1. Introduction
New, sophisticated, and dangerous malware are continuously increasing, which may lead to cybercrimes that affect national security, human beings, and the economy. The expected financial losses due to cybercrimes are estimated to reach USD 10.5 trillion by 2025 [
1].
Ensuring secure networks or guaranteeing the security of the information system at any organization is considered a challenge [
2] owing to the need for monitoring and controlling the data traffic flow in and out of a network’s edge [
3]. Thus, presenting a security defender is a trade-off between the cost and the complexity of this security solution in terms of computation, communication, and storage [
4].
Cybercrime aims either to damage an organization’s infrastructure, to gain unauthorized access, or to leak confidential data. The challenge is that the attackers change their behavior for attempting an attack every day. Thus, detecting a new attack based on a previous pattern or signature is futile. Nowadays, intelligent detection based on anomaly detection for any compromise is the most popular strategy [
5,
6].
Data exfiltration is one of the most common types of attacks on organizations or individuals. It is the process of retrieving, modifying, copying, or transferring sensitive information from a computer, a server, or another device without authorization [
7].
Recently, statistics have shown that the number of data breaches using DNS tunneling has significantly increased. Many approaches have been proposed by researchers to address the DNS tunneling problem [
8]; however, the proposed DNS tunneling detection methods did not consider the method of selecting features based on statistical and/or behavioral features, which affects both the complexity of the system and the overall performance of the network.
In recent years, data exfiltration has been one of the uses for tunneling. Tunneling is the process of encapsulating the original packet inside another packet to cause data leakage. Traditional tunnels have been established based on network layer protocols, but, recently, they have been established via application layer protocols, such as the domain name system (DNS), secure shell (SSH), and the hypertext transfer protocol (HTTP) [
9,
10].
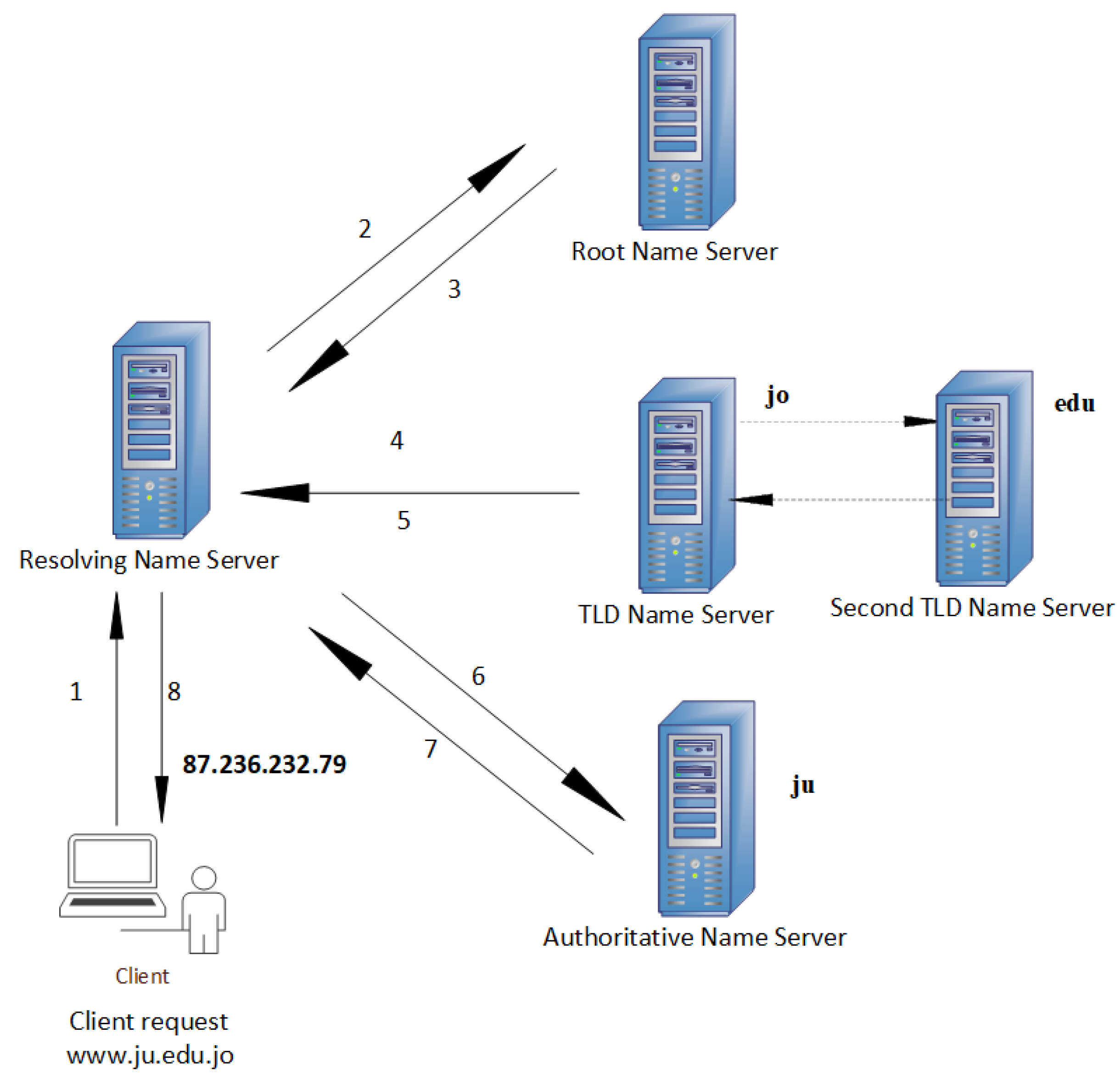
The DNS has a critical role in the network of resolving the domain name to the related IP address; however, DNS communication comparatively has a poor policy, and this point might be exploited by cybercriminals to maintain a covert channel (tunnel) for data leakage from inside the network by an infected host [
11].
