Insu-YOLO: An Insulator Defect Detection Algorithm Based on Multiscale Feature Fusion


Abstract
:1. Introduction
- The GSConv modules are adopted in the backbone and neck networks of the Insu-YOLO model, which can reduce the number of parameters and complexity of our model.
- The original upsampling modules in Insu-YOLO are replaced with a content-aware reassembly of features (CARAFE) structure, which ensures that the model retains the ability to extract information from small targets without losing corresponding detailed features due to interpolation-based upsampling Additionally, the previous SPPF module is replaced with the SimCSPSPPF structure to further enhance the representational power of the model.
- To enhance the detection capability of the model for challenging cases such as small targets and larger variance of aspect ratios, an additional object detection layer is added in Insu-YOLO, which can fuse shallow feature maps with deeper ones to optimize the detection performance of insulator defects.
2. Realted Work
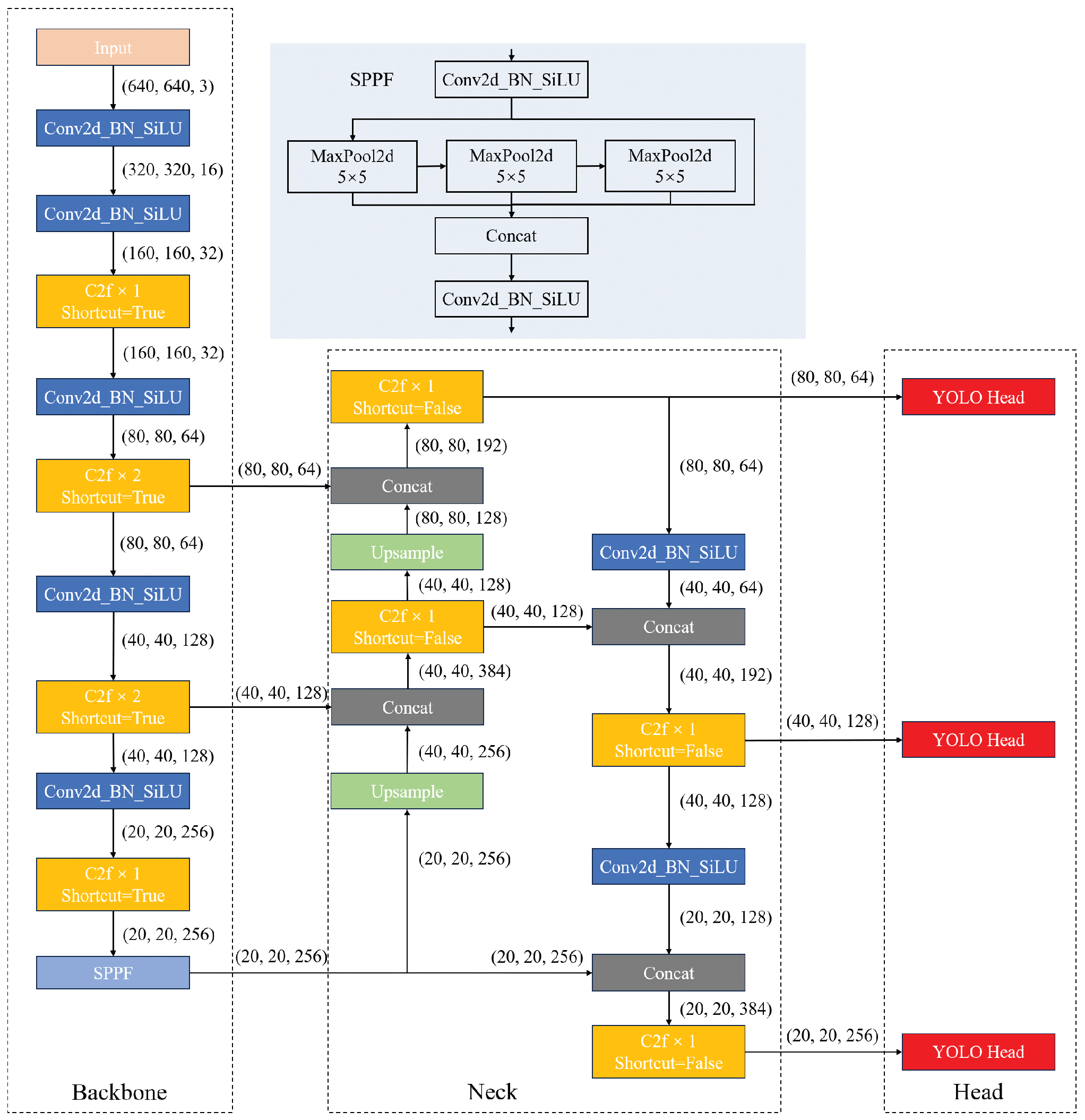
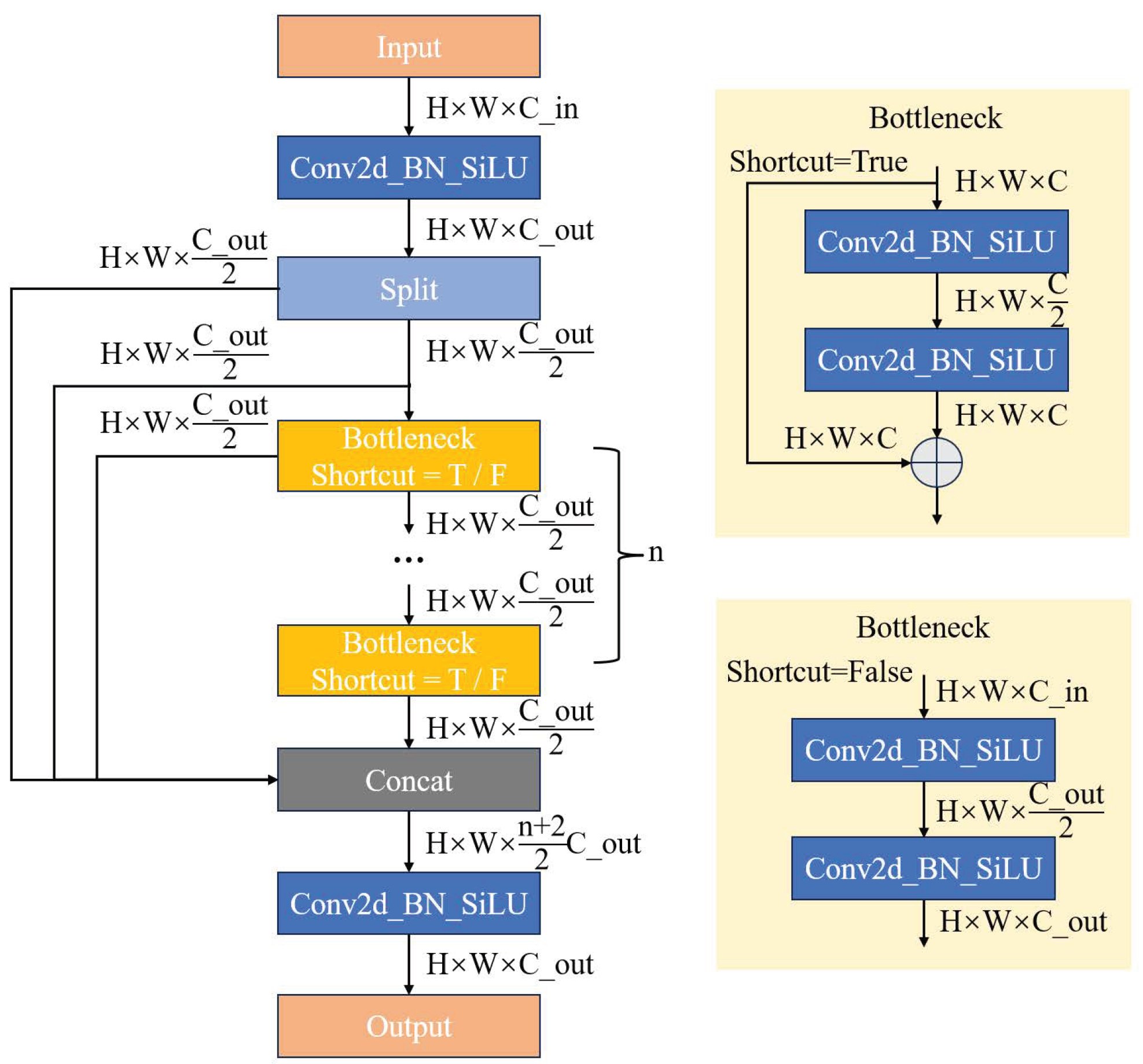
2.1. YOLOv8 Basic Model
2.2. Characteristics of GSConv
2.3. Characteristics of CARAFE
2.4. Characteristics of Small Object Detection Layer
3. Improved YOLOv8 Model Network Structure
- (1)
- Angle cost. The angle in this cost function is the angle between the line connecting the center points of the ground-truth and the predicted boxes. The formula is given as follows.where is the ratio of the opposite side to the right-angled side in the right triangle, is the distance between the center point of the ground-truth and predicted boxes, is the height difference between the center point of the ground-truth and predicted boxes, and are the center coordinates of the ground-truth box, and and are the center coordinates of the predicted box.
- (2)
- Distance cost. The distance cost is related to the minimum bounding rectangle of the ground-truth and predicted boxes. The formula of it is as follows.where and are the width and height of the minimum bounding rectangle.
