
GPU@SAT DevKit: Empowering Edge Computing Development Onboard Satellites in the Space-IoT Era

 , ,
, ,  , ,
, ,  and
and
Abstract
1. Introduction
Edge Computing Onboard Satellites for Space-IoT
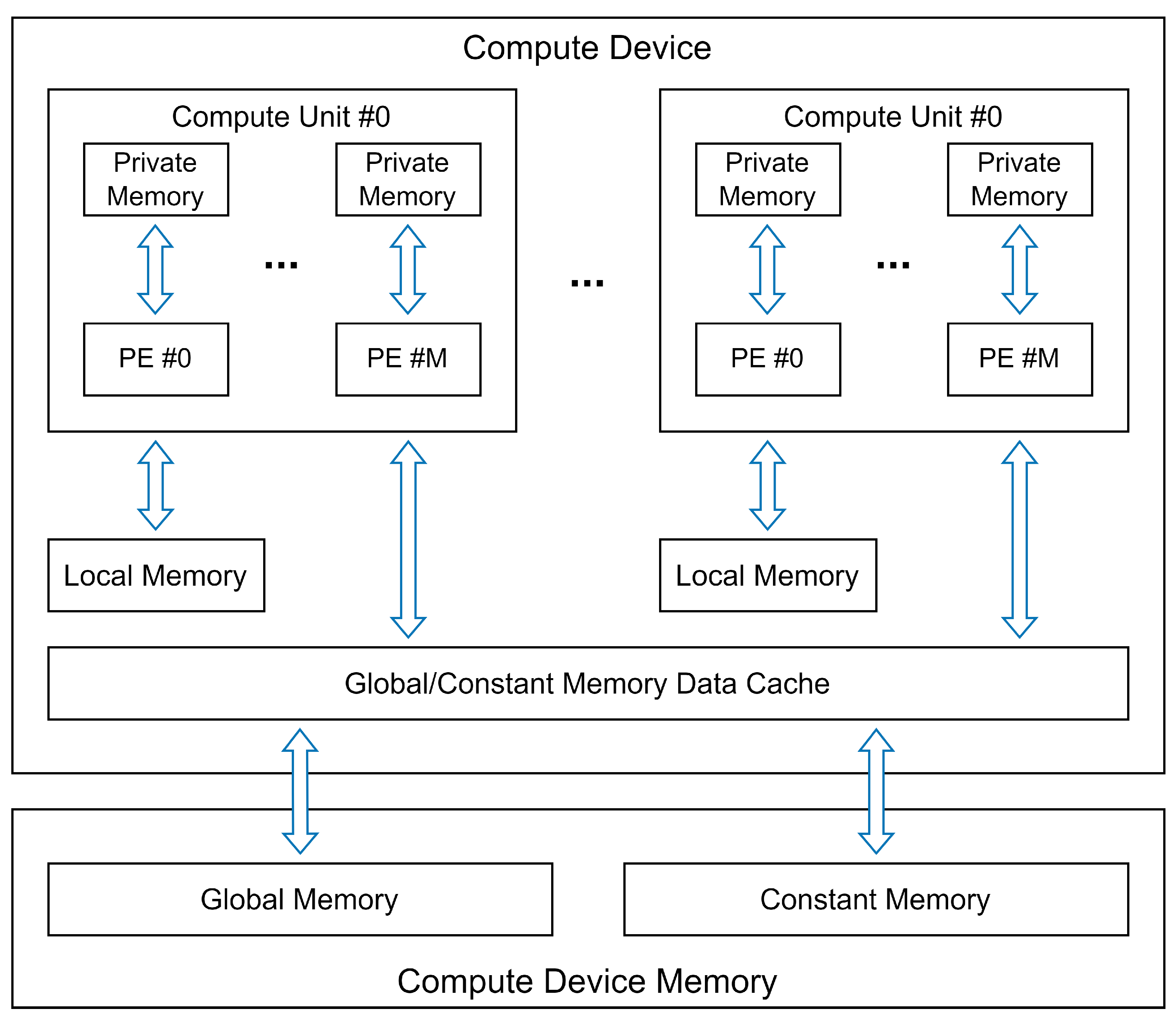
2. Background and Related Work
GPU@SAT Design
- The OpenCL properties of the kernel (such as the number of Work-Items in the kernel context).
