
A Multi-Technique Approach to Exploring the Main Influences of Information Exchange Monitoring Tolerance


Abstract
:1. Introduction
2. Literature Review
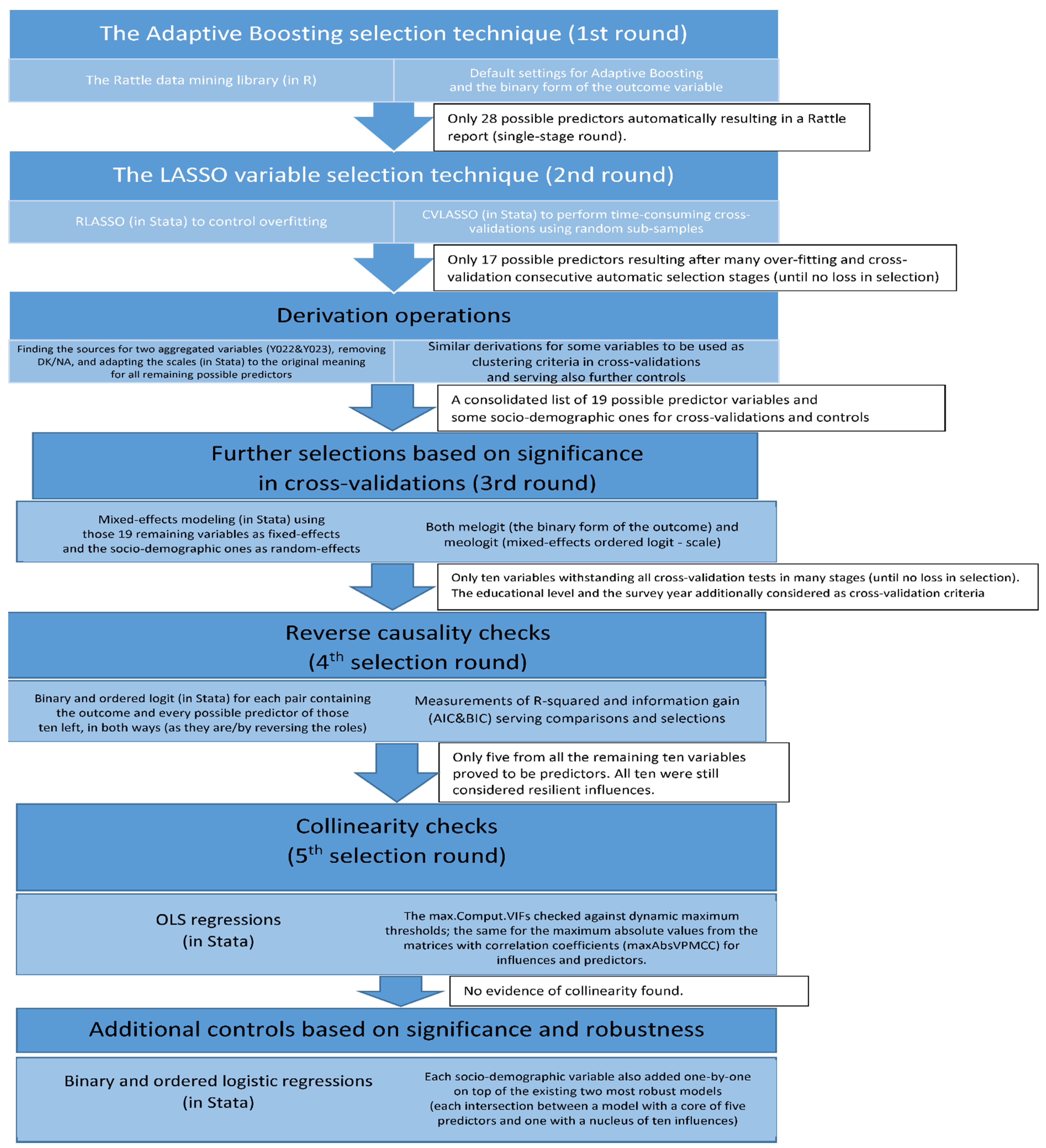
3. Materials and Methods
4. Results
- -
- 1 (cross-validation on gender, binary outcome);
- -
- 6 (cross-validation on employment status, binary outcome);
- -
- 8 (cross-validation on regions and countries, binary outcome);
- -
- 9 (cross-validation on settlement size, binary outcome);
- -
- 12 (cross-validation on marital status as with someone or not, scale outcome);
- -
- 14 (cross-validation on the highest educational level attained, scale outcome);
- -
- 15 (cross-validation on employment status, scale outcome);
- -
- 17 (cross-validation on regions and countries, scale outcome); and
- -
- 18 (cross-validation on settlement size, scale outcome).
5. Discussion
- -
- Those more active in mutual/self-support groups, more hard-working, more committed in terms of societal duties (e.g., having children as a duty);
- -
- The ones more confident in administration and more tolerant towards accepting the collection of information, including surveillance acceptance in public areas by the government;
- -
- Those more inclined to tolerate gender discrimination in education and jobs.
6. Conclusions
7. Limitations and Future Research
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Variable | Short Description | Coding Details |
|---|---|---|
| H010 | Government has the right to monitor all e-mails and any other information exchange (original format) | <0-Don’t know/No Answer/Not applicable/Not Asked/Missing (DK/NA/M); 1-Definitely should have the right … 4-Definitely should not have the right; |
| H010nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (H010nt = 4-H010 if H010! = . & H010>0), VARIABLE TO BE ANALYSED/OUTCOME/RESPONSE | Null (.)-DK/NA/M; 3-Definitely should have the right … 0-Definitely should not have the right; |
| H010bin | Same as above, but in its binary form and with null and DK/NA/M treatment (H010bin = 1 if H010! = . & H010 > 0 & H010 < 3; H010bin = 0 if H010! = . & H010 > 2), ALTERNATIVE OUTCOME VARIABLE | Null (.)-DK/NA/M; 1-Definitely should have the right/Probably should have the right; 0-Probably should not have the right/Definitely should not have the right; |
| A106C | Active/Inactive membership: Self-help group, mutual aid group (original format) | <0—DK/NA/M; 0—Not a member; 1—Inactive member; 2—Active member; |
| A106Cnt | Same as above, but with null and DK/NA/M treatment (A106Cnt = A106C if A106C! = . & A106C >= 0) | Null (.)-DK/NA/M; 0—Not a member; 1—Inactive member; 2—Active member; |
| A124_02 | Neighbors: People of a different race (original format) | <0-DK/NA/M; 0—Not mentioned; 1—Mentioned; |
| A124_02nt | Same as above, but with null and DK/NA/M treatment (A124_02nt = A124_02 if A124_02! = . & A124_02 >= 0) | Null (.)-DK/NA/M; 0—Not mentioned; 1—Mentioned; |
| C001 | Jobs scarce: Men should have more rights to a job than women (original format and source for Y022A = WOMJOB- Welzel equality-1 or Gender equality: job) | <0-DK/NA/M; 1—Agree; 2—Neither agree nor disagree; 3—Neither; |
| C001nt | Same as above, but with a changed scale and DK/NA/M treatment (C001nt = 2 if C001 == 1; C001nt = 0 if C001 == 2; C001nt = 1 if C001 == 3) | Null (.)-DK/NA/M; 2—Agree; 1—Neither agree nor disagree; 0—Disagree; |
| C041 | Work should come the first even if it means less spare time (original format) | <0-DK/NA/M; 1—Strongly agree … 3-Neither agree nor disagree … 5-Strongly disagree; |
| C041nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (C041nt = 5-C041 if C041! = . & C041 > 0) | Null (.)-DK/NA/M; 4-Strongly agree … 2-Neither agree nor disagree … 0-Strongly disagree; |
| D026_03 | Duty towards society to have children (original format) | Identical to the case of C041; |
| D026_03nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (D026_03nt = 5-D026_03 if D026_03! = . & D026_03 > 0) | Identical to the case of C041nt; |
| D059 | Men make better political leaders than women do (original format and source for Y022B = WOMPOL-Welzel equality-2 or Gender equality: politics) | <0-DK/NA/M; 1—Strongly agree… 4-Strongly disagree; |
| D059nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (D059nt = 4-D059 if D059! = . & D059 > 0) | Null (.)-DK/NA/M; 3-Strongly agree … 0-Strongly disagree; |
| D060 | University is more important for a boy than for a girl (original format and source for Y022C = WOMEDU- Welzel equality-3 or Gender equality: education) | Identical to the case of D059; |
| D060nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (D060nt = 4-D060 if D060! = . & D060 > 0) | Identical to the case of D059nt; |
| E069_11 | Confidence: The Government (original format) | <0-DK/NA/M; 1—A great deal… 4—Not at all; |
| E069_11nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (E069_11nt = 4-E069_11 if E069_11! = . & E069_11 > 0) | Null (.)-DK/NA/M; 3—A great deal … 0—Not at all; |
| E228 | Democracy: The army takes over when the government is incompetent (original format) | <0-DK/NA/M; 0—It is against democracy … 10—An essential characteristic of democracy; |
| E228nt | Same as above, but with null and DK/NA/M treatment (E228nt = E228 if E228! = . & E228 >= 0) | Null (.)-DK/NA/M; 0—It is against democracy … 10—An essential characteristic of democracy; |
| E233B | Democracy: People obey their rulers (original format) | Identical to the case of E228B; |
| E233Bnt | Same as above, but with null and DK/NA/M treatment (E233Bnt = E233B if E233B! = . & E233B >= 0) | Identical to the case of E228Bnt; |
| E236 | Democraticness in own country (original format) | <0-DK/NA/M; 0—It is against democracy … 10—Completely democratic; |
| E236nt | Same as above, but with null and DK/NA/M treatment (E236nt = E236 if E236! = . & E236 >= 0) | Null (.)-DK/NA/M; 0—It is against democracy … 10—Completely democratic; |
| E262B | Information source: Internet (original format) | <0-DK/NA/M; 1—Daily … 5 Never; |
| E262Bnt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (E262Bnt = 5-E262B if E262B! = . & E262B > 0) | Null (.)-DK/NA/M; 4—Daily … 0—Never; |
| F118 | Justifiable: Homosexuality (original format and source for Y023A = HOMOLIB- Welzel choice-1 or Homosexuality acceptance) | <0-DK/NA/M; 1—Never justifiable … 10—Always justifiable; |
| F118nt | Same as above, but with null and DK/NA/M treatment (F118nt = F118 if F118! = . & F118 > 0) | Null (.)-DK/NA/M; 1—Never justifiable … 10—Always; |
