Abstract
With a focus on practical applications in the real world, a number of challenges impede the progress of pedestrian detection. Scale variance, cluttered backgrounds and ambiguous pedestrian features are the main culprits of detection failures. According to existing studies, consistent feature fusion, semantic context mining and inherent pedestrian attributes seem to be feasible solutions. In this paper, to tackle the prevalent problems of pedestrian detection, we propose an anchor-free pedestrian detector, named context and attribute perception (CAPNet). In particular, we first generate features with consistent well-defined semantics and local details by introducing a feature extraction module with a multi-stage and parallel-stream structure. Then, a global feature mining and aggregation (GFMA) network is proposed to implicitly reconfigure, reassign and aggregate features so as to suppress irrelevant features in the background. At last, in order to bring more heuristic rules to the network, we improve the detection head with an attribute-guided multiple receptive field (AMRF) module, leveraging the pedestrian shape as an attribute to guide learning. Experimental results demonstrate that introducing the context and attribute perception greatly facilitates detection. As a result, CAPNet achieves new state-of-the-art performance on Caltech and CityPersons datasets.
1. Introduction
Pedestrian detection, which is a branch of object detection, serves as an important research topic in computer vision. For intelligent transportation, fast and accurate pedestrian detection has enormous social significance and can be widely applied in other tasks, such as automatic driving [], video surveillance [] and target tracking []. Recently, with the success of deep learning, detectors based on convolutional neural networks (CNNs) [,,,] have become several top benchmarks in Caltech [] and CityPersons [] datasets. However, despite progressive studies, the detection performance still has a margin for improvement.
Existing studies indicate that as a real-world task, pedestrian detection has inherent challenges [,]. First, one image usually contains pedestrians of various scales. The discrepancy of scales brings huge challenges to accurately detecting pedestrians []. Further, since stacked down-sampling layers gradually lose feature details, detection for small-scale pedestrians becomes more difficult []. Second, pedestrians are surrounded by complex backgrounds in urban scenes []. Complex backgrounds may contain some contexts that partially facilitate detection, but also strongly interferes with the detector’s ability to learn. Third, the features of pedestrian appearance are not distinct enough. Obvious features such as color and texture can not contribute to the detection of pedestrians. More pedestrian-specific discriminative features should be enhanced. It is also worth exploring which is a better architecture for pedestrian detection. Though two-stage networks such as Fast R-CNN [] exhibit good detection performance, the real-world scenario demands real-time detection speed with limited computational resources. One-stage anchor-based detectors have an efficient architecture but often underperform in pedestrian detection []. It may be because setting anchors uniformly over the entire feature map does not allow the network to precisely locate pedestrians during training. The balance of effectiveness and efficiency is critical for pedestrian detectors.
In this paper, in order to address the challenges of pedestrian detection, we propose a one-stage anchor-free detector with a simple structure, named Spatial Perception Center and Scale Prediction (CAPNet). As a one-stage detector, CAPNet consists of three parts: a feature extraction module, a global feature mining and aggregation (GFMA) network and a detection head with an attribute-guided multiple receptive field (AMRF) module. The one-stage hierarchy does not require a Region Proposal Network (RPN), greatly improving the efficiency. As an anchor-free detector, CAPNet considers the pedestrian a special response and directly detects the location of pedestrians directly on the feature maps. It does not need to uniformly pave prior anchors over the feature maps, greatly avoiding detection failures caused by the unbalanced distribution between anchors and objects. Considering the tackling of the scale variance challenge, we employ HRNet [] to generate consistent feature representation as the feature extraction module. Previous approaches [,,] perform feature fusion to enhance the awareness of the scale. However, the shallow information fusion on the extracted feature map is still inadequate. We introduce HRNet to generate features with consistent well-defined semantics and local details. With multi-stage extraction and multi-stream aggregation, HRNet can perform deep information integration on multiple path feature maps, especially beneficial for small-scale pedestrian detection.
To filter off useless semantics in the background, we propose a global feature mining and aggregation (GFMA) network. Some methods [,] leverage semantic labels to provide cues for detection. While this approach enhances the detector’s understanding of the environment, it also inevitably weakens the focus on pedestrians. Some works [,] generate extra data (e.g., attention maps or salience maps) to perform detection with the help of attention mechanisms or saliency detection. However, this would introduce additional computational overhead. We propose the GFMA network to reconfigure, reassign and aggregate features for implicit contextual modeling, without semantic labels and other supervisions. With negligible overhead, the GFMA network emphasizes useful features and suppresses the interference from irrelevant features at a global level, guiding the network to learn information of interest in a flexible way.
Since pedestrian detection only focuses on the pedestrian category, some hand-crafted features can be designed to facilitate detection. Existing studies [,,] exploit the inherent attributes of pedestrians (e.g., geometric shape, body structure) to enhance features. These works are traditional methods based on task-specific manual features. We suggest that task-specific knowledge can also be employed in CNNs to bring heuristic rules and guide the network to learn more semantic and discriminative features. We propose an attribute-guided multiple receptive field (AMRF) module and integrate it into the classification branch of the detection head. By introducing the intrinsic attribute of pedestrians and fusing features with multiple receptive fields, the AMRF module generates representative features and enhances the semantics and distinctiveness of features.
Extensive experiments demonstrate the effectiveness of the proposed CAPNet. We perform training and testing on the Caltech [] and CityPersons [] datasets. On the test set of Caltech, CAPNet achieves 2.75% on Reasonable, 53.42% on All and 39.19% on Heavy. On the CityPersons validation set, CAPNet achieves 8.71% on Reasonable, 6.02% on Bare, 7.43% on Partial and 46.11% on Heavy. The experimental results show that CAPNet outperforms the state-of-the-art methods. In summary, the main contributions of this paper are as follows:
- We extensively analyze the current prevalent problems in pedestrian detection and propose a one-stage anchor-free pedestrian detector, named CAPNet (Spatial Perception Center and Scale Prediction).
