
Research on Mobile Phone Backplane Defect Segmentation Based on MDAF-UNet

Abstract
:1. Introduction
- (1)
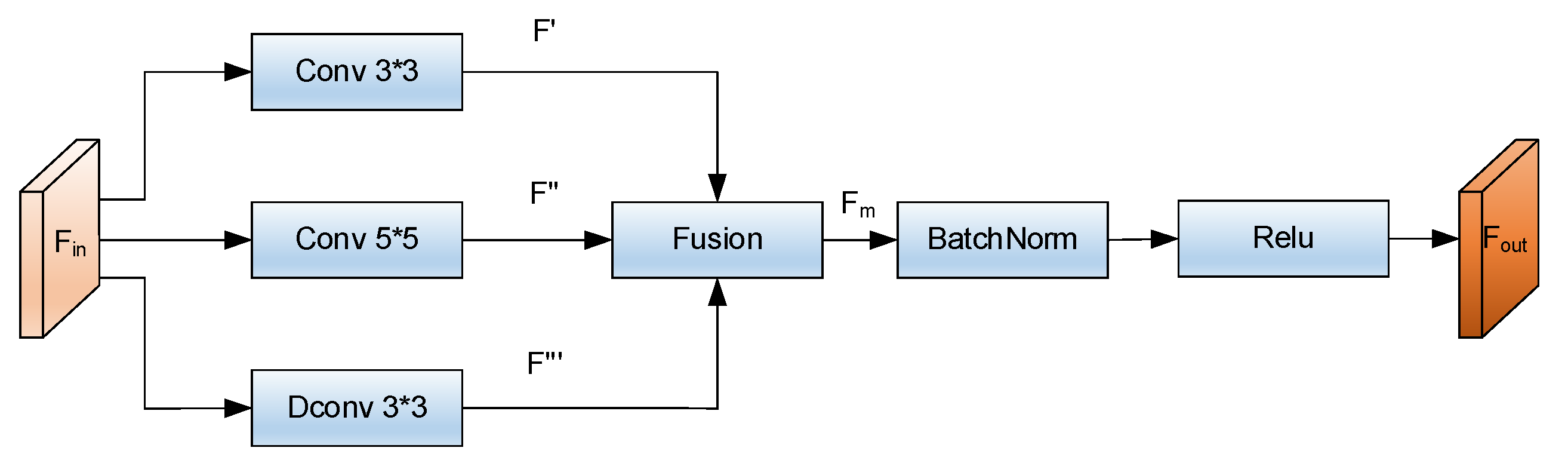
- An innovative multi-scale fusion technique is proposed, which can effectively recognize defects at different scales. The technique utilizes normal and dilated convolutions to enable the model to capture not only the subtle features of defects, but also a wider range of feature variations.
- (2)
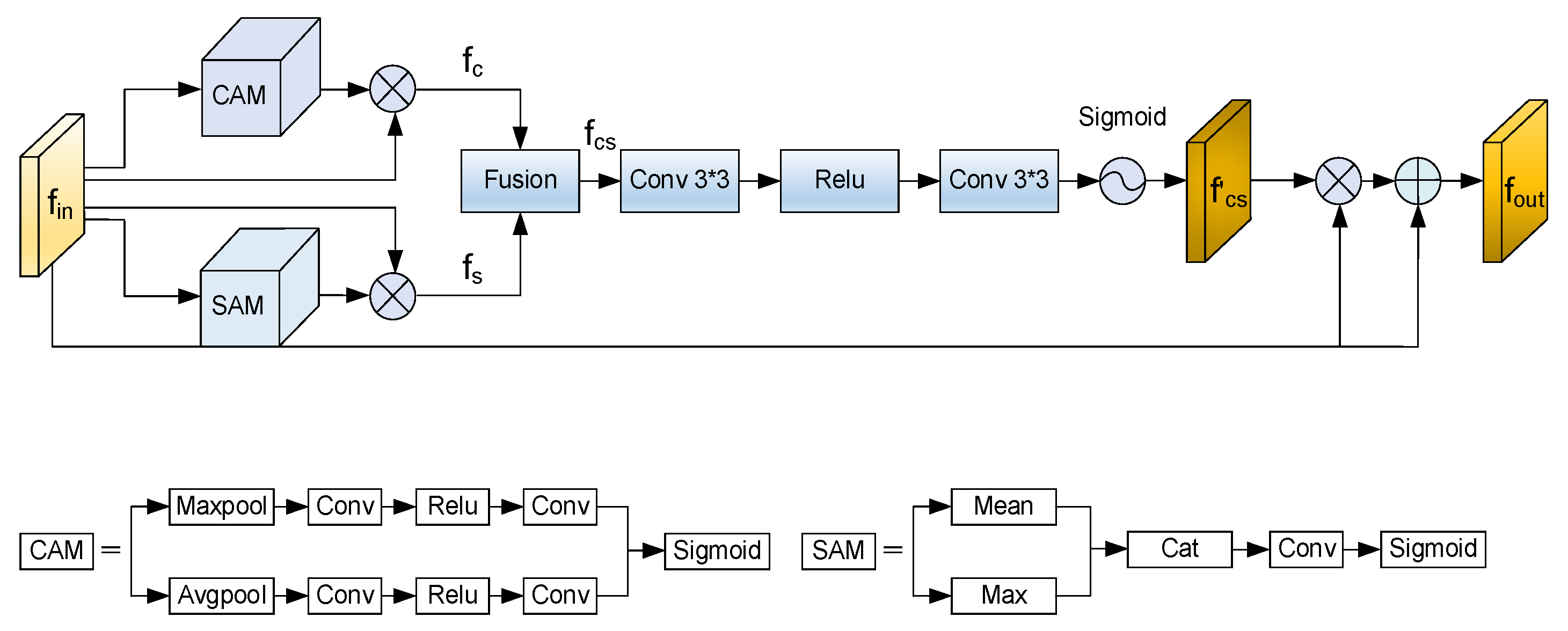
- An improved attention mechanism is proposed. A fusion module is introduced after channel attention and spatial attention to generate the final attention feature map. Additionally, by introducing learnable weights, the model combines the original features with the fused attention features dynamically, further enhancing the feature representation.
- (3)
- The proposed model has been validated on a public dataset, and the results show that the improved module enhances UNet’s segmentation effect. Compared with the existing algorithms, the MDAF-UNet model demonstrates significant advantages in performance.
