1. Introduction
Autoencoders have emerged as deep learning solutions to turn molecules into latent vector representations as well as decode and sample areas of the latent vector space [
1,
2,
3]. An autoencoder consists of an encoder which compresses and changes the input information into a code layer and a decoder part which recreates the original input from the compressed vector representation (the latent space vector). After training, the encoder can be extracted from the autoencoder and used to calculate vector representations of the molecules. These can be used as a sort of molecular fingerprints or GPS for the chemical space of the molecules. The decoder can be used to translate back from the latent representation to the molecular representation used during training, such as simplified molecular-input line-entry system (SMILES). This makes it possible to use the decoder as a steered solution for molecular de novo generation, as the probability outputs of the decoder can be sampled, creating molecules which are novel but close to the point in latent space. Alternatively, the molecules of the nearby latent space can be explored by adding a suitable amount of random noise to the vector.
Various encoder–decoder architectures have been proposed as well as the encoder output functions have been regularized or manipulated using variational autoencoders [
1] and adversarial autoencoders [
2]. Both convolutional neural networks (CNNs), as well as recurrent neural networks (RNNs) have been used for the encoder part [
1,
2,
3], whereas the decoder part has mostly been based on RNNs with either gated recurrent units (GRU) [
4] or long short-term memory cells (LSTM) [
5] to enable longer range sequence memory. The various approaches and their use in both de novo and quantitative structure activity relationship (QSAR) applications in drug discovery are part of a recent mini-review [
