
Unsupervised Forgery Detection of Documents: A Network-Inspired Approach




Abstract
:1. Introduction
- Integrate the fields of forensics sciences and complex networks in one useful area;
- Develop a novel, efficient, and simple approach for forgery detection of documents that formalizes the spectrums of documents’ matters as a computerized network model;
- Provide a forgery detection method that does not need experts to perform forgery detection tests.
2. Related Works
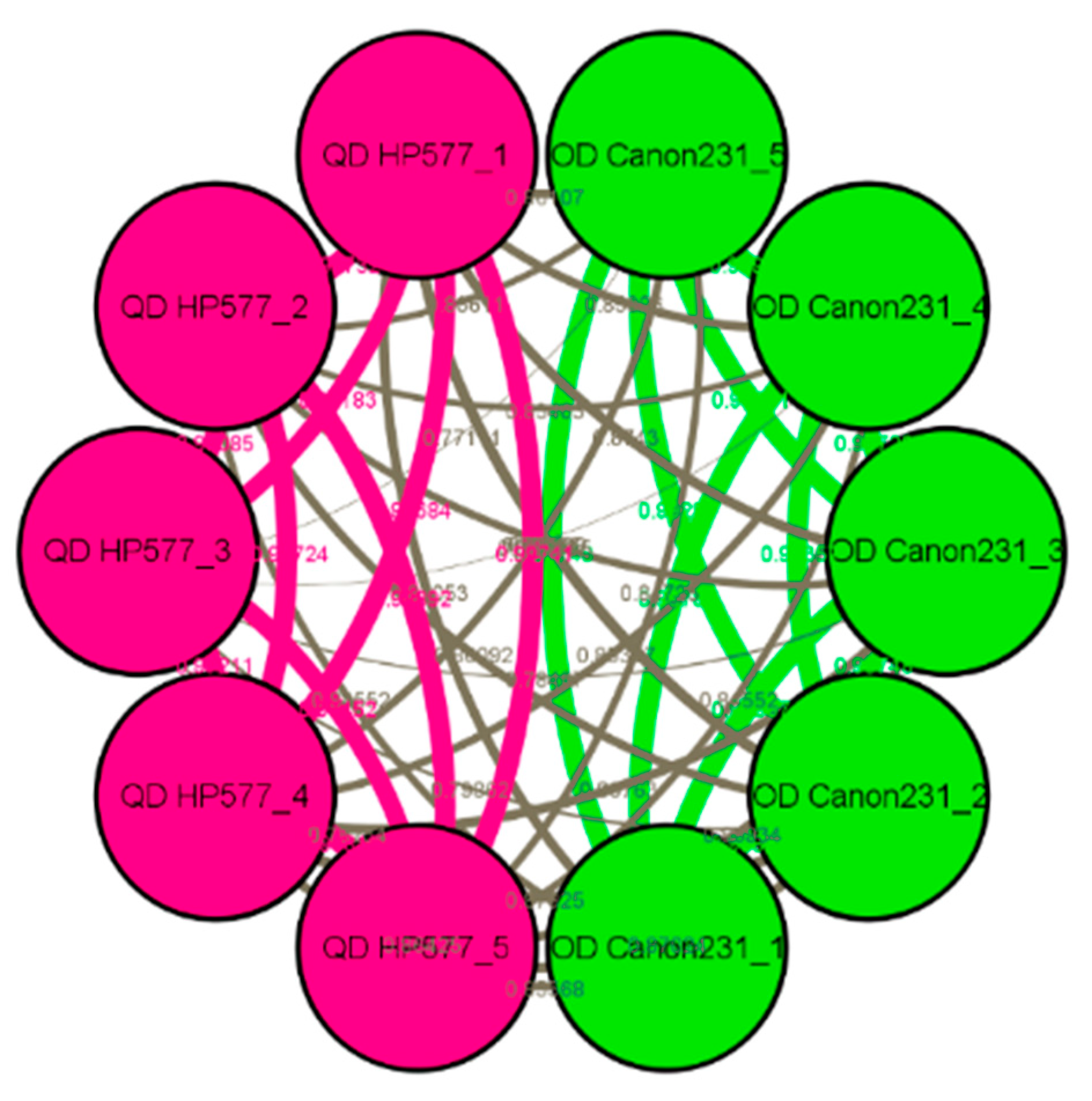
3. Complex Networks
Community Detection Algorithms
4. Research Method
4.1. Dataset and LIBS Settings
4.2. The Proposed Detection Approach
5. Results and Discussions
- −
- Five LIBS tests (scans) are the minimum recommended number. Five scans were used in this work as the experimentally determined threshold. As a result, it is anticipated that the accuracy of the suggested approach will decline as the number of scans falls below the threshold.
