
Multi-Scale Fusion Uncrewed Aerial Vehicle Detection Based on RT-DETR


Abstract
:1. Introduction
2. Related Work
2.1. Drone Detection
2.2. Detection Transformer
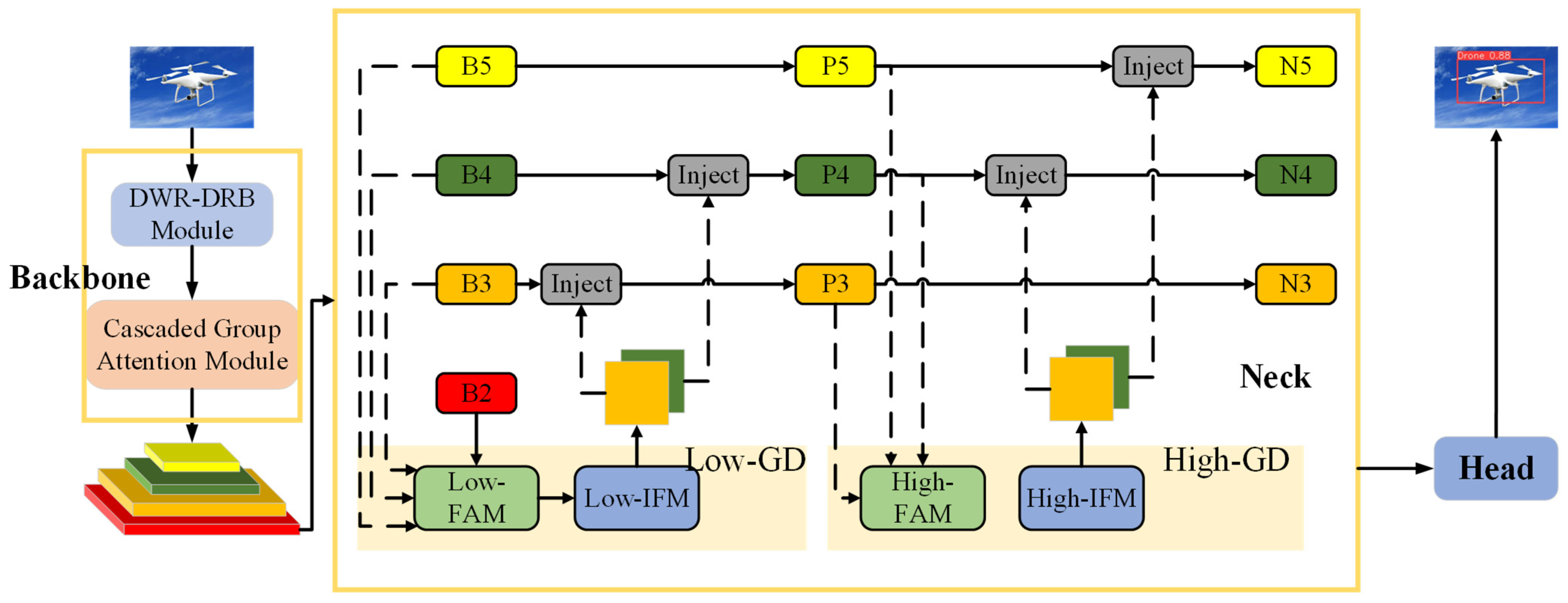
3. Proposed Methods
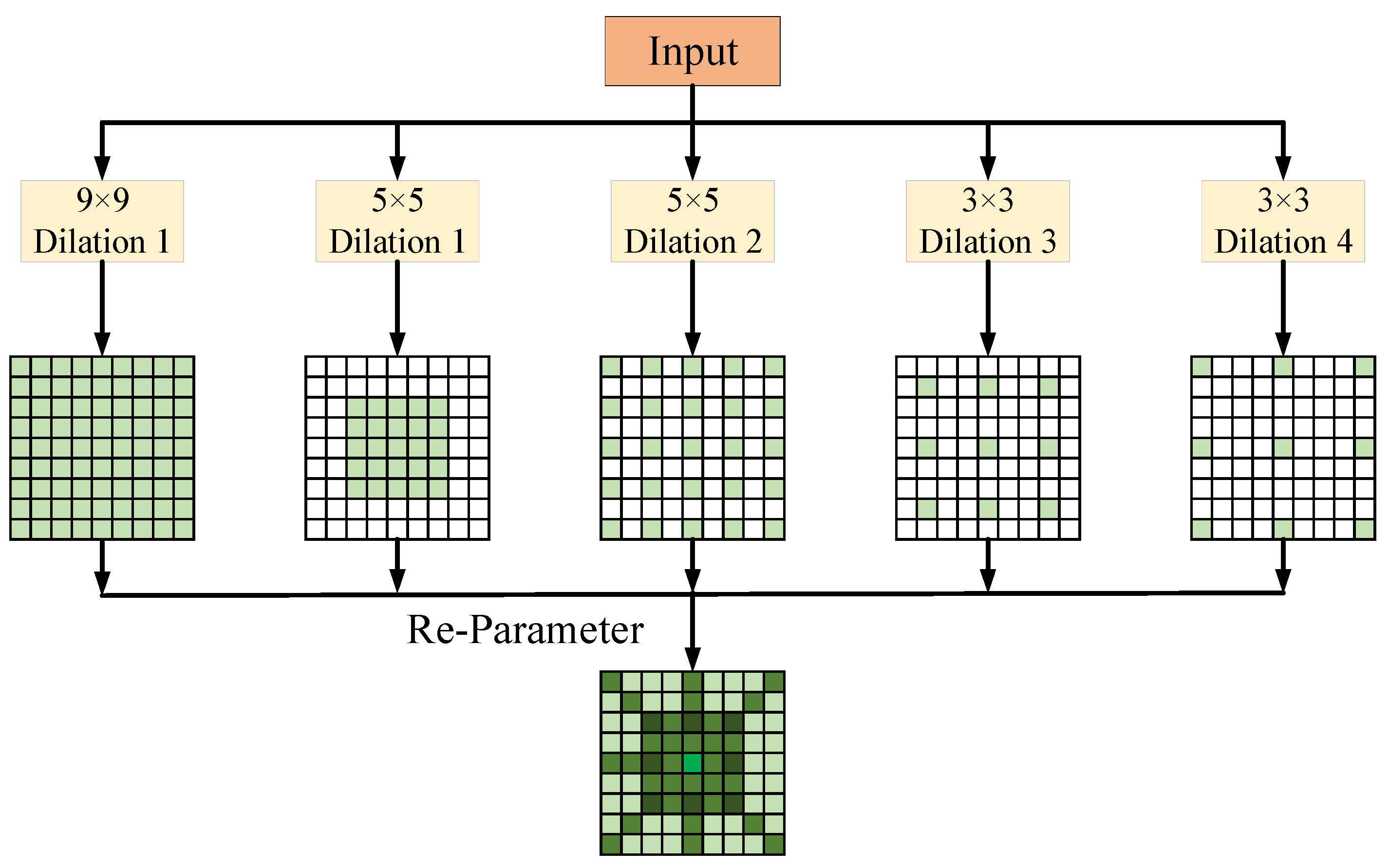
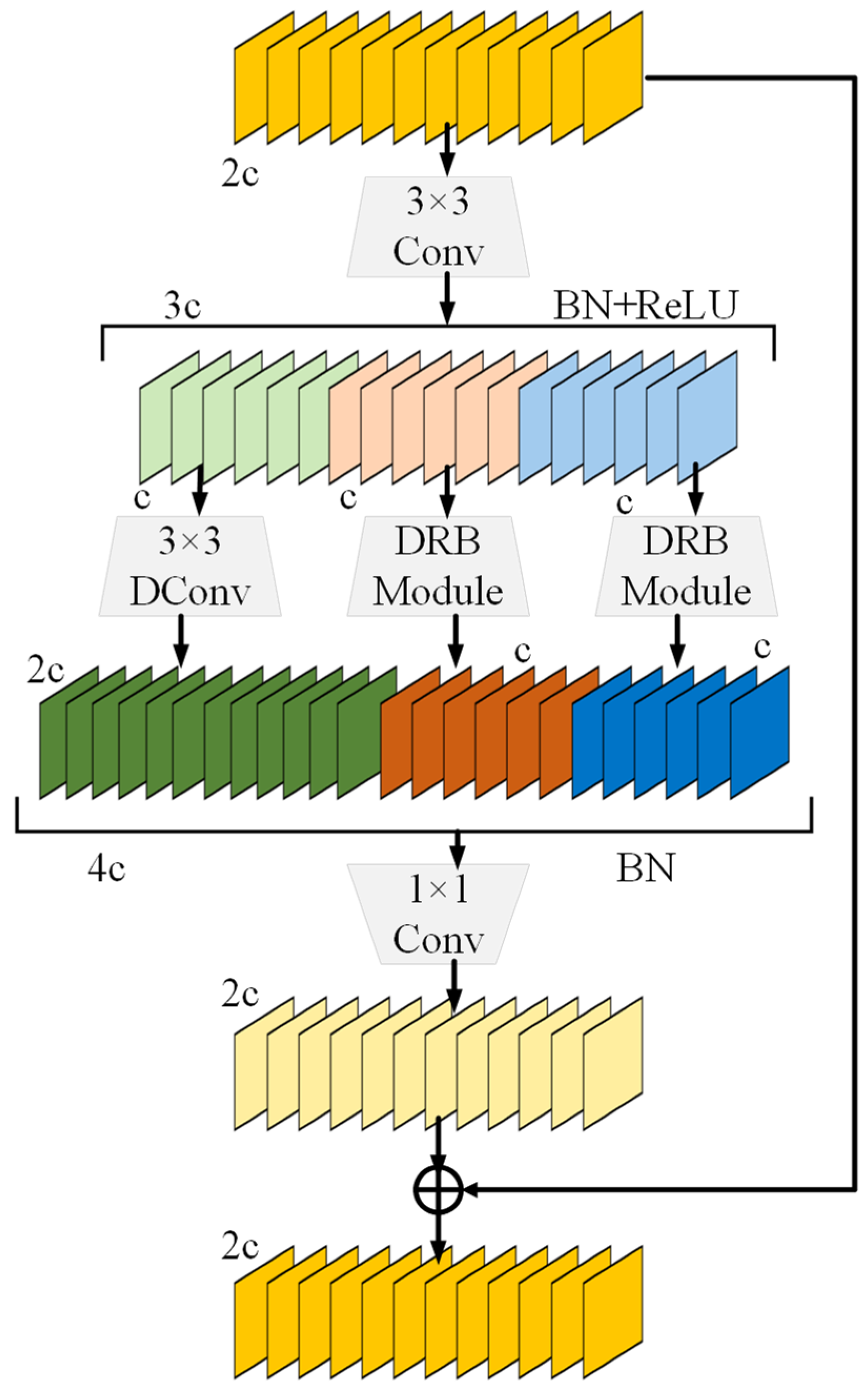
