
A Novel Channel Pruning Compression Algorithm Combined with an Attention Mechanism


Abstract
:1. Introduction
2. Related Work
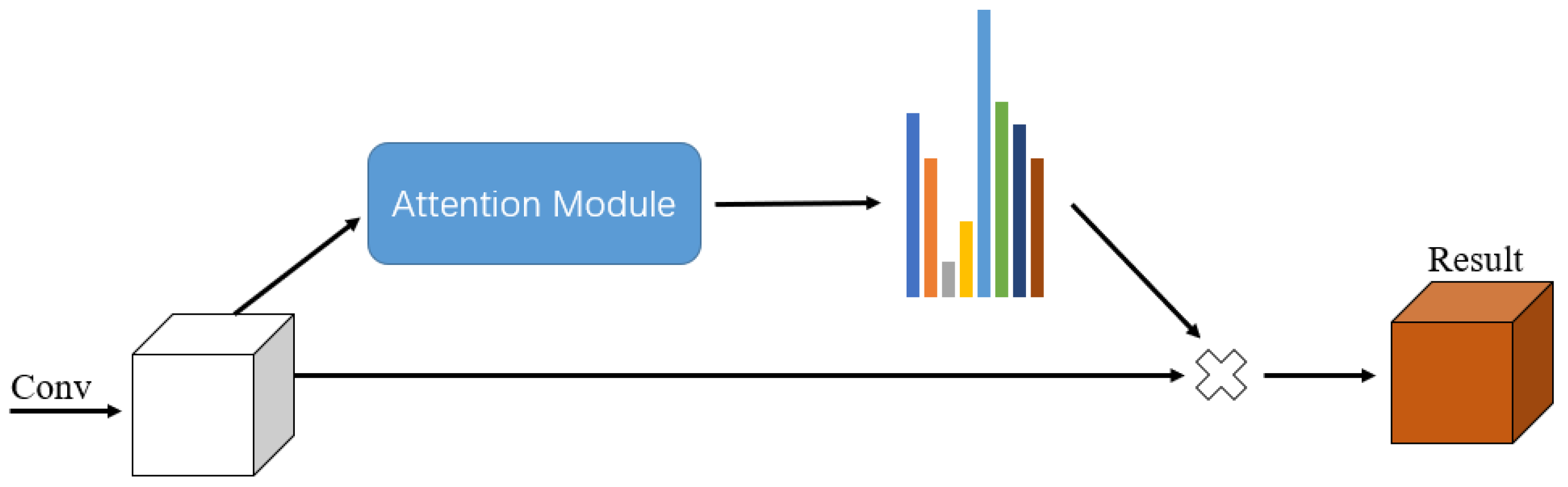
2.1. Attention Mechanism
2.2. Structured Pruning
2.3. Attention-Based Pruning
3. Algorithm
3.1. Attention Mechanism
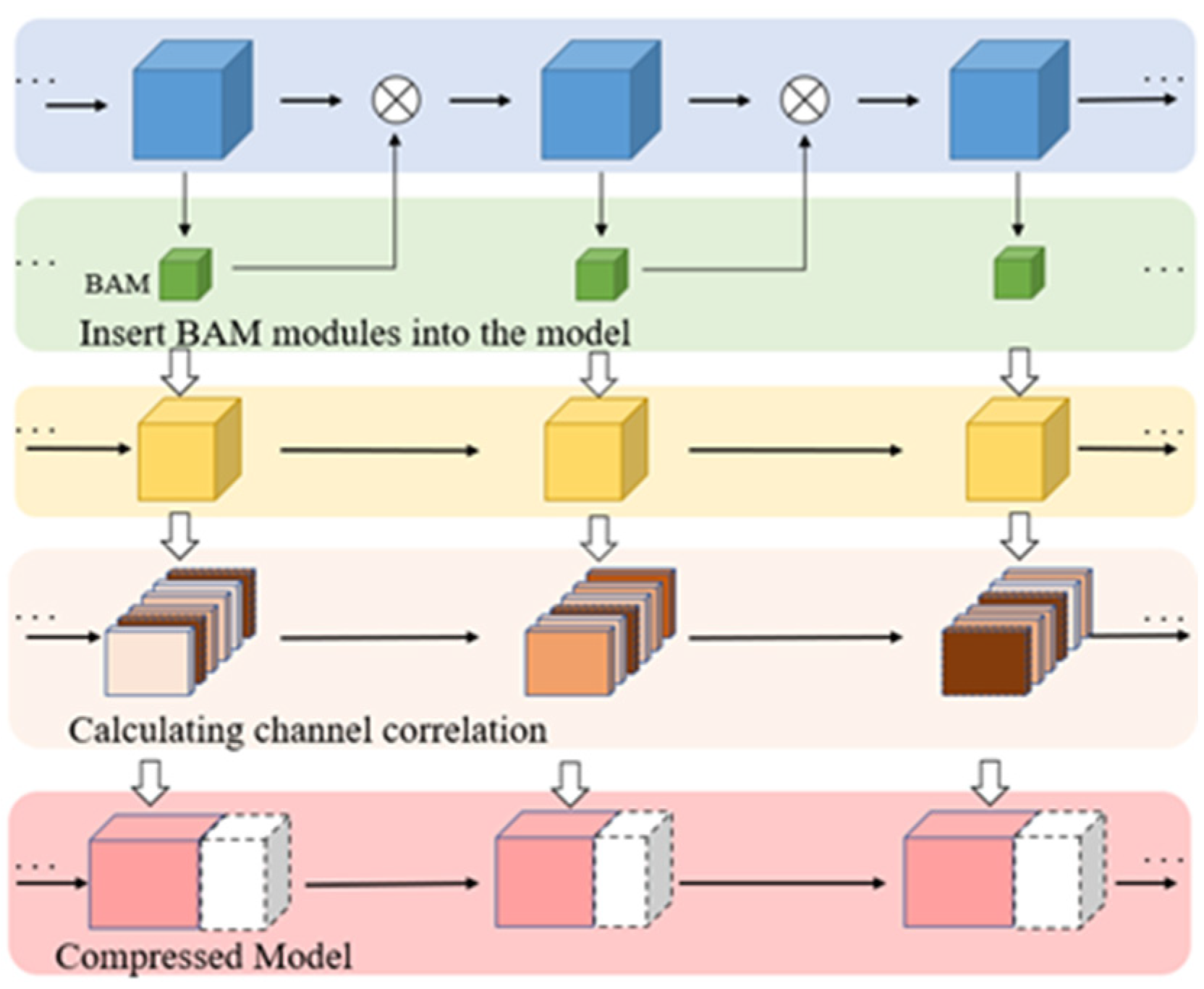
3.2. Pruning Algorithm Based on Channel Correlation
3.3. Overall Flow of the Algorithm
| Algorithm 1. CCPCSA Algorithm | |
| Input: | |
| M: | The initial network model |
| D: | The training dataset |
| L: | The number of the layers in M |
| m: | The number of channel groups removed per epoch |
| Output: | |
| M′: | The pruned network model |
| Steps: | |
| 1: | Obtain ACC by training the model M |
| 2: | Obtain a model named M’ by training model M within BAM modules |
| 3: | For each batch |
| 4: | Train M’ with d |
| 5: | For each layer |
| 6: | For each channel |
| 7: | Calculate the |
| 8: | Sort all the and prune the smaller rows of channels |
| 9: | Fine-tune M’ and obtain the Acc’ |
| 10: | If Acc-Acc’ < 0.5%, then go back to Step 3 |
| 11: | Return M’ |
4. Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Comput. Sci. 2014. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. IEEE Comput. Soc. 2014. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Jiang, Z.F.; He, T.; Shi, Y.L.; Long, X.; Yang, S. Remote sensing image classification based on convolutional block attention module and deep residual network. Laser J. 2022, 43, 76–81. [Google Scholar] [CrossRef]
- Zheng, Q.M.; Xu, L.K.; Wang, F.H.; Lin, C. Pyramid scene parsing network based on improved self-attention mechanism. Comput. Eng. 2022, 1–9. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the ICLR, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Comput. Sci. 2015, 14, 38–39. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up Convolutional Neural Networks with Low Rank Expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- Setiono, R.; Liu, H. Neural-network feature selector. IEEE Trans. Neural Netw. 1997, 8, 654–662. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Li, C.; Wang, X. Convolutional neural network pruning with structural redundancy reduction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14913–14922. [Google Scholar]
- Shao, M.; Dai, J.; Wang, R.; Kuang, J.; Zuo, W. CSHE: Network pruning by using cluster similarity and matrix eigenvalues. Int. J. Mach. Learn. Cybern. 2022, 13, 371–382. [Google Scholar] [CrossRef]
