
An Effective Learning Method for Automatic Speech Recognition in Korean CI Patients’ Speech


Abstract
:1. Introduction
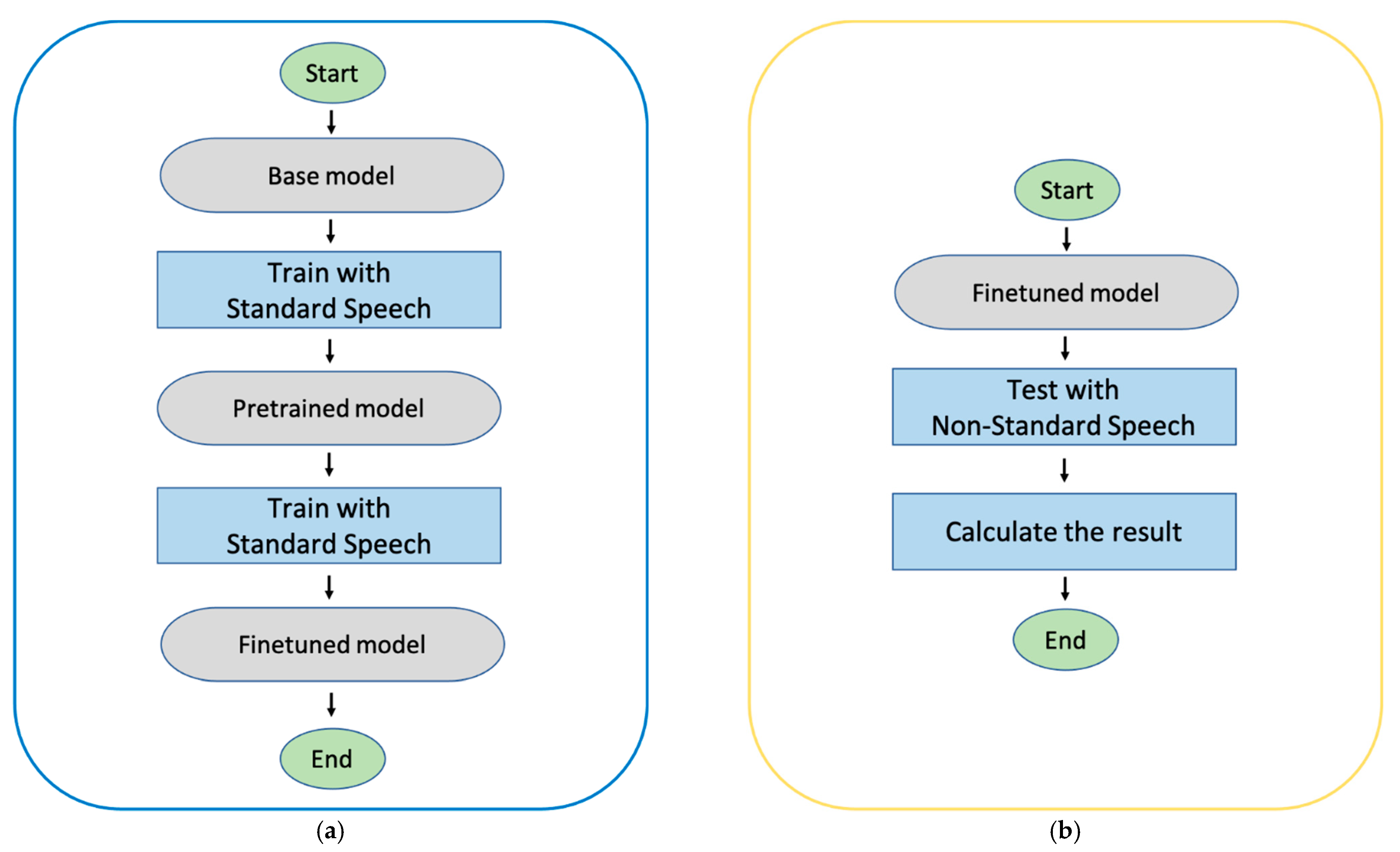
2. Materials and Methods
2.1. Base Model
2.2. Pre-Train Process
2.3. Finetuning
2.3.1. Fixed Decoder
2.3.2. Data Augmentation
Pitch Perturbation
Speed Perturbation
Spec Augmentation
- Frequency masking was performed so that the frequency channels were masked, where is a frequency mask parameter, and is selected from , where v is the number of log-Mel channels.
- Time masking was performed so that the frequency channels were masked, where is a time mask parameter, and is selected from , where is the length of the log-Mel frequency.
