1. Introduction
Industrial internet is the core cornerstone of the fourth industrial revolution [
1], so in the field of electronics manufacturing, printed circuit board (PCB) as a variety of components connected to the important parts [
2], its quality plays a vital role in the quality of electronic products integrated by it. In recent years, the density and complexity of PCB have been increasing, and the production process of PCB is also gradually becoming more cumbersome. PCB in industrial production often has various defects, such as open circuit, short, missing holes, mouse bite, spur, spurious copper [
3], etc. These defects, if not found and dealt with in a timely manner, will affect the subsequent assembly and debugging processes and even cause the failure of the entire product. Therefore, PCB surface defect detection is a key link in the electronic manufacturing process, and its quality directly affects the service life and reliability of electronic products [
4].
The methods used in the field of industrial defect detection are categorized into traditional methods and vision-based detection methods. Traditional methods mainly include manual visual detection [
5] and functional testing [
6], while traditional methods are characterized by low efficiency, slow detection speed, and difficulty in identifying similar defective targets, so they are not suitable for applications in large-scale industrial scenarios, and fast and accurate vision-based detection methods occupy the mainstream at present [
7]. Vision-based industrial defect detection not only has important research value but also offers many potential applications. The traditional machine learning approaches include support vector machines [
8], decision trees [
9], and genetic algorithms [
10], etc., but the traditional machine learning approaches in the domain of industrial defect detection are affected by the diversity of the defects and their weaknesses; the detection effect is poor.
Recent advances in deep learning have led to more mature applications for deep-learning-based visual detection methods, including two-stage detection algorithms R-CNN [
11], Fast R-CNN [
12], Faster R-CNN [
13], and Mask R-CNN [
14], etc.; as well as single-stage detection algorithms SSD [
15] and YOLO [
16,
17,
18,
19] series, etc.
Zhang et al. [
20] learned the high-level features present in the defects by using VGG-16 as a base network, and the authors evaluated SVM in combination with LBP and HOG features, respectively, demonstrating the superior performance of deep feature learning; Xie et al. [
21] introduced a multilevel residual mixed-attention module for feature learning in the YOLOv4 network to improve the shallow network’s capacity for feature representation and focus more attention toward object features while reducing the interference of irrelevant features; Adibhatla et al. [
22] used a miniature YOLOv2 network improved by YOLOv1 in order to achieve faster PCB defect detection and obtained good detection accuracy on 11,000 images of 11 types of defects; Ding et al. [
23] learned a similarity measure between image pairs by designing a Siamese network fusing multi-scale deep features. During the training phase, the authors applied a contrast loss function to optimize the feature extraction network by utilizing the distance between pairs of picture vectors. The described multi-scale model offers a good solution for the defect detection problem and outperforms the single-scale feature structure. Single-stage detection approaches such as YOLO do not require additional candidate region generation [
24], which simplifies the complexity of the target detection procedure and converts the issue into a straightforward regression problem when compared to two-stage candidate region-based detection approaches, simplifies the process of target detection, accelerates the speed of defective target detection, and is more suitable for industrial scenarios, so this paper selects YOLOv5 [
25] as a baseline model for single-stage detection algorithms.
As the production of PCB currently tends to be thin and light and densification, the density of its wiring and welding is increasing day by day [
26]. While the defects on the surface of the PCB have a small target area and the background is complex in industrial scenarios, the defects and the background are easily confused and it is not easy to differentiate between them, with a high rate of misdetection and omission and a poor effect of detection. For the purpose of meeting the demand for accuracy in PCB surface defect detection in industrial situations, this paper proposes a PCB surface defect detection algorithm based on DSASPP-YOLOv5, with the following two main contributions:
Utilize the K-means++ clustering algorithm to re-cluster the initial anchor box parameters and adopt 1-IoU as the distance metric to enhance the model’s capacity to detect defective targets in smaller areas;
In this paper, we design and propose the Depthwise Separable Atrous Spatial Pyramid Pooling (DSASPP) module, which constructs atrous convolution branches with different dilated rates and global average pooling branches to improve the correlation between local and global information. We also introduce depthwise separable convolution using the Gaussian error linear Unit (GELU) as activation function in atrous convolution blocks to balance precision and number of parameters.
2. Methods
2.1. DSASPP-YOLOv5 Network
This study makes improvements based on the YOLOv5 network model, and
Figure 1 displays the improved model’s structure. The original YOLOv5 model itself has excellent detection capability, but the detection accuracy of the model still requires improvement for PCB defective targets that are small in size and easy to confuse with the background. This study uses the K-means++ approach to re-cluster the nine initial anchor values of YOLOv5 in order to precisely locate and identify the target information in the effective region. The re-clustered anchors are more in line with the feature distribution characteristics of the PCB surface defect dataset, so the model is more effective in capturing and extracting the target region information; In order to strengthen the backbone network part’s feature extraction ability for defective targets, improve the network’s anti-interference capability for unimportant background information, and enhance the network’s detection accuracy, this paper designs the DSASPP module and introduces it into the YOLOv5 backbone network in order to make full fusion of multiscale contextual information to get better detection effects and to make misdetection and omission of detection effectively controlled.
