
Automatic Classification of All-Sky Nighttime Cloud Images Based on Machine Learning

 , , , ,
, , , ,
Abstract
1. Introduction
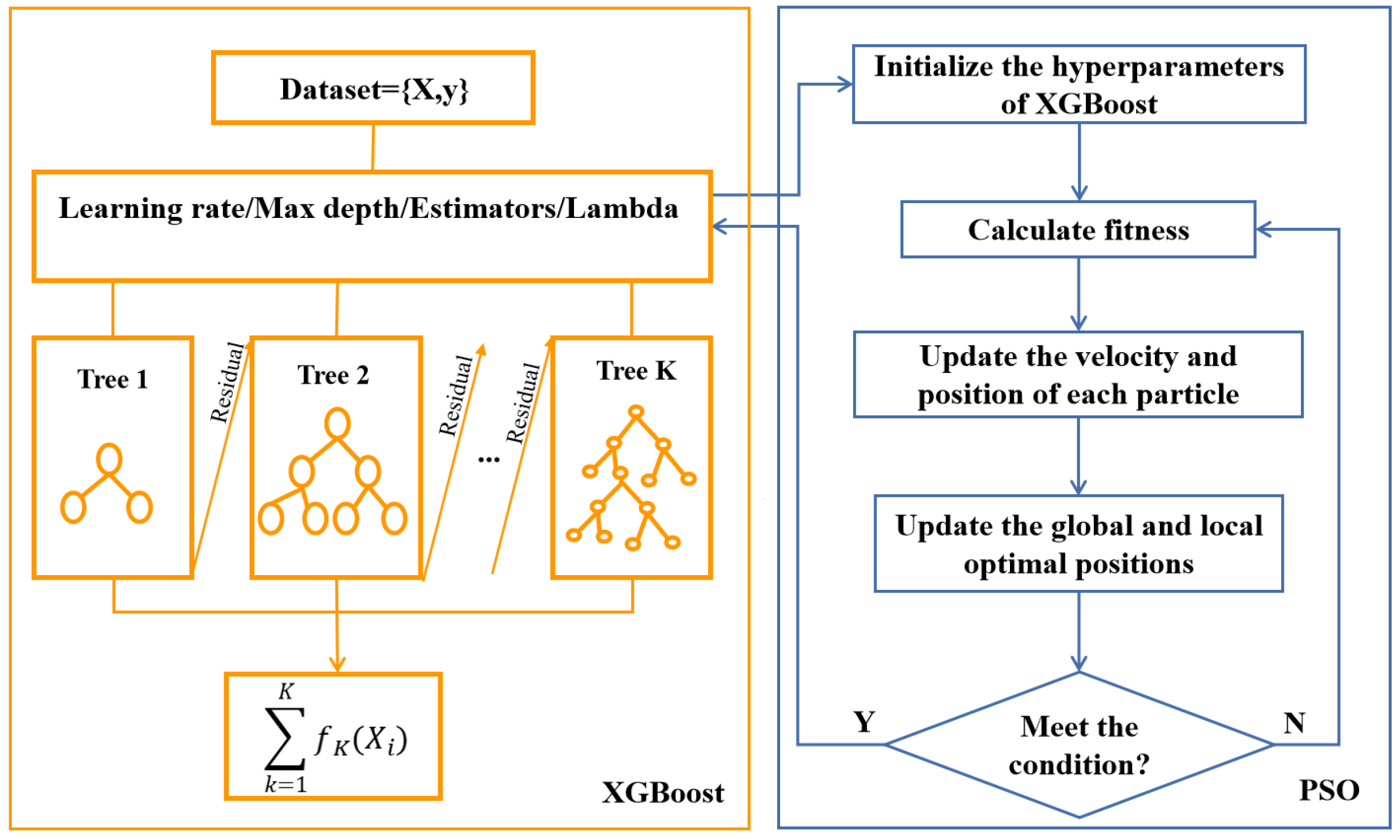
- Considering the limitations of conventional manual observation methods and the constrained computer resources of observatories, a PSO+XGBoost model is proposed to identify cloud coverage. We use the PSO algorithm to optimize the hyperparameters of XGBoost, enhancing the generalization and precision of the proposed model;
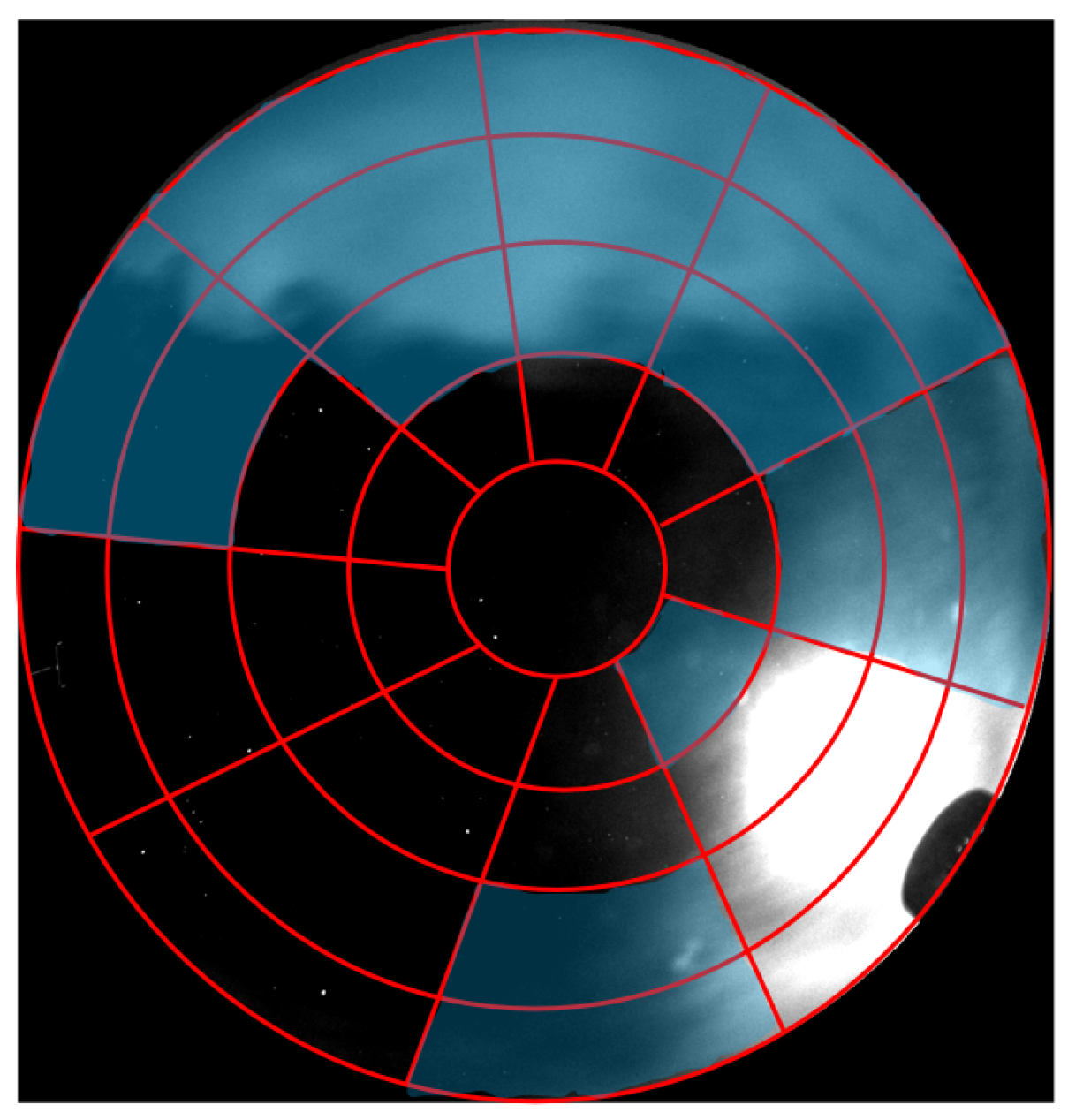
