
Highly Fault-Tolerant Systolic-Array-Based Matrix Multiplication


Abstract
:1. Introduction
- We introduce a fault-tolerant approach using pair-matching, with the analysis results showcasing a notable enhancement in the fault-tolerance capabilities compared to those in the previous work [30].
- We implemented the pair-matching approach in circuitry, with the experimental results indicating reduced areas for both the controller and PEs in comparison to those in the previous work [30].
2. Preliminaries
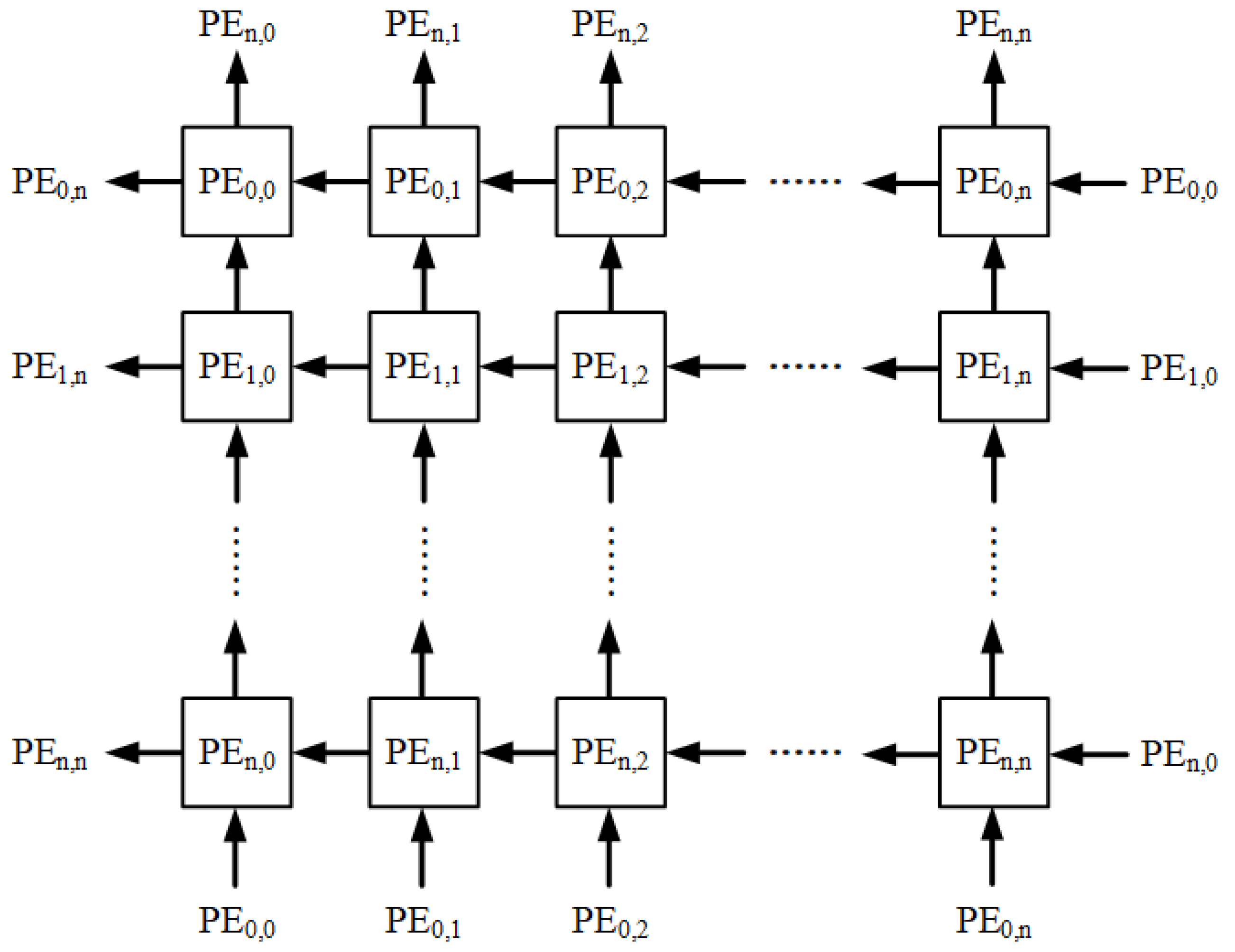
2.1. The Systolic Array Architecture
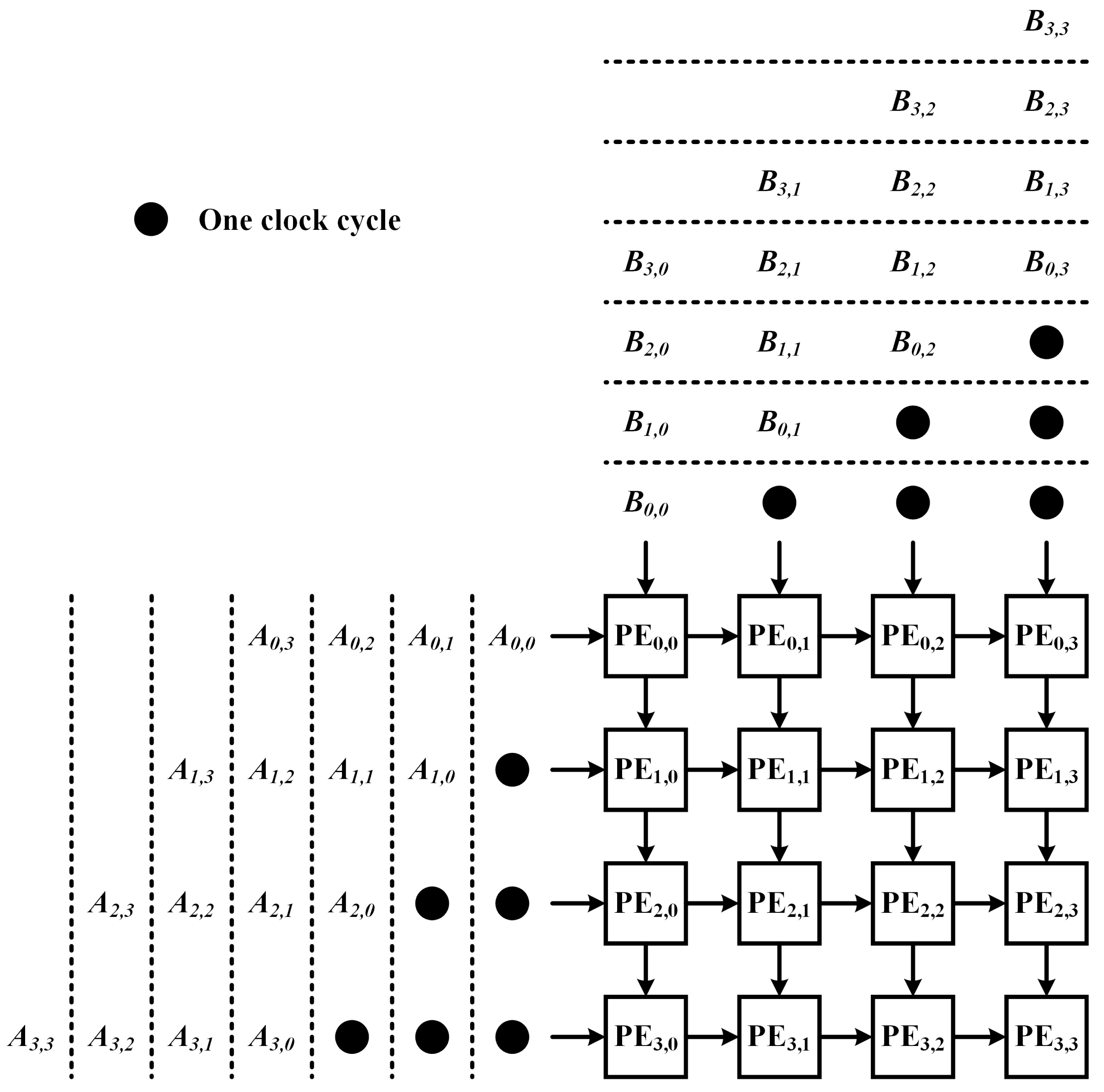
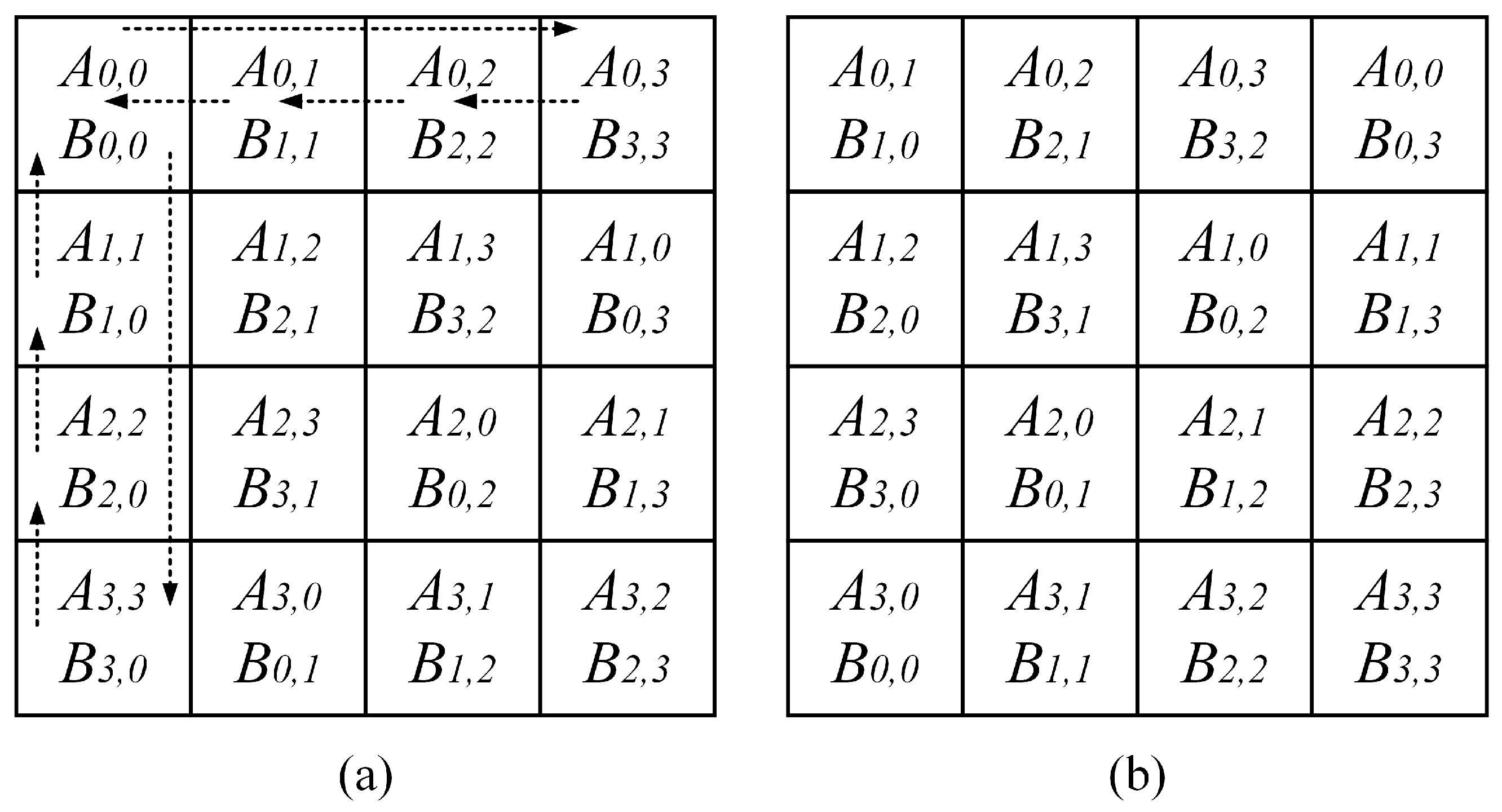
2.2. Cannon’s Algorithm
- Initial alignment: The rows of matrix A are shifted to the left by i steps (), with the 0-th row shifted 0 steps, the 1-st row