
A Convolutional Neural Network-Based Feature Extraction and Weighted Twin Support Vector Machine Algorithm for Context-Aware Human Activity Recognition

 ,
, 
 ,
,  and
and
Abstract
:1. Introduction
- There are two major types of feature extraction. Major works [12,13,14,15,16,17,19,20,21] utilized the traditional feature extraction process. There has been less discussion (e.g., [18]) of automatic feature extraction using a deep learning algorithm, which may extract more representative features and eliminate the domain knowledge of all human activities;
1.1. Research Contributions
- The 3D-2D-1D-CNN algorithm leverages the ability of automatic feature extraction. An ablation study confirms that the 3D-CNN, 2D-CNN, and 1D-CNN achieve accuracy improvements of 6.27%, 4.13%, and 2.40%, respectively;
- The WTSVM takes the advantage of high-dimensional feature space and outperforms the twin SVM by 3.26% in terms of accuracy;
- Context awareness is incorporated to enhance the formulation of the HAR model, with an accuracy improvement of 2.4%; and
- Compared to existing works, our proposed algorithm enhances the accuracy by 0.1–40.1% with an increase of the total number of activities by 230–3100%.
1.2. Paper Organization
2. Methodology
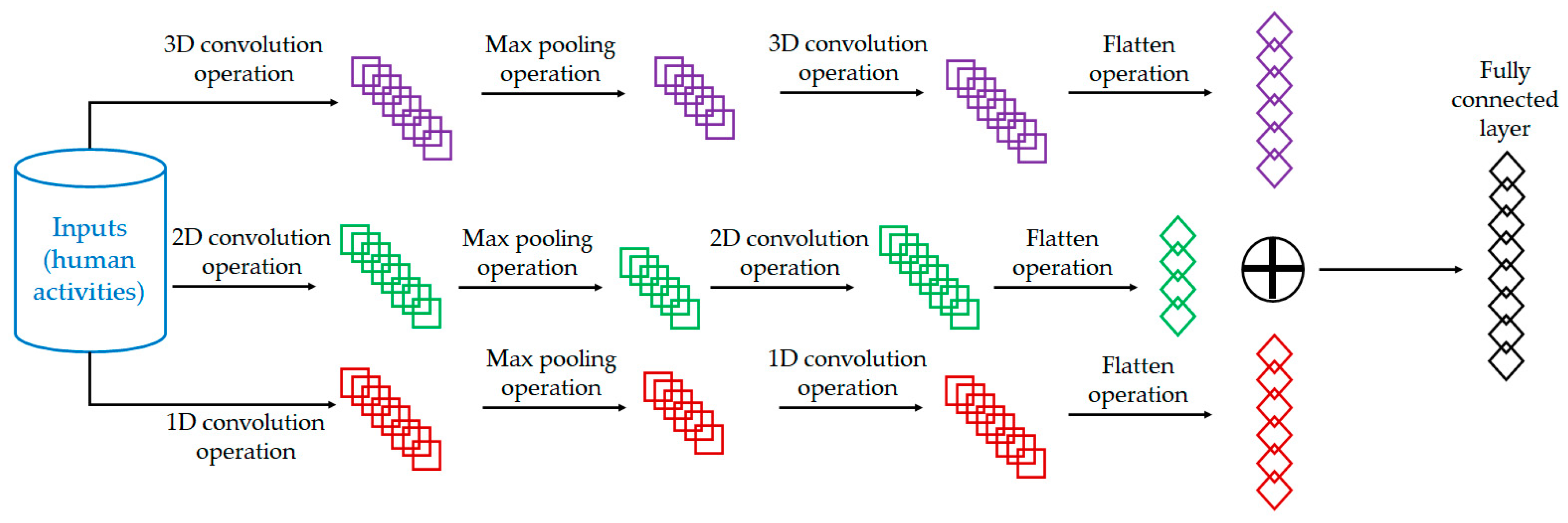
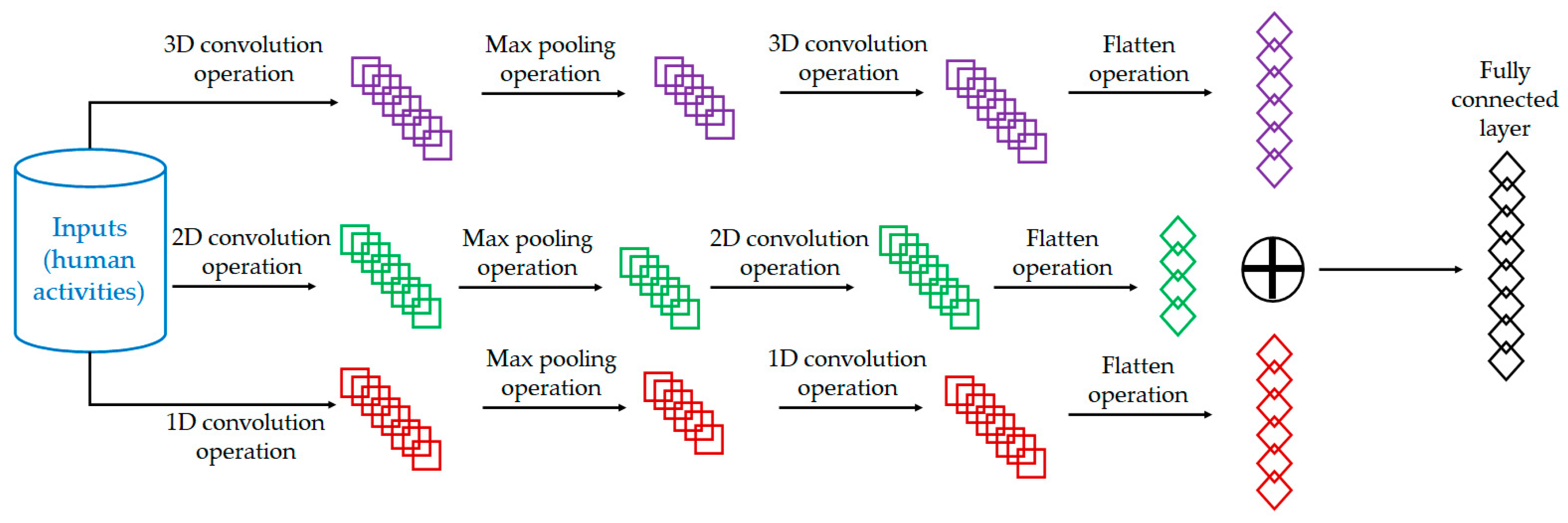
2.1. Feature Extraction Module Using the 3D-2D-1D-CNN
2.2. Classification Module Using a WTSVM
3. Performance Evaluation of the Proposed 3D-2D-1D-CNN-Based WTSVM for HAR
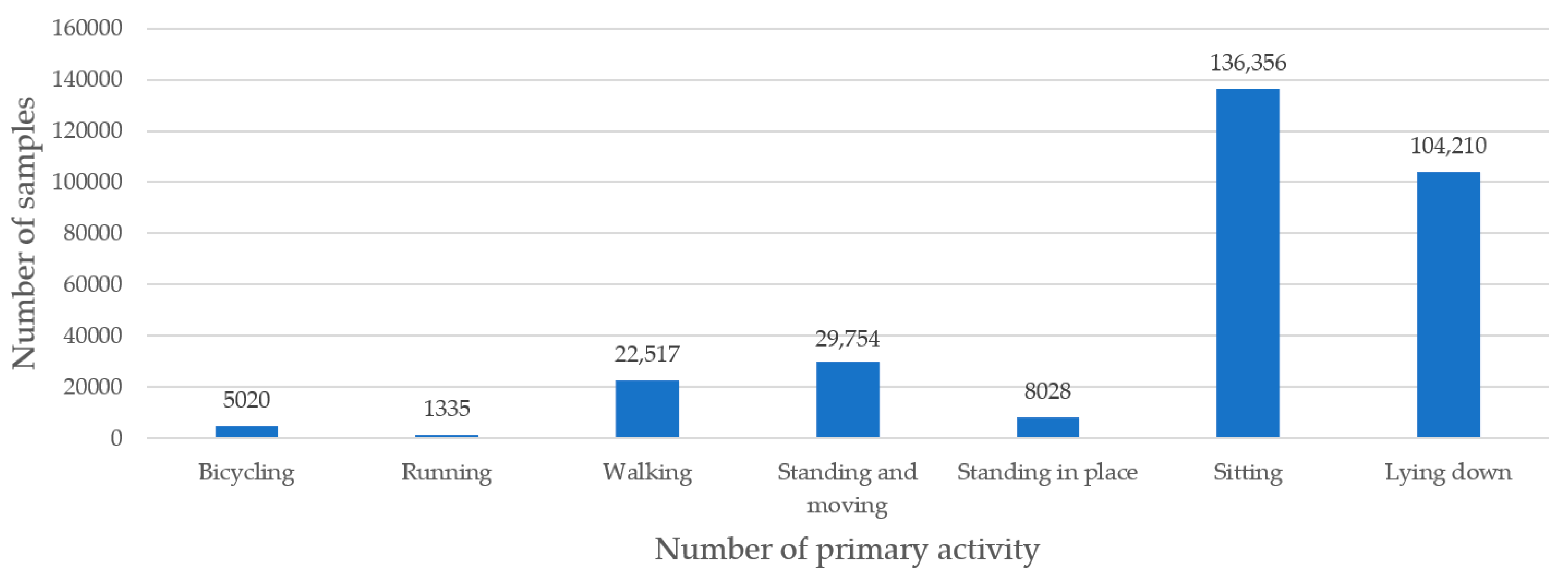
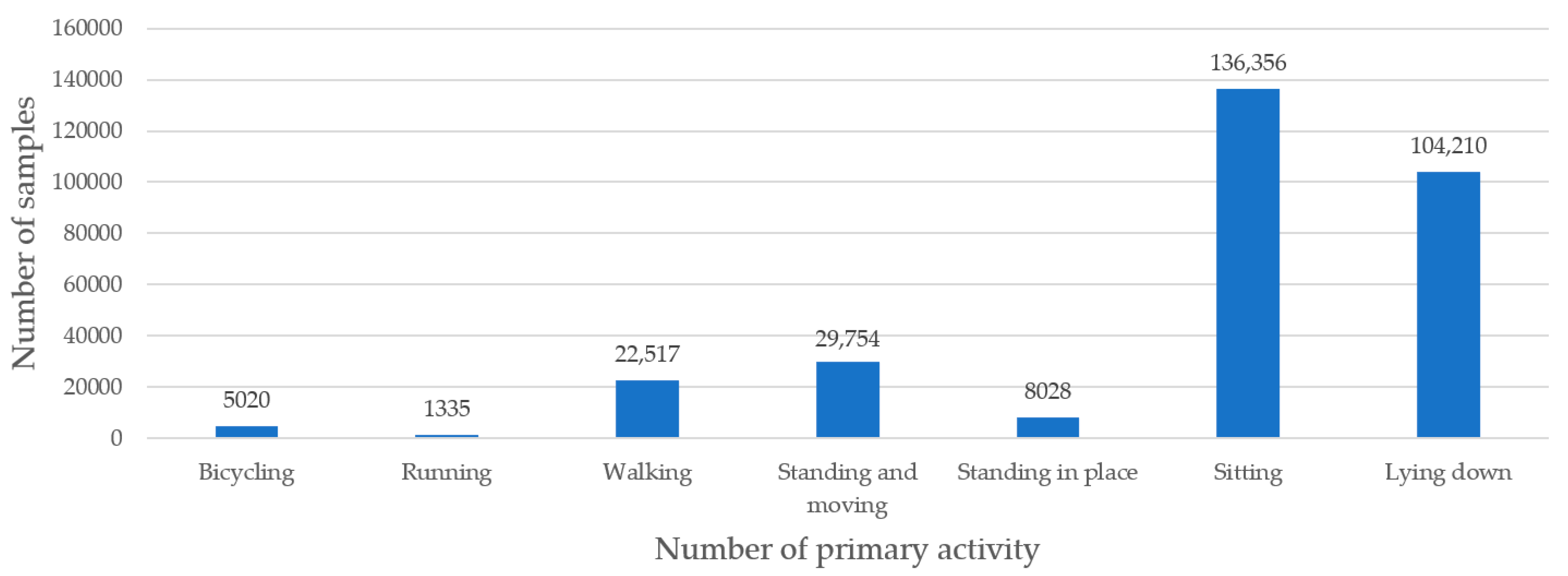
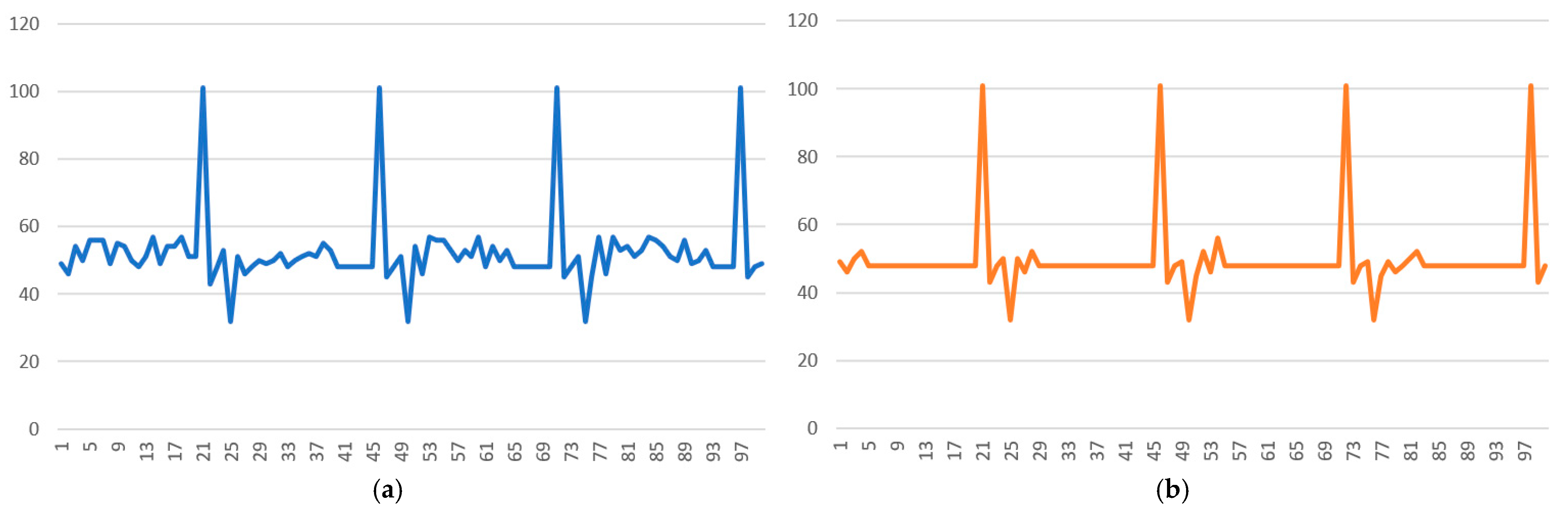
3.1. Dataset
3.2. Results
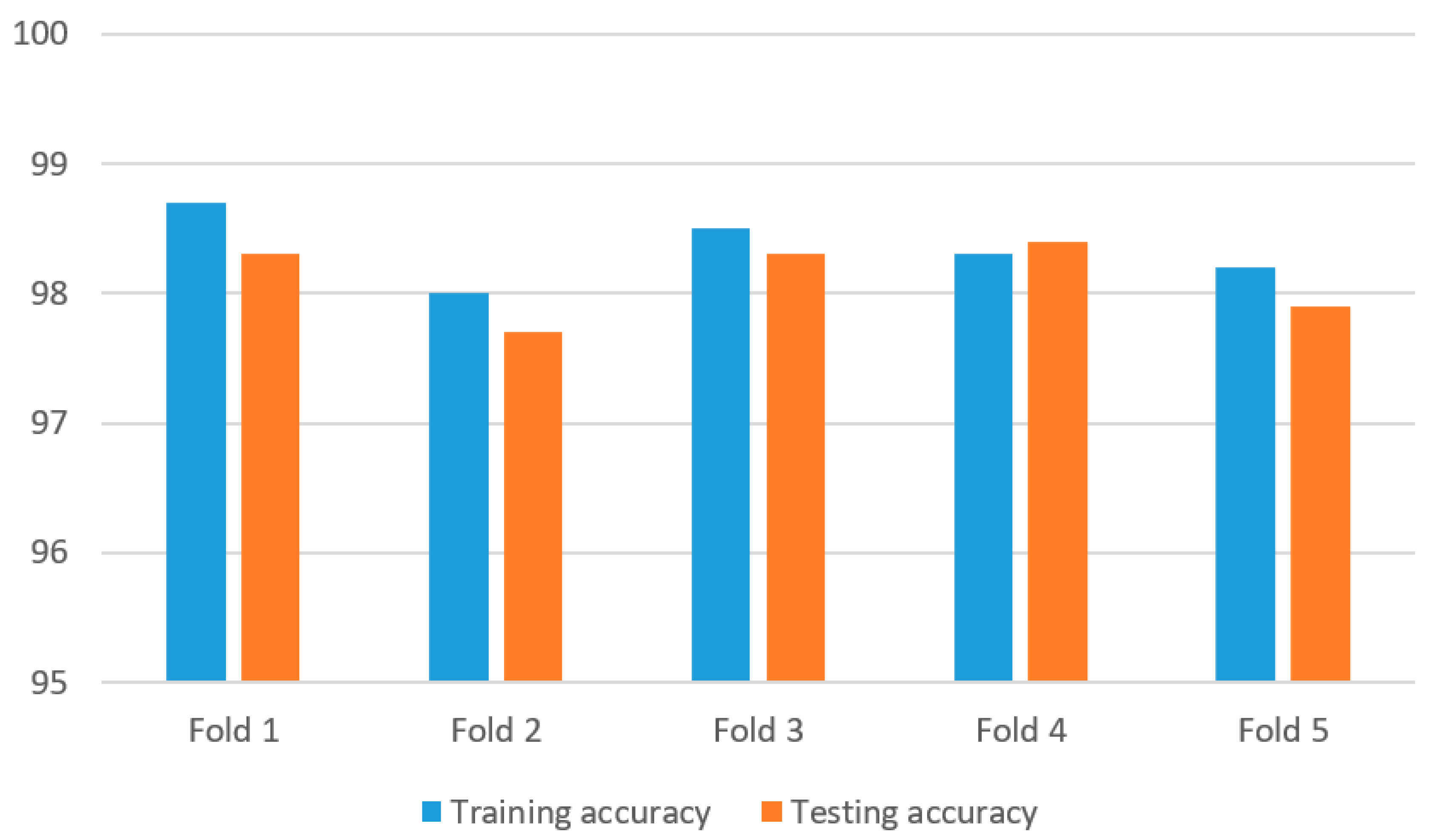
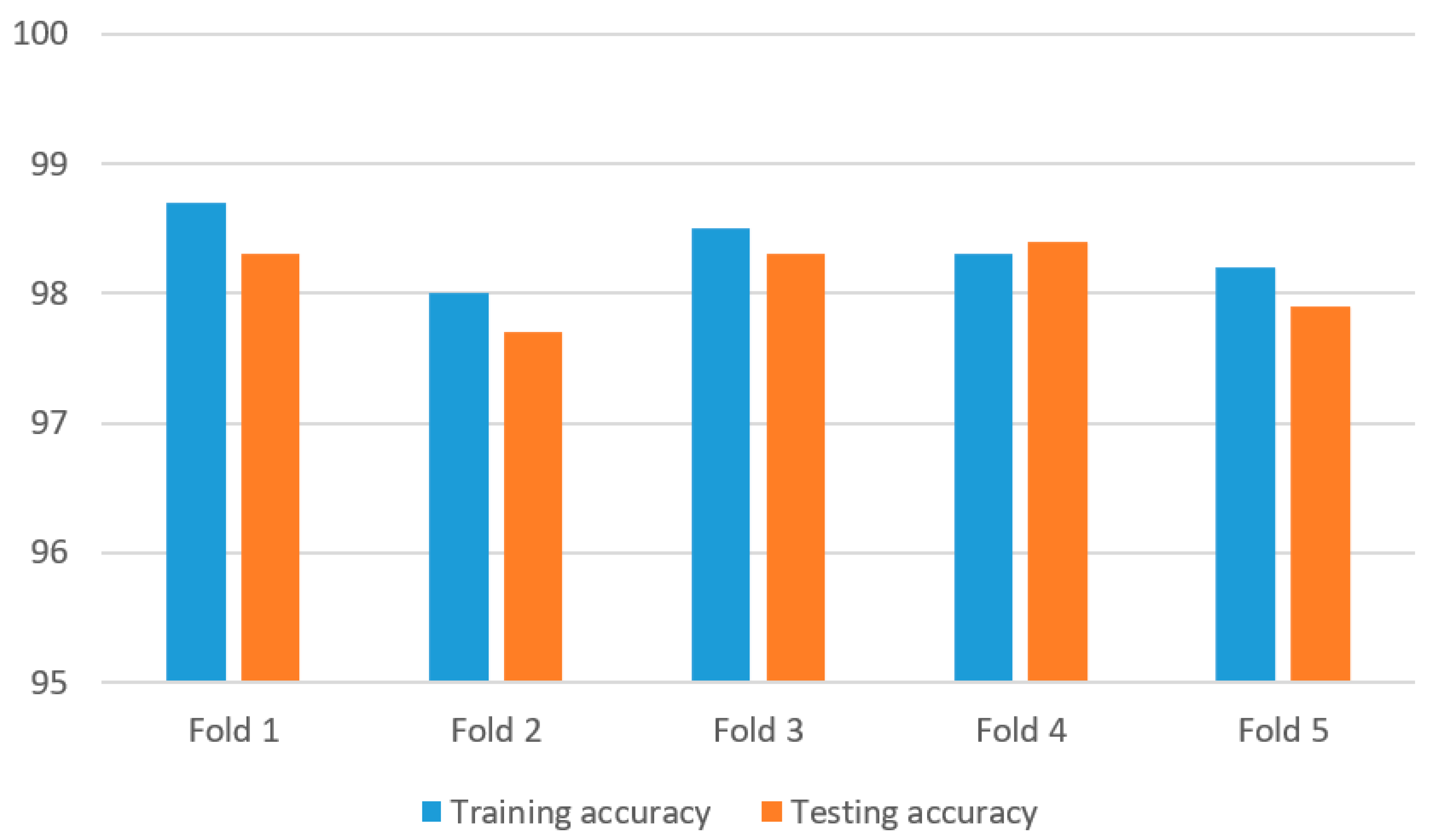
- The average training accuracy, average testing accuracy, average precision, average recall, and average F1 score were 98.3%, 98.1%, 98.4%, 98%, and 98.2%, respectively, for the 3D-2D-1D-CNN algorithm; 92.5%, 92.2%, 92.3%, 92.1%, and 92.2%, respectively, for the 2D-1D-CNN algorithm; 94.4%, 94.3%, 94.6%, 94.2%, and 94.3%, respectively, for the 3D-1D-CNN algorithm; and 96.0%, 95.9%, 96%, 95.8%, and 95.9%, respectively, for the 3D-2D-CNN algorithm. The results show that the average training accuracy was enhanced by 6.27%, 4.13%, and 2.40%, respectively;
- The ranking of the algorithms (from best to worst) based on the training accuracy and testing accuracy was 3D-2D-1D-CNN, 3D-2D-CNN, 3D-1D-CNN, and 2D-1D-CNN. This revealed the contributions of the individual components—the 3D-CNN, 2D-CNN, and 1D-CNN algorithms.
- The average training accuracy, average testing accuracy, average precision, average recall, and average F1 score were 98.3%, 98.1%, 98.4%, 98%, and 98.2%, respectively, for the WTSVM algorithm; 95.2%, 95.1%, 95.2%, 95.0%, and 95.1%, respectively, for the WSVM algorithm; and 96.1%, 95.9%, 96.2%, 95.8%, and 95.9%, respectively, for the TSVM algorithm. The enhancement of the average training accuracy by the WTSVM algorithm was 2.29% and 3.26%, respectively;
- The ranking of the algorithms (from best to worst) based on the training accuracy and testing accuracy was WTSVM, TSVM, and WSVM. This revealed the contributions of the individual components, the WTSVM, WSVM, and TSVM algorithms.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hendry, D.; Chai, K.; Campbell, A.; Hopper, L.; O’Sullivan, P.; Straker, L. Development of a human activity recognition system for ballet tasks. Sports Med.-Open 2020, 6, 10. [Google Scholar] [CrossRef] [PubMed]
