

Diagnosing and Characterizing Chronic Kidney Disease with Machine Learning: The Value of Clinical Patient Characteristics as Evidenced from an Open Dataset
 and
and
Abstract
1. Introduction
1.1. CKD Stages
1.2. Machine Learning Applied to CKD
2. Materials and Methods
2.1. Dataset Description
2.2. Machine Learning
- Feature type inference.
- Feature description (e.g., univariate associations and stats).
- Data cleaning (e.g., NaN handling and imputation).
- Training, validation, and test splitting.
- Feature selection.
- Hyperparameter tuning.
- Model selection and validation.
2.3. Statistical Analysis
3. Results
3.1. Patient Clinical Characteristics
3.2. Machine Learning with Patient Clinical Characteristics
3.3. Machine Learning Without Patient Clinical Characteristics
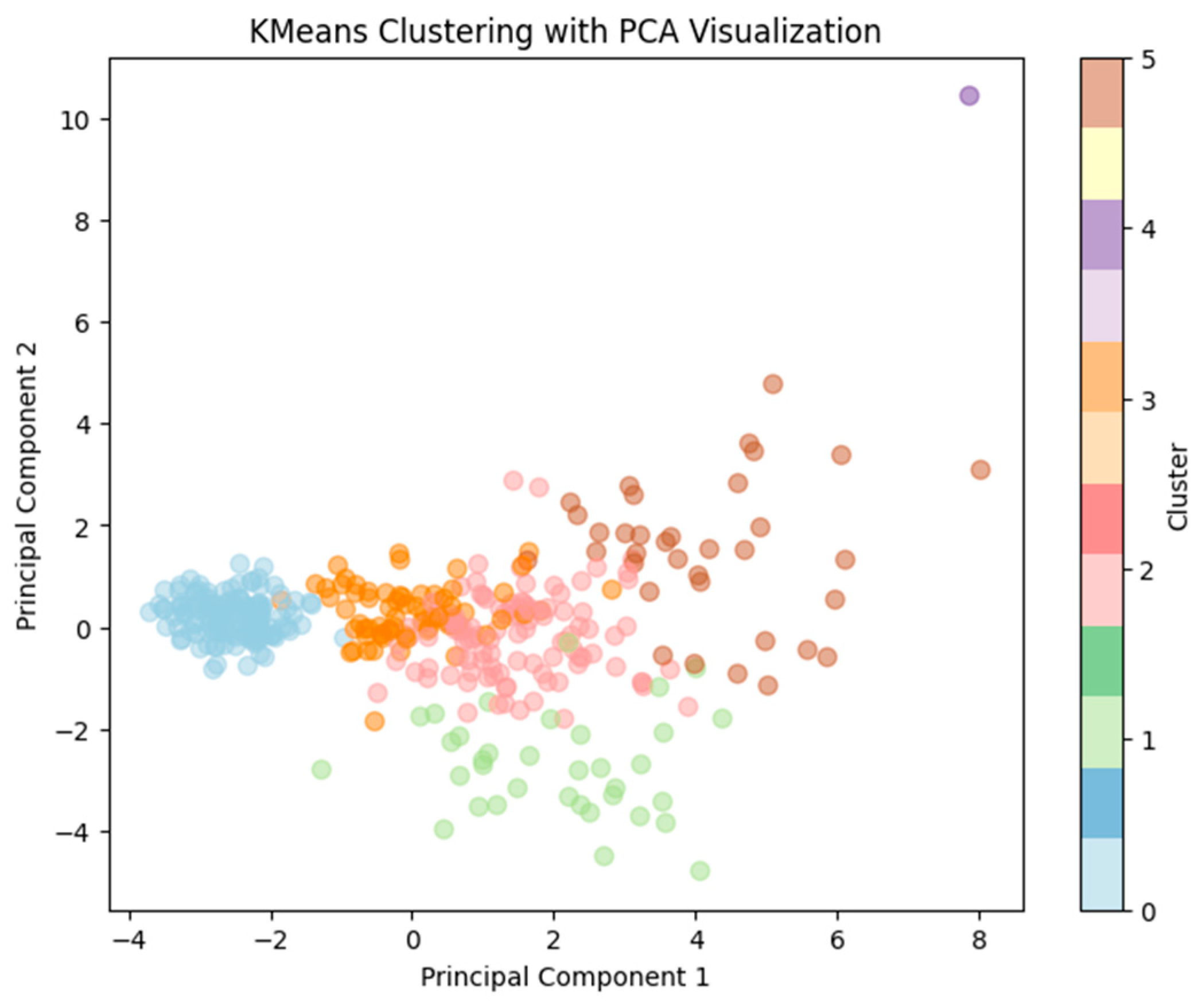
3.4. Cluster Analysis Results
3.5. Results Summary
4. Discussion
4.1. Patient Clinical Characteristics
4.2. Impact of Patient Clinical Characteristics on Machine Learning
4.3. Comparative Machine Learning Results Across Studies
4.4. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
References
- National Institute of Diabetes and Digestive and Kidney Diseases. Your Kidneys & How They Work—National Institute of Diabetes and Digestive and Kidney Diseases. Available online: https://www.niddk.nih.gov/health-information/kidney-disease/kidneys-how-they-work (accessed on 20 February 2024).
