
Short-Term Load Forecasting Method Based on Bidirectional Long Short-Term Memory Model with Stochastic Weight Averaging Algorithm

Abstract
:1. Introduction
2. Load Forecasting Methodology
2.1. PCA Algorithm
2.2. GA-FCM Algorithm
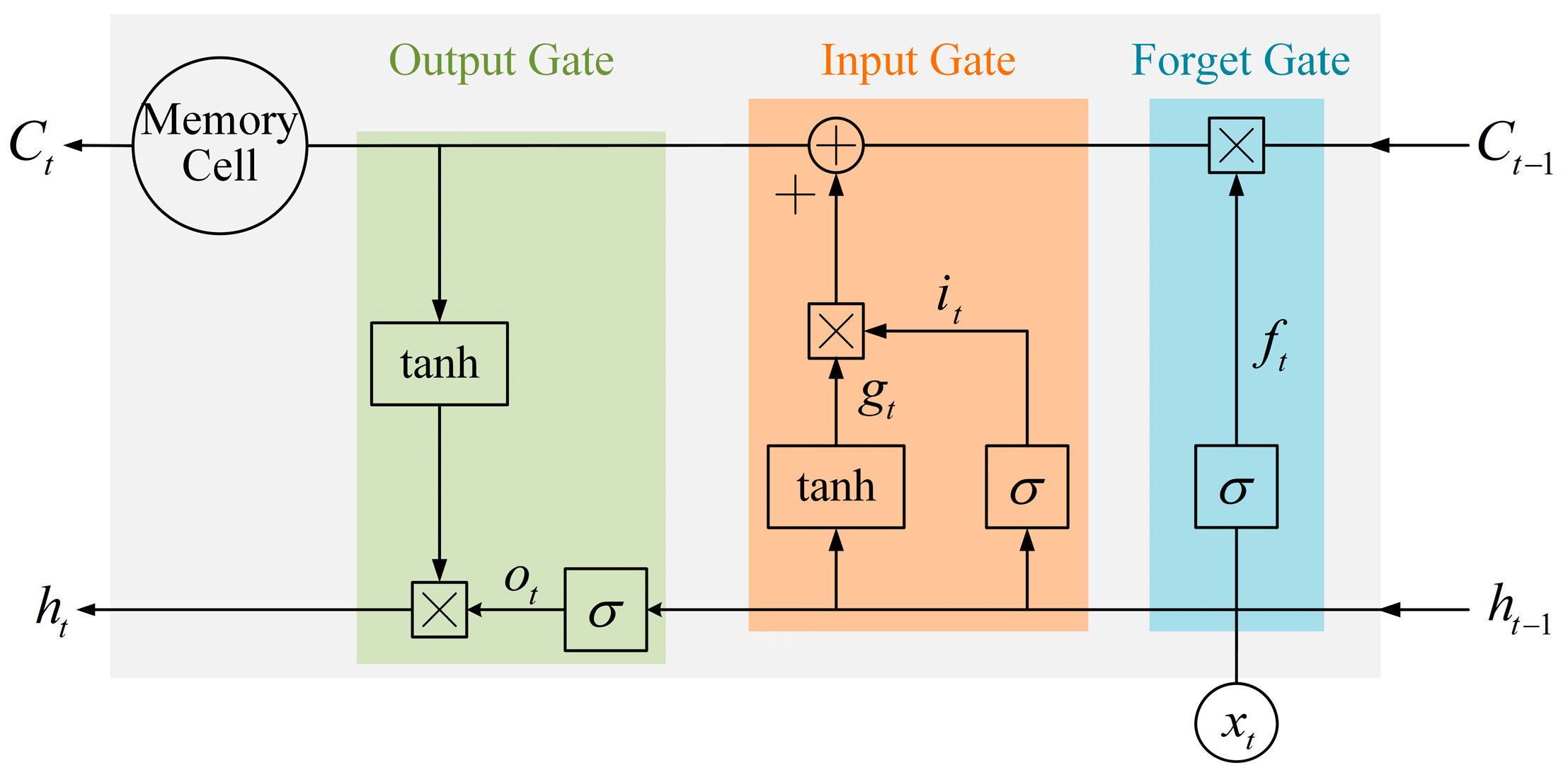
2.3. BiLSTM
3. Modeling of Distribution Substation Load Forecasting
3.1. Forecasting Model Architecture
- (1)
- Analysis of the Characteristics of Influencing Factors.
- (2)
- BiLSTM Forecasting Model Design.
3.2. Data Preprocessing
3.2.1. Data Characteristics
- (1)
- Characteristics of external factors.
