1. Introduction
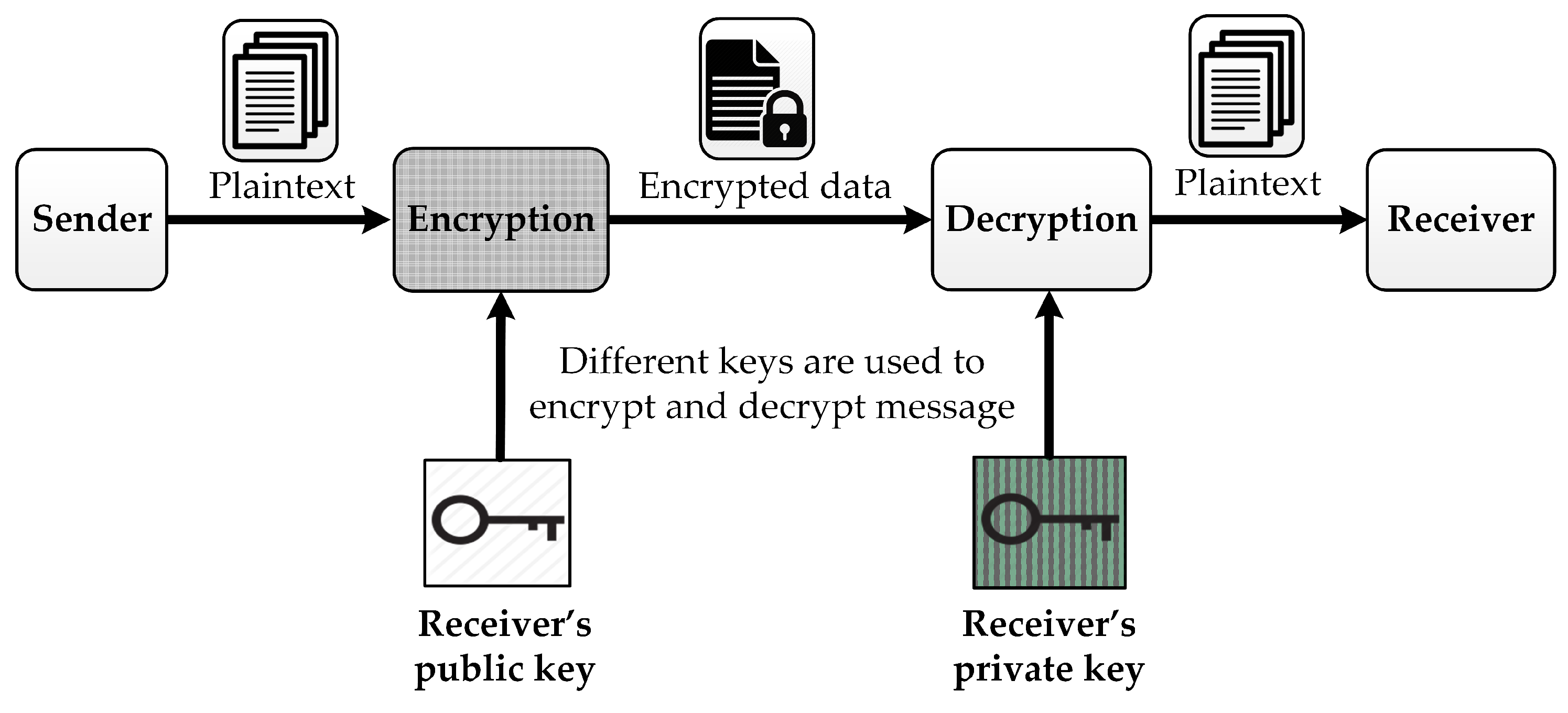
Cryptography is broadly categorized into symmetric key cryptography and asymmetric key cryptography (or public key cryptography). In symmetric key cryptography, a single key is used between a sender and a receiver to enable secure communication, and the key is kept confidential from anyone else. Public key cryptography utilizes a public key in encryption and a private key in decryption, as demonstrated in
Figure 1. While the private key is kept secret to use in the decryption operation, the public key is published to everyone and used in the encryption operation. The encryption process generates the encrypted message (ciphertext) from the input message (plaintext) and the public key. The ciphertext can be decrypted using the private key. One of the most well-known asymmetric cryptographic algorithms was developed by Rivest–Shamir–Adleman (RSA) [
1,
2,
3,
4]. The RSA algorithm is the earliest public key cryptographic algorithm developed and published for commercial use. It is widespread and has been integrated in both Netscape Web and Microsoft browsers to provide security solutions for e-commerce applications. The patented RSA encryption algorithm has, in fact, become a standard for public-use encryption applications. Elliptic curve cryptography (ECC) [
5,
6,
7,
8,
9] is another widely used public key cryptography algorithm. The ECC encryption and decryption operations rely on an elliptic curve and arithmetic operations over a Galois field, either GF(
p) or GF(
). In the key-generation operation, the recipient selects a base point
on the elliptic curve and a random number as its private key
to calculate ECC point multiplication
. The public key is stored publicly so that the sender can use the receiver’s public key to encrypt the input data before sending the data over the network. At the receiver side, the data sent by the transmitter can be retrieved using ECC point multiplication operations and the private key of the receiver.
With the rapid growth of quantum computers, the existing public key schemes can be basically broken in the next few years. In 2016, National Institute of Standard and Technology (NIST) launched the post-quantum cryptography (PQC) project to discover PQC candidates for future standardization [
