1. Introduction
One of the most important study topics in the cloud is resource allocation, which aims at increasing service provider profitability and achieving customer satisfaction by meeting promised SLA conditions [
1]. SLA (Service Level Agreements) must be signed by Service Providers and Cloud Users to assure Quality of Service (QoS) [
2]. Resource allocation has been considered one of the most significant topics to address when dealing with SLA situations. Because the load on the physical server’s changes over time, resource allocations must be managed dynamically. Dynamic resource allocation is exceedingly difficult, especially when QoS needs to change over time while considering processor availability and minimising processor idle time. A WSN is a network of several sensor nodes that are typically put in remote places to monitor environmental characteristics. Sensors such as acoustic, pressure, motion, image, chemical, weather, pressure, temperature, and optical sensors are installed in the sensor nodes (SN). WSNs have a wide range of applications due to the diversity of SN, ranging from healthcare to military, defense, agricultural, and everyday life. Despite their large uses, WSNs have numerous common issues such as restricted energy sources, processing speed, memory, and communication bandwidth, causing SN performance to degrade as well as network lifetime to decrease [
3]. Creating distinct algorithms for various purposes is a difficult endeavor. WSN designers must pay special attention to concerns such as data aggregation, clustering, routing, localization, fault detection, task scheduling, and event tracking, among others.
Wireless sensor nodes are small devices that detect atmospheric conditions including pressure, temperature, and humidity. They have a memory device to store the data and a channel to transfer it to BSas well as other devices. They are frequently dispersed, depending on the number of nodes used to collect data. Many studies have been previously conducted [
4] that address these problems by applying methodologies derived from signal communication theory in telephony, with the primary goal of ensuring reliable data delivery without noise. Because there is no way to provide continuous power to sensors using a battery as a power source, researchers must focus on energy efficiency. Because of the limited energy sources, the sensor node has a short lifespan, which reduces the system’s network lifetime. Machine learning (ML) methods are known for their self-experiencing nature as well as the fact that they do not require reprogramming [
5]. ML is a useful approach that allows for efficient, dependable, and cost-effective computing. Supervised learning, unsupervised learning, and RL are the three main forms. It has been discovered that machine learning technologies are effective in resolving key WSN difficulties. In the realms of IoT, M2M and CPS, these approaches have proven to be beneficial. ML may learn from a generalized structure and propose a generic solution to improve system performance. It is used in numerous scientific domains of medical, engineering, and computing, such as manual data entry, automatic spam detection, medical diagnosis, picture identification, data purification, noise reduction, and so on, due to its diverse uses. Recent research shows that machine learning has been used to overcome a variety of problems in WSNs. Using ML in WSNs enhances system performance while also reducing complicated chores such as reprogramming, manually accessing vast amounts of data, and extracting usable data from data. As a result, ML methods are very beneficial for retrieving enormous amounts of data as well as extracting meaningful data [
6].
The contribution of this research is as follows:
To propose a novel technique in resource allocation (RA) for WSN_IoT with energy efficiency and data optimization using deep learning architectures;
To improve the energy efficiency of the network using a whale-optimization-based deep neural network;
To optimize the data transmission of the network using a heuristic-based multi-objective firefly algorithm.
The organization of this article is as follows:
Section 2 gives the related works, the proposed technique is described in
Section 3,
Section 4 explains the performance analysis, and the conclusion is given in
Section 5.
