

Enhanced Multi-Scale Attention-Driven 3D Human Reconstruction from Single Image

 and
and
Abstract
:1. Introduction
- We propose a novel network model, Enhanced Multi-Scale Attention-Driven 3D Human Reconstruction from Single Image (EMAR), for robustly reconstructing 3D human meshes from a single image.
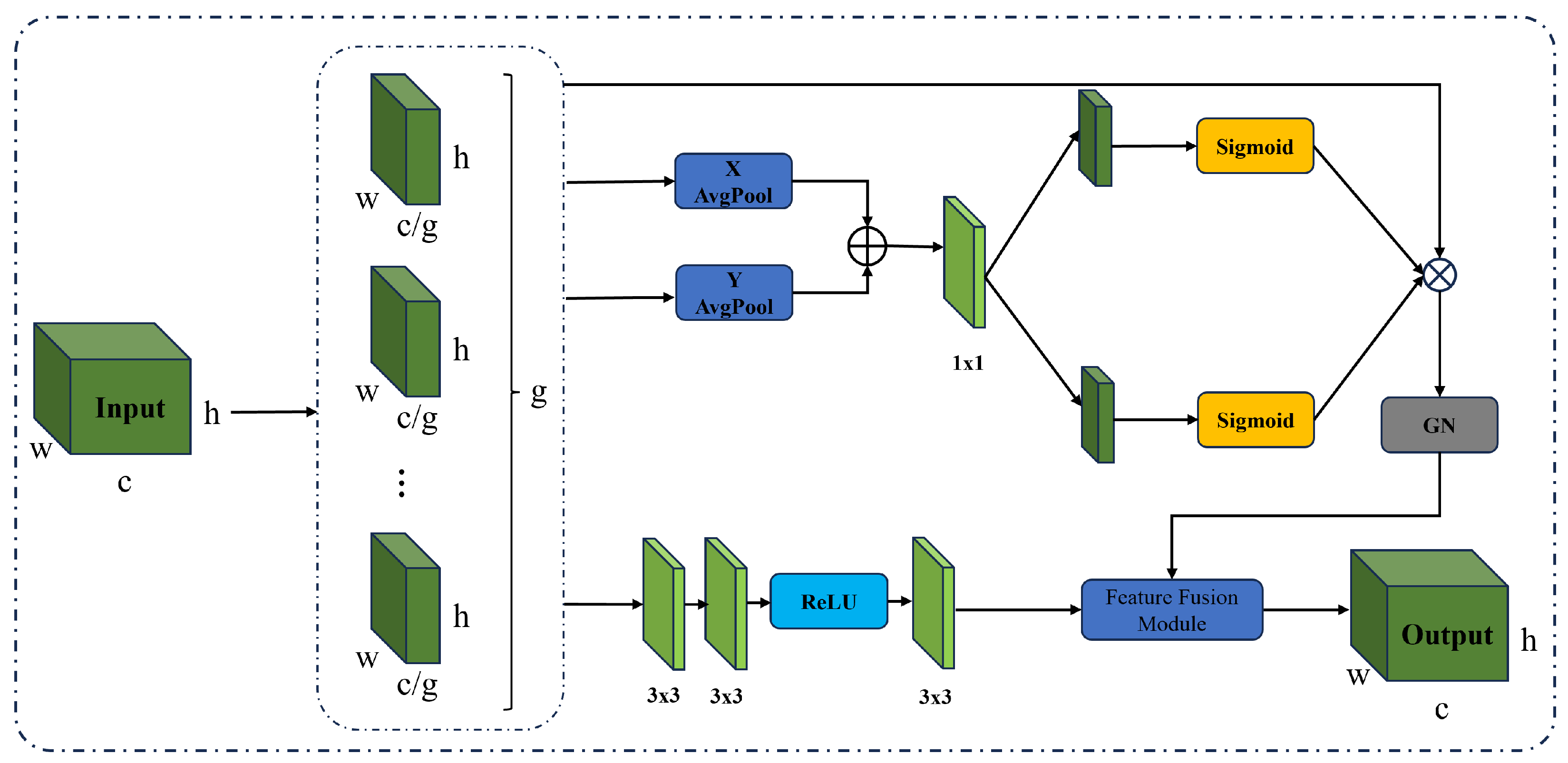
- To effectively capture and integrate global and local features, we introduce an enhanced multi-scale attention module that helps the network learn more discriminative feature representations at different scales, thereby improving its ability to model complex scenes.
