. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A survey of depth and inertial sensor fusion for human action recognition. Multimed. Tools Appl. 2017, 76, 4405–4425. [Google Scholar] [CrossRef]
- Garcia-Ceja, E.; Galván-Tejada, C.E.; Brena, R. Multi-view stacking for activity recognition with sound and accelerometer data. Inf. Fusion 2018, 40, 45–56. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhao, X.; Liang, X.; Liu, L.; Li, T.; Han, Y.; Vasconcelos, N.; Yan, S. Peak-Piloted Deep Network for Facial Expression Recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 425–442. [Google Scholar]
- Zhong, J.; Canamero, L. From continuous affective space to continuous expression space: Non-verbal behaviour recognition and generation. In Proceedings of the 4th International Conference on Development and Learning and on Epigenetic Robotics, Genoa, Italy, 13–16 October 2014; pp. 75–80. [Google Scholar]
- Li, J.; Yang, C.; Zhong, J.; Dai, S. Emotion-Aroused Human Behaviors Perception Using RNNPB. In Proceedings of the 2018 10th International Conference on Modelling, Identification and Control (ICMIC), Guiyang, China, 2–4 July 2018; pp. 1–6. [Google Scholar]
- Noroozi, F.; Kaminska, D.; Corneanu, C.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on emotional body gesture recognition. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef] [Green Version]
- Schuller, B.W. Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends. Commun. ACM 2018, 61, 90–99. [Google Scholar] [CrossRef]
- Poria, S.; Majumder, N.; Mihalcea, R.; Hovy, E. Emotion Recognition in Conversation: Research Challenges, Datasets, and Recent Advances. arXiv 2019, arXiv:1905.02947. [Google Scholar] [CrossRef]
- Schirmer, A.; Adolphs, R. Emotion perception from face, voice, and touch: Comparisons and convergence. Trends Cogn. Sci. 2017, 21, 216–228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. Meld: A multimodal multi-party dataset for emotion recognition in conversations. arXiv 2018, arXiv:1810.02508. [Google Scholar]
- Barros, P.; Churamani, N.; Lakomkin, E.; Siqueira, H.; Sutherland, A.; Wermter, S. The omg-emotion behavior dataset. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Dhall, A.; Goecke, R.; Joshi, J.; Wagner, M.; Gedeon, T. Emotion recognition in the wild challenge 2013. In Proceedings of the 15th ACM on International Conference on Multimodal Interaction, Sydney, Australia, 9–13 December 2013; pp. 509–516. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Zhu, W.; Mo, K.; Zhang, Y.; Zhu, Z.; Peng, X.; Yang, Q. Flexible end-to-end dialogue system for knowledge grounded conversation. arXiv 2017, arXiv:1709.04264. [Google Scholar]
- Serban, I.V.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Lin, G.; Walker, M. Stylistic variation in television dialogue for natural language generation. In Proceedings of the Workshop on Stylistic Variation, Copenhagen, Denmark, 7–11 September 2017; pp. 85–93. [Google Scholar]
- Akama, R.; Inada, K.; Inoue, N.; Kobayashi, S.; Inui, K. Generating stylistically consistent dialog responses with transfer learning. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Taipei, Taiwan, 27 November–1 December 2017; pp. 408–412. [Google Scholar]
- McNeill, D. Hand and Mind: What Gestures Reveal about Thought; University of Chicago Press: London, UK, 1992. [Google Scholar]
- Kita, S. Pointing: Where Language, Culture, and Cognition Meet; Psychology Press: East Sussex, UK, 2003. [Google Scholar]
- Bergmann, K.; Kopp, S. Increasing the expressiveness of virtual agents: Autonomous generation of speech and gesture for spatial description tasks. In Proceedings of the 8th International Conference on Autonomous Agents and Multiagent Systems—Volume 1. International Foundation for Autonomous Agents and Multiagent Systems, Budapest, Hungary, 10–15 May 2009; pp. 361–368. [Google Scholar]
- Chiu, C.C.; Morency, L.P.; Marsella, S. Predicting co-verbal gestures: A deep and temporal modeling approach. In Proceedings of the International Conference on Intelligent Virtual Agents, Delft, The Netherlands, 26–28 August; pp. 152–166.