10]. The goal of the PQC project is to develop cryptographic systems that are secure against both classical and quantum computers, and that can be compatible with existing communications protocols and networks. Round 3 finalists include (1) four candidates for public-key encryption (PKE) and key-establishment (KEM) algorithms (Classic McEliece, CRYSTALS-Kyber, NTRU, Saber), (2) three candidates for digital signature algorithms (CRYSTALS-Dilithium, Falcon, Rainbow), and (3) alternate candidates. Among the PKE and KEM algorithms in the round 3 finalists, the CRYSTALS-Kyber algorithm is a promising candidate.
Learning with errors (LWE) problems are lattice-based problems attracting a lot of attention from research communities in recent years. In LWE problems, given a finite field
with modulus
q, two matrices
A and
p, and a small noise
e, it is a challenge to find the secret key
s from the equation
. Many proposals using standard LWE [
11] and the structured ring-LWE [
12,
13,
14,
15,
16,
17] have been conducted. The typical advantage of standard LWE is easy scalability. However, it introduces a significant decrease in efficiency. The structured LWE offers better efficiency in terms of speed and key and ciphertext sizes. Nevertheless, there is a tradeoff between efficiency and security because of the additional structure [
18]. Module-LWE can balance these two extremes. In [
18], the authors of the CRYSTALS-Kyber algorithm mentioned that Kyber helps to reduce structure and offers much better scalability compared to ring-LWE. The performance of Kyber is very similar to the ring-LWE-based schemes, using 256 bits to encrypt messages [
19].
The implementations of CRYSTALS-Kyber include software design [
18,
20], software and hardware codesign [
20], and pure hardware design [
20,
21,
22,
23,
24]. In [
18], the authors showed the implementation results on Intel Haswell CPUs and ARM Cortex-M4 CPUs. The authors in [
20] described the software implementation of post-quantum cryptography schemes including CRYSTALS-Kyber using C language on ARM Cotex-A53. In order to accelerate the operations of Kyber, the authors in [
25] introduced massively parallel algorithms implemented on a GPU. The authors in [
20] also presented a software and hardware codesign of Kyber. The software and hardware codesign offers a remarkable improvement in encapsulation time and decapsulation time compared with pure software implementation results. The pure hardware implementations in [
20,
21,
22,
23,
24] introduce different approaches, with a focus on reducing hardware complexity and speeding up the processing time.
