
Multi-Representation Joint Dynamic Domain Adaptation Network for Cross-Database Facial Expression Recognition



Abstract
1. Introduction
- (1)
- A novel Joint Dynamic Maximum Mean Difference (JD-MMD) model integrating a subdomain and global domain is proposed, not only enabling adaptation between different domains but also the incorporation of fine-grained information within the same class.
- (2)
- The acquisition of image features from multiple angles enables a more comprehensive description of the features. By incorporating these features into the joint dynamic domain adaptive model, we propose a multi-representation joint dynamic domain adaptive network (MJDDAN) that effectively addresses feature distribution discrepancies across different domains, thereby enhancing model performance and adaptability.
- (3)
- The experimental results demonstrate that the domain adaptive method based on MJDDAN exhibits significant advantages in the task of facial expression recognition. This is validated through experiments conducted on the RAVDESS [19], FABO [20], and eNTERFACE [21] datasets. In comparison to other methods, MJDDAN achieves superior implementation outcomes.
2. Related Work
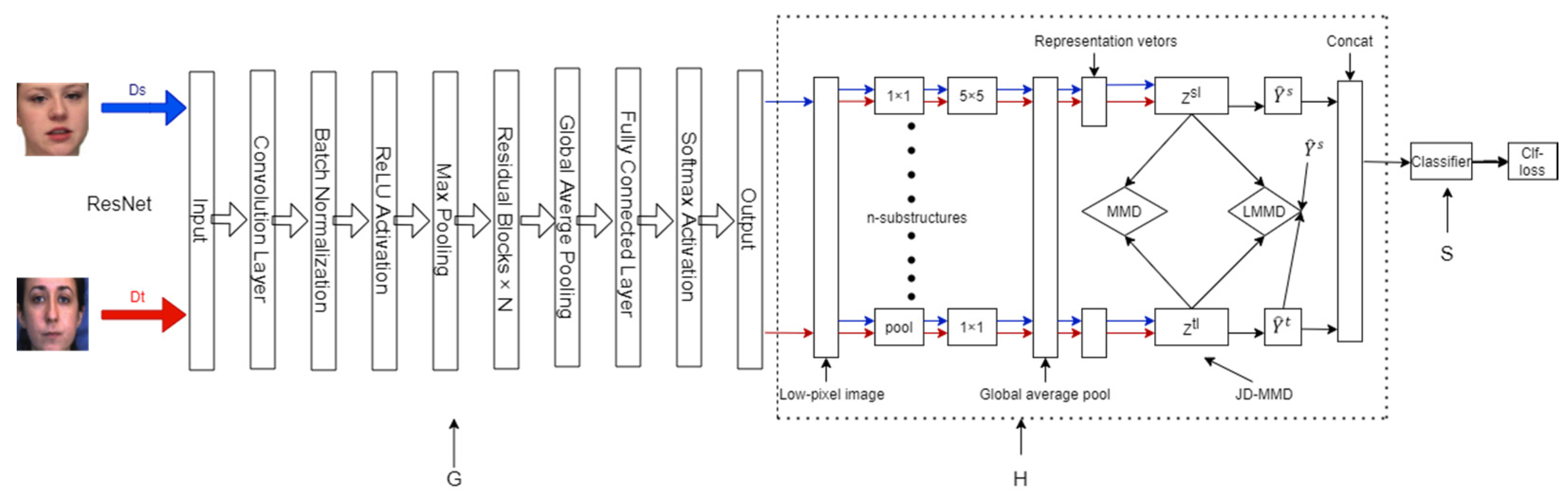
3. Multiple-Representation Joint Dynamic Domain Adaptive Network
3.1. Network Overview
3.2. Multi-Representation Feature Extraction Module
3.3. Joint Dynamic Maximum Mean Difference
4. Experimental Results and Analysis
4.1. Experimental Environment
4.2. Facial Expression Database
- (1)
- The RAVDESS database is a multi-modal emotion database that includes two parts (voice emotions and song emotions). The performances of 12 male and 12 female professional actors were recorded, with each actor performing in a neutral American accent and ensuring correct content matching with different vocabulary. In the song mode, there are five types of emotions (tranquility, joy, grief, fear, and anger), while in the voice mode, there are expressions of serenity, joy, grief, anger, fear, surprise, and disgust. Each emotion has a neutral expression as well as two expressions of varying intensity [19,41,42,43,44]. Figure 3 is a sample of partial expressions in the RAVDESS database.