2.2. K-Means++ Clustering Algorithm
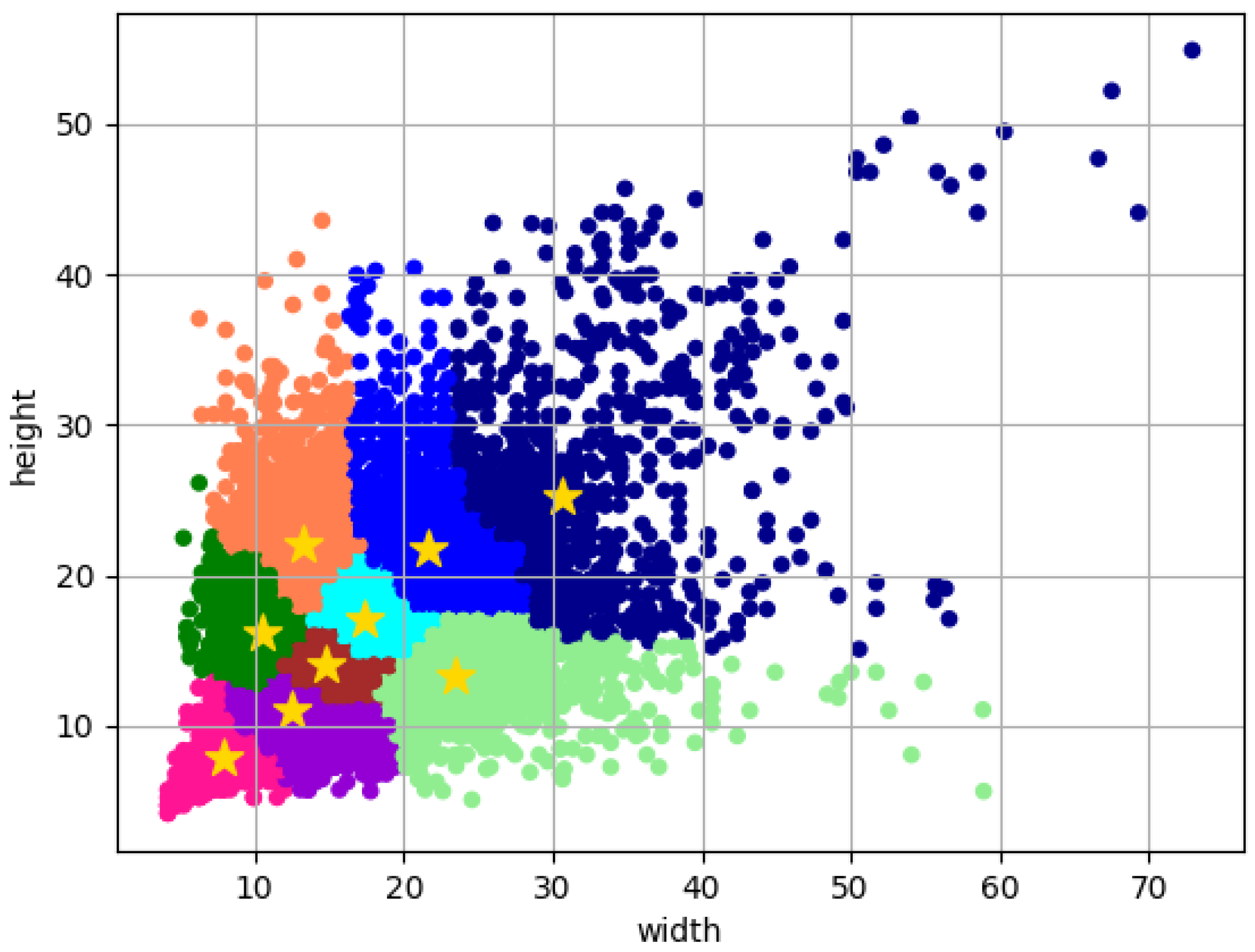
There are three prediction branches in the YOLOv5 network model, and nine different sizes of anchor values (anchors: 10, 13; 16, 30; 33, 23; 30, 61; 62, 45; 59, 119; 116, 90; 156, 198; 373, 326) are set by default, which are applied to the three separate feature map scales for the purpose of predicting the target bounding box. Since the YOLOv5’s default anchor set is derived from the K-means clustering approach on the PASCAL VOC dataset with a size of , it is only applicable to feature maps with a more uniform scale size and a larger target detection area. In this study’s PCB surface defects dataset, the location of various types of PCB defects is not fixed, the target size is more extreme, and most of them are small targets and use the size of the image as the input, so the preset anchor value of YOLOv5 is not applicable to the content of the research in this paper.
The first task of the K-means clustering method is the initial procedure to complete initializing all k cluster centers, and its convergence is extremely dependent on the cluster centers’ initialization state. Consequently, there is a significant risk of running into the local optimum problem when clustering using the K-means clustering method. Compared with the traditional K-means clustering method, the K-means++ [
27] algorithm improves the effectiveness of clustering by optimizing the choice of the initial cluster centers.Under comprehensive consideration, this paper adopts the K-means++ clustering algorithm to re-cluster the anchor box in the PCB surface defects dataset. Intersection over Union (IoU) calculates the overlap between the bounding box and the ground truth. We take the maximum IoU as a reference and use the value of 1-IoU instead of Euclidean distance as a distance metric. The distance is calculated as in Equation (
1), where
is the true labeled box in the dataset, and
is the centroid of the clusters. By recalculating the distance between each cluster, the clustering accuracy of this paper is finally improved.
The process of the K-means++ clustering algorithm is shown below:
2.3. DSASPP Module
For the purpose of better improving the correlation between local and global information, DeepLabV2 [
28] proposes an atrous spatial pyramid pooling (ASPP) structure. The atrous convolution and pooling structure, which together make up ASPP, allow for the extraction of multi-scale features from objects with a larger receptive field while maintaining image resolution, but the module still suffers from the following shortcomings:
Using the same dilation rate consecutively or using a set of dilation rate values with a common factor relationship other than 1, both of which may cause “Gridding Effect” and result in local information loss;
The ReLU function used in the improved ASPP has certain defects, which may cause the problem of “Dying ReLU” and make some effective information lost;
In practice, the ASPP module often introduces a significant number of additional parameters while increasing accuracy, which is not worth the cost for industrial application scenarios with detection speed requirements.
