
Recognition and Detection of Persimmon in a Natural Environment Based on an Improved YOLOv5 Model



Abstract
:1. Introduction
- Combining YOLOv5 with a centralized feature pyramid (CFP) [21] so the model focuses more on feature extraction, which gives strong robustness and generalization ability.
- Based on the traditional model, a convolutional block attention module (CBAM) [22] is integrated to improve the detection effect.
- The GIoU_loss function is replaced by Alpha-IoU loss to improve the detection accuracy [23].
- For the better detection of small targets, a small target detection layer (STDL) is added based on the structure of the YOLOv5 model.
2. Persimmon Datasets
2.1. Image Collection
- Persimmon categories: Unripe persimmon and ripe persimmon.
- Collection environment: In order to avoid overfitting due to the insufficient diversity of the sample data, the samples were collected under normal light in the day and weak light in the night. Figure 1 shows the effect in different lighting. At the same time, different persimmon numbers, different degrees of branch and leave blocking conditions, and different distances of persimmon were photographed to increase the diversity of the datasets. The pictures taken are shown in Figure 2.
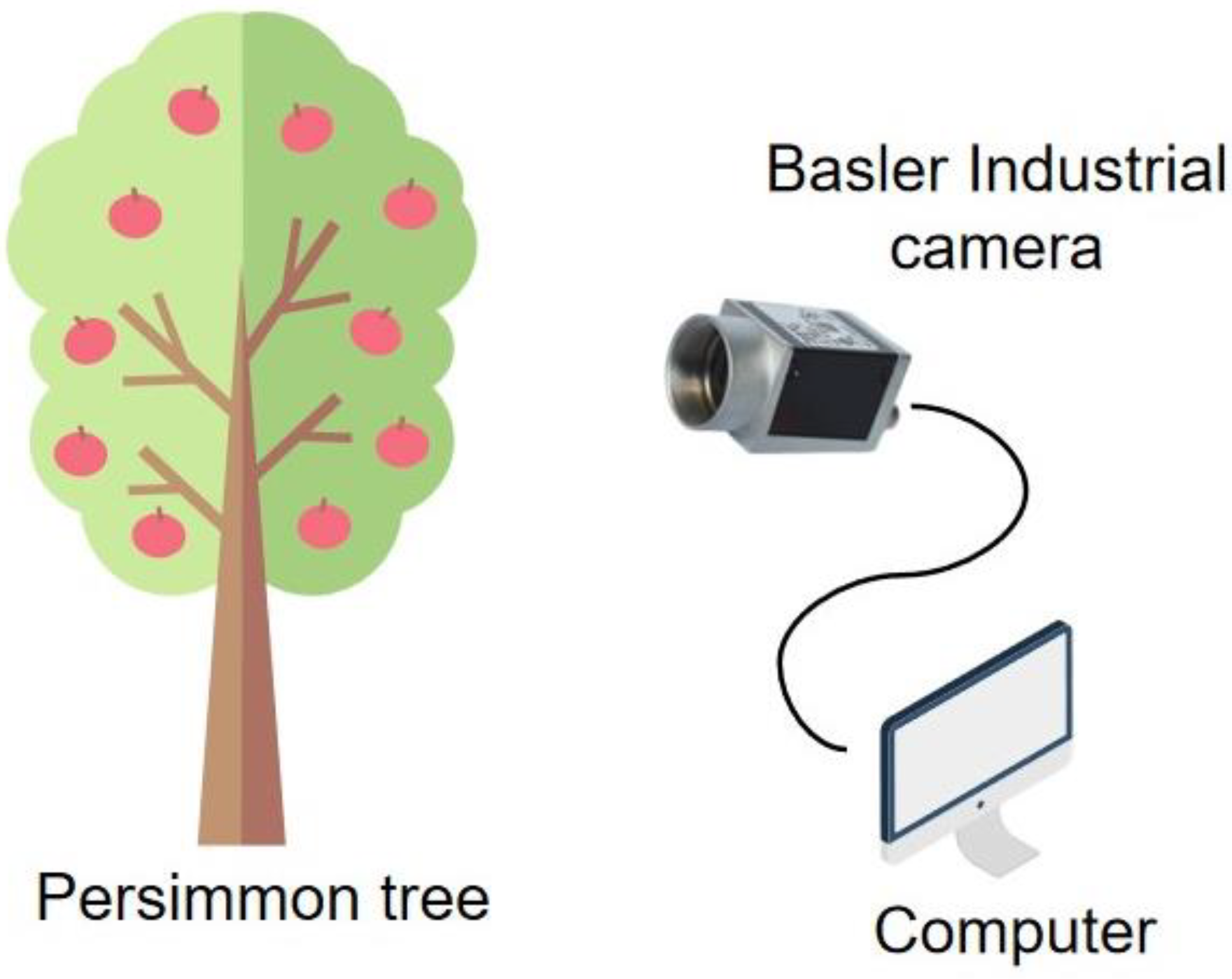
- Collection location and collection device: The persimmon datasets were collected from the NongCuiyuan experimental field of Anhui Agricultural University. The image acquisition equipment was a Basler industrial camera. The dataset acquisition device used in this paper is shown in Figure 3.
