
Multi-Scale Adaptive Feature Network Drainage Pipe Image Dehazing Method Based on Multiple Attention

Abstract
:1. Introduction
2. Related Prerequisite Work Description
2.1. Dehazing Related Work
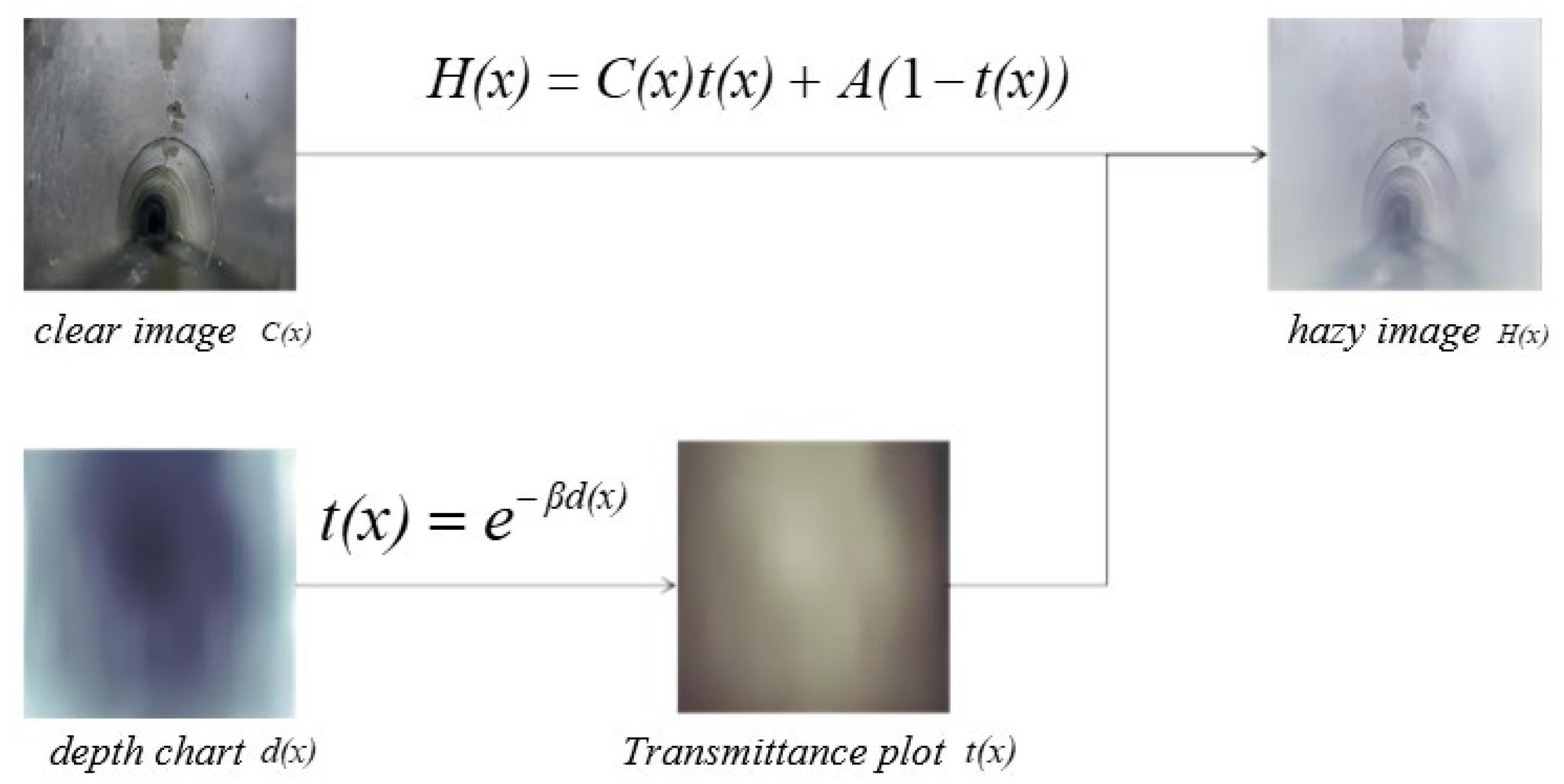
2.1.1. Atmospheric Scattering Model
2.1.2. Dark Channel
2.1.3. Max Contrast
2.1.4. Color Attenuation
2.1.5. Chromaticity Difference
