1. Introduction
WebAssembly is a binary instruction format designed for a virtual machine that operates within web browsers. It serves as a portable target for compiling high-level programming languages, such as C/C++, Rust, Java, and others. Its interpreter is a low-level, stack-based machine. The primary goal of WebAssembly is to offer a secure, efficient, and platform-independent approach to executing code in web browsers (97.14% of web browsers supported it in April 2024, see
https://caniuse.com/wasm, accessed on 11 April 2024), allowing web applications to handle computationally intensive tasks. WebAssembly is widely supported in modern web browsers, including Chrome, Firefox, Safari, and Edge. Its usage is becoming increasingly prevalent in various applications. However, this exposes new attack surfaces in the browser, and errors in the WebAssembly interpreter may result in incorrect program outputs or abnormal termination, potentially leading to security vulnerabilities. In recent years, several security issues have been identified, including vulnerabilities discovered by Natalie Silvanovich in Webkit [
1] and seven CVEs reported for WAVM in 2018 [
2].
Fuzzing has proven to be effective at identifying vulnerabilities [
3], and its application extends to detecting vulnerabilities in WebAssembly interpreters, similar to its use in other high-level programming languages like JavaScript and C/C++. However, disparities emerge when comparing WebAssembly with these languages, particularly in the area of validation. In WebAssembly, the validation process carefully evaluates each instruction within the program input to ensure the integrity of the type and quantity of the values present on the stack. This particular characteristic poses challenges for traditional fuzzing methodologies, such as AFL [
4] and libFuzzer [
5], as generating valid testcases becomes a more complex task. Consequently, the testing process becomes less efficient and effective, necessitating the exploration of alternative approaches to address this limitation within the context of academic research.
To address this demand, we propose a fuzzing framework named ESFuzzer. The contributions of our approach are as follows:
We introduce the concepts of Equivalent-Statement and Equivalent-Exchange, along with a novel intermediate representation to present them. These concepts provide valuable insights into program behavior, allowing us to optimize, transform, and analyze programs more effectively.
We have developed a novel algorithm called the Stack Repair Algorithm. This algorithm tackles challenges associated with stack manipulation in the fuzzing process.
We have developed a fuzzing framework called ESFuzzer and conducted an evaluation using libFuzzer on Chrome for V8. The results demonstrate that our tool effectively addresses the validation challenge and is more efficient than libFuzzer.
2. Background and Related Works
When conducting fuzz testing for WebAssembly interpreters, researchers encounter several challenges. Some of these challenges arise from the fuzz testing technique itself. Others include the execution environment and the semantic complexity of WebAssembly as a low-level bytecode format, which introduce additional challenges to the testing process. To find related works on this topic, a search was conducted using the keywords “WebAssembly interpreter” and “fuzzing”, with the operator “AND”.
2.1. Fuzzing Overview
Fuzzing is a popular area of research that has received a lot of attention in recent years and has proven to be effective. Previous research has applied fuzzing techniques to interpreters and compilers using various approaches, such as fuzzing special-purpose languages like C [
6,
7,
8] or JavaScript [
9,
10,
11,
12], as well as fuzzing general-purpose languages. The choice of approach depends on the requirements of the target system and the availability of input models. Additionally, language-agnostic tools have been developed, which do not make any assumptions about the target language and are more widely applicable [
12,
13,
14,
15]. These findings demonstrate the versatility of fuzzing techniques in identifying vulnerabilities in a wide range of software systems.
A fuzz test begins by generating program inputs, known as testcases. The quality of these testcases directly affects the effectiveness of the test. The inputs should meet the program’s requirements for the input format, while also being varied enough to potentially cause the program to fail. The target programs accept various inputs, such as files with different formats, network communication data, and executable binaries with specified characteristics.
How to generate broken-enough testcases is the main challenge for fuzzers. Van Sprundel [
16] classified these fuzzers into two types: Generative-based and Mutation-based.
- a
Generative-based fuzzing: Generative-based approaches use input models such as configuration files [
6,
13,
14,
17,
18,
19,
20,
21] or static analysis [
22,
23] to generate valid examples. The main advantage of the generative approach is that the produced inputs are syntactically correct by design, since the generator functions respect the underlying syntax expected by the program under test.
- b
Mutation-based fuzzing: Mutation-based approaches require a valid set of initial inputs and generate testcases by mutating these inputs. Examples of mutation-based fuzzers include Honggfuzz [
24], AFL++ [
25], Collafl [
26], POSTER [
27], AFLFast [
28], and Angora [
29], which collect metadata about the execution of a target program using compile-time instrumentation. This classification helps us understand the different approaches to fuzzing and their suitability for different types of software systems.
