
Voltage Scaled Low Power DNN Accelerator Design on Reconfigurable Platform

 ,
, 

Abstract
1. Introduction
1.1. Literature
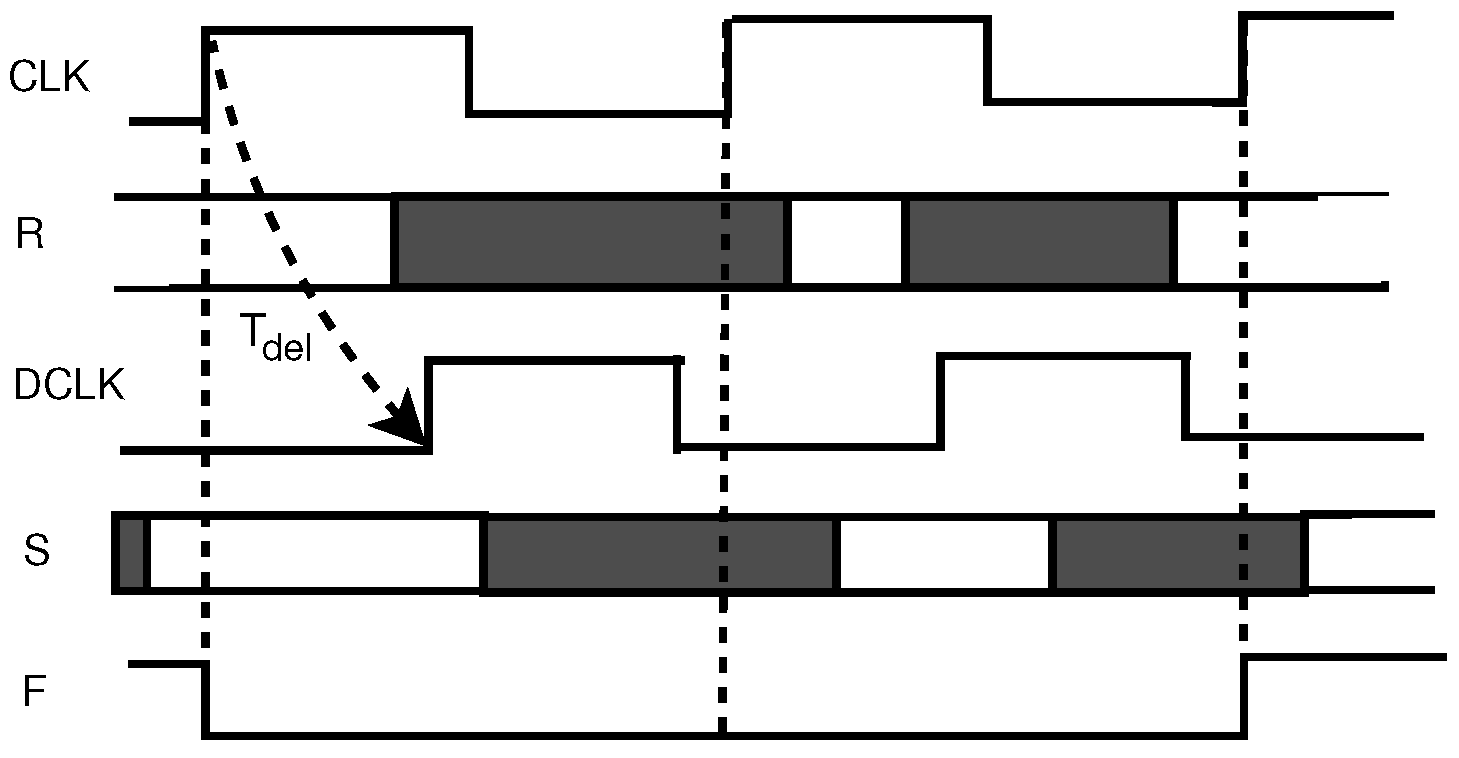
1.1.1. Timing Error Detection and Recovery (TED)
1.1.2. Timing Error Propagation (TEP)
1.1.3. Timing Error Drop (TE-Drop)
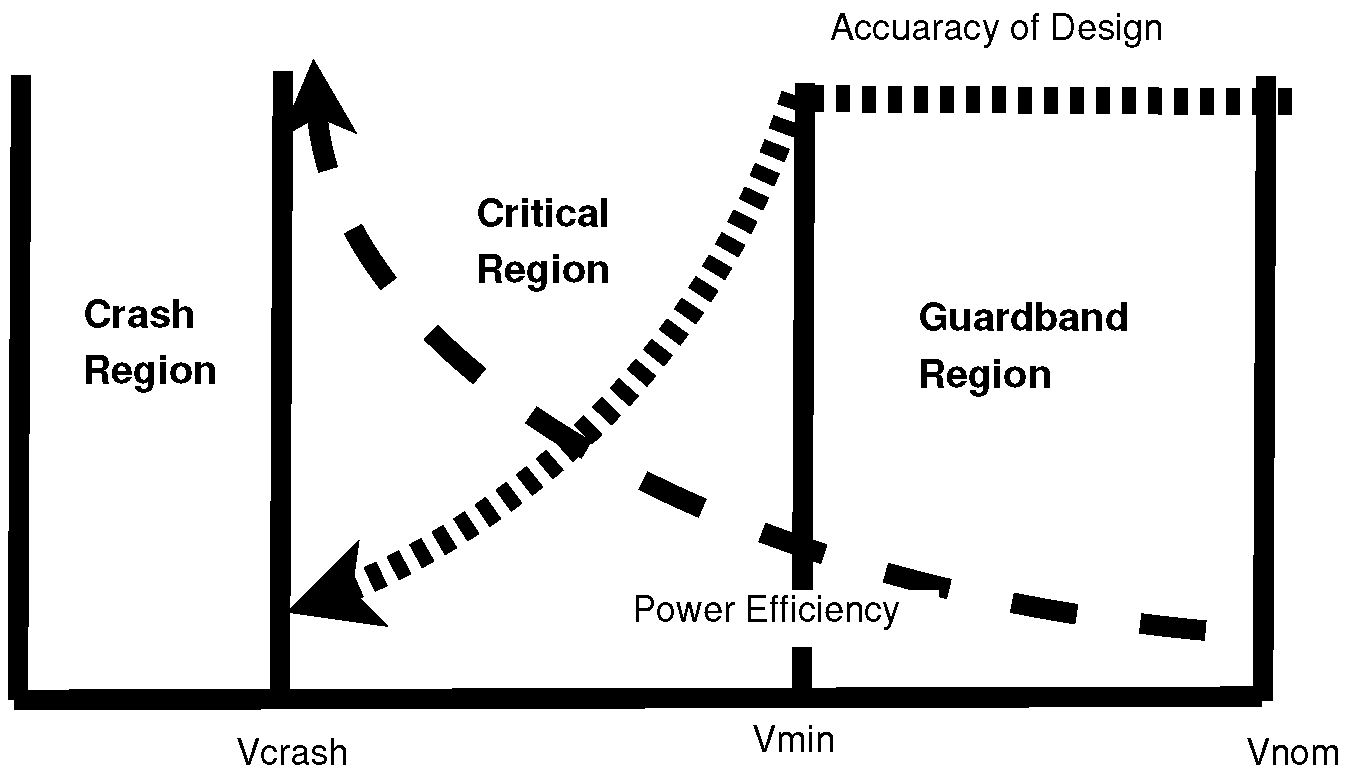
1.2. Contribution
- This paper proposes a new CAD flow to create voltage-scaled TPUs on FPGA-based platforms considering the trade-off between circuit delay and biasing voltage. The proposed CAD flow can be used in any existing low-power neural network architecture for additional power reduction.
