


An Autonomous Humanoid Robot Designed to Assist a Human with a Gesture Recognition System


Abstract
:1. Introduction
2. Materials and Methods
2.1. Construction of the Robot
2.2. Autonomous Navigation
- Communication and receiving data from sensors (e.g., LIDAR) and communication with low-level controllers (e.g., Roboclaw, dedicated low-level controller). Data from sensors such as IMU, ultrasonic sensors, optical sensors, and limit switches were collected by the dedicated low-level controller. The power controller published data on the batteries’ actual state, including the voltage and current usage.
- Localization of the robot in the environment. The robot’s odometry was calculated from the IMU and encoders on its drive wheels. The Extended Kalman Filter (EKF) [28,29] was used to combine the odometry derived from the rotation of the wheels with data from the IMU in order to estimate the final odometry from two different sources.
- Controlling the individual axes of the robot, i.e., controlling the drive wheels, torso, and head. A differential drive mode was used to control the drive wheels. A velocity command was used for controlling, and it was split and then sent to the two wheels of differential drive wheels.
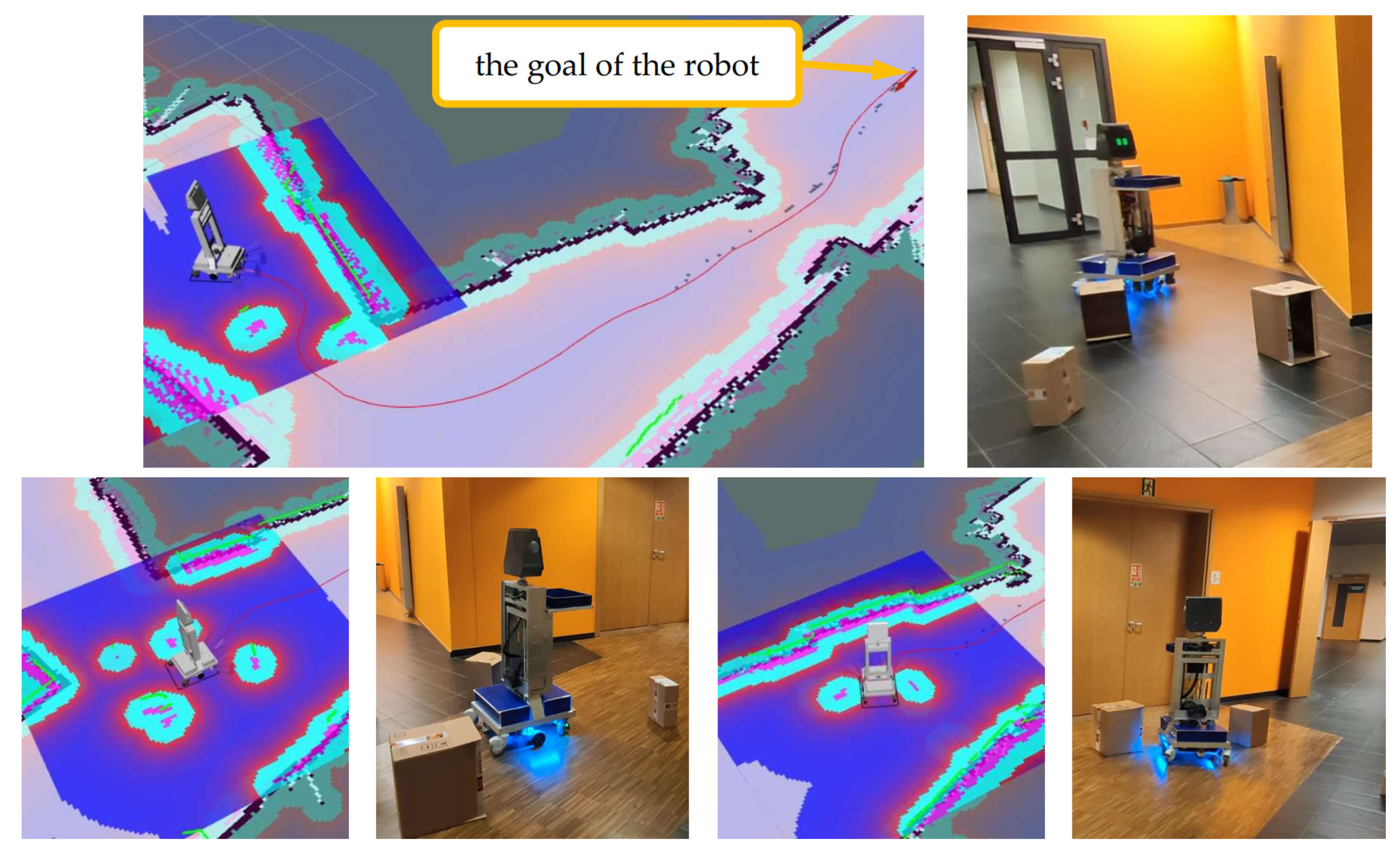
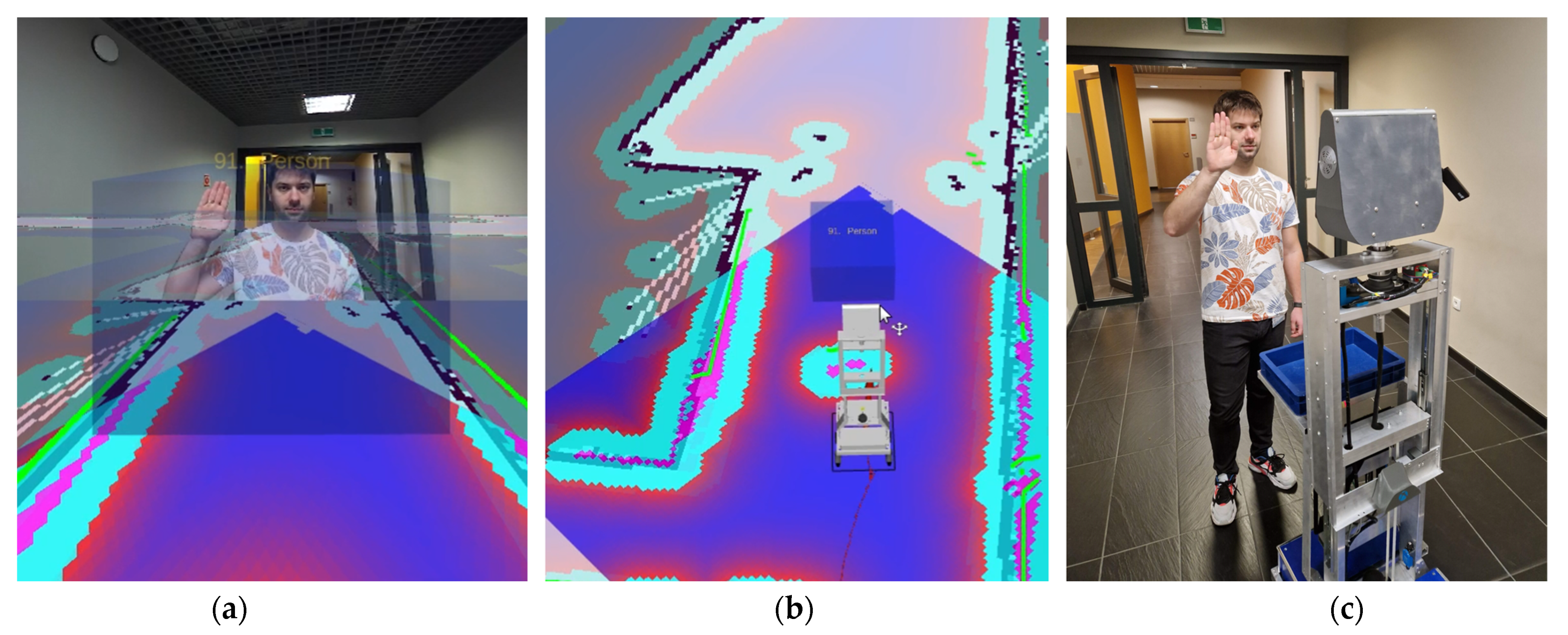
- Autonomous robot movement. The module was used to detect obstacles and avoid them, and to determine the global and local path of the robot’s movement from its actual position on the map to the goal position. For this purpose, the move_base package, whose inputs included the kinematic parameters of the robot, data from the LIDAR and ultrasonic sensors, odometry, and the current map of the environment, was employed. This package’s output was the robot’s velocity, which was computed by the local planner, a submodule of the move_base package responsible for creating a local path for the robot in the robot’s proximity environment. The move_base package additionally generated a global path that connected the robot’s actual position and the goal position.
