A Single Visualization Technique for Displaying Multiple Metabolite–Phenotype Associations


 ,
,
Abstract
:1. Introduction
2. Methods
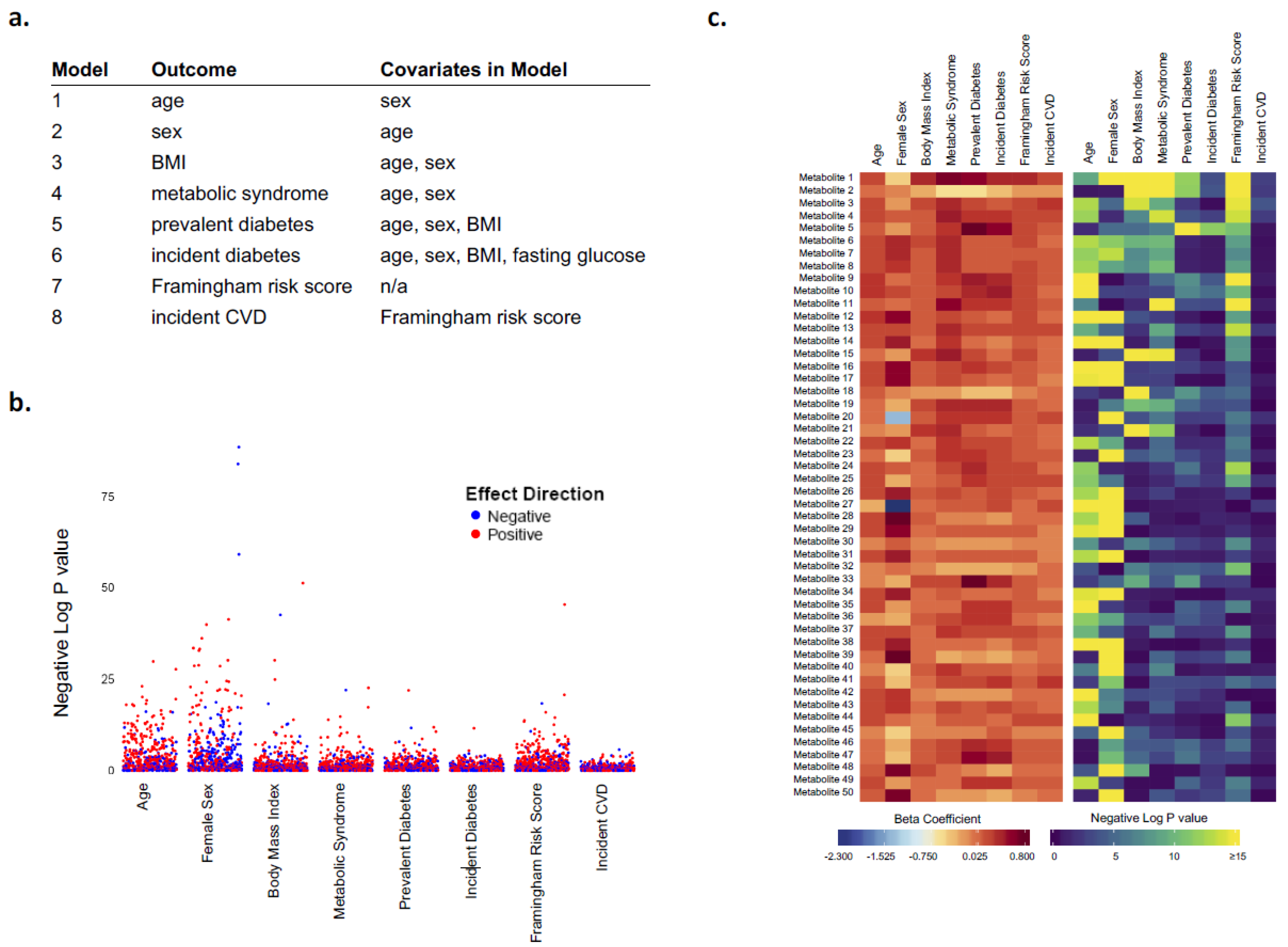
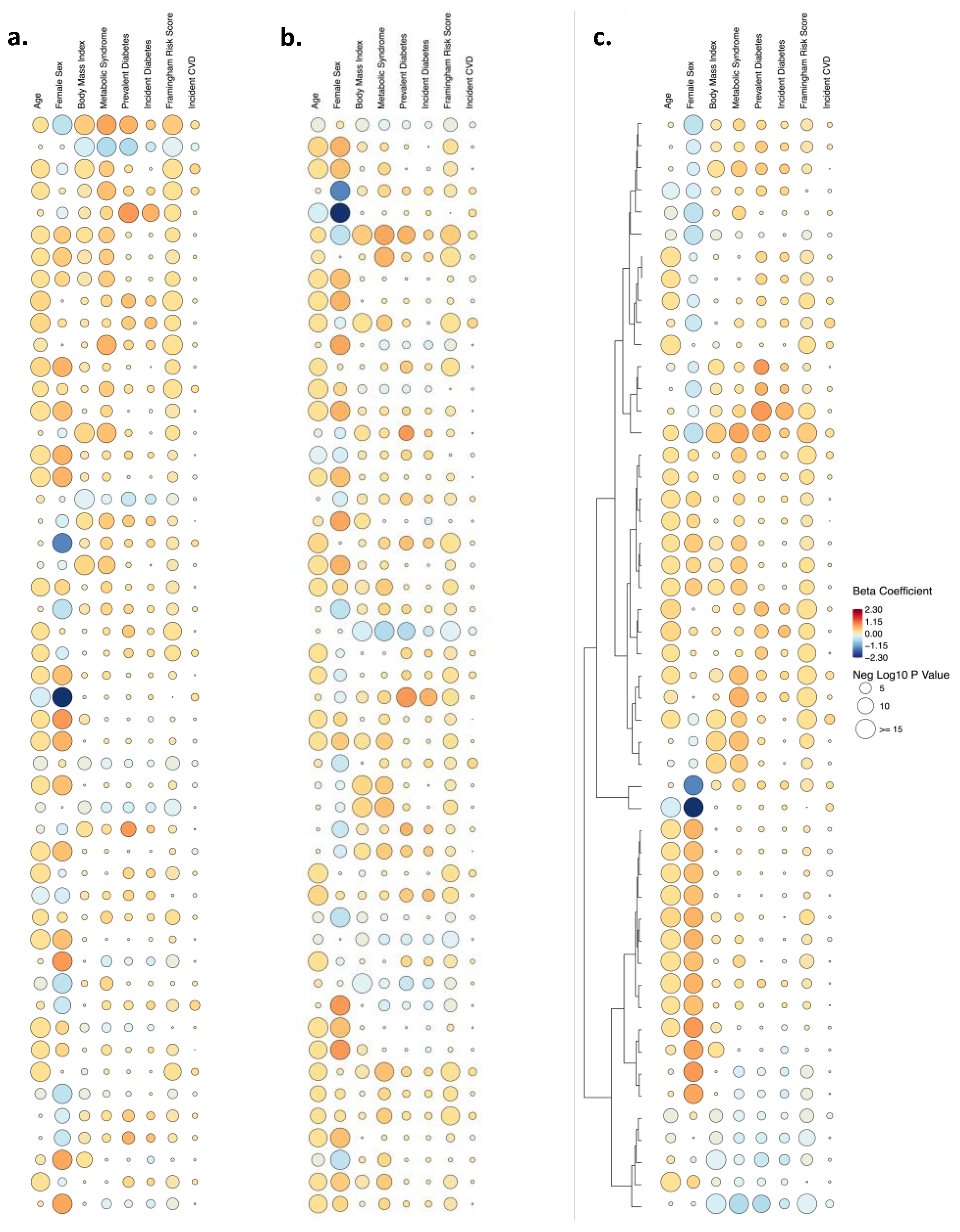
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Misra, B.B.; van der Hooft, J.J. Updates in metabolomics tools and resources: 2014–2015. Electrophoresis 2016, 37, 86–110. [Google Scholar] [CrossRef] [PubMed]
- Chia, P.L.; Gedye, C.; Boutros, P.C.; Wheatley-Price, P.; John, T. Current and Evolving Methods to Visualize Biological Data in Cancer Research. J. Natl. Cancer Inst. 2016, 108. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Perez-Riverol, Y.; Hermjakob, H.; Vizcaino, J.A. Open source libraries and frameworks for biological data visualisation: A guide for developers. Proteomics 2015, 15, 1356–1374. [Google Scholar] [CrossRef] [PubMed]
- Sugimoto, M. Metabolomic pathway visualization tool outsourcing editing function. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2015, 2015, 7659–7662. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Sinelnikov, I.V.; Han, B.; Wishart, D.S. MetaboAnalyst 3.0--making metabolomics more meaningful. Nucleic Acids Res. 2015, 43, W251–W257. [Google Scholar] [CrossRef] [PubMed]
- Clasquin, M.F.; Melamud, E.; Rabinowitz, J.D. LC-MS data processing with MAVEN: A metabolomic analysis and visualization engine. Curr. Protoc. Bioinform. 2012, 14. Unit14 11. [Google Scholar] [CrossRef]