- Through extracting features with consistent semantics and details, mining useful context semantics and bringing hand-craft features to CNNs, we design the network structure to cope with problems in pedestrian detection.
- The experimental results demonstrate that the proposed CAPNet achieves new state-of-the-art performance on both Caltech and CityPersons datasets.
2. Related Work
According to the input data type, the pedestrian detection task can be classified into detection based on static images and detection based on dynamic videos. When the input is a static image, the goal of the pedestrian detection task is to accurately identify the locations and the number of pedestrians in the given image. Most static pedestrian detectors are improved from the generic object detectors based on the characteristics of pedestrians. RPN+BF [], OR-RCNN [] and Beta-RCNN [] are derived from RCNN. RPN+BF [] uses boosted forest for improving pedestrian detection performance despite not being optimized end-to-end. To solve the problem of occlusion, OR-RCNN [] focuses on the locations of proposals so a part occlusion-aware region of interest (PORoI) pooling unit is proposed. Beta-RCNN [] proposes a new representation based on 2D beta distribution, constructing the relationship between full-body and visible boxes. Among one-stage detectors, ALFNet [] is an anchor-based method, while TLL [] and CSP [] are anchor-free. ALFNet [] uses an asymptotic localization fitting module to stack together multiple predictors for the best detection. TLL [] is proposed with a somatic topological line localization module to solve the critical issue that small-scale objects have ambiguous appearance. CSP [] is an anchor-free detector, which provides a new perspective regarding pedestrian detection as a high-level semantic feature detection task. Real-world detection is based on dynamic environments and often accompanied by tasks such as tracking and re-identification. Recently, there are numerous studies investigating dynamic pedestrian detection using videos as inputs. Yang et al. [] proposed a Kalman filter-based convolutional neural network (CNN) for online pedestrian detection in videos. It is based on the SSD algorithm to identify pedestrians and the Kalman filter algorithm to correct the confidence and location of the detection results. AlignPS [] is the first anchor-free method to solve the pedestrian search problem in dynamic videos. The authors proposed an aligned feature aggregation module to generate more discriminative and robust features for detection and re-identification. IGPN [] learns the similarity between query persons and proposals and decreases proposals according to the similarity scores, which significantly improves the performance. Zhao et al. [] proposed a new context contrastive loss by classifying noises to exploit the potential contextual information of the backgrounds. This loss can guide the detector to distinguish between crowded and overlapping pedestrians. Jaffe et al. [] developed a new model for implementing pedestrian detection in dynamic scenes and provide a standardized tool for data processing and evaluation pipeline in pedestrian search studies.
2.1. Scale-Aware Detectors
Due to the scale variance of pedestrians, some scale-aware detectors are proposed to break through this bottleneck. Yang et al. [] extract the region of interest (RoI) features of proposals according to their scales. RoI features of small-scale objects are extracted from shallow layers, and conversely, features of large-scale objects are obtained from deeper layers. According to the scale of the pedestrian, SA-Fast R-CNN [] divides the network into two sub-branches starting from the region proposal network (RPN), and fuse the outputs of the two sub-networks with a scale-aware weighting layer. Similarly, MS-CNN [] designs a multi-scale-aware network, which performs detection with multiple intermediate layers to match objects of various scales. To handle small instances, up-sampling operations are added to upgrade the resolution of feature maps. Hu et al. [] refined the feature pyramid network (FPN) by decreasing the down-scale stride from 2 to 1 in the previous convolutional layers, so as to retain more feature details for small-scale pedestrian detection. Most of these methods design the scale-aware architecture with multi-scale layers from components such as RoI, RPN, FPN, etc. However, they do not focus on feature fusion in the feature extraction part of the network.
2.2. Context-Based Detectors
The urban streetscapes around pedestrians may contain some contextual semantics, which may provide cues for detecting pedestrians. Some approaches intend to combine multi-scales of features to understand the contextual environment. Zhang et al. [] concatenated the multi-scale region of interest (RoI) features to utilize global feature representation. Zhang et al. [] proposed a context feature sampling strategy with a location-aware deformable convolutional layer on a Faster R-CNN baseline. To take advantage of contextual information, Cao et al. [] incorporated the large-kernel convolution within the feature pyramid framework. The process of aggregating features to extract contextual information introduces a higher computational cost and the semantics are ambiguous. Other approaches aid pedestrian detection with the help of semantic labels. Mao et al. [] used a multi-task learning network to study the effects of combining additional supervision for pedestrian detection, including semantic labels. o To understand the backgrounds, Wang et al. [] proposed a network that jointly executes semantic segmentation and pedestrian detection. Based on CSP [], Jiang et al. [] added an extra branch to predict global semantic maps to exclude some unreasonable false positives. However, these methods do not exclude the interference of redundant features in the background.
2.3. Attribute-Based Detectors
Since pedestrian is the only category to be detected, some specific pedestrian characteristics can be exploited for feature design as prior knowledge []. Zhang et al. [] utilized Haar-like features, according to the typical common sense that pedestrians consist of a head, upper body and lower body. In response to the human visual system, Zhang et al. [] further developed the center-surround contrast aspects. Inspired by the consistency of appearance and symmetry of pedestrians, Cao et al. [] designed side-inner difference features and shape symmetrical features to enhance other local characteristics. Scale priors and occlusion analyses were incorporated into deformable part models by Wang et al. []. Since today’s CNN-based approaches rely on data-driven and iterative optimization, most pipelines have abandoned handcrafted features. However, designing task-specific features still has great potential in CNNs to obtain more heuristics.