- (2)
- The FABO database was created by Hatice Gunes and others at the University of Technology Sydney in 2005, and it is the first publicly available bimodal emotion database that contains data on facial expressions and body language. Out of the 23 participants in the database, 11 are men, and 12 are women. During the process of collecting data, each subject was presented with different illustrations and situations, and their generated facial expressions and body language were recorded. Each video contains 2–4 fully displayed emotional expressions of the same type. The database recorded nine emotional expressions (surprise, anger, disgust, fear, boredom, anxiety, and uncertainty) [20,45,46,47,48]. Figure 4 is a sample of partial expressions in the FABO database.
- (3)
- Martin and his team at KU Leuven developed the eNTERFACE database, which is a two-modal emotion database containing speech emotion and video emotion. The database was created with the selection of 46 subjects, 81% of whom were male, with the remaining being female, from 14 different countries. The participants expressed genuine feelings of happiness, fear, anger, surprise, disgust, and sadness in six different situations. Finally, the database was reviewed by a human expert who deleted the video data with unclear emotional expressions. In the end, data from 42 participants were retained [21,49,50,51,52]. Figure 5 is a sample of partial expressions in the eNTERFACE database.
4.3. Experimental Details
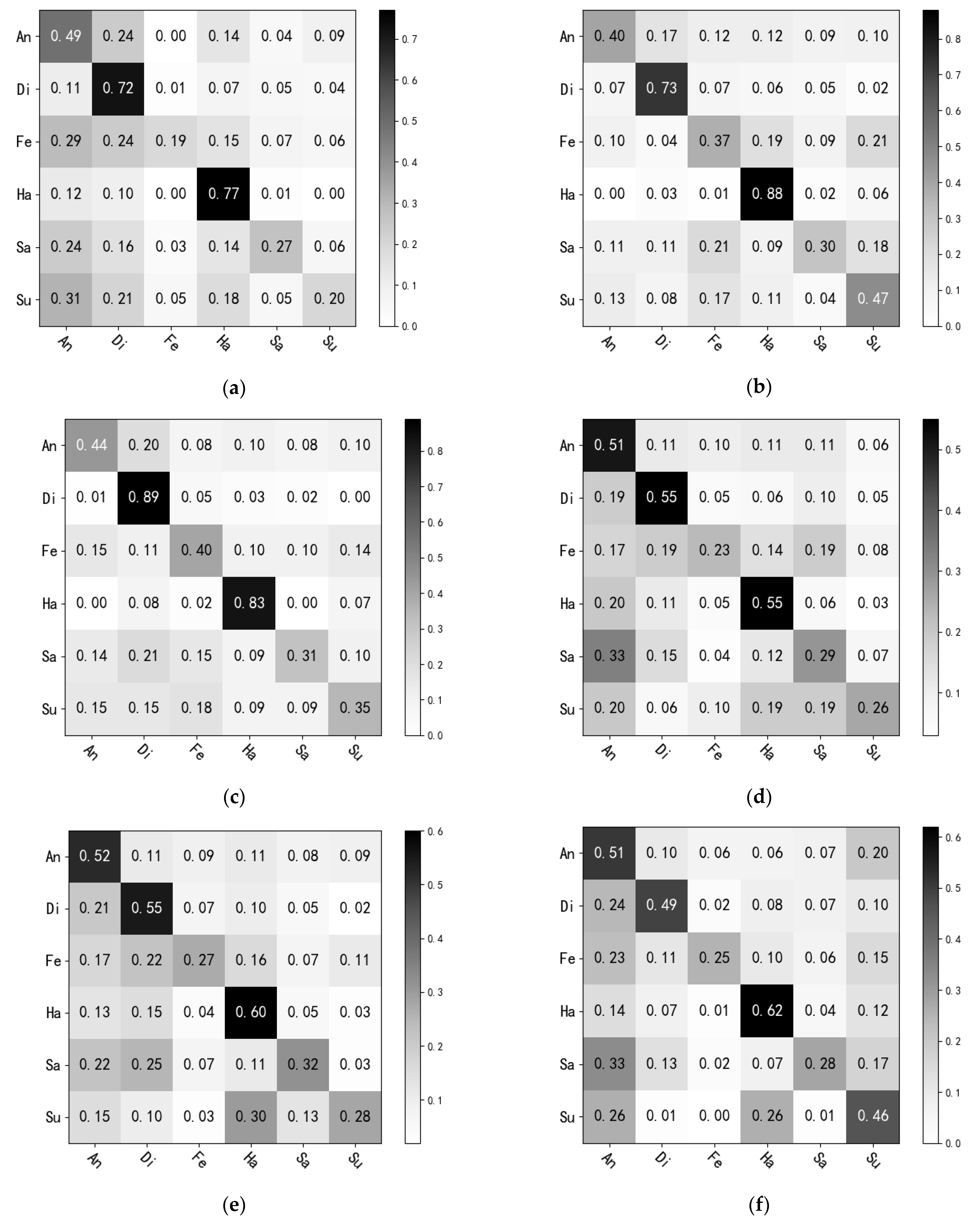
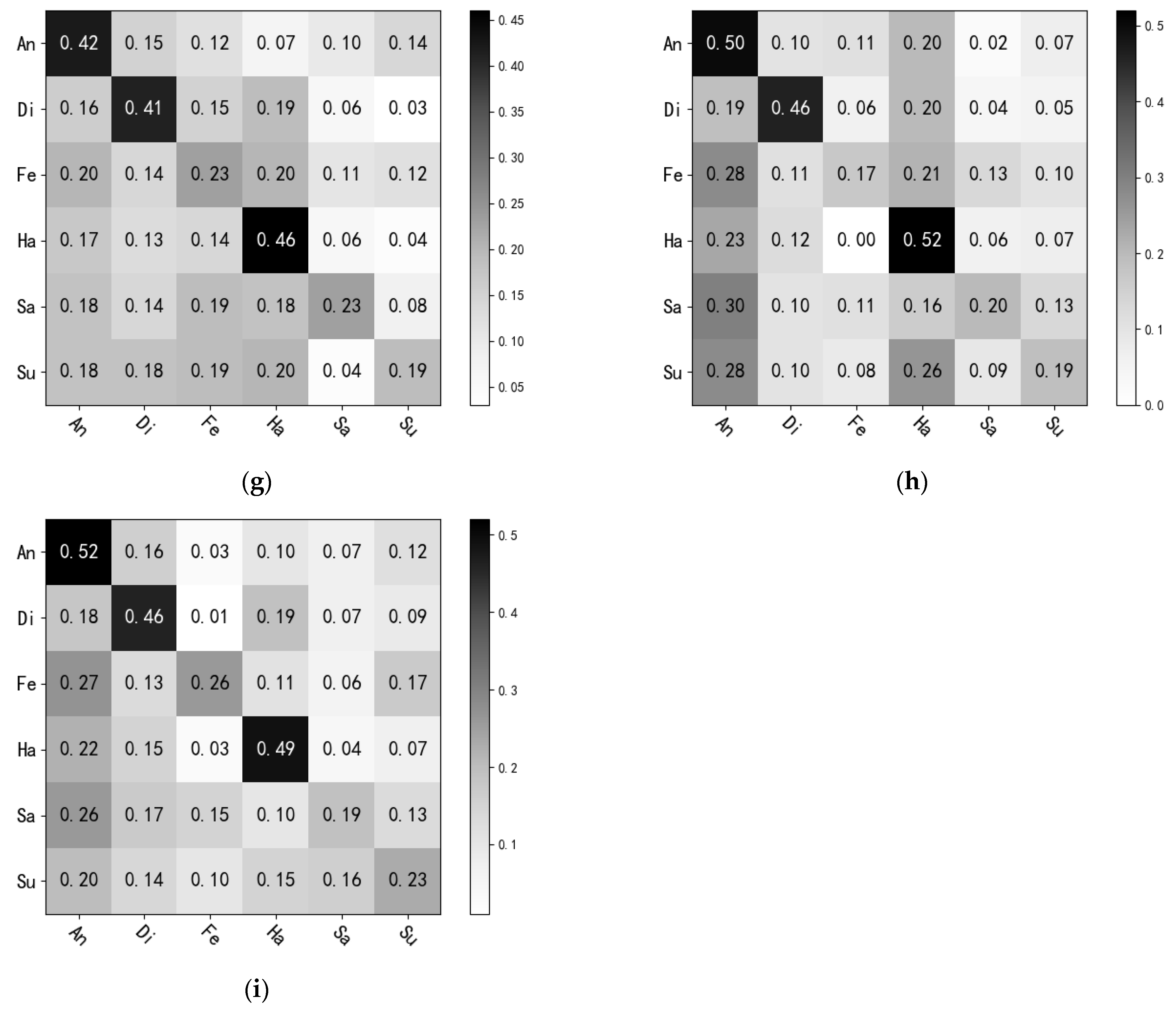
4.4. Cross-Database Facial Expression Recognition Experiment and Result Analysis
4.5. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Wang, A. Enhanced Facial Expression Recognition Based on Facial Action Unit Intensity and Region. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023; pp. 1939–1944. [Google Scholar]
- De, A.; Saha, A. A Comparative Study on Different Approaches of Real Time Human Emotion Recognition Based on Facial Expression Detection. In Proceedings of the 2015 International Conference on Advances in Computer Engineering and Applications, Ghaziabad, India, 19–20 March 2015; pp. 483–487. [Google Scholar]
- Lin, S.-Y.; Tseng, Y.-W.; Wu, C.-R.; Kung, Y.-C.; Chen, Y.-Z.; Wu, C.-M. A Continuous Facial Expression Recognition Model Based on Deep Learning Method. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar]