- (2)
- Characteristics of electricity consumption behavior.
3.2.2. Missing Values
3.2.3. Outliers
3.3. Analysis of Influencing Factor Characteristics
3.3.1. External Factor Characteristic Dimensionality Reduction
3.3.2. Feature Clustering of Electricity Consumption Behavior
3.4. BiLSTM Forecasting Model Design
3.4.1. Forecasting Model Structure
3.4.2. SWA Optimization Algorithm
4. Example Analysis
4.1. Input Variable Selection
4.2. Classification of Electricity Consumption Behavior
4.3. Experimental Results Analysis
4.3.1. Analysis of BiLSTM Forecasting Model
4.3.2. User Load Forecasting Results
- (1)
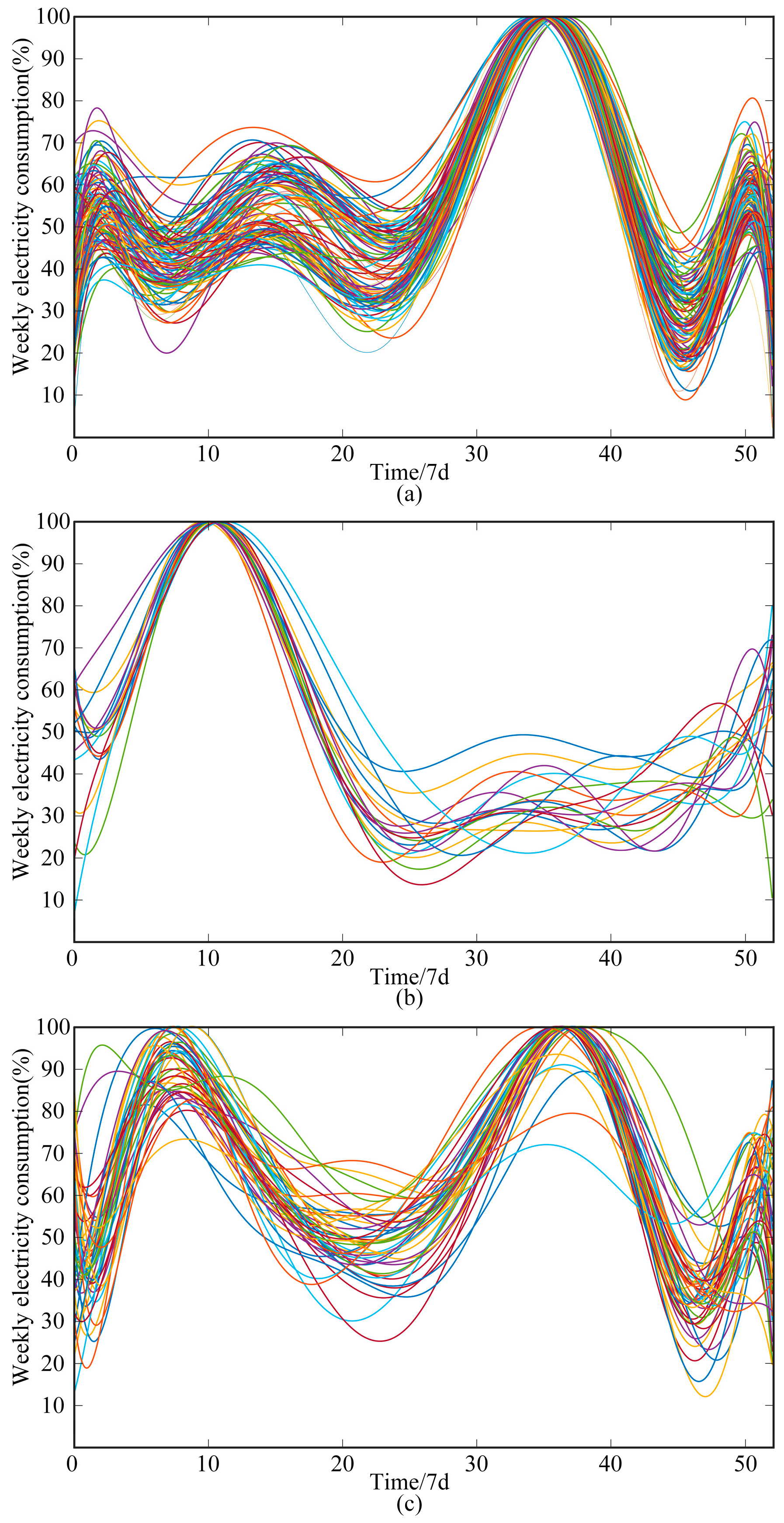
- As shown in Figure 7a, the electricity load curve of the first type of user is unimodal in summer. The electricity consumption has a significant peak in July and August, and the electricity consumption in other periods is relatively stable. Combined with the regional climate characteristics, it is inferred that such users use air conditioners and other electrical equipment in a large area in summer, so the demand for electricity and cooling is high. However, the demand for electricity heating in winter is small. This category can correspond to residential users with better heating effects in winter in the substation.
