


DCGFuzz: An Embedded Firmware Security Analysis Method with Dynamically Co-Directional Guidance Fuzzing


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- How to establish a suitable firmware emulation environment. The problem includes the resolution of all peripheral devices and resetting their state to the required configuration for fuzzing. Additionally, a robust operating environment is necessary for successful fuzzing, and automation should be implemented throughout the execution process. This paper mainly considers rehosting methods, so the problem transforms into selecting the type of rehosting method and framework compatible with the overall algorithmic structure while maintaining high performance.
- How to allocate computing resources, i.e., what fuzzing methods to adopt. In software fuzzing, there are many different types of methods, such as bitmap-based [31], protocol state machine-based [32], DSE (Directed Symbolic Execution) [33], taint analysis, etc. However, many of these approaches are not particularly effective when applied to firmware. For example, Dynamic Symbolic Execution (DSE) is not directly suitable for firmware fuzzing [14], as DSE requires support from the running environment, necessitating extensive modifications to the firmware emulation framework.
- How to integrate fuzzing and rehosting processes effectively. We need to establish a unified statistical mechanism for allocating computational resources. This mechanism should aim to fulfill the requirements of fuzzing to discover as many paths as possible while also addressing the need for rehosting to uncover as many models as feasible. Furthermore, we must reduce computational resource wastage because firmware emulation is generally less efficient compared to desktop platforms like Windows, and the process of hardware abstraction modeling consumes significant resources. In this process, we need to design appropriate metrics and associated algorithms.
- We introduced new parameters and designed a new power schedule algorithm to dynamically and uniformly allocate computational resources for both fuzzing and rehosting. We calculate a score for each seed, taking into account both the performance of fuzzing and rehosting. Through this score, we determine the allocation of computational resources so that both fuzzing and rehosting can influence the direction of resource allocation. Additionally, we designed corresponding seed selection strategies to determine the priority of seeds.
