Abstract
The growing demand for real-time human motion reconstruction in Virtual Reality (VR), Augmented Reality (AR), and the Metaverse requires high accuracy with minimal hardware. This paper presents SSR-HMR, a skeleton-aware, sparse node-based method for full-body motion reconstruction from limited inputs. The approach incorporates a lightweight spatiotemporal graph convolutional module, a torso pose refinement design to mitigate orientation drift, and kinematic tree-based optimization to enhance end-effector positioning accuracy. Smooth motion transitions are achieved via a multi-scale velocity loss. Experiments demonstrate that SSR-HMR achieves high-accuracy reconstruction, with mean joint and end-effector position errors of 1.06 cm and 0.52 cm, respectively, while operating at 267 FPS on a CPU.
1. Introduction
The rapid advancement of Virtual Reality (VR), Augmented Reality (AR), and Metaverse technologies has positioned real-time human motion capture as a critical enabling technology across diverse domains, including entertainment, training and education, medical rehabilitation, and sports analytics. In VR/AR applications, users depend on virtual avatars for natural interactions, necessitating precise full-body motion representation [1]. The immersive experiences offered by the Metaverse demand high-fidelity human motion modeling, while the medical rehabilitation field requires accurate motion analysis for personalized treatment. Despite the growing demand, existing technologies continue to face significant challenges in balancing accuracy, cost, and accessibility.
Traditional motion capture systems, such as optical marker-based setups (e.g., Vicon [2]) and inertial sensor arrays (e.g., Xsens Awinda [3]), achieve high precision but require expensive hardware and complex configurations, limiting their accessibility for consumer applications. To address these limitations, recent studies have focused on sparse-node motion reconstruction with minimal hardware.
Inertial measurement unit (IMU)-based methods [4,5,6] leverage a small number of IMUs to estimate full-body motion but are prone to drift and long-term accuracy degradation. Head-mounted display (HMD)-based approaches [7,8,9] utilize head and hand motion data from VR hardware to improve accessibility but lack constraints for reconstructing lower-body movement. More recently, 6-degrees-of-freedom (6-DoF) trackers [10] have been employed to enhance accuracy, though traditional setups rely on external base stations, reducing usability. The latest self-tracking 6-DoF devices improve flexibility but still face challenges in handling complex motions and ensuring real-time performance.
To address these challenges, we propose SSR-HMR, a skeleton-aware sparse node-based real-time motion reconstruction method (see Figure 1). By integrating skeleton priors into a neural network and incorporating a pose refinement module, SSR-HMR significantly enhances motion accuracy, end-effector positioning, and real-time efficiency. The key contributions of this work are as follows:
- A lightweight and efficient spatiotemporal graph convolutional module for accurate full-body motion reconstruction from sparse inputs.
- A torso pose refinement module that leverages upper-body motion constraints to reduce torso and head orientation drift.
- Integration of a kinematic tree structure and multi-scale velocity error loss into the pose optimization network, enhancing end-effector positioning accuracy and ensuring natural motion transitions.

Figure 1.
Architecture of the SSR-HMR network for full-body motion reconstruction from sparse inputs. The framework consists of two main components: (1) a spatiotemporal graph convolutional generator that predicts joint motion from sparse sensor data, and (2) a pose optimization module that refines the predicted motion to enhance end-effector accuracy and overall motion naturalness.
Figure 1.
Architecture of the SSR-HMR network for full-body motion reconstruction from sparse inputs. The framework consists of two main components: (1) a spatiotemporal graph convolutional generator that predicts joint motion from sparse sensor data, and (2) a pose optimization module that refines the predicted motion to enhance end-effector accuracy and overall motion naturalness.

Experimental results demonstrate that SSR-HMR achieves a mean per-joint position error (MPJPE) of approximately 1.06 cm and an end-effector positioning error (MPEEPE) of around 0.52 cm using only six 6-DoF devices. Furthermore, it attains real-time performance of 267 frames per second (FPS) on a CPU, outperforming existing sparse-node motion reconstruction methods in both accuracy and efficiency.
The remainder of this paper is organized as follows. Section 2 reviews related work on sparse-node human motion reconstruction and learning-based inverse kinematics. Section 3 introduces the proposed SSR-HMR framework, including the spatiotemporal graph convolution module and pose refinement design. Section 4 presents quantitative and qualitative experiments, including comparisons with existing methods, ablation studies, inference efficiency, and evaluations across different user body sizes. Finally, Section 5 summarizes the findings, discusses limitations and practical considerations, and outlines directions for future work.
2. Related Work
Research on human motion reconstruction spans a wide range of domains, driven by applications in VR, AR, and robotics. This section reviews state-of-the-art methods that leverage sparse signals from inertial measurement units (IMUs), VR devices, and position-tracking equipment. We first discuss the fundamental challenges of reconstructing full-body motion from sparse inputs, followed by an exploration of learning-based inverse kinematics (IKs) methods and their role in pose optimization.
2.1. Full-Body Motion Reconstruction from Sparse Inputs
2.1.1. Full-Body Motion Reconstruction from Sparse IMU Sensors
Inertial measurement unit (IMU)-based motion capture has gained popularity due to its portability and cost-effectiveness. However, traditional systems such as Xsens require multiple IMUs, making them cumbersome and expensive. The Sparse Inertial Poser (SIP) [11] was the first to demonstrate that full-body motion could be reconstructed using only six IMUs. Subsequent methods, including DIP [4] and TransPose [12], leveraged deep learning to enable real-time reconstruction. More recent advancements, such as PIP [5] and PNP [6], have integrated physics-based optimization to enhance motion realism. Despite these improvements, IMU-based approaches suffer from a fundamental limitation: the lack of absolute position data, which results in root position drift and compromises global accuracy [13].
2.1.2. Full-Body Motion Reconstruction Using Commercial VR Devices
Commercial VR devices, such as the HTC Vive and Oculus Quest, provide highly accurate tracking for head and hand movements, making them widely adopted in VR applications. However, the absence of direct lower-body tracking often results in pose ambiguities. Early approaches, such as LoBSTr [14] and AvatarPoser [7], attempted to infer full-body motion from limited upper-body signals. Subsequent advancements, including AvatarJLM [8] and HMD-Poser [9], further improved reconstruction accuracy. In addition, these studies demonstrated that adding trackers to key locations, such as the pelvis and feet, significantly enhances motion fidelity. Nevertheless, capturing fine-grained lower-body movements remains a challenge.
2.1.3. Full-Body Motion Reconstruction with Sparse 6-DoF Trackers
The increasing adoption of commercial VR devices has driven significant advancements in full-body motion reconstruction methods based on 6-degrees-of-freedom (6-DoF) trackers. These trackers provide both spatial positions and orientations, offering high-quality input data that significantly enhances reconstruction accuracy. SparsePoser [10] introduced a two-stage optimization framework that combines a skeleton-aware convolutional autoencoder with a learning-based inverse kinematics (IK) module, achieving notable improvements in motion naturalness and end-effector positioning accuracy.
