Abstract
Semantic communication (SemCom), as a revolutionary paradigm for next-generation networks, shifts the focus from traditional bit-level transmission to the delivery of meaning and purpose. Grounded in the Data, Information, Knowledge, Wisdom, Purpose (DIKWP) model and its mapping framework, together with the relativity of understanding theory, the discussion systematically reviews advances in semantic-aware communication and personalized semantic security. By innovatively introducing the “Purpose” dimension atop the classical DIKW hierarchy and establishing interlayer feedback mechanisms, the DIKWP model enables purpose-driven, dynamic semantic processing, providing a theoretical foundation for both SemCom and personalized semantic security based on cognitive differences. A comparative analysis of existing SemCom architectures, personalized artificial intelligence (AI) systems, and secure communication mechanisms highlights the unique value of the DIKWP model. An integrated cognitive–conceptual–semantic network, combined with the principle of semantic relativity, supports the development of explainable, cognitively adaptive, and trustworthy communication systems. Practical implementation paths are explored, including DIKWP-based semantic chip design, white-box AI evaluation standards, and dynamic semantic protection frameworks, establishing theoretical links with emerging trends such as task-oriented communication and personalized foundation models. Embedding knowledge representation and cognitive context into communication protocols is shown to enhance efficiency, reliability, and security significantly. In addition, key research challenges in semantic alignment, cross-domain knowledge sharing, and formal semantic metrics are identified, while future research directions are outlined to guide the evolution of intelligent communication networks and provide a systematic reference for the advancement of the field.
1. Introduction
In recent years, communication systems have been undergoing a fundamental transformation [1], moving beyond the traditional Shannon bit-centric model [2] and towards a semantic communication (SemCom) paradigm [3]. The goal of SemCom is to convey meaning and achieve correct understanding at the receiver end. This shift is driven by the demands of 6G networks and artificial intelligence (AI)-native communication systems, which aim to enhance efficiency by filtering out redundant data and exchanging only the core information necessary to complete specific tasks. Classical information theory focuses on the accurate transmission of symbols (bits) through a channel, without considering their semantic content and treating all bits equally [4]. SemCom has been proposed as a novel paradigm to overcome these limitations [5]. In this paradigm, user intent is explicitly taken into account in the communication process [6]. Moreover, contextual knowledge and communication goals are incorporated to ensure that the conveyed message reflects the intended meaning, rather than merely reproducing the transmitted symbols [7]. By omitting parts that can be inferred from the receiver’s context, this approach reduces bandwidth consumption, improves the reliability of task outcomes, and facilitates more natural human–machine interaction.
As this trend continues, researchers are increasingly recognizing that communication and security mechanisms must become personalized and context-aware [8]. Different users or agents may interpret the same message differently due to variations in their prior knowledge and background. When semantic meaning becomes central to communication, traditional “one-size-fits-all” approaches to messaging and encryption are no longer adequate [9]. This realization has prompted the exploration of frameworks that account for individual knowledge and understanding differences during communication [10] and has given rise to the concept of semantic security—namely, the protection of the meaning of messages and ensuring that only recipients with appropriate knowledge or context can interpret them correctly. Semantic security goes beyond traditional bit-level encryption, as attacks or information leaks may occur at the level of meaning [11,12]. For example, an adversary may infer sensitive facts from contextual clues without needing to access the original plaintext. Consequently, ensuring confidentiality, integrity, and correct understanding in SemCom (sometimes referred to as secure semantic communication, or secure SemCom [13,14]) has become a complex challenge at the intersection of cryptography, artificial intelligence, and communication engineering.
Within this context, the Data, Information, Knowledge, Wisdom, Purpose (DIKWP) model has gradually emerged as an integrated framework bridging data communication, knowledge representation, and cognitive personalization [15]. Based on the well-known Data, Information, Knowledge, Wisdom (DIKW) hierarchy [16,17], the DIKWP model introduces an additional top-level element: “Purpose”. This extension explicitly incorporates the goals or intentions of the cognitive agent into the model, emphasizing the purpose-driven interpretation and use of data. As such, the DIKWP model provides a structured approach to understanding how raw data are progressively transformed into wisdom and action under the guidance of intent. More importantly, it does not treat the five elements (D, I, K, W, P) as a simple linear hierarchy but constructs them as an interconnected network system with interlayer interactions and feedback mechanisms.
The concept of DIKWP × DIKWP mapping refers to the fully connected set of possible transformations between all layers of the DIKWP model, forming a 5 × 5 transformation matrix [18]. This framework encompasses both “bottom-up” pathways (e.g., Data → Information → Knowledge → Wisdom → Purpose) and “top-down” or “lateral” feedback pathways (e.g., higher-level Purpose or Knowledge influencing how lower-level data are collected and interpreted). This mechanism is highly consistent with the essence of SemCom: it not only focuses on building high-level semantics from data but also emphasizes using existing knowledge and goals to select, filter, and even generate the data required for communication.
Another pillar of the DIKWP model is the relativity of understanding [19], which formalizes how misunderstandings can arise in personalized SemCom. Its core argument is that the process of understanding depends on an individual’s cognitive space (CogN) [20]. It also relies on the structure of the concept space (ConC) that organizes and constrains meaning [21]. Furthermore, the semantic space (SemA) provides a computational framework for interpreting and categorizing experiences [22]. Misalignment between these spaces can lead to semantic misinterpretations between the sender and receiver. CogN refers to an individual’s internal cognitive context (e.g., experience, focus of attention); ConC refers to how one defines and relates concepts (i.e., their mental ontology); and SemA refers to the associative network and implied meanings that these concepts carry for the individual. If two communicating agents have different definitions or semantic associations for a particular term, misunderstandings are likely to occur. For instance, the symptom “chest tightness” may carry very different connotations for a doctor and a patient, potentially leading to diagnostic errors.
The relativity of understanding theory emphasizes the identification and quantification of such differences and suggests iteratively optimizing mutual understanding by clarifying the context, adjusting language, and providing feedback. This is particularly critical for personalized SemCom, as the theory suggests that communication systems—especially human–AI systems—must be equipped with mechanisms to detect when the receiver’s interpreted meaning deviates from the sender’s intended one and to correct it in a timely manner.
This paper aims to systematically explore how the DIKWP model and its associated theories empower the two emerging domains of SemCom and personalized semantic security. The main contributions of our study are as follows: we begin by elaborating on the theoretical foundations of the DIKWP model, the DIKWP × DIKWP mapping mechanism, and the relativity of understanding theory. We then review and compare other SemCom models, knowledge representation frameworks in communication, personalized AI systems, and intelligent communication security mechanisms proposed by various researchers, analyzing their similarities and differences regarding DIKWP. We further examine the practical implementability of DIKWP-based approaches (e.g., semantic chips, semantic firewalls) and summarize reported applications and experimental practices. Lastly, we identify emerging trends, unresolved challenges, and research gaps in this interdisciplinary field.
The significance of this work lies in providing a comprehensive and systematic review of the DIKWP model, integrating recent advances across cognitive science, artificial intelligence, communications, and security. Specifically, this study makes the following contributions: it formalizes the DIKWP × DIKWP mapping and demonstrates its operational value through a 25-module example; it incorporates the relativity of understanding theory to explain how differences in cognitive, conceptual, and semantic spaces affect personalized semantic communication; it systematically compares DIKWP with established approaches such as Shannon’s information model, deep learning-based semantic communication, and knowledge graph frameworks, highlighting their complementarities and limitations; and it surveys representative applications, including semantic chip design, white-box AI evaluation, and personalized semantic security strategies. Taken together, these contributions illustrate how the cognitive–semantic modeling approach embodied in DIKWP can transform communication networks into systems that are more intelligent, personalized, and inherently secure. We argue that this framework provides a practical roadmap for overcoming the “Shannon trap”—the limitation of focusing solely on syntactic accuracy—and for advancing a new era of semantic communication in which “the right information is delivered to the right person at the right time.”
2. Methodology of the Systematic Review
This study followed a systematic literature review approach to gather and synthesize research from multiple domains (communications, artificial intelligence, knowledge representation, and security) related to SemCom and the DIKWP model. We adhered to guidelines inspired by PRISMA [23] for transparent reporting. The review process involved several steps: defining the research questions, searching the literature, screening for relevance, and extracting and analyzing data.
2.1. Search Strategy
We conducted comprehensive searches in major scholarly databases and digital libraries, including IEEE Xplore, ACM Digital Library, Springer, Elsevier (ScienceDirect), MDPI, arXiv, and Google Scholar. The search terms were chosen to cover the key concepts of interest. Primary keywords included “DIKWP”, “semantic communication”, “semantic information theory”, “knowledge representation communication”, “personalized AI”, “semantic security”, “semantic firewall”, “cognitive communications”, and “knowledge graph communication”. We also used Boolean combinations, such as “semantic communication” AND (security OR privacy), “semantic communication” AND (knowledge OR ontology), “DIKW” AND “Purpose”, “relativity of understanding”, “semantic understanding communication”, etc. References in relevant papers were recursively scanned to find older foundational works (backward snowballing), as well as to identify any newer papers citing these works (forward snowballing via Google Scholar’s citation feature). We imposed a recency filter to focus on the last ~8 years (2017–2025) for cutting-edge developments, while also including seminal older works (e.g., Shannon and Weaver [24], Carnap and Bar-Hillel [25])to provide background.
2.2. Inclusion and Exclusion Criteria
We included publications that explicitly addressed one or more of the following:
- the DIKW pyramid or its extensions (especially DIKWP) in the context of computing or communications;
- SemCom theories or system implementations;
- personalization of AI or user-centered semantic models;
- security/privacy in semantic or cognitive communications;
- knowledge representation for communication (e.g., use of knowledge graphs (KGs), ontologies in network systems);
- explainable or cognitive communications (e.g., “cognitive networking”) that involve a knowledge plane.
After obtaining the initial search results (over 300 hits), we screened the titles and abstracts to filter out obviously irrelevant ones and then read the full texts of the remaining ~120 publications. Ultimately, about 100 sources were selected as the core references for this review, encompassing theory papers, surveys, and experimental studies.
2.3. Data Extraction and Synthesis
Each included work was analyzed for its contributions and viewpoints on SemCom and related areas. We extracted key points such as definitions of SemCom, proposed system architectures, any mathematical frameworks (e.g., semantic entropy definitions, metrics), approaches to personalization (like training methods for personalized models), and approaches to security (attack models and defenses at the semantic level). For works on DIKWP, we extracted descriptions of the model, any diagrams (some of which we reproduce in textual form or refer to), and results or examples given. We paid attention to any comparative discussions in these sources (some survey papers compared various SemCom strategies; we used these to build comparison tables). Where possible, data were tabulated—for instance, we tabulated the main features of frameworks (as seen later in the comparative analysis). Given the interdisciplinary nature, we also maintained a glossary of terms (such as concept space, semantic space, knowledge graph (KG), semantic noise, semantic fidelity, etc.) to ensure consistency in how we interpreted and reported each term in context—this was important because the same term (like “semantic security”) can have different meanings across fields (cryptographers define “semantic security” in a specific way that is unrelated to semantic meaning, whereas, in communications, we mean securing meaning).
2.4. Quality Appraisal
To ensure high-quality evidence, we prioritized high-impact journals (e.g., IEEE Transactions, Nature family journals) and well-cited surveys or seminal conference papers. We cross-verified claims when possible—e.g., if one paper claimed a certain advantage of SemCom, we looked for any experimental evidence or counterpoints in other works. While our review is qualitative, wherever quantitative results from studies are available (for instance, improvements in bandwidth efficiency or reductions in error rates when using semantic techniques), we mention these to give a sense of the impact. All sources are cited using a numbering format (with cursor numbers linking to full references), preserving attributions as per the instructions.
By following this systematic approach, we aimed to reduce bias and present a balanced and comprehensive overview. However, we acknowledge that the fields covered are rapidly evolving; thus, this review captures the state of the art as of 2025, and some very recent developments (i.e., late-2025 breakthroughs) might not yet be reflected. Nevertheless, the inclusion of numerous 2023–2025 references ensures that emerging ideas (like foundation models for semantic communication, standardization efforts, etc.) are covered.
3. Foundations: DIKWP Theory, DIKWP Network Model, and Semantic Relativity
In this section, we present the foundational concepts necessary for understanding the rest of the review. We begin with an explanation of the DIKWP model, including the meaning of each layer and how this model extends the classic DIKW hierarchy. We then describe the DIKWP network model, which considers the interplay and feedback among these layers (sometimes called a DIKWP “graph” or “networked DIKWP”). This naturally leads to the idea of the DIKWP × DIKWP mapping, essentially the set of all possible transformations between any two layers of DIKWP (a 5 × 5 matrix of modules). Finally, we delve into the relativity of understanding theory (also referred to as the relativity of CogN/SemA), which provides insight into personalized meaning and how the DIKWP model accounts for differences in understanding between individuals.
3.1. The DIKWP Model: Extending Data–Information–Knowledge–Wisdom with Purpose
The DIKWP model is an extended version of the classic DIKW hierarchy model in the field of information science. In the traditional DIKW hierarchy [26], the system starts with raw data—symbols, signals, or observations that lack context or semantics. These data are then transformed into information, which refers to data endowed with context or structure and can answer basic questions such as who, what, when, and where. Furthermore, information is abstracted into knowledge—organized information, patterns, or models that can address questions of how. Finally, knowledge is refined into wisdom, which represents the application of knowledge in the form of principles or insights that answer why-type questions or guide effective decision making. The DIKW model is typically visualized as a pyramid to reflect the progressively abstract and value-adding nature of semantic layers.
However, the traditional DIKW model has notable shortcomings. It does not clearly define the mechanisms for transitioning between levels, nor does it specify the driving forces behind upward progression through the hierarchy. Additionally, some studies suggest that an intermediate concept called Understanding should be included between Knowledge and Wisdom [27]. The DIKWP model addresses these issues by introducing a Purpose layer into the classic DIKW model. The Purpose layer sits at the top of the DIKWP model and reflects that the processes of generating and utilizing data, information, knowledge, and wisdom are driven and guided by clear objectives. In other words, the needs and goals of the cognitive subject determine and permeate the implementation of each stage in the cognitive process.
A comparative summary of the five DIKWP elements is provided in Table 1, which offers a substitute for a lengthy descriptive list.

Table 1.
The five elements of the DIKWP(Data, Information, Knowledge, Wisdom, Purpose) model.
