
Novelty Detection and Fault Diagnosis Method for Bearing Faults Based on the Hybrid Deep Autoencoder Network


Abstract
:1. Introduction
- (1)
- This paper designs a hybrid deep autoencoder network composed of the convolutional autoencoder, new-fault detector, and classifier. It achieves the functionality of detecting novel faults and classifying known faults. By setting a threshold based on reconstruction errors, the proposed method automatically determines whether a fault belongs to unknown faults, thereby addressing the issue of misclassifying unknown faults as known faults.
- (2)
- This method employs unsupervised training of the hybrid deep autoencoder network using data from known fault classes to obtain reconstruction data and low-dimensional features of the samples. Additionally, it utilizes a small amount of labeled data for supervised training of the network. This approach accelerates the training speed of the network and reduces the required sample size for training.
- (3)
- Through comparisons with LSTM and SAE models, in terms of novel fault recognition performance and fault classification, it is demonstrated that the proposed model performs well in both novel fault detection and known fault classification. Experimental results show that the overall detection performance of the hybrid deep autoencoder network model is superior to other models, with higher detection results on all three datasets. This confirms the effectiveness of the proposed method.
2. Related Work
3. Novelty Detection and Fault Diagnosis Method Based on a Hybrid Deep Autoencoder Network
3.1. Network Structure
3.1.1. Encoder
3.1.2. Decoder
3.1.3. Detector
3.1.4. Classifier
3.2. Loss Function
3.3. Diagnostic Process
4. Experiment
4.1. Dataset
4.1.1. CWRU Dataset
4.1.2. The Paderborn Dataset
4.1.3. MFPT Dataset
4.2. Implementation
4.3. Evaluation Indicators
4.4. Experimental Results and Analysis
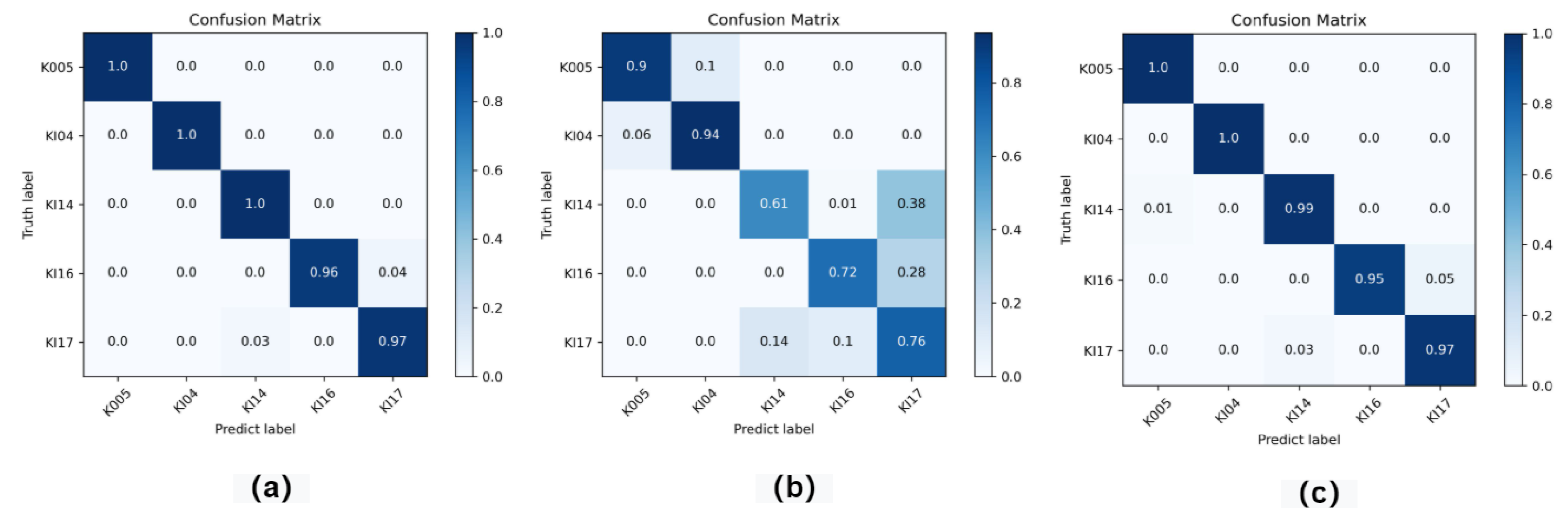
4.4.1. Novelty Detection Performance
4.4.2. Fault Classification Performance
4.4.3. Model Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Malla, C.; Panigrahi, I. Review of condition monitoring of rolling element bearing using vibration analysis and other techniques. J. Vib. Eng. Technol. 2019, 7, 407–414. [Google Scholar] [CrossRef]
- Saufi, S.R.; Isham, M.F.; Ahmad, Z.A.; Hasan, M.D.A. Machinery fault diagnosis based on a modified hybrid deep sparse autoencoder using a raw vibration time-series signal. J. Ambient Intell. Humaniz. Comput. 2023, 14, 3827–3838. [Google Scholar] [CrossRef]
- Asavalertpalakorn, S.; Singhatanadgid, P.; Ardsomang, T. Novelty Detection of a Rolling Bearing using Long Short-Term Memory Autoencoder. In Proceedings of the 2022 37th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Phuket, Thailand, 5–8 July 2022; pp. 1–4. [Google Scholar]
- Yang, Z.; Gjorgjevikj, D.; Long, J.; Zi, Y.; Zhang, S.; Li, C. Sparse autoencoder-based multi-head deep neural networks for machinery fault diagnostics with detection of novelties. Chin. J. Mech. Eng. 2021, 34, 54. [Google Scholar] [CrossRef]
