

FedGAT-DCNN: Advanced Credit Card Fraud Detection Using Federated Learning, Graph Attention Networks, and Dilated Convolutions

Abstract
:1. Introduction
- Improvement in Fraud Detection Accuracy with Limited Data: FedGAT-DCNN employs federated learning, allowing institutions to collaboratively train models using their local datasets. This approach enhances model accuracy and robustness, even with limited local data, and ensures sensitive information remains private.
- Dynamic Adaptation to Evolving Fraud Techniques: By incorporating a GAT into the federated learning system, our framework enables continuous and collaborative model updates across institutions. This integration allows models to quickly adapt to new fraud patterns while maintaining data privacy.
- Effective Detection of Intricate Fraud Patterns: The inclusion of dilated convolutional networks within the GAT framework extends the model’s receptive field without additional computational overhead. This combination enhances the model’s ability to detect subtle and complex fraudulent activities, even with limited data.
2. Related Work
2.1. Machine Learning and Deep Learning Methods in Credit Card Fraud Detection
2.2. Advancements in Graph Neural Networks for Fraud Detection
2.3. Federated Learning for Credit Card Fraud Detection
2.4. Comparative Analysis with State-of-the-Art Methods
3. Methodology
3.1. Transaction Similarity Graph
3.1.1. Graph Construction
3.1.2. Advantages over Traditional Methods
3.1.3. Implementation Details
3.2. Dilated Convolutional Network
3.2.1. Concept and Advantages
3.2.2. Computing Dilated Convolutional Embedding
3.3. Graph Attention Network
3.3.1. Concept and Advantages
3.3.2. GAT Layer
3.3.3. Multi-Head Attention
3.3.4. Benefits in Fraud Detection
3.4. Integration with FedProx
3.4.1. FedProx Algorithm
3.4.2. Integration with Graph-Based Model
- (i)
- Local Model Training: Each client trains the graph-based model on its local transaction similarity graph using the dilated convolutional and GAT layers to extract features and perform fraud detection.
- (ii)
- Proximal Term Adjustment: During local training, the proximal term in the FedProx algorithm ensures that the updates are consistent with the global model parameters, preventing large deviations that could destabilize the training process.
- (iii)
- Model Aggregation: The local model updates from all clients are sent to the central server, where they are aggregated to update the global model parameters.
- (iv)
- Iterative Refinement: The global model is redistributed to all clients, and the process is repeated iteratively until the model converges.
3.4.3. Benefits for Fraud Detection
- Enhanced Privacy: By keeping transaction data local to each institution, the framework ensures that sensitive information is not exposed, addressing privacy concerns.
- Robustness to Data Heterogeneity: The proximal term in FedProx stabilizes the training process despite the presence of heterogeneous data distributions across clients (institutions).
- Improved Model Performance: The collaborative training approach leverages diverse transaction data from multiple institutions, leading to a more generalized and accurate fraud detection model.
- Scalability: The federated learning setup allows the model to scale to a large number of clients, each contributing to the overall improvement of the global model.
3.5. Time Complexity Analysis
- Neighbor Feature Extraction: For each node v, the features of its d neighbors are extracted. This operation involves accessing the feature matrix and has a complexity of , where N is the number of nodes, d is the node degree, and F is the feature dimension.
- Dilated Convolutional Transformations: The neighbors’ features for each node are transformed through c dilated channels. For each channel, the node features are permuted and passed through a linear transformation, resulting in a complexity of . The factor arises from the matrix multiplication involved in the linear transformation.
- Aggregation and Final Transformation: After applying dilated convolutions, the results are concatenated and transformed by an additional linear layer, contributing an additional complexity.
- Overall Complexity for the Dilated Convolution Layer: The overall complexity for the dilated convolution layer is:This simplifies to as the matrix multiplication and transformation are the dominant operations.
- Attention Coefficient Calculation: For each edge, attention coefficients are computed using the node features, resulting in a complexity of , where E is the number of edges and is the number of attention heads.
- Feature Aggregation: Node features are aggregated based on the attention coefficients, leading to a complexity of .
- Overall Complexity for the GAT Layer: The overall complexity for the GAT layer is:The complexity is primarily dominated by the attention coefficient calculation, due to the potentially large number of edges in the graph.
