
LC-MS/MS Quantitation of HILIC-Enriched N-glycopeptides Derived from Low-Abundance Serum Glycoproteins in Patients with Narcolepsy Type 1

 , , ,
, , ,  , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Clinical Information of NT1 Patients and Healthy Controls
2.2. Chemicals and Reagents
2.3. Depletion of High-Abundance Proteins in Serum Samples
2.4. Tryptic Digestion of Low-Abundance Proteins
2.5. HILIC Enrichment of N-glycopeptides in NT1 Samples
2.6. N-Glycopeptide Profiling of NT1 Samples
2.7. Parallel Reaction Monitoring (PRM) Validation of the Obtained Glycoppeides in NT1 Samaples
3. Results
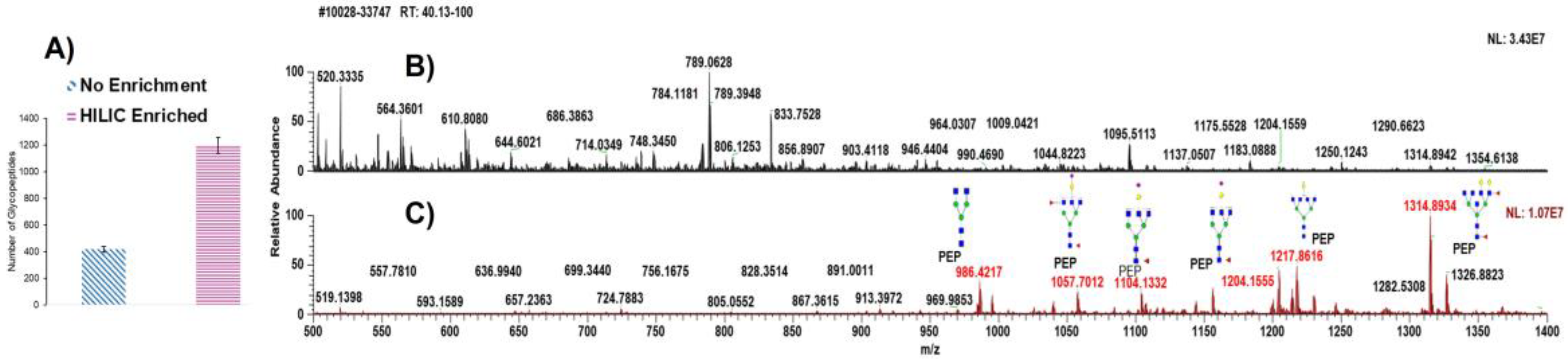
3.1. Analytical Approach of NT1 Serum Samples
3.2. Investigation of N-glycopeptide Abundance and Distribution in NT1 Samples
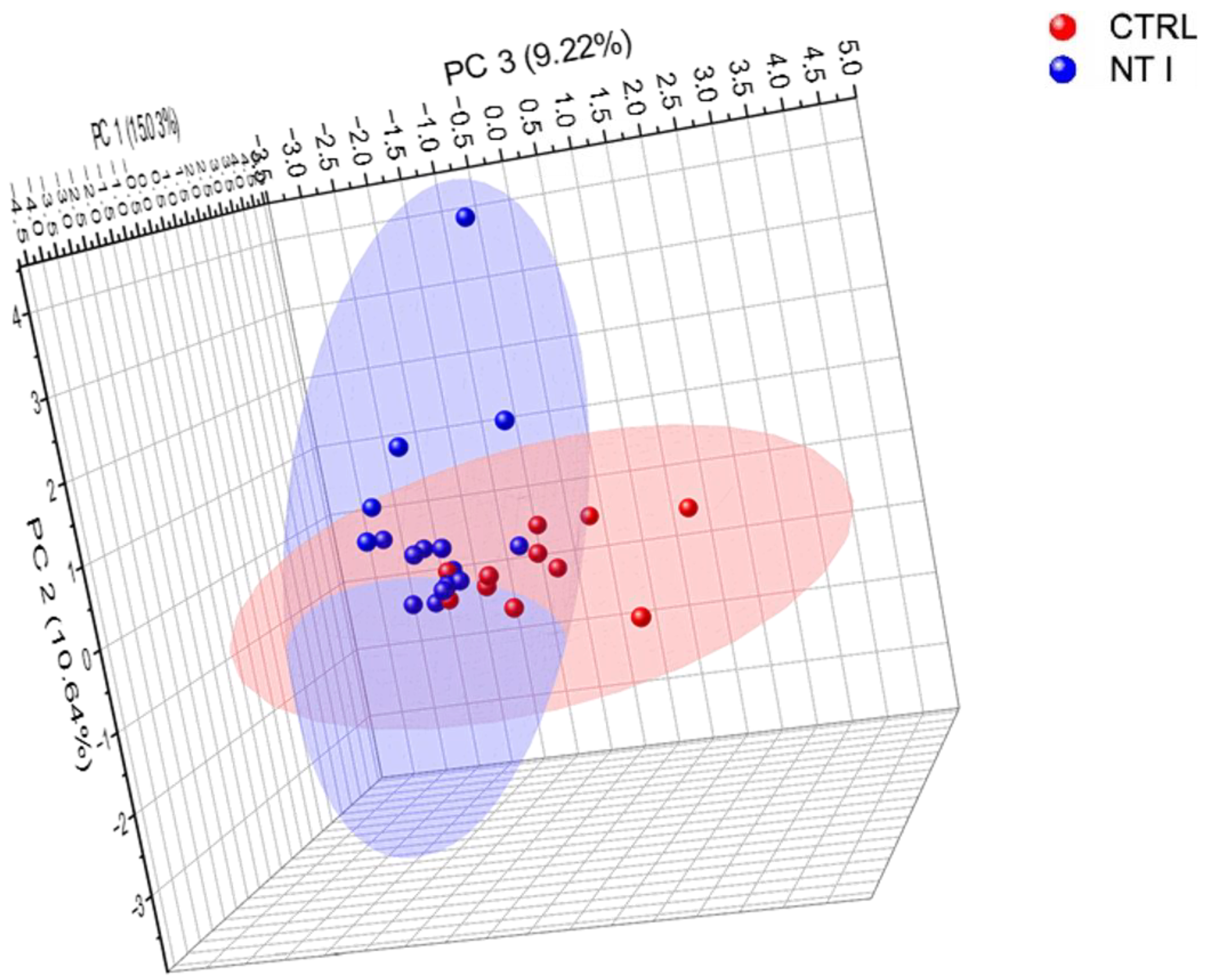
3.3. Comparison of Control and NT1 Analysis of Identified Glycopeptides
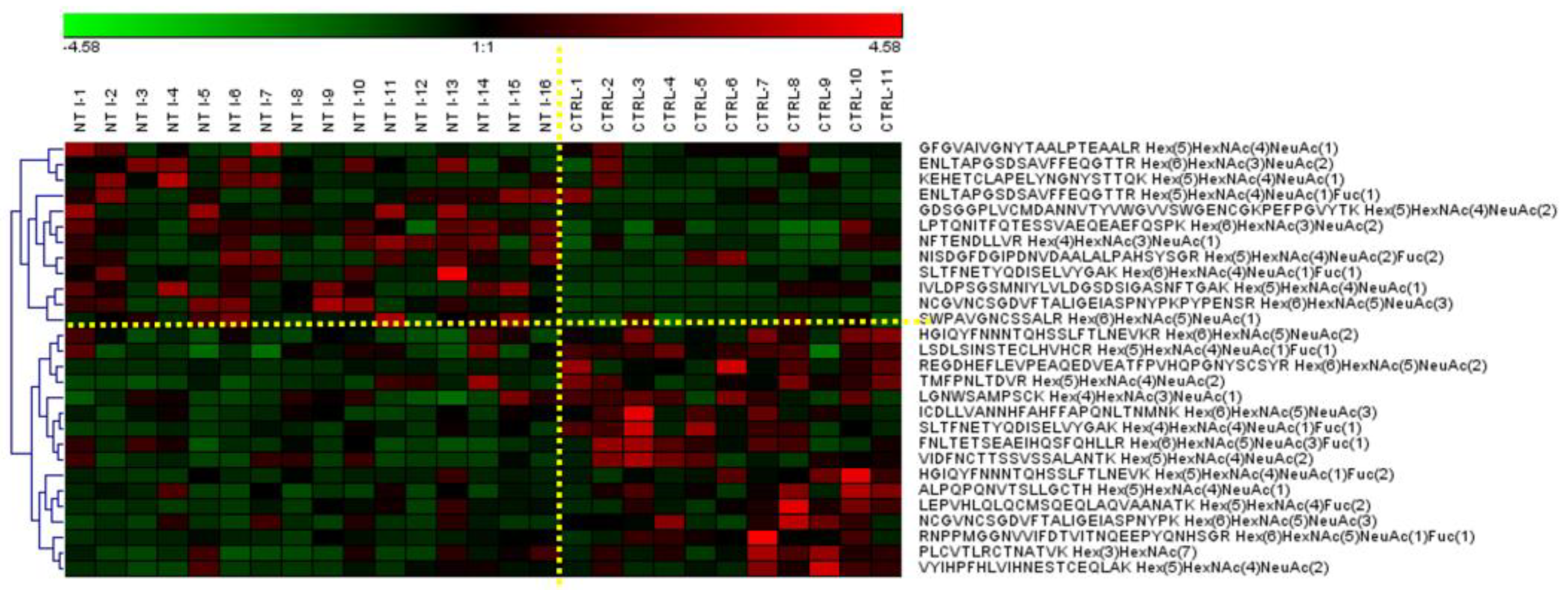
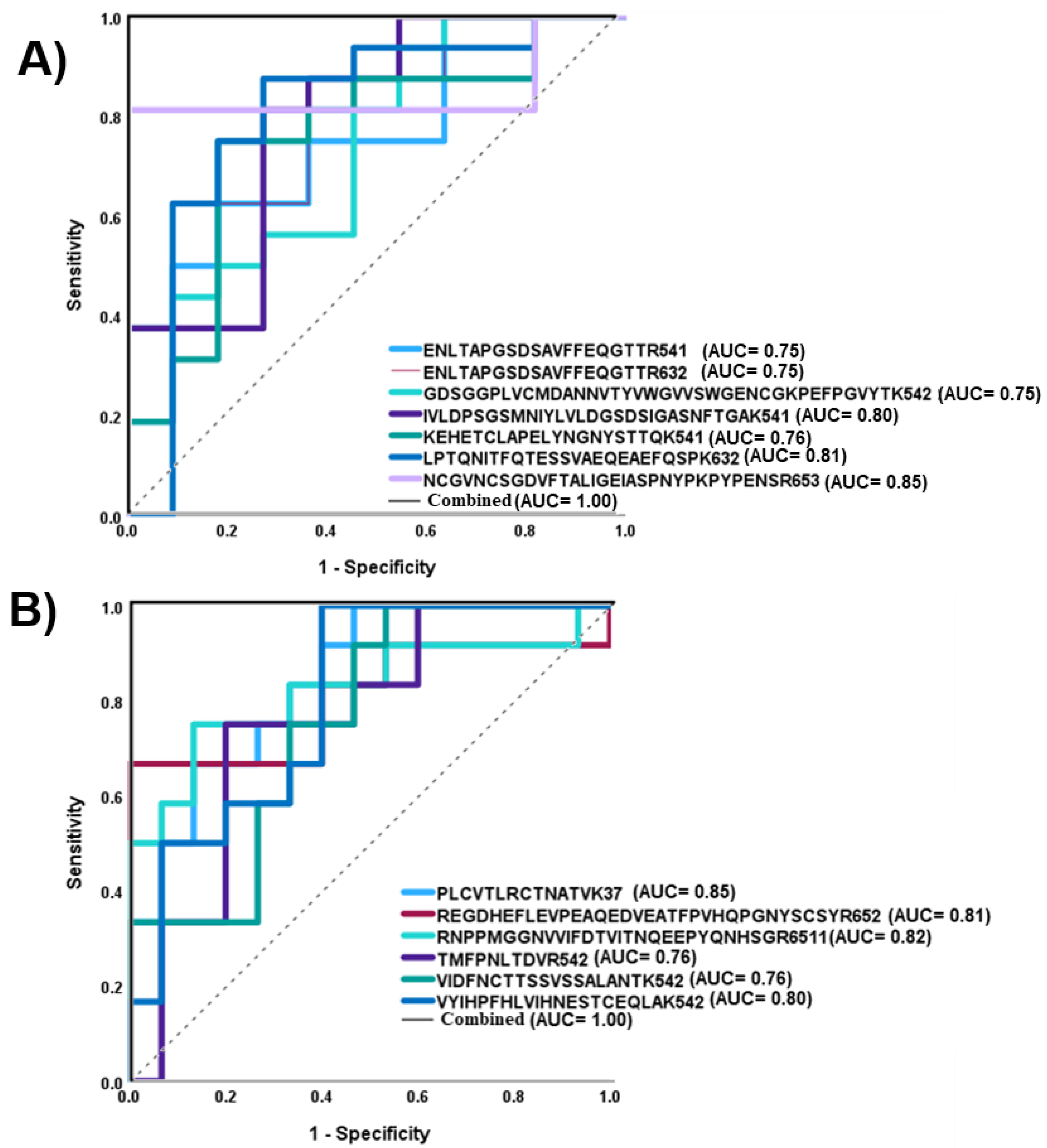
3.4. Differently Expressed Relative Abundance of N-glycopeptides Derived from Low-Abundance Serum Glycoproteins in Control and NT1 Samples
3.5. N-glycopeptide Isomer Quantification
3.6. Validation Strategy of Targeted Glycoproteomics (LC-PRM-MS/MS)
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
References
- Sateia, M.J. International classification of sleep disorders-third edition: Highlights and modifications. Chest 2014, 146, 1387–1394. [Google Scholar] [CrossRef]
- Longenecker, B.M.; Rahman, A.F.; Leigh, J.B.; Purser, R.A.; Greenberg, A.H.; Willans, D.J.; Keller, O.; Petrik, P.K.; Thay, T.Y.; Suresh, M.R. Monoclonal antibody against a cryptic carbohydrate antigen of murine and human lymphocytes. I. Antigen expression in non-cryptic or unsubstituted form on certain murine lymphomas, on a spontaneous murine mammary carcinoma, and on several human adenocarcinomas. Int. J. Cancer 1984, 33, 123. [Google Scholar]
- Swarnakar, R.; Deotare, A. Narcolepsy type 1. Lung India 2019, 36, 337–339. [Google Scholar] [CrossRef] [PubMed]
- Kornum, B.R.; Knudsen, S.; Ollila, H.M.; Pizza, F.; Jennum, P.J.; Dauvilliers, Y.; Overeem, S. Narcolepsy. Nat. Rev. Dis. Primers 2017, 3, 16100. [Google Scholar] [CrossRef] [PubMed]
- Sarkanen, T.O.; Alakuijala, A.P.E.; Dauvilliers, Y.A.; Partinen, M.M. Incidence of narcolepsy after H1N1 influenza and vaccinations: Systematic review and meta-analysis. Sleep Med. Rev. 2018, 38, 177–186. [Google Scholar] [CrossRef] [PubMed]