It is important to note that, while DIKW was often viewed as a linear pyramid, DIKWP is not purely linear. Each layer still represents a level of abstraction, but the model underscores that the process of moving from D to I to K to W is guided at each step by Purpose. In fact, understanding (in human cognition) and intelligent behavior are seen as iterative processes that continuously reference the agent’s goals. For instance, “extracting useful information from raw data, integrating information into knowledge, and making wise decisions based on knowledge are all guided by the ultimate goal (purpose)”. This quote highlights that, at every transition, the cognitive system checks against its purpose: which data to look at (driven by what it is trying to achieve), which knowledge to apply, etc. Thus, Purpose is both the top of the pyramid and an active influence that trickles down throughout the cognitive process.
To illustrate the DIKWP concept, consider a simple scenario: a smart personal assistant that helps a user to maintain health. Here, raw sensor readings (heartbeat, steps, etc.) are data. Information could be derived by contextualizing these readings (e.g., heart rate is 120 bpm while exercising at 5 p.m., above the resting rate). Knowledge is the aggregation of such information with medical understanding (120 bpm during moderate exercise is slightly high for this age—indicating that the user may be stressed or not fit—suggesting knowledge rules linking patterns of exercise and heart response). Wisdom might be personalized health advice (e.g., “it’s best to slow down your run and hydrate to avoid overexertion”). The purpose for this assistant might be “keep the user healthy and safe during exercise.” With this purpose, the assistant will actively look for certain data (e.g., sudden spikes in heart rate), interpret them in this light, and decide whether to alert the user. If the purpose is changed (e.g., the user’s goal is performance optimization for an athlete, not safety), the whole pipeline would adjust: it might push the user harder rather than telling them to slow down. This is shown in Figure 1. This example demonstrates how purpose-driven behavior manifests across the DIKWP layers.
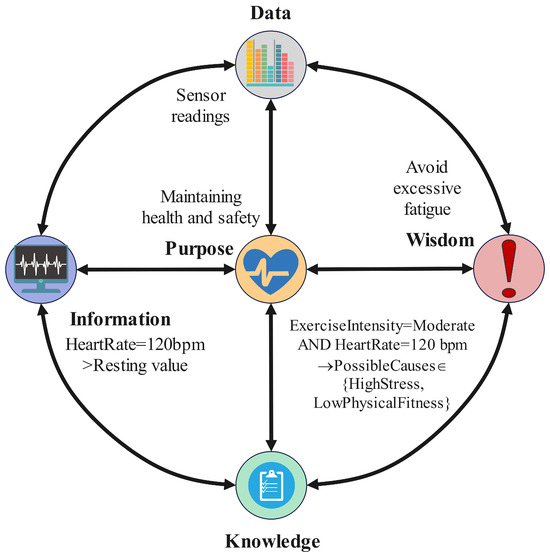
Figure 1.
An example of a purpose-driven DIKWP workflow in a smart health assistant.
3.2. DIKWP Network Model and 5 × 5 Transformation Modules (DIKWP × DIKWP Mapping)
A key innovation within the DIKWP framework lies in treating the DIKWP model as an interconnected network system rather than a strictly unidirectional hierarchy, an approach termed the DIKWP network model or networked DIKWP. In this model, the five elements (D, I, K, W, P) are defined as nodes within a network, interconnected by directed edges representing transformation processes between layers. This network-oriented perspective arises from the inherent feedback loops and nonlinear interactions present in cognitive and communication processes. For instance, not only can data generate information, but existing knowledge also influences how data are perceived, reflecting the top-down perception phenomenon known from cognitive science. Additionally, purpose determines which information is actively sought and prioritized. Thus, the DIKWP network model highlights the close interconnections among the five components, forming an integrated cognitive–conceptual–semantic interaction structure spanning multiple mental spaces.
Hereafter, we denote the five layers as D (Data), I (Information), K (Knowledge), W (Wisdom), and P (Purpose). Moreover, the model formalizes this network system through the concept of “5 × 5 transformation modules”, which enumerate all possible transformations among the five layers, resulting in 25 distinct transformation relationships or modules. Each relationship between layers represents an independent transformation module or subprocess that describes the interaction and transition mechanisms between layers. Common “bottom-up” transformation modules include the following:
- : transforming raw data into meaningful information (e.g., feature extraction, as in converting sensor readings to a recognizable event);
- : generalizing or aggregating information into structured knowledge (e.g., building a KG or model from a collection of information);
- : applying reasoning on knowledge to derive insights or decisions—essentially the step of generating wise judgment from known facts (e.g., using a knowledge base of symptoms to decide on a diagnosis);
- : (if we consider upward as well)—arguably aligning one’s actionable wisdom with the overarching goal (although, in practice, Purpose is more of a guiding constant, but one could imagine refining one’s goals after gaining wisdom).
It also includes downward or feedback transitions:
- : guiding decision-making criteria based on goals (e.g., our purpose will influence which among multiple “wise” choices we consider optimal);
- : using high-level principles to update or refine the knowledge base (for instance, lessons learned from a decision are fed back into the knowledge store as new knowledge);
- : using existing knowledge to reinterpret or filter information (for example, knowledge of language helps to parse a sentence to obtain information from it);
- : deciding which raw data to pay attention to or how to encode them based on current information needs (for instance, focusing sensors on a particular area because the current information suggests something of interest there).
Additionally, intralayer transformations like (e.g., data cleaning or reformatting), , etc., are considered part of the 25 modules as well.
To make the 5 × 5 DIKWP mapping operational, we map one concrete sentence through each of the 25 transformation modules (from/to ), as summarized in Table 2. We reuse the smart health context introduced earlier.
Table 2.
Concrete outputs for each DIKWP transformation on sentence S; the "Module" column uses arrow notation with .
Example sentence S: “At 5 p.m. during exercise, the user’s heart rate reached 120 bpm.”
For design and evaluation, we specify, for each module, (i) the operator family (algorithm or logic), (ii) the input/output schema, and (iii) the evaluation metrics. Typical metrics include semantic task success (whether the intended effect is achieved), alignment errors (the deviation between the receiver’s and the sender’s intent), compression/latency/energy, and safety (false alarms and omissions). In communication studies, we transmit only the semantically necessary artifacts (e.g., I or K units instead of raw D) and evaluate the end-task performance under channel impairments.
By mapping the research contributions from various artificial intelligence researchers onto the modules mentioned above, the positions of different AI subfields within the DIKWP mapping matrix become clear. For instance, researchers in perception and pattern recognition, such as Yann LeCun in computer vision [28], primarily contribute to the data-to-information and data-to-knowledge modules. They focus on transforming raw data, such as image pixels, into structured representations and learned features—namely, information and knowledge. Conversely, Judea Pearl’s work on causal reasoning foregrounds the knowledge-to-wisdom module by showing how knowledge supports decision making and answers “why” questions [29]. Similarly, Stuart Russell’s research on decision planning illustrates how knowledge can be operationalized to make effective decisions within this module [30]. This mapping approach is insightful, demonstrating that the DIKWP framework can serve as a unified perspective with which to categorize artificial intelligence technologies clearly. For example, the lower-left corner of the matrix corresponds to signal processing domains, while the upper-right section corresponds to decision theory areas.
Here, the most critical conclusion is that the DIKWP × DIKWP mapping allows us to interpret any cognitive operation as a transformation between layers. Each such operation can be considered an independent “transformation module”, potentially subject to design, analysis, and optimization. For example, the data-to-information module can be implemented through algorithms involving feature extraction or semantically labeled data compression; the knowledge-to-data module (a reverse operation) can represent the generation of synthetic data from existing knowledge, such as data produced by model-driven simulations for data augmentation purposes; and the purpose-to-data module can describe goal-oriented data collection, such as actively querying specific sensors based on a given objective. Specifically, the network model explicitly states that the data graph (DG)—representing all data within the system—can receive input from the IG, KG, WG, and PG through transformation functions denoted as , respectively. More explicitly, the DG acts not only as the starting point for information processing but also as the result of feedback adjustments from Knowledge, Wisdom, or Purpose. The DG dynamically receives inputs from Information, Knowledge, Wisdom, and Purpose through the transformation functions , thus enabling dynamic updates and adjustments. This structure clearly illustrates the closed-loop characteristic of cognitive processing, where higher-level cognitive outcomes can drive new data collection or modifications of existing data—for instance, decisions at the wisdom layer may trigger new behaviors and generate additional data, or the Purpose layer may require collecting different types of datasets.
From a SemCom perspective, the DIKWP network model is powerful. It suggests that communication between two parties can be thought of as mapping one party’s DIKWP state to the other’s DIKWP state. Conceptually, full DIKWP → DIKWP communication would involve many of these transformation modules in tandem. For example, when person A communicates with person B, the following might occur:
- Person A has a Purpose (intended meaning or goal to convey) and some Knowledge/Wisdom backing it;
- They encode some Information into Data (choosing words, signals) to send—this is a Purpose/Knowledge → Information → Data path on A’s side;
- Person B receives Data and tries to transform them into Information and then into Knowledge that aligns with some Purpose (either B’s own purpose or understanding A’s purpose)—this is Data → Information → Knowledge (and maybe aligning with Purpose) on B’s side;
- Communication succeeds if B’s reconstructed Knowledge/Wisdom aligns with A’s intended Knowledge/Wisdom (i.e., if B’s understanding matches A’s Purpose-driven message).
Any mismatch at any module (data corruption, information misinterpretation, concept mismatch in knowledge, or differing purposes causing misalignment) can cause misunderstanding. The relativity theory, discussed next, addresses these mismatches at the concept and semantic levels specifically.
3.3. Relativity of Understanding Theory: Cognitive, Concept, and Semantic Space Discrepancies
The relativity of understanding theory provides a conceptual framework for analyzing and mitigating misunderstandings in SemCom. According to this theory, different individuals or systems possess unique internal representations and cognitive contexts. Hence, “understanding” is fundamentally relative, and no absolute meaning exists independently of cognitive agents. To structure this concept clearly, the theory defines three key spaces.
- ConC: Refers to the set of concepts and their definitions held by a cognitive agent, similar to an internal dictionary or ontology-like structure. ConC encompasses concepts expressed in certain forms (e.g., language), including their definitions, features, and interrelationships. For example, an agent’s ConC might define a “car” as a transportation tool with four wheels. Formally, ConC can be represented as a graph structure , where nodes represent concepts and edges denote relationships among them. Each concept can have attributes and be linked to other concepts, forming a personalized KG. ConC is independent across agents, meaning that each cognitive agent independently constructs their own concept definitions, potentially differing from those of other agents. Such differences are termed “ConC independence”.
- SemA: Represents the associative and semantic connections among concepts built by cognitive agents through their experiences and accumulated knowledge. While ConC focuses on explicit definitions, SemA emphasizes contextual meaning and associations between concepts derived from personal experiences. For instance, in an individual’s SemA, the concept “car” might evoke associations with driving, fuel consumption, or traffic, representing experiential connections. SemA can thus be viewed as a network of associations and functional relationships beyond simple hierarchical categorizations of concepts. SemA is subjective; merely sharing ConC definitions does not ensure complete semantic sharing. For example, two agents might define a “cloud” as “a visible condensation of water vapor”, yet one might associate “cloud” with rainy weather or a melancholy mood, while another associates it with coolness or agricultural activities. Such differences constitute “semantic space differences”, illustrating that different agents form distinct semantic networks around the same concepts.
- CogN: Refers to the overall cognitive environment where understanding occurs, integrating both ConC and SemA and influenced by perception and purpose. CogN is described as a multidimensional dynamic processing environment in which data, information, knowledge, wisdom, and purpose continuously interact and transform. Specifically, CogN reflects an agent’s dynamic mental state when processing information, including what the agent perceives, focuses on, and contemplates at a particular moment. CogN possesses relativity, as cognitive states vary significantly across different agents and even within a single agent over time. During communication, the sender’s CogN generates the message, while the receiver’s CogN attempts to interpret it. Even when ConC definitions are identical, differences in CogN—such as varying focuses or contextual backgrounds—can still lead to misunderstandings or distortions in communication.
The core idea of the theory of the relativity of understanding can be summarized as follows: Understanding = f(CogN, ConC, SemA). This formula states that understanding is the joint result of CogN, ConC, and SemA, and these factors inherently vary among different individuals. Therefore, communication processes must explicitly address and bridge these individual differences. The theory identifies several typical causes of misunderstanding.
- Misunderstanding in CogN: This type of misunderstanding occurs when the receiver’s cognitive state leads to interpretations that deviate from expectations. For example, when a patient describes symptoms in a certain manner, a physician focusing excessively on a specific hypothesis may incorrectly interpret the symptoms as indicating another condition. Additionally, a receiver whose attention is distracted or situated in a different cognitive context may also experience misunderstandings. Resolving CogN-related misunderstandings generally involves maintaining attentiveness and actively prompting comprehensive questioning. For instance, physicians should guide patients to provide more detailed descriptions, thereby aligning their CogN effectively.
- Misunderstanding in ConC: These misunderstandings occur when communicating parties attribute different definitions to the same terminology. For instance, a patient might describe “chest tightness” as mild discomfort, whereas the physician’s definition of the same term might imply a more severe sensation of pressure. Although both parties use the same term, their conceptual definitions do not fully match. The key to resolving misunderstandings of this type lies in clarifying the definitions—for instance, asking the patient to describe the sensation differently or requesting further explanation—thus aligning the respective ConC.
- Misunderstanding in SemA: Misunderstandings arising from differences in associative or contextual meanings between individuals. For example, a patient might associate certain symptoms with dietary issues, considering them indigestion, while a physician might connect the same symptoms with heart conditions. Although both discuss identical symptoms, their semantic associations differ significantly. Addressing these misunderstandings requires leveraging domain-specific knowledge to reason and exclude less likely explanations and communicating in terms familiar to the receiver. In this scenario, the physician would utilize accessible language to explain the causes to the patient clearly, ensuring semantic alignment and enhanced understanding.
By breaking down understanding into these components, the theory provides a roadmap for personalized SemCom. It implies that, to achieve mutual understanding, communicators (or communication systems) should achieve several goals.
- Recognize individual differences: Differences in background knowledge, experience, and context mean that the same message may not yield the same understanding, e.g., a weather report using the term “cloudy” conveys different meanings to a layperson vs. a pilot. Thus, systems should not assume uniform interpretation.
