
A Perceptual Encryption-Based Image Communication System for Deep Learning-Based Tuberculosis Diagnosis Using Healthcare Cloud Services



Abstract
:1. Introduction
2. Related Work
2.1. Deep Learning-Based Tuberculosis Screening
2.2. Perceptual Encryption Methods
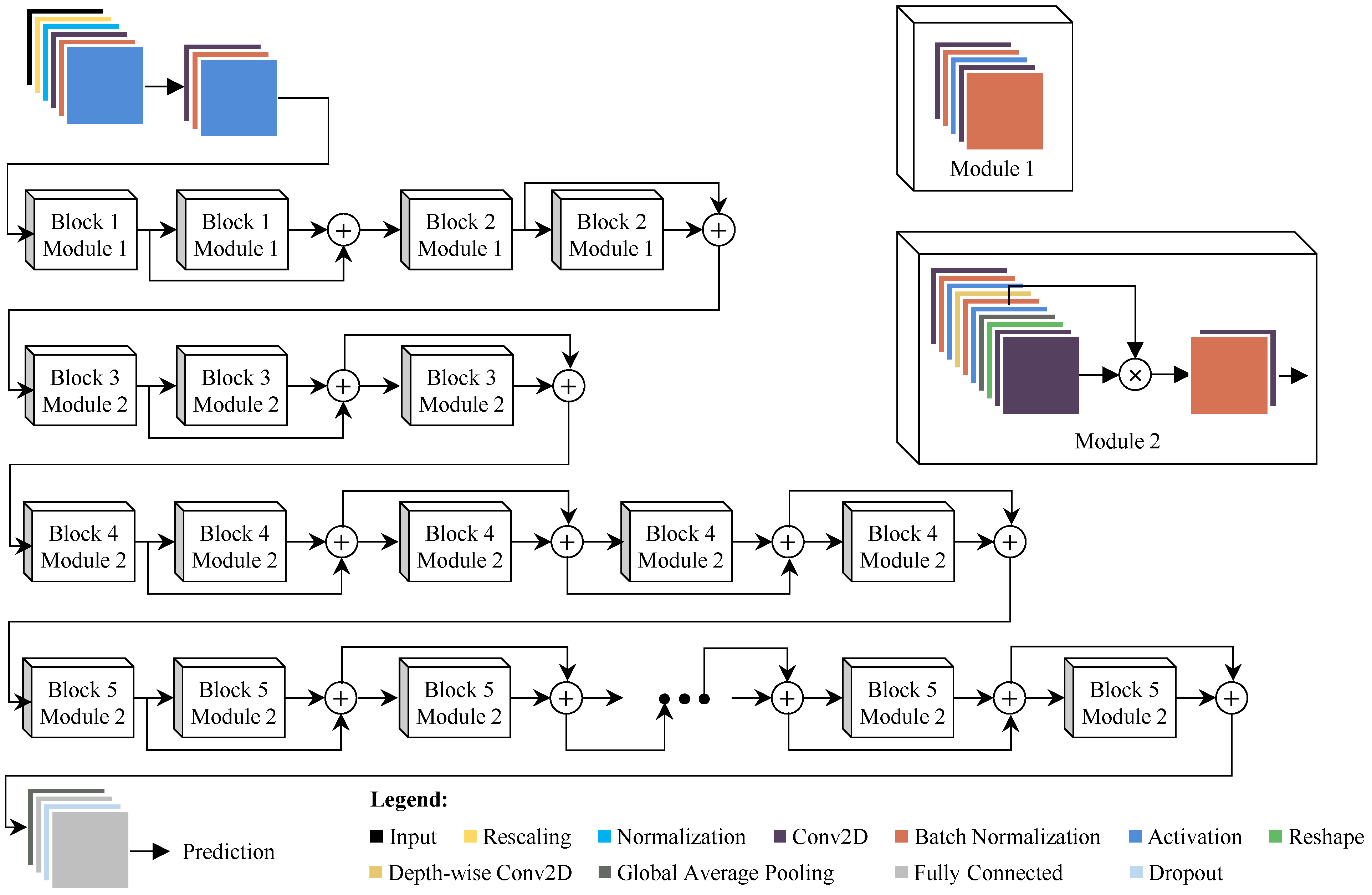
3. Methods
3.1. Color-PE Methods
3.2. Grayscale-PE Methods
3.3. Proposed PE Method
4. Results
4.1. Encryption Analysis
4.1.1. Correlation Analysis
4.1.2. Histogram Analysis
4.1.3. Information Entropy Analysis
4.1.4. Jigsaw Puzzle Solver Attack
4.1.5. Robustness Analysis
4.1.6. Keyspace Analysis
4.1.7. Discussion
4.2. Compression Analysis
4.3. Classification Analysis
4.3.1. Dataset
4.3.2. Proposed Data Augmentation
4.3.3. Evaluation Metrics
4.3.4. Proposed Model
4.3.5. Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Showkatian, E.; Salehi, M.; Ghaffari, H.; Reiazi, R.; Sadighi, N. Deep Learning-Based Automatic Detection of Tuberculosis Disease in Chest X-ray Images. Pol. J. Radiol. 2022, 87, 118–124. [Google Scholar] [CrossRef]
- Ahmad, I.; Shin, S. Encryption-Then-Compression System for Cloud-Based Medical Image Services. In Proceedings of the 2022 International Conference on Information Networking (ICOIN), Jeju-si, Korea, 12–15 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 30–33. [Google Scholar]
- Awad, A.I.; Fouda, M.M.; Khashaba, M.M.; Mohamed, E.R.; Hosny, K.M. Utilization of Mobile Edge Computing on the Internet of Medical Things: A Survey. ICT Express 2022, in press. [CrossRef]
- Jain, J.; Jain, A. Securing E-Healthcare Images Using an Efficient Image Encryption Model. Sci. Program. 2022, 2022, 1–11. [Google Scholar] [CrossRef]
- Ahmad, I.; Shin, S. A Novel Hybrid Image Encryption–Compression Scheme by Combining Chaos Theory and Number Theory. Signal Process. Image Commun. 2021, 98, 116418. [Google Scholar] [CrossRef]
- Siriwardhana, Y.; Gür, G.; Ylianttila, M.; Liyanage, M. The Role of 5G for Digital Healthcare against COVID-19 Pandemic: Opportunities and Challenges. ICT Express 2021, 7, 244–252. [Google Scholar] [CrossRef]
- Macedo, E.L.C.; de Oliveira, E.A.R.; Silva, F.H.; Mello, R.R.; Franca, F.M.G.; Delicato, F.C.; de Rezende, J.F.; de Moraes, L.F.M. On the Security Aspects of Internet of Things: A Systematic Literature Review. J. Commun. Netw. 2019, 21, 444–457. [Google Scholar] [CrossRef]
- Ou, Y.; Sur, C.; Rhee, K.H. Region-Based Selective Encryption for Medical Imaging. In Frontiers in Algorithmics; Preparata, F.P., Fang, Q., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4613, pp. 62–73. ISBN 978-3-540-73813-8. [Google Scholar]
- Puech, W.; Rodrigues, J.M. Crypto-Compression of Medical Images by Selective Encryption of DCT. In Proceedings of the 13th Eurpoean Signal Processing Conference, Antalya, Turkey, 4–8 September 2005; pp. 1–4. [Google Scholar]