2. Related Work
3. Methodology
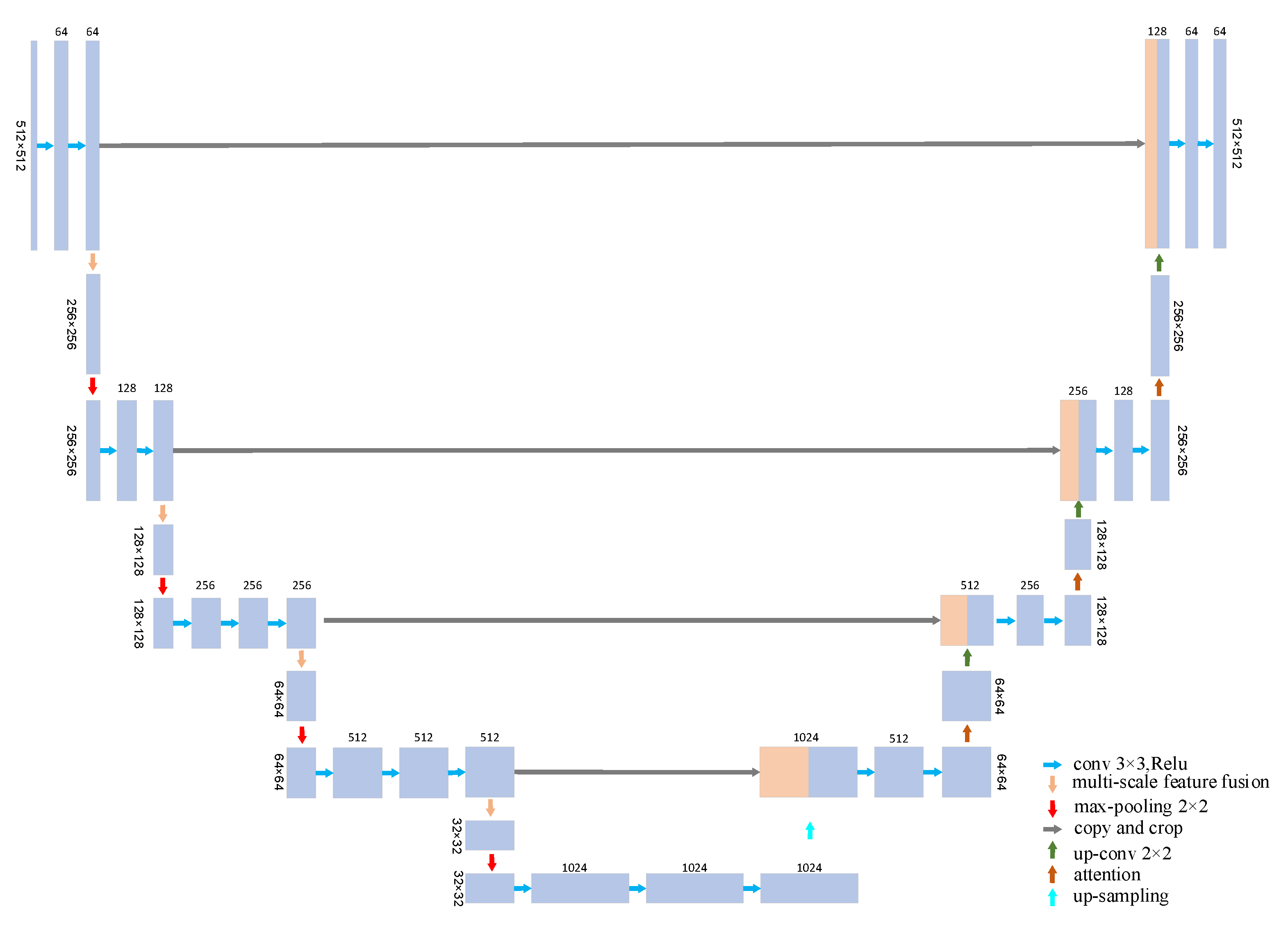
3.1. Model Structure
3.2. Multi-Scale Fusion Module
3.3. Attention Mechanism Module
4. Experimental Setup and Evaluation Indicators
4.1. Dataset
4.2. Experiment Details
4.3. Evaluation Indicators
5. Experiments and Results
5.1. Backbone Network Comparison Experiments
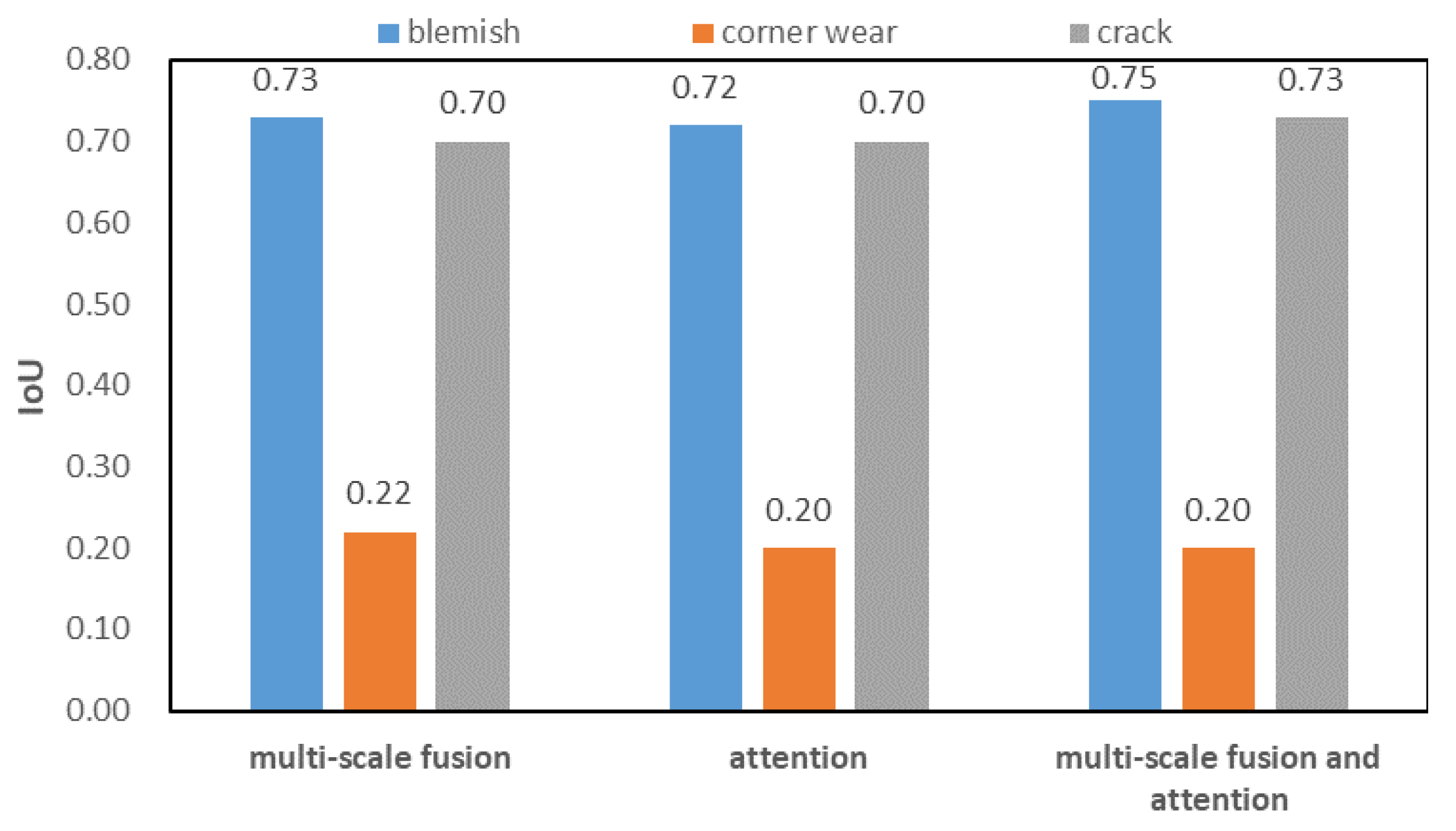
5.2. Ablation Experiments
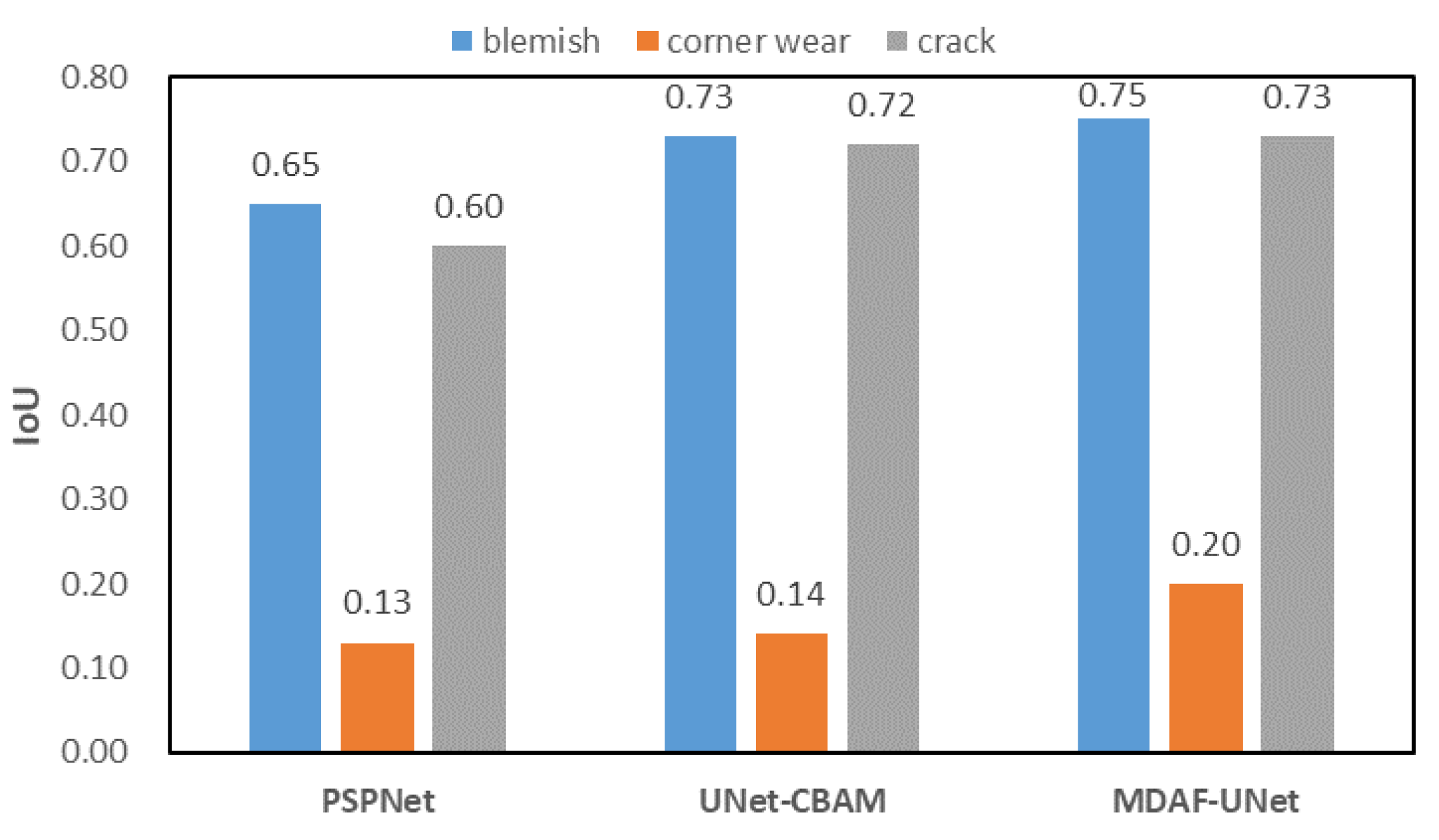
5.3. Comparison Experiments
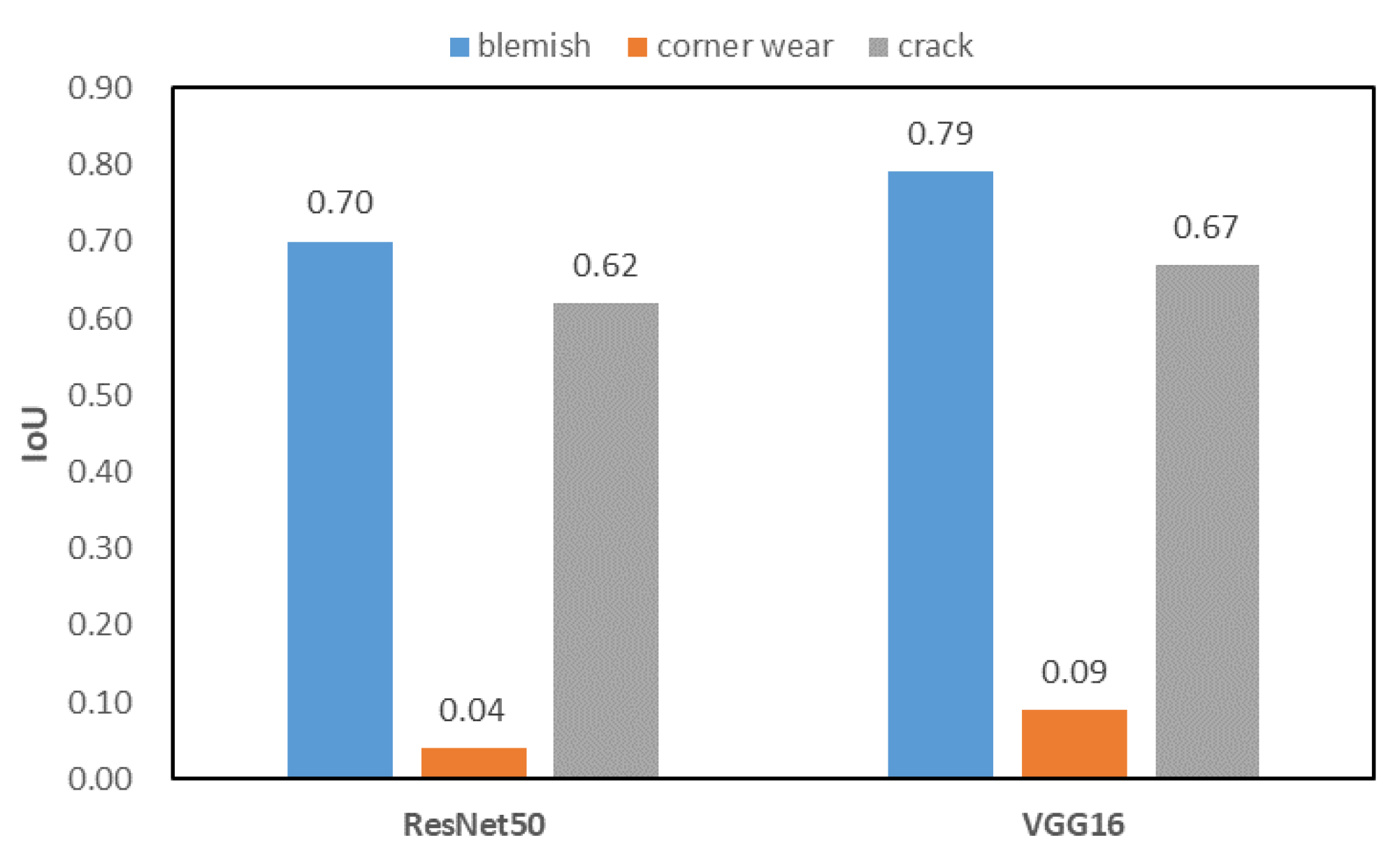
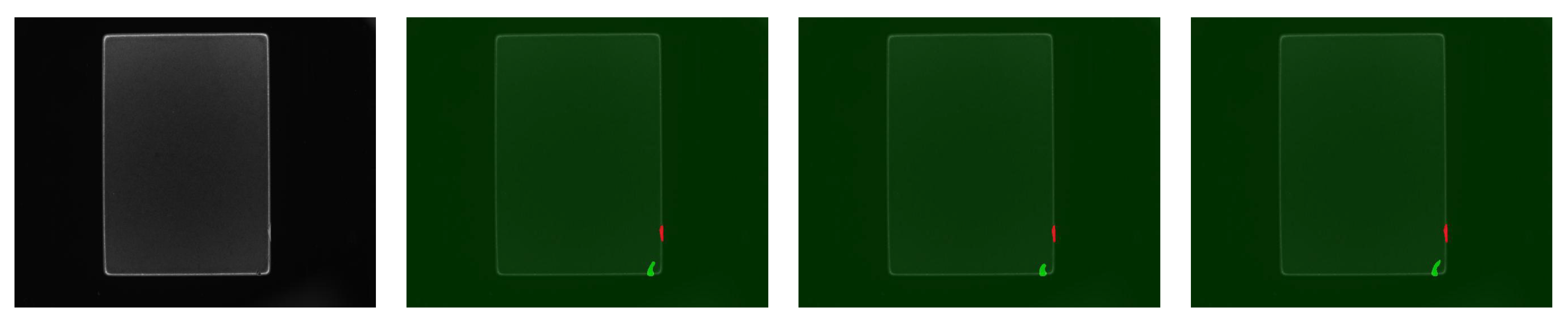
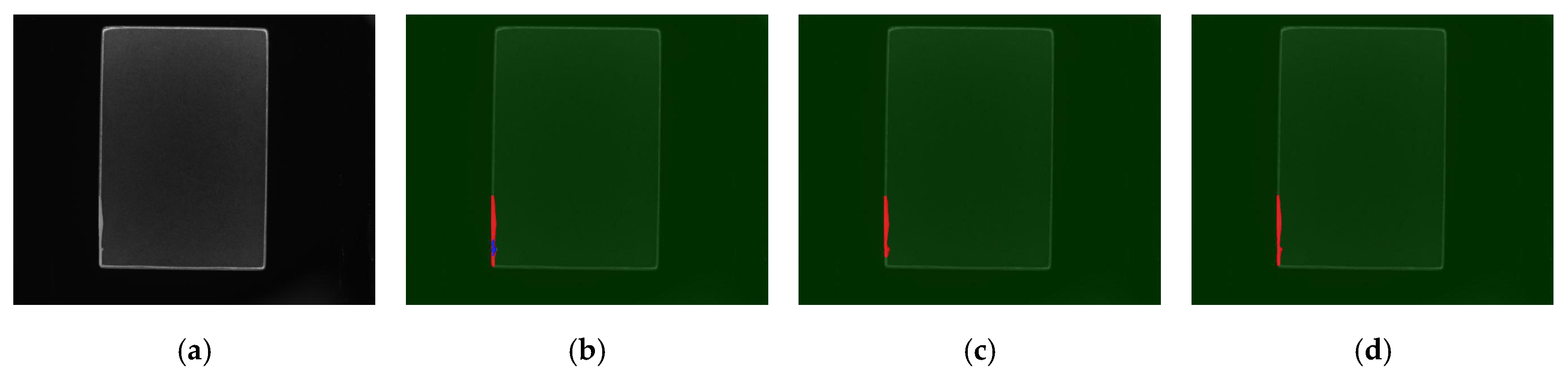
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using deep learning to detect defects in manufacturing: A comprehensive survey and current challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Ding, Y.; Zhao, F.; Zhang, E.; Wu, Z.; Shao, L. Surface defect detection methods for industrial products: A review. Appl. Sci. 2021, 11, 7657. [Google Scholar] [CrossRef]