- Establish common ground: Align concept definitions (like agreeing on terminology). In networking terms, this is like exchanging or negotiating a semantic schema or ontology before deep communication.
- Use feedback mechanisms: Identify misunderstandings by checking if the receiver’s reaction or response indicates a gap. In human conversation, we naturally do this with phrases like “Do you know what I mean?” or noticing confusion and then rephrasing. A SemCom system might similarly require an acknowledgment step to confirm semantic alignment.
- Adapt language or medium: Possibly rephrase information in terms familiar to the receiver (like a doctor switching to layman terms for a patient). In an AI context, this could mean using the receiver’s own known vocabulary or data patterns.
- Personalize security as well (tying to later sections): If meaning can differ per person, one could exploit this for security—e.g., encode a message in terms that only the intended receiver’s SemA would resolve correctly (a form of semantic steganography or personalized encryption). Conversely, one must ensure that an unintended receiver with a different SemA indeed cannot correctly interpret it (providing confidentiality through obscurity of context).
Within DIKWP, relativity of understanding maps to the idea that Purpose and Knowledge shape one’s ConC/SemA. Each person’s DIKWP graph will be unique; their data → information pipeline could produce a different interpretation for the same input data if their Knowledge or Purpose differs. This underscores why personalized AI communication is necessary: a standardized one-size semantic encoder/decoder may fail if it does not account for the user’s context (we will see later in surveys that personalized SemCom is an active research area, addressing exactly this challenge).
In summary, the relativity of understanding theory contributes an analytical lens for SemCom by pointing out where alignment must be achieved.
- Align ConC: Ensure that terms and references have shared meaning (which often involves establishing or referring to a common ontology or protocol).
- Align SemA: Ensure that context and associations are understood (perhaps by sending metadata or related context that disambiguates meaning).
- Align CogN: Ensure that the timing, focus, and modality of communication suit the receiver (e.g., do not send crucial info when the user is overloaded with other tasks; in networks, this could mean scheduling messages when resources are free or, in human–AI interaction, presenting information when the user is attentive).
These foundational concepts—the hierarchical structure of the DIKWP model, purpose-driven cognitive modeling, and the relativity of semantic understanding—form the basis for our subsequent analysis of relevant SemCom models and theories. In the following sections, we will examine SemCom models proposed by other researchers and explore how they align with or complement these theoretical constructs.
4. Related Models in SemCom
SemCom, broadly defined, is a communication paradigm where the correctness and efficiency of communication are judged not by bit-level fidelity but by semantic fidelity—i.e., how accurately the meaning intended by the sender is interpreted by the receiver. This idea traces back to the early days of information theory. Weaver [24] articulated three levels of communication problems: Level A—the technical problem (accurately transmitting symbols), Level B—the semantic problem (conveying the desired meaning of those symbols), and Level C—the effectiveness problem (the effect of the received meaning on behavior). Shannon’s mathematical theory addressed primarily Level A (and, indirectly, aspects of Level C in terms of signaling strategy), deliberately sidestepping semantics (Level B) as “irrelevant to the engineering problem.” However, Weaver himself noted that, in many cases, the critical issue is whether the meaning understood equals the meaning intended.
In this section, we review key models and frameworks from other researchers that have extended or reimagined communication systems to explicitly handle semantics. We categorize them into (1) theoretical frameworks for semantic information (extending information theory to semantics), (2) system architectures for SemCom (often AI-driven encoders/decoders), and (3) knowledge-centric frameworks that incorporate knowledge bases or ontologies into communication. We will see how these relate to or differ from the DIKWP approach described earlier.
4.1. Shannon–Weaver and Early Semantic Information Theory
One of the earliest attempts to quantify semantic information was by Carnap and Bar-Hillel [25], who tried to define the “amount of information” in a logical statement in terms of semantics (they treated information content as the reduction in possible worlds consistent with a statement). Their work was more philosophical and did not result in a practical measure widely used in engineering, but it set the tone for semantics to be discussed in information-theoretic terms. Later, the philosopher Fred Dretske [31] and Luciano Floridi [32] revisited these topics, debating the nature of semantic information. These efforts, however, mostly stayed in the theoretical or philosophical realms and did not directly produce engineering methodologies for communications.
In the engineering community, interest in semantics faded for a while, as digital communications achieved great success using Shannon’s paradigm (ensuring nearly error-free bit delivery with channel coding, etc.). Only recently, motivated by AI and 6G, have researchers begun formulating a semantic information theory. One common notion introduced is semantic entropy—analogous to Shannon entropy but measuring uncertainty over meanings instead of bit strings. For instance, one could consider a source that emits messages with certain meanings and define semantic entropy in terms of a distribution over meanings. There is also the concept of semantic distortion and semantic noise, with distortion meaning the difference between the intended meaning m and interpreted meaning at the receiver and semantic noise referring to anything that causes such a difference (which might not be literal noise but could be, e.g., differences in context or a machine learning model’s error).
Recent theoretical works have started exploring these ideas. For example, Bao, O’Shea, and others [33,34] suggested that the goal of SemCom is to maximize task performance or meaning similarity rather than bit accuracy. They introduced metrics like the “semantic success rate” (did the receiver achieve the desired task after receiving the message?) and studied theoretical limits like the semantic channel capacity (maximum rate of meaning conveyance). Another concept is the information bottleneck (IB) principle applied to semantics—effectively compressing the message in such a way that it retains relevant information for the task (this principle has been used in designing AI encoders that drop irrelevant details, focusing on semantic essence).
While these theoretical explorations do not directly yield a framework like DIKWP, they provide mathematical justification regarding why sending semantics can be more efficient. For instance, if a sender and receiver share a knowledge base, the sender can send a shorthand or partial information that the receiver’s knowledge base can use to infer the full meaning. This is sometimes described as both ends having a common language or knowledge. Shannon’s trap is the idea that focusing on sending all bits reliably might waste resources on bits that are not needed for understanding. The new theory suggests focusing on the core informatic units that influence meaning (which might be, e.g., certain keywords in a sentence or certain features in an image that are relevant to what the receiver needs).
4.2. AI-Driven SemCom Systems (Deep Learning Approaches)
A prominent line of research is to design actual communication systems (transmitter/receiver designs) that incorporate semantics using machine learning, particularly deep learning. In 2021, Xie, Qin, and others [35] proposed a deep learning-enabled SemCom system. The idea is to train an autoencoder: the transmitter is a neural network that encodes a source (text, image, etc.) into a signal to send over a channel, and the receiver is a neural network that decodes the signal back to the source content. However, unlike traditional compression, which tries to reconstruct the exact source, these systems are trained with a semantic fidelity criterion—often by integrating a natural language processing (NLP) or computer vision task into the objective. For example, rather than training the autoencoder to minimize the pixel error for images, one might train it to minimize the error in an image classification task outcome. In one of Xie et al.’s papers, they defined a “text SemCom” where the goal was for the receiver to reconstruct sentences that had the same meaning as the original, possibly not word-for-word but capturing the intent. By using a pretrained language model to judge similarity, they achieved huge compression, sending just a few symbols per sentence and still allowing the core message to be understood.
This approach treats the communication problem as an end-to-end learning problem. The semantic encoder at the transmitter detects and extracts the meaningful features of the source (e.g., a sentence’s embedding vector). The semantic decoder at the receiver then interprets these features into a reconstructed message or directly into a task output (like an answer to a question). Importantly, these learned encoders/decoders often need to share a model or weights—analogous to sharing a “language” or “knowledge”. Some works have both the transmitter and receiver share a common pretrained deep model (like BERT for language) so that they have aligned representations.
While effective, these approaches can be “black boxes”, lacking interpretability. This is a point where DIKWP’s emphasis on knowledge and purpose can potentially help—by adding structure or constraints to what the encoder should consider important (e.g., if we know the Purpose, we might tailor the encoding to it, rather than allowing a neural net to interpret it implicitly). Nonetheless, these systems have shown benefits.
- Bandwidth reduction: For example, DeepSC (2021) by Xie et al. [35] achieved successful text transmission with far fewer bits than a standard source-channel coding approach would by focusing only on semantic content.
- Robustness in low SNR: Because the system does not aim to correctly interpret every bit, it can still succeed in conveying meaning even if the channel is noisy, as long as the key features emerge. In fact, semantic systems can leverage error correction at the meaning level—for instance, if part of a sentence is garbled, a language model can fill in a plausible blank.
A key requirement for these systems is shared context or knowledge. Some researchers incorporate explicit knowledge: for example, Huang and Yang (2022) [36] proposed a system where a KG was shared and used in encoding. In their approach, they convert sentences into triplets (subject–predicate–object triples, a basic unit of KGs) as the semantic representation. By transmitting these triplets (perhaps with priority to the most important ones) instead of full texts, the system can be more efficient and robust. If the channel is very poor, it might send only the single most critical triplet of a sentence (e.g., from “Steve Jobs founded Apple in 1976 after leaving college”, it might choose “SteveJobs—founded—Apple” as the most important aspects, skipping details like the year or college). The receiver, knowing the KG context, could still infer the meaning (i.e., Jobs founded Apple, possibly inferring the rest or considering it less crucial). This approach demonstrated significantly improved reliability under low signal-to-noise ratio (SNR) conditions, precisely because it was semantic-aware and prioritized important content.
Another notable concept is goal-oriented (task-oriented) communication. Proposed by researchers like Strinati and Popovski [37] in the 6G context, the idea is that the success of communication should be measured by task completion. For example, if a user asks an AI agent a question, the goal is to ensure that the correct answer is communicated, not necessarily the entire dataset. If a few key bits can achieve the task, this is enough. This is essentially aligning with the “purpose” of communication. In a way, it resonates with DIKWP’s Purpose layer—the communication system knows the purpose (the question to answer) and only transmits information that contributes to fulfilling this purpose. Petar Popovski (2020) [38] gave an example: instead of a sensor sending all raw measurements to a fusion center, which then decides if an event has occurred, the sensor could just send “Event detected: YES” or “NO” based on a local decision, fulfilling the goal with minimal data. This is a simple form of semantic compression, focusing on relevant outcomes.
To summarize, modern SemCom system architectures often consist of the following:
- Semantic Encoder: This could be a deep neural network that converts input data into a compact representation, using knowledge of the source modality (text, image) and sometimes external knowledge bases.
- Channel Encoder: This is optional if merging with a semantic encoder, but some designs integrate them—it still performs physical-layer adaptation.
- Channel Decoder: This decodes the signal from the physical layer.
- Semantic Decoder: This interprets the representation into output content or directly into a response or action.
Many prototypes have been built in simulation, e.g., transmitting images with only the necessary features to classify them at the receiver (so that the receiver obtains the classification result or can reconstruct an image that is visually similar only in important areas) or text transmission for specific tasks like question answering.
4.3. Knowledge Representation and Ontology-Based Frameworks
Another strand of SemCom research emphasizes explicit knowledge representation. Instead of (or in addition to) using end-to-end learning, these frameworks use structured knowledge (like ontologies or KGs) to ensure shared semantics between sender and receiver.
One approach, as mentioned, is KG-enhanced communication. Jiang et al. (2022) [39] built a system where both ends share a KG of a certain domain. For transmitting text, they parse the text into triples using the KG (like performing semantic parsing/NLP extraction). These triples act as a high-level semantic encoding. The transmitter might then just send the triple identifiers (which could be very short codes if the KG is known to both ends). The receiver, upon receiving these, can look up the triples in its copy of the KG and reconstruct or understand the message. In effect, they are using a semantic codebook (the KG) that is much richer than, e.g., a standard Huffman codebook—it encodes meanings. This can be viewed as a specific case of DIKWP where Data = identifiers, Information = triples, Knowledge = the KG context, etc.
Another concept is semantic ontologies for IoT and networking—applying semantic web technologies to communication. For example, one could define an ontology of messages for an Internet of Vehicles scenario (car-to-car communication) so that, when one car says “Incident ahead”, all cars understand the context (like the location or severity) because it is defined in the ontology. There have been surveys on SemCom for Internet of Vehicles, highlighting the need for shared ontologies.
Cognitive networking (a term used in the early 2000s by Thomas et al. [40]) also aligns with semantic ideas. It introduced a knowledge plane for networks—essentially a layer where the network collects and reasons about knowledge of itself to make smarter decisions (like routing). While not directly focusing on the semantic content of user messages, it was a precursor to the idea that networks need knowledge representation and AI to be more efficient. One might say that DIKWP’s graphs (DG, IG, etc.) in a system are analogous to injecting a knowledge plane into the architecture.
Finally, an interesting related framework is the idea of an AI “white-box” model for communication [41]. The Semantic Firewall concept (which we will detail in a later section) also uses knowledge and wisdom layers to filter content ethically [42]. These aspects show a trend: making communication and AI processes interpretable by structuring them around human-understandable semantic concepts.
In terms of a comparison to DIKWP, we can note the following:
- The surveyed SemCom methods all try to incorporate “semantic knowledge” in some form, but many do so implicitly via learned models. DIKWP would encourage an explicit, multilevel representation (data, info, etc.). For instance, rather than a monolithic neural net, a DIKWP-inspired system might separate processing stages, e.g., first conduct conceptual mapping (data → information) and then reasoning (knowledge → wisdom), etc., possibly with different algorithms at each stage. This could increase interpretability and possibly allow the insertion of expert knowledge at various points.
- The goal-oriented paradigm clearly echoes the Purpose element of DIKWP. Systems are superior if they know “why” the data are being sent. This is something that DIKWP inherently values by having Purpose at the top.
- KG approaches fit well with DIKWP’s focus on knowledge. In fact, recall that Duan [43] proposed DG, IG, KG, WG as part of a system architecture. In such an architecture, each of these is a layer-specific representation. For example, DG could capture raw data relationships or provenance, IG might link processed information units, KG is an ontology or factual DB, and WG might represent rules or best practices (more abstract relations, possibly including Purpose nodes linking to actions). Their paper defined these, and they aimed to use them to build better knowledge systems. Other researchers’ use of KGs is conceptually similar, although they are not always structured as multiple graphs.
In conclusion, SemCom research by others has introduced numerous models:
- The three Shannon–Weaver levels and subsequent semantic information theory attempts give us goals and metrics (semantic capacity, etc.);
- Deep learning-based semantic encoders/decoders show how we can compress meaning and achieve tasks with fewer bits, learning a form of internal “language of thought” for communication;
- Knowledge-based and ontology frameworks ensure that semantics are explicitly handled via shared symbols and structures, reducing ambiguity;
- Goal-oriented designs realign communication with its ultimate purpose, often yielding huge efficiency gains.