- Verma, K.; Khunteta, A. Facial Expression Recognition Using Gabor Filter and Multi-Layer Artificial Neural Network. In Proceedings of the 2017 International Conference on Information, Communication, Instrumentation and Control (ICICIC), Indore, India, 17–19 August 2017; pp. 1–5. [Google Scholar]
- Wei, H.; Zhang, Z. A Survey of Facial Expression Recognition Based on Deep Learning. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 90–94. [Google Scholar]
- Grover, R.; Bansal, S. Facial Expression Recognition: Deep Survey, Progression and Future Perspective. In Proceedings of the 2023 International Conference on Advancement in Computation & Computer Technologies (InCACCT), Gharuan, India, 5–6 May 2023; pp. 111–117. [Google Scholar]
- Singh, Y.B.; Goel, S. Survey on Human Emotion Recognition: Speech Database, Features and Classification. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 12–13 October 2018; pp. 298–301. [Google Scholar]
- Li, Y.; Chao, L.; Liu, Y.; Bao, W.; Tao, J. From Simulated Speech to Natural Speech, What Are the Robust Features for Emotion Recognition? In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 368–373. [Google Scholar]
- Luqin, S. A Survey of Facial Expression Recognition Based on Convolutional Neural Network. In Proceedings of the 2019 IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS), Beijing, China, 17–19 June 2019; pp. 1–6. [Google Scholar]
- Ming, F.J.; Shabana Anhum, S.; Islam, S.; Keoy, K.H. Facial Emotion Recognition System for Mental Stress Detection among University Students. In Proceedings of the 2023 3rd International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Tenerife, Spain, 19–21 July 2023; pp. 1–6. [Google Scholar]
- Dixit, A.N.; Kasbe, T. A Survey on Facial Expression Recognition Using Machine Learning Techniques. In Proceedings of the 2nd International Conference on Data, Engineering and Applications (IDEA), Bhopal, India, 28–29 February 2020; pp. 1–6. [Google Scholar]
- Fatjriyati Anas, L.; Ramadijanti, N.; Basuki, A. Implementation of Facial Expression Recognition System for Selecting Fashion Item Based on Like and Dislike Expression. In Proceedings of the 2018 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC), Bali, Indonesia, 29–30 October 2018; pp. 74–78. [Google Scholar]