3. Method
3.1. Overview of Network Structure
The overall architecture of the proposed CAPNet is illustrated in Figure 1. CAPNet consists of three parts: a feature extraction module, a global feature mining and aggregation (GFMA) network and a detection head with an attribute-guided multiple receptive field (AMRF) module. CAPNet feeds images with the shape of (h, w, 3) into the feature extraction module and produces 4 feature maps with the shapes of (h/4, w/4, 40), (h/8, w/8, 80), (h/16, w/16, 160) and (h/32, w/32, 320), ((.) denotes (height, width, channel)). These 4 feature maps are then each fed into GFMA to adaptively reconfigure and reassign features. The length and width of the feature maps will be unified as (h/4, w/4) by transpose convolution. By concatenation, the feature maps are fused into one (h/4, w/4, 600) feature map. A convolution layer is appended to reduce the channel number to 256. Subsequently, the (h/4, w/4, 600) feature map is transmitted to the detection head. The head has 3 parallel branches to predict the center, scale and offset of pedestrians, respectively. With a convolutional layer, each branch directly regresses the detection results without relying on anchors. We propose AMRF with the help of prior attributes and hand-crafted features and integrate it in the center branch. In the following sections, the details of each module will be elaborated.
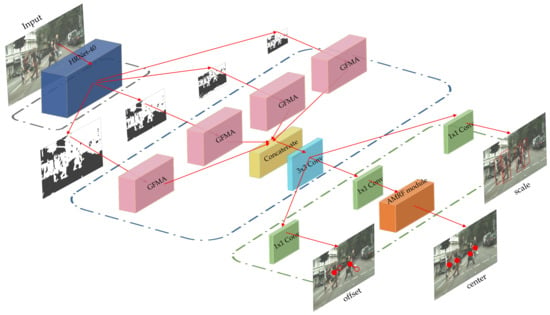
Figure 1.
The overview network architecture of CAPNet consists of three parts: a feature extraction module, a global feature mining and aggregation (GFMA) network and a detection head with an attribute-guided multiple receptive field (AMRF) module.
3.2. Feature Extraction Module
The feature extraction module is critical for the simple structured anchor-free detectors. By improving the backbone, anchor-free methods (e.g., CenterNet [], APD []) can generate better results. To some extent, location-accurate and discriminative feature extraction determines the performance of a detector. Some networks (e.g., ResNet [], EfficientNet []) are used as feature extraction modules because of their excellent performance in classification benchmarks (e.g., ImageNet []). Nevertheless, the structure of these networks follows the pyramidal hierarchy. Shallow feature layers contain rich location-detailed information, but semantic information is insufficient. Deep feature maps have more advanced semantics, but lose location and scale accuracy due to sequential down-sampling, which is particularly detrimental to detecting dense and small pedestrians. Since scale variance exists in pedestrian detection, semantic-clear and location-accurate features are required for each level of scale. To this end, we use HRNet [] to generate features with consistent well-defined semantics and local details.
HRNet is specially designed for location-sensitive tasks, such as semantic segmentation, object detection and attitude estimation []. The network comprises two dimensions: horizontal streams and vertical stages. The resolution of the 4 streams decreases from high to low. Each stream contains multiple convolutional layers that are divided into 4 stages to gradually deepen the feature. At the end of each stage, the feature maps of each stream are resized and appended to all other streams in order to exchange and fuse information. HRNet eventually outputs 4 feature maps , , and ) from 4 streams, with sizes of (h/4, w/4, 40), (h/8, w/8, 80), (h/16, w/16, 160) and (h/32, w/32, 320) (h and w denote the input image size). The multi-stage, parallel-stream feature extraction allows each feature map to contain multiple levels of abstract information, rather than just a pyramidal hierarchy.
3.3. Global Feature Mining and Aggregation Network
After conducting sufficient feature extraction and fusion by HRNet, the proposed global feature mining and aggregation (GFMA) network reorganizes and reconstructs the features, which facilitates the detection head to learn specific tasks in a flexible way. It can be used to enhance the expressiveness of the objects and weaken the interference of redundant backgrounds. Given the sequence of feature maps extracted by the backbone network , the output of the GFMA can be denoted as follows,
where denotes the feature transformation operation and denotes fusing the output feature maps. The architecture of the GFMA network is depicted in Figure 2. In particular, for each feature map, contains the following 3 steps:
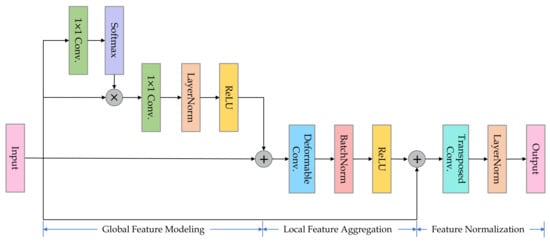
Figure 2.
The structure of the proposed global feature mining and aggregation (GFMA) network.
- (1)
- Global Feature Modeling
To capture information on a global scope, we perform global context modeling (GFM) of features, similar to global context block (GCBlock) []. The GFM is formulated as Equation (2). First, the attention values of all positions are calculated, and the convolutional features are weighted and reconfigured based on them. Then feature normalization and ReLU activation are performed. Shortcut is added to prevent the gradient from disappearing. The GFM aggregates features from all locations to form global context features. It can be regarded as a simplified spatial self-attention mechanism that captures the dependencies between positions and gradually focuses on the areas of interest while eliminating the contributions of irrelevant features.
where represents the context modeling function and is a softmax activation to measure the attention value of each position. and are all convolutional layers, as a linear transformation operation to features.