| F120 | Justifiable: Abortion (original format and source for Y023B = ABORTLIB- Welzel choice-2 or Abortion acceptable) | Identical to the case of F118; |
| F120nt | Same as above, but with null and DK/NA/M treatment (F120nt = F120 if F120! = . & F120 > 0) | Identical to the case of F118nt; |
| F121 | Justifiable: Divorce (original format and source for Y023C = DIVORLIB- Welzel choice-3 or Divorce acceptable) | Identical to the case of F118; |
| F121nt | Same as above, but with null and DK/NA/M treatment (F121nt = F121 if F121! = . & F121 > 0) | Identical to the case of F118nt; |
| H002_01 | Frequency in your neighborhood: Robberies (original format) | <0-DK/NA/M; 1—Very Frequently … 4—Not at all frequently; |
| H002_01nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (H002_01nt = 4-H002_01 if H002_01! = . & H002_01 > 0) | Null (.)-DK/NA/M; 3—Very Frequently … 0—Not at all frequently; |
| H009 | Government has the right to keep people under video surveillance in public areas (original format) | Identical to the case of H010; |
| H009nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (H009nt = 4-H009 if H009! = . & H009 > 0) | Identical to the case of H010nt; |
| H011 | Government has the right to collect information about anyone living in a country (original format) | Identical to the case of H010; |
| H011nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (H011nt = 4-H011 if H011! = . & H011 > 0) | Identical to the case of H010nt; |
| X025A_01 | The highest educational level attained ISCED 2011 (original format) | <0-DK/NA/M; 0—Early childhood education (ISCED 0)/no education … 8—Doctoral or equivalent (ISCED 8); |
| X025A_01nt | Same as above, but with null and DK/NA/M treatment (X025A_01nt = X025A_01 if X025A_01! = . & X025A_01 >= 0) | Null (.)-DK/NA/M; 0—Early childhood education (ISCED 0)/no education … 8—Doctoral or equivalent (ISCED 8); |
| X001 | Gender (original format) | <0-DK/NA/M; 1-Male; 2—Female; |
| X001nt | Same as above, but with null and DK/NA/M treatment (X001nt = X001 if X001! = . & X001 > 0) | Null (.)-DK/NA/M; 1-Male; 2—Female; |
| X003 | Age (original format) | <0-DK/NA/M; |
| X003nt | Same as above, but with null and DK/NA/M treatment (X003nt = X003 if X003! = . & X003 > 0) | Null (.)-DK/NA/M; |
| X007 | Marital status (original format) | <0-DK/NA/M; 1-Married; 2-Living together as married; 3-Divorced; 4-Separated; 5-Widowed; 6-Single/Never married; |
| X007nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (X007nt = 6-X007 if X007! = . & X007 > 0) | Null (.)-DK/NA/M; 5-Married … 0-Single/Never married; |
| X007bin | Same as above, but in its binary form and with null and DK/NA/M treatment (X007bin = 1 if X007 == 1 | X007 == 2; X007bin = 0 if X007! = . & X007 > 2) | Null (.)-DK/NA/M; 1—Married/Living together as married; 0—Otherwise; |
| X011 | How many children do you have (original format) | <0-DK/NA/M; 0-No child; 1—1 child; 2—2 children … 5—5 children or more; |
| X011nt | Same as above, but with null and DK/NA/M treatment (X011nt = X011 if X011! = . & X011 >= 0) | Null (.)-DK/NA/M; 0-No child; 1—1 child; 2—2 children … 5—5 children or more; |
| X028 | Employment status (original format) | <0-DK/NA/M; 1—Full time; 2—Part-time; 3—Self employed; 4—Retired; 5—Housewife; 6—Students; 7—Unemployed; 8—Other; |
| X028nt | Same as above, but with a reversed scale and with null and DK/NA/M treatment (X028nt = 8-X028 if X028! = . & X028 > 0 & X028 < 9) | Null (.)-DK/NA/M; 7—Full time … 0—Other; |
| X047_WVS | The scale of incomes (original format) | <0-DK/NA/M; 1—Lowest step; 2—Second step … 10—Tenth step; 11—Highest step; |
| X047nt | Same as above, but with null and DK/NA/M treatment (X047nt = X047_WVS if X047_WVS! = . & X047_WVS>0) | Null (.)-DK/NA/M; 1—the lowest step … 11—the highest one; |
| X048WVS | The region where the interview was conducted (original format) | <0-DK/NA/M; 8001—Albania: Tirana … 7360013 SD: Nile River; |
| X048WVSnt | Same as above, but with null and DK/NA/M treatment (X048WVSnt = X048WVS if X048WVS! = . & X048WVS > 0) | Null (.)-DK/NA/M; 8001—Albania: Tirana … 7360013 SD: Nile River; |
| X049 | Settlement size (original format) | <0-DK/NA/M; 1—Under 2000; 2—2000–5000; 3—5000–10,000; 4—10,000–20,000; 5—20,000–50,000; 6—50,000–100,000; 7—100,000–500,000; 8—500,000 and more; |
| X049nt | Same as above, but with null and DK/NA/M treatment (X049nt = X049 if X049! = . & X049 > 0) | Null (.)-DK/NA/M; 1—Under 2000 … 8—500,000 and more; |
| S020 | Year of survey (original format-no need for null and DK/NA/M treatment because of its values) | Years between 1981 and 2020 (limited to 2017–2020 for non-NULL observations corresponding to the response variable). |
| Variable | n | Mean | Std.Dev. | Min | 0.25 | Median | 0.75 | Max |
|---|---|---|---|---|---|---|---|---|
| H010nt | 74,410 | 1.12 | 1.07 | 0 | 0 | 1 | 2 | 3 |
| H010bin | 74,410 | 0.36 | 0.48 | 0 | 0 | 0 | 1 | 1 |
| A106Cnt | 164,147 | 0.18 | 0.51 | 0 | 0 | 0 | 0 | 2 |
| A124_02nt | 404,615 | 0.17 | 0.37 | 0 | 0 | 0 | 0 | 1 |
| C001nt | 401,680 | 0.96 | 0.91 | 0 | 0 | 1 | 2 | 2 |
| C041nt | 180,765 | 2.62 | 1.16 | 0 | 2 | 3 | 3 | 4 |
| D026_03nt | 77,074 | 2.29 | 1.24 | 0 | 1 | 3 | 3 | 4 |
| D059nt | 363,866 | 1.52 | 0.98 | 0 | 1 | 1 | 2 | 3 |
| D060nt | 370,788 | 1.03 | 0.92 | 0 | 0 | 1 | 1 | 3 |
| E069_11nt | 368,598 | 1.42 | 0.95 | 0 | 1 | 1 | 2 | 3 |
| E228nt | 221,410 | 4.55 | 3.2 | 0 | 1 | 4 | 7 | 10 |
| E233Bnt | 160,117 | 5.97 | 3.03 | 0 | 4 | 6 | 9 | 10 |
| E236nt | 227,784 | 6.18 | 2.54 | 1 | 5 | 6 | 8 | 10 |
| E262Bnt | 160,550 | 2.01 | 1.81 | 0 | 0 | 2 | 4 | 4 |
| F118nt | 386,945 | 3.26 | 3.07 | 1 | 1 | 1 | 5 | 10 |
| F120nt | 404,884 | 3.41 | 2.87 | 1 | 1 | 2 | 5 | 10 |
| F121nt | 409,708 | 4.68 | 3.1 | 1 | 1 | 5 | 7 | 10 |
| H002_01nt | 158,241 | 0.88 | 0.91 | 0 | 0 | 1 | 1 | 3 |
| H009nt | 75,219 | 1.74 | 1.09 | 0 | 1 | 2 | 3 | 3 |
| H011nt | 74,712 | 1.06 | 1.07 | 0 | 0 | 1 | 2 | 3 |
| X025A_01nt | 77,493 | 3.49 | 2.03 | 0 | 2 | 3 | 5 | 8 |
| X001nt | 427,664 | 1.52 | 0.5 | 1 | 1 | 2 | 2 | 2 |
| X003nt | 427,922 | 41.22 | 16.25 | 13 | 28 | 39 | 53 | 103 |
| X007nt | 427,294 | 3.34 | 2.18 | 0 | 1 | 5 | 5 | 5 |
| X007bin | 427,294 | 0.64 | 0.48 | 0 | 0 | 1 | 1 | 1 |
| X011nt | 416,851 | 1.79 | 1.57 | 0 | 0 | 2 | 3 | 5 |
| X028nt | 419,713 | 4.7 | 2.16 | 0 | 3 | 5 | 7 | 7 |
| X047nt | 395,124 | 4.67 | 2.29 | 1 | 3 | 5 | 6 | 10 |
| X049nt | 307,270 | 4.96 | 2.51 | 1 | 3 | 5 | 7 | 8 |
| S020 | 432,482 | 2005.26 | 9.67 | 1981 | 1998 | 2006 | 2012 | 2020 |