- Johns Hopkins Hospital. Chronic Kidney Disease | Johns Hopkins Medicine. Available online: https://www.hopkinsmedicine.org/health/conditions-and-diseases/chronic-kidney-disease (accessed on 24 February 2024).
- National Kidney Foundation. Chronic Kidney Disease (CKD)—Symptoms, Causes, Treatment | National Kidney Foundation. Available online: https://www.kidney.org/atoz/content/about-chronic-kidney-disease (accessed on 24 February 2024).
- Zhao, J.; Zhang, Y.; Qiu, J.; Zhang, X.; Wei, F.; Feng, J.; Chen, C.; Zhang, K.; Feng, S.; Li, W.D. An early prediction model for chronic kidney disease. Sci. Rep. 2022, 12, 2765. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. The Top 10 Causes of Death—World Health Organization. Available online: https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 24 February 2024).
- Estimating Glomerular Filtration Rate. National Institute of Diabetes and Digestive and Kidney Diseases. Available online: https://www.niddk.nih.gov/health-information/professionals/clinical-tools-patient-management/kidney-disease/laboratory-evaluation/glomerular-filtration-rate/estimating (accessed on 3 February 2024).
- American Kidney Fund. Stage 1 of Chronic Kidney Disease CKD: Causes, Symptoms and Treatment. Available online: https://www.kidneyfund.org/all-about-kidneys/stages-kidney-disease/stage-1-chronic-kidney-disease (accessed on 24 February 2024).
- American Kidney Fund. Stage 2 Chronic Kidney Disease (CKD). Available online: https://www.kidneyfund.org/all-about-kidneys/stages-kidney-disease/stage-2-chronic-kidney-disease-ckd (accessed on 24 February 2024).
- American Kidney Fund. Stage 3 Chronic Kidney Disease (CKD). Available online: https://www.kidneyfund.org/all-about-kidneys/stages-kidney-disease/stage-3-chronic-kidney-disease-ckd (accessed on 24 February 2024).
- American Kidney Fund. Stage 4 Chronic Kidney Disease (CKD). Available online: https://www.kidneyfund.org/all-about-kidneys/stages-kidney-disease/stage-4-chronic-kidney-disease-ckd (accessed on 24 February 2024).
- American Kidney Fund. Stage 5 Chronic Kidney Disease (CKD). Available online: https://www.kidneyfund.org/all-about-kidneys/stages-kidney-disease/stage-5-chronic-kidney-disease-ckd (accessed on 24 February 2024).
- Cleveland Clinic. Chronic Kidney Disease (CKD): Symptoms & Treatment. Available online: https://my.clevelandclinic.org/health/diseases/15096-chronic-kidney-disease (accessed on 7 May 2023).
- Chen, T.K.; Knicely, D.H.; Grams, M.E. Chronic Kidney Disease Diagnosis and Management A Review. National Library of Medicine. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7015670 (accessed on 11 March 2024).
- Lee, H.; Yun, D.; Yoo, J.; Yoo, K.; Kim, Y.C.; Kim, D.K.; Oh, K.H.; Joo, K.W.; Kim, Y.S.; Kwak, N.; et al. Deep learning model for real-time prediction of intradialytic hypotension. Clin. J. Am. Soc. Nephrol. 2021, 16, 396–406. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Ho, K.M.; Hong, Y. Machine learning for the prediction of volume responsiveness in patients with oliguric acute kidney injury in critical care. Crit. Care 2019, 23, 112. [Google Scholar] [CrossRef] [PubMed]
- Dritsas, E.; Trigka, M. Machine Learning Techniques for Chronic Kidney Disease Risk Prediction. Big Data Cogn. Comput. 2022, 6, 98. [Google Scholar] [CrossRef]
- Yashfi, S.; Islam, M.; Pritilata; Sakib, N.; Islam, T.; Shahbaaz, M.; Pantho, S. Risk Prediction Of Chronic Kidney Disease Using Machine Learning Algorithms. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020. [Google Scholar] [CrossRef]