- (2)
- Local Feature Aggregation
After global information extraction, we perform short-distance feature extraction and global-local information fusion by local feature aggregation (LFA). The deformable convolution [] is integrated to extract features at short distances in a flexible way. Convolution operations naturally focus on local information and extract useful features. However, the receptive field of convolution is limited. Leveraging general convolution for short-range feature extraction can not break through the fixed geometric structure. The deformable convolutional layer can adaptively determine the range of local features to be extracted and focus on important features within short distances. Then a skip connection is added with the input of the GFMA. The cross-module skip-connection structure can guide the propagation of gradients to select the useful features by optimization, thus enhancing the usability and richness of features.
- (3)
- Feature Normalization
For concatenation, the 4 feature maps are required to have uniform height and width. The feature maps are resized to (h/r, w/r) by transpose convolution. r is set to 4, as recommended in [,]. The transpose convolutional layers for , and are , and , respectively. ((.) denotes (kernel, channel, stride)). Each feature map employed layer normalization. The final feature maps responsible for detection are (h/4, w/4, 40), (h/4, w/4, 80), (h/4, w/4, 160) and (h/4, w/4, 320).
The 4 output feature maps are concatenated into a (h/4, w/4, 600) feature map. A convolutional layer is connected to reduce the number of channels. Cascaded convolutional layers, global average pooling and other methods can also obtain global information, but they are detrimental to detecting dense, tiny pedestrians. The proposed GFMA adaptively adjusts the global features without a large amount of computational overhead.
3.4. Attribute-Guided Multiple Receptive Field Module
The detection head is a decoupled head with three parallel branches. Each branch integrates a convolution layer to estimate the center heatmap, the scale map and the offset map, respectively, as shown in Figure 1. Experiments suggest that the detector exhibits superior performance for learning scale and offset components, while the center branch is more difficult to learn. Moreover, when we evaluate the experimental results, it is also found that the errors of scale and offset are smaller, while the center branch still has some room for improvement in accuracy. Notably, out of the three branches, the center branch plays a crucial role in determining the presence or absence of pedestrians. Inadequate learning of the center branch may result in false positives or negatives. Therefore, we propose to add an additional module to the center branch to facilitate learning. Since pedestrians have inherent attributes, such as shape and body construction, prior attributes and manually designed features can be used to help detection. These hand-crafted features can be used in CNNs to supplement information, create heuristic regulations and direct the network to learn semantic features.
To this end, we add an attribute-guided multiple receptive field (AMRF) module in front of the convolutional layer of the center branch. We fused the outputs of multiple convolutional layers with different kernel sizes in order to enhance the discriminability of the output features. We further exploit the prior knowledge that the pedestrian has a fixed aspect ratio. We modify the shape of convolutional kernels to make receptive field (RF) consistent with the pedestrian’s inherent shape. In most datasets, the width of a pedestrian is approximately 0.4 × height [], and the RF should follow this attribute. The theoretical receptive field of a one dilated convolutional layer (general convolution with a dilation rate of 1) is formulated as Equation (3),
where is the RF size of layer n, is the convolution kernel, is the dilation rate and is the convolution stride. As Table 1 shows, by setting the size and shape of the RF, the needed convolutional layer parameters can be derived. More branches introduce larger RF and richer features. AMRF contains 3 convolutional branches with different RFs , and a shortcut branch . are concatenated and convolution is used to adjust the weights of each branch. After the shortcut connection, ReLU activation is performed. To reduce the number of parameters, we introduce dilated convolution to AMRF. Each branch consists of a general convolutional layer and a dilated convolutional layer, both with a stride of 1. The network structure of AMRF is shown in Figure 3.

Table 1.
According to the fixed aspect ratio of pedestrians (0.4), the convolution parameters are listed to construct an RF with a similar shape. The input RF size is . denotes an approximation to the nearest odd integer.
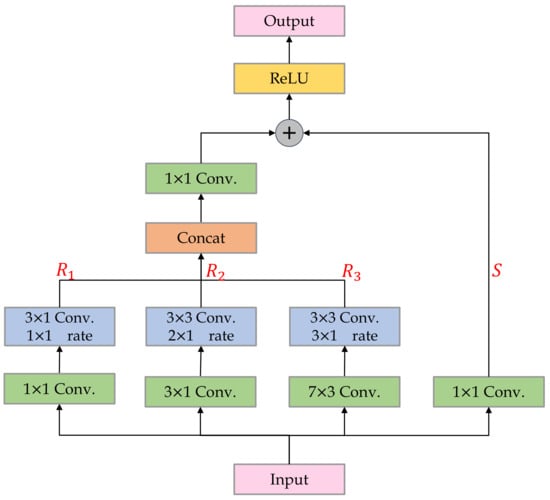
Figure 3.
The structure of the proposed attribute-guided multiple receptive field (AMRF) module.
3.5. Training
The supervision for each branch (center, scale, offset) in the detection head is standalone. The prediction is performed on a feature map of size (h/4, w/4). The center prediction can be formulated as a binary classification task (predicting whether or not the location is a pedestrian’s center location). For the ground truth, the actual center location of a pedestrian is assigned as positive while other locations are negative. Similar to [], we apply the modified focal loss to guide the classification task, as defined in Equation (4),
where K is the number of positive samples in an image. is a hyperparameter, which is set to 2 according to []. and are defined as follows:
where is the probability that the location is predicted to be positive, and indicates the ground truth label when = 1 represents the positives and = 0 the negatives. According to the Gaussian mask M, is utilized to reduce the penalty around the ground truth locations to reduce the ambiguity of surrounding negatives. is set to 4 experimentally, which is similar in [].