- Grapov, D.; Wanichthanarak, K.; Fiehn, O. MetaMapR: Pathway independent metabolomic network analysis incorporating unknowns. Bioinformatics 2015, 31, 2757–2760. [Google Scholar] [CrossRef]
- Matheus, N.; Hansen, S.; Rozet, E.; Peixoto, P.; Maquoi, E.; Lambert, V.; Noel, A.; Frederich, M.; Mottet, D.; de Tullio, P. An easy, convenient cell and tissue extraction protocol for nuclear magnetic resonance metabolomics. Phytochem. Anal. 2014, 25, 342–349. [Google Scholar] [CrossRef]
- Grace, S.C.; Embry, S.; Luo, H. Haystack, a web-based tool for metabolomics research. BMC Bioinform. 2014, 15 (Suppl. 11), S12. [Google Scholar] [CrossRef]
- Eichner, J.; Rosenbaum, L.; Wrzodek, C.; Haring, H.U.; Zell, A.; Lehmann, R. Integrated enrichment analysis and pathway-centered visualization of metabolomics, proteomics, transcriptomics, and genomics data by using the InCroMAP software. J. Chromatogr. B Analyt. Technol. Biomed. Life Sci. 2014, 966, 77–82. [Google Scholar] [CrossRef]
- Xia, J.; Wishart, D.S. Metabolomic data processing, analysis, and interpretation using MetaboAnalyst. Curr. Protoc. Bioinform. 2011, 14. Unit 14 10. [Google Scholar] [CrossRef] [PubMed]
- Chagoyen, M.; Pazos, F. Tools for the functional interpretation of metabolomic experiments. Brief Bioinform. 2013, 14, 737–744. [Google Scholar] [CrossRef] [PubMed]
- Mak, T.D.; Laiakis, E.C.; Goudarzi, M.; Fornace, A.J., Jr. MetaboLyzer: A novel statistical workflow for analyzing Postprocessed LC-MS metabolomics data. Anal. Chem. 2014, 86, 506–513. [Google Scholar] [CrossRef] [PubMed]