- (2)
- As shown in Figure 7b, the electricity load curve of the second type is unimodal in the winter–spring alternating season. The electricity consumption peaks in February and March, and the fluctuation of electricity consumption in other seasons is small. It is inferred that after the end of the winter central heating period, this category has a surge in electricity heating consumption due to poor house insulation.
- (3)
- As shown in Figure 7c, the electricity load curve of the third type is bimodal. There is a peak in the winter–spring season and the summer months, and the peak period of summer electricity demand is more concentrated. According to this, it is inferred that the electricity demand for summer cooling and winter heating of this category is large.
4.3.3. User Load Forecasting Results
4.4. Comparison with Existing Literature
5. Conclusions
- (1)
- A certain correlation among various influencing factors of electricity load exists in the low-voltage substation. By recombining the influencing factors, four principal component variables can be formed to describe the external factor system that affects electricity consumption.
- (2)
- Significant differences exist in electricity consumption behaviors among users in the low-voltage substation. Based on the weekly electricity load curves of each user class, these behaviors can be categorized into three types: summer peak, winter–spring single peak, and double peak.
- (3)
- Compared to the LSTM and BiLSTM models, the PCA-BiLSTM model demonstrates a higher accuracy in load forecasting, which can accurately reflect the electricity consumption behaviors of various user categories in the low-voltage substation. The classification forecasting method based on electricity consumption behavior analysis effectively enhances the accuracy of forecasting results, demonstrating a practical application value.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qiu, Z.T.; Han, X.Y.; Tian, X.; Zhu, R. Research on collaborative needs and typical scenarios of smart distribution network assisting modern infrastructure construction. Distrib. Util. 2024, 41, 47–54. [Google Scholar]
- Yang, X.Y.; Li, S.J. Design of distribution network operation safety monitoring system based on electric power big data and portrait. Electron. Des. Eng. 2023, 31, 54–57+62. [Google Scholar]
- Kong, X.Y.; Ma, Y.Y.; Ai, Q.; Zhang, X.Y.; Li, C.; Xiao, B. Review on Electricity Consumption Characteristic Modeling and Load Forecasting for Diverse Users in New Power System. Autom. Electr. Power Syst. 2023, 47, 2–17. [Google Scholar]
- Lin, J.; Ma, J.; Zhu, J.; Cui, Y. Short-term load forecasting based on LSTM networks considering attention mechanism. Int. J. Electr. Power Energy Syst. 2022, 137, 107818. [Google Scholar] [CrossRef]
- Hong, T.; Fan, S. Probabilistic electric load forecasting: A tutorial review. Int. J. Forecast. 2016, 32, 914–938. [Google Scholar] [CrossRef]
- Li, P.; Xi, W.; Cai, T.T.; Yu, H.; Li, P.; Wang, C.S. Concept, architecture and key technologies of digital power grids. Proc. CSEE 2022, 42, 5002–5016. [Google Scholar]
- Zhou, X.X.; Chen, S.Y.; Lu, Z.X.; Huang, Y.H.; Ma, S.C.; Zhao, Q. Technology Features of the New Generation Power System in China. Proc. CSEE 2018, 38, 1893–1904+2205. [Google Scholar]
- Song, K.B.; Baek, Y.S.; Hong, D.H.; Jang, G. Short-term load forecasting for the holidays using fuzzy linear regression method. IEEE Trans. Power Syst. 2005, 20, 96–101. [Google Scholar] [CrossRef]
- Bunnoon, P.; Chalermyanont, K.; Limsakul, C. Mid term load forecasting of the country using statistical methodology: Case study in Thailand. In Proceedings of the International Conference on Signal Processing Systems, Singapore, 15–17 May 2009; pp. 924–928. [Google Scholar]