- Bassetti, C.L.A.; Adamantidis, A.; Burdakov, D.; Han, F.; Gay, S.; Kallweit, U.; Khatami, R.; Koning, F.; Kornum, B.R.; Lammers, G.J.; et al. Narcolepsy—Clinical spectrum, aetiopathophysiology, diagnosis and treatment. Nat. Rev. Neurol. 2019, 15, 519–539. [Google Scholar] [CrossRef]
- Kornum, B.R. Narcolepsy type 1: What have we learned from immunology? Sleep 2020, 43, zsaa055. [Google Scholar] [CrossRef]
- Phillips, M.L.; Nudelman, E.; Gaeta, F.C.; Perez, M.; Singhal, A.K.; Hakomori, S.; Paulson, J.C. ELAM-1 mediates cell adhesion by recognition of a carbohydrate ligand, sialyl-Lex. Science 1990, 250, 1130–1132. [Google Scholar] [CrossRef]
- Apweiler, R.; Hermjakob, H.; Sharon, N. On the frequency of protein glycosylation, as deduced from analysis of the SWISS-PROT database. Biochim. Biophys. Acta Gen. Subj. 1999, 1473, 4. [Google Scholar] [CrossRef]
- Dwek, R.A. Glycobiology: Toward Understanding the Function of Sugars. Chem. Rev. 1996, 96, 683–720. [Google Scholar] [CrossRef]
- Stanley, P.; Schachter, H.; Taniguchi, N. N-Glycans. In Essentials of Glycobiology; Varki, A., Cummings, R.D., Esko, J.D., Freeze, H.H., Stanley, P., Bertozzi, C.R., Hart, G.W., Etzler, M.E., Eds.; Cold Spring Harbor Laboratory Press: New York, NY, USA, 2009. [Google Scholar]
- Gutierrez Reyes, C.D.; Huang, Y.; Atashi, M.; Zhang, J.; Zhu, J.; Liu, S.; Parikh, N.D.; Singal, A.G.; Dai, J.; Lubman, D.M.; et al. PRM-MS Quantitative Analysis of Isomeric N-Glycopeptides Derived from Human Serum Haptoglobin of Patients with Cirrhosis and Hepatocellular Carcinoma. Metabolites 2021, 11, 563. [Google Scholar] [CrossRef]
- An, H.J.; Froehlich, J.W.; Lebrilla, C.B. Determination of glycosylation sites and site-specific heterogeneity in glycoproteins. Curr. Opin. Chem. Biol. 2009, 13, 421–426. [Google Scholar] [CrossRef] [PubMed]
- Zacharias, L.G.; Hartmann, A.K.; Song, E.; Zhao, J.; Zhu, R.; Mirzaei, P.; Mechref, Y. HILIC and ERLIC Enrichment of Glycopeptides Derived from Breast and Brain Cancer Cells. J. Proteome Res. 2016, 15, 3624–3634. [Google Scholar] [CrossRef]
- Song, E.; Pyreddy, S.; Mechref, Y. Quantification of glycopeptides by multiple reaction monitoring liquid chromatography/tandem mass spectrometry. Rapid Commun. Mass. Spectrom. 2012, 26, 1941–1954. [Google Scholar] [CrossRef] [PubMed]
- Bond, M.R.; Kohler, J.J. Chemical methods for glycoprotein discovery. Curr. Opin. Chem. Biol. 2007, 11, 52–58. [Google Scholar] [CrossRef] [PubMed]