4. Experiment
4.1. Experimental Settings
4.1.1. Benchmark Models
4.1.2. Training Device and Parameter Configuration
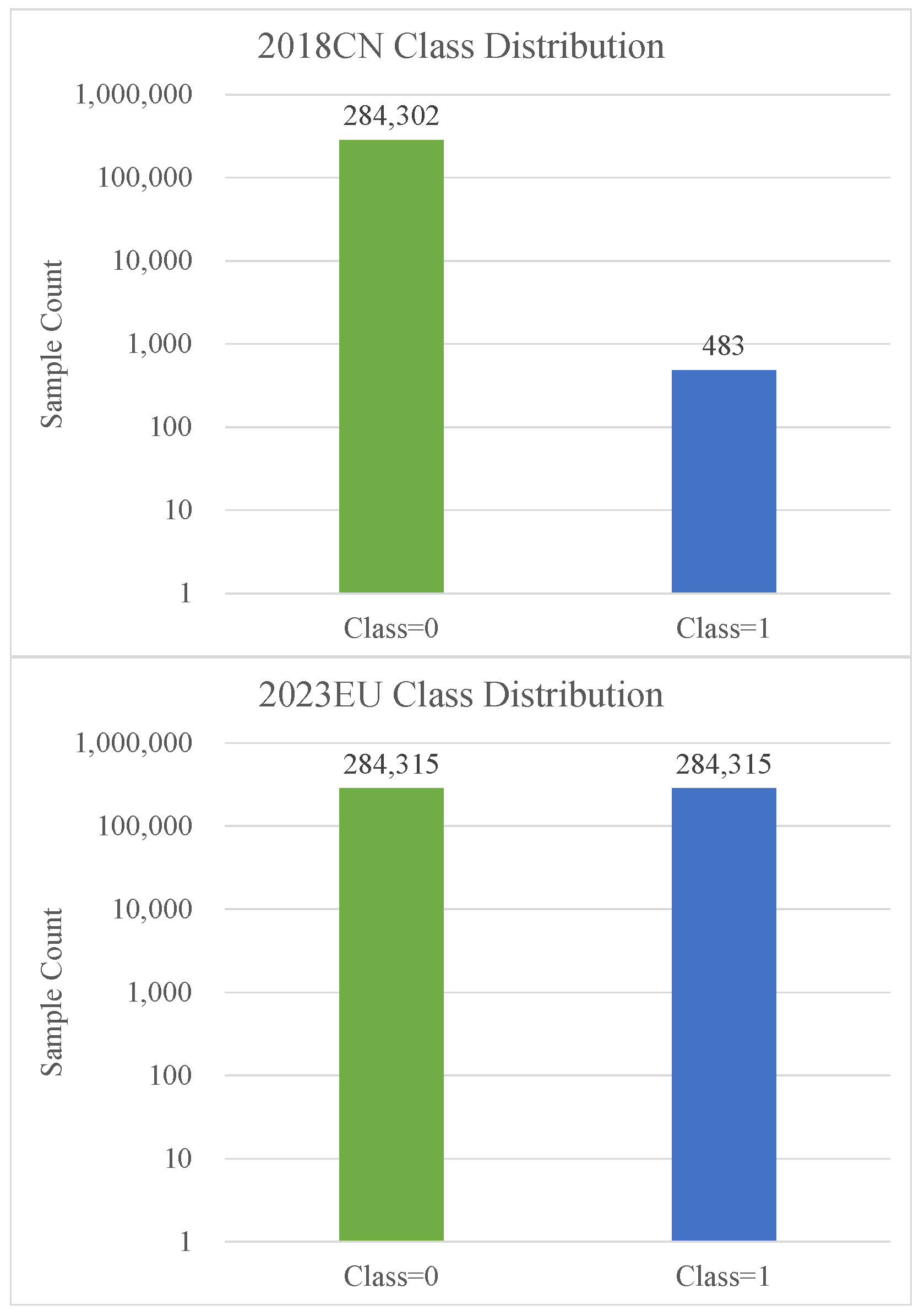
4.2. Dataset Overview and Data Segmentation Strategy
- 1.