3.1. Dilation-Wise Residual and Dilated Re-Param Block Module
3.1.1. Dilated Re-Param Block
3.1.2. Dilation-Wise Residual and Dilated Re-Param Block Module
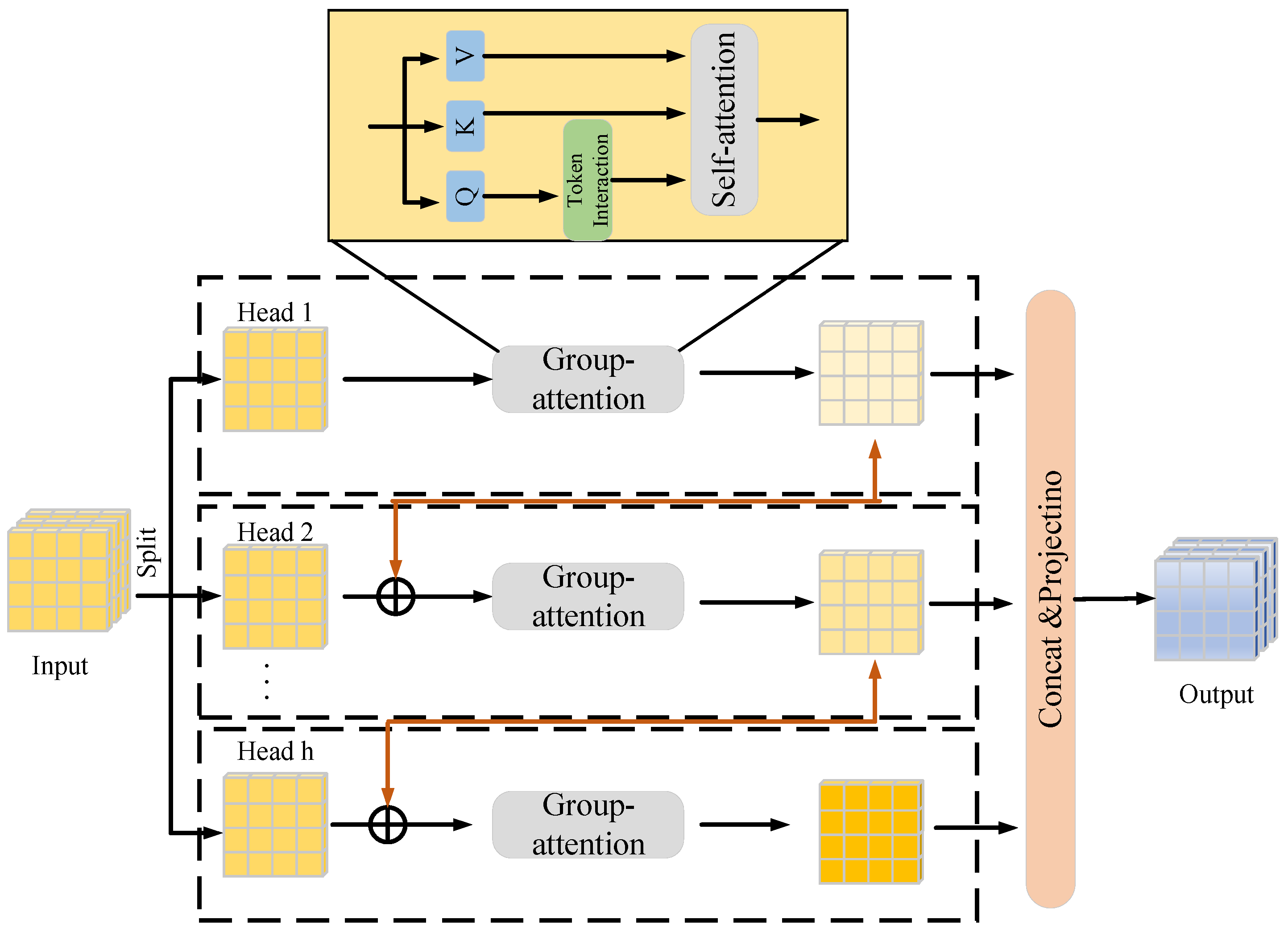
3.2. Cascaded Group Attention
3.3. Gather-and-Distribute Mechanism
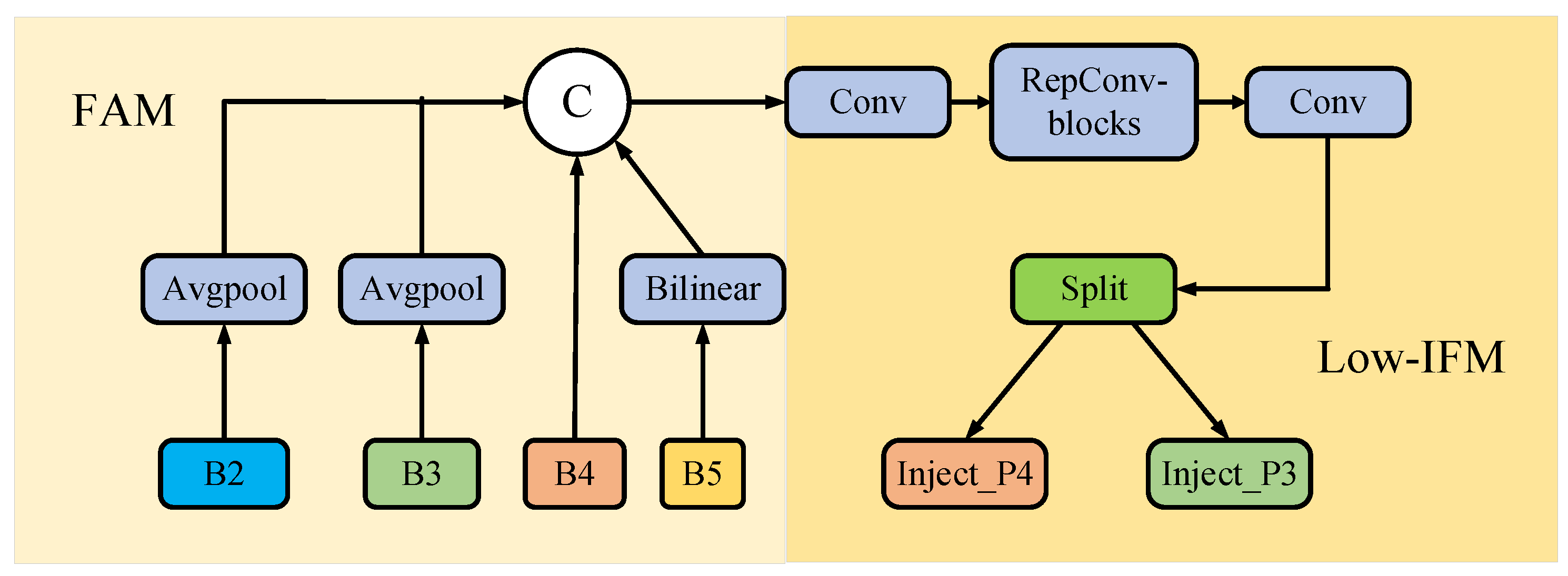
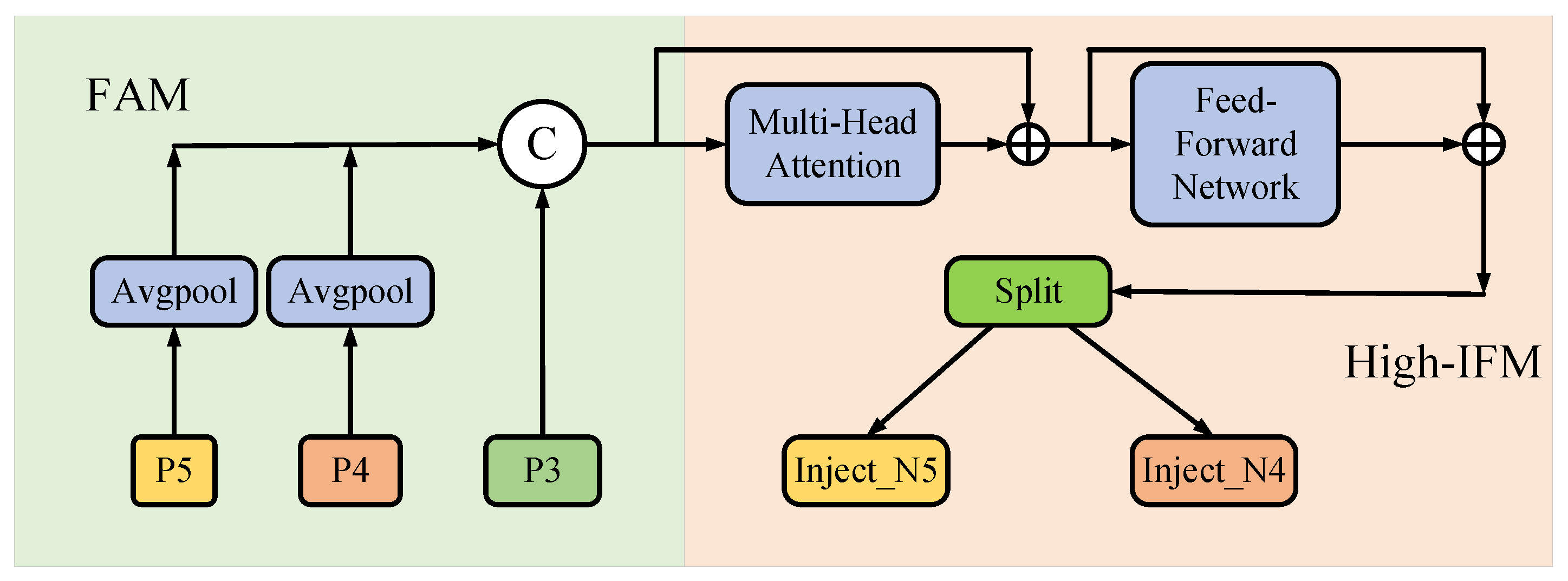
