4. Discussion
Deep learning methods for nephritis WSI analysis have become a hot topic in recent years. Supported by a huge amount of pathological image data, several mature supervised learning analysis models have emerged. The performance of supervised learning models is highly dependent on the efforts of pathologists in data annotation. However, individual differences, staining differences, and even differences in light microscopy equipment contribute to the inter-difference in the analysis results of glomerulus morphology using WSIs. Pathologists often feel overwhelmed with diagnosing the vast amount of appropriate, high-quality training images. On the other hand, pathologists and physicians are always interested in positive images with characteristic tissue structures or lesions. Positive data and annotations are usually easier to obtain, leading to an imbalance in sample diversity for deep learning model training. Resolving these considerations places a heavy burden on pathologists and data scientists, affects the efficiency of data utilization, and creates constraints and challenges for supervised learning model training.
Semi-supervised learning can solve the above problems with a relatively low annotation cost. The classification performance of semi-supervised learning has been demonstrated in cases where the number of available annotated images is limited [
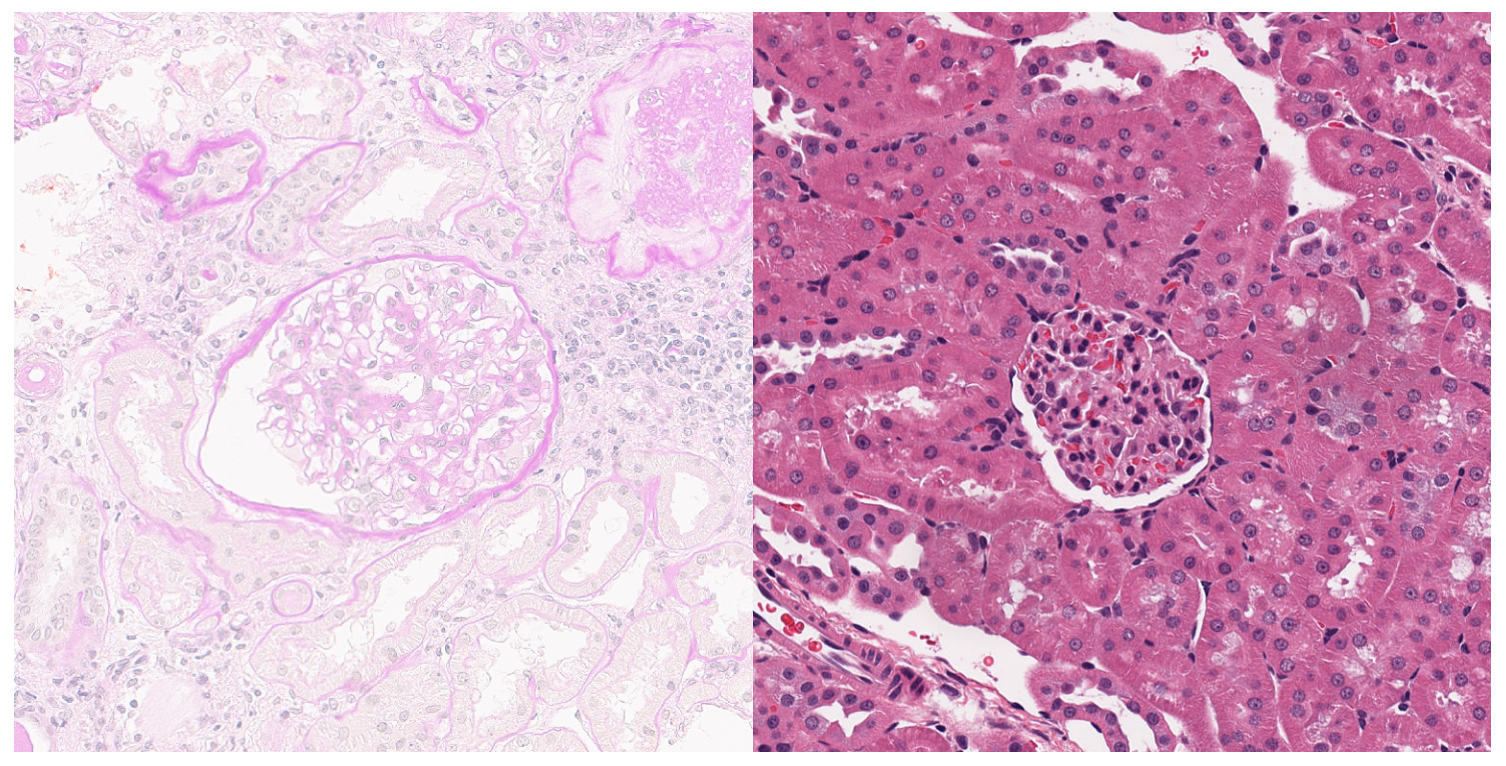
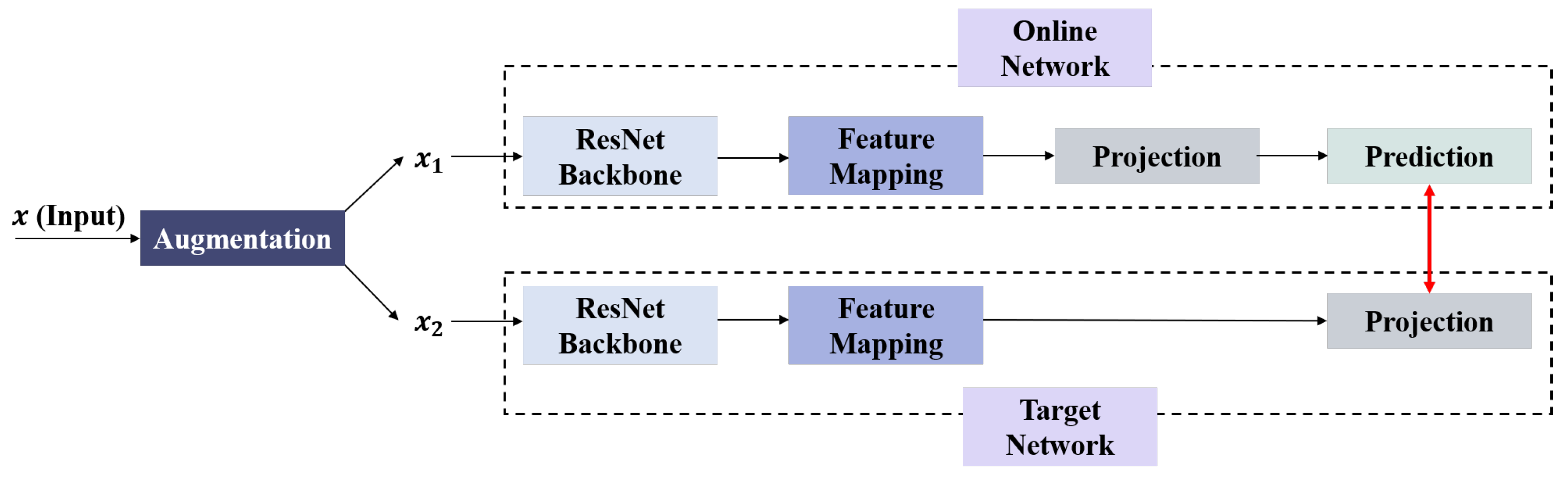
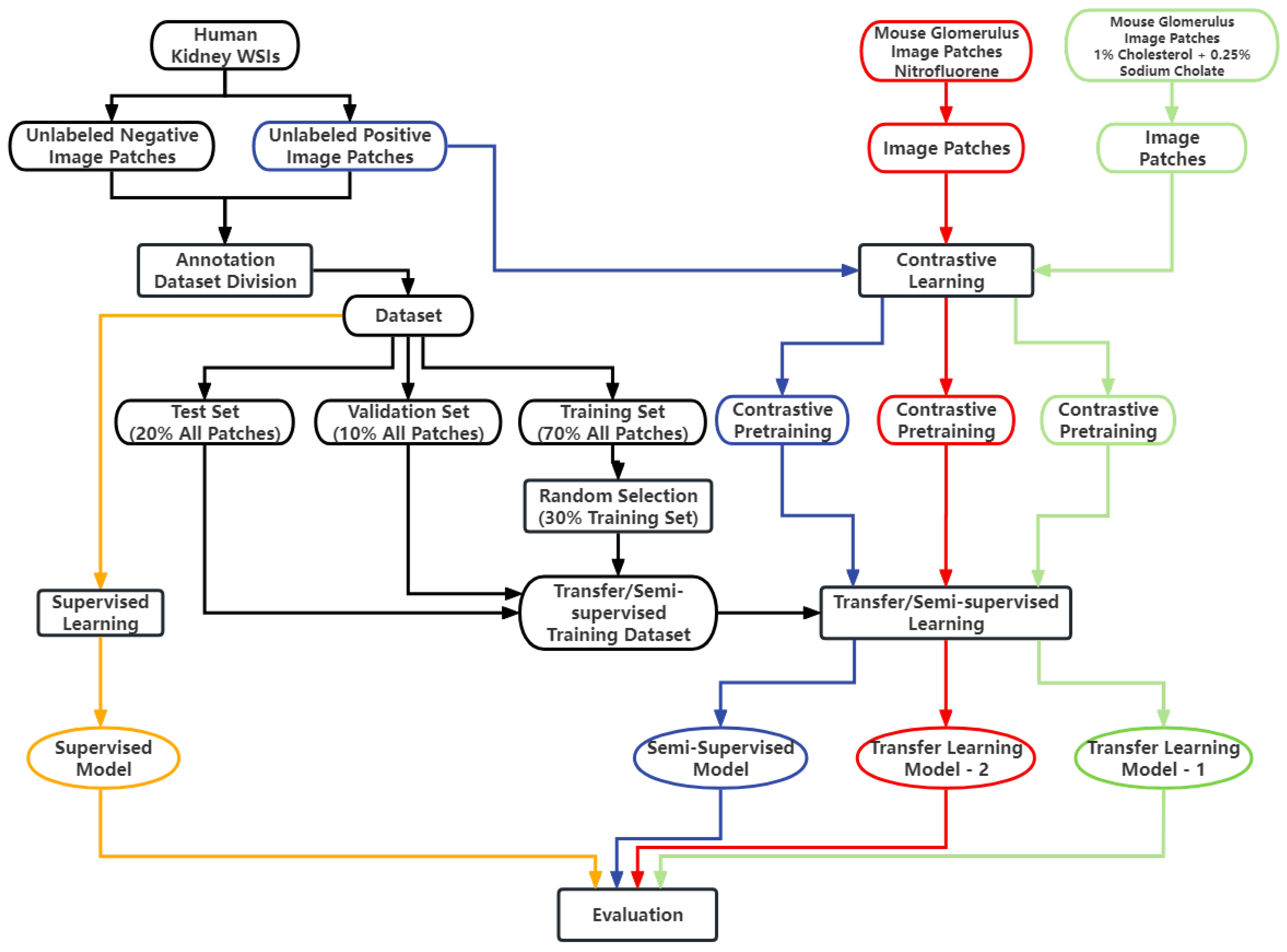
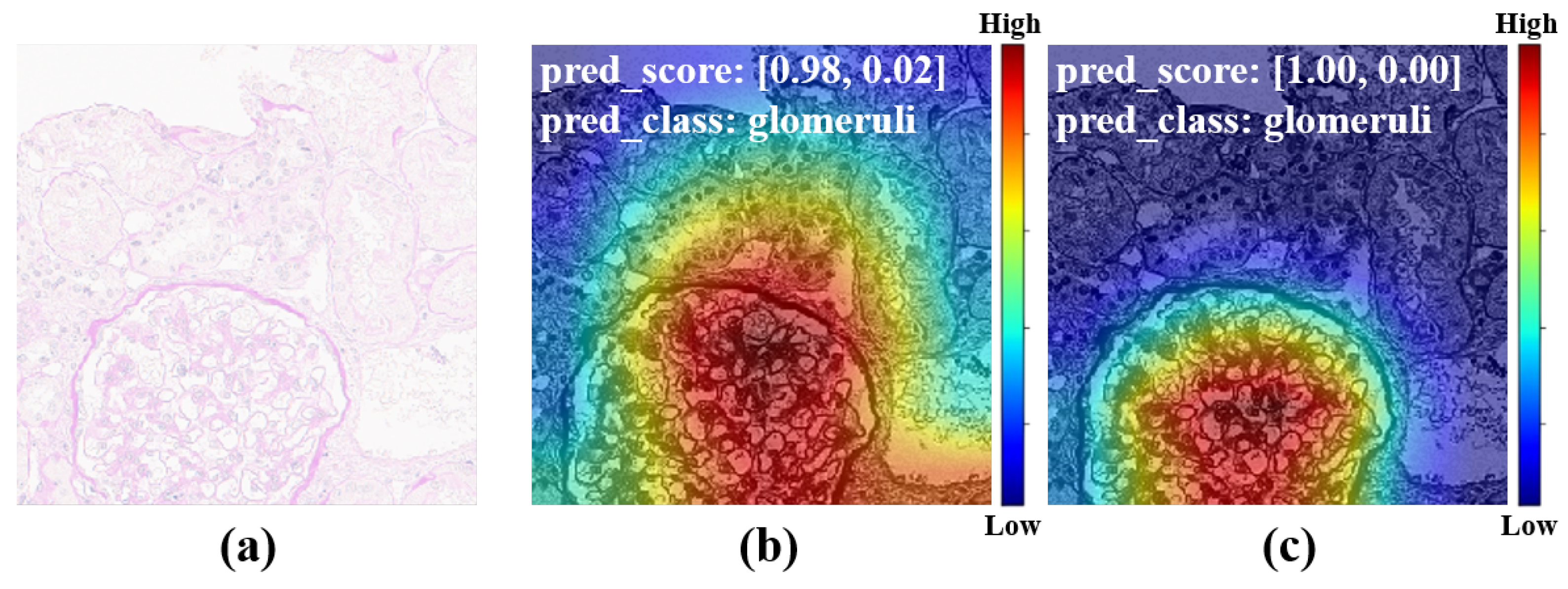
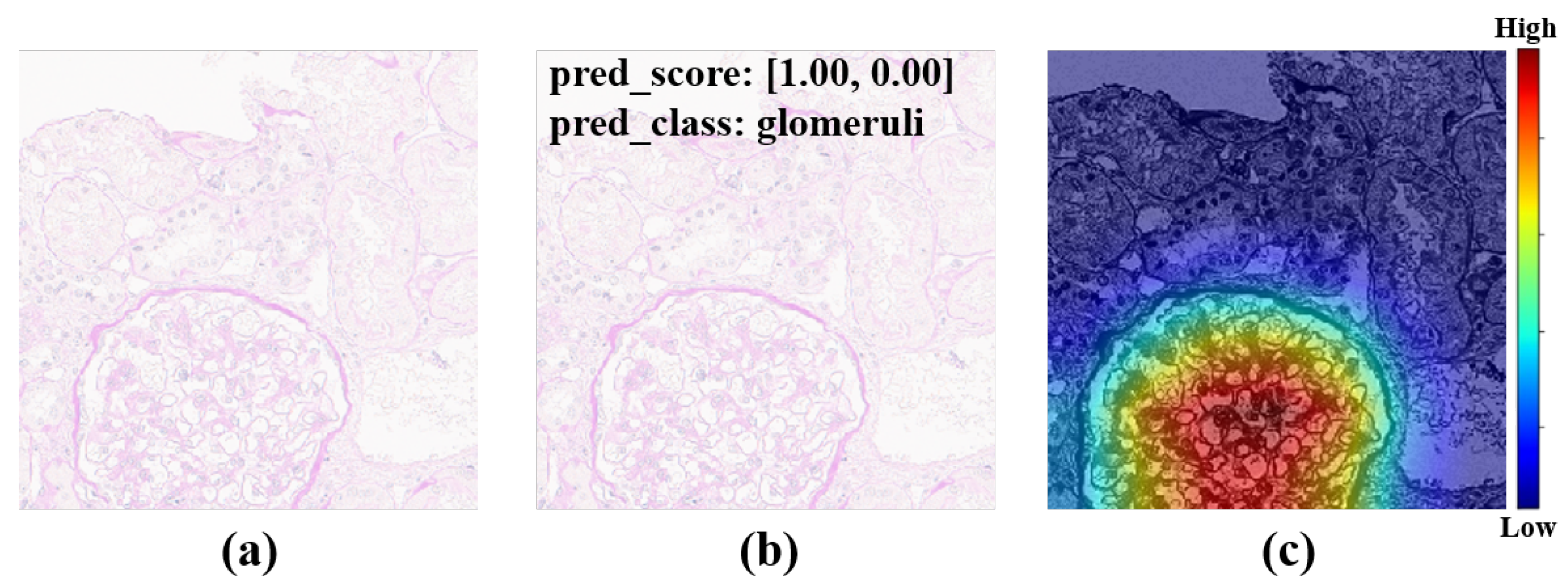