Particularly in the field of fuzz testing for interpreters or compilers, prior research has focused on generating input samples for specific ones. Lindig’s [
8] consistency checker for the C language compiler generates C code using a small grammar and fixed test generation scheme. Yang et al. introduced CSmith [
6], a language-specific fuzzer for testing compilers. The paper’s primary contributions are twofold: First, it advances the state of the art in compiler testing by creating programs that cover a large subset of C while avoiding undefined and unspecified behaviors that could hinder the automatic detection of wrong-code bugs. Second, it presents a collection of qualitative and quantitative results regarding the bugs found in open-source C compilers. Ruderman’s jsfunfuzz [
30] is a generation-based fuzzer trained to handle various JavaScript language features. Domato [
31] generated samples targeting specific DOM logic issues by using HTML, CSS, and JavaScript syntax. CodeAlchemist [
32] employed a semantics-aware assembly approach to produce JavaScript code snippets. Additionally, some works [
10,
15,
33] have focused on the abstract syntax tree (AST) of JavaScript, such as Park’s work [
12], which introduced the concept of aspect-preserving mutations. These techniques demonstrate the diverse approaches to fuzzing compilers and interpreters, highlighting the importance of developing specialized fuzzers for specific languages and systems.
Another challenge is low coverage. The aim of fuzz testing is to cover as many execution paths and code regions of the target system as possible to reveal hidden vulnerabilities. However, real software systems are often complex, with numerous execution paths and code branches. Several studies have explored this challenge. Skyfire [
34] uses data-driven seed generation, while Dharma [
35] and F1 [
36] optimize the input generation process from the grammar itself. Vuzzer [
37] extracts data-flow and control-flow features to create a smart feedback loop, while other studies combine coverage feedback with syntax awareness. Nautilus [
18] combines coverage feedback with syntax awareness and mutation operators inspired by AFL, and Zest [
32] uses a Quickcheck-like [
38] input generator for coverage-guided fuzzing. Montage [
39] leverages machine learning to find bugs by combining AST fragments in unique ways.
2.2. WebAssembly Fuzzing
WebAssembly is a new technique that is currently under research with a focus on security. Some articles [
40,
41,
42,
43,
44,
45,
46] have looked into the security of WebAssembly binaries, such as Daniel Lehmann’s Fuzzm [
42], the first binary-only grey-box fuzzer for WebAssembly. This approach uses canary-based binary instrumentation to detect overflows and underflows on the stack and heap. Other approaches [
47,
48,
49], such as that by Dwfault [
47], have introduced a mechanism of hierarchical variation and instruction correction based on AFL, which partly solves the problem of syntax validation but introduces a large number of nop instructions that can break the program’s logic. Researches [
50,
51] focus on WebAssembly interpreters in smart contracts. Paper [
50] designed and implemented WASAI, a new concolic fuzzer for uncovering vulnerabilities in WebAssembly smart contracts. Paper [
51] implemented a grey-box fuzzer called GFuzzer based on WebAssembly for smart contracts on the EOSIO platform considering that EOSIO contracts are not open-sourced.
In addition to smart contracts, WebAssembly is also widely used in web browsers like Firefox, Safari, and Chrome. These browsers come pre-installed with a WebAssembly interpreter. However, there is a lack of research on fuzz testing the WebAssembly interpreter in browsers.
2.3. Understanding WebAssembly
WebAssembly is a binary instruction format specifically designed for a stack-based virtual machine. This enables the execution of code written in multiple languages on the web at nearly native speed, making it possible for client applications that were previously unable to be run on the web. WebAssembly programs are usually written in high-level programming languages like C/C++ and Rust, or in text format, and then compiled into a binary format for distribution on a web server.
WebAssembly has two concrete representations: One is a compact binary format that uses the extension ".wasm". ".wasm" is the typical distribution format for WebAssembly code, and it has a human-readable text format with the extension ".wat" (short for "WebAssembly Text Format").
In both binary and textual formats, the fundamental unit of code in WebAssembly is a module. In textual format, a module is represented as a large S-expression, as shown in Listing 1. A module contains definitions of types, functions, tables, memories, and globals.
| Listing 1. A WebAssembly program in text format. |
![Electronics 13 01498 i001]() |
Before a WebAssembly program execution, it is validated by an interpreter. Validation of the WebAssembly code is crucial in the execution process, as it ensures that only valid programs can be instantiated. In contrast to traditional programming languages, WebAssembly’s validation procedure extends beyond syntax analysis. This is due to its stack-based virtual machine design, which necessitates the validation of both syntax and the validity of the operands stored on the stack. As a result, the WebAssembly interpreter ensures not only the syntactic correctness of the code, but also its semantic integrity and security.
The validation algorithm of WebAssembly uses two distinct stacks: a value stack and a control stack. The value stack keeps track of the types of operand values on the stack, while the control stack manages structured control instructions and their associated blocks.
When a value is pushed, its type is recorded on the value stack. If the type is unknown, it is marked as “Unknown”. When a value is popped, the stack checks that it does not cause underflow in the current block, and then removes one item. This ensures that the program is semantically correct and that the values are of the expected type.
Upon successful validation, a WebAssembly program proceeds to execution within the WebAssembly interpreter. The execution process involves several essential steps:
- i
Virtual Machine (VM) Initialization: the interpreter initializes the WebAssembly VM and sets up the stack, which serves as a storage mechanism for instruction operands.
- ii
Instruction Parsing: the WebAssembly VM reads and parses instructions from the program, extracting opcodes, operands, and relevant information.
