




Advanced Anomaly Detection in Manufacturing Processes: Leveraging Feature Value Analysis for Normalizing Anomalous Data


Abstract
:1. Introduction
2. Related Works
2.1. Preliminary Research on Predicting Anomaly Data on the Factory Floor
2.2. Machine Learning Models
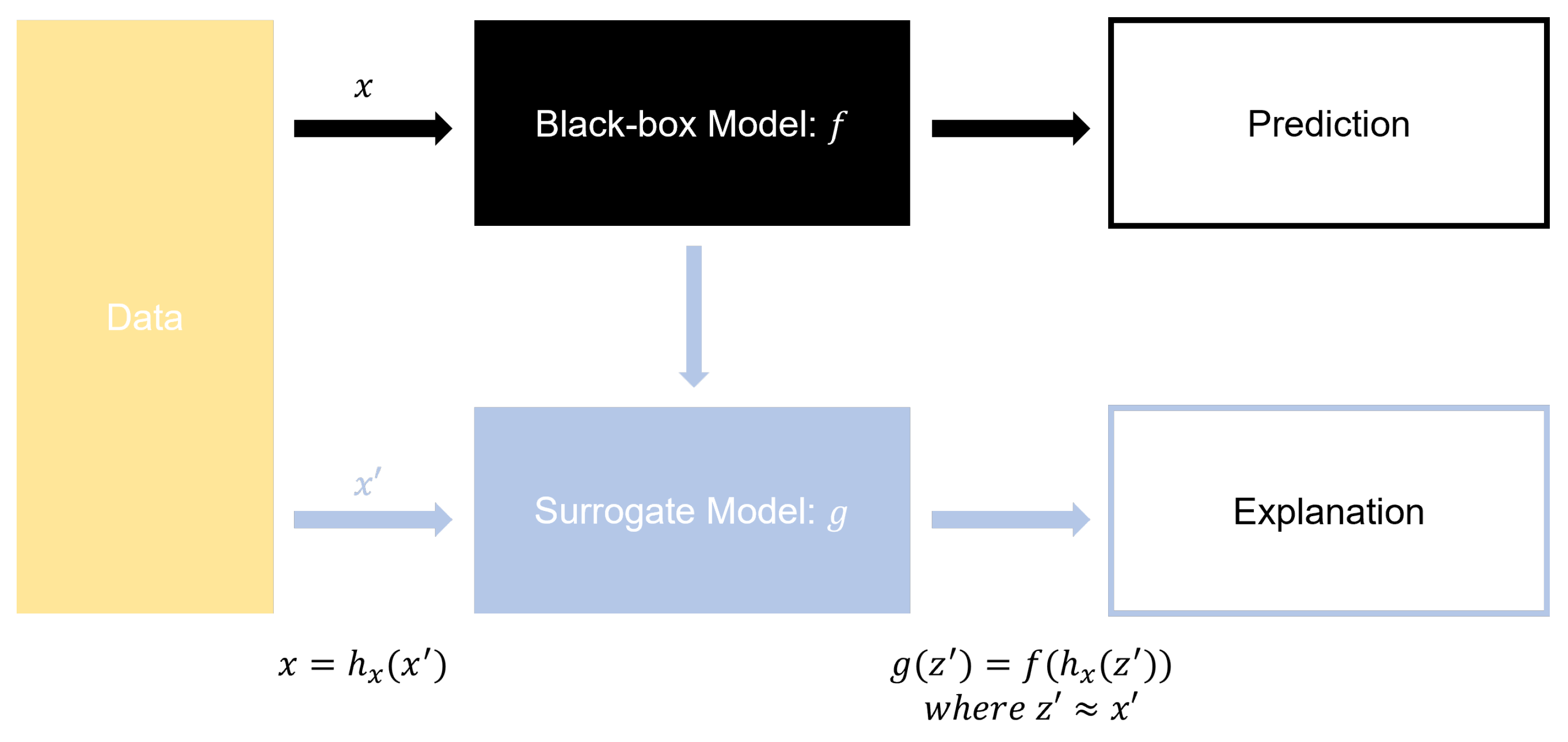
2.3. SHAP
3. Method
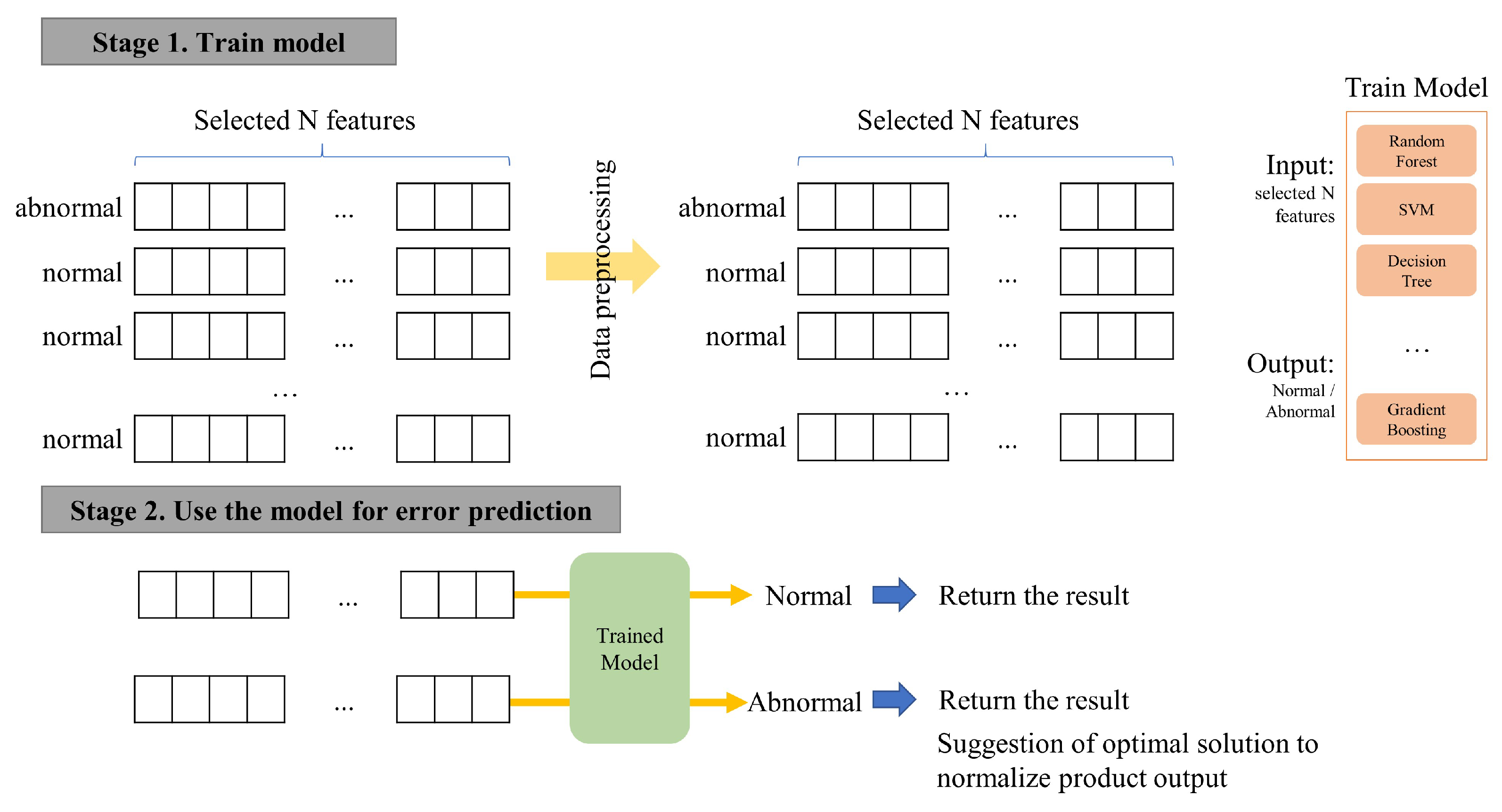
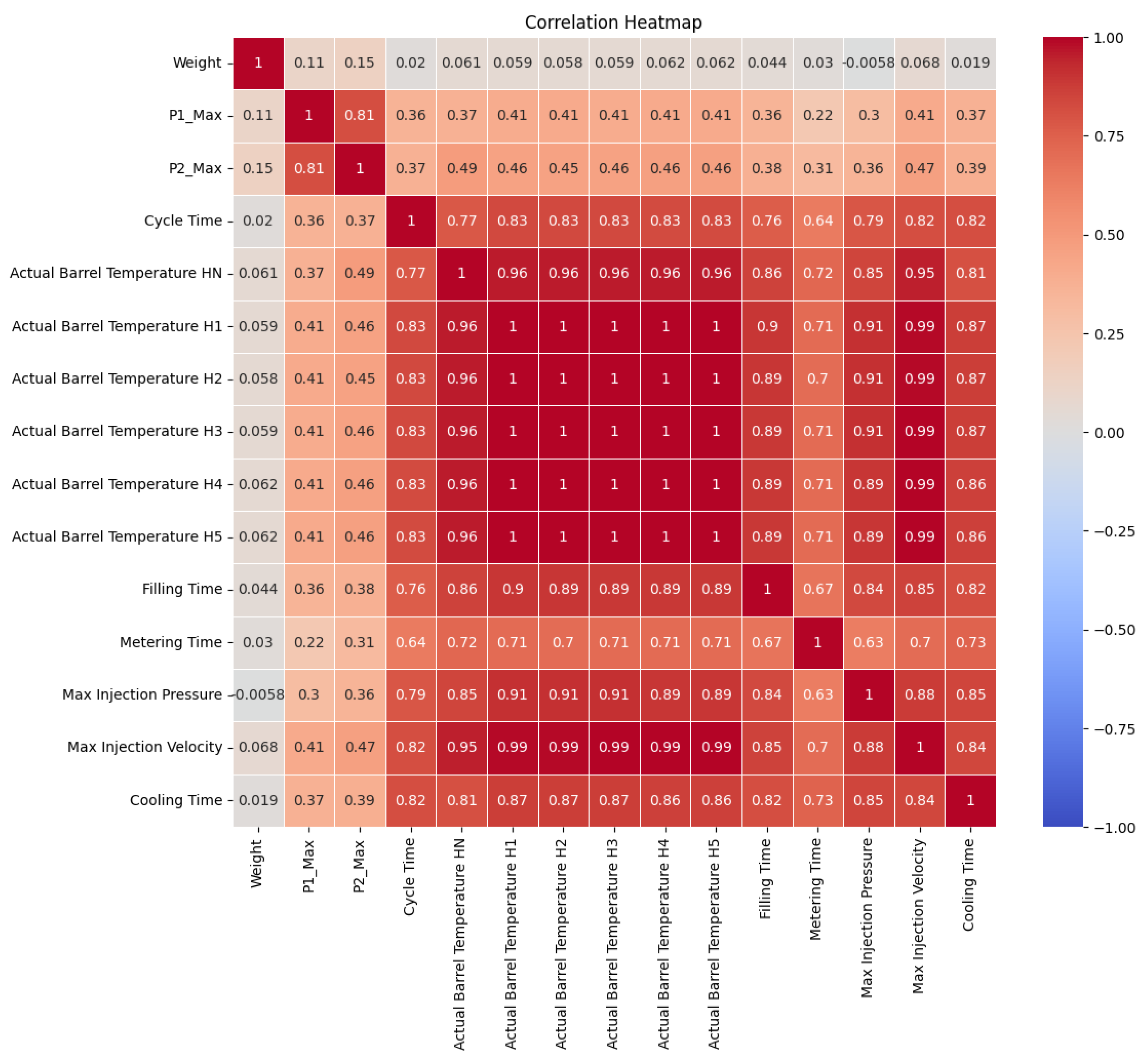
3.1. Data Preprocessing
