1. Introduction
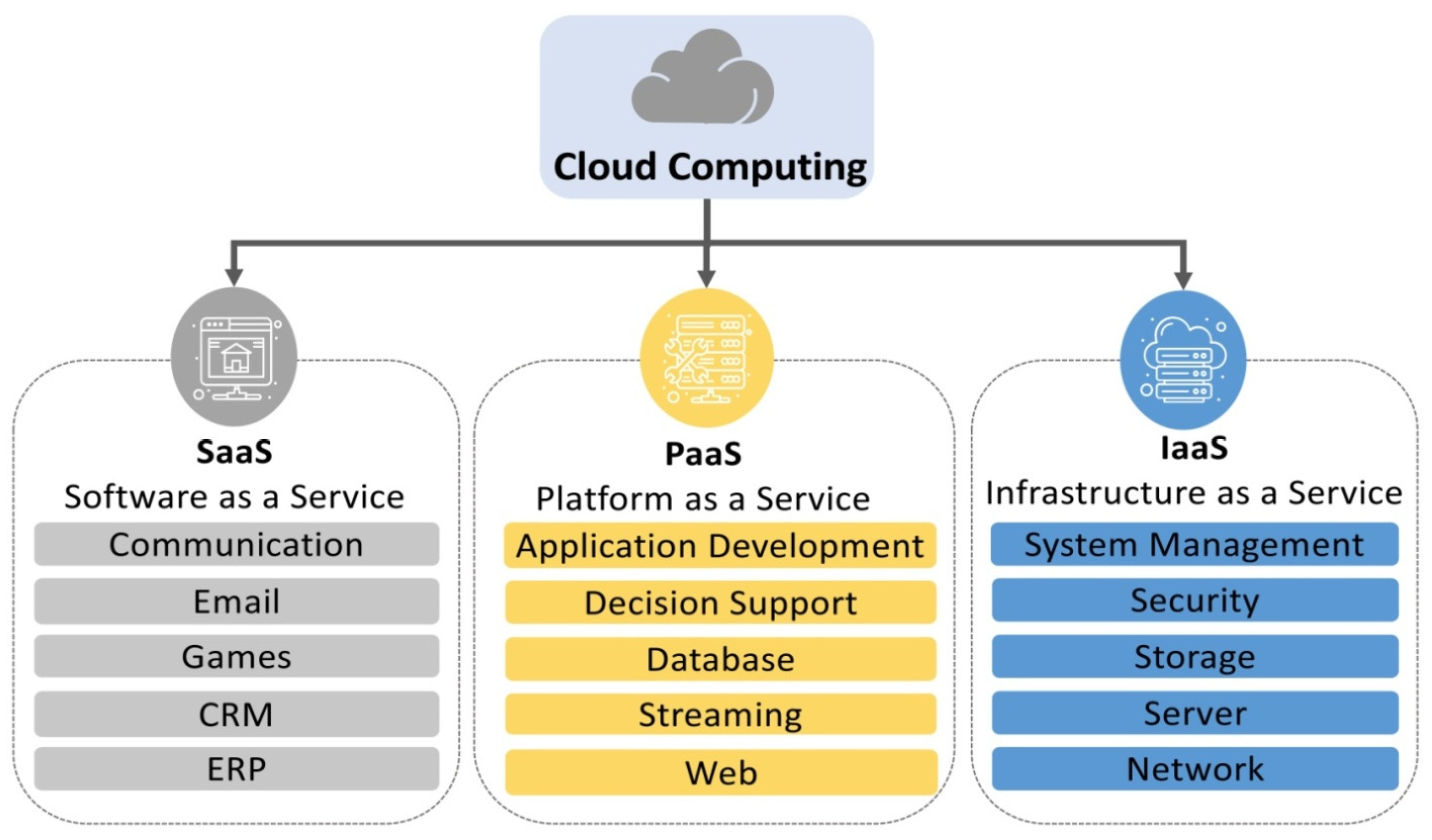
Cloud computing is an increasingly common prototype for accessing computational resources. Cloud service providers primarily offer three service models: software as a service, platform as a service, and infrastructure as a service [
1]. In addition to an interface allowing users to access their virtualized resources, it comprises computing power, networking, and storage.
Figure 1 shows the basic categories mentioned above for cloud services. According to Kelkar [
2], implementing cloud computing involves several challenges, including carefully managed service-level agreements, confidentiality, integrity, and availability. Therefore, it is not easy to implement recommendation services for cloud computing, especially when cloud service providers have new users and no prior information about their preferences in the database [
3]. Although many cloud services are available, developing a recommendation system based on quality of service (QoS) is tedious, and establishing trustworthiness is not simple. It is also challenging for cloud service providers to offer new cloud users expectations that align with their complex demands.
Mohamed et al. [
4] provide a detailed survey of recommendation systems, approaches, and problems. As well known, collaborative filtering (CF), content-based filtering, and hybrid filtering (a combination of CF and content-based filtering) are the three major types of recommendation systems. One of the critical drawbacks of many approaches is due to the cold start problem, which occurs because of the need for more data on new entries and robustly affects precision [
5,
6]. However, the cold start problem cannot be effectively solved using content-based methods and CF, which are the traditional approaches of recommender systems [
7]. For cloud service recommendations, the data sparsity challenge is rising due to the partial ratings provided by existing cloud customers and the various troubles encountered in obtaining the required information [
8]. Some strategies for handling this issue are provided by integrating neural networks into recommender systems. The accuracy of suggestions and predictions has risen regardless of whether more profound learning algorithms with more layers or the ability to retrieve hidden data are used [
7]. The cold start problem, which is due to insufficient data on new customers, purchase history, and browsing behavior, and the data sparsity issue, potentially led by the interactions among a small number of elements, are two major concerns for the design of recommendation systems. These problems negatively affect the suggestion and significantly reduce the variety of options on the specific platform. Many deep-learning (DL) algorithms have already been proposed to reduce the influence of data scarcity. Some studies discuss prediction ratings based on prior knowledge gained from the service ratings of existing cloud users. To improve the rating prediction, a deep autoencoder could extract the QoS latent representations from the input data [
9]. However, further improvement is possible using a hybrid deep-learning architecture with neural factorization and deep autoencoder (NFDA). The proposed framework incorporates auxiliary information to learn sparse data matrices via matrix factorization with neural network (NeuMF) [
10]. The QoS latent representations are extracted from the input data using the concatenation of two models to enhance rating prediction. Furthermore, we carefully structure a questionnaire from the literature review to handle cold start issues. We aim to alleviate the problem of data sparsity and cold start and refer a personalized recommendation list with
N service providers to the cloud users using asymmetrically weighted cosine similarity (AWCS). In summary, this paper makes the following contributions:
We design the hybrid DL cloud recommendation system and direct the coming old users to cloud service providers according to their preferences.
Applying the above system with explicit historical data for old cloud users and using survey data to provide suggestions for new ones or existing customers with no personal data at our hand.
Our solution performs better than other proposed models with enhanced personalized cloud service recommendations.
2. Literature Review
Several studies have been conducted to reduce the issues of cold starts and missing data. For example, the hybrid DL-based recommendation system efficiently addresses the cold start problem and data sparsity challenge. Berisha and Bytyçi [
7] have examined around 40 research papers that attempted to use neural networks to solve the cold start problem. They have studied the implementation of neural networks in recommender systems, how they are integrated into systems, which neural network algorithms are more efficient at dealing with the cold start problem, and which algorithms have improved recommendation accuracy. Zheng et al. [
11] recommended a CF process for the cloud service recommendation that uses Spearman’s coefficient. This method predicts the ratings and rankings of cloud services.
