
Investigating the Effects of Training Set Synthesis for Audio Segmentation of Radio Broadcast




Abstract
:1. Introduction
Paper Structure
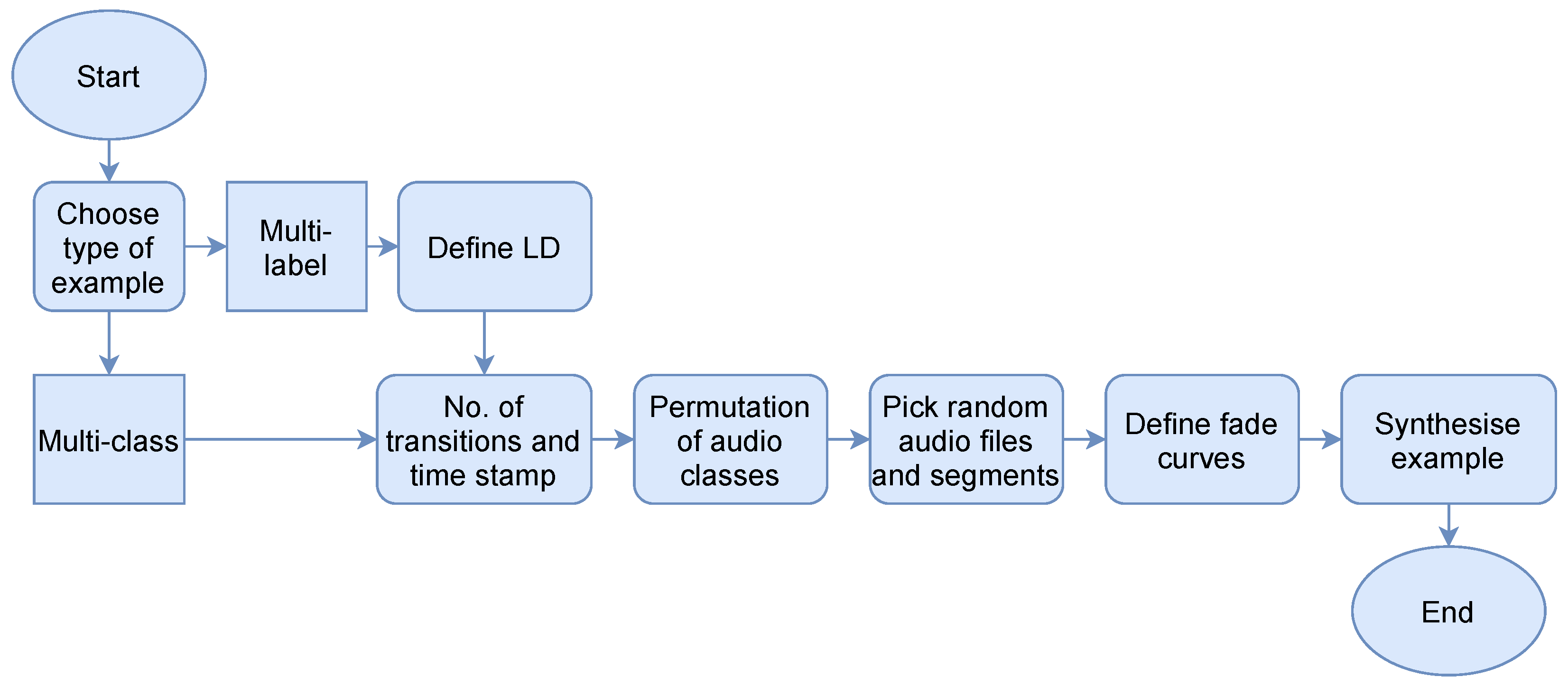
2. Data Synthesis
2.1. Synthetic Examples
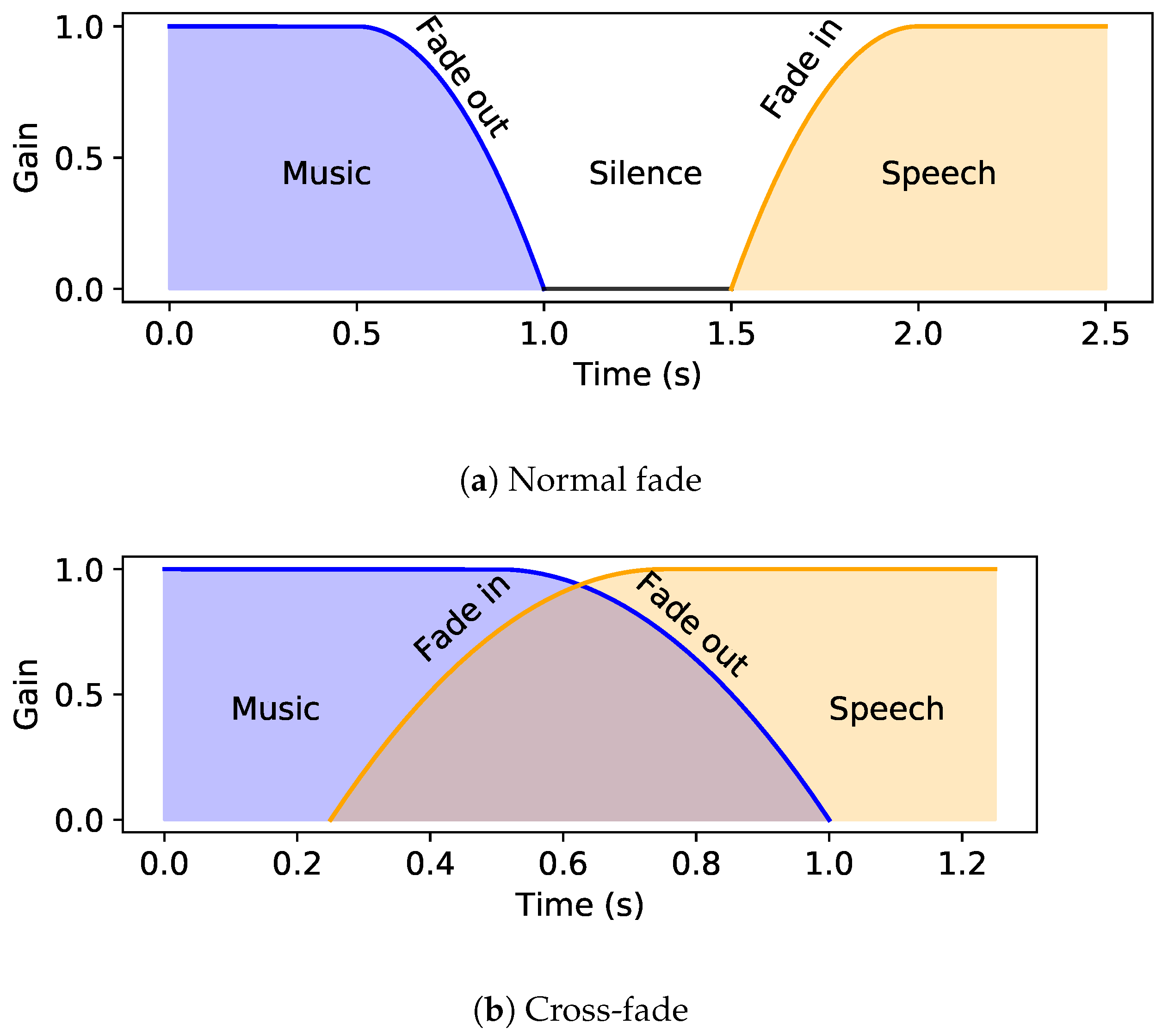
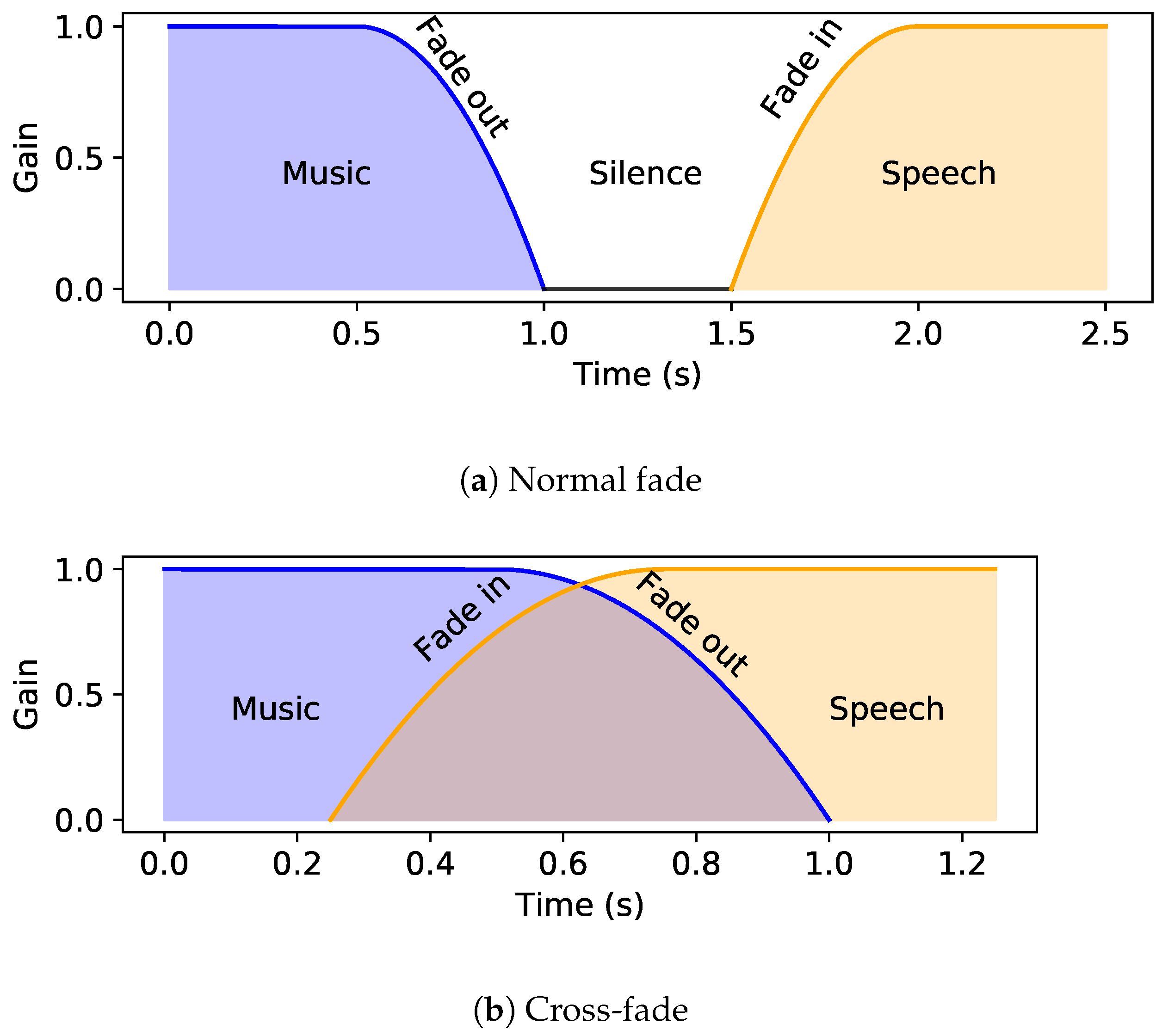
2.2. Audio Transitions
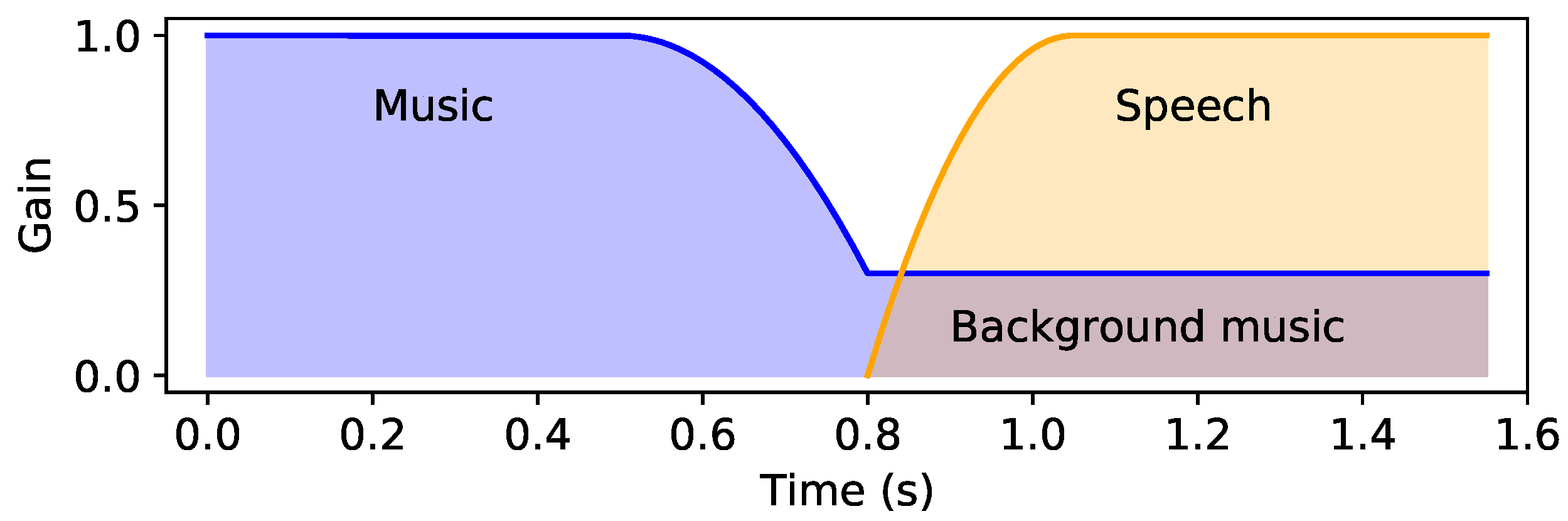
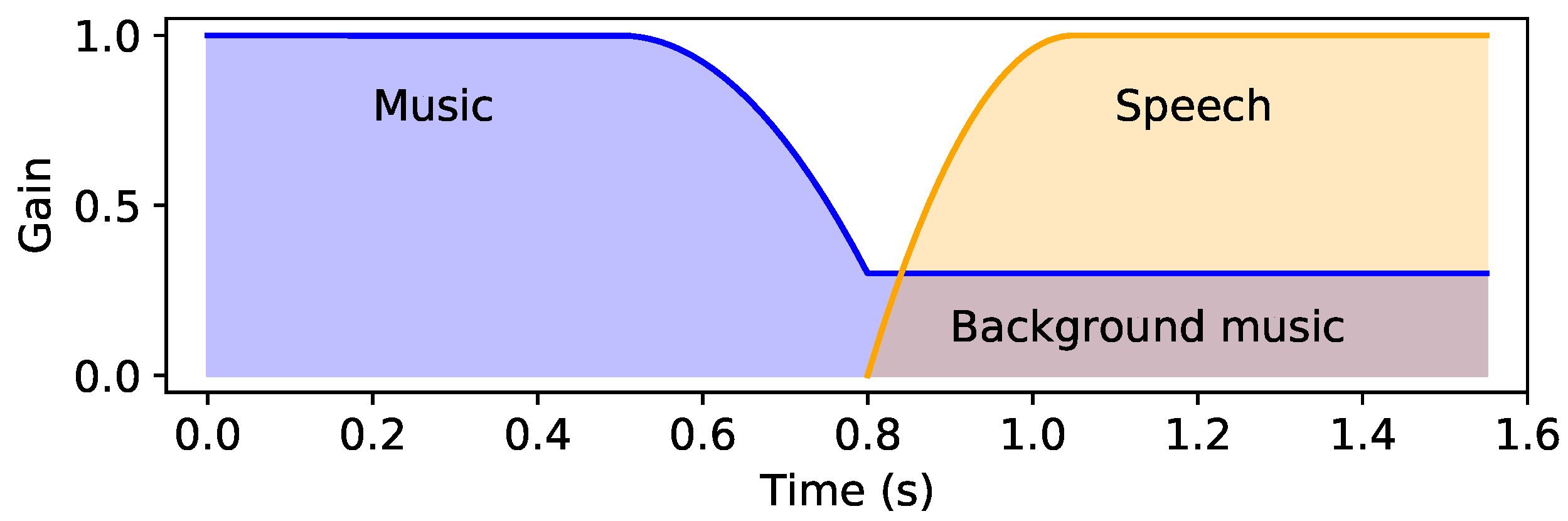
- Music+speech to music: Initially, audio ducking is performed on the music and the volume is increased after the speech stops.
- Music+speech to speech: The background music fades out at the transition point.
- Music to music+speech: Initially, music is being played and ducking is performed when the speech starts.
- Speech to music+speech: Music fades in at the transition point.
2.3. Time-Related Variables
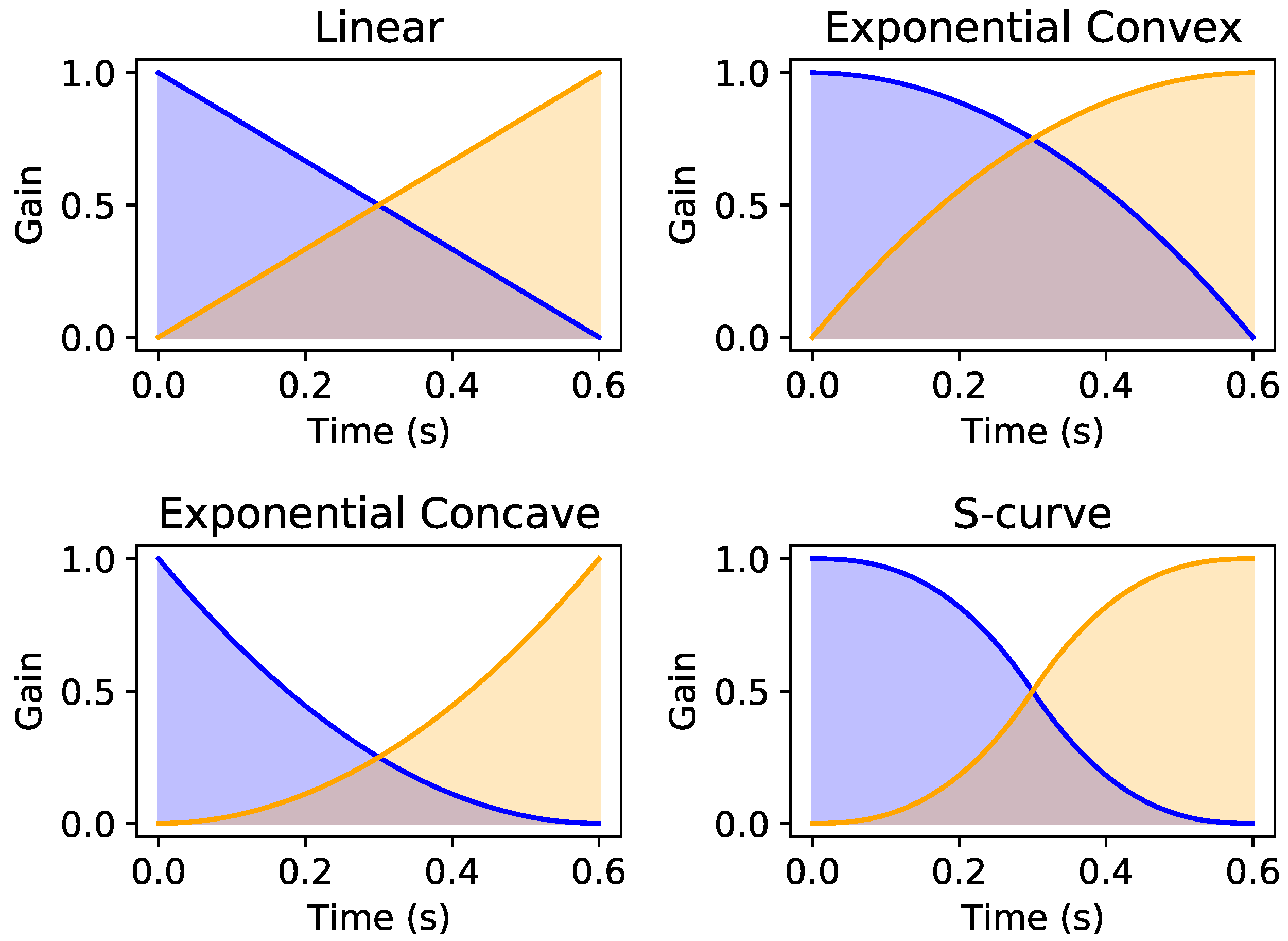
2.4. Fade Curves