- Considering the absence of color features and poor illumination in nighttime images, one image is divided into 37 subregions, and a set of 19 features is extracted from each subregion, which improves reliability and reduces the complexity of cloud-coverage identification;
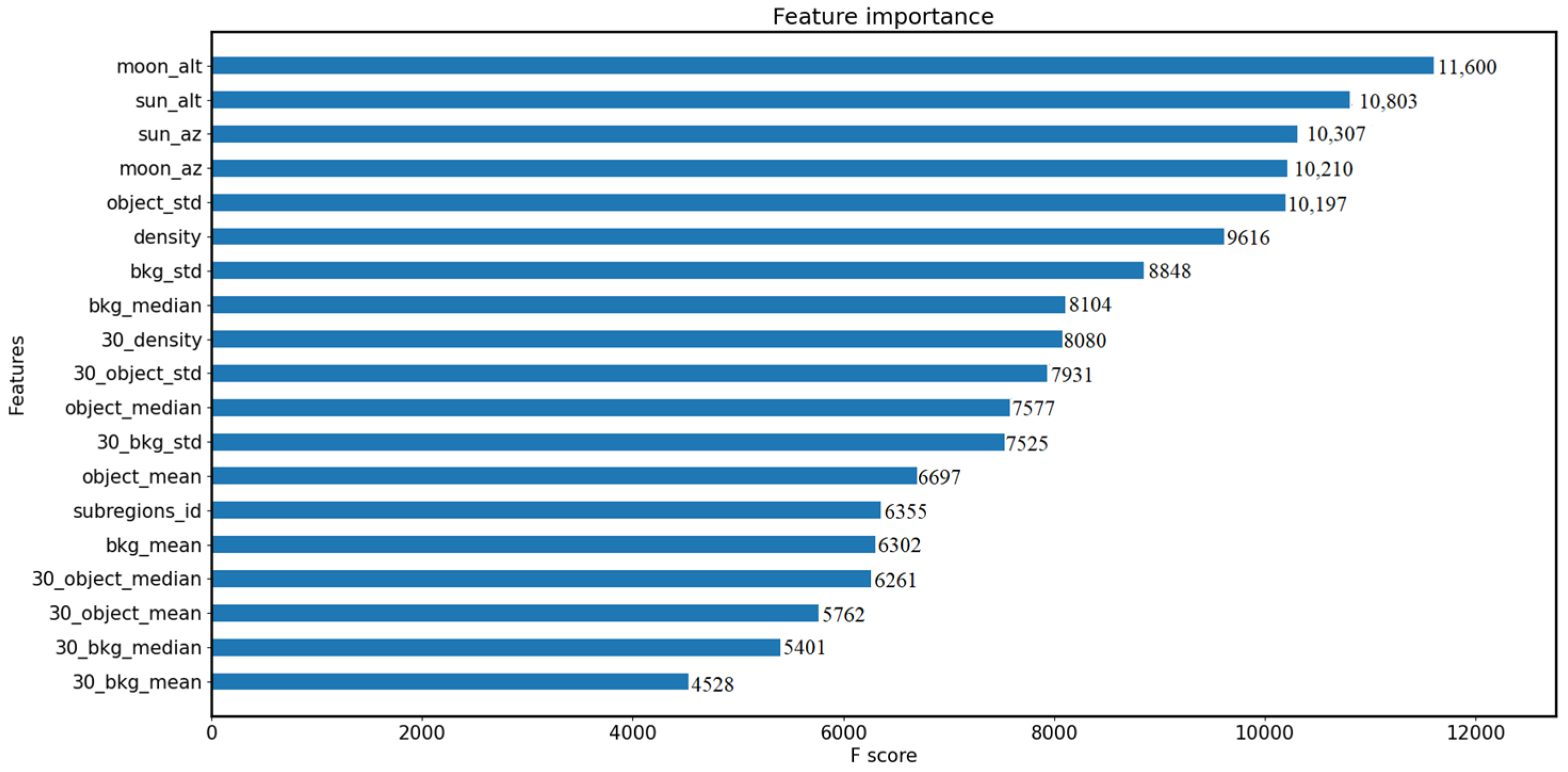
- After analyzing the relative importance of all input features, we find that the most essential feature is the elevation angle of the moon, which offers a comprehensive interpretation of nighttime image identification.