- Image processing: The datasets were first manually annotated using Labelimg to minimize the impact of other useless pixels in the image on the training datasets. In addition, digital image histogram and equalization technology were used to enhance the contrast of the original datasets without changing the basic features of the images [24].
2.2. Dataset Enhancement
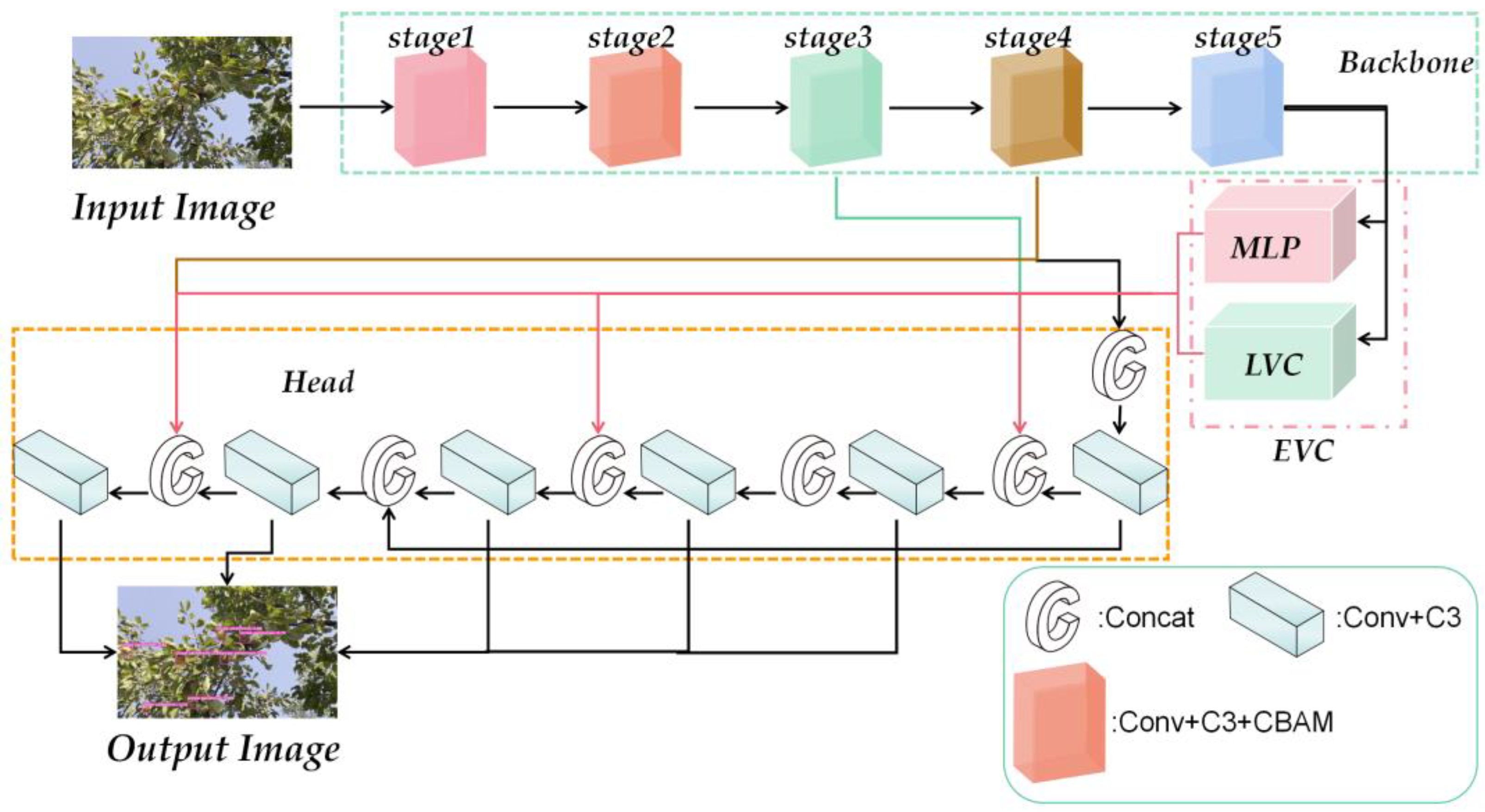
3. An Improved YOLOv5 Model
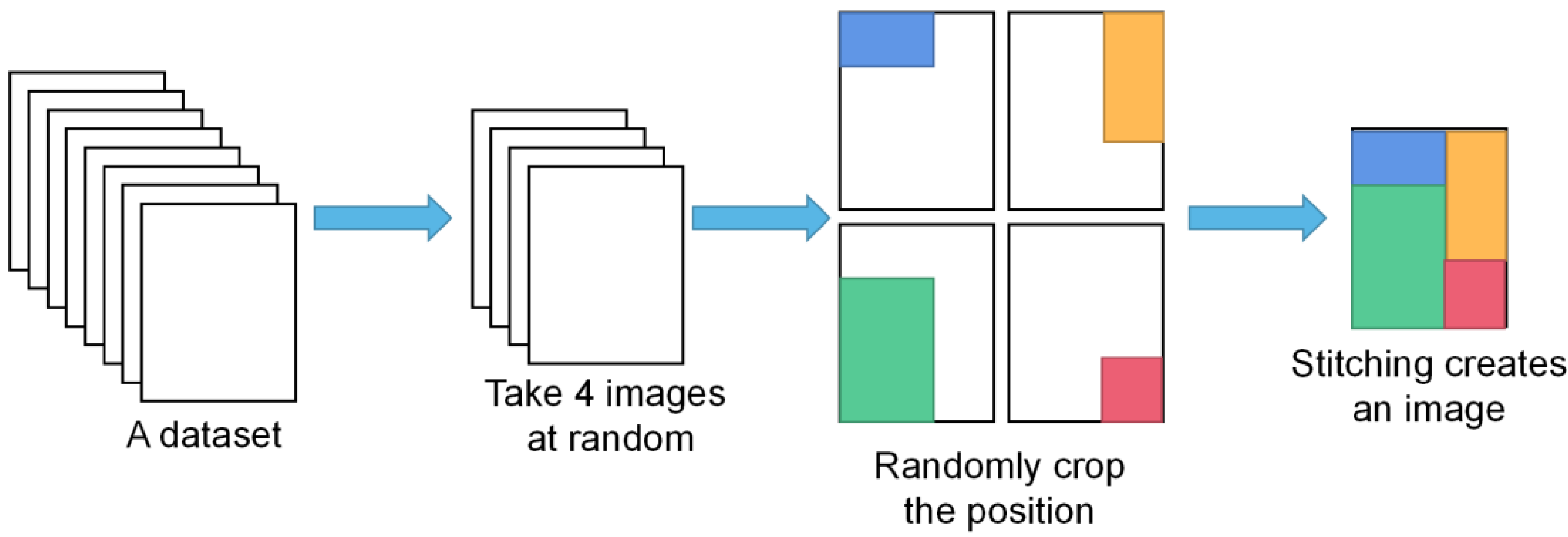
3.1. Mosaic Data Augmentation
3.2. Multi-Scale Feature Extraction
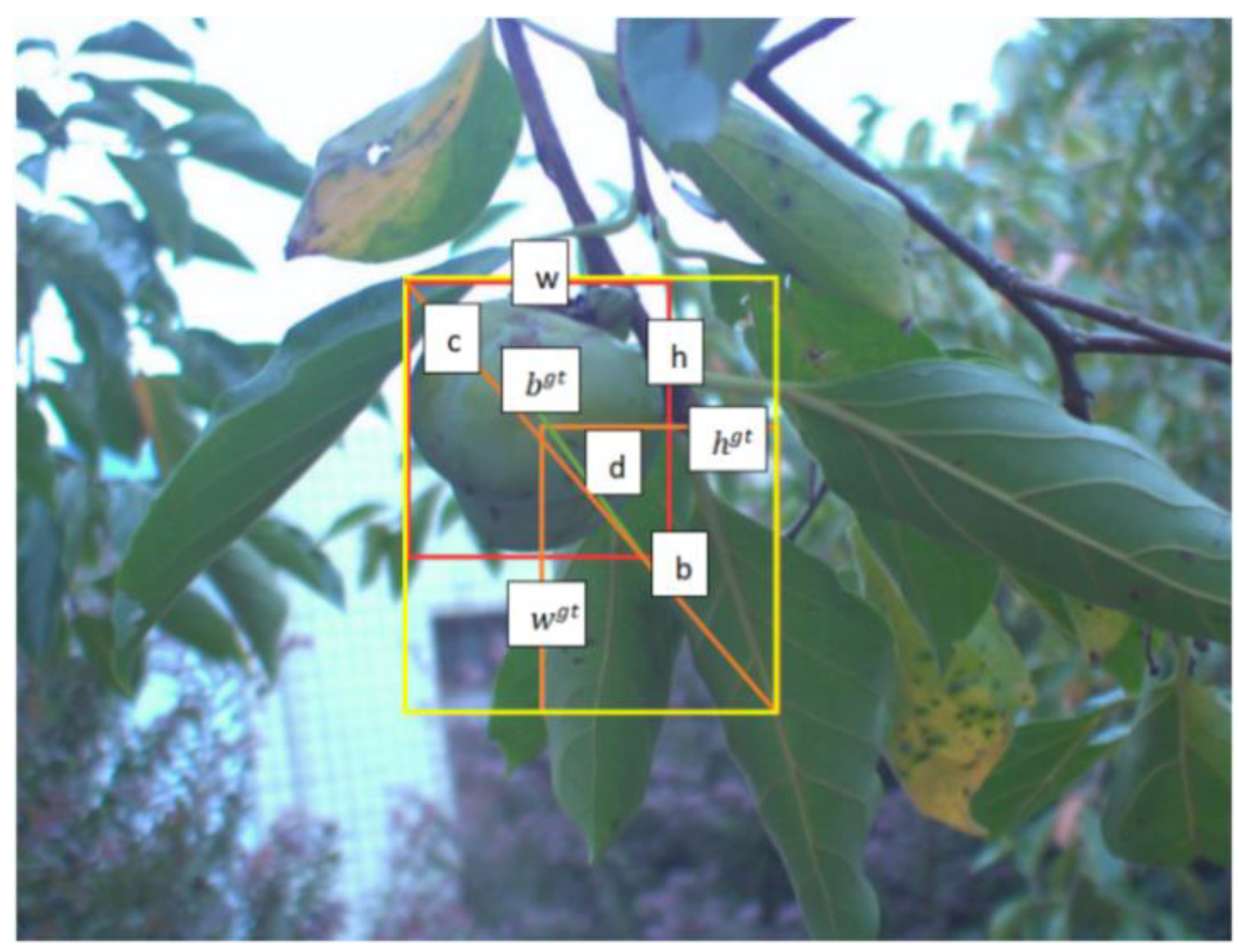
3.3. Loss Function Optimization
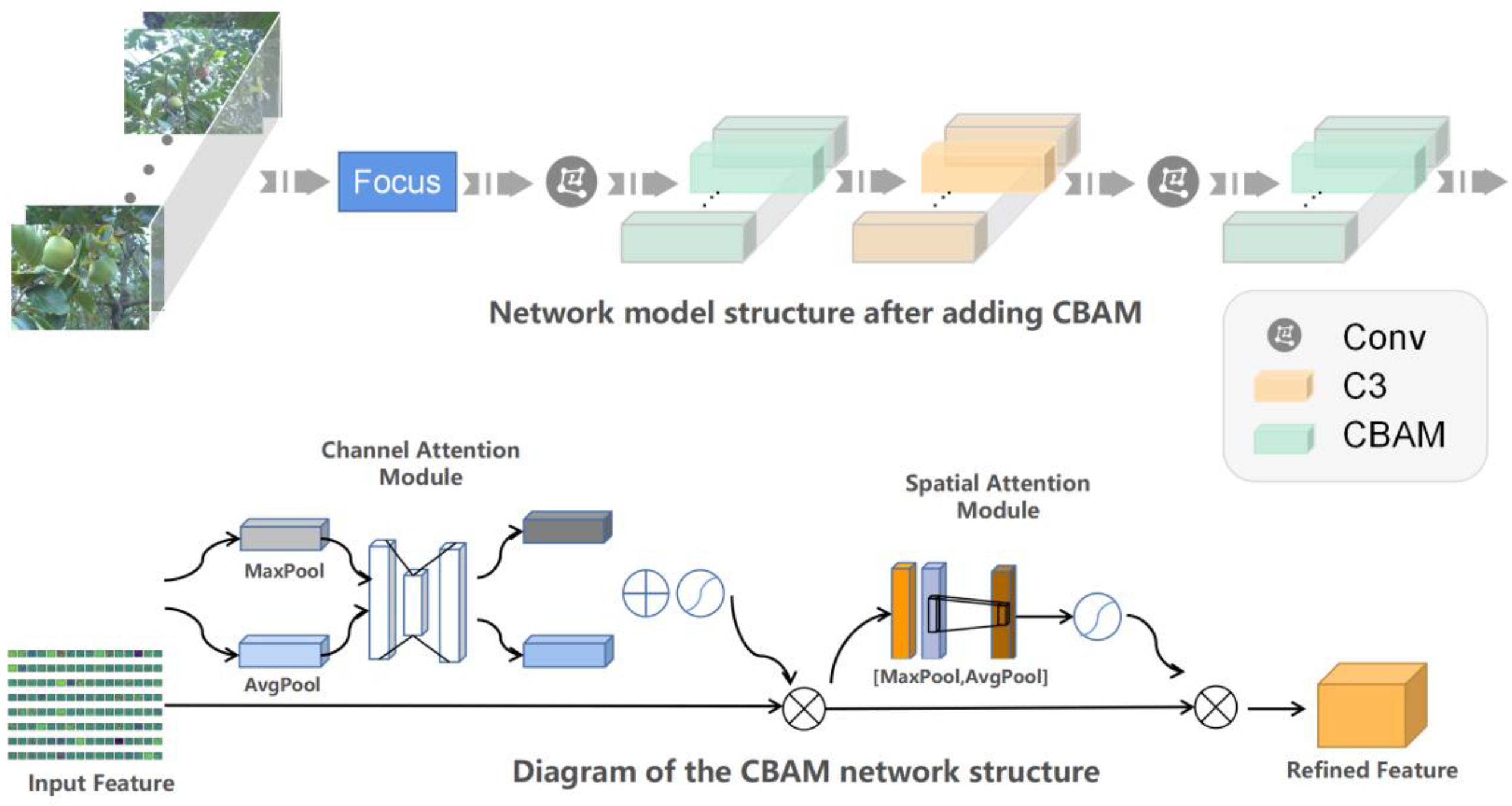
3.4. Integration of the CBAM Attention Mechanism
3.5. Add a Small Target Detection Layer
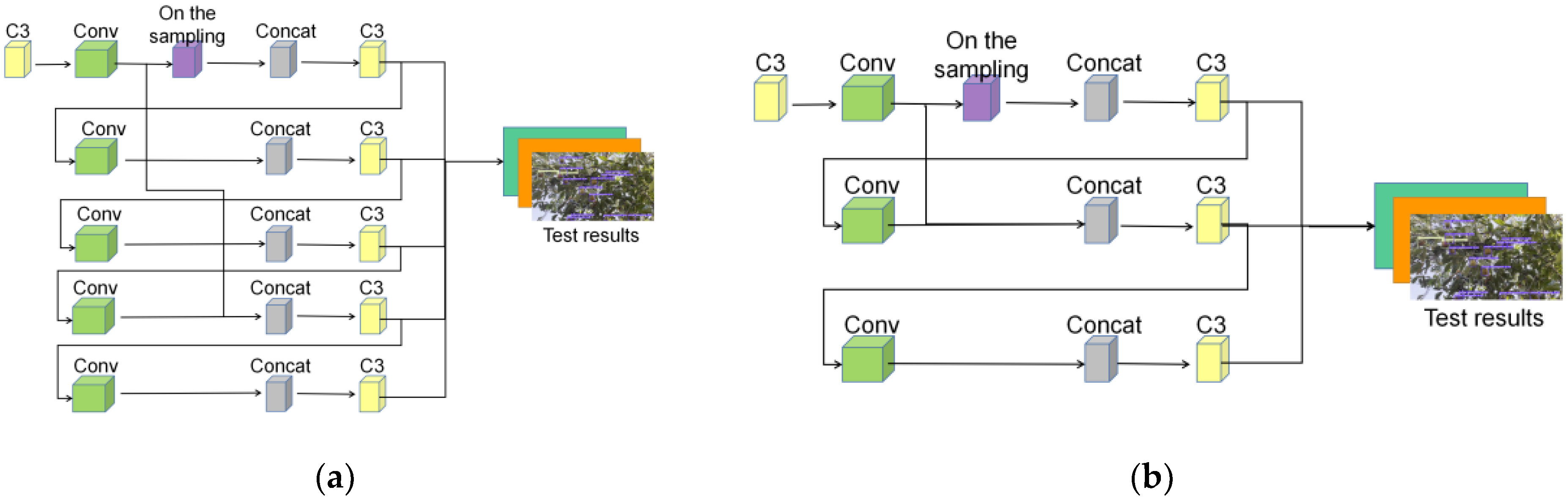
3.6. Combined Centralized Feature Pyramid
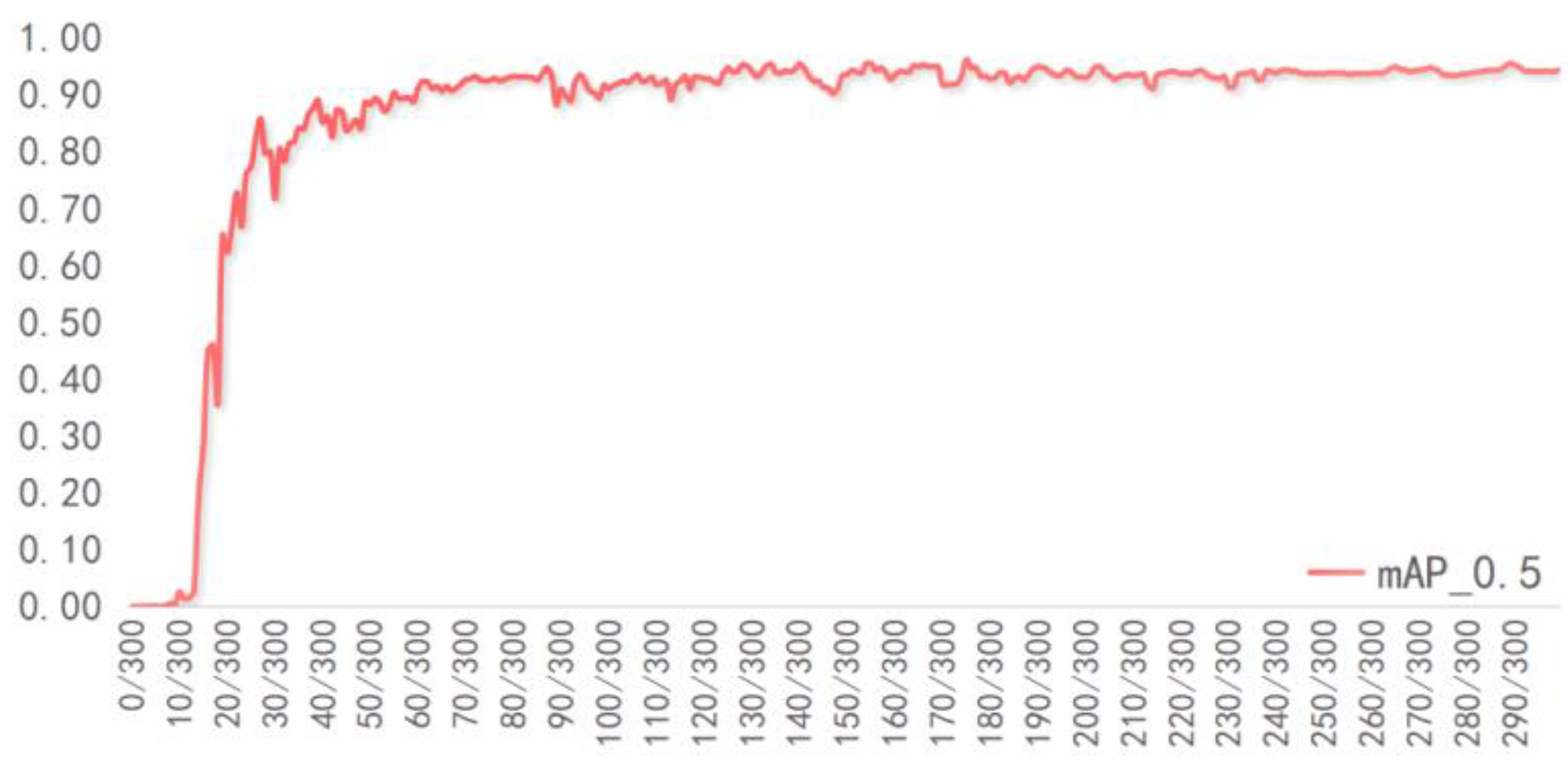
4. Training of the Model