- (3)
- Shape cost. The definition of the shape cost is illustrated in the following formulas.where w, h, , and are the width and height of the ground-truth and predicted boxes, respectively. The value of controls the degree of attention to the shape cost.
- (4)
- IoU cost. IoU refers to the intersection rate between the ground-truth and predicted bounding boxes, which is defined as the ratio of the intersection to the union of the two boxes, and is calculated using the following formula.where A is the predicted box and B denotes the ground-truth box.
4. Experiments
4.1. Dataset Preparation
- (1)
- CPLID. The dataset “Chinese Power Line Insulator Dataset” (CPLID) [27] was collected by the State Grid Corporation of China. It contains 848 aerial images of composite insulators. In order to optimize the generalization ability of the Insu-YOLO in detecting insulators of different materials, this paper also introduces the intelligent defect detection dataset of power inspection provided by the eighth “TipDM Cup” data mining challenge in 2020, which contains 40 aerial images of glass insulators. The final dataset consists of 284 defective insulator images and 604 normal insulator images. Due to the insufficient number of defective insulator images, corresponding data augmentation operations are performed in this paper, including brightness enhancement, color deepening, contrast enhancement, etc. Finally, 2876 insulator aerial images are obtained, which contain the labels insulator defect and insulator.
- (2)
- IDID. The public dataset “Insulator Defect Image Dataset” (IDID) [28] contains 1600 high-resolution insulator images. To make the model learn more insulator features, data augmentation operations such as brightness enhancement, color deepening, and contrast enhancement are conducted to expand the dataset, resulting in 2800 insulator images.
4.2. Experimental Environment and Hyperparameters Settings
4.3. Evaluation Metrics
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13619–13627. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Lu, W.; Zhou, Z.; Ruan, X.; Yan, Z.; Cui, G. Insulator Detection Method Based on Improved Faster R-CNN with Aerial Images. In Proceedings of the 2021 2nd International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), Nanjing, China, 6–8 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 417–420. [Google Scholar]
- Zhao, W.; Xu, M.; Cheng, X.; Zhao, Z. An insulator in transmission lines recognition and fault detection model based on improved faster RCNN. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, J.; Li, B. ARG-Mask RCNN: An Infrared Insulator Fault-Detection Network Based on Improved Mask RCNN. Sensors 2022, 22, 4720. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Xu, Z.; Wang, Y. Bidirection-Fusion-YOLOv3: An Improved Method for Insulator Defect Detection Using UAV Image. IEEE Trans. Instrum. Meas. 2022, 71, 1–8. [Google Scholar] [CrossRef]
- Hao, K.; Chen, G.; Zhao, L.; Li, Z.; Liu, Y.; Wang, C. An insulator defect detection model in aerial images based on Multiscale Feature Pyramid Network. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Xu, S.; Deng, J.; Huang, Y.; Ling, L.; Han, T. Research on Insulator Defect Detection Based on an Improved MobilenetV1-YOLOv4. Entropy 2022, 24, 1588. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. Msft-yolo: Improved yolov5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef] [PubMed]
- Han, G.; Yuan, Q.; Zhao, F.; Wang, R.; Zhao, L.; Li, S.; He, M.; Yang, S.; Qin, L. An Improved Algorithm for Insulator and Defect Detection Based on YOLOv4. Electronics 2023, 12, 933. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. YOLOv6 v3. 0: A Full-Scale Reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Tao, X.; Zhang, D.; Wang, Z.; Liu, X.; Zhang, H.; Xu, D. Detection of Power Line Insulator Defects Using Aerial Images Analyzed With Convolutional Neural Networks. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 1486–1498. [Google Scholar] [CrossRef]
- Vieira-e Silva, A.L.; Chaves, T.; Felix, H.; Macêdo, D.; Simões, F.; Gama-Neto, M.; Teichrieb, V.; Zanchettin, C. Unifying Public Datasets for Insulator Detection and Fault Classification in Electrical Power Lines. 2020. Available online: https://github.com/heitorcfelix/public-insulator-datasets (accessed on 7 February 2020).