- We designed a segmented seed scheduling strategy based on firmware characteristics to improve the allocation of computational resources. The seed scheduling strategy effectively tests high-value paths while preventing excessive testing of certain paths.
- We made significant algorithmic adjustments to the fuzzing framework and performed extensive compatibility work between the fuzzing and rehosting frameworks. Ultimately, we ensured that the overall framework ran smoothly and effectively.
- We validated our proposed method through experiments. Based on the experimental results, we discussed the effectiveness of our approach and proposed directions for future work.
2. Background
2.1. Fuzzing
2.1.1. Seed Schedule
2.1.2. AFL
2.2. Rehosting
2.2.1. Category
2.2.2. P2IM
- (1)
- Access Patterns: The emulator classifies the firmware’s access to memory into accesses to different registers based on the behavior patterns of the registers during operation.
- (2)
- Handling Strategies: The emulator sets different response methods according to the types of registers classified by the access patterns.
- (3)
- Interrupt Firing: The emulator stores interrupts as time-series-based inputs and triggers them at specified intervals.
2.3. Coverage
3. Methodology
3.1. Problem Definition
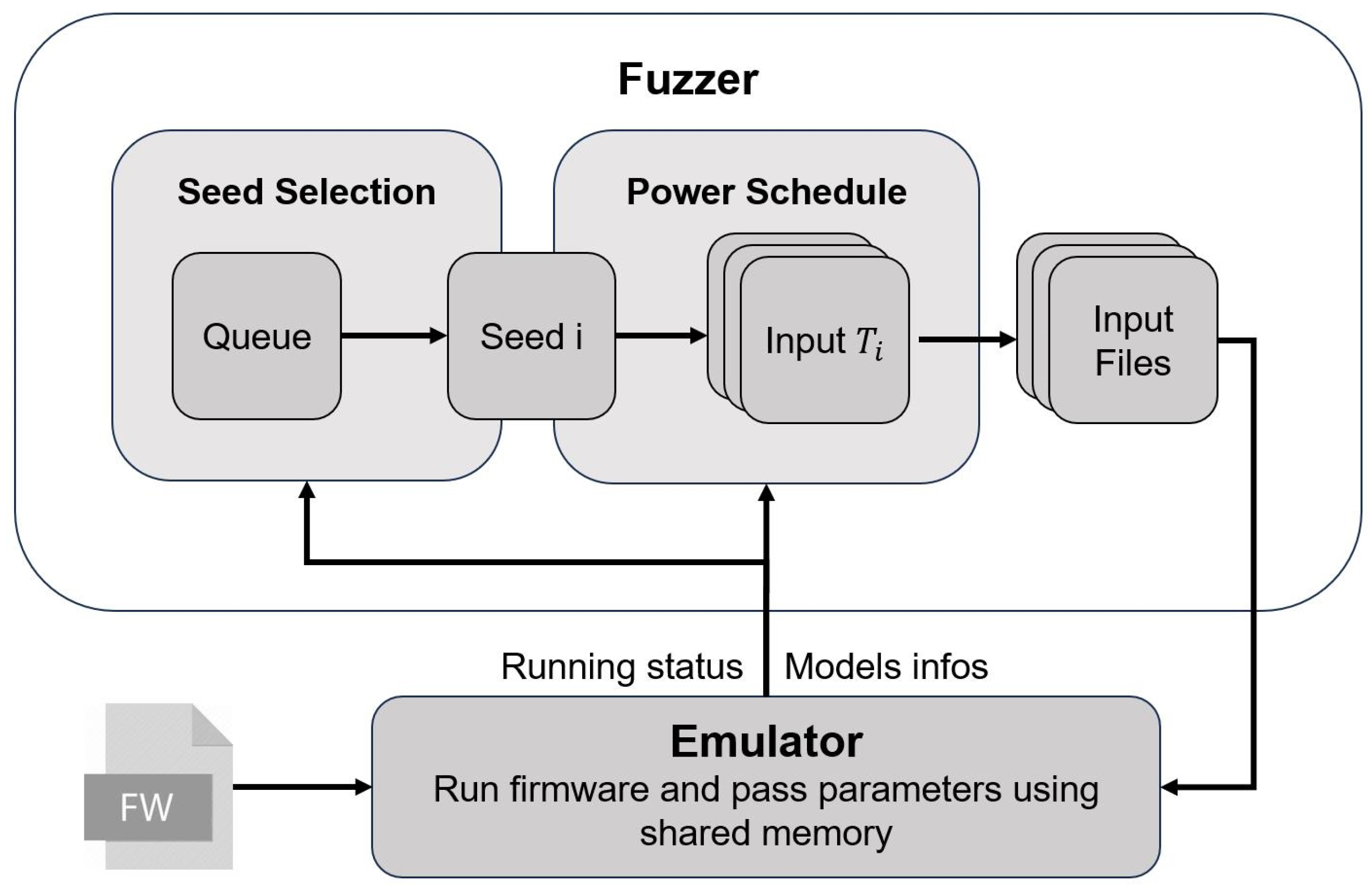
3.2. Framework Overview
3.3. Method Design Principles
3.3.1. Path-Coverage Task
3.3.2. Model-Coverage Task
3.4. Seed Schedule
| Algorithm 1 Seed Schedule |
|
3.5. Power Schedule
3.5.1. Path-Coverage Task
| Algorithm 2 PHASESWITCH() |
|
3.5.2. Model-Coverage Task
3.5.3. Edge Trimming
3.6. Seed Selection
3.6.1. Favorite Queue
3.6.2. Seed Splicing
| Algorithm 3 SPLICING() |
|
4. Evaluation
4.1. Experimental Design
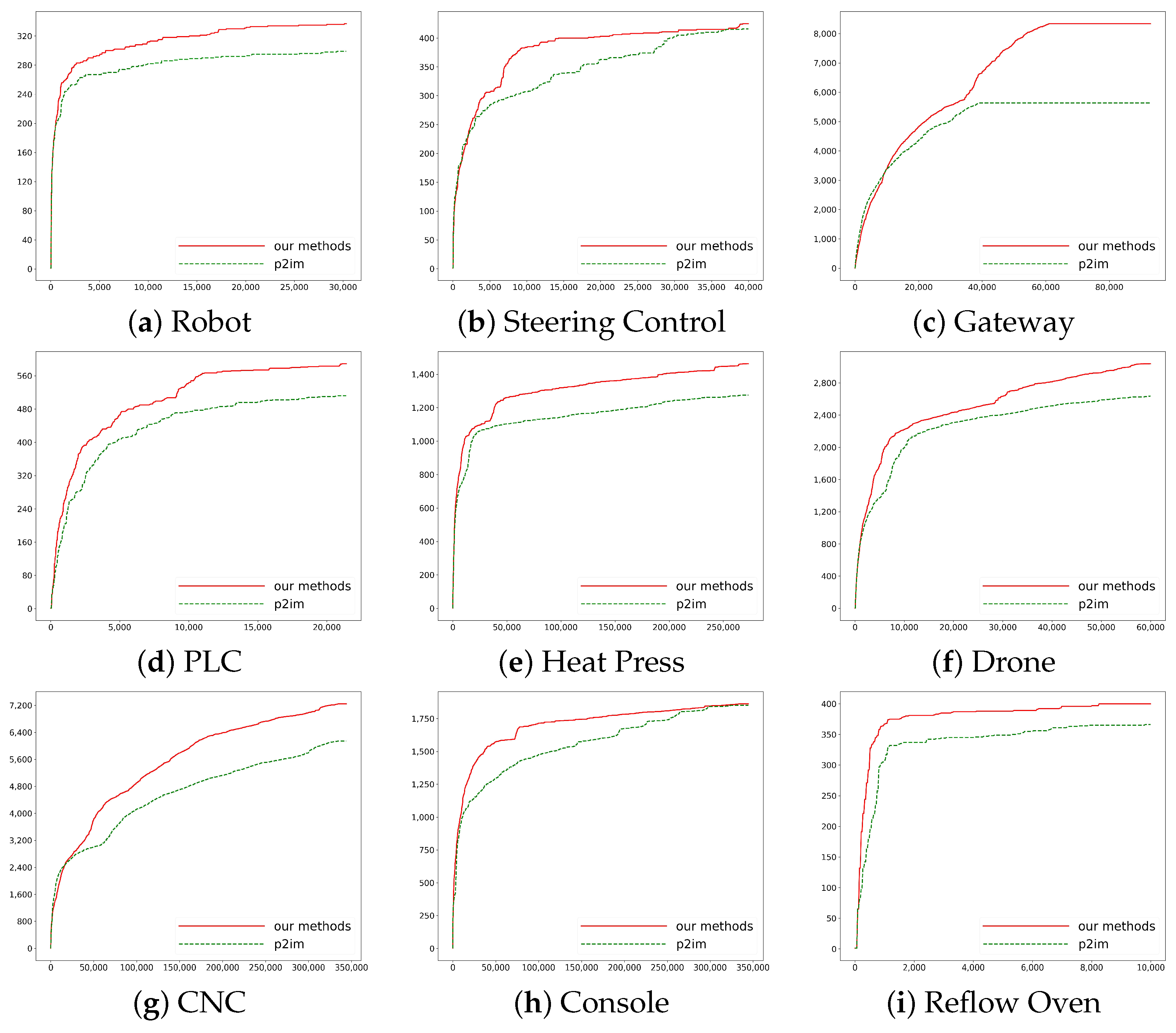
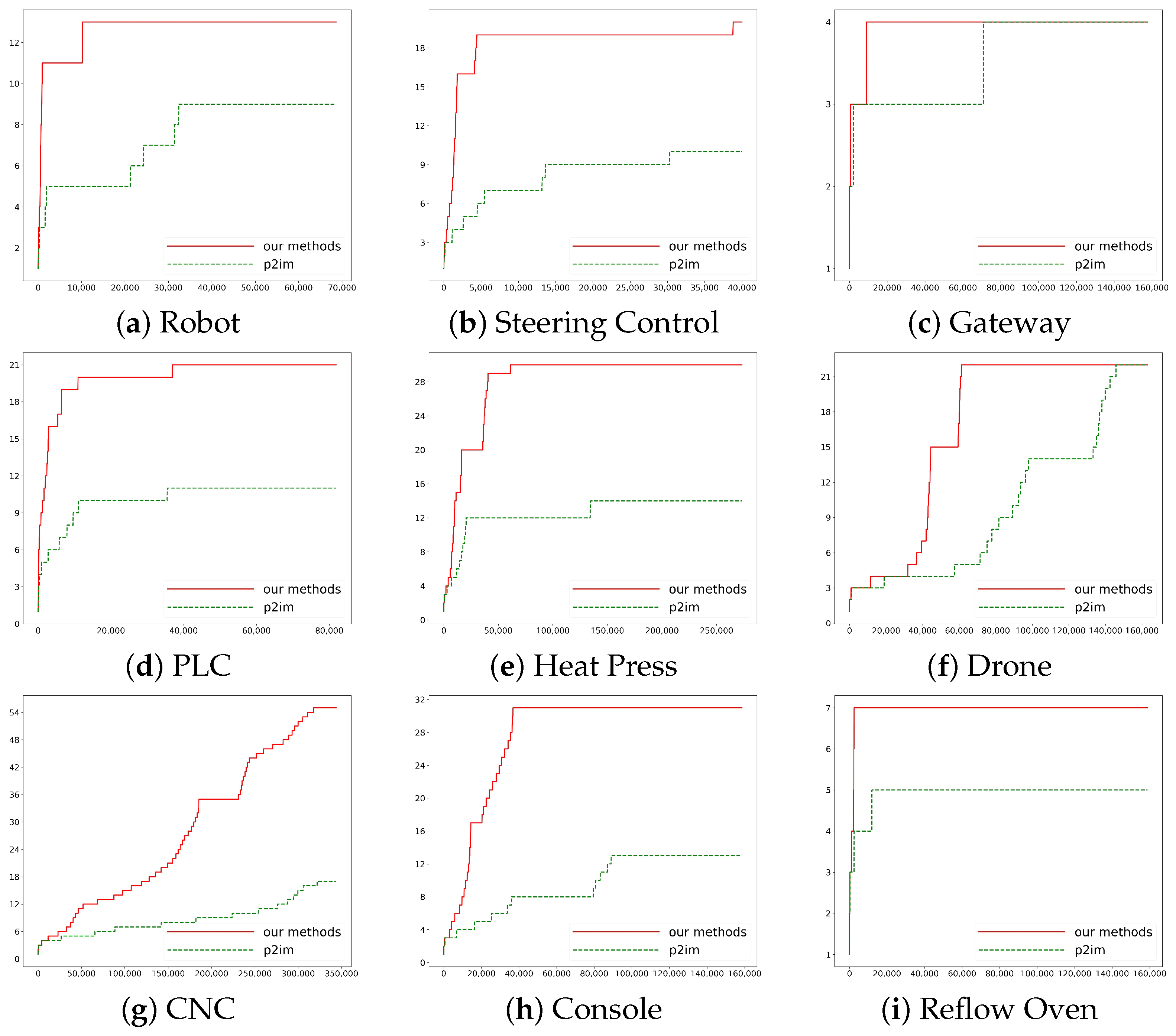
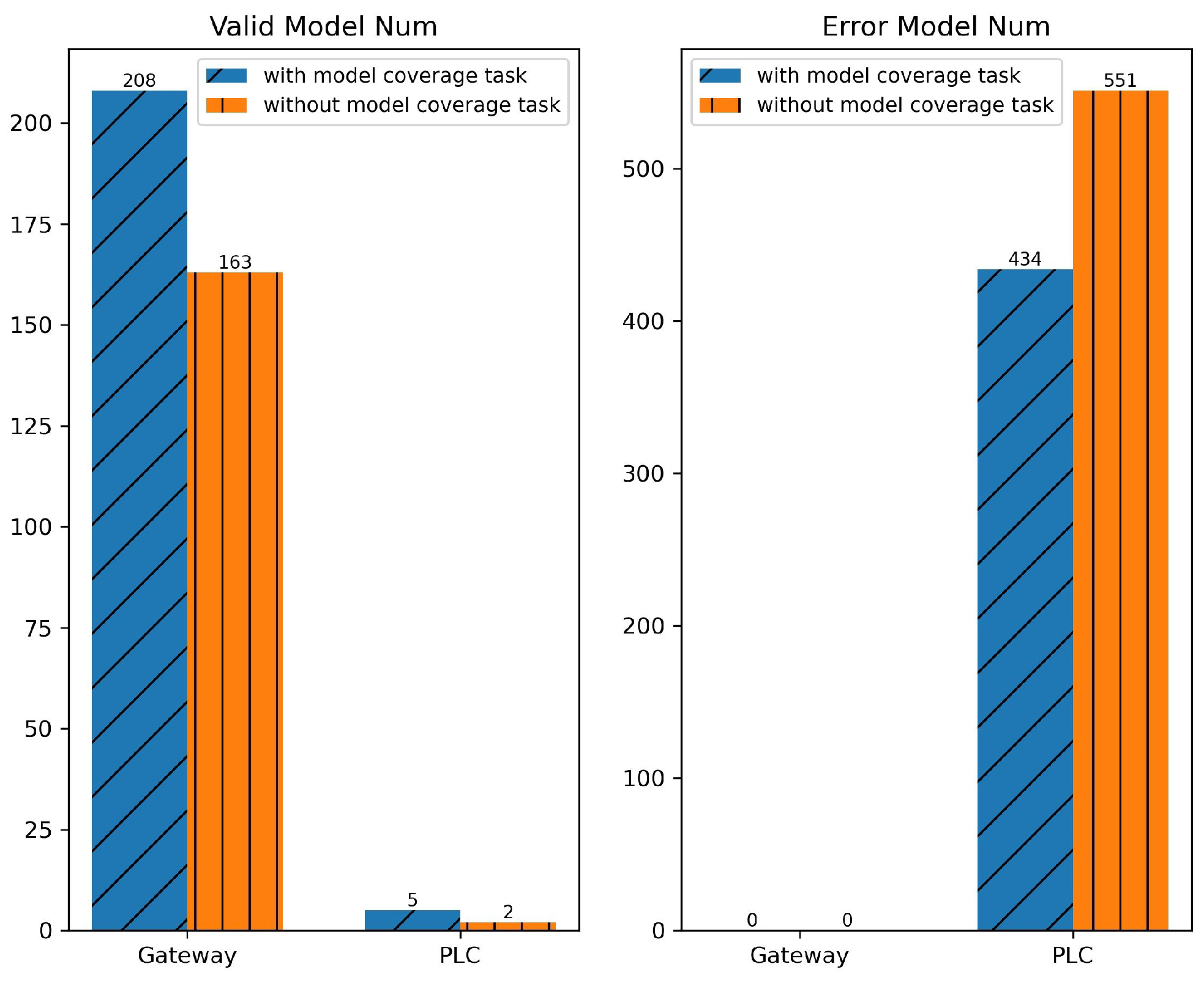
4.2. Results
5. Discussion
5.1. Result Analysis
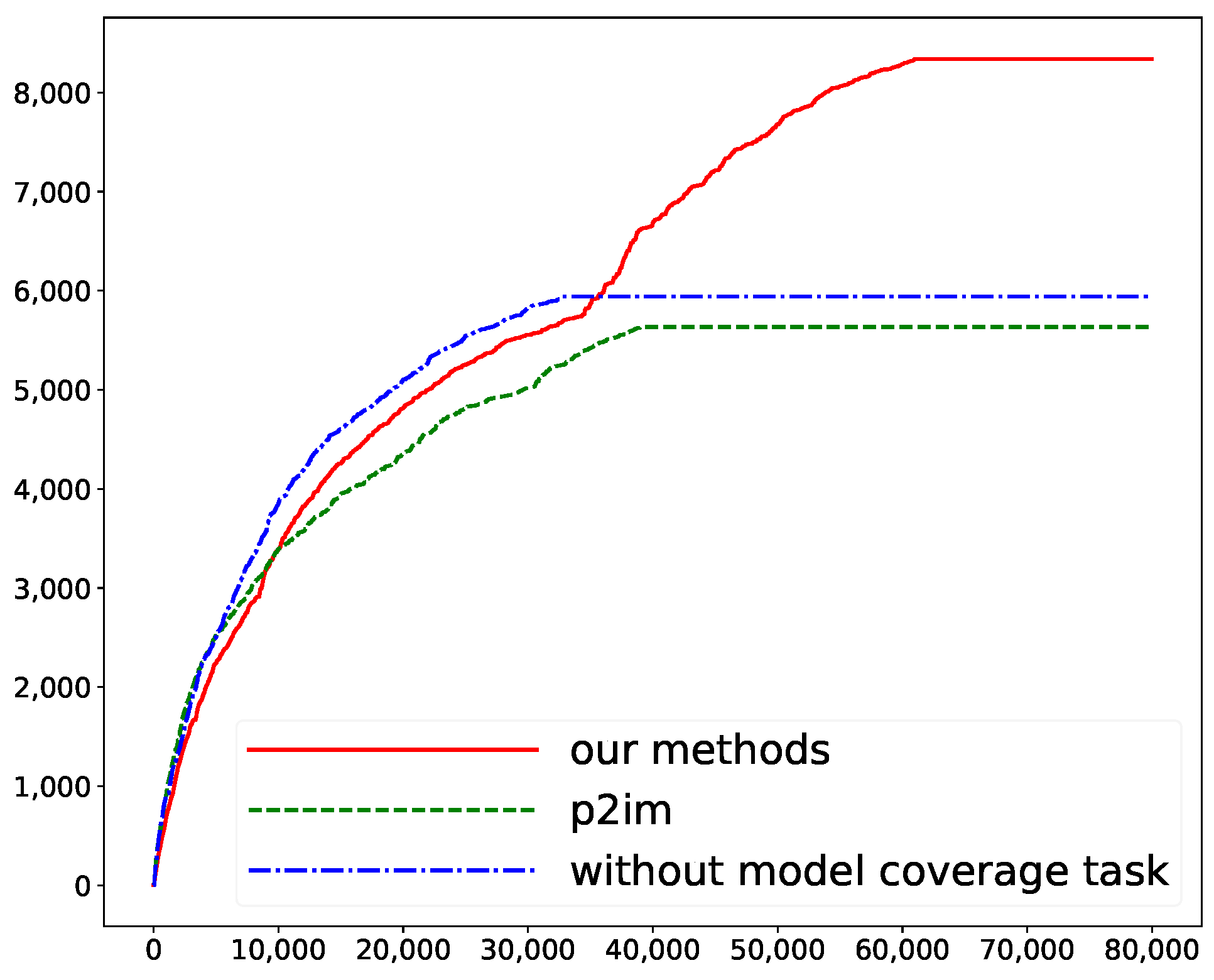
5.2. Method Effectiveness
5.3. Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, P.; Hu, J.; Li, X.; Zhu, Q. Using blockchain technology to enhance the traceability of original achievements. IEEE Trans. Eng. Manag. 2021, 70, 1693–1707. [Google Scholar] [CrossRef]
- Bobde, Y.; Narayanan, G.; Jati, M.; Raj, R.S.P.; Cvitić, I.; Peraković, D. Enhancing Industrial IoT Network Security through Blockchain Integration. Electronics 2024, 13, 687. [Google Scholar] [CrossRef]