- 2018 4th ‘HaoDai Cup’ China Risk Management Control and Capability Challenge Dataset (2018CN): This dataset comprises credit card transaction records from September 2013, spanning over two days with a total of 284,785 transactions, including 483 fraudulent cases. Due to the significant imbalance, with fraudulent transactions accounting for only of the total, this dataset poses challenges to fraud detection models. All features, except for “Time” and “Amount”, have been converted to numerical values through Principal Component Analysis (PCA), maintaining confidentiality of the original data. The V1 to V28 features represent the principal components derived from PCA. The “Time” feature notes the seconds since the first transaction recorded in the dataset, while the “Amount” indicates the transaction value, which is pivotal for cost-sensitive learning algorithms. The “Class” variable specifies the transaction type, where 1 denotes fraud and 0 indicates non-fraud.
- 2.
- European Cardholders’ Credit Card Transaction Records in 2023 (2023EU): This dataset aggregates anonymized transaction data from European cardholders in 2023, featuring over 568,630 entries. Each entry is a distinct transaction with an identifier and 28 anonymized attributes potentially describing aspects like transaction timing and location. The dataset also details transaction amounts and categorizes each transaction as fraudulent (1) or legitimate (0). To facilitate more effective model training and research, the dataset has been adjusted to balance the counts of fraudulent and non-fraudulent transactions, eliminating biases commonly found in unbalanced datasets.
4.3. Comparison with Benchmark Models
4.4. Ablation Study
4.4.1. Ablation Study on Different Number of Clients
4.4.2. Ablation Study on Different Node Degrees in the Transaction Similarity Graph
4.4.3. Ablation Study on Different Number of Attention Heads
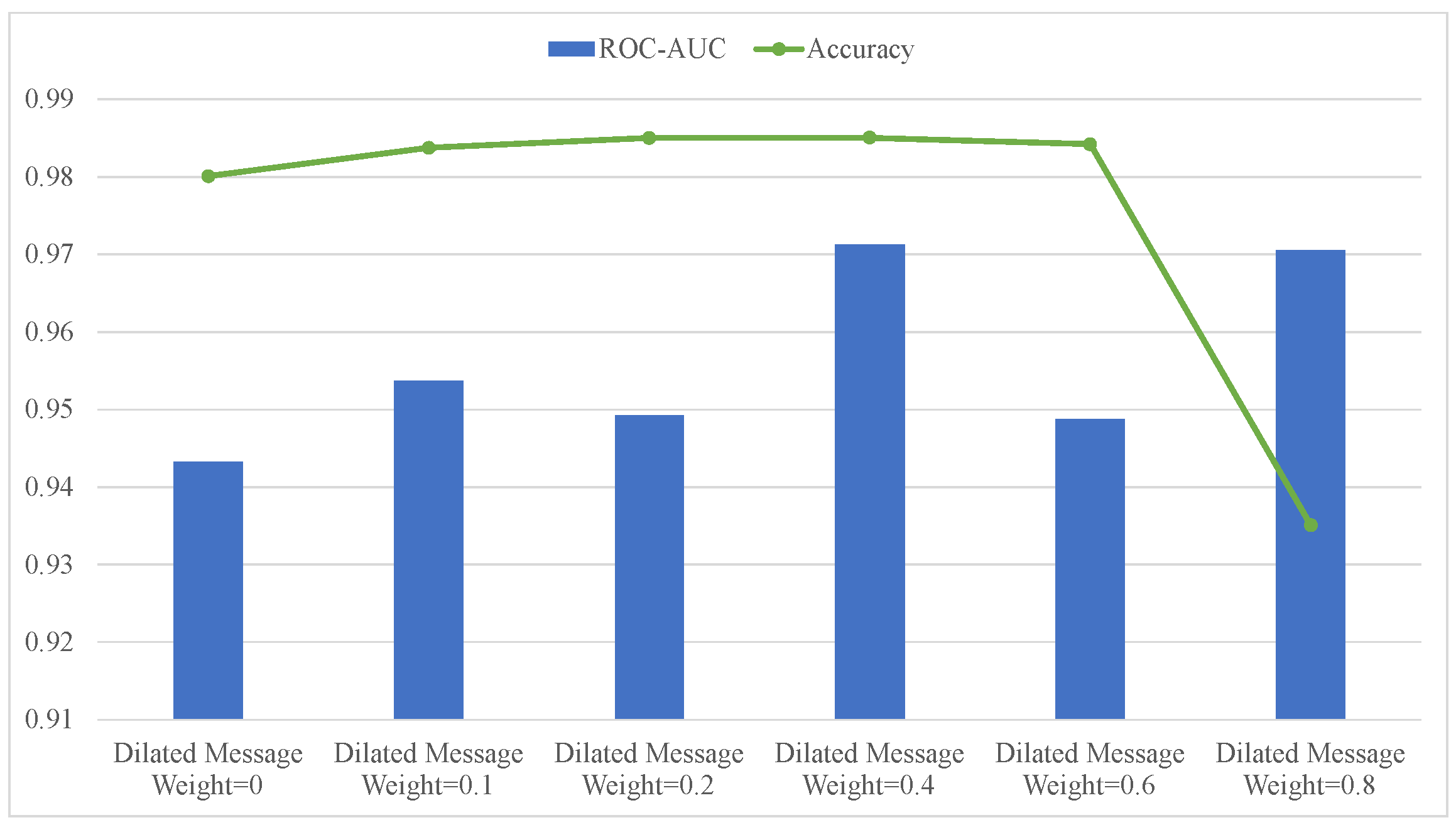
4.4.4. Ablation Study on Different Number of Dilated Channels and Dilated Message Weights
5. Conclusions
- Robust Detection Performance: FedGAT-DCNN significantly enhances fraud detection capabilities, particularly in scenarios with highly imbalanced data. It achieves an ROC-AUC of 0.9712 on the 2018CN dataset and 0.9992 on the 2023EU dataset, demonstrating robust performance across varied data distributions.
- Advanced Feature Integration: The integration of a Graph Attention Network (GAT) and dilated convolutions within the FedGAT-DCNN framework allows for dynamic and efficient adaptation to emerging fraud patterns, enhancing the model’s ability to capture complex transaction patterns and contextual information.
- Privacy and Collaboration: Utilizing federated learning, FedGAT-DCNN enables multiple financial institutions to collaboratively train the model while preserving data privacy. This collaboration not only enhances the detection accuracy by leveraging diverse data sources but also ensures compliance with stringent data protection regulations.
- Future Research Directions: Going forward, we intend to refine the FedGAT-DCNN model further by exploring additional graph-based techniques and expanding its applicability to other types of financial fraud. This future work aims to provide valuable guidelines for deploying effective fraud detection systems in real-world financial environments.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Federal Trade Commission. Consumer Sentinel Network Data Book 2021; Federal Trade Commission: Washington, DC, USA, 2022. [Google Scholar]