- Jalal, A.; Quaid, M.A.K.; Tahir, S.B.U.D.; Kim, K. A study of accelerometer and gyroscope measurements in physical life-log activities detection systems. Sensors 2020, 20, 6670. [Google Scholar] [CrossRef] [PubMed]
- Ullah, F.U.M.; Muhammad, K.; Haq, I.U.; Khan, N.; Heidari, A.A.; Baik, S.W.; de Albuquerque, V.H.C. AI-Assisted Edge Vision for Violence Detection in IoT-Based Industrial Surveillance Networks. IEEE Trans. Ind. Inform. 2022, 18, 5359–5370. [Google Scholar] [CrossRef]
- Yadav, S.K.; Luthra, A.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. ARFDNet: An efficient activity recognition & fall detection system using latent feature pooling. Knowl.-Based Syst. 2022, 239, 107948. [Google Scholar]
- Bhavanasi, G.; Werthen-Brabants, L.; Dhaene, T.; Couckuyt, I. Patient activity recognition using radar sensors and machine learning. Neural Comput. Appl. 2022, 34, 16033–16048. [Google Scholar] [CrossRef]
- Shu, X.; Yang, J.; Yan, R.; Song, Y. Expansion-squeeze-excitation fusion network for elderly activity recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5281–5292. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Miranda, L.; Viterbo, J.; Bernardini, F. A survey on the use of machine learning methods in context-aware middlewares for human activity recognition. Artif. Intell. Rev. 2022, 55, 3369–3400. [Google Scholar] [CrossRef]
- Khowaja, S.A.; Yahya, B.N.; Lee, S.L. CAPHAR: Context-aware personalized human activity recognition using associative learning in smart environments. Hum.-Centric Comput. Inf. Sci. 2020, 10, 35. [Google Scholar] [CrossRef]
- Tsai, J.K.; Hsu, C.C.; Wang, W.Y.; Huang, S.K. Deep learning-based real-time multiple-person action recognition system. Sensors 2020, 20, 4758. [Google Scholar] [CrossRef]
- da Costa, V.G.T.; Zara, G.; Rota, P.; Oliveira-Santos, T.; Sebe, N.; Murino, V.; Ricci, E. Dual-head contrastive domain adaptation for video action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar]
- Medjahed, H.; Istrate, D.; Boudy, J.; Dorizzi, B. Human activities of daily living recognition using fuzzy logic for elderly home monitoring. In Proceedings of the 2009 IEEE International Conference on Fuzzy Systems, Jeju, Republic of Korea, 20–24 August 2009. [Google Scholar]
- Schneider, B.; Banerjee, T. Bridging the Gap between Atomic and Complex Activities in First Person Video. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems, Luxembourg, 11–14 July 2021. [Google Scholar]
- Maswadi, K.; Ghani, N.A.; Hamid, S.; Rasheed, M.B. Human activity classification using Decision Tree and Naive Bayes classifiers. Multimed. Tools Appl. 2021, 80, 21709–21726. [Google Scholar] [CrossRef]
- Hartmann, Y.; Liu, H.; Schultz, T. Interactive and Interpretable Online Human Activity Recognition. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events, Pisa, Italy, 21–25 March 2022. [Google Scholar]
- Radhika, V.; Prasad, C.R.; Chakradhar, A. Smartphone-based human activities recognition system using random forest algorithm. In Proceedings of the 2022 International Conference for Advancement in Technology, Goa, India, 21–22 January 2022. [Google Scholar]
- Agac, S.; Shoaib, M.; Incel, O.D. Context-aware and dynamically adaptable activity recognition with smart watches: A case study on smoking. Comput. Electr. Eng. 2021, 90, 106949. [Google Scholar] [CrossRef]