2. Related Works
ML and DL methods for data processing could make edge devices smarter while also improving privacy and bandwidth usage. The authors of [
7] applied deep learning for IoT to an edge computing environment and provided a method for improving network speed while also protecting user privacy. The authors suggested adaptive sampling-based data reduction methodologies in [
8]. These methods function by analyzing the level of variance between acquired data over time and dynamically altering the sampling frequency of the sensors. In instances where the gathered time series are stationary, adaptive sampling algorithms function well. These methods perform badly when dealing with rapidly changing data. The authors of [
9] developed a dual prediction-based data reduction technique. The suggested technique works by developing and implementing a model that represents the sensed phenomenon on both the edge node and IoT devices. Prediction techniques have the advantage that the model at the edge predicts the detected measurement without requiring a radio connection until the prediction error exceeds a predetermined threshold. Work [
10] demonstrated that man-made consciousness and machine learning can be used to advance to unavoidable systems. AI-assisted ML systems will aid in merging human intuition and ingenuity with AI capacity. AI-powered systems will assist in dynamically analyzing processing scenarios and adapting appropriate scheduling and resource allocation strategies. Ref. [
11] suggests a framework for cloud computing systems to increase QoS while lowering the cost of providing services to end users. The system focuses on condensing VMs based on current resource utilization, creating virtual networks between VMs, and dynamically configuring virtual hubs. In WSN-aided IoT, ref. [
12] proposed a QoS-aware safe DL technique for dynamic cluster-based routing. In the WSN, the author [
13] built a DL link dependability prediction. This research designed a resilient routing algorithm for a better WSN routing mechanism. For lightweight subgraph extraction as well as labelling, a DLmethod known as Weisfeiler–Lehman kernel and dual convolutional neural network (WL-DCNN) technique is presented. A discussion of RA tactics is available in [
14]. They used a multi-target optimization strategy in this research to trade off speed, cost, and availability in a cloud-based application, and their methodology might be up to 20% faster than existing optimization approaches. Their method has been confirmed. The author of [
15] proposed a thermal cognizant workload programming strategy to overcome the excessive power consumption and hotness of data centers. They utilized an ANN to predict the data center’s heat effect. In [
14], a heterogeneous scheduling model is described. Task resource utilization, as observed in the consolidation methods, was not taken into account. Ref. [
15] has a download issue with cloud or fog computing. User fairness and the shortest possible delay are ensured by optimizing discharge results and allocating working out resources. The goal of this optimization problem is to reduce the weighted delay and energy consumption expenses. They devised low-complexity, suboptimal methods to address this NP-hard issue. As a result, half-definite relaxation and randomization are used to make discharge decisions, while fractional programming theory is used to manage resources. The authors of [
16] provide a heuristic approach to resource allocation, and a TSA is presented. Modules such as divide and conquer TSA and resource allocation, modified analytical processes, the longest projected length of processing, and divisible scheduling with bandwidth knowledge are used in this technique. The tasks are processed before they are assigned. With relation to the load and bandwidth of the cloud holdings, the allocation is performed using BAR optimization and associated BATS algorithms [
17] investigates EE for combining BSas well as beamforming in multicell situations. Ref. [
18] investigates the energy and spectrum efficiency of 5G mobile MIMO networks. In [
19], the authors developed an energy-efficient non-cooperative game for distributed CRN over interference channels. For CRNs and IoT, a noncooperative game based on power allocation is proposed in [
20], which investigates a mesh adaptive search technique for device to device-assisted CRN; [
21] proposes a gradient adaptation optimization for power allocation as well as EE in CRNs. Although gradient techniques are reliable, they can fail to accomplish global optimization. Heuristic algorithms are gaining popularity among researchers as a way to lower the computational complexity of optimization approaches. For NP-complete problems, heuristic techniques are simple to use and adapt. In [
22], nonorthogonal multiple access (NOMA) is employed for IoT resource management in smart cities, and mixed-integer linear programming is presented for energy harvesting. To maximize EE and SE trade-off in CR-IoT, a mixed-integer nonlinear programming (MINLP) technique is presented. Optimizing and increasing the efficiency of this communication is an important consideration, and resource allocation is a critical bottleneck. Researchers are using innovative AI methods to optimize resource allocation according to the data flow during network operation to solve the challenge of resource allocation. These measures have moved the industry towards automated resource management on a large and complex scale.