- The executable binary code of the kernel itself.
3. GPU@SAT DevKit
- An evaluation board (DevBoard) that includes the GPU@SAT IP core and embedded software, which operates as the server.
- A Python-based application running on a host PC, which operates as the client.
3.1. GPU@SAT DevBoard and Embedded Software
- Configure the GPU@SAT IP core with OpenCL properties: this involves setting up the necessary parameters for the kernel to be executed, ensuring that the hardware is prepared to handle the specific computational tasks.
- Load the binary code of the kernel: the client can upload the executable binary code corresponding to the kernel, which is then run on the GPU@SAT IP core.
- Allocate memory buffers in DDR4: the client can allocate shared memory spaces in the DDR4, which are used by both the CPU and the GPU@SAT IP core.
- Schedule and execute multiple kernels: the client has the capability to queue multiple kernels for execution, managing the sequence in which they are run and ensuring that dependencies between kernels are handled efficiently.
- Measure and report statistics and performance metrics: the system can collect and report various statistics related to the execution of the kernels, providing valuable insights into performance and helping to identify areas for optimization.
3.2. Client Application and XML Files
- The configuration file: This file contains detailed information about the configuration of the DevBoard, including the setup of its components. It serves as a blueprint that guides the initialization and management of the hardware during the execution of tasks.
- The scheduler file: This file defines the order in which the kernels will be executed and includes various execution-related parameters. It plays a crucial role in managing the workflow, ensuring that the kernels are run in the correct sequence and according to the specified settings.
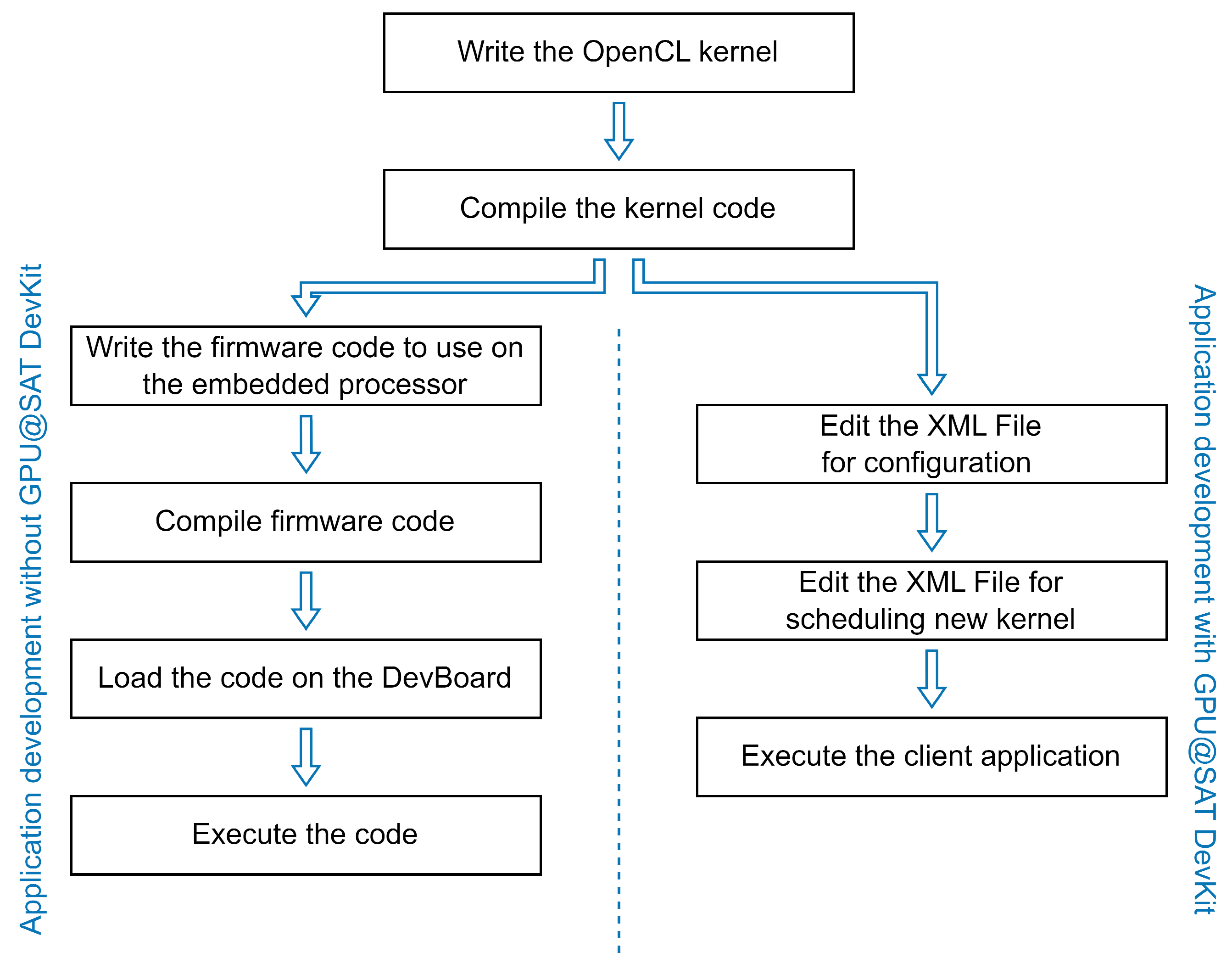
3.3. Application Development Workflow
4. Results
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| API | Application Programming Interface |
| ASIC | Application Specific Integrated Circuit |
| CNN | Convolutional Neural Network |
| COTS | Commercial Off-The-Shelf |
| CPU | Central Processing Unit |
| CU | Compute Unit |
| CV | Computer Vision |