- Fahad, L.G.; Tahir, S.F. Activity recognition in a smart home using local feature weighting and variants of nearest-neighbors classifiers. J. Ambient Intell. Humaniz. Comput. 2021, 12, 2355–2364. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, B.; Coelho, Y.; Bastos, T.; Krishnan, S. Trends in human activity recognition with focus on machine learning and power requirements. Mach. Learn. Appl. 2021, 5, 100072. [Google Scholar] [CrossRef]
- Muralidharan, K.; Ramesh, A.; Rithvik, G.; Prem, S.; Reghunaath, A.A.; Gopinath, M.P. 1D Convolution approach to human activity recognition using sensor data and comparison with machine learning algorithms. Int. J. Cogn. Comput. Eng. 2021, 2, 130–143. [Google Scholar]
- Myo, W.W.; Wettayaprasit, W.; Aiyarak, P. A cyclic attribution technique feature selection method for human activity recognition. Int. J. Intell. Syst. Appl. 2019, 11, 25–32. [Google Scholar] [CrossRef]
- Liu, H.; Schultz, I.T. Biosignal Processing and Activity Modeling for Multimodal Human Activity Recognition. Ph.D. Thesis, Universität Bremen, Bremen, Germany, 2021. [Google Scholar]
- Mekruksavanich, S.; Jantawong, P.; Jitpattanakul, A. A Deep Learning-based Model for Human Activity Recognition using Biosensors embedded into a Smart Knee Bandage. Procedia Comp. Sci. 2022, 214, 621–627. [Google Scholar] [CrossRef]
- Liu, H.; Hartmann, Y.; Schultz, T. Motion Units: Generalized sequence modeling of human activities for sensor-based activity recognition. In Proceedings of the 2021 29th European Signal Processing Conference, Dublin, Ireland, 23–27 August 2021. [Google Scholar]
- Liu, H.; Hartmann, Y.; Schultz, T. A Practical Wearable Sensor-based Human Activity Recognition Research Pipeline. In Proceedings of the 15th International Conference on Health Informatics, Online, 9–11 February 2022. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ugulino, W.; Cardador, D.; Vega, K.; Velloso, E.; Milidiú, R.; Fuks, H. Wearable computing: Accelerometers’ data classification of body postures and movements. In Proceedings of the Advances in Artificial Intelligence-SBIA 2012: 21th Brazilian Symposium on Artificial Intelligence, Curitiba, Brazil, 20–25 October 2012. [Google Scholar]
- Liu, H.; Hartmann, Y.; Schultz, T. CSL-SHARE: A multimodal wearable sensor-based human activity dataset. Front. Comput. Sci. 2021, 3, 759136. [Google Scholar] [CrossRef]
- Shoaib, M.; Scholten, H.; Havinga, P.J.; Incel, O.D. A hierarchical lazy smoking detection algorithm using smartwatch sensors. In Proceedings of the 2016 IEEE 18th International Conference on e-Health Networking, Applications and Services, Munich, Germany, 14–17 September 2016. [Google Scholar]
- Rashidi, P.; Cook, D.J.; Holder, L.B.; Schmitter-Edgecombe, M. Discovering activities to recognize and track in a smart environment. IEEE Trans. Knowl. Data Eng. 2010, 23, 527–539. [Google Scholar] [CrossRef]
- Van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate activity recognition in a home setting. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008. [Google Scholar]