- Tang, H.; Cen, X. A Survey of Transfer Learning Applied in Medical Image Recognition. In Proceedings of the 2021 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 27–28 August 2021; pp. 94–97. [Google Scholar]
- Kusunose, T.; Kang, X.; Kiuchi, K.; Nishimura, R.; Sasayama, M.; Matsumoto, K. Facial Expression Emotion Recognition Based on Transfer Learning and Generative Model. In Proceedings of the 2022 8th International Conference on Systems and Informatics (ICSAI), Kunming, China, 10–12 December 2022; pp. 1–6. [Google Scholar]
- Bousaid, R.; El Hajji, M.; Es-Saady, Y. Facial Emotions Recognition Using Vit and Transfer Learning. In Proceedings of the 2022 5th International Conference on Advanced Communication Technologies and Networking (CommNet), Marrakech, Morocco, 12–14 December 2022; pp. 1–6. [Google Scholar]
- Zhou, J.; Zhuang, J.; Li, B.; Zhou, L. Research on Underwater Image Recognition Based on Transfer Learning. In Proceedings of the OCEANS 2022, Hampton Roads, Virginia Beach, VA, USA, 17–20 October 2022; pp. 1–7. [Google Scholar]
- Xia, K.; Gu, X.; Chen, B. Cross-Dataset Transfer Driver Expression Recognition via Global Discriminative and Local Structure Knowledge Exploitation in Shared Projection Subspace. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1765–1776. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhuang, F.; Wang, J.; Chen, J.; Shi, Z.; Wu, W.; He, Q. Multi-Representation Adaptation Network for Cross-Domain Image Classification. Neural Netw. 2019, 119, 214–221. [Google Scholar] [CrossRef] [PubMed]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A Dynamic, Multimodal Set of Facial and Vocal Expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed]
- Gunes, H.; Piccardi, M. A Bimodal Face and Body Gesture Database for Automatic Analysis of Human Nonverbal Affective Behavior. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 1148–1153. [Google Scholar]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The ENTERFACE’05 Audio-Visual Emotion Database. In Proceedings of the 22nd International Conference on Data Engineering Workshops (ICDEW’06), Atlanta, GA, USA, 3–7 April 2006; p. 8. [Google Scholar]
- Ni, T.; Zhang, C.; Gu, X. Transfer Model Collaborating Metric Learning and Dictionary Learning for Cross-Domain Facial Expression Recognition. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1213–1222. [Google Scholar] [CrossRef]