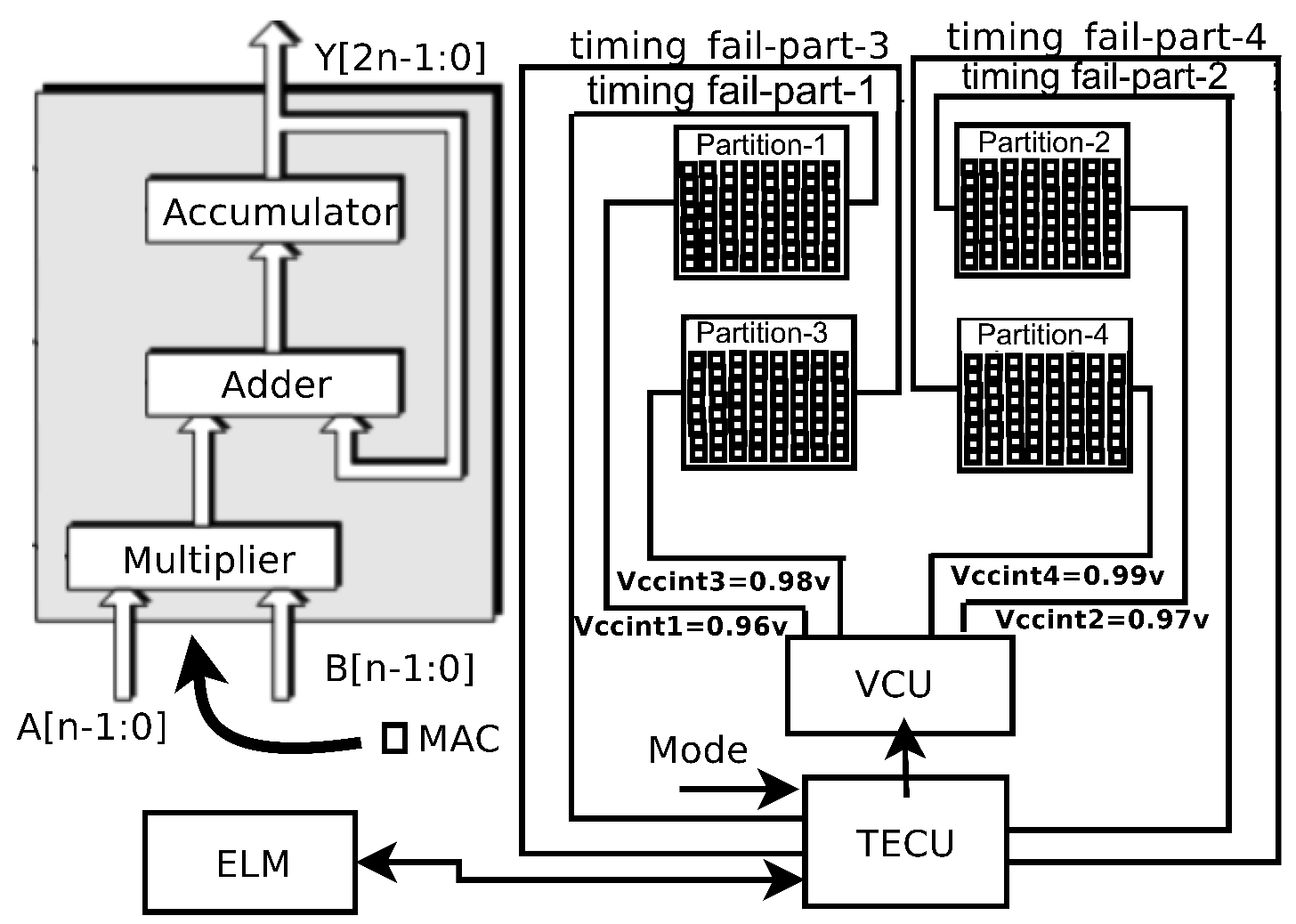
- The cluster algorithms divide the systolic array of a TPU into different partitions (groups or clusters) based on the minimum slacks (critical paths) of MACs. Instead of applying uniform across all MACs in the systolic array, the group of MACs with shorter critical paths is connected with lower , and the group of MACs with longer critical paths is connected with higher .
- The calibration of the of different partitions is performed by the proposed and schemes. The timing errors caused by voltage reduction are detected by a heuristic-based timing error prediction method.