- Xu, L.; Yang, W.; Cao, Y.; Li, Q. Human activity recognition based on random forests. In Proceedings of the 2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery, Guilin, China, 29–31 July 2017. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the ESANN 2013 Proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Prathiba, S.B.; Raja, G.; Bashir, A.K.; AlZubi, A.A.; Gupta, B. SDN-assisted safety message dissemination framework for vehicular critical energy infrastructure. IEEE Trans. Ind. Inf. 2022, 18, 3510–3518. [Google Scholar] [CrossRef]
- Deveci, M.; Pamucar, D.; Gokasar, I.; Köppen, M.; Gupta, B.B. Personal mobility in metaverse with autonomous vehicles using Q-rung orthopair fuzzy sets based OPA-RAFSI model. IEEE Trans. Intell. Transport. Syst. 2022, 1–10. [Google Scholar] [CrossRef]
- Rhif, M.; Ben Abbes, A.; Farah, I.R.; Martínez, B.; Sang, Y. Wavelet transform application for/in non-stationary time-series analysis: A review. Appl. Sci. 2019, 9, 1345. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.Z.; He, H.; Gupta, B.B.; Abd El-Latif, A.A. Joint computation offloading and task caching for multi-user and multi-task MEC systems: Reinforcement learning-based algorithms. Wireless Netw. 2021, 27, 2023–2038. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Jiang, Y.; Wang, P.; Shen, Q.; Shen, C. Hyperspectral classification based on lightweight 3-D-CNN with transfer learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5813–5828. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Chi, H.R.; Arya, V.; Alhalabi, W.; Ruiz, M.T.; Shen, C.W. Transfer learning-based multi-scale denoising convolutional neural network for prostate cancer detection. Cancers 2022, 14, 3687. [Google Scholar] [CrossRef] [PubMed]
- Hakim, M.; Omran, A.A.B.; Inayat-Hussain, J.I.; Ahmed, A.N.; Abdellatef, H.; Abdellatif, A.; Gheni, H.M. Bearing Fault Diagnosis Using Lightweight and Robust One-Dimensional Convolution Neural Network in the Frequency Domain. Sensors 2022, 22, 5793. [Google Scholar] [CrossRef]
- Huang, Y.M.; Du, S.X. Weighted support vector machine for classification with uneven training class sizes. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005. [Google Scholar]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing detailed human context in the wild from smartphones and smartwatches. IEEE Pervasive Comput. 2017, 16, 62–74. [Google Scholar] [CrossRef]
- Tembhurne, J.V.; Almin, M.M.; Diwan, T. Mc-DNN: Fake news detection using multi-channel deep neural networks. Int. J. Semant. Web Inf. Syst. 2022, 18, 1–20. [Google Scholar] [CrossRef]
- Lv, L.; Wu, Z.; Zhang, L.; Gupta, B.B.; Tian, Z. An edge-AI based forecasting approach for improving smart microgrid efficiency. IEEE Trans. Ind. Inf. 2022, 18, 7946–7954. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Liu, R.W.; Zhang, X.; Vasant, P.; Thomas, J.J. Extended-range prediction model using NSGA-III optimized RNN-GRU-LSTM for driver stress and drowsiness. Sensors 2021, 21, 6412. [Google Scholar] [CrossRef]
- Obulesu, O.; Kallam, S.; Dhiman, G.; Patan, R.; Kadiyala, R.; Raparthi, Y.; Kautish, S. Adaptive diagnosis of lung cancer by deep learning classification using wilcoxon gain and generator. J. Health. Eng. 2021, 2021, 5912051. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef]
- Asim, Y.; Azam, M.A.; Ehatisham-ul-Haq, M.; Naeem, U.; Khalid, A. Context-aware human activity recognition (CAHAR) in-the-Wild using smartphone accelerometer. IEEE Sensors J. 2020, 20, 4361–4371. [Google Scholar] [CrossRef]