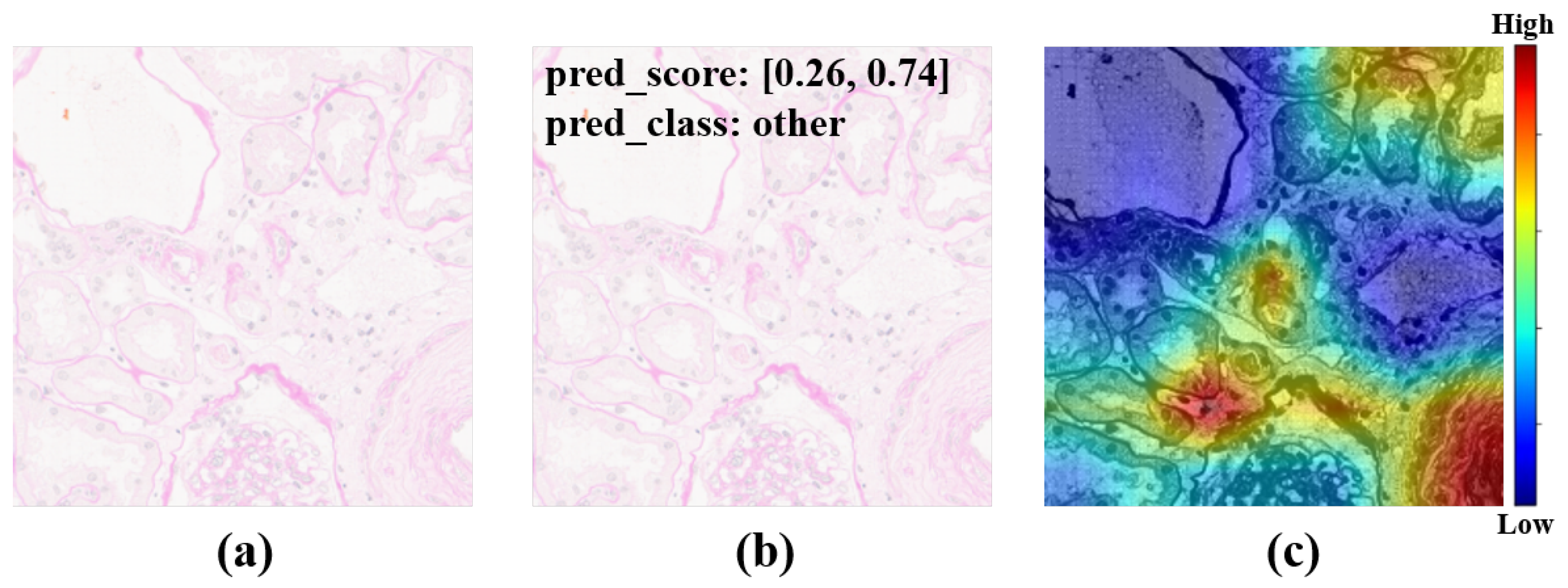
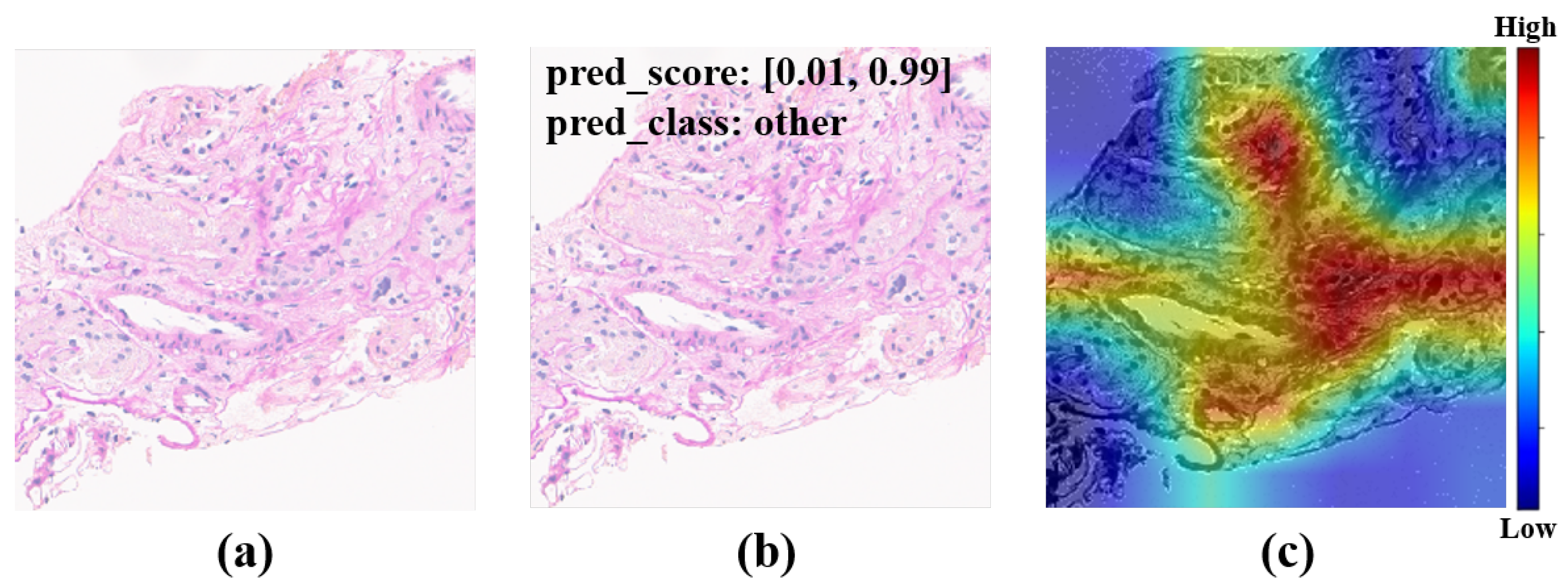
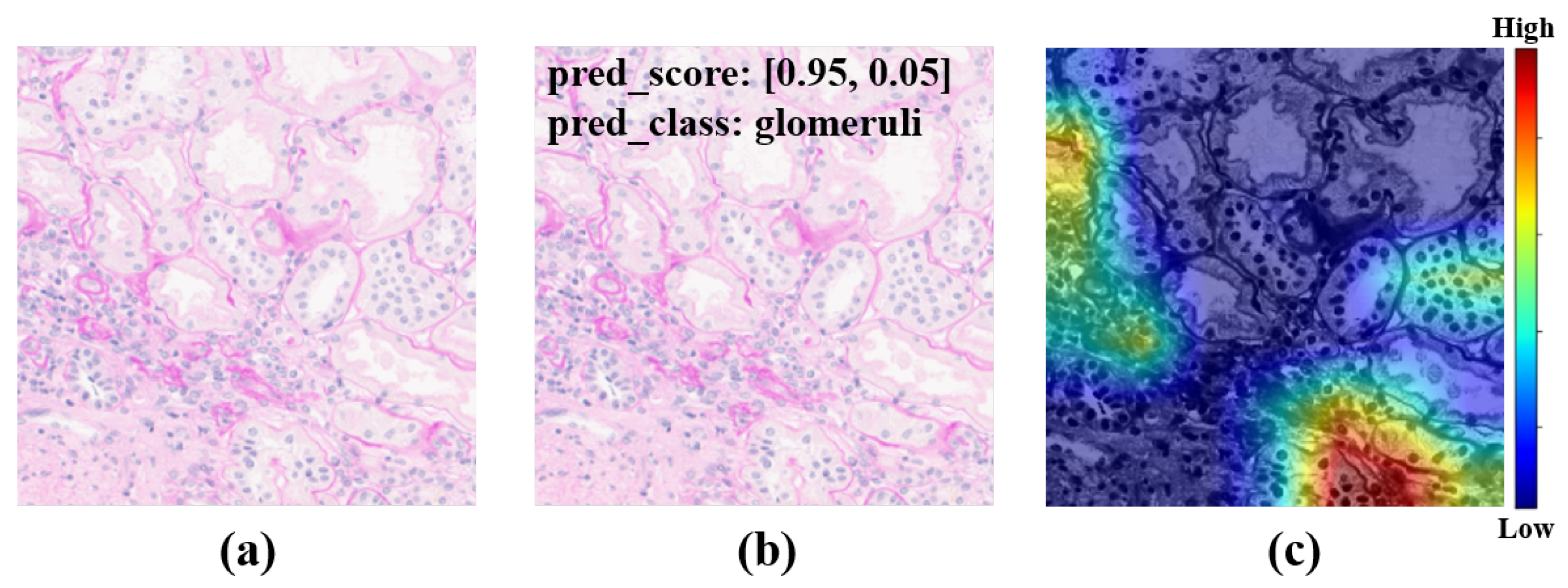
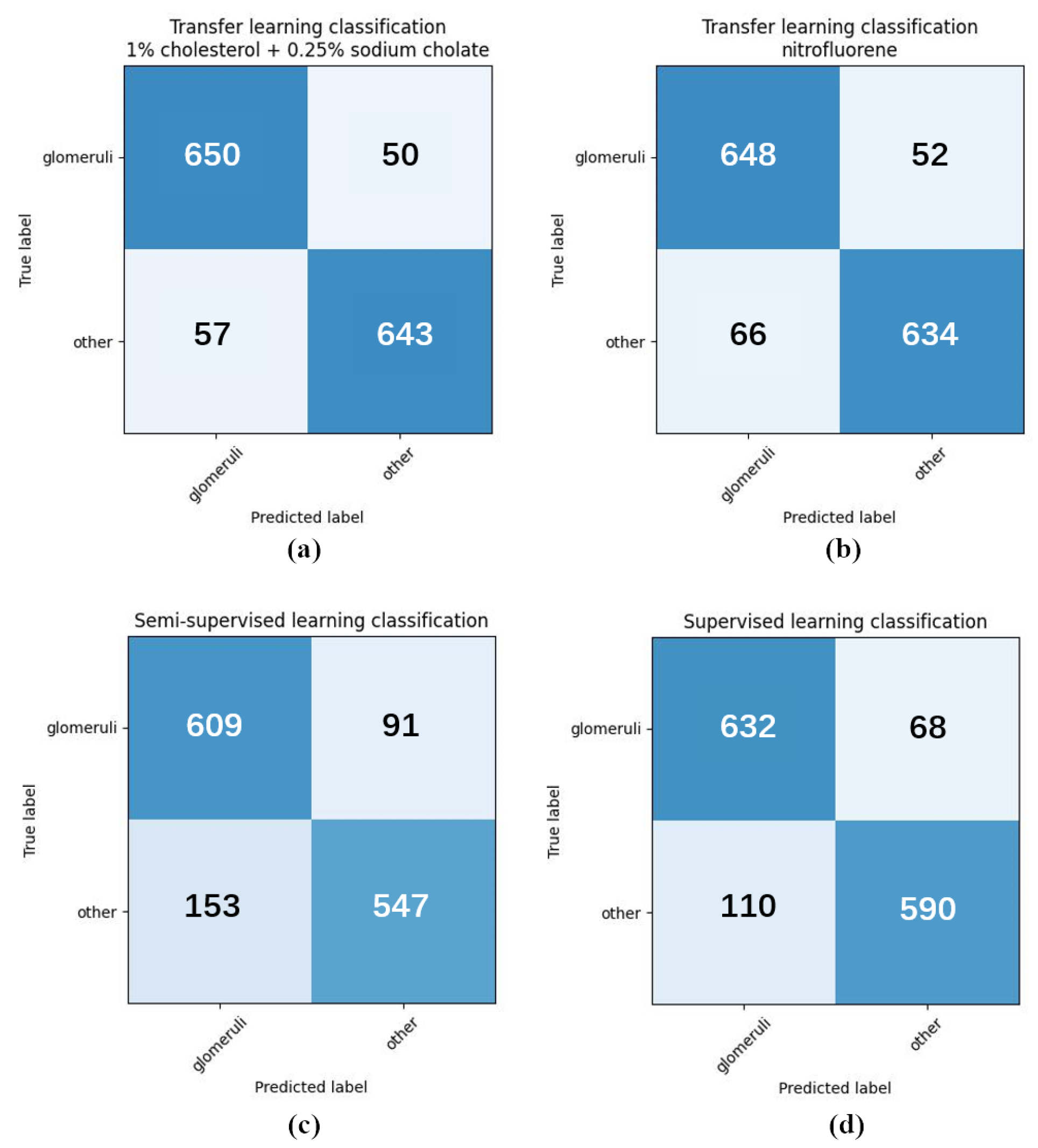
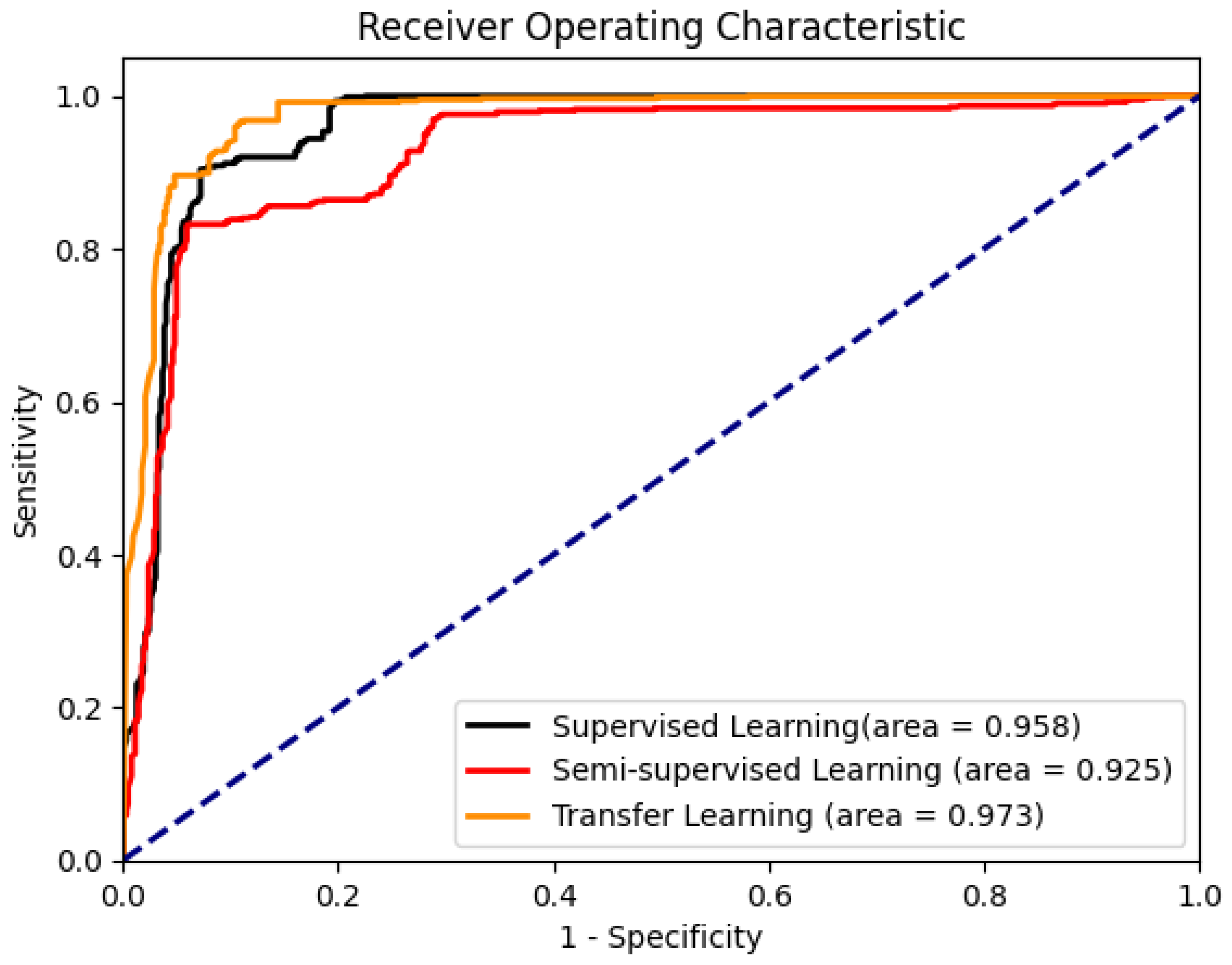
50]. To achieve our goals, a large amount of unlabeled data were used for self-supervised pretraining, and then a small amount of labeled data were used for semi-supervised training. In total, 313 human IgA nephritis WSIs were processed into a human kidney image dataset, inclusive of 7000 glomerulus-containing (positive) images and 7000 non-glomerulus-containing (negative) images; 4900 patches containing human glomeruli were selected randomly for pretraining; the remaining 2100 patches containing glomeruli and 2100 randomly selected non-glomerulus patches were partitioned into