Diverse Taxonomies for Diverse Chemistries: Enhanced Representation of Natural Product Metabolism in UniProtKB

 ,
,  ,
,  , , , , and
, , , , and
Abstract
:1. Introduction
2. Results
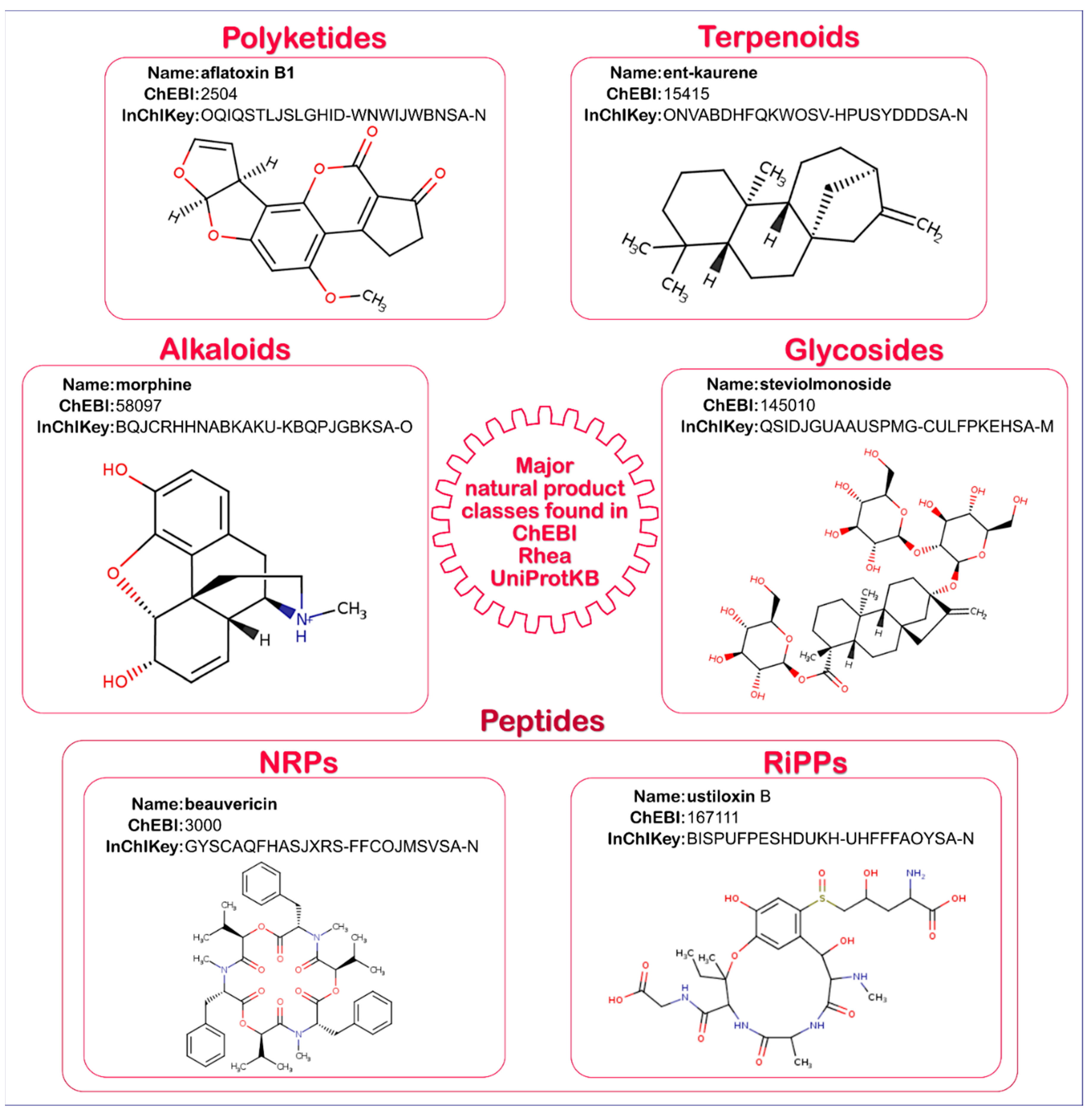
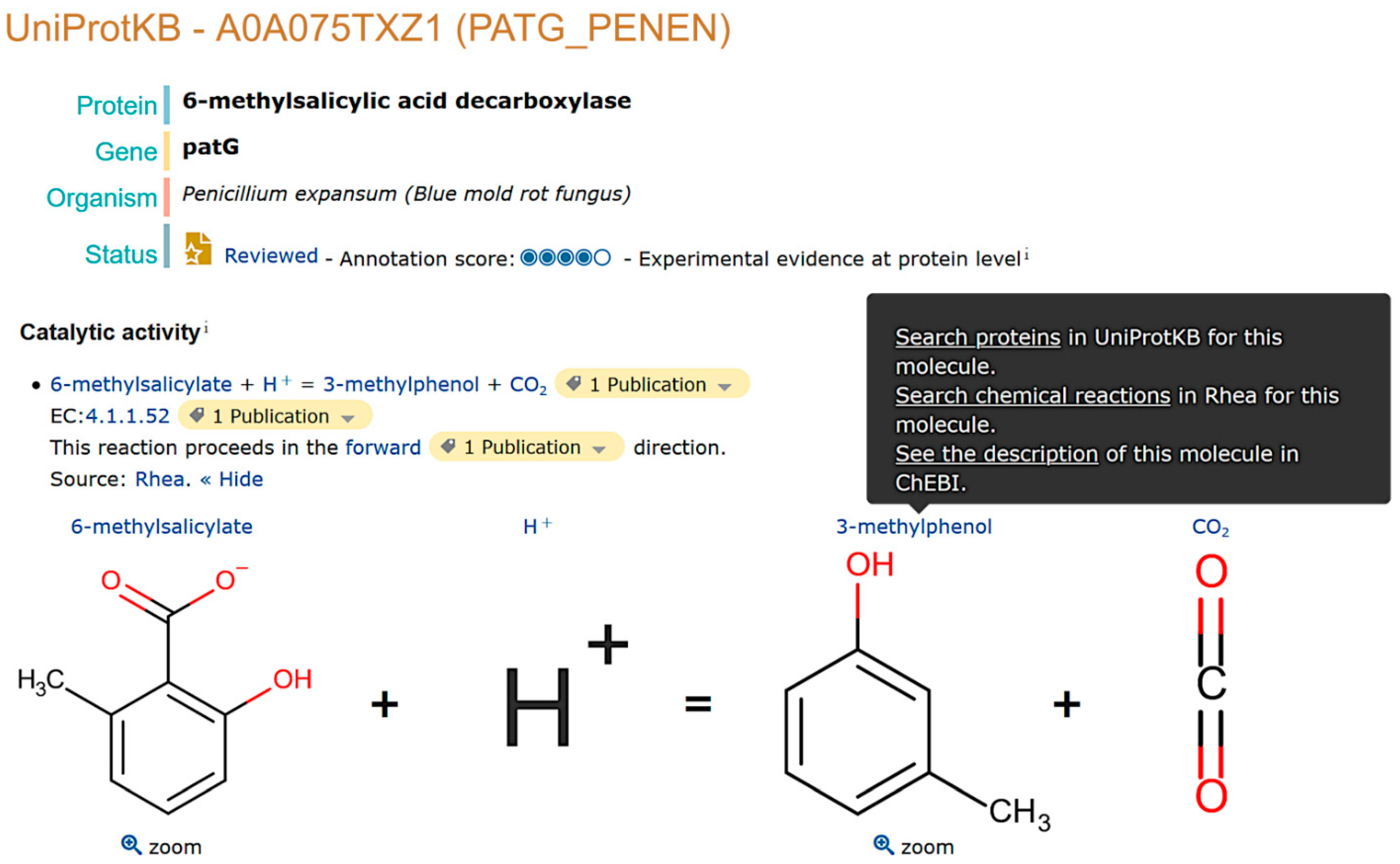
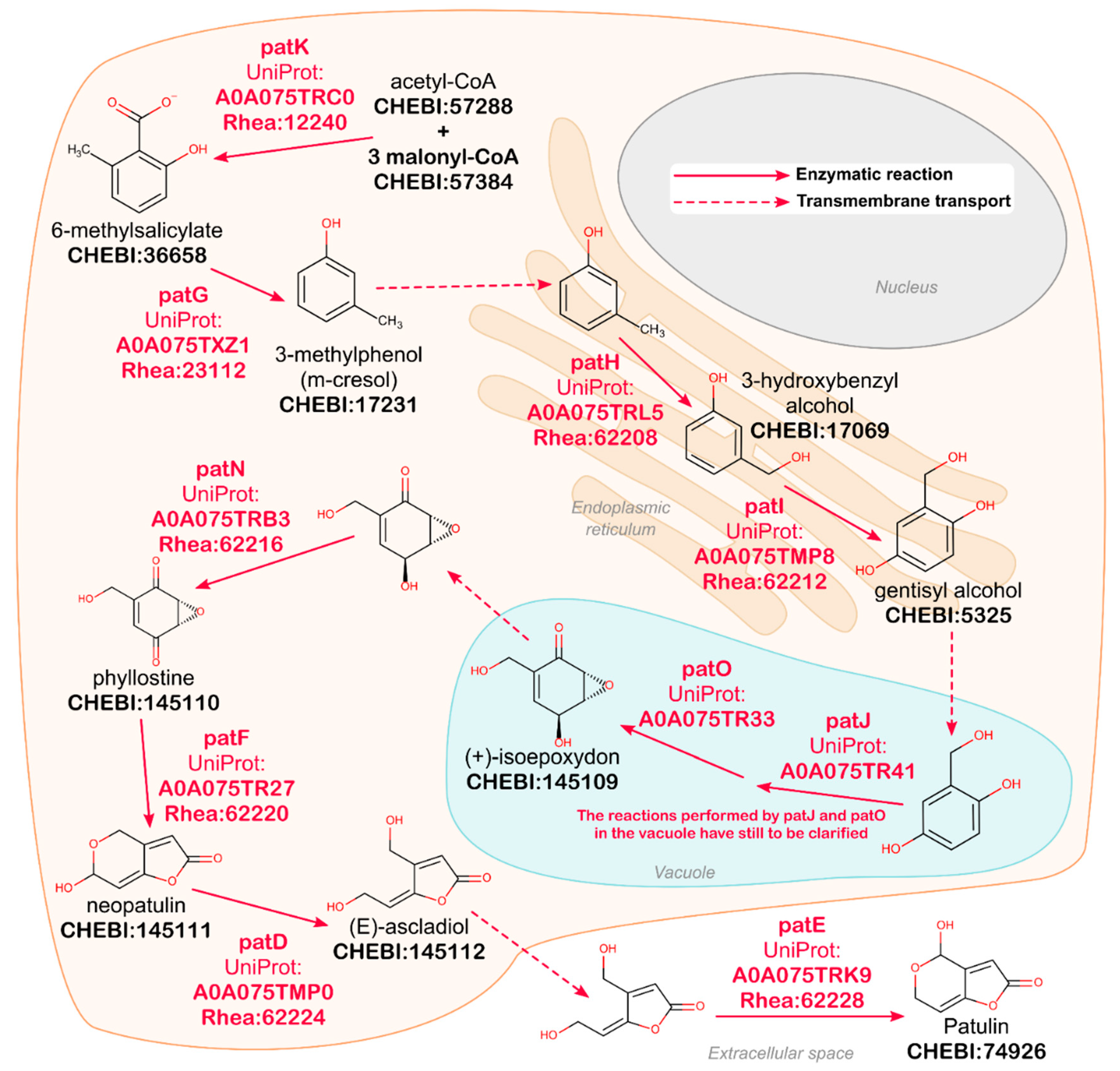
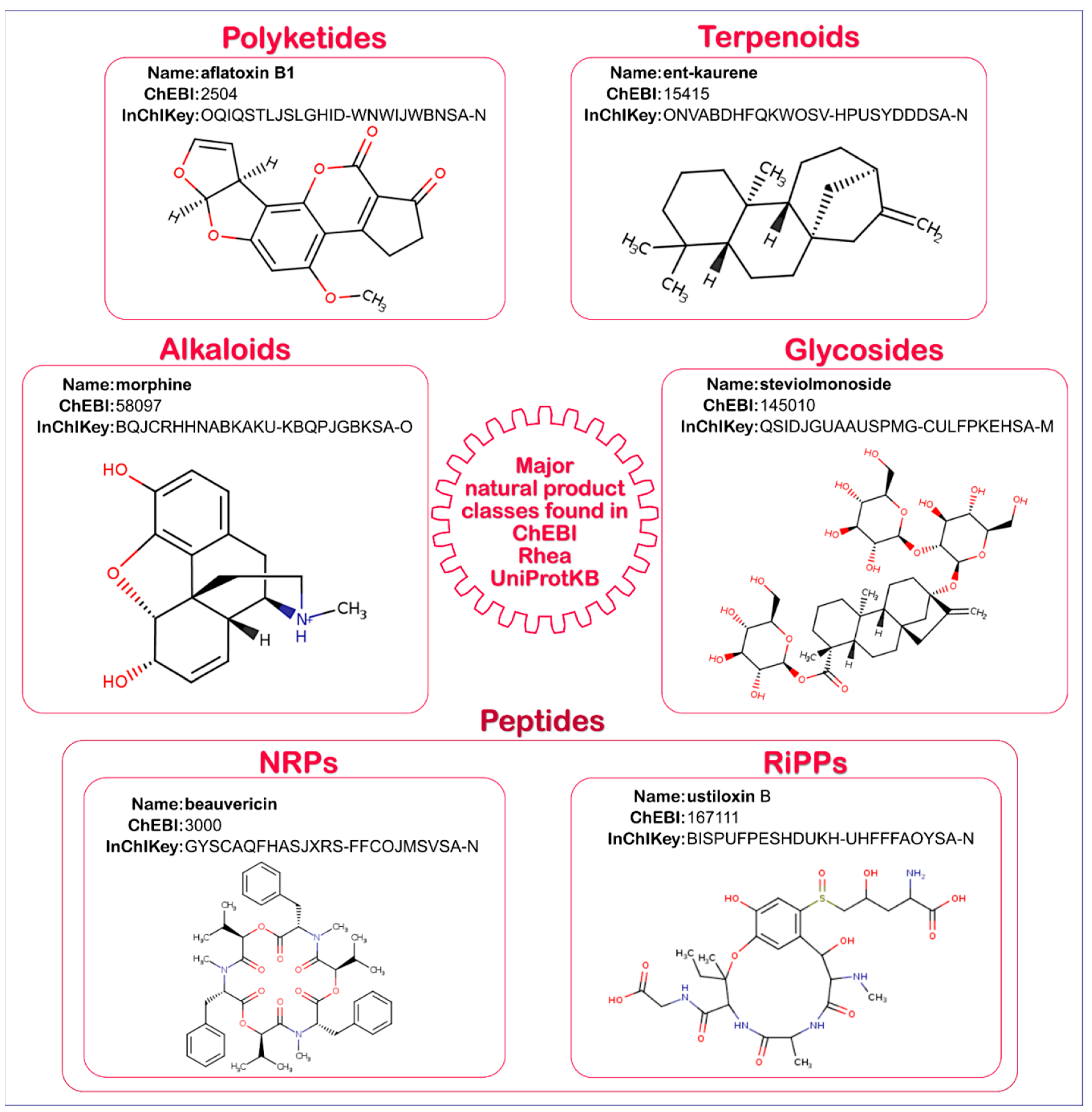
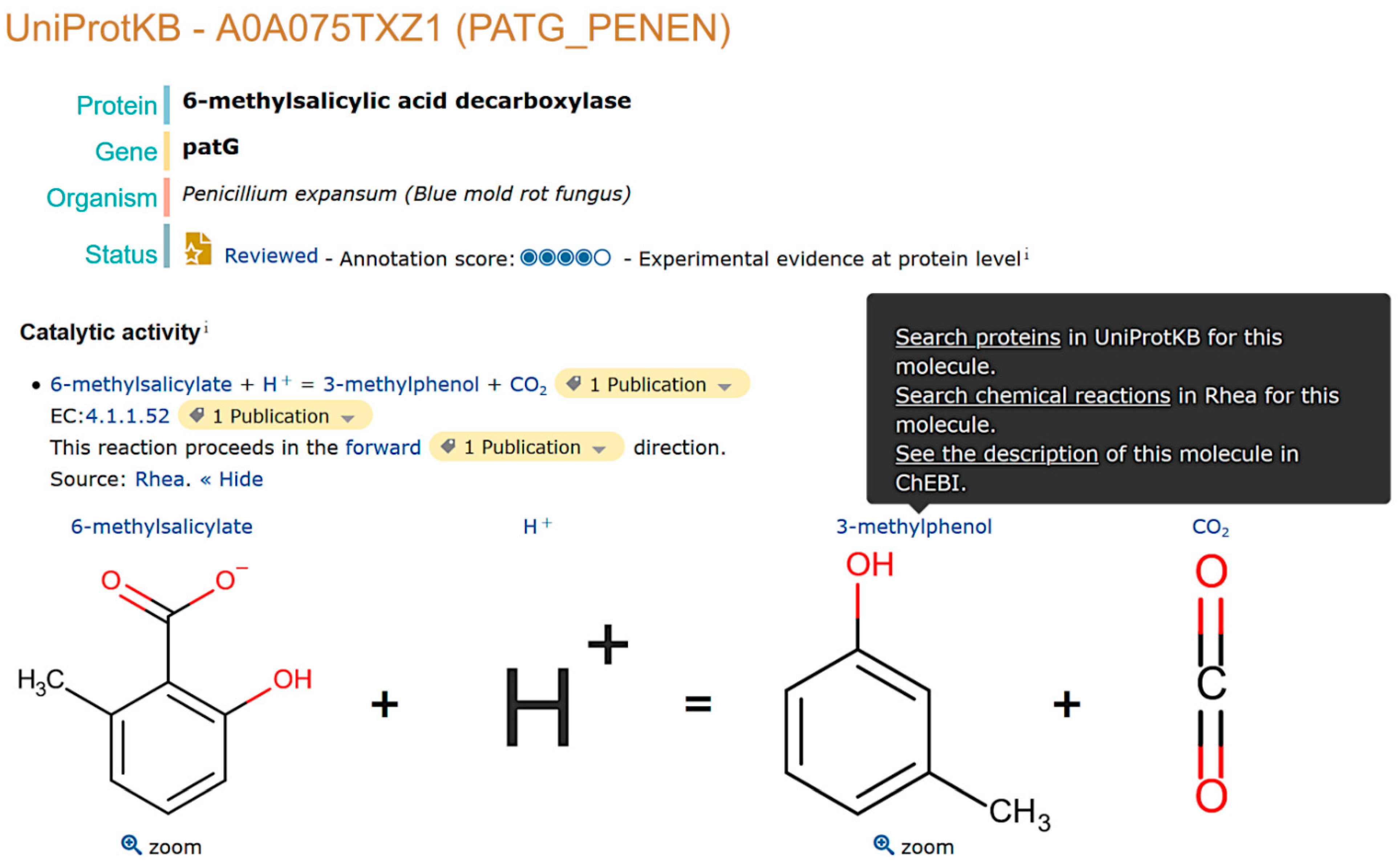
2.1. Natural Product Annotation in UniProtKB
2.2. Data Access
2.2.1. The UniProt Website
2.2.2. Programmatic Access to UniProt-REST API
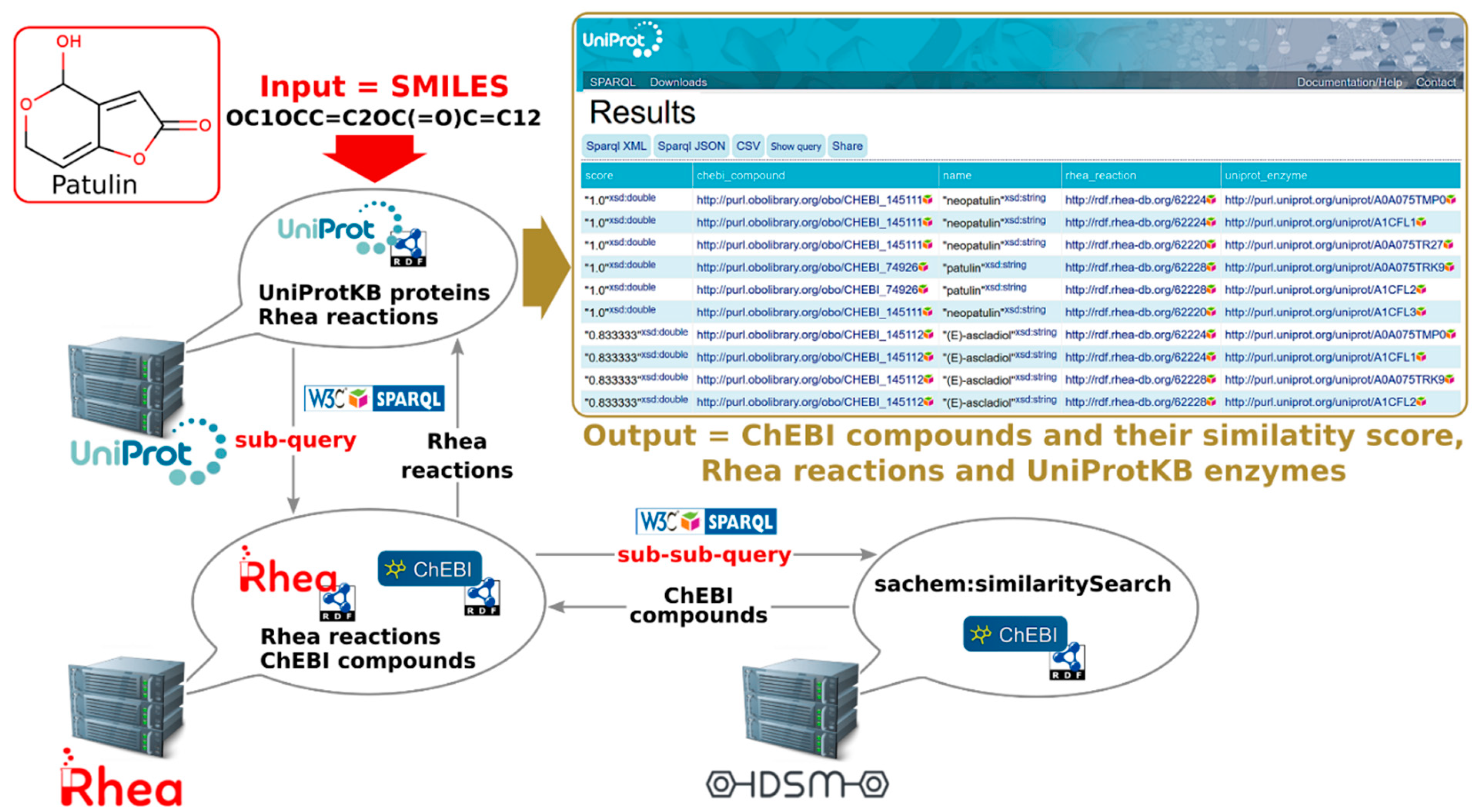
2.2.3. Programmatic Access to UniProt-SPARQL
3. Discussion
4. Materials and Methods
4.1. Protein Sequences in UniProtKB
4.2. UniProtKB Sections
4.3. Expert Curation in UniProtKB/Swiss-Prot
4.4. Automated Annotation in UniProtKB/TrEMBL
4.5. Evidence for and Provenance of Annotations in UniProtKB/Swiss-Prot and UniProtKB/TrEMBL
4.6. Protein Sequence Classification in UniProtKB
4.7. UniProtKB as A Hub
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tetali, S.D. Terpenes and isoprenoids: A wealth of compounds for global use. Planta 2019, 249, 1–8. [Google Scholar] [CrossRef]
- Mutlu-Ingok, A.; Devecioglu, D.; Dikmetas, D.N.; Karbancioglu-Guler, F.; Capanoglu, E. Antibacterial, antifungal, antimycotoxigenic, and antioxidant activities of essential oils: An updated review. Molecules 2020, 25, 4711. [Google Scholar] [CrossRef] [PubMed]
- Bills, G.F.; Gloer, J.B. Biologically Active secondary metabolites from the fungi. Microbiol. Spectr. 2016, 4. [Google Scholar] [CrossRef]
- Cordell, G.A. Fifty years of alkaloid biosynthesis in phytochemistry. Phytochemistry 2013, 91, 29–51. [Google Scholar] [CrossRef] [PubMed]
- Hayes, M.; Pietruszka, J. Synthesis of glycosides by glycosynthases. Molecules 2017, 22, 1434. [Google Scholar] [CrossRef] [PubMed]
- Cressey, P.; Reeve, J. Metabolism of cyanogenic glycosides: A review. Food Chem. Toxicol. 2019, 125, 225–232. [Google Scholar] [CrossRef] [PubMed]
- Demain, A.L. Importance of microbial natural products and the need to revitalize their discovery. J. Ind. Microbiol. Biotechnol. 2014, 41, 185–201. [Google Scholar] [CrossRef]