- iii
Instruction Execution: the VM executes the corresponding operation based on the opcode and operand, performing the required computation.
- iv
State Management: after executing an instruction, the VM updates various components, such as program counters, stacks, and other relevant state information, to ensure the continuity of the execution process.
- v
Control Flow Handling: The interpreter manages the program’s control flow by handling branching, looping, and function calls. It keeps track of program counters and manages conditional and unconditional jumps to different program sections.
3. Conception
Before delving into our proposed methodology, it is imperative to establish a conceptual foundation by formally defining several key notions that underpin the methodologies presented in the subsequent sections.
Definition 1. The Effect-Array use to represent the effect of an instruction on the stack. We can use a two-dimensional array denoted as E. This array encompasses the impact of instructions on the stack, considering both outgoing and incoming operands. Specifically, we define “O” as the outgoing array and “I” as the incoming array. These arrays represent the types and orders of operands in an instruction. The term “” denotes the type of the nth outgoing operand, while “” denotes the type of the nth incoming operand. Currently, there are only four available number types in WebAssembly: i32, f32, i64, and f64. By utilizing this two-dimensional array E, we can capture and analyze the stack behavior that results from the execution of instructions. This representation enables us to compare and assess the impact of different instructions on the stack. It helps identify appropriate replacements and ensures the preservation of stack integrity throughout the program’s execution.
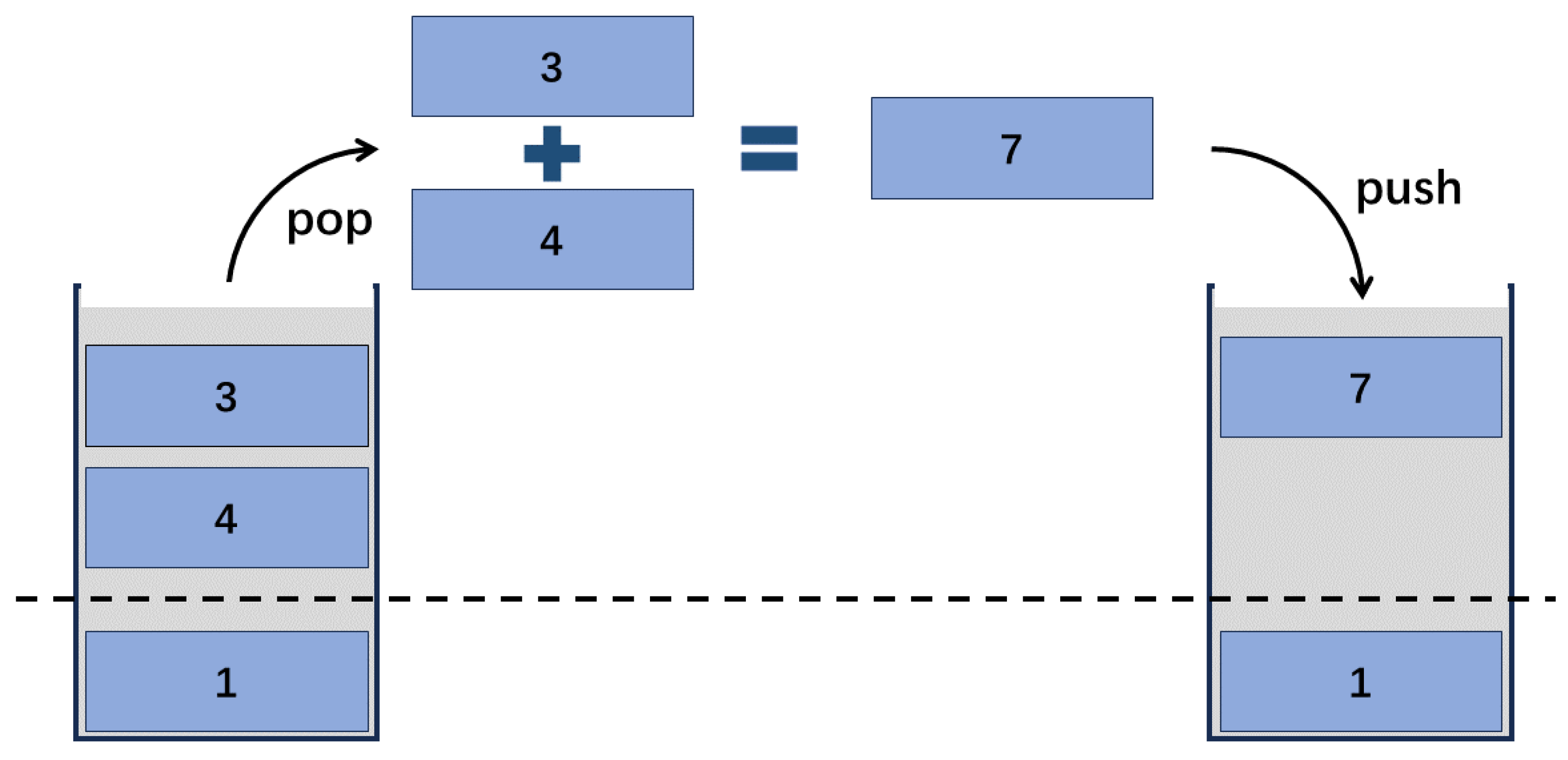
For instance, as shown in
Figure 1, the instruction
removes two operands of type i32 from the stack, computes their sum, and then places the resulting value (of type i32) back onto the stack. Therefore, the Effect-Array for
can be represented as
. This indicates that the instruction requires two i32 operands as inputs and generates a single i32 value as the output.