2.2. Dehazing Related Work
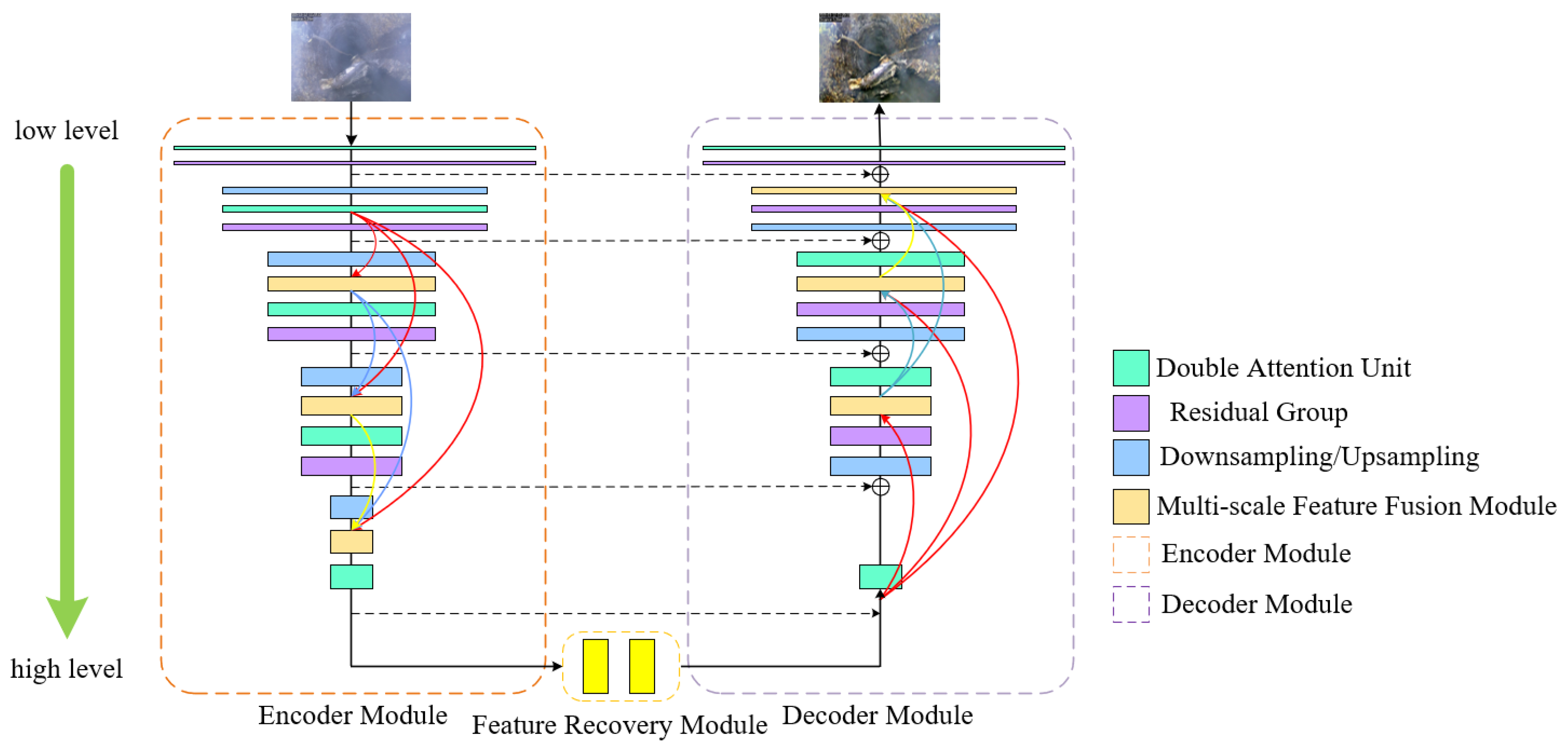
3. Main Network Framework
3.1. Overall Structure
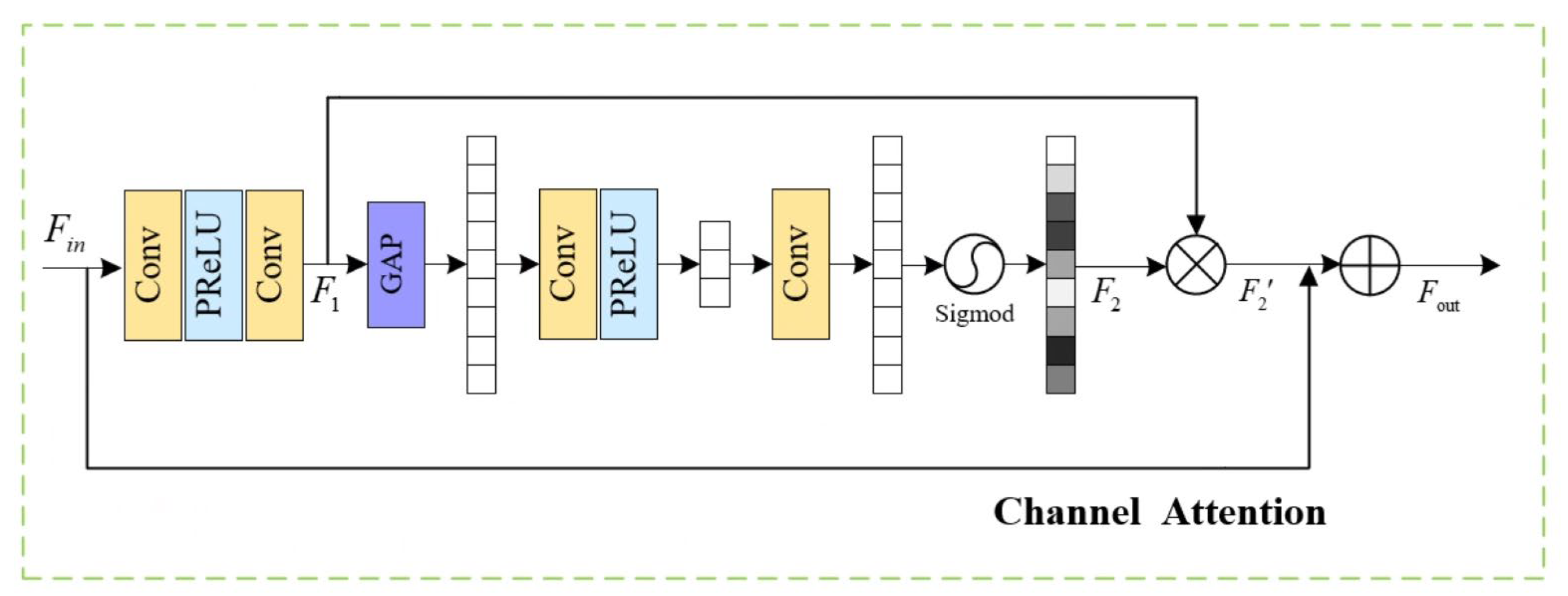
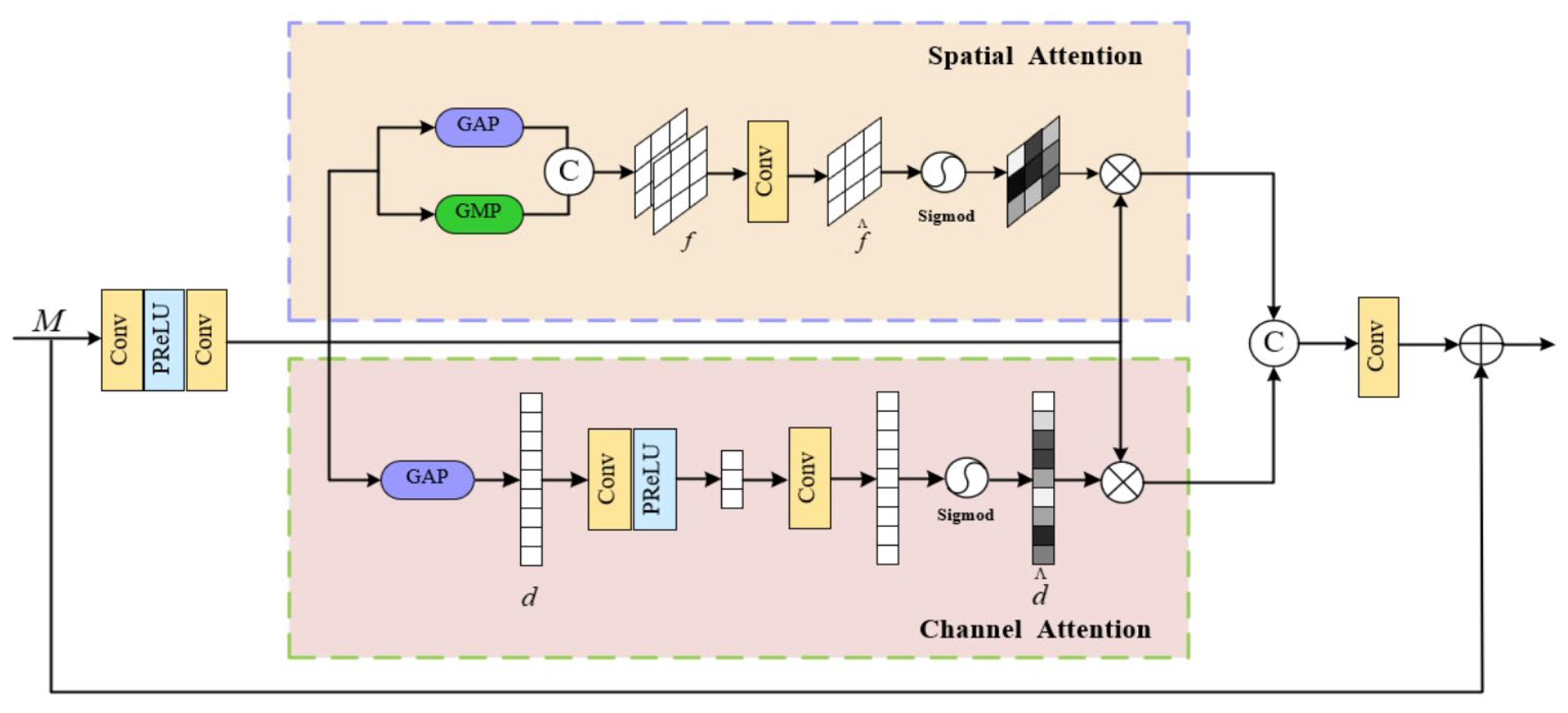
