


DepthCloud2Point: Depth Maps and Initial Point for 3D Point Cloud Reconstruction from a Single Image




Abstract
1. Introduction
- We propose DepthCloud2Point, a framework that uses a CNN with depth maps, image features, and initial point clouds for single-view 3D reconstruction.
- Rather than directly inferring the point cloud, we incorporate depth maps to offer comprehensive spatial cues for maintaining intricate object details and employ initial point clouds as geometric priors to fix the irregular point distribution, ensuring uniformity in point distribution.
- The proposed model is evaluated on the ShapeNet and Pix3D datasets, demonstrating superior performance compared to state-of-the-art methods. Quantitative and qualitative results based on evaluation metrics such as Chamfer Distance (CD) and Earth Mover’s Distance (EMD) highlight its effectiveness in achieving high-quality single-view 3D reconstructions.
2. Related Work
2.1. Single-View Voxel-Based 3D Reconstruction
2.2. Single-View Point Cloud-Based 3D Reconstruction
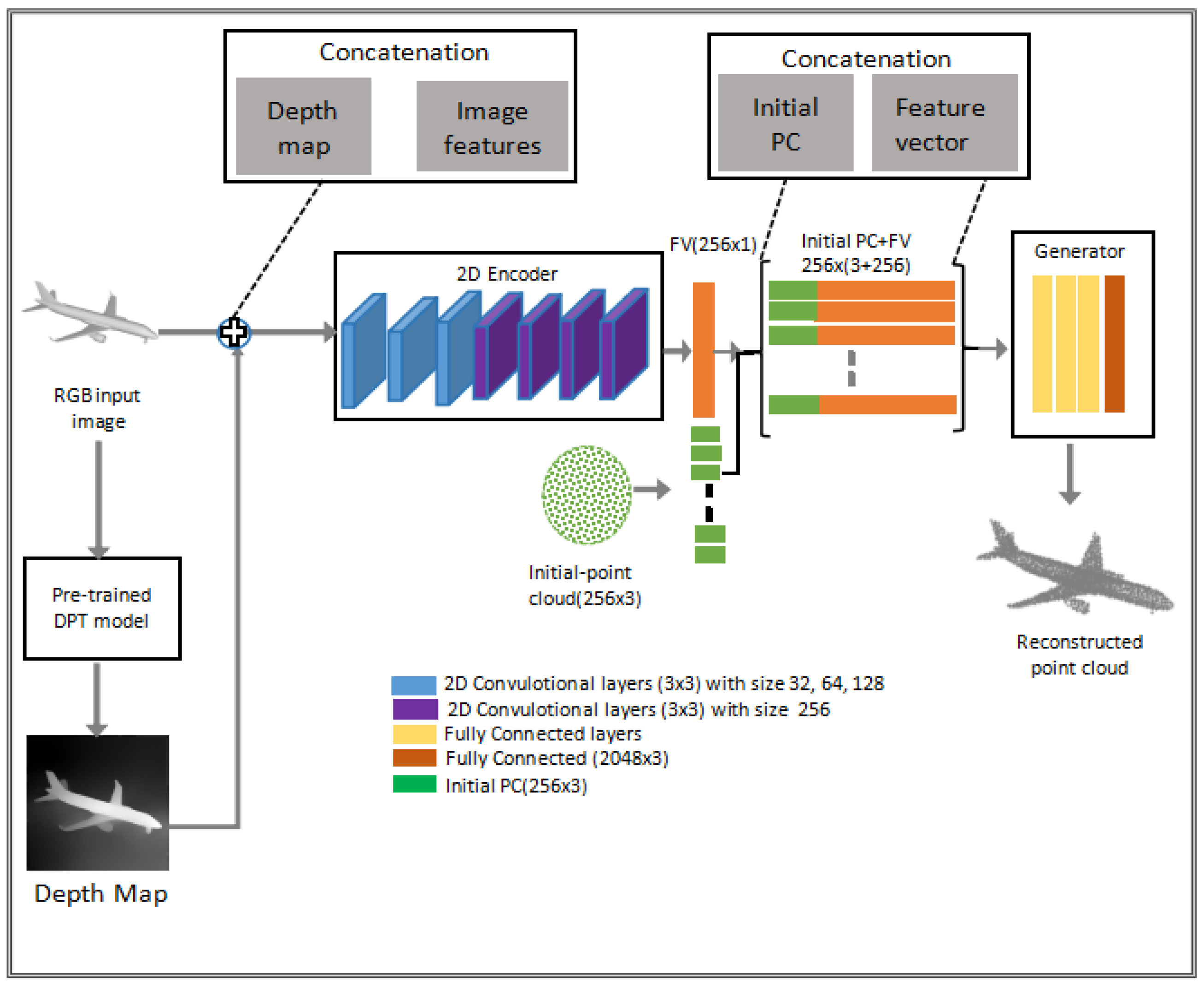
3. Methodology
3.1. Architecture of DepthCloud2Point
3.1.1. Depth Map Branch
| Algorithm 1 Algorithm of Proposed DepthCloud2Point Network |
|
3.1.2. Encoder
3.1.3. Initial Point Cloud Providing Geometric Structure
3.1.4. Generator
3.2. Loss Function
3.2.1. Chamfer Distance (CD)
3.2.2. Earth Mover’s Distance (EMD)
4. Experimental Analysis
4.1. Experimental Setup
4.2. Results and Discussion
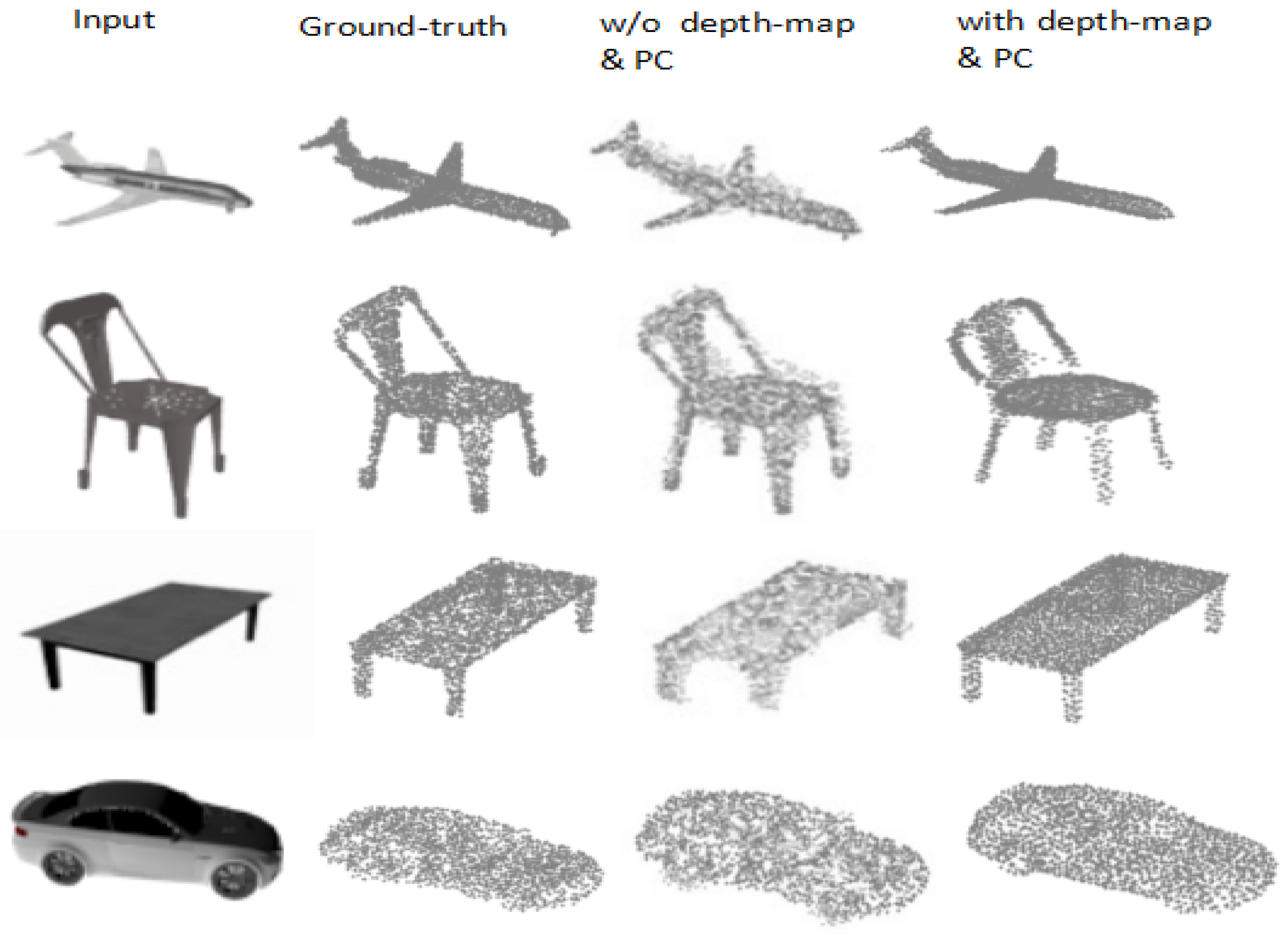
4.3. Ablation Studies
Effect of the Depth Map and Initial Point Cloud
4.4. Failure Cases
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ehsani, K.; Han, W.; Herrasti, A.; VanderBilt, E.; Weihs, L.; Kolve, E.; Kembhavi, A.; Mottaghi, R. Manipulathor: A framework for visual object manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 4497–4506. [Google Scholar]
- Kent, D.; Behrooz, M.; Chernova, S. Construction of a 3D object recognition and manipulation database from grasp demonstrations. Auton. Robot 2016, 40, 175–192. [Google Scholar] [CrossRef]
- Placed, J.A.; Strader, J.; Carrillo, H.; Atanasov, N.; Indelman, V.; Carlone, L.; Castellanos, J.A. A survey on active simultaneous localization and mapping: State of the art and new frontiers. IEEE Trans. Robot. 2023, 39, 1686–1705. [Google Scholar] [CrossRef]