| DDR4 | Double Data Rate 4 |
| DL | Deep Learning |
| DMA | Direct Memory Access |
| DNN | Deep Neural Network |
| DSP | Digital Signal Processing |
| EO | Earth Observation |
| ESA | European Space Agency |
| FPGA | Field Programmable Gate Array |
| FPS | Frames Per Second |
| GOPS | Giga Operations per Second |
| GPGPU | General Purpose computing on GPU |
| GPU | Graphic Processing Unit |
| IoT | Internet of Things |
| IP | Intellectual Property |
| ISL | Inter-Satellite Link |
| KPI | Key Performance Indicator |
| LEO | Low Earth Orbit |
| M2M | Machine-to-Machine |
| ML | Machine Learning |
| MPSoC | Multi-Processor System-on-a-Chip |
| NN | Neural Network |
| PC | Program Counter |
| PE | Processing Element |
| PL | Programmable Logic |
| PS | Processing System |
| QoS | Quality of Service |
| SEE | Single Event Effect |
| SEL | Single Event Latchup |
| SEU | Single Event Upset |
| SIMT | Single Instruction Multiple Thread |
| SoC | System-on-a-Chip |
| TCP | Transmission Control Protocol |
| VBN | Vision-Based Navigation |
| VLEO | Very Low Earth Orbit |
| VPU | Vision Processing Unit |
| WF | Wavefront |
| WG | Work-Group |
| WI | Work-Item |
| XML | eXtensible Markup Language |
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of Things for Smart Cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Ahmed, N.; De, D.; Hussain, I. Internet of Things (IoT) for Smart Precision Agriculture and Farming in Rural Areas. IEEE Internet Things J. 2018, 5, 4890–4899. [Google Scholar] [CrossRef]
- Islam, S.R.; Kwak, D.; Kabir, M.H.; Hossain, M.; Kwak, K.S. The Internet of Things for Health Care: A Comprehensive Survey. IEEE Access 2015, 3, 678–708. [Google Scholar] [CrossRef]
- Chen, X.; Ng, D.W.K.; Yu, W.; Larsson, E.G.; Al-Dhahir, N.; Schober, R. Massive Access for 5G and beyond. IEEE J. Sel. Areas Commun. 2021, 39, 615–637. [Google Scholar] [CrossRef]
- Transforma Insights. Current IoT Forecast Highlights. 2024. Available online: https://transformainsights.com/research/forecast/highlights (accessed on 2 May 2024).
- Statista Research Department. Internet of Things (IoT) Connected Devices Installed Base Worldwide from 2015 to 2025. 2016. Available online: https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide/ (accessed on 2 May 2024).