- Vassaux, A.; Meunier, L.; Vandenbol, M.; Baurain, D.; Fickers, P.; Jacques, P.; Leclère, V. Nonribosomal peptides in fungal cell factories: From genome mining to optimized heterologous production. Biotechnol. Adv. 2019, 37, 107449. [Google Scholar] [CrossRef]
- Montalbán-López, M.; Scott, T.A.; Ramesh, S.; Rahman, I.R.; van Heel, A.J.; Viel, J.H.; Bandarian, V.; Dittmann, E.; Genilloud, O.; Goto, Y.; et al. New developments in RiPP discovery, enzymology and engineering. Nat. Prod. Rep. 2020. [Google Scholar] [CrossRef]
- Skellam, E. Strategies for engineering natural product biosynthesis in fungi. Trends Biotechnol. 2019, 37, 416–427. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Peters, R.J. Why are momilactones always associated with biosynthetic gene clusters in plants? Proc. Natl. Acad. Sci. USA 2020, 117, 13867–13869. [Google Scholar] [CrossRef] [PubMed]
- Keller, N.P. Fungal secondary metabolism: Regulation, function and drug discovery. Nat. Rev. Microbiol. 2019, 17, 167–180. [Google Scholar] [CrossRef] [PubMed]
- Medema, M.H.; Kottmann, R.; Yilmaz, P.; Cummings, M.; Biggins, J.B.; Blin, K.; de Bruijn, I.; Chooi, Y.H.; Claesen, J.; Coates, R.C.; et al. Minimum information about a biosynthetic gene cluster. Nat. Chem. Biol. 2015, 11, 625–631. [Google Scholar] [CrossRef]
- Hansen, B.G.; Genee, H.J.; Kaas, C.S.; Nielsen, J.B.; Regueira, T.B.; Mortensen, U.H.; Frisvad, J.C.; Patil, K.R. A new class of IMP dehydrogenase with a role in self-resistance of mycophenolic acid producing fungi. BMC Microbiol. 2011, 11, 202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- van Santen, J.A.; Jacob, G.; Singh, A.L.; Aniebok, V.; Balunas, M.J.; Bunsko, D.; Neto, F.C.; Castaño-Espriu, L.; Chang, C.; Clark, T.N.; et al. The Natural Products Atlas: An open access knowledge base for microbial natural products discovery. ACS Cent. Sci. 2019, 5, 1824–1833. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sorokina, M.; Steinbeck, C. Review on natural products databases: Where to find data in 2020. J. Cheminform. 2020, 12. [Google Scholar] [CrossRef] [Green Version]