- Gundur, R.; Levi, M.; Topalli, V.; Ouellet, M.; Stolyarova, M.; Chang, L.Y.C.; Mejía, D.D. Evaluating criminal transactional methods in cyberspace as understood in an international context. CrimRxiv 2021. [Google Scholar] [CrossRef]
- Syaufi, A.; Zahra, A.F.; Gholi, F.M.I. Employing Forensic Techniques in Proving and Prosecuting Cross-border Cyber-financial Crimes. Int. J. Cyber Criminol. 2023, 17, 85–101. [Google Scholar]
- Mahalakshmi, V.; Kulkarni, N.; Kumar, K.P.; Kumar, K.S.; Sree, D.N.; Durga, S. The role of implementing artificial intelligence and machine learning technologies in the financial services industry for creating competitive intelligence. Mater. Today Proc. 2022, 56, 2252–2255. [Google Scholar] [CrossRef]
- Hassan, M.; Aziz, L.A.R.; Andriansyah, Y. The role artificial intelligence in modern banking: An exploration of AI-driven approaches for enhanced fraud prevention, risk management, and regulatory compliance. Rev. Contemp. Bus. Anal. 2023, 6, 110–132. [Google Scholar]
- Awoyemi, J.O.; Adetunmbi, A.O.; Oluwadare, S.A. Credit card fraud detection using machine learning techniques: A comparative analysis. In Proceedings of the 2017 international conference on computing networking and informatics (ICCNI), Lagos, Nigeria, 29–31 October 2017; pp. 1–9. [Google Scholar]
- Khalid, A.R.; Owoh, N.; Uthmani, O.; Ashawa, M.; Osamor, J.; Adejoh, J. Enhancing credit card fraud detection: An ensemble machine learning approach. Big Data Cogn. Comput. 2024, 8, 6. [Google Scholar] [CrossRef]
- Mathew, J.C.; Nithya, B.; Vishwanatha, C.; Shetty, P.; Priya, H.; Kavya, G. An analysis on fraud detection in credit card transactions using machine learning techniques. In Proceedings of the 2022 Second International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 23–25 February 2022; pp. 265–272. [Google Scholar]
- Chen, J.I.Z.; Lai, K.L. Deep convolution neural network model for credit-card fraud detection and alert. J. Artif. Intell. 2021, 3, 101–112. [Google Scholar]
- Karthika, J.; Senthilselvi, A. Smart credit card fraud detection system based on dilated convolutional neural network with sampling technique. Multimed. Tools Appl. 2023, 82, 31691–31708. [Google Scholar] [CrossRef]
- Benchaji, I.; Douzi, S.; El Ouahidi, B. Credit card fraud detection model based on LSTM recurrent neural networks. J. Adv. Inf. Technol. 2021, 12, 113–118. [Google Scholar] [CrossRef]
- Forough, J.; Momtazi, S. Ensemble of deep sequential models for credit card fraud detection. Appl. Soft Comput. 2021, 99, 106883. [Google Scholar] [CrossRef]
- Mrčela, L.; Kostanjčar, Z. Probabilistic Deep Learning Approach to Credit Card Fraud Detection. In Proceedings of the 2024 47th MIPRO ICT and Electronics Convention (MIPRO), Opatija, Croatia, 20–24 May 2024; pp. 181–186. [Google Scholar]
- Rtayli, N.; Enneya, N. Enhanced credit card fraud detection based on SVM-recursive feature elimination and hyper-parameters optimization. J. Inf. Secur. Appl. 2020, 55, 102596. [Google Scholar] [CrossRef]
- Kumar, S.; Gunjan, V.K.; Ansari, M.D.; Pathak, R. Credit card fraud detection using support vector machine. In Proceedings of the 2nd International Conference on Recent Trends in Machine Learning, IoT, Smart Cities and Applications: ICMISC 2021; Springer: Singapore, 2022; pp. 27–37. [Google Scholar]