| Model | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) | (11) | (12) | (13) | (14) | (15) | (16) | (17) | (18) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Input/Response | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt |
| A106Cnt | 0.1901 *** | 0.1897 *** | 0.1907 *** | 0.1903 *** | 0.1876 *** | 0.1877 *** | 0.1873 *** | 0.1634 *** | 0.1816 *** | 0.1158 ** | 0.1146 *** | 0.1149 *** | 0.1146 *** | 0.1153 *** | 0.1140 *** | 0.1135 *** | 0.1047 *** | 0.1143 *** |
| (0.0439) | (0.0212) | (0.0145) | (0.0222) | (0.0268) | (0.0210) | (0.0296) | (0.0267) | (0.0174) | (0.0384) | (0.0162) | (0.0040) | (0.0044) | (0.0246) | (0.0153) | (0.0153) | (0.0217) | (0.0213) | |
| A124_02nt | 0.2280 *** | 0.2352 *** | 0.2268 *** | 0.2277 *** | 0.2279 *** | 0.2233 *** | 0.2287 *** | 0.1554 *** | 0.2230 * | 0.1429 *** | 0.1421 *** | 0.1436 *** | 0.1444 *** | 0.1471 * | 0.1397 ** | 0.1431 *** | 0.0582 * | 0.1468 |
| (0.0155) | (0.0359) | (0.0426) | (0.0014) | (0.0642) | (0.0621) | (0.0335) | (0.0411) | (0.1134) | (0.0096) | (0.0253) | (0.0333) | (0.0009) | (0.0615) | (0.0504) | (0.0173) | (0.0293) | (0.0845) | |
| C041nt | 0.0808 *** | 0.0804 *** | 0.0805 *** | 0.0803 *** | 0.0817 *** | 0.0813 *** | 0.0819 *** | 0.0722 *** | 0.0784 *** | 0.0583 *** | 0.0570 *** | 0.0573 *** | 0.0571 *** | 0.0582 *** | 0.0591 *** | 0.0591 *** | 0.0585 *** | 0.0553 *** |
| (0.0012) | (0.0130) | (0.0162) | (0.0239) | (0.0065) | (0.0154) | (0.0109) | (0.0142) | (0.0165) | (0.0045) | (0.0080) | (0.0115) | (0.0152) | (0.0058) | (0.0152) | (0.0069) | (0.0109) | (0.0144) | |
| D026_03nt | 0.0972 *** | 0.0970 *** | 0.0967 *** | 0.0971 *** | 0.0978 *** | 0.0951 *** | 0.0955 *** | 0.0884 *** | 0.0963 *** | 0.0845 *** | 0.0838 *** | 0.0832 *** | 0.0836 *** | 0.0828 *** | 0.0832 *** | 0.0824 *** | 0.0752 *** | 0.0849 *** |
| (0.0116) | (0.0112) | (0.0139) | (0.0016) | (0.0045) | (0.0059) | (0.0075) | (0.0149) | (0.0080) | (0.0058) | (0.0084) | (0.0150) | (0.0115) | (0.0083) | (0.0060) | (0.0064) | (0.0113) | (0.0102) | |
| E069_11nt | 0.1193 *** | 0.1196 *** | 0.1170 *** | 0.1182 *** | 0.1194 *** | 0.1184 *** | 0.1197 *** | 0.1063 *** | 0.1144 *** | 0.1323 *** | 0.1320 *** | 0.1312 *** | 0.1322 *** | 0.1333 *** | 0.1316 *** | 0.1327 *** | 0.1038 *** | 0.1280 *** |
| (0.0043) | (0.0129) | (0.0159) | (0.0231) | (0.0154) | (0.0167) | (0.0143) | (0.0202) | (0.0226) | (0.0024) | (0.0087) | (0.0137) | (0.0110) | (0.0108) | (0.0113) | (0.0080) | (0.0142) | (0.0169) | |
| E228nt | 0.0188 ** | 0.0188 *** | 0.0189 ** | 0.0187 * | 0.0179 * | 0.0184 * | 0.0190 *** | 0.0294 *** | 0.0173 | 0.0133 | 0.0136 *** | 0.0138 * | 0.0137 | 0.0133 * | 0.0129 * | 0.0132 *** | 0.0249 *** | 0.0133 * |
| (0.0069) | (0.0045) | (0.0063) | (0.0087) | (0.0075) | (0.0074) | (0.0044) | (0.0060) | (0.0105) | (0.0077) | (0.0035) | (0.0057) | (0.0072) | (0.0059) | (0.0058) | (0.0037) | (0.0047) | (0.0065) | |
| E233Bnt | 0.0261 *** | 0.0256 *** | 0.0262 *** | 0.0263 *** | 0.0265 *** | 0.0258 * | 0.0261 *** | 0.0230 *** | 0.0234 *** | 0.0142 ** | 0.0141 *** | 0.0143 *** | 0.0144 *** | 0.0143 *** | 0.0143 | 0.0143 *** | 0.0168 *** | 0.0135 |
| (0.0061) | (0.0046) | (0.0030) | (0.0036) | (0.0050) | (0.0120) | (0.0058) | (0.0056) | (0.0068) | (0.0043) | (0.0032) | (0.0035) | (0.0021) | (0.0039) | (0.0123) | (0.0039) | (0.0046) | (0.0085) | |
| E236nt | 0.0201 | 0.0202 *** | 0.0197 | 0.0198 | 0.0202 * | 0.0197 *** | 0.0187 *** | 0.0207 ** | 0.0205 *** | 0.0192 *** | 0.0196 *** | 0.0188 ** | 0.0190 *** | 0.0195 ** | 0.0193 *** | 0.0180 *** | 0.0172 *** | 0.0192 *** |
| (0.0121) | (0.0045) | (0.0111) | (0.0103) | (0.0095) | (0.0054) | (0.0048) | (0.0064) | (0.0029) | (0.0027) | (0.0033) | (0.0069) | (0.0051) | (0.0070) | (0.0032) | (0.0035) | (0.0051) | (0.0024) | |
| E262Bnt | −0.1052 *** | −0.1066 *** | −0.1042 *** | −0.1045 *** | −0.1058 *** | −0.1053 *** | −0.1061 *** | −0.0843 *** | −0.0976 *** | −0.0845 *** | −0.0854 *** | −0.0844 *** | −0.0847 *** | −0.0863 *** | −0.0867 *** | −0.0865 *** | −0.0695 *** | −0.0815 *** |
| (0.0168) | (0.0085) | (0.0070) | (0.0091) | (0.0101) | (0.0089) | (0.0061) | (0.0101) | (0.0088) | (0.0119) | (0.0061) | (0.0059) | (0.0093) | (0.0069) | (0.0072) | (0.0037) | (0.0085) | (0.0064) | |
| H002_01nt | 0.0361 *** | 0.0363 ** | 0.0384 * | 0.0371 | 0.0346 * | 0.0346 * | 0.0348 * | 0.0432 * | 0.0445 ** | −0.0163 *** | −0.0146 | −0.0146 | −0.0158 | −0.0190 | −0.0157 | −0.0168 | 0.0172 | −0.0115 |
| (0.0088) | (0.0139) | (0.0156) | (0.0224) | (0.0174) | (0.0167) | (0.0170) | (0.0175) | (0.0145) | (0.0015) | (0.0116) | (0.0094) | (0.0116) | (0.0142) | (0.0130) | (0.0144) | (0.0132) | (0.0158) | |
| H009nt | 0.8005 *** | 0.7987 *** | 0.7996 *** | 0.7995 *** | 0.7992 *** | 0.7979 *** | 0.8000 *** | 0.7801 *** | 0.7890 *** | 0.7864 *** | 0.7864 *** | 0.7856 *** | 0.7857 *** | 0.7887 *** | 0.7849 *** | 0.7874 *** | 0.7690 *** | 0.7866 *** |
| (0.0314) | (0.0154) | (0.0207) | (0.0184) | (0.0198) | (0.0162) | (0.0121) | (0.0220) | (0.0160) | (0.0164) | (0.0110) | (0.0308) | (0.0251) | (0.0175) | (0.0212) | (0.0135) | (0.0191) | (0.0198) | |
| H011nt | 1.0011 *** | 1.0004 *** | 1.0008 *** | 1.0011 *** | 0.9967 *** | 1.0023 *** | 0.9994 *** | 1.0407 *** | 0.9892 *** | 1.1275 *** | 1.1246 *** | 1.1263 *** | 1.1265 *** | 1.1239 *** | 1.1273 *** | 1.1252 *** | 1.1536 *** | 1.1097 *** |
| (0.0012) | (0.0187) | (0.0088) | (0.0030) | (0.0107) | (0.0401) | (0.0343) | (0.0312) | (0.0561) | (0.0193) | (0.0212) | (0.0201) | (0.0253) | (0.0224) | (0.0746) | (0.0458) | (0.0407) | (0.0819) | |
| X025A_01nt | −0.0524 *** | −0.0517 *** | −0.0530 *** | −0.0525 *** | −0.0535 *** | −0.0479 *** | −0.0528 *** | −0.0482 *** | −0.0439 *** | −0.0312 ** | −0.0319 *** | −0.0322 *** | −0.0319 *** | −0.0337 *** | −0.0301 *** | −0.0327 *** | −0.0315 *** | −0.0311 *** |
| (0.0124) | (0.0074) | (0.0048) | (0.0005) | (0.0111) | (0.0088) | (0.0053) | (0.0077) | (0.0075) | (0.0097) | (0.0057) | (0.0061) | (0.0010) | (0.0096) | (0.0078) | (0.0035) | (0.0058) | (0.0065) | |
| C001nt | 0.1296 *** | 0.1293 *** | 0.1273 *** | 0.1285 *** | 0.1295 *** | 0.1291 *** | 0.1290 *** | 0.0927 *** | 0.1241 *** | 0.0911 *** | 0.0905 *** | 0.0890 *** | 0.0901 *** | 0.0901 *** | 0.0876 *** | 0.0897 *** | 0.0479 *** | 0.0903 *** |
| (0.0001) | (0.0166) | (0.0121) | (0.0011) | (0.0122) | (0.0099) | (0.0173) | (0.0201) | (0.0235) | (0.0058) | (0.0126) | (0.0126) | (0.0068) | (0.0071) | (0.0083) | (0.0117) | (0.0140) | (0.0132) | |
| D059nt | 0.0189 | 0.0192 | 0.0178 | 0.0188 *** | 0.0201 | 0.0196 | 0.0190 | 0.0349 | 0.0158 | 0.0331 | 0.0316 ** | 0.0305 *** | 0.0313 ** | 0.0339 * | 0.0328 * | 0.0320 * | 0.0369 ** | 0.0290 * |