2.5. Sampling Audio Files
2.6. Audio Ducking
3. Methods
3.1. Preprocessing and Feature Extraction
3.2. Datasets
3.2.1. Repository for Data Synthesis
3.2.2. Real-World Radio Data
3.3. Postprocessing and Evaluation
4. Experiment I: Comparison of Neural Network Architectures
4.1. Experimental Set-Up
4.1.1. CNN
4.1.2. B-LSTM and B-GRU
4.1.3. ncTCN
4.1.4. CRNN
4.1.5. Hyperparameter Tuning
4.2. Results
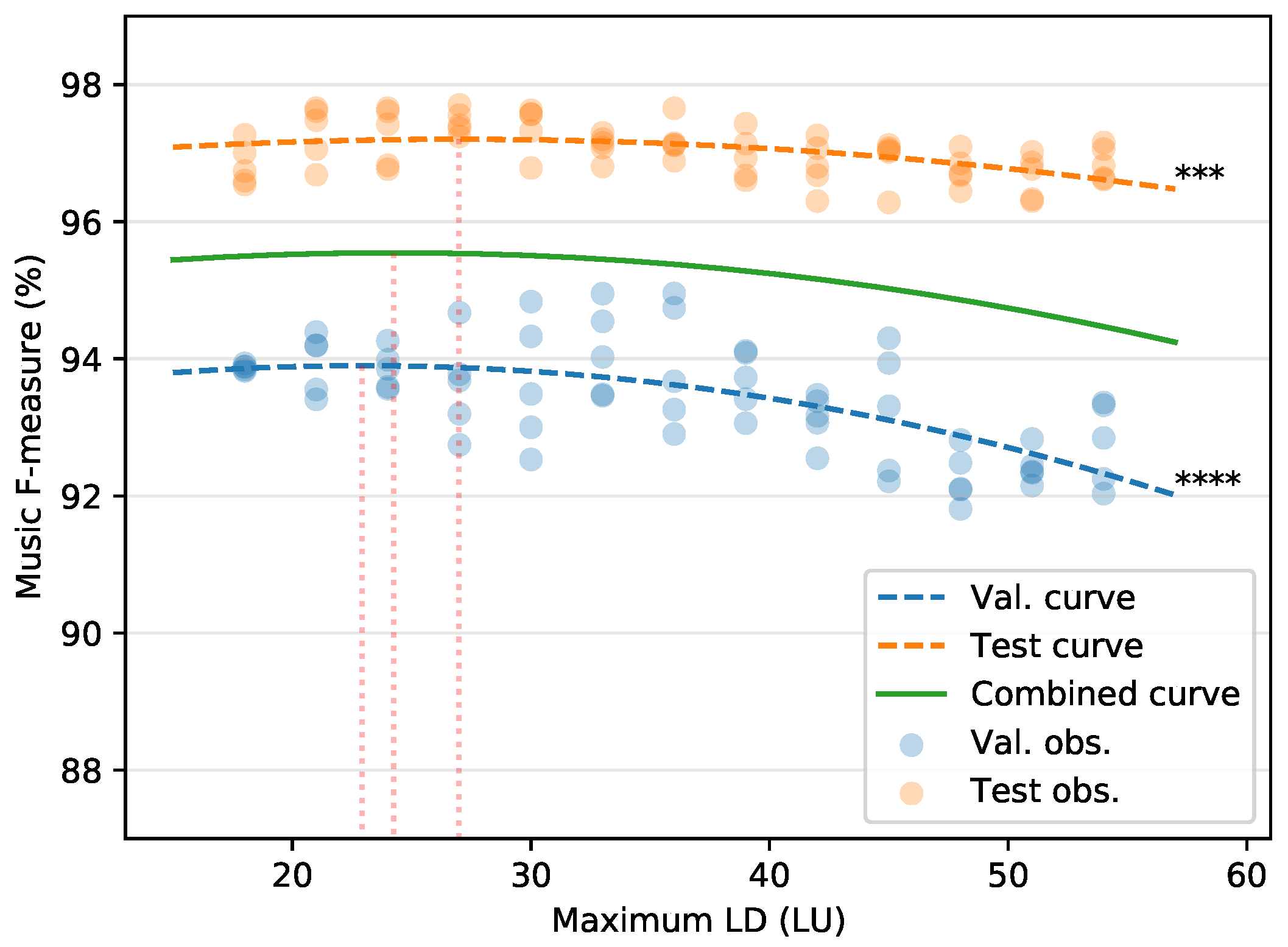
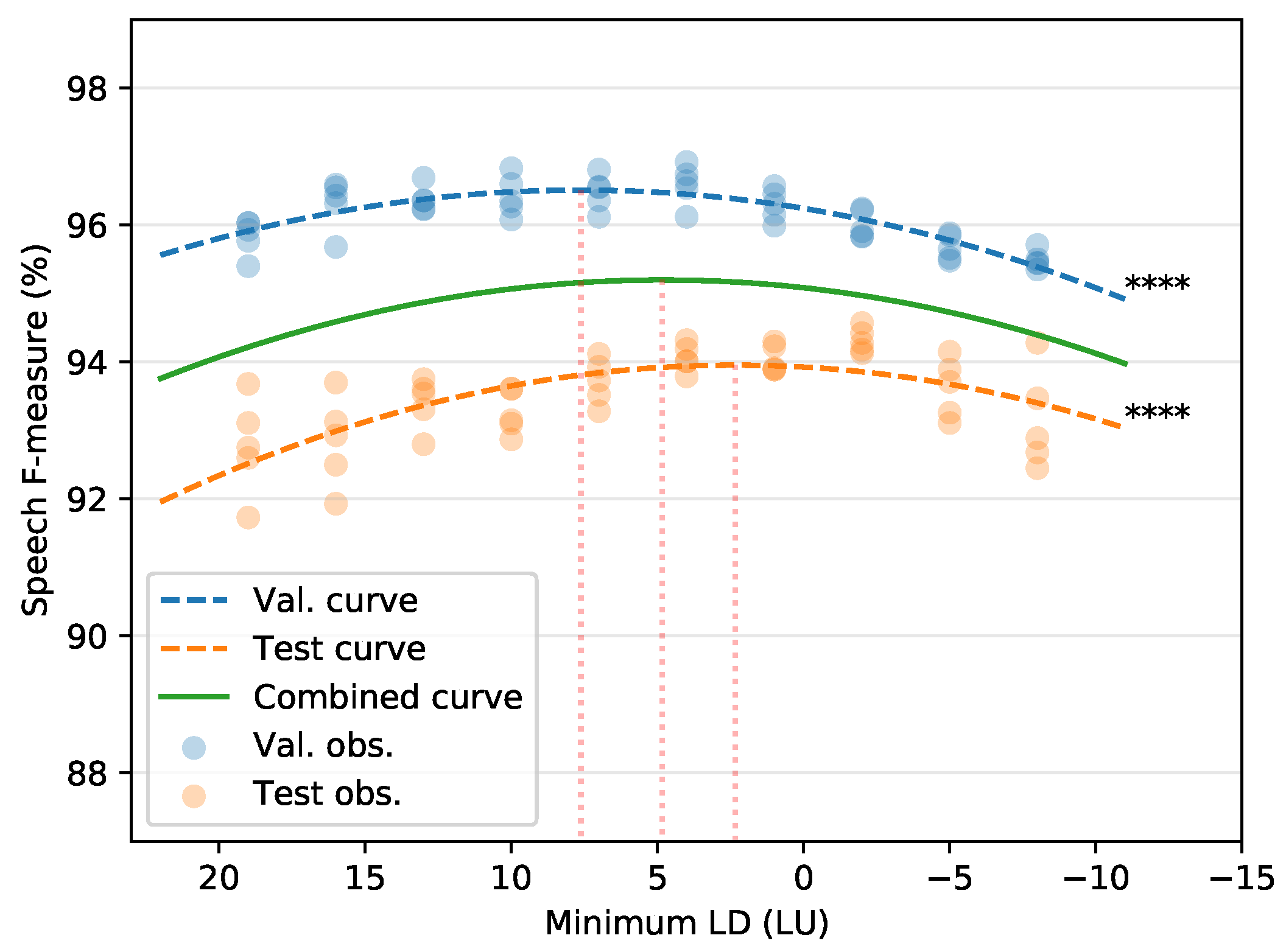
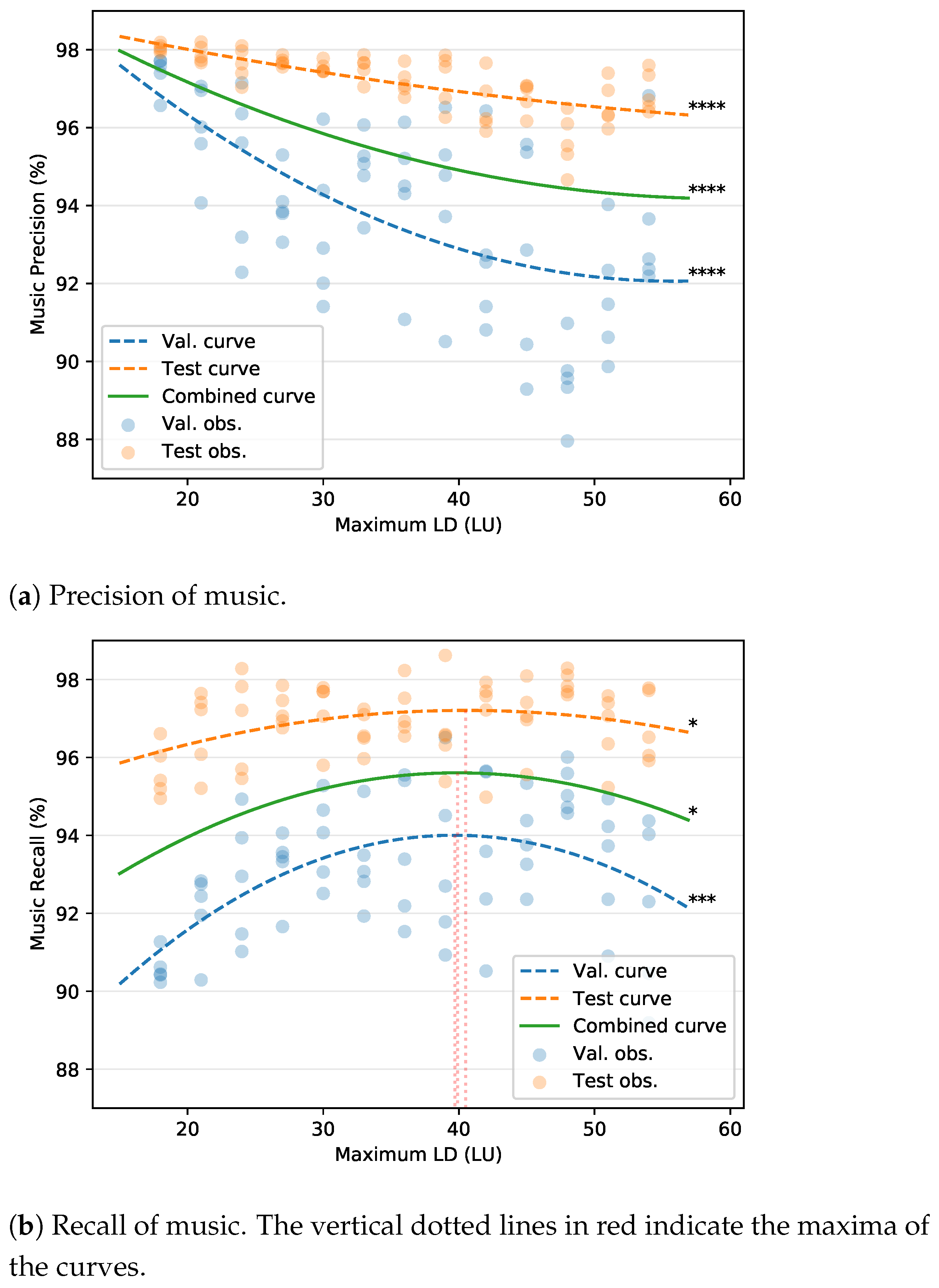
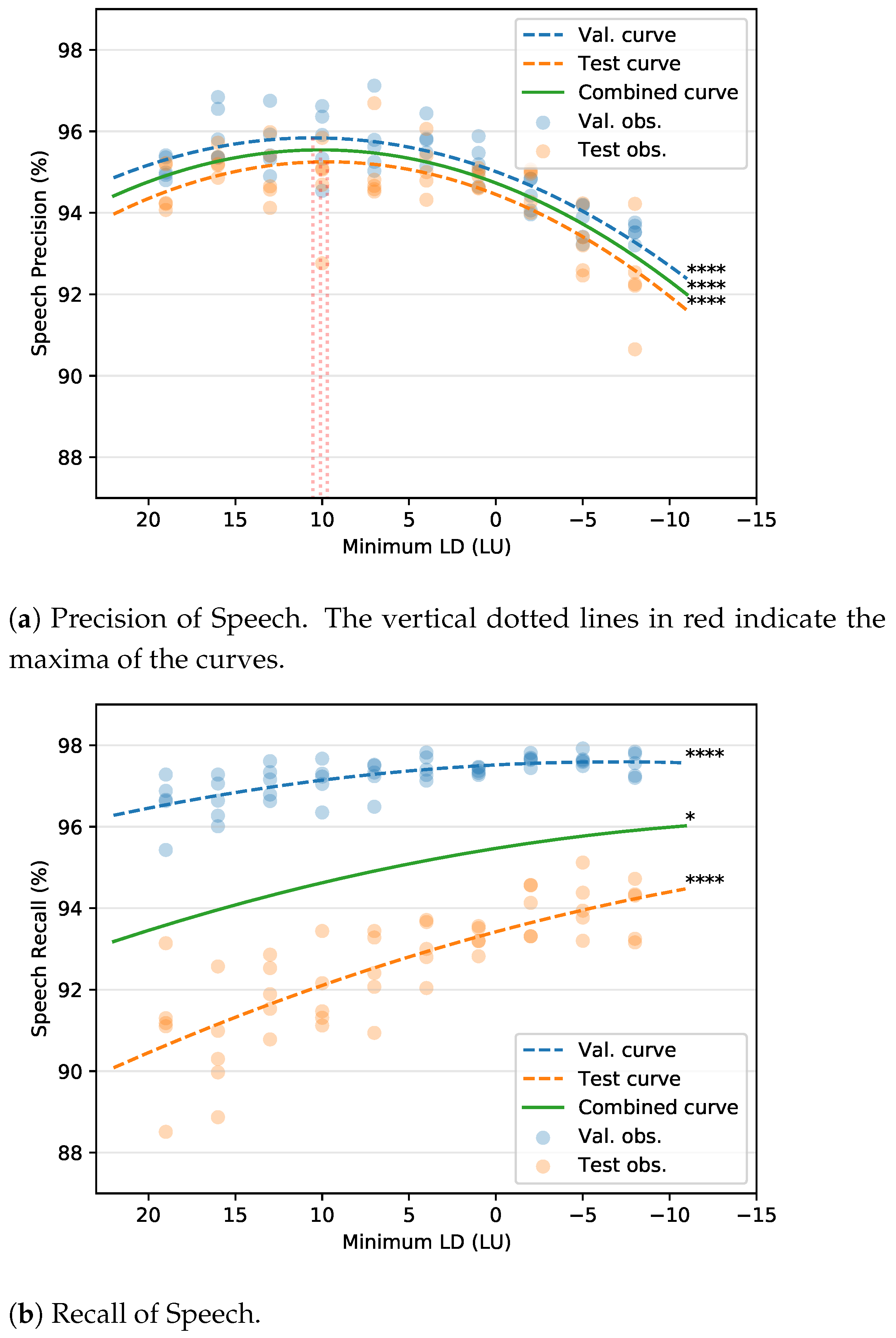
5. Experiment II: Loudness Difference Selection
5.1. Experimental Set-Up
5.2. Results
5.2.1. F-measure
5.2.2. Precision and Recall
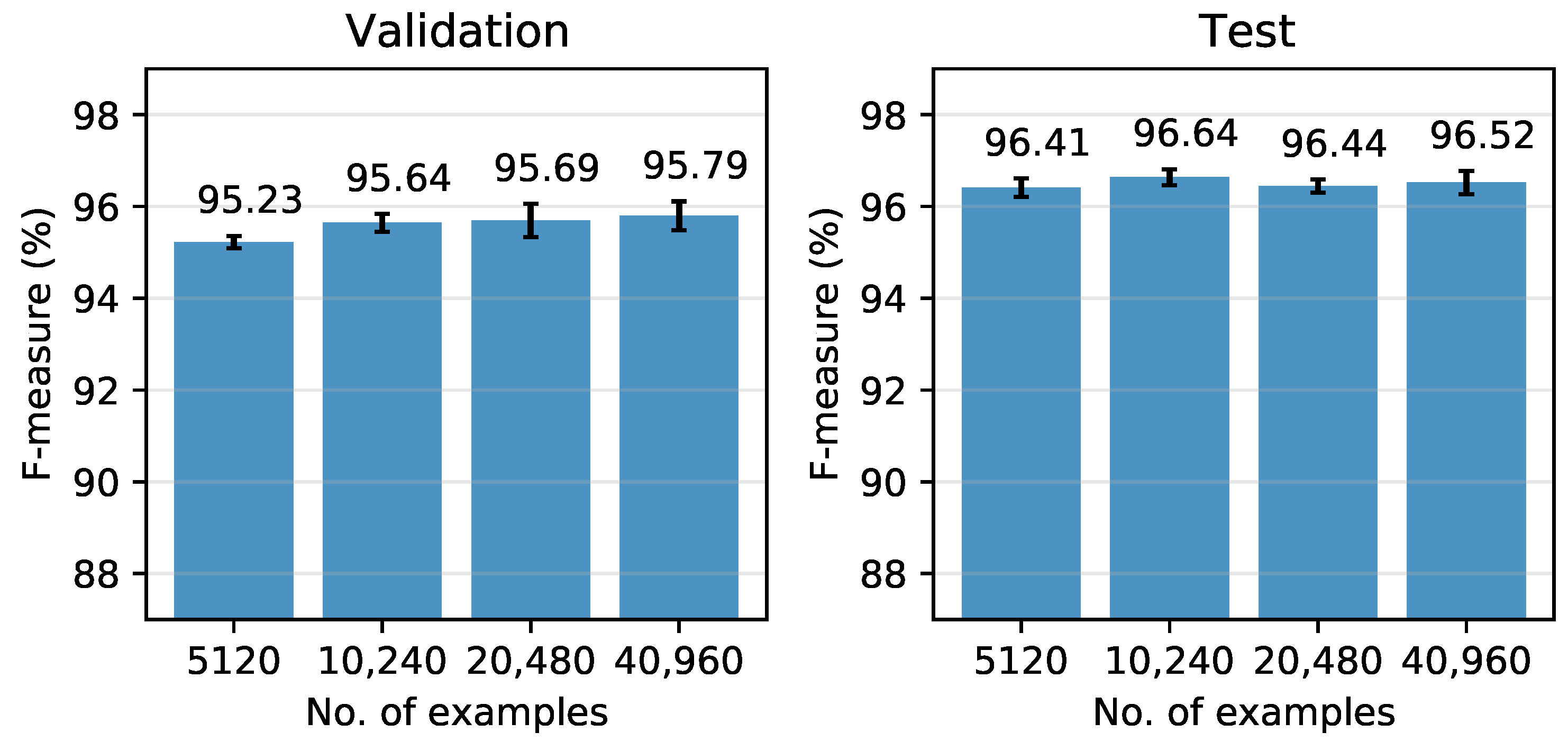
6. Experiment III: Size of the Dataset
6.1. Experimental Set-Up
6.2. Results
7. Experiment IV: Comparison of Real-World and Artificial Data