The scale branch is to regress the height of pedestrians. loss is used, as formulated in Equation (6),
where K is the number of positives in an image, and and are the predicted and ground truth scales, respectively.
Learning the shifted offset from center locations, the offset branch resolves the center mismatch. loss is used to regress the offset, as defined in Equation (7).
where K is the number of positives in an image, and and are the predicted and ground truth offsets relative to ground truth center locations, respectively.
In summary, the total loss function can be formulated as a weighted sum of the loss functions of the three branches, as defined in Equation (8).
where , and represent the weights for loss functions, experimentally set as 0.01, 0.05 and 0.1, respectively, which is similar in [].
3.6. Inference
For inference, the proposed approach performs only forward computation. The decoupled head predicts the pedestrian center map, scale map and offset map, respectively. The positions with a confidence score above 0.1 in the center heatmap are retained and post-processed by Non-Maximum Suppression (NMS). The pedestrian center position is slightly shifted according to the estimated offsets of the offset branch. The scale map only predicts the pedestrian height and the width is calculated by height × 0.36. The obtained pedestrian positions and scales are mapped into the form of bounding boxes to generate the detection results.
4. Experiments and Results
4.1. Experiment Settings
4.1.1. Datasets
To demonstrate the effectiveness of CAPNet, we perform experiments on two of the largest pedestrian detection datasets, Caltech [] and CityPersons [], without extra complementary data. Caltech comprises nearly 10 h of video recorded during driving. The video frames are sampled as a dataset with 42,500 images for training and 4024 images for testing. CityPersons includes 5000 street images from 27 different cities (2975 images for training, 500 images for validation and 1525 images for testing), and pedestrian annotations with various occlusion levels. The Reasonable subset is of most note-worthiness and can be used as a criterion to evaluate the detection performance.
4.1.2. Implement Details
The proposed method is implemented with Pytorch []. The backbone HRNet-40 is pre-trained on ImageNet []. The optimizer is Adam [], and and are set to 0.9 and 0.999, respectively. The initial learning rate is set to . For Caltech, we train the network on 8 NVIDIA A40 GPUs, 16 images per GPU and training is stopped after 10 K iterations. For CityPersons, we train the network on two NVIDIA A5000 GPUs, four images per GPU and training is stopped after 37.5 K iterations. The strategy of moving average weights is applied to make the training more stable.
4.1.3. Evaluation Metric
We evaluate the performance following the evaluation criterion of Caltech evaluation metric [], which is the log-average miss rate () over false positive per image () ranging in , denoted as . Lower represents better performance.
4.2. Evaluation of Results
4.2.1. Results on CityPersons
In this section, the proposed CAPNet is extensively compared with the state-of-the-art methods on the CityPersons validation set, as shown in Table 2. For a fair comparison, all methods are trained on the training set without any additional data (except for ImageNet). The training image size is (640, 1280) for most methods, and (1024, 2048) for Adapted-CSP. When testing, the resolution of each input image is (1024, 2048) for each method, except for Adaptive-NMS of (1280, 2560). The presented testing time is under the same environment on one Nvidia GTX 1080Ti GPU. The best results are highlighted in bold. It can be observed that the proposed CAPNet outperforms the current state-of-the-art on Reasonable and Partial, with of 8.7%, 46.1%, 7.4%, respectively. On the Heavy set, CAPNet ranks second and, notably, CAPNet does not involve any specific occlusion handling techniques. On the Bare set, the performance of CAPNet is relatively competitive, with only a marginal difference when compared to 3 other methods (Adapted-CSP, APD and OAF-Net). The speed of CAPNet is 0.31 s/img, and it is reasonable to conclude that CAPNet strikes a balance between efficiency and effectiveness. Figure 4 shows the detection results of the first anchor-free pedestrian detector, CSP and the proposed detector, CAPNet on the CityPersons validation set.
Table 2.
The performance comparison between CAPNet and other state-of-the-art methods on each subset of the validation set. The best results are highlighted in bold.

Figure 4.
The detection results of the same five images in the validation set on CSP and CAPNet. The area framed by pink boxes is detections output by the two detectors. The area framed by red boxes is negative proposals detected by CSP.
4.2.2. Results on Caltech
To demonstrate the effectiveness of CAPNet, we perform comparison experiments with the state-of-the-art methods on the Caltech test set, as shown in Table 3 and Figure 5. To compare the performance under different challenges, CAPNet is evaluated on three subsets, Reasonable, All and Occ. For a fair comparison, all methods are trained on the training set without any additional data (except for ImageNet). The best results are highlighted in bold. It can be observed that the proposed CAPNet demonstrates a level of performance that surpasses the current state-of-the-art on Reasonable, All and Occ, with of 2.75%, 53.42% and 39.19%, respectively. The results of the experiment show that CAPNet outperforms the other methods on all subsets. CAPNet has excellent robustness and generalizability for various scenarios. Figure 6 shows the detection results of the first anchor-free pedestrian detector, CSP and the proposed detector, CAPNet on Caltech.
Table 3.
The performance comparison between CAPNet and other state-of-the-art methods on three subsets of Caltech. The best results are highlighted in bold.

Figure 5.
Comparisons of the state -of-the-art on three Caltech subsets: Reasonable, All and Occ. (a) Reasonable. (b) All. (c) Occ.

Figure 6.
The detection results of the same five images in the test set on CSP and CAPNet. The area framed by pink boxes is detections output by the two detectors. The area framed by red boxes is pedestrians not detected by CSP.