| (0.0376) | (0.0151) | (0.0125) | (0.0005) | (0.0104) | (0.0118) | (0.0171) | (0.0186) | (0.0135) | (0.0416) | (0.0122) | (0.0080) | (0.0107) | (0.0132) | (0.0163) | (0.0127) | (0.0140) | (0.0124) | |
| D060nt | 0.0693 *** | 0.0698 *** | 0.0705 *** | 0.0698 *** | 0.0692 *** | 0.0691 *** | 0.0700 *** | 0.0923 *** | 0.0803 *** | 0.0970 *** | 0.0947 *** | 0.0962 *** | 0.0956 *** | 0.0954 *** | 0.0943 *** | 0.0956 *** | 0.1014 *** | 0.0988 *** |
| (0.0017) | (0.0167) | (0.0103) | (0.0159) | (0.0166) | (0.0175) | (0.0097) | (0.0191) | (0.0219) | (0.0057) | (0.0140) | (0.0131) | (0.0161) | (0.0157) | (0.0248) | (0.0129) | (0.0154) | (0.0292) | |
| F118nt | −0.0230 *** | −0.0226 *** | −0.0226 *** | −0.0230 *** | −0.0234 ** | −0.0230 *** | −0.0227 *** | −0.0092 | −0.0238 *** | −0.0171 *** | −0.0172 *** | −0.0164 *** | −0.0167 *** | −0.0171 *** | −0.0171 *** | −0.0167 *** | −0.0072 | −0.0174 ** |
| (0.0057) | (0.0046) | (0.0028) | (0.0046) | (0.0074) | (0.0042) | (0.0061) | (0.0066) | (0.0065) | (0.0031) | (0.0033) | (0.0016) | (0.0008) | (0.0039) | (0.0033) | (0.0050) | (0.0046) | (0.0061) | |
| F120nt | 0.0092 | 0.0090 | 0.0088 | 0.0090 | 0.0094 | 0.0109 | 0.0098 | 0.0145 * | 0.0097 | 0.0176 *** | 0.0171 *** | 0.0170 *** | 0.0172 * | 0.0168 ** | 0.0182 *** | 0.0172 ** | 0.0168 ** | 0.0173 *** |
| (0.0066) | (0.0048) | (0.0089) | (0.0134) | (0.0070) | (0.0071) | (0.0085) | (0.0070) | (0.0055) | (0.0031) | (0.0035) | (0.0047) | (0.0078) | (0.0052) | (0.0043) | (0.0064) | (0.0054) | (0.0047) | |
| F121nt | −0.0470 *** | −0.0467 *** | −0.0464 *** | −0.0466 *** | −0.0468 *** | −0.0467 *** | −0.0466 *** | −0.0352 *** | −0.0456 *** | −0.0487 *** | −0.0483 *** | −0.0482 *** | −0.0485 *** | −0.0482 *** | −0.0480 *** | −0.0478 *** | −0.0350 *** | −0.0476 *** |
| (0.0074) | (0.0047) | (0.0061) | (0.0084) | (0.0046) | (0.0097) | (0.0063) | (0.0060) | (0.0061) | (0.0052) | (0.0029) | (0.0038) | (0.0050) | (0.0045) | (0.0045) | (0.0061) | (0.0050) | (0.0048) | |
| _cons | −3.9166 *** | −3.9114 *** | −3.9337 *** | −3.9210 *** | −3.9085 *** | −3.9151 *** | −3.9003 *** | −4.1379 *** | −3.8667 *** | |||||||||
| (0.0562) | (0.0751) | (0.0831) | (0.0614) | (0.1029) | (0.1079) | (0.0721) | (0.1150) | (0.1223) | ||||||||||
| / | ||||||||||||||||||
| var(_cons[X001nt]) | 0.0000 | 0.0006 ** | ||||||||||||||||
| (0.0000) | (0.0002) | |||||||||||||||||
| var(_cons[X003nt]) | 0.0010 | 0.0005 | ||||||||||||||||
| (0.0024) | (0.0009) | |||||||||||||||||
| var(_cons[X007nt]) | 0.0012 *** | 0.0006 | ||||||||||||||||
| (0.0004) | (0.0004) | |||||||||||||||||
| var(_cons[X007bin]) | 0.0008 | 0.0002 | ||||||||||||||||
| (0.0006) | (0.0003) | |||||||||||||||||
| var(_cons[X011nt]) | 0.0009 | 0.0004 | ||||||||||||||||
| (0.0008) | (0.0002) | |||||||||||||||||
| var(_cons[X028nt]) | 0.0037 * | 0.0038 | ||||||||||||||||
| (0.0015) | (0.0020) | |||||||||||||||||
| var(_cons[X047nt]) | 0.0019 | 0.0014 ** | ||||||||||||||||
| (0.0015) | (0.0005) | |||||||||||||||||
| var(_cons[X048WVSnt]) | 0.3928 *** | 0.3348 *** | ||||||||||||||||
| (0.0458) | (0.0369) | |||||||||||||||||
| var(_cons[X049nt]) | 0.0172 | 0.0074 | ||||||||||||||||
| (0.0091) | (0.0049) | |||||||||||||||||
| N | 55,188 | 54,979 | 55,073 | 55,073 | 54,683 | 54,873 | 54,605 | 55,174 | 52,708.0000 | 55,188 | 54,979 | 55,073 | 55,073 | 54,683 | 54,873 | 54,605 | 55,174 | 52,708.0000 |
| AIC | 46,502.417 | 46,404.349 | 46,403.937 | 46,396.022 | 46,129.232 | 46,243.84 | 46,065.607 | 45,197.61 | 44,482.1291 | 108,731.986 | 108,418.235 | 108,541.445 | 108,535.959 | 107,745.234 | 108,124.374 | 107,675.088 | 106,348.426 | 103,955.9908 |
| BIC | 46,511.336 | 46,591.558 | 46,457.435 | 46,404.939 | 46,182.688 | 46,315.142 | 46,154.685 | 45,384.893 | 44,553.1093 | 108,740.905 | 108,623.273 | 108,594.944 | 108,553.791 | 107,789.781 | 108,195.676 | 107,764.166 | 106,553.546 | 104,026.9710 |
| Model | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) | (11) | (12) | (13) | (14) | (15) | (16) | (17) | (18) | (19) | (20) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Input/ Response | H010nt | A106Cnt | H010nt | C001nt | H010nt | C041nt | H010nt | D026_03nt | H010nt | D060nt | H010nt | E069_11nt | H010nt | E262Bnt | H010nt | F121nt | H010nt | H009nt | H010nt | H011nt |
| A106Cnt | 0.2635 *** | |||||||||||||||||||
| (0.0131) | ||||||||||||||||||||
| C001nt | 0.4728 *** | |||||||||||||||||||
| (0.0076) | ||||||||||||||||||||
| C041nt | 0.3198 *** | |||||||||||||||||||
| (0.0062) | ||||||||||||||||||||
| D026_03nt | 0.3561 *** | |||||||||||||||||||
| (0.0059) | ||||||||||||||||||||
| D060nt | 0.4486 *** | |||||||||||||||||||
| (0.0083) | ||||||||||||||||||||
| E069_11nt | 0.4178 *** | |||||||||||||||||||
| (0.0075) | ||||||||||||||||||||
| E262Bnt | −0.1727 *** | |||||||||||||||||||
| (0.0040) | ||||||||||||||||||||
| F121nt | −0.1301 *** | |||||||||||||||||||
| (0.0023) | ||||||||||||||||||||
| H009nt | 1.0775 *** | |||||||||||||||||||
| (0.0084) | ||||||||||||||||||||
| H011nt | 1.4765 *** | |||||||||||||||||||
| (0.0109) | ||||||||||||||||||||
| H010nt | 0.2011 *** | 0.4353 *** | 0.3792 *** | 0.4299 *** | 0.3610 *** | 0.3767 *** | −0.3104 *** | −0.3842 *** | 1.0664 *** | 1.4952 *** | ||||||||||
| (0.0097) | (0.0070) | (0.0066) | (0.0068) | (0.0071) | (0.0070) | (0.0068) | (0.0066) | (0.0084) | (0.0111) | |||||||||||
| N | 72,451 | 72,451 | 73,993 | 73,993 | 73,954 | 73,954 | 73,583 | 73,583 | 73,514 | 73,514 | 73,166 | 73,166 | 72,327 | 72,327 | 73,355 | 73,355 | 73,998 | 73,998 | 73,813 | 73,813 |
| Chi^2 | 404.2073 | 430.0434 | 3832.428 | 3911.895 | 2673.802 | 3262.856 | 3590.434 | 4040.7353 | 2926.924 | 2594.26 | 3078.888 | 2897.7012 | 1818.815 | 2099.86 | 3168.157 | 3397.855 | 16,602.02 | 16,019.41 | 18,228.82 | 18,004.89 |
| p | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| R^2 | 0.0023 | 0.0058 | 0.0207 | 0.0285 | 0.015 | 0.0163 | 0.0209 | 0.0202 | 0.0171 | 0.0169 | 0.0182 | 0.0173 | 0.0102 | 0.0121 | 0.0181 | 0.0121 | 0.1178 | 0.1127 | 0.1901 | 0.1936 |
| AIC | 192,332.9 | 74,666.17 | 192,524.6 | 145,055.7 | 193,522.1 | 213,564 | 191,461.5 | 221,397.92 | 192,014.8 | 174,870.9 | 190,848.2 | 193,132.85 | 190,358.2 | 183,273.8 | 191,512.1 | 307,453.7 | 173,488.4 | 177,413.1 | 158,760.7 | 155,388.6 |
| BIC | 192,369.6 | 74,693.74 | 192,561.5 | 145,083.4 | 193,558.9 | 213,610.1 | 191,498.3 | 221,443.96 | 192,051.6 | 174,907.7 | 190,885 | 193,169.65 | 190,394.9 | 183,319.8 | 191,549 | 307,545.7 | 173,525.2 | 177,450 | 158,797.5 | 155,425.5 |