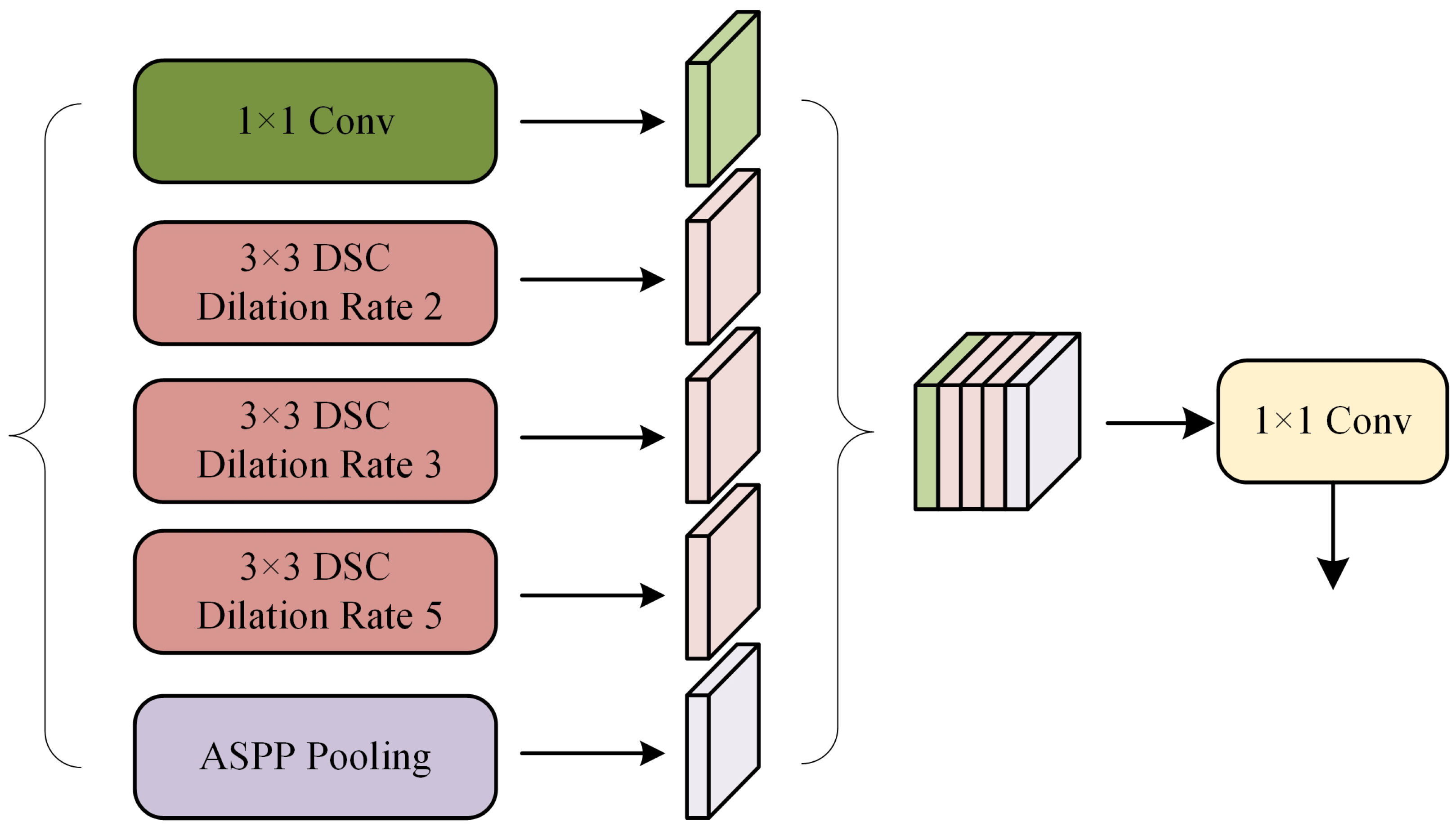
To deal with the problem that exists within the ASPP structure, we have addressed it through several works on standardized construction rules for atrous convolution, the use of the GELU activation function, and the introduction of depthwise separable convolution. Inspired by the related work in this paper, this paper proposes the DSASPP Module. As illustrated in
Figure 2, the YOLOv5 model backbone network’s output feature map is initially sent into the DSASPP module, where there are three primary components to the DSASPP module:
The first component is the first branch, which utilizes a standard convolution in order to maintain the original receptive field;
The second part is the second to the fourth branch, using atrous convolution with a convolution kernel size and dilation rate of 2, 3, and 5 to obtain different size receptive fields while enhancing feature extraction. We decreased the total quantity of parameters in this study by introducing depthwise separable convolution, where the activation function part is chosen to be the theoretically better GELU function;
The third component is the fifth branch, which introduces global average pooling so as to obtain global features, improves the model’s stability and accuracy, and suppresses the overfitting phenomenon in the network.
Ultimately, the five branches of the three DSASPP modules’ components process the feature maps, which are stacked in the channel dimension after that, and then processed by the standard convolution of to make the information at different scales fully integrated.