- Cruciani, F.; Vafeiadis, A.; Nugent, C.; Cleland, I.; McCullagh, P.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Feature learning for human activity recognition using convolutional neural networks: A case study for inertial measurement unit and audio data. CCF Trans. Pervasive Comput. Interact. 2020, 2, 18–32. [Google Scholar] [CrossRef]
- Mohamed, A.; Lejarza, F.; Cahail, S.; Claudel, C.; Thomaz, E. HAR-GCNN: Deep Graph CNNs for Human Activity Recognition from Highly Unlabeled Mobile Sensor Data. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events, Pisa, Italy, 21–25 March 2022. [Google Scholar]
- Tarafdar, P.; Bose, I. Recognition of human activities for wellness management using a smartphone and a smartwatch: A boosting approach. Decis. Support Syst. 2021, 140, 113426. [Google Scholar] [CrossRef]
- Fahad, L.G.; Rajarajan, M. Integration of discriminative and generative models for activity recognition in smart homes. Appl. Soft Comput. 2015, 37, 992–1001. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, D.; Olaniyi, E.; Huang, Y. Generative adversarial networks (GANs) for image augmentation in agriculture: A systematic review. Comput. Electron. Agric. 2022, 200, 107208. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Jhaveri, R.H.; Chi, H.R.; Arya, V.; Almomani, A.; Nauman, A. Multiround Transfer Learning and Modified Generative Adversarial Network for Lung Cancer Detection. Int. J. Intell. Syst. 2023, 2023, 6376275. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, T.; Ng, W.W.; Pedrycz, W. KNNENS: A k-nearest neighbor ensemble-based method for incremental learning under data stream with emerging new classes. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Khosravi, K.; Golkarian, A.; Tiefenbacher, J.P. Using optimized deep learning to predict daily streamflow: A comparison to common machine learning algorithms. Water Resour. Manag. 2022, 36, 699–716. [Google Scholar] [CrossRef]
- Li, C.; Zhao, H.; Lu, W.; Leng, X.; Wang, L.; Lin, X.; Pan, Y.; Jiang, W.; Jiang, J.; Sun, Y.; et al. DeepECG: Image-based electrocardiogram interpretation with deep convolutional neural networks. Biomed. Signal Process. Control 2021, 69, 102824. [Google Scholar] [CrossRef]
- Makimoto, H.; Höckmann, M.; Lin, T.; Glöckner, D.; Gerguri, S.; Clasen, L.; Schmidt, J.; Assadi-Schmidt, A.; Bejinariu, A.; Müller, P.; et al. Performance of a convolutional neural network derived from an ECG database in recognizing myocardial infarction. Sci. Rep. 2020, 10, 8445. [Google Scholar] [CrossRef] [PubMed]
- Hartmann, Y.; Liu, H.; Lahrberg, S.; Schultz, T. Interpretable High-level Features for Human Activity Recognition. In Proceedings of the 15th International Conference on Bio-inspired Systems and Signal Processing, Online, 9–11 February 2022. [Google Scholar]
- Hartmann, Y.; Liu, H.; Schultz, T. Feature Space Reduction for Human Activity Recognition based on Multi-channel Biosignals. In Proceedings of the 14th International Conference on Bio-inspired Systems and Signal Processing, Online, 11–13 February 2021. [Google Scholar]
- Hartmann, Y.; Liu, H.; Schultz, T. Feature Space Reduction for Multimodal Human Activity Recognition. In Proceedings of the 13th International Conference on Bio-inspired Systems and Signal Processing, Valletta, Malta, 24–26 February 2020. [Google Scholar]
- Folgado, D.; Barandas, M.; Antunes, M.; Nunes, M.L.; Liu, H.; Hartmann, Y.; Schultz, T.; Gamboa, H. Tssearch: Time series subsequence search library. SoftwareX 2022, 18, 101049. [Google Scholar] [CrossRef]
