1. Introduction
With the rapid development and wide application of information technology, signal processing algorithms are widely being used in portable wireless devices, such as smartphones, PCs, and wearable devices. Full adders and multipliers are fundamental components in digital signal processing applications [
1], such as convolution, fast Fourier transform (FFT) [
2,
3], finite impulse response (FIR) [
4,
5], discrete cosine transform (DCT) [
6,
7], infinite impulse response (IIR) filters [
8], and audio/video codecs. Conventional multipliers are becoming the bottleneck of low-power digital signal processing applications [
9,
10].
Generally, multipliers could be classified into various types, such as array [
11,
12], Booth [
13,
14], carry-save, and Wallace tree [
15,
16], according to the methods used to produce, pass, and compress the partial products. In an array multiplier, the partial product is generated by the one-bit multiplication of the multiplicand and multiplier, mostly conducted by AND gates. The partial products are directly summed up by an array of adders. The array multiplier has an explicit structure [
17], which makes it easy to design and analyze. However, as the multiplier bit width increases, the critical path increases dramatically.
Instead of passing the output carry to the same-level adder, carry-save array adders pass both carry and sum to the next-level adders. This reduces the carry propagation delay in all rows except the last row. Hence, it reduces both the length and the number of critical paths compared to the array multiplier.
Wallace tree methods use fewer adders for compression and accumulation. The partial product bits are summed up in parallel by means of a tree of carry-save adders. They compress three or four inputs into two outputs and continue the next-level compression with fewer adders.
Full adders are the most important components of multipliers, which in turn increases the demand for low-power full adders for high-performance multipliers [
18]. Complementary metal–oxide–semiconductor (CMOS) full adders are most widely used, especially in the digital standard cells of many CMOS technologies. However, compared to pass-transistor logic (PTL)-based circuits, they consume more power. PTL full adders might be significant for a high-performance multiplier [
19,
20,
21]. In most cases, PTL-based circuits propagate the voltage level directly through the pass transistors instead of through a cascade of pull-up and pull-down transistors. This shortens the propagation paths. PTL-based circuits have fewer connections to the power rail compared to CMOS logic gates, which might reduce power consumption. Some digital standard cells use PTL full adders and half adders, such as the TSMC 65 nm process and 40 nm process, as shown in
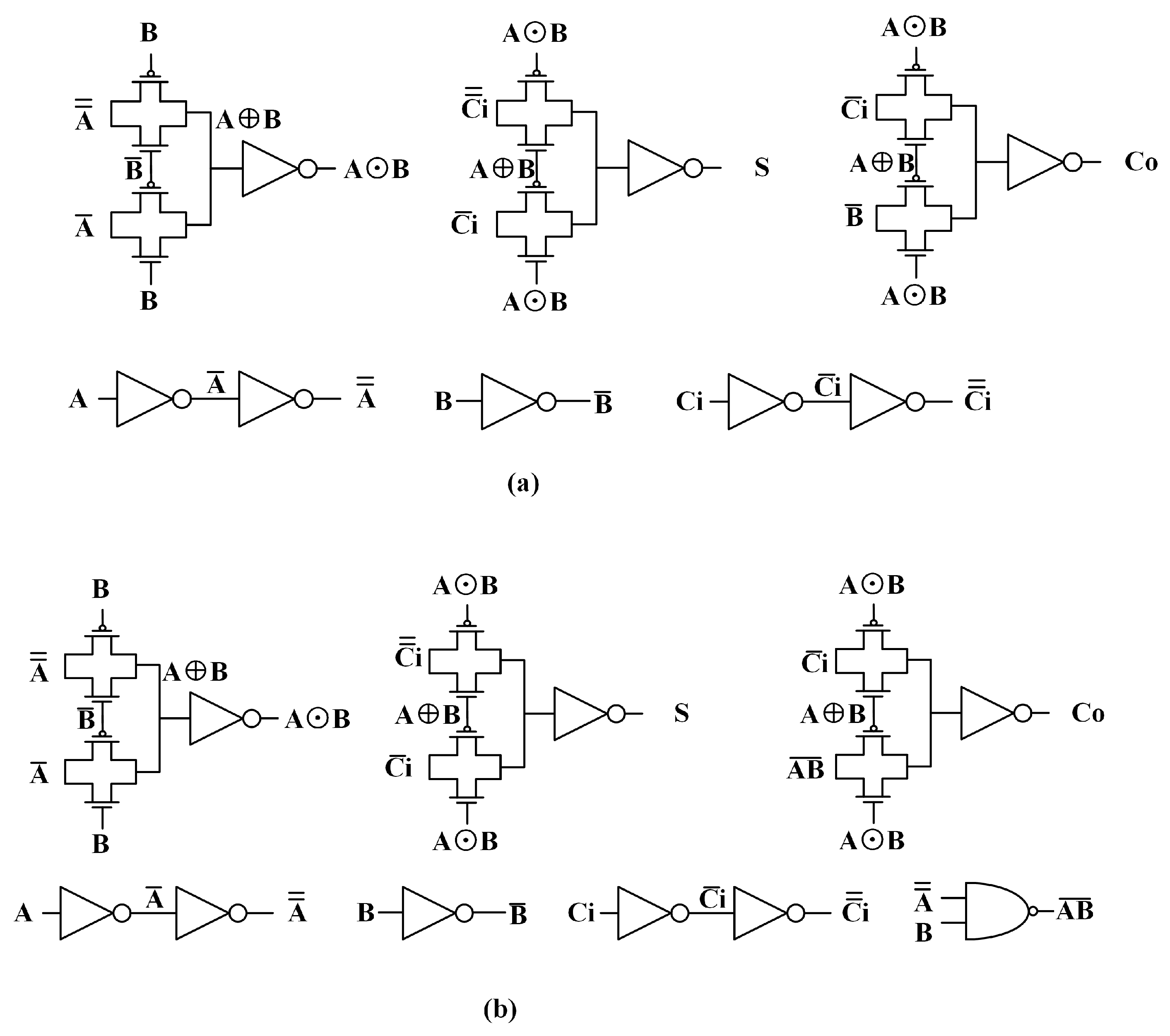
Figure 1. By applying PTL full adders to multipliers, the advantages could be exploited.