- Chittora, P.; Sandeep, C.; Chakrabarti, P.; Kumawat, G.; Chakrabarti, T.; Leonowicz, Z.; Jasiński, M.; Jasiński, Ł.; Gono, R.; Jasińska, E.; et al. Prediction of Chronic Kidney Disease—A Machine Learning Perspective. IEEE Access 2021, 9, 17312–17334. [Google Scholar] [CrossRef]
- Baidya, D.; Umaima, U.; Islam, M.N.; Shamrat, F.M.J.M.; Pramanik, A.; Rahman, M.S. A Deep Prediction of Chronic Kidney Disease by Employing Machine Learning Method. In Proceedings of the 2022 6th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 28–30 April 2022; pp. 1305–1310. [Google Scholar] [CrossRef]
- Abdur, M.; Rahat, R.; Cao, D.M.; Tayaba, M.; Ghosh, B.P.; Ayon, H.; Nobe Nur Akter, T.; Rahman, M.; Bhuiyan, M.S. Comparing Machine Learning Techniques for Detecting Chronic Kidney Disease in Early Stage. J. Comput. Sci. Technol. Stud. 2024, 6, 20–32. [Google Scholar] [CrossRef]
- Islam, M.A.; Majumder, M.Z.H.; Hussein, M.A. Chronic kidney disease prediction based on machine learning algorithms. J. Pathol. Inform. 2023, 14, 100189. [Google Scholar] [CrossRef] [PubMed]
- Debal, D.A.; Sitote, T.M. Chronic kidney disease prediction using machine learning techniques. J. Big Data 2022, 9, 109. [Google Scholar] [CrossRef]
- Ghosh, S.K.; Khandoker, A.H. A machine learning driven nomogram for predicting chronic kidney disease stages 3–5. Sci. Rep. 2023, 13, 21613. [Google Scholar] [CrossRef] [PubMed]
- Xiao, J.; Ding, R.; Xu, X.; Guan, H.; Feng, X.; Sun, T.; Zhu, S.; Ye, Z. Comparison and development of machine learning tools in the prediction of chronic kidney disease progression. J. Transl. Med. 2019, 17, 119. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Rubini, L.; Soundarapandian, P.; Eswaran, P. Chronic Kidney Disease; UCI Machine Learning Repository: Espoo, Finland, 2015. [Google Scholar] [CrossRef]
- DM-Berger. stfxecutables/df-analyze: Sensitivity/Specificity Update; Zenodo: Geneva, Switzerland, 2021. [Google Scholar] [CrossRef]
- Levman, J.; Jennings, M.; Rouse, E.; Berger, D.; Kabaria, P.; Nangaku, M.; Gondra, I.; Takahashi, E. A morphological study of schizophrenia with Magnetic Resonance Imaging, advanced analytics, and Machine Learning. Front. Neurosci. 2022, 16, 926426. [Google Scholar] [CrossRef] [PubMed]
- Wella, Y.; Okfalisa, O.; Insani, F.; Saeed, F.; Hussin, A. Service quality dealer identification: The optimization of K-Means clustering. SINERGI 2023, 27, 433. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition | Type | Value | Class of Interest = CKD | Class of Not Interest = NOTCKD | ||
|---|---|---|---|---|---|---|---|
| Mean | Standard Deviation | Mean | Standard Deviation | ||||
| age—age | Age of the patient | Numerical | years | 54.5 | 17.4 | 46.3 | 15.5 |
| bp—blood pressure (Diastolic) | Pressure of blood pumped by heart into wall’s vessels | Numerical | mm/Hg | 79.6 | 15.2 | 71.4 | 8.6 |
| sg—specific gravity | Specific indicator of renal function; varies between 1.005 and 1.025 for humans | Numerical | (1.005, 1.010, 1.015, 1.020, 1.025) | 1.0 | 0.0 | 1.0 | 0.0 |
| bgr—blood glucose random | Measure of the glucose in the blood at the moment of the test | Numerical | mgs/dL | 175.4 | 92.1 | 107.7 | 18.6 |
| bu—blood urea | Measurement of urea nitrogenic blood or serum, a major indicator of kidney failure | Numerical | mgs/dL | 72.4 | 58.6 | 32.7 | 11.4 |
| sc—serum creatinine | Creatinine is a waste component that is removed by the kidneys from the blood | Numerical | mgs/dL | 4.4 | 7.0 | 0.9 | 0.3 |
| sod—sodium | Concentration of sodium in blood | Numerical | mEq/L | 133.9 | 12.4 | 141.7 | 4.8 |
| pot—potassium | Concentration of potassium in blood | Numerical | mEq/L | 4.9 | 4.3 | 4.3 | 0.6 |