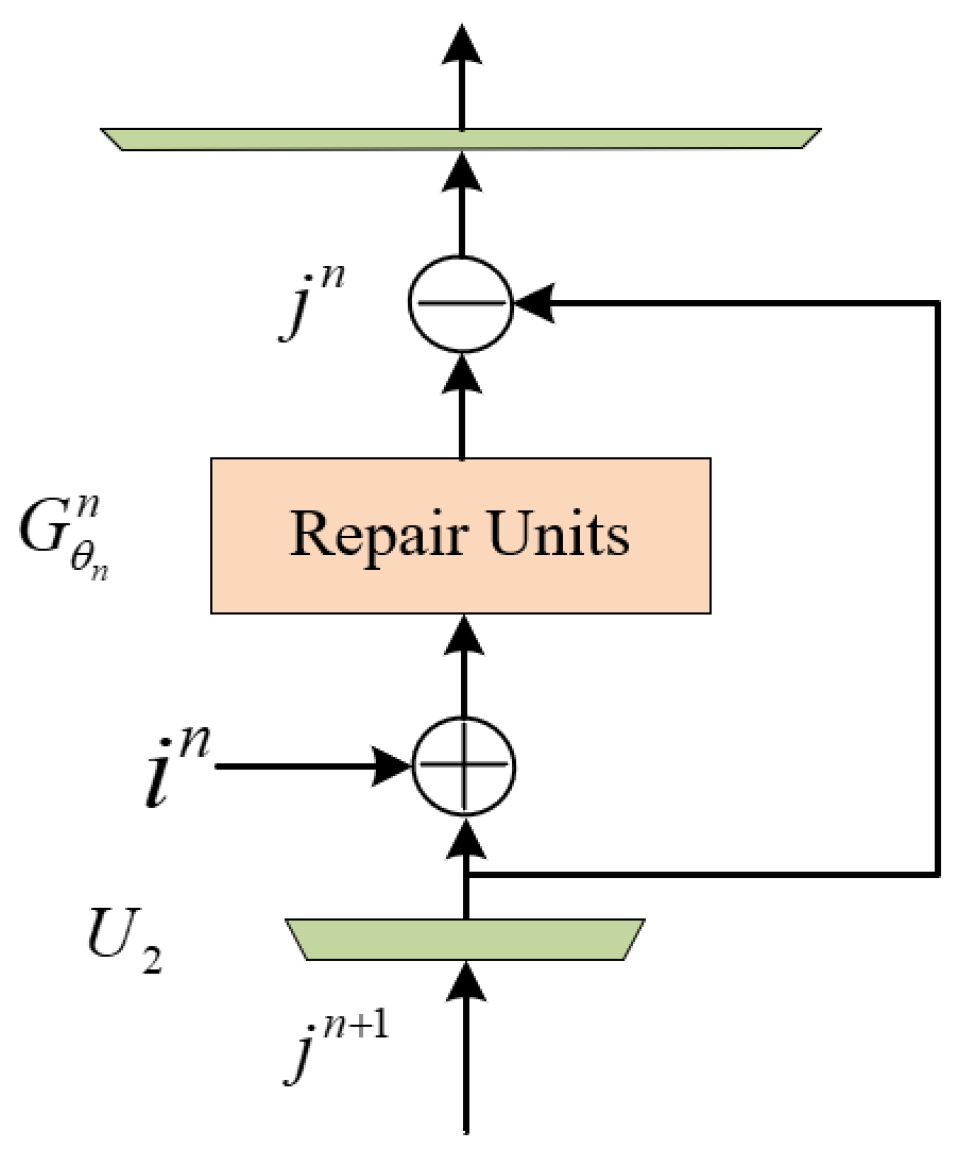
3.2. Multiple Attention Module
3.3. Multiple Attention Module
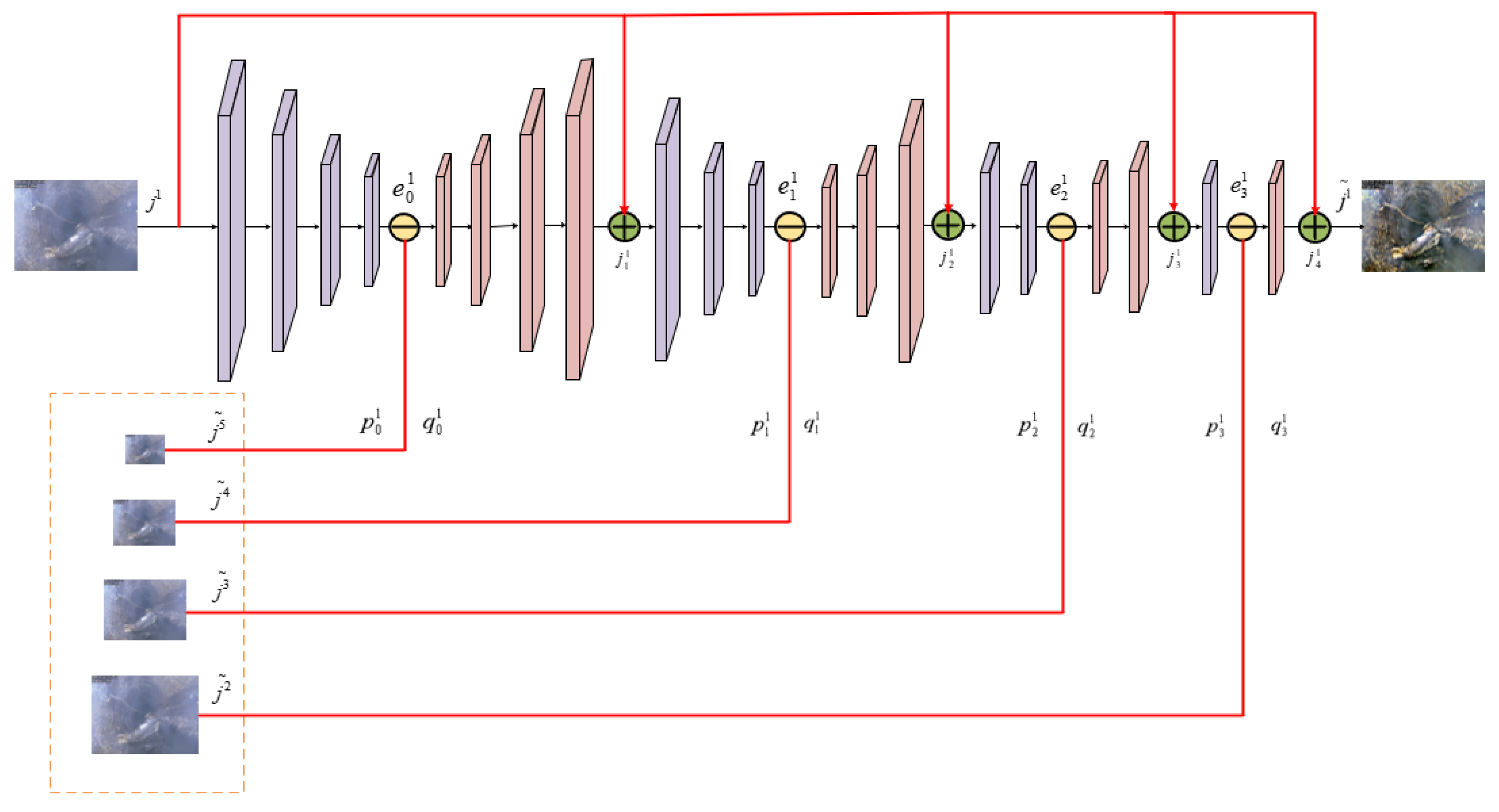
- Calculate the difference between and at the t-th iteration using Equation (2). Among them, represents the projection operator, which downsamples the enhanced feature to the same dimension as the fused feature ;
- 2.