2.3.1. Atrous Convolution
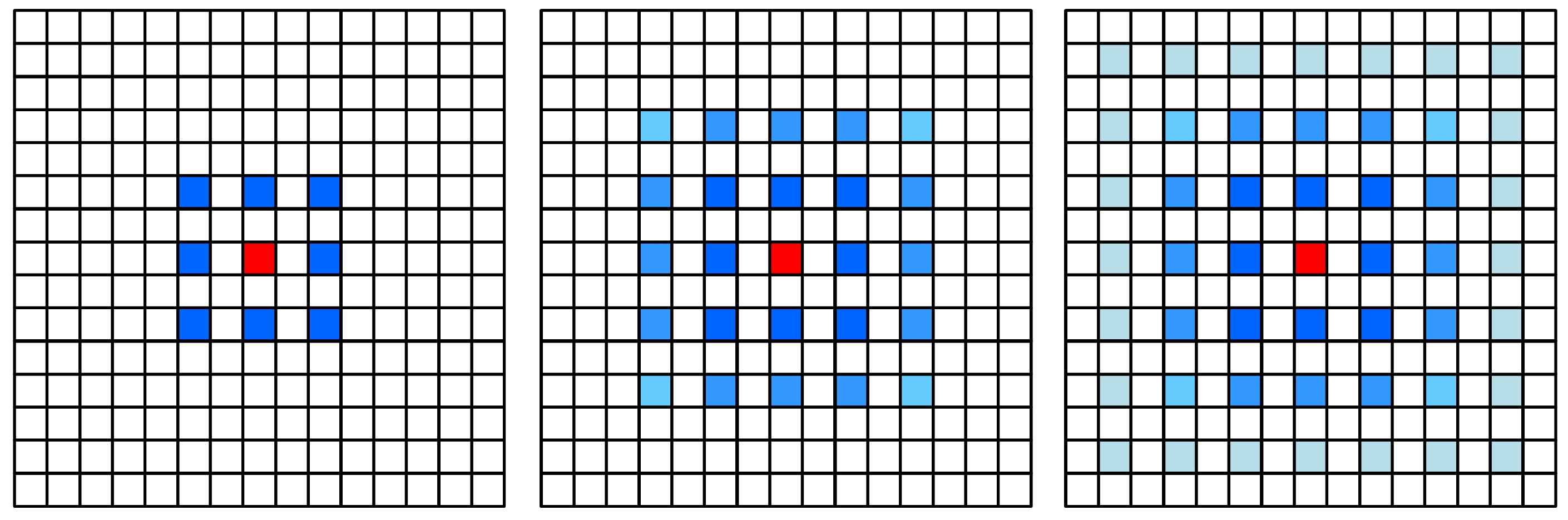
It has been found that the practice of successive atrous convolution at the same dilation rate to obtain the same spatial resolution fills zero between the expanded pixels of the convolution kernel, but the model only samples the locations with non-zero values, thus losing local information and generating the “Gridding” problem, also known as the “Gridding Effect”, as illustrated within
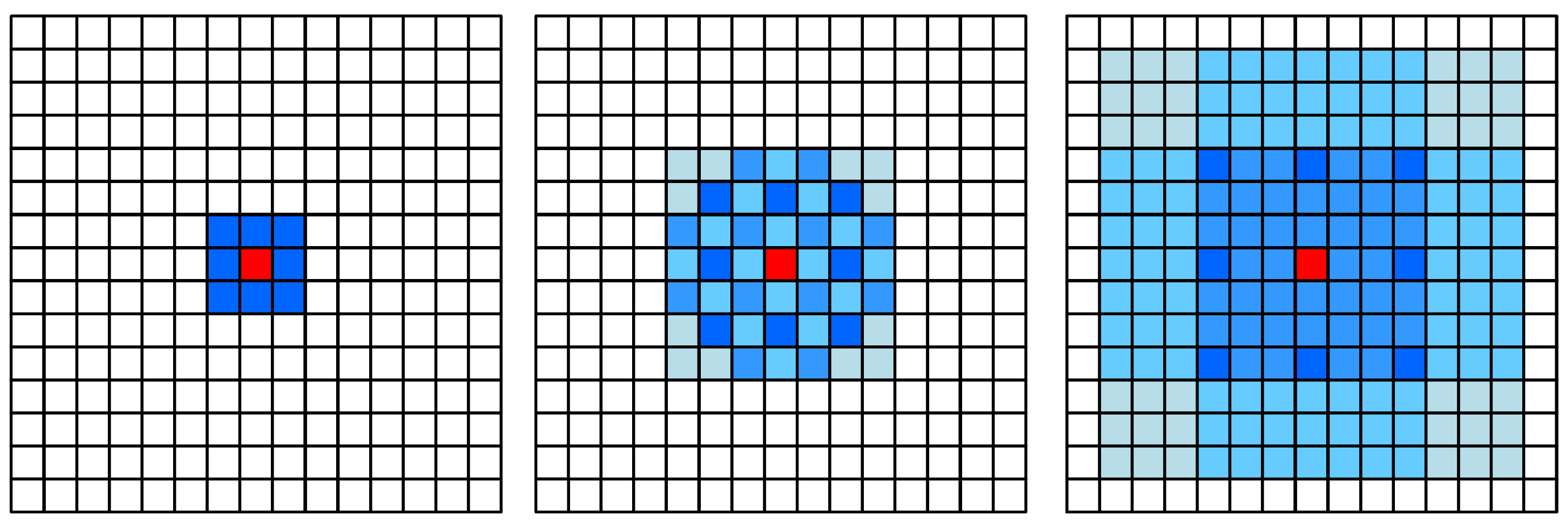
Figure 3. The reasonable dilation rate is set as shown in
Figure 4. Wang and others [
29] proposed the concept of hybrid dilated convolution (HDC), which aims to enable the receptive field’s final size to completely cover a square region with no empty or missing edges after a sequence of convolution processes. Thus, it specifies the standardized construction rule of the atrous convolution:
The dilation rate of different layers should not have a common factor relationship other than 1, otherwise the problem of the “Gridding Effect” at higher levels remains;
Define “the maximum distance between two non-zero values” as :
As shown in Equation (
3), where
stands for the maximum distance in the
i-th layer between two non-zero values and
is the
i-th layer’s dilation rate, for the last layer, the maximum distance
should be equal to the size of
. Assuming
is the actual convolution kernel’s size, for
n atrous convolution layers, our design goal is to make
, that is, to require that the maximum distance between two non-zero elements in each layer is less than or equal to the actual convolution kernel’s size in that layer.