3. System Model
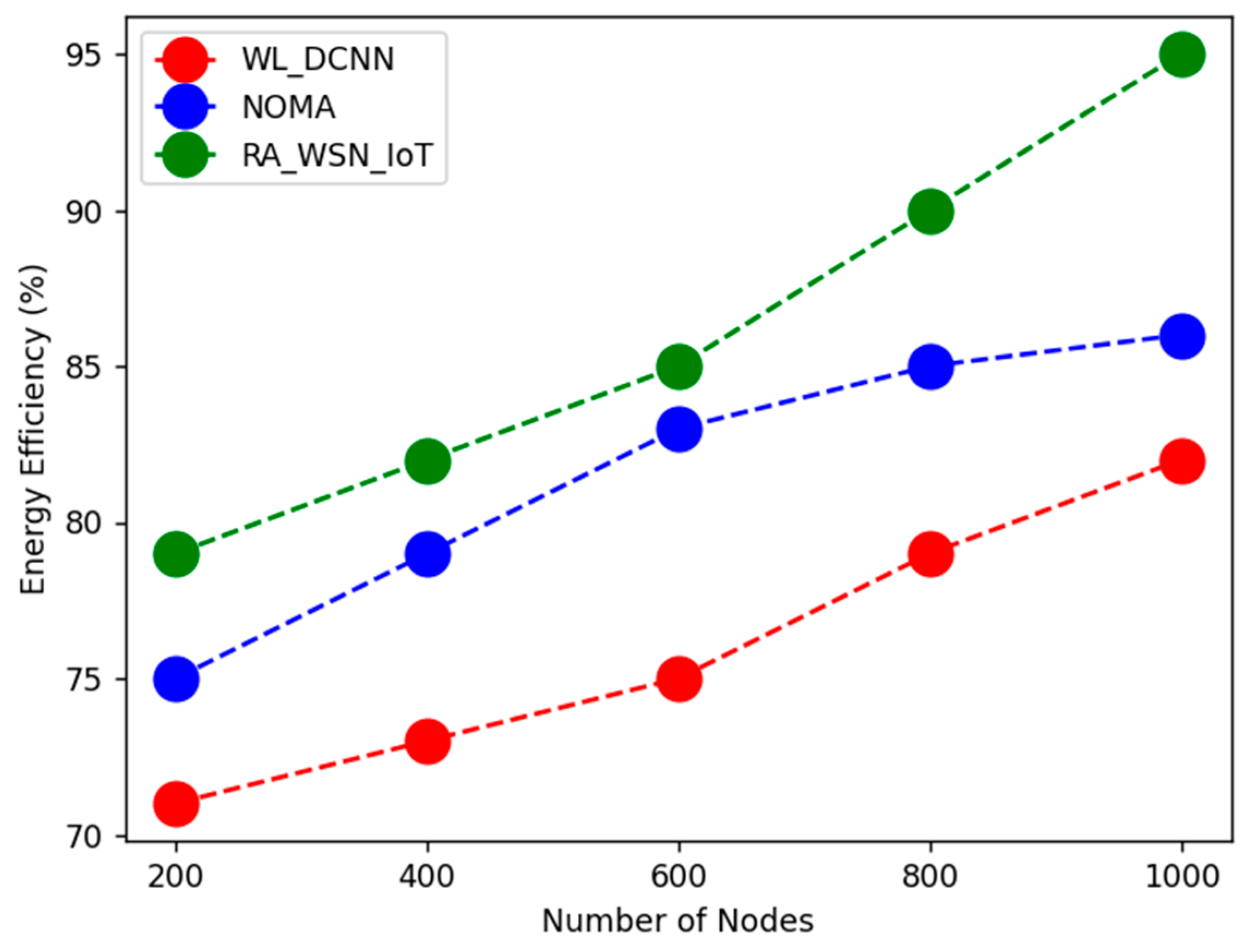
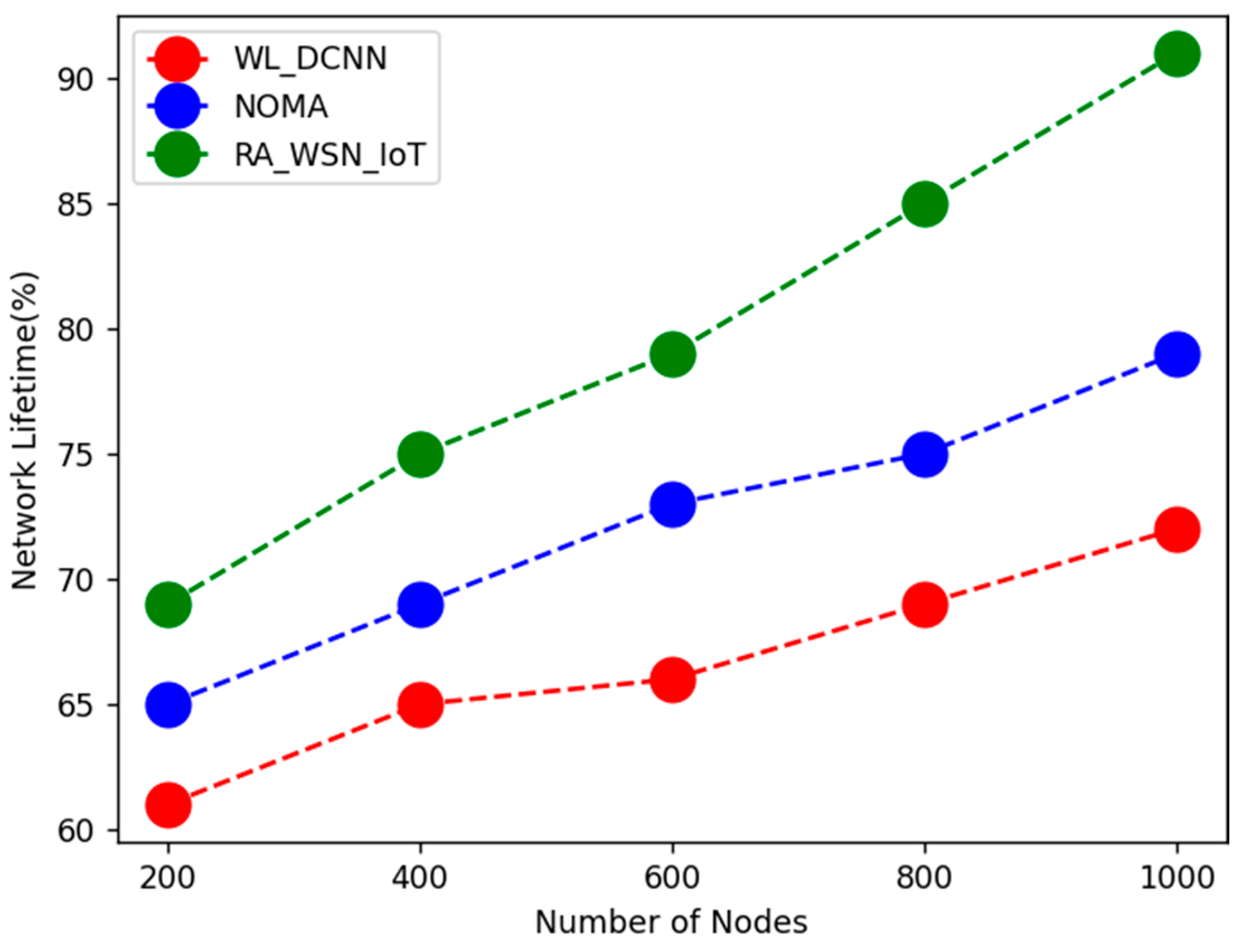
This section discusses novel techniques in RA for WSN_IoT with energy efficiency and data optimization using deep learning architectures. Here, EE and SE are considered conflicting optimization objectives. EE of the network is enhanced using a whale-optimization-based deep neural network. Data optimization has been carried out using a heuristic-based multi-objective firefly algorithm.
RA vector p(h) R m and a function ff: R·m × R·n → R·u are associated with each fading channel realization. When the channel realization is h, the components of vector valued function f·p(h), h relates performance indicators linked with resource allocation p(h). The system allocates resources instantly in fast time changing fading channels, and consumers. This supports examining vector ergodic average x = E·f·p(h), h ∈ R·u, which is relaxed to the inequality for defining optimal wireless design issues by Equation (1).
At ideal operating points, we will obtain x = E·f·p(h), h, but this is not required a priori. In optimally designed WCS, the goal is to identify instantaneous RA·p(h) that in some way improves performance metric x.P has bounded functions, implying that resources being allocated are finite. With these definitions, we can write a software to solve optimal RA problems in WCN by Equation (2).
Because (5) requires RA functions to follow parametrization p(h) = φ(h, θ), this results in a loss of optimality. We focus our attention in this paper on a frequently utilized family of parameterizations known as near universal, which may represent any function in P to a specified precision.
Energy optimization using whale-optimization-based deep neural network:
There are two stages to the optimization process. The spiral position is updated in the first step, and the prey is circled. The second stage involves a random search for prey. Following is a mathematical representation of the stated step.