DragPoser [15] proposed a structured latent-space optimization approach that improves reconstruction flexibility as well as whole-body joint and end-effector accuracy. These enhancements are important for practical applications, since prior methods often lack sufficient precision for real-world use, and performance in complex motion scenarios remains limited. In addition, Yao et al. [16] introduced a Body Pose Graph (BPG) to explicitly model spatial and temporal relationships between joints from sparse sensors, demonstrating the benefits of graph-based representations for capturing joint dependencies. Despite these advancements, existing methods still face limitations in achieving both high-precision reconstruction and real-time performance, particularly in complex motion scenarios where precise joint and end-effector positioning is critical.
To address these limitations, the proposed method, SSR-HMR, introduces a skeleton-aware, sparse node-based framework for real-time human motion reconstruction. By leveraging skeletal connectivity within a spatiotemporal graph module, SSR-HMR enhances feature extraction from sparse inputs, improving full-body reconstruction accuracy and end-effector positioning. A subsequent pose optimization network further refines joint predictions and ensures smooth motion transitions, enabling accurate and efficient reconstruction even in complex motion scenarios.
2.2. Learning-Based Inverse Kinematics
Inverse kinematics (IK) solvers are extensively used in robotics and computer animation to determine joint configurations that satisfy target end-effector positions, such as those of the hands, feet and head. Traditional IK methods, including analytical and numerical solvers, excel at optimizing end-effector alignment but often fail to generate natural human poses due to high-dimensional search spaces and local optima. Recent advancements in data-driven methods have significantly enhanced IK performance by leveraging large-scale motion datasets.
In robotics, lightweight feedforward networks [17,18], generative adversarial networks (GANs) [19], and conditional normalizing flow networks [20] have been employed to learn IK solutions for specific kinematic chains. While these methods improve computational efficiency, they are primarily limited to low-degree-of-freedom robotic arms. In computer animation, learning-based approaches such as scaled Gaussian processes [21,22] and multivariate Gaussian models [23] have been used to generate natural poses, but they suffer from limited training data and high computational costs. Additionally, ref. [24] proposed an autoencoder-based IK solver for hand joint alignment. However, this approach modifies the entire skeleton when adjusting end-effectors, which can introduce artifacts such as foot sliding and temporal incoherence.
In VR/AR systems, accurate end-effector positioning is crucial for achieving natural and immersive user interactions. Although existing full-body motion reconstruction methods based on sparse inputs can generate smooth animations, they often struggle with precise end-effector positioning. To address this challenge, several approaches have integrated IK modules to refine poses. For instance, AvatarPoser [7] uses a Transformer-based framework with an IK module to optimize shoulder and elbow positions, reducing hand deviations. Similarly, ref. [25] applied IK to refine arm poses after motion matching, and LoBSTr [14] adjusts upper-body poses to match tracked end-effector transformations. However, these methods face a trade-off between pose naturalness and end-effector accuracy, with the final IK adjustment often overriding the learned poses and reintroducing issues inherent to traditional IK methods.
Building on these advancements, SparsePoser [10] introduced an IK module composed of lightweight feedforward neural networks. This module independently adjusts each limb’s posture based on the initial body pose and target end-effector positions, leading to precise pose reconstruction. Additionally, SparsePoser integrates an end-effector position loss and an intermediate joint position loss, balancing precision with naturalness. However, SparsePoser’s reliance on a parent–child skeletal model limits the accuracy of upper-body reconstructions, particularly the torso, which negatively affects the overall pose quality. Moreover, the method does not explicitly enforce temporal continuity, which can result in less smooth motion transitions.
In response to the limitations of these methods, our method extends SparsePoser with three key innovations: (1) an upper-body torso adjustment module for enhanced pose quality, (2) the integration of a hierarchical skeletal structure to improve end-effector positioning, and (3) a multi-scale velocity loss that improves temporal continuity, reducing long-term errors and enhancing motion stability. These improvements lead to more accurate and smoother full-body motion reconstruction from sparse inputs.
3. Method
3.1. Overview
This paper presents Skeleton-aware Sparse Node-based Real-time Human Motion Reconstruction (SSR-HMR), a novel method for real-time full-body motion reconstruction from sparse node motion data (see Figure 1). By encoding skeletal priors into both the input data and the neural network, SSR-HMR achieves accurate reconstruction of full-body joint motion.
Specifically, SSR-HMR extracts position and rotation information from six key joints—head, hands, feet, and pelvis (root)—and transforms them into root-centered dual quaternion pose representations based on skeletal priors. This transformation facilitates implicit skeletal structure capture within the neural network, enabling accurate pose synthesis. Subsequently, SSR-HMR maps the sparse input to full-body joint motion using skeletal topology and reconstructs it with a simplified spatiotemporal graph convolutional network (ST-GCN) [26], ensuring realistic and temporally coherent motion generation. Finally, SSR-HMR incorporates a skeleton-aware pose refinement network to precisely optimize end-effector positioning, further enhancing motion naturalness through a multi-scale velocity error loss.
3.2. Background
In this study, we adopt dual quaternions for human pose representation due to their superior ability to handle both rotation and translation. Dual quaternions unify these components into a compact and efficient representation, avoiding gimbal lock issues inherent in Euler angles while providing stable and continuous rotational encoding. Dual quaternions are particularly well-suited for pose representation, as they independently encode each joint’s position and orientation relative to the root, preserving continuity and accuracy in motion chains [27]. Additionally, experiments in SparsePoser [10] show that dual quaternions outperform other common pose representations, such as quaternions and ortho6D [28], in terms of pose reconstruction accuracy and continuity.
Our method takes as input a motion sequence of length T, comprising skeletal information for J joints. The sparse input consists of rotation and translation data from six joints (), which are directly converted into dual quaternion representations. For output, we follow prior research [7,12] and use the first 22 joints of the SMPL model [29] as the full-body skeleton representation (). The root translation and axis-angle rotations are transformed into root-centered unit dual quaternions, encoding all joint rotations and translations relative to the root. This approach enables the neural network to implicitly capture skeletal priors while mitigating accumulated motion chain errors, resulting in more accurate pose synthesis.
To reconstruct natural and temporally coherent full-body motion, we model both spatial and temporal dependencies in the input motion sequence. Inspired by ST-GCN [26], we introduce a mask-based spatiotemporal graph convolution approach to leverage skeletal topology and enhance motion pattern modeling.
In the following sections, we detail the construction of dual quaternions, the root-centering process, and the implementation of our spatiotemporal graph convolution with skeletal masks, laying the foundation for our motion reconstruction framework.
3.2.1. Dual Quaternion
A dual quaternion is a mathematical representation that simultaneously encodes rotation and translation. It is defined as:
where represents the rotation quaternion, represents the translation quaternion, and is the dual unit satisfying .
Given a rotation in the axis-angle form and a translation vector , the corresponding rotation and translation quaternions are computed as follows:
where and ⊗ denotes quaternion multiplication.
The dual quaternion formulation provides a compact and continuous representation for modeling human poses. Given , the translation component can be conveniently extracted as:
where denotes the conjugate of the rotation quaternion . The conjugate of a quaternion is obtained by reversing the signs of its imaginary components.