- Czeczot, G.; Rojek, I.; Mikołajewski, D. Autonomous Threat Response at the Edge Processing Level in the Industrial Internet of Things. Electronics 2024, 13, 1161. [Google Scholar] [CrossRef]
- Li, Y.; Liu, W.; Liu, Q.; Zheng, X.; Sun, K.; Huang, C. Complying with ISO 26262 and ISO/SAE 21434: A Safety and Security Co-Analysis Method for Intelligent Connected Vehicle. Sensors 2024, 24, 1848. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Upton, O.; Beebe, N.L.; Choo, K.R. Iot Botnet Forensics: A Comprehensive Digital Forensic Case Study on Mirai Botnet Servers. Forensic Sci. Int. Digit. Investig. 2020, 32, 300926. [Google Scholar] [CrossRef]
- Garcia, L.; Brasser, F.; Cintuglu, M.H.; Sadeghi, A.R.; Mohammed, O.A.; Zonouz, S.A. Hey, My Malware Knows Physics! Attacking PLCs with Physical Model Aware Rootkit. In Proceedings of the NDSS, San Diego, CA, USA, 26 February–1 March 2017; pp. 1–15. [Google Scholar]
- Boone, A. Why Is Traditional IT Security Failing to Protect the IoT? 2018. Available online: https://www.timesys.com/security/traditional-it-security-failing-to-protect-iot/ (accessed on 25 January 2022).