- Hoang, D.T.; Kang, H.J. A survey on deep learning based bearing fault diagnosis. Neurocomputing 2019, 335, 327–335. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Guo, R.; Xu, G.; Yin, Z.; Li, J.; Zhang, F. A Neural Network Method for Bearing Fault Diagnosis. In Proceedings of the 2022 IEEE 8th International Conference on Computer and Communications (ICCC), Virtual, 9–12 December 2022; pp. 116–121. [Google Scholar]
- Nacer, S.M.; Nadia, B.; Abdelghani, R.; Mohamed, B. A novel method for bearing fault diagnosis based on BiLSTM neural 561 networks. Int. J. Adv. Manuf. Technol. 2023, 125, 1477–1492. [Google Scholar] [CrossRef]
- Yu, C.; Wang, H. Rolling Bearing Fault Diagnosis Based on BP Neural Network. In Proceedings of the TEPEN 2022: Efficiency and Performance Engineering Network, Baotou, China, 18–21 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 576–595. [Google Scholar]
- Guoxin, W.; Ge, W.; Xiuli, L.; Ruilong, D. Bearing Fault Diagnosis Method Based on STFT Image and AlexNet Network. In Proceedings of the TEPEN 2022: Efficiency and Performance Engineering Network, Baotou, China, 18–21 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1056–1068. [Google Scholar]
- Lu, Z.; Qin, Y.; Cheng, X.; Zhang, S.; Zeng, Y. Bearing Fault Diagnosis Method of Bearing Based on LSTM Auto-Encoder. In Proceedings of the 5th International Conference on Electrical Engineering and Information Technologies for Rail Transportation (EITRT) 2021: Rail Transportation System Safety and Maintenance Technologies, Qingdao, China, 21–23 October 2021; pp. 582–591. [Google Scholar]
- Chi, F.l.; Yang, X.y. Research on simulation of motor bearing fault diagnosis based on auto-encoder. In Proceedings of the Sixth International Conference on Electromechanical Control Technology and Transportation (ICECTT 2021), Chongqing, China, 14–16 May 2021; SPIE: Bellingham, WA, USA, 2022; Volume 12081, pp. 20–28. [Google Scholar]
- Xu, Y.; Li, C.; Xie, T. Intelligent diagnosis of subway traction motor bearing fault based on improved stacked denoising autoencoder. Shock Vib. 2021, 2021, 6656635. [Google Scholar] [CrossRef]
- Lu, C.; Wang, Z.Y.; Qin, W.L.; Ma, J. Fault diagnosis of rotary machinery components using a stacked denoising autoencoder-based health state identification. Signal Process. 2017, 130, 377–388. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Jiao, J.; Zhao, M.; Lin, J.; Liang, K. A comprehensive review on convolutional neural network in machine fault diagnosis. Neurocomputing 2020, 417, 36–63. [Google Scholar] [CrossRef]
- Xia, M.; Li, T.; Xu, L.; Liu, L.; De Silva, C.W. Fault diagnosis for rotating machinery using multiple sensors and convolutional neural networks. IEEE/ASME Trans. Mechatronics 2017, 23, 101–110. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Ind. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Y.; Wang, B.; Wu, Z. Bearing fault diagnosis base on multi-scale 2D-CNN model. In Proceedings of the 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 3–5 December 2021; pp. 72–75. [Google Scholar]
- Xu, Y.; Li, Z.; Wang, S.; Li, W.; Sarkodie-Gyan, T.; Feng, S. A hybrid deep-learning model for fault diagnosis of rolling bearings. Measurement 2021, 169, 108502. [Google Scholar] [CrossRef]