| Model | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) |
|---|---|---|---|---|---|---|---|---|
| Input/Response | H010bin | C041bin | H010bin | C041bin | H010bin | D060bin | H010bin | D060bin |
| C041nt | 0.3776 *** | |||||||
| (0.0072) | ||||||||
| C041bin | 0.8160 *** | |||||||
| (0.0162) | ||||||||
| D060nt | 0.4316 *** | |||||||
| (0.0088) | ||||||||
| D060bin | 0.8426 *** | |||||||
| (0.0178) | ||||||||
| H010nt | 0.3721 *** | 0.4219 *** | ||||||
| (0.0071) | (0.0082) | |||||||
| H010bin | 0.8160 *** | 0.8426 *** | ||||||
| (0.0162) | (0.0178) | |||||||
| _cons | −1.5546 *** | −0.1084 *** | −1.0843 *** | 0.0191 * | −1.0408 *** | −1.7288 *** | −0.7986 *** | −1.5445 *** |
| (0.0207) | (0.0108) | (0.0130) | (0.0092) | (0.0124) | (0.0143) | (0.0091) | (0.0121) | |
| N | 73,954 | 73,954 | 73,954 | 73,954 | 73,514 | 73,514 | 73,514 | 73,514 |
| Chi^2 | 2725.804 | 2750.781 | 2523.5227 | 2523.5228 | 2380.0361 | 2676.8774 | 2232.7201 | 2232.7204 |
| p | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| R^2 | 0.0314 | 0.027 | 0.0273 | 0.026 | 0.0259 | 0.0343 | 0.0233 | 0.028 |
| AIC | 93,307.504 | 98,201.668 | 93,702.834 | 98,298.75 | 93,319.924 | 76,806.588 | 93,568.675 | 77,305.442 |
| BIC | 93,325.926 | 98,220.091 | 93,721.256 | 98,317.173 | 93,338.335 | 76,824.999 | 93,587.086 | 77,323.852 |
| Pearson Chi^2 GOF | 177.65 | 720.56 | 0.00 | 0.00 | 122.74 | 1.68 | 0.00 | 0.00 |
| p GOF | 0.0000 | 0.0000 | . | . | 0.0000 | 0.4313 | . | . |
| AUCROC | 0.6184 | 0.599 | 0.5963 | 0.5903 | 0.597 | 0.6248 | 0.5778 | 0.6003 |
| Model | (1) | (2) | (3) | (4) | (5) | (6) |
|---|---|---|---|---|---|---|
| Input/Response | H010bin | H010bin | H010bin | H010nt | H010nt | H010nt |
| A106Cnt | 0.0284 *** | 0.0363 *** | 0.0502 *** | 0.0715 *** | ||
| (0.0028) | (0.0029) | (0.0060) | (0.0064) | |||
| C001nt | 0.0240 *** | 0.0413 *** | 0.0505 *** | 0.0909 *** | ||
| (0.0019) | (0.0019) | (0.0039) | (0.0040) | |||
| C041nt | 0.0151 *** | 0.0352 *** | 0.0287 *** | 0.0772 *** | ||
| (0.0014) | (0.0015) | (0.0030) | (0.0033) | |||
| D026_03nt | 0.0158 *** | 0.0377 *** | 0.0345 *** | 0.0879 *** | ||
| (0.0014) | (0.0015) | (0.0030) | (0.0032) | |||
| D060nt | 0.0144 *** | 0.0272 *** | 0.0485 *** | 0.0800 *** | ||
| (0.0019) | (0.0019) | (0.0040) | (0.0042) | |||
| E069_11nt | 0.0207 *** | 0.0378 *** | 0.0623 *** | 0.1049 *** | ||
| (0.0015) | (0.0017) | (0.0033) | (0.0036) | |||
| E262Bnt | −0.0202 *** | −0.0265 *** | −0.0414 *** | −0.0558 *** | ||
| (0.0009) | (0.0009) | (0.0018) | (0.0019) | |||
| F121nt | −0.0079 *** | −0.0161 *** | −0.0204 *** | −0.0398 *** | ||
| (0.0005) | (0.0005) | (0.0011) | (0.0012) | |||
| H009nt | 0.1049 *** | 0.1743 *** | 0.2837 *** | 0.4557 *** | ||
| (0.0015) | (0.0013) | (0.0034) | (0.0031) | |||
| H011nt | 0.1782 *** | 0.2298 *** | 0.4444 *** | 0.5826 *** | ||
| (0.0017) | (0.0014) | (0.0039) | (0.0034) | |||
| _cons | −0.0704 *** | 0.1050 *** | −0.0924 *** | 0.0223 | 0.4659 *** | −0.0083 |
| (0.0063) | (0.0036) | (0.0060) | (0.0133) | (0.0080) | (0.0133) | |
| N | 67,377 | 69,962 | 70,974 | 67,377 | 69,962 | 70,974 |
| p | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| R^2 | 0.3875 | 0.3297 | 0.2468 | 0.4967 | 0.4134 | 0.3235 |
| RMSE | 0.3755 | 0.3923 | 0.4162 | 0.7598 | 0.8204 | 0.8814 |
| AIC | 59,215.6944 | 67,616.1367 | 77,007.7923 | 15,4207.1372 | 17,0845.1385 | 183,498.0811 |
| BIC | 59,315.9930 | 67,671.0710 | 77,062.8127 | 15,4307.4358 | 17,0900.0727 | 183,553.1015 |
| maxAbsVPMCC | 0.4164 | 0.4083 | 0.4139 | 0.4164 | 0.4083 | 0.4139 |
| OLS max.Accept.VIF | 1.6325 | 1.4918 | 1.3276 | 1.9867 | 1.7047 | 1.4783 |
| OLS max.Comput.VIF | 1.4165 | 1.2547 | 1.3054 | 1.4165 | 1.2547 | 1.3054 |
| Model | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) | (11) | (12) | (13) | (14) | (15) | (16) | (17) | (18) | (19) | (20) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Input/Response | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt |
| A106Cnt | 0.1899 *** | 0.1897 *** | 0.1882 *** | 0.1916 *** | 0.1911 *** | 0.1863 *** | 0.1892 *** | 0.1934 *** | 0.1879 *** | 0.1793 *** | 0.1000 *** | 0.1004 *** | 0.0987 *** | 0.1005 *** | 0.1003 *** | 0.1004 *** | 0.1003 *** | 0.1031 *** | 0.0984 *** | 0.0973 *** |
| (0.0193) | (0.0193) | (0.0193) | (0.0193) | (0.0193) | (0.0194) | (0.0194) | (0.0194) | (0.0194) | (0.0197) | (0.0151) | (0.0151) | (0.0151) | (0.0151) | (0.0151) | (0.0152) | (0.0152) | (0.0152) | (0.0152) | (0.0153) | |
| C001nt | 0.1528 *** | 0.1534 *** | 0.1517 *** | 0.1502 *** | 0.1505 *** | 0.1515 *** | 0.1441 *** | 0.1541 *** | 0.1507 *** | 0.1441 *** | 0.1143 *** | 0.1156 *** | 0.1142 *** | 0.1131 *** | 0.1132 *** | 0.1147 *** | 0.1097 *** | 0.1146 *** | 0.1125 *** | 0.1135 *** |
| (0.0131) | (0.0131) | (0.0132) | (0.0132) | (0.0132) | (0.0132) | (0.0132) | (0.0132) | (0.0132) | (0.0134) | (0.0098) | (0.0098) | (0.0098) | (0.0098) | (0.0098) | (0.0098) | (0.0099) | (0.0098) | (0.0099) | (0.0100) | |
| C041nt | 0.1021 *** | 0.1023 *** | 0.1004 *** | 0.1018 *** | 0.1017 *** | 0.1021 *** | 0.0940 *** | 0.1031 *** | 0.1040 *** | 0.0967 *** | 0.0605 *** | 0.0613 *** | 0.0597 *** | 0.0601 *** | 0.0601 *** | 0.0614 *** | 0.0559 *** | 0.0623 *** | 0.0619 *** | 0.0572 *** |
| (0.0107) | (0.0107) | (0.0107) | (0.0107) | (0.0107) | (0.0108) | (0.0108) | (0.0107) | (0.0108) | (0.0109) | (0.0080) | (0.0080) | (0.0080) | (0.0080) | (0.0080) | (0.0080) | (0.0080) | (0.0080) | (0.0080) | (0.0081) | |
| D026_03nt | 0.1086 *** | 0.1091 *** | 0.1076 *** | 0.1082 *** | 0.1082 *** | 0.1080 *** | 0.1068 *** | 0.1060 *** | 0.1074 *** | 0.1048 *** | 0.0888 *** | 0.0897 *** | 0.0883 *** | 0.0887 *** | 0.0888 *** | 0.0879 *** | 0.0883 *** | 0.0878 *** | 0.0878 *** | 0.0880 *** |
| (0.0102) | (0.0102) | (0.0102) | (0.0102) | (0.0102) | (0.0103) | (0.0102) | (0.0102) | (0.0102) | (0.0103) | (0.0077) | (0.0077) | (0.0077) | (0.0077) | (0.0077) | (0.0078) | (0.0077) | (0.0078) | (0.0078) | (0.0078) | |
| D060nt | 0.1077 *** | 0.1083 *** | 0.1066 *** | 0.1083 *** | 0.1082 *** | 0.1073 *** | 0.1015 *** | 0.1065 *** | 0.1065 *** | 0.1114 *** | 0.1258 *** | 0.1277 *** | 0.1239 *** | 0.1258 *** | 0.1257 *** | 0.1260 *** | 0.1214 *** | 0.1244 *** | 0.1255 *** | 0.1275 *** |
| (0.0134) | (0.0134) | (0.0134) | (0.0134) | (0.0134) | (0.0134) | (0.0134) | (0.0134) | (0.0134) | (0.0135) | (0.0102) | (0.0103) | (0.0103) | (0.0103) | (0.0103) | (0.0103) | (0.0103) | (0.0103) | (0.0103) | (0.0104) | |