shifted 1 step, and so forth; the columns of matrix B are shifted upwards by j steps (), with the 0-th column shifted 0 step, the 1-st column shifted 1 step, and so forth.
- Multiplication and accumulation: The two aligned matrices are overlapped, and multiply–accumulate operations are conducted on the PEs.
- Global matrix shifting: All elements in matrix A are shifted one step to the left, and all elements in matrix B are shifted one step upward. Then, one proceeds to step 2.
2.3. Fault-Tolerant Matrix Multiplier Design
- To circumvent faulty PEs when data flows from bottom to top, each PE can transmit data to the upper-left PE, the upper PE, and the upper-right PE, respectively. This means that in each PE, a multiplexer is required to select the data coming from the bottom-left PE, the bottom PE, the bottom-right PE, and the host control circuit.
- To bypass a faulty PE when data flows from right to left, the data will pass through the faulty PE (without executing any multiply–accumulate operations) and enter the next PE in the subsequent cycle. This implies that in each PE, another multiplexer is necessary to choose the data arriving from the multiply–accumulate unit (MAC unit), the right PE, and the control circuit.
3. The Proposed Approach
3.1. Fault-Tolerance Mechanism and Corresponding PE Architecture
- In the first stage, Cannon’s algorithm is executed in the systolic array. Each fault-free PE completes the computations that it should perform. However, each faulty PE does not engage in computations. Nevertheless, during the process of global shifting, both faulty PEs and fault-free PEs engage in data transmissions.