3.2. Anomaly Detection Using Machine Learning Models
3.3. Finding the Optimal Solution for Abnormal Data
3.3.1. SHAP
3.3.2. Optimal Solution Presentation Using Mode
| Algorithm 1 Correct Features Based on Frequency |
|
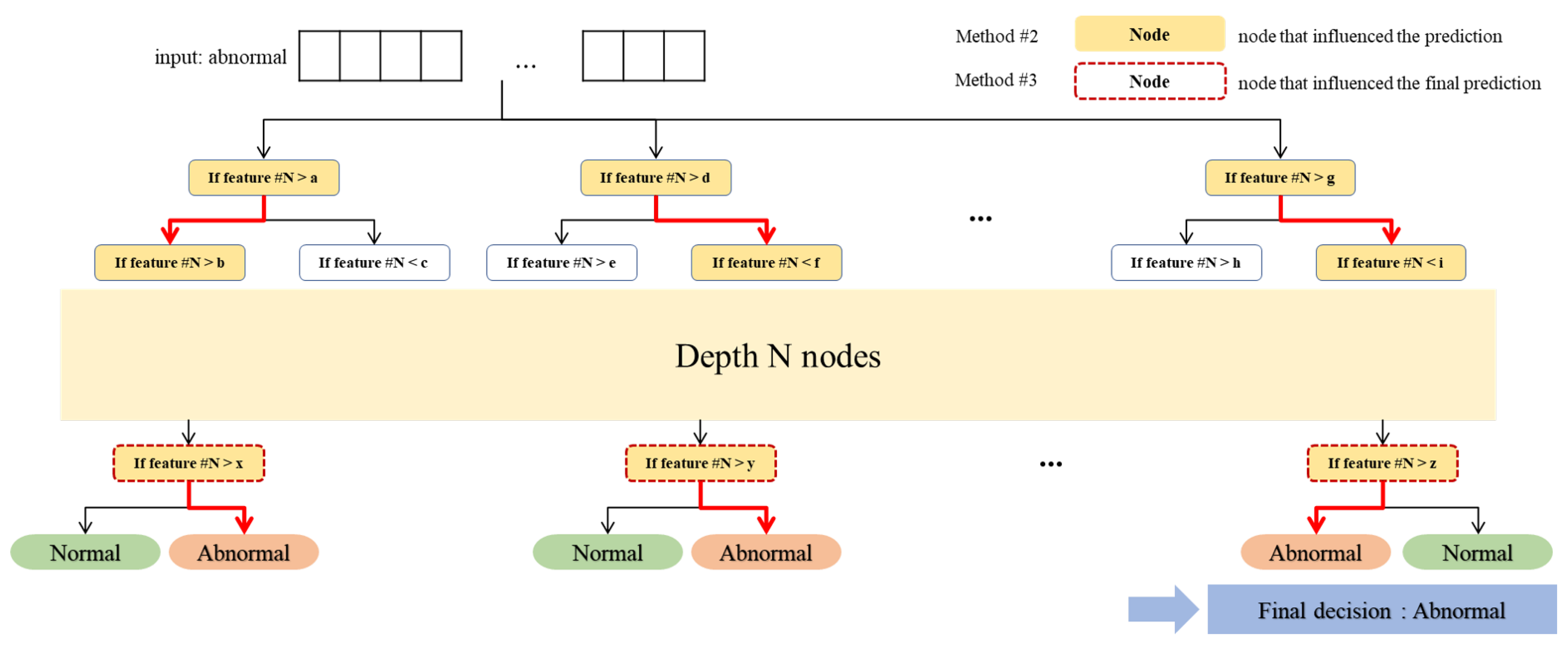
3.3.3. Optimization Using Conditions on Nodes
| Algorithm 2 Adjust Features for Normalization |
|
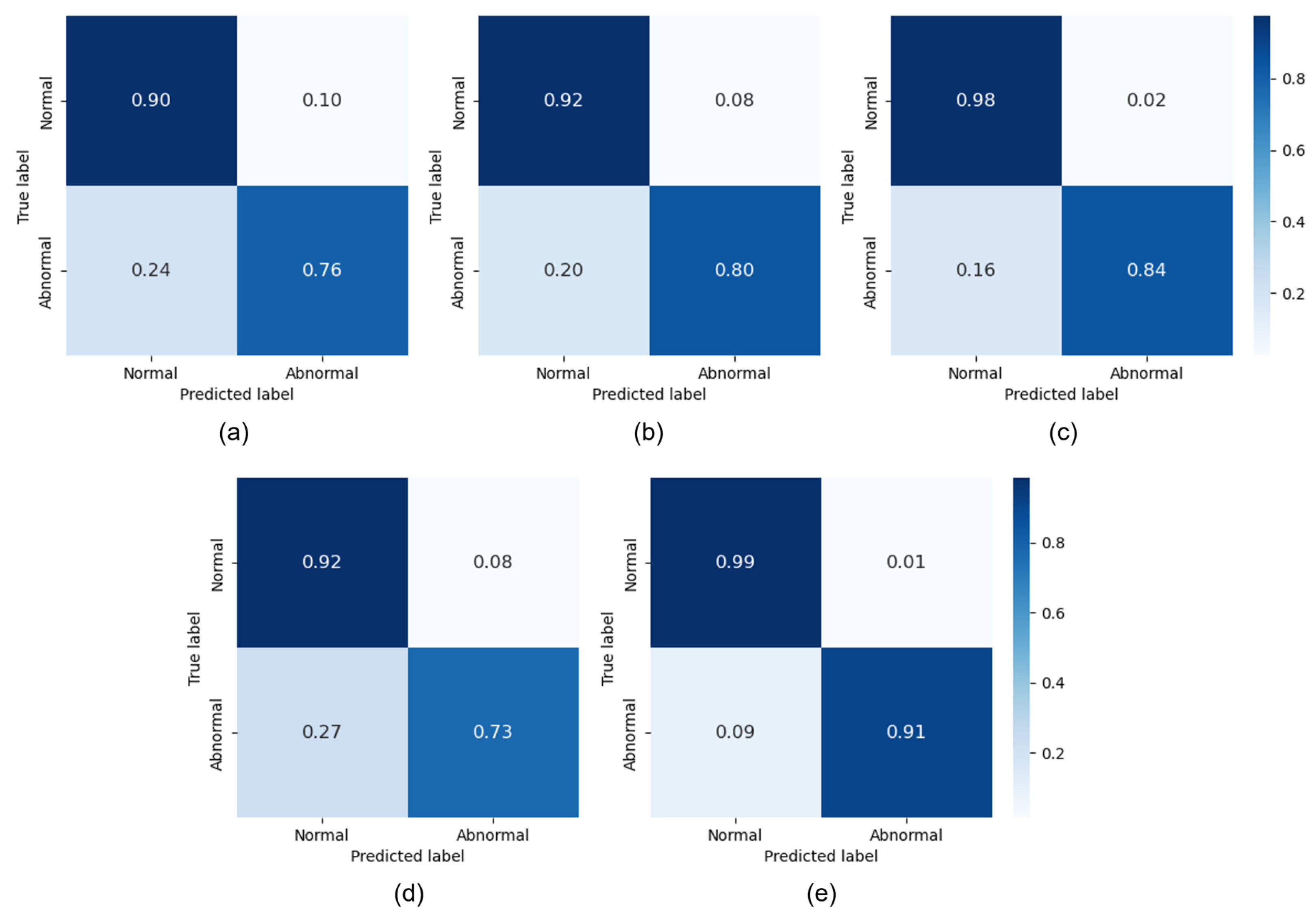
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Maklin, S. The Ultimate Guide to Plastic Injection Moulding Cost. Available online: https://medium.com/@maklin.si/the-ultimate-guide-to-plastic-injection-moulding-cost-fdf3e5c14760 (accessed on 2 March 2024).