| E069_11nt | 0.1546 *** | 0.1546 *** | 0.1563 *** | 0.1515 *** | 0.1520 *** | 0.1551 *** | 0.1524 *** | 0.1536 *** | 0.1542 *** | 0.1523 *** | 0.1639 *** | 0.1635 *** | 0.1645 *** | 0.1616 *** | 0.1619 *** | 0.1640 *** | 0.1628 *** | 0.1625 *** | 0.1626 *** | 0.1616 *** |
| (0.0111) | (0.0112) | (0.0112) | (0.0112) | (0.0112) | (0.0112) | (0.0112) | (0.0112) | (0.0112) | (0.0113) | (0.0084) | (0.0084) | (0.0084) | (0.0084) | (0.0084) | (0.0085) | (0.0084) | (0.0085) | (0.0085) | (0.0085) | |
| E262Bnt | −0.1319 *** | −0.1313 *** | −0.1390 *** | −0.1297 *** | −0.1305 *** | −0.1292 *** | −0.1140 *** | −0.1305 *** | −0.1320 *** | −0.1210 *** | −0.0944 *** | −0.0931 *** | −0.0992 *** | −0.0930 *** | −0.0935 *** | −0.0949 *** | −0.0836 *** | −0.0955 *** | −0.0963 *** | −0.0896 *** |
| (0.0062) | (0.0062) | (0.0065) | (0.0062) | (0.0062) | (0.0064) | (0.0067) | (0.0063) | (0.0064) | (0.0064) | (0.0046) | (0.0046) | (0.0048) | (0.0046) | (0.0046) | (0.0048) | (0.0049) | (0.0047) | (0.0047) | (0.0048) | |
| F121nt | −0.0571 *** | −0.0572 *** | −0.0559 *** | −0.0567 *** | −0.0565 *** | −0.0570 *** | −0.0557 *** | −0.0571 *** | −0.0569 *** | −0.0549 *** | −0.0515 *** | −0.0515 *** | −0.0508 *** | −0.0512 *** | −0.0511 *** | −0.0515 *** | −0.0501 *** | −0.0518 *** | −0.0513 *** | −0.0501 *** |
| (0.0038) | (0.0038) | (0.0038) | (0.0038) | (0.0038) | (0.0038) | (0.0038) | (0.0038) | (0.0038) | (0.0038) | (0.0028) | (0.0028) | (0.0028) | (0.0028) | (0.0028) | (0.0028) | (0.0028) | (0.0028) | (0.0028) | (0.0029) | |
| H009nt | 0.8030 *** | 0.8029 *** | 0.8018 *** | 0.8026 *** | 0.8027 *** | 0.8013 *** | 0.8030 *** | 0.8018 *** | 0.8021 *** | 0.7930 *** | 0.7881 *** | 0.7880 *** | 0.7885 *** | 0.7876 *** | 0.7876 *** | 0.7901 *** | 0.7888 *** | 0.7873 *** | 0.7892 *** | 0.7881 *** |
| (0.0118) | (0.0118) | (0.0118) | (0.0118) | (0.0118) | (0.0119) | (0.0118) | (0.0118) | (0.0119) | (0.0119) | (0.0095) | (0.0095) | (0.0095) | (0.0095) | (0.0095) | (0.0096) | (0.0095) | (0.0096) | (0.0096) | (0.0097) | |
| H011nt | 1.0250 *** | 1.0247 *** | 1.0234 *** | 1.0244 *** | 1.0244 *** | 1.0204 *** | 1.0239 *** | 1.0234 *** | 1.0226 *** | 1.0147 *** | 1.1635 *** | 1.1637 *** | 1.1610 *** | 1.1624 *** | 1.1623 *** | 1.1607 *** | 1.1622 *** | 1.1622 *** | 1.1608 *** | 1.1480 *** |
| (0.0113) | (0.0113) | (0.0114) | (0.0114) | (0.0114) | (0.0114) | (0.0114) | (0.0114) | (0.0114) | (0.0115) | (0.0120) | (0.0120) | (0.0120) | (0.0120) | (0.0120) | (0.0121) | (0.0120) | (0.0121) | (0.0121) | (0.0121) | |
| X001nt | 0.0225 | 0.0488 ** | ||||||||||||||||||
| (0.0211) | (0.0153) | |||||||||||||||||||
| X003nt | −0.0025 *** | −0.0018 *** | ||||||||||||||||||
| (0.0007) | (0.0005) | |||||||||||||||||||
| X007nt | 0.0193 *** | 0.0115 ** | ||||||||||||||||||
| (0.0050) | (0.0036) | |||||||||||||||||||
| X007bin | 0.0831 *** | 0.0483 ** | ||||||||||||||||||
| (0.0223) | (0.0160) | |||||||||||||||||||
| X011nt | 0.0126 | −0.0019 | ||||||||||||||||||
| (0.0075) | (0.0056) | |||||||||||||||||||
| X025A_01nt | −0.0450 *** | −0.0276 *** | ||||||||||||||||||
| (0.0059) | (0.0043) | |||||||||||||||||||
| X028nt | −0.0074 | 0.0082 * | ||||||||||||||||||
| (0.0052) | (0.0038) | |||||||||||||||||||
| X047nt | −0.0063 | 0.0004 | ||||||||||||||||||
| (0.0053) | (0.0040) | |||||||||||||||||||
| X049nt | −0.0479 *** | −0.0204 *** | ||||||||||||||||||
| (0.0045) | (0.0033) | |||||||||||||||||||
| _cons | −3.8106 *** | −3.8479 *** | −3.6797 *** | −3.8749 *** | −3.8628 *** | −3.8262 *** | −3.6551 *** | −3.7709 *** | −3.7733 *** | −3.5200 *** | ||||||||||
| (0.0533) | (0.0648) | (0.0627) | (0.0561) | (0.0553) | (0.0553) | (0.0566) | (0.0581) | (0.0587) | (0.0591) | |||||||||||
| N | 67,377 | 67,346 | 67,111 | 67,166 | 67,166 | 66,717 | 66,941 | 66,735 | 66,374 | 64,646 | 67,377 | 67,346 | 67,111 | 67,166 | 67,166 | 66,717 | 66,941 | 66,735 | 66,374 | 64,646 |
| R^2 | 0.3499 | 0.3499 | 0.3500 | 0.3502 | 0.3502 | 0.3492 | 0.3505 | 0.3495 | 0.3495 | 0.3516 | 0.2601 | 0.2602 | 0.2601 | 0.2600 | 0.2600 | 0.2600 | 0.2603 | 0.2598 | 0.2599 | 0.2603 |
| AIC | 57,207.6288 | 57,186.9382 | 57,012.9242 | 57,005.7674 | 57,006.8554 | 56,694.9987 | 56,785.6819 | 56,673.5036 | 56,428.0744 | 54,946.7610 | 132,726.0600 | 132,652.6488 | 132,238.9031 | 132,328.9613 | 132,330.2019 | 131,434.8931 | 131,825.2968 | 131,498.0829 | 130,856.8815 | 127,518.0001 |
| BIC | 57,307.9274 | 57,296.3493 | 57,122.2935 | 57,115.1464 | 57,116.2345 | 56,804.2972 | 56,895.0207 | 56,782.8054 | 56,537.3111 | 55,055.6811 | 132,844.5948 | 132,780.2951 | 132,366.5005 | 132,456.5702 | 132,457.8108 | 131,562.4081 | 131,952.8588 | 131,625.6017 | 130,984.3244 | 127,645.0736 |
| maxAbsVPMCC | 0.4164 | 0.4163 | 0.4166 | 0.4169 | 0.4169 | 0.4178 | 0.4189 | 0.4163 | 0.4159 | 0.4186 | 0.4164 | 0.4163 | 0.4166 | 0.4169 | 0.4169 | 0.4178 | 0.4189 | 0.4163 | 0.4159 | 0.4186 |
| Pearson Chi^2 GOF | 49,072.86 | 54,175.52 | 66,145.49 | 56,518.63 | 53,719.81 | 58,831.49 | 59,859.76 | 59,604.95 | 60,555.55 | 58,717.32 | ||||||||||
| p GOF | 0.0000 | 0.0000 | 0.1113 | 0.0000 | 0.0000 | 0.0001 | 0.0005 | 0.0000 | 0.0010 | 0.0001 | ||||||||||
| AUCROC | 0.8743 | 0.8743 | 0.8744 | 0.8745 | 0.8745 | 0.8741 | 0.8746 | 0.8742 | 0.8742 | 0.8750 |
| Model | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) | (11) | (12) | (13) | (14) | (15) | (16) | (17) | (18) | (19) | (20) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Input/Response | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010bin | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt | H010nt |
| C041nt | 0.1925 *** | 0.1918 *** | 0.1919 *** | 0.1920 *** | 0.1921 *** | 0.1868 *** | 0.1655 *** | 0.1917 *** | 0.1914 *** | 0.1763 *** | 0.1569 *** | 0.1567 *** | 0.1565 *** | 0.1564 *** | 0.1566 *** | 0.1529 *** | 0.1365 *** | 0.1576 *** | 0.1580 *** | 0.1456 *** |
| (0.0090) | (0.0090) | (0.0090) | (0.0090) | (0.0090) | (0.0091) | (0.0091) | (0.0090) | (0.0091) | (0.0092) | (0.0074) | (0.0074) | (0.0074) | (0.0074) | (0.0074) | (0.0074) | (0.0075) | (0.0074) | (0.0075) | (0.0076) | |
| D026_03nt | 0.2099 *** | 0.2093 *** | 0.2100 *** | 0.2068 *** | 0.2073 *** | 0.2021 *** | 0.1959 *** | 0.2070 *** | 0.2091 *** | 0.2031 *** | 0.1920 *** | 0.1919 *** | 0.1923 *** | 0.1900 *** | 0.1905 *** | 0.1858 *** | 0.1814 *** | 0.1905 *** | 0.1898 *** | 0.1877 *** |
| (0.0085) | (0.0085) | (0.0085) | (0.0085) | (0.0085) | (0.0086) | (0.0085) | (0.0085) | (0.0086) | (0.0087) | (0.0071) | (0.0071) | (0.0071) | (0.0071) | (0.0071) | (0.0072) | (0.0072) | (0.0072) | (0.0072) | (0.0073) | |