- Sorokina, M.; Steinbeck, C. COCONUT: The COlleCtion of Open NatUral producTs. (Version 4) (Data set). Zenodo 2020. [Google Scholar] [CrossRef]
- Palaniappan, K.; Chen, I.-M.A.; Chu, K.; Ratner, A.; Seshadri, R.; Kyrpides, N.C.; Ivanova, N.N.; Mouncey, N.J. IMG-ABC v.5.0: An update to the IMG/Atlas of biosynthetic gene clusters knowledgebase. Nucleic Acids Res. 2020, 48, D422–D430. [Google Scholar] [CrossRef]
- Conway, K.R.; Boddy, C.N. ClusterMine360: A database of microbial PKS/NRPS biosynthesis. Nucleic Acids Res. 2013, 41, D402–D407. [Google Scholar] [CrossRef] [Green Version]
- Blin, K.; Shaw, S.; Steinke, K.; Villebro, R.; Ziemert, N.; Lee, S.Y.; Medema, M.H.; Weber, T. antiSMASH 5.0: Updates to the secondary metabolite genome mining pipeline. Nucleic Acids Res. 2019, 47, W81–W87. [Google Scholar] [CrossRef] [Green Version]
- Kautsar, S.A.; Suarez Duran, H.G.; Blin, K.; Osbourn, A.; Medema, M.H. plantiSMASH: Automated identification, annotation and expression analysis of plant biosynthetic gene clusters. Nucleic Acids Res. 2017, 45, W55–W63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- UniProt Consortium. UniProt: The universal protein knowledgebase in 2021. Nucleic Acids Res. 2020, 49, D480–D489. [Google Scholar] [CrossRef]
- Morgat, A.; Lombardot, T.; Coudert, E.; Axelsen, K.; Neto, T.B.; Gehant, S.; Bansal, P.; Bolleman, J.; Gasteiger, E.; de Castro, E.; et al. Enzyme annotation in UniProtKB using Rhea. Bioinformatics 2020, 36, 1896–1901. [Google Scholar] [CrossRef] [PubMed]
- Lombardot, T.; Morgat, A.; Axelsen, K.B.; Aimo, L.; Hyka-Nouspikel, N.; Niknejad, A.; Ignatchenko, A.; Xenarios, I.; Coudert, E.; Redaschi, N.; et al. Updates in Rhea: SPARQLing biochemical reaction data. Nucleic Acids Res. 2019, 47, D596–D600. [Google Scholar] [CrossRef] [PubMed]
- Hastings, J.; Owen, G.; Dekker, A.; Ennis, M.; Kale, N.; Muthukrishnan, V.; Turner, S.; Swainston, N.; Mendes, P.; Steinbeck, C. ChEBI in 2016: Improved services and an expanding collection of metabolites. Nucleic Acids Res. 2016, 44, D1214–D1219. [Google Scholar] [CrossRef] [PubMed]