Considering the characteristics of the PCB surface defect dataset, this study confirms the impacts of different combinations of dilation rate of the model performance after experiments and finally designs the ASPP module based on the dilation rate combinations of 1, 2, 3, and 5.
2.3.2. GELU Activation Function
The activation function can help the model fit the training data better. ReLU is a common and critical activation function in various studies of neural networks, but the ReLU function has certain shortcomings in practical use.
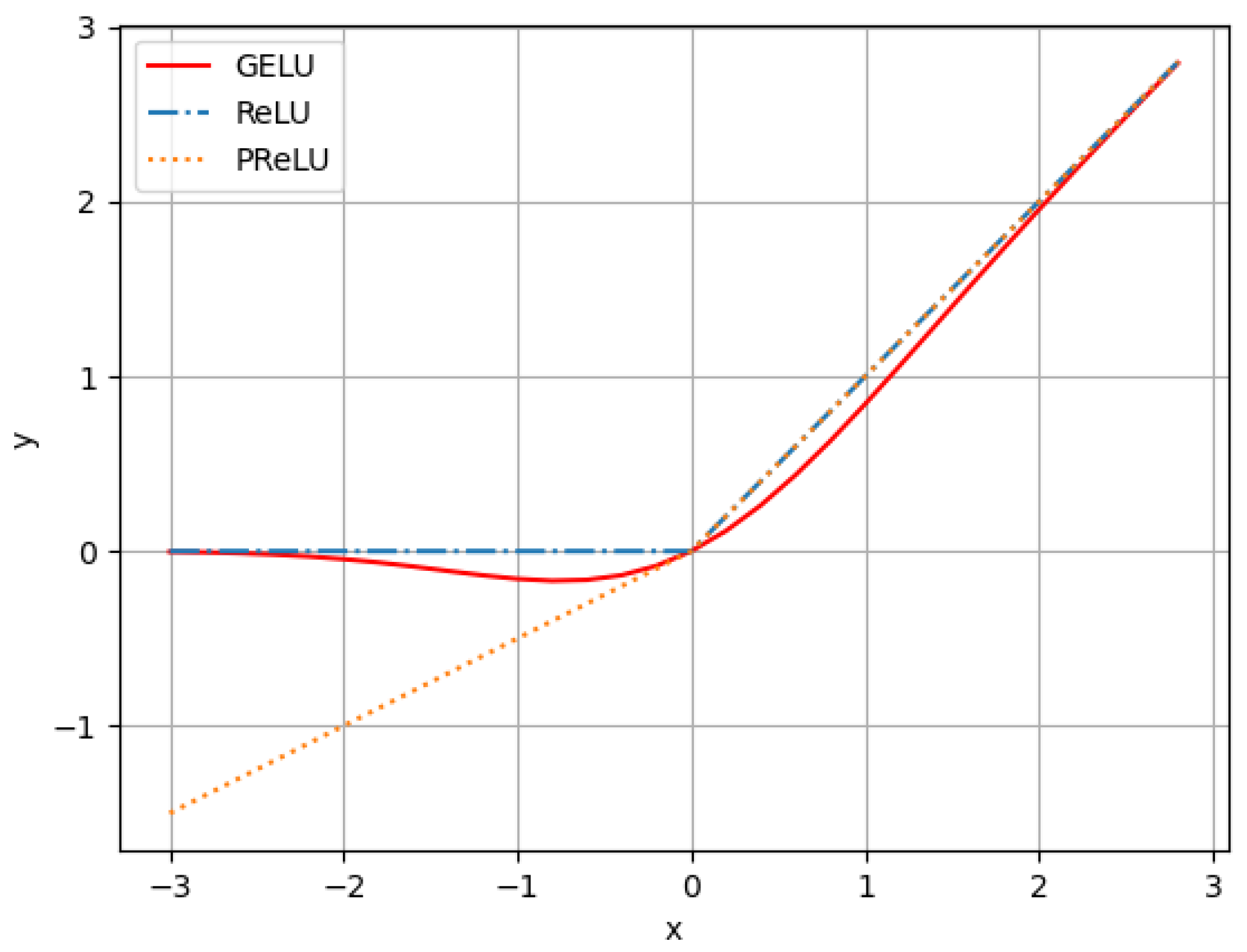
The image of the ReLU function is shown in
Figure 5. Since the gradient of the ReLU function is zero at
, this directly leads to the negative gradient being directly set to zero in the ReLU function, and this neuron will probably not be activated by the data in the subsequent training, and when this happens, the neuron that cannot be activated will be zero forever in the subsequent gradient change, which also shows the situation of “Dying ReLU” and will not respond to any data, making the effective information partially lost.