3.2.2. Root-Centered Dual Quaternion Calculation
Given the following inputs: the axis-angle representation of the full-body joints , where each represents the axis-angle vector for the j-th joint; the global translation vector for the root joint ; the offset , where each represents the offset of the j-th joint relative to its parent joint; and the parent–child relationship , where denotes the index of the parent joint for the j-th joint. Note that the root joint is indexed as 0, and for each joint j, .
For each joint j (from 0 to ), the translation vector and axis-angle representation are converted into a root-centered dual quaternion through the following steps:
First, the local rotation quaternion is computed using the axis-angle to quaternion conversion formula:
where represents the axis-angle vector of joint j.
Next, the global rotation quaternion is computed as follows:
where denotes the global rotation quaternion of the parent joint, and ⊗ represents quaternion multiplication.
Subsequently, the rotation matrix is derived from the global rotation quaternion :
Using the rotation matrix and the global translation vector of the parent joint , the global translation vector for joint j is computed as:
where represents the offset of joint j relative to its parent joint.
Finally, the root-centered global dual quaternion is calculated as:
where is the quaternion representation of the translation vector (i.e., ), and denotes the dual unit.
3.2.3. Mask-Based Spatiotemporal Graph Convolution
Graph convolution-based methods have been widely adopted for motion modeling due to their ability to capture spatiotemporal features in skeletal motion. Inspired by ST-GCN [26], we introduce a mask-based spatiotemporal graph convolution method (see Figure 2) to explicitly encode skeletal topology and enhance the model’s motion reconstruction capabilities.
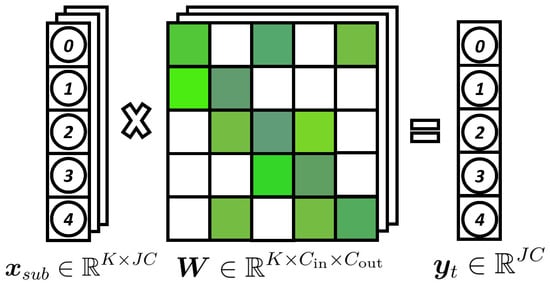
Figure 2.
Illustration of the mask-based spatiotemporal graph convolution. White areas in the mask matrix represent masked-out weights, and the numbered circles indicate joint indices.
In this method, a fixed mask matrix is constructed based on the shortest path distances between joints. Information transfer is restricted to joints whose distance does not exceed d (with in our experiments), thereby controlling computational complexity and minimizing interference from non-directly connected joints. The mask matrix is element-wise multiplied with the convolutional weight matrix during computation, ensuring that information propagation adheres to skeletal topology constraints.
The input skeletal motion data is flattened into a two-dimensional spatiotemporal feature representation , and one-dimensional convolution is applied along the temporal dimension. This enables a single convolutional kernel to capture the spatial structure of the skeleton, while multiple kernels collaboratively model both temporal dynamics and spatial relationships. The reconstructed motion at the t-th frame is computed as:
where K is the number of convolution kernels, is the learnable convolutional weight matrix, ⊙ denotes element-wise multiplication, and is the bias term.
3.3. Generator
The generator’s primary task is to reconstruct complete full-body motion from sparse joint inputs, ensuring that the generated motion sequence adheres to human motion principles and closely approximates real-world movement.
Initially, a fixed partition strategy is employed, as shown in Figure 3, to map the sparse input to the full skeletal representation :
where denotes the number of joints in the sparse input, is the number of joints in the full skeleton, T represents the number of time steps, and is the feature dimension per joint.
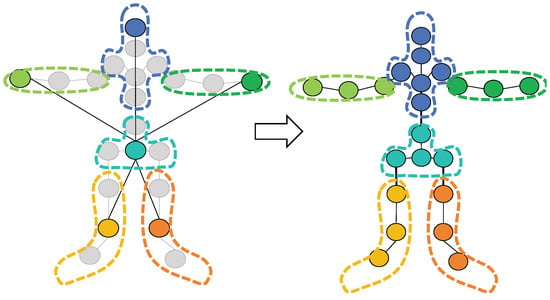
Figure 3.
Fixed partition strategy for mapping sparse input to full skeletal representation.
Next, the full-body skeletal motion sequence is flattened into a space feature vector:
Subsequently, mask-based spatiotemporal convolution is applied using Conv1D from PyTorch v2.6.0 [30], with three layers of spatiotemporal modeling to generate full-body motion. As illustrated in Figure 4, a set of convolution kernels with masks is employed, where each spatiotemporal graph convolution operation utilizes the current frame and the preceding 14 frames of sparse input data (with kernels) to reconstruct the full skeletal motion information of the current frame.
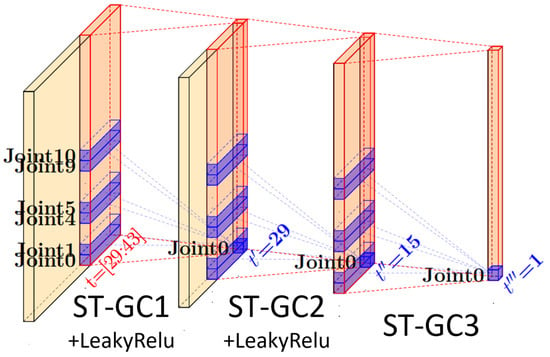
Figure 4.
Illustration of the three-layer spatiotemporal graph convolution (example using the 0th joint of the current frame).
The convolution kernels slide along the temporal dimension with a stride of 1. To avoid introducing artifacts into the motion sequence, no padding is applied during convolution. As a result, after three spatiotemporal graph convolution operations, the temporal dimension length is reduced to . Additionally, a LeakyReLU activation function is applied between each pair of spatiotemporal graph convolutions to enhance the model’s ability to capture nonlinear representations.
3.4. Pose Optimization
The second component is the Pose Optimization Network, a set of neural networks designed to refine the body’s orientation to better align with the target end-effectors.
In applications such as Virtual Reality (VR), precise end-effector positioning is often required [31]. However, the motion generator typically struggles to accurately align the end-effectors with the expected positions (see Figure 5). Inspired by SparsePoser [10], we employ a multi-layer perceptron (MLP) to fine-tune the body pose. Given the hierarchical structure of the kinematic tree, joint errors propagate along the skeletal chain, meaning even small discrepancies in the torso can significantly affect the positioning of the arms and head (as illustrated in Figure 6). To mitigate this, we first introduce a torso adjustment stage based on upper-body joint motion before refining individual limb positions. By incrementally incorporating adjustments through key skeletal nodes, the network encodes the kinematic hierarchy, enabling more precise control over end-effector positioning.
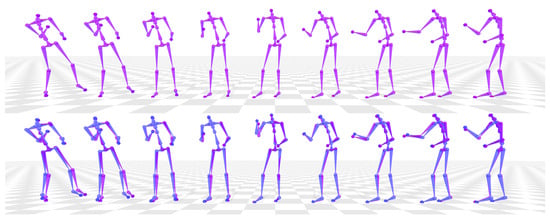
Figure 5.
Comparison of motion generation and real data. (Top) Generator output (purple) produces continuous motion. (Bottom) Comparison between generator output (purple) and real data (blue), showing misalignment of end-effectors.