2. Instrument and Data Description
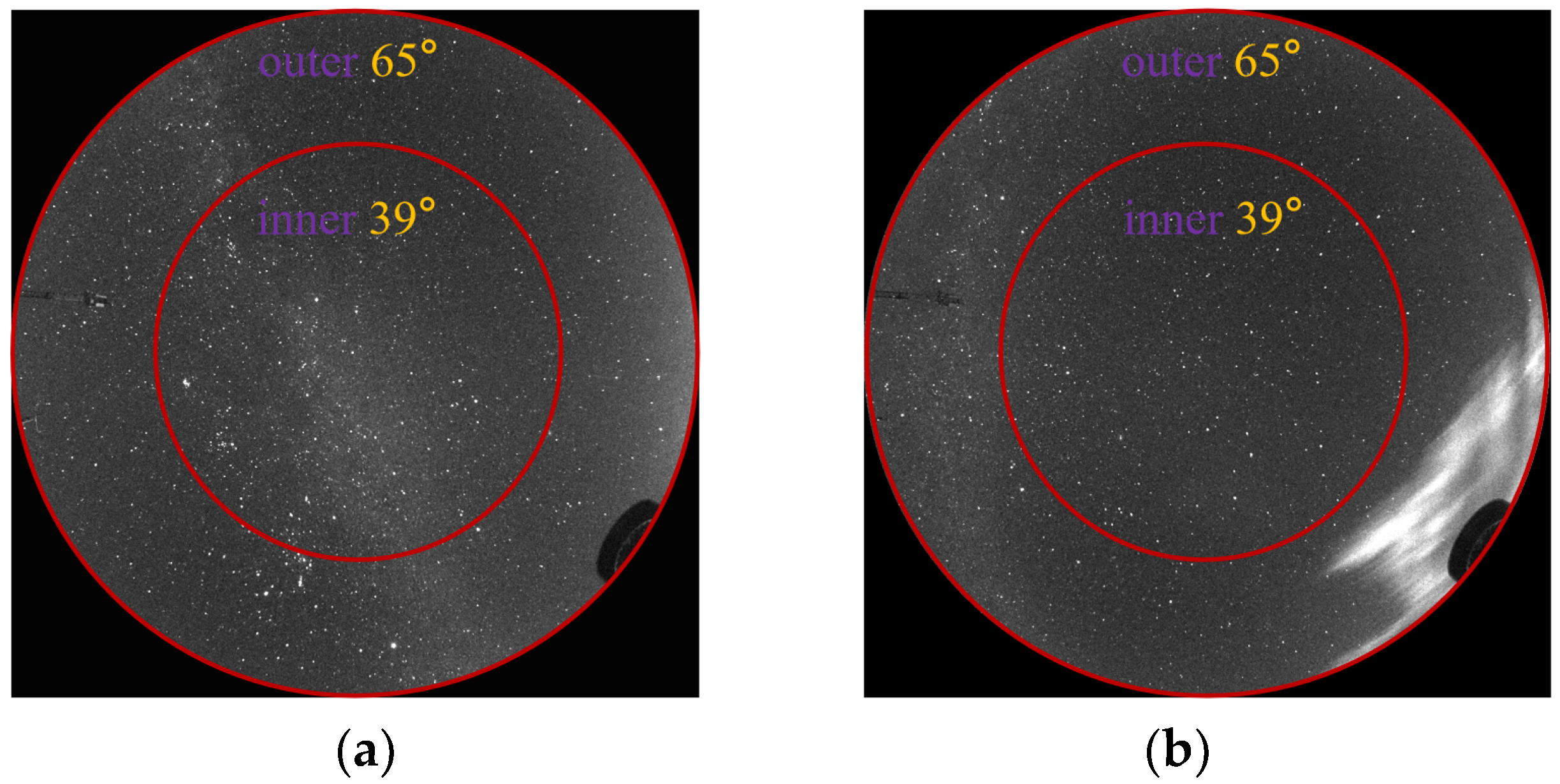
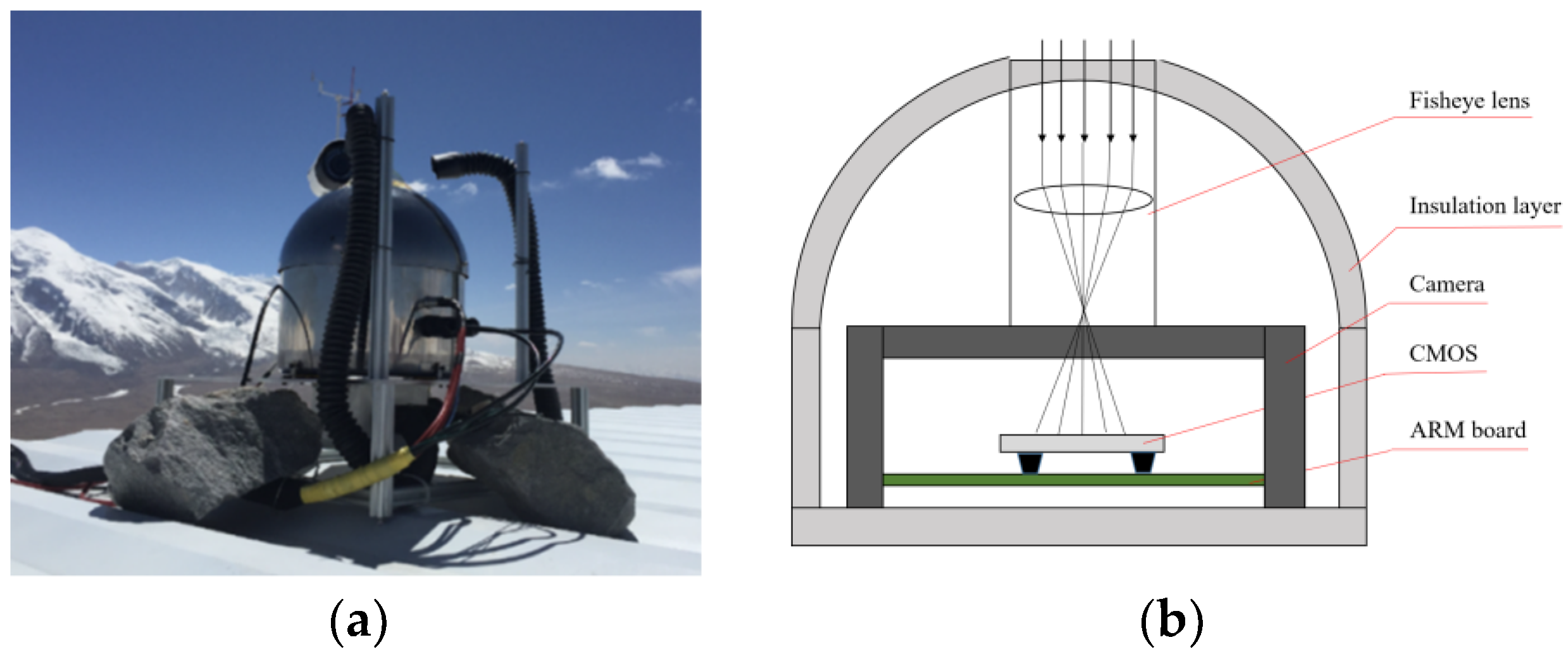
2.1. Instrument
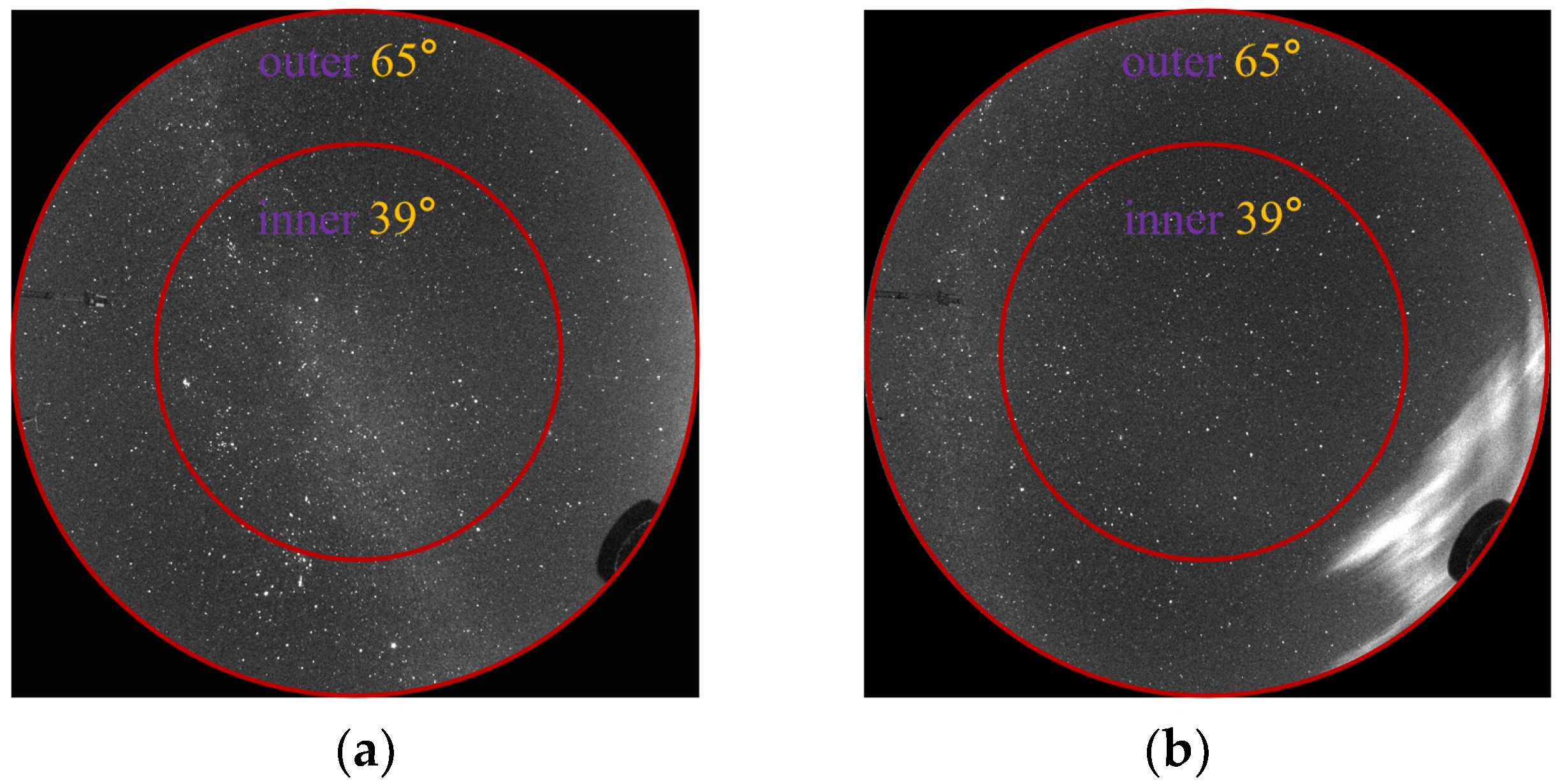
2.2. Image Preprocessing
2.3. Data-Set Description
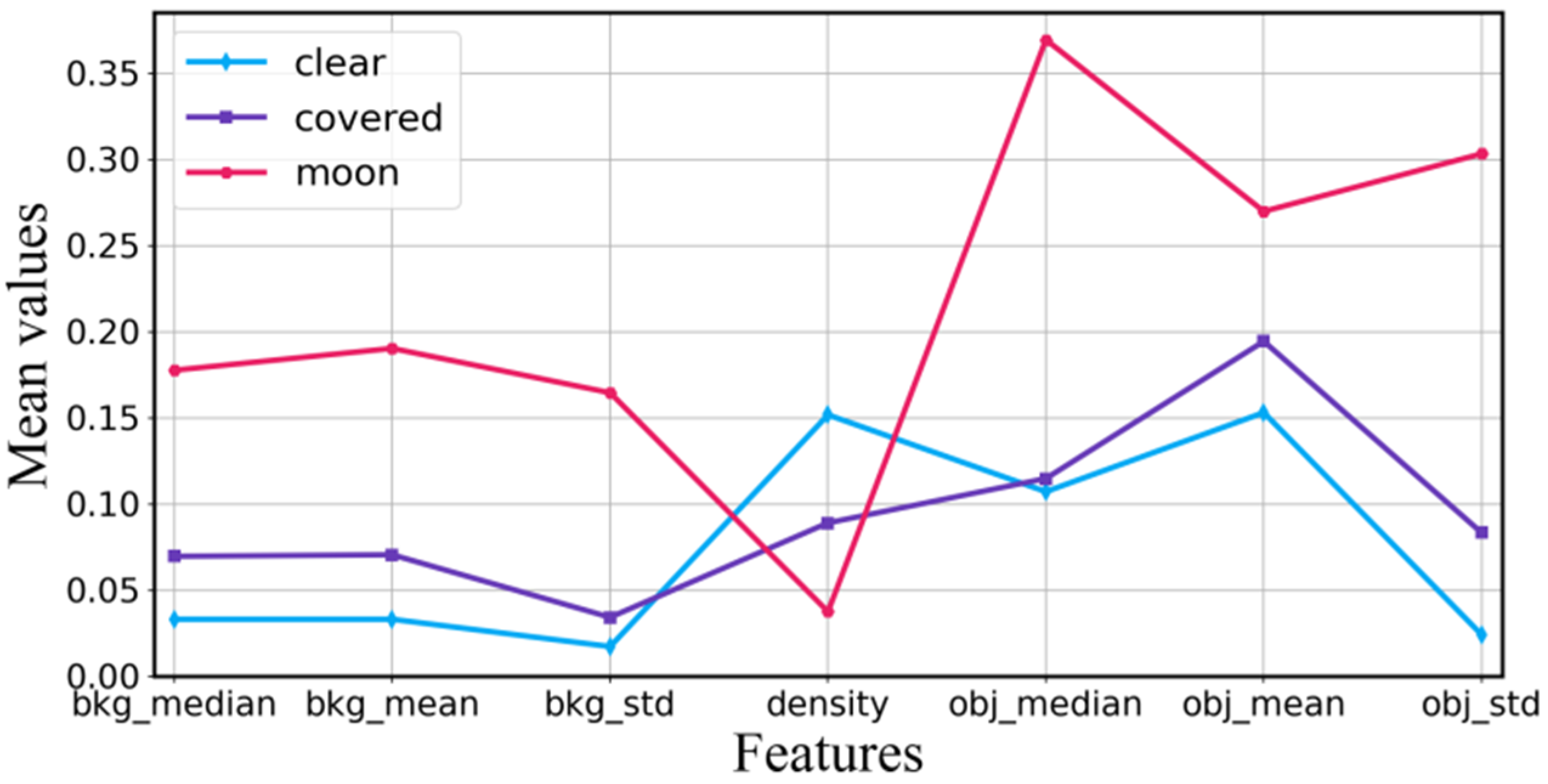
- Clear: no clouds are detected in the subregions;
- Moon: The moon’s presence distorts or obscures the edges and details of low-brightness clouds. Meanwhile, the moon significantly changes the background of the sky, making astronomical observations unimplementable. Therefore, the subregion with the moon is labeled as a “moon” category;
- Covered: all subregions that do not belong to the “clear” and “moon” categories are classified into this category.