- Use the back-projection difference to update and calculate according to Equation (3). Among them, represents the back-projection operator, which upsamples the difference of the previous iteration to the same dimension as the fused feature ;
- 3.
- All previous fusion features are iteratively processed to obtain the final fusion features .
- 4.
- Similarly, the MSFFM module at the encoder level can be defined using Equation (4):
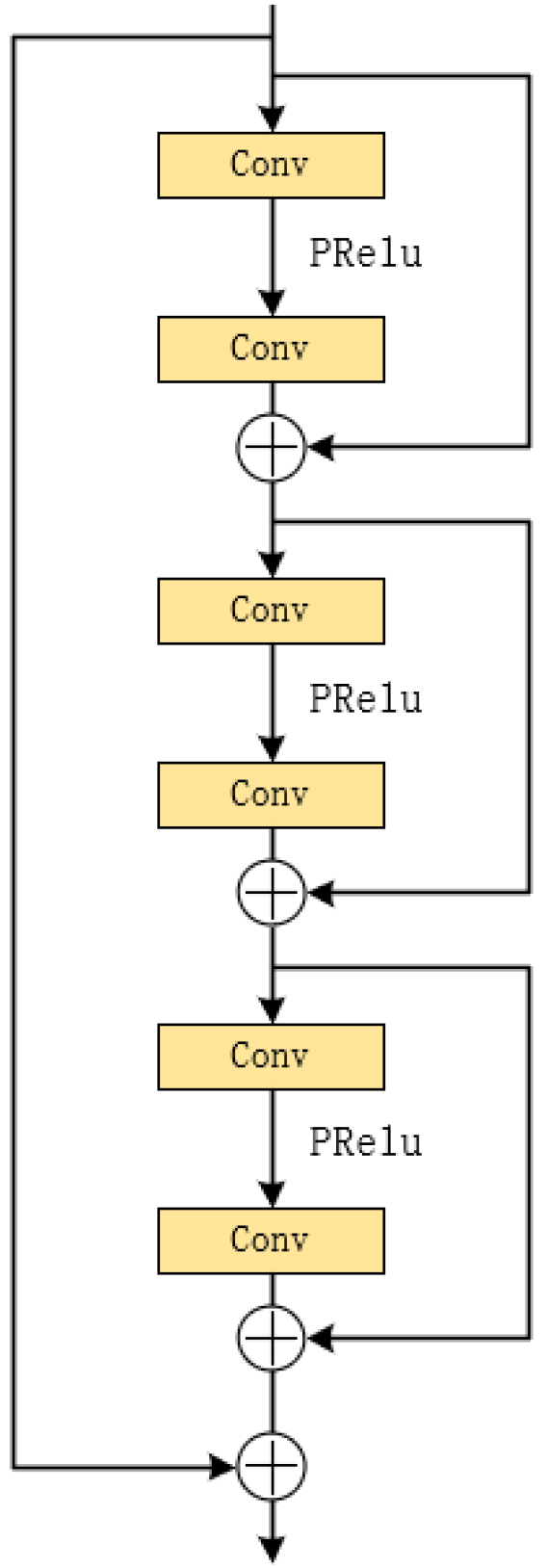
3.4. Multi-Scale Feature Enhancement Module
4. Discussion and Analysis of Experimental Results
4.1. Drainage Pipe Data Set
- Collect clear images: Use the high-definition camera mounted on the pipeline robot to capture clear images in various scenarios.
- Train the deep learning model: Use the collected clear images to train the deep learning model and extract scene features.
- Generate hazy images: Based on the trained model and atmospheric scattering model, simulate the haze effects of different concentrations to generate hazy images, as shown in Figure 9.
- Analysis and evaluation: Perform quality assessment and analysis on the generated hazy images and explore the impact of different haze concentrations on image quality.