2. Background: FPGA Environment
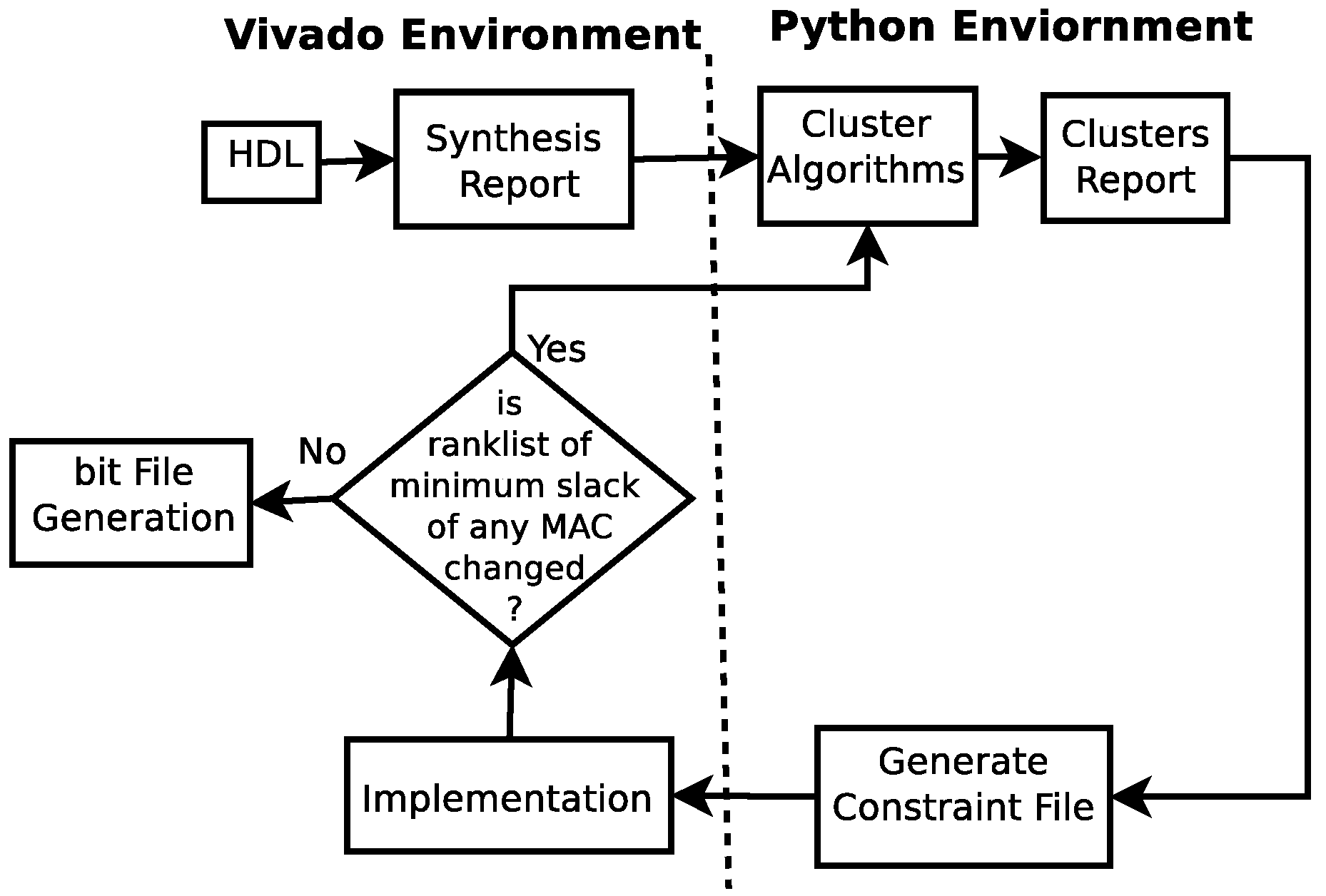
2.1. Vivado Environment
2.1.1. Synthesis
2.1.2. Implementation
2.1.3. Bit File Generation
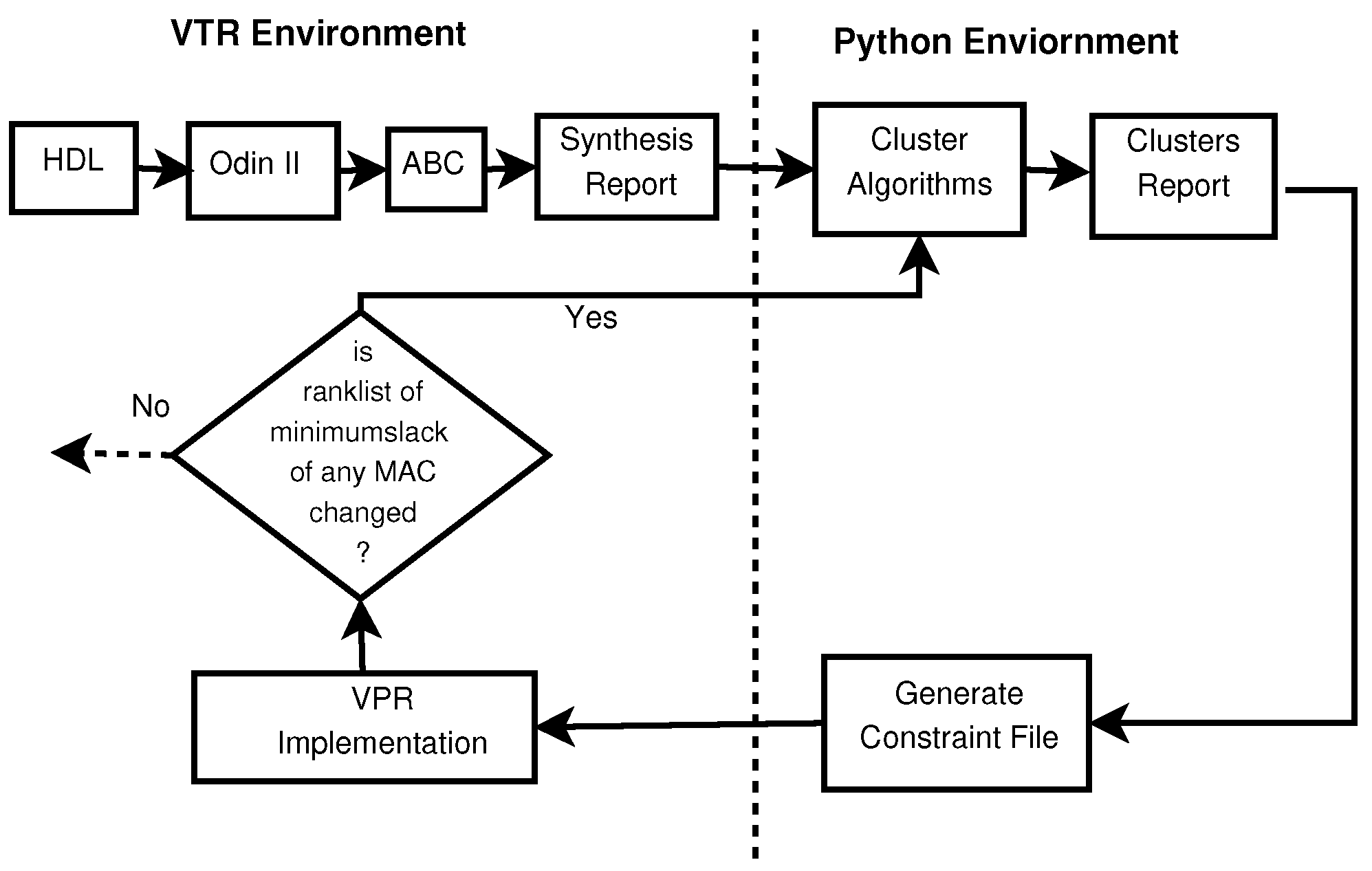
2.2. VTR Environment
2.2.1. Synthesis
2.2.2. Implementation
2.3. Python Environment
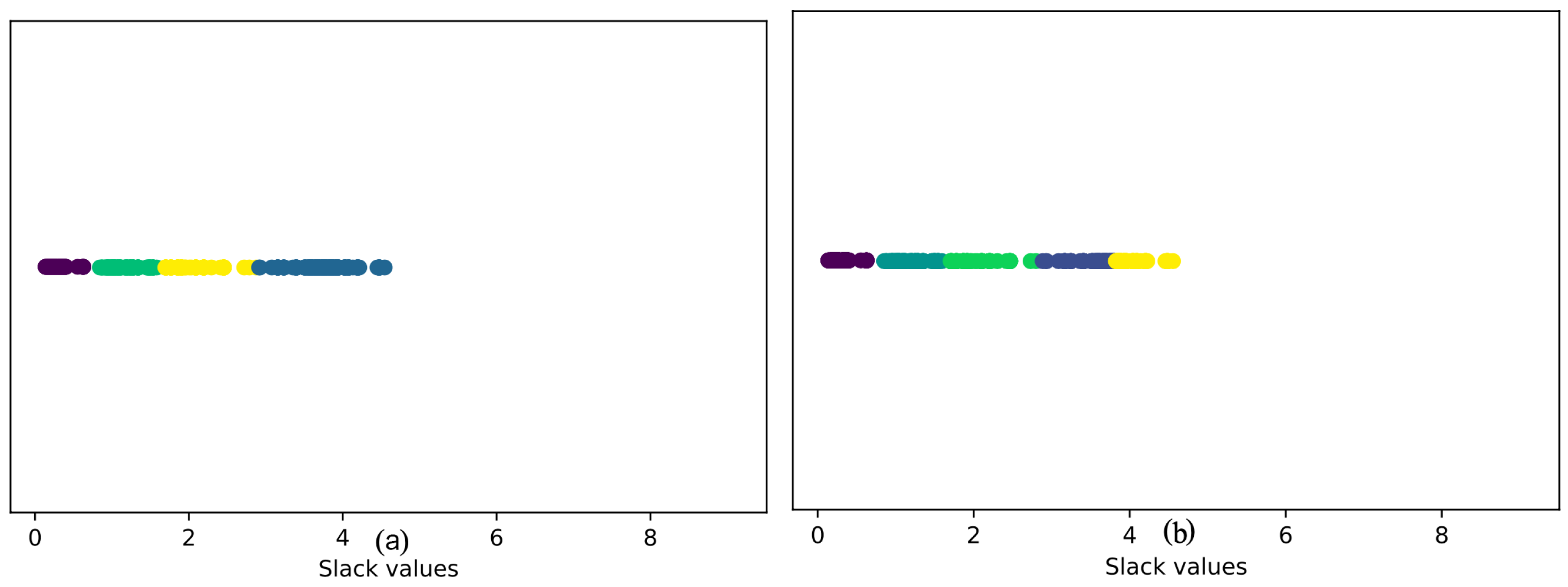
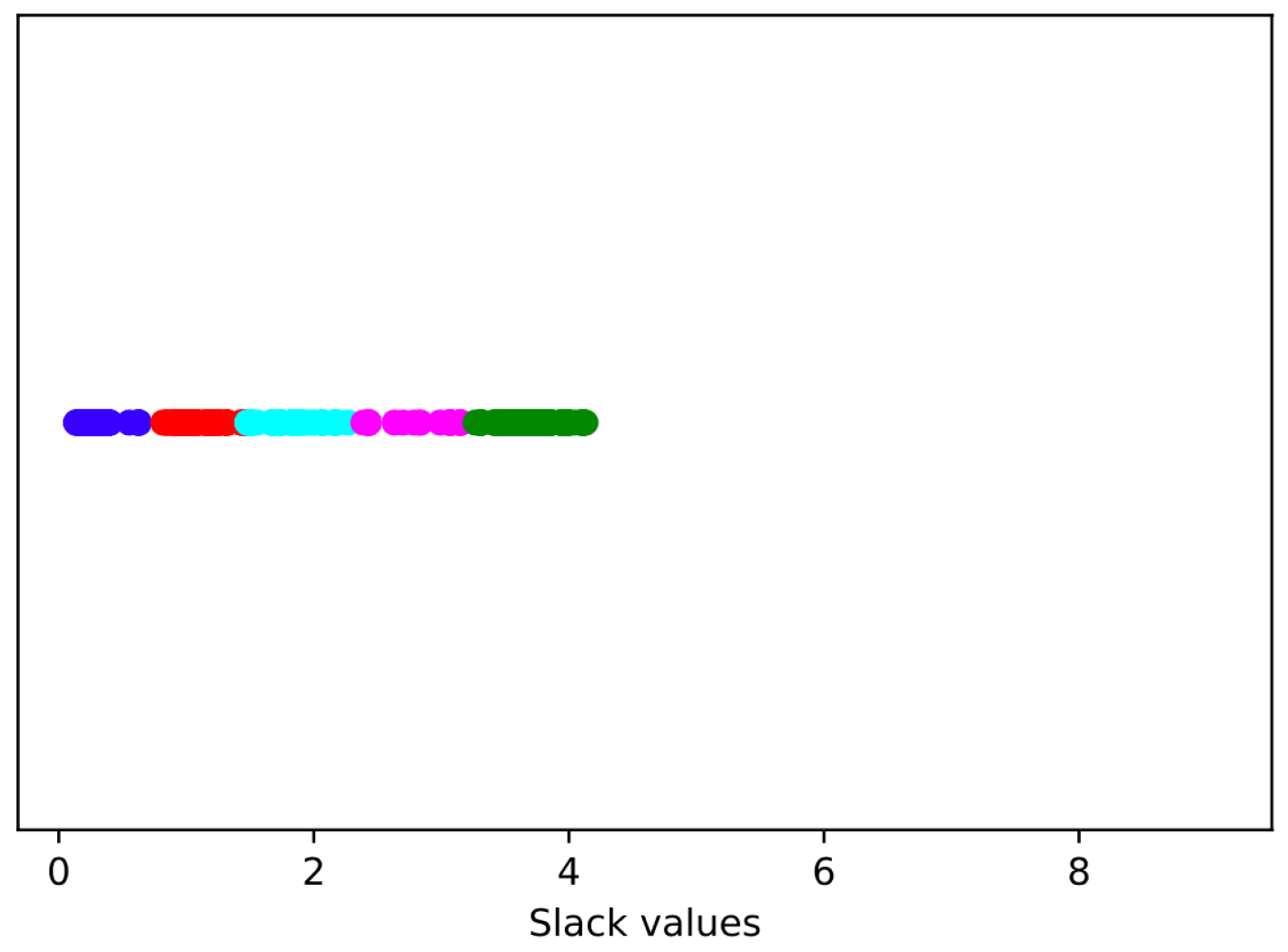
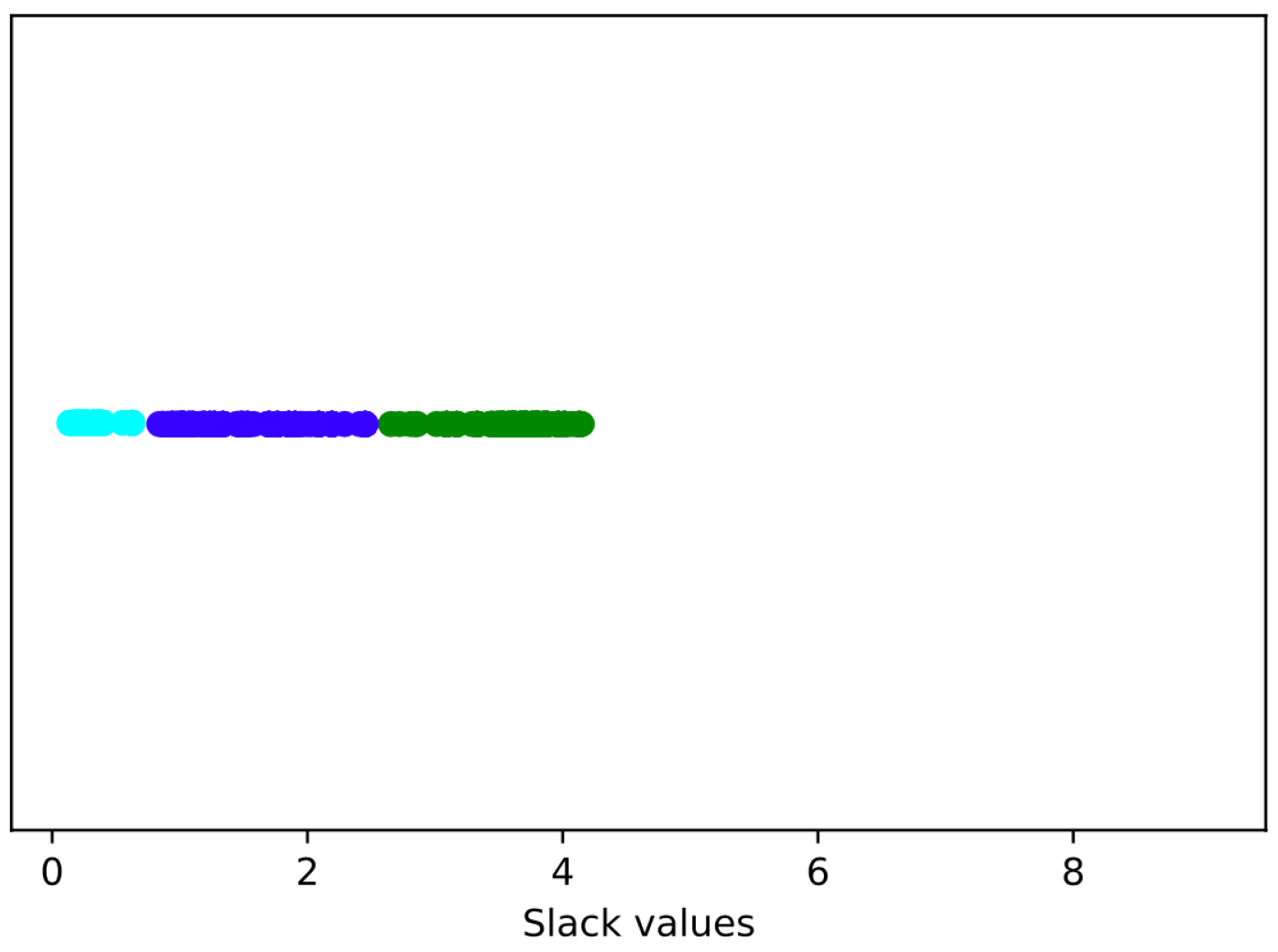
2.3.1. Choice of Clustering Algorithms
2.3.2. Cluster Generation
2.3.3. Constraint Generation
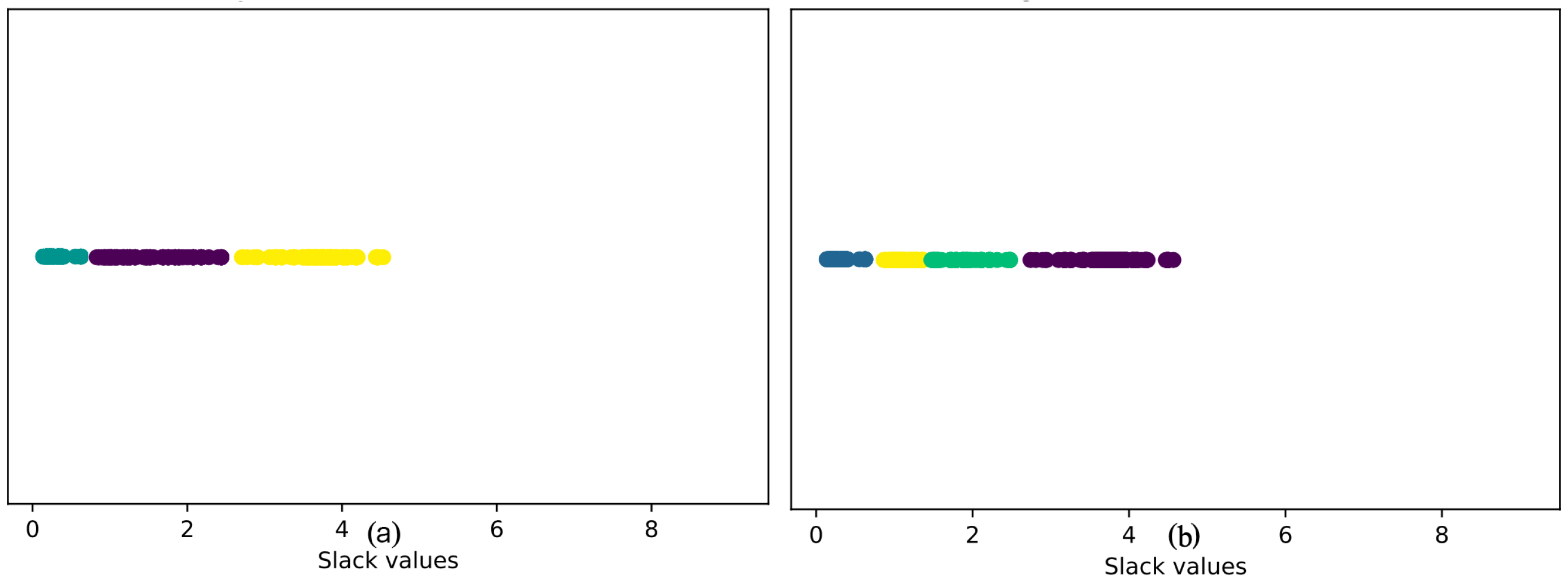
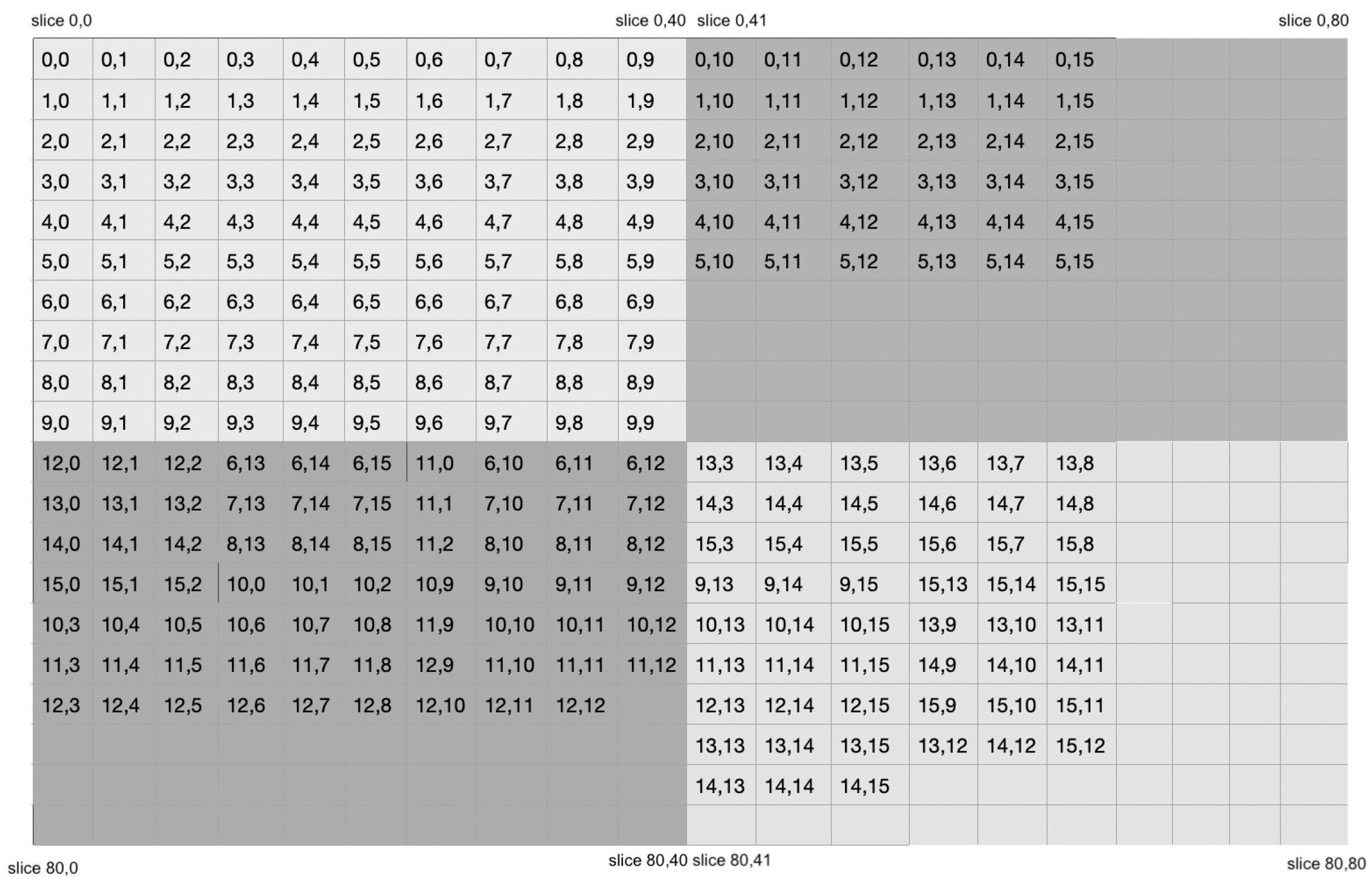
2.4. Clustering MACs Based on Their Minimum Slacks
- For the clustering of MACs based on their minimum slack, the intervention of the vendor’s technology-dependent placement and routing algorithm is far greater compared to the previous idea. As a result, the critical path variation in the synthesis and implementation process is very minimal.
- Placing all design paths in a constraint file is much more complicated compared to placing entire MACs in a constraint file.
- The routing of wires on the FPGA floor is comparatively simpler for MAC clustering based on their minimum slacks.