- In the second stage, the computations that each faulty PE should carry out are completed by the fault-free PE that it is acting as a proxy for. Since there are data transmission paths between the host control circuit and each PE, the data required by each fault-free PE can be directly transmitted by the host control circuit.
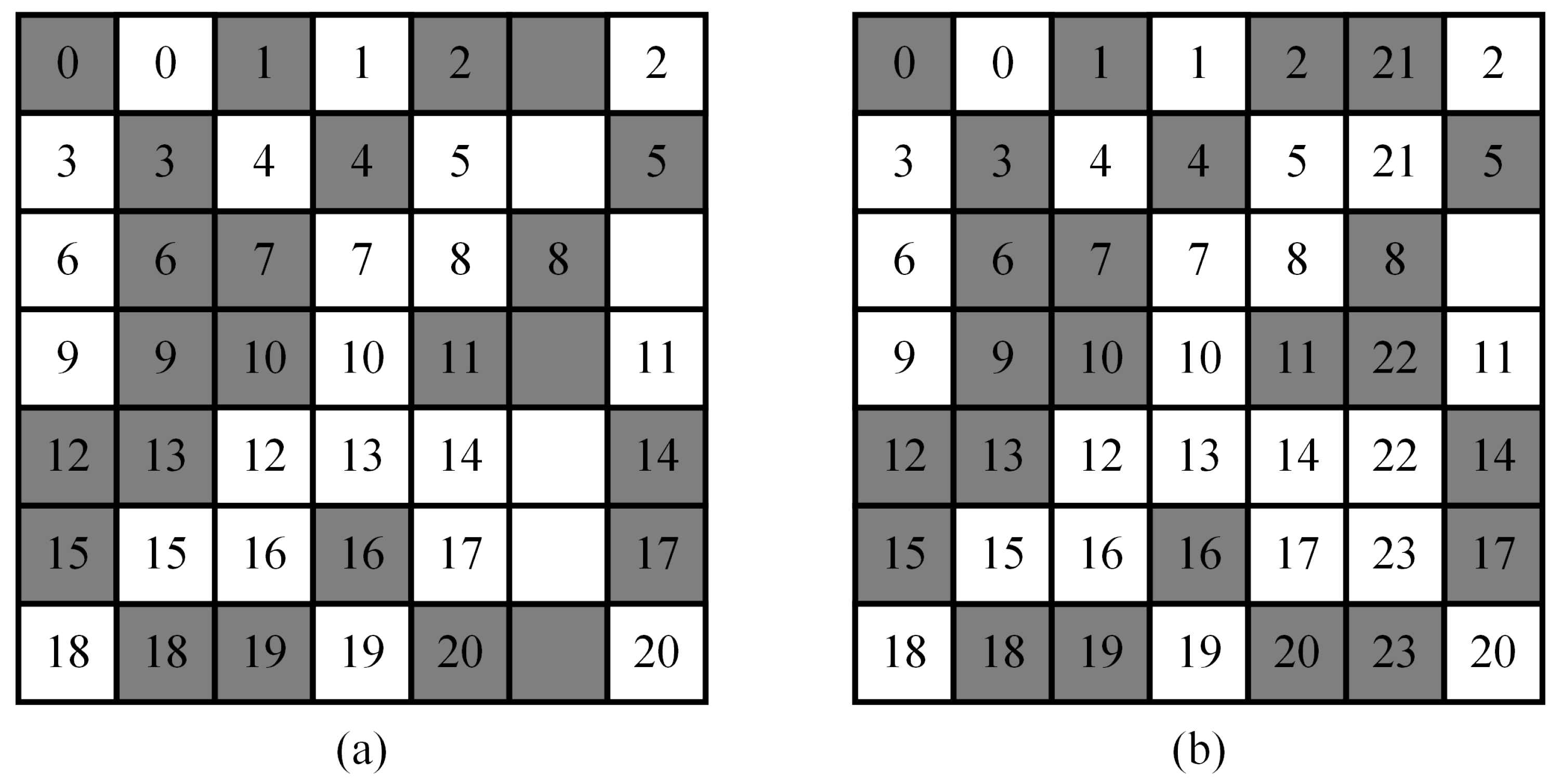
3.2. Proposed Pair-Matching Algorithms
- Each fault-free PE can only proxy for at most one faulty PE. Thus, all tasks of faulty PEs can be executed simultaneously by fault-free PEs acting as their proxies.
- We perform pair-matching independently for each row (or each column). Hence, pair-matching can be conducted in parallel for all rows (or all columns).
- One-dimensional pair-matching algorithm: This algorithm only executes the row-based pair-matching scheme.
