
Detection System Based on Text Adversarial and Multi-Information Fusion for Inappropriate Comments in Mobile Application Reviews

Abstract
:1. Introduction
- We introduce a novel dataset of Chinese app reviews, marking the first comprehensive and realistic training resource for developing tools to detect inappropriate Chinese reviews.
- We propose a data enhancement strategy using adversarial text to address the imbalance problem and improve model generalizability.
- We offer a multi-information fusion technique that enables developers to leverage the strengths of various deep learning models, thereby increasing detection accuracy and system robustness.
- We develop a standalone model based on Chinese bidirectional encoder representations from transformers (BERTs), presenting a unique solution to the problem of detecting inappropriate Chinese comments.
2. Related Works
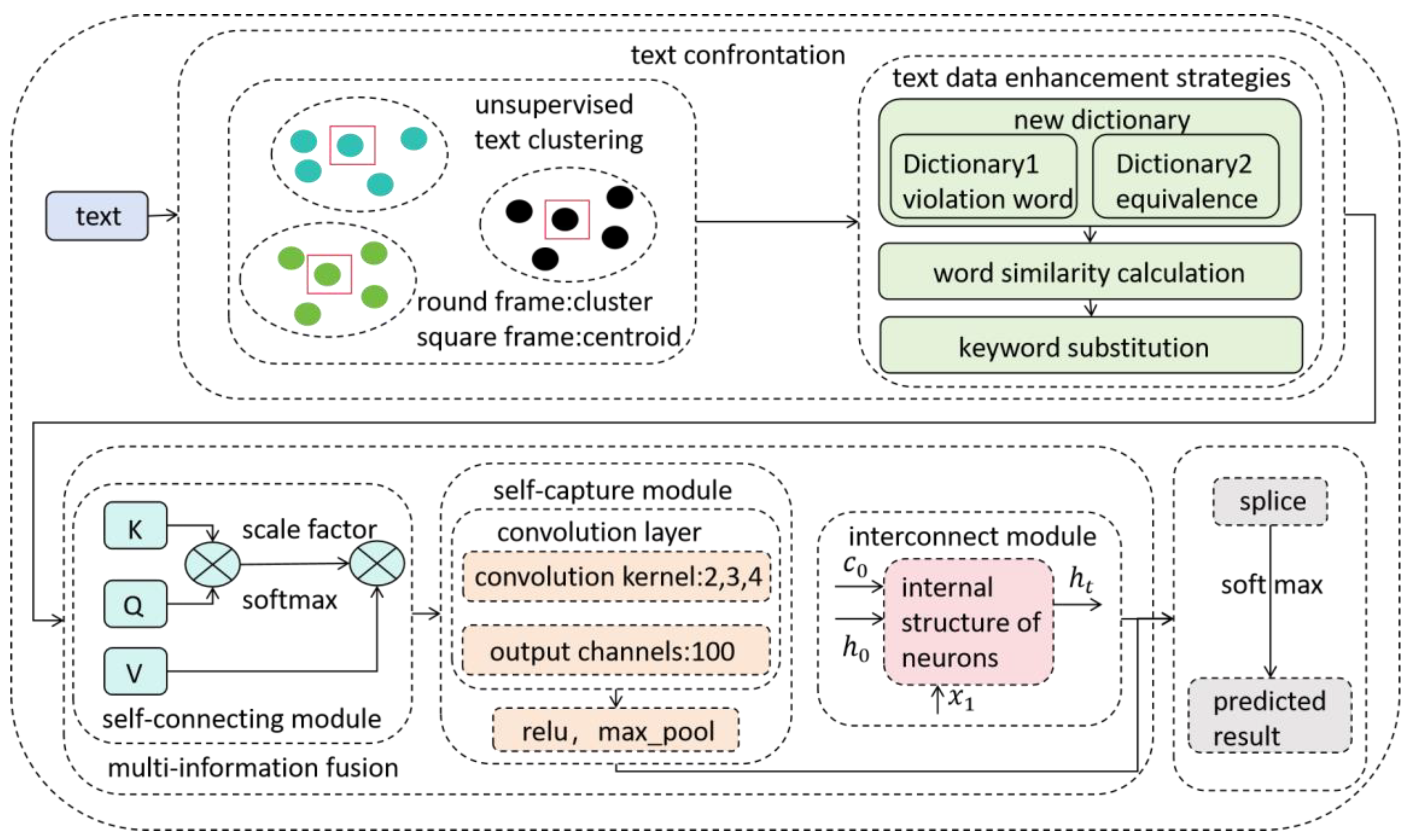
3. Methods
3.1. Overview
3.2. Text Confrontation Method
3.2.1. Unsupervised Text Clustering of Comment Content Features