PTL circuits have a lower transistor count. However, the lower transistor count might not lead to a smaller area because PTL circuits have more complex connections. Fewer transistors with more connections might cause large wire loads and unexpected delays. Moreover, PTL-based cells might suffer from issues such as threshold loss [
22,
23], weak driving capacity [
24], and uneven delay and power distribution. Circuits with PTL need to be properly designed to fully exploit their advantages.
In this paper, we propose a novel PTL full adder and a multiplier based on the proposed full adder. The main contributions of this paper are as follows:
- (1)
A novel PTL full adder is proposed using two parallel PTL XOR gates to produce XOR and XNOR simultaneously, which reduces the parasitic capacitance on the critical path. The post-layout simulation shows a power improvement of 13.78% compared to conventional CMOS full adders.
- (2)
We take a deep look at common issues with PTL-based adders, such as voltage loss, cascade delay, and glitch issues. Design principles regarding PTL circuits are concluded.
- (3)
A multiplier based on the proposed full adder is designed. The post-layout simulation shows a power improvement of 8% compared to the multiplier produced by the Design Compiler synthesis tool.
The remainder of this paper is organized as follows:
Section 2 reviews existing logic gates and full adders, including CMOS- and PTL-based adders.
Section 3 presents our proposed full adder.
Section 4 presents the multiplier based on the proposed full adder.
Section 5 verifies the performance of our proposed multiplier. Finally, we conclude the paper in
Section 6.
3. Proposed PTL Full Adder
3.1. Circuit Design
In this section, a novel PTL full adder is presented. The circuit of the proposed PTL full adder is shown in
Figure 17. The novel proposed full adder consists of 18 transistors.
Instead of using an inverter to produce XNOR from XOR, we used a parallel PTL XOR gate (“XOR2” conducting “”) to provide XNOR. As a result, the inverter was no longer needed. Similar to 16T-1996 and 14T-1996, we used two pass gates to form a majority gate to produce the output carry “Co”.
As the main reason for the large worst-case delay of 16T-1992 was the large parasitic capacitance at “A ⊕B”, by using a parallel PTL XOR gate, we distributed the connection count of “A ⊕B” to “A ⊙B”. The propagation path was, thus, split into two parallel paths, each with less parasitic capacitance. Theoretically, the “A ⊕B” and “A ⊙B” results arrived at the third PTL XOR gate, “XOR3”, or the PTL majority gate at the same time. Either path drives less load than 16T-1992.
Table 4 shows the parasitic capacitance of 16T-1992 and the proposed full adders. Both full adders are modeled with 28 nm process. The parasitic capacitance was extracted by the Calibre tool. The parasitic capacitance at the “A ⊕ B” node of the proposed 18T is 21% less than 16T-1992. The load capacitance is divided by the “A ⊙B” node. Since the two paths propagate parallelly, the worst-case delay could be reduced.
The worst-case delay could be further reduced by removing the inverter. Since there are fewer connections to the power rail, the power consumption of the proposed full adder is also reduced.