Based on this, some authors [
30] proposed the Parametric Rectified Linear Unit (PReLU) with self-learning capability as the activation function to alleviate the problems of ReLU function, while in this paper, Gaussian Error based the GELU [
31] is used as the activation function of the ASPP module. The expression of the GELU function can be approximated as Equation (
4), and the comparative images of activation functions are shown in
Figure 5.
Compared to the ReLU function, although the PReLU function solves the problem of dead neurons by introducing a learnable parameter in the negative part of the function, it can be seen from the function images that the nonlinearities of the ReLU function and the PReLU function itself are obtained due to the segmentation function itself, and thus they are both non-frivolous at the zeros, which will have a certain impact on the network’s performance. The GELU function introduces the stochastic regularization idea compared with ReLU and similar functions, the GELU function is smoother at the zero point; it not only increases the nonlinearity of the network but can also inhibit the overfitting phenomenon of the network, so that the network converges faster; and it can also avoid the problem of dead neurons.
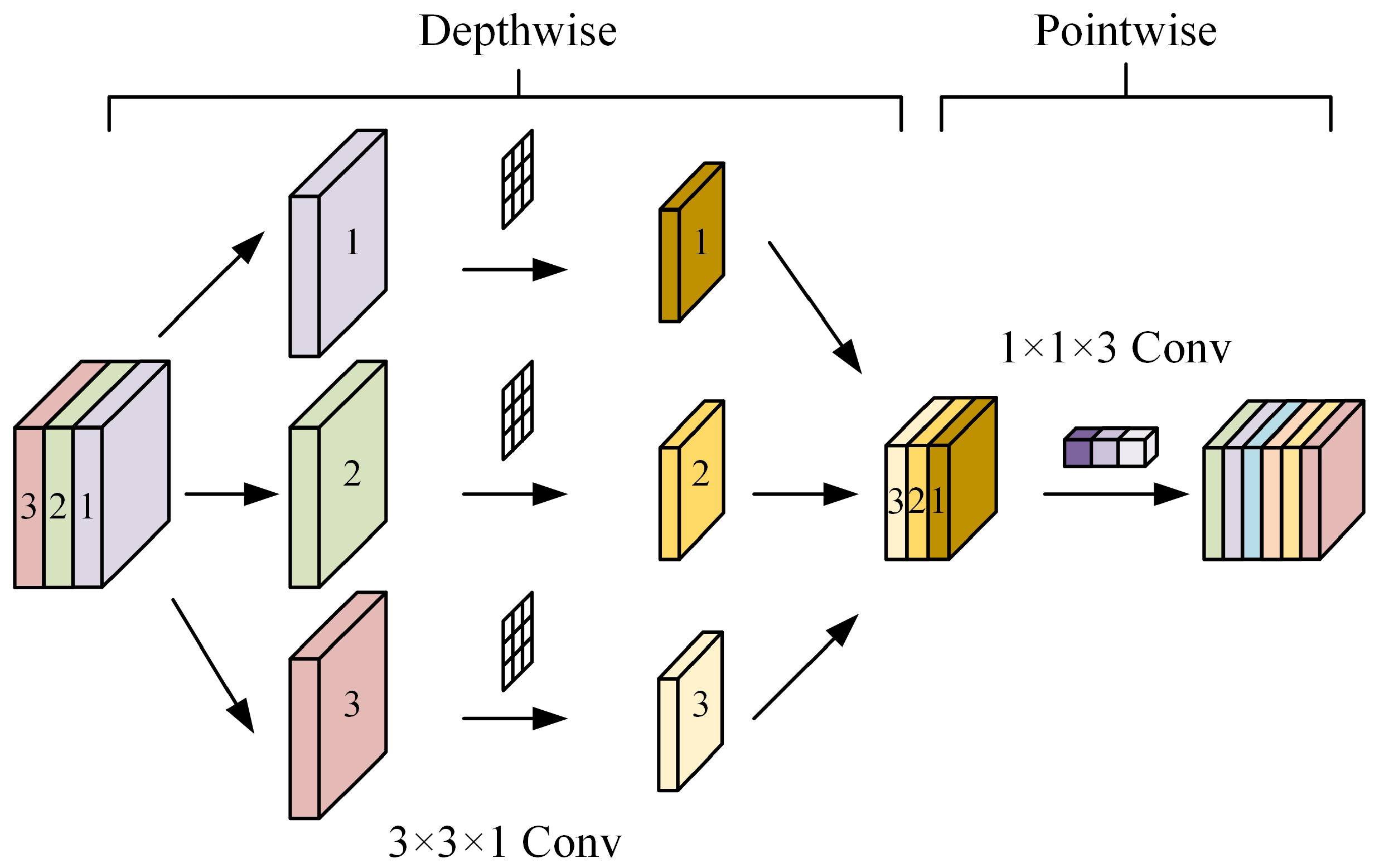
2.3.3. Depthwise Separable Convolution
In order to better meet the lightweight requirements of models in industrial scenarios based on the standard convolution operation, the literature [
32] first proposed a more efficient separable convolution (SC) to decrease the model’s parameters and computational effort, which is usually utilized in neural networks in the form of depthwise separable convolution (DSC) [
33,
34]. Depthwise separable convolution provides a new way of thinking about convolution by decomposing the normal convolution process into two components: depthwise (DW) convolution and pointwise (PW) convolution.