For a given code block, such as Listing 2, the signature of the code block indicates that it requires two i32 parameters and returns an i32 result. Based on this information, we determine that the Effect-Array is
.
| Listing 2. WebAssembly code block. |
![Electronics 13 01498 i002]() |
Definition 2. An Equivalent-Statement is a set of instructions or code blocks that produce the same Effect-Array.
An instruction or code block can be considered equivalent if it has the same characteristics in terms of the type, number, and order of its input and output operands on the stack. This equivalence ensures that replacing one statement with another from the set of Equivalent-Statements maintains the stack behavior and overall functionality of the program.
As previously noted, the i32.add instruction and the code block in Listing 2 produce identical Effect-Arrays , demonstrating their equivalence. So, we can say that i32.add and the code block in Listing 2 belong to the same Equivalent-Statement.
Based on the impact of instruction and the code block on the stack, we can classify Equivalent-Statement into three categories:
Expanded Statement: statements have more out-stack operands than in-stack operands (), which causes an increase in the stack when inserted into a program.
Common Statement: statements have an equal number of out-stack and in-stack operands (), resulting in no change to the stack.
Contracted Statement: statements have fewer out-stack operands than in-stack operands (), resulting in a reduction in the stack when inserted into a program.
In program structure, we often observe the following pattern: At the outset, there are numerous Expanded Statements that push a large number of operands onto the stack. Common Statements are interspersed throughout the program to represent routine computations. Towards the end, there are Contracted Statements that consume the stack, leaving only the correct number and type of operands.
By categorizing Equivalent-Statements into these groups, we can easily manage their effects on the stack and streamline the generation of Equivalent-Statements in a program.
For the sake of simplicity, we developed a compact intermediate representation (IR) to depict Equivalent-Statements. An IR instruction looks like this:
For example, an intermediate instruction with the format IR.OP O:[i32, i32], I:[i32] denotes an Equivalent-Statement that pops out two operands of type i32 from the stack and pushes one operand of type i32 back, such as or .
Definition 3. The Equivalent-Exchange involves replacing an instruction or code block with any statement from its corresponding Equivalent-Statement, while maintaining the stack configuration of the program.
This replacement does not alter the stack behavior or the overall functionality of the program, and it provides valuable flexibility in code transformations and optimizations. It also enables the generation of diverse testcases while maintaining the desired stack behavior. This technique plays a crucial role in generating and mutating testcases for fuzzing.
4. Stack Repair Algorithm
As mentioned earlier, the WebAssembly interpreter conducts the validation process before the program execution. This verification ensures that the type and quantity of values on the top of the stack are congruent with the corresponding instructions. Only samples that pass this validation check are allowed to proceed to the execution phase, while those that fail are rejected. In response to this, we developed a methodology known as the Stack Repair Algorithm, with the goal of improving the success rate of the validation check for the provided samples.
The Stack Repair Algorithm is used to restore the correct stack state after generation or mutation. This was implemented to ensure that the sample passed validation by the WebAssembly interpreter. This was accomplished by calculating the Effect-Array of each Equivalent-Statement in the sample.
Algorithm 1 presents a systematic approach to stack repair that involves maintaining a virtual stack. At the beginning, the algorithm initializes the virtual stack to match its initial state. Subsequently, it iterates through each statement in the queue, individually evaluating the correctness of the current stack state in relation to the statement’s Effect-Array.
To verify the correctness of the stack state, the algorithm compares the virtual stack with the expected Effect-Array associated with the statement. If the virtual stack aligns with the expected Effect-Array, the algorithm proceeds to the next step. If the virtual stack does not match the expected Effect-Array, the algorithm initiates a repair process to indicate an incorrect stack state.
| Algorithm 1 Stack Repair |
Input: ops
Output: ops
- 1:
virtual_stack = initStack() - 2:
for op in ops do - 3:
if staticCheck(virtual_stack, op) then - 4:
continue - 5:
else - 6:
repair(ops) - 7:
end if - 8:
end for
|
During the stack repair process, two main situations may require fixing:
If the number of operands on the stack is less than what the next statement requires, the algorithm can insert the necessary statement to push the required number of operands onto the stack.
If the type or order of the operands on the stack is incorrect or does not match what the next statement expects, the algorithm needs to perform a stack rollback. This involves locating and modifying the statement that pushed the incorrect operand onto the stack. Once the correct operand is pushed, the stack can be rolled forward to resume normal execution.
The first case is simpler and does not require an example, whereas the second case is more specific. Therefore, an instance will be provided.