These complement DIKWP by providing concrete methodologies and highlighting what is important. DIKWP can be seen as a unifying theoretical model that can encompass these—for example, a deep semantic encoder could be interpreted as implementing a subset of DIKWP transformations (perhaps directly mapping data to knowledge in one learned step; DIKWP would question if we can break this down or make it more transparent). The next sections will consider personalized AI and security, which are also being explored by researchers, but DIKWP’s comprehensive view might offer a more holistic solution.
5. Approaches in Personalized AI and Semantic Security
Two crucial aspects of modern intelligent communication systems are personalization (adapting to individual users’ needs, preferences, and knowledge) and security (ensuring confidentiality, integrity, and the appropriate use of information). In SemCom, these aspects take on new dimensions. Personalized AI means that the system’s AI models and knowledge should be tailored to or learned from each user, which aligns with handling semantic differences and user-specific context. Semantic security means protecting communications against eavesdropping or manipulation, not just at the bit level but at the meaning level—including scenarios where an adversary might attempt to misguide an AI’s understanding (adversarial semantics) or glean sensitive information from intercepted semantic data.
In this section, we first examine how personalized AI is approached, especially in the context of communication and user interaction. Then, we explore frameworks for semantic security, including encryption and defenses specific to SemCom. We highlight related work and then consider how DIKWP addresses these issues (or could enhance them).
5.1. Personalized AI: User-Specific Models and Knowledge
Personalization in AI refers to adapting AI behavior or outputs to a specific user’s characteristics. This could involve learning a user’s preferences (like a recommender system), their vocabulary and style (for a personal assistant), or their knowledge level (for an educational app). In communications, personalization is critical because, as discussed regarding relativity of understanding, different users may interpret messages differently. A personalized SemCom system would know what a user already knows, so it does not send redundant information, and it ensures that what is sent is in a form that the user will understand.
KGs for Personalization: One way to represent a user’s knowledge or context is a personal knowledge graph (PKG). Companies like Google have user interest graphs; in research, there are user profile ontologies. For example, if we have a PKG [44] that contains what concepts a user is familiar with or their areas of expertise, an AI system can present information using terms that the user knows. This is akin to aligning ConC between the AI and user: by referencing the user’s PKG, the AI avoids using unfamiliar jargon (which would cause a ConC mismatch). There is work on personalized dialog systems that maintain a model of the user’s knowledge and tailor responses accordingly—essentially the dynamic adjustment of semantics for this user [45].
Federated and Continual Learning: Personalized models can also be achieved by having each user’s device or data fine-tune a base AI model to their specifics. For instance, in SemCom, Wang et al. [46] introduced a federated contrastive learning approach for personalized SemCom. In their setup, multiple users share a base semantic encoder model but each user’s data are used to fine-tune a personalized version (via federated learning, meaning that they update the model locally and share some gradients or model parts but not raw data). Contrastive learning is used to ensure that the model’s embedding space clusters meaning effectively while accounting for user-specific distribution. This resulted in improved performance for each user because the encoder/decoder learned to accommodate the particular qualities of the user’s input and usage patterns. The federated aspect ensures privacy (user data are not centralized)—a bonus for security.
Foundation Models with Personalization: A very recent direction is the use of large pretrained models (like GPT-4, BERT, etc.) as a base and then specializing them per user. Chen et al. (2024) [47] discussed a “Foundation Model Approach” to personalized SemCom. The general idea is as follows: instead of training separate models for each new task or user, leverage a giant model that has broad knowledge (foundation model) and condition or prompt it with user-specific data. For example, we might have a base model that knows general language and facts; we can then provide it with a user’s past conversation logs or profiles (as additional context prompts). When encoding/decoding messages for this user, the model uses this context to shape understanding. This is similar to giving the model the user’s SemA as part of the input. This approach is powerful because foundation models possess a great deal of commonsense and language capabilities, so the personalization is mostly concerned with differences from the norm for each user.
Contextual User Modeling: In cognitive communications, there is also the idea of maintaining a user context model, which can include the current context (location, device, attention state) as well as long-term preferences. Communication systems can use this for both semantic compression (e.g., if it knows that a user is driving, it may deliver information in audio form with minimal distraction using known phrases) and for content selection (not sending what user already has). In networking, similar principles arise in content-centric networking (CCN), where network caches deliver content based on interests and presumably would not send data that the user has cached already—an analogy in semantics would be not providing the user with data that they already have.
From the DIKWP perspective, personalization is essentially acknowledging that each user has their own DIKWP network state. DIKWP’s relativity theory inherently supports personalization by design—we treat each cognitive subject individually, not as having the same semantic model. The DIKWP network for User A will have different content than for User B. One could imagine each user’s DIKWP model as a subgraph in a larger “social DIKWP network”, and communication is about mapping one subgraph to another (which loops back to the DIKWP × DIKWP mapping idea in a multiagent scenario).
Personalized Semantics in Practice—Some Practical Examples
- Machine Translation Personalization, e.g., customizing translation to a user’s speaking style or dialect. A translator could use knowledge of a user’s background to choose certain phrasing.
- Personalized Search (Semantic Search): The query “apple” can carry different meanings if the user is a fruit farmer versus a technology enthusiast. Search engines incorporate personal data to disambiguate (fruit vs. Apple Inc., Cupertino, CA, USA).
- Human–Robot Interaction: If a household robot knows the family’s particular terms (perhaps they call the living room the “den”), it will understand commands better. It builds a small ontology for the household (mapping “den” to the standard concept “living room”). There is research on the personalized grounding of language for robots.
In summary, personalized AI in communication often involves building or adapting semantic models (encoders/decoders, knowledge bases) to each user. This ensures that communications are more efficient (no need to overexplain known concepts) and more effective (less misunderstanding). The challenges include obtaining enough data about each user to personalize (hence, federated learning is attractive in catering to many users collectively without centralizing data) and maintaining privacy (personalization means that there are a lot of personal data influences, which must be protected from misuse—bridging to security).
5.2. Semantic Security: Securing Meaning in Communication
Semantic security in the context of communications is an emerging concept that extends the goals of conventional security (confidentiality, integrity, availability) to the semantic layer. Traditional cryptography ensures that an eavesdropper cannot decode the plaintext from the ciphertext (this is sometimes called “semantic security” in cryptography, meaning that the ciphertext reveals no information about the plaintext). Here, we discuss semantic security in a broader sense:
- Ensuring that an adversary cannot infer the meaning of intercepted communications (even if they break bits, they may lack context to obtain meaning).
- Protecting against attacks that target the AI models or knowledge that SemCom relies on. For instance, an attacker might try to feed malicious inputs that cause the AI to misunderstand (like adversarial examples causing misclassification, which, in semantic communication, could lead to wrong interpretations).
- Ensuring the integrity of semantic content—this means ensuring not only that the bits are not flipped but that the meaning is not subtly altered. A sophisticated attacker might alter a few words in a message to dramatically change its meaning while barely changing the bit count (such as intercepting a command like “do not execute order” and dropping the “not”).
Meng et al. [48] identified numerous threats in SemCom systems. These include the following:
- Eavesdropping and Privacy Leakage: Since semantic systems often share models or knowledge bases, an eavesdropper might try to glean information either by intercepting the semantic data or by analyzing the shared model. For example, if messages are transmitted as KG triples, an eavesdropper could accumulate these and piece together sensitive information about the participants.
- Adversarial Attacks: Attackers can exploit the neural components of semantic communications, e.g., sending inputs that cause the semantic encoder to output misleading encodings or cause the semantic decoder to produce wrong interpretations. There is existing evidence in NLP and vision that attackers can craft inputs that appear normal to humans but fool AI—this directly translates to semantic communication being vulnerable if, say, a malicious speaker sends a sentence that confuses the AI assistant into performing a wrong action (effectively an integrity attack at the semantic level).
- Poisoning and Model Transfer Attacks: During model training or updating (like federated learning), attackers could poison the data so that the model learns a backdoor—for instance, normally, it communicates appropriately, but, for some trigger input, it outputs a codeword or wrong information, which could be exploited.
- Knowledge Base Attacks: If the system uses a KG, an attacker might attempt to insert false knowledge or alter entries (like misinformation injection) so that future communications are interpreted incorrectly or leak information.
Given these threats, solutions are being proposed:
- Semantic Encryption: One module in the SemProtector framework (2023) [49] is an encryption method at the semantic level. This implies transforming the semantic representations (like embeddings or triplets) using keys such that, even if intercepted, the adversary cannot decode the real meaning. For instance, one could encrypt the indices of KG triples or use homomorphic encryption so that the receiver can still decode with a key but an eavesdropper only sees random-like symbols. Another, simpler example is as follows: if two parties share a secret mapping of words (a codebook), they could communicate with those codes—only with the codebook (knowledge) can one interpret it. This is old-school cryptography applied at semantic units rather than bits.
- Perturbation for Privacy: SemProtector also adds a perturbation mechanism to mitigate privacy risks. This could mean adding noise to the transmitted semantics such that sensitive details are blurred but the overall meaning is preserved. This is akin to not sending ultra-precise data if not needed. For example, if reporting a location for traffic, it could be quantized to the nearest block rather than providing exact coordinates—an eavesdropper cannot pinpoint an individual, but the receiver still knows where they are generally.
- Semantic Signature for Integrity: The third module in SemProtector is generating a semantic signature. This likely means attaching some digest to the semantic content that the receiver can verify, such as a cryptographic hash of the intended meaning or a watermark in the encoded message that confirms authenticity. If an attacker alters the content (even if bits are reassembled into valid words), the signature will not match and the receiver knows that it has been tampered with.
- Adaptive Protection: The idea of “dynamically assemble pluggable modules to meet customized semantic protection requirements” means that we might not always need all protections, or we might need different levels for different messages. A trivial example is as follows: a weather report might not need heavy encryption because it is public information (but it may need integrity to ensure that it is not faked); a personal health message needs strong encryption and privacy; a command to a drone needs encryption and integrity (so that an adversary cannot change it), etc. Systems could decide on-the-fly which protections to use depending on the context, risk, and overhead.
Beyond these, the semantic firewall is described as an embedded mechanism in AI systems that reviews and controls content at the semantic level throughout the input, inference, and output stages. Essentially, it resembles a guard that ensures that the system’s behavior adheres to certain ethical and functional guidelines by filtering out or modifying content that violates them. For example, if a user asks an AI agent a potentially harmful question, a semantic firewall (knowing the AI’s wisdom and purpose layers) might block or reframe the answer to prevent unethical use. In personalized security, one could imagine a user having their own semantic firewall rules—e.g., “Never show me violent content” or “Translate profanity to mild words for me.” This is a type of personalized security at the semantic preference level.
Another interesting security angle is steganography in semantics. Instead of hiding a message in bits, one could hide a message in meaning. For instance, two parties could communicate in such a way that, if someone does not share certain knowledge, they will interpret it innocuously, but, if one does have the key knowledge, it reveals a hidden meaning. This is like speaking in code or allusion. In networking, there is the concept of “security through obscurity”, which is usually not favored if it is the only method. However, here, it could be an additional layer: even if the encryption is broken, if the adversary does not have contextual knowledge, they still might not fully derive the meaning. As an example, two agents might refer to a past shared experience in shorthand (like inside jokes). Anyone else overhearing this does not understand the meaning. This is naturally how humans sometimes securely communicate in plain language (akin to spies with code phrases). AI semantic systems could achieve a similar goal automatically—although implementing this systematically would be complex.
Physical Layer vs. Semantic Layer Security: We note that semantic security does not replace physical-layer or bit-layer security but complements it. Traditional wiretap codes and encryption ensure that bits are safe. However, consider LLM-based communication: if an attacker cannot crack the cryptography but can trick the model into outputting sensitive information (by manipulating the context), this is a semantic breach. Thus, one needs AI robustness techniques (adversarial training, robust model design) in tandem.
Summarizing related work, we can conclude the following:
- Meng et al.’s survey [48] outlines threats and calls for research on secure SemCom.
- SemProtector (2023) provides a unified framework of three modules, encryption, perturbation (privacy), and signature (integrity), for semantic protection.
- Other works (e.g., an IEEE ComMag 2022 article on semantic security) have discussed scenario-specific solutions like securing semantic model distribution (since, often, a model must be shared, they consider sending the model itself securely).
- There is also the initial exploration of “adversarial semantic coding”—designing encoders that are inherently robust to adversarial noise, e.g., making sure that small perturbations in input (like synonyms or pixel tweaks) do not drastically change the encoded meaning, thus resisting adversarial attacks.
DIKWP’s Contribution to Personalized Semantic Security
The DIKWP model, by virtue of its Purpose and Wisdom layers, encourages the building of systems that understand the context and implications of communication. A DIKWP-based system could, for example, check at the Wisdom layer whether sending certain information might violate a security policy (e.g., Purpose might include “Protect user privacy”) and thus automatically sanitize or encrypt the information. The Wisdom and Purpose layers can act as an internal semantic firewall, performing ethical and purpose-driven filtering. Indeed, a DIKWP semantic firewall, as per Duan, would use the top layers to decide which content should be allowed out or in. This is a more cognitive approach compared to rule-based firewalls, meaning that it could reason, “This output might be technically correct but is against policy or user’s intent, so I will block/modify it.”.
Additionally, the DIKWP network’s feedback means that, if a security issue is detected at a higher layer, it could adjust the lower layers. For example, if, at the Wisdom layer, the system realizes that the conversation has veered into sensitive territory, it might adjust the information or data being transmitted (perhaps switching to a secure channel or adding cryptographic padding). This dynamic adjustment is akin to the adaptive protection concept in SemProtector, but DIKWP could determine when to implement it based on the semantic understanding of the content.
Finally, DIKWP emphasizes explainability (white-box AI), which is crucial in security. If an AI agent can explain why it decided to filter a message, or how it interpreted a message, we can audit it for correctness and bias. Many AI failures in security (like a content filter blocking harmless content or allowing harmful content) arise from opaque models. DIKWP’s structure might make the AI’s reasoning chain visible (e.g., the Data → Information → Knowledge chain that led to marking something as sensitive), which can be examined and improved.