- Rodrigues, J.; Liu, H.; Folgado, D.; Belo, D.; Schultz, T.; Gamboa, H. Feature-Based Information Retrieval of Multimodal Biosignals with a Self-Similarity Matrix: Focus on Automatic Segmentation. Biosensors 2022, 12, 1182. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Sensors | Feature Extraction | Method | Context Awareness | Dataset | Activities | CV | Results |
|---|---|---|---|---|---|---|---|---|
| [12] | Physiological, infrared debit, and state-change sensors; microphones | Raw sensor data | FL | No | One-day of data (simulated data) | Exercising, laying, sitting down, standing up, walking, and sleeping | No | Accuracy: 97% |
| [13] | Head-mounted camera | Motion coefficient | FL | No | Epic kitchens dataset (3088 samples) [26] | Cleaning, washing dishes, and cooking | No | Accuracy: 70% Precision: 58.4% Recall: 54.7% |
| [14] | Accelerometer | Value and variance of the magnitude, pitch, and roll; fundamental DC component of FFT | NB | No | 16,5633 samples [27] | Walking, standing-up, standing, laying down, and sitting | No | Accuracy: 89.5% |
| [15] | Airborne microphone, electrogoniometer accelerometer, electromyography, and gyroscope | Built-in function using ASK2.0 | HMM | No | CSL-SHARE dataset [28] | Two-leg jump, one-leg jump, shuffle-right, shuffle-left, V-cut-right-right-first, V-cut-right-left-first, V-cut-left-left-first, run, spin-right-right-first, spin-right-left-first, spin-left-right-first, spin-left-left-first, walk-downstairs, walk-upstairs, walk-curve-right, walk-curve-left, walk, stand-to-sit, sit-to-stand, stand, and sit | five-fold | Accuracy: 84.5% |
| [16] | Gyroscope and accelerometer | Time –frequency domain analysis | RF | No | New dataset (30 volunteers) | Walking upstairs, walking downstairs, walking, standing, sitting, and laying | No | Accuracy: 98% F1-score: 98% Sensitivity: 98% Precision: 98.5% |
| [17] | Gyroscope and accelerometer | Absolute difference, correlation, integration, range, median, kurtosis, root-mean-square skewness, standard deviation, mean, maximum, and minimum | DT | Yes | 3 month dataset (11 volunteers) [29] | Walk, stand, sit, eat, drink (standing), drink (sitting), sit (standing), smoke (sitting), smoke (standing), and smoke (walking) | No | Accuracy: 72% (static activities) Accuracy: 78% (dynamic activities) |
| [18] | Accelerometer, gyroscope | CNN | KNN with random projection | No | Wearable action recognition database [30,31] | Push wheelchair, jump, jog, go downstairs, go upstairs, turn right, turn left, walk right (circle), walk left (circle), walk forward, lie down, sit, and stand | k-fold (unspecified k) | Accuracy: 92.6% |
| [19] | Motion, temperature, phone usage, door, and pressure sensors | Weighted features from all sensors | Evidence theoretic KNN and fuzzy KNN | No | Kyoto1, Kyoto7, and Kasteren | Clean, cook, eat, phone call, wash hands, bed to toilet, prepare breakfast, groom, sleep, work at computer, work at dining room table, groom, prepare dinner, prepare lunch, watch tv, leave the house, the use toilet, take shower, obtain snack, obtain a drink, use washing machine, and wash dishes | LOO | Accuracy: 97% (Kyoto1) Accuracy: 77% (Kyoto7) Accuracy: 93% (Kasteren) |
| [20] | Accelerometer and gyroscope | Time–frequency domain analysis | SVM | No | 10,299 samples [32] | Laying, standing, sitting, walking downstairs, walking upstairs, and walking | No | Accuracy: 96.6% |
