
MDP-SLAM: A Visual SLAM towards a Dynamic Indoor Scene Based on Adaptive Mask Dilation and Dynamic Probability

Abstract
:1. Introduction
2. Related Works
2.1. Dynamic SLAM Based on Conventional Method
2.2. Dynamic SLAM Based on Deep Learning Model
3. Methodology
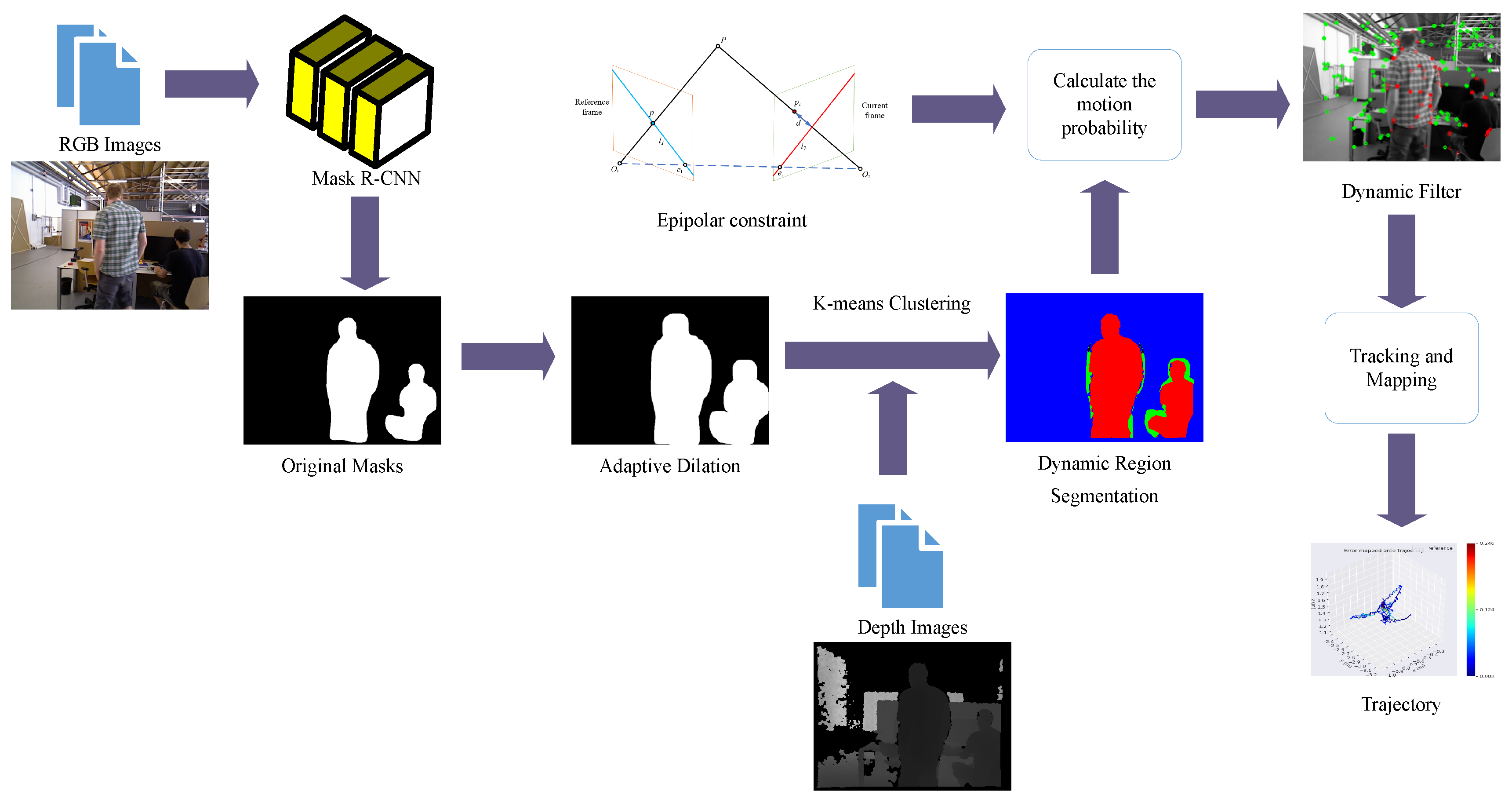
3.1. Overview of Framework
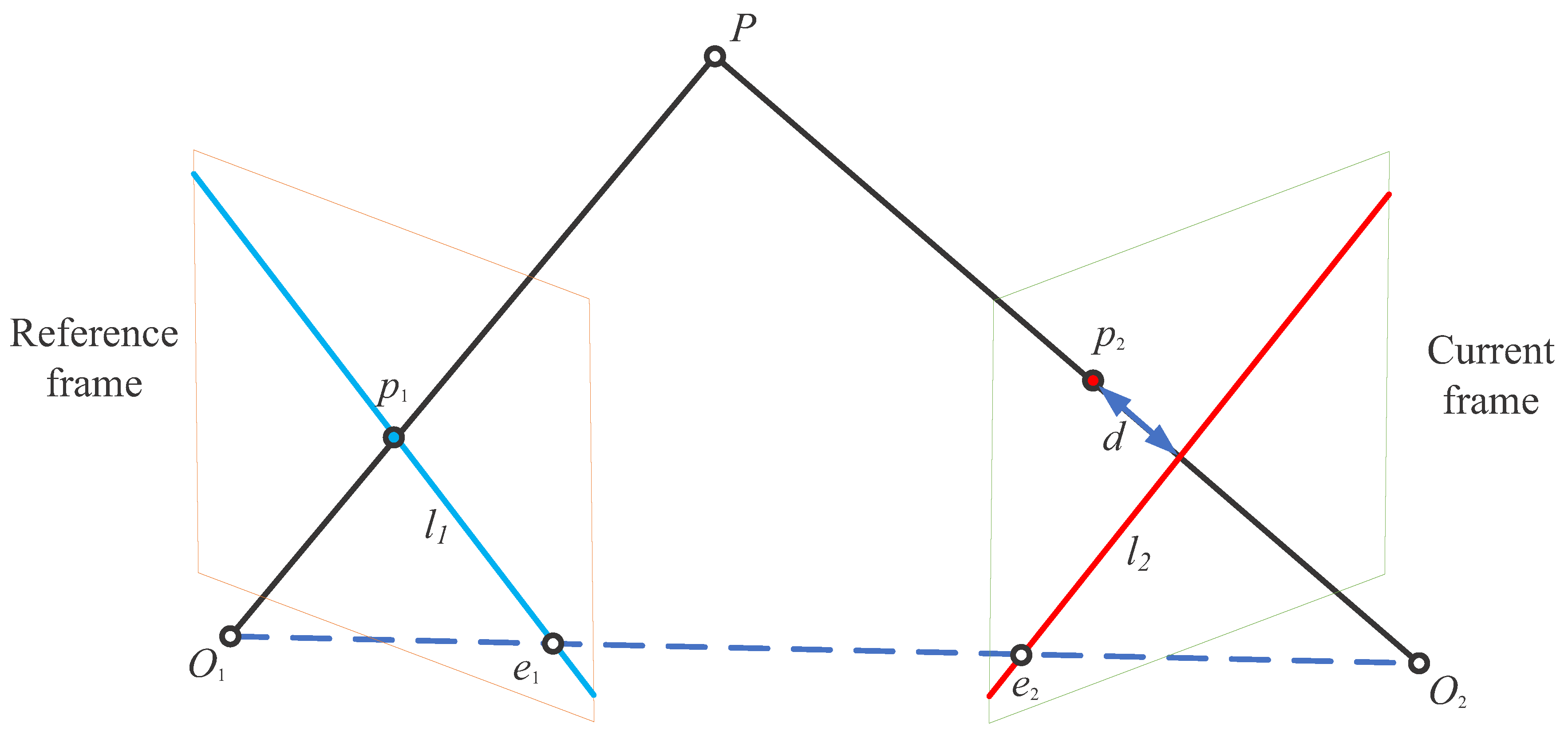
3.2. Geometric Constraint
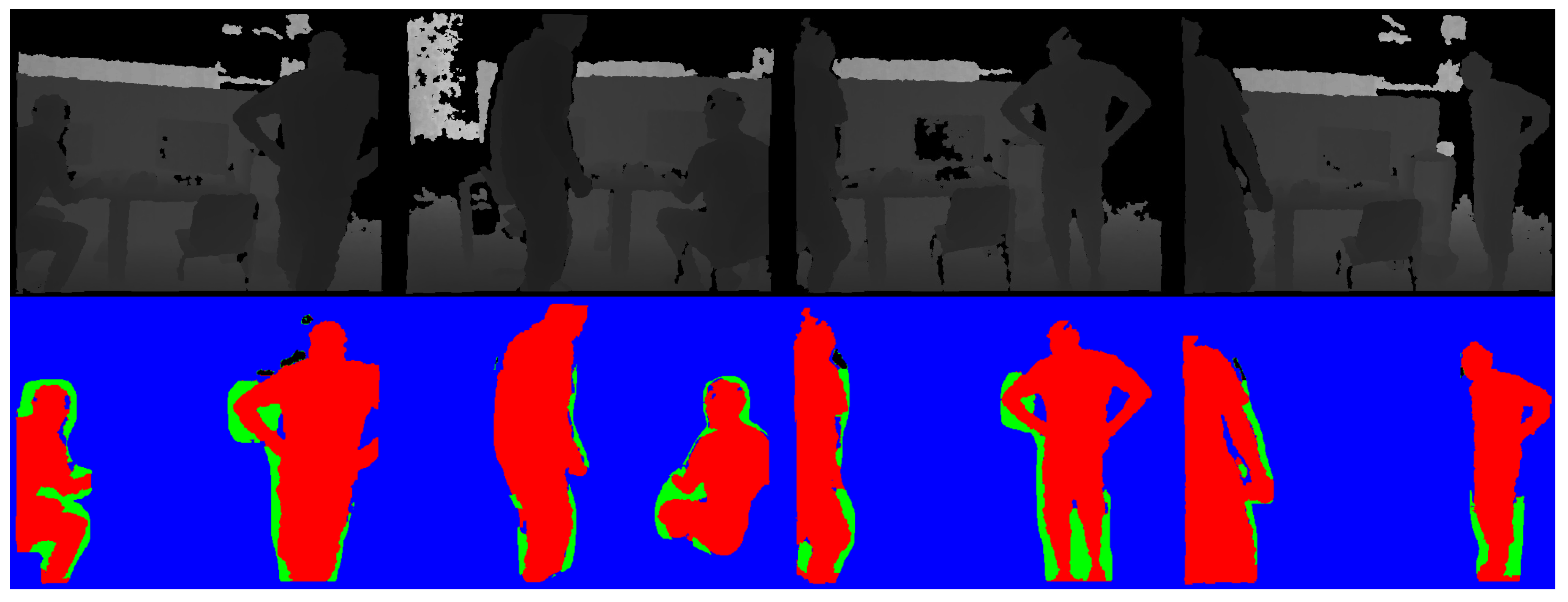
3.3. Segmentation of Dynamic Objects
3.4. Adaptive Mask-Dilation Algorithm
4. Experimental Results
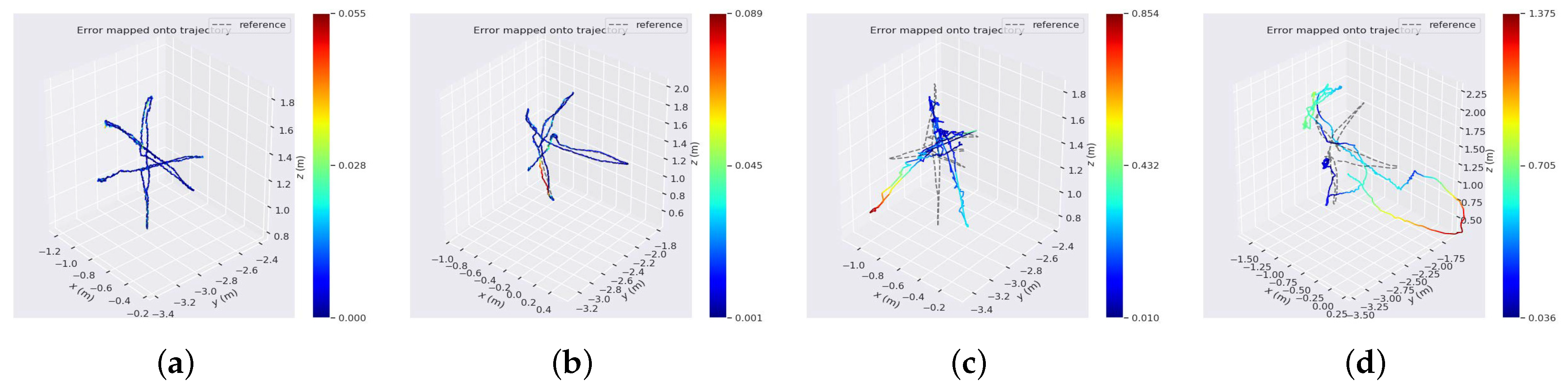
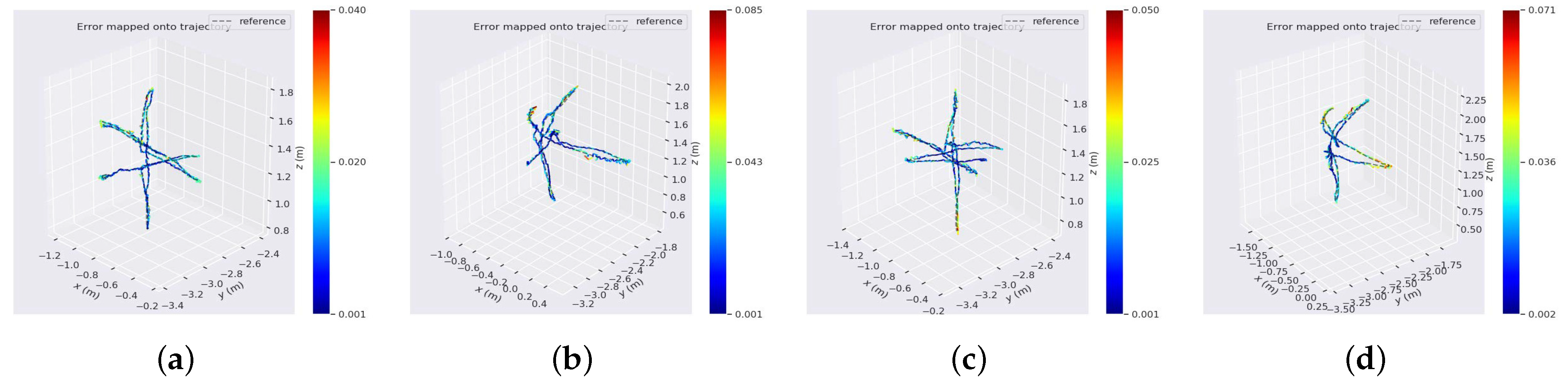
4.1. Comparison with ORB-SLAM2
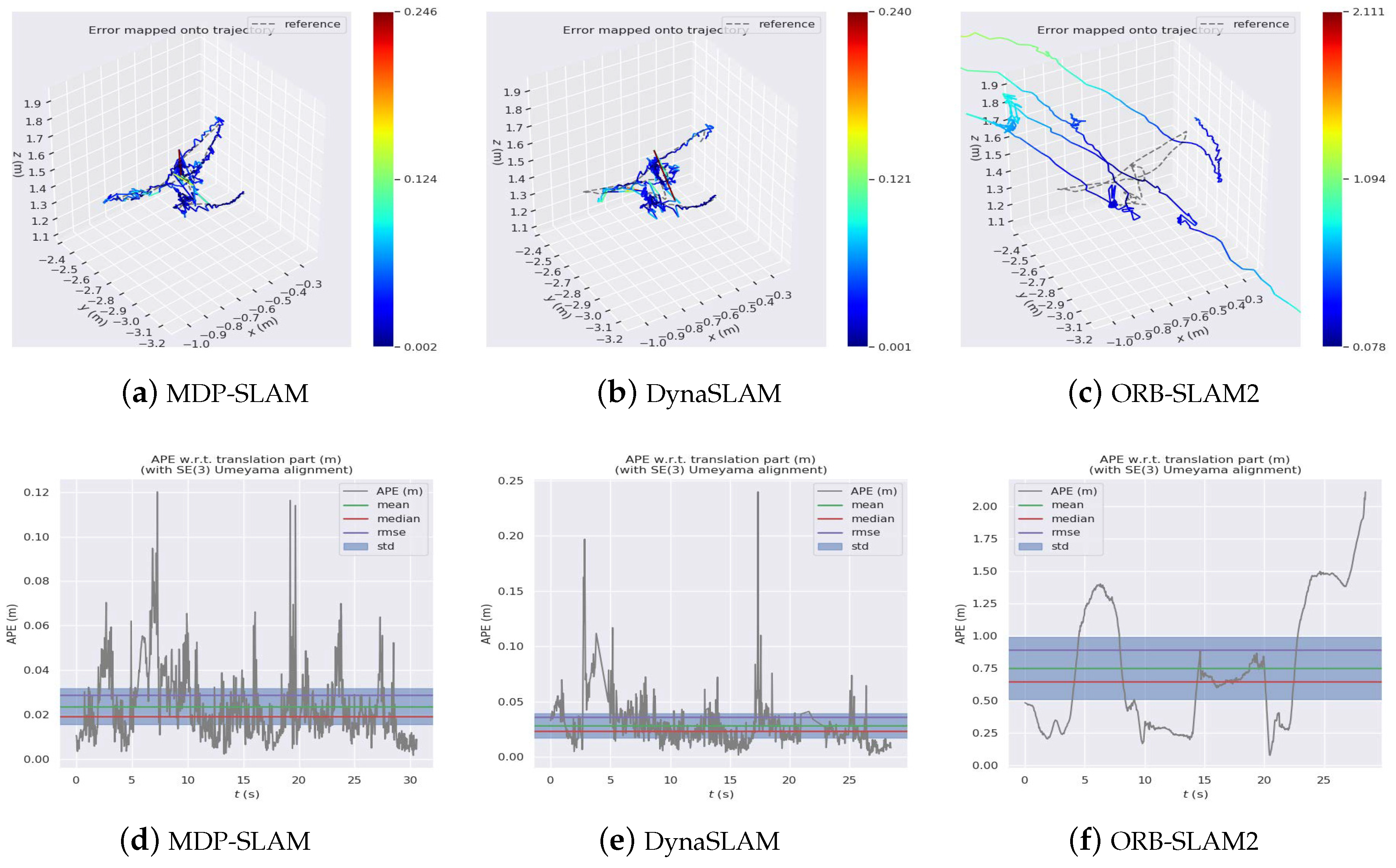
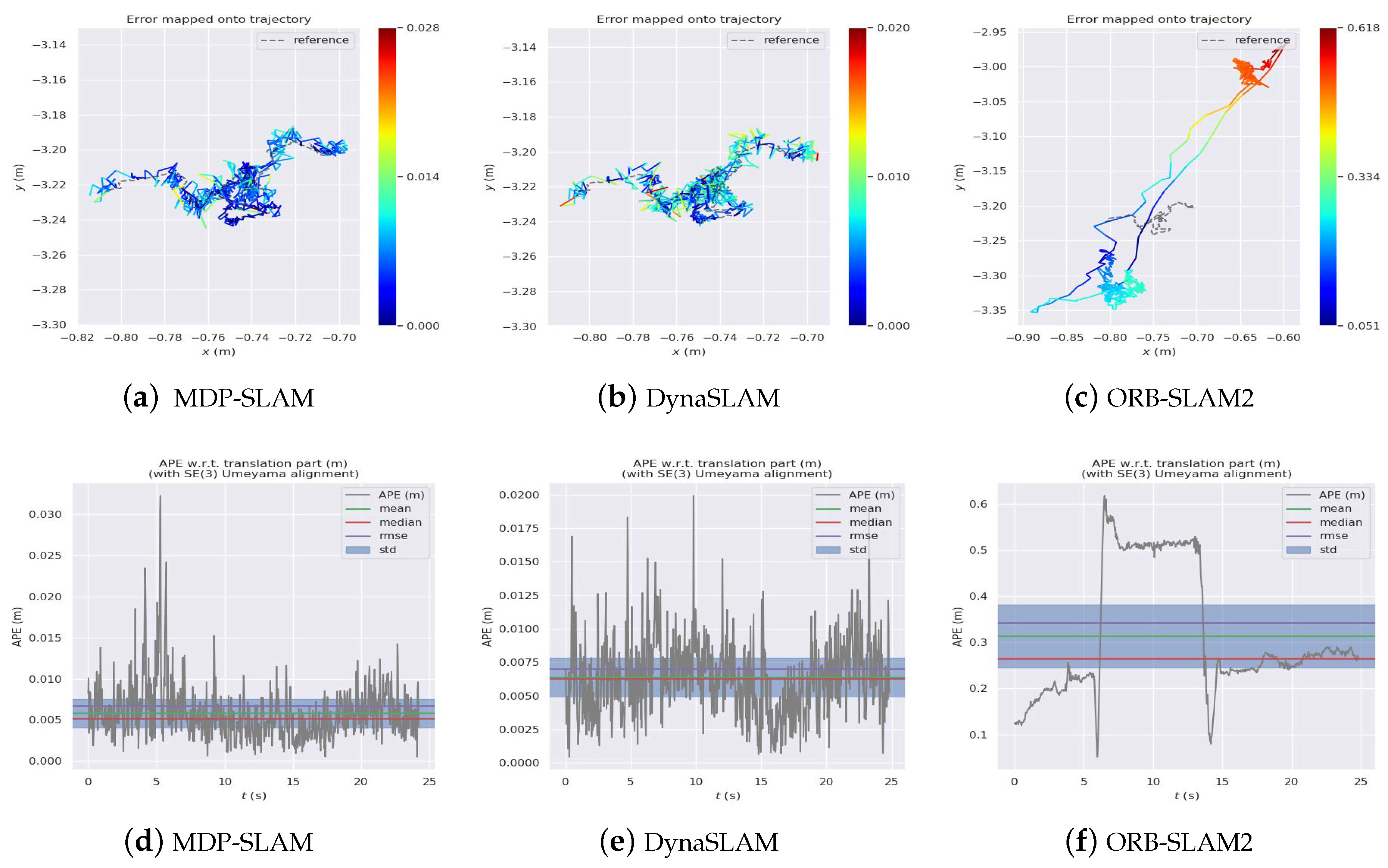
4.2. Comparison with Other Dynamic SLAM Algorithms
4.3. Ablation Experiment
4.4. Time Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 834–849. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, G.; Zeng, W.; Feng, B.; Xu, F. DMS-SLAM: A general visual SLAM system for dynamic scenes with multiple sensors. Sensors 2019, 19, 3714. [Google Scholar] [CrossRef] [PubMed]
- Bian, J.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. Gms: Grid-based motion statistics for fast, ultra-robust feature correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4181–4190. [Google Scholar]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Improving RGB-D SLAM in dynamic environments: A motion removal approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar] [CrossRef]
- Wang, R.; Wan, W.; Wang, Y.; Di, K. A new RGB-D SLAM method with moving object detection for dynamic indoor scenes. Remote Sens. 2019, 11, 1143. [Google Scholar] [CrossRef]
- Cheng, J.; Sun, Y.; Meng, M.Q.H. Improving monocular visual SLAM in dynamic environments: An optical-flow-based approach. Adv. Robot. 2019, 33, 576–589. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, S. Motion segmentation based robust RGB-D SLAM. In Proceedings of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 29 June–4 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 3122–3127. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Rünz, M.; Buffier, M.; Agapito, L. MaskFusion: Real-Time Recognition. Track. Reconstr. Mult. Mov. Objects 2018, 1, 2. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 27–28 October 2019; pp. 9157–9166. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Li, A.; Wang, J.; Xu, M.; Chen, Z. DP-SLAM: A visual SLAM with moving probability towards dynamic environments. Inf. Sci. 2021, 556, 128–142. [Google Scholar] [CrossRef]
- Yang, B.; Ran, W.; Wang, L.; Lu, H.; Chen, Y.P.P. Multi-classes and motion properties for concurrent visual slam in dynamic environments. IEEE Trans. Multimed. 2021, 24, 3947–3960. [Google Scholar] [CrossRef]
- Liu, Y.; Miura, J. RDS-SLAM: Real-time dynamic SLAM using semantic segmentation methods. IEEE Access 2021, 9, 23772–23785. [Google Scholar] [CrossRef]