To conclude this section, personalized AI and semantic security are interlinked: personalization often requires privacy (we do not want personalized data to be leaked), and security measures often need to be personalized (different users, different threat models or preferences). The reviewed approaches show initial solutions: federated learning for personalization, KGs to share context, and encryption and semantic-aware filtering for security. The DIKWP framework can be seen as offering a cohesive way to integrate these: each user’s DIKWP model is personalized, and rules/policies (part of Purpose/Wisdom) enforce security on a per-user basis.
In the next section, we will provide a comparative analysis of DIKWP and the various related frameworks that we have discussed, highlighting where they align (or differ) in addressing SemCom and security challenges.
6. Comparative Analysis of DIKWP and Related Frameworks
In the preceding section, we introduced various related models proposed by researchers, covering areas such as SemCom, personalized AI, and semantic security. This section will provide a systematic comparison of these frameworks to clarify their respective strengths, limitations, and potential complementarities. We structure this analysis along key dimensions: architecture and conceptual layers, the treatment of knowledge and context, personalization mechanisms, security approaches, and interpretability. A summary comparison is presented in Table 3 for a concise overview, followed by a detailed discussion.
Table 3.
Comparison of DIKWP vs. selected SemCom frameworks.
Discussion
From Table 3 and our earlier descriptions, we can draw several comparative insights.
- Layering and Abstraction: DIKWP is unique in providing a full-stack cognitive model from Data up to Purpose. Other approaches tend to focus either on one or two levels. For example, deep learning SemCom compresses data to an embedding (covering roughly Data → Information/Knowledge in one step), but it does not explicitly separate knowledge or wisdom. Knowledge graph approaches explicitly handle Data → Information (by extracting information units like triples) and partially Information → Knowledge (because such triples reside in a knowledge base), but they often do not include a notion of wisdom or intent. Shannon’s model only considers data transmission (the technical layer). Meanwhile, Popovski’s three-level view (technical, semantic, effective) is conceptually similar to DIKWP’s bottom, middle, top, but Popovski’s does not break the semantic level down further into knowledge and wisdom or offer an implementation framework—it is rather a descriptive stack. DIKWP’s advantage is a granular breakdown that might allow targeted improvements at each stage (e.g., one can discuss uncertainty at Data vs. at Information vs. at Knowledge separately and handle them accordingly). On the downside, implementing a full DIKWP pipeline could be complex—a deep learning approach might be simpler in terms of the pipeline (only requiring one model to be trained).
- Purpose-Driven vs. Task-Oriented: Many recent works highlight goal-oriented communication (which is essentially task-oriented). DIKWP’s notion of Purpose maps well to this; it formalizes in the model what others treat as an external objective. For instance, in a deep semantic communications paper, they might say “we train the system to do question answering well”—i.e., the task is embedded in training. In DIKWP, one would say “the purpose is answering questions; hence, all layers operate to fulfill this.” Both yield goal-oriented behavior, but DIKWP could allow dynamic changes in purpose and an agent could theoretically switch goals mid-run and reconfigure processing (with knowledge of how to adjust each layer). Standard learned systems might need retraining to change tasks drastically. This shows DIKWP’s potential flexibility.
- Knowledge Utilization: DIKWP explicitly integrates knowledge (with K and W layers). Knowledge graph approaches similarly make knowledge explicit. Deep learning often encodes knowledge implicitly (in weights or word vectors), which can be powerful (foundation models have vast knowledge incorporated), but it is less controllable. One advantage of explicit KGs is easier knowledge updates—e.g., if a fact changes, one update the triple, whereas a deep model might still output outdated information because it is buried in weights. For SemCom networks that must adapt to new facts or user data, the DIKWP or KG approach is more agile in updating knowledge. On the other hand, deep nets can capture very subtle statistical knowledge (like idioms, correlations) that a manually curated KG might not. A hybrid could be best: DIKWP could integrate deep learning at specific modules (e.g., use a neural network to implement Data → Information mapping but then use a symbolic KB for Knowledge → Wisdom reasoning, etc.).
- Personalization Approaches: DIKWP accounts for differences through ConC/SemA alignment strategies (like iterative clarification). This is a sort of interactive personalization—it is about conversation or iterative communication to adapt to the user. Modern personalized AI tends to be data-driven: either fine-tuning a model on the user or feeding user data as context. This works well when we have many user data or a static scenario. DIKWP’s approach might be more relevant in one-off communications (e.g., a doctor explains something to a patient by checking their understanding step by step—the system analog would be dynamic adjustment). Possibly, both approaches could converge: we could fine-tune an AI model to a user over time (long-term personalization) and also have it monitor and clarify during a specific dialog (short-term personalization in context). A fully personalized semantic communication system should do both: maintain a user model (long-term knowledge and preferences) and be able to clarify miscommunications in real time. DIKWP inherently encourages the second part with its focus on understanding confirmation, whereas typical ML personalization might neglect real-time feedback unless explicitly programmed.
- Security Orientation: Traditional communication frameworks rely on separate cryptographic measures. SemCom adds vulnerabilities at new points (like model and data). DIKWP was not initially a security framework, but its structure can enhance security in terms of the detection of anomalies or undesired content. For example, if someone tries to inject a malicious concept, a DIKWP-based system might notice an inconsistency in its KG or a contradiction with its purpose (such as “This doesn’t fit known knowledge or our goal—possibly malicious”). This is a kind of semantic intrusion detection. Related frameworks like SemProtector explicitly add security features. One could argue that DIKWP plus a semantic firewall covers similar ground, e.g., encryption in SemProtector is analogous to ensuring that only those with an appropriate Purpose/Knowledge can decode the meaning (with DIKWP, if a third-party does not share the knowledge context, they naturally cannot interpret fully—although this is not foolproof security but security by context obscurity). For serious threats, cryptography is still needed, but DIKWP might inform smarter key management or encryption at semantic units (e.g., one may encrypt only the knowledge that is sensitive and leave benign data to save resources, guided by the Purpose/Wisdom classification of what is sensitive).
- Interpretability and Verification: DIKWP’s white-box nature means that one can potentially verify what is happening at each layer. This is important not just for explainability but also for validation and debugging. In safety-critical communications (e.g., autonomous vehicles exchanging information), being able to verify that a system’s “knowledge” and “wisdom” align with reality and rules could be crucial (e.g., to prevent accidents, we might require the AI car to justify certain communications or decisions—DIKWP provides tools for this). In contrast, if two cars communicate with end-to-end neural nets, this might work well statistically, but, if something goes wrong, it is challenging to determine why. Regulators or users might trust a system more if it can output a reasoning chain (like “I did not send a stop warning because my knowledge indicates that the obstacle is a plastic bag, not a solid object; thus, there is no danger—and my purpose is safety so irrelevant warnings are suppressed”). This chain is human-readable, matching the DIKWP layers. Achieving this level of clarity is challenging, but the structure aids it.
- Compatibility and Integration: The frameworks are not mutually exclusive. We can envision a hybrid: DIKWP as the overarching design, using deep neural modules for certain transformations (where they excel, e.g., pattern recognition for Data → Information), using KGs for representing domain knowledge (for Knowledge layer), and using tools like SemProtector modules to ensure encryption and integrity on selected channels. Personalization can be integrated by having each agent’s DIKWP model be partly unique (like their own KG and possibly their own tuned neural nets at the Data → Information stage, etc.) but also having a shared semantic ontology for communication (ensuring that enough common ground exists to communicate).
A concrete case study to illustrate the differences and synergies is given in the following.
Imagine a personalized healthcare chatbot that communicates with a patient and doctor and updates medical records.
- A pure deep learning SemCom approach would train a model on many doctor–patient dialogs to compress messages; it would implicitly learn how patients speak and perhaps to simplify its language for them. However, if a rare case arises or the patient’s phrasing is unusual, it might fail.
- A DIKWP approach would represent the patient’s statements through Data (audio) → Information (text symptoms) → Knowledge (medical concepts) → Wisdom (possible diagnosis) with Purpose (help diagnose). It has the patient’s concept of illness and the doctor’s concept in mind separately and checks for mismatches (such as clarifying symptom meanings). It uses a medical KG (explicit disease–symptom relationships) and perhaps uses a learned model to interpret raw speech (D → I). It can explain, “Given your symptom description, I think it’s X because, in my knowledge base, X matches these symptoms.” The Purpose (diagnosis) guides it to focus on pertinent questions. For security, suppose that privacy is crucial: the system might perturb some data when logging them to a central server (such as obscuring the patient’s identity in the data transmitted). A semantic firewall ensures that it does not reveal the patient’s information to unauthorized staff (perhaps by recognizing, “This query is coming from someone not on this patient’s care team, so block this content”).
This scenario shows that DIKWP can incorporate deep learning (for speech recognition, etc.), KGs (medical KB), personalization (patient’s own record, concept alignments), and security (privacy rules). The synergy is clear, but it requires many components, which is a challenge, whereas a single deep model might be easier to deploy but less transparent or flexible in these nuanced ways.
In summary, our comparative analysis yields the following findings.
- DIKWP vs. others: DIKWP is holistic and interpretable but requires management of complexity; it excels in scenarios needing explainability and explicit knowledge integration. Other models often optimize specific aspects—e.g., deep nets for compression efficiency or KGs for clarity—but might ignore other aspects (e.g., deep nets ignore interpretability, and KGs might not easily handle noise).
- Personalization: DIKWP natively acknowledges individual differences; other models need additional processes to handle personalization (e.g., separate fine-tuning).
- Security: DIKWP was not primarily a security framework, but its philosophy can improve semantic security by design (embedding ethical and purposeful constraints). Formal security frameworks (like cryptography or SemProtector) are complementary—DIKWP does not provide encryption by itself but can identify what to encrypt.
- The future likely lies in hybridization: indeed, researchers have begun to realize that purely data-driven or purely symbolic approaches each have limitations. A combination (“neurosymbolic” systems) is a trend in AI. DIKWP can be seen as a blueprint for a neurosymbolic SemCom system: neural nets to handle raw data and probabilities, symbolic graphs for knowledge and logic, and an overall cognitive loop guided by goals. Each part addresses specific aspects—for example, neural nets handle high-dimensional signals (images, speech) and symbolic reasoning handles discrete knowledge and explanation.
We will further reflect on these points in the next section on implementation and applications, where theoretical differences are manifested in practical aspects like system performance, scalability, and user acceptance.
7. Evaluation of Implementation Approaches and Applications
Translating the above theories and models into real-world systems involves numerous practical considerations. In this section, we survey how DIKWP-inspired frameworks and other SemCom models have been implemented or prototyped and their applications. We also discuss the performance evaluations reported (where available) and practical challenges encountered. Key domains of application include intelligent assistants and chatbots, Internet of Things (IoT) and edge networks, medical and industrial communications, and emerging areas like artificial consciousness (AC) systems. We will highlight notable examples and, where possible, quantitative outcomes (like improvements in bandwidth usage, accuracy of understanding, etc.).
7.1. Prototypical Implementations of DIKWP Models
Because DIKWP is a high-level conceptual framework, an off-the-shelf “DIKWP protocol” does not exist on the market. However, the following lists concrete applications embodying the DIKWP principles.
- DIKWP Semantic Chip and Architecture: As mentioned, Duan and Wu [50] proposed a design for a DIKWP processing chip. This includes a microarchitecture with an understanding processing unit (UPU) and semantic computing unit (SCU) based on DIKWP communication. The chip is paired with a DIKWP-specific programming language and runtime. While the details are mostly conceptual at this stage (published as a conference abstract), the goal is to create hardware that natively supports operations like semantic association, KG traversal, and purposeful adjustments. If realized, such hardware could accelerate semantic reasoning tasks analogously to how GPUs accelerate neural networks. No performance metrics were given in the abstract beyond qualitative claims that it surpasses the limitations of traditional architectures, making semantic operations more convenient. In Figure 2, CT denotes textual content, SC denotes semantic content, and CG denotes cognitive content. The diagram outlines a DIKWP semantic chip/network architecture that maps CT → SC and aligns SC ↔ CG via semantic communication under purpose-driven control, with diagnostics for inconsistency, incompleteness, and inaccuracy. This diagram depicts a DIKWP semantic chip/network architecture. The chip maintains five graph memories for and a transformation scheduler that executes modules to move between layers. Mapping–deconstruction converts TC into SC, while construction–association renders SC back to CT. A purpose engine prioritizes sensing, interpretation, and action, and a 3-No diagnoser (inconsistency, incompleteness, inaccuracy) detects and triggers corrective flows. Through the semantic communication interface, the system exchanges only semantically necessary artifacts with the human cognitive side (CG), aligning meaning rather than reproducing bits. A white-box logger records the per-module latency and energy and preserves layer-wise states for auditability. For evaluation, we profile the relevant paths and report the end-task success, alignment error, latency, and energy under channel impairments.
 Figure 2. DIKWP semantic chip/network block diagram with content layers.
Figure 2. DIKWP semantic chip/network block diagram with content layers. - DIKWP White-Box AI Systems: An example application is in AI evaluation and consciousness. Duan [51] discusses a white-box evaluation standard for AI using DIKWP. The idea is to instrument AI systems such that their internal states can be mapped to DIKWP graphs at runtime, allowing one to measure, for instance, how well an AI’s KG is updated or how its wisdom (decisions) aligns with given purposes. This has been applied in limited scopes, like analyzing an AI’s processing of simple tasks by mapping the data that it took in and the intermediate information/knowledge that it formed. While not offering a commercial product, these experiments help to validate that one can indeed extract meaningful “white-box” information from AI processes using DIKWP ontology. For instance, an evaluation might show that a certain AI agent, when solving a problem, only progressed to the “information” level and did not form new knowledge—which might correlate with its inability to generalize. Such granular evaluation is challenging to achieve with black-box models. We further conduct a quantitative white-box study on SIQA [52], GSM8K [53], and LogiQA-zh [54]. We uniformly sample 1000 instances from each dataset (total N = 3000), require models to output both a final answer and a brief rationale, and evaluate the following systems: ChatGPT-4o, ChatGPT-o3, ChatGPT-o3-mini, ChatGPT-o3-mini-high, DeepSeek-R1, and DeepSeek-V3. We report the black-box accuracy metric together with the white-box DIKWP shares (); the results are summarized in Table 4. We define as the normalized share (%) of internal DIKWP transformations whose target layer is , so that per model–dataset pair.
Table 4. White-box profiling on three benchmarks.