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emoticons | The Actual Meanings or Interpretations |
|---|---|
 | can, pronunciation: kě |
 | penguin, pronunciation: qǐ é |
 | telephone, pronunciation: diàn huà |
 | money, pronunciation: qián |
 | micro, pronunciation: wēi |
 | red envelope, pronunciation: hóng bāo |
 | fresh flowers, pronunciation: xiān huā |
 | point to, pronunciation: zhǐ xiàng |
 | mouth, pronunciation: zuǐ bā |
 | have, pronunciation: yǒu |
 | heart, pronunciation: ài xīn |
3.2.2. Text Enhancement Strategy Based on Sensitive Word Confrontation
| Original Word | Original Word Splitting Result | Dictionary Word | Dictionary Word Splitting Result | Similarity | Whether to Replace? | Replacement Word Examples |
|---|---|---|---|---|---|---|
| 薇 (WeChat, pronunciation: wēi) | 艹(cǎo),彳(chì),山(shān),兀(wù),攴(pū) | 微 (micro, pronunciation: wēi) | 彳(chì),山(shān),兀(wù),攴(pū) | 0.8 | yes | 委 (entrust, pronunciation: wěi), 围(surround, pronunciation: wéi) et al. |
| 直播 (live broadcast, pronunciation: zhí bō) | 十(shí),囗(kǒu),二(èr),丨(gǔn),一(yī),手(shǒu),丿(piě),米(mǐ),田(tián) | 直拨 (direct dial, pronunciation: zhí bō) | 十(shí),囗(kǒu),二(èr),丨(gǔn),一(yī),手(shǒu),丿(piě),犮(bá) | 0.77 | yes | 紙箔 (foil paper, pronunciation: zhǐ bó), 之播(broadcast, pronunciation: zhǐ bó) et al. |
| 听 (listen, pronunciation: tīng) | 口(kǒu),斤(jīn) | 味 (taste, pronunciation: wèi) | 口(kǒu),一(yī),木(mù) | 0.33 | no | / |
| Original Sentence | New Sentence |
|---|---|
| 佳薇Q***23找我领取力拉 (Add WeChat Q***23, contact me to claim XXX reward) | 家維Q***23找另力拉 (maintenance Q***23, contact me for another XX reward.) |
| 骚女acg. **/k2看私密直播 ( Slut acg. **/k2 Watch Private Live Streaming) | 骚女acg. **/k2看司迷製播 ( Slut acg. **/k2 watch fan-made broadcasts) |
| 9***29 QQ 全网比较齐全的返利平台 (9***29 QQ The more complete rebate platform of the whole network) | 9***29 全网比较齐全的范例平台 (9***29 A more complete example of the platform of the whole network) |
3.3. Multi-Information Fusion
3.3.1. Self-Connecting Module
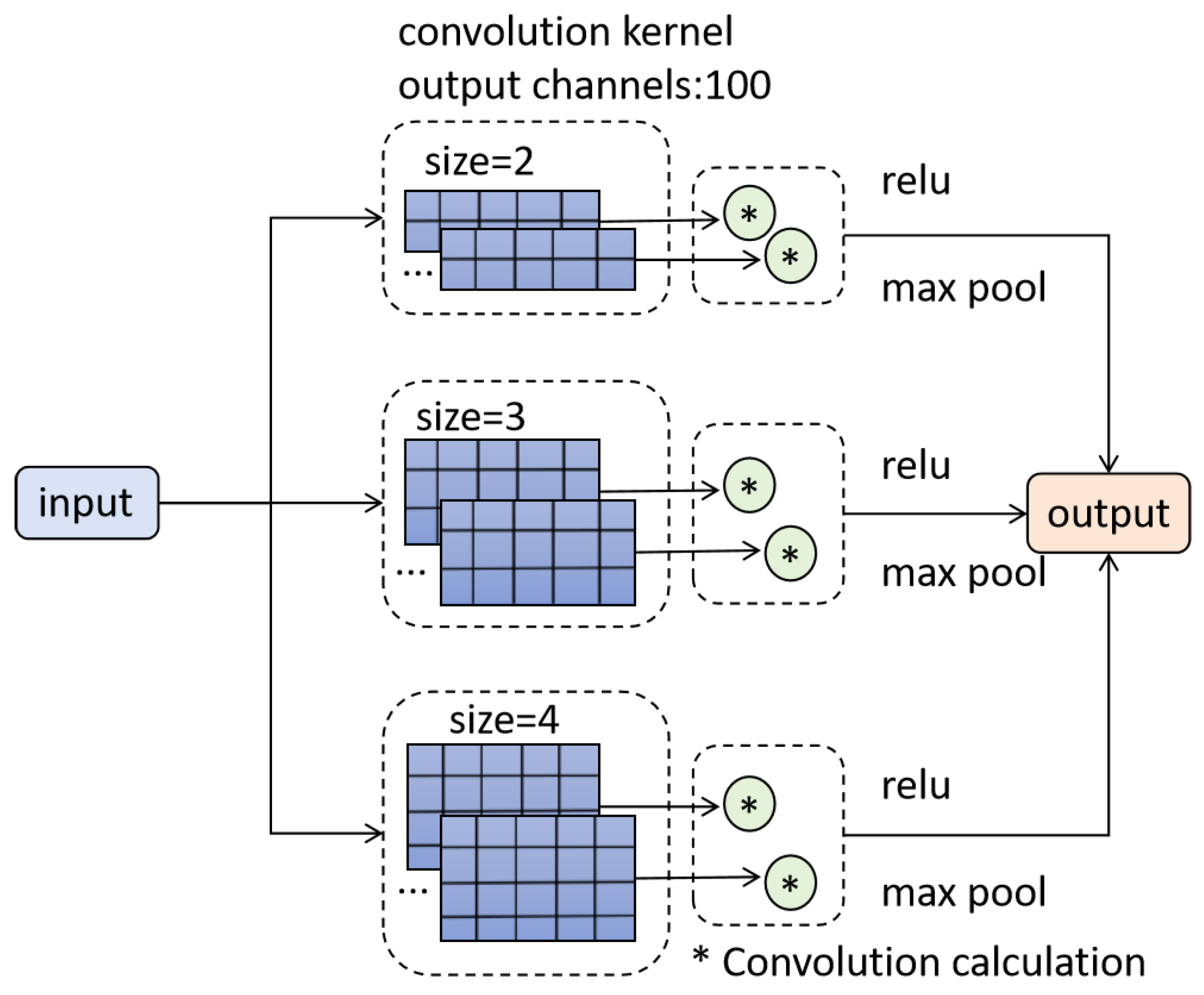
3.3.2. Self-Capture Module
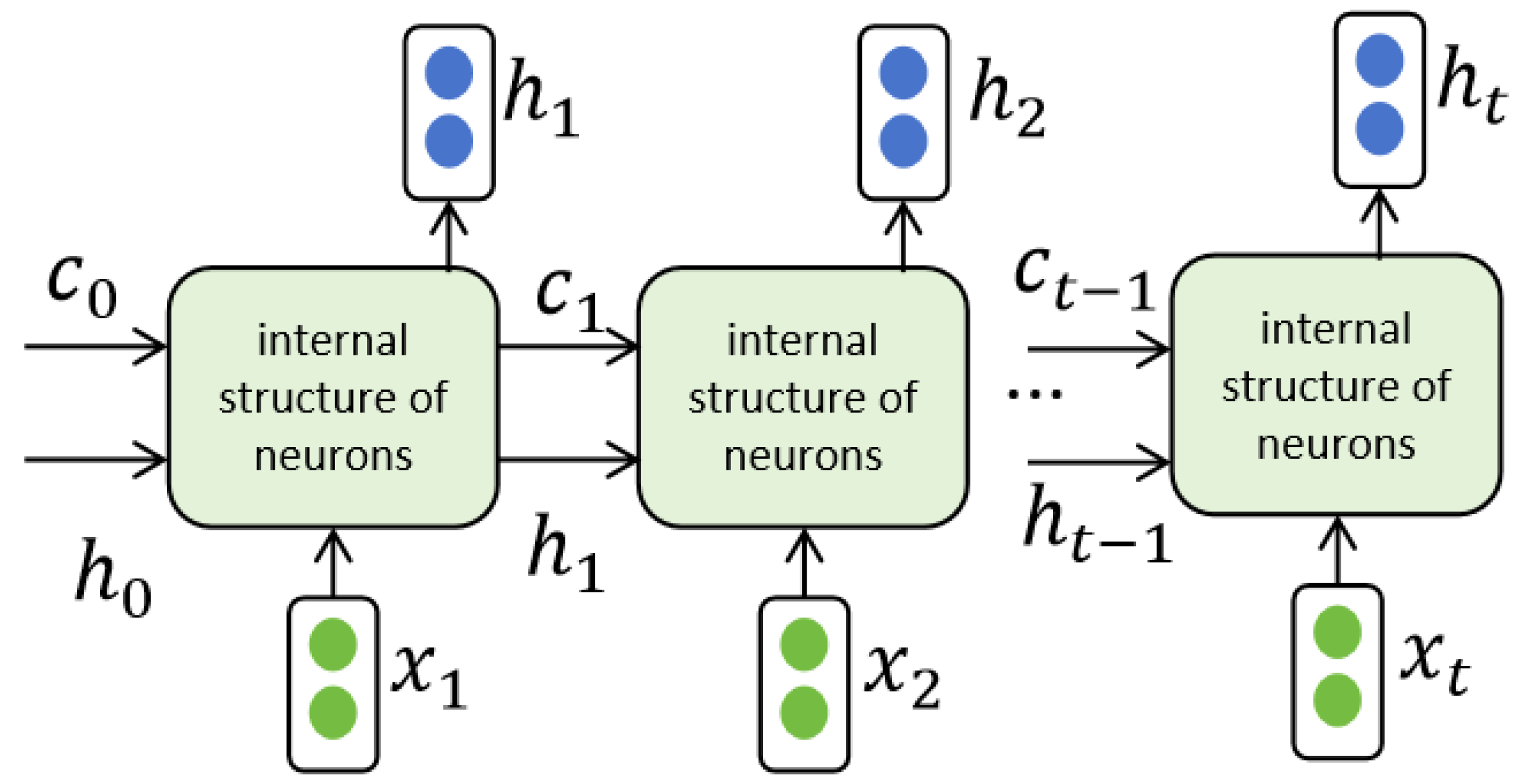
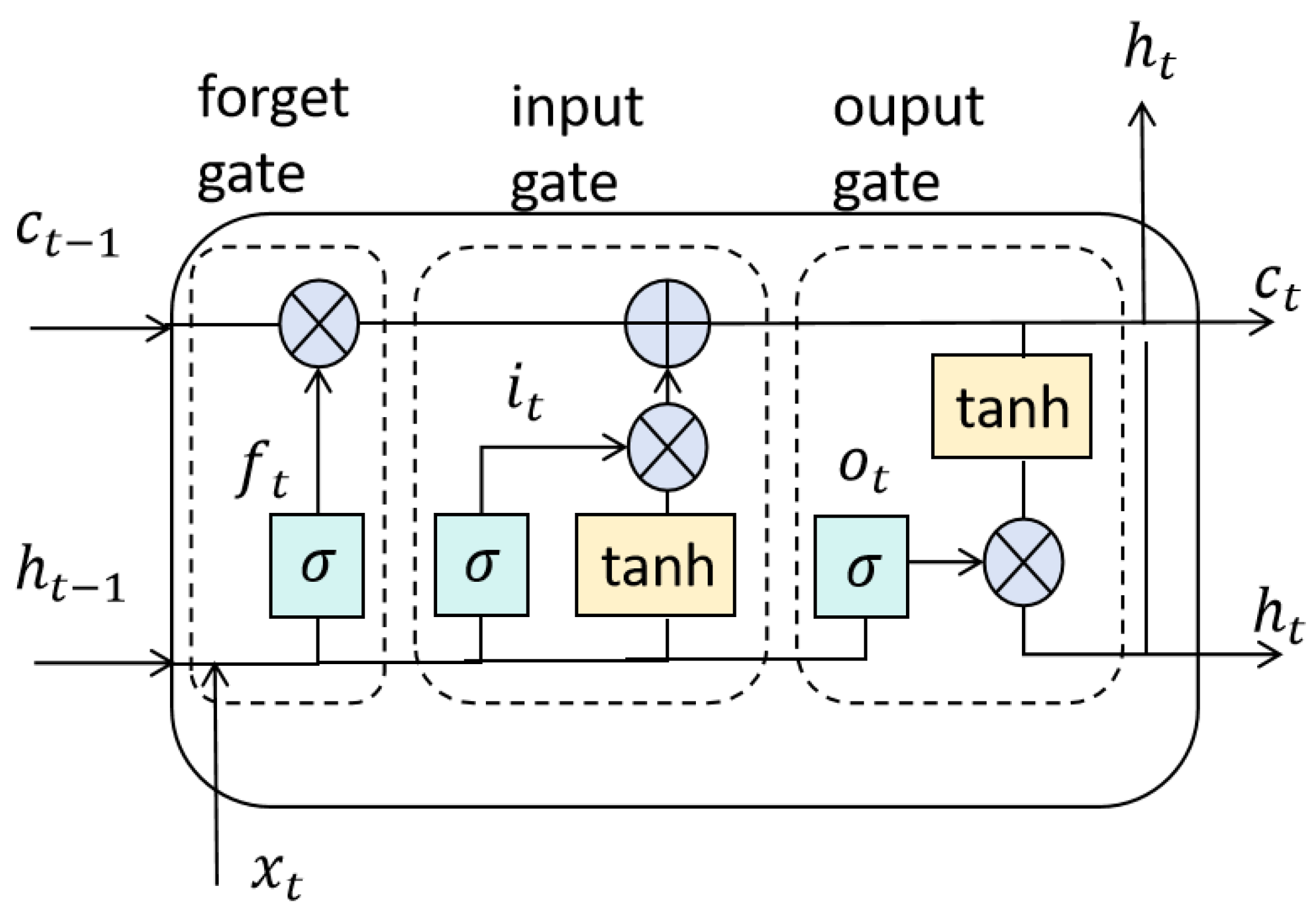
3.3.3. Interconnect Module