- Nousias, S.; Lourakis, M.; Bergeles, C. Large-scale, metric structure from motion for unordered light fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3292–3301. [Google Scholar]
- Tatarchenko, M.; Richter, S.R.; Ranftl, R.; Li, Z.; Koltun, V.; Brox, T. What do single-view 3D reconstruction networks learn? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3405–3414. [Google Scholar]
- Henderson, P.; Ferrari, V. Learning single-image 3D reconstruction by generative modelling of shape, pose and shading. Int. J. Comput. Vis. 2020, 128, 835–854. [Google Scholar] [CrossRef]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-CNN: Towards high performance voxel-based 3D object detection. AAAI Conf. Artif. Intell. 2021, 35, 1201–1209. [Google Scholar] [CrossRef]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching efficient 3D architectures with sparse point-voxel convolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 685–702. [Google Scholar]
- Fahim, G.; Amin, K.; Zarif, S. Single-View 3D reconstruction: A survey of deep learning methods. Comput. Graph. 2021, 94, 164–190. [Google Scholar] [CrossRef]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3D object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Afifi, A.J.; Magnusson, J.; Soomro, T.A.; Hellwich, O. Pixel2Point: 3D object reconstruction from a single image using CNN and initial sphere. IEEE Access 2020, 9, 110–121. [Google Scholar] [CrossRef]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 12179–12188. [Google Scholar]
- Li, Z.; Wang, X.; Liu, X.; Jiang, J. Binsformer: Revisiting adaptive bins for monocular depth estimation. IEEE Trans. Image Process. 2024, 33, 3964–3976. [Google Scholar] [CrossRef] [PubMed]
- Sohail, S.S.; Himeur, Y.; Kheddar, H.; Amira, A.; Fadli, F.; Atalla, S.; Copiaco, A.; Mansoor, W. Advancing 3D point cloud understanding through deep transfer learning: A comprehensive survey. Inf. Fusion 2024, 9, 110–121. [Google Scholar] [CrossRef]
- Mandikal, P.; Navaneet, K.L.; Agarwal, M.; Babu, R.V. 3D-LMNet: Latent embedding matching for accurate and diverse 3D point cloud reconstruction from a single image. arXiv 2018, arXiv:1807.07796. [Google Scholar]
