Hardware Resource Analysis in Distributed Training with Edge Devices


Abstract
:1. Introduction
- We trained the DL model using distributed training on edge devices. We demonstrate that DL models can be trained locally on edge devices without offloading to the server.
- We demonstrated a hardware resource-efficient distributed training model configuration for resource-constrained edge devices. We monitored the hardware resources used during the training phase. Results find that distributed training with smaller batch sizes and fewer layer sizes reduces training time and increases accuracy.
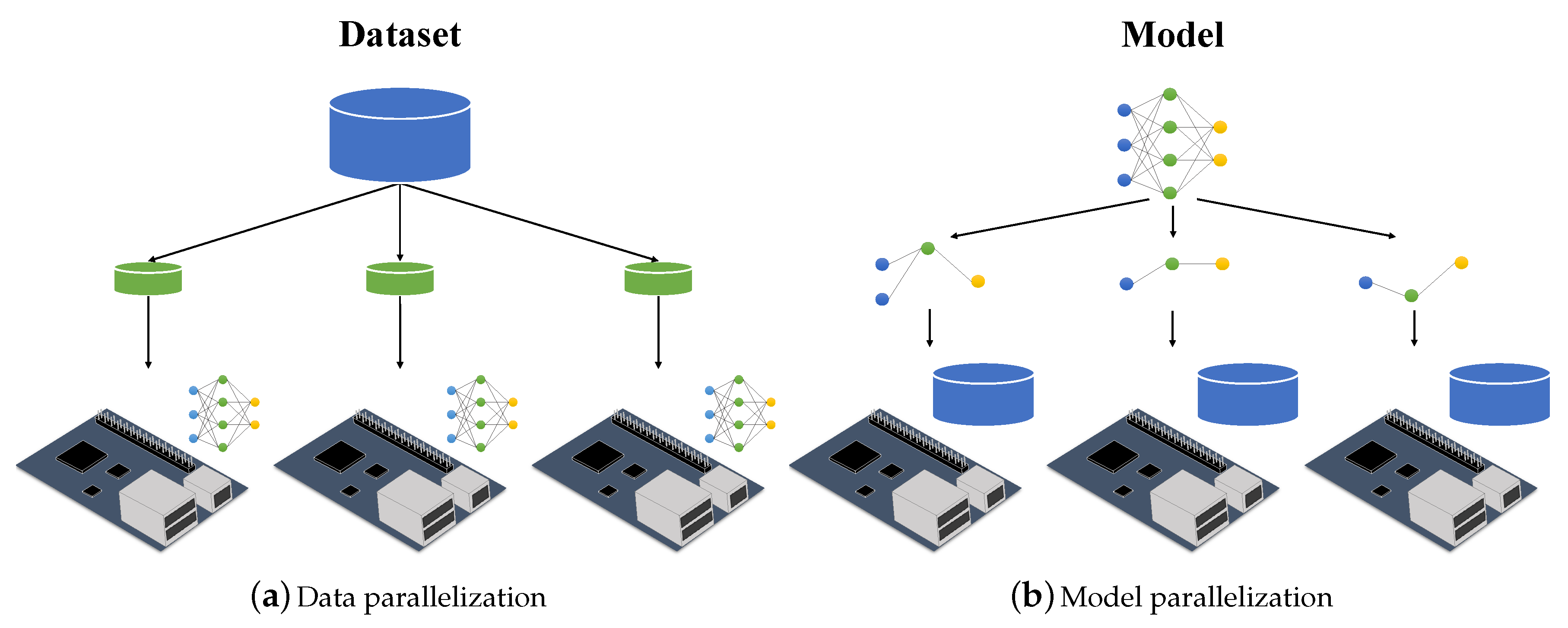
2. Backgrounds
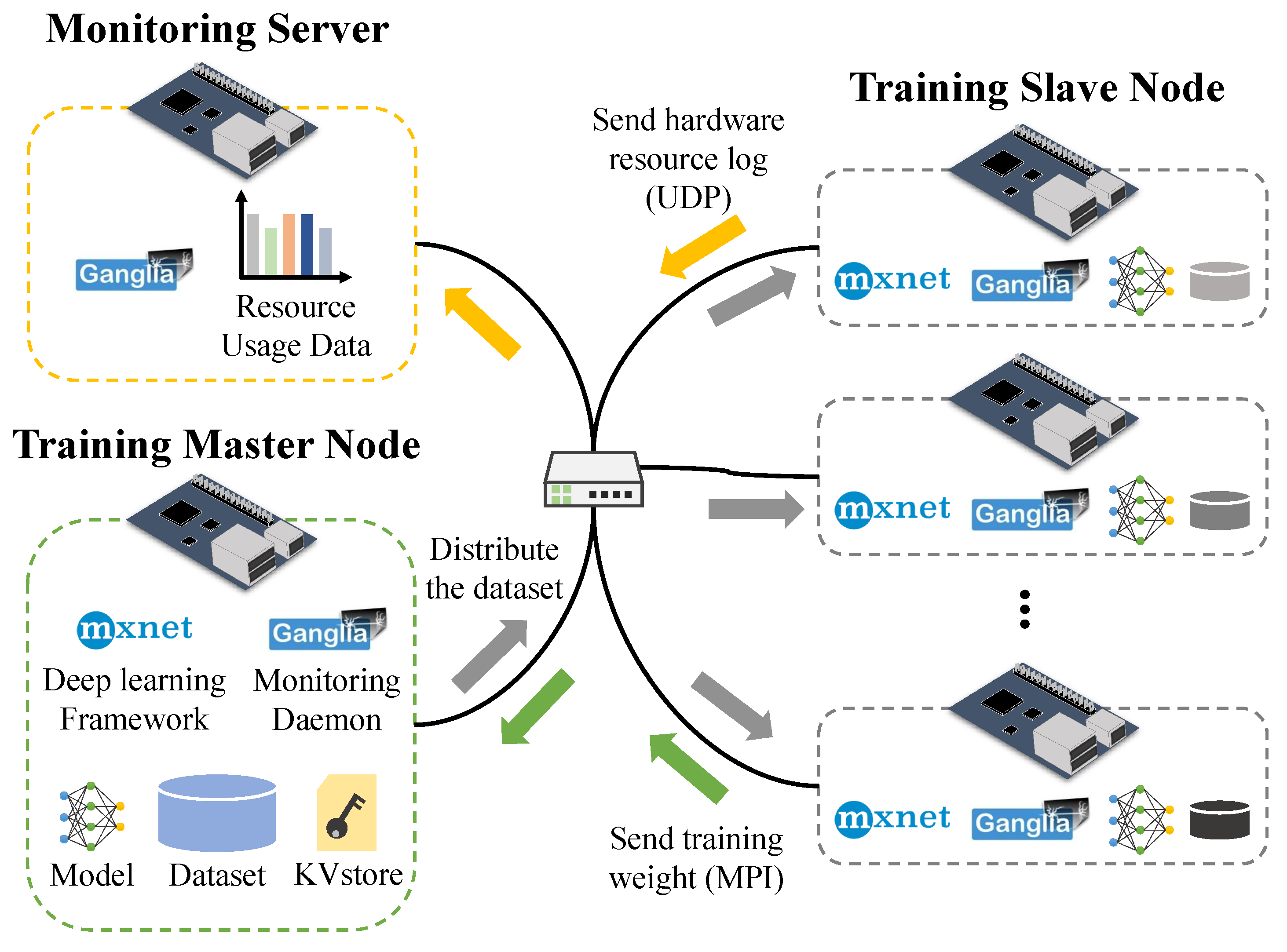
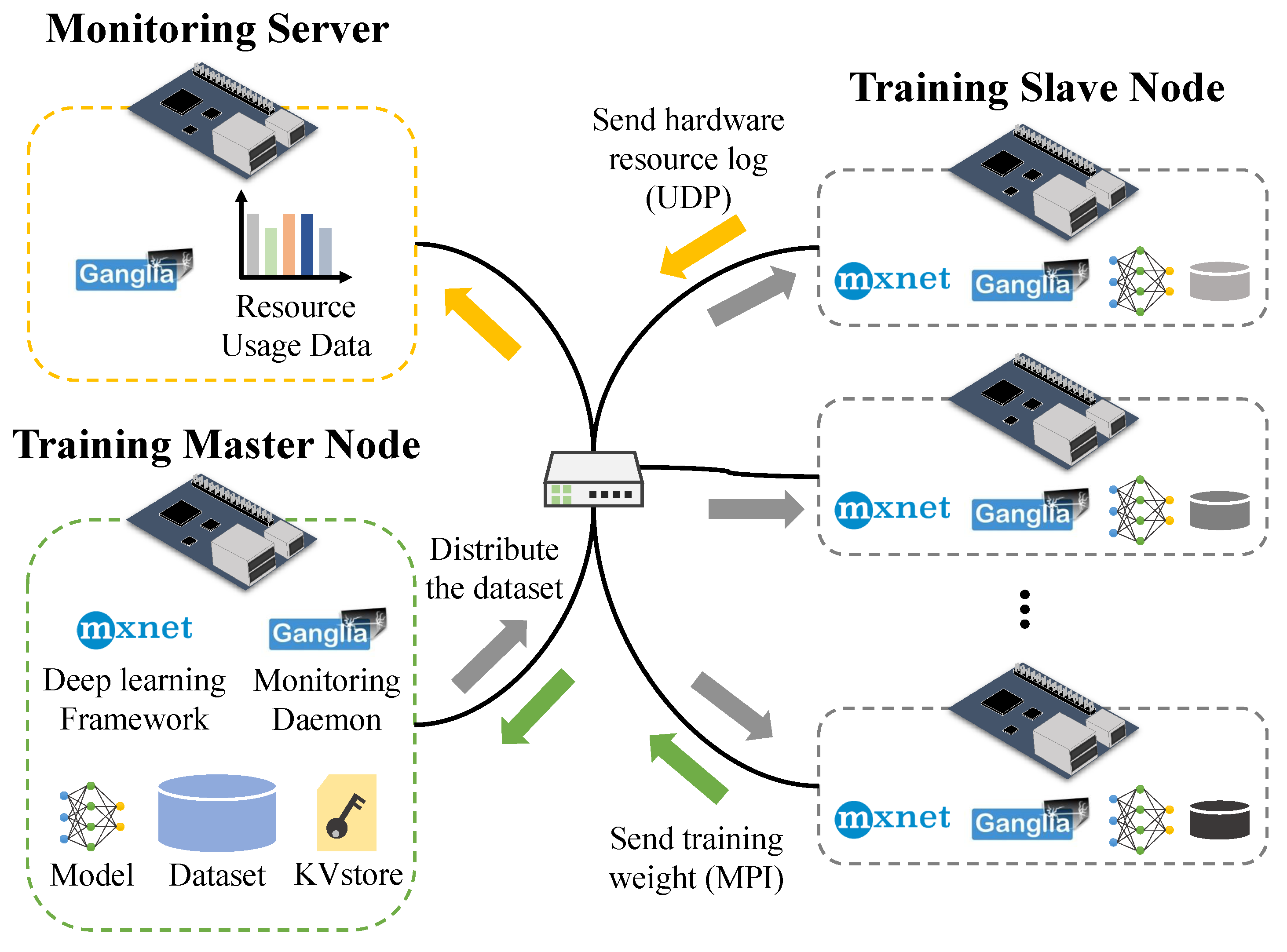
3. Distributed Training on Edge Devices
4. Evaluations
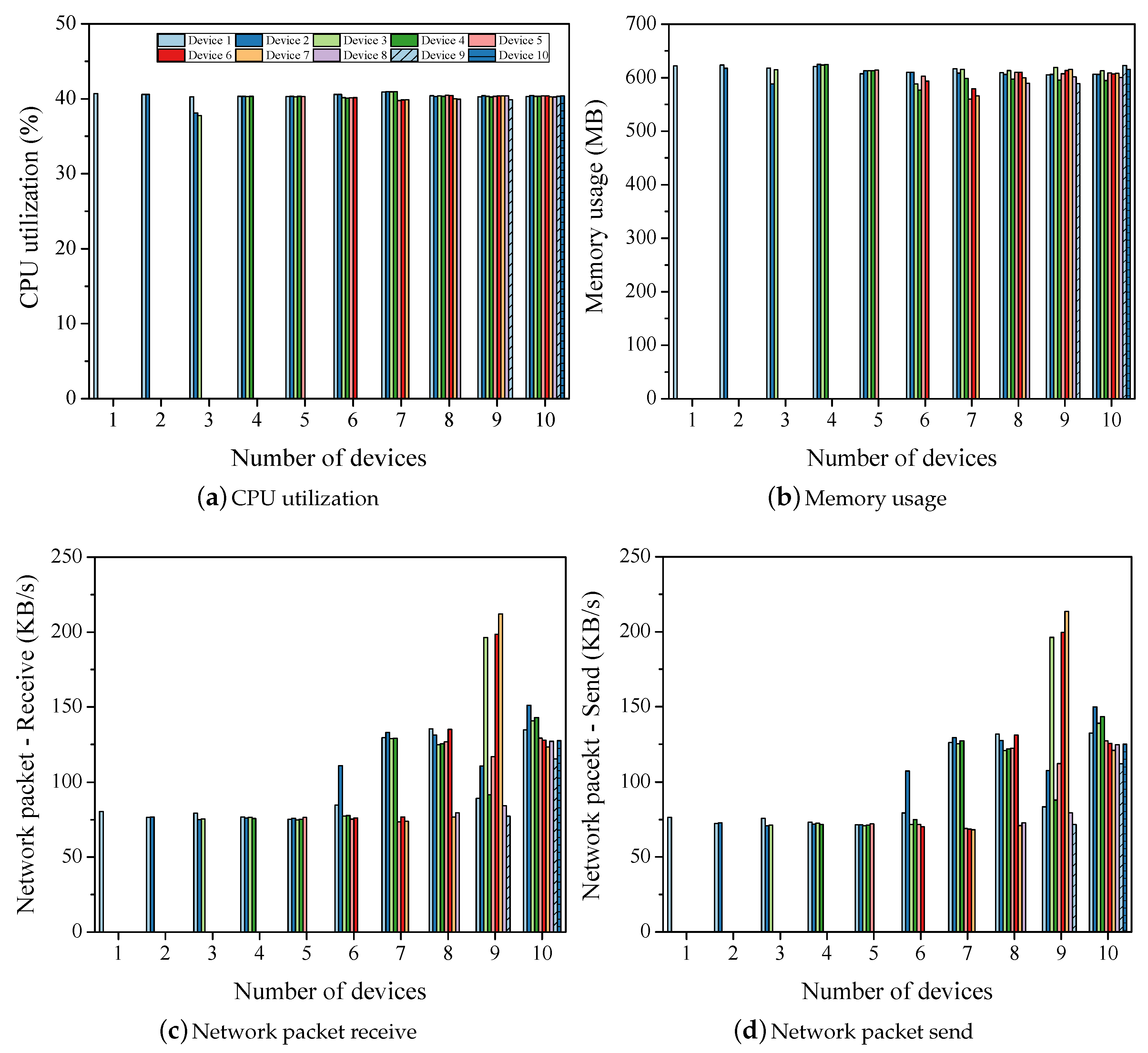
4.1. Experimental Environment
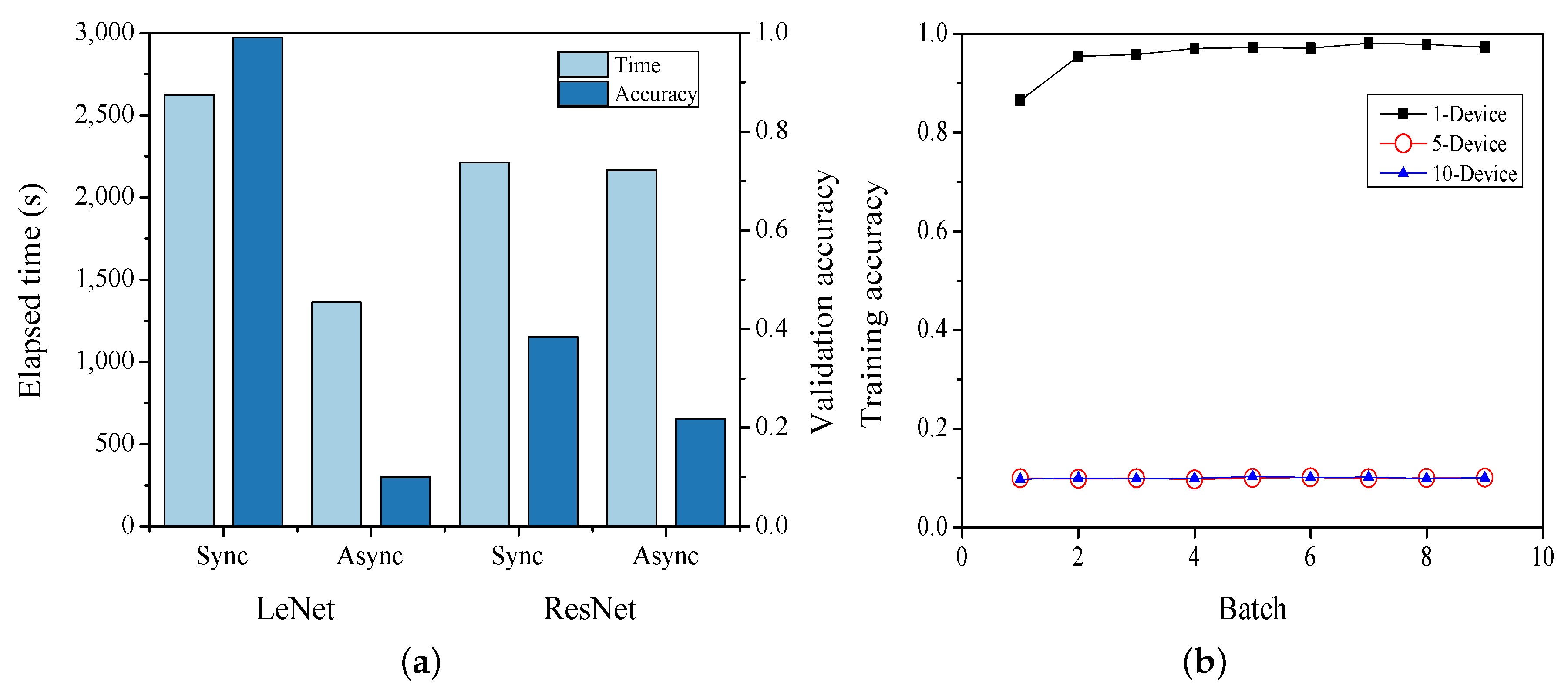
4.2. Comparison of Synchronization Method
4.3. Experiment Results: LeNet
4.4. Experiment Results: ResNet
5. Related Works
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Satyanarayanan, M. The emergence of edge computing. Computer 2017, 50, 30–39. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Manic, M.; Amarasinghe, K.; Rodriguez-Andina, J.J.; Rieger, C. Intelligent buildings of the future: Cyberaware, deep learning powered, and human interacting. IEEE Ind. Electron. Mag. 2016, 10, 32–49. [Google Scholar] [CrossRef]