In this paper, we summarize the CRYSTALS-Kyber public-key encryption and key-establishment algorithms. We then present an analysis of the state-of-the-art implementations of CRYSTALS-Kyber in pure software, software and hardware codesign, and pure hardware. From the existing implementation results, we recommend the most suitable Kyber hardware architecture for various systems which have different requirements of hardware resources and latency.
The rest of this paper is structured as follows.
Section 2 gives background information about CRYSTALS-Kyber.
Section 3 presents an analysis of the implementation of the state-of-the-art designs. We discuss some potential solutions to improve the existing works in
Section 4. Finally, conclusions are drawn in
Section 5.
2. Background
In this section, we introduce CRYSTALS-Kyber, an MLWE-based public-key encryption and key-establishment algorithms that entered round 3 of the PQC standardization. Kyber has first been introduced in [
26], which includes three parameter sets, as reported in
Table 1, corresponding to three security levels of NIST. Polynomials are of the same degree
, and the polynomial coefficients are members of the prime field
, where
q = 3329 for all security levels. However, for each security level, different numbers of polynomials are required. These polynomials are considered as a vector whose size is specified by a parameter
k. The values of
k are 2, 3, and 4, corresponding to the security levels 1, 3, and 5, respectively. The remaining parameters
,
,
, and
are chosen to balance between security, ciphertext size, and failure probability. A detailed explanation of parameter selection can be found in [
18]. Centered binomial distribution (CBD) is used to generate secret noise polynomials. In this paper, the same notation presented in [
18] is used. For example, regular font letters represent elements in
R or
, bold lower-case letters denote vectors with coefficients in
R or
, bold upper-case letters are matrices. For bytes and byte arrays,
is the set of byte arrays of length
k, and
is the concatenation of two byte arrays
a and
b. More details about notation can be found in [
18].
2.1. Public-Key Encryption Algorithm
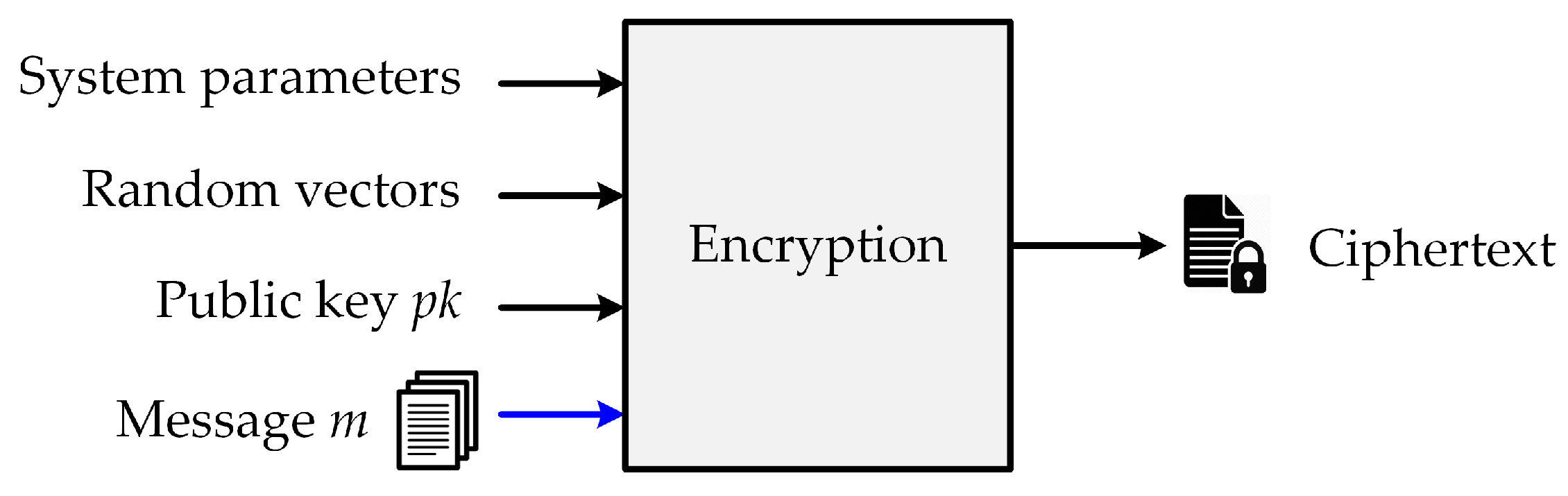
Operations in the PKE algorithm includes key generation, encryption, and decryption. The key-generation function generates a public key
and a private key
, which are then used in encryption and decryption operations, respectively. Particularly, the public key participates in the encryption process to generate a ciphertext
c from the input message
m and the public key
. The public-key encryption process is illustrated in
Figure 2.