- Two-dimensional pair-matching algorithm: This algorithm first executes the row-based pair-matching scheme. If there are faulty PEs that fail to complete pairing, this algorithm then attempts pairing using the column-based pair-matching scheme.
| Algorithm 1 One-Dimensional Pair-Matching |
|
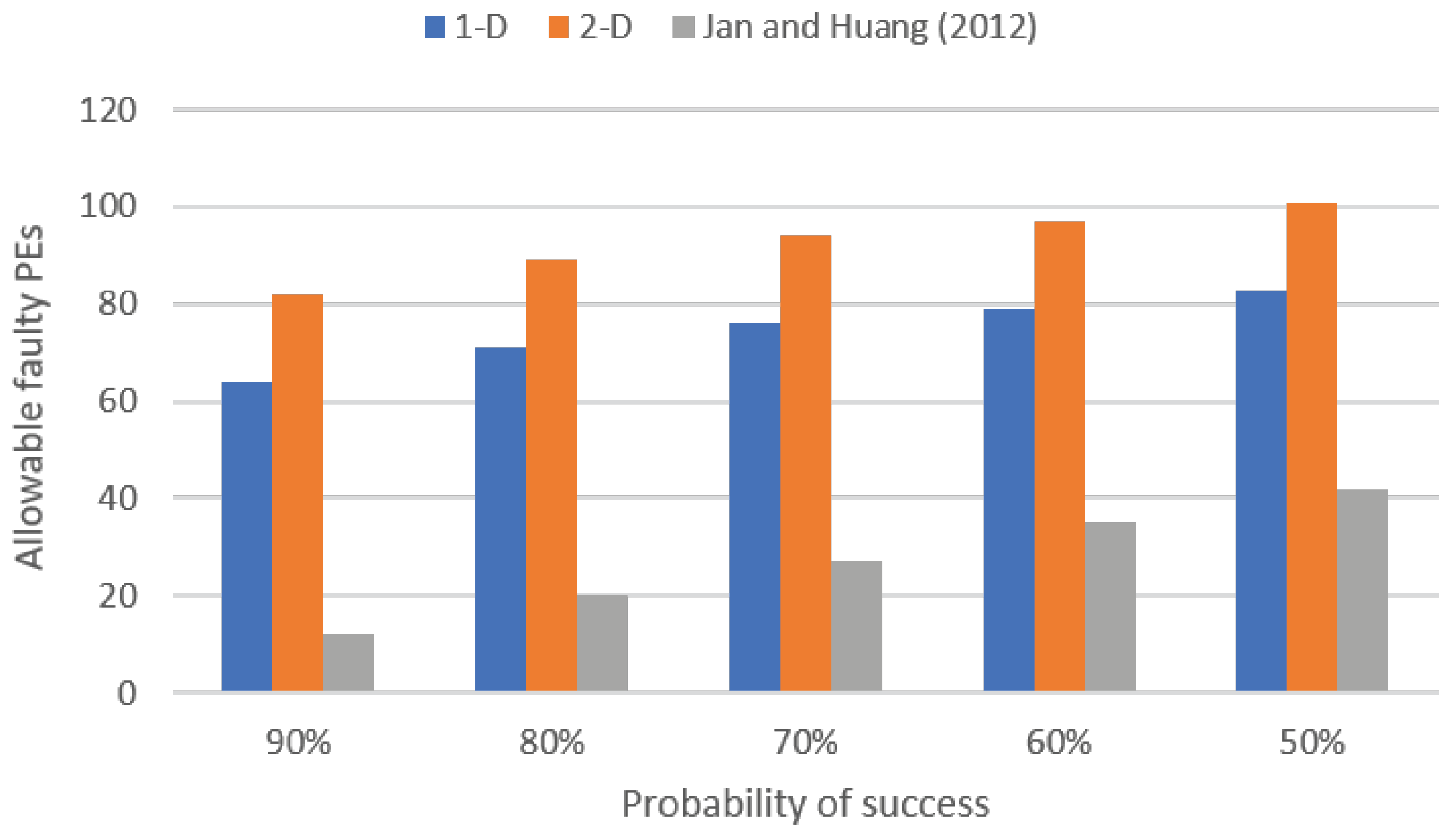
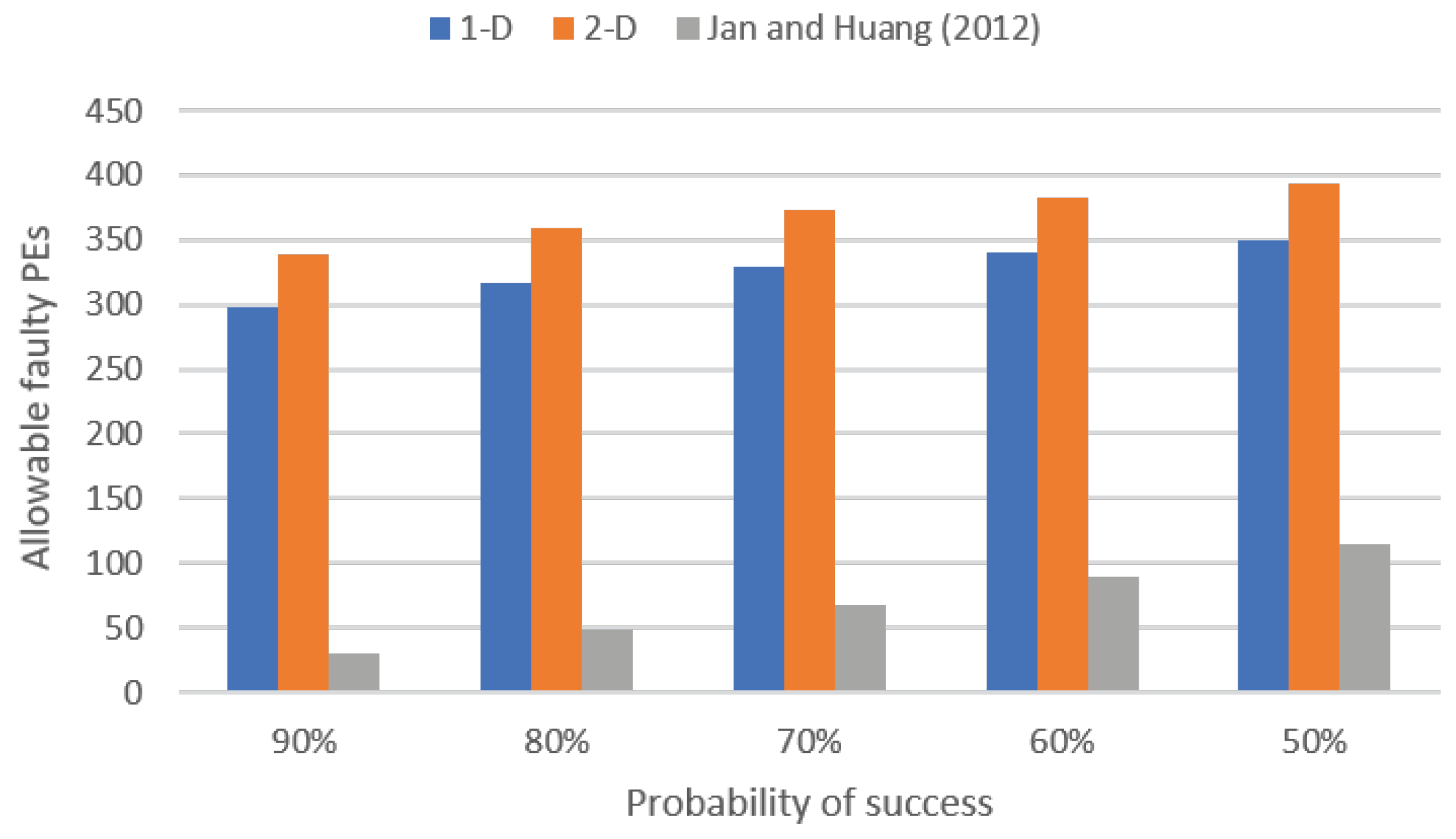
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cannon, L. A Cellular Computer to Implement The Kalman Filter Algorithm. Ph.D. Dissertation, Montana State University, Bozeman, MT, USA, 1969. [Google Scholar]
- Coppersmith, D.; Winograd, S. Matrix Multiplication via Arithmetic Progressions. In Proceedings of the Annual ACM Symposium on Theory of Computing, New York, NY, USA, 25–27 May 1987; pp. 1–6. [Google Scholar]
- Kung, H. Why Systolic Architectures? Computer 1982, 15, 37–46. [Google Scholar] [CrossRef]
- Wei, X.; Yu, C.; Zhang, P.; Chen, Y.; Wang, Y.; Hu, H.; Liang, Y.; Cong, J. Automated Systolic Array Architecture Synthesis for High Throughput CNN Inference on FPGAs. In Proceedings of the ACM/IEEE Design Automation Conference, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Lahari, P.; Yellampalli, S.; Vaddi, R. Systolic Array Based Multiply Accumulation Unit for IoT Edge Accelerators. In Proceedings of the IEEE International Symposium on Smart Electronic Systems, Jaipur, India, 18–22 December 2021; pp. 220–223. [Google Scholar]
- Chiper, D.; Cracan, A.; Andries, V.D. An Overview of Systolic Arrays for Forward and Inverse Discrete Sine Transforms and Their Exploitation in View of an Improved Approach. Electronics 2022, 11, 2416. [Google Scholar] [CrossRef]
- Inayat, K.; Muslim, F.B.; Iqbal, J.; Hassnain Mohsan, S.; Alkahtani, H.; Mostafa, S. Power-Intent Systolic Array Using Modified Parallel Multiplier for Machine Learning Acceleration. Sensors 2023, 23, 4297. [Google Scholar] [CrossRef] [PubMed]
- Aviles, P.; Schäfer, L.; Lindoso, A.; Belloch, J.; Entrena, L. High Complexity Reliable Space Applications in Commercial Microprocessors. Microelectron. Reliab. 2022, 138, 114679. [Google Scholar] [CrossRef]
- Ra, H.; Youn, C.; Kim, K. High-Reliability Underwater Acoustic Communication Using an M-ary Cyclic Spread Spectrum. Electronics 2022, 11, 1698. [Google Scholar] [CrossRef]