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Gers, F.A.; Schmidhuber, E. LSTM recurrent networks learn simple context-free and context-sensitive languages. IEEE Trans. Neural Netw. 2001, 12, 1333–1340. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Winograd, T. Procedures as a Representation for Data in a Computer Program for Understanding Natural Language. Available online: http://dspace.mit.edu/handle/1721.1/7095 (accessed on 1 January 1971).
- Huang, M.; Zhu, X.; Gao, J. Challenges in Building Intelligent Open-domain Dialog Systems. arXiv 2019, arXiv:1905.05709. [Google Scholar]
- Schlangen, D.; Skantze, G. A general, abstract model of incremental dialogue processing. In Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, Athens, Greece, 30 March–3 April 2009; pp. 710–718. [Google Scholar]
- Kopp, S.; Gesellensetter, L.; Krämer, N.C.; Wachsmuth, I. A conversational agent as museum guide–design and evaluation of a real-world application. In Proceedings of the International Workshop on Intelligent Virtual Agents, Kos, Greece, 12–14 September 2005; pp. 329–343. [Google Scholar]
- Marge, M.; Nogar, S.; Hayes, C.; Lukin, S.; Bloecker, J.; Holder, E.; Voss, C. A Research Platform for Multi-Robot Dialogue with Humans. arXiv 2019, arXiv:1910.05624. [Google Scholar]
- Anderson, P.; Wu, Q.; Teney, D.; Bruce, J.; Johnson, M.; Sünderhauf, N.; Reid, I.; Gould, S.; van den Hengel, A. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3674–3683. [Google Scholar]
- Hu, R.; Fried, D.; Rohrbach, A.; Klein, D.; Saenko, K. Are You Looking? Grounding to Multiple Modalities in Vision-and-Language Navigation. arXiv 2019, arXiv:1906.00347. [Google Scholar]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef]
- Konyushkova, K.; Sznitman, R.; Fua, P. Learning active learning from data. Adv. Neural Inf. Process. Syst. 2017, 30, 4225–4235. [Google Scholar]
- Xin, D.; Ma, L.; Liu, J.; Macke, S.; Song, S.; Parameswaran, A. Accelerating human-in-the-loop machine learning: Challenges and opportunities. In Proceedings of the Second Workshop on Data Management for End-To-End Machine Learning, Houston, TX, USA, 15 June 2018; pp. 1–4. [Google Scholar]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Gao, J.; Jurafsky, D. Deep reinforcement learning for dialogue generation. arXiv 2016, arXiv:1606.01541. [Google Scholar]
- Yao, K.; Zweig, G.; Peng, B. Attention with intention for a neural network conversation model. arXiv 2015, arXiv:1510.08565. [Google Scholar]
- Han, T.; Hough, J.; Schlangen, D. Natural Language Informs the Interpretation of Iconic Gestures. A Computational Approach. In Proceedings of the 8th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Taipei, Taiwan, 27 November–1 December 2017. [Google Scholar]
- Wagner, P.; Malisz, Z.; Kopp, S. Gesture and Speech in Interaction: An Overview. Speech Commun. 2014, 57, 209–232. [Google Scholar] [CrossRef]
- Picard, R.W. Affective computing: Challenges. Int. J. Hum. Comput. Stud. 2003, 59, 55–64. [Google Scholar] [CrossRef]
- Breazeal, C.L. Designing Sociable Robots; MIT Press: London, UK, 2004. [Google Scholar]
- Lowe, R.; Andreasson, R.; Alenljung, B.; Lund, A.; Billing, E. Designing for a wearable affective interface for the NAO Robot: A study of emotion conveyance by touch. Multimodal Technol. Interact. 2018, 2, 2. [Google Scholar] [CrossRef] [Green Version]
- Battarbee, K.; Koskinen, I. Co-experience: User experience as interaction. CoDesign 2005, 1, 5–18. [Google Scholar] [CrossRef]