| [21] | Accelerometer | Cyclic attribution technique | ANN | No | UCI-HAR (30 volunteers) [33] | Laying, standing, sitting, walking, walking downstairs, and walking upstairs | No | Accuracy: 96.7% |
| Name of Activity | No. of Samples | Name of Activity | No. of Samples | Name of Activity | No. of Samples | Name of Activity | No. of Samples |
|---|---|---|---|---|---|---|---|
| Phone on table | 11,6425 | At home | 10,3889 | Sleeping | 83,055 | Indoors | 57,021 |
| At school | 43,221 | Computer work | 38,081 | Talking | 36,293 | At work | 29,574 |
| Studying | 26,277 | With friends | 24,737 | Phone in pocket | 24,226 | Relaxing | 21,223 |
| Surfing the internet | 19,416 | Phone away from me | 17,937 | Eating | 16,594 | Phone in hand | 16,308 |
| Watching TV | 13,311 | Outside | 11,967 | Phone in bag | 10,760 | Listening to music with earphones | 10,228 |
| Written work | 9083 | Driving as driver | 7975 | With family | 7975 | With co-workers | 6224 |
| In class | 6110 | In a car | 6083 | Texting | 5936 | Listening to music without earphones | 5589 |
| Drinking non-alcohol | 5544 | In a meeting | 5153 | With a pet | 5125 | Listening to audio without earphones | 4359 |
| Reading a book | 4223 | Cooking | 4029 | Listening to audio with earphones | 4029 | Lab work | 3848 |
| Cleaning | 3806 | Grooming | 3064 | Exercising | 2679 | Toilet | 2655 |
| Driving as a passenger | 2526 | At a restaurant | 2519 | Playing videogames | 2441 | Laughing | 2428 |
| Dressing | 2233 | Shower bath | 2087 | Shopping | 1841 | On a bus | 1794 |
| Stretching | 1667 | At a party | 1470 | Drinking alcohol | 1456 | Washing dishes | 1228 |
| Smoking | 1183 | At the gym | 1151 | On a date | 1086 | Strolling | 806 |
| Going up the stairs | 798 | Going down the stairs | 774 | Singing | 651 | On a plane | 630 |
| Doing laundry | 556 | At a bar | 551 | At a concert | 538 | Manual labor | 494 |
| Playing phone games | 403 | On a train | 344 | Drawing | 273 | Elliptical machine | 233 |
| At the beach | 230 | At the pool | 216 | Elevator | 200 | Treadmill | 164 |
| Playing baseball | 163 | Lifting weights | 162 | Skateboarding | 131 | Yoga | 128 |
| Bathing | 121 | Dancing | 115 | Playing a musical instrument | 114 | Stationary bike | 86 |
| Motorbike | 86 | Transfer from bed to stand | 73 | Vacuuming | 68 | Transfer from stand to bed | 63 |
| Limping | 62 | Playing frisbee | 54 | At a sports event | 52 | Phone someone else using IT | 41 |
| Jumping | 29 | Phone strapped | 27 | Gardening | 21 | Ranking leaves | 21 |
| At sea | 18 | On a boat | 18 | Wheelchair | 9 | Whistling | 5 |
| Method | Training Accuracy (%)/Testing Accuracy (%)/Precision (%)/Recall (%)/F1 Score (%) | ||||
|---|---|---|---|---|---|
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | |
| 3D-2D-1D-CNN | 98.7/98.3/98.5/98.2/98.3 | 98.0/97.7/98.1/97.6/97.8 | 98.5/98.3/98.4/98.2/98.3 | 98.3/98.4/98.6/98.3/98.4 | 98.2/97.9/98.3/97.7/98.0 |
| 2D-1D-CNN | 92.8/92.5/92.8/92.3/92.5 | 92.2/92.4/92.3/92.4/92.3 | 93.1/92.6/92.8/92.5/92.6 | 92.5/92.0/91.8/92.0/91.9 | 92.1/91.7/92.0/91.6/91.8 |
| 3D-1D-CNN | 94.4/93.9/94.2/93.8/94.0 | 94.8/94.6/94.9/94.5/94.7 | 94.2/94.5/94.7/94.4/94.5 | 93.9/94.2/94.6/94.0/94.3 | 94.5/94.2/94.4/94.1/94.2 |
| 3D-2D-CNN | 95.9/95.5/95.7/95.4/95.5 | 95.7/96.1/96.0/96.1/96.0 | 96.3/95.8/96.2/95.7/95.9 | 96.0/96.4/96.3/96.4/96.3 | 95.9/95.7/96.0/95.6/95.8 |