4. Experiment
4.1. Data Collection
- For each application, the review data encompass either 200 comments from both the earlier and later periods or fewer than 200 comments in the initial period with the subsequent period reaching 200 comments. Begin by calculating the number of new reviews in the subsequent period for the application and incorporate this into the review data from the earlier period. The review from the earlier period should then be extended in a sequence, and any reviews exceeding the 200 mark, after sorting, are excluded. Subsequently, conduct a one-by-one comparison of this sequentially extended review order against the review data from the earlier period during the subsequent time frame to obtain the deleted reviews.
- If the review data for the application are insufficient to reach 200 comments in both the earlier and later time periods, a direct comparison between these periods is feasible. In case the reviews present in the earlier period are missing in the later period, this absence signals their deletion.
4.2. Description of Dataset Structure
4.3. Dataset Division
- Without data augmentation and without introducing the adversarial text component, all data were randomly split into training and testing sets at a ratio of 7:3.
- No data augmentation was performed, but the adversarial text component was incorporated. In this case, both the categories with a small number of inappropriate reviews and the categories with a significant number of inappropriate reviews, as well as the compliant reviews, were allocated to the training and testing sets at a ratio of 7:3.
- The complete experiment was conducted with data augmentation. For the categories with a small number of inappropriate reviews, they were first split into training and testing sets at a ratio of 7:3. Subsequently, for the reviews assigned to the training set, data augmentation techniques were employed to generate two additional new reviews for each original review, thereby expanding the dataset. The categories with a significant number of inappropriate reviews and the compliant reviews were still split at a ratio of 7:3.