2.5. Razor Flipflop
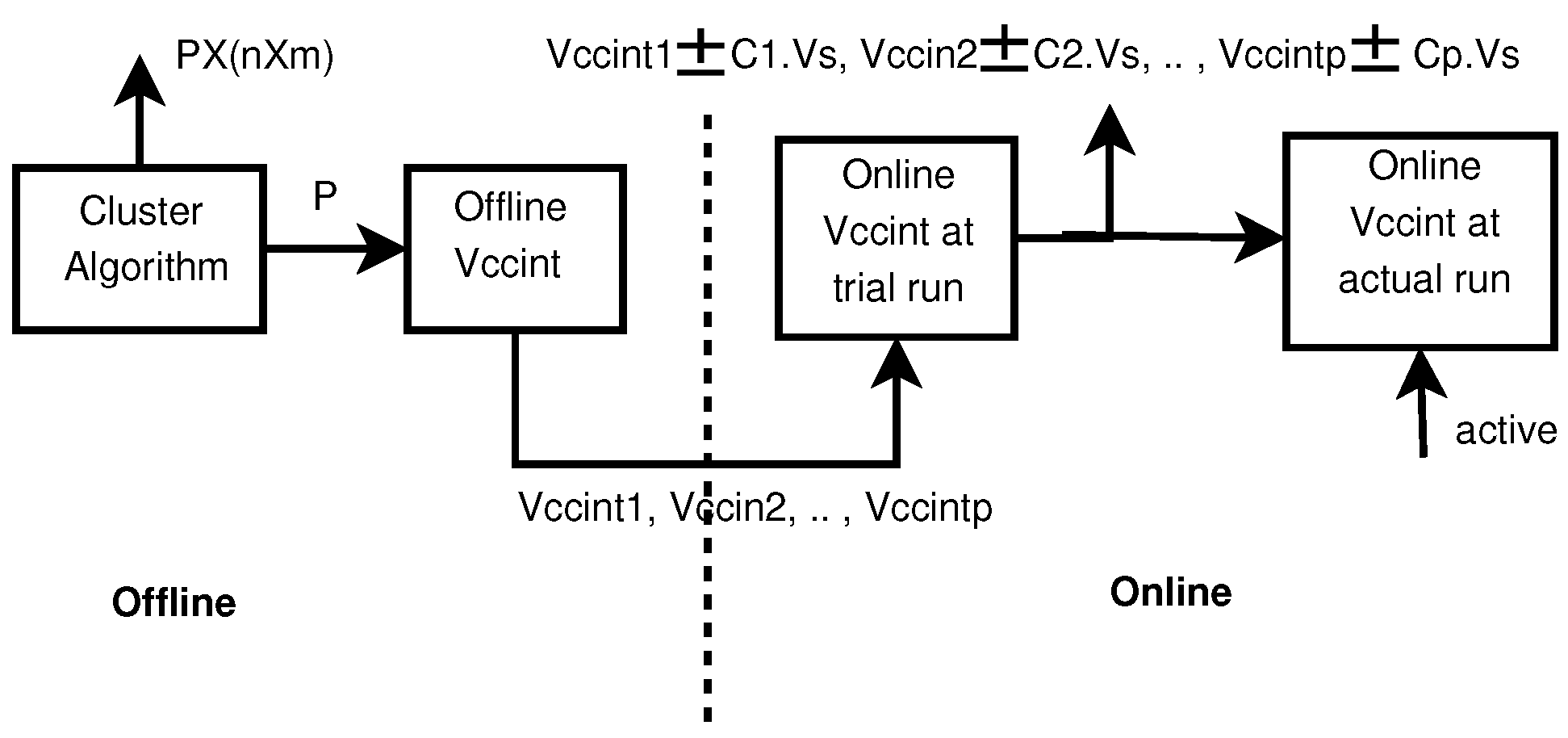
3. Hybrid Configuration: Static and Runtime Schemes
3.1. Static Scheme
| Algorithm 1 Static Voltage Scaling |
Require: , , & P
|
3.2. Runtime Scheme
3.2.1. Runtime Error Correction (REC)
| Algorithm 2 Runtime Voltage Scaling |
Require:
,
|
3.2.2. Runtime Error Prediction and Correction (REPC)
| Algorithm 3 Pattern Storing/Matching Heuristic |
|
4. Clustering Algorithms
4.1. Hierarchical

4.2. K-Means Clustering

4.3. Mean-Shift Clustering

4.4. DBSCAN

5. Implementation and Result
5.1. Implementational Challenges
5.2. Our Validation Strategy
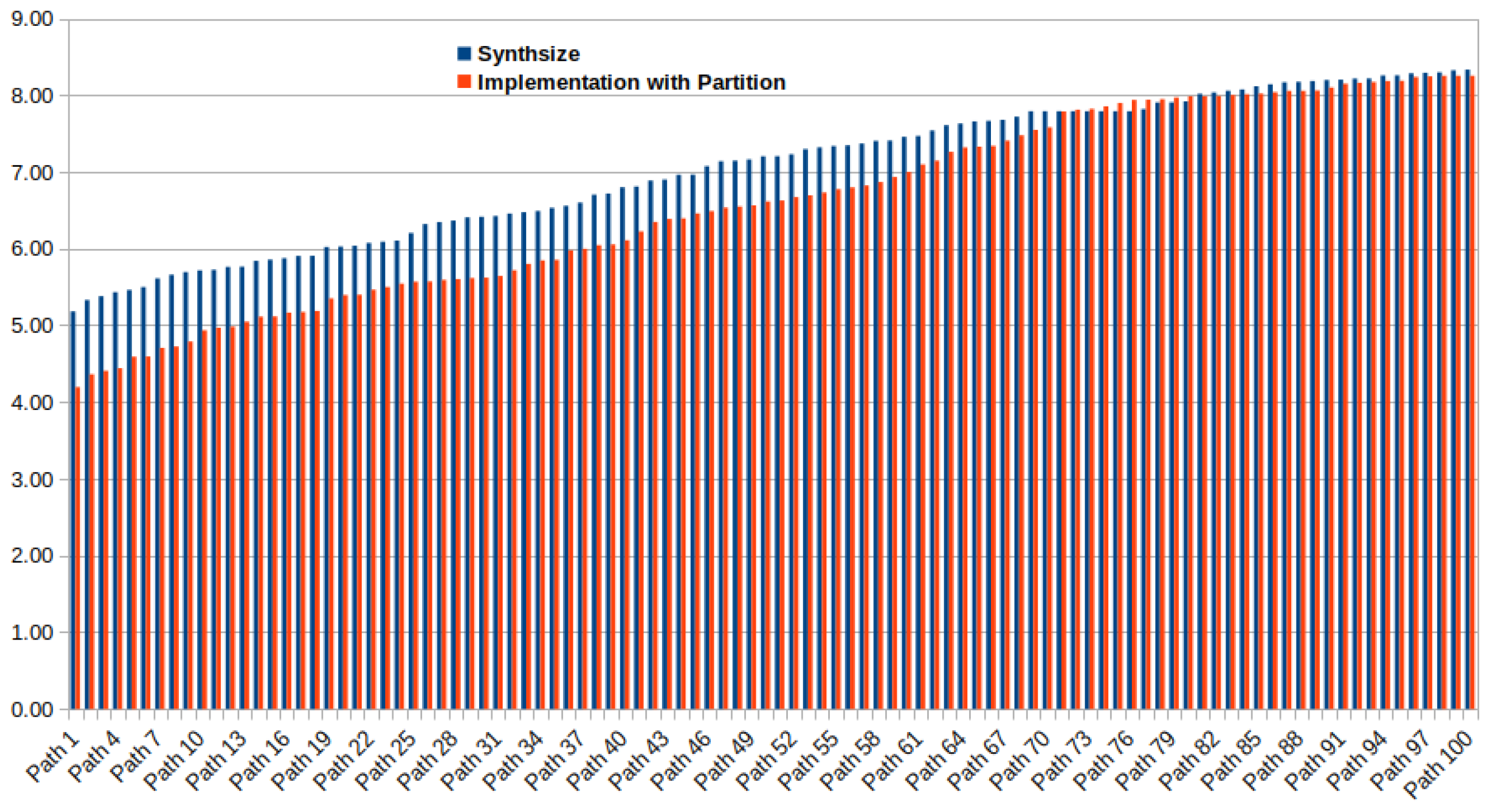
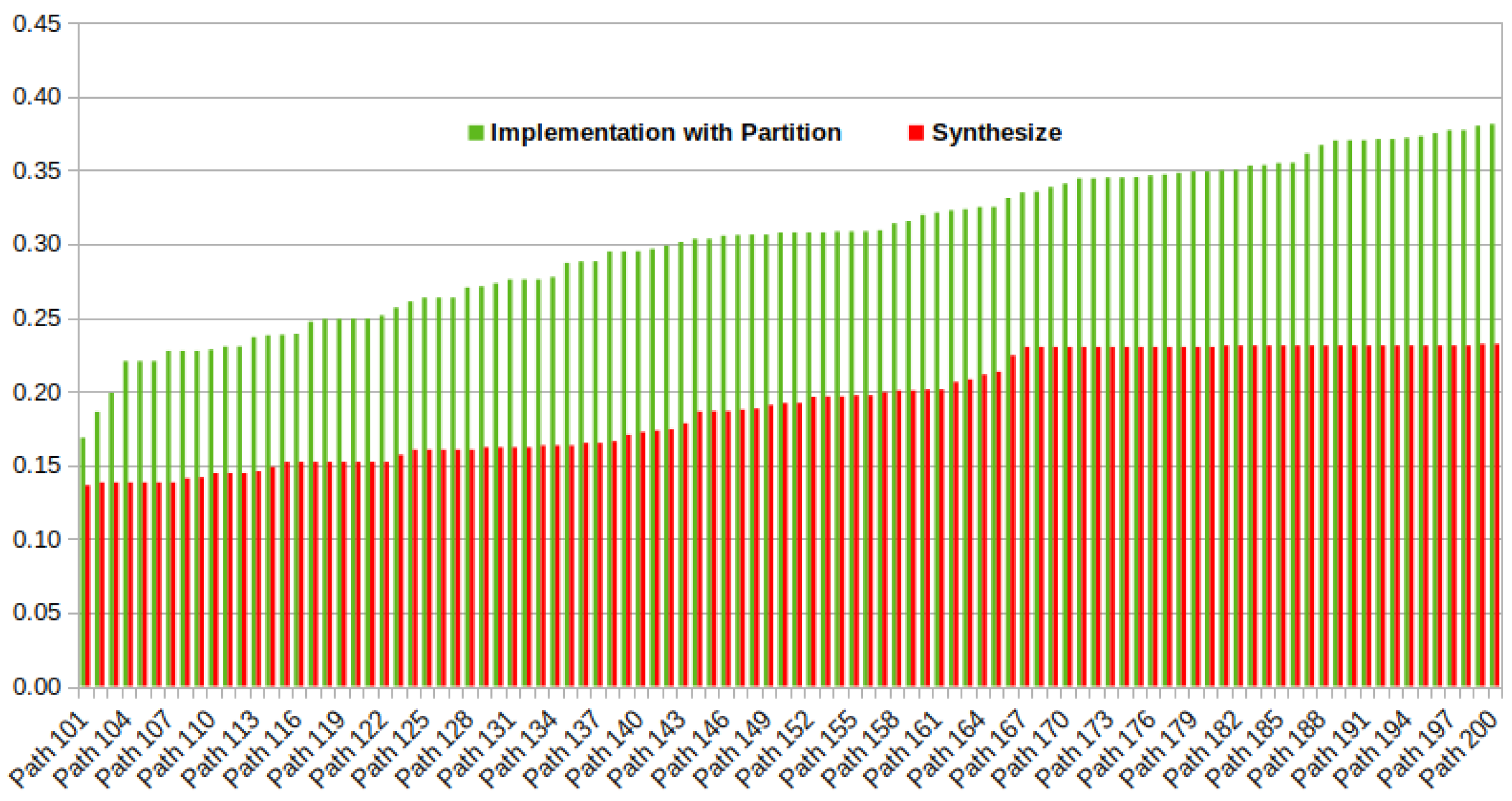
5.3. Results
5.3.1. Different Sizes of Systolic Arrays
5.3.2. Variants of Systolic Array Architecture
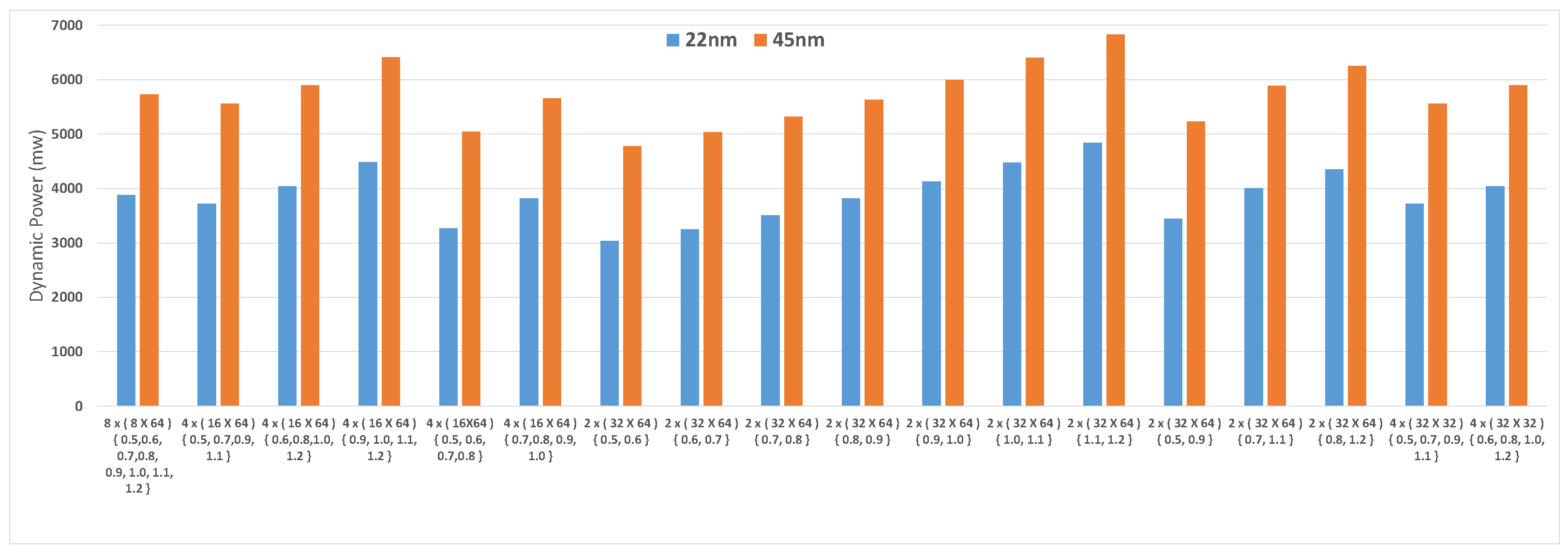
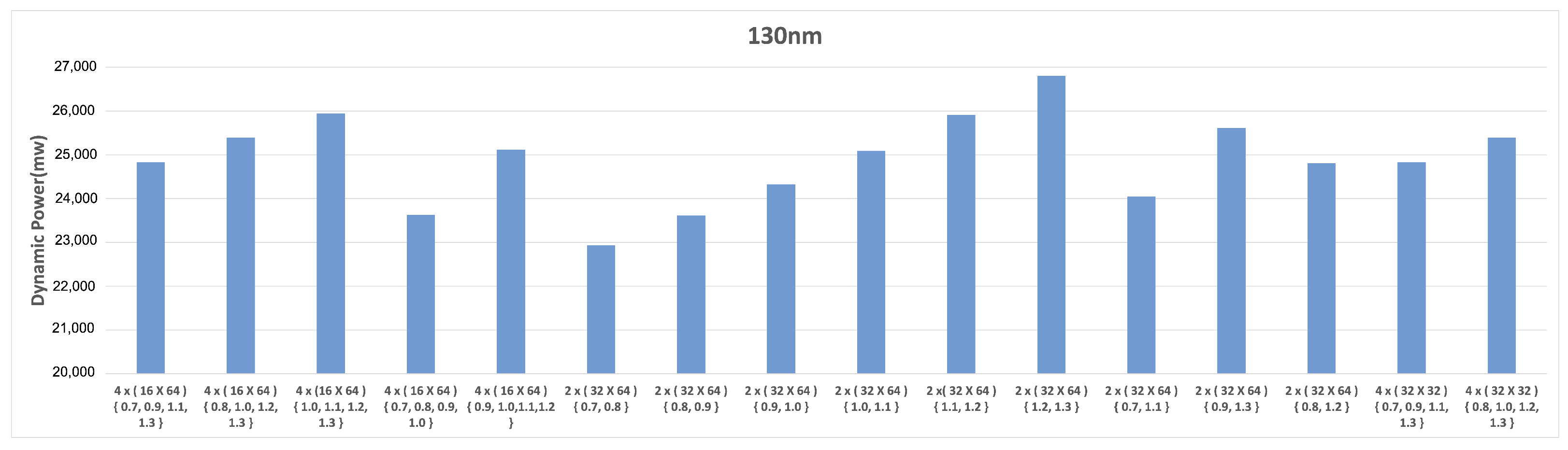
5.3.3. Effects of P, and in Dynamic Power
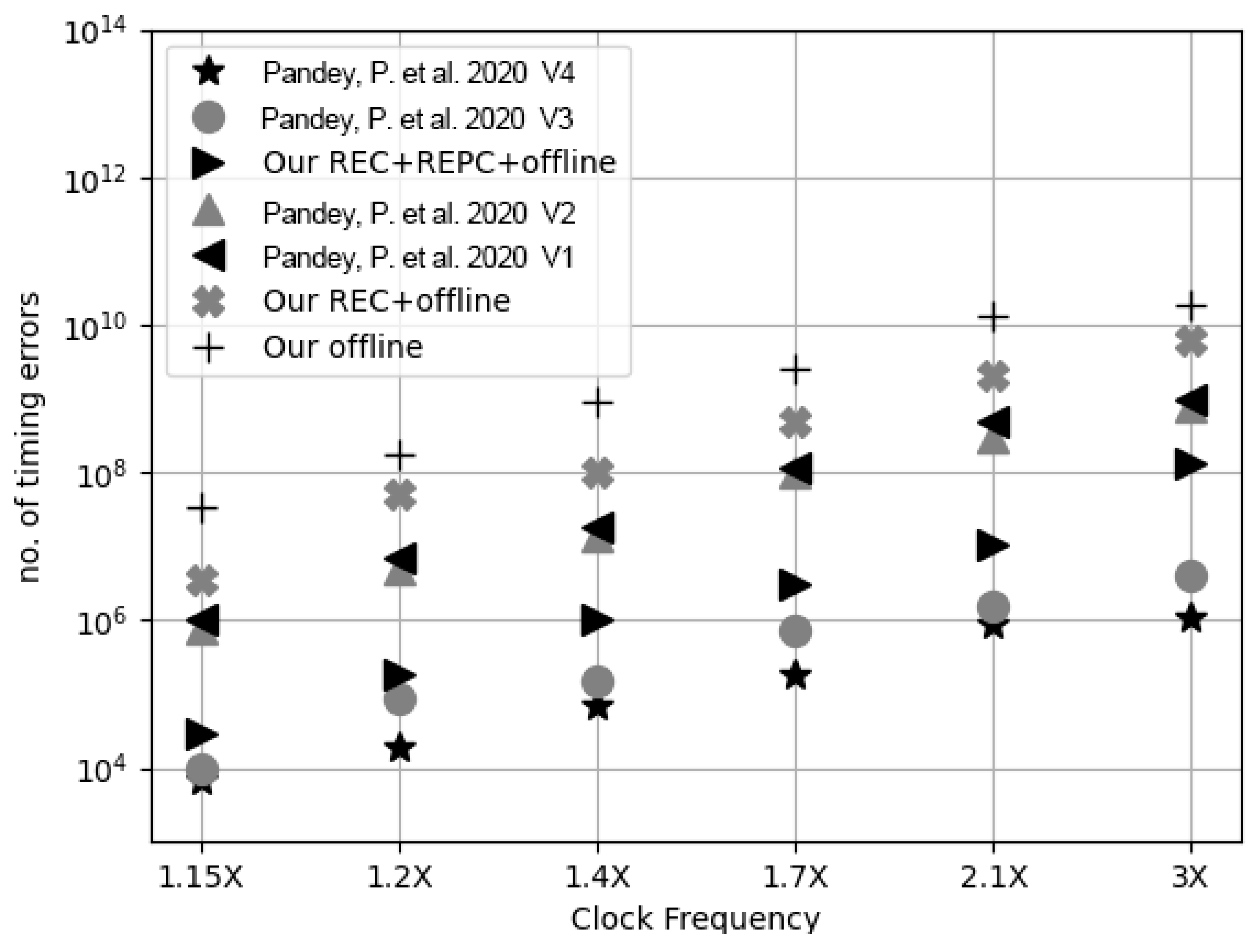
5.3.4. Normalized Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kimm, H.; Paik, I.; Kimm, H. Performance Comparision of TPU, GPU, CPU on Google Colaboratory Over Distributed Deep Learning. In Proceedings of the 2021 IEEE 14th International Symposium on Embedded Multicore/Many-Core Systems-on-Chip (MCSoC), Singapore, 20–23 December 2021; pp. 312–319. [Google Scholar] [CrossRef]
- Caulfield, A.M.; Chung, E.S.; Putnam, A.; Angepat, H.; Fowers, J.; Haselman, M.; Heil, S.; Humphrey, M.; Kaur, P.; Kim, J.Y.; et al. A cloud-scale acceleration architecture. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–13. [Google Scholar] [CrossRef]
- Putnam, A.; Caulfield, A.M.; Chung, E.S.; Chiou, D.; Constantinides, K.; Demme, J.; Esmaeilzadeh, H.; Fowers, J.; Gopal, G.P.; Gray, J.; et al. A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services. IEEE Micro 2015, 35, 10–22. [Google Scholar] [CrossRef]
- Salami, B.; Onural, E.B.; Yuksel, I.E.; Koc, F.; Ergin, O.; Cristal Kestelman, A.; Unsal, O.; Sarbazi-Azad, H.; Mutlu, O. An Experimental Study of Reduced-Voltage Operation in Modern FPGAs for Neural Network Acceleration. In Proceedings of the 2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Valencia, Spain, 29 June–2 July 2020; pp. 138–149. [Google Scholar] [CrossRef]
- Pandey, P.; Basu, P.; Chakraborty, K.; Roy, S. GreenTPU: Predictive Design Paradigm for Improving Timing Error Resilience of a Near-Threshold Tensor Processing Unit. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 1557–1566. [Google Scholar] [CrossRef]