Encircling prey: Whales track down their prey and surround them. The position of prey in the search space is unknown. According to the WOA, the leading factor is an ideal prey. The surviving search agents aim to improve their performance by switching locations. The following are examples of search agent behaviors by Equation (3):
after iteration u,
defines the whale’s ideal location. The whale’s current location is Y·u + 1, and a d distance vector represents the distance between whale and prey. The absolute value is represented by ||. B and C coefficient vectors are calculated as follows by Equation (4):
The value of b is minimized in order to apply to shrink, and B’s oscillation range is reduced to. The value of B is lowered from 2 to 0 iterations, while the value of b is minimized from 2 to 0. The best agent’s position as well as an agent’s initial location are decided by choosing a random value of B between (1, 1).
A. Spiral position updating
Calculating the distance between whale location Y, Z and prey location Y, Z defines a helix shape for whale prey tracking. The movement toward prey is described as by Equation (5)
The constant b identifies the curvature of the logarithmic spiral, and random numbers vary from 1 to 1. Whales can shift their location while undertaking reduction thanks to their circular movement. Between spiral and diminishing encircling, there is a 50% chance of selection by Equation (6)
B. Prey search
The exploration step, which is dependent on vector variations, is also known as the prey hunting stage. The whale conducts a random search for the prey based on its position. The search agent flees the seeking whale due to the whale’s location. WOA uses the vector B, which has random values less than or equal to 1. The search agent is chosen at random during the exploration phase. By lowering the local optimization problem, random selection makes WOA a GSA. The following is definition of a global search by Equation (7):
where Y
rand is a randomly chosen whale from the specified population. The whale population is given random outcomes by the WOA, which assumes the optimal solution of function. Fitness function analyses selected features from this phase and found that a few are still redundant, affecting accuracy of final classification. The fitness function is an ESD classifier, and the error is evaluated for every iteration. As a result, we established a new phase called “additional features approval” (EFA). The standard error of the mean is used in this step (SEM). For the final recognition, the SEM value is put through a threshold function. This function is described by Equation (8):
The final recognition is performed using an ensemble subspace classifier (Algorithm 1).
| Algorithm 1 The whale optimization algorithm |
| 1. Initial population where |
| 2. Fitness evaluation for every solution |
| 3. best search agent |
| 4. For each solution |
| 5. While Max_iteration) |
| 6. Updated and |
| 7. |
| 8. |
| 9. Random search agent selection () |
| 10. Else if |
| 11. Current search agent location changes. |
| 12. End if |
| 13. Else if l |
| 14. End While |
| 15. Change if better solution is accessible |
| 16. Return |
| 17. Output: Best Feature Vector |
We used the whale optimization algorithm in our research to determine the ideal set of parameters for DNN method training as well as hyperparameter selection. We establish three things to specify our problem. To ensure the easy replication of our results, we kept the initial divides into train and test subsets throughout our studies. The creators of the dataset submitted an unmodified, fixed test set, which was used to evaluate the final results. We used a simple DL architecture built from fully connected layers to handle these basic tasks. We used the following layers to train the network for picture classification:
Flatten layer to resize images;
512 neurons in a dense (fully linked) layer with ReLU activation function;
To categorize 10 classes, use a dense layer with 10 neurons and the Softmax activation function.
The following layers make up the network utilised for Reuters dataset:
To begin, a separate class with an optimization function is described to optimize the cost function. It accepts training parameters as arguments and performs a fitting operation on them. We decided to optimize solely on cross-validation accuracy metrics, which function returns as well as serves as a cost function value. The specifications that control the search space and constraints must be properly modified while utilising the whale optimisation algorithm. The issue with the technique was that WOA only operates in continuous space, whereas the specifications of NN have discrete values. As a result, the WOA had to be modified to handle discrete optimization problems. To do this, discretization was carried out within the algorithm class’s main body. At the time as solution vector formation, all parameters were rounded to the nearest integer; fresh solutions produced by WOA were instantly converted to nearest integer as well as returned to main body of method as discrete values. Furthermore, lookup table encoding has been employed in some circumstances, such as for coding optimizer selections. Furthermore, we move through a search space appropriate for a specific issue by adding appropriate restrictions to the solutions. The first argument determines number of iterations to execute, while second gives number of agents. Both specifications have a significant impact on method output: the higher they are, the more swarm-based the method becomes. Each successive generation or agent necessitates the training of a deep neural network from the ground up. The default values for parameters a and b have been specified.