7.1. Experimental Set-Up
- SSE: Sound segment examples (SSE) consisted of audio directly sampled from the data repository. This does not contain mixed audio.
- SSE+RRE: This is the combination of SSE and Real-world radio examples (RRE). This is the type of training set used by most audio segmentation studies.
- ARE+RRE: In this set, we used a combination of Artificial Radio Examples (ARE), which are synthesised using our data synthesis procedure and RRE.
- ARE: Here, we used only ARE for training the model.
7.2. Results
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Algo. | Algorithm |
| ANOVA | Analysis of variance |
| ARE | Artificial Radio Examples |
| B-GRU | Bidirectional Gated Recurrent Unit |
| B-LSTM | Bidirectional Long Short-Term Memory |
| BN | Batch Normalization |
| CNN | Convolutional Neural Network |
| CRNN | Convolutional Recurrent Neural Network |
| FFT | Fast Fourier Transform |
| LD | Loudness Difference |
| LN | Layer Normalization |
| LU | Loudness Units |
| MIREX | Music Information Retrieval Evaluation eXchange |
| MFCC | Mel-Frequency Cepstral Coefficients |
| ncTCN | Noncausal Temporal Convolutional Neural Network |
| Obs. | Observations |
| OpenBMAT | Open Broadcast Media Audio from TV |
| RRE | Real-world Radio Examples |
| SSE | Sound Segment Examples |
| TCN | Temporal Convolutional Neural Network |
| Val. | Validation |
References
- Theodorou, T.; Mporas, I.; Fakotakis, N. An overview of automatic audio segmentation. Int. J. Inf. Technol. Comput. Sci. 2014, 6, 1. [Google Scholar] [CrossRef] [Green Version]
- Butko, T.; Nadeu, C. Audio segmentation of broadcast news in the Albayzin-2010 evaluation: Overview, results, and discussion. EURASIP J. Audio Speech Music Process. 2011, 2011, 1. [Google Scholar] [CrossRef] [Green Version]