| hemo—hemoglobin | Hemoglobin is a protein in charge of transport of oxygen in the red blood cells | Numerical | gms | 10.6 | 2.2 | 15.2 | 1.3 |
| pcv—packed cell volume | Proportion of blood cells within serum | Numerical | percentage | 32.9 | 7.2 | 46.3 | 4.1 |
| wc—white blood cell count | Count of white blood cells | Numerical | cells/cmm | 9069.5 | 3580.5 | 7687.3 | 1833.2 |
| rc—red blood cell count | Count of red blood cells | Numerical | millions/cmm | 3.9 | 0.9 | 5.4 | 0.6 |
| Variable | Definition | Counts for Each Value | Values as a Percentage (%) of All Samples |
|---|---|---|---|
| al—albumin | Measurement of albumin protein in blood | (199:0, 44:1, 43:2, 43:3, 24:4, 1:5, 46:undefined) | (49.75% 0, 11% 1, 10.75% 2, 10.75% 3, 6% 4, 0.25% 5, 11.5% undefined) |
| su—sugar | Measurement of sugar (glucose) in blood | (290:0, 13:1, 18:2, 14:3, 13:4, 3:5, 49:undefined) | (72.5% 0, 3.25% 1, 4.5% 2, 3.5% 3, 3.25% 4, 0.75% 5, 12.25% undefined) |
| rbc—red blood cells | Assessment of red blood cells | (201 normal, 47 abnormal, 152 undefined) | (50.25% normal, 11.75% abnormal, 38% undefined) |
| pc—pus cell | Accumulation of dead white blood cells in the urine | (259 normal, 76 abnormal, 65 undefined) | (64.75% normal, 19% abnormal, 16.25% undefined) |
| pcc—pus cell clumps | Presence of dead cells in urine, which indicates kidney infection, or a sexually transmitted disease | (42 present, 354 not present, 4 undefined) | (10.5% present, 88.5% not present, 1% undefined) |
| ba—bacteria | Presence of bacteria in urine | (22 present, 374 not present, 4 undefined) | (5.5% present, 93.5% not present, 1% undefined) |
| htn—hypertension | Patient with hypertension diagnosed | (147 yes, 251 no, 2 undefined) | (36.75% yes, 62.75% no, 0.50% undefined) |
| dm—diabetes mellitus | Failure of the body to react to insulin to control blood glucose levels | (137 yes, 261 no, 2 undefined) | (34.25% yes, 65.25% no, 0.50% undefined) |
| cad—coronary artery disease | Narrow arteries can cause obstructions of blood flow | (34 yes, 364 no, 2 undefined) | (8.5% yes, 91% no, 0.50% undefined) |
| appet—appetite | Abnormal appetite | (317 good, 82 poor, 1 undefined) | (79.25% good, 20.5% poor, 0.25% undefined) |
| pe—pedal edema | Excess fluid in the lower extremities or knees | (76 yes, 323 no, 1 undefined) | (19% yes, 80.75% no, 0.25% undefined) |
| ane—anemia | Reduction in red blood cells | (60 yes, 339 no, 1 undefined) | (15% yes, 84.75% no, 0.25% undefined) |
| class—diagnosis | The target value to predict | (250 CKD, 150 not CKD) | (62.5% CKD, 37.5% not CKD) |
| Model | Selection | Embed_Selector | ACC | AUROC | BAL-ACC | F1 | NPV | PPV | Sens | Spec |
|---|---|---|---|---|---|---|---|---|---|---|
| lgbm | none | none | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| lgbm | embed_lgbm | lgbm | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| lgbm | embed_linear | linear | 0.994 | 1 | 0.995 | 0.993 | 0.984 | 1 | 0.995 | 1 |
| lgbm | assoc | none | 0.994 | 1 | 0.995 | 0.993 | 0.984 | 1 | 0.995 | 1 |
| rf | assoc | none | 0.994 | 1 | 0.992 | 0.993 | 1 | 0.99 | 0.992 | 0.983 |
| lr | wrap | none | 0.988 | 0.998 | 0.99 | 0.987 | 0.968 | 1 | 0.99 | 1 |
| rf | embed_lgbm | lgbm | 0.988 | 0.999 | 0.987 | 0.987 | 0.983 | 0.99 | 0.987 | 0.983 |
| lgbm | pred | none | 0.988 | 1 | 0.99 | 0.987 | 0.968 | 1 | 0.99 | 1 |
| mlp | pred | none | 0.988 | 1 | 0.99 | 0.987 | 0.968 | 1 | 0.99 | 1 |
| sgd | wrap | none | 0.988 | 0.998 | 0.99 | 0.987 | 0.968 | 1 | 0.99 | 1 |
| mlp | wrap | none | 0.981 | 0.999 | 0.985 | 0.98 | 0.952 | 1 | 0.985 | 1 |
| rf | pred | none | 0.981 | 0.999 | 0.978 | 0.98 | 0.983 | 0.98 | 0.978 | 0.967 |