- Robot model and kinematic structure description. The model took into account the masses and moments of inertia as well as the kinematic structure of the robot.
- Mapping and localization in the created map. The SLAM-Gmapping algorithm was used for simultaneous creation and localization in the created map. The localization in the already produced map was carried out using the Adaptive Monte Carlo Localization (AMCL) algorithm.
- Camera and artificial intelligence model packages. The robot was equipped with algorithms for face detection, gesture recognition, etc.
3. Results
3.1. Robot Operation in a Cluttered Environment
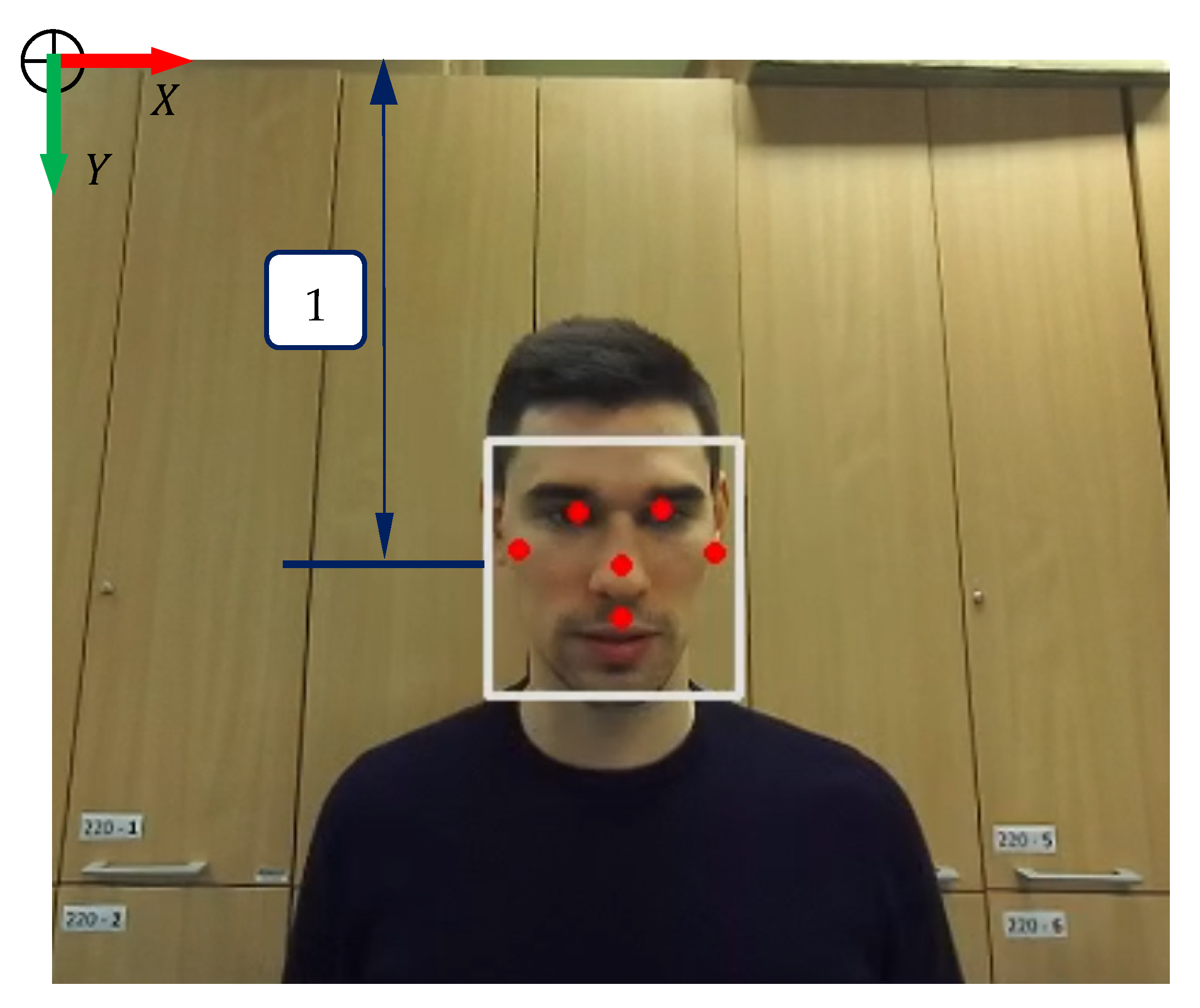
3.2. Human Tracking with Robotic Head Rotation
3.3. Adjusting the Height of the Torso According to Human Height
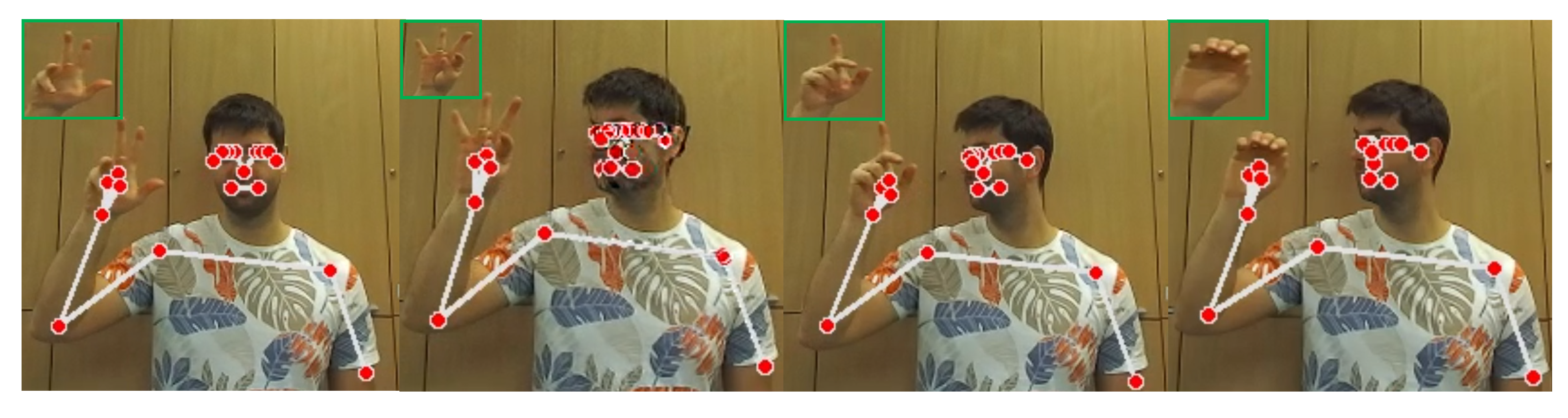
3.4. Gesture Recognition System for Issuing Commands to the Robot
- fist—hand clenched into a fist; command: follow human, human requires robot assistance;
- palm—open hand; command: go back to the starting place, the human no longer needs the robot’s assistance,
- unknown—unknown gesture, any other hand shape; command: execute the last command.