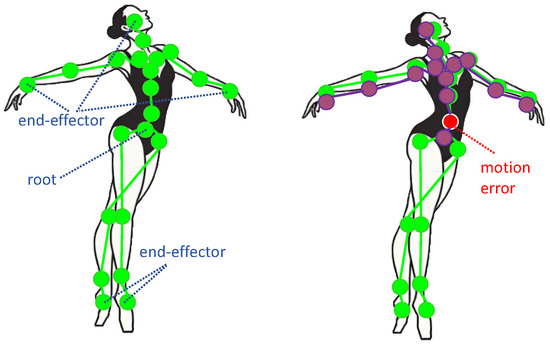
Figure 6.
Errors propagate along the kinematic tree due to its hierarchical structure, affecting joint positions and end-effector accuracy.
As illustrated in Figure 1, all pose adjustment MLP modules take the generator’s output—dual-quaternion motion sequences for 22 joints—as the core input, alongside raw sparse input and static skeletal offsets as guidance. We do not modify the end joints since treating the raw sparse inputs as fixed degrees of freedom helps the network better model the data, achieving precise end-effector positioning.
For torso adjustment, we use the joint motion sequences of the entire upper body, joint offsets, and sparse input for the root, hands, and head, adjusting the torso step-by-step around the chest. For limb adjustments, we input the previous results from all joints in the motion chain from the root to the corresponding end-effector, joint offsets, and raw sparse input for the root and end-effector. We make three successive adjustments for each limb, progressively refining the pose by moving from the root toward the end-effector and adjusting three additional joints outside of the end-effectors.
3.5. Training SSR-HMR
To achieve human motion reconstruction from sparse nodes, we design two types of loss functions: the Generator Loss and the Pose Optimization Loss. The Generator Loss optimizes the generator’s output to improve motion reconstruction accuracy, while the Pose Optimization Loss enhances the naturalness and temporal continuity of the motion.
3.5.1. Generator Loss
Following the approach outlined in [10], we avoid directly using a forward kinematics-based loss function in the generator module, as this may lead to training instability and poor convergence. Instead, we employ the Mean Squared Error (MSE) between the predicted motion sequence in dual-quaternion form, , and the ground truth , to optimize the generator’s output. This method ensures that the generated motion sequence closely approximates the target dual-quaternion sequence. Specifically, the dual-quaternion loss is defined as:
This formulation ensures that the generated motion sequence closely approximates the target motion while maintaining consistency in dual-quaternion space. Since the dual-quaternion representation we adopt is centered at the root joint, its accuracy is crucial for correctly propagating transformations throughout the kinematic chain. To account for this, we assign a higher weight to the root joint loss and define the total Generator Loss function as:
where to emphasize the importance of root reconstruction.
3.5.2. Pose Optimization Loss
The Pose Optimization Loss function is designed to optimize the pose estimation process, ensuring accurate full-body joint motion reconstruction from sparse node inputs. This loss consists of three components: end-effector loss, intermediate joint loss, and multi-scale velocity loss.
During the pose optimization process, dual-quaternions are utilized to effectively represent the rotation and translation information of all joints, helping the network to understand and model the motion. However, directly recovering joint positions from dual-quaternions does not adequately enforce bone length constraints, which are critical for accurate skeletal structure representation. To address this issue, we combine the original skeletal offsets with the rotation matrices derived from the dual-quaternions and compute the joint positions using forward kinematics (FK), ensuring that the skeletal structure constraints are satisfied.
The Pose Optimization Loss function is defined as:
where and are the predicted joint positions and rotation matrices, and and are the ground truth joint positions and rotation matrices, respectively.
To ensure temporal continuity and reduce accumulated errors, we introduce velocity errors as an explicit constraint. Using velocity errors over larger intervals helps mitigate long-term cumulative errors and improves motion consistency [12]. Thus, we define the multi-scale velocity error to measure the differences in predicted joint positions and ground truth joint positions over varying time intervals:
where T is the time series length, n is the frame interval, and denotes the Euclidean norm.
To further enhance the smoothness of motion, we compute the total of the velocity errors over adjacent frames, two-frame intervals, and four-frame intervals as the multi-scale velocity error:
The total pose optimization loss is then defined as:
where , , and are the weighting parameters balancing the end-effector, intermediate joint, and velocity losses, respectively.
4. Experiments
In this section, we evaluate the performance of our method against state-of-the-art approaches on the publicly available AMASS [32] dataset and conduct an ablation study. We also compare our method with SparsePoser using real-world motion capture data obtained with Xsens, presenting both quantitative and qualitative results. Notably, our model is compatible with commercially available VR systems such as HTC VIVE Trackers, which provide both orientation and positional information. All visualizations presented in this paper are generated using aitviewer [33], an open-source tool for 3D motion visualization.
Implementation Details. In Equations (7) and (11), the hyperparameters are set as , , , , and . The posture optimization module is implemented as a two-layer MLP with 128 hidden units per layer. Our method is developed in PyTorch [30] and trained using the AdamW optimizer [34] with a batch size of 256 and an initial learning rate of . The learning rate is adjusted by a ReduceLROnPlateau scheduler with a decay factor of 0.5 and a patience of 20 epochs.
During training, motion sequences are divided into windows of 64 frames with a stride of 16. All components, including the generator and the pose optimization module, are trained in an end-to-end manner. In each iteration, the generator is first optimized, followed by updates to the pose optimization module while keeping the generator frozen.
For real-time deployment, motion streams are processed with a 43-frame sliding window using a stride of one. At each time step, the past 42 frames and the current frame are used for spatiotemporal modeling. The reconstruction of the current frame is obtained through three layers of spatiotemporal convolutions, followed by pose optimization to further enhance accuracy and motion naturalness.
Evaluation Metrics. In line with previous works [9,10], we evaluate our method using seven metrics grouped into three categories. For tracking accuracy, we report the mean per-joint position error (MPJPE), defined as the Euclidean distance between predicted and ground-truth joint positions with the root aligned; the mean per-joint rotation error (MPJRE), defined as the average angular difference between predicted and ground-truth rotations, where the error between two rotations and is computed as the angle of the relative rotation ; and the mean per-end-effector position error (MPEEPE), defined as the Euclidean distance between predicted and ground-truth end-effector positions, excluding the root.
For motion smoothness, we adopt the mean per-joint velocity error (MPJVE), defined as the Euclidean distance between predicted and ground-truth joint velocities, and jitter, defined as the mean jerk of all joints, where jerk is the third derivative of position with respect to time and serves as a measure of motion smoothness. Inference efficiency is further assessed in terms of model size and frame rate (FPS). For both accuracy and smoothness metrics, standard deviations are also reported to evaluate the stability and reliability of the results.
4.1. Experiments on the AMASS Dataset
Following established practices [9,10,15] for training and evaluation, AMASS [32] was selected for its comprehensive coverage of human motion and SMPL [29] compatibility, which is essential for comparison with HMD-Poser [9] and SparsePoser [10]. AMASS integrates multiple publicly available motion capture datasets into a unified representation, providing large-scale sequences with diverse body shapes, genders, and motion styles, including gender-based skeleton offsets, full-body local joint rotations, and root positions. Global joint positions, including end-effectors, can be derived via forward kinematics.