- For effective multi-scale information fusion and interaction, we design a novel feature fusion module based on the enhanced multi-scale attention module, improving the accuracy and robustness of normal prediction.
- We introduce a hybrid loss function to supervise network training and ensure fast convergence, enhancing the network’s robustness in handling complex structures and resulting in high-fidelity 3D human models.
2. Related Works
3. Methodology
3.1. Network Overview
3.2. Enhanced Multi-Scale Attention Module
3.3. Feature Fusion Module
3.4. Hybrid Loss Function
4. Experiments
4.1. Datasets and Implementation
4.2. Comparison Experiments
4.3. Ablation Experiments
4.4. Failure Cases and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Yoon, J.S.; Wang, T.Y.; Singh, K.K.; Neumann, U. Complete 3D Human Reconstruction from a Single Incomplete Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8748–8758. [Google Scholar]
- Lochner, J.; Gain, J.; Perche, S.; Peytavie, A.; Galin, E.; Guérin, E. Interactive Authoring of Terrain using Diffusion Models. Comput. Graph. Forum 2023, 42, e14941. [Google Scholar] [CrossRef]
- Zhu, H.; Cao, Y.; Jin, H.; Chen, W.; Du, D.; Wang, Z.; Cui, S.; Han, X. Deep fashion3d: A dataset and benchmark for 3d garment reconstruction from single images. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Cham, Switzerland, 2020; pp. 512–530. [Google Scholar]
- Chen, H.; Huang, Y.; Huang, H.; Ge, X.; Shao, D. GaussianVTON: 3D Human Virtual Try-ON via Multi-Stage Gaussian Splatting Editing with Image Prompting. arXiv 2024, arXiv:2405.07472. [Google Scholar]
- Xiu, Y.; Yang, J.; Tzionas, D.; Black, M.J. Icon: Implicit clothed humans obtained from normals. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 13286–13296. [Google Scholar]
- Ma, X.; Zhao, J.; Teng, Y.; Yao, L. Multi-Level Implicit Function for Detailed Human Reconstruction by Relaxing SMPL Constraints. Comput. Graph. Forum 2023, 42, e14951. [Google Scholar] [CrossRef]
- Ren, Y.; Zhou, M.; Wang, Y.; Feng, L.; Zhu, Q.; Li, K.; Geng, G. Implicit 3D Human Reconstruction Guided by Parametric Models and Normal Maps. J. Imaging 2024, 10, 133. [Google Scholar] [CrossRef] [PubMed]
- Varol, G.; Ceylan, D.; Russell, B.; Yang, J.; Yumer, E.; Laptev, I.; Schmid, C. BodyNet: Volumetric inference of 3D human body shapes. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.; Tzionas, D.; Black, M.J. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10975–10985. [Google Scholar]
- Xu, W.; Chatterjee, A.; Zollhöfer, M.; Rhodin, H.; Mehta, D.; Seidel, H.P.; Theobalt, C. Monoperfcap: Human performance capture from monocular video. ACM Trans. Graph. (ToG) 2018, 37, 1–15. [Google Scholar] [CrossRef]
- Saito, S.; Huang, Z.; Natsume, R.; Morishima, S.; Kanazawa, A.; Li, H. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2304–2314. [Google Scholar]
- Muttagi, S.I.; Patil, V.; Babar, P.P.; Chunamari, R.; Kulkarni, U.; Chikkamath, S.; Meena, S. 3D Avatar Reconstruction Using Multi-level Pixel-Aligned Implicit Function. In Proceedings of the International Conference on Recent Trends in Machine Learning, IOT, Smart Cities & Applications, Hyderabad, India, 16–17 September 2023; Springer: Cham, Switzerland, 2023; pp. 221–231. [Google Scholar]
- Saito, S.; Simon, T.; Saragih, J.; Joo, H. Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 84–93. [Google Scholar]