- Liu, F.; Liu, X. Voxel-based 3D detection and reconstruction of multiple objects from a single image. Adv. Neural Inf. Process. Syst. 2021, 34, 2413–2426. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.Y.; Chen, K.; Savarese, S. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 628–644. [Google Scholar]
- Tulsiani, S.; Efros, A.A.; Malik, J. Multi-view consistency as supervisory signal for learning shape and pose prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2897–2905. [Google Scholar]
- Tulsiani, S.; Zhou, T.; Efros, A.A.; Malik, J. Multi-view supervision for single-view reconstruction via differentiable ray consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2626–2634. [Google Scholar]
- Lu, Y.; Wang, S.; Fan, S.; Lu, J.; Li, P.; Tang, P. Image-based 3D reconstruction for Multi-Scale civil and infrastructure projects: A review from 2012 to 2022 with new perspective from deep learning methods. Adv. Eng. Inform. 2024, 59, 102268. [Google Scholar] [CrossRef]
- Xia, Y.; Wang, C.; Xu, Y.; Zang, Y.; Liu, W.; Li, J.; Stilla, U. RealPoint3D: Generating 3D point clouds from a single image of complex scenarios. Remote Sens. 2019, 11, 2644. [Google Scholar] [CrossRef]
- Lu, F.; Chen, G.; Liu, Y.; Zhan, Y.; Li, Z.; Tao, D.; Jiang, C. Sparse-to-dense matching network for large-scale LiDAR point cloud registration. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11270–11282. [Google Scholar] [CrossRef] [PubMed]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3D reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4460–4470. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3D point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Qi, Z.; Li, F. PointConv: Deep convolutional networks on 3D point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Pan, M.; Liu, J.; Zhang, R.; Huang, P.; Li, X.; Xie, H.; Wang, B.; Liu, L.; Zhang, S. RenderOcc: Vision-centric 3D occupancy prediction with 2D rendering supervision. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 12404–12411. [Google Scholar]
- Shen, W.; Jia, Y.; Wu, Y. 3D shape reconstruction from images in the frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4471–4479. [Google Scholar]
- Zhang, Z.; Zhang, Y.; Zhao, X.; Gao, Y. EMD metric learning. AAAI Conf. Artif. Intell. 2018, 32, 4490–4497. [Google Scholar] [CrossRef]