- Mr, A.B.; Humbe, D.M.K. Optimization of Critical Processing Parameters Forplastic Injection Molding of Polypropylene for Enhancedproductivity and Reduced Time for New Productdevelopment. Int. J. Mech. Eng. Technol. (IJMET) 2013, 5, 108–115. [Google Scholar]
- Sofianidis, G.; Rožanec, J.M.; Mladenic, D.; Kyriazis, D. A review of explainable artificial intelligence in manufacturing. arXiv 2021, arXiv:2107.02295. [Google Scholar]
- Sheuly, S.S.; Ahmed, M.U.; Begum, S.; Osbakk, M. Explainable machine learning to improve assembly line automation. In Proceedings of the 2021 4th International Conference on Artificial Intelligence for Industries (AI4I), Laguna Hills, CA, USA, 20–22 September 2021; pp. 81–85. [Google Scholar]
- Wang, Y.; Bai, X.; Liu, C.; Tan, J. A multi-source data feature fusion and expert knowledge integration approach on lithium-ion battery anomaly detection. J. Electrochem. Energy Convers. Storage 2022, 19, 021003. [Google Scholar]
- Yeh, C.C.M.; Zhu, Y.; Dau, H.A.; Darvishzadeh, A.; Noskov, M.; Keogh, E. Online amnestic dtw to allow real-time golden batch monitoring. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2604–2612. [Google Scholar]
- Paul, K.C.; Schweizer, L.; Zhao, T.; Chen, C.; Wang, Y. Series AC arc fault detection using decision tree-based machine learning algorithm and raw current. In Proceedings of the 2022 IEEE Energy Conversion Congress and Exposition (ECCE), Detroit, MI, USA, 9–13 October 2022; pp. 1–8. [Google Scholar]
- Kariri, E.; Louati, H.; Louati, A.; Masmoudi, F. Exploring the advancements and future research directions of artificial neural networks: A text mining approach. Appl. Sci. 2023, 13, 3186. [Google Scholar] [CrossRef]
- Gupta, A.K.; Sharma, R.; Ojha, R.P. Video anomaly detection with spatio-temporal inspired deep neural networks (DNN). In Proceedings of the 2023 6th International Conference on Contemporary Computing and Informatics (IC3I), Uttar Pradesh, India, 14–16 September 2023; Volume 6, pp. 1112–1118. [Google Scholar]
- Fang, C.; Wang, Q.; Huang, B. A Machine Learning Approach for Anomaly Detection in Power Mixing Equipment Intelligent Bearing Fault Diagnosis. In Proceedings of the 2023 IEEE 3rd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 29–31 January 2023; pp. 912–919. [Google Scholar]
- Li, D.; Liu, Z.; Armaghani, D.J.; Xiao, P.; Zhou, J. Novel ensemble tree solution for rockburst prediction using deep forest. Mathematics 2022, 10, 787. [Google Scholar] [CrossRef]
- Aghaabbasi, M.; Ali, M.; Jasiński, M.; Leonowicz, Z.; Novák, T. On hyperparameter optimization of machine learning methods using a Bayesian optimization algorithm to predict work travel mode choice. IEEE Access 2023, 11, 19762–19774. [Google Scholar]
- Kramer, O.; Kramer, O. K-nearest neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar]
- Dinata, R.K.; Adek, R.T.; Hasdyna, N.; Retno, S. K-nearest neighbor classifier optimization using purity. In Proceedings of the AIP Conference Proceedings; AIP Publishing: Lhokseumawe, Aceh, Indonesia, 2023; Volume 2431. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar]
- Colledani, D.; Anselmi, P.; Robusto, E. Machine learning-decision tree classifiers in psychiatric assessment: An application to the diagnosis of major depressive disorder. Psychiatry Res. 2023, 322, 115127. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Shaheed, K.; Szczuko, P.; Abbas, Q.; Hussain, A.; Albathan, M. Computer-aided diagnosis of COVID-19 from chest x-ray images using hybrid-features and random forest classifier. Healthcare 2023, 11, 837. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Pagliaro, A. Forecasting Significant Stock Market Price Changes Using Machine Learning: Extra Trees Classifier Leads. Electronics 2023, 12, 4551. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Torky, M.; Gad, I.; Hassanien, A.E. Explainable AI model for recognizing financial crisis roots based on Pigeon optimization and gradient boosting model. Int. J. Comput. Intell. Syst. 2023, 16, 50. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Hassija, V.; Chamola, V.; Mahapatra, A.; Singal, A.; Goel, D.; Huang, K.; Scardapane, S.; Spinelli, I.; Mahmud, M.; Hussain, A. Interpreting black-box models: A review on explainable artificial intelligence. Cogn. Comput. 2024, 16, 45–74. [Google Scholar] [CrossRef]
- Mariotti, E.; Sivaprasad, A.; Moral, J.M.A. Beyond prediction similarity: ShapGAP for evaluating faithful surrogate models in XAI. In Proceedings of the World Conference on Explainable Artificial Intelligence, Lisbon, Portugal, 26–28 July 2023; pp. 160–173. [Google Scholar]
- Lundberg, S.M.; Erion, G.G.; Lee, S.I. Consistent individualized feature attribution for tree ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Celik, S.; Logsdon, B.; Lee, S.I. Efficient dimensionality reduction for high-dimensional network estimation. In Proceedings of the International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. 1953–1961. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Joloudari, J.H.; Marefat, A.; Nematollahi, M.A.; Oyelere, S.S.; Hussain, S. Effective class-imbalance learning based on SMOTE and convolutional neural networks. Appl. Sci. 2023, 13, 4006. [Google Scholar] [CrossRef]
- Umar, M.A.; Chen, Z.; Shuaib, K.; Liu, Y. Effects of feature selection and normalization on network intrusion detection. Authorea Prepr. 2024. [Google Scholar] [CrossRef]
- Inyang, U.G.; Ijebu, F.F.; Osang, F.B.; Afolorunso, A.A.; Udoh, S.S.; Eyoh, I.J. A Dataset-Driven Parameter Tuning Approach for Enhanced K-Nearest Neighbour Algorithm Performance. Int. J. Adv. Sci. Eng. Inf. Technol. 2023, 13, 380–391. [Google Scholar] [CrossRef]
- Patange, A.D.; Pardeshi, S.S.; Jegadeeshwaran, R.; Zarkar, A.; Verma, K. Augmentation of decision tree model through hyper-parameters tuning for monitoring of cutting tool faults based on vibration signatures. J. Vib. Eng. Technol. 2023, 11, 3759–3777. [Google Scholar] [CrossRef]
- Yang, D.; Xu, P.; Zaman, A.; Alomayri, T.; Houda, M.; Alaskar, A.; Javed, M.F. Compressive strength prediction of concrete blended with carbon nanotubes using gene expression programming and random forest: Hyper-tuning and optimization. J. Mater. Res. Technol. 2023, 24, 7198–7218. [Google Scholar] [CrossRef]
- Talukder, M.S.H.; Akter, S. An improved ensemble model of hyper parameter tuned ML algorithms for fetal health prediction. Int. J. Inf. Technol. 2024, 16, 1831–1840. [Google Scholar] [CrossRef]
- Abbas, M.A.; Al-Mudhafar, W.J.; Wood, D.A. Improving permeability prediction in carbonate reservoirs through gradient boosting hyperparameter tuning. Earth Sci. Inform. 2023, 16, 3417–3432. [Google Scholar] [CrossRef]
- Shekar, B.; Dagnew, G. Grid search-based hyperparameter tuning and classification of microarray cancer data. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; pp. 1–8. [Google Scholar]
- Zhang, X.; Liu, C.A. Model averaging prediction by K-fold cross-validation. J. Econom. 2023, 235, 280–301. [Google Scholar] [CrossRef]
- Du, S.; Wang, K.; Cao, Z. Bpr-net: Balancing precision and recall for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Y.; Shi, X.; Almpanidis, G.; Fan, G.; Shen, X. On incremental learning for gradient boosting decision trees. Neural Process. Lett. 2019, 50, 957–987. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | Max | Min | Std | |