4.3. Ablation Study
A series of ablative analyses is conducted on the CityPersons validation dataset. We perform validation on each module, including the feature extraction module, the global feature mining and aggregation (GFMA) network and the attribute-guided multiple receptive field (AMRF) head.
4.3.1. Feature Extraction Module
First, we compare the effectiveness of several different backbone networks, including ResNet-50, ResNet-101, EfficientNet-b0, EfficientNet-b6 and HRNet-40 (ours). All experiments are conducted in the same environment, and no other additional modules or training strategies are applied. To evaluate the impact of feature extraction on the scale variance in pedestrian detection, we also perform comparison experiments on Small, Medium and Large subsets. The amount of parameters of each approach is reported. As shown in Table 4, HRNet-40 outperforms on each subset with 9.8%, 48.0% and 13.2% , on Reasonable, Heavy and Small. Significantly, on the Small subset, the method with HRNet-40 has an improvement of 2.7% compared to ResNet-50. This demonstrates that improving the feature extraction module can substantially alleviate the difficulties of small-scale pedestrian detection. The approach with ResNet-101 has almost equivalent performance to HRNet-40 on the Medium and Large sets. However, it does not perform well in hard example subsets such as Heavy and Small. This might be because the deep feature maps lose details that facilitate localization. Although EfficientNet-b6 performs well on the ImageNet classification benchmark, the method with EfficientNet-b6 achieves only 10.3% on the Reasonable set. This may be due to the fact that the EfficientNet network is designed by neural architecture search. Object detectors based on NAS, such as EfficientDet need delicate hyper-parameter tuning tricks, which are important for the detection performance. EfficientNet-b0 has the lightest network structure but inferior detection performance to EfficientNet-b6. Moreover, the HRNet-40 method has only 13.6 MB more parameters than that of ResNet-50, which is much less than ResNet-101. In overview, applying HRNet-40 as a feature extraction module can meet both performance and lightness.
Table 4.
The detection performance comparison between different feature extraction modules. The best results are highlighted in bold.
4.3.2. Global Feature Mining and Aggregation Network
The proposed global feature mining and aggregation (GFMA) network explores the context with underlying semantic information so as to enhance useful features and suppress irrelevant features on a global level. Specifically, our design for the GFMA network includes three parts: (1) global feature modeling (GFM), (2) local feature aggregation (LFA) and (3) feature normalization. We conduct a series of ablation studies to demonstrate the effectiveness of each component. All experiments are conducted in the same environment and take HRNet-40 as the backbone. As shown in Table 5, the approach with GFM achieves 9.3%, 47.5%, 8.0% and 6.4% increased in Reasonable, Heavy, Partial and Bare sets, respectively, which has been substantially improved compared to the baseline. Secondly, we extract short-distance features and fuse them with the global context. Skip connection is constructed with the input of GFM, in order to prevent the gradients from directly flowing to the backbone, hence, it gives more opportunity for better optimization. With LFA in the network, the performance of the detector becomes more excellent, with a gain of 0.1%, 0.5%, 0.1% in Reasonable, Heavy and Bare, respectively. Finally, we explore which normalization method is better for feature maps. We compare transposed convolution, which is suggested in CSP [], and interpolate, which is suggested in HRNet []. Table 5 reports that despite the better performance on the Heavy set, the method with interpolate deteriorates in the three other subsets. The transposed convolution not only expands the feature map size but also adaptively allows the network to learn how to recombine and adjust the features, which can be considered a generalized interpolation.
Table 5.
The ablation studies of each component in the GFMA network. The best results are highlighted in bold.
We further visualize the gradient-weighted class activation map of the center branch, as shown in Figure 7. For one pedestrian, the positive example is the center and other positions are negative. It can be seen that with the GFMA network, the activation area of the network is more concentrated in the center of the pedestrian, which leads to accurate detection results. The disparity in the number of positive and negative examples presents a challenge for detection. When pedestrians are crowded, the ambiguity caused by negatives is spread and accumulated, the GFMA network helps to exclude interference from negatives and decrease the uncertainty of the central location, thus significantly improving the detection performance.
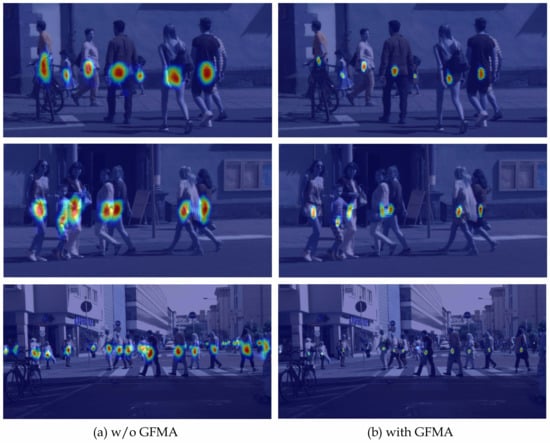
Figure 7.
The gradient-weighted class activation maps with or without the GFMA network.