- Kim, M.; Choi, H.-C. Compact Image-Style Transfer: Channel Pruning on the Single Training of a Network. Sensors 2022, 22, 8427. [Google Scholar] [CrossRef]
- Xue, Z.; Yu, X.; Liu, B.; Tan, X.; Wei, X. HResNetAM: Hierarchical Residual Network with Attention Mechanism for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3566–3580. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, L.; Phonevilay, V.; Gu, K.; Xia, R.; Xie, J.; Zhang, Q.; Yang, K. Image super-resolution reconstruction based on feature map attention mechanism. Appl. Intell. 2021, 51, 4367–4380. [Google Scholar] [CrossRef]
- Cai, W.; Zhai, B.; Liu, Y.; Liu, R.; Ning, X. Quadratic Polynomial Guided Fuzzy C-means and Dual Attention Mechanism for Medical Image Segmentation. Displays 2021, 70, 102106. [Google Scholar] [CrossRef]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Liu, M.; Li, L.; Hu, H.; Guan, W.; Tian, J. Image caption generation with dual attention mechanism. Inf. Process. Manag. 2020, 57, 102178. [Google Scholar] [CrossRef]
- Li, W.; Liu, K.; Zhang, L.; Cheng, F. Object detection based on an adaptive attention mechanism. Sci. Rep. 2020, 10, 11307. [Google Scholar] [CrossRef]
- Dollar, O.; Joshi, N.; Beck DA, C.; Pfaendtner, J. Attention-based generative models for de novo molecular design. Chem. Sci. 2021, 12, 8362–8372. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Hu, X.; Yang, J. Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I. Bam: Bottleneck attention module. arXiv 2018, arXiv:180706514. [Google Scholar]
- Zhang, X.; Colbert, I.; Das, S. Learning Low-Precision Structured Subnetworks Using Joint Layerwise Channel Pruning and Uniform Quantization. Appl. Sci. 2022, 12, 7829. [Google Scholar] [CrossRef]
- Zhang, T.; Ye, S.; Zhang, K.; Tang, J.; Wen, W.; Fardad, M.; Wang, Y. A systematic dnn weight pruning framework using alternating direction method of multipliers. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 184–199. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both Weights and Connections for Efficient Neural Networks. In Proceedings of the NIPS 2015, Montreal, QC, Canada, 7–10 December 2015. [Google Scholar]
- Luo, J.H.; Wu, J. An Entropy-based Pruning Method for CNN Compression. arXiv 2017, arXiv:1706.05791. [Google Scholar]