- Guo, Z.; Yang, M.; Huang, X. Bearing fault diagnosis based on speed signal and CNN model. Energy Rep. 2022, 8, 904–913. [Google Scholar] [CrossRef]
- Xu, T.; Lv, H.; Lin, S.; Tan, H.; Zhang, Q. A fault diagnosis method based on improved parallel convolutional neural network for rolling bearing. Proc. Inst. Mech. Eng. Part J. Aerosp. Eng. 2023, 09544100. [Google Scholar] [CrossRef]
- Zhang, J.; Yi, S.; Liang, G.; Hongli, G.; Xin, H.; Hongliang, S. A new bearing fault diagnosis method based on modified convolutional neural networks. Chin. J. Aeronaut. 2020, 33, 439–447. [Google Scholar] [CrossRef]
- Yan, S.; Shao, H.; Xiao, Y.; Liu, B.; Wan, J. Hybrid robust convolutional autoencoder for unsupervised anomaly detection of machine tools under noises. Robot. Comput.-Integr. Manuf. 2023, 79, 102441. [Google Scholar] [CrossRef]
- Jana, D.; Patil, J.; Herkal, S.; Nagarajaiah, S.; Duenas-Osorio, L. CNN and Convolutional Autoencoder (CAE) based real-time sensor fault detection, localization, and correction. Mech. Syst. Signal Process. 2022, 169, 108723. [Google Scholar] [CrossRef]
- Zou, L.; Zhuang, K.; Zhou, A.; Hu, J. Bayesian optimization and channel-fusion-based convolutional autoencoder network for fault diagnosis of rotating machinery. Eng. Struct. 2023, 280, 115708. [Google Scholar] [CrossRef]
- Yu, F.; Liu, J.; Liu, D.; Wang, H. Supervised convolutional autoencoder-based fault-relevant feature learning for fault diagnosis in industrial processes. J. Taiwan Inst. Chem. Eng. 2022, 132, 104200. [Google Scholar] [CrossRef]
- Zheng, L.; Xu, P.; Bai, J. Power Grid Fault Location Method Based on Pretraining of Convolutional Autoencoder. In Proceedings of the 2021 IEEE International Conference on Computer Science, Artificial Intelligence and Electronic Engineering (CSAIEE), Virtual, 20–22 August 2021; pp. 324–327. [Google Scholar]
- Song, W.; Lin, J.; Zhou, F.; Li, Z.; Zhao, K.; Zhou, H. Wind turbine bearing fault diagnosis method based on an improved denoising AutoEncoder. Power Syst. Prot. Control 2022, 50, 61–68. [Google Scholar]
- Wu, X.; Zhang, Y.; Cheng, C.; Peng, Z. A hybrid classification autoencoder for semi-supervised fault diagnosis in rotating machinery. Mech. Syst. Signal Process. 2021, 149, 107327. [Google Scholar] [CrossRef]
- Zhou, J.; Gao, S.; Li, J.; Xiong, W. Bearing life prediction method based on parallel multichannel recurrent convolutional neural network. Shock Vib. 2021, 2021, 6142975. [Google Scholar] [CrossRef]
- Niri, M.F.; Bui, T.M.; Dinh, T.Q.; Hosseinzadeh, E.; Yu, T.F.; Marco, J. Remaining energy estimation for lithium-ion batteries via Gaussian mixture and Markov models for future load prediction. J. Energy Storage 2020, 28, 101271. [Google Scholar] [CrossRef]
- Bui, T.M.N.; Holmes, N.; Dinh, T.Q. Baseline Strategy for Remaining Range Estimation of Electric Motorcycle Applications. In Proceedings of the 2022 25th International Conference on Mechatronics Technology (ICMT), Kaohsiung, Taiwan, 18–21 November 2022; pp. 1–4. [Google Scholar]