DNS tunneling is a well-known cyber attack used for stealing sensitive information. The attacker encapsulates confidential information into DNS requests or responses to bypass intrusion detection, intrusion prevention, or other network security monitoring mechanisms [
12].
The attacker can use many techniques to exploit DNS, one of which is to register a domain name (e.g.,
attacker.com) and install a malware victim host so that the attacker will be able to take the control of this infected host. Thus, the attacker can steal sensitive data, such as credit card numbers, personal passwords, or intellectual property information, in a DNS request of the form
arbitrary-string.attacker.com [
13].
Interestingly, the firewalls in most enterprises are configured to allow DNS packets. The attacker can control the infected host and use a crafted DNS request packet on UDP port 53 to establish a tunnel to steal sensitive data. The crafted DNS has encapsulated confidential information into the DNS packet [
14,
15].
The default configuration of any security solution allows any packet carrying port 53. Port 53 is used for DNS, and it is always open to transfer DNS queries. Checking DNS packets with firewalls, intrusion detection/prevention systems, or any security solution will degrade the performance of the network significantly [
16]. On the other hand, DNS packets are used by intruders to exfiltrate the data. So, there is a need for intelligent techniques that can cope with detecting the covert channel and, at the same time, keep the efficiency of the organization.
The difference between malicious and normal traffic can be easily detected or noticed, but wading inside the details of the normal packet to detect if there is a bypass for the security policies is a challenge.
1.1. Motivation
The motivation of this paper is to take advantage of the outcome results conducted using the testbed and Tabu-PIO feature selection algorithm to propose a hybrid DNS tunneling detection system based on the packet length and selected features for the network traffic that can enhance accuracy, F-score, and the run-time of DNS tunneling system.
1.2. Contributions
The main contributions of this paper are summarized as follows:
It focuses on designing a lightweight DNS tunneling detection system to detect data exfiltration.
It provides a clear idea about the name resolution system using the DNS protocol and DNS tunneling.
It presents a list of ranges recommended for the DNS packet length to detect if there is a DNS covert channel.
It proposes a hybrid DNS tunneling system based on the M-PIO and a specific DNS packet length range.