- Zhang, W.; Song, P.; Zheng, W. Joint Local-Global Discriminative Subspace Transfer Learning for Facial Expression Recognition. IEEE Trans. Affect. Comput. 2023, 14, 2484–2495. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic Flow Kernel for Unsupervised Domain Adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised Visual Domain Adaptation Using Subspace Alignment. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; PMLR: Cambridge, MA, USA, 2015; Volume 37, pp. 1180–1189. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep Subdomain Adaptation Network for Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1713–1722. [Google Scholar] [CrossRef] [PubMed]
- Ren, C.-X.; Dai, D.-Q.; Huang, K.-K.; Lai, Z.-R. Transfer Learning of Structured Representation for Face Recognition. IEEE Trans. Image Process. 2014, 23, 5440–5454. [Google Scholar] [CrossRef] [PubMed]
- Long, M.; Wang, J.; Ding, G.; Shen, D.; Yang, Q. Transfer Learning with Graph Co-Regularization. IEEE Trans. Knowl. Data Eng. 2014, 26, 1805–1818. [Google Scholar] [CrossRef]
- Zou, X.; Yan, Y.; Xue, J.H.; Chen, S.; Wang, H. Learn-to-Decompose: Cascaded Decomposition Network for Cross-Domain Few-Shot Facial Expression Recognition. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 683–700. [Google Scholar]
- Zhang, W.; Wu, D. Discriminative Joint Probability Maximum Mean Discrepancy (DJP-MMD) for Domain Adaptation. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Lin, W.; Mak, M.-M.; Li, N.; Su, D.; Yu, D. Multi-Level Deep Neural Network Adaptation for Speaker Verification Using MMD and Consistency Regularization. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6839–6843. [Google Scholar]
- Zhang, Z.; Wu, D.; Zhu, D.; Zhang, X. Ground Moving Target Detection for Multichannel SAR System Based on Subdomain Adaptation. In Proceedings of the 2023 IEEE 23rd International Conference on Communication Technology (ICCT), Wuxi, China, 20–22 October 2023; pp. 156–161. [Google Scholar]
- Xiao, H.; Dong, L.; Wang, W.; Ogai, H. Distribution Sub-Domain Adaptation Deep Transfer Learning Method for Bridge Structure Damage Diagnosis Using Unlabeled Data. IEEE Sens. J. 2022, 22, 15258–15272. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, W.; Wang, J.; Wang, Y.; Wang, F.-Y. ParaUDA: Invariant Feature Learning With Auxiliary Synthetic Samples for Unsupervised Domain Adaptation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20217–20229. [Google Scholar] [CrossRef]