- Ernst, D.; Kim, N.S.; Das, S.; Pant, S.; Rao, R.; Pham, T.; Ziesler, C.; Blaauw, D.; Austin, T.; Flautner, K.; et al. Razor: A low-power pipeline based on circuit-level timing speculation. In Proceedings of the 36th Annual IEEE/ACM International Symposium on Microarchitecture, 2003, MICRO-36, San Diego, CA, USA, 5 December 2003; pp. 7–18. [Google Scholar] [CrossRef]
- Ernst, D.; Das, S.; Lee, S.; Blaauw, D.; Austin, T.; Mudge, T.; Kim, N.S.; Flautner, K. Razor: Circuit-level correction of timing errors for low-power operation. IEEE Micro 2004, 24, 10–20. [Google Scholar] [CrossRef]
- Jiao, X.; Luo, M.; Lin, J.H.; Gupta, R.K. An Assessment of Vulnerability of Hardware Neural Networks to Dynamic Voltage and Temperature Variations. In Proceedings of the 36th International Conference on Computer-Aided Design, Irvine, CA, USA, 13–16 November 2017; pp. 945–950. [Google Scholar]
- Kim, E.P.; Choi, J.; Shanbhag, N.R.; Rutenbar, R.A. Error Resilient and Energy Efficient MRF Message-Passing-Based Stereo Matching. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2016, 24, 897–908. [Google Scholar] [CrossRef]
- Zhang, J.; Rangineni, K.; Ghodsi, Z.; Garg, S. ThUnderVolt: Enabling Aggressive Voltage Underscaling and Timing Error Resilience for Energy Efficient Deep Learning Accelerators. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Azghadi, M.R.; Lammie, C.; Eshraghian, J.K.; Payvand, M.; Donati, E.; Linares-Barranco, B.; Indiveri, G. Hardware Implementation of Deep Network Accelerators Towards Healthcare and Biomedical Applications. IEEE Trans. Biomed. Circuits Syst. 2020, 14, 1138–1159. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Kan, H.; Wang, Y.; Zhao, Q.; Su, D.; Huang, G. A Specification That Supports FPGA Devices on the TensorFlow Framework. In Proceedings of the 2020 4th International Conference on Electronic Information Technology and Computer Engineering, Xiamen, China, 6–8 November 2020; pp. 819–823. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, H.; Yadav, N.; Li, S.; Choi, K.K. Low-Power RTL Code Generation for Advanced CNN Algorithms toward Object Detection in Autonomous Vehicles. Electronics 2020, 9, 478. [Google Scholar] [CrossRef]