In [
12], the authors proposed a strategy for recommending cloud services based on learning and data mining approaches to improve user visibility. In addition, they suggest using this approach to study how various users interact with cloud services (consulting, using, unsubscribing, etc.) to specify user requirements in real time while accounting for changes in requirements over time. In [
13], association rules and clustering were used to address the issues of accuracy and sparsity for the suggested items. They addressed the cold start problem by employing the root-mean-square error to determine the standard of the rated songs.
An autoencoder is an artificial neural network used to learn an encoded representation of an input data set, and it is generally used to reduce data dimensionality [
9]. A feed-forward neural network in the form of an autoencoder has an input layer, a hidden layer, and an output layer. A deep autoencoder is an enhancement of the simple autoencoder. The extra hidden layers allow the autoencoder to recognize more difficult underlying patterns in the data mathematically. CF requires additional layers to handle increasingly complicated data. The NeuMF method [
10] is a CF technique used in recommender systems. CF algorithms estimate a user’s interests based on their previous activities or the behaviors of similar users. NeuMF divides the user–item interaction matrix into two lower dimensional matrices: user and item matrices. These matrices represent the latent factors or features contributing to a user’s interest in objects. According to Han et al. [
14], the cosine similarity index determines the two vectors’ similarities in the inner product space. The cosine of the angle formed by two vectors is used to determine whether or not they roughly point in the same direction. To calculate the cosine similarity between the two vectors, we first computed their dot product. The sum of the two vectors’ element-wise products is the dot product. Then, they divide the dot product by the product of the magnitudes of the two vectors. The square root of the sum of the squares of a vector’s elements determines its magnitude.
Pearson correlation and cosine similarity are two popular measurements of similarity. However, these metrics regard any resemblance between two users or products as equivalent. According to Mishra et al. [
15], the AWCS enables the same features in many vectors with varying weights. This implies that a given user may value “action” differently from another, and the similarity calculation takes these different feature weights into effect. To calculate the missing QoS values, CF has become a popular solution to the sparsity problem. Fu et al. [
16] presented a novel neighbor-based QoS prediction technique for service suggestions. In addition, the popularity of each stable or unstable candidate is determined by the closest graph method. A notion and computation technique is used to characterize the stable state of users and services with measurable QoS values.
Khan et al. [
17] discussed how DL-based techniques improve performance and create representations from scratch. With new studies verifying its usefulness, DL has also influenced the research of information recovery and recommender systems. A comprehensive overview of deep-learning-based rating prediction algorithms is presented in this article to assist new researchers interested in the field. A deep autoencoder is powerful for reducing the data dimensions. Bougteb et al. [
18] helped accurately fill in the missing data values. The autoencoder learns the user’s interest, reconstructs the user’s missing ratings, and then uses singular value decomposition (SVD)++ decomposition to hold information on correlation; it also provides a deep analysis of the top
N recommendation items.
Another study used the hybrid model to recommend cloud services; Sahu et al. [
19] anticipated an ensemble deep neural network, a hybrid of neighborhood and neural networks, to predict QoS values. Deep CF is essential when recommending web services. Xiong et al. [
20] addressed this by merging CF with textual content; furthermore, researchers offer a novel hybrid deep learning strategy for web service recommendation. A deep neural network that can differentiate the complicated relationships amid mashups and services is seamlessly linked to their invocation interactions and functions. The effectiveness of the proposed methodology in service recommendation is demonstrated by experiments carried out on a real-world web service dataset, which show that this strategy can produce a superior recommendation performance compared to several state-of-the-art methods.
Efficient assessment of the user-side quality of cloud components has emerged as a pressing and significant research issue. Evaluating every cloud component available from the user’s perspective would be costly and unfeasible. It is easier to perform appropriate service recommendations with QoS values. Most current algorithms approach the QoS prediction problem by combining the QoS values of the user’s similar neighbors, which naturally results in local optimization. The authors of [
21] formulated it as a global search optimization issue in the QoS value distribution space and introduced a new algorithm, PSO-USRec. The approach enhanced and customized particle swarm optimization (PSO) by smoothing the outlier particles and diversifying the initial solutions. On a well-known public QoS dataset, comparison experiments were carried out to verify the efficiency of the PSO-USRec algorithm. A hybrid recommendation strategy was proposed by Nabli et al. [
22] and provided the active user with a list of personalized cloud services. User and service clustering are the basis of this strategy. Cloud services are recommended according to the user’s functional and non-functional needs and preferred QoSs. Following that, the services are organized based on cost and reliability, and the recommendation approach provides a list of various cloud services.
Memory and model-based techniques have been combined into hybrid CF techniques. A few papers [
23,
24] presented privacy protection strategies to maintain user privacy while achieving high QoS prediction accuracy, as gathering QoS values may provide privacy challenges. The advantages of model-based approaches and memory are combined in these strategies. They involve many calculations as well. To address cold start and data sparsity issues, Patro et al. [
25] developed a novel methodological technique, termed sparsity and cold start aware hybrid recommended system (SCSHRS), to reduce the impact of data sparsity and cold start in recommendation systems. Chen et al. [
26] proposed a hybrid QoS prediction technique that utilized empirical mode decomposition and a multivariate long short-term memory (LSTM) model. Their feature extraction and preliminary data treatment retain considerable potential for improvement, as do their network architecture and QoS forecast accuracy. A combined QoS prediction technique for web services based on the profound fusion of features was presented to address the issue of insufficient accuracy of QoS prediction. Ding et al. [
27] considered the common characteristics of multi-class QoS and the hidden environmental preference information in QoS. Initially, QoS data were modeled as a user–service bipartite graph. Next, features were extracted and mapped using a multi-component graph convolution neural network (CNN). Finally, the same dimensional mapping of multiple classes of QoS features was accomplished using the weighted fusion approach.
To avoid costly and time-consuming web service invocations, Xiong et al. [
28] suggested a location-aware collaborative method for the QoS prediction of web services using the usage history of service users. They begin by gathering and processing client-side geographical location data. Then, a method is developed to obtain a higher prediction accuracy for web service QoS values based on the gathered QoS and location data, integrating geographical location constraints, the (location-aware matrix factorization method) LFM, and considering the imbalanced data distribution. To build a sophisticated ML system, Handri and Idrissi [
29] used singular value decomposition (SVD) and matrix factorization. This strategy was designed to achieve multi-criteria decision-making support and dominate query approaches. Concurrently, applying the resilient distributed dataset paradigm in cloud computing creates an environment conducive to big data management. According to extensive experimental results, the new method has an advantage over other Topk algorithms in precision and scalability. Although DL-based techniques have been proposed for QoS prediction, their neural network topologies still need to be improved to increase prediction accuracy. The study of Zhang et al. [
30] added individual assessments and multi-stage multi-scale feature fusion to a DL model for more precise QoS prediction. This model extracts three-scale features, i.e., global, local, and individual, using non-negative matrix factorization. Similarity in distance is utilized to identify similar users and services. Then, a multi-stage deep neural network is designed to fuse multi-scale features, and the individual evaluations are input to each stage to correct QoS features.
Many cloud suppliers offer services, frameworks, and tools that can be utilized to deploy applications on a cloud infrastructure to simplify the migration process. Identifying the infrastructure and services that best enable a given application to deliver the desired performance at the lowest possible cost may be difficult. Chahal et al. [
31] offered a strategy for moving a recommender system based on a deep-learning model to a serverless architecture and machine learning (ML) platform. They also present their experimental evaluation of Lambda, a serverless platform service, and SageMaker, an AWS-ML platform. They discussed the tradeoff between performance and cost when leveraging the cloud infrastructure.