3. Methodology
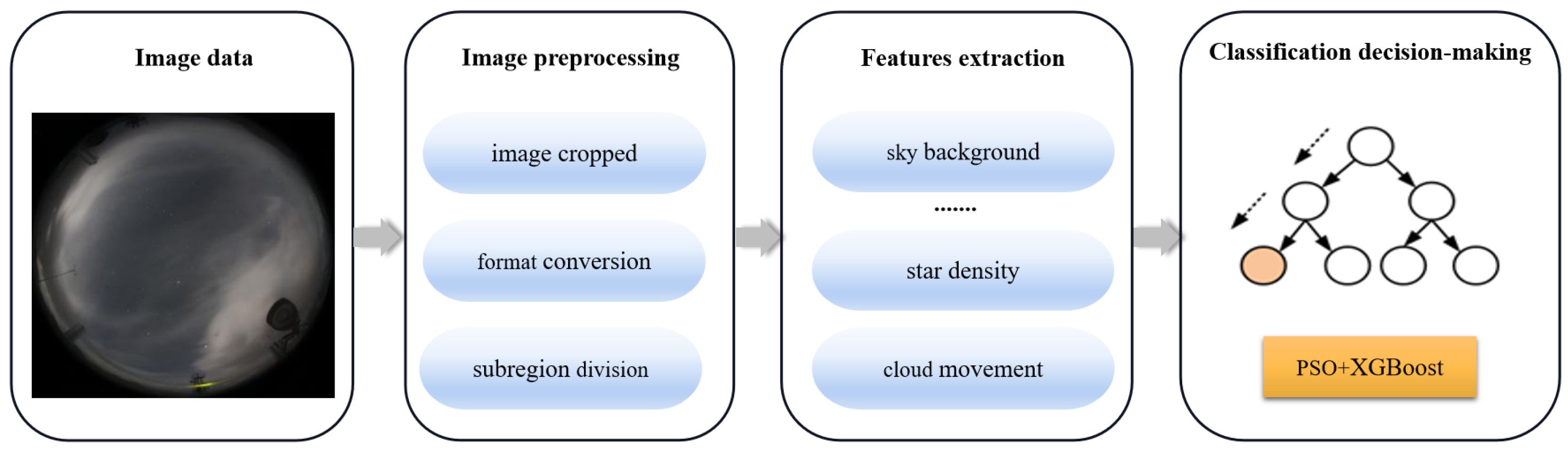
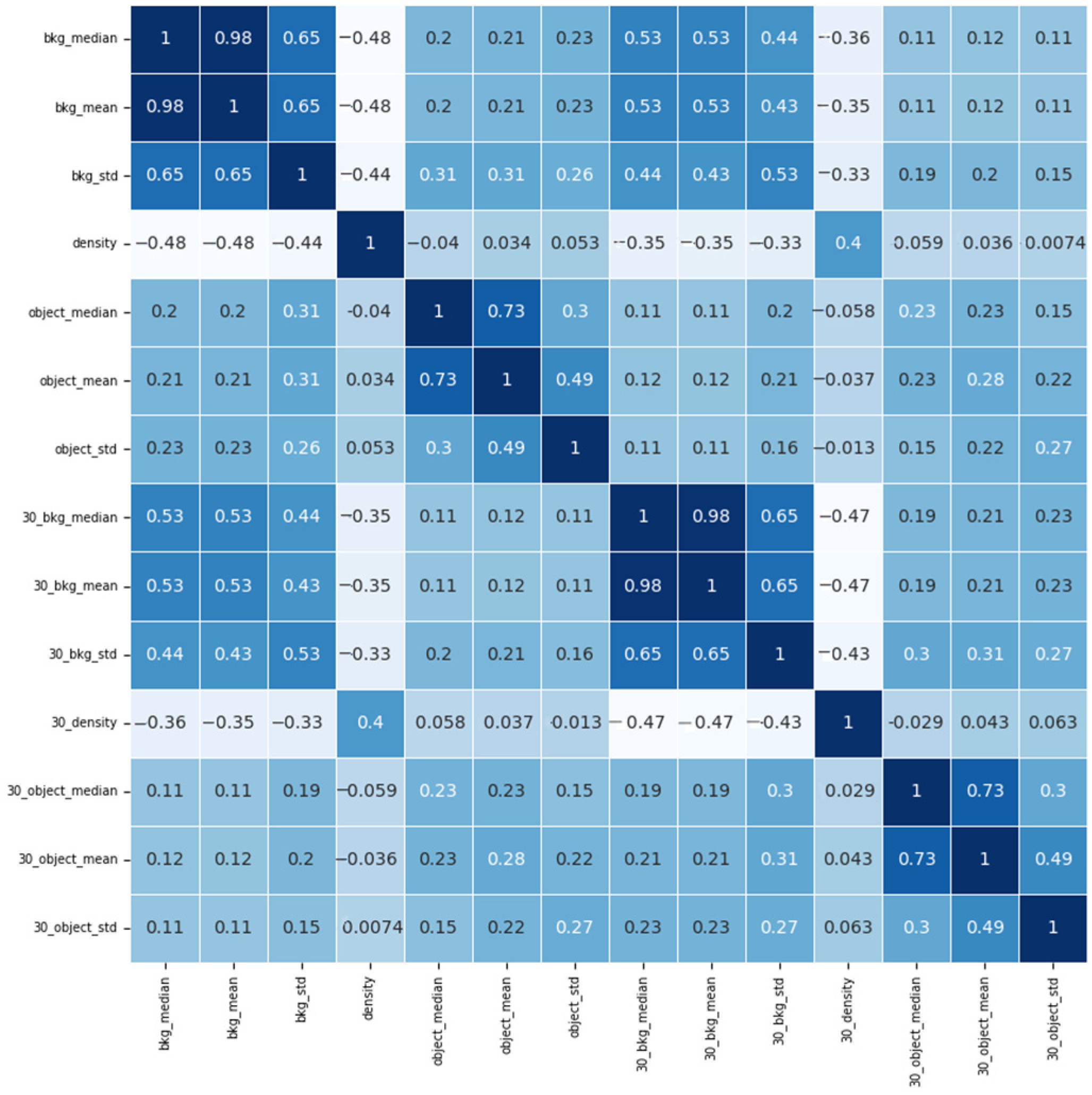
3.1. Feature Extraction
- (1)
- Sky background: The brightness of clouds depends on the conditions of the sky’s illumination. Clouds then appear as dark or bright patches against the clear sky. Furthermore, the brightness distribution of the sky background is usually uneven due to the solar or lunar elevation [17]. We utilize the sky-background estimation technique in SExtractor [18,19] to assess the gray level of the sky background of different subregions. The sky-background estimation technique uses the mode value via σ-clipping, and its formula is:Mode = 2.5Median − 1.5Mean
- (2)
- Star density: The number of stars in one subregion varies significantly at different times due to the Earth’s rotation and the uneven distribution of stars. However, star density can directly reflect the clarity of the sky. For example, the presence of stars precludes the presence of thick clouds, and a high density of stars typically indicates a clear sky. Therefore, star density is utilized as a characteristic in cloud image classification. We calculate the star density by dividing the number of stars by the total subregion pixel area. This method can eliminate the variability of subregion sizes;
- (3)
- Cloud gray values: The sky and clouds have different light scattering and reflection characteristics, which induces the different gray values for the sky and clouds. Therefore, to indirectly reflect the distribution and thickness of clouds, we first calculate the gray values of each subregion and background. Then, the background’s gray values are subtracted from the gray values of each subregion to obtain the gray values of the residual image. The average, median, and standard deviation of grayscale values are calculated from residual images as features. Moreover, the gray values of subregions are also highly influenced by the elevation and azimuth angles of the moon and sun. Therefore, in addition to three grayscale features from the residual images, we extract four other features for each subregion: solar elevation angle, solar azimuth, moon elevation angle, and moon azimuth;
- (4)
- Cloud movement: In addition to the image’s visual characteristics, non-visual elements like the surrounding environment can influence cloud properties. Clouds are seldom stationary because the wind blows the clouds and causes clouds to move at different speeds. The dynamic behavior of clouds influences the distribution within the same subregion. Seven features have been derived from the nighttime images that were taken 30 min ago. The features include the star density, the median, mean, and standard deviation of gray values of the sky background, and the median, mean, and standard deviation of gray values of residual images.