- Standardization Efforts: The mention of an “International Standardization Committee of Networked DIKWP for AI Evaluation (DIKWP-SC)” implies ongoing work to formalize DIKWP representations. Standardizing aspects like how to encode a DG or KG so that different systems can interoperate is a step toward implementation. If such standards mature, we might see interoperable SemCom protocols where, for example, IoT devices share not only raw data but DIKWP-structured information. However, at present, these are in the early stage (the references hint at technical reports and white papers rather than ISO/IEEE standards already in effect).
In terms of tools, building a DIKWP system likely means integrating multiple AI components: natural language processing, knowledge representation systems, inference engines, etc. Off the shelf, one might use the following:
- NLP pipelines for Data → Information (like speech-to-text, entity recognition);
- KG databases (Neo4j, RDF stores) for storing DGs/IGs/KGs;
- Reasoners (rule engines or even neural networks) for Knowledge → Wisdom (decision making);
- Agent frameworks where one can encode a goal (Purpose) and allow the agent to plan actions.
One experimental platform could be a multiagent simulation where agents communicate with messages annotated in a DIKWP manner (for example, using a JSON structure with fields for each layer). Some research prototypes in cognitive radio networks attempted a similar task (knowledge sharing among nodes). However, scalability is a concern: representing everything explicitly can increase the message size and computing needs dramatically. This is where a DIKWP chip would help by speeding up these manipulations.
7.2. Performance and Applications of SemCom Models
Regarding non-DIKWP SemCom prototypes, we note the following:
- Text Transmission: Xie et al. [35] in IEEE TSP reported that their deep learning SemCom system achieved the same text transmission accuracy as traditional methods at a fraction of the SNR or bandwidth. Specifically, for certain sentence similarity or question answering tasks, their system could operate at very low SNRs, where a standard system (Shannon-style with source coding + channel coding) would fail to transmit any meaningful data, yet the semantic system still communicated the message because it was focusing on meaning. This demonstrates robustness. Statistically, they showed that, e.g., to achieve 90% task success, the semantic system needed around one-third or one-quarter of the bandwidth of a baseline (specifically, e.g., “DeepSC could maintain a bilingual evaluation score within 5% of the original text even at SNR = 0 dB, whereas a traditional scheme’s BLEU score dropped drastically”, as per their claims).
- Image Transmission: Other works (e.g., on sending images for classification) have shown that, if the goal is classification, one can compress the image heavily (such as sending only high-level features) and the classifier on the other end would still work, even though the image cannot be fully reconstructed. This indicates semantic success with fewer data. However, one challenge observed is generalization: if the task changes slightly, the learned system might need retraining. For example, if it was trained to classify 10 objects and a new object appeared, the system might not transmit information about it successfully because it was not included in its training.
- KG Approach Performance: Jiang et al. [39], with the KG triplet approach, reported that their scheme improves reliability, especially in low-SNR scenario. They specifically mention that, at very low SNRs, transmitting only the most important triplet yields much better semantic success than trying to send the whole sentence with a conventional scheme. One trade-off is loss of detail—if only part of the information is sent, some less important semantic content is omitted. For certain applications (like critical instructions), one might not wish to omit anything. Thus, this scheme fits scenarios where a partial understanding is acceptable and preferable to total breakdown. This was validated in their simulations, e.g., at an SNR where the baseline yields 0% correct sentences, their scheme might still communicate the main facts, e.g., 80% of the time, albeit with minor details missing.
- Multiuser and Federated setups: A letter by Wang et al. [46] (2024, IEEE Comm. Letters) implemented the federated learning approach in personalized semantic communications. They simulated multiple users, each with slightly different data distributions. The FedContrastive method outperformed both a single global model and separate models per user in terms of the semantic error rate and model convergence. This indicates personalization without losing the benefit of collective training. It suggests that, in practical networks, one can train a “community” semantic model and still have it fine-tuned to individuals. This was tested in tasks such as image recognition or text classification across different users. For instance, they achieved a 10% improvement in the accuracy of the semantic task for underrepresented user data compared to no personalization.
- Edge/IoT scenarios: There have been demonstrations of SemCom in IoT, such as in vehicle-to-infrastructure communications where only event descriptions are sent, rather than full sensor feeds. For example, a project might show an autonomous car sending the message “pedestrian crossing ahead” to nearby cars, instead of raw camera images. This reduces the latency and bandwidth usage significantly. Implementation-wise, it requires the car to detect the event (AI on board) and then encode a standard message. In one trial, hypothetically, this could cut the required bandwidth from, e.g., several Mbps of video to a few bytes of text per second—enabling communication in bandwidth-limited or congested networks. The trade-off is that the receiver must trust the sender’s detection (if the sender misdetects, others might not receive data that would have been in the raw feed).
- Medical Application: In a paper titled “Paradigm Shift in Medicine via DIKWP” (Wang et al., 2023 [42]), the authors mention DIKWP SemCom promoting medical intelligence collaboration. In particular, doctors and patients could communicate symptoms and diagnoses with fewer misunderstandings by using DIKWP modeling. For example, a patient describes symptoms (Data → Information), the system maps this to medical concepts (Knowledge) and suggests likely causes (Wisdom), and then the doctor confirms and explains this to the patient, adjusting the concept definitions. Although this might not have a numerical evaluation, we could measure outcomes like reduced misdiagnosis or time saved in consultations. If one were to test DIKWP vs. normal consultation for complex symptoms, for example, a DIKWP-aided approach (with an AI mediator ensuring mutual understanding) could show improved understanding scores (e.g., both patient and doctor correctly recalling what was said) or higher patient satisfaction.
- AC Simulation: Research on AC systems uses DIKWP to structure AI internals. Such systems may include a prototype where an AI agent (in a simulated environment) uses DIKWP to perceive (Data → Information), learn (Info → Knowledge), reason (Knowledge → Wisdom), and set goals (Purpose). Performance evaluation could involve measuring how well the agent performs tasks and whether it can explain its decisions. Since AC is rather conceptual, the “evaluation” might be qualitative or based on benchmark tasks. For example, an AC agent with DIKWP layers could be compared against one without, assessing its stability and interpretability. Possible metrics include the task error rate combined with an interpretability index (e.g., the number of questions about its decisions that it can answer).
Challenges Observed
- Computational Overhead: Semantic processing, such as extracting meaning or running neural models, can be heavy. A concern in, e.g., IoT is whether devices can run these AI models. In this context, ideas like splitting the workload (edge computing) or using special chips (like DIKWP chip) emerge. Some experiments offload semantic encoding to an edge server rather than the device—which itself raises trust and privacy issues (if the edge performs this, one might leak raw data to the edge).
- Standardization and Interoperability: Without common standards, each research work uses its own dataset and metrics, making comparisons challenging. One barrier to real adoption is achieving agreement on semantic protocols (such as how exactly to represent meaning). At present, many works are siloed (one group’s autoencoder vs. another’s KG—they cannot interact with each other). There has been a drive in 6G forums to define semantic layer protocols, but this is in the early stages. There is potential for concepts like “semantic headers” in packets that carry context information or “common knowledge bases” for certain domains.
- User Acceptance: Personalization and semantic methods have to respect user comfort and privacy. If an AI agent changes how it communicates based on what it knows about the user, this could be beneficial (the user feels like it understands them) or detrimental (it appears to use personal information in unexpected ways). Thus, applications must carefully implement these with transparency and opt-out options. This can be seen in recommender systems, which have received backlash as users desire explanations. In communications, if a system filters out content for security (like a semantic firewall blocking a message because it deems it harmful), users might need an explanation or override option.
- Evaluation Metrics: New metrics are needed to evaluate success. The traditional bit error rate or throughput is not enough. Some works use the task success rate (did the AI answer correctly?) or similarity scores (how close was the received sentence to the original meaning?). For security, one may use metrics like the degree of privacy (e.g., can an adversary infer some property from intercepted data better than random guessing?). The community is still converging on these metrics. An MDPI survey notes the lack of a unified semantic information theory, which means that evaluation across papers is not always straightforward.
Real-world deployment scenarios, as summarized in Table 5, illustrate how SemCom concepts can be applied across different domains. Each scenario demonstrates the integration of DIKWP principles—linking Data, Information, Knowledge, Wisdom, and Purpose—to achieve efficient, interpretable, and goal-oriented communication. These cases also highlight the trade-offs between semantic compression efficiency and the potential risks if semantic interpretation fails.
Table 5.
Real-world deployment scenarios of SemCom.
In summary, various prototypes and applications demonstrate the viability and benefits of semantic and personalized communication:
- Efficiency gains in bandwidth/latency (especially in low-resource scenarios);
- Maintaining performance in noisy environments where bit-accurate communication would fail;
- Better user satisfaction or task success due to personalization and clarity.
- However, they also highlight the need for robust AI (because, if the semantic analysis is incorrect, the whole communication is flawed, whereas bit errors in traditional communication might simply trigger a request for repeats—ironically, semantic errors might be undetected if the message appears plausible but has the wrong meaning).
We can glean that the initial results are promising (often indicating significant savings or improvements), but implementations must carefully handle error cases and integrate knowledge and security.
Now, having looked at the current evaluations and usage, we identify emerging trends and consider where gaps remain for future research.
8. Emerging Trends and Research Gaps
The field of SemCom and personalized semantic security is rapidly evolving, intersecting with advancements in AI, 6G network research, and cognitive science. In this final section, we discuss some emerging trends that are likely to shape the next wave of research and development. We also point out key open issues and gaps that need to be addressed to fulfill the vision of semantic-aware, cognitively personalized secure communication systems.
Emerging Trends
- Integration of Large Language Models (LLMs) in Communication: With the dramatic success of LLMs like GPT-4 in understanding and generating human-like text, there is a trend of using these models as semantic engines in communication systems. An LLM can serve as a powerful semantic encoder/decoder that already has a vast amount of world knowledge. For example, an LLM-based agent could summarize a lengthy message into a shorter one for transmission or predict which information the receiver needs to know (based on its pretraining). Researchers are looking at prompting LLMs for compression—essentially giving the model instructions like “Convert this message into a form that someone with context X will understand fully with minimal content.” Early explorations show that GPT-4 can perform summarization or explanation tailored to user profiles reasonably well (since it has seen many styles). However, challenges include controlling the model’s output precisely (they can be verbose or introduce minor inaccuracies). Thus, combining LLMs with frameworks like DIKWP could be fruitful: the LLM can be constrained to fill certain slots (Data/Information) or adhere to certain knowledge checks (with a KG verifying facts). A research gap here is how to systematically prompt or fine-tune LLMs for the role of a semantic transceiver—effectively transforming them into communication agents that obey bandwidth or security constraints. Another is ensuring that the LLM does not hallucinate in mission-critical communication.
- Cross-Modal SemCom: Most research so far has siloed text, speech, and image modalities. An emerging trend is unified SemCom across modalities—e.g., a system that can send either an image or a description depending on what is more efficient for the meaning. With advances in multimodal models (like CLIP, which aligns images and text semantics), a transmitter might dynamically choose to send a picture vs. words vs. a coded signal to convey a message, based on which one will be interpreted best by the receiver. For instance, two agents might share a learned embedding space where an image of a cat and the word “cat” have similar embeddings; then, if one wishes to communicate “cat”, it does not matter whether it sends the image or the word embedding—the receiver can decode it to the concept "cat". This fluid use of modality can optimize the use of available channels (perhaps sending an image when there is high bandwidth and reverting to text when there is low bandwidth). It also suits personalized needs (perhaps one user understands diagrams better and another prefers text—the system can adapt). The DIKWP model’s ConC/SemA is inherently modality-agnostic (concepts are concepts regardless of representation), so it aligns well with this trend. A research challenge is designing encoders/decoders that can handle multiple input/output types and a switching mechanism (e.g., using AI to judge the semantic “cost” of each modality for a given message).
- Semantic Feedback and Channel Adaptation: Traditional communication has feedback channels for ACKs, etc. In semantic communication, we foresee feedback on understanding becoming normal. This might be explicit (“I got it” or “I don’t understand X part”) or implicit (the system detecting from user behavior that something was misunderstood). There is a trend of research into active learning and query in communications, e.g., the receiver can send back a request like “Clarify term Y” if uncertain. This can dramatically reduce misunderstandings but at the cost of extra round trips. Some proposals include negotiating a shared context before data transfer—e.g., devices exchanging brief “semantic headers” about which knowledge they assume. DIKWP’s iterative understanding process fits this (identification of misunderstanding, followed by supplementation). An open question is how to implement this efficiently in networks: how to quantify the confidence of understanding to decide when to trigger feedback and how to minimize the overhead (perhaps through piggyback feedback on existing control packets). This overlaps with reliability: semantic error detection is not straightforward like bit error detection. It might involve the receiver’s AI model estimating whether the decoded message fits plausibly or conflicts with its knowledge. There is research gap in developing metrics and algorithms for semantic error detection and correction (akin to CRC and ARQ but for meaning).
- Standardization of Semantic Information Representation: This is now an active area of research. Bodies like IEEE ComSoc or ITU have had focus groups on “Semantic and Goal-Oriented Communications”. Early outputs might be a common framework or definitions (such as defining what a “semantic bit” is or a “semantic alignment score”). One possible standardization effort is to define a semantic description language for networked communication, which could be akin to XML/JSON but enriched with ontology references. For example, a message might be annotated with ontology URI references for key terms, enabling a generic receiver to parse the meaning if it has the ontology. This is somewhat akin to the Semantic Web’s RDF but applied to dynamic messages. DIKWP graphs could be serialized in such a standard format (perhaps using existing KG standards). The gap here is performance: such self-descriptive semantic messages tend to be bulky (textual URIs, etc.), so balancing readability/standardization with compactness is challenging. Possibly, binary semantic protocols (like protocol buffers for semantics) could emerge.
- Network Support for Semantics: Future networks might have features at the infrastructure level to support SemCom. This might include edge caches of knowledge: an edge server could store common data patterns or models so that devices do not have to transmit them. An alternative is in-network reasoning: a router might aggregate multiple sensor inputs and directly infer a meaning (like an edge aggregator that collects raw data from many IoT sensors and only sends upward a semantic summary). This changes the role of network nodes from dumb forwarding to the active processing of meaning (which is a paradigm shift—reminiscent of information-centric networking). Projects in 6G research, like semantic-aware routing, could route data not by destination address but by asking “where can this meaning be fulfilled?” (similar to how CCN routes by content name). Implementation is nascent, but content-based networking prototypes (like NDNoT) might incorporate semantic tags for routing. The gap is in ensuring security and consistency when network nodes interfere with content—it requires trust frameworks (perhaps the network node has to cryptographically prove that it did not alter the semantics wrongly, e.g., via semantic signatures or blockchain).