- Xue, H.; Li, H.; Gao, C.; Shi, Z. Computationally efficient audio segmentation through a multi-stage BIC approach. In Proceedings of the 2010 3rd IEEE International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; Volume 8, pp. 3774–3777. [Google Scholar]
- Huang, R.; Hansen, J.H. Advances in unsupervised audio classification and segmentation for the broadcast news and NGSW corpora. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 907–919. [Google Scholar] [CrossRef]
- Wang, D.; Vogt, R.; Mason, M.; Sridharan, S. Automatic audio segmentation using the generalized likelihood ratio. In Proceedings of the 2008 2nd International Conference on Signal Processing and Communication Systems, Gold Coast, QLD, Australia, 15–17 December 2008; pp. 1–5. [Google Scholar]
- Schlüter, J.; Sonnleitner, R. Unsupervised feature learning for speech and music detection in radio broadcasts. In Proceedings of the 15th International Conference on Digital Audio Effects (DAFx), York, UK, 17–21 September 2012. [Google Scholar]
- Lemaire, Q.; Holzapfel, A. Temporal Convolutional Networks for Speech and Music Detection in Radio Broadcast. In Proceedings of the 20th International Society for Music Information Retrieval Conference (ISMIR), Delft, The Netherlands, 4–8 November 2019. [Google Scholar]
- Gimeno, P.; Viñals, I.; Ortega, A.; Miguel, A.; Lleida, E. Multiclass audio segmentation based on recurrent neural networks for broadcast domain data. EURASIP J. Audio Speech Music Process. 2020, 2020, 5. [Google Scholar] [CrossRef] [Green Version]
- MuSpeak Team. MIREX MuSpeak Sample Dataset. 2015. Available online: http://mirg.city.ac.uk/datasets/muspeak/ (accessed on 26 February 2021).