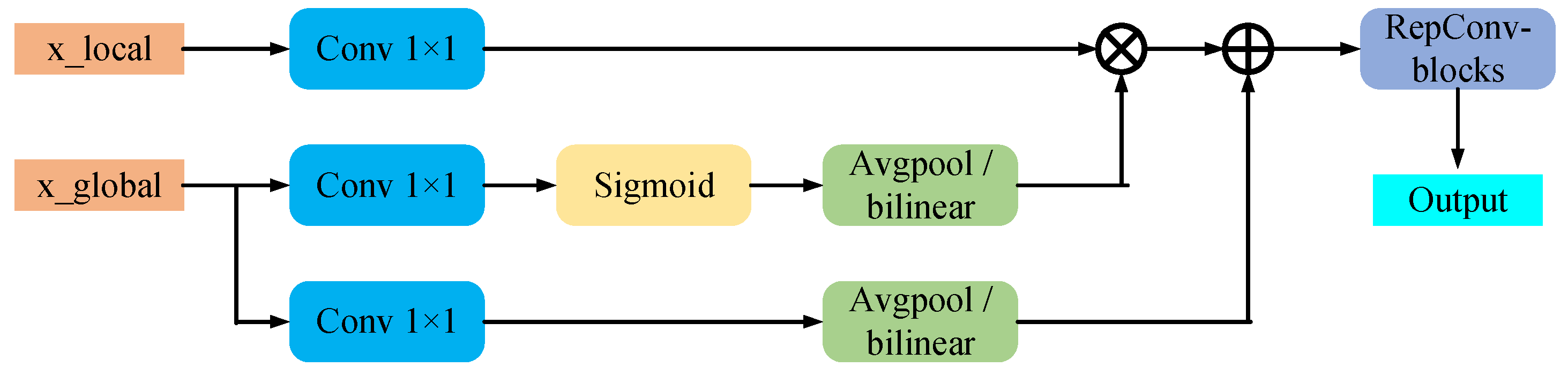
3.3.1. Feature Alignment Module
3.3.2. Information Fusion Module
3.3.3. Information Injection Module
4. Experiments
4.1. Datasets and Implementation Details
4.2. Comparision Results
4.2.1. Comparison with Prior Works
4.2.2. Comparison of Evaluation Metrics
4.2.3. Comparison of Detection