- Lakomkin, E.; Zamani, M.A.; Weber, C.; Magg, S.; Wermter, S. On the robustness of speech emotion recognition for human-robot interaction with deep neural networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 854–860. [Google Scholar]
- Liu, Z.; Wu, M.; Cao, W.; Chen, L.; Xu, J.; Zhang, R.; Zhou, M.; Mao, J. A facial expression emotion recognition based human-robot interaction system. IEEE/CAA J. Autom. Sin. 2017, 4, 668–676. [Google Scholar] [CrossRef]
- Zhong, J.; Yang, C. A Compositionality Assembled Model for Learning and Recognizing Emotion from Bodily Expression. In Proceedings of the 2019 IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM), Toyonaka, Japan, 3–5 July 2019; pp. 821–826. [Google Scholar]
- Gallagher, S. Empathy, simulation, and narrative. Sci. Context 2012, 25, 355–381. [Google Scholar] [CrossRef] [Green Version]
- Asada, M. Development of artificial empathy. Neurosci. Res. 2015, 90, 41–50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Asada, M. Artificial Pain May Induce Empathy, Morality, and Ethics in the Conscious Mind of Robots. Philosophies 2019, 4, 38. [Google Scholar] [CrossRef] [Green Version]
- Aytar, Y.; Vondrick, C.; Torralba, A. See, hear, and read: Deep aligned representations. arXiv 2017, arXiv:1706.00932. [Google Scholar]
- Kaiser, L.; Gomez, A.N.; Shazeer, N.; Vaswani, A.; Parmar, N.; Jones, L.; Uszkoreit, J. One model to learn them all. arXiv 2017, arXiv:1706.05137. [Google Scholar]
- Kralik, J.D. Architectural design of mind & brain from an evolutionary perspective. Common Model Cogn. Bull. 2020, 1, 394–400. [Google Scholar]
- Jackson, P.C. Toward Human-Level Artificial Intelligence: Representation and Computation of Meaning in Natural Language; Courier Dover Publications: Mineola, NY, USA, 2019. [Google Scholar]
- Flavell, J.H. Metacognition and cognitive monitoring: A new area of cognitive–developmental inquiry. Am. Psychol. 1979, 34, 906. [Google Scholar] [CrossRef]
- Cangelosi, A. Grounding language in action and perception: From cognitive agents to humanoid robots. Phys. Life Rev. 2010, 7, 139–151. [Google Scholar] [CrossRef] [PubMed]
- Müller, V.C. Which symbol grounding problem should we try to solve? J. Exp. Theor. Artif. Intell. 2015, 27, 73–78. [Google Scholar] [CrossRef]
- Chalmers, D. The hard problem of consciousness. In The Blackwell Companion to Consciousness; Wiley-Blackwell: Hoboken, NJ, USA, 2007; pp. 225–235. [Google Scholar]
- Cubek, R.; Ertel, W.; Palm, G. A critical review on the symbol grounding problem as an issue of autonomous agents. In Proceedings of the Joint German/Austrian conference on artificial intelligence (Künstliche Intelligenz), Dresden, Germany, 21–25 September 2015; pp. 256–263. [Google Scholar]
- Wang, P. On defining artificial intelligence. J. Artif. Gen. Intell. 2019, 10, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Frith, C.; Frith, U. Theory of mind. Curr. Biol. 2005, 15, R644–R645. [Google Scholar] [CrossRef] [Green Version]
- Pagallo, U. The impact of domestic robots on privacy and data protection, and the troubles with legal regulation by design. In Data Protection on the Move; Springer: Cham, Switzerland, 2016; pp. 387–410. [Google Scholar]
- Voigt, P.; Von dem Bussche, A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10, p. 3152676. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Selsam, D.; Liang, P.; Dill, D.L. Developing bug-free machine learning systems with formal mathematics. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3047–3056. [Google Scholar]