In line with SparsePoser and DragPoser [15], which reconstruct full-body motion from sparse input using six 6-degrees-of-freedom (6DoF) devices, DanceDB [35] is used for training, while HUMAN4D [36] and SOMA [37] are used for evaluation. Together, these two datasets include ten subjects performing over 200 actions, covering daily activities, sports training (e.g., gymnastics, weightlifting), dance movements, and interactive actions, totaling more than 300,000 frames.
4.1.1. Comparison Experiments
As outlined in Section 2, sparse-node-based motion reconstruction methods can be broadly categorized into four types: methods based on inertial measurement units (IMUs), those utilizing 6-degrees-of-freedom (6DoF) inputs from head-mounted displays (HMDs) and controllers, methods using 6DoF trackers, and hybrid schemes combining the aforementioned approaches. To systematically compare these methods under comparable experimental conditions, we select the following representative approaches for evaluation: the PIP method [5], which uses six IMU devices; the HMD-Poser method, which combines 6DoF inputs from HMDs and controllers with three IMUs; and the Final IK [38], SparsePoser, and DragPoser methods, which combine 6DoF inputs from HMDs and controllers with three 6DoF trackers.
Notably, Final IK is a method based on inverse kinematics (IKs), specifically designed for animating full-body VR characters with sparse 6DoF trackers, while the other methods are data-driven deep learning algorithms representing cutting-edge advancements in their respective domains. In our experiments, the Final IK plugin for Unity was employed to estimate full-body motion using 6DoF positional inputs from the headset, hand controllers, hip trackers, and foot trackers. The plugin’s inverse kinematics solver generated real-time joint rotations and global positions, the outputs of which were used for subsequent evaluation.
Although the PNP method [6] with six IMU devices and the DragPoser method [15] with six 6DoF trackers represent important advances, they are not evaluated independently in this study. IMU-based approaches suffer from inherent limitations, and the accuracy improvement of PNP over PIP is marginal; therefore, the PIP data provided in SparsePoser is adopted for benchmarking. For DragPoser, since the AMASS-specific processing details have not been publicly released, quantitative experiments could not be conducted in our setting, and its reported results are referenced instead. Nevertheless, all compared methods are evaluated under the same configuration and dataset, as described in Section 4.1.
Regarding SparsePoser, while the authors provided partial code implementations, the AMASS dataset’s data processing code, which involves third-party software, could not be publicly shared. This limitation prevented us from fully reproducing its original experimental results. To ensure transparency and reproducibility, we re-implemented the data preprocessing code based on the official description and trained SparsePoser*.
Under the same configuration for comparison. For fairness, we also refer to the original results of SparsePoser.
Quantitative Results
SSR-HMR is quantitatively compared with Final IK, PIP, HMD-Poser, and SparsePoser, with detailed results presented in Table 1. Several observations can be made from this comparison. First, SSR-HMR demonstrates notable improvements in mean joint position error and mean end-effector position error, establishing competitive performance on the AMASS dataset and providing high-quality joint position reconstruction with overall smooth motion. Second, SSR-HMR exhibits slightly suboptimal performance in jitter, performing marginally worse than the physics-based PIP method in terms of mean, although the standard deviation is lower. This behavior can be attributed to the inherent trade-off between position accuracy and motion smoothness: with larger position errors, the latent space allows greater freedom for smoothing. Third, SSR-HMR ranks third in mean joint rotation error, reflecting the design of the pose optimization network, which prioritizes end-effector positions by treating both their position and rotation as fixed while adjusting intermediate joint rotations to match the sparse input.

Table 1.
Quantitative comparison of sparse node-based motion reconstruction methods on the combined AMASS dataset. The table reports the mean and standard deviation (in parentheses) of metrics reflecting the pose quality and motion smoothness of reconstructed human motion. Bold numbers indicate the best results.
Qualitative Results
We qualitatively compare SSR-HMR with HMD-Poser and SparsePoser*, with detailed results presented in Figure 7. As shown in the figure, our method demonstrates superior motion reconstruction performance. HMD-Poser exhibits inconsistencies in body parts, such as leg overlap during rapid movements (e.g., Figure 7a). The lack of lower limb position information leads to significant deviations in the core and lower body during fast movements (e.g., Figure 7b), or ghosting artifacts are visible (e.g., Figure 7c,d). In contrast, SparsePoser* generates more accurate results with minimal deviation from the ground truth; however, minor misalignments in the head, torso, end-effectors, and occasionally the limbs still affect the user experience. Our model’s predictions closely align with the real motion, achieving precise end-effector positioning. Nevertheless, we acknowledge some deviations in intermediate joints, such as the knees and elbows, which remain visible in certain cases (e.g., Figure 7b,d).
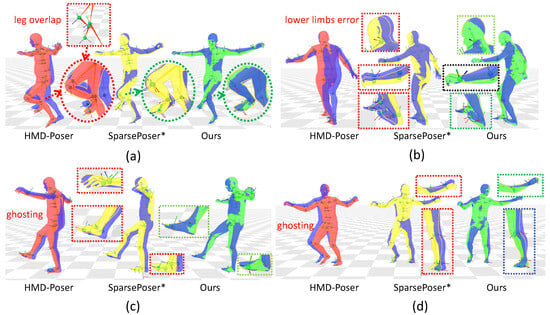
Figure 7.
Qualitative results on AMASS. Human bodies reconstructed by HMD-Poser, SparsePoser*, and SSR-HMR are shown in red, yellow, and green, respectively, while the ground truth is in blue. Subfigures represent different motion examples: (a) dance; (b) fast turn; (c) kicking; (d) lateral jump. Red dashed boxes indicate larger deviations, green dashed boxes indicate smaller errors, and black dashed boxes represent cases where significant body part deviations occur, but the end-effector error is minimal. Corresponding video at: https://github.com/Lucifer-G0/SSR-HMR/blob/main/AMASS_dance.mp4 (accessed on 17 August 2025).
To further assess motion sequence smoothness, we quantitatively evaluate the motion reconstruction performance of HMD-Poser, SparsePoser*, and our proposed model using a jumping jack motion sequence, as shown in Figure 8. In the first row of reconstructed sequences, all models generate realistic and smooth motion without noticeable distortions. However, in the second row, when compared with the real motion data (in blue), HMD-Poser struggles with positioning accuracy, particularly in the body core and lower limbs, during high-speed, complex movements. Even the upper-limb end-effector, which incorporates positional information, shows some deviation. While SparsePoser* achieves better reconstruction accuracy, it still exhibits noticeable torso and head shifts in certain frames, along with foot positioning errors, which could affect user stability and experience. In contrast, our method, although not perfectly aligned with the real motion trajectory, maintains a high degree of consistency with the ground truth, without visually significant deviations.
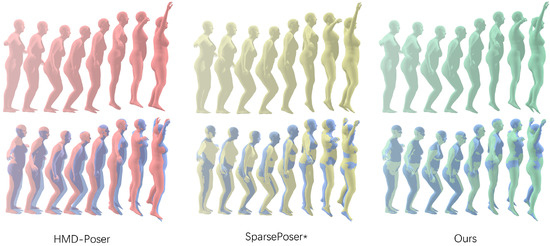
Figure 8.