- Tabernik, D.; Šela, S.; Skvarč, J.; Skočaj, D. Segmentation-based deep-learning approach for surface-defect detection. J. Intell. Manuf. 2020, 31, 759–776. [Google Scholar] [CrossRef]
- Liang, Y.; Xu, K.; Zhou, P. Mask gradient response-based threshold segmentation for surface defect detection of milled aluminum ingot. Sensors 2020, 20, 4519. [Google Scholar] [CrossRef] [PubMed]
- Ni, X.; Liu, H.; Wang, C.; Liu, J. Detection for rail surface defects via partitioned edge feature. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5806–5822. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, Y.; Yang, S.; Xiang, Z. A method of blasted rock image segmentation based on improved watershed algorithm. Sci. Rep. 2022, 12, 7143. [Google Scholar] [CrossRef] [PubMed]
- Qin, J.; Pan, W.; Xiang, X.; Tan, Y.; Hou, G. A biological image classification method based on improved CNN. Ecol. Informa. 2020, 58, 101093. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. Evolution of image segmentation using deep convolutional neural network: A survey. Knowl.-Based Syst. 2020, 201, 106062. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sun, X.; Li, J.; Ma, J.; Xu, H.; Chen, B.; Zhang, Y.; Feng, T. Segmentation of overlapping chromosome images using U-Net with improved dilated convolutions. J. Intell. Fuzzy Syst. 2021; 40, 5653–5668. [Google Scholar]
- Wu, H.; Zhao, Z.; Wang, Z. META-Unet: Multi-scale efficient transformer attention Unet for fast and high-accuracy polyp segmentation. IEEE Trans. Autom. Sci. Eng. 2023. [Google Scholar] [CrossRef]
- Maji, D.; Sigedar, P.; Singh, M. Attention Res-UNet with Guided Decoder for semantic segmentation of brain tumors. Biomed. Signal Process. Control 2022, 71, 103077. [Google Scholar] [CrossRef]
- Cao, G.; Ruan, S.; Peng, Y.; Huang, S.; Kwok, N. Large-complex-surface defect detection by hybrid gradient threshold segmentation and image registration. IEEE Access 2018, 6, 36235–36246. [Google Scholar] [CrossRef]