- Hussein, A.S.; Khairy, R.S.; Najeeb, S.M.M.; Alrikabi, H.T.S. Credit Card Fraud Detection Using Fuzzy Rough Nearest Neighbor and Sequential Minimal Optimization with Logistic Regression. Int. J. Interact. Mob. Technol. 2021, 15, 24–42. [Google Scholar] [CrossRef]
- Alenzi, H.Z.; Aljehane, N.O. Fraud detection in credit cards using logistic regression. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 540–551. [Google Scholar] [CrossRef]
- Xuan, S.; Liu, G.; Li, Z.; Zheng, L.; Wang, S.; Jiang, C. Random forest for credit card fraud detection. In Proceedings of the 2018 IEEE 15th International Conference on Networking, Sensing and Control (ICNSC), Zhuhai, China, 27–29 March 2018; pp. 1–6. [Google Scholar]
- Dileep, M.; Navaneeth, A.; Abhishek, M. A novel approach for credit card fraud detection using decision tree and random forest algorithms. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1025–1028. [Google Scholar]
- Taha, A.A.; Malebary, S.J. An intelligent approach to credit card fraud detection using an optimized light gradient boosting machine. IEEE Access 2020, 8, 25579–25587. [Google Scholar] [CrossRef]
- Mishra, A.; Ghorpade, C. Credit card fraud detection on the skewed data using various classification and ensemble techniques. In Proceedings of the 2018 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 24–25 February 2018; pp. 1–5. [Google Scholar]
- Fu, K.; Cheng, D.; Tu, Y.; Zhang, L. Credit card fraud detection using convolutional neural networks. In Neural Information Processing, Proceedings of the 23rd International Conference, ICONIP 2016, Kyoto, Japan, 16–21 October 2016, Proceedings, Part III 23; Springer: Berlin, Germany, 2016; pp. 483–490. [Google Scholar]
- Sadgali, I.; Sael, N.; Benabbou, F. Fraud detection in credit card transaction using neural networks. In Proceedings of the 4th International Conference on Smart City Applications, Casablanca, Morocco, 2–4 October 2019; pp. 1–4. [Google Scholar]
- Roy, A.; Sun, J.; Mahoney, R.; Alonzi, L.; Adams, S.; Beling, P. Deep learning detecting fraud in credit card transactions. In Proceedings of the 2018 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27 April 2018; pp. 129–134. [Google Scholar]
- Wiese, B.; Omlin, C. Credit card transactions, fraud detection, and machine learning: Modelling time with LSTM recurrent neural networks. In Innovations in Neural Information Paradigms and Applications; Springer: Berlin/Heidelberg, Germany, 2009; pp. 231–268. [Google Scholar]
- Liu, G.; Tang, J.; Tian, Y.; Wang, J. Graph neural network for credit card fraud detection. In Proceedings of the 2021 International Conference on Cyber-Physical Social Intelligence (ICCSI), Beijing, China, 18–20 December 2021; pp. 1–6. [Google Scholar]
- Jing, R.; Tian, H.; Zhou, G.; Zhang, X.; Zheng, X.; Zeng, D.D. A GNN-based Few-shot learning model on the Credit Card Fraud detection. In Proceedings of the 2021 IEEE 1st International Conference on Digital Twins and Parallel Intelligence (DTPI), Beijing, China, 15 July–15 August 2021; pp. 320–323. [Google Scholar]
- Shi, F.; Zhao, C. Enhancing financial fraud detection with hierarchical graph attention networks: A study on integrating local and extensive structural information. Financ. Res. Lett. 2023, 58, 104458. [Google Scholar] [CrossRef]