| lr | pred | none | 0.981 | 0.998 | 0.982 | 0.98 | 0.967 | 0.99 | 0.982 | 0.983 |
| rf | none | none | 0.969 | 0.997 | 0.962 | 0.966 | 0.982 | 0.961 | 0.962 | 0.933 |
| knn | pred | none | 0.963 | 0.97 | 0.97 | 0.961 | 0.909 | 1 | 0.97 | 1 |
| lgbm | wrap | none | 0.956 | 0.996 | 0.958 | 0.954 | 0.921 | 0.979 | 0.958 | 0.967 |
| rf | embed_linear | linear | 0.956 | 0.992 | 0.962 | 0.954 | 0.908 | 0.989 | 0.962 | 0.983 |
| rf | wrap | none | 0.938 | 0.989 | 0.937 | 0.934 | 0.903 | 0.959 | 0.937 | 0.933 |
| sgd | pred | none | 0.906 | 0.888 | 0.888 | 0.897 | 0.925 | 0.897 | 0.888 | 0.817 |
| knn | assoc | none | 0.863 | 0.927 | 0.86 | 0.855 | 0.797 | 0.906 | 0.86 | 0.85 |
| knn | embed_linear | linear | 0.844 | 0.835 | 0.835 | 0.834 | 0.787 | 0.879 | 0.835 | 0.8 |
| knn | embed_lgbm | lgbm | 0.838 | 0.911 | 0.83 | 0.828 | 0.774 | 0.878 | 0.83 | 0.8 |
| mlp | embed_linear | linear | 0.812 | 0.919 | 0.773 | 0.786 | 0.841 | 0.802 | 0.773 | 0.617 |
| knn | none | none | 0.775 | 0.77 | 0.77 | 0.764 | 0.682 | 0.84 | 0.77 | 0.75 |
| knn | wrap | none | 0.769 | 0.854 | 0.785 | 0.765 | 0.646 | 0.889 | 0.785 | 0.85 |
| mlp | embed_lgbm | lgbm | 0.769 | 0.882 | 0.778 | 0.763 | 0.653 | 0.871 | 0.778 | 0.817 |
| sgd | embed_linear | linear | 0.688 | 0.67 | 0.67 | 0.669 | 0.581 | 0.755 | 0.67 | 0.6 |
| sgd | assoc | none | 0.681 | 0.737 | 0.648 | 0.651 | 0.585 | 0.729 | 0.648 | 0.517 |
| lr | none | none | 0.675 | 0.83 | 0.583 | 0.559 | 0.722 | 0.669 | 0.583 | 0.217 |
| sgd | none | none | 0.662 | 0.654 | 0.627 | 0.629 | 0.558 | 0.713 | 0.627 | 0.483 |
| lr | embed_linear | linear | 0.656 | 0.821 | 0.548 | 0.492 | 0.778 | 0.649 | 0.548 | 0.117 |
| lr | assoc | none | 0.644 | 0.819 | 0.532 | 0.462 | 0.714 | 0.641 | 0.532 | 0.083 |
| lr | embed_lgbm | lgbm | 0.631 | 0.761 | 0.515 | 0.43 | 0.6 | 0.632 | 0.515 | 0.05 |
| mlp | none | none | 0.625 | 0.61 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| mlp | assoc | none | 0.625 | 0.66 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | embed_lgbm | lgbm | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | wrap | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | pred | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| sgd | embed_lgbm | lgbm | 0.625 | 0.593 | 0.593 | 0.594 | 0.5 | 0.692 | 0.593 | 0.467 |
| dummy | none | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | embed_linear | linear | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | assoc | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| Model | Selection | Embed_Selector | ACC | AUROC | BAL-ACC | F1 | NPV | PPV | Sens | Spec |
|---|---|---|---|---|---|---|---|---|---|---|
| lgbm | pred | none | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| lgbm | embed_lgbm | lgbm | 0.994 | 1 | 0.992 | 0.993 | 1 | 0.99 | 0.992 | 0.983 |
| lgbm | assoc | none | 0.994 | 1 | 0.992 | 0.993 | 1 | 0.99 | 0.992 | 0.983 |
| lgbm | none | none | 0.994 | 1 | 0.992 | 0.993 | 1 | 0.99 | 0.992 | 0.983 |
| lgbm | embed_linear | linear | 0.994 | 1 | 0.992 | 0.993 | 1 | 0.99 | 0.992 | 0.983 |
| sgd | wrap | none | 0.988 | 1 | 0.99 | 0.987 | 0.971 | 1 | 0.99 | 1 |
| lgbm | wrap | none | 0.981 | 0.997 | 0.982 | 0.98 | 0.969 | 0.99 | 0.982 | 0.983 |
| rf | embed_linear | linear | 0.981 | 1 | 0.985 | 0.98 | 0.954 | 1 | 0.985 | 1 |
| lr | wrap | none | 0.981 | 1 | 0.982 | 0.98 | 0.971 | 0.99 | 0.982 | 0.983 |
| lr | pred | none | 0.975 | 0.995 | 0.977 | 0.974 | 0.955 | 0.99 | 0.977 | 0.983 |
| rf | wrap | none | 0.969 | 0.994 | 0.972 | 0.967 | 0.937 | 0.99 | 0.972 | 0.983 |
| rf | none | none | 0.963 | 0.995 | 0.957 | 0.96 | 0.966 | 0.962 | 0.957 | 0.933 |