- Ahmad, I.; Shin, S. Region-Based Selective Compression and Selective Encryption of Medical Images. In Proceedings of the 9th International Conference on Smart Media and Applications, Jeju-si, Korea, 17 September 2020; pp. 34–38. [Google Scholar] [CrossRef]
- Kawamura, A.; Kinoshita, Y.; Nakachi, T.; Shiota, S.; Kiya, H. A Privacy-Preserving Machine Learning Scheme Using EtC Images. IEICE Trans. Fundam. 2020, 103, 1571–1578. [Google Scholar] [CrossRef]
- Ahmad, I.; Kim, E.; Hwang, S.-S.; Shin, S. Privacy-Preserving Surveillance for Smart Cities. In Proceedings of the 2022 Thirteenth International Conference on Ubiquitous and Future Networks (ICUFN), Barcelona, Spain, 5 July 2022; pp. 301–306. [Google Scholar] [CrossRef]
- Chuman, T.; Sirichotedumrong, W.; Kiya, H. Encryption-Then-Compression Systems Using Grayscale-Based Image Encryption for JPEG Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1515–1525. [Google Scholar] [CrossRef]
- Sirichotedumrong, W.; Kiya, H. Grayscale-Based Block Scrambling Image Encryption Using YCbCr Color Space for Encryption-Then-Compression Systems. APSIPA Trans. Signal Inf. Process. 2019, 8, e7. [Google Scholar] [CrossRef]
- Iida, K.; Kiya, H. Privacy-Preserving Content-Based Image Retrieval Using Compressible Encrypted Images. IEEE Access 2020, 8, 200038–200050. [Google Scholar] [CrossRef]
- Chuman, T.; Kurihara, K.; Kiya, H. On the Security of Block Scrambling-Based EtC Systems against Extended Jigsaw Puzzle Solver Attacks. IEICE Trans. Inf. Syst. 2018, 101, 37–44. [Google Scholar] [CrossRef]
- Kurihara, K.; Shiota, S.; Kiya, H. An Encryption-Then-Compression System for JPEG Standard. In Proceedings of the 2015 Picture Coding Symposium (PCS), Cairns, QLD, Australia, 31 May–3 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 119–123. [Google Scholar]
- Ahmad, I.; Shin, S. Block-Based Perceptual Encryption Algorithm with Improved Color Components Scrambling. In Proceedings of the Korean Institute of Next Generation Computing, Jeju-si, Korea, 19 May 2022; pp. 155–158. [Google Scholar]
- Grivkov, A.V.; Smirnov, A.A. Application of Convolutional Neural Networks for Diagnostics of Tuberculosis; AIP Publishing LLC: Ekaterinburg, Russia, 2020; p. 080011. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Jaeger, S.; Candemir, S.; Antani, S.; Wáng, Y.-X.J.; Lu, P.-X.; Thoma, G. Two Public Chest X-Ray Datasets for Computer-Aided Screening of Pulmonary Diseases. Quant. Imaging Med. Surg. 2014, 4, 475–477. [Google Scholar]
- Das, D.; Santosh, K.C.; Pal, U. Inception-Based Deep Learning Architecture for Tuberculosis Screening Using Chest X-Rays. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3612–3619. [Google Scholar]