- Wu, T.; Pan, L.; Zhang, J.; Wang, T.; Liu, Z.; Lin, D. Balanced Chamfer distance as a comprehensive metric for point cloud completion. Adv. Neural Inf. Process. Syst. 2021, 34, 29088–29100. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Sun, X.; Wu, J.; Zhang, X.; Zhang, Z.; Zhang, C.; Xue, T.; Tenenbaum, J.B.; Freeman, W.T. Pix3D: Dataset and methods for single-image 3D shape modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2974–2983. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Zhang, Z. Improved Adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Limitation | Voxel-Based Methods | Point Cloud-Based Methods | How DepthCloud2Point Solves It |
|---|---|---|---|
| Memory and Computation | Limited scalability due to volumetric grids. | Efficient, but suffers from irregular point distribution. | Uses depth maps and initial point clouds to optimize memory usage. |
| Representation Precision | Loss of details in voxelization. | Point clouds provide rich geometric details. | Enhances detail preservation through improved point distribution. |
| Occlusion and Depth Ambiguities | Struggles with resolving occlusions. | Depth ambiguity due to point distribution. | Addresses occlusions effectively using depth maps. |
| Fine Detail Preservation | Difficulty capturing fine details due to voxelization. | Allows for precise fine details to preserve distinct object details. | Captures fine details by leveraging depth information. |
| Parameter | Description |
|---|---|
| Batch Size | 32 |
| Learning Rate | 0.00005 |
| Optimizer | Adam |
| Loss Function | Chamfer Distance (CD), Earth Mover’s Distance (EMD) |
| Number of Epochs | 100 |
| Hardware | NVIDIA RTX 3090 |
| Dataset Used | ShapeNet, Pix3D |
| Dataset Split | 80% Training, 20% Test |
| Evaluation Metrics | Chamfer Distance (CD), Earth Mover’s Distance (EMD) |
| Category | CD | EMD | ||||
|---|---|---|---|---|---|---|
| 3D-LMNNet | Pixel2Point | Ours | 3D-LMNNet | Pixel2Point | Ours | |
| Airplane | 3.34 | 3.29 | 2.25 | 4.77 | 3.82 | 2.76 |
| Bench | 4.55 | 4.59 | 3.01 | 4.99 | 4.31 | 3.23 |
| Cabinet | 6.09 | 6.07 | 6.19 | 6.35 | 4.94 | 3.56 |
| Car | 4.55 | 4.39 | 3.45 | 4.10 | 3.61 | 2.45 |
| Chair | 6.41 | 6.48 | 3.90 | 8.02 | 6.45 | 5.03 |
| Lamp | 7.10 | 6.58 | 4.13 | 15.80 | 8.45 | 6.58 |
| Monitor | 6.40 | 6.39 | 4.21 | 7.13 | 5.94 | 4.42 |
| Rifle | 2.75 | 2.89 | 2.82 | 6.08 | 4.25 | 4.53 |