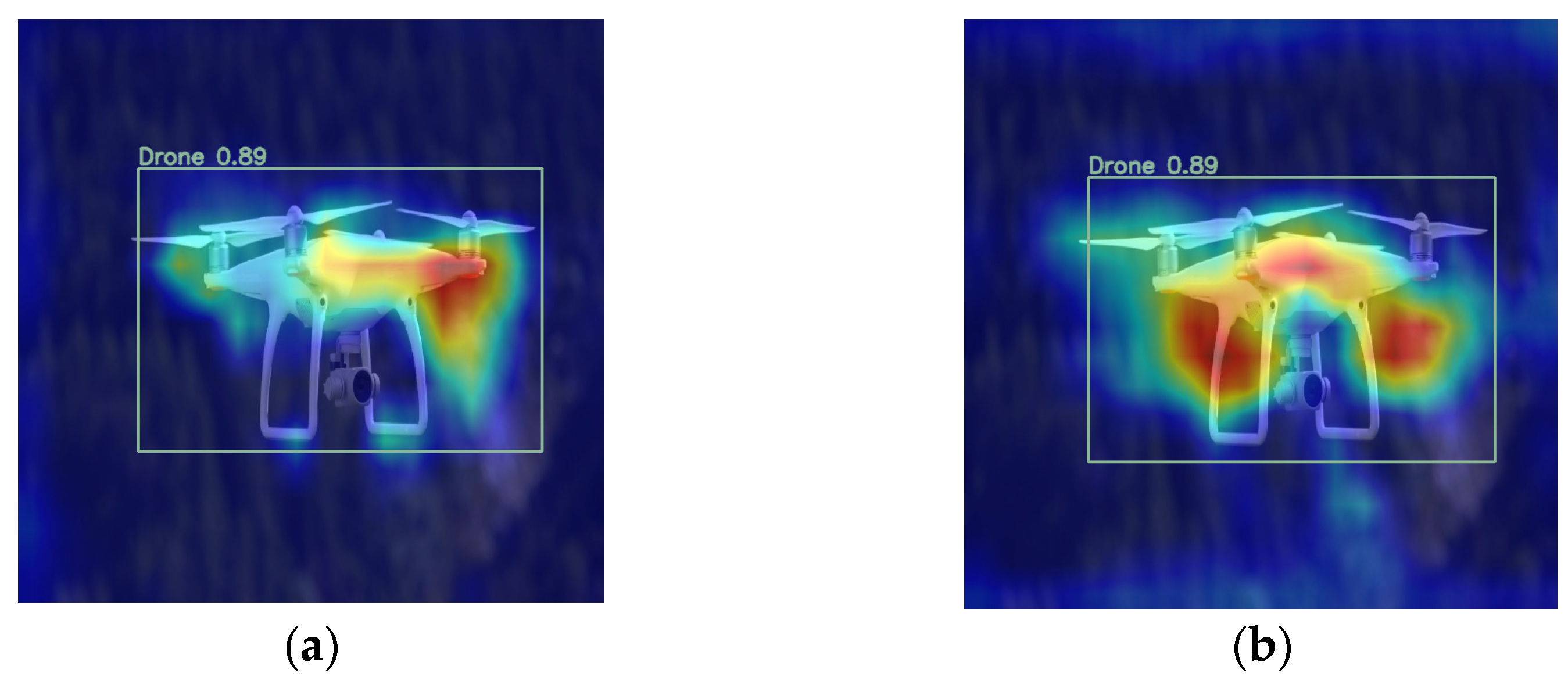
4.2.4. Comparison of Heatmap
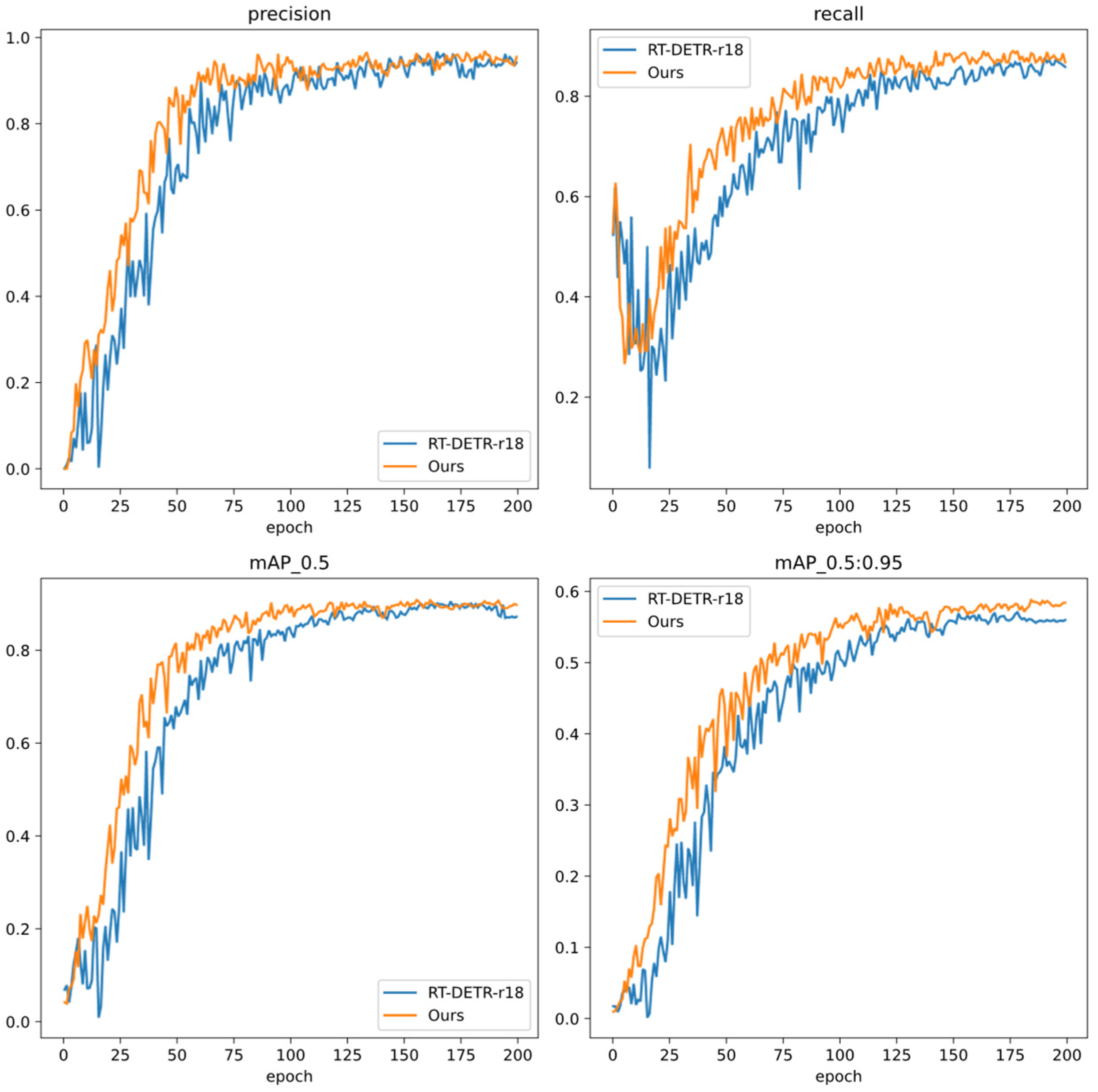
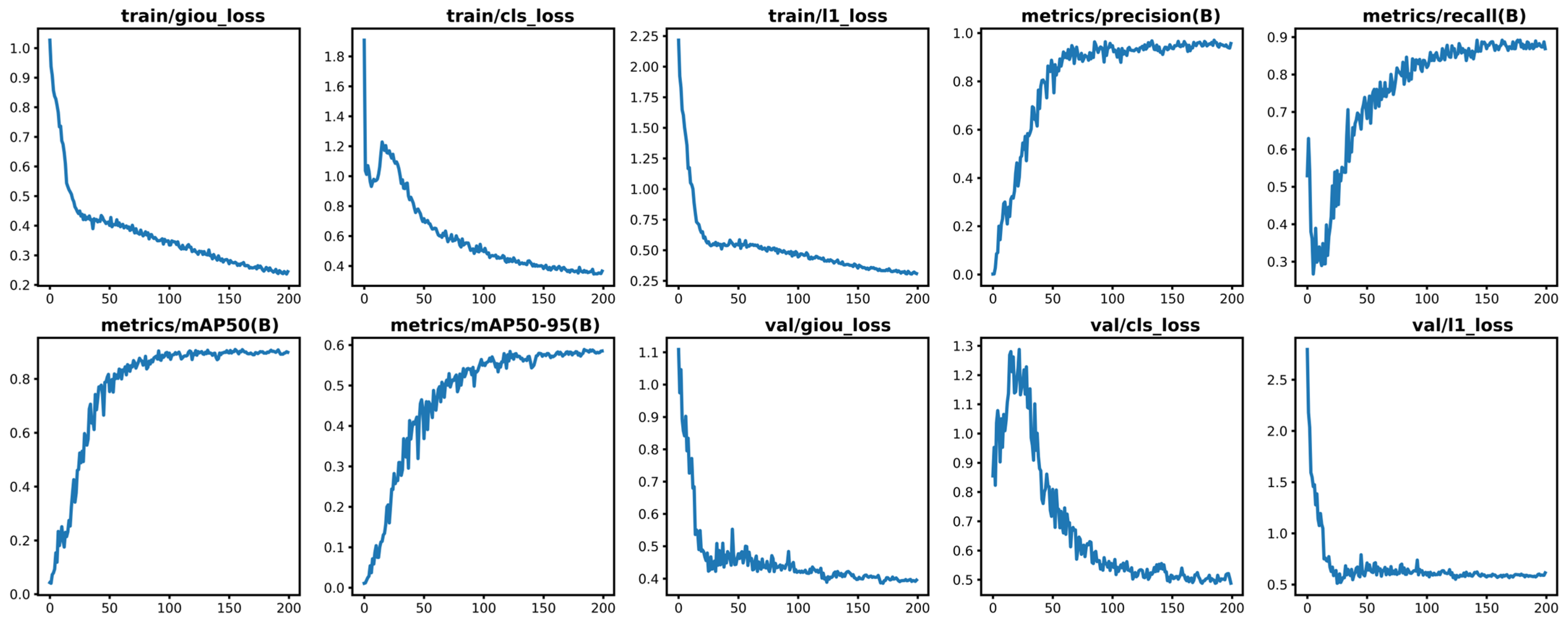
4.3. Training Metrics
4.4. Ablation Results
4.5. Detection Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kaleem, Z.; Rehmani, M.H. Amateur drone monitoring: State-of-the-art architectures key enabling technologies and future research directions. IEEE Wirel. Commun. 2018, 25, 150–159. [Google Scholar] [CrossRef]
- Rossiter, A. Military technology and revolutions in warfare: Priming the drone debate. Def. Secur. Anal. 2023, 39, 253–255. [Google Scholar] [CrossRef]
- Emimi, M.; Khaleel, M.; Alkrash, A. The current opportunities and challenges in drone technology. Int. J. Electr. Eng. Sustain. 2023, 1, 74–89. [Google Scholar]
- McFarland, M. Airports Scramble to Handle Drone Incidents. Available online: https://edition.cnn.com/2019/03/05/tech/airports-drones/index.html (accessed on 5 March 2019).