- Harazono, A.; Kawasaki, N.; Itoh, S.; Hashii, N.; Ishii-Watabe, A.; Kawanishi, T.; Hayakawa, T. Site-specific N-glycosylation analysis of human plasma ceruloplasmin using liquid chromatography with electrospray ionization tandem mass spectrometry. Anal. Biochem. 2006, 348, 259–268. [Google Scholar] [CrossRef] [PubMed]
- Mechref, Y.; Muzikar, J.; Novotny, M.V. Comprehensive assessment of N-glycans derived from a murine monoclonal antibody: A case for multimethodological approach. Electrophoresis 2005, 26, 2034–2046. [Google Scholar] [CrossRef]
- Gutierrez-Reyes, C.D.; Jiang, P.; Atashi, M.; Bennett, A.; Yu, A.; Peng, W.; Zhong, J.; Mechref, Y. Advances in mass spectrometry-based glycoproteomics: An update covering the period 2017–2021. Electrophoresis 2022, 43, 370–387. [Google Scholar] [CrossRef]
- Dong, X.; Mondello, S.; Kobeissy, F.; Talih, F.; Ferri, R.; Mechref, Y. LC-MS/MS glycomics of idiopathic rapid eye movement sleep behavior disorder. Electrophoresis 2018, 39, 3096–3103. [Google Scholar] [CrossRef]
- Novotny, M.V.; Alley, W.R., Jr. Recent trends in analytical and structural glycobiology. Curr. Opin. Chem. Biol. 2013, 17, 832–840. [Google Scholar] [CrossRef]
- Yu, A.; Zhao, J.; Peng, W.; Banazadeh, A.; Williamson, S.D.; Goli, M.; Huang, Y.; Mechref, Y. Advances in mass spectrometry-based glycoproteomics. Electrophoresis 2018, 39, 3104–3122. [Google Scholar] [CrossRef] [PubMed]
- Ji, E.S.; Lee, H.K.; Park, G.W.; Kim, K.H.; Kim, J.Y.; Yoo, J.S. Isomer separation of sialylated O- and N-linked glycopeptides using reversed-phase LC-MS/MS at high temperature. J. Chromatogr. B 2019, 1110–1111, 101–107. [Google Scholar] [CrossRef] [PubMed]
- Vreeker, G.C.; Wuhrer, M. Reversed-phase separation methods for glycan analysis. Anal. Bioanal. Chem. 2017, 409, 359–378. [Google Scholar] [CrossRef]
- Zhou, S.; Hu, Y.; Mechref, Y. High-temperature LC-MS/MS of permethylated glycans derived from glycoproteins. Electrophoresis 2016, 37, 1506–1513. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Dong, X.; Veillon, L.; Huang, Y.; Mechref, Y. LC-MS/MS analysis of permethylated N-glycans facilitating isomeric characterization. Anal. Bioanal. Chem. 2017, 409, 453–466. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Nie, Y.; Boyes, B.; Orlando, R. Resolving Isomeric Glycopeptide Glycoforms with Hydrophilic Interaction Chromatography (HILIC). J. Biomol. Tech. 2016, 27, 98–104. [Google Scholar] [CrossRef]