- Zheng, J.; Wu, H.; Zhang, H.; Wang, Z.; Xu, W. Insulator-Defect Detection Algorithm Based on Improved YOLOv7. Sensors 2022, 22, 8801. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total Number | Training Set | Validation Set | Testing Set | Image Size |
|---|---|---|---|---|---|
| CPLID | 2876 | 2329 | 259 | 288 | |
| IDID | 2800 | 2268 | 252 | 280 |
| Item | Value |
|---|---|
| Input Size | |
| Training Epochs | 200 |
| Batch Size | 16 |
| Optimizer | SGD |
| Initial Learning Rate | 0.01 |
| Momentum | 0.937 |
| Weight Decay | 5 |
| Fraction of Hue Augmentation | 0.015 |
| Fraction of Saturation Augmentation | 0.7 |
| Fraction of Value Augmentation | 0.4 |
| Probability of Image Flip Up–Down | 0 |
| Probability of Image Flip Left–Right | 0.5 |
| Probability of Image Mosaic | 1.0 |
| Probability of Image Mixup | 0 |
| Method | CPLID | IDID | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AP (Def.) | AP (Ins.) | mAP | FPS | Memory (MB) | P | R | mAP | F1 | FPS | |
| RT-DETR [1] | 90.4 | 98.8 | 94.6 | 32 | 66.1 | 91.0 | 87.9 | 91.0 | 0.894 | 17 |
| YOLOv3t | 88.2 | 95.4 | 91.8 | 85 | 9.2 | 81.3 | 78.2 | 85.3 | 0.797 | 66 |
| YOLOv5n | 87.5 | 99.5 | 93.5 | 103 | 5.2 | 92.6 | 94.3 | 97.4 | 0.931 | 54 |
| YOLOv6n [25] | 88.5 | 97.7 | 93.1 | 94 | 8.6 | 83.2 | 82.4 | 88.4 | 0.828 | 39 |
| YOLOv7t [14] | 88.1 | 98.5 | 93.3 | 65 | 12.3 | 83.8 | 89.7 | 84.3 | 0.866 | 41 |
| YOLOv8n | 88.7 | 99.5 | 94.1 | 118 | 6.2 | 93.8 | 93.9 | 97.5 | 0.939 | 51 |
| BF-YOLO [8] | 89.0 | 94.0 | 91.5 | 11 | - | - | - | - | - | - |
| ID-YOLO [9] | 92.1 | 99.1 | 95.6 | 63 | 227 | - | - | - | - | - |
| YOLOv7 [29] | - | - | - | - | - | 94.9 | 93.4 | 93.8 | 0.940 | 95 |
| Insu-YOLO | 92.2 | 99.5 | 95.9 | 87 | 9.2 | 97.6 | 96.7 | 99.1 | 0.971 | 43 |
| Model | #Param. | FLOPS | FPS | AP (%) | AP (%) |
|---|---|---|---|---|---|
| YOLOXs | 9.0 M | 26.8 G | 102 | 40.5 | 40.5 |
| PPYOLOEs | 7.9 M | 17.4 G | 208 | 43.1 | 42.7 |
| YOLOv5n | 1.9 M | 4.5 G | 159 | - | 28.0 |
| YOLOv5s | 7.2 M | 16.5 G | 156 | - | 37.4 |
| YOLOv7n | 6.2 M | 13.8 G | 286 | 38.7 | 38.7 |
| YOLOv8n | 3.2 M | 8.7 G | - | 37.3 | - |
| YOLOv8s | 11.2 M | 28.6 G | - | - | 44.9 |
| Ours | 6.4 M | 13.8 G | 174 | 39.5 | 39.1 |
| GS | CARAFE | Sim | Det. | AP/% | F1 | mAP/% | FPS | Memory | GFLOPs | |
|---|---|---|---|---|---|---|---|---|---|---|
| Layer | Def. | Ins. | (MB) | |||||||
| × | × | × | × | 88.7 | 99.3 | 0.955 | 94.0 | 118 | 6.2 | 8.1 |
| ✓ | × | × | × | 89.3 | 99.5 | 0.961 | 94.4 | 130 | 5.7 | 7.6 |
| × | ✓ | × | × | 89.0 | 99.5 | 0.959 | 94.2 | 135 | 6.5 | 8.6 |
| ✓ | ✓ | × | × | 89.9 | 99.5 | 0.962 | 94.7 | 96 | 5.9 | 8.0 |
| ✓ | ✓ | ✓ | × | 90.2 | 99.5 | 0.964 | 94.9 | 93 | 7.2 | 9.3 |
| ✓ | ✓ | ✓ | ✓ | 92.2 | 99.5 | 0.969 | 95.9 | 87 | 9.2 | 13.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Liu, H.; Chen, J.; Hu, J.; Zheng, E. Insu-YOLO: An Insulator Defect Detection Algorithm Based on Multiscale Feature Fusion. Electronics 2023, 12, 3210. https://doi.org/10.3390/electronics12153210
Chen Y, Liu H, Chen J, Hu J, Zheng E. Insu-YOLO: An Insulator Defect Detection Algorithm Based on Multiscale Feature Fusion. Electronics. 2023; 12(15):3210. https://doi.org/10.3390/electronics12153210
Chicago/Turabian StyleChen, Yifu, Hongye Liu, Jiahao Chen, Jianhong Hu, and Enhui Zheng. 2023. "Insu-YOLO: An Insulator Defect Detection Algorithm Based on Multiscale Feature Fusion" Electronics 12, no. 15: 3210. https://doi.org/10.3390/electronics12153210