- Kuo, T.C.; Tian, T.F.; Tseng, Y.J. 3Omics: A web-based systems biology tool for analysis, integration and visualization of human transcriptomic, proteomic and metabolomic data. BMC Syst. Biol. 2013, 7, 64. [Google Scholar] [CrossRef] [PubMed]
- Karnovsky, A.; Weymouth, T.; Hull, T.; Tarcea, V.G.; Scardoni, G.; Laudanna, C.; Sartor, M.A.; Stringer, K.A.; Jagadish, H.V.; Burant, C.; et al. Metscape 2 bioinformatics tool for the analysis and visualization of metabolomics and gene expression data. Bioinformatics 2012, 28, 373–380. [Google Scholar] [CrossRef]
- Cheng, S.; Mueller, K. The Data Context Map: Fusing Data and Attributes into a Unified Display. IEEE Trans Vis Comput. Graph 2016, 22, 121–130. [Google Scholar] [CrossRef] [PubMed]
- Cheng, S.; Xu, W.; Mueller, K. ColorMap(ND): A Data-Driven Approach and Tool for Mapping Multivariate Data to Color. IEEE Trans Vis Comput. Graph 2019, 25, 1361–1377. [Google Scholar] [CrossRef]
- Cheng, S.; Zhong, W.; Isaacs, K.E.; Mueller, K. Visualizing the Topology and Data Traffic of Multi-Dimensional Torus Interconnect Networks. IEEE Access 2018, 6, 57191–57204. [Google Scholar] [CrossRef]
- Shenghui, C.; Mueller, K. Improving the fidelity of contextual data layouts using a Generalized Barycentric Coordinates framework. In Proceedings of the 2015 IEEE Pacific Visualization Symposium (PacificVis), Hangzhou, China, 14–17 April 2015; pp. 295–302. [Google Scholar]
- DaGoo. Available online: http://www.dagoo.work (accessed on 13 June 2019).