3. Proposed Model
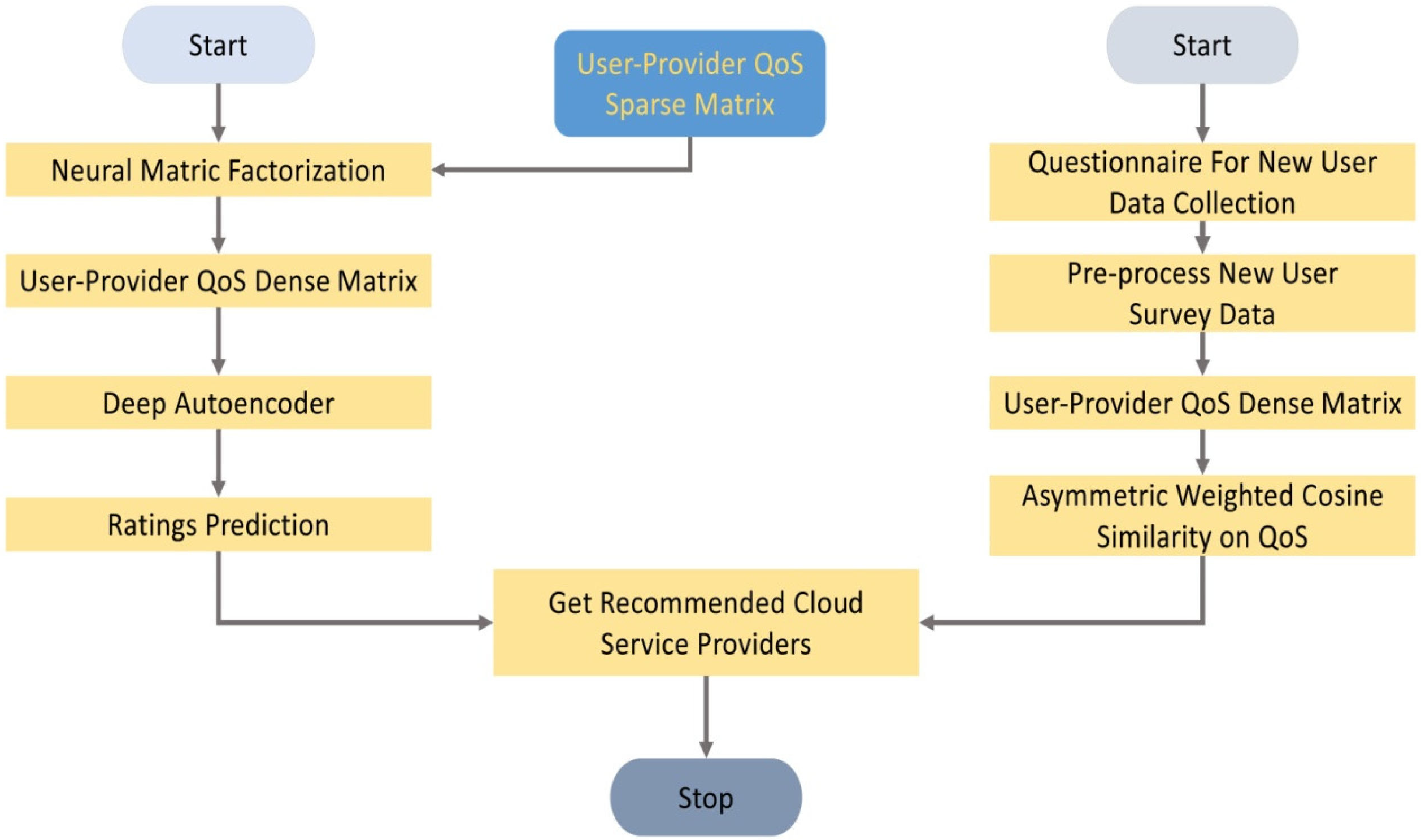
This proposed hybrid solution is structured to address the challenges of the sparse data and cold start problems. The flowchart in
Figure 2 provides an overview of this method and its related design. The QoS matrices of old cloud users and service providers are inputted to NeuMF to obtain a dense rating matrix; subsequently, these matrices are utilized by a deep autoencoder to mine more deeply into the QoS of cloud users and providers to make a better prediction. We use these ratings to suggest the top cloud providers to old users. For new users or existing customers with no personal data at our hand, survey data are preprocessed to generate the rating matrices. They are used to calculate AWCS on QoS features to obtain personalized service recommendations.
3.1. Preliminary
We define the QoS values of our cloud users and cloud providers. First, the cloud user set is denoted as and user is represented by where . The QoS attribute set is represented by , and QoS is represented as where . is the rating matrix, where represents the rate that cloud user gives about . Moreover, denotes the user bias, is the quality attributes bias, represents the bias term for user , and is the bias term for QoS . Additionally, as cloud users do not rate every QoS attribute, the matrices are often sparse, and most entries are missing. In our design, we handle sparse data matrices using NeuMF to make them denser and perform DL with a deep autoencoder.
3.2. Data Collection for New Users
For requests from new users or existing customers with no personal data at our hand, a Google Survey with the questionnaire is adopted to collect preference data, which are exported to a CSV file for further analysis. This questionnaire is designed based on the questions retrieved from many research papers [
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45]. A 5-point Likert scale is used for rating each question as follows: (1) Not Important, (2) Less Important, (3) Neutral, (4) Important, and (5) Extremely Important. Demographic features are concluded to determine the distribution of types of new cloud users. Furthermore, the QoS sets with the same attributes for new cloud users are created from collected preference data. Based on the QoS rates provided by new cloud users, we can work on their preferences and predict suitable recommendations of service providers. The cited papers have already validated the survey questions, and the details of this questionnaire are introduced in
Appendix A.
3.3. Neural Network Matrix Factorization
The NeuMF is commonly used in recommendation systems, particularly for rating prediction tasks. It models the connections between users and objects in a rating matrix by combining the power of matrix factorization and neural networks. NeuMF uses underlying latent features that influence user ratings. Low-dimensional matrices are used to predict the missing values in the original scanty matrices, which tremendously helps. The goal of matrix factorization is to divide the rating matrix
into two lower-rank matrices, the user matrix
and the QoS matrix
. These matrices record the latent qualities or factors affecting the ratings. An approximation of the rating is given by the dot product of the latent representations of the users and the objects. The use of NeuMF can capture nonlinear interactions between the user and object embedding, which can lead to more accurate predictions. The following is an expression for the factorization:
where
is an
matrix,
is an
matrix, and
is the dimensionality of the latent space. Row
of
represents the latent representation of user
, and column
of
represents the latent representation of QoS attributes
. Here, * represents the dot product between two matrices.