4.2. Implementation Process
4.3. Performance Analysis
4.4. Subjective Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, D.; Tan, J.; Peng, S.; Zhong, Z.; Chen, G.; Li, G. Intelligent identification system of drainage pipelines defects based on deep learning model. Bull. Surv. Mapp. 2021, 141–145. [Google Scholar]
- Wang, H.; Zhang, Y.; Shen, H.; Zhang, J. Review of image enhancement algorithms. Chin. Opt. 2017, 10, 438–448. [Google Scholar] [CrossRef]
- Shi, Z.; Zhu, J.; Yang, W.; Wang, X.; Huang, H. Research on Cloud Processing Method of Solar Flare Area in Remote Sensing Images. J. Beijing Electron. Sci. Technol. Inst. 2018, 26, 46–52. [Google Scholar]
- Li, X. Research and Application of Image dehazing and Enhancement Technology. Master’s Thesis, Qilu University of Technology, Jinan, China, 2019. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7313–7322. [Google Scholar]
- Shugar, D.H.; Jacquemart, M.; Shean, D.; Bhushan, S.; Upadhyay, K.; Sattar, A.; Schwanghart, W.; McBride, S.; de Vries, M.V.W.; Mergili, M.; et al. A massive rock and ice avalanche caused the 2021 disaster at Chamoli, Indian Himalaya. Science 2021, 373, 300–306. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Sun, X.; Chen, Y.; Duan, Y.; Wang, Y. Single-Image Dehazing Algorithm Based on Improved Cycle-Consistent Adversarial Network. Electronics 2023, 12, 2186. [Google Scholar] [CrossRef]
- Zhu, Q.S.; Mai, J.M.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed]
- Berman, D.; Treibitz, T.; Avidan, S. Single Image Dehazing Using Haze-Lines. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 3, 720–734. [Google Scholar] [CrossRef]
- He, T.; Li, C.; Liu, R.; Wang, X.; Sheng, L. Pipeline Image Dehazing Algorithm Based on Atmospheric Scattering Model and Multi-Scale Retinex Strategy. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems and Artificial Intelligence (ICUSAI), Xi’an, China, 22–24 November 2019; pp. 120–124. [Google Scholar]
- Agrawal, A.; Raskar, R.; Chellappa, R. Edge suppression by gradient field transformation using cross-projection tensors. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2301–2308. [Google Scholar]
- Wu, D.; Velten, A.; O’toole, M.; Masia, B.; Agrawal, A.; Dai, Q.; Raskar, R. Decomposing global light transport using time of flight imaging. Int. J. Comput. Vis. 2014, 107, 123–138. [Google Scholar] [CrossRef]
- Muhuri, A.; Goïta, K.; Magagi, R.; Wang, H. Geodesic distance based scattering power decomposition for compact polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004412. [Google Scholar] [CrossRef]
- Yang, F.; Tang, S. Adaptive Tolerance Dehazing Algorithm Based on Dark Channel Prior. Algorithms 2020, 13, 45. [Google Scholar] [CrossRef]
- Yang, J.; Yang, J.; Luo, L.; Wang, Y.; Wang, S.; Liu, J. Robust Visual Recognition in Poor Visibility Conditions: A Prior Knowledge-Guided Adversarial Learning Approach. Electronics 2023, 12, 3711. [Google Scholar] [CrossRef]
- Tian, E.; Kim, J. Improved Vehicle Detection Using Weather Classification and Faster R-CNN with Dark Channel Prior. Electronics 2023, 12, 3022. [Google Scholar] [CrossRef]
- Zheng, M.; Luo, W. Underwater image enhancement using improved CNN based dehazing. Electronics 2022, 11, 150. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 154–169. [Google Scholar]
- He, Z.; Patel, V.M. Densely Connected Pyramid Dehazing Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Liu, R.; Fan, X.; Hou, M.; Jiang, Z.; Luo, Z.; Zhang, L. Learning aggregated transmission propagation networks for haze removal and beyond. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 2973–2986. [Google Scholar] [CrossRef]
- Qian, W.; Zhou, C.; Zhang, D. CIASM-Net: A novel convolutional neural network for dehazing image. In Proceedings of the 2020 5th International Conference on Computer and Communication Systems (ICCCS), Shanghai, China, 15–18 May 2020; pp. 329–333. [Google Scholar]
- Ma, J.; Yu, W.; Chen, C.; Liang, P.; Guo, X.; Jiang, J. Pan-GAN: An unsupervised pan-sharpening method for remote sensing image fusion. Inf. Fusion 2020, 62, 110–120. [Google Scholar] [CrossRef]
- Engin, D.; Genç, A.; Kemal Ekenel, H. Cycle-dehaze: Enhanced cyclegan for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 825–833. [Google Scholar]