- (5)
- Subregion index: The subregion index of each subregion indicates the location of the local sky. Therefore, the subregion index is selected as a feature.
3.2. PSO+XGBoost
4. Experimental Results and Discussion
4.1. Experimental Setup
4.2. Model Parameters
4.3. Evaluation Metrics
4.4. Experimental Results
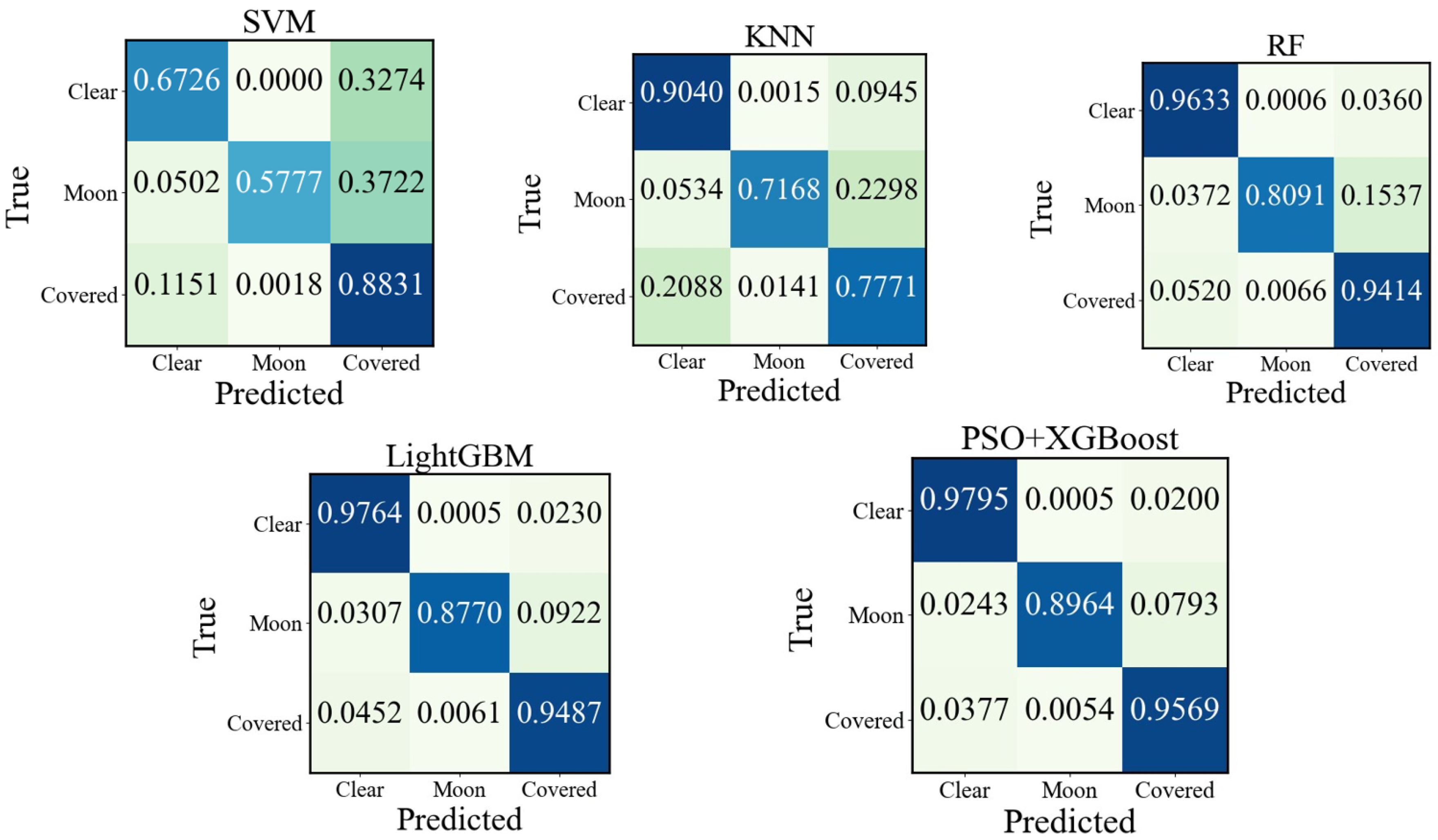
4.4.1. Comparison of Different Models
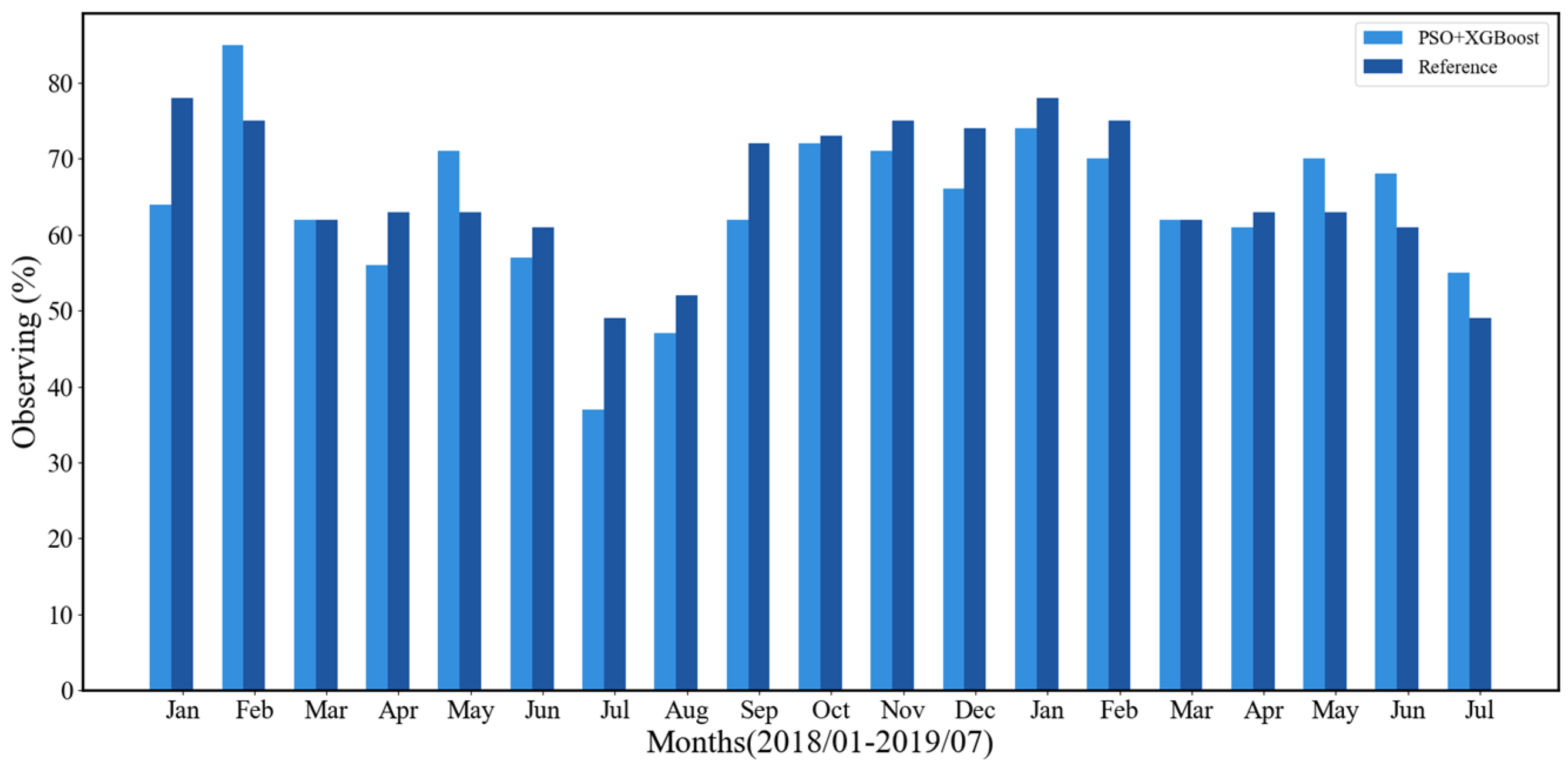
4.4.2. Comparative Results of the Manual Observation Technique
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zou, H.; Zhou, X.; Jiang, Z.; Ashley, M.C.B.; Cui, X.; Feng, L.; Gong, X.; Hu, J.; Kulesa, C.A.; Lawrence, J.S. Sky brightness and transparency in THEI-BAND at dome a, antarctica. Astron. J. 2010, 140, 602–611. [Google Scholar] [CrossRef]
- Lawrence, J.S.; Ashley, M.C.B.; Tokovinin, A.; Travouillon, T. Exceptional Astronomical Seeing Conditions above Dome C in Antarctica. Nature 2004, 431, 278–281. [Google Scholar] [CrossRef] [PubMed]
- Skidmore, W.; Schöck, M.; Magnier, E.; Walker, D.; Feldman, D.; Riddle, R.; Els, S.; Travouillon, T.; Bustos, E.; Seguel, J.; et al. Using All Sky Cameras to Determine Cloud Statistics for the Thirty Meter Telescope Candidate Sites. Proc. SPIE 2008, 7012, 701224. [Google Scholar]
- Cao, Z.H.; Hao, J.X.; Feng, L.; Jones, H.R.A.; Li, J.; Xu, J.; Liu, L.Y.; Song, T.F.; Wang, J.F.; Chen, H.L. Data Processing and Data Products from 2017 to 2019 Campaign of Astronomical Site Testing at Ali, Daocheng and Muztagh-Ata. Res. Astron. Astrophys. 2020, 20, 082–0104. [Google Scholar] [CrossRef]
- Yang, X.; Shang, Z.H.; Hu, K.L.; Hu, Y.; Ma, B.; Wang, Y.J.; Cao, Z.H.; Ashley, M.C.B.; Wang, W. Cloud Cover and Aurora Contamination at Dome A in 2017 from KLCAM. Mon. Not. R. Astron. Soc. 2020, 501, 3614–3620. [Google Scholar] [CrossRef]
- Dev, S.; Savoy, F.M.; Lee, Y.-H.; Winkler, S. Nighttime Sky/Cloud Image Segmentation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; 2017; 2017, pp. 345–349. [Google Scholar]
- Afiq, M.; Hamid, A.; Mohd, W.; Mohamad, N.S. Urban Night Sky Conditions Determination Method Based on a Low Resolution All-Sky Images. IEEE Conf. Proc. 2019, 2019, 158–162. [Google Scholar]
- Jadhav, T.; Aditi, K. Cloud Detection in All Sky ConCam Images by Gaussian Fitting and Valley Detection in Histogram. In Proceedings of the 2015 Eighth International Conference on Contemporary Computing (IC3), Noida, India, 20–22 August 2015; pp. 275–278. [Google Scholar]
- Yin, J.; Yao, Y.Q.; Liu, L.Y.; Qian, X.; Wang, H.S. Cloud Cover Measurement from All-Sky Nighttime Images. J. Phys. Conf. Ser. 2015, 595, 012040–012045. [Google Scholar] [CrossRef]
- Mandát, D.; Pech, M.; Ebr, J.; Miroslav, H.; Prouza, M.; Bulik, T.; Ingomar, A. All Sky Cameras for the Characterization of the Cherenkov Telescope Array Candidate Sites. arXiv 2013, arXiv:1307.3880. [Google Scholar]