- Del Buono, F.; Calabrese, F.; Baraldi, A.; Paganelli, M.; Regattieri, A. Data-driven predictive maintenance in evolving environments: A comparison between machine learning and deep learning for novelty detection. In Proceedings of the 8th International Conference on Sustainable Design and Manufacturing (KES-SDM 2021), Split, Croatia, 15–17 September 2021; pp. 109–119. [Google Scholar]
- Wu, H.; Triebe, M.J.; Sutherland, J.W. A transformer-based approach for novel fault detection and fault classification/diagnosis in manufacturing: A rotary system application. J. Manuf. Syst. 2023, 67, 439–452. [Google Scholar] [CrossRef]
- Jiang, Y.; Sun, H.; Hong, L.; Lin, R.; Yan, W.; Li, Z. Research on Voiceprint Recognition of Electrical Faults With Lower False Alarm Rate. In Proceedings of the 2021 Power System and Green Energy Conference (PSGEC), Shanghai, China, 20–22 August 2021; pp. 599–603. [Google Scholar]
- Li, Y.; Yang, S.; Wu, J.; Zhongbo, G. Novelty Faults Detection Method Based on SVM Observer and Its Application. J. Vib. Meas. Diagn. 2021, 41, 292–298. [Google Scholar]
- Górski, J.; Jabłoński, A.; Heesch, M.; Dziendzikowski, M.; Dworakowski, Z. Comparison of novelty detection methods for detection of various rotary machinery faults. Sensors 2021, 21, 3536. [Google Scholar] [CrossRef]
- Lou, X.; Loparo, K.A. Bearing fault diagnosis based on wavelet transform and fuzzy inference. Mech. Syst. Signal Process. 2004, 18, 1077–1095. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the PHM Society European Conference, Bilbao, Spain, 5–8 July 2016; Volume 3. [Google Scholar]
- Bechhoefer, E.; Condition Based Maintenance Fault Database for Testing Diagnostics and Prognostic Algorithms. MFPT Data 2013. Available online: https://www.mfpt.org/fault-data-sets/ (accessed on 23 June 2023).
- Zhou, Z.H. Machine Learning; Springer Nature: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Layer Types | Output Size | Other Parameter Configurations |
|---|---|---|---|
| Encoder | Input layer | (1, 64, 64) | |
| Convolutional layer | (16, 32, 32) | kernel = 3 × 3, stride = 2, padding = 1 | |
| Convolutional layer | (32, 16, 16) | kernel = 3× 3, stride = 2, padding = 1 | |
| Batch Normalization layer | (32, 16, 16) | ||
| Convolutional layer | (32, 8, 8) | kernel = 3 × 3, stride = 2, padding = 1 | |
| Convolutional layer | (32, 4, 4) | kernel = 3 × 3, stride = 2, padding = 1 | |
| Flatten layer | (512) | ||
| Fully connected layer | (64) | ||
| Fully connected layer | (32) | ||
| Decoder | Fully connected layer | (64) | |
| Flatten layer | (512) | ||
| Unflattened layer | (32, 4, 4) | ||
| Deconvolutional layer | (32, 8, 8) | kernel = 3 × 3, stride = 2, padding = 1 | |
| Deconvolutional layer | (32, 16, 16) | kernel = 3 × 3, stride = 2, padding = 1 | |
| Batch Normalization layer | (32, 16, 16) | ||
| Deconvolutional layer | (16, 32, 32) | kernel = 3 × 3, stride = 2, padding = 1 | |
| Deconvolutional layer | (16, 32, 32) | kernel = 3 × 3, stride = 2, padding = 1 | |
| Classifier | Softmax layer | (C) |
| Fault Class | Fault Diameter (inch) | Class Label | Number of Original Data Points | Number of Samples |
|---|---|---|---|---|