- Vailshery, L.S. Industrial Internet of Things (IIoT) Market Size Worldwide from 2020 to 2030. 2024. Available online: https://www.statista.com/statistics/611004/global-industrial-internet-of-things-market-size/ (accessed on 3 May 2024).
- Qu, Z.; Zhang, G.; Cao, H.; Xie, J. LEO Satellite Constellation for Internet of Things. IEEE Access 2017, 5, 18391–18401. [Google Scholar] [CrossRef]
- Kodheli, O.; Maturo, N.; Chatzinotas, S.; Andrenacci, S.; Zimmer, F. NB-IoT via LEO Satellites: An Efficient Resource Allocation Strategy for Uplink Data Transmission. IEEE Internet Things J. 2022, 9, 5094–5107. [Google Scholar] [CrossRef]
- Narayana, S. Space Internet of Things (Space-IoT). Ph.D. Thesis, TU Delft, Delft University of Technology, Delft, The Netherlands, 2023. [Google Scholar]
- Routray, S.K.; Tengshe, R.; Javali, A.; Sarkar, S.; Sharma, L.; Ghosh, A.D. Satellite Based IoT for Mission Critical Applications. In Proceedings of the 2019 International Conference on Data Science and Communication (IconDSC), Bangalore, India, 1–2 March 2019; pp. 1–6. [Google Scholar]
- Centenaro, M.; Costa, C.E.; Granelli, F.; Sacchi, C.; Vangelista, L. A Survey on Technologies, Standards and Open Challenges in Satellite IoT. IEEE Commun. Surv. Tutor. 2021, 23, 1693–1720. [Google Scholar] [CrossRef]
- Iridium Communications Website. Available online: https://www.iridium.com/ (accessed on 9 May 2024).
- Globalstar Website. Available online: https://www.globalstar.com/en-us/ (accessed on 9 May 2024).
- Orbcomm Website. Available online: https://www.orbcomm.com/ (accessed on 9 May 2024).
- Astrocast Website. Available online: https://www.astrocast.com/ (accessed on 10 May 2024).
- Lacuna Space Website. Available online: https://lacuna.space/ (accessed on 10 May 2024).
- FOSSA Systems Website. Available online: https://fossa.systems/ (accessed on 10 May 2024).
- Myriota Website. Available online: https://myriota.com/ (accessed on 10 May 2024).
- Saeed, N.; Elzanaty, A.; Almorad, H.; Dahrouj, H.; Al-Naffouri, T.Y.; Alouini, M.S. CubeSat Communications: Recent Advances and Future Challenges. IEEE Commun. Surv. Tutor. 2020, 22, 1839–1862. [Google Scholar] [CrossRef]
- Hamdan, S.; Ayyash, M.; Almajali, S. Edge-Computing Architectures for Internet of Things Applications: A Survey. Sensors 2020, 20, 6441. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A Survey on the Edge Computing for the Internet of Things. IEEE Access 2018, 6, 6900–6919. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Guo, X.; Qu, Z. Satellite Edge Computing for the Internet of Things in Aerospace. Sensors 2019, 19, 4375. [Google Scholar] [CrossRef]
- Wei, J.; Han, J.; Cao, S. Satellite IoT Edge Intelligent Computing: A Research on Architecture. Electronics 2019, 8, 1247. [Google Scholar] [CrossRef]
- Song, Z.; Hao, Y.; Liu, Y.; Sun, X. Energy-Efficient Multiaccess Edge Computing for Terrestrial-Satellite Internet of Things. IEEE Internet Things J. 2021, 8, 14202–14218. [Google Scholar] [CrossRef]
- Li, C.; Zhang, Y.; Xie, R.; Hao, X.; Huang, T. Integrating Edge Computing into Low Earth Orbit Satellite Networks: Architecture and Prototype. IEEE Access 2021, 9, 39126–39137. [Google Scholar] [CrossRef]
- Kim, T.; Kwak, J.; Choi, J.P. Satellite Edge Computing Architecture and Network Slice Scheduling for IoT Support. IEEE Internet Things J. 2022, 9, 14938–14951. [Google Scholar] [CrossRef]
- Kua, J.; Loke, S.W.; Arora, C.; Fernando, N.; Ranaweera, C. Internet of Things in Space: A Review of Opportunities and Challenges from Satellite-Aided Computing to Digitally-Enhanced Space Living. Sensors 2021, 21, 8117. [Google Scholar] [CrossRef] [PubMed]