- Kozlik, P.; Goldman, R.; Sanda, M. Hydrophilic interaction liquid chromatography in the separation of glycopeptides and their isomers. Anal. Bioanal. Chem. 2018, 410, 5001–5008. [Google Scholar] [CrossRef]
- Mancera-Arteu, M.; Giménez, E.; Barbosa, J.; Peracaula, R.; Sanz-Nebot, V. Zwitterionic-hydrophilic interaction capillary liquid chromatography coupled to tandem mass spectrometry for the characterization of human alpha-acid-glycoprotein N-glycan isomers. Anal. Chim. Acta 2017, 991, 76–88. [Google Scholar] [CrossRef]
- Zhu, R.; Huang, Y.; Zhao, J.; Zhong, J.; Mechref, Y. Isomeric Separation of N-Glycopeptides Derived from Glycoproteins by Porous Graphitic Carbon (PGC) LC-MS/MS. Anal. Chem. 2020, 92, 9556–9565. [Google Scholar] [CrossRef]
- Molnarova, K.; Kozlík, P. Comparison of Different HILIC Stationary Phases in the Separation of Hemopexin and Immunoglobulin G Glycopeptides and Their Isomers. Molecules 2020, 25, 4655. [Google Scholar] [CrossRef]
- Huang, B.Y.; Yang, C.K.; Liu, C.P.; Liu, C.Y. Stationary phases for the enrichment of glycoproteins and glycopeptides. Electrophoresis 2014, 35, 2091–2107. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.C.; Su, W.C.; Huang, B.Y.; Chen, Y.J.; Tai, H.C.; Obena, R.P. Interaction modes and approaches to glycopeptide and glycoprotein enrichment. Analyst 2014, 139, 688–704. [Google Scholar] [CrossRef]
- Tsai, H.Y.; Boonyapranai, K.; Sriyam, S.; Yu, C.J.; Wu, S.W.; Khoo, K.H.; Phutrakul, S.; Chen, S.T. Glycoproteomics analysis to identify a glycoform on haptoglobin associated with lung cancer. Proteomics 2011, 11, 2162–2170. [Google Scholar] [CrossRef]
- Wang, D.; Hincapie, M.; Rejtar, T.; Karger, B.L. Ultrasensitive characterization of site-specific glycosylation of affinity-purified haptoglobin from lung cancer patient plasma using 10 μm i.d. porous layer open tubular liquid chromatography-linear ion trap collision-induced dissociation/electron transfer dissociation mass spectrometry. Anal. Chem. 2011, 83, 2029–2037. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Li, X.J.; Martin, D.B.; Aebersold, R. Identification and quantification of N-linked glycoproteins using hydrazide chemistry, stable isotope labeling and mass spectrometry. Nat. Biotechnol. 2003, 21, 660–666. [Google Scholar] [CrossRef]
- Nilsson, J.; Rüetschi, U.; Halim, A.; Hesse, C.; Carlsohn, E.; Brinkmalm, G.; Larson, G. Enrichment of glycopeptides for glycan structure and attachment site identification. Nat. Methods 2009, 6, 809–811. [Google Scholar] [CrossRef] [PubMed]