4.4. Parameter Setting
4.5. Experimental Performance Indicators
4.6. Baseline Experimental Model
4.7. Experimental Outcomes
4.7.1. Comparison Experiment
| Methods | Accuracy | Recall |
|---|---|---|
| BERT [26] | 0.893 | 0.916 |
| ROBERT [29] | 0.871 | 0.910 |
| Chinese-BERT [28] | 0.923 | 0.936 |
| gzip [30] | 0.906 | 0.913 |
| blend net (our method) | 0.940 | 0.953 |
| Method | Accuracy | Recall |
|---|---|---|
| BERT [26] | 0.930 | 0.919 |
| ROBERT [29] | 0.926 | 0.773 |
| Chinese-BERT [28] | 0.940 | 0.937 |
| gzip [30] | 0.937 | 0.910 |
| blend net (our method) | 0.961 | 0.954 |
| Method | Accuracy | Recall |
|---|---|---|
| BERT [26] | 0.950 | 0.931 |
| ROBERT [29] | 0.933 | 0.767 |
| Chinese-BERT [28] | 0.969 | 0.966 |
| gzip [30] | 0.960 | 0.929 |
| blend net (our method) | 0.984 | 0.988 |
4.7.2. Ablation Experiments
| Methods | Accuracy | Recall |
|---|---|---|
| base model + interconnect module | 0.970 | 0.975 |
| base model + self-connecting module | 0.973 | 0.972 |
| base model + self-capture module | 0.971 | 0.968 |
| base model + interconnect module + self-capture module | 0.982 | 0.977 |
| base model + interconnect module + self-connecting module | 0.976 | 0.981 |
| base model + self-capture module + self-connecting module | 0.979 | 0.983 |
| base model + interconnect module + self-capture module + self-connecting module (our method) | 0.984 | 0.988 |
5. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Bai, B.; Lin, Y.; Liang, J.; Bai, K.; Wang, F. General-purpose user embeddings based on mobile app usage. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery Data Mining, Virtual Event, 6–10 July 2020; pp. 2831–2840. [Google Scholar] [CrossRef]
- Kim, A.R.; Brazinskas, A.; Suhara, Y.; Wang, X.; Liu, B. Beyond opinion mining: Summarizing opinions of customer reviews. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 3447–3450. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, W.; Chen, S. An aspect-based semi-supervised generative model for online review spam detection. In Ubiquitous Security. UbiSec 2022. Communications in Computer and Information Science; Wang, G., Choo, K.K.R., Wu, J., Damiani, E., Eds.; Springer: Singapore, 2023; Volume 1768, pp. 207–219. [Google Scholar] [CrossRef]
- Poojitha, K.; Charish, A.S.; Reddy, M.; Ayyasamy, S. Classification of social media toxic comments using machine learning models. arXiv 2023, arXiv:2304.06934. [Google Scholar] [CrossRef]
- Sarker, J.; Sultana, S.; Wilson, S.R.; Bosu, A. ToxiSpanSE: An explainable toxicity detection in code review comments. In Proceedings of the ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), New Orleans, LA, USA, 26–27 October 2023; pp. 1–12. [Google Scholar] [CrossRef]
- He, L.; Wang, X.; Chen, H.; Xu, G. Online spam review detection: A survey of literature. Hum. Cent. Intell. Syst. 2022, 2, 14–30. [Google Scholar] [CrossRef]
- Barrientos, G.M.; Alaiz-Rodríguez, R.; González-Castro, V.; Parnell, A.C. Machine learning techniques for the detection of inappropriate erotic content in text. Int. J. Comput. Intell. Syst. 2020, 13, 591–603. [Google Scholar] [CrossRef]
- Sifat, H.R.; Sabab, N.H.N.; Ahmed, T. Evaluating the effectiveness of capsule neural network in toxic comment classification using pre-trained BERT embeddings. In Proceedings of the TENCON IEEE Region 10 Conference (TENCON), Chiang Mai, Thailand, 31 October–3 November 2023; pp. 42–46. [Google Scholar] [CrossRef]
- Shringi, S.; Sharma, H. Detection of spam reviews using hybrid grey wolf optimizer clustering method. Multimed. Tools Appl. 2022, 81, 38623–38641. [Google Scholar] [CrossRef]
- Raj, A.; Susan, S. Clustering Analysis for Newsgroup Classification. In Data Engineering and Intelligent Computing: Proceedings of 5th ICICC 2021; Springer Nature Singapore: Singapore, 2022; Volume 1, pp. 271–279. [Google Scholar]