- Heller, S.; McNaught, A.; Stein, S.; Tchekhovskoi, D.; Pletnev, I. InChI the worldwide chemical structure identifier standard. J. Cheminform. 2013, 5, 7. [Google Scholar] [CrossRef] [Green Version]
- Boutet, E.; Lieberherr, D.; Tognolli, M.; Schneider, M.; Bansal, P.; Bridge, A.J.; Poux, S.; Bougueleret, L.; Xenarios, I. UniProtKB/Swiss-Prot, the Manually Annotated Section of the UniProt KnowledgeBase: How to Use the Entry View. Methods Mol. Biol. 2016, 1374, 23–54. [Google Scholar]
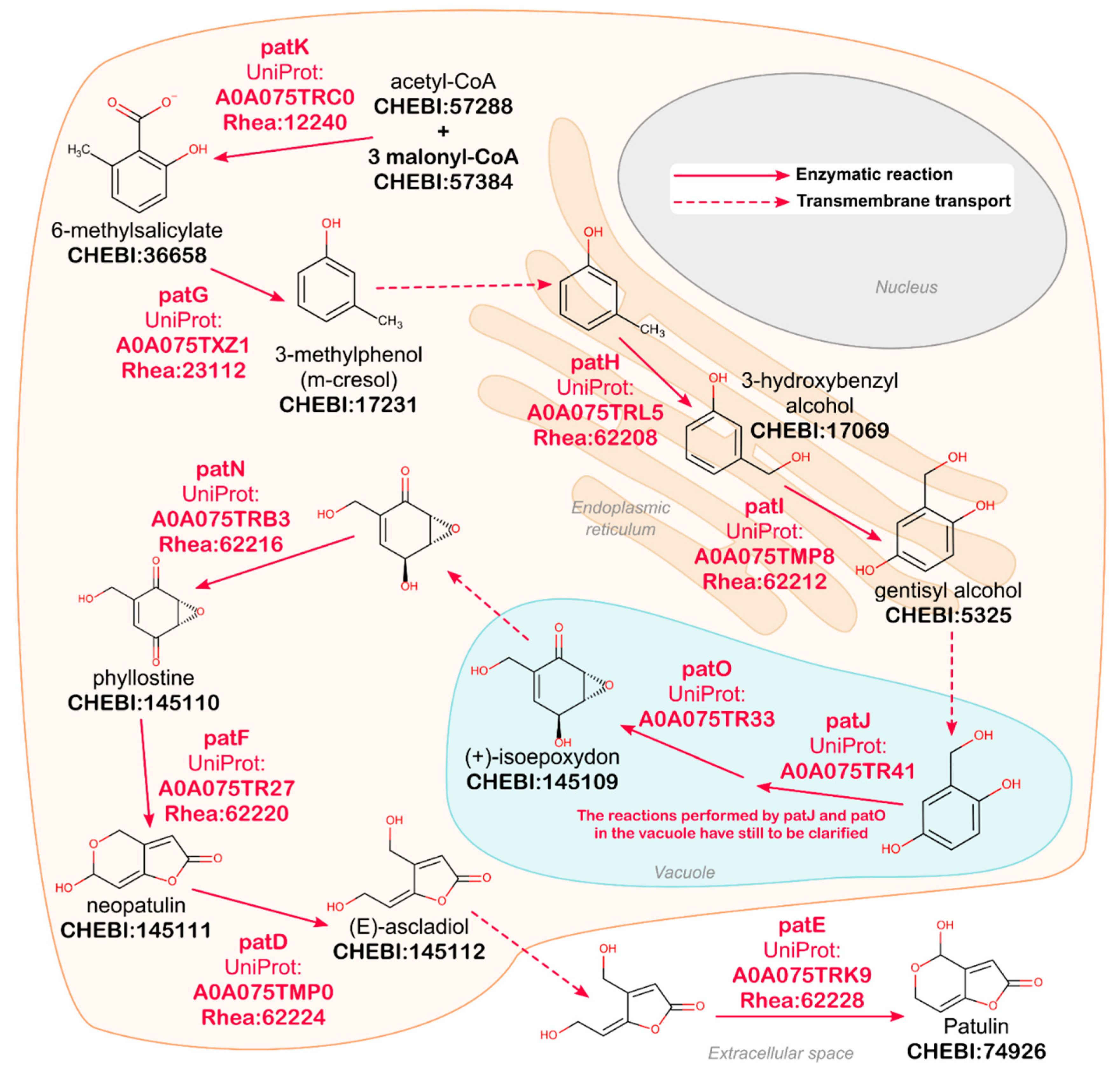
- Li, B.; Chen, Y.; Zong, Y.; Shang, Y.; Zhang, Z.; Xu, X.; Wang, X.; Long, M.; Tian, S. Dissection of patulin biosynthesis, spatial control and regulation mechanism in Penicillium expansum. Environ. Microbiol. 2019, 21, 1124–1139. [Google Scholar] [CrossRef]
- Galgonek, J.; Hurt, Z.; Michlíková, V.; Onderka, P.; Schwarz, J.; Vondrášek, J. Advanced SPARQL querying in small molecule databases. J. Cheminform. 2016, 8, 31. [Google Scholar] [CrossRef] [Green Version]
- Altenhoff, A.M.; Train, C.-M.; Gilbert, K.J.; Mediratta, I.; Mendes de Farias, T.; Moi, D.; Nevers, Y.; Radoykova, H.-S.; Rossier, V.; Warwick Vesztrocy, A.; et al. OMA orthology in 2021: Website overhaul, conserved isoforms, ancestral gene order and more. Nucleic Acids Res. 2020, 49, D373–D379. [Google Scholar] [CrossRef]
- Zdobnov, E.M.; Kuznetsov, D.; Tegenfeldt, F.; Manni, M.; Berkeley, M.; Kriventseva, E.V. OrthoDB in 2020: Evolutionary and functional annotations of orthologs. Nucleic Acids Res. 2020, 49, D389–D393. [Google Scholar] [CrossRef]
- Moretti, S.; Tran, V.D.T.; Mehl, F.; Ibberson, M.; Pagni, M. MetaNetX/MNXref: Unified namespace for metabolites and biochemical reactions in the context of metabolic models. Nucleic Acids Res. 2020, 49, D570–D574. [Google Scholar] [CrossRef]
- Kratochvíl, M.; Vondrášek, J.; Galgonek, J. Interoperable chemical structure search service. J. Cheminform. 2019, 11, 45. [Google Scholar] [CrossRef]