- pose detection submodule,
- hand detection submodule,
- ResNet152.
3.5. Issuing Commands to the Robot by the Human
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ye, H.; Sun, S.; Law, R. A Review of Robotic Applications in Hospitality and Tourism Research. Sustainability 2022, 14, 10827. [Google Scholar] [CrossRef]
- Holland, J.; Kingston, L.; McCarthy, C.; Armstrong, E.; O’Dwyer, P.; Merz, F.; McConnell, M. Service Robots in the Healthcare Sector. Robotics 2021, 10, 47. [Google Scholar] [CrossRef]
- Vasco, V.; Antunes, A.; Tikhanoff, V.; Pattacini, U.; Natale, L.; Gower, V.; Maggiali, M. HR1 Robot: An Assistant for Healthcare Applications. Front. Robot. AI 2022, 9, 813843. [Google Scholar] [CrossRef] [PubMed]
- Palacín, J.; Clotet, E.; Martínez, D.; Martínez, D.; Moreno, J. Extending the Application of an Assistant Personal Robot as a Walk-Helper Tool. Robotics 2019, 8, 27. [Google Scholar] [CrossRef] [Green Version]
- Moreno, J.; Clotet, E.; Lupiañez, R.; Tresanchez, M.; Martínez, D.; Pallejà, T.; Casanovas, J.; Palacín, J. Design, Implementation and Validation of the Three-Wheel Holonomic Motion System of the Assistant Personal Robot (APR). Sensors 2016, 16, 1658. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clotet, E.; Martínez, D.; Moreno, J.; Tresanchez, M.; Palacín, J. Assistant Personal Robot (APR): Conception and Application of a Tele-Operated Assisted Living Robot. Sensors 2016, 16, 610. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, M.; Xu, R.; Wu, H.; Pan, J.; Luo, X. Human–Robot Collaboration for on-Site Construction. Autom. Constr. 2023, 150, 104812. [Google Scholar] [CrossRef]
- Smart Delivery Robot-Pudu Robotics. Available online: https://www.pudurobotics.com/ (accessed on 2 April 2023).
- Cheetah Mobile—Make the World Smarter. Available online: https://www.cmcm.com/en/ (accessed on 2 April 2023).
- Schulenburg, E.; Elkmann, N.; Fritzsche, M.; Girstl, A.; Stiene, S.; Teutsch, C. LiSA: A Robot Assistant for Life Sciences. In Proceedings of the KI 2007: Advances in Artificial Intelligence, Osnabrück, Germany, 10–13 September 2007; Hertzberg, J., Beetz, M., Englert, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 502–505. [Google Scholar]
- ARI—The Social and Collaborative Robot. Available online: https://pal-robotics.com/robots/ari/ (accessed on 2 April 2023).
- Intelligent Telepresence Healthcare Robot—SIFROBOT-1. Available online: https://sifsof.com/product/intelligent-telepresence-robot-sifrobot-1-1 (accessed on 2 April 2023).