Listing 3 contains a code error on line 4. The WebAssembly interpreter validation will detect an error because for IR.OP O:[[i64,i64], I:[i64]] requires two i64 operands, but the current stack only contains i32 and i64 operands. To fix this issue, stack rollback is necessary, which can be achieved by reversing the execution order of statements and the outgoing and incoming operands.
Starting from line 4, the algorithm first clears the temporary stack and then adds the two i64 operands to it. On line 3, an i64 is taken from the stack and placed into the stack as an i32. The stack now holds [i64, i32]. Line 2 removes an i32 from the stack, leaving only [i64]. The error occurred due to a type mismatch. We remove i64 and replace it with i32 in the stack. The operation should be reversed, resulting in IR. OP O:[i32], I:[i64]. The final result is displayed in Listing 4.
| Listing 3. IR code fragment before repair. |
![Electronics 13 01498 i003]() |
| Listing 4. IR code fragment after repair. |
![Electronics 13 01498 i004]() |
5. ESFuzzer
After discussing the main concepts and algorithm proposed in this paper, we will now shift our focus to our tool, ESFuzzer. In this section, we will provide a detailed overview of the architecture and implementation of ESFuzzer.
5.1. Overview
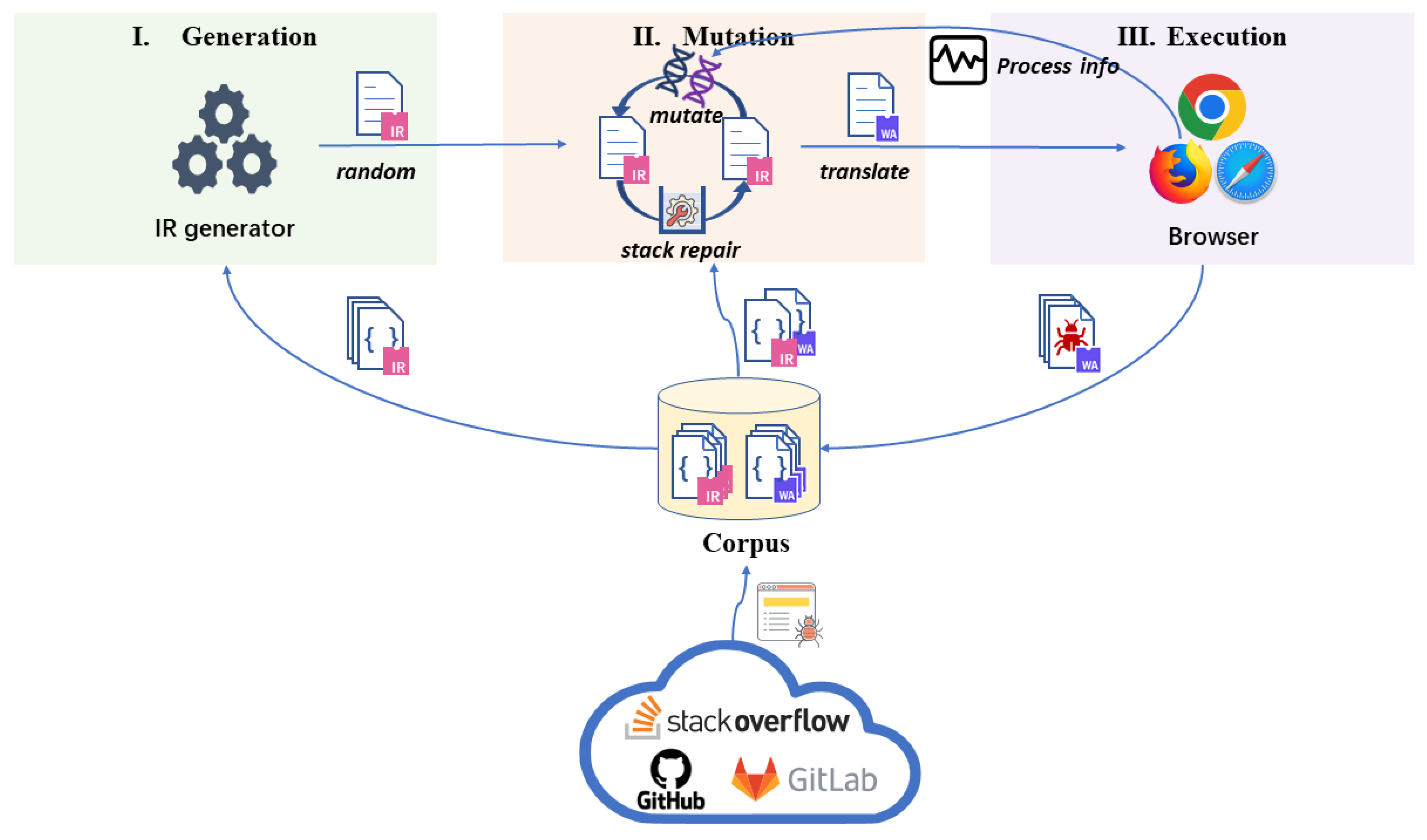
ESFuzzer ’s workflow is illustrated in
Figure 2 and comprises three phases, Generation, Mutation, and Execution. In the Generation phase, ESFuzzer randomly combines intermediate instructions from Corpus to create an intermediate program and send it to the next phase. During the Mutation phase, ESFuzzer mutates the intermediate programs based on the mutation strategy we designed and the process information obtained from the Execution phase; subsequently, ESFuzzer repairs the results using the Stack Repair Algorithm and translates them into a WAT format script for compilation and execution. Finally, in the Execution phase, ESFuzzer monitors the execution of the WebAssembly interpreter and collects test samples that can trigger a crash or explore new paths.