- Xu, K.; Wang, X.; Wei, W.; Song, H.; Mao, B. Toward software defined smart home. IEEE Commun. Mag. 2016, 54, 116–122. [Google Scholar] [CrossRef]
- Chen, B.; Wan, J.; Shu, L.; Li, P.; Mukherjee, M.; Yin, B. Smart factory of industry 4.0: Key technologies, application case, and challenges. IEEE Access 2017, 6, 6505–6519. [Google Scholar] [CrossRef]
- Candanedo, I.S.; Nieves, E.H.; González, S.R.; Martín, M.T.S.; Briones, A.G. Machine learning predictive model for industry 4.0. In Proceedings of the International Conference on Knowledge Management in Organizations, Zilina, Slovakia, 6–10 August 2018; pp. 501–510. [Google Scholar]
- Li, H.; Ota, K.; Dong, M. Learning IoT in edge: Deep learning for the Internet of Things with edge computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhang, Z.; Taleb, T. Special issue on security and privacy of IoT. World Wide Web 2018, 21, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Jacobsson, A.; Boldt, M.; Carlsson, B. A risk analysis of a smart home automation system. Future Gener. Comput. Syst. 2016, 56, 719–733. [Google Scholar] [CrossRef] [Green Version]
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Ranzato, M.; Senior, A.; Tucker, P.; Yang, K.; et al. Large scale distributed deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012; pp. 1223–1231. [Google Scholar]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. Distributed deep neural networks over the cloud, the edge and end devices. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 328–339. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 525–542. [Google Scholar]
- Zhang, J.; Xiao, J.; Wan, J.; Yang, J.; Ren, Y.; Si, H.; Zhou, L.; Tu, H. A parallel strategy for convolutional neural network based on heterogeneous cluster for mobile information system. Mob. Inf. Syst. 2017, 2017, 1–12. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Jackel, L.; Bottou, L.; Cortes, C.; Denker, J.S.; Drucker, H.; Guyon, I.; Muller, U.A.; Sackinger, E.; Simard, P.; et al. Learning algorithms for classification: A comparison on handwritten digit recognition. Neural Netw. Stat. Mech. Perspect. 1995, 261, 276. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances In Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Zhang, K.; Alqahtani, S.; Demirbas, M. A comparison of distributed machine learning platforms. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–9. [Google Scholar]
- Massie, M.; Li, B.; Nicholes, B.; Vuksan, V.; Alexander, R.; Buchbinder, J.; Costa, F.; Dean, A.; Josephsen, D.; Phaal, P.; et al. Monitoring with Ganglia: Tracking Dynamic Host and Application Metrics at Scale; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Gardner, M.W.