- Yang, Y.; Zhao, X.; Huang, M.; Wang, X.; Zhu, Q. Multispectral image based germination detection of potato by using supervised multiple threshold segmentation model and Canny edge detector. Comput. Electron. Agric. 2021, 182, 106041. [Google Scholar] [CrossRef]
- Meiju, L.; Rui, Z.; Xifeng, G.; Junrui, Z. Application of improved Otsu threshold segmentation algorithm in mobile phone screen defect detection. In Proceedings of the 2020 Chinese Dontrol and Decision Conference CCDC, Hefei, China, 22–24 August 2020; pp. 4919–4924. [Google Scholar]
- Xu, Y.; Li, D.; Xie, Q.; Wu, Q.; Wang, J. Automatic defect detection and segmentation of tunnel surface using modified Mask R-CNN. Measurement 2021, 178, 109316. [Google Scholar] [CrossRef]
- Cao, J.; Yang, G.; Yang, X. A pixel-level segmentation convolutional neural network based on deep feature fusion for surface defect detection. IEEE Trans. Instrum. Meas. 2020, 70, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Li, J. An end-to-end defect detection method for mobile phone light guide plate via multitask learning. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Song, Y.; Xia, W.; Li, Y.; Li, H.; Yuan, M.; Zhang, Q. AnomalySeg: Deep Learning-Based Fast Anomaly Segmentation Approach for Surface Defect Detection. Electronics 2024, 13, 284. [Google Scholar] [CrossRef]
- Jiang, J.; Cao, P.; Lu, Z.; Lou, W.; Yang, Y. Surface defect detection for mobile phone back glass based on symmetric convolutional neural network deep learning. Appl. Sci. 2020, 10, 3621. [Google Scholar] [CrossRef]
- Mao, J.; Xu, G.; He, L.; Luo, J. Attention-relation network for mobile phone screen defect classification via a few samples. Digit. Commun. Netw. 2023. In Press. [Google Scholar] [CrossRef]
- Pan, J.; Zeng, D.; Tan, Q.; Wu, Z.; Ren, Z. EU-Net: A novel semantic segmentation architecture for surface defect detection of mobile phone screens. IET Image Process. 2022, 16, 2568–2576. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. SA-UNet: Spatial attention U-Net for retinal vessel segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Lu, P.; Jing, J.; Huang, Y. MRD-net: An effective CNN-based segmentation network for surface defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Zhu, Y.; Ding, R.; Huang, W.; Wei, P.; Yang, G.; Wang, Y. HMFCA-Net: Hierarchical multi-frequency based Channel attention net for mobile phone surface defect detection. Pattern Recognit. Lett. 2022, 153, 118–125. [Google Scholar] [CrossRef]
- Moreno-Torres, J.G.; Sáez, J.A.; Herrera, F. Study on the impact of partition-induced dataset shift on $ k $-fold cross-validation. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1304–1312. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Module | MIoU (%) | Precision (%) | Recall (%) | |
|---|---|---|---|---|---|
| VGG16 | ResNet50 | ||||
| UNet | ✓ | 63.7 | 78.2 | 70.0 | |
| ✓ | 58.9 | 69.4 | 65.4 | ||
| Model | Module | MIoU (%) | Precision (%) | Recall (%) | |
|---|---|---|---|---|---|
| Multi-Scale | Attention | ||||
| UNet | 63.7 | 78.2 | 70.0 | ||
| ✓ | 66.1 | 77.9 | 73.4 | ||
| ✓ | 65.5 | 76.8 | 74.0 | ||
| ✓ | ✓ | 66.9 | 78.6 | 74.3 | |
| Model | MIoU (%) | Precision (%) | Recall (%) |
|---|---|---|---|
| PSPNet [29] | 59.4 | 76.9 | 72.2 |
| UNet-CBAM | 64.7 | 75.0 | 72.7 |
| MDAF-UNet | 66.9 | 78.6 | 74.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Min, B.-W. Research on Mobile Phone Backplane Defect Segmentation Based on MDAF-UNet. Electronics 2024, 13, 1385. https://doi.org/10.3390/electronics13071385
Chen H, Min B-W. Research on Mobile Phone Backplane Defect Segmentation Based on MDAF-UNet. Electronics. 2024; 13(7):1385. https://doi.org/10.3390/electronics13071385
Chicago/Turabian StyleChen, Hao, and Byung-Won Min. 2024. "Research on Mobile Phone Backplane Defect Segmentation Based on MDAF-UNet" Electronics 13, no. 7: 1385. https://doi.org/10.3390/electronics13071385
APA StyleChen, H., & Min, B.-W. (2024). Research on Mobile Phone Backplane Defect Segmentation Based on MDAF-UNet. Electronics, 13(7), 1385. https://doi.org/10.3390/electronics13071385