- Cui, L.; Ma, C. SDF-SLAM: Semantic depth filter SLAM for dynamic environments. IEEE Access 2020, 8, 95301–95311. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 573–580. [Google Scholar]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A semantic visual SLAM towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1168–1174. [Google Scholar]
- Fan, Y.; Zhang, Q.; Tang, Y.; Liu, S.; Han, H. Blitz-SLAM: A semantic SLAM in dynamic environments. Pattern Recognit. 2022, 121, 108225. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | ORB-SLAM2/m | MDP-SLAM/m | Improvements | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | Mean | Std | RMSE | Mean | Std | RMSE | Mean | Std | |
| sitting_xyz | 0.0085 | 0.0072 | 0.0052 | 0.0120 | 0.0104 | 0.0060 | −41.18% | −94.44% | −15.38% |
| sitting_half | 0.0207 | 0.0163 | 0.0134 | 0.0140 | 0.0126 | 0.0072 | 32.37% | 22.70% | 46.27% |
| sitting_static | 0.0104 | 0.0092 | 0.0038 | 0.0056 | 0.0049 | 0.0026 | 46.15% | 46.74% | 31.58% |
| sitting_rpy | 0.0363 | 0.0295 | 0.0214 | 0.0324 | 0.0282 | 0.0156 | 10.47% | 4.41% | 27.10% |
| walking_xyz | 0.5183 | 0.4431 | 0.2712 | 0.0165 | 0.0143 | 0.0081 | 96.82% | 96.77% | 97.01% |
| walking_half | 0.4354 | 0.3982 | 0.1751 | 0.0250 | 0.0219 | 0.0121 | 94.25% | 94.50% | 93.09% |
| walking_static | 0.3419 | 0.3132 | 0.1370 | 0.0067 | 0.0053 | 0.0034 | 98.04% | 98.31% | 97.52% |
| walking_rpy | 0.8898 | 0.7493 | 0.4798 | 0.0289 | 0.0237 | 0.0164 | 96.75% | 96.84% | 96.58% |
| Sequences | ORB-SLAM2/m | MDP-SLAM/m | Improvements | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | Mean | Std | RMSE | Mean | Std | RMSE | Mean | Std | |
| sitting_xyz | 0.0143 | 0.0119 | 0.0075 | 0.0097 | 0.0084 | 0.0050 | 32.17% | 29.41% | 33.33% |
| sitting_half | 0.0169 | 0.0137 | 0.0110 | 0.0143 | 0.0115 | 0.0085 | 15.38% | 16.06% | 22.73% |