- Blum, M.; Chang, H.-Y.; Chuguransky, S.; Grego, T.; Kandasaamy, S.; Mitchell, A.; Nuka, G.; Paysan-Lafosse, T.; Qureshi, M.; Raj, S.; et al. The InterPro protein families and domains database: 20 years on. Nucleic Acids Res. 2020, 49, D344–D354. [Google Scholar] [CrossRef] [PubMed]
- Mir, S.; Alhroub, Y.; Anyango, S.; Armstrong, D.R.; Berrisford, J.M.; Clark, A.R.; Conroy, M.J.; Dana, J.M.; Deshpande, M.; Gupta, D.; et al. PDBe: Towards reusable data delivery infrastructure at protein data bank in Europe. Nucleic Acids Res. 2018, 46, D486–D492. [Google Scholar] [CrossRef] [PubMed]
- Fabregat, A.; Jupe, S.; Matthews, L. The reactome pathway knowledgebase. Nucleic Acids Res. 2018, 46, D649–D655. [Google Scholar] [CrossRef] [PubMed]
- Porras, P.; Barrera, E.; Bridge, A.; Del-Toro, N.; Cesareni, G.; Duesbury, M.; Hermjakob, H.; Iannuccelli, M.; Jurisica, I.; Kotlyar, M.; et al. Towards a unified open access dataset of molecular interactions. Nat. Commun. 2020, 11, 6144. [Google Scholar] [CrossRef]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef] [Green Version]
- The Gene Ontology Consortium. The Gene Ontology Resource: 20 years and still GOing strong. Nucleic Acids Res. 2019, 47, D330–D338. [Google Scholar] [CrossRef] [Green Version]
- Kanehisa, M.; Goto, S. KEGG: Kyoto Encyclopedia of Genes and Genomes. Nucleic Acids Res. 2000, 28, 27–30. [Google Scholar] [CrossRef]
- Kanehisa, M. Toward understanding the origin and evolution of cellular organisms. Protein Sci. 2019, 28, 1947–1951. [Google Scholar] [CrossRef] [PubMed]
- Kanehisa, M.; Furumichi, M.; Sato, Y.; Ishiguro-Watanabe, M.; Tanabe, M. KEGG: Integrating viruses and cellular organisms. Nucleic Acids Res. 2021, 49, D545–D551. [Google Scholar] [CrossRef] [PubMed]
- Kautsar, S.A.; Blin, K.; Shaw, S.; Weber, T.; Medema, M.H. BiG-FAM: The biosynthetic gene cluster families database. Nucleic Acids Res. 2020, 49, D490–D497. [Google Scholar] [CrossRef] [PubMed]
- Wicker, J.; Lorsbach, T.; Gütlein, M.; Schmid, E.; Latino, D.; Kramer, S.; Fenner, K. enviPath--The environmental contaminant biotransformation pathway resource. Nucleic Acids Res. 2016, 44, D502–D508. [Google Scholar] [CrossRef] [Green Version]