Listing 5 presents a real-world test case generated by ESFuzzer based on Listing 4. It is executable by the WebAssembly interpreter.
| Listing 5. A real-world test case generated by ESFuzzer. |
![Electronics 13 01498 i005]() |
5.2. Corpus
Furthermore, we establish a corpus to store the associations between IR instructions and WebAssembly statements. Each IR instruction is associated with a set of WebAssembly instructions or code blocks. This corpus facilitates efficient translation and ensures the accurate representation of IR instructions in WebAssembly during the Generation and Mutation processes.
ESFuzzer uses the corpus to store code snippets as input. The corpus is sourced from two places: the internet, where code snippets are obtained from public repositories, forums, blogs, and documentation, and refined samples that trigger new paths or crashes.
5.3. Generation
During the Generation phase, the tool randomly combines intermediate instructions to create a program. This process involves selecting instructions from a pool of available options and arranging them in a sequence. The resulting program may contain inconsistencies or errors in the stack behavior.
To tackle these issues, we implement our Stack Repair Algorithm. The algorithm systematically analyzes the generated program, checking the correctness of the stack state at each statement based on the expected Effect-Array. If any inconsistencies or errors are detected, the algorithm performs repairs to align the stack state with the expected behavior.
5.4. Mutation
During the Mutation phase, the tool uses three important mutation methods to modify the IR program, based on program information received from the executor. These methods play a crucial role in the program’s transformation process.
5.4.1. Statement-Based Mutation
The statement-based mutation offers three options for modifying programs:
The first option involves exchanging the WebAssembly instructions or code blocks that correspond to the same IR instructions. This allows for the replacement of specific sections of the program while maintaining the overall structure and behavior.
The second option is to randomly mutate the operands within the IR instructions. This involves modifying the values or variables used in the IR instructions (e.g., ), introducing variations in the program’s data flow and computation.
The third option combines both the exchange of WebAssembly instructions or code blocks and the random mutation of operands within the IR instructions. This comprehensive approach allows for a wider range of modifications to the program, increasing the potential for creating new and diverse program instances.
By offering these three options, statement-based mutation provides flexibility for modifying programs, facilitating the exploration of different program configurations and behaviors.
5.4.2. Size-Based Mutation
To effectively manage program complexity, we employ three categories of Equivalent-Statements as discussed in
Section 3: Expanded Statement, Common Statement, and Contracted Statement.
To increase the complexity of a program, we can add more Expanded Statements at the beginning or introduce Common Statements in the middle. Conversely, reducing the number of Expanded Statements decreases program complexity. These strategies enable the fine-tuning of the complexity of the program’s computation and control flow.
5.4.3. Control Flow-Based Mutation
In the representation of a WebAssembly module, it is typically expressed as a single S-expression (
https://en.wikipedia.org/wiki/S-expression, accessed on 11 April 2024). Within this S-expression, functions are defined, and each function contains a sequential list of instructions in its body. This structure enables the modification of the program’s control flow by altering the sequence of IR instructions.
By rearranging the order of IR instructions within the linear list of instructions in a function’s body, we can effectively modify the program’s control flow. This flexibility enables us to rearrange the execution order of instructions and introduce conditional branching, or implement loops, among other control flow modifications.
This trade-off, in which the instruction sequence of the IR is modified to reflect changes in the program’s control flow, allows for dynamic and flexible program execution. By manipulating the instruction sequence in the IR, we can customize the program’s behavior and achieve the desired control flow patterns within the WebAssembly module.
6. Evaluation
In this section, we will assess our approach by addressing three questions:
RQ1: Did our tool effectively meet the validation challenge?
RQ2: Has the code coverage improved with our tool?
RQ3: Has the efficiency of fuzzing improved with the use of our tool?
6.1. Experimental Setup
6.1.1. Contrast
Coverage-guided fuzzing (CGF) is a powerful testing technique for identifying a wide range of bugs in software applications. One of the most well-known tools based on CGF is libFuzzer, an in-process, coverage-guided, evolutionary fuzzing engine. Due to its in-process nature, libFuzzer enables rapid testing speeds, and its coverage-guided approach makes the testing process highly efficient. As a result, libFuzzer is a powerful tool that has helped uncover thousands of bugs in real-world programs. To ensure an accurate evaluation of our approach, we chose libFuzzer as our experimental control.
6.1.2. Repetitions and System Configuration
To address the variability in results stemming from the inherent non-determinism of fuzzing, we conducted three rounds of fuzzing on the WebAssembly interpreter in V8 using both ESFuzzer and libFuzzer [
5]. The experiments were conducted using two machines, each equipped with an Intel Core i7-6700 four-core eight-thread CPU running at 3.4 GHz, 64 GB of RAM, and Ubuntu 20.04 LTS. For libFuzzer, we used LLVM version 13.0.0, and for V8, the version was 9.2.88.