The decryption function restores the original message
m from the ciphertext
c and the private key
, as described in
Figure 3.
The functions of the Kyber chosen-plaintext attack public-key encryption (Kyber.CPAPKE) are defined as follows:
The Kyber.CPAPKE key-generation function generates a public key
used for the encryption process and a secret key
used for the decryption process. Noise vectors
s and
e are sampled from a CBD. The public matrix
is generated from a rejection sampler. The public key
and private key
are computed as
, and
, in which
. The details of the Kyber.CPAPKE key-generation function are described in Algorithm 1. In this algorithm, XOF is an extendable output function instantiated with SHAKE-128. A parse function returns the NTT-representation of the input byte stream. G is a hash function G:
. PRF and NTT represent a pseudo-random function and the number theoretic transform, respectively.
| Algorithm 1: Kyber PKE key-generation algorithm (Kyber.CPAPKE.KeyGen) [18]. |
| Output: Public key , |
| Secret key |
| 1 |
| 2 |
| 3 |
| 4 for i from 0 to do |
| 5 for j from 0 to do |
| 6 |
| 7 end for |
| 8 end for |
| 9 for i from 0 to do |
| 10 |
| 11 |
| 12 end for |
| 13 for i from 0 to do |
| 14 |
| 15 |
| 16 end for |
| 17 |
| 18 |
| 19 |
| 20 |
| 21 |
| 22 return |
The Kyber.CPAPKE encryption function constructs ciphertext
from input message
m, random coins
, and the public key
, as presented in Algorithm 2. As described in Algorithm 2,
is generated from a uniform distribution, and
r,
e, and
are sampled from a binomial sampler. The ciphertext
c is constructed as
, where
and
. NTT
is the inverse number theoretic transform.
| Algorithm 2: Kyber PKE encryption algorithm (Kyber.CPAPKE.Enc()) [18]. |
| Input: Message , |
|
Public key , |
| Random coins |
| Output: Ciphertext |
| 1 |
| 2 |
| 3 |
| 4 for i from 0 to do |
| 5 for j from 0 to do |
| 6 |
| 7 end for |
| 8 end for |
| 9 for i from 0 to do |
| 10 |
| 11 |
| 12 end for |
| 13 for i from 0 to do |
| 14 |
| 15 |
| 16 end for |
| 17 |
| 18 |
| 19 |
| 20 |
| 21 |
| 22 |
| 23 return |
The Kyber.CPAPKE decryption function shown in Algorithm 3 recovers the original message
m from the ciphertext
c using a secret key
. The value of
m is calculated as
, where
u and
v are extracted from
c.