- Piyasena, D.; Wickramasinghe, R.; Paul, D.; Lam, S.K.; Wu, M. Reducing Dynamic Power in Streaming CNN Hardware Accelerators by Exploiting Computational Redundancies. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 354–359. [Google Scholar] [CrossRef]
- Pandey, P.; Gundi, N.D.; Chakraborty, K.; Roy, S. UPTPU: Improving Energy Efficiency of a Tensor Processing Unit through Underutilization Based Power-Gating. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 8–12 September 2021; pp. 325–330. [Google Scholar] [CrossRef]
- Murray, K.E.; Petelin, O.; Zhong, S.; Wang, J.M.; Eldafrawy, M.; Legault, J.P.; Sha, E.; Graham, A.G.; Wu, J.; Walker, M.J.P.; et al. VTR 8: High-Performance CAD and Customizable FPGA Architecture Modelling. ACM Trans. Reconfig. Technol. Syst. 2020, 13, 1–55. [Google Scholar] [CrossRef]
- Jamieson, P.; Kent, K.B.; Gharibian, F.; Shannon, L. Odin II—An Open-Source Verilog HDL Synthesis Tool for CAD Research. In Proceedings of the 2010 18th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, Charlotte, NC, USA, 2–4 May 2010; pp. 149–156. [Google Scholar] [CrossRef]
- Synthesis, B.L.; Verification Group. ABC: A System for Sequential Synthesis and Verification. 2018. Available online: https://people.eecs.berkeley.edu/~alanmi/abc/ (accessed on 6 April 2024).
- Luu, J.; Kuon, I.; Jamieson, P.; Campbell, T.; Ye, A.; Fang, W.M.; Kent, K.; Rose, J. VPR 5.0: FPGA CAD and Architecture Exploration Tools with Single-Driver Routing, Heterogeneity and Process Scaling. ACM Trans. Reconfig. Technol. Syst. 2011, 4, 1–23. [Google Scholar] [CrossRef]
- Mukherjee, R.; Memik, S.O. Realizing Low Power FPGAs: A Design Partitioning Algorithm for Voltage Scaling and a Comparative Evaluation of Voltage Scaling Techniques for FPGAs; Semanticschola, 2005. Available online: https://api.semanticscholar.org/CorpusID:14769411 (accessed on 6 April 2024).
- Miller, T.N.; Pan, X.; Thomas, R.; Sedaghati, N.; Teodorescu, R. Booster: Reactive core acceleration for mitigating the effects of process variation and application imbalance in low-voltage chips. In Proceedings of the IEEE International Symposium on High-Performance Comp Architecture, New Orleans, LA, USA, 25–29 February 2012; pp. 1–12. [Google Scholar] [CrossRef]
- Stanford University, Hierarchical Agglomerative Clustering; 2008. Available online: https://nlp.stanford.edu/IR-book/html/htmledition/hierarchical-agglomerative-clustering-1.html (accessed on 6 April 2024).