- Xiu, Y.; Yang, J.; Cao, X.; Tzionas, D.; Black, M.J. Econ: Explicit clothed humans optimized via normal integration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 512–523. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Yang, K.; Gu, R.; Wang, M.; Toyoura, M.; Xu, G. Lasor: Learning accurate 3d human pose and shape via synthetic occlusion-aware data and neural mesh rendering. IEEE Trans. Image Process. 2022, 31, 1938–1948. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Liu, J.; Zhang, Z.; Xu, S.; Yan, Y. Cliff: Carrying location information in full frames into human pose and shape estimation. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part V; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2022; Volume 13695, pp. 590–606. [Google Scholar]
- Chen, M.; Chen, J.; Ye, X.; Gao, H.a.; Chen, X.; Fan, Z.; Zhao, H. Ultraman: Single Image 3D Human Reconstruction with Ultra Speed and Detail. arXiv 2024, arXiv:2403.12028. [Google Scholar]
- Tang, Y.; Zhang, Q.; Hou, J.; Liu, Y. Human as Points: Explicit Point-based 3D Human Reconstruction from Single-view RGB Images. arXiv 2023, arXiv:2311.02892. [Google Scholar]
- Zheng, Z.; Yu, T.; Liu, Y.; Dai, Q. Pamir: Parametric model-conditioned implicit representation for image-based human reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3170–3184. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Deng, Y.; Yang, Y.; Zhao, X. An Embeddable Implicit IUVD Representation for Part-Based 3D Human Surface Reconstruction. IEEE Trans. Image Process. 2024, 33, 4334–4347. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Gao, A.; Wan, Y. Implicit Clothed Human Reconstruction Based on Self-attention and SDF. In Proceedings of the International Conference on Neural Information Processing, Changsha, China, 20–23 November 2023; Springer: Cham, Switzerland, 2023; pp. 313–324. [Google Scholar]
- Wei, W.L.; Lin, J.C.; Liu, T.L.; Liao, H.Y.M. Capturing humans in motion: Temporal-attentive 3D human pose and shape estimation from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13211–13220. [Google Scholar]
- Cho, J.; Kim, Y.; Oh, T.H. Cross-attention of disentangled modalities for 3d human mesh recovery with transformers. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part I; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2022; Volume 13684, pp. 342–359. [Google Scholar]
- Xue, Y.; Chen, J.; Zhang, Y.; Yu, C.; Ma, H.; Ma, H. 3d human mesh reconstruction by learning to sample joint adaptive tokens for transformers. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 6765–6773. [Google Scholar]
- Lin, K.; Wang, L.; Liu, Z. End-to-end human pose and mesh reconstruction with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1954–1963. [Google Scholar]
- Qiu, Z.; Yang, Q.; Wang, J.; Feng, H.; Han, J.; Ding, E.; Xu, C.; Fu, D.; Wang, J. Psvt: End-to-end multi-person 3d pose and shape estimation with progressive video transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21254–21263. [Google Scholar]
- Zhang, Z.; Yang, Z.; Yang, Y. SIFU: Side-view Conditioned Implicit Function for Real-world Usable Clothed Human Reconstruction. arXiv 2023, arXiv:2312.06704. [Google Scholar]
- Li, C.; Xiao, M.; Gao, M. R3D-SWIN: Use Shifted Window Attention for Single-View 3D Reconstruction. arXiv 2023, arXiv:2312.02725. [Google Scholar]
- Yu, T.; Zheng, Z.; Guo, K.; Liu, P.; Dai, Q.; Liu, Y. Function4D: Real-time human volumetric capture from very sparse consumer RGBD sensors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5746–5756. [Google Scholar]
- Ma, Q.; Yang, J.; Ranjan, A.; Pujades, S.; Pons-Moll, G.; Tang, S.; Black, M.J. Learning to dress 3D people in generative clothing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6469–6478. [Google Scholar]
- Renderpeople. Available online: https://renderpeople.com/ (accessed on 19 October 2024).