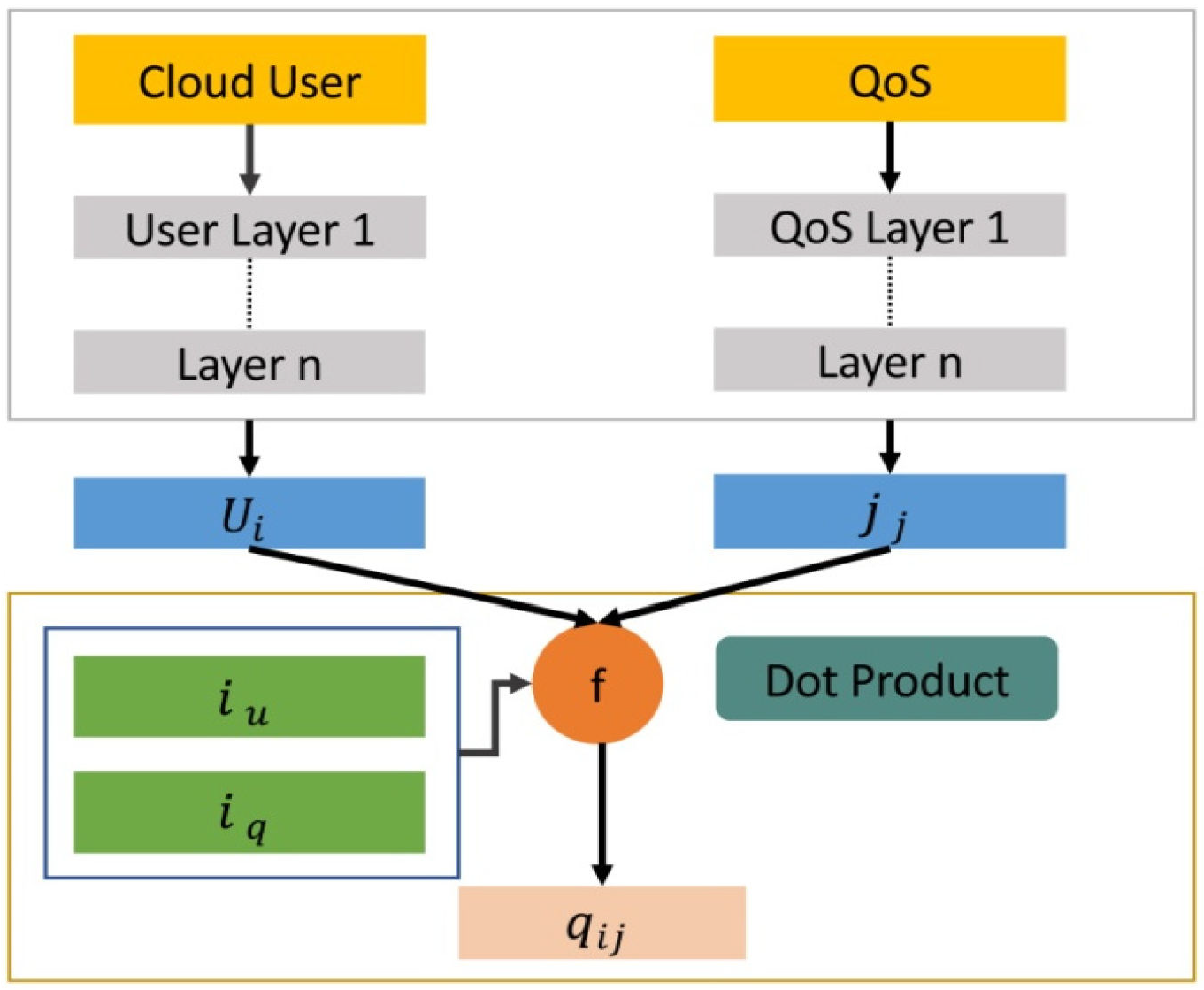
Figure 3 indicates that cloud users and QoS features are collections of matrix communications. The matrix factorization also adopts bias terms, which may excel in model performance. By incorporating bias terms, calculating the error rate with binary cross-entropy, and introducing regularization, the NeuMF model can capture user and object biases, predict ratings within the desired range, manage overfitting, and enhance recommendation performance [
46].
The fundamental matrix factorization approach is expanded with biased terms for customers and cloud service providers in NeuMF. These biases can capture user and object choices that are not influenced by the latent factors. The rating matrix is referred to as
in the context of cloud-service recommendations, where each entry
reflects the rating provided by the user
for QoS attribute
. The purpose of this matrix is to predict the missing ratings.
where
represents the predicted rating for user
for QoS
,
is the global average rating,
is the bias term for user
,
is the bias term for QoS attributes
,
represents the latent representation of user
, and
represents the latent representation of QoS
.
We used weight matrices
and
to denote the user and object latent factor matrices. These weight matrices enable learning and updating parameters
and
during optimization. The latent factor vectors of users and objects are modified by multiplying them by their respective weight matrices as follows:
During the optimization process, the weight matrices
and
are updated by adjusting their parameters based on the gradient of the loss function. The specific updating rules, such as gradient descent, depend on the chosen optimization algorithm. The weight matrices control the contribution of each latent factor for each user and object, allowing the model to learn the importance of different factors for prediction. After that, we can better train the matrix factorization model by minimizing the mean squared error between the predicted and actual rating scores [
47]. The objective function is defined as
where the regularization rate is
. The regularizing term
penalizes the scale of the parameters to prevent overfitting. Stochastic gradient descent or Adam, two optimization algorithms, can be used to learn the model parameters [
47].
3.4. Deep Autoencoder
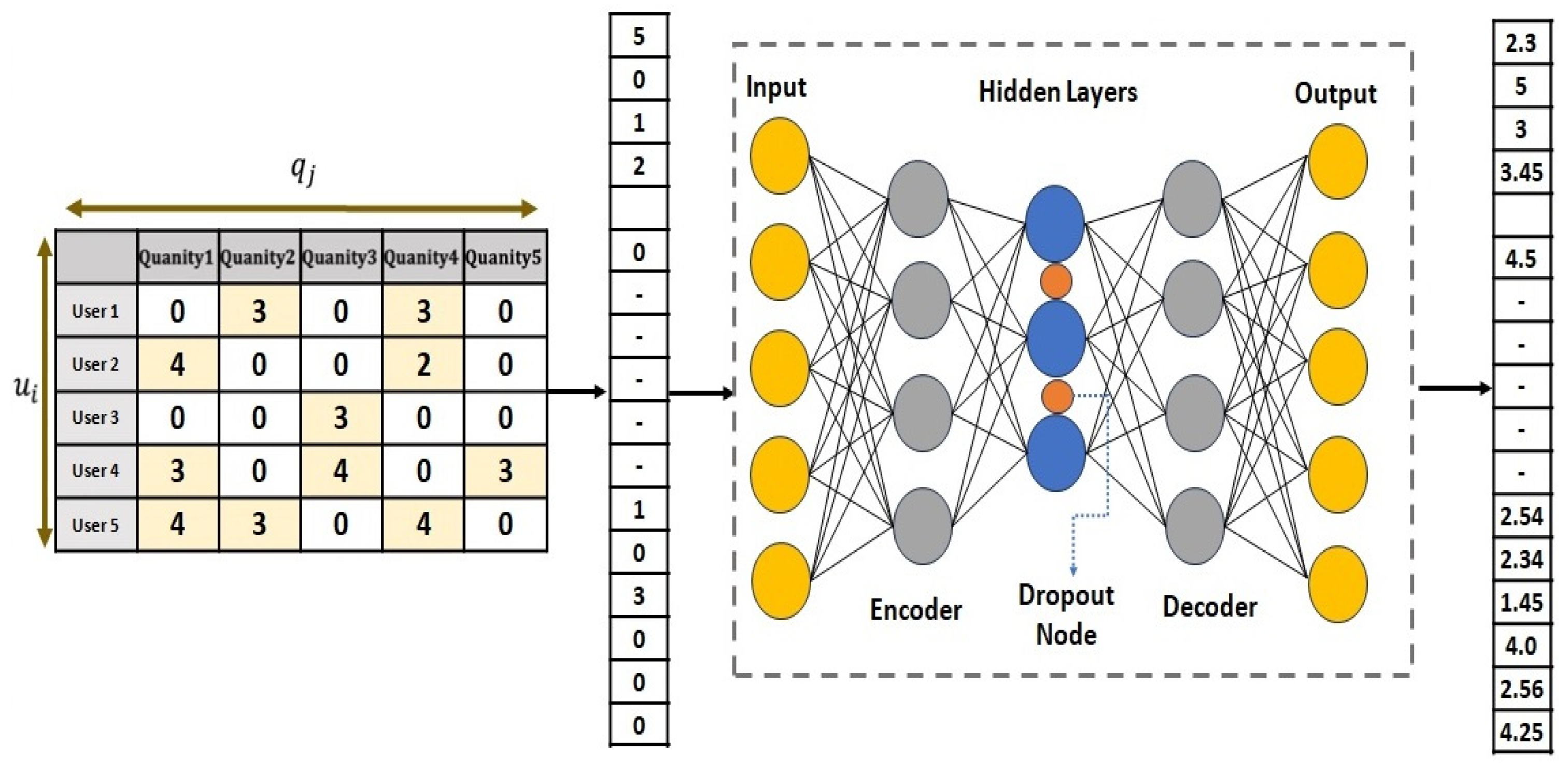
A deep autoencoder is a form of the deep neural network whose input and output vectors have the same dimensions. It is frequently used in hidden layers to learn the representation of something very close to the original data. A deep autoencoder, as shown in
Figure 4, with three hidden layers representing the modified feature, an optimal dropout, and an output layer identical to the input layer for reconstruction, is selected in our framework. The input layer represents the input feature vectors. The dropout is considered to reduce overfitting.