Additionally, to maintain consistency in our experimental design, we limited the use of libFuzzer to the WebAssembly module of V8. Using it directly on V8 would introduce mutations that are inconsistent with our research goals. Fuzzing the WebAssembly module with libFuzzer allowed us to take full advantage of its in-process and coverage-guided features. This ensured that any discrepancies between the results of ESFuzzer and libFuzzer were attributable to variations in the fuzzing techniques rather than the execution environment. To prepare for our experiments, we made some modifications to the V8 codebase:
We replaced the default LLVM compiler used by V8 with a complete version to ensure the proper functionality of libFuzzer. We disabled the Chrome Clang plugin by setting the “clang_use_chrome_plugins” flag to false, as it could potentially cause compatibility issues with the tool.
We modified the entry process to work with libFuzzer, which is designed as a library. To accomplish this, we removed the link to the V8/test/fuzzer/fuzzer.cc file and added the “fsanitize=fuzzer” compiler option in the ninja build file “obj/V8_simple_wasm_fuzzer.ninja”. This enabled libFuzzer to exclusively work with the WebAssembly V8 module without interfering with other parts of the V8 codebase.
6.2. Results and Analysis
RQ1: Did our tool effectively address the validation challenge?
The “WebAssembly.validate()” (
https://developer.mozilla.org/en-US/docs/WebAssembly/JavaScript_interface/validate, accessed on 11 April 2024) function is commonly used in WebAssembly testing and evaluation to verify the successful validation of code for testcases. This function accepts a WebAssembly binary as input and returns a Boolean value indicating whether the binary is valid or not. By using this method, we can guarantee that programs are free of syntax errors or other issues that could lead to test failures. The validation process helps ensure the integrity and correctness of the WebAssembly programs being evaluated, ensuring their compliance with the WebAssembly specification.
In order to enhance the statistical significance of the results and minimize the impact of chance, we conducted three rounds of 24 h experiments. We counted the number of samples generated and the number of valid samples in each round, and the results are presented in
Table 1. It is noteworthy that every sample generated by ESFuzzer successfully passed the validation process conducted using the JavaScript API function. This result indicates that ESFuzzer was successful in producing valid and syntactically correct testcases that comply with the requirements of the JavaScript API. This validation step instills confidence in the quality and reliability of the generated samples, further supporting the effectiveness of ESFuzzer in producing valid test inputs.
RQ2: Has the code coverage improved with our tool?
To assess the impact of ESFuzzer on enhancing code coverage, we utilized the llvm-cov component.
Table 2 summarizes the results of the analysis, presenting the four statistics for particle size in the first four rows.
Table 2 demonstrates that ESFuzzer achieved twice the coverage advantage of LibFuzzer over three 24 h sessions in terms of code coverage across all categories, including lines, regions, branches, and functions. This indicates that ESFuzzer explored a larger portion of the codebase compared to LibFuzzer.
RQ3: Has the efficiency of fuzzing improved with the use of our tool?
To compare the efficiency of the two fuzzers, we assessed their average sample size and execution rate in the experiment. These metrics provide insights into the performance and resource utilization of the fuzzing processes.
The average sample size indicates the size of the testcases or inputs generated and used by the tools during the experiment. It serves as an indicator of the complexity and diversity of the test inputs generated by each tool. A larger average sample size indicates that the tool has explored a broader range of potential inputs, which could potentially result in better code coverage and bug detection.Therefore, we calculated the average sample size hourly and present the results in
Appendix A.