Table 5 shows the performance of the proposed full adder. The simulation was conducted on the Cadence platform. Due to the reduction of the inner load, the critical delay is improved. Moreover, the power consumption is also the smallest among the three types of full adders.
However, the results shown in
Table 4 might not necessarily suggest the true superiority of the proposed full adder. Since the inverter at the node “A ⊕ B” was removed, it lowered the driving capacity. It has more complex circuitry than 16T-1992, which might make the advantages shrink in a post-layout simulation.
Therefore, it is necessary to verify the post-layout performance to obtain more realistic characteristics of the proposed circuit.
We designed the layout of the proposed full adder, as well as the 16T-1992. The layout of the proposed full adder is shown in
Figure 18.
Figure 19 shows the layout of 16T-1992. Both layouts were designed based on a 28 nm CMOS process.
Table 6 lists the post-simulation results. According to the table, the average delay of the three types of full adders is similar. The worst-case delay of the three types of adders increased. However, the delay of the two PTL-based adders increased more than that of the 28T adder, which turned the advantages of the delay into disadvantages. This suggests a stronger trend in PTL-based circuits, where power and delay tend to expand significantly if the parasitic parameter is considered.
Moreover, our proposed adder and 16T-1992 adder have similar average delays to those of 28T but higher worst-case delays than 28T. This proves their uneven distribution.
Compared to 28T adder, a 13.78% power reduction could be obtained.
3.2. Analysis of Cascade Characteristics
A single PTL full adder has a delay similar to that of the 28T CMOS full adder. However, the delay of cascaded PTL-based adders increases exponentially. If we set up a PTL full adder chain, as shown in
Figure 20, the delay of each adder is shown in
Table 7.
A dramatic increase in delay with cascade-level rises could be observed in the table. This is because the pass gate chain lacks a pull-up or pull-down transistor to provide drive. To model such a PTL-based adder chain, the pass gate chain could be simplified as an RC cascade, as shown in
Figure 21. The delay of such a chain can be expressed as in (3). The term “
n” denotes the cascade level.
Figure 22 shows the delay of each adder in cascade and the fit curve based on Equation (
3). The factor “RC” could be estimated as in (4).
Therefore, it is not optimal to use too many PTL full adders in cascade, especially in multipliers that include adder arrays or adder trees. We could simply replace some 28T adders to break the PTL chain. If we consider an integer “
m”, and replace a 28T with every
m PTL full adder, the delay of the PTL-CMOS hybrid chain could be expressed as in (5).
The term
denotes the Ci → Co delay difference between the 28T adder and the proposed PTL adder.
Table 8 shows the post-layout simulation result of the Ci → Co delay of 28T and the proposed adder. The up arrow denotes the 0→1 flip of Ci, and the down arrow denotes the 1→0 flip of Ci. According to (5), “
Delay (m)” could obtain a minimum value when
, in other words,
m = (2
− 1. According to
Table 8, we take
(ps). Therefore, the optimal value of m is 2.08, which means that we could obtain the best speed for an adder chain of every two PTL adders and one 28T adder.
3.3. Glitch Issue
Most PTL-based adders suffer from a glitch issue. Due to its weak driving capacity, the state of a pass gate is easily influenced by other inner flipping signals. It might be turned on unexpectedly and turned off immediately, thus forming a glitch. In most cases, the glitch might not lead to logic errors. But for the next-level circuits driven by the glitched adder, the dynamic power rises.
Table 9 shows the input flipping that causes glitches at output ports “Sum” and “Co”. Among all 56 cases, there are 13 cases with glitches. A total of 11 out of 13 cases are related to multi-input-flipping. This means that the proposed adder tends to cause glitch issues and increase the power of next-level circuits when more than one input flips.
Therefore, to design a low-power multiplier, it is better to avoid having more than one input of the PTL full adder to flip at the same moment.
4. PTL-Based Multiplier
In this section, a low-power 8-bit signed multiplier based on the proposed adder is presented. Firstly, the key to optimizing the multiplication is to reduce the computation count. To achieve this purpose, carry-save array multipliers pass the carry to the next level adders, and Wallace tree methods compress the number of partial products in each level. Although Wallace tree methods have the most complex structure, they use the fewest adders.
Booth encoder methods [
13], on the other hand, encode the input sequence according to a certain concept. An improved version of Booth encoding, known as modified Booth encoding (MBE), was proposed [
14]. It enables parallel operations at higher radices.