- Liu, C.; Sun, L.; Ao, X.; Feng, J.; He, Q.; Yang, H. Intention-aware heterogeneous graph attention networks for fraud transactions detection. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3280–3288. [Google Scholar]
- Yang, Q. Toward responsible ai: An overview of federated learning for user-centered privacy-preserving computing. Acm Trans. Interact. Intell. Syst. (TiiS) 2021, 11, 1–22. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, Y.; Ye, K.; Li, L.; Xu, C.Z. Ffd: A federated learning based method for credit card fraud detection. In Big Data–BigData 2019, Proceedings of the 8th International Congress, Held as Part of the Services Conference Federation, SCF 2019, San Diego, CA, USA, 25–30 June 2019, Proceedings 8; Springer: Cham, Switzerland, 2019; pp. 18–32. [Google Scholar]
- Abdul Salam, M.; Fouad, K.M.; Elbably, D.L.; Elsayed, S.M. Federated learning model for credit card fraud detection with data balancing techniques. Neural Comput. Appl. 2024, 36, 6231–6256. [Google Scholar] [CrossRef]
- Zheng, W.; Yan, L.; Gou, C.; Wang, F.Y. Federated meta-learning for fraudulent credit card detection. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 4654–4660. [Google Scholar]
- Byrd, D.; Polychroniadou, A. Differentially private secure multi-party computation for federated learning in financial applications. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–9. [Google Scholar]
- Kanamori, S.; Abe, T.; Ito, T.; Emura, K.; Wang, L.; Yamamoto, S.; Le, T.P.; Abe, K.; Kim, S.; Nojima, R.; et al. Privacy-preserving federated learning for detecting fraudulent financial transactions in japanese banks. J. Inf. Process. 2022, 30, 789–795. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmark Model | Description |
|---|---|
| Logistic Regression | A statistical model well-suited for binary classification tasks. It estimates the probability of an event’s occurrence, making it ideal for linearly separable data. |
| K-Nearest Neighbors (KNN) | This instance-based learning algorithm classifies a new data point based on the majority class among its k nearest neighbors, effective in datasets with discernible clusters of similar data points. |
| Histogram-based Gradient Boosting Classifier (HGBC) | A robust ensemble method that leverages decision trees, built in a sequential error-correcting process to enhance prediction accuracy, particularly effective for extensive datasets. |
| Support Vector Machine (SVM) | An algorithm that identifies the optimal separating hyperplane in high-dimensional space, making it particularly effective when the feature space is larger than the sample size. |
| Random Forest Classifier | This technique builds multiple decision trees and integrates their outcomes either by averaging or majority vote, reducing overfitting and improving model accuracy. |
| AdaBoost Classifier | Utilizes a sequence of weak classifiers to build a strong classifier by focusing on the misclassified instances by previous models, dynamically adapting to the peculiarities of the data. |
| Multi-layer Perceptron Classifier (MLP) | A deep neural network with one or more hidden layers, capable of capturing complex non-linear relationships in data, suitable for intricate classification tasks. |
| FedProx | A federated learning approach that incorporates a proximal term in the aggregation process to handle data and system heterogeneity, stabilizing training over disparate and partial datasets. |