- Meléndez-Catalán, B.; Molina, E.; Gómez, E. Open broadcast media audio from TV: A dataset of TV broadcast audio with relative music loudness annotations. Trans. Int. Soc. Music. Inf. Retr. 2019, 2, 43–51. [Google Scholar] [CrossRef] [Green Version]
- Venkatesh, S.; Moffat, D.; Kirke, A.; Shakeri, G.; Brewster, S.; Fachner, J.; Odell-Miller, H.; Street, A.; Farina, N.; Banerjee, S.; et al. Artificially Synthesising Data for Audio Classification and Segmentation to Improve Speech and Music Detection in Radio Broadcast. arXiv 2021, arXiv:2102.09959. [Google Scholar]
- Tarr, E. Hack Audio: An Introduction to Computer Programming and Digital Signal Processing in MATLAB; Routledge: Abingdon-on-Thames, UK, 2018. [Google Scholar]
- Torcoli, M.; Freke-Morin, A.; Paulus, J.; Simon, C.; Shirley, B. Background ducking to produce esthetically pleasing audio for TV with clear speech. In Proceedings of the 146th Audio Engineering Society Convention, Dublin, Ireland, 20–23 March 2019. [Google Scholar]
- UK Digital Production Partnership (DPP). Technical Specification for the Delivery of Television Programmesas As-11 Files v5.0. Section 2.2.1. Loudness Terms. 2017. Available online: https://www.channel4.com/media/documents/commissioning/DOCUMENTS%20RESOURCES%20WEBSITES/ProgrammeDeliverySpecificationFile_DPP-Channel4_v5.pdf (accessed on 26 February 2021).
- ITU-R. ITU-R Rec. BS.1770-4: Algorithms to Measure Audio Programme Loudness and True-Peak Audio Level; BS Series; International Telecommunication Union (ITU): Geneva, Switzerland, 2017. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference (SciPy 2015), Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Snyder, D.; Chen, G.; Povey, D. Musan: A music, speech, and noise corpus. arXiv 2015, arXiv:1510.08484. [Google Scholar]
- Tzanetakis, G.; Cook, P. Marsyas: A framework for audio analysis. Organ. Sound 2000, 4, 169–175. [Google Scholar] [CrossRef] [Green Version]
- Scheirer, E.; Slaney, M. Construction and evaluation of a robust multifeature speech/music discriminator. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal processing (ICASSP), Munich, Germany, 21–24 April 1997; Volume 2, pp. 1331–1334. [Google Scholar]
- Bosch, J.J.; Janer, J.; Fuhrmann, F.; Herrera, P. A Comparison of Sound Segregation Techniques for Predominant Instrument Recognition in Musical Audio Signals. In Proceedings of the 13th International Society for Music Information Retrieval Conference (ISMIR), Porto, Portugal, 8–12 October 2012; pp. 559–564. [Google Scholar]
- Tzanetakis, G.; Cook, P. Musical genre classification of audio signals. IEEE Trans. Speech Audio Process. 2002, 10, 293–302. [Google Scholar] [CrossRef]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. LibriSpeech: An ASR corpus based on public domain audio books. In Proceedings of the 13th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Black, D.A.A.; Li, M.; Tian, M. Automatic Identification of Emotional Cues in Chinese Opera Singing. In Proceedings of the 13th International Conference on Music Perception and Cognition and the 5th Conference for the Asian-Pacific Society for Cognitive Sciences of Music, Seoul, Korea, 4–8 August 2014. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. Metrics for polyphonic sound event detection. Appl. Sci. 2016, 6, 162. [Google Scholar] [CrossRef]
- Cakır, E.; Parascandolo, G.; Heittola, T.; Huttunen, H.; Virtanen, T. Convolutional recurrent neural networks for polyphonic sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1291–1303. [Google Scholar] [CrossRef] [Green Version]
- Mesaros, A.; Heittola, T.; Diment, A.; Elizalde, B.; Shah, A.; Vincent, E.; Raj, B.; Virtanen, T. DCASE 2017 challenge setup: Tasks, datasets and baseline system. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events, Munich, Germany, 16–17 November 2017. [Google Scholar]
- Meléndez-Catalán, B.; Molina, E.; Gomez, E. Music and/or Speech Detection MIREX 2018 Submission. Music Information Retrieval Evaluation eXchange (MIREX). 2018. Available online: https://www.music-ir.org/mirex/abstracts/2018/MMG.pdf (accessed on 26 February 2021).
- Mustaqeem; Kwon, S. A CNN-assisted enhanced audio signal processing for speech emotion recognition. Sensors 2020, 20, 183. [Google Scholar] [CrossRef] [Green Version]
- Lee, Y.; Lim, S.; Kwak, I.Y. CNN-Based Acoustic Scene Classification System. Electronics 2021, 10, 371. [Google Scholar] [CrossRef]
- Phan, H.; Koch, P.; Katzberg, F.; Maass, M.; Mazur, R.; Mertins, A. Audio Scene Classification with Deep Recurrent Neural Networks. In Proceedings of the INTERSPEECH 2017: Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 3043–3047. [Google Scholar]
- Choi, K.; Fazekas, G.; Sandler, M.; Cho, K. Convolutional recurrent neural networks for music classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2392–2396. [Google Scholar]
- Zhang, X.; Yu, Y.; Gao, Y.; Chen, X.; Li, W. Research on Singing Voice Detection Based on a Long-Term Recurrent Convolutional Network with Vocal Separation and Temporal Smoothing. Electronics 2020, 9, 1458. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning PMLR, Lille, France, 7–9 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 2017, 18, 6765–6816. [Google Scholar]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On early stopping in gradient descent learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Seyerlehner, K.; Pohle, T.; Schedl, M.; Widmer, G. Automatic music detection in television productions. In Proceedings of the 10th International Conference on Digital Audio Effects (DAFx’07), Bordeaux, France, 10–15 September 2007. [Google Scholar]
- Jang, B.Y.; Heo, W.H.; Kim, J.H.; Kwon, O.W. Music detection from broadcast contents using convolutional neural networks with a Mel-scale kernel. EURASIP J. Audio Speech Music Process. 2019, 2019, 11. [Google Scholar] [CrossRef]
- IBM Corporation. SPSS Statistics for Windows; Version 25.0; IBM Corporation: Armonk, NY, USA, 2017. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Schlüter, J.; Grill, T. Exploring Data Augmentation for Improved Singing Voice Detection with Neural Networks. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR), Malaga, Spain, 26–30 October 2015; pp. 121–126. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Choi, M.; Lee, J.; Nam, J. Hybrid Features for Music and Speech Detection. Music Information Retrieval Evaluation eXchange (MIREX). 2018. Available online: https://www.music-ir.org/mirex/abstracts/2018/LN1.pdf (accessed on 26 February 2021).