4.1. Experimental Setup
4.2. Detection Experiment
4.3. Comparative Experiments
5. Model Test on Small Target Detection
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tripathi, M.K.; Maktedar, D.D. A role of computer vision in fruits and vegetables among various horticulture products of agriculture fields: A survey. Inf. Process. Agric. 2020, 7, 183–203. [Google Scholar] [CrossRef]
- Kapach, K.; Barnea, E.; Mairon, R.; Edan, Y.; Ben-Shahar, O. Computer vision for fruit harvesting robots-state of the art and challenges ahead. Int. J. Comput. Vis. Robot. 2012, 3, 4–34. [Google Scholar] [CrossRef]
- Bergerman, M.; Van Henten, E.; Billingsley, J.; Reid, J.; Mingcong, D. IEEE Robotics and Automation Society Technical Committee on Agricultural Robotics and Automation. IEEE Robot. Autom. Mag. 2013, 20, 20–23. [Google Scholar] [CrossRef]
- Bechar, A.; Vigneault, C. Agricultural robots for field operations: Concepts and components. Biosyst. Eng. 2016, 149, 94–111. [Google Scholar] [CrossRef]
- Wang, Z.F.; Jia, W.K.; Mou, S.H.; Hou, S.J.; Yin, X.; Ze, J. KDC: A Green Apple Segmentation Method. Spectrosc. Spectr. Anal. 2021, 41, 2980–2988. [Google Scholar]
- Jia, W.; Zhang, Y.; Lian, J.; Zheng, Y.; Zhao, D.; Li, C. Apple harvesting robot under information technology: A review. Int. J. Adv. Robot. Syst. 2020, 17, 1–16. [Google Scholar] [CrossRef]
- Chaivivatrakul, S.; Dailey, M.N. Texture-based fruit detection. Precis. Agric. 2014, 15, 662–683. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining AdaBoost classifier and colour analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Tian, Y.; Duan, H.; Luo, R.; Zhang, Y.; Jia, W.; Lian, J.; Zheng, Y.; Ruan, C.; Li, C. Fast Recognition and Location of Target Fruit Based on Depth Information. IEEE Access 2019, 7, 170553–170563. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning-Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey. Knowl. -Based Syst. 2020, 201–202, 106062. [Google Scholar] [CrossRef]
- Li, J.Q.; Liu, Z.M.; Li, C.; Zheng, Z.X. Improved Artificial Immune System Algorithm for Type-2 Fuzzy Flexible Job Shop Scheduling Problem. IEEE Trans. Fuzzy Syst. 2021, 29, 3234–3248. [Google Scholar] [CrossRef]
- Hou, S.; Zhou, S.; Liu, W.; Zheng, Y. Classifying advertising video by topicalizing high-level semantic concepts. Multimed. Tools Appl. 2018, 77, 25475–25511. [Google Scholar] [CrossRef]
- Inkyu, S.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef]
- Ghoury, S.; Sungur, C.; Durdu, A. Real-Time Diseases Detection of Grape and Grape Leaves using Faster R-CNN and SSD MobileNet Architectures. In Proceedings of the International Conference on Advanced Technologies, Computer Engineering and Science (ICATCES 2019), Antalya, Turkey, 26–28 April 2019. [Google Scholar]
- Liang, C.; Xiong, J.; Zheng, Z.; Zhong, Z.; Li, Z.; Chen, S.; Yang, Z. A visual detection method for nighttime litchi fruits and fruiting stems. Comput. Electron. Agric. 2020, 169, 105192. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized Feature Pyramid for Object Detection. arXiv 2022, arXiv:2210.02093. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- Wang, Y.; Cai, J.; Zhang, D.; Chen, X.; Wang, Y. Nonlinear Correction for Fringe Projection Profilometry with Shifted-Phase Histogram Equalization. IEEE Trans. Instrum. Meas. 2022, 71, 5005509. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P | R | mAP | |
|---|---|---|---|
| Training set | 98.95% | 88.18% | 94.47% |
| Validation set | 92.69% | 94.05% | 95.53% |
| Test set | 94.26% | 90.73% | 93.18% |
| Methods | P | R |