The encoder unit of the deep autoencoder maps input data, i.e., the NeuMF output, into a lower-dimensional space as
. A decoder unit that maps input data from a lower-dimensional space
to the realm of the rating matrix as
[
48]. The encoder
produces latent representations from the row of rating matrix
(vector
) as follows
where
.
and
are the user-encoding layers’ weights and biases, respectively, with dimensions
and
representing the amount of user hidden layer units and the amount of user and QoS parameters, and
being the activation function [
48].
The decoder unit reconstructs the original row vector using encoded representation
. A reverse operation of the encoder is performed in the decoder component, which comes after the bottleneck layer as follows
where
.
and
are the weight and bias of the object hidden layer, respectively, with the same number of hidden units
h [
48].
represents the reconstructed row vector, and
f is the activation function.
A deep autoencoder typically experiences overfitting owing to a large number of parameters. To control the overfitting of this model using two regularized terms of the loss function, we include a parameter λ with dropout to avoid this problem.
3.5. Rating Similarities
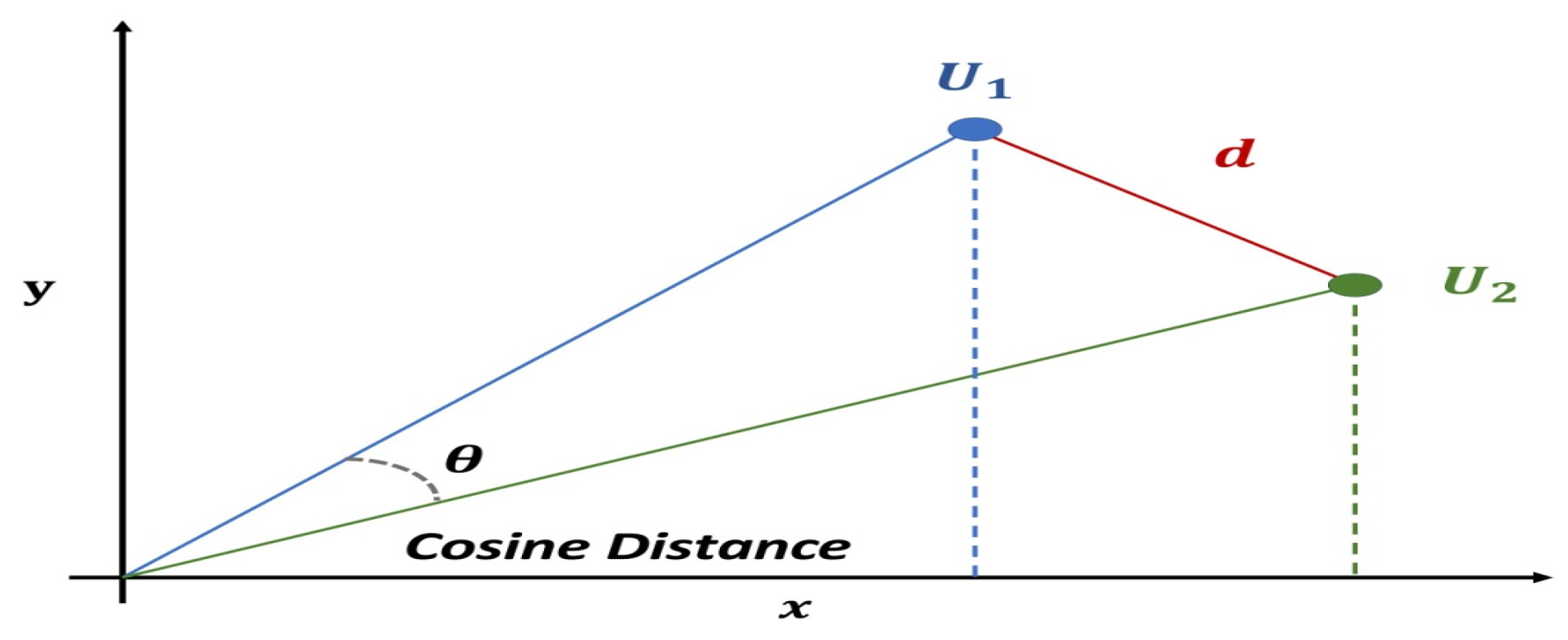
After making predictions, the most suitable cloud services should be suggested to the cloud customers. Therefore, the cloud services with top degrees of preference from other users similar to the arriving users are better candidates based on a CF algorithm. Cosine similarity measures how similar two vectors are in a two-dimensional space.