- Vermeulen, R.; Schymanski, E.L.; Barabási, A.-L.; Miller, G.W. The exposome and health: Where chemistry meets biology. Science 2020, 367, 392–396. [Google Scholar] [CrossRef]
- Karsch-Mizrachi, I.; Takagi, T.; Cochrane, G. The international nucleotide sequence database collaboration. Nucleic Acids Res. 2018, 46, D48–D51. [Google Scholar] [CrossRef] [Green Version]
- Yates, A.D.; Achuthan, P.; Akanni, W.; Allen, J.; Allen, J.; Alvarez-Jarreta, J.; Amode, M.R.; Armean, I.M.; Azov, A.G.; Bennett, R.; et al. Ensembl 2020. Nucleic Acids Res. 2020, 48, D682–D688. [Google Scholar] [CrossRef]
- Howe, K.L.; Contreras-Moreira, B.; De Silva, N.; Maslen, G.; Akanni, W.; Allen, J.; Alvarez-Jarreta, J.; Barba, M.; Bolser, D.M.; Cambell, L.; et al. Ensembl Genomes 2020-enabling non-vertebrate genomic research. Nucleic Acids Res. 2020, 48, D689–D695. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Du, L.; Qu, Z.; Zhang, X.; Li, F.; Li, Z.; Qi, F.; Wang, X.; Jiang, Y.; Men, P.; et al. Compartmentalized biosynthesis of mycophenolic acid. Proc. Natl. Acad. Sci. USA 2019, 116, 13305–13310. [Google Scholar] [CrossRef] [Green Version]
- MacDougall, A.; Volynkin, V.; Saidi, R.; Poggioli, D.; Zellner, H.; Hatton-Ellis, E.; Joshi, V.; O’Donovan, C.; Orchard, S.; Auchincloss, A.H.; et al. UniRule: A unified rule resource for automatic annotation in the UniProt Knowledgebase. Bioinformatics 2020, 36, 4643–4648. [Google Scholar]
- Bolleman, J.; de Castro, E.; Baratin, D.; Gehant, S.; Cuche, B.A.; Auchincloss, A.H.; Coudert, E.; Hulo, C.; Masson, P.; Pedruzzi, I.; et al. HAMAP as SPARQL rules-A portable annotation pipeline for genomes and proteomes. Gigascience 2020, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giglio, M.; Tauber, R.; Nadendla, S.; Munro, J.; Olley, D.; Ball, S.; Mitraka, E.; Schriml, L.M.; Gaudet, P.; Hobbs, E.T.; et al. ECO, the Evidence & Conclusion Ontology: Community standard for evidence information. Nucleic Acids Res. 2019, 47, D1186–D1194. [Google Scholar] [PubMed] [Green Version]