| rf | assoc | none | 0.956 | 0.998 | 0.962 | 0.954 | 0.913 | 0.99 | 0.962 | 0.983 |
| rf | embed_lgbm | lgbm | 0.95 | 0.993 | 0.957 | 0.948 | 0.903 | 0.99 | 0.957 | 0.983 |
| knn | pred | none | 0.95 | 0.957 | 0.957 | 0.948 | 0.903 | 0.99 | 0.957 | 0.983 |
| rf | pred | none | 0.944 | 0.993 | 0.948 | 0.941 | 0.901 | 0.98 | 0.948 | 0.967 |
| sgd | pred | none | 0.9 | 0.897 | 0.897 | 0.894 | 0.864 | 0.932 | 0.897 | 0.883 |
| knn | embed_lgbm | lgbm | 0.838 | 0.91 | 0.833 | 0.83 | 0.784 | 0.883 | 0.833 | 0.817 |
| sgd | embed_linear | linear | 0.819 | 0.815 | 0.815 | 0.806 | 0.775 | 0.885 | 0.815 | 0.8 |
| sgd | assoc | none | 0.812 | 0.889 | 0.807 | 0.801 | 0.744 | 0.873 | 0.807 | 0.783 |
| sgd | none | none | 0.812 | 0.872 | 0.793 | 0.797 | 0.776 | 0.837 | 0.793 | 0.717 |
| knn | assoc | none | 0.812 | 0.929 | 0.833 | 0.809 | 0.693 | 0.939 | 0.833 | 0.917 |
| knn | embed_linear | linear | 0.794 | 0.785 | 0.785 | 0.781 | 0.731 | 0.849 | 0.785 | 0.75 |
| knn | none | none | 0.781 | 0.782 | 0.782 | 0.771 | 0.689 | 0.862 | 0.782 | 0.783 |
| sgd | embed_lgbm | lgbm | 0.725 | 0.715 | 0.71 | 0.708 | 0.648 | 0.786 | 0.71 | 0.65 |
| knn | wrap | none | 0.706 | 0.791 | 0.738 | 0.702 | 0.57 | 0.905 | 0.738 | 0.867 |
| lr | none | none | 0.65 | 0.907 | 0.533 | 0.452 | 1 | 0.641 | 0.533 | 0.067 |
| lr | embed_lgbm | lgbm | 0.637 | 0.855 | 0.52 | 0.424 | 0.75 | 0.636 | 0.52 | 0.05 |
| lr | embed_linear | linear | 0.631 | 0.908 | 0.508 | 0.402 | 1 | 0.629 | 0.508 | 0.017 |
| dummy | embed_lgbm | lgbm | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| lr | assoc | none | 0.625 | 0.907 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | wrap | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | pred | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | none | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | embed_linear | linear | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | assoc | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| mlp | assoc | none | 0.575 | 0.642 | 0.5 | 0.362 | 0.375 | 0.625 | 0.5 | 0.2 |
| mlp | pred | none | 0.475 | 0.735 | 0.5 | 0.317 | 0.375 | 0.625 | 0.5 | 0.6 |
| mlp | embed_linear | linear | 0.475 | 0.637 | 0.5 | 0.317 | 0.375 | 0.625 | 0.5 | 0.6 |
| mlp | embed_lgbm | lgbm | 0.475 | 0.63 | 0.5 | 0.317 | 0.375 | 0.625 | 0.5 | 0.6 |
| mlp | wrap | none | 0.444 | 0.724 | 0.472 | 0.368 | 0.35 | 0.565 | 0.472 | 0.583 |
| mlp | none | none | 0.375 | 0.652 | 0.5 | 0.273 | 0.375 | nan | 0.5 | 1 |
| Model | Selection | Embed_Selector | ACC | AUROC | BAL-ACC | F1 | NPV | PPV | Sens | Spec |
|---|---|---|---|---|---|---|---|---|---|---|
| lgbm | none | none | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| rf | wrap | none | 0.994 | 1 | 0.995 | 0.993 | 0.984 | 1 | 0.995 | 1 |
| lgbm | wrap | none | 0.994 | 1 | 0.995 | 0.993 | 0.984 | 1 | 0.995 | 1 |
| lgbm | pred | none | 0.994 | 1 | 0.995 | 0.993 | 0.984 | 1 | 0.995 | 1 |
| lgbm | assoc | none | 0.994 | 1 | 0.995 | 0.993 | 0.984 | 1 | 0.995 | 1 |
| knn | wrap | none | 0.988 | 0.999 | 0.99 | 0.987 | 0.968 | 1 | 0.99 | 1 |
| mlp | pred | none | 0.988 | 1 | 0.987 | 0.987 | 0.983 | 0.99 | 0.987 | 0.983 |
| lr | wrap | none | 0.988 | 0.999 | 0.987 | 0.987 | 0.983 | 0.99 | 0.987 | 0.983 |
| rf | assoc | none | 0.988 | 1 | 0.987 | 0.987 | 0.983 | 0.99 | 0.987 | 0.983 |
| lgbm | embed_lgbm | lgbm | 0.988 | 1 | 0.99 | 0.987 | 0.968 | 1 | 0.99 | 1 |
| sgd | wrap | none | 0.988 | 0.999 | 0.987 | 0.987 | 0.983 | 0.99 | 0.987 | 0.983 |
| mlp | wrap | none | 0.988 | 1 | 0.99 | 0.987 | 0.968 | 1 | 0.99 | 1 |
| rf | pred | none | 0.988 | 0.998 | 0.99 | 0.987 | 0.968 | 1 | 0.99 | 1 |
| lr | pred | none | 0.981 | 0.999 | 0.978 | 0.98 | 0.983 | 0.98 | 0.978 | 0.967 |