1.3. The Paper’s Organization
We organized our paper as follows. In
Section 3, we present the previous work on the DNS tunneling techniques in machine learning. In
Section 4, we describe our design and implementation for the DNS tunneling environment.
Section 4 explores the background of attack models and ML techniques for detection.
Section 6 presents the experiments and evaluations for three different datasets. Finally, in
Section 7, our conclusions and possibilities for future work are given.
3. Related Works
DNS tunneling can be detected using two popular methods: traffic analysis and payload analysis [
23]. In payload analysis, only a single DNS request is analyzed in terms of the DNS packet attributes, such as the number of bytes, the packet length, and the packet contents. In this method, the analysis aims to detect general rules or a signature for the packet. The second method aims to analyze the total traffic over a specific period of time. This method focuses on analyzing the volume (size) of DNS traffic or the total number of host names per domain [
24]. The domain history is used when a traffic analysis is used as an indication of tunneling [
25].
A malware program that is meant to steal data must use a covert channel in the presence of security countermeasures. Today, malware developers frequently employ the DNS protocol as a covert conduit for this purpose [
26,
27].
A detection method for DNS tunneling and low throughput for data exfiltration has been proposed [
28]. The proposed method has three phases: data collection, feature extraction, and anomaly detection. The evolution of the proposed method has been conducted using 47 million DNS requests per hour.
In [
29], a method for DNS tunnel detection is proposed, which is mainly based on the isolated forest for Android. Their proposed approach, called KRTunnel for mobile devices, achieved an accuracy of 98.1%.
Chen et al., in [
30], proposed the use of the LSTM model for a DNS covert channel detection method, noting that their proposed method does not rely on feature engineering. To clarify it further, they use the FQDNs of DNS packets as the input in the first stage, and then, they implement an end-to-end detection approach using the LSTM model.
Liu et al., in [
31], proposed a DNS tunnel detection mechanism based on behavior features. The authors used four DNS tunnel tools to generate the DNS records (i.e., OzymanDN, nscat2, dns2tcp, and iodine). The normal traffic was collected from the ISP DNS server, while the tunnel traffic was collected from the Intranet DNS server. The generated data contain four categories of features with 18 behavior features, including packet size, time interval, records type, and domain entropy. The proposed mechanism was deployed at the recursive DNS to identify the tunnel. The accuracy of the system reached 99.6%.
Bubnov, in [
32], addressed the problem of DNS tunneling. The author used the feed-forward neural network with multi-labels, in which each label represents a DNS tunneling technique (i.e., tunnel dnscapy, tunnel dns2tcp, tunnel iodine, tunnel tuns, and plain). The dataset was collected from a peer-to-peer topology network with a client-created DNS tunnel and a DNS server. The proposed approach evaluation yielded 83% in terms of accuracy and 81% and 84% for recall and precision, respectively.
Lambion et al., in [
33], developed machine learning classifiers for the detection of DNS tunneling attacks by using the random forest (RF) and convolutional neural network (NN) structures. The results of the developed machine learning classifiers showed that the accuracy of the proposed detector using the RF and NN is 96%.
Chowdhary, Bhowmik, and Rudra, in [
34], built a DNS tunneling attack detector. The authors of this paper combined two methods to build a detector. The first method relies on the cache misses on the DNS server cache, while the second method uses machine learning to classify the DNS query. Several classifiers were used and evaluated in terms of accuracy, f-score, and time. The proposed detector was able to inform the user if there is any DNS tunneling attack in real time.
Altuncu et al. proposed a deep learning-based detector that detects and prevents tunneling attacks over the DNS in real time [
35]. The results showed that the DNS tunneling in a system was detected with 99.9% accuracy and 99.8% precision, which means that the proposed system has a high success rate in preventing tunneling threats in DNS traffic.
Sabir et al. presented a review study that identifies and classifies machine learning approaches, evaluation datasets, and performance metrics using a systematic literature review method [
9]. The authors conclude that the integration of behavior and data-driven mechanisms should be explored. Moreover, they conclude that there is a need to develop large-size and high-quality datasets.