4.3.3. Attribute-Guided Multiple Receptive Field Module
To demonstrate the validity of constructing a RF that conforms to the pedestrian shape, we conduct comparison experiments with an attribute-shaped RF, square-shaped RF and transpose-shaped RF, as Table 6 shows. We modify the aspect ratio of the RF to 1:1 on the basis of the AMRF module to construct a square-shaped RF, denoted as SMRF. Similarly, we swap the length and width of the convolutional kernels in the AMRF module to construct a transpose-shaped RF, denoted as TMRF. The SMRF, TMRF and AMRF are integrated at the head of the classification branch. For a fair comparison, all experiments are carried out in the same environment, HRNet-40 as the backbone and with a GFMA network. Table 6 illustrates that AMRF reaches the optimum result of 8.7 on Reasonable, 7.4 on Partial and 6.0 on Bare. On the Heavy set, the performance of AMRF is slightly inferior to SMRF, with a gap of 0.1 . This is probably because the Heavy set has more pedestrians with irregular aspect ratios due to severe occlusion. It can be assumed that there is no dramatic performance deterioration. Moreover, the excellent performance on Reasonable, Partial and Bare sets indicates that AMRF can improve the overall performance rather than optimizing specifically for individual subsets. On the contrary, adding TMRF to the detector weakens the performance, probably because TMRF inhibits the detector to understand pedestrian semantics. In Figure 8, we visualize the effective receptive field (eRF) [] of the SMRF, TMRF and AMRF, which represents the actual responding area of a network structure over the input image. We used the gradient back-propagation method mentioned in [] and output the eRF of the corresponding layers. The eRF is depicted as a colored heat map, on which a more reddish color for a location means more attention from the network. It can be observed that the feature response of AMRF is concentrated in the center, which indicates that the location of the pedestrian is accurately perceived and distinguished from the background. The dispersion of the SMRF feature responses is not conducive to the localization of pedestrians, as evidenced by the scattered response spots. The feature response of TMRF does not show strong semantics.
Table 6.
The comparative experiments of SMRF, TMRF and AMRF. The best results are highlighted in bold.
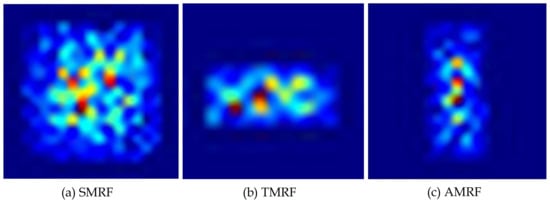
Figure 8.
The eRF [] of SMRF, TMRF and AMRF, which represent the actual responding area of a network structure over the input image.
Since it accommodates information from multiple convolutions of different sizes, AMRF can generate richer and more discriminative features. To investigate the level of feature enrichment required by AMRF, we adjust the number of branches fused by AMRF and conduct a comparative experiment, as shown in Table 7. We gradually increase the number of branches included in the AMRF, starting from 1, and set the perceptual field of each branch to conform to the pedestrian shape according to Table 1. It can be seen that the performance of the detector is best when the number of branches is three. It is worth noting that the detector generates good results when there is only one branch. The performance deteriorates when the number of branches increases to four, probably because of the redundant features introduced by too many branches.
Table 7.
The ablation experiments on the number of branches in the AMRF. The best results are highlighted in bold.
5. Conclusions
In this work, we propose an anchor-free pedestrian method named context and attribute perception (CAPNet). According to the existing research, we deeply analyze the prevailing challenges of pedestrian detection and propose to introduce context and attribute perception to the network. Through generating features with consistent semantics and details, semantic context mining and applying hand-craft features to the network, we achieve state-of-the-art results on standardized pedestrian detection datasets Caltech and CityPersons. Extensive comparative experiments and ablation studies demonstrate the effectiveness and robustness of CAPNet. We believe that CAPNet can be widely used in automatic driving, video surveillance and other fields. In future work, we will focus on enhancing the lightness and detection speed of CAPNet, so that it can be more efficiently applied to practical industrial scenes.
Author Contributions
Conceptualization, Y.Z. and H.H.; methodology, Y.Z. and H.H.; software, Y.Z. and H.Y.; validation, Y.Z., H.Y. and A.C.; formal analysis, H.H.; investigation, G.Z.; resources, H.H.; data curation, Y.Z. and A.C.; writing—original draft preparation, Y.Z.; writing—review and editing, H.H.; visualization, G.Z.; supervision, H.H.; project administration, H.H.; funding acquisition, H.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China under Grant 2021YFF0900700 and BUPT innovation and entrepreneurship support program under Grant 2023-YC-A002.