- Lei, S.L.; Sun, C.X.; Zhou, Q.; Zhang, X.X. The research of local linear model of short term electrical load on multivariate time series. In Proceedings of the IEEE Russia Power Tech, St. Petersburg, Russia, 27–30 June 2005; pp. 1–5. [Google Scholar]
- Soares, L.J.; Medeiros, M.C. Modeling and forecasting short-term electricity load: A comparison of methods with an application to Brazilian data. Int. J. Forecast. 2008, 24, 630–644. [Google Scholar] [CrossRef]
- Tao, Y.; He, L.; Zhang, H.; Wang, X. Research on the prediction of fatigue life of tower crane based on grey system. Mech. Sci. Technol. Aerosp. Eng. 2012, 31, 1236–1240. [Google Scholar]
- Wang, Q.; Li, S.; Li, R. Forecasting energy demand in China and India: Using single-linear, hybrid-linear, and non-linear time series forecast techniques. Energy 2018, 161, 821–831. [Google Scholar] [CrossRef]
- Ma, J.; Yang, H.G. Application of adaptive kalman filter in power system short-term load forecasting. Power Syst. Technol. 2005, 29, 75–79. [Google Scholar]
- Guan, C.; Luh, P.B.; Michel, L.D.; Chi, Z. Hybrid Kalman filters for very short-term load forecasting and prediction interval estimation. IEEE Trans. Power Syst. 2013, 28, 3806–3817. [Google Scholar] [CrossRef]
- Chapagain, K.; Kittipiyakul, S. Short-term electricity load forecasting model and Bayesian estimation for Thailand data. In Proceedings of the Asia Conference on Power and Electrical Engineering (ACPEE), Bangkok, Thailand, 20–22 March 2016. [Google Scholar]
- Jiang, W.; Huang, L.L.; Feng, W.; Yang, L.; Wang, L.; Xu, Q.S.; Wu, J.; Yang, H.B. Research on load forecasting technology of transformer areas based on distributed graph computing. Proc. CSEE 2018, 38, 3419–3430. [Google Scholar]
- Xi, Y.W.; Wu, J.Y.; Shi, C.; Zhu, X.W.; Cai, R. A refined load forecasting based on historical data and real-time influencing factors. Power Syst. Prot. Control 2019, 47, 80–87. [Google Scholar]
- Zhang, Z.; Hong, W.C. Application of variational mode decomposition and chaotic grey wolf optimizer with support vector regression for forecasting electric loads. Knowl.-Based Syst. 2021, 228, 107297. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- Bedi, J.; Toshniwal, D. Deep learning framework to forecast electricity demand. Appl. Energy 2019, 238, 1312–1326. [Google Scholar] [CrossRef]
- Sha, F.; Zhu, F.; Guo, S.N.; Gao, J.T. Based on the EMD and PSO-BP neural network of short-term load forecasting. Adv. Mater. Res. 2012, 614, 1872–1875. [Google Scholar] [CrossRef]
- Dong, Y.; Dong, Z.; Zhao, T.; Li, Z.; Ding, Z. Short term load forecasting with markovian switching distributed deep belief networks. Int. J. Electr. Power Energy Syst. 2021, 130, 106942. [Google Scholar] [CrossRef]
- Ciechulski, T.; Osowski, S. High precision LSTM model for short-time load forecasting in power systems. Energies 2021, 14, 2983. [Google Scholar] [CrossRef]
- Zheng, J.; Xu, C.; Zhang, Z.; Li, X. Electric load forecasting in smart grids using long-short-term-memory based recurrent neural network. In Proceedings of the 51st Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2017; pp. 1–6. [Google Scholar]
- Ding, B.; Xing, Z.K.; Wang, F.; Yuan, B.; Liu, Y.; Sun, Y. Short-term load forecasting of LSTM network based on Stacking model integration. China Meas. Test 2020, 46, 40–45. [Google Scholar]
- Wu, K.; Wu, J.; Feng, L.; Yang, B.; Liang, R.; Yang, S.; Zhao, R. An attention-based CNN-LSTM-BiLSTM model for short-term electric load forecasting in integrated energy system. Int. Trans. Electr. Energy Syst. 2021, 31, e12637. [Google Scholar] [CrossRef]
- Shi, H.B. Power Load Forecasting Based on Principal Component Analysis and Support Vector Machine. Comput. Simul. 2010, 27, 279–282. [Google Scholar]