| Algorithm 3: Kyber PKE decryption algorithm (Kyber.CPAPKE.Dec) [18]. |
| Input: Ciphertext , |
| Secret key |
| Output: Message |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 return m |
2.2. Key-Establishment Algorithm
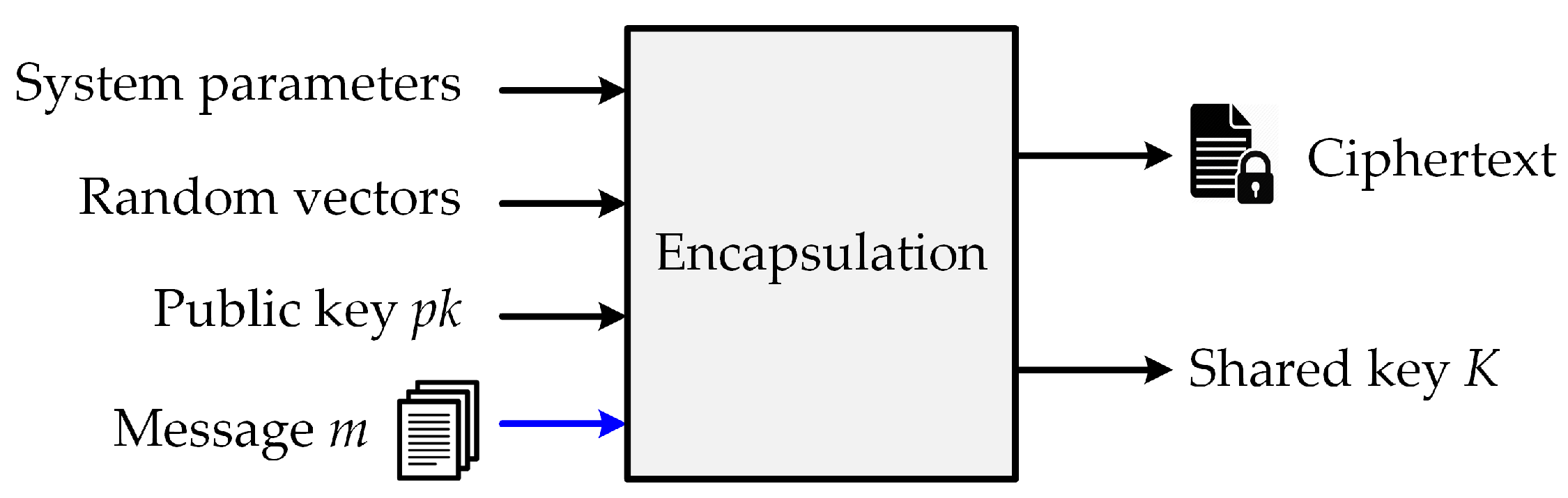
The Kyber key-establishment algorithm (Kyber.CCAKEM) includes key generation, encapsulation, and decapsulation. Kyber.CCAKEM is constructed from the CPA-secure public-key encryption described in Algorithms 1–3. The encapsulation operation constructs ciphertext
c and a shared key
K from the input message
m, public key
, and random vectors, as illustrated in
Figure 4.
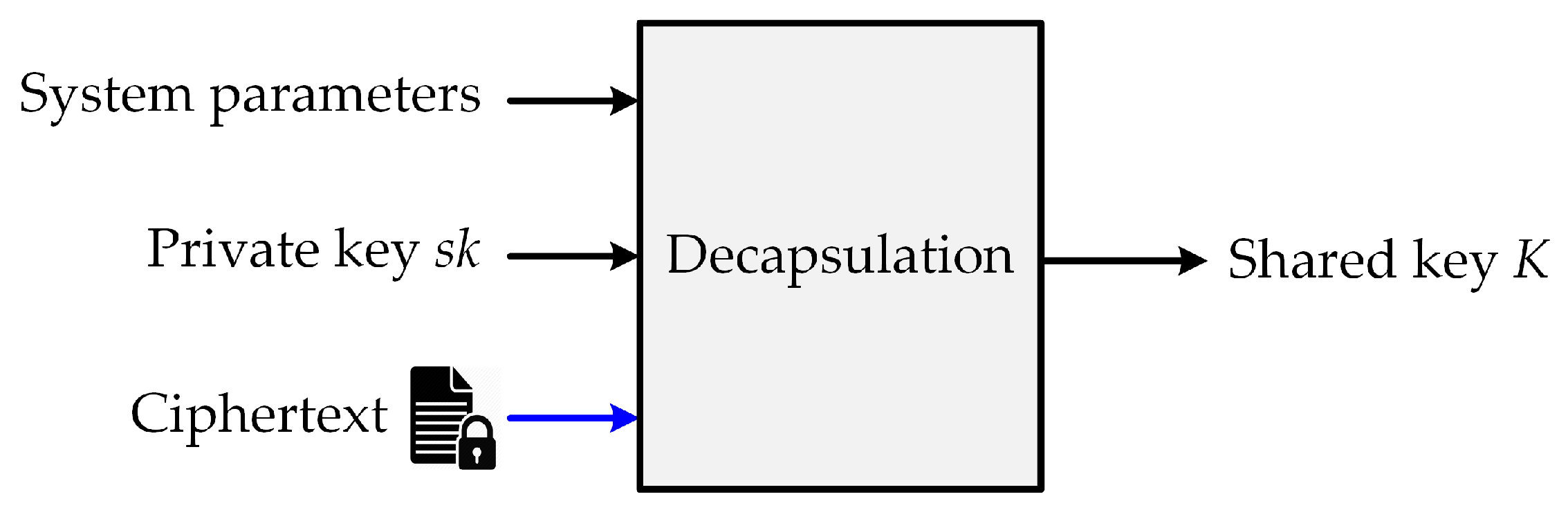
Figure 5 describes the decapsulation operation, which recovers the shared key
K from ciphertext
c and private key
.