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Ooi, B.C.; Tan, K.L.; Wang, S.; Wang, W.; Cai, Q.; Chen, G.; Gao, J.; Luo, Z.; Tung, A.K.; Wang, Y.; et al. SINGA: A distributed deep learning platform. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 685–688. [Google Scholar]
- Zhang, H.; Zheng, Z.; Xu, S.; Dai, W.; Ho, Q.; Liang, X.; Hu, Z.; Wei, J.; Xie, P.; Xing, E.P. Poseidon: An efficient communication architecture for distributed deep learning on {GPU} clusters. In Proceedings of the 2017 USENIX Annual Technical Conference (USENIX ATC 17), Santa Clara, CA, USA, 12–14 July 2017; pp. 181–193. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Shams, S.; Platania, R.; Lee, K.; Park, S.J. Evaluation of deep learning frameworks over different HPC architectures. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 1389–1396. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, X.; Wang, Y.; Shi, W. pcamp: Performance comparison of machine learning packages on the edges. In Proceedings of the USENIX Workshop on Hot Topics in Edge Computing (HotEdge 18), Boston, MA, USA, 11–13 July 2018. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the NIPS 2019—Neural Information Processing Systems, Vancouver, CO, Canada, 10–12 December 2019; pp. 8024–8035. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Coates, A.; Huval, B.; Wang, T.; Wu, D.; Catanzaro, B.; Andrew, N. Deep learning with COTS HPC systems. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1337–1345. [Google Scholar]
- Cui, H.; Zhang, H.; Ganger, G.R.; Gibbons, P.B.; Xing, E.P. Geeps: Scalable deep learning on distributed gpus with a gpu-specialized parameter server. In Proceedings of the Eleventh European Conference on Computer Systems, London, UK, 18–21 April 2016; p. 4. [Google Scholar]
- Konečnỳ, J.; McMahan, B.; Ramage, D. Federated optimization: Distributed optimization beyond the datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Jiang, P.; Agrawal, G. Accelerating distributed stochastic gradient descent with adaptive periodic parameter averaging: poster. In Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming, Washington, DC, USA, 16–20 February 2019; pp. 403–404. [Google Scholar]
- Morabito, R. Virtualization on internet of things edge devices with container technologies: A performance evaluation. IEEE Access 2017, 5, 8835–8850. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of Devices | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Elapsed Time (s) | 105 | 168 | 228 | 286 | 342 | 287 | 442 | 453 | 510 | 566 |
| Validation Accuracy | 0.961 | 0.971 | 0.970 | 0.970 | 0.975 | 0.974 | 0.974 | 0.974 | 0.973 | 0.971 |