- Shi, C.J.; Zhou, Y.T.; Qiu, B.; Guo, D.J.; Li, M.C. CloudU-Net: A Deep Convolutional Neural Network Architecture for Daytime and Nighttime Cloud Images’ Segmentation. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1688–1692. [Google Scholar] [CrossRef]
- Li, X.T.; Wang, B.Z.; Qiu, B.; Wu, C. An All-Sky Camera Image Classification Method Using Cloud Cover Features. Atmos. Meas. Tech. 2022, 15, 3629–3639. [Google Scholar] [CrossRef]
- Mommert, M. Cloud Identification from All-Sky Camera Data with Machine Learning. Astron. J. 2020, 159, 178–185. [Google Scholar] [CrossRef]
- Chen, T.Q.; Guestrin, Q. XGBoost: A Scalable Tree Boosting System. CoRR 2016, 2016, 785–794. [Google Scholar]
- Jin, Q.W.; Fan, X.T.; Liu, J.; Xue, Z.X.; Jian, H.D. Estimating Tropical Cyclone Intensity in the South China Sea Using the XGBoost Model and FengYun Satellite Images. Atmosphere 2020, 11, 423–445. [Google Scholar] [CrossRef]
- Shang, Z.H.; Hu, K.L.; Yang, X.; Hu, Y.; Ma, B.; Wang, W. Kunlun Cloud and Aurora Monitor. Proc. SPIE Astron. Telesc. Instrum. 2018, 10700, 1070057. [Google Scholar]
- Yang, J.; Min, Q.L.; Lu, W.T.; Ma, Y.; Yao, W.; Lu, T.S.; Du, J.; Liu, G.Y. A Total Sky Cloud Detection Method Using Real Clear Sky Background. Atmos. Meas. Tech. 2016, 9, 587–597. [Google Scholar] [CrossRef]
- Bertin, E.; Arnouts, S. SExtractor: Software for Source Extraction. Astron. Astrophys. Suppl. Ser. 1996, 117, 393–404. [Google Scholar] [CrossRef]
- Annunziatella, M.; Mercurio, A.; Brescia, M.; Cavuoti, S.; Longo, G. Inside Catalogs: A Comparison of Source Extraction Software. Publ. Astron. Soc. Pac. 2013, 125, 68–82. [Google Scholar] [CrossRef]
- Du, M.S.; Wei, Y.X.; Hu, Y.P.; Zheng, X.W.; Ji, C. Multivariate Time Series Classification Based on Fusion Features. Expert Syst. Appl. 2024, 248, 123452–123465. [Google Scholar] [CrossRef]
- Liu, S.C.; Luo, Y. Square-Based Black-Box Adversarial Attack on Time Series Classification Using Simulated Annealing and Post-Processing-Based Defense. Electronics 2024, 13, 650–663. [Google Scholar] [CrossRef]
- Diaz, A.; Darin, J.M.; Edwin, R.T. Optimization of Topological Reconfiguration in Electric Power Systems Using Genetic Algorithm and Nonlinear Programming with Discontinuous Derivatives. Electronics 2024, 13, 616–638. [Google Scholar] [CrossRef]
- Zhang, J.Y.; Chen, K.J. Research on Carbon Asset Trading Strategy Based on PSO-VMD and Deep Reinforcement Learning. J. Clean. Prod. 2023, 140322–140337. [Google Scholar] [CrossRef]
- Belete, D.M.; Huchaiah, M.D. Grid search in hyperparameter optimization of machine learning models for prediction of HIV/AIDS test results. Int. J. Comput. Appl. 2022, 44, 875–886. [Google Scholar] [CrossRef]