| E069_11nt | 0.2221 *** | 0.2227 *** | 0.2232 *** | 0.2165 *** | 0.2176 *** | 0.2231 *** | 0.2144 *** | 0.2235 *** | 0.2212 *** | 0.2210 *** | 0.2328 *** | 0.2331 *** | 0.2327 *** | 0.2286 *** | 0.2293 *** | 0.2336 *** | 0.2277 *** | 0.2334 *** | 0.2308 *** | 0.2316 *** |
| (0.0095) | (0.0095) | (0.0096) | (0.0096) | (0.0096) | (0.0096) | (0.0096) | (0.0096) | (0.0096) | (0.0098) | (0.0080) | (0.0080) | (0.0080) | (0.0081) | (0.0081) | (0.0081) | (0.0081) | (0.0081) | (0.0081) | (0.0082) | |
| F121nt | −0.0907 *** | −0.0909 *** | −0.0905 *** | −0.0895 *** | −0.0893 *** | −0.0877 *** | −0.0835 *** | −0.0901 *** | −0.0875 *** | −0.0846 *** | −0.0882 *** | −0.0883 *** | −0.0880 *** | −0.0871 *** | −0.0870 *** | −0.0858 *** | −0.0817 *** | −0.0882 *** | −0.0854 *** | −0.0828 *** |
| (0.0032) | (0.0032) | (0.0032) | (0.0032) | (0.0032) | (0.0032) | (0.0032) | (0.0032) | (0.0032) | (0.0033) | (0.0027) | (0.0027) | (0.0027) | (0.0027) | (0.0027) | (0.0027) | (0.0027) | (0.0027) | (0.0027) | (0.0028) | |
| H009nt | 1.0048 *** | 1.0048 *** | 1.0034 *** | 1.0036 *** | 1.0038 *** | 1.0010 *** | 1.0038 *** | 1.0032 *** | 1.0050 *** | 0.9967 *** | 1.0583 *** | 1.0583 *** | 1.0579 *** | 1.0567 *** | 1.0569 *** | 1.0573 *** | 1.0592 *** | 1.0574 *** | 1.0645 *** | 1.0612 *** |
| (0.0098) | (0.0098) | (0.0098) | (0.0098) | (0.0098) | (0.0098) | (0.0098) | (0.0098) | (0.0099) | (0.0100) | (0.0087) | (0.0087) | (0.0088) | (0.0088) | (0.0088) | (0.0088) | (0.0088) | (0.0088) | (0.0089) | (0.0090) | |
| X001nt | −0.0295 | −0.0082 | ||||||||||||||||||
| (0.0183) | (0.0144) | |||||||||||||||||||
| X003nt | −0.0005 | −0.0007 | ||||||||||||||||||
| (0.0006) | (0.0004) | |||||||||||||||||||
| X007nt | 0.0349 *** | 0.0247 *** | ||||||||||||||||||
| (0.0043) | (0.0034) | |||||||||||||||||||
| X007bin | 0.1448 *** | 0.1012 *** | ||||||||||||||||||
| (0.0194) | (0.0153) | |||||||||||||||||||
| X011nt | 0.0719 *** | 0.0525 *** | ||||||||||||||||||
| (0.0062) | (0.0051) | |||||||||||||||||||
| X025A_01nt | −0.0933 *** | −0.0709 *** | ||||||||||||||||||
| (0.0048) | (0.0038) | |||||||||||||||||||
| X028nt | −0.0209 *** | −0.0039 | ||||||||||||||||||
| (0.0045) | (0.0036) | |||||||||||||||||||
| X047nt | −0.0280 *** | −0.0195 *** | ||||||||||||||||||
| (0.0046) | (0.0037) | |||||||||||||||||||
| X049nt | −0.0649 *** | −0.0413 *** | ||||||||||||||||||
| (0.0039) | (0.0032) | |||||||||||||||||||
| _cons | −3.3930 *** | −3.3457 *** | −3.3678 *** | −3.4998 *** | −3.4795 *** | −3.4893 *** | −2.9883 *** | −3.2861 *** | −3.2555 *** | −2.9777 *** | ||||||||||
| (0.0416) | (0.0509) | (0.0476) | (0.0437) | (0.0432) | (0.0426) | (0.0460) | (0.0470) | (0.0478) | (0.0480) | |||||||||||
| N | 70,974 | 70,940 | 70,692 | 70,742 | 70,742 | 70,277 | 70,505 | 70,270 | 68,850 | 67,172 | 70,974 | 70,940 | 70,692 | 70,742 | 70,742 | 70,277 | 70,505 | 70,270 | 68,850 | 67,172 |
| R^2 | 0.2161 | 0.2162 | 0.2160 | 0.2169 | 0.2168 | 0.2179 | 0.2204 | 0.2160 | 0.2166 | 0.2220 | 0.1525 | 0.1525 | 0.1525 | 0.1527 | 0.1526 | 0.1535 | 0.1544 | 0.1524 | 0.1532 | 0.1558 |
| AIC | 72,631.1723 | 72,587.9587 | 72,391.7277 | 72,325.7279 | 72,335.0446 | 71,738.3853 | 71,755.0539 | 71,881.2558 | 70,645.7933 | 68,640.2891 | 160,060.0135 | 159,971.7406 | 159,443.7541 | 159,498.0080 | 159,506.9062 | 158,290.3255 | 158,630.8924 | 158,466.4417 | 155,509.3879 | 151,404.6398 |
| BIC | 72,686.1927 | 72,652.1458 | 72,455.8903 | 72,389.8954 | 72,399.2122 | 71,802.5067 | 71,819.1979 | 71,945.3765 | 70,709.7711 | 68,704.0942 | 160,133.3741 | 160,054.2670 | 159,526.2489 | 159,580.5092 | 159,589.4073 | 158,372.7673 | 158,713.3633 | 158,548.8826 | 155,591.6451 | 151,486.6749 |
| maxAbsVPMCC | 0.4139 | 0.4138 | 0.4142 | 0.4144 | 0.4144 | 0.4153 | 0.4141 | 0.4140 | 0.4158 | 0.4182 | 0.4139 | 0.4138 | 0.4142 | 0.4144 | 0.4144 | 0.4153 | 0.4141 | 0.4140 | 0.4158 | 0.4182 |
| Pearson chi^2 GOF | 4834.96 | 8010.25 | 47,228.82 | 13,499.05 | 8007.53 | 15,896.96 | 19,233.09 | 17,955.00 | 20,540.01 | 18,830.05 | ||||||||||
| p GOF | 0.0000 | 0.0000 | 0.1302 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||||||||||
| AUCROC | 0.8032 | 0.8032 | 0.8031 | 0.8036 | 0.8036 | 0.8042 | 0.8057 | 0.8032 | 0.8034 | 0.8067 |

References
- Mishra, S.; Alowaidi, M.A.; Sharma, S.K. Impact of security standards and policies on the credibility of e-government. J. Amb. Intellig. Hum. Comput. 2021, 1–12. [Google Scholar] [CrossRef]
- Gupta, P.P. A New Era in Computation. Comput. J. 1995, 38, 87. [Google Scholar] [CrossRef] [Green Version]
- Atzeni, M. Alternatives to State-Socialism in Britain. Other Worlds of Labour in the Twentieth Century. Ed. by Peter Ackers and Alastair J. Reid. [Palgrave Studies in the History of Social Movements.] Palgrave Macmillan, London2016. xvii, 354 pp.€ 96.29.(E-book:€ 74.96.). Int. Rev. Soc. Hist. 2019, 64, 153–156. [Google Scholar] [CrossRef]
- Alqodsi, E.M. The right to pre-contractual information in e-commerce consumer contracts: UAE law and comparative per-spectives. J. Leg. Ethical Regul. Issues 2021, 24, 1–16. [Google Scholar]
- Udo, G.J. Privacy and security concerns as major barriers for e-commerce: A survey study. Inf. Manag. Comput. Sec. 2001, 9, 165–174. [Google Scholar] [CrossRef] [Green Version]
- MacFarlane, K.; Holmes, V. Agent-Mediated Information Exchange: Child Safety Online. In Proceedings of the International Conference on Management and Service Science, Beijing, China, 20–22 September 2009; pp. 1–5. [Google Scholar] [CrossRef]
- Boerman, S.C.; Kruikemeier, S.; Zuiderveen Borgesius, F.J. Exploring Motivations for Online Privacy Protection Behavior: Insights from Panel Data. Commun. Res. 2018, 48, 953–977. [Google Scholar] [CrossRef] [Green Version]
- Milne, G.R.; Rohm, A.J.; Bahl, S. Consumers’ Protection of Online Privacy and Identity. J. Consum. Aff. 2004, 38, 217–232. [Google Scholar] [CrossRef]
- Kostka, G.; Steinacker, L.; Meckel, M. Between security and convenience: Facial recognition technology in the eyes of citizens in China, Germany, the United Kingdom, and the United States. Public Underst. Sci. 2021, 30, 671–690. [Google Scholar] [CrossRef]
- Leas, E.C.; Moy, N.; McMenamin, S.B.; Shi, Y.; Benmarhnia, T.; Stone, M.D.; Trinidad, D.R.; White, M. Availability and Pro-motion of Cannabidiol (CBD) Products in Online Vape Shops. Int. J. Environ. Res. Public Health 2021, 18, 6719. [Google Scholar] [CrossRef]
- Xiao, Y.; Guan, J.; Xu, L. Wildlife Cybercrime in China. E-Commerce and Social Media Monitoring in 2016. Available online: https://www.traffic.org/site/assets/files/2108/briefing-online_wildlife_trade-2016.pdf (accessed on 27 November 2021).