| sitting_static | 0.0176 | 0.0163 | 0.0058 | 0.0049 | 0.0043 | 0.0023 | 72.16% | 73.62% | 60.34% |
| sitting_rpy | 0.0253 | 0.0201 | 0.0134 | 0.0182 | 0.0130 | 0.0127 | 28.06% | 35.32% | 5.22% |
| walking_xyz | 0.0371 | 0.0305 | 0.0241 | 0.0112 | 0.0094 | 0.0063 | 69.81% | 69.18% | 73.86% |
| walking_half | 0.0357 | 0.0270 | 0.0234 | 0.0124 | 0.0104 | 0.0069 | 65.27% | 61.48% | 70.51% |
| walking_static | 0.0425 | 0.0283 | 0.0364 | 0.0071 | 0.0059 | 0.0037 | 83.29% | 79.15% | 89.84% |
| walking_rpy | 0.0432 | 0.0318 | 0.0288 | 0.0181 | 0.0136 | 0.0119 | 58.10% | 57.23% | 58.68% |
| Sequences | DS-SLAM/m | DynaSLAM/m | Blitz-SLAM/m | MDP-SLAM/m | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | |
| sitting_xyz | 0.0185 | 0.0118 | 0.0135 | 0.0056 | 0.0114 | 0.0071 | 0.0120 | 0.0060 |
| sitting_half | 0.0164 | 0.0067 | 0.0187 | 0.0085 | 0.0160 | 0.0076 | 0.0140 | 0.0072 |
| sitting_static | 0.0065 | 0.0036 | 0.0083 | 0.0050 | / | / | 0.0056 | 0.0026 |