- Xu, J.; Feng, G.J.; Pu, G.X.; Wang, L.T.; Cao, Z.H.; Ren, L.Q.; Zhang, X.; Ma, S.G.; Bai, C.H.; Esamdin, A. Site-Testing at the Muztagh-Ata Site V. Nighttime Cloud Amount during the Last Five Years. Res. Astron. Astrophys. 2023, 23, 045015. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Clear | Moon | Covered | Total |
|---|---|---|---|---|
| Number | 47,378 | 2928 | 22,140 | 72,446 |
| Models | SVM | KNN | RF | LightGBM | PSO+XGBoost |
|---|---|---|---|---|---|
| Parameters | kernel: RBF C: 0.1 gamma: 1 max iterations: 1200 | neighbors: 7 | estimators: 1200 max depth: 32 | max depth: 12 estimators: 1200 learning rate: 0.02 num leaves: 32 min child samples: 20 alpha: 1 lambda: 25 | learning rate: 0.16 max depth: 8 estimators: 1200 L2: 4.15 |
| Class | Clear | Moon | Covered | Average Accuracy | Time (s) | |
|---|---|---|---|---|---|---|
| SVM | Precision | 99.21 | 97.81 | 53.89 | 73.26 | 2.492 |
| Recall | 67.26 | 57.77 | 88.31 | |||
| F1 score | 77.78 | 72.63 | 66.94 | |||
| KNN | Precision | 89.98 | 85.36 | 76.75 | 85.74 | 2.547 |
| Recall | 90.40 | 71.68 | 77.71 | |||
| F1 score | 90.19 | 77.92 | 77.23 | |||
| RF | Precision | 97.31 | 93.46 | 90.49 | 95.01 | 2.122 |
| Recall | 96.33 | 80.91 | 94.14 | |||
| F1 score | 96.82 | 86.73 | 92.28 | |||
| LightGBM | Precision | 97.70 | 94.43 | 93.83 | 96.38 | 1.279 |
| Recall | 97.64 | 87.70 | 94.87 | |||
| F1 score | 97.70 | 90.94 | 94.35 | |||
| PSO+XGBoost | Precision | 98.09 | 95.03 | 94.66 | 96.91 | 0.975 |
| Recall | 97.95 | 89.64 | 95.69 | |||
| F1 score | 98.02 | 92.26 | 95.17 | |||
| Models | Accuracy | t-Value | p-Value |
|---|---|---|---|
| PSO+XGBoost | 0.9691 | 3.748 | 0.006 |
| LightGBM | 0.9638 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, X.; Du, F.; Hu, Y.; Hou, X.; Zhu, Z.; Zheng, X.; Huang, K.; Ren, Z.; Hou, Y. Automatic Classification of All-Sky Nighttime Cloud Images Based on Machine Learning. Electronics 2024, 13, 1503. https://doi.org/10.3390/electronics13081503
Zhong X, Du F, Hu Y, Hou X, Zhu Z, Zheng X, Huang K, Ren Z, Hou Y. Automatic Classification of All-Sky Nighttime Cloud Images Based on Machine Learning. Electronics. 2024; 13(8):1503. https://doi.org/10.3390/electronics13081503
Chicago/Turabian StyleZhong, Xin, Fujia Du, Yi Hu, Xu Hou, Zonghong Zhu, Xiaogang Zheng, Kang Huang, Zhimin Ren, and Yonghui Hou. 2024. "Automatic Classification of All-Sky Nighttime Cloud Images Based on Machine Learning" Electronics 13, no. 8: 1503. https://doi.org/10.3390/electronics13081503
APA StyleZhong, X., Du, F., Hu, Y., Hou, X., Zhu, Z., Zheng, X., Huang, K., Ren, Z., & Hou, Y. (2024). Automatic Classification of All-Sky Nighttime Cloud Images Based on Machine Learning. Electronics, 13(8), 1503. https://doi.org/10.3390/electronics13081503