- Raivi, A.M.; Huda, S.A.; Alam, M.M.; Moh, S. Drone Routing for Drone-Based Delivery Systems: A Review of Trajectory Planning, Charging, and Security. Sensors 2023, 23, 1463. [Google Scholar] [CrossRef] [PubMed]
- Taha, B.; Shoufan, A. Machine learning-based drone detection and classification: State-of-the-art in research. IEEE Access 2019, 7, 138669–138682. [Google Scholar] [CrossRef]
- Ahmad, B.I.; Harman, S.; Godsill, S. A Bayesian track management scheme for improved multi-target tracking and classification in drone surveillance radar. IET Radar Sonar Navig. 2024, 18, 137–146. [Google Scholar] [CrossRef]
- Zhang, H.; Li, T.; Li, Y.; Li, J.; Dobre, O.A.; Wen, Z. RF-based drone classification under complex electromagnetic environments using deep learning. IEEE Sens. J. 2023, 23, 6099–6108. [Google Scholar] [CrossRef]
- Han, Z.; Zhang, C.; Feng, H.; Yue, M.; Quan, K. PFFNET: A Fast Progressive Feature Fusion Network for Detecting Drones in Infrared Images. Drones 2023, 7, 424. [Google Scholar] [CrossRef]
- Valaboju, R.; Harshitha, C.; Kallam, A.R.; Babu, B.S. Drone Detection and Classification using Computer Vision. In Proceedings of the 2023 7th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–13 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1320–1328. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Ashraf, M.W.; Sultani, W.; Shah, M. Dogfight: Detecting dronesfrom drones videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7067–7076. [Google Scholar]
- Sangam, T.; Dave, I.R.; Sultani, W.; Shah, M. Transvisdrone: Spatio-temporal transformer for vision-based drone-to-drone detection in aerial videos. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 6006–6013. [Google Scholar]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Wei, H.; Liu, X.; Xu, S.; Dai, Z.; Dai, Y.; Xu, X. DWRSeg: Rethinking Efficient Acquisition of Multi-scale Contextual Information for Real-time Semantic Segmentation. arXiv 2022, arXiv:2212.01173. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. In Proceedings of the 37th Conference on Neural Information Processing Systems, Virtual, 10–16 December 2024; Volume 36. [Google Scholar]
- Seidaliyeva, U.; Akhmetov, D.; Ilipbayeva, L.; Matson, E.T. Real-time and accurate drone detection in a video with a static background. Sensors 2020, 20, 3856. [Google Scholar] [CrossRef] [PubMed]
- Sharjeel, A.; Naqvi, S.A.Z.; Ahsan, M. Real time drone detection by moving camera using COROLA and CNN algorithm. J. Chin. Inst. Eng. 2021, 44, 128–137. [Google Scholar] [CrossRef]
- Lv, Y.; Ai, Z.; Chen, M.; Gong, X.; Wang, Y.; Lu, Z. High-Resolution Drone Detection Based on Background Difference and SAG-YOLOv5s. Sensors 2022, 22, 5825. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Ju, Z.; Sun, T.; Dong, F.; Li, J.; Yang, R.; Fu, Q.; Lian, C.; Shan, P. TGC-YOLOv5: An Enhanced YOLOv5 Drone Detection Model Based on Transformer, GAM & CA Attention Mechanism. Drones 2023, 7, 446. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, N.; Won, C.S. High-Speed Drone Detection Based On Yolo-V8. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–2. [Google Scholar]
- Cheng, Q.; Li, X.; Zhu, B.; Shi, Y.; Xie, B. Drone detection method based on MobileViT and CA-PANet. Electronics 2023, 12, 223. [Google Scholar] [CrossRef]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3651–3660. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Roh, B.; Shin, J.; Shin, W.; Kim, S. Sparse detr: Efficient end-to-end object detection with learnable sparsity. arXiv 2021, arXiv:2111.14330. [Google Scholar]
- Chen, Q.; Chen, X.; Wang, J.; Zhang, S.; Yao, K.; Feng, H.; Han, J.; Ding, E.; Zeng, G.; Wang, J. Group detr: Fast detr training with group-wise one-to-many assignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6633–6642. [Google Scholar]
- Zhang, M.; Song, G.; Liu, Y.; Li, H. Decoupled detr: Spatially disentangling localization and classification for improved end-to-end object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6601–6610. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 11963–11975. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Ding, X.; Zhang, Y.; Ge, Y.; Zhao, S.; Song, L.; Yue, X.; Shan, Y. Unireplknet: A universal perception large-kernel convnet for audio, video, point cloud, time-series and image recognition. arXiv 2023, arXiv:2311.15599. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Input Size | Backbone | Neck | Layers | Parameters | GFLOPs | Recall | AP@50 | AP@50:95 |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv7 [12] | 640 | CBS + ELAN | SPPSCP + E-ELAN | 415 | 37,196,556 | 105.1 | 0.814 | 0.858 | 0.476 |