- O’Dougherty, P.; Ferrel, K.; Varol, S. A Study of Semiconductor Defects within Automotive Manufacturing using Predictive Analytics. In Proceedings of the IEEE International Symposium on Digital Forensics and Security, Elazig, Turkey, 28–29 June 2021; pp. 1–6. [Google Scholar]
- Kundu, S.; Banerjee, S.; Raha, A.; Natarajan, S.; Basu, K. Toward Functional Safety of Systolic Array-Based Deep Learning Hardware Accelerators. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2021, 29, 485–498. [Google Scholar] [CrossRef]
- Huang, S.H.; Tu, W.P.; Chang, C.M.; Pan, S.B. Low-power Anti-aging Zero Skew Clock Gating. ACM Trans. Des. Autom. Electron. Syst. 2013, 18, 27. [Google Scholar] [CrossRef]
- Meric, I.; Ramey, S.; Novak, S.; Gupta, S.; Mudanai, S.P.; Hicks, J. Modeling Framework for Transistor Aging Playback in Advanced Technology Nodes. In Proceedings of the IEEE International Reliability Physics Symposium, Dallas, TX, USA, 28 April–30 May 2020; pp. 1–6. [Google Scholar]
- Cheong, M.; Lee, I.; Kang, S. A Test Methodology for Neural Computing Unit. In Proceedings of the IEEE International SoC Design Conference, Daegu, Republic of Korea, 12–15 November 2018; pp. 11–12. [Google Scholar]
- Solangi, U.; Ibtesam, M.; Ansari, M.; Kim, J.; Park, S. Test Architecture for Systolic Array of Edge-Based AI Accelerator. IEEE Access 2021, 9, 96700–96710. [Google Scholar] [CrossRef]
- Vijayan, A.; Koneru, A.; Kiamehr, S.; Chakrabarty, K.; Tahoori, M. Fine-Grained Aging-Induced Delay Prediction Based on the Monitoring of Run-Time Stress. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 1064–1075. [Google Scholar] [CrossRef]
- Huang, K.; Hasan, A.M.T.; Zhang, X.; Karimi, N. Real-Time IC Aging Prediction via On-Chip Sensors. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI, Tampa, FL, USA, 7–9 July 2021; pp. 13–18. [Google Scholar]
- Bjelica, M.; Mrazovac, B. Reliability of Self-Driving Cars: When Can We Remove the Safety Driver? IEEE Intell. Transp. Syst. Mag. 2023, 15, 46–54. [Google Scholar] [CrossRef]
- Wahba, A.; Fahmy, H. Area Efficient and Fast Combined Binary/Decimal Floating Point Fused Multiply Add Unit. IEEE Trans. Comput. 2017, 66, 226–239. [Google Scholar] [CrossRef]