| rf | none | none | 0.981 | 0.999 | 0.982 | 0.98 | 0.967 | 0.99 | 0.982 | 0.983 |
| knn | pred | none | 0.975 | 0.977 | 0.977 | 0.974 | 0.952 | 0.99 | 0.977 | 0.983 |
| lgbm | embed_linear | linear | 0.963 | 0.988 | 0.957 | 0.96 | 0.966 | 0.961 | 0.957 | 0.933 |
| rf | embed_lgbm | lgbm | 0.956 | 0.993 | 0.952 | 0.953 | 0.949 | 0.96 | 0.952 | 0.933 |
| rf | embed_linear | linear | 0.944 | 0.988 | 0.938 | 0.94 | 0.932 | 0.95 | 0.938 | 0.917 |
| lr | embed_lgbm | lgbm | 0.925 | 0.98 | 0.917 | 0.919 | 0.914 | 0.931 | 0.917 | 0.883 |
| sgd | pred | none | 0.912 | 0.935 | 0.907 | 0.907 | 0.883 | 0.93 | 0.907 | 0.883 |
| sgd | embed_lgbm | lgbm | 0.906 | 0.969 | 0.892 | 0.898 | 0.909 | 0.905 | 0.892 | 0.833 |
| knn | embed_linear | linear | 0.869 | 0.932 | 0.855 | 0.859 | 0.842 | 0.883 | 0.855 | 0.8 |
| knn | embed_lgbm | lgbm | 0.85 | 0.92 | 0.847 | 0.842 | 0.781 | 0.896 | 0.847 | 0.833 |
| knn | assoc | none | 0.812 | 0.797 | 0.797 | 0.799 | 0.759 | 0.843 | 0.797 | 0.733 |
| mlp | assoc | none | 0.8 | 0.885 | 0.747 | 0.762 | 0.889 | 0.774 | 0.747 | 0.533 |
| knn | none | none | 0.787 | 0.877 | 0.783 | 0.777 | 0.697 | 0.851 | 0.783 | 0.767 |
| mlp | embed_lgbm | lgbm | 0.775 | 0.97 | 0.7 | 0.709 | 1 | 0.735 | 0.7 | 0.4 |
| mlp | none | none | 0.775 | 0.896 | 0.783 | 0.769 | 0.662 | 0.872 | 0.783 | 0.817 |
| mlp | embed_linear | linear | 0.762 | 0.852 | 0.777 | 0.758 | 0.641 | 0.878 | 0.777 | 0.833 |
| lr | none | none | 0.738 | 0.865 | 0.67 | 0.675 | 0.8 | 0.723 | 0.67 | 0.4 |
| lr | assoc | none | 0.738 | 0.865 | 0.67 | 0.675 | 0.8 | 0.723 | 0.67 | 0.4 |
| lr | embed_linear | linear | 0.719 | 0.866 | 0.645 | 0.645 | 0.778 | 0.707 | 0.645 | 0.35 |
| sgd | assoc | none | 0.681 | 0.632 | 0.632 | 0.635 | 0.605 | 0.709 | 0.632 | 0.433 |
| sgd | embed_linear | linear | 0.681 | 0.635 | 0.635 | 0.639 | 0.6 | 0.713 | 0.635 | 0.45 |
| sgd | none | none | 0.662 | 0.79 | 0.603 | 0.603 | 0.579 | 0.689 | 0.603 | 0.367 |
| dummy | embed_lgbm | lgbm | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | wrap | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | pred | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | none | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | embed_linear | linear | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | assoc | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| Model | Selection | Embed_Selector | ACC | AUROC | BAL-ACC | F1 | NPV | PPV | Sens | Spec |
|---|---|---|---|---|---|---|---|---|---|---|
| sgd | wrap | none | 0.981 | 1 | 0.982 | 0.98 | 0.969 | 0.99 | 0.982 | 0.983 |
| lr | wrap | none | 0.981 | 1 | 0.982 | 0.98 | 0.969 | 0.99 | 0.982 | 0.983 |
| knn | wrap | none | 0.975 | 0.995 | 0.98 | 0.974 | 0.941 | 1 | 0.98 | 1 |
| lgbm | none | none | 0.975 | 0.998 | 0.97 | 0.973 | 0.985 | 0.972 | 0.97 | 0.95 |
| lgbm | assoc | none | 0.975 | 0.997 | 0.97 | 0.973 | 0.985 | 0.972 | 0.97 | 0.95 |
| lgbm | embed_lgbm | lgbm | 0.975 | 0.998 | 0.97 | 0.973 | 0.985 | 0.972 | 0.97 | 0.95 |
| lgbm | pred | none | 0.969 | 0.997 | 0.965 | 0.966 | 0.966 | 0.971 | 0.965 | 0.95 |
| lgbm | wrap | none | 0.963 | 0.996 | 0.963 | 0.96 | 0.938 | 0.981 | 0.963 | 0.967 |
| rf | assoc | none | 0.963 | 0.997 | 0.96 | 0.96 | 0.95 | 0.971 | 0.96 | 0.95 |
| rf | none | none | 0.956 | 0.996 | 0.958 | 0.954 | 0.922 | 0.981 | 0.958 | 0.967 |
| lr | pred | none | 0.956 | 0.997 | 0.958 | 0.954 | 0.922 | 0.981 | 0.958 | 0.967 |
| lgbm | embed_linear | linear | 0.956 | 0.992 | 0.955 | 0.953 | 0.938 | 0.971 | 0.955 | 0.95 |
| rf | wrap | none | 0.944 | 0.99 | 0.942 | 0.94 | 0.92 | 0.96 | 0.942 | 0.933 |
| knn | pred | none | 0.938 | 0.94 | 0.94 | 0.934 | 0.895 | 0.969 | 0.94 | 0.95 |