Table 10 illustrates the radix-4 MBE pattern, where the multiplicand is encoded in groups of 3 bits. The modified Booth encoder methods and Wallace tree combine to form the modified Booth Wallace tree (MBW) [
13,
32,
33].
In this design, we use the MBE and Wallace adder tree to reduce the circuitry. According to
Table 10, the modified Booth encoder circuit could be implemented as shown in
Figure 23. It produces partial products to the adder tree.
The adder tree for an 8-bit signed multiplier is shown in
Figure 24. The adder tree consists of four rows, with each row composed of full adders and half adders. They compress the partial products in each row. After compression, the partial products are finally summed up by a series of carry-propagating adders.
According to
Table 6, the proposed full adder has a 13.78% power advantage over the 28T CMOS full adder. This motivates the use of the proposed full adder in the adder tree to obtain the power advantage. As explained in
Section 3.2, it is preferable to stagger the proposed adder and 28T adder both vertically and horizontally. In particular, in row 3, a minimum horizontally propagated delay could be obtained by staggering each proposed adder with one 28T adder. However, to pursue more low-power advantages, we decided to stagger one proposed adder and one 28T adder.
Moreover, as explained in
Section 3.3, it is better to use the proposed adder, where three inputs flip at different moments. It is not optimal to use it in row 0 and row 1. Row 0 includes only a half adder. The inputs of adders in row 1 are mostly provided by the Booth encoder. It is reasonable to assume that the partial products arrive in row 1 at the same time. In this case, more than one input of an adder in row 1 would flip at the same time, leading to the glitch issue. Therefore, it is proper to put the proposed adders in row 2 and row 3. In row 2, the inputs of each adder are provided by different adders or the Booth encoder. We might assume different arrival moments for the propagation of each input flip. In row 3, the proposed adders and CMOS adders are staggered, as explained before. In row 0 and row 1, only CMOS half adders and full adders are used.
The final circuit of the adder tree is shown in
Figure 25. It consists of 28 full adders and 3 half adders. Among the 28 full adders, 14 adders are the proposed adders. The rest of the full adders and half adders are CMOS-based.
5. Simulation Results
In this section, the performance of the proposed multiplier is verified via post-layout simulation. The simulation was conducted on the Cadence platform. The multiplier was designed based on a 28 nm CMOS process. The typical power voltage was 0.9 V.
Firstly, we designed the layout of the proposed multiplier. We also used the Design Compiler (DC) synthesis tool to produce a multiplier for comparison, and we used the IC compiler to produce the layout of the synthesis multiplier. The layout is shown in
Figure 26.
Figure 27 shows the post-layout simulation results of power consumption at multiple process corners. The red curve denotes the proposed multiplier, and the black curve denotes the synthesis multiplier. The simulation was conducted at room temperature at 27 °C. The simulation frequency was 500 MHz.
For all corners, an 8% power reduction could be observed. The power reduction is mainly attributed to the power advantage from the proposed full adder.
Figure 28 shows the post-layout simulation results of the worst-case delay. A 6% delay increase could be observed. According to the post-layout simulation listed in
Table 6, the proposed adder has a larger worst-case delay than the 28T full adder. The staggered carry-propagating adders in row 3 have delay advantages over the synthesis multiplier. The final 6% increase in the worst-case delay is the comprehensive result of delay optimization. It is the trade-off with the power advantage.
Table 11 shows the comparison between our work and other multiplier studies. In the table, the term “PDP” denotes the product of power and delay, and the term “APP” denotes the product of power and area. We obtained the best PDP and ADP of all works. Admittedly, our work was based on the latest process. It might contribute to the performance advantages. Some of the work listed in the table was about the approximate multiplier design, which obtained better performance in delay and power compared to exact multipliers. Our work still maintained an advantage compared to approximate multipliers. The work “CSSP 2019 [
34]” was based on the 32 nm process, which is close to our 28 nm process. Our work achieved only 19.02% of the PDP and 3.5% of the APP compared to “CSSP 2019”. This indicates the contribution of our work.
6. Conclusions
In this paper, we propose a novel PTL full adder circuit based on the 28 nm process. By using a parallel PTL XOR gate, we reduced the parasitic capacitance at the critical path of the adder and, thereby, reduced the worst-case delay. We also removed the inverter, which was to produce the XNOR result. Compared to a conventional CMOS-based full adder, the power consumption was reduced by 13.78%.
We also designed a low-power 8-bit signed multiplier based on the proposed full adder. The post-layout simulation showed an 8% power reduction compared to the multiplier produced by the DC synthesis tool. Compared to an 8-bit multiplier based on 32 nm presented in the references, our work achieved only 19.02% PDP and 3.5% APP of the reference.

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}