- Marolt, M. Music/Speech Classification and Detection Submission for MIREX. Music Information Retrieval Evaluation eXchange (MIREX). 2018. Available online: https://www.music-ir.org/mirex/abstracts/2018/MM2.pdf (accessed on 26 February 2021).
- Lee, J.; Kim, T.; Park, J.; Nam, J. Raw waveform-based audio classification using sample-level CNN architectures. In Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 28th Conference on Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 8–13 December 2014; Volume 27, pp. 2672–2680. [Google Scholar]
- Yang, J.H.; Kim, N.K.; Kim, H.K. SE-ResNet with GAN-based data augmentation applied to acoustic scene classification. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE Workshop), Woking, Surrey, UK, 19–20 November 2018. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Parameter | Range | Step Size |
|---|---|---|---|
| CNN | No. of Conv. layers | 1 to 4 | 1 |
| Kernel size | 3 to 15 | 2 | |
| No. of filters | {16, 32, 64, 128} | - | |
| No. of FC layers | 1 to 4 | 1 | |
| No. of FC units | 128 to 1024 | 128 | |
| Dropout | 0.0 to 0.5 | 0.05 | |
| B-LSTM & B-GRU | No. of layers | 1 to 4 | 1 |
| No. of hidden units | 20 to 260 | 20 | |
| TCN | No. of layers | 1 to 4 | 1 |
| Kernel size | 3 to 19 | 2 | |
| No. of filters | {16, 32} | - | |
| No. of stacks | 1 to 10 | 1 | |
| No. of dilations | {20, 21, …, 2N} N = 1 to 8 | 1 | |
| Use skip connections | {True, False} | - | |
| CRNN | No. of Conv. layers | 1 to 4 | 1 |
| Kernel size | 3 to 15 | 2 | |
| No. of filters | {16, 32, 64, 128} | - | |
| No. of GRU layers | 1 to 4 | 1 | |
| No. of GRU Units | 20 to 160 | 20 |
| Architecture | Parameter | Chosen Value |
|---|---|---|
| CNN | No. of Conv. layers | 3 |
| Kernel size | {9, 11, 11} | |
| No. of filters | {32, 128, 32} | |
| No. of FC layers | 4 | |
| No. of FC units | {256, 384, 896, 384} | |
| Dropout | 0.45 | |
| B-LSTM | No. of layers | 3 |
| No. of hidden units | {140, 160, 80} | |
| B-GRU | No. of layers | 3 |
| No. of hidden units | {60, 140, 100} | |
| TCN | No. of layers | 3 |
| Kernel size | {7, 13, 17} | |
| No. of filters | {32, 16, 32} | |
| No. of stacks | {9, 5, 2} | |
| No. of dilations | N = {3, 7, 2} | |
| Use skip connections | {False, True, True} | |
| CRNN | No. of Conv. layers | 3 |
| Kernel size | {3, 11, 11} | |
| No. of filters | {128, 128, 16} | |
| No. of GRU layers | 2 | |
| No. of GRU Units | {80, 40} |
| Validation | Test | |||||
|---|---|---|---|---|---|---|
| Architecture | Foverall | Fs | Fm | Foverall | Fs | Fm |
| CNN | 95.87 | 94.75 | 96.78 | 95.23 | 89.62 | 97.72 |
| B-LSTM | 96.55 | 97.02 | 96.19 | 95.85 | 92.41 | 97.3 |
| B-GRU | 96.24 | 96.86 | 95.75 | 96.11 | 93.16 | 97.37 |
| ncTCN | 96.56 | 97.18 | 96.09 | 95.9 | 91.99 | 97.55 |
| CRNN | 97.39 | 97.75 | 97.12 | 96.37 | 94 | 97.37 |
| CRNN-small | 97.21 | 97.39 | 97.07 | 96.46 | 93.64 | 97.65 |
| Training Set | Foverall | Fs | Ps | Rs | Fm | Pm | Rm |
|---|---|---|---|---|---|---|---|
| SSE | 92.23 | 88.21 | 97.34 | 80.64 | 93.84 | 98.06 | 89.97 |
| SSE+RRE | 96.64 | 93.78 | 95.11 | 92.49 | 97.81 | 97.3 | 98.33 |
| ARE | 96.89 | 94.73 | 96.64 | 92.9 | 97.77 | 97.72 | 97.82 |
| ARE+RRE | 97.35 | 95.05 | 96.21 | 93.92 | 98.3 | 97.73 | 98.87 |
| Training Set/Algo. | Foverall | Fs | Ps | Rs | Fm | Pm | Rm |
|---|---|---|---|---|---|---|---|
| SSE | 79.61 | 81.79 | 89.16 | 75.54 | 76.27 | 86.62 | 68.12 |
| SSE+RRE | 86.57 | 88.15 | 92.48 | 84.2 | 84.3 | 85.33 | 83.3 |
| ARE | 88.52 | 90.73 | 91.96 | 89.53 | 85.51 | 79.55 | 92.43 |
| ARE+RRE | 89.09 | 92.16 | 92.64 | 91.69 | 85.01 | 77.22 | 94.55 |
| [46] | - | 77.18 | 96.83 | 64.15 | 49.36 | 62.4 | 40.82 |
| [47] | - | 91.15 | 87.95 | 94.6 | 38.99 | 80.72 | 25.7 |
| [47] | - | 90.9 | 89.45 | 92.41 | 54.78 | 85.7 | 40.26 |
| [47] | - | 90.86 | 83.83 | 99.17 | 31.24 | 98.73 | 18.56 |
| [11] | 89.53 | 92.21 | 89.71 | 94.85 | 85.76 | 79.37 | 93.27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Venkatesh, S.; Moffat, D.; Miranda, E.R. Investigating the Effects of Training Set Synthesis for Audio Segmentation of Radio Broadcast. Electronics 2021, 10, 827. https://doi.org/10.3390/electronics10070827
Venkatesh S, Moffat D, Miranda ER. Investigating the Effects of Training Set Synthesis for Audio Segmentation of Radio Broadcast. Electronics. 2021; 10(7):827. https://doi.org/10.3390/electronics10070827
Chicago/Turabian StyleVenkatesh, Satvik, David Moffat, and Eduardo Reck Miranda. 2021. "Investigating the Effects of Training Set Synthesis for Audio Segmentation of Radio Broadcast" Electronics 10, no. 7: 827. https://doi.org/10.3390/electronics10070827
APA StyleVenkatesh, S., Moffat, D., & Miranda, E. R. (2021). Investigating the Effects of Training Set Synthesis for Audio Segmentation of Radio Broadcast. Electronics, 10(7), 827. https://doi.org/10.3390/electronics10070827