As illustrated within
Figure 6, the idea of depthwise convolution procedure is to split the convolution kernel in the form of a single channel, perform the convolution of a single channel separately, and then stack them together so that not only the convolution operation can be performed separately for each channel but also maintain the input feature map’s depth. After the depthwise convolution procedure, we get the output feature map with an equal number of channels given the input feature map. After that, the pointwise convolution operation, which is 1 × 1 convolutions, is performed to raise and lower the feature map’s dimension, and the output channels of the depthwise convolution operation are projected onto the new channel space.
As for the input feature map of size
and convolution kernels of size
, the computational effort
of the standard convolution is given by Equation (
5):
where
denotes the size of the input feature map,
k denotes the convolution kernel size,
M indicates the input channel’s number, and
N indicates the output channel’s number.
A similar analysis taken for depthwise separable convolution shows that the computational effort
of the depthwise convolution operation and the pointwise convolution operation is shown in Equation (
6):
The ratio of computation of depthwise separable convolution to standard convolution is Equation (
7):
From Equation (
7), it can be seen that when the convolution kernel size
k is 3, the utilization of depthwise separable convolution might decrease nearly 90% of the computation, thus achieving the purpose of model light-weighting. In this paper, we introduced depthwise separable convolution for light-weighting in the ASPP module and obtained significant results to improve the computational efficiency without significantly degrading the model performance.
4. Conclusions
For the challenges of PCB surface defect detection difficulty and high omission rate in the industrial production process, we proposed a PCB surface defect detection method based on DSASPP through research, which improved the existing model. First, the data augmentation method improved the model’s detection accuracy. Then the dataset used in this study was re-clustered using the K-means++ clustering algorithm. Finally, the DSASPP module designed for this study is introduced into the backbone network, which is jointly optimized by the GELU activation function and the depthwise separable convolution. It not only acquires multi-scale target context information but also combines local and global information, which effectively improves the model’s detection effect.