| Method | Training Accuracy (%)/Testing Accuracy (%) | ||||
|---|---|---|---|---|---|
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | |
| WTSVM | 98.7/98.3/98.5/98.2/98.3 | 98.0/97.7/98.1/97.6/97.8 | 98.5/98.3/98.4/98.2/98.3 | 98.3/98.4/98.6/98.3/98.4 | 98.2/97.9/98.3/97.7/98.0 |
| WSVM | 95.5/95.8/96.0/95.7/95.8 | 94.9/94.6/94.4/94.7/94.5 | 95.0/94.5/94.7/94.4/94.5 | 95.4/95.8/96.0/95.7/95.8 | 95.0/94.6/94.9/94.5/94.7 |
| TSVM | 96.1/95.7/95.9/95.6/95.7 | 95.9/96.2/96.5/96.1/96.3 | 96.3/96.0/96.3/95.9/96.1 | 96.0/95.6/95.8/95.5/95.6 | 96.3/95.9/96.3/95.7/96.0 |
| Hypotheses | Results |
|---|---|
| H0: 3D-2D-1D-CNN = 2D-1D-CNN; H1: 3D-2D-1D-CNN > 2D-1D-CNN | Reject H0 |
| H0: 3D-2D-1D-CNN = 3D-1D-CNN; H1: 3D-2D-1D-CNN > 3D-1D-CNN | Reject H0 |
| H0: 3D-2D-1D-CNN = 3D-2D-CNN; H1: 3D-2D-1D-CNN > 3D-2D-CNN | Reject H0 |
| H0: WTSVM = WSVM; H1: WTSVM > WSVM | Reject H0 |
| H0: WTSVM = TSVM; H1: WTSVM > TSVM | Reject H0 |
| Work | Methodology | Dataset | Number of Activities | Cross-Validation | Accuracy (%) |
|---|---|---|---|---|---|
| [42] | Early fusion | ExtraSensory [42] | 25 | 5-fold | 87 |
| [48] | Random forest | 15 | 10-fold | 84 | |
| [49] | CNN with random forest | 4 | 5-fold | 52.8 (F score) | |
| [50] | Deep graph CNN | 25 | N/A | 83.8 (F score) | |
| [51] | SVM | 5 | Single-split | 81.6 | |
| Proposed | 3D-2D-1D-CNN-based WTSVM | 96 | 5-fold | 98.1 | |
| [18] | Evidence-theoretic KNN and fuzzy KNN | Kyoto1 [30] | 5 | Leave-one-out | 97 |
| [52] | discriminative and generative SVM | 5 | Leave-one-out | 98 | |
| Proposed | 3D-2D-1D-CNN-based WTSVM | 5 | 5-fold | 98.9 | |
| [18] | Evidence-theoretic KNN and fuzzy KNN | Kyoto7 [30] | 14 | Leave-one-out | 78 |
| [52] | discriminative and generative SVM | 14 | Leave-one-out | 81 | |
| Proposed | 3D-2D-1D-CNN-based WTSVM | 14 | 5-fold | 88.2 | |
| [18] | Evidence-theoretic KNN and fuzzy KNN | Kasteren [31] | 10 | Leave-one-out | 92 |
| [52] | discriminative and generative SVM | 10 | Leave-one-out | 95 | |
| Proposed | 3D-2D-1D-CNN-based WTSVM | 10 | 5-fold | 97.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chui, K.T.; Gupta, B.B.; Torres-Ruiz, M.; Arya, V.; Alhalabi, W.; Zamzami, I.F. A Convolutional Neural Network-Based Feature Extraction and Weighted Twin Support Vector Machine Algorithm for Context-Aware Human Activity Recognition. Electronics 2023, 12, 1915. https://doi.org/10.3390/electronics12081915
Chui KT, Gupta BB, Torres-Ruiz M, Arya V, Alhalabi W, Zamzami IF. A Convolutional Neural Network-Based Feature Extraction and Weighted Twin Support Vector Machine Algorithm for Context-Aware Human Activity Recognition. Electronics. 2023; 12(8):1915. https://doi.org/10.3390/electronics12081915
Chicago/Turabian StyleChui, Kwok Tai, Brij B. Gupta, Miguel Torres-Ruiz, Varsha Arya, Wadee Alhalabi, and Ikhlas Fuad Zamzami. 2023. "A Convolutional Neural Network-Based Feature Extraction and Weighted Twin Support Vector Machine Algorithm for Context-Aware Human Activity Recognition" Electronics 12, no. 8: 1915. https://doi.org/10.3390/electronics12081915
APA StyleChui, K. T., Gupta, B. B., Torres-Ruiz, M., Arya, V., Alhalabi, W., & Zamzami, I. F. (2023). A Convolutional Neural Network-Based Feature Extraction and Weighted Twin Support Vector Machine Algorithm for Context-Aware Human Activity Recognition. Electronics, 12(8), 1915. https://doi.org/10.3390/electronics12081915