- Anu Priya, P.; Vimina, E.R. Tuberculosis Detection from CXR: An Approach Using Transfer Learning with Various CNN Architectures. In International Conference on Communication, Computing and Electronics Systems; Bindhu, V., Tavares, J.M.R.S., Boulogeorgos, A.-A.A., Vuppalapati, C., Eds.; Lecture Notes in Electrical Engineering; Springer: Singapore, 2021; Volume 733, pp. 407–418. ISBN 978-981-334-908-7. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993. [Google Scholar]
- Cao, K.; Zhang, J.; Huang, M.; Deng, T. X-Ray Classification of Tuberculosis Based on Convolutional Networks. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Industrial Design (AIID), Guangzhou, China, 28–30 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 125–129. [Google Scholar]
- Rahman, M.; Cao, Y.; Sun, X.; Li, B.; Hao, Y. Deep Pre-Trained Networks as a Feature Extractor with XGBoost to Detect Tuberculosis from Chest X-ray. Comput. Electr. Eng. 2021, 93, 107252. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Munadi, K.; Muchtar, K.; Maulina, N.; Pradhan, B. Image Enhancement for Tuberculosis Detection Using Deep Learning. IEEE Access 2020, 8, 217897–217907. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Msonda, P.; Uymaz, S.A.; Karaağaç, S.S. Spatial Pyramid Pooling in Deep Convolutional Networks for Automatic Tuberculosis Diagnosis. Trait. Du Signal 2020, 37, 1075–1084. [Google Scholar] [CrossRef]
- Szegedy, C.; Wei, L.; Yangqing, J.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 8691, 346–361. [Google Scholar]
- Rajaraman, S.; Antani, S.K. Modality-Specific Deep Learning Model Ensembles Toward Improving TB Detection in Chest Radiographs. IEEE Access 2020, 8, 27318–27326. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar]
- Dasanayaka, C.; Dissanayake, M.B. Deep Learning Methods for Screening Pulmonary Tuberculosis Using Chest X-Rays. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2021, 9, 39–49. [Google Scholar] [CrossRef]
- Oloko-Oba, M.; Viriri, S. Ensemble of Convolution Neural Networks for Automatic Tuberculosis Classification. In Computational Collective Intelligence; Nguyen, N.T., Iliadis, L., Maglogiannis, I., Trawiński, B., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12876, pp. 549–559. ISBN 978-3-030-88080-4. [Google Scholar]
- Oloko-Oba, M.; Viriri, S. Ensemble of EfficientNets for the Diagnosis of Tuberculosis. Comput. Intell. Neurosci. 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Saif, A.F.M.; Imtiaz, T.; Shahnaz, C.; Zhu, W.-P.; Ahmad, M.O. Exploiting Cascaded Ensemble of Features for the Detection of Tuberculosis Using Chest Radiographs. IEEE Access 2021, 9, 112388–112399. [Google Scholar] [CrossRef]
- Imaizumi, S.; Kiya, H. A Block-Permutation-Based Encryption Scheme with Independent Processing of RGB Components. IEICE Trans. Inf. Syst. 2018, 101, 3150–3157. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- SIPI Image Database-Misc. Available online: https://sipi.usc.edu/database/database.php?volume=misc (accessed on 4 July 2022).