| Sofa | 5.85 | 5.85 | 4.78 | 5.65 | 5.03 | 3.82 |
| Speaker | 8.10 | 8.39 | 8.45 | 9.15 | 7.37 | 7.43 |
| Table | 6.05 | 6.26 | 4.89 | 7.82 | 6.05 | 5.15 |
| Telephone | 4.63 | 4.27 | 4.33 | 5.43 | 3.77 | 2.65 |
| Vessel | 4.37 | 4.55 | 4.45 | 5.68 | 4.89 | 4.06 |
| Mean | 5.40 | 5.38 | 4.37 | 7.00 | 5.30 | 4.28 |
| Category | CD | EMD | ||||
|---|---|---|---|---|---|---|
| 3D-LMNNet | Pixel2Point | Ours | 3D-LMNNet | Pixel2Point | Ours | |
| Chair | 7.35 | 6.82 | 3.79 | 9.14 | 7.45 | 5.23 |
| Sofa | 8.18 | 3.95 | 6.75 | 7.22 | 3.28 | 6.12 |
| Table | 11.20 | 5.22 | 3.70 | 12.73 | 5.17 | 4.45 |
| Mean | 8.91 | 5.33 | 4.75 | 9.70 | 5.30 | 5.16 |
| Category | CD | EMD | ||
|---|---|---|---|---|
| w/o Depth & PC | With Depth & PC | w/o Depth & PC | With Depth & PC | |
| Airplane | 4.65 | 2.25 | 5.92 | 2.76 |
| Bench | 5.74 | 3.01 | 7.23 | 3.23 |
| Cabinet | 5.82 | 6.19 | 4.12 | 3.56 |
| Car | 6.32 | 3.45 | 6.13 | 2.45 |
| Chair | 7.11 | 3.90 | 11.16 | 5.03 |
| Lamp | 6.07 | 4.13 | 8.13 | 6.58 |
| Monitor | 7.22 | 4.21 | 9.32 | 4.42 |
| Rifle | 3.45 | 2.82 | 10.46 | 4.53 |
| Sofa | 6.32 | 4.78 | 4.14 | 3.82 |
| Speaker | 7.12 | 8.45 | 8.12 | 7.43 |
| Table | 6.21 | 4.89 | 7.23 | 5.15 |
| Telephone | 4.14 | 4.33 | 3.12 | 2.65 |
| Vessel | 5.00 | 4.45 | 7.51 | 4.06 |
| Mean | 5.76 | 4.37 | 7.12 | 4.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asafa, G.F.; Ren, S.; Mamun, S.S.; Gobena, K.A. DepthCloud2Point: Depth Maps and Initial Point for 3D Point Cloud Reconstruction from a Single Image. Electronics 2025, 14, 1119. https://doi.org/10.3390/electronics14061119
Asafa GF, Ren S, Mamun SS, Gobena KA. DepthCloud2Point: Depth Maps and Initial Point for 3D Point Cloud Reconstruction from a Single Image. Electronics. 2025; 14(6):1119. https://doi.org/10.3390/electronics14061119
Chicago/Turabian StyleAsafa, Galana Fekadu, Shengbing Ren, Sheikh Sohan Mamun, and Kaleb Amsalu Gobena. 2025. "DepthCloud2Point: Depth Maps and Initial Point for 3D Point Cloud Reconstruction from a Single Image" Electronics 14, no. 6: 1119. https://doi.org/10.3390/electronics14061119
APA StyleAsafa, G. F., Ren, S., Mamun, S. S., & Gobena, K. A. (2025). DepthCloud2Point: Depth Maps and Initial Point for 3D Point Cloud Reconstruction from a Single Image. Electronics, 14(6), 1119. https://doi.org/10.3390/electronics14061119