Figure 5 shows the distance between two users and their cosine distance, which ranges from 0 to 1. The
can calculate the cosine distance and cosine similarity between two vectors (data points),
and
, on the plane with two axes
and
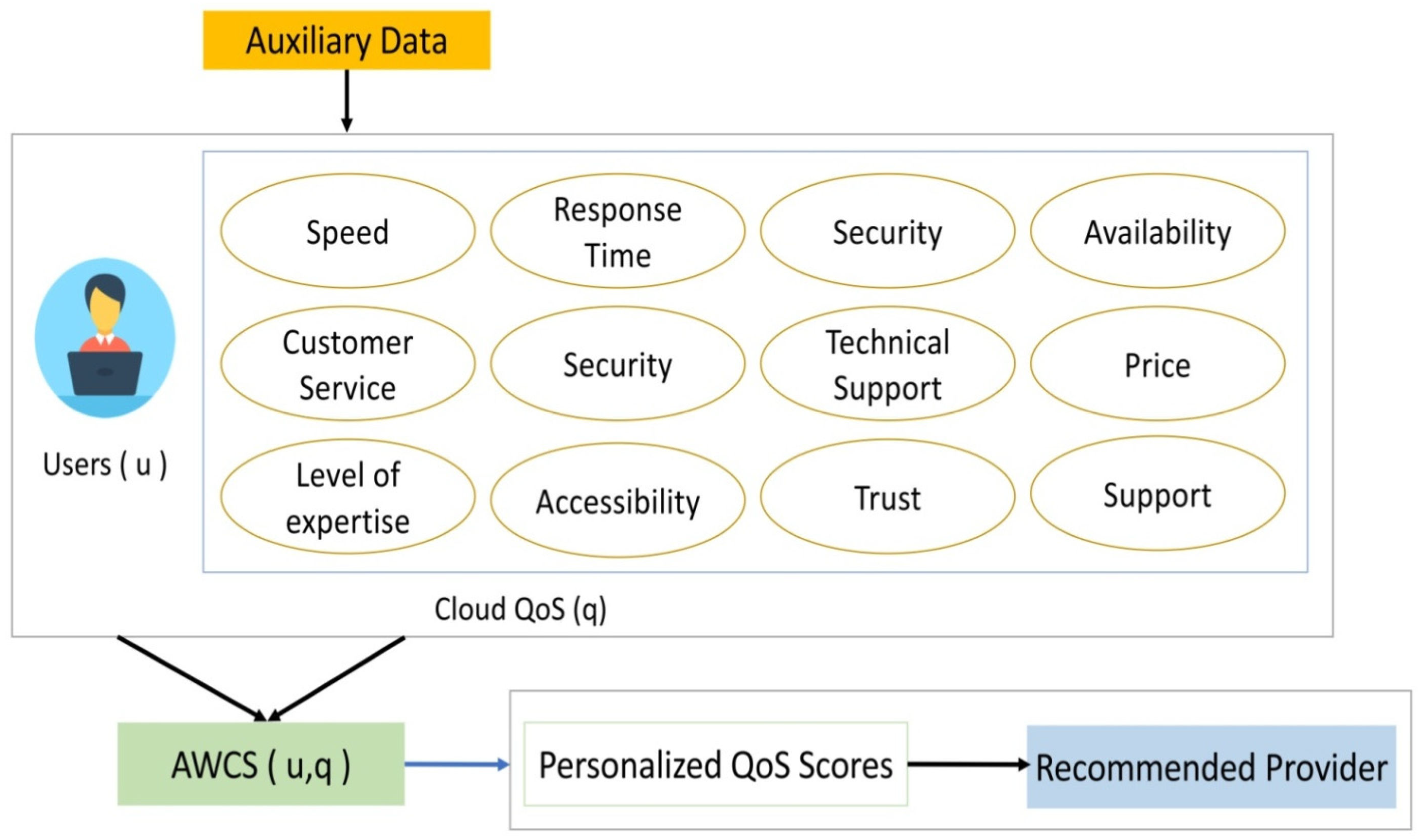
. The distance between users is obtained by computing their cosine similarity using their QoS metrics. A value close to 1 indicates a significant correlation between the two variables. If the value is near 0, these independent variables are not correlated. An asymmetric weight refers to distinct and potentially customized feature weighting assignments for each vector, whereas symmetric weight refers to equal or identical feature weighting results for both vectors. The similarity between two users who have evaluated the same QoS features can be determined using weighted cosine similarity.
To compute the similarities between users, we choose the algorithm of AWCS [
15]. According to Filali and Yagoubi [
49], their approach is beneficial for determining how similar two users are. They suggest that precise similarity measurements might not be obtained if user ratings are evaluated exclusively based on particular criteria or fundamental demographic information. Thus, studying a more comprehensive range of user attributes becomes necessary to describe people with different backgrounds accurately. We need to standardize features so that they reliably record user preferences and make data interpretation easier. A detailed evaluation of various aspects to achieve this regularity is also required. These factors include usage history, behavioral tendencies, contextual data, and demographic information. Another complication to the standardization process is guaranteeing the representativeness and trustworthiness of the accompanying data. Moreover, many computing techniques are available to determine user weights of the AWCS method. This flexibility allows different weights to be assigned to shared features between vectors.
Figure 6 illustrates that the auxiliary data from users and QoS features can identify asymmetric similarities between users and give personalized recommendations. These auxiliary data could include various QoS metrics such as response time, trust, availability, price, etc., which are essential for evaluating cloud service providers. The AWCS considers the different importance of each QoS in formatting the similarity between users. This weighting ensures that more significant QoS factors contribute more to the similarity calculation than less important ones. Each user receives a personalized QoS score calculated based on the AWCS computations. The approach determines which cloud service providers are the most suitable for each customer based on their QoS score. With each customer’s unique requirements, these providers can deliver the preferred QoS features. Generally, the consumer is recommended a fixed number of highly rated providers, e.g., the top
providers. The following steps were performed:
All ratings each user provides for QoS attributes would be averaged to form the vector for individual users.
Each cloud user assigns every QoS attribute a weight value, reflecting the user’s preference for various dimensions. We assign weights based on ratings in the Likert scale. Higher weights indicate stronger preferences and vice versa.
A matrix with weights is created. The columns represent the QoS features, whereas the rows represent users.
The weighted cosine similarity of the two user vectors is calculated by dividing their dot product by the product of their norms.
where
and
are the user vectors,
is the weight vector, and
indexes the features of the QoS set.
3.6. Proposed Design of Hybrid Approach
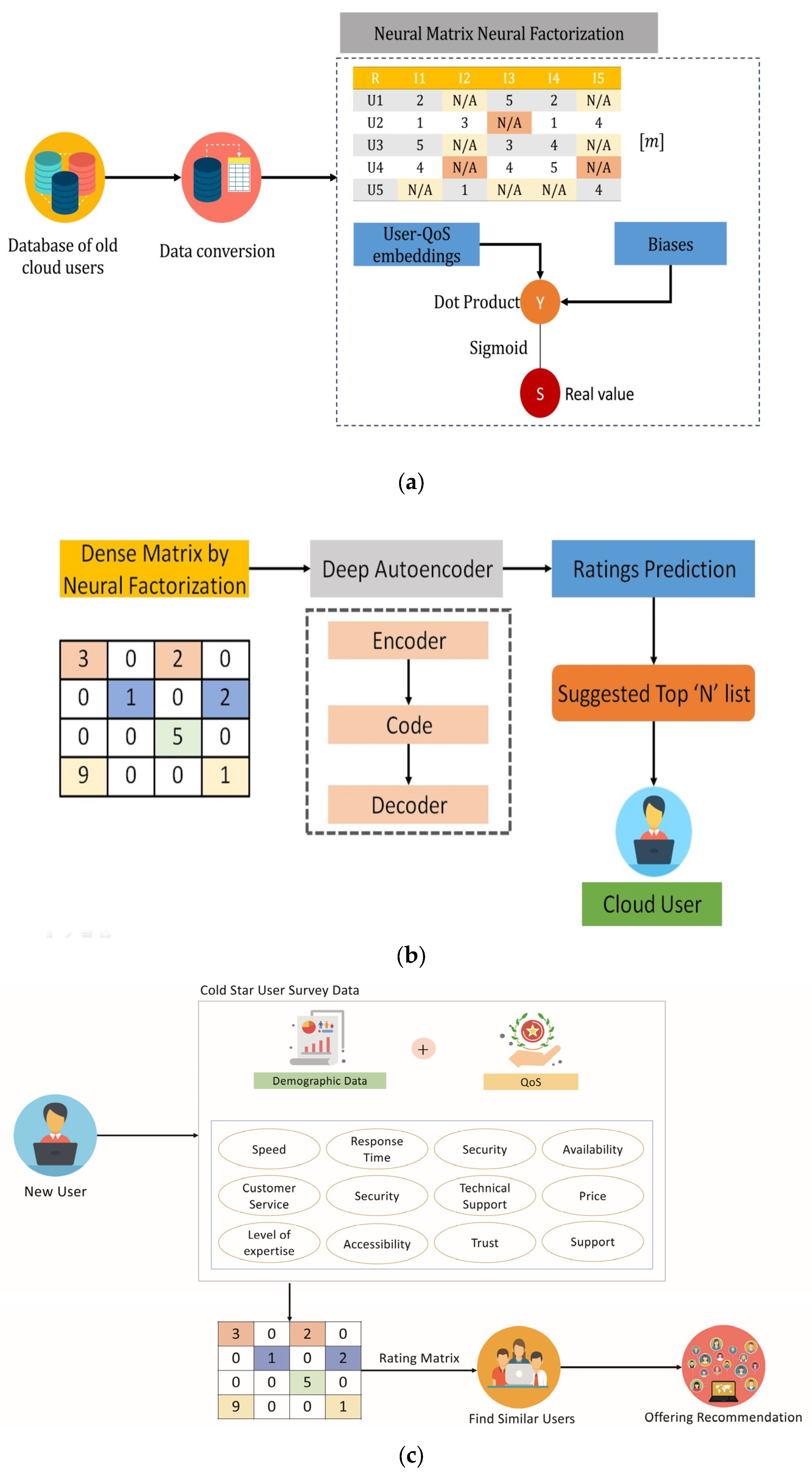
Our hybrid approach design is divided into three parts, as shown in
Figure 7a–c. We deal with the old and new cloud users individually through DL processes and survey questionnaires.