- Schaefer, G.; Stich, M. UCID: An Uncompressed Color Image Database; Yeung, M.M., Lienhart, R.W., Li, C.-S., Eds.; SPIE: San Jose, CA, USA, 2003; pp. 472–480. [Google Scholar]
- Gallagher, A.C. Jigsaw Puzzles with Pieces of Unknown Orientation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 382–389. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale Structural Similarity for Image Quality Assessment. In Proceedings of the The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 1398–1402. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Gisle Bjontegaard. Calculation of Average PSNR Differences between RD-Curves. Doc. VCEG-M33 ITU-T Q6/16, Austin, USA, 2–4 April 2001.
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Kim, D.; Joo, J.; Kim, S.C. Fake Data Generation for Medical Image Augmentation Using GANs. In Proceedings of the 2022 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju-si, Korea, 21–24 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 197–199. [Google Scholar]
- Momeny, M.; Neshat, A.A.; Hussain, M.A.; Kia, S.; Marhamati, M.; Jahanbakhshi, A.; Hamarneh, G. Learning-to-Augment Strategy Using Noisy and Denoised Data: Improving Generalizability of Deep CNN for the Detection of COVID-19 in X-Ray Images. Comput. Biol. Med. 2021, 136, 104704. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.; Kim, J.; Lee, H.; Kim, S. Adaptive Data Augmentation to Achieve Noise Robustness and Overcome Data Deficiency for Deep Learning. Appl. Sci. 2021, 11, 5586. [Google Scholar] [CrossRef]
- Luz, E.; Silva, P.L.; Silva, R.; Silva, L.; Moreira, G.; Menotti, D. Towards an Effective and Efficient Deep Learning Model for COVID-19 Patterns Detection in X-Ray Images. Res. Biomed. Eng. 2022, 38, 149–162. [Google Scholar] [CrossRef]
- Chetoui, M.; Akhloufi, M.A. Deep Efficient Neural Networks for Explainable COVID-19 Detection on CXR Images. In Advances and Trends in Artificial Intelligence; Fujita, H., Selamat, A., Lin, J.C.-W., Ali, M., Eds.; Artificial Intelligence Practices; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12798, pp. 329–340. ISBN 978-3-030-79456-9. [Google Scholar]
- Khan, I.U.; Aslam, N.; Anwar, T.; Aljameel, S.S.; Ullah, M.; Khan, R.; Rehman, A.; Akhtar, N. Remote Diagnosis and Triaging Model for Skin Cancer Using EfficientNet and Extreme Gradient Boosting. Complexity 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Marques, G.; Agarwal, D.; de la Torre Díez, I. Automated Medical Diagnosis of COVID-19 through EfficientNet Convolutional Neural Network. Appl. Soft Comput. 2020, 96, 106691. [Google Scholar] [CrossRef]
- Chetoui, M.; Akhloufi, M.A.; Yousefi, B.; Bouattane, E.M. Explainable COVID-19 Detection on Chest X-Rays Using an End-to-End Deep Convolutional Neural Network Architecture. Big Data Cogn. Comput. 2021, 5, 73. [Google Scholar] [CrossRef]