- Schardl, C.L.; Young, C.A.; Hesse, U.; Amyotte, S.G.; Andreeva, K.; Calie, P.J.; Fleetwood, D.J.; Haws, D.C.; Moore, N.; Oeser, B.; et al. Plant-symbiotic fungi as chemical engineers: Multi-genome analysis of the clavicipitaceae reveals dynamics of alkaloid loci. PLoS Genet. 2013, 9, e1003323. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deutsch, E.W.; Bandeira, N.; Sharma, V.; Perez-Riverol, Y.; Carver, J.J.; Kundu, D.J.; García-Seisdedos, D.; Jarnuczak, A.F.; Hewapathirana, S.; Pullman, B.S.; et al. The ProteomeXchange consortium in 2020: Enabling “big data” approaches in proteomics. Nucleic Acids Res. 2020, 48, D1145–D1152. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Landrum, M.J.; Kattman, B.L. ClinVar at five years: Delivering on the promise. Hum. Mutat. 2018, 39, 1623–1630. [Google Scholar] [CrossRef] [PubMed]
- Tate, J.G.; Bamford, S.; Jubb, H.C.; Sondka, Z.; Beare, D.M.; Bindal, N.; Boutselakis, H.; Cole, C.G.; Creatore, C.; Dawson, E.; et al. COSMIC: The Catalogue of Somatic Mutations In Cancer. Nucleic Acids Res. 2019, 47, D941–D947. [Google Scholar] [CrossRef] [Green Version]
- Dong, Z.; Wang, H.; Chen, H.; Jiang, H.; Yuan, J.; Yang, Z.; Wang, W.-J.; Xu, F.; Guo, X.; Cao, Y.; et al. Identification of balanced chromosomal rearrangements previously unknown among participants in the 1000 Genomes Project: Implications for interpretation of structural variation in genomes and the future of clinical cytogenetics. Genet. Med. 2018, 20, 697–707. [Google Scholar] [CrossRef] [Green Version]
- Wheeler, D.L.; Barrett, T.; Benson, D.A.; Bryant, S.H.; Canese, K.; Chetvernin, V.; Church, D.M.; DiCuccio, M.; Edgar, R.; Federhen, S.; et al. Database resources of the National Center for Biotechnology Information. Nucleic Acids Res. 2007, 35, D5–D12. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
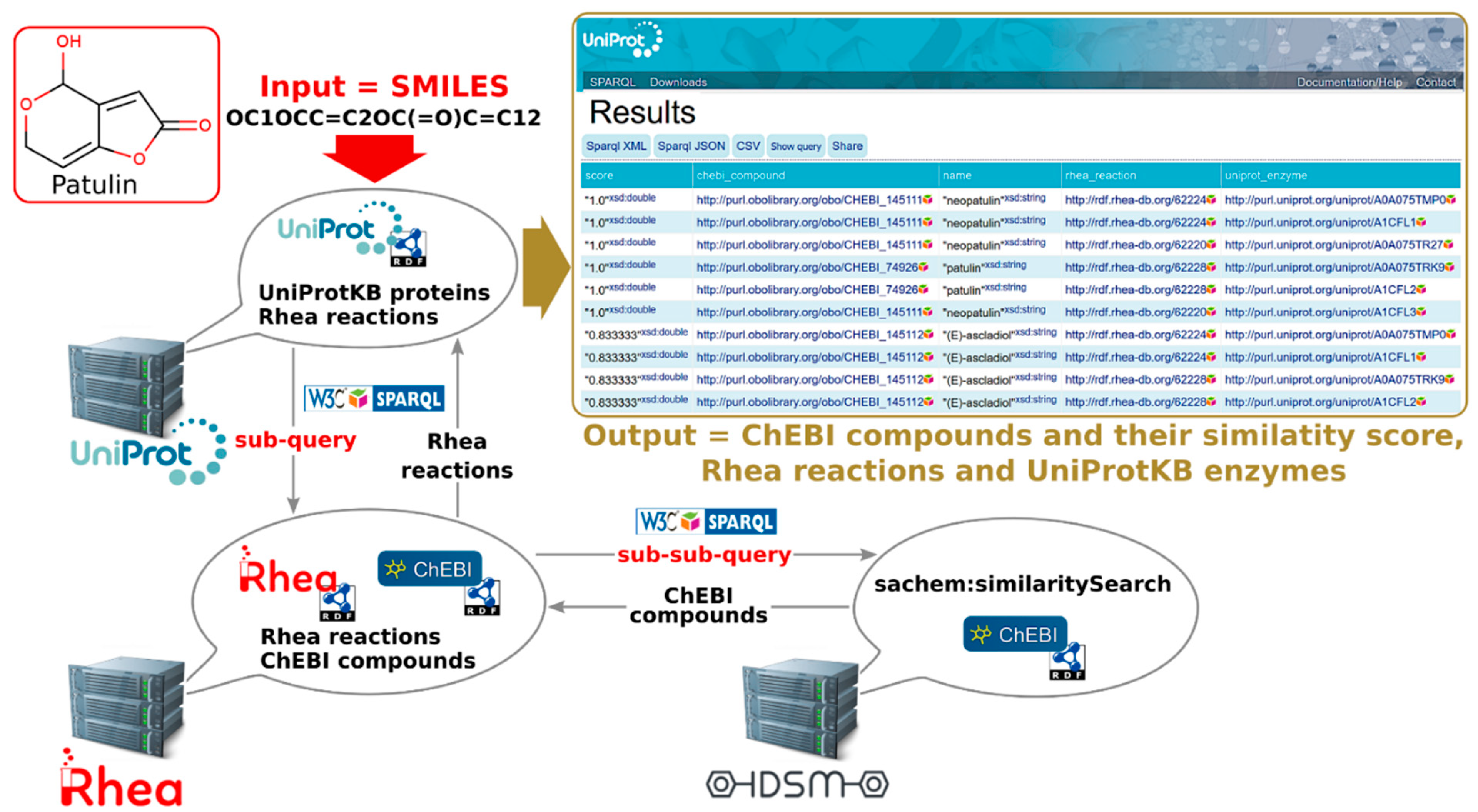{kind=link}
| Query on UniProtKB | URL |
|---|---|
| patulin, by name | uniprot.org/uniprot/?query=patulin |
| patulin, by structure (using the first two blocks of the InChIKey) | uniprot.org/uniprot/?query=inchikey:ZRWPUFFVAOMMNM-UHFFFAOYSA |
| patulin, by chemical identifier (CHEBI:74926) | uniprot.org/uniprot/?query=%09CHEBI%3A74926 |