- Johnson, C.H.; Ivanisevic, J.; Siuzdak, G. Metabolomics: Beyond biomarkers and towards mechanisms. Nat. Rev. Mol. Cell Biol. 2016, 17, 451–459. [Google Scholar] [CrossRef]
- Watrous, J.D.; Henglin, M.; Claggett, B.; Lehmann, K.A.; Larson, M.G.; Cheng, S.; Jain, M. Visualization, Quantification, and Alignment of Spectral Drift in Population Scale Untargeted Metabolomics Data. Anal. Chem. 2017, 89, 1399–1404. [Google Scholar] [CrossRef] [Green Version]
- Huan, T.; Li, L. Counting missing values in a metabolite-intensity data set for measuring the analytical performance of a metabolomics platform. Anal Chem. 2015, 87, 1306–1313. [Google Scholar] [CrossRef] [PubMed]
- Grundy, S.M.; Cleeman, J.I.; Daniels, S.R.; Donato, K.A.; Eckel, R.H.; Franklin, B.A.; Gordon, D.J.; Krauss, R.M.; Savage, P.J.; Smith, S.C., Jr.; et al. Diagnosis and management of the metabolic syndrome: An American Heart Association/National Heart, Lung, and Blood Institute Scientific Statement. Circulation 2005, 112, 2735–2752. [Google Scholar] [CrossRef] [PubMed]
- Abraham, T.M.; Pencina, K.M.; Pencina, M.J.; Fox, C.S. Trends in Diabetes Incidence: The Framingham Heart Study. Diabetes Care 2015, 38, 482–487. [Google Scholar] [CrossRef] [PubMed]
- Wilson, P.W.; D’Agostino, R.B.; Levy, D.; Belanger, A.M.; Silbershatz, H.; Kannel, W.B. Prediction of coronary heart disease using risk factor categories. Circulation 1998, 97, 1837–1847. [Google Scholar] [CrossRef] [PubMed]
- Niiranen, T.J.; Lyass, A.; Larson, M.G.; Hamburg, N.M.; Benjamin, E.J.; Mitchell, G.F.; Vasan, R.S. Prevalence, Correlates, and Prognosis of Healthy Vascular Aging in a Western Community-Dwelling Cohort. Framingham Heart Study 2017, 70, 267–274. [Google Scholar] [CrossRef] [PubMed]
- Raindrop Plot. Available online: http://mc-3.ca/raindrop-plot (accessed on 1 July 2019).
- Barrowman, N.J.; Myers, R.A. Raindrop Plots. Am. Stat. 2003, 57, 268–274. [Google Scholar] [CrossRef]
- Gehlenborg, N.; O’Donoghue, S.I.; Baliga, N.S.; Goesmann, A.; Hibbs, M.A.; Kitano, H.; Kohlbacher, O.; Neuweger, H.; Schneider, R.; Tenenbaum, D.; et al. Visualization of omics data for systems biology. Nat. Methods 2010, 7, S56–S68. [Google Scholar] [CrossRef] [PubMed]
- O’Donoghue, S.I.; Gavin, A.C.; Gehlenborg, N.; Goodsell, D.S.; Heriche, J.K.; Nielsen, C.B.; North, C.; Olson, A.J.; Procter, J.B.; Shattuck, D.W.; et al. Visualizing biological data-now and in the future. Nat. Methods 2010, 7, S2–S4. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Visualization Method | ||||
|---|---|---|---|---|
| Dimension of Information | Manhattan Plot | Bar and Scatter Plots | Heatmap | Rain Plot |
| Example | Figure 1 and Figure S1 | Figure S3 | Figure 1 and Figure S2 | Figure 2 |
| Significance of associations with an outcome | X | X | X | |
| Magnitude of associations with an outcome | X | X | X | |
| Directionality of associations with an outcome | X | X | X | X |
| Clustering | X | X | ||
| Significance of associations with multiple outcomes | X | X | X | |
| Magnitude of associations with multiple outcomes | X | |||
| Directionality of associations with multiple outcomes | X | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Henglin, M.; Niiranen, T.; Watrous, J.D.; Lagerborg, K.A.; Antonelli, J.; Claggett, B.L.; Demosthenes, E.J.; von Jeinsen, B.; Demler, O.; Vasan, R.S.; et al. A Single Visualization Technique for Displaying Multiple Metabolite–Phenotype Associations. Metabolites 2019, 9, 128. https://doi.org/10.3390/metabo9070128
Henglin M, Niiranen T, Watrous JD, Lagerborg KA, Antonelli J, Claggett BL, Demosthenes EJ, von Jeinsen B, Demler O, Vasan RS, et al. A Single Visualization Technique for Displaying Multiple Metabolite–Phenotype Associations. Metabolites. 2019; 9(7):128. https://doi.org/10.3390/metabo9070128
Chicago/Turabian StyleHenglin, Mir, Teemu Niiranen, Jeramie D. Watrous, Kim A. Lagerborg, Joseph Antonelli, Brian L. Claggett, Emmanuella J. Demosthenes, Beatrice von Jeinsen, Olga Demler, Ramachandran S. Vasan, and et al. 2019. "A Single Visualization Technique for Displaying Multiple Metabolite–Phenotype Associations" Metabolites 9, no. 7: 128. https://doi.org/10.3390/metabo9070128
APA StyleHenglin, M., Niiranen, T., Watrous, J. D., Lagerborg, K. A., Antonelli, J., Claggett, B. L., Demosthenes, E. J., von Jeinsen, B., Demler, O., Vasan, R. S., Larson, M. G., Jain, M., & Cheng, S. (2019). A Single Visualization Technique for Displaying Multiple Metabolite–Phenotype Associations. Metabolites, 9(7), 128. https://doi.org/10.3390/metabo9070128