- Garcia, L.P.; Furano, G.; Ghiglione, M.; Zancan, V.; Imbembo, E.; Ilioudis, C.; Clemente, C.; Trucco, P. Advancements in On-Board Processing of Synthetic Aperture Radar (SAR) Data: Enhancing Efficiency and Real-Time Capabilities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 16625–16645. [Google Scholar] [CrossRef]
- Kothari, V.; Liberis, E.; Lane, N.D. The Final Frontier: Deep Learning in Space. In Proceedings of the 21st International Workshop on Mobile Computing Systems and Applications, New York, NY, USA, 3–4 March 2020; pp. 45–49. [Google Scholar]
- Furano, G.; Meoni, G.; Dunne, A.; Moloney, D.; Ferlet-Cavrois, V.; Tavoularis, A.; Byrne, J.; Buckley, L.; Psarakis, M.; Voss, K.O.; et al. Towards the Use of Artificial Intelligence on the Edge in Space Systems: Challenges and Opportunities. IEEE Aerosp. Electron. Syst. Mag. 2020, 35, 44–56. [Google Scholar] [CrossRef]
- Fourati, F.; Alouini, M.S. Artificial intelligence for satellite communication: A review. Intell. Converg. Netw. 2021, 2, 213–243. [Google Scholar] [CrossRef]
- Ortiz, F.; Monzon Baeza, V.; Garces-Socarras, L.M.; Vásquez-Peralvo, J.A.; Gonzalez, J.L.; Fontanesi, G.; Lagunas, E.; Querol, J.; Chatzinotas, S. Onboard Processing in Satellite Communications Using AI Accelerators. Aerospace 2023, 10, 101. [Google Scholar] [CrossRef]
- Chintalapati, B.; Precht, A.; Hanra, S.; Laufer, R.; Liwicki, M.; Eickhoff, J. Opportunities and challenges of on-board AI-based image recognition for small satellite Earth observation missions. Adv. Space Res. 2024. [Google Scholar] [CrossRef]
- Wei, J.; Cao, S. Application of Edge Intelligent Computing in Satellite Internet of Things. In Proceedings of the 2019 IEEE International Conference on Smart Internet of Things (SmartIoT), Tianjin, China, 9–11 August 2019; pp. 85–91. [Google Scholar]
- Gaillard, R. Single Event Effects: Mechanisms and Classification. In Soft Errors in Modern Electronic Systems; Nicolaidis, M., Ed.; Springer: Boston, MA, USA, 2011; pp. 27–54. [Google Scholar]
- Quinn, H. Radiation effects in reconfigurable FPGAs. Semicond. Sci. Technol. 2017, 32, 044001. [Google Scholar] [CrossRef]
- Rockett, L.; Patel, D.; Danziger, S.; Cronquist, B.; Wang, J. Radiation Hardened FPGA Technology for Space Applications. In Proceedings of the 2007 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2007; pp. 1–7. [Google Scholar]
- Cong, J.; Sarkar, V.; Reinman, G.; Bui, A. Customizable domain-specific computing. IEEE Des. Test Comput. 2010, 28, 6–15. [Google Scholar] [CrossRef]
- Ghiglione, M.; Serra, V. Opportunities and challenges of AI on satellite processing units. In Proceedings of the 19th ACM International Conference on Computing Frontiers (CF’22), New York, NY, USA, 17–22 May 2022; pp. 221–224. [Google Scholar]
- Todaro, G.; Monopoli, M.; Benelli, G.; Zulberti, L.; Pacini, T. Enhanced Soft GPU Architecture for FPGAs. In Proceedings of the 2023 18th Conference on Ph.D Research in Microelectronics and Electronics (PRIME), Valencia, Spain, 18–21 June 2023; pp. 177–180. [Google Scholar]
- Monopoli, M.; Zulberti, L.; Todaro, G.; Nannipieri, P.; Fanucci, L. Exploiting FPGA Dynamic Partial Reconfiguration for a Soft GPU-based System-on-Chip. In Proceedings of the 2023 18th Conference on Ph.D Research in Microelectronics and Electronics (PRIME), Valencia, Spain, 18–21 June 2023; pp. 181–184. [Google Scholar]
- Lemaire, E.; Moretti, M.; Daniel, L.; Miramond, B.; Millet, P.; Feresin, F.; Bilavarn, S. An FPGA-Based Hybrid Neural Network Accelerator for Embedded Satellite Image Classification. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- OPS-SAT Satelite Website. Available online: https://www.eoportal.org/satellite-missions/ops-sat (accessed on 10 May 2024).