Data Availability Statement
Caltech dataset link: http://www.vision.caltech.edu/datasets (accessed on 4 August 2011). CityPersons dataset link: https://www.cityscapes-dataset.com (accessed on 9 November 2017).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, P.; Chen, X.; Shen, S. Stereo R-CNN based 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7636–7644. [Google Scholar] [CrossRef]
- Tseng, B.L.; Lin, C.Y.; Smith, J.R. Real-time video surveillance for traffic monitoring using virtual line analysis. In Proceedings of the IEEE International Conference on Multimedia and Expo, Lausanne, Switzerland, 26–29 August 2002; pp. 541–544. [Google Scholar] [CrossRef]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 941–951. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is Faster R-CNN Doing Well for Pedestrian Detection? In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 443–457. [Google Scholar] [CrossRef]
- Zhang, S.; Li, S.Z. Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 657–674. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-Aware Fast R-CNN for Pedestrian Detection. IEEE Trans. Multimed. 2018, 20, 985–996. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Adaptive NMS: Refining pedestrian detection in a crowd. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6452–6461. [Google Scholar] [CrossRef]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar] [CrossRef]
- Cao, J.; Pang, Y.; Xie, J.; Khan, F.S.; Shao, L. From Handcrafted to Deep Features for Pedestrian Detection: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4913–4934. [Google Scholar] [CrossRef] [PubMed]
- Mao, J.; Xiao, T.; Jiang, Y.; Cao, Z. What Can Help Pedestrian Detection? In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6034–6043. [Google Scholar] [CrossRef]
- Song, T.; Sun, L.; Xie, D.; Sun, H.; Pu, S. Small-scale Pedestrian Detection Based on Somatic Topology Localization and Temporal Feature Aggregation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 554–569. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Liu, W.; Liao, S.; Hu, W.; Liang, X.; Chen, X. Learning Efficient Single-stage Pedestrian Detectors by Asymptotic Localization Fitting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 634–659. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Jin, L.; Gao, S. FPN++: A Simple Baseline for Pedestrian Detection. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shanghai, China, 8–12 July 2019; pp. 1138–1143. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9908, pp. 354–370. [Google Scholar] [CrossRef]
- Wang, X.; Shen, C.; Li, H.; Xu, S. Human Detection Aided by Deeply Learned Semantic Masks. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2663–2673. [Google Scholar] [CrossRef]
- Jiang, H.; Liao, S.; Li, J.; Prinet, V.; Xiang, S. Urban scene based Semantical Modulation for Pedestrian Detection. Neurocomputing 2022, 474, 1–12. [Google Scholar] [CrossRef]
- Zhang, C.; Kim, J. Object Detection With Location-Aware Deformable Convolution and Backward Attention Filtering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9452–9461. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, J.; Schiele, B. Occluded Pedestrian Detection Through Guided Attention in CNNs. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6995–7003. [Google Scholar] [CrossRef]
- Zhang, S.; Bauckhage, C.; Klein, D.A.; Cremers, A.B. Exploring Human Vision Driven Features for Pedestrian Detection. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1709–1720. [Google Scholar] [CrossRef]
- Cao, J.; Pang, Y.; Li, X. Pedestrian Detection Inspired by Appearance Constancy and Shape Symmetry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1316–1324. [Google Scholar] [CrossRef]
- Zhang, S.; Bauckhage, C.; Cremers, A.B. Informed Haar-Like Features Improve Pedestrian Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 947–954. [Google Scholar] [CrossRef]
- Xu, Z.; Li, B.; Yuan, Y.; Dang, A. Beta R-CNN: Looking into Pedestrian Detection from Another Perspective. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 19953–19963. [Google Scholar]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5182–5191. [Google Scholar] [CrossRef]
- Yang, F.; Chen, H.; Li, J.; Li, F.; Wang, L.; Yan, X. Single Shot Multibox Detector with Kalman Filter for Online Pedestrian Detection in Video. IEEE Access 2019, 7, 15478–15488. [Google Scholar] [CrossRef]
- Yan, Y.; Li, J.; Qin, J.; Bai, S.; Liao, S.; Liu, L.; Zhu, F.; Shao, L. Anchor-Free Person Search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 7690–7699. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, Z.; Song, C.; Tan, T. Instance Guided Proposal Network for Person Search. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 2582–2591. [Google Scholar] [CrossRef]
- Zhao, C.; Chen, Z.; Dou, S.; Qu, Z.; Yao, J.; Wu, J.; Miao, D. Context-Aware Feature Learning for Noise Robust Person Search. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7047–7060. [Google Scholar] [CrossRef]
- Jaffe, L.; Zakhor, A. Gallery Filter Network for Person Search. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2023, Waikoloa, HI, USA, 2–7 January 2023; pp. 1684–1693. [Google Scholar] [CrossRef]
- Yang, F.; Choi, W.; Lin, Y. Exploit All the Layers: Fast and Accurate CNN Object Detector with Scale Dependent Pooling and Cascaded Rejection Classifiers. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2129–2137. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, K.; Tian, Y.; Gou, C.; Wang, F. MFR-CNN: Incorporating Multi-Scale Features and Global Information for Traffic Object Detection. IEEE Trans. Veh. Technol. 2018, 67, 8019–8030. [Google Scholar] [CrossRef]
- Cao, J.; Pang, Y.; Han, J.; Gao, B.; Li, X. Taking a Look at Small-Scale Pedestrians and Occluded Pedestrians. IEEE Trans. Image Process. 2020, 29, 3143–3152. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Xu, L.; Yang, M. Pedestrian detection in crowded scenes via scale and occlusion analysis. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 1210–1214. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Zhang, J.; Lin, L.; Zhu, J.; Li, Y.; Chen, Y.; Hu, Y.; Hoi, S.C.H. Attribute-Aware Pedestrian Detection in a Crowd. IEEE Trans. Multimed. 2021, 23, 3085–3097. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 248–255. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Seoul, Republic of Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 765–781. [Google Scholar] [CrossRef]
- Wang, W. Detection of panoramic vision pedestrian based on deep learning. Image Vis. Comput. 2020, 103, 986–993. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the Advances in Neural Information Processing Systems Workshop on Autodiff, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion Loss: Detecting Pedestrians in a Crowd. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7774–7783. [Google Scholar] [CrossRef]
- Xie, J.; Cholakkal, H.; Anwer, R.M.; Khan, F.S.; Pang, Y.; Shao, L.; Shah, M. Count- and Similarity-Aware R-CNN for Pedestrian Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Volume 12362, pp. 88–104. [Google Scholar] [CrossRef]
- Luo, Z.; Fang, Z.; Zheng, S.; Wang, Y.; Fu, Y. NMS-Loss: Learning with Non-Maximum Suppression for Crowded Pedestrian Detection. In Proceedings of the International Conference on Multimedia Retrieval, Taipei, Taiwan, 12 July 2021; pp. 481–485. [Google Scholar] [CrossRef]
- Li, Q.; Su, Y.; Gao, Y.; Xie, F.; Li, J. OAF-Net: An Occlusion-Aware Anchor-Free Network for Pedestrian Detection in a Crowd. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21291–21300. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29, pp. 4898–4906. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).