| rf | pred | none | 0.931 | 0.989 | 0.928 | 0.927 | 0.909 | 0.951 | 0.928 | 0.917 |
| rf | embed_linear | linear | 0.925 | 0.982 | 0.927 | 0.921 | 0.881 | 0.959 | 0.927 | 0.933 |
| rf | embed_lgbm | lgbm | 0.919 | 0.992 | 0.928 | 0.915 | 0.846 | 0.981 | 0.928 | 0.967 |
| lr | embed_lgbm | lgbm | 0.906 | 0.973 | 0.902 | 0.9 | 0.873 | 0.93 | 0.902 | 0.883 |
| sgd | pred | none | 0.9 | 0.922 | 0.893 | 0.894 | 0.882 | 0.92 | 0.893 | 0.867 |
| sgd | embed_lgbm | lgbm | 0.881 | 0.955 | 0.872 | 0.873 | 0.852 | 0.903 | 0.872 | 0.833 |
| knn | none | none | 0.844 | 0.945 | 0.872 | 0.842 | 0.73 | 0.988 | 0.872 | 0.983 |
| knn | embed_linear | linear | 0.844 | 0.95 | 0.838 | 0.834 | 0.789 | 0.89 | 0.838 | 0.817 |
| knn | embed_lgbm | lgbm | 0.831 | 0.924 | 0.835 | 0.825 | 0.765 | 0.903 | 0.835 | 0.85 |
| sgd | none | none | 0.806 | 0.875 | 0.795 | 0.794 | 0.746 | 0.85 | 0.795 | 0.75 |
| sgd | assoc | none | 0.794 | 0.785 | 0.785 | 0.782 | 0.725 | 0.845 | 0.785 | 0.75 |
| knn | assoc | none | 0.787 | 0.793 | 0.793 | 0.78 | 0.687 | 0.879 | 0.793 | 0.817 |
| sgd | embed_linear | linear | 0.781 | 0.762 | 0.762 | 0.764 | 0.728 | 0.815 | 0.762 | 0.683 |
| lr | none | none | 0.631 | 0.876 | 0.512 | 0.415 | 0.75 | 0.631 | 0.512 | 0.033 |
| lr | assoc | none | 0.631 | 0.876 | 0.512 | 0.415 | 0.75 | 0.631 | 0.512 | 0.033 |
| dummy | embed_lgbm | lgbm | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | wrap | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | pred | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | none | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | embed_linear | linear | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| dummy | assoc | none | 0.625 | 0.5 | 0.5 | 0.385 | nan | 0.625 | 0.5 | 0 |
| lr | embed_linear | linear | 0.619 | 0.872 | 0.495 | 0.382 | 0 | 0.623 | 0.495 | 0 |
| mlp | embed_lgbm | lgbm | 0.556 | 0.724 | 0.525 | 0.402 | 0.292 | 0.709 | 0.525 | 0.4 |
| mlp | pred | none | 0.537 | 0.813 | 0.543 | 0.4 | 0.435 | 0.702 | 0.543 | 0.567 |
| mlp | wrap | none | 0.525 | 0.736 | 0.5 | 0.34 | 0.375 | 0.625 | 0.5 | 0.4 |
| mlp | none | none | 0.475 | 0.619 | 0.5 | 0.317 | 0.375 | 0.625 | 0.5 | 0.6 |
| mlp | embed_linear | linear | 0.475 | 0.579 | 0.5 | 0.317 | 0.375 | 0.625 | 0.5 | 0.6 |
| mlp | assoc | none | 0.375 | 0.633 | 0.5 | 0.273 | 0.375 | nan | 0.5 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Figueroa, J.; Etim, P.; Shibu, A.K.; Berger, D.; Levman, J. Diagnosing and Characterizing Chronic Kidney Disease with Machine Learning: The Value of Clinical Patient Characteristics as Evidenced from an Open Dataset. Electronics 2024, 13, 4326. https://doi.org/10.3390/electronics13214326
Figueroa J, Etim P, Shibu AK, Berger D, Levman J. Diagnosing and Characterizing Chronic Kidney Disease with Machine Learning: The Value of Clinical Patient Characteristics as Evidenced from an Open Dataset. Electronics. 2024; 13(21):4326. https://doi.org/10.3390/electronics13214326
Chicago/Turabian StyleFigueroa, Juan, Patrick Etim, Adithyan Karanathu Shibu, Derek Berger, and Jacob Levman. 2024. "Diagnosing and Characterizing Chronic Kidney Disease with Machine Learning: The Value of Clinical Patient Characteristics as Evidenced from an Open Dataset" Electronics 13, no. 21: 4326. https://doi.org/10.3390/electronics13214326
APA StyleFigueroa, J., Etim, P., Shibu, A. K., Berger, D., & Levman, J. (2024). Diagnosing and Characterizing Chronic Kidney Disease with Machine Learning: The Value of Clinical Patient Characteristics as Evidenced from an Open Dataset. Electronics, 13(21), 4326. https://doi.org/10.3390/electronics13214326