- Xie, J.; Zhou, Y.; Xu, X.; Wang, G.; Shen, F.; Yang, Y. Region-Aware Semantic Consistency for Unsupervised Domain-Adaptive Semantic Segmentation. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 90–95. [Google Scholar]
- Gan, B.; Dong, Q. Unsupervised Domain-Adaptive Image Classification Algorithm Incorporating Generative Adversarial Networks. In Proceedings of the 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 3–5 December 2021; pp. 305–310. [Google Scholar]
- Chen, Y.; Yang, C.; Zhang, Y.; Li, Y. Conditional Adaptation Deep Networks for Unsupervised Cross Domain Image Classifcation. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 517–521. [Google Scholar]
- Rochlani, Y.R.; Raut, A.B. Machine Learning Approach for Detection of Speech Emotions for RAVDESS Audio Dataset. In Proceedings of the 2024 Fourth International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 11–12 January 2024; pp. 1–7. [Google Scholar]
- Agrima, A.; Barakat, A.; Mounir, I.; Farchi, A.; ElMazouzi, L.; Mounir, B. Speech Emotion Recognition Using Energies in Six Bands and Multilayer Perceptron on RAVDESS Dataset. In Proceedings of the 2022 5th International Conference on Advanced Communication Technologies and Networking (CommNet), Marrakech, Morocco, 12–14 December 2022; pp. 1–5. [Google Scholar]
- Sowmya, G.; Naresh, K.; Sri, J.D.; Sai, K.P.; Indira, D.N.V.S.L.S. Speech2Emotion: Intensifying Emotion Detection Using MLP through RAVDESS Dataset. In Proceedings of the 2022 International Conference on Electronics and Renewable Systems (ICEARS), Tuticorin, India, 16–18 March 2022; pp. 1–3. [Google Scholar]
- Singh, V.; Prasad, S. Speech Emotion Recognition Using Fully Convolutional Network and Augmented RAVDESS Dataset. In Proceedings of the 2023 International Conference on Advanced Computing Technologies and Applications (ICACTA), Bali, Indonesia, 5–6 October 2023; pp. 1–7. [Google Scholar]
- Noroozi, F.; Corneanu, C.A.; Kaminska, D.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on Emotional Body Gesture Recognition. IEEE Trans. Affect. Comput. 2021, 12, 505–523. [Google Scholar] [CrossRef]
- Gunes, H.; Piccardi, M. Creating and Annotating Affect Databases from Face and Body Display: A Contemporary Survey. In Proceedings of the 2006 IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; pp. 2426–2433. [Google Scholar]