| Personalized Federated Learning (Personalised FL) | This technique adapts federated learning models to individual users or devices by allowing local deviations from the global model, optimizing performance for unique data characteristics. |
| FedAMP | Enhances federated learning by using an adaptive parameter to aggregate updates effectively, improving convergence and performance in non-IID data scenarios. |
| FedFomo | A federated learning strategy that uses a regret-based mechanism to prioritize client updates, optimizing the learning process by evaluating potential against actual updates. |
| Adaptive Personalized Federated Learning (APFL) | A federated learning model that combines local and global updates to tailor personalization, improving performance through individualized adjustments. |
| pFedMe | Employs a Moreau envelope-based regularization in personalized federated learning to optimize personal models for each client, enhancing convergence and personalization across diverse data. |
| Agnostic Personalized Private Learning (APPLE) | Integrates differential privacy with personalized model learning, allowing for privacy-preserving adaptations to diverse client data distributions. |
| Parameters | Parameter Values |
|---|---|
| seed | 42 |
| communication rounds | 300 |
| local epochs | 10 |
| dropout | 0.3 |
| batch size | 64 |
| node degree | 3 |
| learning rate | 0.01 |
| alpha | 0.4 |
| no. attention head | 8 |
| no. dilated channels | 2 |
| optimizer | Adam |
| weight decay | 1 × 10−4 |
| loss function | BinaryCrossEntropyLoss |
| 2018CN | 2023EU | |||
|---|---|---|---|---|
| Accuracy | ROC-AUC | Accuracy | ROC-AUC | |
| Logistic Regression | 0.9984 | 0.7698 | 0.9652 | 0.9648 |
| KNN | 0.9988 | 0.8674 | 0.9898 | 0.9897 |
| HGBC | 0.9985 | 0.7635 | 0.9813 | 0.9812 |
| SVM | 0.9993 | 0.8398 | 0.9614 | 0.9618 |
| Random Forest | 0.9982 | 0.6745 | 0.9318 | 0.9316 |
| AdaBoost Classifier | 0.9992 | 0.7719 | 0.9565 | 0.9567 |
| MLP | 0.9992 | 0.7841 | 0.9976 | 0.9979 |
| FedProx | 0.9989 | 0.8100 | 0.5005 | 0.5583 |
| Personalised FL | 0.9976 | 0.5000 | 0.9395 | 0.9596 |
| FedAMP | 0.9980 | 0.5927 | 0.5001 | 0.5000 |
| FedFomo | 0.9996 | 0.8581 | 0.9270 | 0.9826 |
| APFL | 0.9983 | 0.7030 | 0.9028 | 0.9622 |
| pFedMe | 0.9977 | 0.8509 | 0.5003 | 0.9291 |
| APPLE | 0.9989 | 0.7389 | 0.9495 | 0.9832 |
| FedGAT-DCNN | 0.9851 | 0.9712 | 0.9889 | 0.9992 |
| Degree = 3 | Degree = 5 | Degree = 7 | ||||
|---|---|---|---|---|---|---|
| Accuracy | ROC-AUC | Accuracy | ROC-AUC | Accuracy | ROC-AUC | |
| 2018CN | 0.9851 | 0.9712 | 0.9794 | 0.9701 | 0.9770 | 0.9565 |
| 2023EU | 0.9828 | 0.9988 | 0.9889 | 0.9992 | 0.9882 | 0.9991 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Walsh, J. FedGAT-DCNN: Advanced Credit Card Fraud Detection Using Federated Learning, Graph Attention Networks, and Dilated Convolutions. Electronics 2024, 13, 3169. https://doi.org/10.3390/electronics13163169
Li M, Walsh J. FedGAT-DCNN: Advanced Credit Card Fraud Detection Using Federated Learning, Graph Attention Networks, and Dilated Convolutions. Electronics. 2024; 13(16):3169. https://doi.org/10.3390/electronics13163169
Chicago/Turabian StyleLi, Mengqiu, and John Walsh. 2024. "FedGAT-DCNN: Advanced Credit Card Fraud Detection Using Federated Learning, Graph Attention Networks, and Dilated Convolutions" Electronics 13, no. 16: 3169. https://doi.org/10.3390/electronics13163169