Ishikura et al., in [
12], proposed a DNS tunneling detection method based on the cache-property-aware features. The proposed approach used the cache miss count to characterize the DNS tunneling traffic. Based on the selected feature, two filters have been introduced to detect DNS tunneling: a long short-term memory (LSTM) and a rule-based filter. The rule-based filter achieved a higher detection rate than the LSTM filter. The authors use a DNS cache server installed on the local network to capture the DNS traffic generated on the DNS cache server. The generated data were used to evaluate the proposed methods.
Zhan et al. proposed a method for detecting data exfiltration of the DNS over HTTPS (DoH) [
36]. The proposed method analyzed the fingerprints of DoH clients and extracted flow-based features to identify the DNS tunneling. The results proved that the proposed method is effective and hard to evade.
Nguyen and Park, in [
37], proposed a two-layer transformer system to detect DoH tunneling attacks. The proposed system can be integrated with a secure operating system in an enterprise network. The accuracy of the system was 99.4%, and it only needs 20% labeled data compared to other supervised machine learning classifiers.
The main challenge of this research is the dataset. There is no standard dataset for DNS tunneling used by researchers. All datasets used by researchers have been generated by DNS tunnel tools on private networks. Moreover, the proposed approaches that used machine learning did not consider the number of features used to train the model. The feature selection step is very critical and affects the speed and accuracy of the model.
Table 1 presents the related works mentioned in this section and compares them in terms of datasets or tools used to generate the DNS tunneling data.
4. Testbed Environment Setting for Dataset Generation
This section features a detailed description of the testbed setting and the DNS tunneling tools that were used, as well as a description of how the network was organized with the corresponding IP address for each device.
A virtual machine infrastructure (VMI) was used to build the proposed network.
Figure 4 presents the testbed environment for setting up a DNS tunnel with the corresponding IP addresses that were used for each device. Windows 10 was used for the nonvulnerable host, and Kali Linux (Ubuntu) kernels were used as the infected host. The attacker controls the victim from outside the network and has its own authoritative server with the “
attacker.com“ domain name.
In this paper, four DNS tunneling tools were used in the testbed. The attack passes through different stages before the DNS tunneling begins data leakage. The first stage is initial access to the victim using reconnaissance, scanning, and exploitation of any vulnerability. The second stage is exploitation to add malicious software to obtain full access to the victim. The final stage is the attack, in which the sensitive and conditional data are exfiltrated through the DNS packets.
To generate the datasets dnscat2, dns2tcp, dnsteal, and iodine, DNS tunneling tools have been used on Kali Linux (Ubuntu).
Table 2 features the description of each tool and the number of records that have been generated from each tool. After this, all records generated using the DNS tools were merged into a DNS tunnel, which holds 34,109, while the normal traffic is 3240.
Generally speaking, when a client sends a DNS query to the DNS server normally the length of the DNS packet is between 50 and 550 bytes [
38]. The reason that the length of a DNS packet is that there are various types of DNS packets, such as query messages, response messages, and recursive queries, and each type has a different packet length.
Overall, the range of the DNS packet lengths must be clarified in order to filter the suspicious DNS packets in the network. Thus, any length outside this range is suspicious, but the question of how to detect the abnormality, even though the length of the packet is within the normal range, remains.
Based on the testbed that has been conducted using different DNS tunneling tools, the length of the packet was changed. Additionally, a specific length of DNS packets was found for the DNS tunneling, which is 101, 110, 115, 148, 149, 156, 157, 167, 173, 183, 229, 269, 325. On the other hand, determining a specific package length enhances the performance of the DNS tunneling detection system by presenting a fast filtering approach based on only one attribute: “length”.
More details about tools, packets and the packet content will be found in
Appendix A.
5. The Proposed Hybrid DNS Tunneling Detection Approach
This section introduces the proposed hybrid DNS tunneling detection approach. The proposed hybrid approach consists of three main phases, as illustrated in
Figure 5: data processing, model development, and model testing. The first phase is data preprocessing, which has been discussed in
Section 5.1.