2.4. Dataset & Metric
3. Results & Discussion
3.1. Method 1 Result: The Pre-Train Process
3.2. Method 2 Result: Fixed Decoder without Augmentation
3.3. Method 3 Resul: Fixed Decoder with Augmentation
3.4. Comparison of the Results of the Three Methods
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end Speech Recognition in English and Mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Glasser, A.T.; Kushalnagar, K.R.; Kushalnagar, R.S.; Hurst, A.; Findlater, L.; Morris, M.R. Feasibility of Using Automatic Speech Recognition with Voices of Deaf and Hard-of-Hearing Individuals. In Proceedings of the 2018 ACM Conference Companion Publication on Designing Interactive Systems; ACM: New York, NY, USA, 2017; pp. 373–374. [Google Scholar]
- Tu, M.; Wisler, A.; Berisha, V.; Liss, J.M. The relationship between perceptual disturbances in dysarthric speech and automatic speech recognition performance. J. Acoust. Soc. Am. 2016, 140, EL416–EL422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mendel, L.L.; Lee, S.; Pousson, M.; Patro, C.; McSorley, S.; Banerjee, B.; Najnin, S.; Kapourchali, M.H. Corpus of deaf speech for acoustic and speech production research. J. Acoust. Soc. Am. 2017, 142, EL102–EL107. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McGarr, N.S.; Osberger, M.J. Pitch deviancy and intelligibility of deaf speech. J. Commun. Disord. 1978, 11, 237–247. [Google Scholar] [CrossRef]
- Shor, J.; Emanuel, D.; Lang, O.; Tuval, O.; Brenner, M.; Cattiau, J.; Vieira, F.; McNally, M.; Charbonneau, T.; Nollstadt, M.; et al. Personalizing ASR for Dysarthric and Accented Speech with Limited Data. Interspeech 2019 2019. [Google Scholar] [CrossRef] [Green Version]
- Jiao, Y.; Tu, M.; Berisha, V.; Liss, J. Simulating Dysarthric Speech for Training Data Augmentation in Clinical Speech Applications. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6009–6013. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3586–3589. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Prabhavalkar, R.; Rao, K.; Sainath, T.N.; Li, B.; Johnson, L.; Jaitly, N. A Comparison of Sequence-to-Sequence Models for Speech Recognition. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 939–943. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- AIHub Homepage. Available online: http://www.aihub.or.kr/aidata/105 (accessed on 5 August 2020).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference Learn. Represent. (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Park, S.K. Chapter 2: Phonetics and Phonology. In Korean Phonetic Phonology Education; Hankook Publishing House Co. Ltd.: Seoul, Korea, 2013; pp. 9–67. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exp | RNN-T | |
|---|---|---|
| - | Standard-Speech 1 | CI-Speech 2 |
| E1 | - | 98.40 |
| E2 | 18.09 | 42.13 |
| Exp | RNN-T |
|---|---|
| - | CI-Speech |
| E2 | 42.13 |
| E3 | 37.35 |
| Exp | RNN-T |
|---|---|
| - | CI-Speech |
| E4 | 41.33 |
| E5 | 44.86 |
| Exp | SpecAugment Policy | RNN-T | |||
|---|---|---|---|---|---|
| - | F | T | CI-Speech | ||
| E6 | 1 | 15 | 1 | 50 | 37.23 |
| E7 | 1 | 15 | 2 | 25 | 36.07 |
| E8 | 2 | 7 | 2 | 25 | 36.03 |
| E9 | 1 | 7 | 1 | 25 | 36.41 |
| Exp | RNN-T |
|---|---|
| - | CI-Speech |
| E2(Method 1) | 42.13 |
| E3(Method 2) | 37.35 |
| E8(Method 3) | 36.03 |
| Model | CER (%) | WER (Word Error Rate) (%) | ||
|---|---|---|---|---|
| - | Base | CI-Speech | Base | ALS |
| RNN-T (Method 3) | 98.40 | 36.03 | - | - |
| RNN-T [8] | - | - | 59.7 | 20.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, J.; Mondol, S.I.M.M.R.; Kim, Y.W.; Lee, S. An Effective Learning Method for Automatic Speech Recognition in Korean CI Patients’ Speech. Electronics 2021, 10, 807. https://doi.org/10.3390/electronics10070807
Jeong J, Mondol SIMMR, Kim YW, Lee S. An Effective Learning Method for Automatic Speech Recognition in Korean CI Patients’ Speech. Electronics. 2021; 10(7):807. https://doi.org/10.3390/electronics10070807
Chicago/Turabian StyleJeong, Jiho, S. I. M. M. Raton Mondol, Yeon Wook Kim, and Sangmin Lee. 2021. "An Effective Learning Method for Automatic Speech Recognition in Korean CI Patients’ Speech" Electronics 10, no. 7: 807. https://doi.org/10.3390/electronics10070807
APA StyleJeong, J., Mondol, S. I. M. M. R., Kim, Y. W., & Lee, S. (2021). An Effective Learning Method for Automatic Speech Recognition in Korean CI Patients’ Speech. Electronics, 10(7), 807. https://doi.org/10.3390/electronics10070807