|---|---|---|
| YOLOv5-AIoU | 92.07% | 91.02% |
| YOLOv5-EIoU | 91.30% | 90.82% |
| Traditional YOLOv5 | 90.56% | 87.39% |
| Methods | mAP (Unripe Persimmon) | mAP (Ripe Persimmon) |
|---|---|---|
| Proposed model | 98.73% | 98.03% |
| AIoU-CBAM | 98.67% | 97.62% |
| Traditional YOLOv5 | 98.10% | 95.20% |
| SSD | 70.85% | 72.81% |
| Methods | FDR | LDR |
|---|---|---|
| Traditional YOLOv5 | 5.7% | 35.6% |
| YOLOv5-AIoU | 6.3% | 30.5% |
| AIoU-CBAM | 5.2% | 26.9% |
| AIoU-CBAM-STDL | 4.8% | 24.5% |
| Proposed in this paper | 4.3% | 23.7% |
| Parameter | Single Fruit | Overlapping Fruit | ||
|---|---|---|---|---|
| Occlusion | No Occlusion | Occlusion | No Occlusion | |
| Number of pictures/pictures | 40 | 75 | 70 | 50 |
| Rate of identification/% | 92.5 | 97.3 | 94.3 | 94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Z.; Mei, F.; Zhang, D.; Liu, B.; Wang, Y.; Hou, W. Recognition and Detection of Persimmon in a Natural Environment Based on an Improved YOLOv5 Model. Electronics 2023, 12, 785. https://doi.org/10.3390/electronics12040785
Cao Z, Mei F, Zhang D, Liu B, Wang Y, Hou W. Recognition and Detection of Persimmon in a Natural Environment Based on an Improved YOLOv5 Model. Electronics. 2023; 12(4):785. https://doi.org/10.3390/electronics12040785
Chicago/Turabian StyleCao, Ziang, Fangfang Mei, Dashan Zhang, Bingyou Liu, Yuwei Wang, and Wenhui Hou. 2023. "Recognition and Detection of Persimmon in a Natural Environment Based on an Improved YOLOv5 Model" Electronics 12, no. 4: 785. https://doi.org/10.3390/electronics12040785
APA StyleCao, Z., Mei, F., Zhang, D., Liu, B., Wang, Y., & Hou, W. (2023). Recognition and Detection of Persimmon in a Natural Environment Based on an Improved YOLOv5 Model. Electronics, 12(4), 785. https://doi.org/10.3390/electronics12040785