- Tung, C.W.; Huang, S.H. A High-Performance Multiply-Accumulate Unit by Integrating Additions and Accumulations into Partial Product Reduction Process. IEEE Access 2020, 8, 87367–87377. [Google Scholar] [CrossRef]
- She, X.; Li, N.; Jensen, D. SEU Tolerant Memory Using Error Correction Code. IEEE Trans. Nucl. Sci. 2012, 59, 205–210. [Google Scholar] [CrossRef]
- Wu, M.S.; Chua, Y.L.; Li, J.F.; Chuan, Y.T.; Huang, S.H. Fault-Aware ECC Scheme for Enhancing the Read Reliability of STT-MRAMs. In Proceedings of the IEEE International Test Conference in Asia, Matsue, Japan, 13–15 September 2023; pp. 1–6. [Google Scholar]
- Chen, T.J.; Li, J.F.; Tseng, T.W. Cost-efficient Built-in Redundancy Analysis with Optimal Repair Rate for RAMs. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2012, 31, 930–940. [Google Scholar] [CrossRef]
- Lee, H.; Kim, J.; Cho, K.; Kang, S. Fast Built-in Redundancy Analysis Based on Sequential Spare Line Allocation. IEEE Trans. Reliab. 2018, 67, 264–273. [Google Scholar] [CrossRef]
- Johnson, J.; Wirthlin, M. Voter Insertion Algorithms for FPGA Designs Using Triple Modular Redundancy. In Proceedings of the ACM International Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2010; pp. 249–258. [Google Scholar]
- Santhiya, M.; Saranya, S.; Vijayachitra, S.; Lavanya, C.; Rajarajeswari, M. Application of Voter Insertion Algorithm for Fault Management Using Triple Modular Redundancy (TMR) Technique. In Proceedings of the IEEE International Conference on Intelligent Communication Technologies and Virtual Mobile Networks, Tirunelveli, India, 4–6 February 2021; pp. 578–583. [Google Scholar]
- Kim, J.; Reddy, S. On The Design of Fault-Tolerant Two-Dimensional Systolic Arrays for Yield Enhancement. IEEE Trans. Comput. 1989, 38, 515–525. [Google Scholar] [CrossRef]
- Stojanovic, N.; Milovanovic, E.; Stojmenovic, I.; Milovanovic, T.; Tokic, T. Mapping Matrix Multiplication Algorithm onto Fault-Tolerant Systolic Array. Comput. Math. Appl. 2004, 48, 275–289. [Google Scholar] [CrossRef]
- Milovanovic, I.; Milovanovic, E.; Stojcev, M. A Class of fault-Tolerant Systolic Arrays for Matrix Multiplication. Math. Comput. Model. 2011, 54, 140–151. [Google Scholar] [CrossRef]