The following algorithms describe the key generation, encapsulation, and decapsulation of Kyber.CCAKEM in detail.
The Kyber.CCAKEM key-generation algorithm generating public key
and secret key
is presented in Algorithm 4. Initially,
and
are constructed by the Kyber.CPAPKE.KeyGen() algorithm presented in Algorithm 1. The value of the secret key
is then calculated using the formula
, where
z is a value in
. H is a hash function, H:
.
| Algorithm 4: Kyber KEM key-generation algorithm (Kyber.CCAKEM.KeyGen) [18]. |
| Output: Public key , |
| Secret key |
| 1 |
| 2 |
| 3 |
| 4 return |
The Kyber.CCAKEM encapsulation algorithm returns the ciphertext
and shared key
from input public key
that was generated from Algorithm 5. Specifically, the ciphertext
c is constructed by the Kyber.CPAPKE encryption function in Algorithm 2, and the shared key
K is generated using the SHA3-256, SHA3-512, and SHAKE-256 algorithms from the input message
m and ciphertext
c. More details about the functions used to generate
K can be found in [
18].
| Algorithm 5: Kyber.CCAKEM.Enc() [18]. |
| Input: Public key |
| Output: Ciphertext , |
| Shared key |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 return |
The Kyber.CCAKEM decapsulation algorithm restores the shared key
K from the input ciphertext
and secret key
, as described in Algorithm 6.
| Algorithm 6: Kyber.CCAKEM.Dec() [18]. |
| Input: Ciphertext , |
| Secret key |
| Output: Shared key |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 else |
| 10 |
| 11 endif |
| 12 return K |
The Kyber PKE enrcryption/decryption and Kyber KEM encapsulation/decapsulation algorithms are summarized in
Table 2.
2.3. Arithmetic Operations in CRYSTALS-Kyber
In this section, we introduce the typical arithmetic operations in CRYSTALS-Kyber, which include number theoretic transform (NTT), modular reduction, and sampling.
Polynomial multiplication in
using NTT offers multiple advantages [
18]: simple code space, high speed, and no additional memory is required. NTT is a form of the well-known fast Fourier transform (FFT) [
27,
28], with all arithmetic operations performed in a finite field. NTT uses the
n-th primitive root of unity
in the ring
. Given a polynomial
a in
:
Since NTT plays a crucial role in the hardware architecture design of post-quantum cryptography, improving NTT performance has received great attention. In [
29], the authors proposed the algorithmic and hardware optimizations to design the NTT-based polynomial multiplication architecture. In [
30], the authors introduced a fast modular multiplication method and a memory access scheme using doubled bandwidth ping-pong; the polynomial multiplication can be accelerated using the significantly fewer hardware resources.
Modular reduction for Kyber is specified in [
18] as follows: define
as the unique element
in
such that
for an even positive integer
. For an odd positive integer
, the rank becomes
. Define
as the unique element
in
such that
. Generally, modular reduction can be simplified as
.