- −
- The settings of LIBS should be as described in the previous section. The results of the suggested approach may vary depending on how these settings are changed, according to the pre-experiments that were conducted.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alameri, M.A.A.; Ciylan, B.; Mahmood, B. Computational Methods for Forgery Detection in Printed Official Documents. In Proceedings of the 2022 ASU International Conference in Emerging Technologies for Sustainability and Intelligent Systems (ICETSIS), Virtual, 22–23 June 2022; pp. 307–331. [Google Scholar]
- Montasari, R.; Hill, R.; Parkinson, S.; Peltola, P.; Hosseinian-Far, A.; Daneshkhah, A. Digital forensics: Challenges and opportunities for future studies. Int. J. Organ. Collect. Intell. 2020, 10, 37–53. [Google Scholar] [CrossRef] [Green Version]
- Dyer, A.G.; Found, B.; Rogers, D. An insight into forensic document examiner expertise for discriminating between forged and disguised signatures. J. Forensic Sci. 2008, 53, 1154–1159. [Google Scholar] [CrossRef] [PubMed]
- Parkinson, A.; Colella, M.; Evans, T. The development and evaluation of radiological decontamination procedures for documents, document inks, and latent fingermarks on porous surfaces. J. Forensic Sci. 2010, 55, 728–734. [Google Scholar] [CrossRef] [PubMed]
- Ragai, J. Scientist And The Forger, The: Insights Into The Scientific Detection Of Forgery In Paintings; World Scientific: Singapore, 2015. [Google Scholar]
- Warif, N.B.A.; Wahab, A.W.A.; Idris, M.Y.I.; Ramli, R.; Salleh, R.; Shamshirband, S.; Choo, K.-K.R. Copy-move forgery detection: Survey, challenges, and future directions. J. Netw. Comput. Appl. 2016, 75, 259–278. [Google Scholar]
- Valderrama, L.; Março, P.H.; Valderrama, P. Model precision in partial least squares with discriminant analysis: A case study in document forgery through crossing lines. J. Chemom. 2020, 34, e3265. [Google Scholar] [CrossRef]
- Niu, P.; Wang, C.; Chen, W.; Yang, H.; Wang, X. Fast and effective Keypoint-based image copy-move forgery detection using complex-valued moment invariants. J. Vis. Commun. Image Represent. 2021, 77, 103068. [Google Scholar] [CrossRef]
- Muthukrishnan, R.; Radha, M. Edge detection techniques for image segmentation. Int. J. Comput. Sci. Inf. Technol. 2011, 3, 259. [Google Scholar] [CrossRef]
- Gorai, A.; Pal, R.; Gupta, P. Document fraud detection by ink analysis using texture features and histogram matching. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar]
- Markiewicz-Keszycka, M.; Cama-Moncunill, X.; Casado-Gavalda, M.P.; Dixit, Y.; Cama-Moncunill, R.; Cullen, P.J.; Sullivan, C. Laser-induced breakdown spectroscopy (LIBS) for food analysis: A review. Trends Food Sci. Technol. 2017, 65, 80–93. [Google Scholar]
- Elsherbiny, N.; Nassef, O.A. Wavelength dependence of laser-induced breakdown spectroscopy (LIBS) on questioned document investigation. Sci. Justice 2015, 55, 254–263. [Google Scholar] [CrossRef]
- Raman Spectroscopy of Two-Dimensional Materials; Tan, P.H. (Ed.) Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Laserna, J.; Vadillo, J.M.; Purohit, P. Laser-Induced Breakdown Spectroscopy (LIBS): Fast, Effective, and Agile Leading Edge Analytical Technology. Appl. Spectrosc. 2018, 72 (Suppl. 1), 35–50. [Google Scholar] [CrossRef]
- Noll, R.; Fricke-Begemann, C.; Connemann, S.; Meinhardt, C.; Sturm, V. LIBS analyses for industrial applications–an overview of developments from 2014 to 2018. J. Anal. At. Spectrom. 2018, 33, 945–956. [Google Scholar]
- Hui, Y.W.; Mahat, N.A.; Ismail, D.; Ibrahim RK, R. Laser-induced breakdown spectroscopy (LIBS) for printing ink analysis coupled with principle component analysis (PCA). AIP Conf. Proc. 2019, 2155, 020010. [Google Scholar]
- Ameh, P.O.; Ozovehe, M.S. Forensic examination of inks extracted from printed documents using Fourier transform infrared spectroscopy. Edelweiss Appl. Sci. Technol. 2018, 2, 10–17. [Google Scholar] [CrossRef]
- Verma, N.; Kumar, R.; Sharma, V. Analysis of laser printer and photocopier toners by spectral properties and chemometrics. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 196, 40–48. [Google Scholar] [CrossRef]
- Zięba-Palus, J.; Wesełucha-Birczyńska, A.; Trzcińska, B.; Kowalski, R.; Moskal, P. Analysis of degraded papers by infrared and Raman spectroscopy for forensic purposes. J. Mol. Struct. 2017, 1140, 154–162. [Google Scholar]
- Steiger, J.H. Tests for comparing elements of a correlation matrix. Psychol. Bull. 1980, 87, 245. [Google Scholar] [CrossRef]