- Feng, X.; Sun, R.; Zhu, X.; Xue, M.; Wen, S.; Liu, D.; Nepal, S.; Xiang, Y. Snipuzz: Black-box fuzzing of iot firmware via message snippet inference. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 15–19 November 2021; pp. 337–350. [Google Scholar]
- Chen, J.; Diao, W.; Zhao, Q.; Zuo, C.; Lin, Z.; Wang, X.; Lau, W.C.; Sun, M.; Yang, R.; Zhang, K. IoTFuzzer: Discovering Memory Corruptions in IoT Through App-based Fuzzing. In Proceedings of the NDSS, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Böhme, M.; Manès, V.J.; Cha, S.K. Boosting fuzzer efficiency: An information theoretic perspective. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, 8–13 November 2020; pp. 678–689. [Google Scholar]
- Wang, J.; Song, C.; Yin, H. Reinforcement learning-based hierarchical seed scheduling for greybox fuzzing. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium 2021, San Diego, CA, USA, 21–24 February 2021. [Google Scholar]
- Rawat, S.; Jain, V.; Kumar, A.; Cojocar, L.; Giuffrida, C.; Bos, H. VUzzer: Application-aware Evolutionary Fuzzing. In Proceedings of the NDSS, San Diego, CA, USA, 26 February–1 March 2017; Volume 17, pp. 1–14. [Google Scholar]
- Yue, T.; Wang, P.; Tang, Y.; Wang, E.; Yu, B.; Lu, K.; Zhou, X. EcoFuzz: Adaptive Energy-Saving greybox fuzzing as a variant of the adversarial Multi-Armed bandit. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 2307–2324. [Google Scholar]
- Yun, J.; Rustamov, F.; Kim, J.; Shin, Y. Fuzzing of Embedded Systems: A Survey. ACM Comput. Surv. 2022, 55, 137. [Google Scholar] [CrossRef]
- Kim, M.; Kim, D.; Kim, E.; Kim, S.; Jang, Y.; Kim, Y. Firmae: Towards large-scale emulation of iot firmware for dynamic analysis. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7–11 December 2020; pp. 733–745. [Google Scholar]
- Zheng, Y.; Davanian, A.; Yin, H.; Song, C.; Zhu, H.; Sun, L. FIRM-AFL: High-Throughput greybox fuzzing of IoT firmware via augmented process emulation. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 1099–1114. [Google Scholar]
- Scharnowski, T.; Bars, N.; Schloegel, M.; Gustafson, E.; Muench, M.; Vigna, G.; Kruegel, C.; Holz, T.; Abbasi, A. Fuzzware: Using Precise MMIO Modeling for Effective Firmware Fuzzing. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 1239–1256. [Google Scholar]
- Zalewski, M. American Fuzzy Lop (AFL) Fuzzer. 2015, p. 33. Available online: http://lcamtuf.coredump.cx/afl/ (accessed on 5 December 2019).
- Hertz, J.; Newsham, T. TriforceAFL. AFL Qemu Fuzzing with Full-System Emulation. QEMU Fuzzing with Full-System Emulation. 2019. Available online: https://github.com/nccgroup/TriforceAFL (accessed on 11 March 2023).
- Bellard, F. QEMU, a fast and portable dynamic translator. In Proceedings of the USENIX Annual Technical Conference, FREENIX Track, Anaheim, CA, USA, 10–15 April 2005; Volume 41, pp. 10–5555. [Google Scholar]
- Quynh, N.A.; Vu, D.H. Unicorn: Next generation cpu emulator framework. In Proceedings of the BlackHat USA, Las Vegas, NV, USA, 1–6 August 2015; Volume 476. [Google Scholar]
- Gustafson, E.; Muench, M.; Spensky, C.; Redini, N.; Machiry, A.; Fratantonio, Y.; Balzarotti, D.; Francillon, A.; Choe, Y.R.; Kruegel, C.; et al. Toward the analysis of embedded firmware through automated re-hosting. In Proceedings of the 22nd International Symposium on Research in Attacks, Intrusions and Defenses (RAID 2019), Beijing, China, 23–25 September 2019; pp. 135–150. [Google Scholar]
- Costin, A.; Zarras, A.; Francillon, A. Automated dynamic firmware analysis at scale: A case study on embedded web interfaces. In Proceedings of the 11th ACM on Asia Conference on Computer and Communications Security, Xi’an, China, 30 May–3 June 2016; pp. 437–448. [Google Scholar]
- Clements, A.A.; Gustafson, E.; Scharnowski, T.; Grosen, P.; Fritz, D.; Kruegel, C.; Vigna, G.; Bagchi, S.; Payer, M. HALucinator: Firmware re-hosting through abstraction layer emulation. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1201–1218. [Google Scholar]
- Li, W.; Guan, L.; Lin, J.; Shi, J.; Li, F. From library portability to para-rehosting: Natively executing microcontroller software on commodity hardware. arXiv 2021, arXiv:2107.12867. [Google Scholar]
- Maier, D.; Seidel, L.; Park, S. Basesafe: Baseband sanitized fuzzing through emulation. In Proceedings of the 13th ACM Conference on Security and Privacy in Wireless and Mobile Networks, Virtual Event, 8–10 July 2020; pp. 122–132. [Google Scholar]