- Xiang, K.; Peng, L.; Yang, H.; Li, M.; Cao, Z.; Jiang, S.; Qu, G. A novel weight pruning strategy for light weight neural net-works with application to the diagnosis of skin disease. Appl. Soft Comput. 2021, 111, 107707. [Google Scholar] [CrossRef]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning Structured Sparsity in Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel Pruning for Accelerating Very Deep Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Min, C.; Wang, A.; Chen, Y.; Xu, W.; Chen, X. 2PFPCE: Two-Phase Filter Pruning Based on Conditional Entropy. arXiv 2018, arXiv:1809.02220. [Google Scholar]
- Yang, C.; Yang, Z.; Khattak, A.M.; Yang, L.; Zhang, W.; Gao, W.; Wang, M. Structured pruning of convolutional neural networks via l1 regularization. IEEE Access 2019, 7, 106385–106394. [Google Scholar] [CrossRef]
- Zhuang, L.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, G. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yu, R.; Li, A.; Chen, C.-F.; Lai, J.-H.; Morariu, V.; Han, X.; Gao, M.; Lin, Y.; Davis, L. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Song, F.; Wang, Y.; Guo, Y.; Zhu, C. A channel-level pruning strategy for convolutional layers in cnns. In Proceedings of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018. [Google Scholar]
- Yamamoto, K.; Maeno, K. PCAS: Pruning Channels with Attention Statistics for Deep Network Compression. arXiv 2018, arXiv:1806.05382. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sui, Y.; Yin, M.; Xie, Y.; Phan, H.; Aliari Zonouz, S.; Yuan, B. Chip: Channel independence-based pruning for compact neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 24604–24616. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. Comput. Sci. 2015, 2048–2057. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, T.; Cui, Z.; Cao, Z. Filter pruning with a feature map entropy importance criterion for convolution neural networks compressing. Neurocomputing 2021, 461, 41–54. [Google Scholar] [CrossRef]
- Hu, Y.; Sun, S.; Li, J.; Wang, X.; Gu, Q. A novel channel pruning method for deep neural network compression. arXiv 2018, arXiv:1805.11394. [Google Scholar]
- Shao, W.; Yu, H.; Zhang, Z.; Xu, H.; Li, Z.; Luo, P. BWCP: Probabilistic Learning-to-Prune Channels for ConvNets via Batch Whitening. arXiv 2021, arXiv:2105.06423. [Google Scholar]
- Wang, Z.; Li, F.; Shi, G.; Xie, X.; Wang, F. Network pruning using sparse learning and genetic algorithm—ScienceDirect. Neurocomputing 2020, 404, 247–256. [Google Scholar] [CrossRef]
- Aflalo, Y.; Noy, A.; Lin, M.; Friedman, I.; Zelnik, L. Knapsack Pruning with Inner Distillation. arXiv 2020, arXiv:2002.08258. [Google Scholar]