- Kim, S.; Rim, B.; Choi, S.; Lee, A.; Min, S.; Hong, M. Deep Learning in Multi-Class Lung Diseases’ Classification on Chest X-Ray Images. Diagnostics 2022, 12, 915. [Google Scholar] [CrossRef]
- Zhu, H.; Salcudean, S.; Rohling, R. Gaze-Guided Class Activation Mapping: Leveraging Human Attention for Network Attention in Chest X-rays Classification. arXiv 2022, arXiv:2202.07107. [Google Scholar]
- Liu, J.; Sun, W.; Zhao, X.; Zhao, J.; Jiang, Z. Deep Feature Fusion Classification Network (DFFCNet): Towards Accurate Diagnosis of COVID-19 Using Chest X-Rays Images. Biomed. Signal Process. Control 2022, 76, 103677. [Google Scholar] [CrossRef]
- EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML. Google AI Blog. Available online: https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html (accessed on 4 July 2022).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2019, arXiv:1801.04381. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Hwang, S.; Kim, H.-E.; Jeong, J.; Kim, H.-J. A Novel Approach for Tuberculosis Screening Based on Deep Convolutional Neural Networks; Tourassi, G.D., Armato, S.G., Eds.; SPIE: San Diego, CA, USA, 2016; p. 97852W. [Google Scholar]
- Pasa, F.; Golkov, V.; Pfeiffer, F.; Cremers, D.; Pfeiffer, D. Efficient Deep Network Architectures for Fast Chest X-Ray Tuberculosis Screening and Visualization. Sci. Rep. 2019, 9, 6268. [Google Scholar] [CrossRef]
- An, L.; Peng, K.; Yang, X.; Huang, P.; Luo, Y.; Feng, P.; Wei, B. E-TBNet: Light Deep Neural Network for Automatic Detection of Tuberculosis with X-Ray DR Imaging. Sensors 2022, 22, 821. [Google Scholar] [CrossRef]
- Oloko-Oba, M.; Viriri, S. A Systematic Review of Deep Learning Techniques for Tuberculosis Detection from Chest Radiograph. Front. Med. 2022, 9, 830515. [Google Scholar] [CrossRef]
- Venkatanath, N.; Praneeth, D.; Maruthi Chandrasekhar, B.h.; Channappayya, S.S.; Medasani, S.S. Blind Image Quality Evaluation Using Perception Based Features. In Proceedings of the 2015 Twenty First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Wong, A.; Lee, J.R.H.; Rahmat-Khah, H.; Sabri, A.; Alaref, A. TB-Net: A Tailored, Self-Attention Deep Convolutional Neural Network Design for Detection of Tuberculosis Cases from Chest X-Ray Images. Front. Artif. Intell. 2021, 5, 827299. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Plain Images | Conventional PE Images | Proposed PE Images | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 × 4 | 2 × 2 | |||||||||||
| D | H | V | D | H | V | D | H | V | D | H | V | |
| 256 × 256 | ||||||||||||
| 5.1.09 | 0.90|0.85 | 0.90|0.83 | 0.94|0.88 | 0.68|0.04 | 0.81|−0.04 | 0.80|−0.03 | 0.67|−0.01 | 0.79|−0.02 | 0.80|−0.01 | 0.67|−0.05 | 0.78|0.02 | 0.80|0.05 |
| 5.1.10 | 0.82|0.64 | 0.91|0.78 | 0.86|0.66 | 0.62|0.04 | 0.78|0.03 | 0.78|−0.02 | 0.56|−0.08 | 0.74|0.05 | 0.73|−0.01 | 0.57|−0.02 | 0.73|0.02 | 0.70|0.00 |