- Furano, G.; Tavoularis, A.; Rovatti, M. AI in space: Applications examples and challenges. In Proceedings of the 2020 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Frascati, Italy, 19–21 October 2020; pp. 1–6. [Google Scholar]
- Cosmas, K.; Kenichi, A. Utilization of FPGA for Onboard Inference of Landmark Localization in CNN-Based Spacecraft Pose Estimation. Aerospace 2020, 7, 159. [Google Scholar] [CrossRef]
- Leon, V.; Stamoulias, I.; Lentaris, G.; Soudris, D.; Gonzalez-Arjona, D.; Domingo, R.; Codinachs, D.M.; Conway, I. Development and Testing on the European Space-Grade BRAVE FPGAs: Evaluation of NG-Large Using High-Performance DSP Benchmarks. IEEE Access 2021, 9, 131877–131892. [Google Scholar] [CrossRef]
- Rapuano, E.; Meoni, G.; Pacini, T.; Dinelli, G.; Furano, G.; Giuffrida, G.; Fanucci, L. An FPGA-Based Hardware Accelerator for CNNs Inference on Board Satellites: Benchmarking with Myriad 2-Based Solution for the CloudScout Case Study. Remote Sens. 2021, 13, 1518. [Google Scholar] [CrossRef]
- Giuffrida, G.; Diana, L.; de Gioia, F.; Benelli, G.; Meoni, G.; Donati, M.; Fanucci, L. CloudScout: A deep neural network for on-board cloud detection on hyperspectral images. Remote Sens. 2020, 12, 2205. [Google Scholar] [CrossRef]
- Pitonak, R.; Mucha, J.; Dobis, L.; Javorka, M.; Marusin, M. CloudSatNet-1: FPGA-Based Hardware-Accelerated Quantized CNN for Satellite On-Board Cloud Coverage Classification. Remote Sens. 2022, 14, 3180. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, Y.; Liu, Z. A Survey on Convolutional Neural Network Accelerators: GPU, FPGA and ASIC. In Proceedings of the 2022 14th International Conference on Computer Research and Development (ICCRD), Shenzhen, China, 7–9 January 2022; pp. 100–107. [Google Scholar]
- Xu, C.; Jiang, S.; Luo, G.; Sun, G.; An, N.; Huang, G.; Liu, X. The Case for FPGA-Based Edge Computing. IEEE Trans. Mob. Comput. 2022, 21, 2610–2619. [Google Scholar] [CrossRef]
- Powell, W.A.; Campola, M.J.; Sheets, T.; Davidson, A.; Welsh, S. Commercial Off-the-Shelf GPU Qualification for Space Applications; National Aeronautics and Space Administration: Washington, DC, USA, 2018. [Google Scholar]
- Kosmidis, L.; Lachaize, J.; Abella, J.; Notebaert, O.; Cazorla, F.J.; Steenari, D. GPU4S: Embedded GPUs in Space. In Proceedings of the 2019 22nd Euromicro Conference on Digital System Design (DSD), Kallithea, Greece, 28–30 August 2019; pp. 399–405. [Google Scholar]
- Rodriguez, I.; Kosmidis, L.; Notebaert, O.; Cazorla, F.J.; Steenari, D. An On-board Algorithm Implementation on an Embedded GPU: A Space Case Study. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 1718–1719. [Google Scholar]
- Solé, M.; Wolf, J.; Rodriguez, I.; Jover, A.; Trompouki, M.M.; Kosmidis, L.; Steenari, D. Evaluation of the Multicore Performance Capabilities of the Next Generation Flight Computers. In Proceedings of the 2023 IEEE/AIAA 42nd Digital Avionics Systems Conference (DASC), Barcelona, Spain, 1–5 October 2023; pp. 1–10. [Google Scholar]
- Bersuker, G.; Mason, M.; Jones, K.L. Neuromorphic Computing: The Potential for High-Performance Processing in Space. The Aerospace Corporation’s Center for Space Policy and Strategy. 2018. Available online: https://csps.aerospace.org (accessed on 1 October 2024).