- Chen, T.; Ji, B.; Ding, T.; Fang, B.; Wang, G.; Zhu, Z.; Liang, L.; Shi, Y.; Yi, S.; Tu, X. Only Train Once: A One-Shot Neural Network Training and Pruning Framework. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; Kautz, J. Importance Estimation for Neural Network Pruning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Acc (%) | Para (M) | FLOPs (M) | |||
|---|---|---|---|---|---|---|
| Baseline [3] | 78.51 | - | 23.71 | - | 1224 | - |
| PCAS-60 [38] | 77.89 | ↓0.62 | 5.57 | ↓76.5% | 412 | ↓66.3% |
| Pruned-B [43] | 74.85 | ↓3.66 | 13.64 | ↓42.47% | 610 | ↓50.16% |
| 16% Pruned [44] | 78.32 | ↓0.19 | 8.5356 | ↓64.0% | 670 | ↓45.3% |
| Proposed | 77.78 | ↓0.73 | 4.67 | ↓80.3% | 375 | ↓69.4% |
| Model | Method | Acc (%) | Para (M) | GFLOPs | |||
|---|---|---|---|---|---|---|---|
| ResNet50 | Baseline [3] | 75.44 | - | 25.56 | - | 3.86 | - |
| PCAS-50 [38] | 75.40 | ↓0.04 | 12.47 | ↓51.2% | 1.56 | ↓56.7% | |
| BWCP [45] | 74.96 | ↓0.48 | - | - | 1.87 | ↓51.8% | |
| Wang [46] | 75.23 | ↓0.21 | 19.86 | ↓22.3% | 1.65 | ↓57.3% | |
| Afalo [47] | 75.71 | ↑0.27 | - | - | 2.29 | ↓40.6% | |
| OTO* [48] | 74.52 | ↓0.92 | 9.07 | ↓64.5% | 1.33 | ↓65.5% | |
| Proposed-low rate | 75.75 | ↑0.31 | 14.36 | ↓43.8% | 1.94 | ↓49.7% | |
| Proposed | 75.38 | ↓0.06 | 10.28 | ↓59.8% | 1.28 | ↓66.8% | |
| ResNet101 | Baseline [3] | 76.62 | - | 44.55 | - | 7.57 | - |
| Afalo [47] | 75.37 | ↓1.25 | - | - | 2.33 | ↓69.21% | |
| TFB-55% [49] | 75.95 | ↓0.67 | 20.7 | ↓53.5% | 2.85 | ↓62.35% | |
| Proposed | 75.76 | ↓0.86 | 17.28 | ↓61.2% | 2.38 | ↓68.5% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, M.; Luo, T.; Peng, S.-L.; Tan, J. A Novel Channel Pruning Compression Algorithm Combined with an Attention Mechanism. Electronics 2023, 12, 1683. https://doi.org/10.3390/electronics12071683
Zhao M, Luo T, Peng S-L, Tan J. A Novel Channel Pruning Compression Algorithm Combined with an Attention Mechanism. Electronics. 2023; 12(7):1683. https://doi.org/10.3390/electronics12071683
Chicago/Turabian StyleZhao, Ming, Tie Luo, Sheng-Lung Peng, and Junbo Tan. 2023. "A Novel Channel Pruning Compression Algorithm Combined with an Attention Mechanism" Electronics 12, no. 7: 1683. https://doi.org/10.3390/electronics12071683
APA StyleZhao, M., Luo, T., Peng, S.-L., & Tan, J. (2023). A Novel Channel Pruning Compression Algorithm Combined with an Attention Mechanism. Electronics, 12(7), 1683. https://doi.org/10.3390/electronics12071683