C. Heuristic based multi-objective firefly algorithm
One method for multiobjective optimization is to integrate all objectives into a single goal, allowing single-objective optimization techniques to be employed without significant change (Algorithm 2). FA are utilized to solve multiobjective issues directly in this way. Another option is to expand the firefly technique to directly produce Pareto optimum fronts. We may construct MOFA by extending core ideas of FA.
| Algorithm 2 The multiobjective optimization algorithm |
| 1. Describe objective functions where |
| 2. while ( MaxGeneration) |
| 3. Start a population of fireflies |
| 4. for (all firefties) |
| 5. Calculate their approximations and to Pareto front |
| 6. if dominates , |
| 7. if and when all constraints are gratified |
| 8. Move firefly towards using (2) |
| 9. if no non-dominated solutions are found |
| 10. Produce new ones if moves do not satisfy all constraints end if |
| 11. Determine best solution to reduce in (4) |
| 12. Produce random weights |
| 13. Random walk around |
| 14. end if |
| 15. Sort and determine current best approximation to Pareto front |
| 16. Update |
| 17. end while |
- D.
Postprocess results and visualization
The method starts with the correct specification of goal functions as well as nonlinear constraints. After that, a random weight vector is constructed in order to obtain a combined best solution g·t. Answers that are not dominated are then passed on to the next iteration. In general, n non-dominated solution locations are obtained after a certain number of repetitions to method genuine Pareto front. We can identify the current best g·t, which reduces a combined objective to execute random walks more efficiently by Equation (9):
where p
k is a set of random numbers selected from a uniformly distributed Unif [0, 1]. After creating K uniformly distributed numbers, a rescaling procedure is undertaken to ensure that P
k·w
k = 1. It is worth noting that the weights w
k should be picked at random by Equation (10).
In iteration progress, randomness is minimized in a way similar to that of simulated annealing and other random reduction methods [
11].
where α
0 is the initial randomness factor.
It is worth noting that the dominance may be defined for maximization issues by replacing ≺ with ≻. As a result, if no solution dominates a point x, it is called a non-dominated solution [
5]. The set of non-dominated solutions in a multiobjective Pareto front P·F can be described as Equation (13):
where
is solution set. A variety of solutions should be created utilizing efficient strategies. As we may see from later simulations, L’evy flights, for example, ensure a good diversity of options.
When xi approaches, the discrete components of xi are more likely to convert from binary to real numbers to convert a real number into a binary one by Equation (14):
where
is component l of position vector xi of firefly I, following migration in the context of FA—recall (7) and (4). Equation (9) represents a solution’s floating-point components as a set of probabilities. The proper binary values are then assigned using Equation (15).
where sig(
) is the likelihood that a component is 0 or 1, and rand U [0, 1] is the probability that the component is 0 or 1. The firefly positions, x, were not permitted to shift beyond the search space Ω during the iterative procedure.
Error function is a specific shape function that is mostly used in probability and statistics. The mathematical function described by an integral is denoted by “erf” in Equation (16)
which satisfies the following properties:
The erf function’s derivative follows directly from its definition by Equation (18):
Thus, the erf function’s favorable features are utilized to describe a new sigmoid function, sigmoid erf function by Equation (19):
which is a bounded differentiable real function with a positive derivative at every point and defined for any
x ∈ R. Note that the sigmoid function in (14) has a slope of about 0.5641895 at the origin, whereas Equation (9) has a slope of 0.25, resulting in a faster rise from 0 to 1. The simplest discretization process is for the floor function, which rounds to the integer part. For l = 1, …, n, each continuous value
xil ∈ R is changed into a binary one, 0 bit or 1 bit, in the following way by Equation (20):
where ⌊z⌋ is the z floor function and returns the greatest integer not exceeding z. The absolute value of the remainder is floored after the floating-point value xi·l is divided by 2.
The movement of evert firefly is made on continuous space in this implementation of previously mentioned heuristics, indicated by “movement on continuous space” (mCS), using true location vector. Only after all motions toward brighter fireflies are completed is the real position of firefly I discretized. The fitness evaluation of each firefly is always dependent on the binary position for firefly ranking.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}