Qualitative comparison of the jumping jack motion sequence reconstructed by different models. The first row shows the visual results of the motion reconstruction for each model, while the second row compares the reconstruction results with the real human motion (represented in blue).
4.1.2. Ablation Study
This section systematically evaluates the impact of each component of the network on pose quality and motion smoothness through ablation experiments. The experiments are conducted using the same dataset as in Section 4.1.1, with all ablation variants compared to the full model (Ours).
The impact of the Pose Optimization module is first assessed (denoted as noIK in Table 2). Without the IK module, the joint position error (MPJPE) and end-effector position error (MPEEPE) increase substantially to 2.91 cm and 4.27 cm, respectively, while jitter also rises. This highlights the critical role of the IK module in improving end-effector accuracy and motion smoothness.
Table 2.
Ablation study on the AMASS dataset. Mean and standard deviation (in parentheses) of pose quality and motion smoothness metrics are reported. Bold numbers indicate the best performance.
Next, the effect of removing the multi-scale velocity loss is analyzed (denoted as noVelLoss). In this variant, the joint velocity error (MPJVE) increases from 4.37 cm/s to 9.69 cm/s, and both joint position and end-effector errors also rise, indicating the importance of the velocity loss in maintaining motion smoothness.
The contribution of the torso adjustment module is then evaluated (denoted as noTorso). Removing this component results in increased joint position and end-effector errors (1.51 cm and 1.19 cm, respectively) and higher jitter, suggesting that torso adjustment significantly supports overall pose quality and motion stability.
Finally, the hierarchical limb optimization is examined (denoted as no3Layer). Retaining only the last layer of limb adjustments while removing the incremental node adjustment mechanism increases joint position and end-effector errors to 1.15 cm and 0.73 cm, respectively, with elevated MPJVE and jitter. This demonstrates that the deeper, hierarchical network structure better captures motion details, improving reconstruction accuracy and smoothness.
The quantitative results of these ablation experiments are summarized in Table 2, where all metrics report mean values with standard deviations in parentheses. Bold numbers indicate the best performance.
The convergence behavior of each ablation variant is further illustrated in Figure 9, measured by the sum of MPJPE and MPEEPE. Panel (a) shows the full training process from Epoch 0 to 800, while panel (b) focuses on the convergence stage (Epoch 500–800), with the learning rate indicated at Epoch 800. The curves demonstrate the stability and convergence trends of all ablation variants, with noticeable drops corresponding to learning rate reductions applied using the ReduceLROnPlateau scheduler.
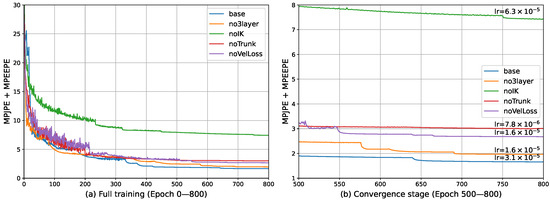
Figure 9.
Training curves of the ablation experiments, measured by the sum of MPJPE and MPEEPE. (a) Shows the full training process from Epoch 0 to 800. (b) Focuses on the convergence stage (Epoch 500—800), with the learning rate indicated at Epoch 800. The model is trained using the ReduceLROnPlateau strategy, and the noticeable drops in the curves correspond to learning rate reductions by half.
In summary, the ablation study demonstrates that the Pose Optimization module, multi-scale velocity loss, torso adjustment, and hierarchical limb optimization all contribute meaningfully to improving pose quality and motion smoothness. The full model (Ours) consistently achieves the best performance across all metrics.
4.2. Experiments on the Xsens Dataset
To complement the experiments conducted on the synthetic AMASS dataset, we further evaluated the performance of our method on real-world data using the publicly available motion capture database provided by SparsePoser. This dataset comprises approximately two million poses sampled at 60 frames per second (equivalent to roughly 9 h of data), captured from nine different actors. The motion data was recorded using the Xsens Awinda system, with actors engaging in a variety of activities, including exercise routines, warm-ups, sitting, VR gaming, and dancing. This evaluation on real-world data ensures the robustness and generalizability of our approach beyond synthetic environments.
4.2.1. Quantitative Results
Table 3 presents the quantitative results of SparsePoser and our method for reconstructing human motion from sparse inputs using the real-world Xsens motion capture dataset. Unlike the experiments on the AMASS dataset, this experiment uses real motion data, providing a more practical evaluation of the algorithm’s performance.
Table 3.
Quantitative results of human motion reconstruction from sparse inputs on Xsens. Bold numbers indicate the best results.
From the results, our method outperforms SparsePoser in both pose reconstruction quality and motion smoothness. In terms of pose reconstruction quality, our method achieves lower errors in position, rotation, and end-effector position, reducing them by 56.7%, 38.0%, and 68.4%, respectively, compared to SparsePoser. This indicates that our method can more accurately reconstruct full-body joint positions and rotation angles in real-world scenarios.
In terms of motion smoothness, our method also demonstrates superior performance, reducing velocity error by 71.9% and jitter by 12.5% compared to SparsePoser. This indicates that our method generates smoother motion sequences while effectively reducing unnecessary motion jitter.
Overall, on the real-world Xsens dataset, our method not only improves reconstruction accuracy but also demonstrates superior motion smoothness, making the generated motion sequences more natural and stable. It offers a reliable solution for high-precision human motion reconstruction under sparse input conditions.
4.2.2. Qualitative Results
Figure 10 shows the qualitative comparison between SparsePoser and our method on the real-world motion capture dataset. Both methods are capable of effectively reconstructing human motion, and the generated motion sequences are overall consistent and natural without noticeable jitter. However, as observed in the figure, some deviations in the position of the elbows and knees are visible in certain cases. This phenomenon mainly arises from the uncertainty introduced by sparse node reconstruction, where the same end-effector position might correspond to different elbow and knee poses.
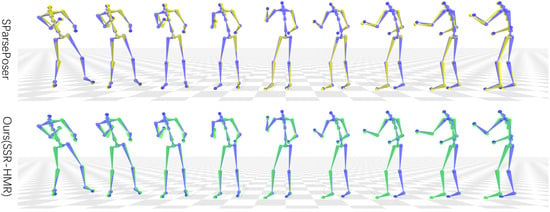
Figure 10.
Qualitative comparison of different methods on the real motion capture dataset. The first row shows the SparsePoser method, and the second row shows our method. Each row displays the motion sequence of the user in a VR game.
Despite these deviations, our method demonstrates better overall reconstruction accuracy for full-body joints and maintains better temporal continuity of motion, with no significant jitter caused by joint uncertainty. This is due to the spatiotemporal correlation modeling capabilities of the spatiotemporal graph convolutions and the optimization of multi-scale velocity loss. Furthermore, compared to SparsePoser, our method shows a clear advantage in the accuracy of the end-effector position. SparsePoser sometimes produces noticeable end-effector offsets, whereas our method maintains a more accurate end-effector position, even when minor errors exist in intermediate joints. This further validates the robustness and accuracy of our method under sparse input conditions.