- Izzo, D.; Hadjiivanov, A.; Dold, D.; Meoni, G.; Blazquez, E. Neuromorphic computing and sensing in space. In Artificial Intelligence for Space: AI4SPACE; CRC Press: Boca Raton, FL, USA, 2022; pp. 107–159. [Google Scholar]
- Munshi, A.; Gaster, B.; Mattson, T.G.; Ginsburg, D. OpenCL Programming Guide; Pearson Education: London, UK, 2011. [Google Scholar]
- AMD. ZCU104 Evaluation Board-User Guide v1.1. Available online: https://docs.amd.com/v/u/en-US/ug1267-zcu104-eval-bd (accessed on 1 October 2024).
- Kosmidis, L.; Solé, M.; Rodriguez, I.; Wolf, J.; Trompouki, M.M. The METASAT Hardware Platform: A High-Performance Multicore, AI SIMD and GPU RISC-V Platform for On-board Processing. In Proceedings of the 2023 European Data Handling & Data Processing Conference (EDHPC), Juan Les Pins, France, 2–6 October 2023; pp. 1–6. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Name | Input Size [# Pixels] | Duration [µs] |
|---|---|---|
| 1125 | ||
| 1 | 2243 | |
| 6172 | ||
| 2804 | ||
| 2 | 5051 | |
| 12,892 | ||
| 3378 | ||
| 3 | 6172 | |
| 23,374 | ||
| 1686 | ||
| Average pool | 3367 | |
| 11,209 | ||
| 1681 | ||
| Max pool | 3364 | |
| 11,212 | ||
| 2803 | ||
| Matrix Multiplication | 15,131 | |
| 118,420 |
| Platform | Device | FPS |
|---|---|---|
| GPU@SAT DevKit | Xilinx ZCU104 | 35 |
| METASAT | Xilinx VCU118 | 32 |
| Resource | Utilization | Available | Percentage (%) |
|---|---|---|---|
| LUT | 140,721 | 230,400 | 61.08 |
| LUTRAM | 10,201 | 101,760 | 10.02 |
| FF | 220,804 | 460,800 | 47.92 |
| BRAM | 312 | 312 | 100 |
| URAM | 1 | 96 | 1.04 |
| DSP | 256 | 1728 | 14.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benelli, G.; Todaro, G.; Monopoli, M.; Giuffrida, G.; Donati, M.; Fanucci, L. GPU@SAT DevKit: Empowering Edge Computing Development Onboard Satellites in the Space-IoT Era. Electronics 2024, 13, 3928. https://doi.org/10.3390/electronics13193928
Benelli G, Todaro G, Monopoli M, Giuffrida G, Donati M, Fanucci L. GPU@SAT DevKit: Empowering Edge Computing Development Onboard Satellites in the Space-IoT Era. Electronics. 2024; 13(19):3928. https://doi.org/10.3390/electronics13193928
Chicago/Turabian StyleBenelli, Gionata, Giovanni Todaro, Matteo Monopoli, Gianluca Giuffrida, Massimiliano Donati, and Luca Fanucci. 2024. "GPU@SAT DevKit: Empowering Edge Computing Development Onboard Satellites in the Space-IoT Era" Electronics 13, no. 19: 3928. https://doi.org/10.3390/electronics13193928
APA StyleBenelli, G., Todaro, G., Monopoli, M., Giuffrida, G., Donati, M., & Fanucci, L. (2024). GPU@SAT DevKit: Empowering Edge Computing Development Onboard Satellites in the Space-IoT Era. Electronics, 13(19), 3928. https://doi.org/10.3390/electronics13193928