- Mitra, S.; Acharya, T. Gesture Recognition: A Survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Cheng, H.; Yang, L.; Liu, Z. Survey on 3D Hand Gesture Recognition. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1659–1673. [Google Scholar] [CrossRef]
- Suarez, J.; Murphy, R.R. Hand Gesture Recognition with Depth Images: A Review. In Proceedings of the 2012 IEEE RO-MAN: The 21st IEEE International Symposium on Robot and Human Interactive Communication, Paris, France, 9–13 September 2012; pp. 411–417. [Google Scholar]
- Rautaray, S.S.; Agrawal, A. Vision Based Hand Gesture Recognition for Human Computer Interaction: A Survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Ivani, A.S.; Giubergia, A.; Santos, L.; Geminiani, A.; Annunziata, S.; Caglio, A.; Olivieri, I.; Pedrocchi, A. A Gesture Recognition Algorithm in a Robot Therapy for ASD Children. Biomed. Signal Process. Control 2022, 74, 103512. [Google Scholar] [CrossRef]
- Illuri, B.; Sadu, V.B.; Sathish, E.; Valavala, M.; Roy, T.L.D.; Srilakshmi, G. A Humanoid Robot for Hand-Sign Recognition in Human-Robot Interaction (HRI). In Proceedings of the 2022 Second International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 21–22 April 2022; pp. 1–5. [Google Scholar]
- Scoccia, C.; Menchi, G.; Ciccarelli, M.; Forlini, M.; Papetti, A. Adaptive Real-Time Gesture Recognition in a Dynamic Scenario for Human-Robot Collaborative Applications. Mech. Mach. Sci. 2022, 122 MMS, 637–644. [Google Scholar] [CrossRef]
- Mustafin, M.; Chebotareva, E.; Li, H.; Martínez-García, E.A.; Magid, E. Features of Interaction Between a Human and a Gestures-Controlled Collaborative Robot in an Assembly Task: Pilot Experiments. In Proceedings of the International Conference on Artificial Life and Robotics (ICAROB2023), Oita, Japan; 2023; pp. 158–162. [Google Scholar]
- Zhang, W.; Cheng, H.; Zhao, L.; Hao, L.; Tao, M.; Xiang, C. A Gesture-Based Teleoperation System for Compliant Robot Motion. Appl. Sci. 2019, 9, 5290. [Google Scholar] [CrossRef] [Green Version]
- Moysiadis, V.; Katikaridis, D.; Benos, L.; Busato, P.; Anagnostis, A.; Kateris, D.; Pearson, S.; Bochtis, D. An Integrated Real-Time Hand Gesture Recognition Framework for Human–Robot Interaction in Agriculture. Appl. Sci. 2022, 12, 8160. [Google Scholar] [CrossRef]
- Damindarov, R.; Fam, C.A.; Boby, R.A.; Fahim, M.; Klimchik, A.; Matsumaru, T. A Depth Camera-Based System to Enable Touch-Less Interaction Using Hand Gestures. In Proceedings of the 2021 International Conference “Nonlinearity, Information and Robotics” (NIR), Innopolis, Russia, 26–29 August 2021; pp. 1–7. [Google Scholar]
- Veluri, R.K.; Sree, S.R.; Vanathi, A.; Aparna, G.; Vaidya, S.P. Hand Gesture Mapping Using MediaPipe Algorithm. In Proceedings of the Third International Conference on Communication, Computing and Electronics Systems, Coimbatore, India, 28–29 October 2021; Bindhu, V., Tavares, J.M.R.S., Du, K.-L., Eds.; Springer: Singapore, 2022; pp. 597–614. [Google Scholar]
- Boruah, B.J.; Talukdar, A.K.; Sarma, K.K. Development of a Learning-Aid Tool Using Hand Gesture Based Human Computer Interaction System. In Proceedings of the 2021 Advanced Communication Technologies and Signal Processing (ACTS), Virtural, 15–17 December 2021; pp. 1–5. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.-L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Stanford Artificial Intelligence Laboratory; Quigley, M.; Gerkey, B.; Conley, K.; Faust, J.; Foote, T.; Leibs, J.; Berger, E.; Wheeler, R.; Ng, A. Robotic Operating System (ROS). Available online: http://robotics.stanford.edu/~ang/papers/icraoss09-ROS.pdf (accessed on 13 April 2023).
- Kalman Filter and Its Application|IEEE Conference Publication|IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/7528889 (accessed on 2 April 2023).