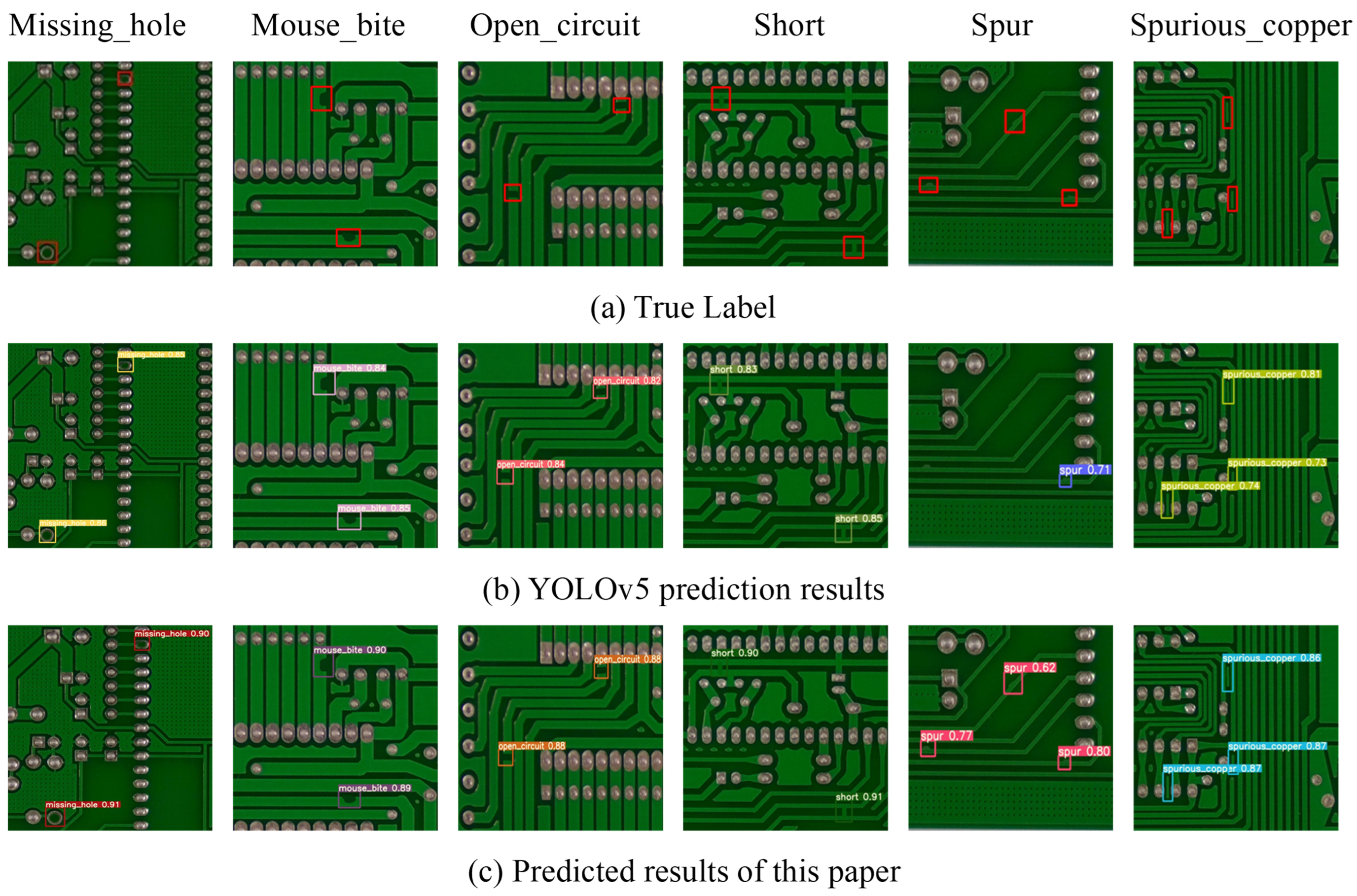
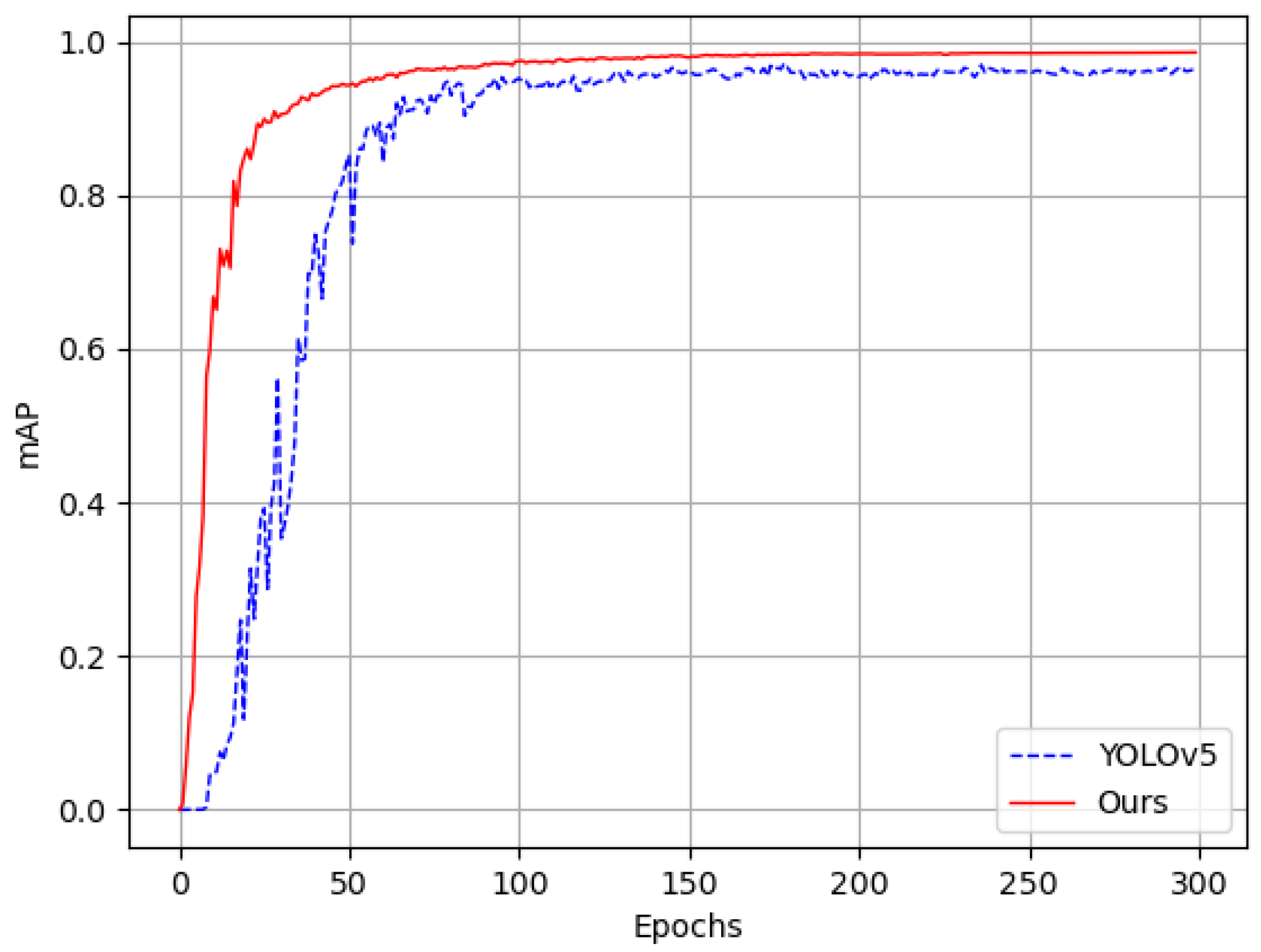
Experiments are conducted in this paper to evaluate the model against other neural network models in the same field. According to the results of the ablation experiment and comparison experiment of the model, the improved model in this study has different degrees of lead in the mean average precision index compared to other models. At the expense of several parametric quantities and computational effort, the model in this study obtains a 2.85%, 1.16%, and 2.71% improvement in precision rate, recall rate, and mAP_0.5, respectively, when compared to the unimproved YOLOv5 model. The final model is capable of detecting defects at nearly 100 frames per second, making it meet the requirements of industrial defect detection. Overall, the experiments conducted in this study demonstrate that our model has excellent comprehensive performance and can realize accurate detection and recognition tasks.
Due to the existence of limitations in time and hardware cost, the relevant experiments in this paper are conducted on a limited number of PKU-Market-PCB datasets. Despite the expansion using the data augmentation method, the dataset is not rich enough in samples, and the generalization ability of the model needs to be strengthened. Considering that the samples collected in real application scenarios are affected by the environment and other factors, detection is more difficult compared to the laboratory environment. In addition to this, although the detection precision of the method in this paper has improved, the detection speed needs to be optimized with the increase in model complexity and number of parameters.
We will later try to prune unimportant channels in the network to train PCB defect detection models with fewer parameters, a smaller size, and faster detection. In order to better improve the detection effect of the algorithms in this paper under real industrial scenarios, we are prepared to travel to real industrial environments in our subsequent work, use small portable devices for image acquisition, and carry out the task of real-time PCB defect detection.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}