| # of Devices | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Elapsed Time (s) | 1079 | 1177 | 1338 | 1484 | 1778 | 2009 | 1970 | 2436 | 2665 | 2625 |
| Validation Accuracy | 0.982 | 0.988 | 0.989 | 0.990 | 0.990 | 0.991 | 0.989 | 0.990 | 0.990 | 0.991 |
| Number of Layers × Batch Size | |||||
|---|---|---|---|---|---|
| CPU utilization (%) | 39.5 | 38.9 | 38.9 | 39.3 | 39.3 |
| Memory usage (MB) | 253.6 | 314.5 | 314.5 | 348.8 | 398.1 |
| Network-receive (KB) | 245.3 | 121.3 | 121.3 | 246.1 | 242.6 |
| Network-send (KB) | 245.7 | 119.6 | 119.6 | 250.8 | 243.7 |
| # of Epochs | |||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| Elapsed time (s) | 2212 | 4391 | 6598 | 8787 | 10,989 |
| Validation accuracy | 0.384 | 0.510 | 0.584 | 0.669 | 0.649 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.; Lee, J.; Kim, H. Hardware Resource Analysis in Distributed Training with Edge Devices. Electronics 2020, 9, 28. https://doi.org/10.3390/electronics9010028
Park S, Lee J, Kim H. Hardware Resource Analysis in Distributed Training with Edge Devices. Electronics. 2020; 9(1):28. https://doi.org/10.3390/electronics9010028
Chicago/Turabian StylePark, Sihyeong, Jemin Lee, and Hyungshin Kim. 2020. "Hardware Resource Analysis in Distributed Training with Edge Devices" Electronics 9, no. 1: 28. https://doi.org/10.3390/electronics9010028