- Han, S.H.; Park, M.G.; Yoon, J.H.; Kang, J.M.; Park, Y.J.; Jeon, H.G. High-fidelity 3d human digitization from single 2k resolution images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12869–12879. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Time Complexity |
|---|---|
| PIFu | O(n²) |
| PaMIR | O(n) |
| ICON | O(n) |
| 2K2K | O(n) |
| EMAR | O(n) |
| Dataset Method | CAPE-Easy | CAPE-Hard | CAPE | Thuman2.0 | RenderPeople | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Chamfer↓ | P2S↓ | Normals↓ | Chamfer↓ | P2S↓ | Normals↓ | Chamfer↓ | P2S↓ | Normals↓ | Chamfer↓ | P2S↓ | Normals↓ | Chamfer↓ | P2S↓ | Normals↓ | |
| PIFu (2019) | 2.823 | 2.796 | 0.100 | 4.029 | 4.195 | 0.124 | 3.627 | 3.729 | 0.116 | 3.024 | 2.297 | 0.201 | 2.103 | 1.452 | 0.191 |
| PaMIR (2021) | 1.936 | 1.263 | 0.078 | 2.216 | 1.611 | 0.093 | 2.123 | 1.495 | 0.088 | 1.730 | 1.330 | 0.118 | 1.196 | 0.984 | 0.124 |
| ICON (2022) | 1.233 | 1.170 | 0.072 | 1.096 | 1.013 | 0.063 | 1.142 | 1.065 | 0.066 | 1.013 | 1.050 | 0.082 | 0.735 | 0.831 | 0.080 |
| 2K2K (2023) | 1.264 | 1.213 | 0.070 | 1.437 | 1.385 | 0.060 | 1.379 | 1.328 | 0.063 | 1.651 | 1.247 | 0.079 | 1.032 | 0.932 | 0.077 |
| Ours (T) | 0.802 | 0.768 | 0.050 | 0.884 | 0.861 | 0.053 | 0.857 | 0.830 | 0.052 | 0.986 | 1.024 | 0.076 | 0.735 | 0.797 | 0.051 |
| Ours (C) | - | - | - | - | - | - | - | - | - | 1.097 | 1.192 | 0.081 | 0.906 | 0.839 | 0.069 |
| Baseline | EMSA | FFM | Chamfer↓ | P2S↓ | Normals↓ |
|---|---|---|---|---|---|
| ✓ | 1.142 | 1.065 | 0.066 | ||
| ✓ | ✓ | 0.998 | 0.943 | 0.055 | |
| ✓ | ✓ | 1.041 | 0.973 | 0.060 | |
| ✓ | ✓ | ✓ | 0.857 | 0.830 | 0.052 |
| Baseline | L1 | LVGG | LTV | Chamfer↓ | P2S↓ | Normals↓ |
|---|---|---|---|---|---|---|
| ✓ | ✓ | 0.855 | 0.835 | 0.065 | ||
| ✓ | ✓ | 0.860 | 0.840 | 0.080 | ||
| ✓ | ✓ | 0.865 | 0.845 | 0.090 | ||
| ✓ | ✓ | ✓ | 0.840 | 0.820 | 0.055 | |
| ✓ | ✓ | ✓ | 0.845 | 0.825 | 0.060 | |
| ✓ | ✓ | ✓ | 0.855 | 0.830 | 0.075 | |
| ✓ | ✓ | ✓ | ✓ | 0.857 | 0.830 | 0.052 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Zhou, M.; Zhou, P.; Wang, S.; Liu, Y.; Geng, G.; Li, K.; Cao, X. Enhanced Multi-Scale Attention-Driven 3D Human Reconstruction from Single Image. Electronics 2024, 13, 4264. https://doi.org/10.3390/electronics13214264
Ren Y, Zhou M, Zhou P, Wang S, Liu Y, Geng G, Li K, Cao X. Enhanced Multi-Scale Attention-Driven 3D Human Reconstruction from Single Image. Electronics. 2024; 13(21):4264. https://doi.org/10.3390/electronics13214264
Chicago/Turabian StyleRen, Yong, Mingquan Zhou, Pengbo Zhou, Shibo Wang, Yangyang Liu, Guohua Geng, Kang Li, and Xin Cao. 2024. "Enhanced Multi-Scale Attention-Driven 3D Human Reconstruction from Single Image" Electronics 13, no. 21: 4264. https://doi.org/10.3390/electronics13214264
APA StyleRen, Y., Zhou, M., Zhou, P., Wang, S., Liu, Y., Geng, G., Li, K., & Cao, X. (2024). Enhanced Multi-Scale Attention-Driven 3D Human Reconstruction from Single Image. Electronics, 13(21), 4264. https://doi.org/10.3390/electronics13214264