- Alepis, E.; Stathopoulou, I.-O.; Virvou, M.; Tsihrintzis, G.A.; Kabassi, K. Audio-Lingual and Visual-Facial Emotion Recognition: Towards a Bi-Modal Interaction System. In Proceedings of the 2010 22nd IEEE International Conference on Tools with Artificial Intelligence, Arras, France, 27–29 October 2010; pp. 274–281. [Google Scholar]
- Chen, S.; Tian, Y.; Liu, Q.; Metaxas, D.N. Segment and Recognize Expression Phase by Fusion of Motion Area and Neutral Divergence Features. In Proceedings of the Face and Gesture 2011, Santa Barbara, CA, USA, 21–23 March 2011; pp. 330–335. [Google Scholar]
- Chen, L.; Wang, K.; Li, M.; Wu, M.; Pedrycz, W.; Hirota, K. K-Means Clustering-Based Kernel Canonical Correlation Analysis for Multimodal Emotion Recognition in Human–Robot Interaction. IEEE Trans. Ind. Electron. 2023, 70, 1016–1024. [Google Scholar] [CrossRef]
- Li, L.; Zhao, Y.; Jiang, D.; Zhang, Y.; Wang, F.; Gonzalez, I.; Valentin, E.; Sahli, H. Hybrid Deep Neural Network--Hidden Markov Model (DNN-HMM) Based Speech Emotion Recognition. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 312–317. [Google Scholar]
- Dhoot, A.; Hadj-Alouane, N.B.; Turki-Hadj Alouane, M. 2D CNN vs 3D CNN: An Empirical Study on Deep Learning-Based Facial Emotion Recognition. In Proceedings of the 2023 International Conference on Modeling, Simulation & Intelligent Computing (MoSICom), Dubai, UAE, 7–9 December 2023; pp. 138–143. [Google Scholar]
- Toledo-Ronen, O.; Sorin, A. Voice-Based Sadness and Anger Recognition with Cross-Corpora Evaluation. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7517–7521. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TCA | GFK | SA | DANN | DSAN | CDNet | MRAN | MJDDAN | |
|---|---|---|---|---|---|---|---|---|
| F→R | 31.47% | 34.83% | 35.65% | 38.94% | 40.75% | 41.06% | 43.27% | 43.92% |
| e→R | 39.28% | 42.39% | 42.76% | 44.27% | 46.89% | 48.66% | 50.52% | 52.53% |
| 39.75% | 43.27% | 43.94% | 46.63% | 48.37% | 51.85% | 50.95% | 53.64% | |
| 28.35% | 31.62% | 31.82% | 34.28% | 35.89% | 38.63% | 38.10% | 39.84% | |
| 33.91% | 37.83% | 37.42% | 39.16% | 40.23% | 42.72% | 40.79% | 42.54% | |
| 33.33% | 38.42% | 37.33% | 40.49% | 40.98% | 42.81% | 41.36% | 43.66% | |
| 27.83% | 29.73% | 30.03% | 29.06% | 31.67% | 31.56% | 30.92% | 32.29% | |
| 27.79% | 30.92% | 31.84% | 32.23% | 32.78% | 33.37% | 32.68% | 33.96% | |