training, validation, and test sets in a 7:1:2 ratio with classification labels for the fine-tuning phase. To minimize the dependence on negative images and capture stable glomerulus characteristics, contrastive pretraining was conducted with the BYOL algorithm. The feature representation of images containing glomeruli was obtained by enhancing the positive input with BYOL. The weights of the contrastive learning model were then fine-tuned to form a semi-supervised model. The proposed semi-supervised learning model achieved an average accuracy of 82.25%, a sensitivity of 80.78%, a specificity of 83.46%, and an AUROC of 0.925 in four parallel trials. The Grad-CAMs generated by this model showed that pretraining with contrastive learning based on positive images helps with the glomerulus image feature representation, and the areas associated with the glomeruli can provide a basis for correct predictions. In contrast, the supervised learning models based on the same dataset training and the same backbone were trained simultaneously. The supervised learning models achieved an average accuracy of 86.85%, a sensitivity of 87.48%, a specificity of 85.99%, and an AUROC of 0.958 in four parallel trials. The above results show that for IgA nephritis glomeruli, the semi-supervised classification model based on BYOL can achieve similar performance to that of the supervised learning classification model.
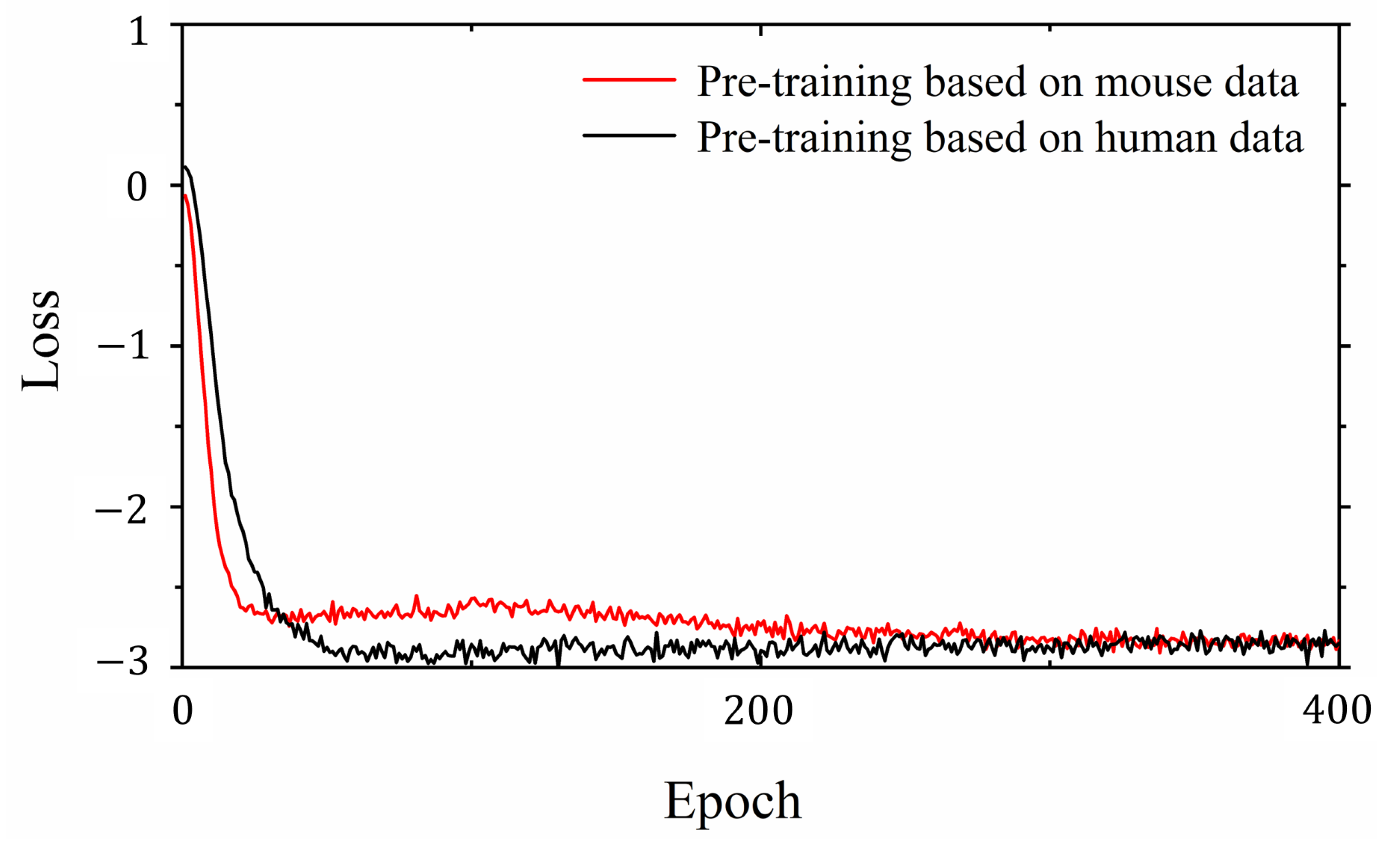
However, the supervised learning models still demonstrated obvious advantages through the Delong test analysis. This indicates that there is still room for improvement of classification models based on contrastive learning. In human kidney images, the morphology of other tissues that are not glomerulus might be similar to that of glomerulus. This implies that human kidney images may be more complex and may reduce the expressive effect of contrastive learning training. In mouse kidney images, the difference between glomerulus and other renal tissues is more significant, so the images are relatively simple. Given that the similarity between mouse glomeruli and human glomeruli is high, the same number of mouse glomerulus images could be introduced into contrastive learning to replace the human glomerulus images mentioned above. The same number of labeled human kidney images was then introduced for transfer training.