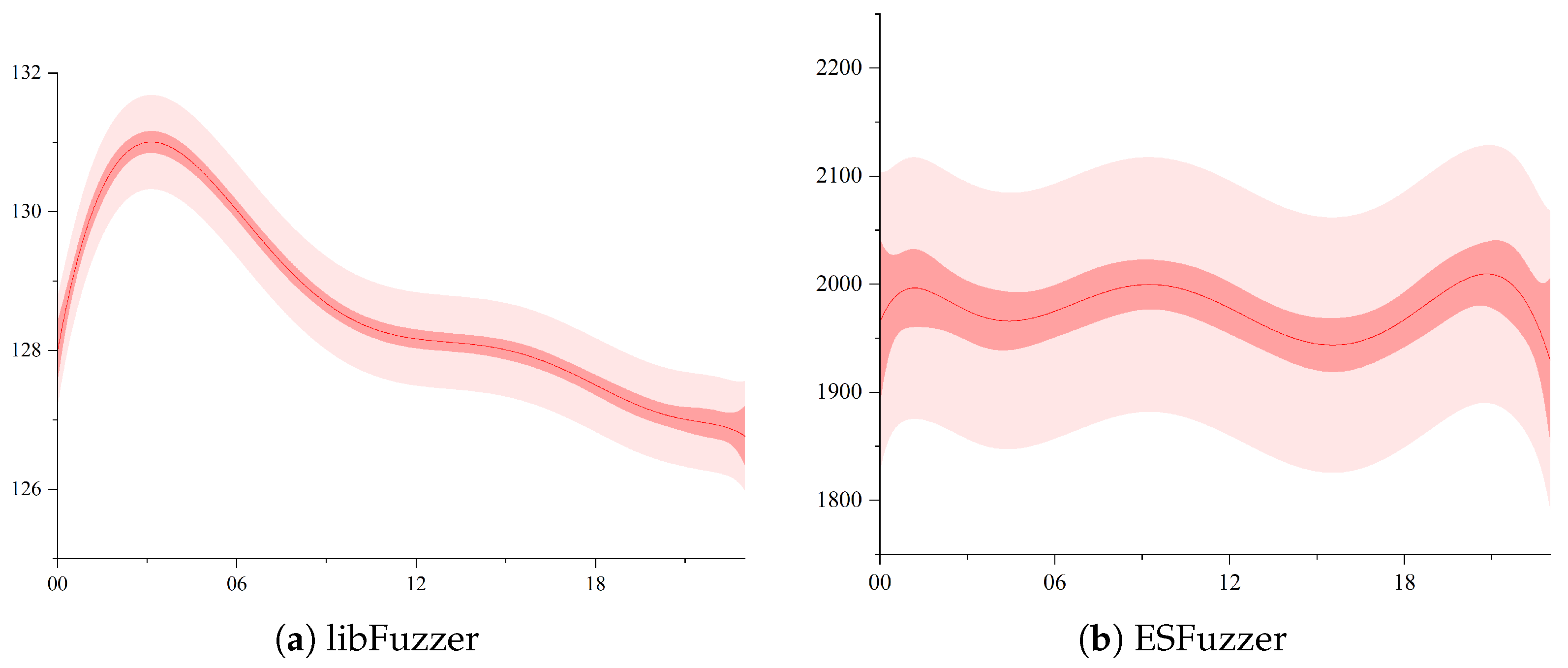
Figure 3 illustrates the variation in the average sample size over time. The results for libFuzzer (
Figure 3a) indicate an initial increase of 131.4 bytes per second, followed by a gradual decrease. This decline can be attributed to the fact that after 4 h, the samples generated by libFuzzer were no longer able to trigger new paths in the WebAssembly interpreter, and therefore could not generate any more complex code.
In contrast, ESFuzzer (see
Figure 3b) outperformed libFuzzer, achieving an average sample size change of approximately 1980 bytes per second. ESFuzzer’s mutation strategy was designed to maintain the stability of the average sample size, ensuring the complexity of the samples and the possibility of triggering new paths.
The execution rate measures the speed at which the tools execute testcases. It quantifies the number of testcases processed or executed per unit of time. A higher execution rate indicates greater efficiency in processing testcases, enabling more thorough exploration of the target system within a given time frame.
Table 3 compares the efficiency of libFuzzer and ESFuzzer based on the average sample size and execution rate metrics.
The table shows that libFuzzer generated 0.17 GB, 0.16 GB, and 0.19 GB of valid samples in three separate measurements, while ESFuzzer generated significantly larger average sample sizes of 1.77 GB, 1.76 GB, and 1.81 GB. The variation in the valid sample size between the two tools can be attributed to ESFuzzer achieving a larger average sample size compared to libFuzzer. This suggests that ESFuzzer explored a broader range of potential inputs, potentially resulting in improved code coverage and bug detection.
Table 3 shows that libFuzzer had execution rates of only 2120 bytes, 1954 bytes, and 2327 bytes per second in the three experimental runs. In contrast, ESFuzzer achieved much higher execution rates of 21,939 bytes, 21,833 bytes, and 22,571 bytes per second. These results suggest that ESFuzzer outperformed libFuzzer in terms of execution speed, allowing for more efficient processing of testcases and exploration of the target system within a specified time frame.
Overall, the results presented in
Table 3 indicate that ESFuzzer outperformed libFuzzer in terms of sample quality, as demonstrated by the larger average sample size and execution rate. ESFuzzer generated significantly larger valid samples and demonstrated faster execution rates, indicating improved performance and efficiency compared to libFuzzer.
7. Conclusions
This paper presents ESFuzzer as a solution to the challenges of fuzzing WebAssembly interpreters. The first challenge addressed is the inefficiencies in the execution of fuzzing tests caused by WebAssembly’s static checking mechanism. The second challenge addressed is the low coverage problems caused by the lack of a targeted mutation strategy.
This paper proposes an algorithm called the Stack Repair Algorithm that can effectively address the challenges of WebAssembly’s interpreter static validation mechanism. Additionally, three mutation strategies based on the concepts of Equivalent-Statement and Equivalent-Exchange are designed to increase the complexity of testcases and improve code coverage. The evaluation results demonstrate that the proposed approach outperforms libFuzzer in several aspects.
Although our scheme effectively addresses the first challenge, it only partially addresses the second challenge and does not completely solve the problem. Therefore, future research should focus on improving the efficiency of fuzzing WebAssembly interpreters by increasing code coverage.









{kind=link}
{kind=link}
{kind=link}