We utilize stored feedback results from existing users about different cloud providers’ services and convert them into matrices. These matrices are subjected to a NeuMF algorithm to be converted from sparse to dense, as shown in
Figure 7a.
The NeuMF outputs are fed into the well-trained deep autoencoder, and we can generate better rating predictions. Then, top
cloud service providers are offered to the arriving cloud user for reference based on the predicted rates, as demonstrated in
Figure 7b. The deep autoencoder is selected because it often develops a more compact and efficient representation of user–provider interactions, which is perfect for recommendation.
Figure 7c indicates the service recommendation to the new cloud user, where data are collected through a customer survey. Once the data are collected, they are compared with existing user profiles, and the weighted similarities between existing and new users are calculated. Finally, a recommendation list of personalized service providers is created.
5. Conclusions
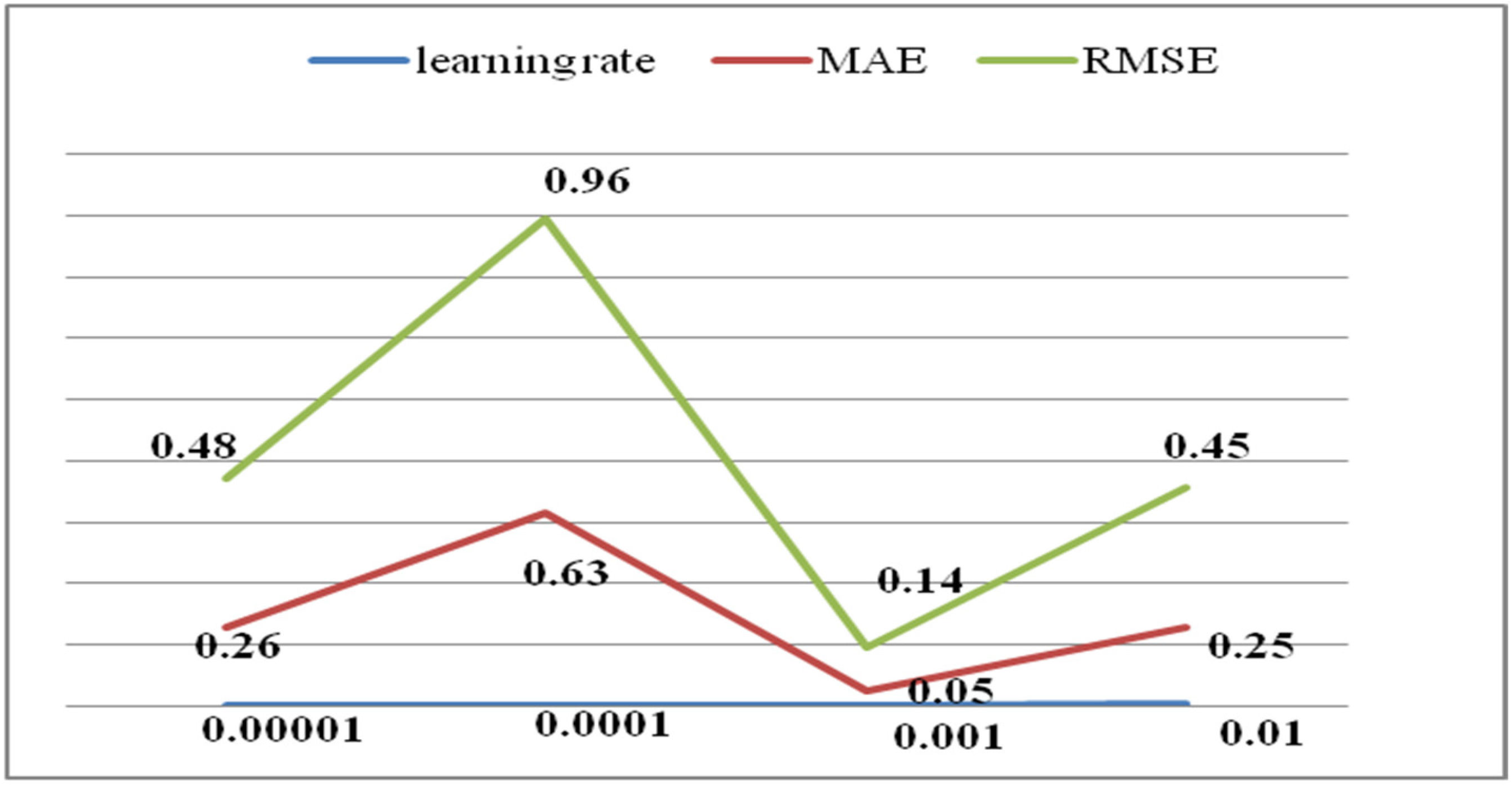
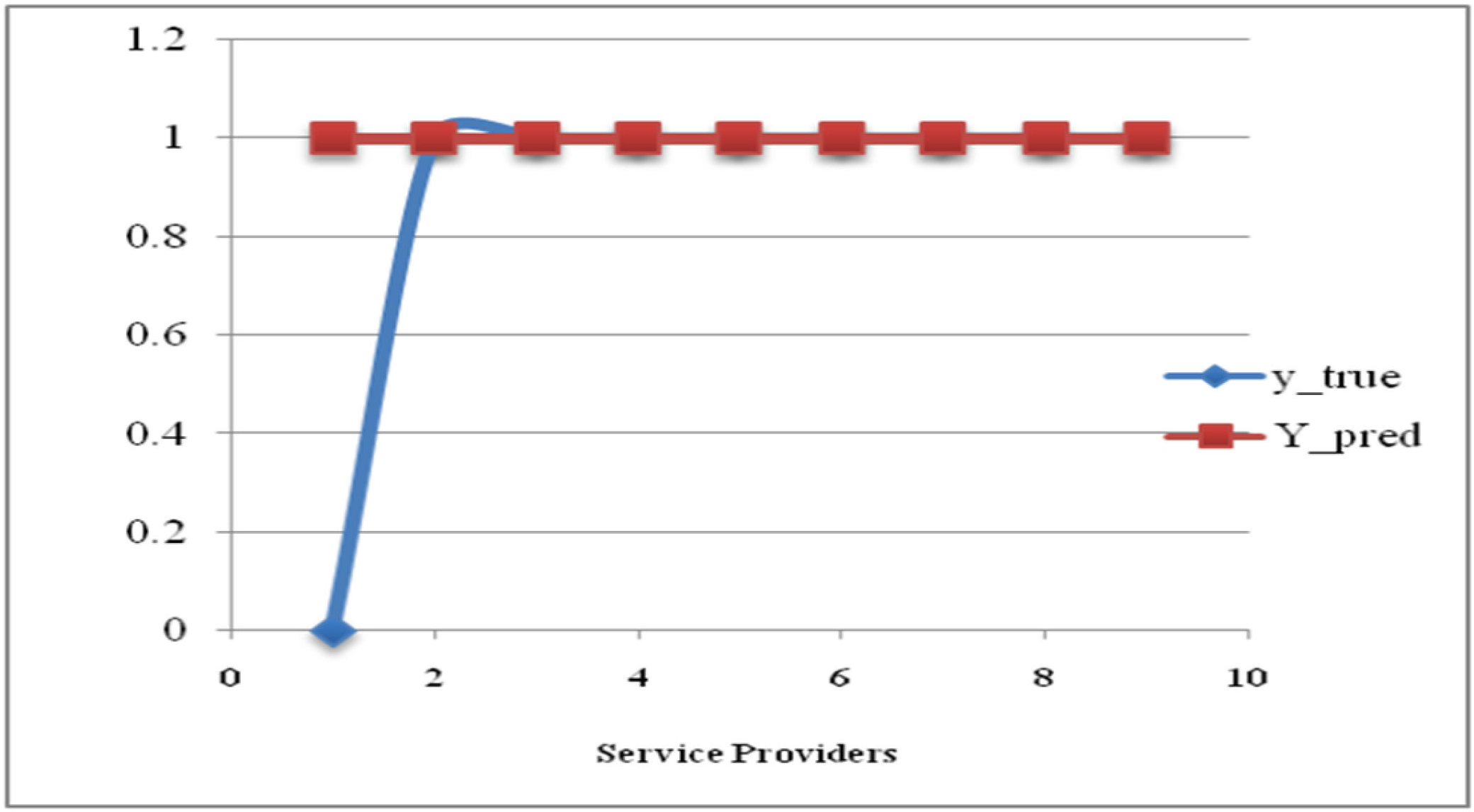
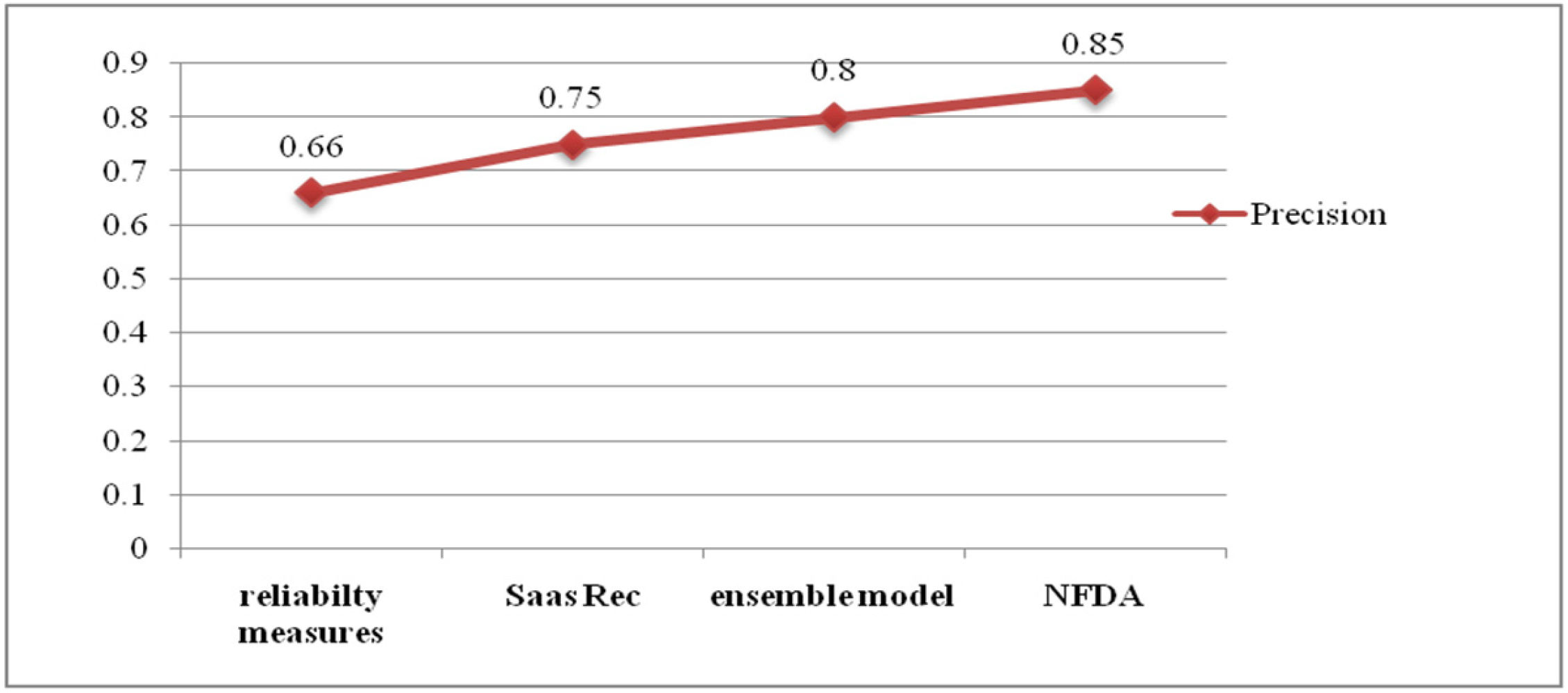
Hybrid model-based recommendation systems have attracted significant attention in personalized services. This paper proposes an appropriate technique of rating prediction for existing customers in recommendation systems. It combines NeuMF and a deep autoencoder in the hybrid framework. To predict ratings, our design examines the effects of combining user data, QoS data, a DL method (NeuMF), and an autoencoder. Integrating NeuMF and a deep autoencoder capable of handling complicated and high-dimensional data yields a robust and accurate recommendation result. The experiments based on the Cloud Armor database are evaluated according to three indexes, i.e., RMSE, MAE, and precision. The hybrid approach offering top cloud service providers improves the accuracy and efficiency of suggestions. For new cloud service users, we adopt a carefully designed questionnaire and AWCS to derive the recommendation list, which includes three service providers. A feedback questionnaire with personalized suggestions is used to assess the users’ satisfaction levels.
Our approach to providing the recommendation lists of cloud service providers is measured with an MAE of 0.05, an RMSE of 0.14, and a precision rate of 85%. These measurements show that our approach can handle the problems of data sparsity and cold start with relatively low errors, indicating it is successful in detecting the underlying patterns in the data. We also provide a satisfaction level of nearly 78.5% for new cloud service customers. In this study, both cloud service provider recommendations for existing and new customers demonstrate notable performance. To summarize, our research has provided valuable insights on how to handle data sparsity and cold start.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