To train the transfer learning model, mouse dataset A was constructed with 5000 image patches containing mouse glomeruli affected by 1% cholesterol and 0.25% sodium cholate. To avoid drug-regimen differences in animal experiments, 5000 image patches containing mouse glomeruli affected by nitrofluorene comprised mouse dataset B for contrastive learning. Similar to the semi-supervised model training process described above, mouse datasets A and B were used for the contrastive learning phases, respectively. Then, 2100 patches containing human glomeruli and 2100 human non-glomerulus patches, both randomly selected, were partitioned into training, validation, and test sets in a 7:1:2 ratio with classification labels for the fine-tuning phase. The proposed transfer learning model with mouse dataset A achieved an average accuracy of 92.22%, a sensitivity of 92.74%, and a specificity of 91.58% in four parallel trials. The proposed transfer learning model with mouse dataset B achieved an average accuracy of 91.97%, a sensitivity of 92.56%, and a specificity of 91.21% in four parallel trials. The proposed transfer learning models achieved significant performance advantages under the Delong test, with an AUROC of 0.973, compared to the semi-supervised models and supervised models.
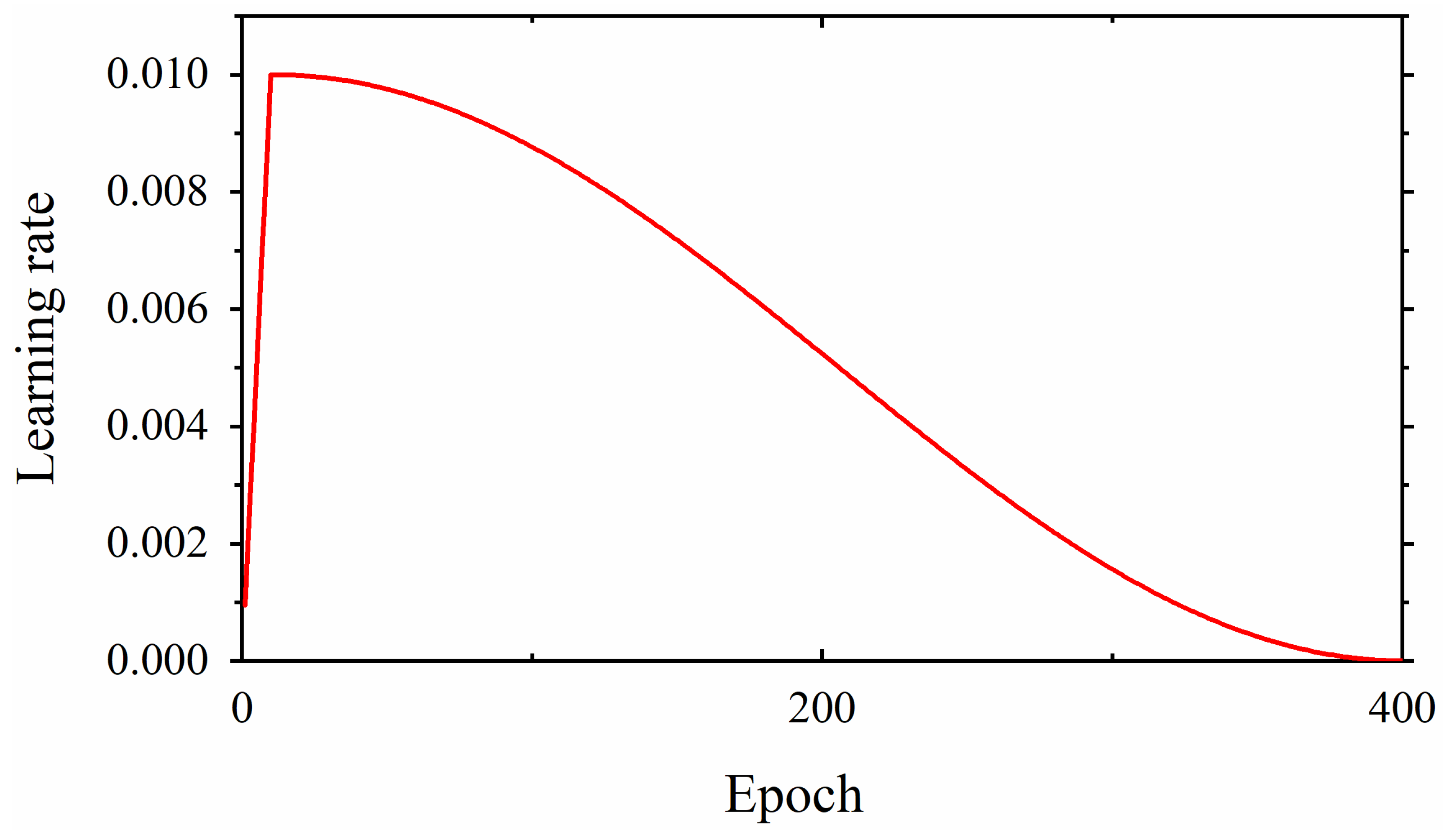
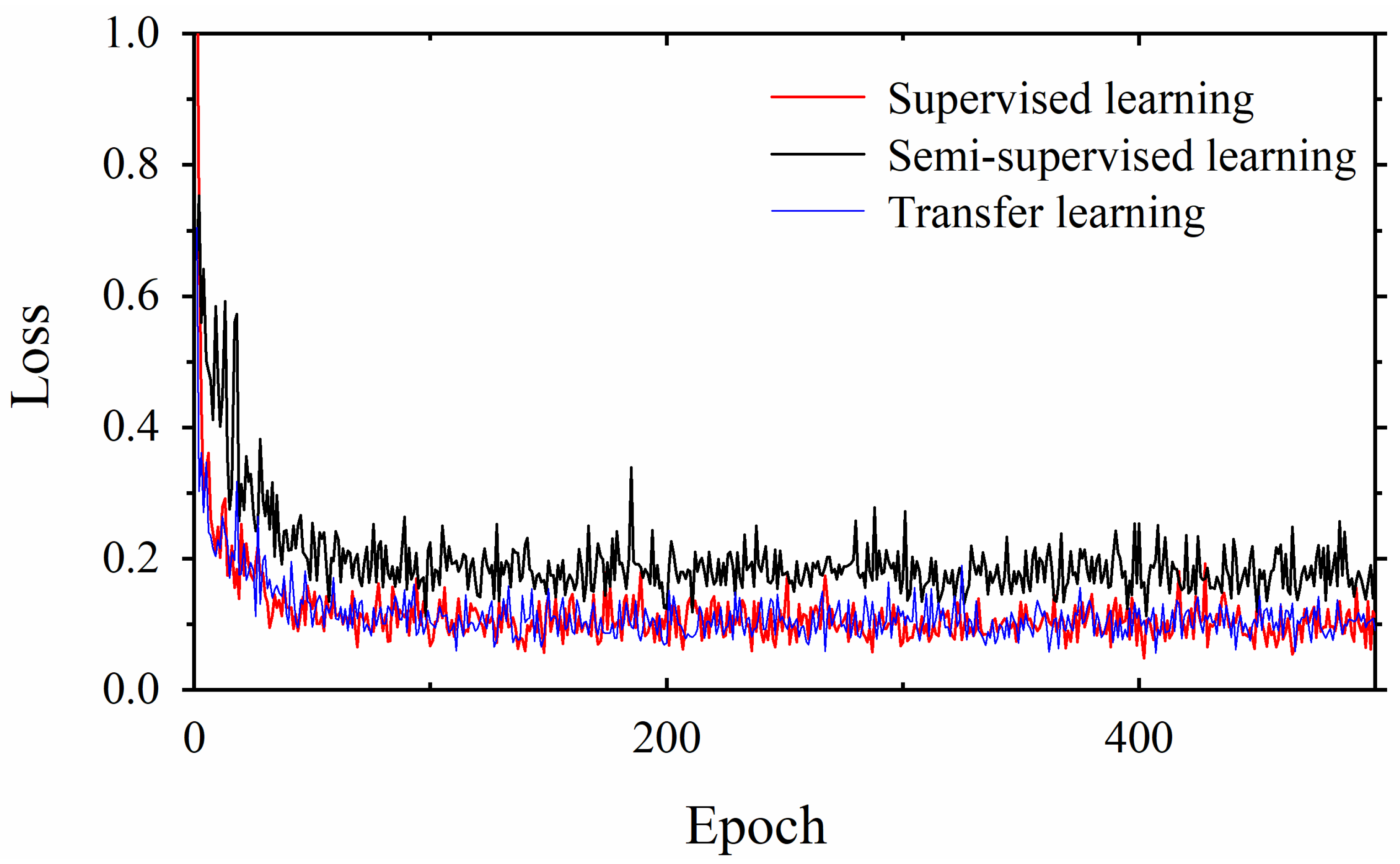
By comparing the loss curves of the above semi-supervised, supervised, and proposed transfer learning models, it was clear that when mouse glomerulus images were used for contrastive pretraining, the convergence speed was faster and the value of the loss function at convergence was lower. Observing the evaluation metrics and the confusion matrices of the two transfer learning models, the performance of the two transfer learning models was better than that of the semi-supervised learning model and the supervised learning model, and there was no significant difference in performance between the two transfer learning models. Comparing the previous results and Grad-CAMs, it was demonstrated that glomerulus images helped form better feature representations and improved the classification accuracy of human kidney images via transfer learning, surpassing the supervised learning methods. It can be demonstrated that the key to improving model performance lies in training the feature representations during the pretraining phase. The results of this study also show that semi-supervised learning and transfer learning models can be built using contrastive learning pretraining to improve the training results with small training datasets.
This study also examined the difference in the classification performance of the proposed transfer learning model with two ResNet backbones of different depths. This study confirmed the difference in the classification performance of the proposed transfer learning model with two ResNet backbones of different depths. With the same datasets, the transfer learning models based on ResNet-101 were trained and achieved an average classification accuracy of 92.73% in four parallel trials. Under the Delong test, the ResNet-101 backbone with an AUROC of 0.978 did not achieve a significant difference compared to that of the ResNet-50 backbone. This may be attributed to the simplicity of the mouse kidney images. Therefore, the ResNet-50 backbone has sufficient capability for feature learning and representation. Considering the storage and computational cost, the ResNet-50 backbone is more practical.