- Jan, B.Y.; Huang, J.L. A Fault-Tolerant PE Array Based Matrix Multiplier Design. In Proceedings of the IEEE VLSI Design, Automation and Test, Hsinchu, Taiwan, 23–25 April 2012; pp. 1–4. [Google Scholar]
- Zhang, J.; Gu, T.; Basu, K.; Garg, S. Analyzing and Mitigating The Impact of Permanent Faults on a Systolic Array Based Neural Network Accelerator. In Proceedings of the IEEE VLSI Test Symposium, San Francisco, CA, USA, 22–25 April 2018; pp. 1–6. [Google Scholar]
- Zhang, J.; Basu, K.; Garg, S. Fault-Tolerant Systolic Array Based Accelerators for Deep Neural Network Execution. IEEE Des. Test 2019, 36, 44–53. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, K.; Louri, A. FSA: An Efficient Fault-tolerant Systolic Array-based DNN Accelerator Architecture. In Proceedings of the IEEE International Conference on Computer Design, Olympic Valley, CA, USA, 23–26 October 2022; pp. 545–552. [Google Scholar]
- Moghaddasi, I.; Gorgin, S.; Lee, J.A. Dependable DNN Accelerator for Safety-Critical Systems: A Review on the Aging Perspective. IEEE Access 2023, 11, 89803–89834. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Area |
|---|---|
| 1-D | 9553 |
| 2-D | 11,675 |
| [30] | 14,589 |
| PE Design | Area | Normalization |
|---|---|---|
| Conventional | 434 | 100% |
| Ours | 462 | 106% |
| [30] | 736 | 170% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.-C.; Su, L.-Y.; Huang, S.-H. Highly Fault-Tolerant Systolic-Array-Based Matrix Multiplication. Electronics 2024, 13, 1780. https://doi.org/10.3390/electronics13091780
Lu H-C, Su L-Y, Huang S-H. Highly Fault-Tolerant Systolic-Array-Based Matrix Multiplication. Electronics. 2024; 13(9):1780. https://doi.org/10.3390/electronics13091780
Chicago/Turabian StyleLu, Hsin-Chen, Liang-Ying Su, and Shih-Hsu Huang. 2024. "Highly Fault-Tolerant Systolic-Array-Based Matrix Multiplication" Electronics 13, no. 9: 1780. https://doi.org/10.3390/electronics13091780
APA StyleLu, H. -C., Su, L. -Y., & Huang, S. -H. (2024). Highly Fault-Tolerant Systolic-Array-Based Matrix Multiplication. Electronics, 13(9), 1780. https://doi.org/10.3390/electronics13091780