- Ongay, S.; Boichenko, A.; Govorukhina, N.; Bischoff, R. Glycopeptide enrichment and separation for protein glycosylation analysis. J. Sep. Sci. 2012, 35, 2341–2372. [Google Scholar] [CrossRef]
- Madera, M.; Mann, B.; Mechref, Y.; Novotny, M.V. Efficacy of glycoprotein enrichment by microscale lectin affinity chromatography. J. Sep. Sci. 2008, 31, 2722–2732. [Google Scholar] [CrossRef]
- Selman, M.H.; Hemayatkar, M.; Deelder, A.M.; Wuhrer, M. Cotton HILIC SPE microtips for microscale purification and enrichment of glycans and glycopeptides. Anal. Chem. 2011, 83, 2492–2499. [Google Scholar] [CrossRef]
- Buszewski, B.; Noga, S. Hydrophilic interaction liquid chromatography (HILIC)—A powerful separation technique. Anal. Bioanal. Chem. 2012, 402, 231–247. [Google Scholar] [CrossRef] [PubMed]
- Defossez, E.; Bourquin, J.; von Reuss, S.; Rasmann, S.; Glauser, G. Eight key rules for successful data-dependent acquisition in mass spectrometry-based metabolomics. Mass. Spectrom. Rev. 2023, 42, 131–143. [Google Scholar] [CrossRef]
- Sanni, A.; Goli, M.; Zhao, J.; Wang, J.; Barsa, C.; El Hayek, S.; Talih, F.; Lanuzza, B.; Kobeissy, F.; Plazzi, G.; et al. LC-MS/MS-Based Proteomics Approach for the Identification of Candidate Serum Biomarkers in Patients with Narcolepsy Type 1. Biomolecules 2023, 13. [Google Scholar] [CrossRef]
- Tu, C.; Rudnick, P.A.; Martinez, M.Y.; Cheek, K.L.; Stein, S.E.; Slebos, R.J.; Liebler, D.C. Depletion of abundant plasma proteins and limitations of plasma proteomics. J. Proteome Res. 2010, 9, 4982–4991. [Google Scholar] [CrossRef] [PubMed]
- Mysling, S.; Palmisano, G.; Højrup, P.; Thaysen-Andersen, M. Utilizing Ion-Pairing Hydrophilic Interaction Chromatography Solid Phase Extraction for Efficient Glycopeptide Enrichment in Glycoproteomics. Anal. Chem. 2010, 82, 5598–5609. [Google Scholar] [CrossRef]
- Fang, Z.; Qin, H.; Mao, J.; Wang, Z.; Zhang, N.; Wang, Y.; Liu, L.; Nie, Y.; Dong, M.; Ye, M. Glyco-Decipher enables glycan database-independent peptide matching and in-depth characterization of site-specific N-glycosylation. Nat. Commun. 2022, 13, 1900. [Google Scholar] [CrossRef]
- Yin, X.; Bern, M.; Xing, Q.; Ho, J.; Viner, R.; Mayr, M. Glycoproteomic analysis of the secretome of human endothelial cells. Mol. Cell. Proteomics 2013, 12, 956–978. [Google Scholar] [CrossRef]