- Zhu, Y.; Newsam, S. Densenet for dense flow. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 790–794. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings Part III 18. Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Shahin, A.I.; Aly, W.; Aly, S. MBTFCN: A novel modular fully convolutional network for MRI brain tumor multi-classification. Expert Syst. Appl. 2023, 212, 118776. [Google Scholar] [CrossRef]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Wei, W.; Li, C.; Li, S.; Chen, Z.; Yang, F. SewerOD: A visual sewer disease detection dataset for machine learning. J. Phys. Conf. Series 2023, 2646, 012011. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Setiadi, D.R.I.M. PSNR vs SSIM: Imperceptibility quality assessment for image steganography. Multimed. Tools Appl. 2021, 80, 8423–8444. [Google Scholar] [CrossRef]
- Wang, S.; Rehman, A.; Wang, Z.; Ma, S.; Gao, W. SSIM-motivated rate-distortion optimization for video coding. IEEE Trans. Circuits Syst. Video Technol. 2011, 22, 516–529. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Methods/Techniques | Main Contributions/Features | Application Effect in Drainage Pipes | PSNR/SSIM |
|---|---|---|---|---|
| [11] | Combining dark channel prior with multi-scale Retinex strategy | Improved dark channel prior dehazing effect and enhanced color recovery | Performs well in some scenarios but is sensitive to certain atmospheric conditions | 27.74/0.88 |
| [12] | Cross-projected tensor gradient field transformation | Powerful edge protection capabilities to avoid loss of details | Suitable for scenarios that require high edge information | \ |
| [13] | Global light transport decomposition for time-of-flight imaging | Improve the dehazing effect by obtaining depth information | Suitable for scenes that require depth information | \ |
| [14] | Scattering power decomposition based on geodesic distance | Understand the characteristics of image components and distinguish haze from real scenes | Currently not directly applied to haze correction, but has potential value | \ |
| [17] | Dense pyramid defogging network | Estimating transmittance and atmospheric light values using subnetworks | Produces haze-free images with higher quality, but may be more computationally complex | \ |
| [18] | AOD-Net | Combine transmittance and atmospheric light into a single variable to simplify the training process | The restoration result is overall darker and needs further adjustment | 24.14/0.92 |
| [20] | DehazeNet | Learn the mapping relationship between foggy images and projection images | Improved defogging effect, but may be limited by training data | 23.16/0.82 |
| [21] | Multi-scale convolutional neural network | Improve dehazing performance through multi-scale features | Suitable for a variety of scenarios, but may require further optimization | 21.32/0.85 |
| [22] | Image enhancement using generative adversarial networks | Ability to extract more details from input images and improve brightness and contrast | Suitable for a variety of image enhancement tasks, but may require specific optimization in dehazing tasks | 21.56/0.86 |
| [23] | Direct end-to-end network | Generate haze-free images directly from hazy images | Simplified dehazing process, but may need to be optimized for pipeline scenarios | 30.16/0.93 |
| [25] | CIASM-Net | Including color feature extraction and deep dehazing sub-network | Improving transmittance estimation accuracy through multi-scale convolution | 21.26/0.85 |
| Our research team | Multi-scale adaptive feature network based on multiple attention | Utilize multiple attention mechanisms and multi-scale feature fusion to improve the dehazing effect | Achieve superior dehazing and preserve detail in sewer environments | 39.87/0.98 |
| Method | DCP | DehazeNet | AOD-Net | MSBDN | Ours |
|---|---|---|---|---|---|
| PSNR | 25.74 | 27.86 | 28.98 | 33.50 | 39.87 |
| SSIM | 0.759 | 0.797 | 0.859 | 0.926 | 0.988 |
| Method | MSBDN | MSBDN + DAU | MSBDN + MSFFM | Ours |
|---|---|---|---|---|
| PSNR | 33.50 | 34.28 | 38.86 | 39.87 |
| SSIM | 0.926 | 0.954 | 0.985 | 0.988 |
| Method | DarkChannel | DehazeNet | AOD-Net | MSCNN | MSBDN | Ours |
|---|---|---|---|---|---|---|
| Average Time | 26.90 | 7.02 | 3.23 | 1.34 | 1.10 | 1.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Tang, Z.; Qiao, J.; Su, C.; Yang, F. Multi-Scale Adaptive Feature Network Drainage Pipe Image Dehazing Method Based on Multiple Attention. Electronics 2024, 13, 1406. https://doi.org/10.3390/electronics13071406
Li C, Tang Z, Qiao J, Su C, Yang F. Multi-Scale Adaptive Feature Network Drainage Pipe Image Dehazing Method Based on Multiple Attention. Electronics. 2024; 13(7):1406. https://doi.org/10.3390/electronics13071406
Chicago/Turabian StyleLi, Ce, Zhengyan Tang, Jingyi Qiao, Chi Su, and Feng Yang. 2024. "Multi-Scale Adaptive Feature Network Drainage Pipe Image Dehazing Method Based on Multiple Attention" Electronics 13, no. 7: 1406. https://doi.org/10.3390/electronics13071406