Section 5.3 and
Section 5.5 present the standard pigeon-inspired optimizer (PIO) and the modified version of the PIO used in DNS tunneling model development. Finally,
Section 5.5 presents the hybrid testing procedure that checks the packet length range before using the developed model in phase two.
5.1. Data Preprocessing
The dataset preprocessing phase is very important before building the training to eliminate bias or incorrect classification. It passes through different steps, such as data normalization, reduction, cleaning, and transformation. Preprocessing was applied to all datasets before their use for the feature selection or for the hybrid approach.
In this paper, a new DNS tunneling dataset has been generated from the UNSW-NB15 dataset by extracting only the DNS packet and calling DNS records from UNSW-NB15. The new DNS records extracted from the UNSW-NB15 training set do not include any redundant records. All symbolic data have been converted to numeric values. The attack class is considered to be a DNS tunnel and has been replaced by “1”, while the normal class label has been set to “0”. A DNS tunneling detection system is supposed to be used in the early stages of a network and filter only the DNS packets.
In the data normalization step, a new scaling has been performed for all data values into a proportional range of each feature. To avoid the classifier’s bias for the majority class over the minority in an ambulance dataset, this step is crucial [
39]. Equation (
1) presents the normalization scale for all applied datasets.
5.2. Pigeon-Inspired Optimization (PIO)
The pigeon-inspired optimizer belongs to bio-inspired swarm intelligence. The idea of the PIO algorithm is inherited from the homing behavior of pigeons. In the past, pigeons were used to carry messages between people over long distances [
40]. Pigeons used the magnetic particles in their beak to navigate to their homes. The PIO algorithm is based on two main operators: map and compass and landmark operators [
41]. During the map and compass operator, the pigeon used the location of the sun and the Earth’s magnetic field while using the landmark operator to navigate toward the destination [
42]. Using the landmark operator, the pigeon guides the swarm if it is familiar with the location; otherwise, it will follow the leader. As mentioned earlier, the PIO has two main operators. The following clarifies the mathematical model of these operators:
The of a solution or the selected pigeon reflects the quality of the solution based on the false positive rate (FPR), the number of the selected features, and the true positive rate (TPR).
5.3. Modified Pigeon-Inspired Optimization (M-PIO)
Feature selection is a vital process used to remove irrelevant features, thus reducing the dimensionality of the dataset, which also improves the accuracy of the system and reduces the processing time. In this section, a modified version of the pigeon-inspired optimizer (M-PIO) for feature selection is used [
6]. The modified version of the M-PIO contains a local search algorithm as an extra operator. Two variations of the local search PIO (LS_PIO) are used; the first one uses the hill climbing algorithm, while the second one uses the Tabu search algorithm. Additionally, a DNS tunneling detection approach based on a one-class support vector machine is proposed, as shown in
Figure 5.
In LS-PIO, the first population is randomly generated; the solution is presented as a vector that includes all of the features. The vector length is fixed, and the value of the index indicates the absence or presence of the corresponding feature by zero or one, respectively.
The solution (pigeon) that has the highest fitness value is called the global solution, and the rest of the solutions (pigeons) will update their positions toward the global solution. The position of the pigeon, as illustrated in Equation (
7), depends on the pigeon’s velocity. The pigeon’s velocity determines the amount of change that will be applied to the solution. A pigeon’s velocity is calculated by the cosine similarity value for the pigeon and the best pigeon in Equation (
8).
In each iteration, after determining the global solution, it will be entered into the local search algorithm. The local search algorithm tries to find a better solution. In this paper, the Tabu search and the hill climbing algorithms have been used.
Modified Landmark Operator
The modified landmark operator works as the base in
Section 5.2, but it uses Equations (
7) and (
8) to update the pigeon’s position and to calculate the velocity, respectively. At each iteration, only half the number of pigeons is considered after sorting them by their fitness value. This eliminates the pigeons or the solutions that have bad fitness values.
5.4. Fitness Function
The fitness function has been used to evaluate the pigeons (solutions) in each iteration. In the LS_PIO, the fitness function used is presented in Equation (
9). Based on Equation (
9), the best pigeon is the pigeon that has the
minimum fitness value [
45]. As illustrated in Equation (
9),
N is the number of features in the dataset, and
F is the number of selected features in the solution.