- Explainable and Trustworthy AI Communication: As AI-driven communication becomes prevalent, user trust is critical. Thus, a trend is to build explainability features into communication interfaces, e.g., an email client in the future might say, “We have summarized 5 emails for you. [Show summary]. (Click to see full details or how summary was generated).” Alternatively, a personal assistant might ask, “Do you want a detailed explanation or just the gist?”, giving the user control. The DIKWP approach naturally supports explanation at each step (since each step’s output is interpretable), making it an ideal basis for such transparent systems. A research area is human-in-the-loop semantic AI: how to present explanations of semantic processing to users in a helpful way (not too technical). This also ties into user training—users might need to learn new mental models of what the AI is doing (e.g., understanding that it is not transmitting everything, so, if something is missing, it might have filtered it out). There is a sociotechnical gap: aligning user expectations with semantic communication behavior.
- Quantum SemCom: Furthermore, some have speculated on merging quantum communication with semantic concepts. Quantum communication excels in transmitting bits securely (via entanglement, etc.), but there are concepts like quantum-based language understanding or using quantum computing to perform semantic compression more efficiently. This is in the very early stage (mostly conceptual papers). It may be irrelevant for the near future but is worth noting as a far-term idea—e.g., could a quantum system store a superposition representing multiple meanings and then collapse to the needed one at the receiver, potentially sending less? While this appears unrealistic, there is a field emerging called quantum natural language processing that might one day inform communication. The gap is enormous here, combining two complex domains with few results, so progress remains to be seen.
Key Research Gaps
- Unified Theoretical Framework: As identified by survey authors, we lack a unified semantic information theory. There is no direct analog for “Shannon’s capacity” in semantics that everyone agrees on. Notions like semantic entropy or goal-oriented capacity are promising but not fully validated. Researchers need to converge on definitions of metrics like semantic fidelity, semantic capacity, semantic noise, etc. Without these, optimizing systems is ad hoc. DIKWP provides a conceptual framework but it is not a mathematical theory by itself. One gap is bridging DIKWP with information theory—e.g., formalizing how much purpose-driven compression can reduce the required bits (some theoretical models consider “relevant information” measures). Work on the information bottleneck for semantics is one avenue, but it is still in progress.
- Misalignment and Ontology Mapping: If two systems do not share the same ontology or knowledge base, how do they communicate? In human terms, this is akin to two experts from different fields talking—they have to find a common ground. In machines, this could happen if, say, two companies have different data schemas and their AI agents must collaborate. We need automatic ontology alignment algorithms in communication, i.e., ways for agents to identify that concept A from agent 1 is similar to concept B of agent 2, even if their labels differ. There is research in the semantic web community on ontology alignment, but performing this on-the-fly in communications is challenging (it can be computationally heavy). This is a gap, especially for open networks (like IoT devices from different vendors interacting). DIKWP relativity theory highlights the problem but does not solve it—it is an open research problem to allow semantic interoperability without pre-agreed standards in every case.
- Scalability in Multiparty Communication: Most research looks at one sender and one receiver. However, in reality, we often have group chats, broadcasting, or mesh networks. Ensuring that all members of a group share understanding is even more difficult—it is akin to multilateral relativity of understanding. For example, in a team, two people might interpret differently; how does an AI mediator ensure that everyone is on the same page? This may be possible via iterative consensus (the team might need to have a short discussion to clarify). In networks, broadcasting semantic information that is universally understood might require sending multiple versions tailored to subsets of receivers. The gap is in multitarget semantic encoding, i.e., how to encode a message such that different receivers can decode it to their own context correctly (somewhat like layered coding in video, where different qualities are embedded). The solution may be to include multiple semantic cues—but this would increase the overhead. This trade-off and technique are not well studied yet.
- Security Gaps: While encryption and adversarial defenses exist, new types of attacks are likely present. One is model inversion attacks: if an adversary intercepts semantic vectors, could they query a generative model to find a plausible input that leads to that vector, effectively reconstructing private information? Early studies in ML security show that it is possible to approximately invert embeddings to words or images. Thus, one gap lies in designing semantic representations that are difficult to invert without key knowledge (this could tie to encryption or purposely underspecified encodings that require context to resolve). Another gap is trust in knowledge—if an adversary can poison the knowledge base (disinformation attack), the system might semantically communicate incorrect or harmful meanings. Traditional communication did not have this vulnerability (bits are bits—they do not carry truth value inherently), but, here, if knowledge is incorrect, communication can mislead, even if the bits are correct. How can we validate knowledge in a distributed way? Blockchains or distributed ledgers may ensure data integrity for shared knowledge.
- Ethical Considerations: As systems become semantic and personalized, ethical issues become more pronounced. For example, could a personalized system inadvertently amplify a user’s cognitive biases by tailoring too much? (This is akin to the “filter bubble” issue in social networks—if the system only sends what one likes to hear, one’s knowledge may narrow). Moreover, if communication is goal-oriented, who sets the goal? An AI agent might overly prioritize a goal at the cost of other values (such as a goal to maximize clickthrough—it might communicate sensationalized content because this achieves the goal, even if it is not wise). Ensuring that Purpose layers encapsulate ethical objectives (like fairness, truthfulness) is a gap. There is a push for value alignment in AI (enabling AI to follow human ethics), which applies here too. SemCom systems will need guidelines to avoid misuse (e.g., deepfake content might be considered a “semantic attack”; policies must mitigate this—perhaps by watermarking legitimate content so that fakes can be detected).
- User Studies and HCI: A lot of the research is technical. We also need studies involving real users interacting with semantic communication systems to see how they react, what they prefer, and where misunderstandings still occur—for example, testing a DIKWP-based chatbot vs. a regular chatbot with diverse users and measuring trust and efficiency, or deploying a semantic IoT network in a smart home to see if it indeed saves bandwidth and if any failures occur. These practical evaluations will highlight gaps that theoretical work might miss—e.g., perhaps users find the explanations annoying, or perhaps an IoT device’s semantic compression saves bandwidth but misses a rare critical event. Such insights would feed back into model refinement. So far, few such user-centric evaluations have been published, which is a gap given how user-facing this technology can be.
In conclusion, while substantial progress has been made, the journey toward fully realized semantic, personalized, secure communications is just beginning. The convergence of communication engineering, AI, and knowledge representation opens up exciting possibilities but also demands cross-disciplinary solutions:
- Communication engineers must learn to incorporate knowledge and AI into designs;
- AI researchers must consider communication constraints and security issues;
- Domain experts (e.g., in medicine, automotive, etc.) need to help build ontologies and evaluate whether the semantics captured are truly the ones that matter.
The DIKWP model, with its comprehensive view, could serve as a guiding framework in addressing these emerging topics, ensuring that, as we add new capabilities, we maintain a focus on the end goal: making communication more effective, efficient, and aligned with human needs and values.
In the next section, we conclude the review with final thoughts and suggestions for future research directions, building upon the gaps and trends identified.
9. Conclusions and Future Research Directions
In this literature review, we have undertaken a comprehensive examination of SemCom and personalized semantic security through the lens of the DIKWP model and related frameworks. The DIKWP theory extends the classic Data–Information–Knowledge–Wisdom hierarchy with the critical layer of Purpose, framing understanding as a purposeful, context-driven process rather than a purely mechanistic one. We have explored how this model, combined with relativity of understanding (which highlights individual differences in ConC and SemA), provides a conceptual foundation for addressing challenges in SemCom—notably ensuring that meaning is preserved and correctly interpreted across diverse agents—and in personalized semantic security—ensuring that communication aligns with individual contexts and remains protected against semantic-level threats.
Our review of related work has revealed that many parallel efforts are pushing the boundaries of communication:
- Researchers in the 6G and AI communities have developed semantic-focused communication systems using deep learning, achieving impressive reductions in bandwidth requirements by transmitting meaning instead of verbatim data. These systems implicitly echo DIKWP’s rationale by prioritizing relevant information (akin to moving up the DIKWP pyramid) and ignoring or compressing irrelevant details.
- Knowledge-centric frameworks incorporate ontologies and KGs to ensure that the sender and receiver share a common understanding context. This resonates strongly with DIKWP’s explicit Data/Information/Knowledge structures.
- Efforts in personalized AI—from the federated learning of user-specific models to foundation models with contextual prompts—address the need to tailor communication to the individual, a need foreseen by the DIKWP’s relativity theory. Personalization is not just a user convenience but, as we have argued, a necessity for semantic fidelity when different receivers have different knowledge bases.
- In the realm of security, nascent frameworks like SemProtector and semantic firewalls directly tackle the confidentiality, integrity, and safety of semantic content. They complement DIKWP by adding the protective layers that any real deployment would require.
Our comparative analysis has highlighted that, while DIKWP is comprehensive and prescriptive (specifying which elements a SemCom system should account for), other approaches often provide specialized tools or algorithms. There is considerable opportunity for synergy:
- DIKWP can serve as an architectural blueprint under which the best of various approaches can be unified—for instance, using deep neural encoders at the Data→Information stage, symbolic AI for Knowledge representation, and explicit Purpose logic for decision making, all within one coherent system.
- Conversely, advances like large pretrained models or efficient semantic coding schemes can complement DIKWP’s abstract components with concrete, high-performance implementations.
In terms of applications and evaluations, we saw early evidence that semantic and personalized approaches can yield significant gains:
- Bandwidth and energy savings in IoT and wireless scenarios by transmitting semantic summaries instead of raw data.
- Improved quality of service in low-SNR or congested environments by focusing on what really matters to the communication goal.
- Enhanced user experiences, whether it is a more intuitive interaction with AI assistants (a reduced need for the user to phrase content precisely, as the system “understands” their meaning) or reduced information overload (through intelligent summarization guided by the user’s purpose and preferences).
However, these benefits come with new challenges. Our survey of emerging trends and gaps underlines that this field is still in an exploratory phase:
- Metrics and theories need to catch up—stakeholders will need a common language to evaluate SemCom systems (perhaps an analog of the “bit error rate” at the semantic level or standardized semantic compatibility scores).
- Robustness and security must be front-and-center in future research: making communications more intelligent should not render them more vulnerable (e.g., adversaries exploiting high-level understanding to deceive systems). Future systems must be resilient, possibly through redundancy at the semantic level (like checking consistency against a knowledge base to catch anomalies) or through novel encryption that protects the meaning itself, not just raw bits.
- Ethical design and value alignment will be an important research direction, ensuring that these systems augment human communication in a beneficial way. For example, semantic compression should not be allowed to become semantic distortion that hides inconvenient truths or injects bias. Transparency tools (like the ability to request the original uncompressed data or an explanation of what was omitted) might become standard components.
Regarding future research directions, building on our findings, we outline a few concrete directions that researchers and engineers in this interdisciplinary area could pursue.
- Formal Semantic Information Theory Development: Researchers should strive to formalize concepts such as semantic entropy, mutual understanding probability, and semantic channel capacity. One possible route is to extend Shannon’s theory by conditioning on a shared knowledge context. For instance, define the information content of a message relative to what the receiver already knows (which reduces uncertainty about the message’s meaning). Recent works on “common information” and “pointwise mutual information in embeddings” could be starting points. Validating these theories with experiments (e.g., does higher semantic mutual information correlate with better task success?) will be crucial.
- Neurosymbolic Communication Systems: Implement end-to-end prototypes that combine neural and symbolic techniques under the DIKWP paradigm. For example, create an AI assistant that uses a neural network to interpret user utterances (Data → Information), updates a KG about the user’s context (Information → Knowledge), uses symbolic reasoning or logical rules to draw conclusions or plans (Knowledge → Wisdom), and always references the user’s goals (Purpose) before responding. Compare this hybrid against a purely neural end-to-end system in terms of user satisfaction, the ability to explain decisions, and the ease of updating the system when new knowledge arises. This will empirically demonstrate the value (or limitations) of DIKWP’s structured approach.
- Semantic Alignment Protocols: Develop lightweight protocols for agents to negotiate and align on semantic context before and during communication. This might involve sharing hashes or identifiers of one’s knowledge base items to check for overlap, or conducting a quick Q&A session between agents to calibrate (similar to humans defining terms at the start of a technical discussion). One could simulate scenarios where two agents initially misunderstand each other and then apply an alignment protocol to measure the improvement in communication success. This also ties into multiparty settings and could extend to group protocols, such as a group chat establishing a common conceptual ground.
- Secure Semantic Exchange Mechanisms: Future research should design encryption schemes and authentication mechanisms specifically for semantic data. For example, one could encrypt the semantic representation (e.g., a vector or a triple) such that only a receiver with the right knowledge can decrypt it—perhaps leveraging attribute-based encryption, where attributes are semantic concepts. Another angle is watermarking semantic content, ensuring that any generated summary or content can be verified as coming from a legitimate source and not altered (embedding a hidden watermark in the phrasing that is invisible to humans but machine-checkable). These techniques would address concerns about deepfakes or semantic tampering. Researchers can borrow techniques from NLP watermarking and adapt them to SemCom.
- Cross-Layer Optimization in Networks: Traditional network design separates layers, but semantic communication cuts across them. Future research might consider cross-layer optimization where physical-layer parameters (power, coding) are adjusted based on the semantic importance of the data being sent. For instance, crucial semantic bits (that carry key meaning) could be given stronger error protection or higher power, whereas less important ones are sent on a best-effort basis. One might simulate a network where a semantic-aware scheduler allocates resources not just by packet size or QoS class but according to semantic content tags (like “urgent safety information” vs. “redundant data”). This blends ideas from DIKWP (where purpose determines priority) with networking. Studies could show improved reliability for important messages without increasing the overall load, demonstrating smarter resource use.
- Human Factors and User Training: Recognizing that communication is ultimately about humans (even if machine-mediated), research should also engage communication scientists, linguists, and cognitive psychologists. There is room to study how human communication strategies (like the use of metaphor, summarization, and clarification) can inspire algorithmic approaches—essentially bringing more of the pragmatic and social layer into SemCom models. Conversely, as humans start interacting with these systems, they may need to adjust their communication patterns (for example, a user might learn that saying a certain keyword triggers a summary mode). Studying this co-adaptation will ensure that the technology actually aligns with human behavior. This direction might involve controlled experiments with users interacting with different system variants and measuring outcomes like understanding, trust, and efficiency.