| YOLOv7x [12] | 640 | CBS + ELAN | SPPSCP + E-ELAN | 467 | 70,815,092 | 188.9 | 0.837 | 0.883 | 0.53 |
| YOLOv7-w6 [12] | 1280 | CBS + ELAN | SPPSCP + E-ELAN | 477 | 80,944,472 | 102.4 | 0.824 | 0.924 | 0.57 |
| YOLOv7-d6 [12] | 1280 | CBS + ELAN | SPPSCP + E-ELAN | 733 | 152,886,360 | 198.3 | 0.878 | 0.934 | 0.588 |
| YOLOv8s | 640 | C2F + SPPF | C2F | 168 | 11,125,971 | 28.4 | 0.878 | 0.941 | 0.626 |
| YOLOv8m | 640 | C2F + SPPF | C2F | 295 | 25,856,899 | 79.1 | 0.864 | 0.948 | 0.631 |
| YOLOv8n | 640 | C2F + SPPF | C2F | 225 | 3,157,200 | 8.9 | 0.90 | 0.949 | 0.626 |
| Gold-YOLO-s [23] | 640 | Efficient-Rep | Gather-and-Distribute | / | 21.5M | 46.0 | 0.670 | 0.928 | 0.582 |
| Gold-YOLO-m [23] | 640 | Efficient-Rep | Gather-and-Distribute | / | 41.3M | 87.5 | 0.693 | 0.934 | 0.604 |
| Gold-YOLO-n [23] | 640 | Efficient-Rep | Gather-and-Distribute | / | 5.6M | 12.1 | 0.671 | 0.919 | 0.580 |
| RT-DETR-r18 [20] | 640 | ResNet 18 | AIFI + CCFM | 299 | 19,873,044 | 56.9 | 0.941 | 0.936 | 0.621 |
| RT-DETR-r34 [20] | 640 | ResNet 34 | AIFI + CCFM | 387 | 31,106,233 | 88.8 | 0.896 | 0.933 | 0.602 |
| RT-DETR-r50 [20] | 640 | ResNet 50 | AIFI + CCFM | 629 | 42,782,275 | 134.4 | 0.878 | 0.905 | 0.581 |
| GCD-DETR (Ours) | 640 | DWR-DRB + CGB | Gather-and-Distribute | 494 | 23,262,488 | 61.0 | 0.93 | 0.956 | 0.624 |
| Model | Input Size | Year | Layers | Parameters | GFLOPs | Recall | AP@50 | AP@50:95 |
|---|---|---|---|---|---|---|---|---|
| YOLOv7 [12] | 640 | 2022 | 415 | 37,196,556 | 105.1 | 0.914 | 0.955 | 0.624 |
| YOLOv7x [12] | 640 | 2022 | 467 | 70,815,092 | 188.9 | 0.919 | 0.958 | 0.631 |
| YOLOv7-w6 [12] | 1280 | 2022 | 477 | 80,944,472 | 102.4 | 0.92 | 0.954 | 0.633 |
| YOLOv7-d6 [12] | 1280 | 2022 | 733 | 152,886,360 | 198.3 | 0.922 | 0.964 | 0.657 |
| YOLOv8s | 640 | 2023 | 168 | 11,125,971 | 28.4 | 0.934 | 0.968 | 0.687 |
| YOLOv8m | 640 | 2023 | 295 | 25,856,899 | 79.1 | 0.946 | 0.959 | 0.658 |
| YOLOv8n | 640 | 2023 | 225 | 3,157,200 | 8.9 | 0.957 | 0.962 | 0.676 |
| Gold-YOLO-s [23] | 640 | 2023 | / | 21.5M | 46.0 | 0.897 | 0.973 | 0.680 |
| Gold-YOLO-m [23] | 640 | 2023 | / | 41.3M | 87.5 | 0.944 | 0.953 | 0.636 |
| Gold-YOLO-n [23] | 640 | 2023 | / | 5.6M | 12.1 | 0.950 | 0.958 | 0.675 |
| RT-DETR-r18 [20] | 640 | 2023 | 299 | 19,873,044 | 56.9 | 0.954 | 0.953 | 0.692 |
| RT-DETR-r34 [20] | 640 | 2023 | 387 | 31,106,233 | 88.8 | 0.925 | 0.977 | 0.639 |
| RT-DETR-r50 [20] | 640 | 2023 | 629 | 42,782,275 | 134.4 | 0.927 | 0.967 | 0.657 |
| GCD-DETR (Ours) | 640 | / | 494 | 23,262,488 | 61.0 | 0.966 | 0.978 | 0.711 |
| RT-DETR | DWR-DRB | CGA | GD | Layers | Parameters | GFLOPs | Recall | AP@50 | AP@50:95 | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 299 | 19,873,044 | 56.9 | 0.941 | 0.937 | 0.621 | 31.7 | |||
| ✓ | ✓ | 330 | 19,703,192 | 57.0 | 0.94 | 0.95 | 0.629 | 52.5 | ||
| ✓ | ✓ | 328 | 21,048,084 | 57.9 | 0.953 | 0.947 | 0.625 | 29.8 | ||
| ✓ | ✓ | 434 | 22,257,300 | 59.9 | 0.92 | 0.949 | 0.624 | 27.9 | ||
| ✓ | ✓ | ✓ | 463 | 23,432,340 | 60.9 | 0.899 | 0.952 | 0.635 | 25.0 | |
| ✓ | ✓ | ✓ | ✓ | 494 | 23,262,488 | 61.0 | 0.93 | 0.956 | 0.624 | 41.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Kong, E. Multi-Scale Fusion Uncrewed Aerial Vehicle Detection Based on RT-DETR. Electronics 2024, 13, 1489. https://doi.org/10.3390/electronics13081489
Zhu M, Kong E. Multi-Scale Fusion Uncrewed Aerial Vehicle Detection Based on RT-DETR. Electronics. 2024; 13(8):1489. https://doi.org/10.3390/electronics13081489
Chicago/Turabian StyleZhu, Minling, and En Kong. 2024. "Multi-Scale Fusion Uncrewed Aerial Vehicle Detection Based on RT-DETR" Electronics 13, no. 8: 1489. https://doi.org/10.3390/electronics13081489
APA StyleZhu, M., & Kong, E. (2024). Multi-Scale Fusion Uncrewed Aerial Vehicle Detection Based on RT-DETR. Electronics, 13(8), 1489. https://doi.org/10.3390/electronics13081489