| 5.1.11 | 0.89|0.83 | 0.96|0.88 | 0.94|0.91 | 0.75|0.03 | 0.86|−0.01 | 0.87|−0.04 | 0.75|−0.06 | 0.86|−0.02 | 0.87|0.07 | 0.75|−0.02 | 0.86|−0.02 | 0.86|0.02 |
| 5.1.12 | 0.94|0.89 | 0.96|0.92 | 0.97|0.93 | 0.74|0.03 | 0.86|−0.02 | 0.86|−0.04 | 0.73|0.01 | 0.85|−0.04 | 0.86|0.0 | 0.75|0.01 | 0.85|0.01 | 0.86|0.02 |
| 5.1.13 | 0.76|0.49 | 0.87|0.71 | 0.87|0.72 | 0.70|0.02 | 0.83|−0.05 | 0.84|0.04 | 0.67|−0.08 | 0.81|0.00 | 0.82|0.04 | 0.67|−0.04 | 0.81|0.00 | 0.80|−0.04 |
| 5.1.14 | 0.85|0.68 | 0.95|0.85 | 0.90|0.78 | 0.70|0.02 | 0.83|0.00 | 0.83|0.02 | 0.66|0.00 | 0.81|0.01 | 0.80|0.02 | 0.66|0.05 | 0.80|−0.02 | 0.80|0.05 |
| 512 × 512 | ||||||||||||
| 5.2.08 | 0.86|0.74 | 0.94|0.87 | 0.89|0.80 | 0.65|−0.01 | 0.80|0.01 | 0.80|−0.03 | 0.61|−0.01 | 0.78|0.04 | 0.76|0.01 | 0.61|0.00 | 0.77|−0.01 | 0.74|−0.01 |
| 5.2.09 | 0.80|0.60 | 0.90|0.74 | 0.86|0.68 | 0.71|0.00 | 0.84|0.00 | 0.84|0.01 | 0.69|0.00 | 0.82|−0.01 | 0.82|0.00 | 0.69|0.01 | 0.82|−0.01 | 0.81|0.01 |
| 5.2.10 | 0.90|0.82 | 0.94|0.89 | 0.93|0.86 | 0.70|−0.04 | 0.82|−0.02 | 0.82|−0.01 | 0.67|0.01 | 0.81|0.00 | 0.80|0.00 | 0.68|−0.01 | 0.80|0.01 | 0.80|0.04 |
| 7.1.01 | 0.91|0.82 | 0.96|0.91 | 0.92|0.84 | 0.72|0.03 | 0.84|−0.01 | 0.85|0.01 | 0.70|0.00 | 0.83|−0.02 | 0.83|−0.02 | 0.70|0.01 | 0.83|0.01 | 0.82|−0.02 |
| 7.1.05 | 0.89|0.81 | 0.94|0.89 | 0.91|0.83 | 0.71|0.01 | 0.83|−0.02 | 0.83|0.01 | 0.69|0.01 | 0.82|0.02 | 0.81|0.00 | 0.69|−0.01 | 0.82|0.00 | 0.80|0.02 |
| 7.1.10 | 0.93|0.86 | 0.96|0.93 | 0.95|0.88 | 0.72|−0.02 | 0.85|0.01 | 0.84|0.01 | 0.70|0.01 | 0.83|0.00 | 0.82|0.00 | 0.70|0.00 | 0.83|−0.03 | 0.81|−0.02 |
| 1024 × 1024 | ||||||||||||
| 5.3.01 | 0.97|0.93 | 0.98|0.95 | 0.98|0.96 | 0.75|−0.02 | 0.86|0.01 | 0.86|−0.01 | 0.74|0.01 | 0.85|−0.02 | 0.86|−0.01 | 0.74|0.00 | 0.85|0.01 | 0.85|−0.01 |
| 5.3.02 | 0.86|0.73 | 0.91|0.78 | 0.90|0.83 | 0.72|0.00 | 0.84|−0.01 | 0.84|0.00 | 0.71|0.01 | 0.83|0.00 | 0.84|0.01 | 0.71|0.00 | 0.83|0.01 | 0.83|0.00 |
| 7.2.01 | 0.95|0.93 | 0.96|0.94 | 0.95|0.94 | 0.76|0.00 | 0.87|−0.02 | 0.87|0.00 | 0.76|0.00 | 0.87|−0.01 | 0.87|0.00 | 0.76|0.00 | 0.87|0.00 | 0.87|0.00 |
| Mean | 0.88|0.77 | 0.94|0.86 | 0.92|0.83 | 0.71|0.01 | 0.83|−0.01 | 0.84|−0.01 | 0.69|−0.01 | 0.82|0.00 | 0.82|0.01 | 0.69|0.00 | 0.82|0.00 | 0.81|0.01 |
| Original Images | Conventional PE | Proposed PE | ||
|---|---|---|---|---|
| 4 × 4 | 2 × 2 | |||
| 256 × 256 | ||||
| 5.1.09 | 6.71|1.36 | 6.75|1.3 | 6.75|1.3 | 6.75|1.3 |
| 5.1.10 | 7.31|0.51 | 7.54|0.37 | 7.54|0.37 | 7.54|0.37 |
| 5.1.11 | 6.45|2.22 | 7.30|0.81 | 7.29|0.82 | 7.29|0.83 |
| 5.1.12 | 6.71|2.83 | 7.22|1.23 | 7.22|1.23 | 7.22|1.23 |
| 5.1.13 | 1.55|120.3 | 2.46|59.83 | 2.46|59.84 | 2.46|59.83 |
| 5.1.14 | 7.34|0.51 | 7.58|0.33 | 7.58|0.32 | 7.58|0.33 |
| 512 × 512 | ||||
| 5.2.08 | 7.20|12.00 | 7.26|11.48 | 7.26|11.48 | 7.26|11.47 |
| 5.2.09 | 6.99|17.74 | 7.58|5.63 | 7.58|5.62 | 7.58|5.63 |