- Daum, F.E. Extended Kalman Filters. In Encyclopedia of Systems and Control; Baillieul, J., Samad, T., Eds.; Springer: London, UK, 2015; pp. 411–413. ISBN 978-1-4471-5058-9. [Google Scholar]
- Tsardoulias, E.; Petrou, L. Critical Rays Scan Match SLAM. J. Intell. Robot. Syst. 2013, 72, 441–462. [Google Scholar] [CrossRef]
- Kohlbrecher, S.; von Stryk, O.; Meyer, J.; Klingauf, U. A Flexible and Scalable SLAM System with Full 3D Motion Estimation. In Proceedings of the 2011 IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan, 1–5 November 2011; pp. 155–160. [Google Scholar]
- Cartographer ROS Integration—Cartographer ROS Documentation. Available online: https://google-cartographer-ros.readthedocs.io/en/latest/ (accessed on 29 March 2023).
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-Time Loop Closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improving Grid-Based SLAM with Rao-Blackwellized Particle Filters by Adaptive Proposals and Selective Resampling. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; IEEE: Barcelona, Spain, 2005; pp. 2432–2437. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef] [Green Version]
- Brian Gerkey. Gmapping. Available online: http://wiki.ros.org/gmapping (accessed on 2 April 2023).
- Fox, D.; Burgard, W.; Dellaert, F.; Thrun, S. Monte Carlo Localization: Efficient Position Estimation for Mobile Robots. Proc. Natl. Conf. Artif. Intell. 1999, 343–349. Available online: http://robots.stanford.edu/papers/fox.aaai99.pdf (accessed on 13 April 2023).
- Dellaert, F.; Fox, D.; Burgard, W.; Thrun, S. Monte Carlo Localization for Mobile Robots. In Proceedings of the 1999 IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), Detroit, MI, USA, 10–15 May 1999; IEEE: Detroit, MI, USA, 1999; Volume 2, pp. 1322–1328. [Google Scholar]
- Thrun, S. Probabilistic Robotics. Commun. ACM 2002, 45, 52–57. [Google Scholar] [CrossRef]
- Kapitanov, A.; Makhlyarchuk, A.; Kvanchiani, K. HaGRID—HAnd Gesture Recognition Image Dataset. arXiv 2022, arXiv:2206.08219. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA; 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 July 2016. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part I 14; Springer International Publishing: New York, NY, USA, 2016; Volume 9905, pp. 21–37. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Maximum speed | 0.25 m/s |
| Robot height | min: 1.40 m, max: 1.75 m |
| Head rotation range | ±45° |
| Base dimension | length: 470 mm, width: 560 mm |
| Torso move range | 0.35 m |
| Model Name | Validation Set Accuracy |
|---|---|
| ResNet50 | 92.13% |
| ResNet101 | 95.23% |
| ResNet152V2 | 96.09% |
| InceptionV3 | 95.24% |
| InceptionResNetV2 | 95.47% |
| EfficientNetV2 | 94.04% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lindner, T.; Wyrwał, D.; Milecki, A. An Autonomous Humanoid Robot Designed to Assist a Human with a Gesture Recognition System. Electronics 2023, 12, 2652. https://doi.org/10.3390/electronics12122652
Lindner T, Wyrwał D, Milecki A. An Autonomous Humanoid Robot Designed to Assist a Human with a Gesture Recognition System. Electronics. 2023; 12(12):2652. https://doi.org/10.3390/electronics12122652
Chicago/Turabian StyleLindner, Tymoteusz, Daniel Wyrwał, and Andrzej Milecki. 2023. "An Autonomous Humanoid Robot Designed to Assist a Human with a Gesture Recognition System" Electronics 12, no. 12: 2652. https://doi.org/10.3390/electronics12122652
APA StyleLindner, T., Wyrwał, D., & Milecki, A. (2023). An Autonomous Humanoid Robot Designed to Assist a Human with a Gesture Recognition System. Electronics, 12(12), 2652. https://doi.org/10.3390/electronics12122652