- Buzzini, P.; Polston, C.; Schackmuth, M. On the criteria for the discrimination of inkjet printer inks using micro-R aman spectroscopy. J. Raman Spectrosc. 2018, 49, 1791–1801. [Google Scholar] [CrossRef]
- Shergin, V.; Udovenko, S.; Chala, L. Assortativity Properties of Barabási-Albert Networks. In Data-Centric Business and Applications: ICT Systems-Theory, Radio-Electronics, Information Technologies and Cybersecurity; Springer: Berlin/Heidelberg, Germany, 2021; Volume 5, pp. 55–66. [Google Scholar]
- Wiedmer, R.; Griffis, S.E. Structural characteristics of complex supply chain networks. J. Bus. Logist. 2021, 42, 264–290. [Google Scholar] [CrossRef]
- Mahmood, B.; Younis, Z.; Hadeed, W. Analyzing Iraqi Social Settings After ISIS: Individual Interactions in Social Networks. Am. Behav. Sci. 2018, 62, 300–319. [Google Scholar]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Ursino, D.; Virgili, L. Applying Social Network Analysis to Model and Handle a Cross-Blockchain Ecosystem. Electronics 2023, 12, 1086. [Google Scholar] [CrossRef]
- Hu, Z.; Shao, F.; Sun, R. A New Perspective on Traffic Flow Prediction: A Graph Spatial-Temporal Network with Complex Network Information. Electronics 2022, 11, 2432. [Google Scholar] [CrossRef]
- Barrat, A.; Barthelemy, M.; Vespignani, A. Dynamical Processes on Complex Networks; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Wei, B.; Deng, Y. A cluster-growing dimension of complex networks: From the view of node closeness centrality. Phys. A Stat. Mech. Its Appl. 2019, 522, 80–87. [Google Scholar] [CrossRef]
- Mahmood, B. Prioritizing CWE/SANS and OWASP Vulnerabilities: A Network-Based Model. Int. J. Comput. Digit. Syst. 2021, 10, 361–372. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, B. Indicators on the Feasibility of Curfew on Pandemics Outbreaks in Metropolitan/Micropolitan Cities. In Proceedings of the 2021 IEEE International Conference on Communication, Networks and Satellite (COMNETSAT), Purwokerto, Indonesia, 17–18 July 2021; pp. 179–183. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Traag, V.A.; Waltman, L.; Van Eck, N.J. From Louvain to Leiden: Guaranteeing well-connected communities. Sci. Rep. 2019, 9, 5233. [Google Scholar] [CrossRef] [Green Version]
- Amjed, A.; Mahmood, B.; AlMukhtar, K.A.K. Network Science as a Forgery Detection Tool in Digital Forensics. In Proceedings of the 2021 IEEE International Conference on Communication, Networks, and Satellite (COMNETSAT), Purwokerto, Indonesia, 17–18 July 2021; pp. 200–205. [Google Scholar] [CrossRef]
- Traag, V.A.; Van Dooren, P.; Nesterov, Y. Narrow scope for resolution-limit-free community detection. Phys. Rev. E 2011, 84, 016114. [Google Scholar] [CrossRef] [Green Version]
- Al-Ameri, M.A.A.; Ciylan, B.; Mahmood, B. Spectral Data Analysis for Forgery Detection in Official Documents: A Network-Based Approach. Electronics 2022, 11, 4036. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Printer Type | Brand | Model | Cartridge |
|---|---|---|---|---|
| 1 | LaserPrinter | Canon | i-SENSYS MF231 | AR CRG 737 |
| 2 | LaserPrinter | Canon | i-SENSYS MF4010 | AR FX 10 |
| 3 | LaserPrinter | Canon | i-SENSYS LBP6000 | AR CRG725 |
| 4 | LaserPrinter | Canon | Image CLASS MF264DW | CRG 51 |
| 5 | LaserPrinter | Canon | i-SENSYS LBP2900 | AR FX 10 |
| 6 | InkjetPrinter | Epson | EcoTank ITS L3070 | # |
| 7 | InkjetPrinter | Canon | Pixma TS6020 | # |
| 8 | InkjetPrinter | HP | PageWidePro 577dw | # |
| 9 | LaserPrinter | Ricoh | Aficio MP 4001 | Toner Black MP c4500 |
| 10 | LaserPrinter | Ricoh | Aficio MP C2051 | Toner Black MP c2051c |
| Resolution | Iterations | Restarts | Weight-Based | Randomization |
|---|---|---|---|---|
| 0.95 | 10 | 1 | ON | ON |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Ameri, M.A.A.; Mahmood, B.; Ciylan, B.; Amged, A. Unsupervised Forgery Detection of Documents: A Network-Inspired Approach. Electronics 2023, 12, 1682. https://doi.org/10.3390/electronics12071682
Al-Ameri MAA, Mahmood B, Ciylan B, Amged A. Unsupervised Forgery Detection of Documents: A Network-Inspired Approach. Electronics. 2023; 12(7):1682. https://doi.org/10.3390/electronics12071682
Chicago/Turabian StyleAl-Ameri, Mohammed Abdulbasit Ali, Basim Mahmood, Bünyamin Ciylan, and Alaa Amged. 2023. "Unsupervised Forgery Detection of Documents: A Network-Inspired Approach" Electronics 12, no. 7: 1682. https://doi.org/10.3390/electronics12071682