In this study, we proposed a classification model for analyzing human IgA nephritis WSIs by combining contrastive learning pretrained with mouse glomerulus images and transfer learning with human glomerulus images. The method achieved a high classification accuracy and facilitated the diagnosis using pathological WSI images. Additionally, the proposed method greatly reduced the requirement and burden of data annotation for training renal WSI analysis models. This study also provided a solid foundation for subsequent segmentation and classification tasks. There are some limitations of this study. First, this study only performed the classification of glomerulus and non-glomerulus tissue images and did not consider the classification for glomeruli and other tissues in different types of nephritis. The establishment of a comprehensive renal WSI-wide classification system is essential for a CAD system for chronic nephritis. Second, due to limitations in data collection, only mouse and human glomerulus images were used for pretraining by contrastive learning. The complexity and relationship between mouse and human glomerulus images have yet to be analyzed. In addition, the visualizations on the representation of features generated by mouse and human glomerulus images should be further studied. This may help to explain the role of contrastive learning in this study. Finally, the number of images in the dataset is insufficient to fully evaluate the performance of the models on large datasets. The evaluation of the model could be improved by incorporating a wider range of contrastive learning algorithms. BYOL is a generic contrastive learning algorithm, and its advantages over other algorithms have been extensively proved [
23,
31,
51]. Future studies should be performed to develop a specific contrastive learning algorithm in renal pathological image analysis.
In future work, we will aim to address the above issues. The downstream tasks of the transfer learning classification model proposed in this study are also expected to progress, including multiclassification problems, detection, and semantic segmentation. In addition, we are approaching the application of transfer learning to downstream tasks in IgA nephritis, such as segmentation of internal sclerotic tissue, quantitative analysis of specific stained spots, and area statistics. WSIs with higher resolution and magnification can support this further study. Moreover, we would like to explore the feasibility of transfer learning with renal pathological images from appropriate animal experiments for the analysis of some rare glomerulus lesions, such as crescents. Additional data and models are expected to be available to address the problems identified above.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}