- Lin, X.; Huang, X.; Liu, S.; Li, Y.; Luo, H.; Yu, S. Social Welfare Analysis under Different Levels of Consumers’ Privacy Regulation. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 2943–2964. [Google Scholar] [CrossRef]
- Thompson, N.; McGill, T.; Bunn, A.; Alexander, R. Cultural factors, and the role of privacy concerns in acceptance of gov-ernment surveillance. J. Assoc. Inf. Sci. Technol. 2020, 71, 1129–1142. [Google Scholar] [CrossRef]
- Bates, A. Learning “in the hive”: Social character and student wellbeing in the age of psychometric data. Crit. Stud. Educ. 2021, 1–16. [Google Scholar] [CrossRef]
- Westerlund, M.; Isabelle, D.A.; Leminen, S. The Acceptance of Digital Surveillance in an Age of Big Data. Technol. Innov. Manag. Rev. 2021, 11, 32–44. [Google Scholar] [CrossRef]
- Moucheraud, C.; Guo, H.; Macinko, J. Trust in Governments and Health Workers Low Globally, Influencing Attitudes toward Health Information, Vaccines: Study examines changes in public trust in governments, health workers, and attitudes toward vaccines. Health Aff. 2021, 40, 1215–1224. [Google Scholar] [CrossRef]
- Van Heek, J.; Arning, K.; Ziefle, M. The Surveillance Society: Which Factors Form Public Acceptance of Surveillance Tech-nologies? In Smart Cities, Green Technologies, and Intelligent Transport Systems; Springer: Cham, Switzerland, 2017; pp. 170–191. [Google Scholar] [CrossRef]
- Keddell, E. “Make Them Dance”: Shoshana Zuboff’s Surveillance Capitalism, Behavior Modification and Fraser’s “Abnormal Justice”. J. Technol. Hum. Serv. 2021, 39, 426–431. [Google Scholar] [CrossRef]
- Winter, J.S. Introduction to the Special Issue: Digital Inequalities and Discrimination in the Big Data Era. J. Inf. Policy 2018, 8, 1–4. [Google Scholar] [CrossRef]
- Fox, G.; Clohessy, T.; van der Werff, L.; Rosati, P.; Lynn, T. Exploring the competing influences of privacy concerns and positive beliefs on citizen acceptance of contact tracing mobile applications. Comput. Hum. Behav. 2021, 121, 106806. [Google Scholar] [CrossRef]
- Karabulut, E.M.; Ibrikci, T. Analysis of Cardiotocogram Data for Fetal Distress Determination by Decision Tree-Based Adaptive Boosting Approach. J. Comput. Commun. 2014, 2, 32–37. [Google Scholar] [CrossRef] [Green Version]
- Williams, G. Data Mining with Rattle and R: The Art of Excavating Data for Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2011; pp. 269–291. [Google Scholar]
- Chen, Y.-K.; Li, W.; Tong, X. Parallelization of AdaBoost algorithm on multi-core processors. In Proceedings of the 2008 IEEE Workshop on Signal Processing Systems 2008, Washington, DC, USA, 8–10 October 2008; pp. 275–280. [Google Scholar] [CrossRef]
- Ahrens, A.; Hansen, C.B.; Schaffer, M.E. lassopack: Model selection and prediction with regularized regression in Stata. Stata J. 2020, 20, 176–235. [Google Scholar] [CrossRef] [Green Version]
- DeBruine, L.M.; Barr, D.J. Understanding Mixed-Effects Models Through Data Simulation. Adv. Meth. Pract. Psych. 2021, 4, 1–15. [Google Scholar] [CrossRef]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Picard, R.R.; Cook, R.D. Cross-validation of Regression Models. J. Am. Stat. Assoc. 1984, 79, 575–583. [Google Scholar] [CrossRef]
- Sheridan, R.P. Time-split cross-validation as a method for estimating the goodness of prospective prediction. J. Chem. Inf. Model. 2013, 53, 783–790. [Google Scholar] [CrossRef]
- Irandoukht, A. Optimum ridge regression parameter using R-squared of prediction as a criterion for regression analysis. J. Stat. Theory Appl. 2021, 20, 242. [Google Scholar] [CrossRef]
- Lai, K. Using Information Criteria Under Missing Data: Full Information Maximum Likelihood Versus Two-Stage Estimation. Struct. Equ. Modeling A Multidiscip. J. 2021, 28, 278–291. [Google Scholar] [CrossRef]
- Zlotnik, A.; Abraira, V. A General-purpose Nomogram Generator for Predictive Logistic Regression Models. Stata J. 2015, 15, 537–546. [Google Scholar] [CrossRef] [Green Version]
- Vatcheva, K.P.; Lee, M.; McCormick, J.B.; Rahbar, M.H. Multicollinearity in Regression Analyses Conducted in Epidemiologic Studies. Epidemiology 2016, 6, 227. [Google Scholar] [CrossRef] [Green Version]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation Coefficients. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Mukaka, M.M. Statistics corner: A guide to appropriate use of correlation coefficient in medical research. Malawi Med. J. 2012, 24, 69–71. [Google Scholar]
- Yao, Z.; Holmbom, A.H.; Eklund, T.; Back, B. Combining Unsupervised and Supervised Data Mining Techniques for Conducting Customer Portfolio Analysis. In Advances in Data Mining. Applications and Theoretical Aspects; Perner, P., Ed.; ICDM 2010; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6171. [Google Scholar] [CrossRef]
- Martín-Valdivia, M.T.; Martínez-Cámara, E.; Perea-Ortega, J.M.; Ureña-López, L.A. Sentiment polarity detection in Spanish reviews combining supervised and unsupervised approaches. Expert Syst. Appl. 2013, 40, 3934–3942. [Google Scholar] [CrossRef]
- El Aissaoui, O.; El Alami El Madani, Y.; Oughdir, L.; El Allioui, Y. Combining supervised and unsupervised machine learning algorithms to predict the learners’ learning styles. Procedia Comput. Sci. 2019, 148, 87–96. [Google Scholar] [CrossRef]
- Feldmesser, E.; Olender, T.; Khen, M.; Yanai, I.; Ophir, R.; Lancet, R. Widespread ectopic expression of olfactory receptor genes. BMC Gen. 2006, 7, 121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boley, M.; Mampaey, M.; Kang, B.; Tokmakov, P.; Wrobel, S. One click mining: Interactive local pattern discovery through implicit preference and performance learning. In Proceedings of the ACM SIGKDD Workshop on Interactive Data Exploration and Analytics (IDEA ’13), Association for Computing Machinery, New York, NY, USA, 11 August 2013; pp. 27–35. [Google Scholar] [CrossRef]
- Kopf, O.; Homocianu, D. The Business Intelligence Based Business Process Management Challenge. Inform. Econ. J. 2016, 20, 7–19. [Google Scholar] [CrossRef]
- Areal, F.J. The Role of Personality Traits, Cooperative Behaviour and Trust in Governments on the Brexit Referendum Out-come. Soc. Sci. 2021, 10, 309. [Google Scholar] [CrossRef]
- Booker, J.A.; Graci, M.E. Between- and within-person differences in communion given gender and personality. Pers. Indiv. Diff. 2021, 183, 111117. [Google Scholar] [CrossRef]
- Nakhaie, R.; de Lint, W. Trust and support for surveillance policies in Canadian and American opinion. Int. Crim. Justice Rev. 2013, 23, 149–169. [Google Scholar] [CrossRef]
- Zweig, D.; Webster, J. Personality as a moderator of monitoring acceptance. Comput. Hum. Behav. 2003, 19, 479–493. [Google Scholar] [CrossRef]
- Distler, V.; Lallemand, C.; Koenig, V. How acceptable is this? how user experience factors can broaden our understanding of the acceptance of privacy trade-offs. Comput. Hum. Behav. 2020, 106, 106227. [Google Scholar] [CrossRef]
- Axinn, W.G.; Thornton, A. The Relationship between Cohabitation and Divorce: Selectivity or Causal Influence? Demography 1992, 29, 357. [Google Scholar] [CrossRef]
- Gronlund, K.; Setala, M. Political trust, satisfaction, and voter turnout. Comp. Eur. Politics 2007, 5, 400–422. [Google Scholar] [CrossRef]
- Zhao, D.; Hu, W. Determinants of public Trust in Government: Empirical evidence from urban China. Int. Rev. Admin. Sci. 2017, 83, 358–377. [Google Scholar] [CrossRef]
- Xie, Y.; Tong, Y.; Yang, F. Does ideological education in China Suppress Trust in Religion and Foster Trust in Government? Religions 2017, 8, 94. [Google Scholar] [CrossRef] [Green Version]
- Macoubrie, J. Nanotechnology: Public concerns, reasoning and trust in government. Public Underst. Sci. 2006, 15, 221–241. [Google Scholar] [CrossRef]
- Alesina, A.; Di Tella, R.; MacCulloch, R. Inequality and happiness: Are Europeans and Americans different? J. Public Econ. 2004, 88, 2009–2042. [Google Scholar] [CrossRef] [Green Version]
- Bradley, J.M.; Hojjat, M. A model of resilience and marital satisfaction. J. Soc. Psychol. 2016, 157, 588–601. [Google Scholar] [CrossRef] [PubMed]
- Munafò, M.R.; Smith, G.D. Robust research needs many lines of evidence. Nature 2018, 553, 399–401. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baker, M. 1500 Scientists Lift the Lid on Reproducibility. Nature 2016, 533, 452–454. [Google Scholar] [CrossRef] [Green Version]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Homocianu, D. A Multi-Technique Approach to Exploring the Main Influences of Information Exchange Monitoring Tolerance. Electronics 2022, 11, 528. https://doi.org/10.3390/electronics11040528
Homocianu D. A Multi-Technique Approach to Exploring the Main Influences of Information Exchange Monitoring Tolerance. Electronics. 2022; 11(4):528. https://doi.org/10.3390/electronics11040528
Chicago/Turabian StyleHomocianu, Daniel. 2022. "A Multi-Technique Approach to Exploring the Main Influences of Information Exchange Monitoring Tolerance" Electronics 11, no. 4: 528. https://doi.org/10.3390/electronics11040528
APA StyleHomocianu, D. (2022). A Multi-Technique Approach to Exploring the Main Influences of Information Exchange Monitoring Tolerance. Electronics, 11(4), 528. https://doi.org/10.3390/electronics11040528