- Seidel, L.; Maier, D.; Muench, M. Forming Faster Firmware Fuzzers. In Proceedings of the USENIX Security, Anaheim, CA, USA, 9–11 August 2023. [Google Scholar]
- Liang, J.; Jiang, Y.; Wang, M.; Jiao, X.; Chen, Y.; Song, H.; Choo, K.K.R. Deepfuzzer: Accelerated deep greybox fuzzing. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2675–2688. [Google Scholar] [CrossRef]
- Böhme, M.; Pham, V.T.; Roychoudhury, A. Coverage-based greybox fuzzing as markov chain. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 August 2016; pp. 1032–1043. [Google Scholar]
- Feng, B.; Mera, A.; Lu, L. P2IM: Scalable and hardware-independent firmware testing via automatic peripheral interface modeling. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1237–1254. [Google Scholar]
- Lyu, C.; Ji, S.; Zhang, C.; Li, Y.; Lee, W.H.; Song, Y.; Beyah, R. MOPT: Optimized mutation scheduling for fuzzers. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 1949–1966. [Google Scholar]
- Pham, V.T.; Böhme, M.; Roychoudhury, A. Aflnet: A greybox fuzzer for network protocols. In Proceedings of the 2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST), Porto, Portugal, 23–27 March 2020; IEEE: New York, NY, USA, 2020; pp. 460–465. [Google Scholar]
- Stephens, N.; Grosen, J.; Salls, C.; Dutcher, A.; Wang, R.; Corbetta, J.; Shoshitaishvili, Y.; Kruegel, C.; Vigna, G. Driller: Augmenting fuzzing through selective symbolic execution. In Proceedings of the NDSS, San Diego, CA, USA, 21–24 February 2016; Volume 16, pp. 1–16. [Google Scholar]
- Neugass, H.; Espin, G.; Nunoe, H.; Thomas, R.; Wilner, D. VxWorks: An interactive development environment and real-time kernel for Gmicro. In Proceedings of the Eighth TRON Project Symposium, IEEE Computer Society, Tokyo, Japan, 26–27 November 1991; pp. 196–197. [Google Scholar]
- Sastry, D.C.; Demirci, M. The QNX operating system. Computer 1995, 28, 75–77. [Google Scholar]
- Hardin, T.; Scott, R.; Proctor, P.; Hester, J.; Sorber, J.; Kotz, D. Application memory isolation on ultra-Low-powerMCUs. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 127–132. [Google Scholar]
- Sun, Z.; Feng, B.; Lu, L.; Jha, S. OAT: Attesting operation integrity of embedded devices. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Diego, CA, USA, 18–20 May 2020; IEEE: New York, NY, USA, 2020; pp. 1433–1449. [Google Scholar]
- Seshadri, A.; Perrig, A.; Van Doorn, L.; Khosla, P. SWATT: Software-based attestation for embedded devices. In Proceedings of the IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 9–12 May 2004; IEEE: New York, NY, USA, 2004; pp. 272–282. [Google Scholar]
- Zaddach, J.; Bruno, L.; Francillon, A.; Balzarotti, D. AVATAR: A Framework to Support Dynamic Security Analysis of Embedded Systems’ Firmwares. In Proceedings of the NDSS, San Diego, CA, USA, 27 February 27–3 March 2014; Volume 14, pp. 1–16. [Google Scholar]
- Kammerstetter, M.; Platzer, C.; Kastner, W. Prospect: Peripheral proxying supported embedded code testing. In Proceedings of the 9th ACM Symposium on Information, Computer and Communications Security, Kyoto, Japan, 4–6 June 2014; pp. 329–340. [Google Scholar]
- Yu, J.; Kim, J.; Yun, Y.; Yun, J. Poster: Combining Fuzzing with Concolic Execution for IoT Firmware Testing. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, Copenhagen, Denmark, 26–30 November 2023; pp. 3564–3566. [Google Scholar]
- Qasem, A.; Shirani, P.; Debbabi, M.; Wang, L.; Lebel, B.; Agba, B.L. Automatic vulnerability detection in embedded devices and firmware: Survey and layered taxonomies. ACM Comput. Surv. (CSUR) 2021, 54, 25. [Google Scholar] [CrossRef]
- Aschermann, C.; Schumilo, S.; Blazytko, T.; Gawlik, R.; Holz, T. REDQUEEN: Fuzzing with Input-to-State Correspondence. In Proceedings of the NDSS, San Diego, CA, USA, 24–27 February 2019; Volume 19, pp. 1–15. [Google Scholar]
- Fioraldi, A.; Maier, D.; Eißfeldt, H.; Heuse, M. AFL++: Combining incremental steps of fuzzing research. In Proceedings of the 14th USENIX Workshop on Offensive Technologies (WOOT 20), Virtual Event, 11 August 2020. [Google Scholar]
- Zhu, X.; Wen, S.; Camtepe, S.; Xiang, Y. Fuzzing: A survey for roadmap. ACM Comput. Surv. (CSUR) 2022, 54, 1–36. [Google Scholar] [CrossRef]