- Anonsen, J.H.; Vik, Å.; Egge-Jacobsen, W.; Koomey, M. An Extended Spectrum of Target Proteins and Modification Sites in the General O-Linked Protein Glycosylation System in Neisseria gonorrhoeae. J. Proteome Res. 2012, 11, 5781–5793. [Google Scholar] [CrossRef]
- Giannoccaro, M.P.; Liguori, R.; Plazzi, G.; Pizza, F. Reviewing the Clinical Implications of Treating Narcolepsy as an Autoimmune Disorder. Nat. Sci. Sleep. 2021, 13, 557–577. [Google Scholar] [CrossRef] [PubMed]
- de Jesus, J.R.; de Campos, B.K.; Galazzi, R.M.; Martinez, J.L.; Arruda, M.A. Bipolar disorder: Recent advances and future trends in bioanalytical developments for biomarker discovery. Anal. Bioanal. Chem. 2015, 407, 661–667. [Google Scholar] [CrossRef]
- Shakil, M.S.; Niloy, M.S.; Mahmud, K.M.; Kamal, M.A.; Islam, M.A. Theranostic Potentials of Gold Nanomaterials in Hematological Malignancies. Cancers 2022, 14, 3047. [Google Scholar] [CrossRef] [PubMed]
- Klein, A.; Carre, Y.; Louvet, A.; Michalski, J.C.; Morelle, W. Immunoglobulins are the major glycoproteins involved in the modifications of total serum N-glycome in cirrhotic patients. Proteomics Clin. Appl. 2010, 4, 379–393. [Google Scholar] [CrossRef]
- Cui, Y.; Tabang, D.N.; Zhang, Z.; Ma, M.; Alpert, A.J.; Li, L. Counterion Optimization Dramatically Improves Selectivity for Phosphopeptides and Glycopeptides in Electrostatic Repulsion-Hydrophilic Interaction Chromatography. Anal. Chem. 2021, 93, 7908–7916. [Google Scholar] [CrossRef] [PubMed]
- Riley, N.M.; Bertozzi, C.R.; Pitteri, S.J. A Pragmatic Guide to Enrichment Strategies for Mass Spectrometry-Based Glycoproteomics. Mol. Cell. Proteom. 2021, 20, 100029. [Google Scholar] [CrossRef]
- Wang, J.; Tong, L.; Lin, G.; Wang, H.; Zhang, L.; Yang, X. Immunological and clinicopathological characteristics of C1RL in 2120 glioma patients. BMC Cancer 2020, 20. [Google Scholar] [CrossRef]
- Palmigiano, A.; Barone, R.; Sturiale, L.; Sanfilippo, C.; Bua, R.O.; Romeo, D.A.; Messina, A.; Capuana, M.L.; Maci, T.; Le Pira, F.; et al. CSF N-glycoproteomics for early diagnosis in Alzheimer’s disease. J. Proteom. 2016, 131, 29–37. [Google Scholar] [CrossRef] [PubMed]
- van der Burgt, Y.E.M.; Siliakus, K.M.; Cobbaert, C.M.; Ruhaak, L.R. HILIC–MRM–MS for Linkage-Specific Separation of Sialylated Glycopeptides to Quantify Prostate-Specific Antigen Proteoforms. J. Proteome Res. 2020, 19, 2708–2716. [Google Scholar] [CrossRef] [PubMed]