| 28.67% | 31.85% | 32.29% | 32.03% | 34.34% | 34.85% | 33.77% | 35.87% |
| TCA | GFK | SA | DANN | DSAN | CDNet | MRAN | MJDDAN | |
|---|---|---|---|---|---|---|---|---|
| F→R | 0.3168 | 0.3462 | 0.3527 | 0.3940 | 0.4088 | 0.4127 | 0.4478 | 0.4672 |
| e→R | 0.3953 | 0.4271 | 0.4288 | 0.4436 | 0.4657 | 0.4835 | 0.5004 | 0.5191 |
| 0.3992 | 0.4357 | 0.4425 | 0.4683 | 0.4851 | 0.5127 | 0.5063 | 0.5295 | |
| 0.2965 | 0.3133 | 0.3171 | 0.3491 | 0.3588 | 0.3759 | 0.3905 | 0.4028 | |
| 0.3477 | 0.3791 | 0.3769 | 0.3966 | 0.4016 | 0.4236 | 0.4153 | 0.4314 | |
| 0.3448 | 0.3869 | 0.3745 | 0.4027 | 0.4077 | 0.4257 | 0.4285 | 0.4652 | |
| 0.2864 | 0.3016 | 0.3020 | 0.2973 | 0.3181 | 0.3282 | 0.3127 | 0.3250 | |
| 0.2839 | 0.3077 | 0.3154 | 0.3244 | 0.3292 | 0.3384 | 0.3239 | 0.3436 | |
| 0.2894 | 0.3150 | 0.3251 | 0.3252 | 0.3450 | 0.3404 | 0.3356 | 0.3612 |
| ACC | F1-Score | ACC | F1-Score | ACC | F1-Score | |
|---|---|---|---|---|---|---|
| ResNet | 26.74% | 0.2693 | 34.66% | 0.3417 | 35.62% | 0.3451 |
| MFER | 28.59% | 0.2945 | 36.43% | 0.3629 | 37.92% | 0.3751 |
| JDDAN | 40.75% | 0.4088 | 46.89% | 0.4657 | 48.37% | 0.4851 |
| MGDAN | 41.66% | 0.4281 | 50.47% | 0.5017 | 51.03% | 0.5152 |
| MLDAN | 43.74% | 0.4625 | 52.25% | 0.5173 | 53.27% | 0.5228 |
| MJDDAN | 43.92% | 0.4672 | 52.53% | 0.5191 | 53.64% | 0.5295 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, J.; Yue, Y.; Yu, K.; Zhou, X.; Liu, Y.; Wei, J.; Yang, Y. Multi-Representation Joint Dynamic Domain Adaptation Network for Cross-Database Facial Expression Recognition. Electronics 2024, 13, 1470. https://doi.org/10.3390/electronics13081470
Yan J, Yue Y, Yu K, Zhou X, Liu Y, Wei J, Yang Y. Multi-Representation Joint Dynamic Domain Adaptation Network for Cross-Database Facial Expression Recognition. Electronics. 2024; 13(8):1470. https://doi.org/10.3390/electronics13081470
Chicago/Turabian StyleYan, Jingjie, Yuebo Yue, Kai Yu, Xiaoyang Zhou, Ying Liu, Jinsheng Wei, and Yuan Yang. 2024. "Multi-Representation Joint Dynamic Domain Adaptation Network for Cross-Database Facial Expression Recognition" Electronics 13, no. 8: 1470. https://doi.org/10.3390/electronics13081470
APA StyleYan, J., Yue, Y., Yu, K., Zhou, X., Liu, Y., Wei, J., & Yang, Y. (2024). Multi-Representation Joint Dynamic Domain Adaptation Network for Cross-Database Facial Expression Recognition. Electronics, 13(8), 1470. https://doi.org/10.3390/electronics13081470