- Bian, H.; Zhong, Y.; Sun, J.; Shi, F. Study on power consumption load forecast based on K-means clustering and FCM–BP model. Energy Rep. 2020, 6, 693–700. [Google Scholar] [CrossRef]
- Zhang, L.; Lu, W.; Liu, X.; Pedrycz, W.; Zhong, C.; Wang, L. A global clustering approach using hybrid optimization for incomplete data based on interval reconstruction of missing value. Int. J. Intell. Syst. 2016, 31, 297–313. [Google Scholar] [CrossRef]
- Varadharajan, S.K.; Nallasamy, V. P-SCADA—A novel area and energy efficient FPGA architectures for LSTM prediction of heart arrthymias in BIoT applications. Expert Syst. 2022, 39, e12687. [Google Scholar] [CrossRef]
- Li, B.; Lu, M.Z. Short-term load forecasting modeling of regional power grid considering real-time meteorological coupling effect. Autom. Electr. Power Syst. 2020, 44, 60–68. [Google Scholar]
- Dong, Y.; Ma, X.; Ma, C.; Wang, J. Research and application of a hybrid forecasting model based on data decomposition for electrical load forecasting. Energies 2016, 9, 1050. [Google Scholar] [CrossRef]
- Wang, C.L.; Zheng, H.Y. A portrait of electricity consumption behavior mode of power users based on fuzzy clustering. Electr. Meas. Instrum. 2018, 55, 77–81. [Google Scholar]
- Xu, M.; Liu, Z.C.; Yan, X.; Huang, B.X.; Wang, Y.; Wang, J.G. Online detection method for incremental capacity internal resistance consistency. Energy Storage Sci. Technol. 2019, 8, 1197–1203. [Google Scholar]
- Chen, T.; Wang, Y.C. Long-term load forecasting by a collaborative fuzzy-neural approach. Int. J. Electr. Power Energy Syst. 2012, 43, 454–464. [Google Scholar] [CrossRef]
- Afshar, K.; Bigdeli, N. Data analysis and short term load forecasting in Iran electricity market using singular spectral analysis (SSA). Energy 2011, 36, 2620–2627. [Google Scholar] [CrossRef]
- Jiang, Z.H.; Wang, Y.X.; Yan, J.J.; Zhou, T.R. Modeling and analysis of cotton price forecast based on BILSTM. J. Chin. Agric. Mech. 2021, 42, 151–160. [Google Scholar]
- Hu, Q.; Zhang, S.; Yu, M.; Xie, Z. Short-term wind speed or power forecasting with heteroscedastic support vector regression. IEEE Trans. Sustain. Energy 2015, 7, 241–249. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Maximum Power/kW | Minimum Power/kW |
|---|---|---|
| 2018 | 488.890 | 151.792 |
| 2019 | 524.355 | 183.294 |
| 2020 | 501.634 | 157.415 |
| 2021 | 519.181 | 180.428 |
| Principal Component | Eigenvalue | Variance Contribution/% | Cumulative Variance Contribution/% |
|---|---|---|---|
| 1 | 12.782 | 29.491 | 29.491 |
| 2 | 10.433 | 24.071 | 53.562 |
| 3 | 8.365 | 19.300 | 71.862 |
| 4 | 5.964 | 13.760 | 86.622 |
| Evaluation Metric | LSTM/% | BiLSTM/% | PCA-BiLSTM/% |
|---|---|---|---|
| MAPE | 13.29 | 6.69 | 5.61 |
| RMSPE | 17.56 | 12.31 | 8.93 |
| Evaluation Metric | LSTM/% | BiLSTM/% | PCA-BiLSTM/% |
|---|---|---|---|
| MAPE | 12.18 | 5.80 | 5.56 |
| RMSPE | 15.73 | 11.08 | 8.87 |
| Evaluation Metric | LSTM/% | BiLSTM/% | PCA-BiLSTM/% |
|---|---|---|---|
| MAPE | 12.44 | 7.01 | 5.43 |
| RMSPE | 16.41 | 12.39 | 8.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Q.; Zeng, S.; Chen, M.; Wang, F.; Zhang, Z. Short-Term Load Forecasting Method Based on Bidirectional Long Short-Term Memory Model with Stochastic Weight Averaging Algorithm. Electronics 2024, 13, 3098. https://doi.org/10.3390/electronics13153098
Zhu Q, Zeng S, Chen M, Wang F, Zhang Z. Short-Term Load Forecasting Method Based on Bidirectional Long Short-Term Memory Model with Stochastic Weight Averaging Algorithm. Electronics. 2024; 13(15):3098. https://doi.org/10.3390/electronics13153098
Chicago/Turabian StyleZhu, Qingyun, Shunqi Zeng, Minghui Chen, Fei Wang, and Zhen Zhang. 2024. "Short-Term Load Forecasting Method Based on Bidirectional Long Short-Term Memory Model with Stochastic Weight Averaging Algorithm" Electronics 13, no. 15: 3098. https://doi.org/10.3390/electronics13153098