4.2.3. User Size Evaluation
Adapting pose estimation to users with different body proportions without retraining the network is essential for personalized motion capture and customized VR experiences. Individual differences, such as height and body shape, can significantly impact motion capture accuracy. Traditional methods often rely on IMU sensors and a fixed skeleton structure during training, which limits their adaptability to different users. In contrast, our method utilizes dual quaternions for pose representation, enabling the network to flexibly adapt to various body proportions.
To evaluate the generalization ability of our method across different body types, we conducted experiments using motion capture data collected with the Xsens system provided by SparsePoser. Specifically, we reconstructed motion poses from nine users with different body proportions to assess the model’s adaptability and accuracy. The results demonstrate that our method accurately reconstructs human motion while maintaining robustness across different body types. Figure 11 presents the reconstruction results for users with varying body proportions. Different colors distinguish users, each row represents a different action type, and the blue trajectory denotes the real motion capture data from the dataset.

Figure 11.
Pose reconstruction for users with different body proportions. Each row corresponds to a different action, and each column represents a different user. Different users are visually distinguished, while the blue trajectories represent the real motion capture data from the dataset. Corresponding video at https://github.com/Lucifer-G0/SSR-HMR/blob/main/xsens_nineperson.mp4 (accessed on 17 August 2025).
4.3. Inference Efficiency
To comprehensively evaluate inference performance, we compared the model size and inference speed of different methods. The results are presented in Table 4. FPS data for PIP and HMDPoser were taken from their original papers, while SparsePoser and our model were evaluated on an Intel Xeon E5-2697 v3 @ 2.60GHz CPU (Intel, Santa Clara, CA, USA) and an NVIDIA 2080Ti GPU (NVIDIA, Santa Clara, CA, USA). The inference time per frame was defined as the time taken to process sparse inputs and generate full-body joint rotations and positions. To ensure stable evaluation, inference was repeated 10,000 times, and the average frame rate (FPS) was computed.
Table 4.
Comparison of model size and inference speed. Bold numbers indicate the best results.
Our model exhibits significant advantages in both model size and inference speed. Compared to PIP, SparsePoser, and HMDPoser, our method is more lightweight, with a PyTorch model size of only 12.43 MB, which reduces further to 7.31 MB in ONNX format, significantly lowering storage requirements while enhancing inference efficiency. Benefiting from this compact design, our method achieves 267.13 FPS on the CPU, representing a 4.3× speedup over SparsePoser and a 2.97× improvement over HMDPoser. On the GPU, it reaches 121.83 FPS, outperforming SparsePoser by 4.7× and PIP by 1.95×. Although slightly slower than HMDPoser (0.59×), our method maintains a favorable balance between accuracy and efficiency.
The performance gap between CPU and GPU inference is primarily due to the ONNX input data transfer mechanism. During ONNX-based GPU inference, input data is typically provided by the CPU, requiring each frame to undergo CPU-to-GPU data transfer, which introduces overhead and limits efficiency. In contrast, CPU inference avoids data transfer delays, making better use of computational resources. As a result, our method achieves exceptional inference efficiency on the CPU, making it particularly suitable for edge devices or scenarios with limited GPU resources. This enables real-time motion reconstruction while maintaining a compact model size, ensuring flexibility in real-world deployment.
5. Conclusions
This paper presents SSR-HMR, a skeleton-aware, sparse node-based real-time human motion reconstruction method that achieves high-accuracy full-body joint recovery from sparse motion data. The framework combines a lightweight spatiotemporal graph convolutional module with a torso pose refinement design, effectively reducing torso and head orientation drift. In addition, the incorporation of skeletal kinematic tree constraints and a multi-scale velocity error loss improves both the accuracy of end-effector positioning and the smoothness of reconstructed motion.
Experimental results indicate that SSR-HMR achieves sub-centimeter accuracy with real-time performance under a fixed six-node tracker setup, making it well-suited for VR/AR and motion capture applications. Nevertheless, several limitations remain. The system is tailored to a specific six 6-DoF node configuration, which enables lightweight design and strong accuracy but does not directly generalize to other sensor layouts or reduced input settings. Preliminary evaluation under node-missing conditions without re-training showed noticeable performance degradation, suggesting the need for robustness-oriented extensions. Joint ambiguities, especially in elbows and knees, also remain challenging due to the inherent sparsity of the input. For highly dynamic motions, performance is slightly reduced but remains stable, benefiting from directly available positional signals rather than fully relying on inertial measurements. Finally, deployment in practical scenarios requires attention to privacy, safety, and usability, as noisy or missing signals may lead to unreliable feedback in safety-critical environments, while extreme clothing or severe occlusions remain outside the tested domain.
Future work will explore improving scalability to variable node numbers and placements, leveraging multimodal fusion strategies such as IMU integration, and incorporating physics-based priors to further constrain motion plausibility. In addition, diffusion-based generative models may be introduced to enhance adaptability and expand SSR-HMR’s applicability to broader real-world use cases.
Author Contributions
Conceptualization, L.L.; methodology, L.L. and J.L.; software, L.L.; validation, L.L. and J.L.; formal analysis, L.L.; investigation, L.L. and J.L.; data curation, J.L.; writing—original draft preparation, L.L.; writing—review and editing, J.L. and W.Z.; visualization, L.L.; supervision, W.Z.; project administration, W.Z.; funding acquisition, W.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China Regional Project (grant number 61966007) and Guangxi Natural Science Foundation for the surface project (grant number 2022GXNSFAA035629). The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Code and data supporting the results of this study are available at https://github.com/Lucifer-G0/SSR-HMR (accessed on 17 August 2025). The experimental data were obtained from the publicly available AMASS dataset (https://amass.is.tue.mpg.de/, accessed on 6 August 2025).