| all members of the class gamma lactone, by chemical identifier (CHEBI:37581) | uniprot.org/uniprot/?query=CHEBI%3A37581 |
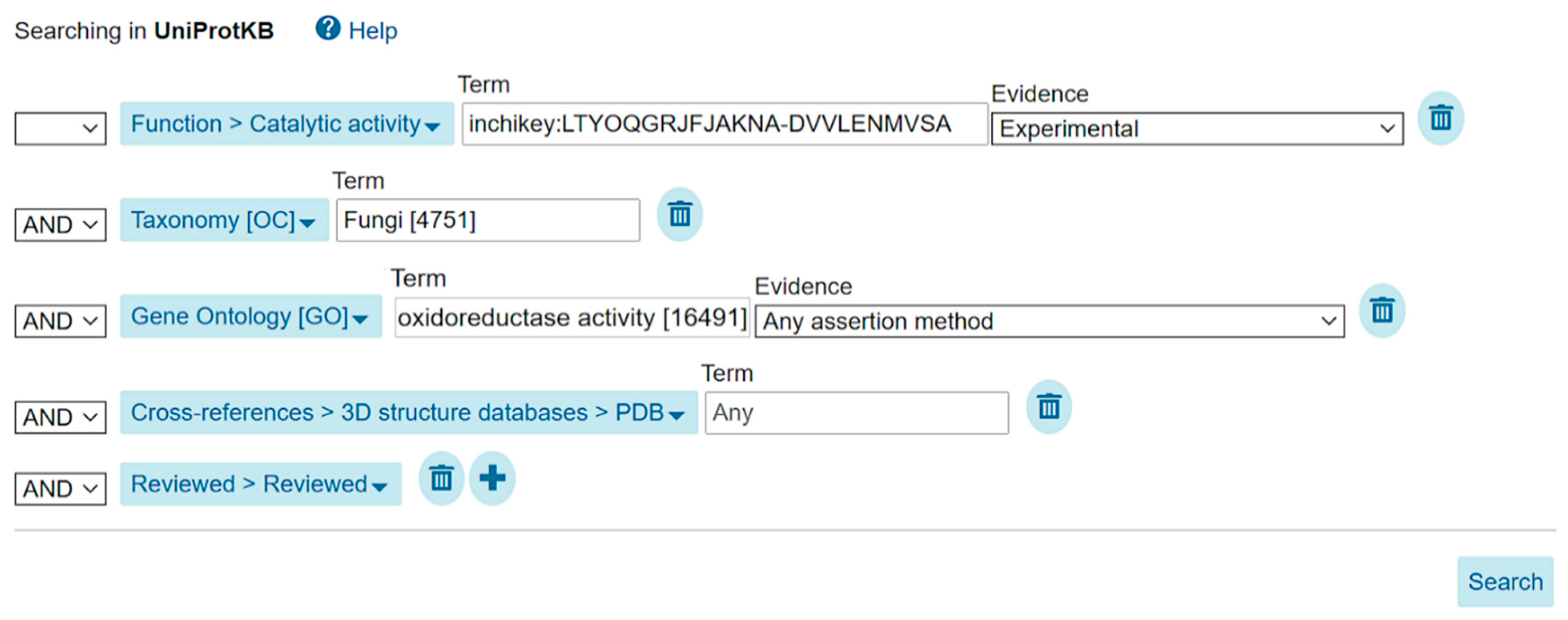
| fungal oxidoreductases proven to metabolize malonyl-CoA and linked to protein structure data of any type in the Protein Data Bank | www.uniprot.org/uniprot/?query=annotation%3A%28type%3A%22catalytic+activity%22+inchikey%3ALTYOQGRJFJAKNA-DVVLENMVSA%29+taxonomy%3A%22Fungi+%289FUNG%29+%5B4751%5D%22+goa%3A%28%22oxidoreductase+activity+%5B16491%5D%22%29+reviewed%3Ayes+database%3A%28type%3Apdb%29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feuermann, M.; Boutet, E.; Morgat, A.; Axelsen, K.B.; Bansal, P.; Bolleman, J.; de Castro, E.; Coudert, E.; Gasteiger, E.; Géhant, S.; et al. Diverse Taxonomies for Diverse Chemistries: Enhanced Representation of Natural Product Metabolism in UniProtKB. Metabolites 2021, 11, 48. https://doi.org/10.3390/metabo11010048
Feuermann M, Boutet E, Morgat A, Axelsen KB, Bansal P, Bolleman J, de Castro E, Coudert E, Gasteiger E, Géhant S, et al. Diverse Taxonomies for Diverse Chemistries: Enhanced Representation of Natural Product Metabolism in UniProtKB. Metabolites. 2021; 11(1):48. https://doi.org/10.3390/metabo11010048
Chicago/Turabian StyleFeuermann, Marc, Emmanuel Boutet, Anne Morgat, Kristian B. Axelsen, Parit Bansal, Jerven Bolleman, Edouard de Castro, Elisabeth Coudert, Elisabeth Gasteiger, Sébastien Géhant, and et al. 2021. "Diverse Taxonomies for Diverse Chemistries: Enhanced Representation of Natural Product Metabolism in UniProtKB" Metabolites 11, no. 1: 48. https://doi.org/10.3390/metabo11010048
APA StyleFeuermann, M., Boutet, E., Morgat, A., Axelsen, K. B., Bansal, P., Bolleman, J., de Castro, E., Coudert, E., Gasteiger, E., Géhant, S., Lieberherr, D., Lombardot, T., Neto, T. B., Pedruzzi, I., Poux, S., Pozzato, M., Redaschi, N., Bridge, A., & on behalf of the UniProt Consortium. (2021). Diverse Taxonomies for Diverse Chemistries: Enhanced Representation of Natural Product Metabolism in UniProtKB. Metabolites, 11(1), 48. https://doi.org/10.3390/metabo11010048