|---|---|---|---|---|
| P1_Max | 184.4 | 253.1 | 0.3 | 14.5 |
| P2_Max | 326.4 | 400.3 | 0.2 | 20.7 |
| Cycle Time | 49.8 | 100 | 0 | 6.2 |
| Actual Barrel Temperature HN | 202,2 | 257.9 | 0 | 21.7 |
| Actual Barrel Temperature H1 | 207.9 | 230.3 | 0 | 21.4 |
| Actual Barrel Temperature H2 | 213.1 | 230.3 | 0 | 21.9 |
| Actual Barrel Temperature H3 | 222.6 | 225.8 | 0 | 22.9 |
| Actual Barrel Temperature H4 | 217.5 | 221.6 | 0 | 22.4 |
| Actual Barrel Temperature H5 | 207.6 | 212.1 | 0 | 21.4 |
| Filling Time | 0.9 | 6.1 | 0 | 0.1 |
| Metering Time | 17.1 | 41.8 | 0 | 2.5 |
| Max Injection Pressure | 93.2 | 132.2 | 0 | 10.5 |
| Max Injection Velocity | 107.4 | 118.2 | 0 | 11.1 |
| Cooling Time | 18.1 | 32 | 0 | 2.1 |
| Model | Parameters | |||
|---|---|---|---|---|
| n_neighbors | n_estimators | max_depth | learning_rate | |
| K Neighbors Classifier | 5 | - | - | - |
| Decision Tree Classifier | - | - | 11 | - |
| Random Forest Classifier | - | 20 | 13 | - |
| Extra Trees Classifier | - | 15 | 17 | - |
| Gradient Boosting Classifier | - | 25 | 11 | 0.1 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| K-Nearest Neighbors Classifier | 82.94% | 0.8869 | 0.7551 | 0.8157 |
| Decision Tree Classifier | 85.88% | 0.9110 | 0.7952 | 0.8492 |
| Random Forest Classifier | 90.73% | 0.9724 | 0.8384 | 0.9004 |
| Extra Trees Classifier | 82.50% | 0.8970 | 0.7343 | 0.8075 |
| Gradient Boosting Classifier | 94.80% | 0.9851 | 0.9097 | 0.9459 |
| Method | Explanation | Rate of Anomaly Data Normalization |
|---|---|---|
| Method #1 | SHAP + feature mean | 97.30% |
| Method #2 | Most frequent feature + feature mean | 97.30% |
| Method #3 | Last node feature + last node condition | 100.00% |
| Sample | Method | Feature | Value |
|---|---|---|---|
| Sample 1 | Method #1 | P2_Max | −20.2260 |
| Max Injection Pressure | 3.1238 | ||
| Max Injection Velocity | 0.1854 | ||
| Method #2 | P2_Max | −20.2260 | |
| Max Injection Pressure | 3.1238 | ||
| Cycle Time | 0.8976 | ||
| Method #3 | Cycle Time | 20.2875 | |
| Metering Time | 5.5550 | ||
| Max Injection Pressure | 3.4275 | ||
| Sample 2 | Method #1 | P2_Max | −19.5260 |
| Max Injection Pressure | 3.2238 | ||
| Actual Barrel Temperature H5 | −0.0064 | ||
| Method #2 | P2_Max | −19.5260 | |
| Max Injection Pressure | 3.2238 | ||
| Cycle Time | 1.0976 | ||
| Method #3 | Cycle Time | 20.4895 | |
| Max Injection Pressure | 3.5285 | ||
| - | - |
| Method | Explanation | Rate of Anomaly Data Normalization |
|---|---|---|
| Method #1 | SHAP + feature mean | 99.32% |
| Method #2 | Most frequent feature + feature mean | 86.59% |
| Method #3 | Last node feature + last node condition | 80.49% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Seo, H.; Lee, E.C. Advanced Anomaly Detection in Manufacturing Processes: Leveraging Feature Value Analysis for Normalizing Anomalous Data. Electronics 2024, 13, 1384. https://doi.org/10.3390/electronics13071384
Kim S, Seo H, Lee EC. Advanced Anomaly Detection in Manufacturing Processes: Leveraging Feature Value Analysis for Normalizing Anomalous Data. Electronics. 2024; 13(7):1384. https://doi.org/10.3390/electronics13071384
Chicago/Turabian StyleKim, Seunghyun, Hyunsoo Seo, and Eui Chul Lee. 2024. "Advanced Anomaly Detection in Manufacturing Processes: Leveraging Feature Value Analysis for Normalizing Anomalous Data" Electronics 13, no. 7: 1384. https://doi.org/10.3390/electronics13071384
APA StyleKim, S., Seo, H., & Lee, E. C. (2024). Advanced Anomaly Detection in Manufacturing Processes: Leveraging Feature Value Analysis for Normalizing Anomalous Data. Electronics, 13(7), 1384. https://doi.org/10.3390/electronics13071384