In closing, the quest for semantic-aware, personalized, and secure communication is a significant step toward cognitive networks—networks that do not merely transmit data but also interpret, reason, and adapt to meaning and user intent. The DIKWP model provides a timely theoretical cornerstone for this evolution, emphasizing that data gain value only through information, knowledge, and wisdom and that all of it must serve a purpose. As we have reviewed, aligning this theory with parallel advances in AI and communications yields a rich research tapestry. The eventual payoff is compelling: communication systems that are far more efficient (by being context-aware), more effective (by focusing on the receiver’s understanding and goals), and more trustworthy (by being explainable and secure). Realizing this vision will require continued interdisciplinary collaboration, experimental validation, and a conscious effort to embed human values into technical designs. However, if successful, it stands to revolutionize how we connect and collaborate, making the digital exchange of ideas as nuanced and powerful as human face-to-face dialog—if not more so—by leveraging the collective knowledge of the digital realm.
Author Contributions
Conceptualization, Y.M. and Y.D.; methodology, Y.M. and Y.D.; formal analysis, Y.M.; writing—original draft, Y.M.; writing—review and editing, Y.D.; supervision, Y.D.; validation, Y.M.; visualization, Y.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research project was supported in part by the Hainan Province Health Science and Technology Innovation Joint Program (WSJK2024QN025), in part by the Hainan Province Key R&D Program (ZDYF2022GXJS007, ZDYF2022GXJS010), and in part by the Hainan Province Key Laboratory of Meteorological Disaster Prevention and Mitigation in the South China Sea, Open Fund Project (SCSF202210).
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zeybek, M.; Kartal Çetin, B.; Engin, E.Z. A Hybrid Approach to Semantic Digital Speech: Enabling Gradual Transition in Practical Communication Systems. Electronics 2025, 14, 1130. [Google Scholar] [CrossRef]
- Strinati, E.C.; Barbarossa, S. 6G networks: Beyond Shannon towards semantic and goal-oriented communications. Comput. Netw. 2021, 190, 107930. [Google Scholar] [CrossRef]
- Getu, T.M.; Kaddoum, G.; Bennis, M. Semantic Communication: A Survey on Research Landscape, Challenges, and Future Directions. Proc. IEEE 2024, 112, 1649–1685. [Google Scholar] [CrossRef]
- Radicchi, F.; Krioukov, D. Harrison Hartle and Ginestra Bianconi, Classical information theory of networks. J. Phys. Complex. 2020, 1, 025001. [Google Scholar] [CrossRef]
- Luo, X.; Chen, H.-H.; Guo, Q. Semantic Communications: Overview, Open Issues, and Future Research Directions. IEEE Wirel. Commun. 2022, 29, 210–219. [Google Scholar] [CrossRef]
- Yang, W.; Du, H.; Liew, Z.Q.; Lim, W.Y.B.; Xiong, Z.; Niyato, D.; Chi, X.; Shen, X.; Miao, C. Semantic Communications for Future Internet: Fundamentals, Applications, and Challenges. IEEE Commun. Surv. Tutor. 2023, 295, 213–250. [Google Scholar] [CrossRef]
- Chaccour, C.; Saad, W.; Debbah, M.; Han, Z.; Vincent Poor, H. Less Data, More Knowledge: Building Next-Generation Semantic Communication Networks. IEEE Commun. Surv. Tutor. 2025, 27, 37–76. [Google Scholar] [CrossRef]
- Al-Muhtadi, J.; Saleem, K.; Al-Rabiaah, S.; Imran, M.; Gawanmeh, A.; Rodrigues, J.J.P.C. A lightweight cyber security framework with context-awareness for pervasive computing environments. Sustain. Cities Soc. 2021, 66, 102610. [Google Scholar] [CrossRef]
- Javadpour, A.; Ja’fari, F.; Taleb, T.; Zhao, Y.; Yang, B.; Benzaïd, C. Encryption as a Service for IoT: Opportunities, Challenges, and Solutions. IEEE Internet Things J. 2024, 11, 7525–7558. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, M.; Li, G.; Yang, Y.; Zhang, Z. Secure Semantic Communications: Fundamentals and Challenges. IEEE Netw. 2024, 38, 513–520. [Google Scholar] [CrossRef]
- Won, D.; Woraphonbenjakul, G.; Wondmagegn, A.B.; Tran, A.-T.; Lee, D.; Lakew, D.S. Resource Management, Security, and Privacy Issues in Semantic Communications: A Survey. IEEE Commun. Surv. Tutor. 2025, 27, 1758–1797. [Google Scholar] [CrossRef]
- Li, C.; Zeng, L.; Huang, X.; Miao, X.; Wang, S. Secure Semantic Communication Model for Black-Box Attack Challenge Under Metaverse. IEEE Wirel. Commun. 2023, 30, 56–62. [Google Scholar] [CrossRef]
- Meng, R.; Gao, S.; Fan, D.; Gao, H.; Wang, Y.; Xu, X.; Wang, B.; Lv, S.; Zhang, Z.; Sun, M.; et al. A survey of secure semantic communications. J. Netw. Comput. Appl. 2025, 239, 104181. [Google Scholar] [CrossRef]
- Alsamhi, S.H.; Hawbani, A.; Mohsen, N.; Kumar, S.; Porwol, L.; Curry, E. SemCom for Metaverse: Challenges, Opportunities and Future Trends. In Proceedings of the 2023 3rd International Conference on Computing and Information Technology (ICCIT), Tabuk, Saudi Arabia, 13–14 September 2023; pp. 130–134. [Google Scholar] [CrossRef]
- Mei, Y.; Duan, Y. The DIKWP (Data, Information, Knowledge, Wisdom, Purpose) Revolution: A New Horizon in Medical Dispute Resolution. Appl. Sci. 2024, 14, 3994. [Google Scholar] [CrossRef]
- van Meter, H.J. Revising the DIKW pyramid and the real relationship between data, information, knowledge, and wisdom. Law Technol. Humans 2020, 2, 69–80. [Google Scholar] [CrossRef]
- Peters, M.A.; Jandrić, P.; Green, B.J. The DIKW Model in the Age of Artificial Intelligence. Postdigital Sci. Educ. 2024, 6, 1–10. [Google Scholar] [CrossRef]
- Wu, K.; Duan, Y. DIKWP-TRIZ: A Revolution on Traditional TRIZ Towards Invention for Artificial Consciousness. Appl. Sci. 2024, 14, 10865. [Google Scholar] [CrossRef]
- d’Inverno, R.; Vickers, J. Introducing Einstein’s Relativity: A Deeper Understanding; Oxford University Press: Oxford, UK, 2022. [Google Scholar]
- Tommasi, M.; Sergi, M.R.; Picconi, L.; Saggino, A. The location of emotional intelligence measured by EQ-i in the personality and cognitive space: Are there gender differences? Front. Psychol. 2023, 13, 985847. [Google Scholar] [CrossRef]
- Bendifallah, L.; Abbou, J.; Douven, I.; Burnett, H. Conceptual Spaces for Conceptual Engineering? Feminism as a Case Study. Rev. Phil. Psych. 2025, 16, 199–229. [Google Scholar] [CrossRef]
- Cowen, A.S.; Dacher, K. Semantic Space Theory: A Computational Approach to Emotion. Trends Cogn. Sci. 2021, 25, 124–136. [Google Scholar] [CrossRef]
- Sarkis-Onofre, R.; Catalá-López, F.; Aromataris, E.; Lockwood, C. How to properly use the PRISMA Statement. Syst. Rev. 2021, 10, 117. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; The University of Illinois Press: Urbana, IL, USA, 1949; pp. 1–117. [Google Scholar]
- Bar-Hillel, Y.; Rudolf, C. Semantic information. Br. J. Philos. Sci. 1953, 4, 147–157. [Google Scholar] [CrossRef]
- Dickerson, J.E. Data, information, knowledge, wisdom, and understanding. Anaesth. Intensive Care Med. 2022, 23, 737–739. [Google Scholar] [CrossRef]
- Ackoff, R. From data to wisdom. J. Appl. Syst. Anal. 1989, 16, 3–9. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Pearl, J. Direct and Indirect Effects. Probabilistic and Causal Inference: The Works of Judea Pearl, 1st ed.; Association for Computing Machinery: New York, NY, USA, 2022; pp. 373–392. [Google Scholar] [CrossRef]
- Russell, S.J. Rationality and intelligence. Artif. Intell. 1997, 94, 57–77. [Google Scholar] [CrossRef]
- Dretske, F. The pragmatic dimension of knowledge. Philos. Stud. Int. J. Philos. Anal. Tradit. 1981, 40, 363–378. [Google Scholar] [CrossRef]
- Floridi, L. Understanding Epistemic Relevance. Erkenn 2008, 69, 69–92. [Google Scholar] [CrossRef]
- Bao, J. Towards a theory of semantic communication. In Proceedings of the 2011 IEEE Network Science Workshop, West Point, NY, USA, 22–24 June 2011; pp. 110–117. [Google Scholar] [CrossRef]
- O’Shea, K. An approach to conversational agent design using semantic sentence similarity. Appl. Intell. 2012, 37, 558–568. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z.; Li, G.Y.; Juang, B.-H. Deep Learning Enabled Semantic Communication Systems. IEEE Trans. Signal Process. 2021, 69, 2663–2675. [Google Scholar] [CrossRef]
- Yang, Y.; Huang, C.; Xia, L.; Li, C. Knowledge Graph Contrastive Learning for Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22), Madrid, Spain, 11–15 July 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1434–1443. [Google Scholar] [CrossRef]
- Strinati, E.C.; Alexandropoulos, G.C.; Wymeersch, H.; Denis, B.; Sciancalepore, V.; D’Errico, R.; Clemente, A.; Phan-Huy, D.-T.; De Carvalho, E.; Popovski, P. Reconfigurable, Intelligent, and Sustainable Wireless Environments for 6G Smart Connectivity. IEEE Commun. Mag. 2021, 59, 99–105. [Google Scholar] [CrossRef]
- Popovski, P.; Simeone, O.; Boccardi, F.; Gündüz, D.; Sahin, O. Semantic-Effectiveness Filtering and Control for Post-5G Wireless Connectivity. J. Indian Inst. Sci. 2020, 100, 435–443. [Google Scholar] [CrossRef]
- Jiang, P.; Agarwal, S.; Jin, B.; Wang, X.; Sun, J.; Han, J. Text-Augmented Open Knowledge Graph Completion via Pre-Trained Language Models. arXiv 2023, arXiv:2305.15597. [Google Scholar] [CrossRef]
- Thomas, R.W.; DaSilva, L.A.; MacKenzie, A.B. Cognitive networks. In Proceedings of the First IEEE International Symposium on New Frontiers in Dynamic Spectrum Access Networks, DySPAN 2005, Baltimore, MD, USA, 8–11 November 2005; pp. 352–360. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, J.; Xu, B. White-Box AI Model: Next Frontier of Wireless Communications. arXiv 2025, arXiv:2504.09138. [Google Scholar] [CrossRef]
- Wang, Z.; Xie, W.; Chen, K. Self-Deception: Reverse Penetrating the Semantic Firewall of Large Language Models. arXiv 2023, arXiv:2308.11521. [Google Scholar] [CrossRef]
- Duan, Y.; Sun, X.; Che, H.; Cao, C.; Li, Z.; Yang, X. Modeling data, information and knowledge for security protection of hybrid IoT and edge resources. IEEE Access 2019, 7, 99161–99176. [Google Scholar] [CrossRef]
- Skjæveland, M.G.; Balog, K.; Bernard, N.; Łajewska, W.; Linjordet, T. An Ecosystem for Personal Knowledge Graphs: A Survey and Research Roadmap. AI Open 2024, 5, 100246. [Google Scholar] [CrossRef]
- Al-Nazer, A.; Helmy, T.; Al-Mulhem, M. User’s Profile Ontology-based Semantic Framework for Personalized Food and Nutrition Recommendation. Procedia Comput. Sci. 2014, 32, 282–289. [Google Scholar] [CrossRef]
- Wang, Y.; Ni, W.; Yi, W.; Xu, X.; Zhang, P.; Nallanathan, A. Federated Contrastive Learning for Personalized Semantic Communication. IEEE Commun. Lett. 2024, 28, 1875–1879. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, H.H.; Chong, K.F.E.; Quek, T.Q.S. Personalizing Semantic Communication: A Foundation Model Approach. In Proceedings of the 2024 IEEE 25th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Lucca, Italy, 10–13 September 2024; pp. 846–850. [Google Scholar] [CrossRef]
- Meng, R.; Fan, D.; Gao, H.; Yuan, Y.; Wang, B.; Xu, X.; Sun, M.; Dong, C.; Tao, X.; Zhang, P.; et al. Secure Semantic Communication With Homomorphic Encryption. arXiv 2025, arXiv:2501.10182. [Google Scholar] [CrossRef]
- Liu, X.; Nan, G.; Cui, Q.; Li, Z.; Liu, P.; Xing, Z.; Mu, H.; Tao, X.; Quek, T.Q.S. SemProtector: A Unified Framework for Semantic Protection in Deep Learning-based Semantic Communication Systems. IEEE Commun. Mag. 2023, 61, 56–62. [Google Scholar] [CrossRef]
- Wu, K.; Duan, Y. Modeling and Resolving Uncertainty in DIKWP Model. Appl. Sci. 2024, 14, 4776. [Google Scholar] [CrossRef]
- Tang, F.; Duan, Y.; Wei, J.; Che, H.; Wu, Y. DIKWP Artificial Consciousness White Box Measurement Standards Framework Design and Practice. In Proceedings of the 2023 IEEE International Conference on High Performance Computing & Communications, Data Science & Systems, Smart City & Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Melbourne, Australia, 17–21 December 2023; pp. 1067–1074. [Google Scholar] [CrossRef]
- Sap, M.; Rashkin, H.; Chen, D.; Bras, R.L.; Choi, Y. Social IQa: Commonsense Reasoning about Social Interactions. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4463–4473. [Google Scholar] [CrossRef]
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems. arXiv 2021, arXiv:2110.14168. [Google Scholar] [CrossRef]
- Liu, J.; Cui, L.; Liu, H.; Huang, D.; Wang, Y.; Zhang, Y. LogiQA: A challenge dataset for machine reading comprehension with logical reasoning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI’20), Yokohama, Japan, 7–15 January 2021; pp. 3622–3628. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).