In hardware design, the modular reduction operation in multiplication can be executed using Barrett’s reduction [
31] or Montgomery’s reduction [
32]. Montgomery’s reduction algorithm requires converting numbers into and out of Montgomery form [
33]. For Barrett’s modular reduction, the SAM2 technique is utilized to accelerate its operation in hardware. Barrett’s modular reduction requires a large number of shift blocks, adders, subtractors, and may be subject to timing attacks [
33].
The Kyber design is based on the module ring learning with errors encryption scheme, which typically considers LWE with either a rounded Gaussian [
34] or a discrete Gaussian [
35]. The authors of Kyber use centered binomial noise, which relies on LWE, in the design of Kyber.
In uniform sampling, Kyber uses a deterministic approach to sample elements in
, where
. These elements are statistically close to a uniform distribution [
18]. Specifically, a byte stream
is the input of a
, to compute the number theoretic transform of
. The details of the parse function can be found in [
18]. The output of the parse function is as follows:
Centered binomial distribution
is used to sample noise in Kyber, where
or
. The centered binomial distribution is described in Algorithm 7.
| Algorithm 7: [18]. |
| Input: Byte array |
| Output: Polynomial |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 end for |
| 7 return |
3. Implementation of CRYSTALS-Kyber
In this section, we introduce existing implementation results of CRYSTALS-Kyber in pure software, software/hardware codesign, and pure hardware. We then analyze these results with a focus on hardware architecture design, and recommend suitable Kyber hardware architectures among the state-of-the-art designs for specific design goals.
The pure software implementation results of Kyber on Intel Haswell CPUs and ARM Cortex-M4 CPUs are reported in
Table 3. Cycle counts are obtained on one core of a CPU and the results on an Intel Haswell CPU are the C-reference implementation results. As can be seen from
Table 3, the software implementation on Intel Haswell CPUs offers a better performance, in terms of number of clock cyles, than the implementation on ARM Cortex-M4 CPUs, for both encapsulation and decapsulation processes at all security levels.
Table 4 shows the processing time in microseconds of the Kyber encapsulation and decapsulation operations in both software design and software/hardware codesign. As can be seen, the Kyber encapsulation and decapsulation operations implemented in the software/hardware codesign are much faster than those on pure software design. Specifically, with Kyber-1024, the encapsulation time and decapsulation time in software/hardware codesign are accelerated by up to 35.8 times and 38.6 times, compared with those in pure software design, respectively.
The pure hardware implementation results of Kyber-512, Kyber-768, and Kyber-1024 are presented in
Table 5,
Table 6 and
Table 7, respectively. As can be seen in
Table 5, among the Kyber-512 architectures, the design in [
37] requires the highest hardware resources. In addition, the architecture in [
37] introduces the longest latency compared with other works. The architecture in [
23] helps reduce the hardware complexity, in terms of LUTs, and the processing time, compared with [
37]. However, the area-to-time ratio of the architecture in [
23] is still large. The architectures in [
21,
24,
29,
36] offer better values of hardware complexity and latency. Therefore, these architectures are suitable for the systems which require high speed and low complexity. Among the Kyber-512 architectures in
Table 5, the design in [
21] offers the best value of area-to-time ratio, and the design in [
24] requires the lowest hardware resources to execute the Kyber-512 functions.
Among the Kyber-768 architectures in
Table 6, the proposal in [
29] obtains the best value of area-to-time ratio compared with other designs, followed by the architecture in [
36]. Therefore, the design in [
29] is the best candidate for systems which strictly consider the balance between hardware resource and latency. In addition, the design in [
24] offers a reasonable area–time efficiency on the lowest hardware resources. Therefore, the work in [
24] is an ideal candidate to deploy Kyber-768 on low hardware resource systems.
At NIST security level 5, the Kyber-1024 architecture in [
29] is still the best work in terms of area–time ratio. For the resource-constraint systems, the architecture in [
24] is the best choice. The design in [
36] can be implemented on low hardware resources and offers an acceptable value of area–time ratio.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}