| 5.2.10 | 5.71|47.61 | 5.78|42.09 | 5.78|42.1 | 5.78|42.08 |
| 7.1.01 | 6.03|46.32 | 6.56|35.97 | 6.56|35.96 | 6.56|35.95 |
| 7.1.05 | 6.56|22.38 | 7.24|11.68 | 7.23|11.69 | 7.24|11.68 |
| 7.1.10 | 5.91|47.97 | 6.60|28.09 | 6.60|28.1 | 6.60|28.11 |
| 1024 × 1024 | ||||
| 5.3.01 | 7.52|113.94 | 7.83|45.13 | 7.83|45.13 | 7.83|45.15 |
| 5.3.02 | 6.83|317.2 | 7.41|110.18 | 7.41|110.15 | 7.41|110.15 |
| 7.2.01 | 5.64|1156.51 | 6.58|494.9 | 6.58|494.89 | 6.58|494.87 |
| Mean | 6.30|127.29 | 6.78|56.6 | 6.78|56.6 | 6.78|56.6 |
| Methods (Block Size) | Dc | Lc | Nc |
|---|---|---|---|
| Color-PE (16 × 16) | 0.01 | 0.12 | 0.11 |
| Grayscale-PE (8 × 8) | 0.001 | 0.002 | 0.001 |
| Proposed-PE (4 × 4) | 0.01 | 0.02 | 0.05 |
| Proposed-PE (2 × 2) | 0.01 | 0.02 | 0.06 |
| Noise Type | Conventional | Proposed | |
|---|---|---|---|
| 4 × 4 | 2 × 2 | ||
| Salt and Pepper Noise | |||
| 0.05 | 0.78 | 0.78 | 0.78 |
| 0.025 | 0.87 | 0.87 | 0.87 |
| 0.0125 | 0.92 | 0.93 | 0.92 |
| 0.01 | 0.94 | 0.94 | 0.93 |
| 0.001 | 0.99 | 0.99 | 0.99 |
| Gaussian Noise | |||
| 0.05 | 0.57 | 0.57 | 0.57 |
| 0.025 | 0.68 | 0.68 | 0.68 |
| 0.0125 | 0.77 | 0.77 | 0.77 |
| 0.01 | 0.8 | 0.8 | 0.8 |
| 0.001 | 0.96 | 0.96 | 0.96 |
| [66] | [67] | [68] | [1] | Proposed |
|---|---|---|---|---|
| 83.7 | 84.4 | 85.0 | 87.0 | 89.52 |
| Qf | Original | Conventional (8 × 8) | Conventional (4 × 4) | Conventional (2 × 2) | Proposed (4 × 4) | Proposed (2 × 2) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Image Quality | Acc | Image Quality | Acc | Image Quality | Acc | Image Quality | Acc | Image Quality | Acc | Image Quality | Acc | |
| − | 43.16|− | 89.52 | 43.16|− | 89.52 | 43.16|− | 89.52 | 43.16|− | 89.52 | 43.16|− | 89.52 | 43.16|− | 89.52 |
| 71 | 42.65|38.49 | 87.9 | 42.60|38.49 | 84.68 | 42.19|32.59 | 84.68 | 40.43|31.66 | 84.68 | 43.37|38.28 | 85.48 | 43.51|38.34 | 84.68 |
| 75 | 42.77|39.21 | 87.1 | 42.77|39.21 | 86.29 | 42.37|32.81 | 84.68 | 41.18|32.00 | 84.68 | 43.38|39.05 | 86.29 | 43.41|39.08 | 84.68 |
| 80 | 42.87|40.28 | 84.68 | 42.92|40.33 | 85.48 | 42.75|33.17 | 86.29 | 41.81|32.47 | 86.29 | 43.45|40.11 | 88.71 | 43.54|40.13 | 84.68 |
| 85 | 43.12|41.09 | 86.29 | 42.92|41.11 | 87.9 | 42.83|33.47 | 85.48 | 42.43|32.92 | 84.68 | 43.44|40.90 | 87.9 | 43.54|40.90 | 87.1 |
| 90 | 43.03|42.90 | 84.68 | 43.13|42.9 | 86.29 | 43.06|33.78 | 88.71 | 42.73|33.39 | 88.71 | 43.31|42.62 | 84.68 | 43.41|42.61 | 85.48 |
| 95 | 43.02|44.04 | 87.9 | 43.07|44.04 | 84.68 | 43.11|34.03 | 84.68 | 43.06|33.83 | 84.68 | 43.15|43.86 | 84.68 | 43.14|43.83 | 87.1 |
| 100 | 43.13|45.99 | 86.29 | 43.13|45.88 | 87.1 | 43.12|34.21 | 87.1 | 43.20|34.15 | 84.68 | 43.11|45.88 | 84.68 | 43.10|45.63 | 86.29 |
| σ2 | 0.03|7.37 | 1.82 | 00.04|7.19 | 1.45 | 0.14|0.37 | 2.35 | 1.06|0.87 | 2.38 | 0.02|7.44 | 2.75 | 0.03|6.97 | 1.24 |