| sitting_rpy | 0.0266 | 0.0153 | 0.0450 | 0.0330 | / | / | 0.0324 | 0.0156 |
| walking_xyz | 0.0247 | 0.0174 | 0.0178 | 0.0087 | 0.0153 | 0.0078 | 0.0165 | 0.0081 |
| walking_half | 0.0303 | 0.0159 | 0.0271 | 0.0127 | 0.0256 | 0.0126 | 0.0250 | 0.0121 |
| walking_static | 0.0081 | 0.0034 | 0.0070 | 0.0029 | 0.0102 | 0.0052 | 0.0067 | 0.0034 |
| walking_rpy | 0.4442 | 0.0235 | 0.0360 | 0.0220 | 0.0356 | 0.0220 | 0.0288 | 0.0164 |
| Sequences | M/m | MD/m | MDP/m | |||
|---|---|---|---|---|---|---|
| RMSE | Std | RMSE | Std | RMSE | Std | |
| sitting_xyz | 0.0142 | 0.0061 | 0.0153 | 0.0063 | 0.0120 | 0.0060 |
| sitting_half | 0.0189 | 0.0086 | 0.0192 | 0.0088 | 0.0140 | 0.0072 |
| sitting_static | 0.0094 | 0.0052 | 0.0078 | 0.0034 | 0.0056 | 0.0026 |
| sitting_rpy | 0.0455 | 0.0303 | 0.0356 | 0.0241 | 0.0324 | 0.0156 |
| walking_xyz | 0.0183 | 0.0088 | 0.0173 | 0.0084 | 0.0165 | 0.0081 |
| walking_half | 0.0278 | 0.0131 | 0.0253 | 0.0126 | 0.0250 | 0.0121 |
| walking_static | 0.0081 | 0.0042 | 0.0076 | 0.0037 | 0.0067 | 0.0034 |
| walking_rpy | 0.0387 | 0.0252 | 0.0341 | 0.0233 | 0.0289 | 0.0164 |
| Module | A | B | C | D | E | Total |
|---|---|---|---|---|---|---|
| Time (ms) | 117.23 | 22.38 | 8.42 | 5.27 | 27.89 | 181.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Shi, Z. MDP-SLAM: A Visual SLAM towards a Dynamic Indoor Scene Based on Adaptive Mask Dilation and Dynamic Probability. Electronics 2024, 13, 1497. https://doi.org/10.3390/electronics13081497
Zhang X, Shi Z. MDP-SLAM: A Visual SLAM towards a Dynamic Indoor Scene Based on Adaptive Mask Dilation and Dynamic Probability. Electronics. 2024; 13(8):1497. https://doi.org/10.3390/electronics13081497
Chicago/Turabian StyleZhang, Xiaofeng, and Zhengyang Shi. 2024. "MDP-SLAM: A Visual SLAM towards a Dynamic Indoor Scene Based on Adaptive Mask Dilation and Dynamic Probability" Electronics 13, no. 8: 1497. https://doi.org/10.3390/electronics13081497