| Normal | / | C1 | 243,938 | 238 |
| Inner race fault | 0.007 | C2 | 121,265 | 118 |
| Inner race fault | 0.014 | C3 | 121,846 | 118 |
| Inner race fault | 0.021 | C4 | 122,136 | 119 |
| Balls fault | 0.007 | C5 | 122,571 | 119 |
| Balls fault | 0.014 | C6 | 121,846 | 118 |
| Balls fault | 0.021 | C7 | 121,991 | 119 |
| Outer race fault (at 6 o ’clock) | 0.007 | C8 | 121,991 | 119 |
| Outer race fault (at 6 o ’clock) | 0.014 | C9 | 121,846 | 118 |
| Outer race fault (at 6 o ’clock) | 0.021 | C10 | 122,426 | 119 |
| File Number | Location of Damage | Class | Damage Mode | Mode of Distribution | Degree of Damage |
|---|---|---|---|---|---|
| K005 | / | C1 | / | / | / |
| KI04 | Inner | C2 | multiple | no repetition | 1 |
| KI14 | Inner | C3 | multiple | no repetition | 1 |
| KI16 | Inner | C4 | single | no repetition | 3 |
| KI17 | Inner | C5 | single | random | 1 |
| KA04 | Outer | C6 | single | no repetition | 1 |
| KA16 | Outer | C7 | repetitive | random | 2 |
| Type of Fault | Class | Sampling Rate (sps) | Load (Ibs) | Number of Data Points | Sample Size |
|---|---|---|---|---|---|
| normal | C1 | 97,656 | 270 | 58,5936 | 572 |
| Outer | C2 | 97,656 | 270 | 58,5936 | 572 |
| Outer | C3 | 48,828 | 25 | 146,484 | 143 |
| Outer | C4 | 48,828 | 50 | 146,484 | 143 |
| Outer | C5 | 48,828 | 100 | 146,484 | 143 |
| Inner | C6 | 48,828 | 0 | 146,484 | 143 |
| Inner | C7 | 48,828 | 50 | 146,484 | 143 |
| Inner | C8 | 48,828 | 100 | 146,484 | 143 |
| TPR | TNR | F1 | |
|---|---|---|---|
| Ours | 98.98% | 98.59% | 0.98 |
| LSTM | 98.86% | 60.35% | 0.75 |
| SAE | 88.57% | 98.53% | 0.93 |
| TPR | TNR | F1 | |
|---|---|---|---|
| Ours | 92.83% | 96.79% | 0.94 |
| LSTM | 80.53% | 56.24% | 0.63 |
| SAE | 87.00% | 96.99% | 0.91 |
| TPR | TNR | F1 | |
|---|---|---|---|
| Ours | 98.31% | 84.34% | 0.92 |
| LSTM | 94.27% | 53.57% | 0.71 |
| SAE | 88.52% | 92.35% | 0.89 |
| CWRU | Paderborn | MFPT | |
|---|---|---|---|
| Ours | 100% | 98.53% | 97.03% |
| LSTM | 79.85% | 79.35% | 72.89% |
| SAE | 100% | 97.98% | 96.73% |
| Total Params | Training Time (s) | |
|---|---|---|
| Ours | 117,224 | 203 |
| LSTM | 1,084,544 | 1272 |
| SAE | 1,678,629 | 869 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Hao, H.; Chen, Y.; Zhang, Y. Novelty Detection and Fault Diagnosis Method for Bearing Faults Based on the Hybrid Deep Autoencoder Network. Electronics 2023, 12, 2826. https://doi.org/10.3390/electronics12132826
Zhao Y, Hao H, Chen Y, Zhang Y. Novelty Detection and Fault Diagnosis Method for Bearing Faults Based on the Hybrid Deep Autoencoder Network. Electronics. 2023; 12(13):2826. https://doi.org/10.3390/electronics12132826
Chicago/Turabian StyleZhao, Yuanyuan, Huijuan Hao, Yu Chen, and Yu Zhang. 2023. "Novelty Detection and Fault Diagnosis Method for Bearing Faults Based on the Hybrid Deep Autoencoder Network" Electronics 12, no. 13: 2826. https://doi.org/10.3390/electronics12132826
APA StyleZhao, Y., Hao, H., Chen, Y., & Zhang, Y. (2023). Novelty Detection and Fault Diagnosis Method for Bearing Faults Based on the Hybrid Deep Autoencoder Network. Electronics, 12(13), 2826. https://doi.org/10.3390/electronics12132826