- Gunawan, P.H.; Alhafidh, T.D.; Wahyudi, B.A. The sentiment analysis of spider-man: No way home film based on imdb reviews. J. RESTI (Rekayasa Sist. Dan Teknol. Inf.) 2022, 6, 177–182. [Google Scholar] [CrossRef]
- Saraiva, G.D.; Anchiêta, R.; Neto, F.A.; Moura, R. A semi-supervised approach to detect toxic comments. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), Online, 1–3 September 2021; pp. 1261–1267. [Google Scholar] [CrossRef]
- Lu, J.; Xu, B.; Zhang, X.; Min, C.; Yang, L.; Lin, H. Facilitating fine-grained detection of Chinese toxic language: Hierarchical taxonomy, resources, and benchmarks. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 4–9 July 2023; pp. 16235–16250. [Google Scholar] [CrossRef]
- Zhang, B.; Zhou, W. Transformer-encoder-GRU (TE-GRU) for Chinese sentiment analysis on Chinese comment text. Neural Process. Lett. 2023, 55, 1847–1867. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, J. The evolution of Chinese grammar from the perspective of language contact. In the Palgrave HANDBOOK of Chinese Language Studies; Springer Nature Singapore: Singapore, 2022; pp. 333–367. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; pp. 512–515. [Google Scholar] [CrossRef]
- Schmidt, A.; Wiegand, M. A survey on hate speech detection using natural language processing. In Proceedings of the 5th International Workshop on Natural Language Processing for Social Media, Valencia, Spain, 3 April 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, B. Toxic comment classification based on bidirectional gated recurrent unit and convolutional neural network. ACM Trans. Asian Low Res. Lang Inform. Proc. 2021, 21, 1–12. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, Z.; Hopfgartner, F. A comparative study of using pretrained language models for toxic comment classification. In Proceedings of the Companion Proceedings of the Web Conference 2021 (WWW ’21 Companion), Ljubljana, Slovenia, 19–23 April 2021; pp. 500–507. [Google Scholar] [CrossRef]
- Saumya, S.; Singh, J.P. Spam review detection using LSTM autoencoder: An unsupervised approach. Electron. Com. Res. 2022, 22, 113–133. [Google Scholar] [CrossRef]
- Maurya, S.K.; Singh, D.; Maurya, A.K. Deceptive opinion spam detection approaches: A literature survey. Appl. Intell. 2023, 53, 2189–2234. [Google Scholar] [CrossRef]
- Fahfouh, A.; Riffi, J.; Mahraz, M.A.; Yahyaouy, A.; Tairi, H. A contextual relationship model for deceptive opinion spam detection. IEEE Trans. Neural. Netw. Learn. Syst. 2022, 35, 1228–1239. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Hu, Z.; Zhu, G.; Jin, M.; Li, K.C. Sentiment classification model for Chinese micro-blog comments based on key sentences extraction. Soft Comput. 2021, 25, 463–476. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, Z. Character-level Chinese toxic comment classification algorithm based on CNN and Bi-GRU. In Proceedings of the 5th International Conference on Computer Science and Software Engineering, Guilin, China, 21–23 October 2022; pp. 108–114. [Google Scholar] [CrossRef]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pretraining text encoders as discriminators rather than generators. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020; pp. 1–14. [Google Scholar]
- Kenton, J.D.; Toutanova, L.K. BERT: Pretraining of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, Minnesota, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Feng, L. Research on the Formation of Chinese Characters. J. Neuro Spine 2023, 1, 1–15. [Google Scholar]