- Mogavero, M.P.; DelRosso, L.M.; Bruni, O.; Salemi, M.; Salsone, M.; Novellino, F.; Zucconi, M.; Ferini Strambi, L.; Ferri, R. Genetics and epigenetics of rare hypersomnia. Trends Genet. 2023, 39, 415–429. [Google Scholar] [CrossRef] [PubMed]
- van Kooyk, Y.; Rabinovich, G.A. Protein-glycan interactions in the control of innate and adaptive immune responses. Nat. Immunol. 2008, 9, 593–601. [Google Scholar] [CrossRef]
- Blixt, O.; Collins, B.E.; van den Nieuwenhof, I.M.; Crocker, P.R.; Paulson, J.C. Sialoside specificity of the siglec family assessed using novel multivalent probes: Identification of potent inhibitors of myelin-associated glycoprotein. J. Biol. Chem. 2003, 278, 31007–31019. [Google Scholar] [CrossRef]
- Bhide, G.P.; Colley, K.J. Sialylation of N-glycans: Mechanism, cellular compartmentalization and function. Histochem. Cell. Biol. 2017, 147, 149–174. [Google Scholar] [CrossRef] [PubMed]
- Reyes, C.D.G.; Hakim, M.A.; Atashi, M.; Goli, M.; Gautam, S.; Wang, J.; Bennett, A.I.; Zhu, J.; Lubman, D.M.; Mechref, Y. LC-MS/MS Isomeric Profiling of N-Glycans Derived from Low-Abundant Serum Glycoproteins in Mild Cognitive Impairment Patients. Biomolecules 2022, 12, 1657. [Google Scholar]
- Crocker, P.R.; Paulson, J.C.; Varki, A. Siglecs and their roles in the immune system. Nat. Rev. Immunol. 2007, 7, 255. [Google Scholar] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Information | Control | NT1 |
|---|---|---|
| Sample size | 11 | 16 |
| Gender (M/F) | 7/4 | 11/5 |
| Age ranges (year) | 28–73 | 19–71 |
| Orexin level in CSF (pg/mL) | Not available | 0–119.6 |
| HLA1 DQB110602 allele | 2 | 15 |
| Body mass index | Not available | 20.2–28.6 |
| Glycopeptides | Protein Name | p Value | ROC/AUC |
|---|---|---|---|
| ENLTAPGSDSAVFFEQGTTR + 5-4-1-1 | Ceruloplasmin | 0.03 | 0.75 |
| ENLTAPGSDSAVFFEQGTTR + 6-3-0-2 | Ceruloplasmin | 0.03 | 0.75 |
| GDSGGPLVCMDANNVTYVWGVVSWGENCGKPEFPGVYTK + 5-4-0-2 | Inter-alpha-trypsin inhibitor heavy chain H4 | 0.03 | 0.75 |
| IVLDPSGSMNIYLVLDGSDSIGASNFTGAK + 5-4-1-0 | Complement factor B | 0.01 | 0.80 |
| KEHETCLAPELYNGNYSTTQK + 5-4-0-1 | Coagulation factor XIII B chain | 0.02 | 0.76 |
| LPTQNITFQTESSVAEQEAEFQSPK + 6-3-0-2 | Inter-alpha-trypsin inhibitor heavy chain H4 | 0.008 | 0.81 |
| NCGVNCSGDVFTALIGEIASPNYPK + 6-5-0-3 | Complement C1s | 0.02 | 0.85 |
| REGDHEFLEVPEAQEDVEATFPVHQPGNYSCSYR + 6-5-0-2 | Alpha-1B-glycoprotein | 0.006 | 0.81 |
| RNPPMGGNVVIFDTVITNQEEPYQNHSGR + 6-5-1-1 | Alpha-1B-glycoprotein | 0.01 | 0.82 |
| VIDFNCTTSSVSSALANTK + 5-4-2-0 | Histidine-rich glycoprotein | 0.01 | 0.76 |