- Sun, X.; Khedr, H.; Shoukry, Y. Formal verification of neural network controlled autonomous systems. In Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, Montreal, QC, Canada, 16–18 April 2019; pp. 147–156. [Google Scholar]
- Platanios, E.; Poon, H.; Mitchell, T.M.; Horvitz, E.J. Estimating accuracy from unlabeled data: A probabilistic logic approach. arXiv 2017, arXiv:1705.07086. [Google Scholar]
- Edmonds, M.; Gao, F.; Liu, H.; Xie, X.; Qi, S.; Rothrock, B.; Zhu, Y.; Wu, Y.N.; Lu, H.; Zhu, S.C. A tale of two explanations: Enhancing human trust by explaining robot behavior. Sci. Robot. 2019, 4, eaay4663. [Google Scholar] [CrossRef] [PubMed]
- Naser, A.; Lotfi, A.; Zhong, J. Adaptive Thermal Sensor Array Placement for Human Segmentation and Occupancy Estimation. IEEE Sens. J. 2020, 21, 1993–2002. [Google Scholar] [CrossRef]
- Naser, A.; Lotfi, A.; Zhong, J.; He, J. Heat-map based occupancy estimation using adaptive boosting. In Proceedings of the 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Cheng, Y.; Wang, G.Y. Mobile robot navigation based on lidar. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1243–1246. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spectrum | Category | Examples | Applications | ||
|---|---|---|---|---|---|
| Physical Assistance | Social Assistance | Cognitive Assistance | |||
 | Virtual Robots | Google Assistant | ✗ | Assisting Scheduling Calling, etc. | Entertainment |
| Google Nest Hub | ✗ | Assisting Scheduling Calling, etc. | Entertainment | ||
| Amazon Echo | ✗ | Q & A Online ordering | Entertainment | ||
| Siri | ✗ | Q & A Online ordering | Entertainment | ||
| XiaoIce | ✗ | Q & A Online ordering | Entertainment | ||
| IoT Robots | Nest Thermostat | Adjust heating | ✗ | ✗ | |
| Samsung Hub Freezer | Watch food storage | Q&A Online ordering | TV Music | ||
| Wemo | Switch of electricity | ✗ | ✗ | ||
| Phyn Plus | Managing water level | ✗ | ✗ | ||
| Interactive Robots | Pepper | Limited | Assistant Receptionist Healthcare | Conversing | |
| Moxie | Q&A Education | ✗ | Entertainment | ||
| Paro [4] | ✗ | ✗ | Entertaining comforting elderly | ||
| Aibo | ✗ | Online ordering, etc | Entertainment, Respond to actions | ||
| Service Robots | HSR [5] | Multiple actions | Very limited | ✗ | |
| Stretch | Cleaning Manipulating Objects | ✗ | ✗ | ||
| iRobot Roomba | Cleaning | ✗ | ✗ | ||
| Virtual Robots | IoT Robots | Interactive Robots | Service Robots | |
|---|---|---|---|---|
| SLAM and Navigation | ✗ | ✗ | ➙ | ➙ |
| Object Recognition | ➙ | ➙ | ➚ | ➚ |
| Facial recognition | ➙ | ➚ | ➚ | ➚ |
| Action Recognition | ✗ | ➚ | ➚ | ➚ |
| Emotion Recognition | ✗ | ➚ | ➚➚ | ✗ |
| Speech Recognition | ➙ | ➙ | ➙ | ➙ |
| Dialog System | ➙ | ➙ | ➚ | ➚ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, J.; Ling, C.; Cangelosi, A.; Lotfi, A.; Liu, X. On the Gap between Domestic Robotic Applications and Computational Intelligence. Electronics 2021, 10, 793. https://doi.org/10.3390/electronics10070793
Zhong J, Ling C, Cangelosi A, Lotfi A, Liu X. On the Gap between Domestic Robotic Applications and Computational Intelligence. Electronics. 2021; 10(7):793. https://doi.org/10.3390/electronics10070793
Chicago/Turabian StyleZhong, Junpei, Chaofan Ling, Angelo Cangelosi, Ahmad Lotfi, and Xiaofeng Liu. 2021. "On the Gap between Domestic Robotic Applications and Computational Intelligence" Electronics 10, no. 7: 793. https://doi.org/10.3390/electronics10070793
APA StyleZhong, J., Ling, C., Cangelosi, A., Lotfi, A., & Liu, X. (2021). On the Gap between Domestic Robotic Applications and Computational Intelligence. Electronics, 10(7), 793. https://doi.org/10.3390/electronics10070793