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Makled, E.; Gerhardt, C.; Schwandt, T.; Weidner, F.; Broll, W. Evaluating behavioral realism in AR and VR: A comparison of single-point IK and full-body motion capture virtual humans. Vis. Comput. 2025. [Google Scholar] [CrossRef]
- Merriaux, P.; Dupuis, Y.; Boutteau, R.; Vasseur, P.; Savatier, X. A Study of Vicon System Positioning Performance. Sensors 2017, 17, 1591. [Google Scholar] [CrossRef] [PubMed]
- Paulich, M.; Schepers, M.; Rudigkeit, N.; Bellusci, G. Xsens MTw Awinda: Miniature Wireless Inertial-Magnetic Motion Tracker for Highly Accurate 3D Kinematic Applications; Xsense Technol. B.V.: Enschede, The Netherlands, 2018. [Google Scholar] [CrossRef]
- Huang, Y.; Kaufmann, M.; Aksan, E.; Black, M.J.; Hilliges, O.; Pons-Moll, G. Deep inertial poser: Learning to reconstruct human pose from sparse inertial measurements in real time. ACM Trans. Graph. 2018, 37, 185. [Google Scholar] [CrossRef]
- Yi, X.; Zhou, Y.; Habermann, M.; Shimada, S.; Golyanik, V.; Theobalt, C.; Xu, F. Physical Inertial Poser (PIP): Physics-aware Real-time Human Motion Tracking from Sparse Inertial Sensors. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 13157–13168. [Google Scholar] [CrossRef]
- Yi, X.; Zhou, Y.; Xu, F. Physical Non-inertial Poser (PNP): Modeling Non-inertial Effects in Sparse-inertial Human Motion Capture. In Proceedings of the ACM SIGGRAPH 2024 Conference Papers; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Jiang, J.; Streli, P.; Qiu, H.; Fender, A.; Laich, L.; Snape, P.; Holz, C. AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part V. Springer: Berlin/Heidelberg, Germany, 2022; pp. 443–460. [Google Scholar] [CrossRef]
- Zheng, X.; Su, Z.; Wen, C.; Xue, Z.; Jin, X. Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 14632–14642. [Google Scholar] [CrossRef]
- Dai, P.; Zhang, Y.; Liu, T.; Fan, Z.; Du, T.; Su, Z.; Zheng, X.; Li, Z. HMD-Poser: On-Device Real-time Human Motion Tracking from Scalable Sparse Observations. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 874–884. [Google Scholar] [CrossRef]
- Ponton, J.L.; Yun, H.; Aristidou, A.; Andujar, C.; Pelechano, N. SparsePoser: Real-time Full-body Motion Reconstruction from Sparse Data. ACM Trans. Graph. 2023, 43, 5. [Google Scholar] [CrossRef]
- von Marcard, T.; Rosenhahn, B.; Black, M.J.; Pons-Moll, G. Sparse Inertial Poser: Automatic 3D Human Pose Estimation from Sparse IMUs. Comput. Graph. Forum 2017, 36, 349–360. [Google Scholar] [CrossRef]
- Yi, X.; Zhou, Y.; Xu, F. TransPose: Real-time 3D human translation and pose estimation with six inertial sensors. ACM Trans. Graph. 2021, 40, 86. [Google Scholar] [CrossRef]
- Ami-Williams, T.; Serghides, C.G.; Aristidou, A. Digitizing traditional dances under extreme clothing: The case study of Eyo. J. Cult. Herit. 2024, 67, 145–157. [Google Scholar] [CrossRef]
- Yang, D.; Kim, D.; Lee, S.H. LoBSTr: Real-time Lower-body Pose Prediction from Sparse Upper-body Tracking Signals. Comput. Graph. Forum 2021, 40, 265–275. [Google Scholar] [CrossRef]
- Ponton, J.L.; Pujol, E.; Aristidou, A.; Andujar, C.; Pelechano, N. Dragposer: Motion reconstruction from variable sparse tracking signals via latent space optimization. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2024; p. e70026. [Google Scholar] [CrossRef]
- Yao, F.; Wu, Z.; Yi, L. Full-body motion reconstruction with sparse sensing from graph perspective. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; AAAI Press: Washington, DC, USA, 2024; p. AAAI’24/IAAI’24/EAAI’24. [Google Scholar] [CrossRef]
- Bócsi, B.; Nguyen-Tuong, D.; Csató, L.; Schölkopf, B.; Peters, J. Learning inverse kinematics with structured prediction. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 698–703. [Google Scholar] [CrossRef]
- Duka, A.V. Neural Network based Inverse Kinematics Solution for Trajectory Tracking of a Robotic Arm. Procedia Technol. 2014, 12, 20–27. [Google Scholar] [CrossRef]
- Ren, H.; Ben-Tzvi, P. Learning inverse kinematics and dynamics of a robotic manipulator using generative adversarial networks. Robot. Auton. Syst. 2020, 124, 103386. [Google Scholar] [CrossRef]
- Ames, B.; Morgan, J.; Konidaris, G. IKFlow: Generating Diverse Inverse Kinematics Solutions. IEEE Robot. Autom. Lett. 2022, 7, 7177–7184. [Google Scholar] [CrossRef]
- Grochow, K.; Martin, S.L.; Hertzmann, A.; Popović, Z. Style-based inverse kinematics. ACM Trans. Graph. 2004, 23, 522–531. [Google Scholar] [CrossRef]
- Wu, X.; Tournier, M.; Reveret, L. Natural Character Posing from a Large Motion Database. IEEE Comput. Graph. Appl. 2011, 31, 69–77. [Google Scholar] [CrossRef]
- Huang, J.; Wang, Q.; Fratarcangeli, M.; Yan, K.; Pelachaud, C. Multi-Variate Gaussian-Based Inverse Kinematics. Comput. Graph. Forum 2017, 36, 418–428. [Google Scholar] [CrossRef]
- Victor, L.; Meyer, A.; Bouakaz, S. Learning-based pose edition for efficient and interactive design. Comput. Animat. Virtual Worlds 2021, 32, e2013. [Google Scholar] [CrossRef]
- Ponton, J.L.; Yun, H.; Andujar, C.; Pelechano, N. Combining Motion Matching and Orientation Prediction to Animate Avatars for Consumer-Grade VR Devices. Comput. Graph. Forum 2022, 41, 107–118. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Washington, DC, USA, 2018; p. AAAI’18/IAAI’18/EAAI’18. [Google Scholar]
- Andreou, N.; Aristidou, A.; Chrysanthou, Y. Pose Representations for Deep Skeletal Animation. Comput. Graph. Forum 2022, 41, 155–167. [Google Scholar] [CrossRef]
- Zhou, Y.; Barnes, C.; Lu, J.; Yang, J.; Li, H. On the Continuity of Rotation Representations in Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5738–5746. [Google Scholar] [CrossRef]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A Skinned Multi-Person Linear Model. Acm Trans. Graph. 2015, 34, 248:1–248:16. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar] [CrossRef]
- Yun, H.; Ponton, J.L.; Andujar, C.; Pelechano, N. Animation Fidelity in Self-Avatars: Impact on User Performance and Sense of Agency. In Proceedings of the 2023 IEEE Conference Virtual Reality and 3D User Interfaces (VR), Shanghai, China, 25–29 March 2023. [Google Scholar] [CrossRef]
- Mahmood, N.; Ghorbani, N.; Troje, N.F.; Pons-Moll, G.; Black, M. AMASS: Archive of Motion Capture As Surface Shapes. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 5441–5450. [Google Scholar] [CrossRef]
- Kaufmann, M.; Vechev, V.; Mylonopoulos, D. Aitviewer. 2022. Available online: https://github.com/eth-ait/aitviewer (accessed on 10 September 2025).
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Aristidou, A.; Shamir, A.; Chrysanthou, Y. Digital Dance Ethnography: Organizing Large Dance Collections. J. Comput. Cult. Herit. 2019, 12, 29. [Google Scholar] [CrossRef]
- Chatzitofis, A.; Saroglou, L.; Boutis, P.; Drakoulis, P.; Zioulis, N.; Subramanyam, S.; Kevelham, B.; Charbonnier, C.; Cesar, P.; Zarpalas, D.; et al. HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media. IEEE Access 2020, 8, 176241–176262. [Google Scholar] [CrossRef]
- Ghorbani, N.; Black, M.J. SOMA: Solving Optical Marker-Based MoCap Automatically. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11097–11106. [Google Scholar] [CrossRef]
- RootMotion. Final IK. Unity Asset Store. 2017. Available online: https://assetstore.unity.com/packages/tools/animation/final-ik-14290 (accessed on 10 September 2025).










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).