| σ | 0.18|2.71 | 1.35 | 00.20|2.68 | 1.21 | 0.37|0.61 | 1.53 | 1.03|0.93 | 1.54 | 0.14|2.73 | 1.66 | 0.19|2.64 | 1.11 |
| Qf. | Original | Conventional (8 × 8) | Conventional (4 × 4) | Conventional (2 × 2) | Proposed (4 × 4) | Proposed (2 × 2) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SPE|SEN | Acc | SPE|SEN | Acc | SPE|SEN | Acc | SPE|SEN | Acc | SPE|SEN | Acc | SPE|SEN | Acc | |
| − | 0.87|0.92 | 89.52 | 0.87|0.92 | 89.52 | 0.87|0.92 | 89.52 | 0.87|0.92 | 89.52 | 0.87|0.92 | 89.52 | 0.87|0.92 | 89.52 |
| 71 | 0.87|0.89 | 87.9 | 0.81|0.89 | 84.68 | 0.87|0.82 | 84.68 | 0.79|0.90 | 84.68 | 0.87|0.84 | 85.48 | 0.76|0.94 | 84.68 |
| 75 | 0.84|0.90 | 87.1 | 0.81|0.92 | 86.29 | 0.81|0.89 | 84.68 | 0.77|0.92 | 84.68 | 0.81|0.92 | 86.29 | 0.76|0.94 | 84.68 |
| 80 | 0.79|0.90 | 84.68 | 0.79|0.92 | 85.48 | 0.82|0.90 | 86.29 | 0.81|0.92 | 86.29 | 0.85|0.92 | 88.71 | 0.82|0.87 | 84.68 |
| 85 | 0.79|0.94 | 86.29 | 0.87|0.89 | 87.9 | 0.85|0.85 | 85.48 | 0.84|0.85 | 84.68 | 0.85|0.90 | 87.9 | 0.81|0.94 | 87.1 |
| 90 | 0.82|0.87 | 84.68 | 0.77|0.95 | 86.29 | 0.87|0.90 | 88.71 | 0.90|0.87 | 88.71 | 0.79|0.90 | 84.68 | 0.84|0.87 | 85.48 |
| 95 | 0.85|0.90 | 87.9 | 0.79|0.90 | 84.68 | 0.85|0.84 | 84.68 | 0.79|0.90 | 84.68 | 0.84|0.85 | 84.68 | 0.82|0.92 | 87.1 |
| 100 | 0.76|0.90 | 86.29 | 0.90|0.84 | 87.1 | 0.76|0.85 | 87.1 | 0.81|0.89 | 84.68 | 0.85|0.84 | 84.68 | 0.79|0.94 | 86.29 |
| σ2 × 100 | 0.17|0.04 | 1.82 | 0.22|0.11 | 1.45 | 0.15|0.13 | 2.35 | 0.2|0.07 | 2.38 | 0.08|0.13 | 2.75 | 0.14|0.09 | 1.24 |
| σ | 0.04|0.02 | 1.35 | 0.05|0.03 | 1.21 | 0.04|0.04 | 1.53 | 0.04|0.03 | 1.54 | 0.03|0.04 | 1.66 | 0.04|0.03 | 1.11 |
| [71] | Proposed Data Augmentation Method | |||||
|---|---|---|---|---|---|---|
| Original | Conventional | Proposed | ||||
| 8 × 8 | 4 × 4 | 2 × 2 | 4 × 4 | 2 × 2 | ||
| 99.86 | 99.77 | 99.77 | 99.54 | 99.31 | 99.71 | 99.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, I.; Shin, S. A Perceptual Encryption-Based Image Communication System for Deep Learning-Based Tuberculosis Diagnosis Using Healthcare Cloud Services. Electronics 2022, 11, 2514. https://doi.org/10.3390/electronics11162514
Ahmad I, Shin S. A Perceptual Encryption-Based Image Communication System for Deep Learning-Based Tuberculosis Diagnosis Using Healthcare Cloud Services. Electronics. 2022; 11(16):2514. https://doi.org/10.3390/electronics11162514
Chicago/Turabian StyleAhmad, Ijaz, and Seokjoo Shin. 2022. "A Perceptual Encryption-Based Image Communication System for Deep Learning-Based Tuberculosis Diagnosis Using Healthcare Cloud Services" Electronics 11, no. 16: 2514. https://doi.org/10.3390/electronics11162514
APA StyleAhmad, I., & Shin, S. (2022). A Perceptual Encryption-Based Image Communication System for Deep Learning-Based Tuberculosis Diagnosis Using Healthcare Cloud Services. Electronics, 11(16), 2514. https://doi.org/10.3390/electronics11162514