- Sun, Z.; Li, X.; Sun, X.; Meng, Y.; Ao, X.; He, Q.; Wu, F.; Li, J. ChineseBERT: Chinese pretraining enhanced by glyph and pinyin information. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Virtual, 1–6 August 2021; pp. 2065–2075. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewins, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Jiang, Z.; Yang, M.; Tsirlin, M.; Tang, R.; Dai, Y.; Lin, J. Low-resource text classification: A parameter-free classification method with compressors. Find. Assoc. Comp. Linguist. 2023, 6810–6828. [Google Scholar] [CrossRef]





| Emoticons | Obvious Punctuation Marks | Other |
|---|---|---|
| , , , , etc. | +,《,!!,》,● | Two consecutive numeric characters, for example |
| Dictionary 1 | Dictionary 2 |
|---|---|
| 出接 (lend, pronunciation: chū jiē), 薇 (WeChat, pronunciation: wēi), 佳 (Contact, pronunciation: jiā), 福利 (welfare, pronunciation: fú lì), 魏欣 (WeChat, pronunciation: Wèi Xīn), 淇牌 (chess, pronunciation: Qí Pái), etc. | v = 薇 (WeChat, pronunciation: wēi) = 微 (micro, pronunciation: wēi) = = 微信 (WeChat, pronunciation: Wēi Xìn),= 企鹅 (penguin, pronunciation: Qǐ é) = qq, etc. |
| Category | Total Number of Samples (Items) | Proportion of Total Sample Number | Number of Violation Samples (Items) | Proportion of Illegal Samples |
|---|---|---|---|---|
| economy | 3606 | 13.6% | 169 | 12.9% |
| games | 14,690 | 55.5% | 925 | 71.0% |
| shopping | 4127 | 15.6% | 39 | 3.0% |
| social | 4020 | 15.3% | 168 | 13.1% |
| Economy | Games | Shopping | Social |
|---|---|---|---|
| 只要是苹果都可以借, 不看征信 v: cyt***5 (As long as it is an Apple, you can borrow it without looking at your credit report v; cyt***5) | 現唫\真人\琪牌❽❷*❽. me官网下栽树木流水 (Planting trees and running water under Xian Xinbi\zhenren\Qipai❽❷*❽. me official website) | +Q13***517套 信 用 卡ieuj ( +Q13***517 set of credit card ieuj) | 骚女t a** . c n看私密直播翅膀 (Hot girl t a ** . c n watch private live broadcast wings) |
| 纯私人出接 (Purely private pick-up) | 微 175***83 招拖包路费 (Micro 175***83 Recruitment and towing, including tolls) | 《取花貝jd白條等》看名字》我很喜欢先推荐下 ( Take Hua Bei JD Bai Tiao, etc. Look at the name. I like it very much and recommend it first.) | 騒㚢   点©©看俬密 点©©看俬密(Slut Point©©Kanfumi) |
| Methods | Accuracy | Recall |
|---|---|---|
| base model + interconnect module | 0.924 | 0.939 |
| base model + self-connecting module | 0.928 | 0.938 |
| base model + self-capture module | 0.926 | 0.938 |
| base model + interconnect module + self-capture module | 0.936 | 0.941 |
| base model + interconnect module + self-connecting module | 0.931 | 0.944 |
| base model + self-capture module + self-connecting module | 0.934 | 0.951 |
| base model + interconnect module + self-capture module + self-connecting module (our method) | 0.940 | 0.953 |
| Methods | Accuracy | Recall |
|---|---|---|
| base model + interconnect module | 0.942 | 0.942 |
| base model + self-connecting module | 0.950 | 0.940 |
| base model + self-capture module | 0.944 | 0.939 |
| base model + interconnect module + self-capture module | 0.959 | 0.945 |
| base model + interconnect module + self-connecting module | 0.952 | 0.949 |
| base model + self-capture module + self-connecting module | 0.957 | 0.951 |
| base model + interconnect module + self-capture module + self-connecting module (our method) | 0.961 | 0.954 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Z.; Jia, Y.; Hong, Z. Detection System Based on Text Adversarial and Multi-Information Fusion for Inappropriate Comments in Mobile Application Reviews. Electronics 2024, 13, 1432. https://doi.org/10.3390/electronics13081432
Yu Z, Jia Y, Hong Z. Detection System Based on Text Adversarial and Multi-Information Fusion for Inappropriate Comments in Mobile Application Reviews. Electronics. 2024; 13(8):1432. https://doi.org/10.3390/electronics13081432
Chicago/Turabian StyleYu, Zhicheng, Yuhao Jia, and Zhen Hong. 2024. "Detection System Based on Text Adversarial and Multi-Information Fusion for Inappropriate Comments in Mobile Application Reviews" Electronics 13, no. 8: 1432. https://doi.org/10.3390/electronics13081432