- Li, W.; Ruan, J.; Yi, G.; Cheng, L.; Luo, X.; Cai, H. PolyFuzz: Holistic Greybox Fuzzing of Multi-Language Systems. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 1379–1396. [Google Scholar]
- Binosi, L.; Rullo, L.; Polino, M.; Carminati, M.; Zanero, S. Rainfuzz: Reinforcement-Learning Driven Heat-Maps for Boosting Coverage-Guided Fuzzing. In Proceedings of the 12th International Conference on Pattern Recognition Applications and Methods-ICPRAM, Lisbon, Portugal, 22–24 February 2023; pp. 39–50. [Google Scholar]
- Gan, S.; Zhang, C.; Chen, P.; Zhao, B.; Qin, X.; Wu, D.; Chen, Z. GREYONE: Data flow sensitive fuzzing. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 2577–2594. [Google Scholar]
- She, D.; Shah, A.; Jana, S. Effective seed scheduling for fuzzing with graph centrality analysis. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; IEEE: New York, NY, USA, 2022; pp. 2194–2211. [Google Scholar]
- Wang, J.; Duan, Y.; Song, W.; Yin, H.; Song, C. Be sensitive and collaborative: Analyzing impact of coverage metrics in greybox fuzzing. In Proceedings of the 22nd International Symposium on Research in Attacks, Intrusions and Defenses (RAID 2019), Beijing, China, 23–25 September 2019; pp. 1–15. [Google Scholar]
- Herrera, A.; Gunadi, H.; Magrath, S.; Norrish, M.; Payer, M.; Hosking, A.L. Seed selection for successful fuzzing. In Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Event, 11–17 July 2021; pp. 230–243. [Google Scholar]
- Fasano, A.; Ballo, T.; Muench, M.; Leek, T.; Bulekov, A.; Dolan-Gavitt, B.; Egele, M.; Francillon, A.; Lu, L.; Gregory, N.; et al. Sok: Enabling security analyses of embedded systems via rehosting. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, Hong Kong, China, 7–11 June 2021; pp. 687–701. [Google Scholar]
- Corteggiani, N.; Camurati, G.; Francillon, A. Inception:System-Wide security testing of Real-World embedded systems software. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 309–326. [Google Scholar]
- Koscher, K.; Kohno, T.; Molnar, D. SURROGATES: Enabling Near-Real-Time dynamic analyses of embedded systems. In Proceedings of the 9th USENIX Workshop on Offensive Technologies (WOOT 15), Washington, DC, USA, 10–11 August 2015. [Google Scholar]
- Baezner, M.; Robin, P. Stuxnet; Technical Report; ETH Zurich: Zurich, Switzerland, 2017. [Google Scholar]
- Chen, D.D.; Woo, M.; Brumley, D.; Egele, M. Towards automated dynamic analysis for linux-based embedded firmware. In Proceedings of the NDSS, San Diego, CA, USA, 21–24 February 2016; Volume 1, p. 1. [Google Scholar]
- Zhou, W.; Guan, L.; Liu, P.; Zhang, Y. Automatic firmware emulation through invalidity-guided knowledge inference. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Vancouver, BC, Canada, 11–13 August 2021; pp. 2007–2024. [Google Scholar]
- Wu, Y.; Zhang, T.; Jung, C.; Lee, D. DEVFUZZ: Automatic Device Model-Guided Device Driver Fuzzing. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–24 May 2023; pp. 3246–3261. [Google Scholar]
- Harrison, L.; Vijayakumar, H.; Padhye, R.; Sen, K.; Grace, M. PARTEMU: Enabling Dynamic Analysis of Real-WorldTrustZone Software Using Emulation. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 789–806. [Google Scholar]
- Miller, C. Fuzz by Number: More Data about Fuzzing Than You Ever Wanted to Know. Proceedings of the CanSecWest. 2008. Available online: https://fuzzinginfo.wordpress.com/wp-content/uploads/2012/05/cmiller_cansecwest2008.pdf (accessed on 7 April 2024).







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, Y. DCGFuzz: An Embedded Firmware Security Analysis Method with Dynamically Co-Directional Guidance Fuzzing. Electronics 2024, 13, 1433. https://doi.org/10.3390/electronics13081433
Wang Y, Li Y. DCGFuzz: An Embedded Firmware Security Analysis Method with Dynamically Co-Directional Guidance Fuzzing. Electronics. 2024; 13(8):1433. https://doi.org/10.3390/electronics13081433
Chicago/Turabian StyleWang, Yunzhi, and Yufeng Li. 2024. "DCGFuzz: An Embedded Firmware Security Analysis Method with Dynamically Co-Directional Guidance Fuzzing" Electronics 13, no. 8: 1433. https://doi.org/10.3390/electronics13081433
APA StyleWang, Y., & Li, Y. (2024). DCGFuzz: An Embedded Firmware Security Analysis Method with Dynamically Co-Directional Guidance Fuzzing. Electronics, 13(8), 1433. https://doi.org/10.3390/electronics13081433