,
, and
are weights that reflect the importance of each corresponding measure. The summation of all the weights is equal to one where
,
, and
. The weights of TPR and FPR are equal since they have the same importance regarding the DNS tunneling detection system. Though the weight of the number of selected features is smaller than other weights, this small fraction is used to give preference to solutions that have the same TPR and FPR but a different number of selected features.
Algorithm 1 presents the pseudocode of the modified LS_PIO.
In this paper, a hybrid DNS tunneling detection system has been proposed based on the M-PIO and packet range attributes. It can be noticed that the M-PIO produces the best set of features for the ingress packet. On the other hand, it is time-consuming to check at least the selected features that are produced from the M-PIO. Thus, in the hybrid approach, first, the check will be only based on one attribute: the packet length.
If the packet length matches any range, then the packet will classify as tunneling. When none of the ranges are matched, the system will check on the other selected M-PIO features.
5.5. Hybrid Model Testing
This subsection clarifies the testing phase for each packet that passes the DNS tunneling detection system. As illustrated in
Figure 5 each packet will be checked for the packet length range condition; if the packet length falls within the specified range, then it will be identified as a DNS tunneling packet regardless of the model’s decision. If the packet is not within the specified packet length range, then the model’s decision will be considered. Based on our testbed experiments, we notice that DNS tunneling packets fall within a specified length range. Thus, the packets that fall within the specified range are definitely DNS tunneling packets. However, not all packets may fall within the specified range, since our testbed only uses four tools to generate the DNS tunneling data. For this, we use it as an extra filter to enhance the detection rate of the system.
| Algorithm 1 Hybrid intelligent DNS tunneling detection system based on (Tabu-PIO and packet length) |
Input: : population size, R: ratio of map and compass, : local search iterations, : pigeons iterations, : packet length , : a solution Output: : global solution (set of features) |
- 1:
Initialize the first population randomly (). - 2:
Evaluate the population members according to their fitness by Equation ( 9). - 3:
Determine (the pigeon that has the minimum fitness value). - 4:
while () do - 5:
Update pigeon velocity and path toward using Equations ( 2) and ( 3). - 6:
Evaluate the updated pigeons according to their fitness by Equation ( 9). - 7:
Determine (the pigeon that has the minimum fitness value). - 8:
= Tabu_search () - 9:
if then = - 10:
end while - 11:
while () do - 12:
Sort solutions (pigeons) according to their fitness. - 13:
- 14:
Determine the desired location by Equation ( 5) - 15:
Update the position of the pigeon by Equation ( 6). - 16:
Update the best pigeon . - 17:
end while
|
7. Conclusions
Data exfiltration is one of the most current issues in the security field, and the ability to detect data leakage in the network is an issue, especially when the data are leaked by the DNS protocol. DNS tunneling is used to exfiltrate sensitive or confidential data using DNS packets. The attacker exploits the DNS packets that have been configured to bypass motoring the security systems by default. In this paper, a hybrid DNS tunneling detection has been presented based on the Tabu-PIO and packet length range. Moreover, a testbed has been conducted using virtual machines to generate DNS tunneling datasets with different classes. Our generated dataset summarized the different ranges of the packet length, which helps us to modify the Tabu-PIO.
The evaluation was conducted based on three datasets: the DNS records from the UNSW-NB15 dataset, the labeled DNS exfiltration dataset [
32], and our testbed dataset. The results show that using the Tabu-PIO reduces the number of features in all datasets, i.e., from 42 to 13 features and from 17 to 5 in the DNS records from the UNSW-NB15 dataset and DNS tunneling [
32], respectively. Moreover, the results demonstrate that using a hybrid approach (the M-PIO + packet length) enhances the run-time significantly when the size of the data increased.
In future works, the proposed approach can be improved by allowing it to adapt to new records with minimal human intervention. Moreover, regarding the main challenge of this research, there is no robust dataset specifically designed for the DNS tunneling problem. As a result, we intend to build a benchmark dataset specialized for DNS tunneling.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}