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Uramoto, S.i.; Takabatake, A.; Suzuki, M.; Sakurai, H.; Yoshimoto, M. A half-pel precision motion estimation processor for NTSC-resolution video. In Proceedings of the IEEE Custom Integrated Circuits Conference—CICC ’93, San Diego, CA, USA, 9–12 May 1993; pp. 11.2.1–11.2.4. [Google Scholar] [CrossRef]
- Kung, H.; Picard, R. One-Dimensional Systolic Arrays for Multidimensional Convolution and Resampling. In VLSI for Pattern Recognition and Image Processing; Springer: Berlin/Heidelberg, Germany, 1984; pp. 9–24. [Google Scholar] [CrossRef]
- Jehng, Y.S.; Chen, L.G.; Chiueh, T.D. An efficient and simple VLSI tree architecture for motion estimation algorithms. IEEE Trans. Signal Process. 1993, 41, 889–900. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Static | Runtime | Runtime | Name of | Transistor | Power Reduction | Remarks | |||
|---|---|---|---|---|---|---|---|---|---|
| Paper | Offline Calibration | Error Correction (REC) | Error Prediction and Correction (REPC) | Error Detection | Error Correction Technique | Platform | Technology | Strategy | |
| J. Zhang et al. [10], 2018 | × | × | × | 🗸 | TE-Drop | ASIC | 45 nm | Underscaling single | Underscaling of , accuracy study of DNN, -based timing error detection, correction with TE-Drop |
| Pandey er al. [5], 2019 | × | × | 🗸 | 🗸 | TE-Drop | ASIC | 15 nm | Underscaling multiple | Underscaling of , accuracy study of CNN, -based timing error detection, heuristic error prediction, correction with TE-Drop |
| Salami et al. [4], 2020 | × | × | × | × | × | Xilinx ZCU-102 FPGA | 16 nm | Underscaling single | Underscaling of , accuracy study of CNN |
| Ernst et al. [7], 2006 | × | × | × | 🗸 | TED | ASIC | 180 nm | Underscaling single | Underscaling of , accuracy study of DNN, -based timing error detection, correction with TED |
| Jiao et al. [8] | × | × | × | 🗸 | TEP | ASIC | 45 nm | Underscaling single | Underscaling of with variation of temperature, changing training set accuracy study of CNN |
| Azghadi et al. [11], 2020 | × | × | × | × | × | Virtex-VU9 FPGA | 28 nm | Architectural optimization | Resource-optimized hardware architecture for DNN |
| Zhao et al. [12], 2020 | × | × | × | × | × | Intel Aria10 FPGA | 18 nm | Architectural optimization | Resource-optimized hardware architecture for CNN, accuracy study of CNN |
| Kim et al. [13], 2020 | × | × | × | × | × | Xilinx Zynq FPGA | 28 nm | Clock gating | Low-power CNN architecture, clock gating used to optimize power |
| Duvindu et al. [14], 2020 | × | × | × | × | × | Xilinx Zynq FPGA | 28 nm | Clock gating | Power savings with minimal accuracy and performance loss |
| Pandey et al. [15], 2021 | × | × | × | × | × | ASIC | 15 nm | Power gating | It addresses a significant hardware underutilization problem in weight-stationary systolic arrays |
| Our | 🗸 | 🗸 | 🗸 | 🗸 | TE-Drop | Xilinx Artix 7 FPGA | 28 nm | Underscaling multiple | Underscaling of , partitioning FPGA based on critical paths of MACs, accuracy study of DNN, -based timing error detection, heuristic error prediction, correction with TE-Drop |
| Dimension of Systolic Array | Systolic Array | TECU | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ELM Size = 32 | ELM Size = 64 | ELM Size = 128 | ELM Size = 256 | |||||||
| LUT | FF | LUT | FF | LUT | FF | LUT | FF | LUT | FF | |
| 16 × 16 | 4892 | 3040 | 866 | 404 | 858 | 455 | 949 | 477 | 1254 | 603 |
| 32 × 32 | 19,563 | 12,163 | 2256 | 404 | 2346 | 455 | 2570 | 477 | 2982 | 603 |
| 64 × 64 | 34,234 | 21,282 | 3631 | 404 | 3836 | 455 | 4189 | 477 | 4711 | 603 |
| Dynamic Power (mw) | ||||||||
|---|---|---|---|---|---|---|---|---|
| 25 °C Ambient Temperature and 100 MHz Clock | Size of Systolic Array | Partition No. | (Volts) | Vivado 28 nm Artix-7 (D1) | VTR 22 nm (D2) | VTR 45 nm (D3) | VTR 130 nm (D3) | Remarks |
| Without Voltage Scaling | NA | 1.00 | 408 | 328 | 469 | 1808 |
D1, D2, D3 and D4 required | |
| partition-1 | 0.96 | 382 | 310 | 446 | 1753 | 1 stage K-Means clustering | ||
| Voltage | partition-2 | 0.97 | ||||||
| Scaled | partition-3 | 0.98 | ||||||
| partition-4 | 0.99 | |||||||
| Test:1 *: % of Dynamic Power Reduction | 6.4 | 5.4 | 4.9 | 3.1 | ||||
| % of timing overhead of our tool flow | 11 | 15 | 12 | 13 | ||||
| Without Voltage Scaling | NA | 1.00 | 1538 | 1072 | 1549 | 6172 | D1, D2, D3 and D4 required | |
| Voltage Scaled | partition-1 | 0.96 | 1411 | 1001 | 1472 | 5956 | 1 stage K-Means clustering | |
| partition-2 | 0.97 | |||||||
| partition-3 | 0.98 | |||||||
| partition-4 | 0.99 | |||||||
| partition-5 | 1.00 | |||||||
| Test:2 *: % of Dynamic Power Reduction | 8.2 | 6.6 | 4.8 | 3.5 | ||||
| % of timing overhead of our tool flow | 15 | 16 | 17 | 17 | ||||
| Without Voltage Scaling | NA | 1.1 | not supported | 4127 | 6023 | 24,896 | D2, D3 and D4 required 2 stages K-Means | |
| Voltage Scaled | partition-1 | 0.7 | Not Supported | 3648 | 5402 | 22,716 | clustering; D1 Not supported, < 0.95 NA in Artix-7 | |
| partition-2 | 0.78 | |||||||
| partition-3 | 0.86 | |||||||
| partition-4 | 0.92 | |||||||
| partition-5 | 0.98 | |||||||
| partition-6 | 1.04 | |||||||
| partition-7 | 1.1 | |||||||
| Test:3: % of Dynamic Power Reduction | - | 11.6 | 10.3 | 8.7 | ||||
| % of timing overhead of our tool flow | - | 29 | 28 | 30 | ||||
| Tool | Size = 16 × 16, Temp—25 °C, Clock = 100 MGhz, # MAC = 256 | Dynamic Power (mw) | % Dynamic Power Reduction | # Accessed Data | # Load Clock | # Idle Clock | # Working Clock | # Total Clock |
|---|---|---|---|---|---|---|---|---|
| Vivado-Artix7 | 1DSA0 | 489 | 6.14 | 1024 | 512 | 256 | 256 | 1024 |
| 1DSA0-VS | 459 | |||||||
| VTR-22 nm | 1DSA0 | 387 | 7.24 | |||||
| 1DSA0-VS | 359 | |||||||
| VTR-45 nm | 1DSA0 | 502 | 5.17 | |||||
| 1DSA0-VS | 476 | |||||||
| VTR-130 nm | 1DSA0 | 2251 | 4.35 | |||||
| 1DSA0-VS | 2153 | |||||||
| Vivado-Artix7 | 1DSA1 | 481 | 6.65 | 256 | 1024 | 240 | 256 | 752 |
| 1DSA1-VS | 449 | |||||||
| VTR-22 nm | 1DSA1 | 381 | 7.87 | |||||
| 1DSA1-VS | 351 | |||||||
| VTR-45 nm | 1DSA1 | 496 | 5.24 | |||||
| 1DSA1-VS | 470 | |||||||
| VTR-130 nm | 1DSA1 | 2242 | 3.92 | |||||
| 1DSA1-VS | 2154 | |||||||
| Vivado-Artix7 | 2DSA | 509 | 6.87 | 8192 | 16 | 240 | 256 | 512 |
| 2DSA-VS | 474 | |||||||
| VTR-22 nm | 2DSA | 411 | 8.27 | |||||
| 2DSA-VS | 377 | |||||||
| VTR-45 nm | 2DSA | 596 | 5.2 | |||||
| 2DSA-VS | 565 | |||||||
| VTR-130 nm | 2DSA | 2311 | 4.28 | |||||
| 2DSA-VS | 2212 | |||||||
| Vivado-Artix7 | Tree | 528 | 6.25 | 8192 | 16 | 240 | 256 | 512 |
| Tree-VS | 495 | |||||||
| VTR-22 nm | Tree | 431 | 7.65 | |||||
| Tree-VS | 398 | |||||||
| VTR-45 nm | Tree | 613 | 5.22 | |||||
| Tree-VS | 581 | |||||||
| VTR-130 nm | Tree | 2423 | 4.29 | |||||
| Tree-VS | 2319 | |||||||
| Vivado-Artix7 | Proposed TPU SA | 408 | 6.37 | 1024 | 16 | 0 | 256 | 272 |
| Proposed TPU SA-VS | 382 | |||||||
| VTR-22 nm | Proposed TPU SA | 328 | 5.8 | |||||
| Proposed TPU SA-VS | 310 | |||||||
| VTR-45 nm | Proposed TPU SA | 469 | 5.15 | |||||
| Proposed TPU SA-VS | 446 | |||||||
| VTR-130 nm | Proposed TPU SA | 1808 | 3.13 | |||||
| Proposed TPU SA-VS | 1753 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paul, R.; Sarkar, S.; Sau, S.; Roy, S.; Chakraborty, K.; Chakrabarti, A. Voltage Scaled Low Power DNN Accelerator Design on Reconfigurable Platform. Electronics 2024, 13, 1431. https://doi.org/10.3390/electronics13081431
Paul R, Sarkar S, Sau S, Roy S, Chakraborty K, Chakrabarti A. Voltage Scaled Low Power DNN Accelerator Design on Reconfigurable Platform. Electronics. 2024; 13(8):1431. https://doi.org/10.3390/electronics13081431
Chicago/Turabian StylePaul, Rourab, Sreetama Sarkar, Suman Sau, Sanghamitra Roy, Koushik Chakraborty, and Amlan Chakrabarti. 2024. "Voltage Scaled Low Power DNN Accelerator Design on Reconfigurable Platform" Electronics 13, no. 8: 1431. https://doi.org/10.3390/electronics13081431
APA StylePaul, R., Sarkar, S., Sau, S., Roy, S., Chakraborty, K., & Chakrabarti, A. (2024). Voltage Scaled Low Power DNN Accelerator Design on Reconfigurable Platform. Electronics, 13(8), 1431. https://doi.org/10.3390/electronics13081431