| PLCVTLRCTNATVK + 3-7-0-0 | Angiotensinogen | 0.01 | 0.85 |
| Glycopeptides | p Value | Precursor Mass | ROC/AUC |
|---|---|---|---|
| LHINHNNLTESVGPLPK + 6-5-1-1 Isomer 1 | 0.009 | 985.919 | 0.88 |
| ELHHLQEQNVSNAFLDKGEFYIGSK + 6-5-2-2 Isomer 1 | 0.01 | 1213.826 | 0.66 |
| FNLTETSEAEIHQSFQHLLR + 7-6-0-4 Isomer 1 | 0.02 | 1203.824 | 0.72 |
| FNLTETSEAEIHQSFQHLLR + 7-6-0-4 Isomer 2 | 0.0005 | 1203.824 | 0.84 |
| ALPQPQNVTSLLGCTH + 6-4-1-1 Isomer 1 | 0.006 | 1006.766 | 0.84 |
| ALPQPQNVTSLLGCTH + 6-5-0-2 Isomer 1 | 0.02 | 1152.453 | 0.81 |
| NHSCSEGQISIFR + 5-4-0-2 Isomer 1 | 0.02 | 925.7962 | 0.65 |
| GLNVTLSSTGR + 5-4-2-1 Isomer 1 | 0.003 | 1057.447 | 0.69 |
| LDAPTNLQFVNETDSTVLVR + 6-5-0-3 Isomer 2 | 0.001 | 1326.211 | 0.70 |
| ALPQPQNVTSLLGCTH + 6-4-1-1 Isomer 2 | 0.001 | 1006.766 | 0.71 |
| Glycopeptides | Protein Name | FC | FC (PRM) |
|---|---|---|---|
| ALPQPQNVTSLLGCTH + 5-4-0-1 | HPX | 0.42 | 0.95 |
| KEHETCLAPELYNGNYSTTQK + 5-4-0-1 | Coagulation factor XIII B chain | 2.88 | 1.02 |
| VYIHPFHLVIHNESTCEQLAK + 5-4-0-2 | Angiotensinogen | 0.42 | 0.97 |
| SPYYNVSDEISFHCYDGYTLR + 4-3-0-1 | Complement factor B | 1.17 | 1.03 |
| YPHKPEINSTTHPGADLQENFCR + 5-4-1-1 | F2(Prothrombin) | 1.47 | 1.15 |
| YPHKPEINSTTHPGADLQENFCR + 6-6-00 | F2 | 0.86 | 0.75 |
| YPHKPEINSTTHPGADLQENFCR + 7-5-2-0 | F2 | 1.13 | 1.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atashi, M.; Reyes, C.D.G.; Sandilya, V.; Purba, W.; Ahmadi, P.; Hakim, M.A.; Kobeissy, F.; Plazzi, G.; Moresco, M.; Lanuzza, B.; et al. LC-MS/MS Quantitation of HILIC-Enriched N-glycopeptides Derived from Low-Abundance Serum Glycoproteins in Patients with Narcolepsy Type 1. Biomolecules 2023, 13, 1589. https://doi.org/10.3390/biom13111589
Atashi M, Reyes CDG, Sandilya V, Purba W, Ahmadi P, Hakim MA, Kobeissy F, Plazzi G, Moresco M, Lanuzza B, et al. LC-MS/MS Quantitation of HILIC-Enriched N-glycopeptides Derived from Low-Abundance Serum Glycoproteins in Patients with Narcolepsy Type 1. Biomolecules. 2023; 13(11):1589. https://doi.org/10.3390/biom13111589
Chicago/Turabian StyleAtashi, Mojgan, Cristian D. Gutierrez Reyes, Vishal Sandilya, Waziha Purba, Parisa Ahmadi, Md. Abdul Hakim, Firas Kobeissy, Giuseppe Plazzi, Monica Moresco, Bartolo Lanuzza, and et al. 2023. "LC-MS/MS Quantitation of HILIC-Enriched N-glycopeptides Derived from Low-Abundance Serum Glycoproteins in Patients with Narcolepsy Type 1" Biomolecules 13, no. 11: 1589. https://doi.org/10.3390/biom13111589