6].
A famous painting of René Magritte, “The Treachery of Images”, shows a pipe, and also has the text “Ceci n’est pas une pipe”: This is not a pipe. The sentence is true as it is a painting of pipe, not the pipe itself, kindly reminding us that representation is not reality. Autoencoders based on SMILES strings [
7] face the same fundamental issue. Is the latent space a representation of the molecules or is it a condensed representation of the SMILES strings representing the molecules?
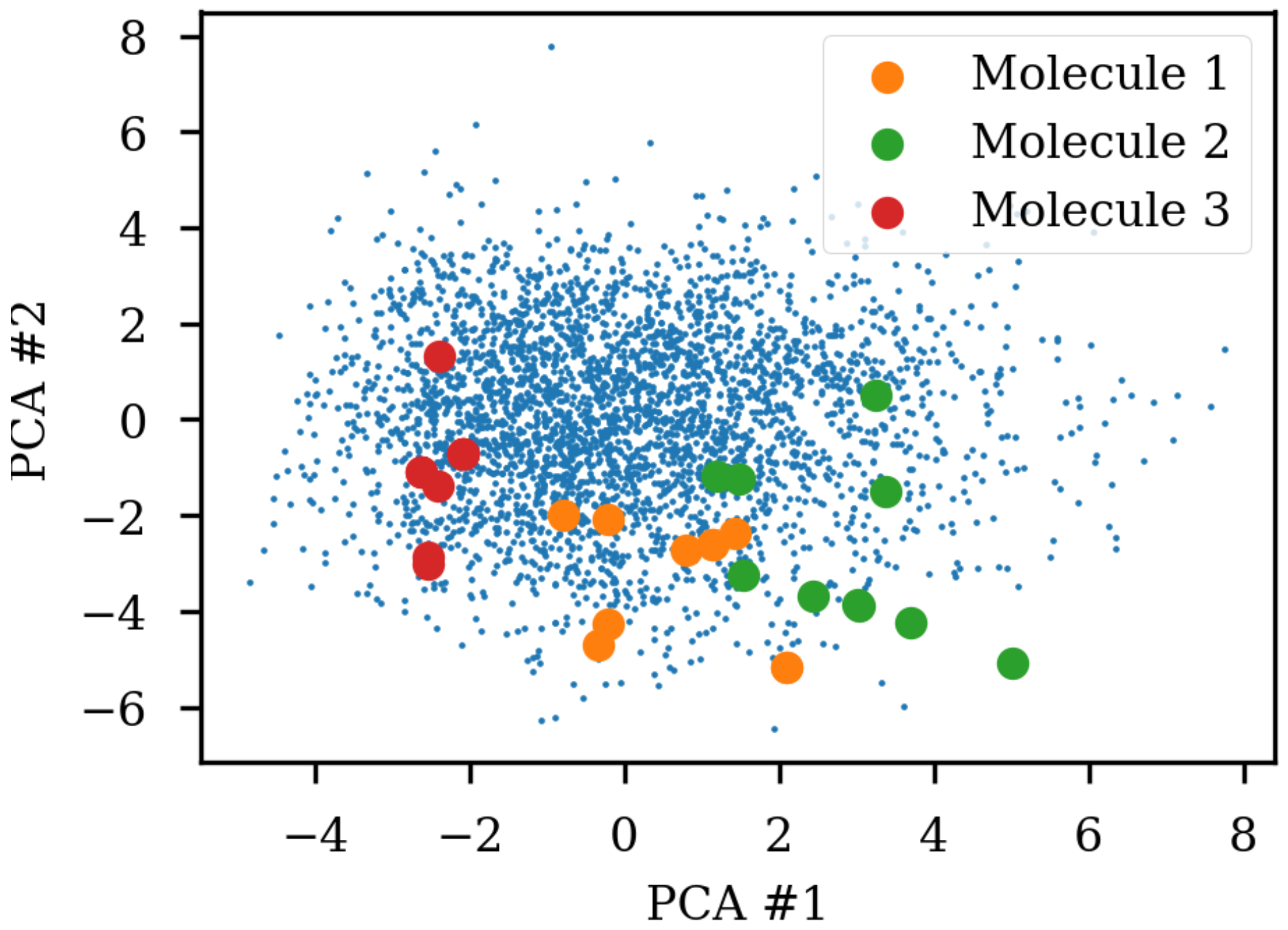
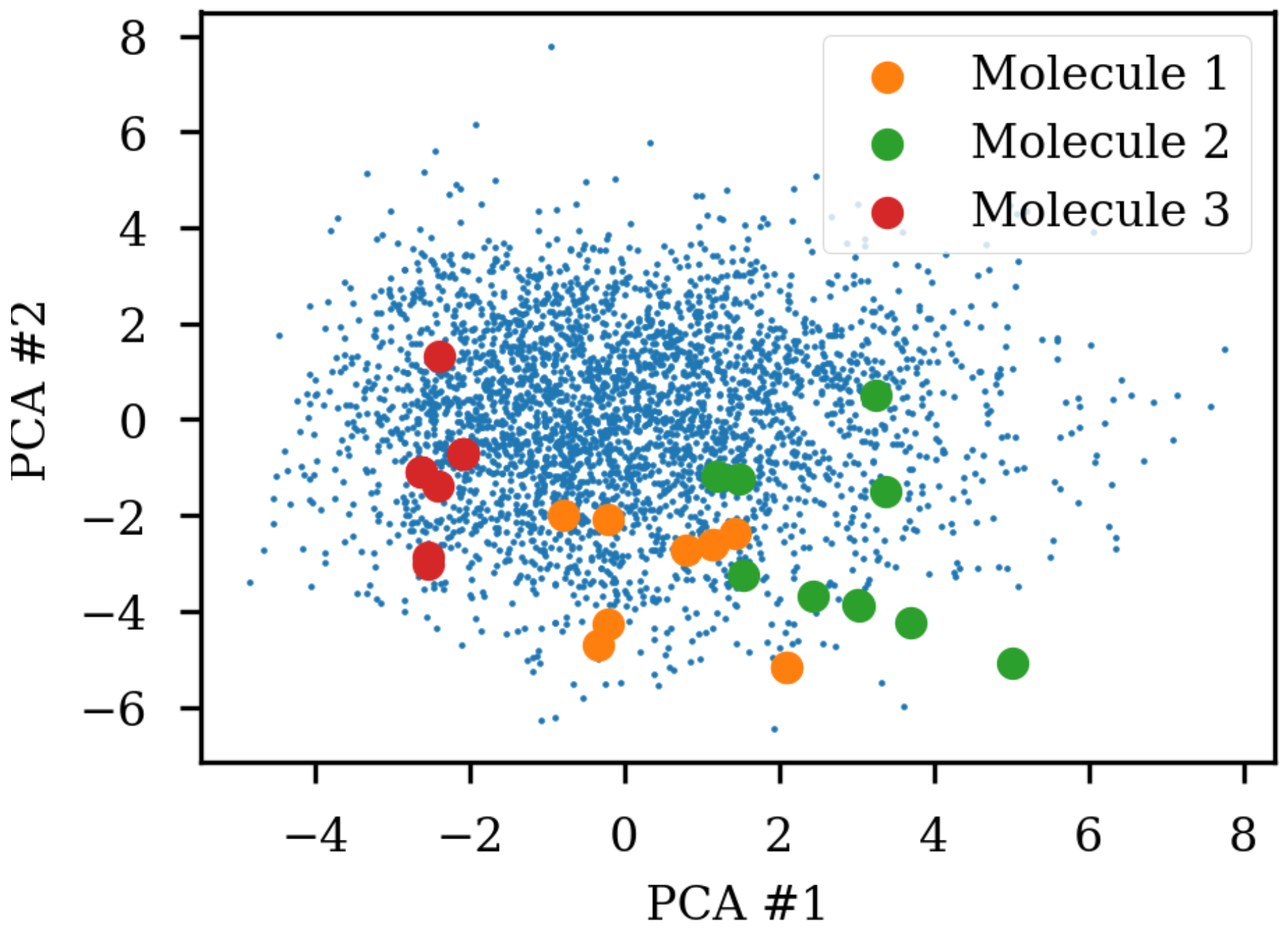
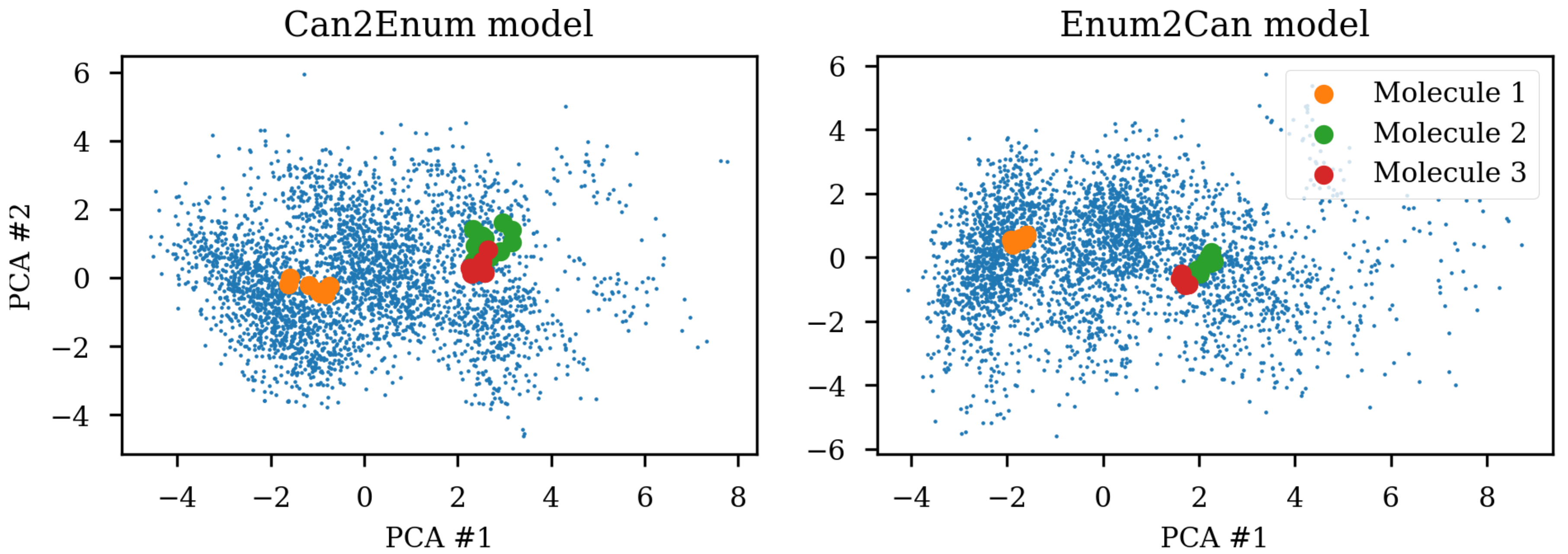
Due to the SMILES language rules, multiple different SMILES can represent the same molecule. This has been exploited as data augmentation with the SMILES enumeration technique [
8]. A simple challenge with different SMILES representations of the same molecule shows that the same molecule end up in different parts of the latent space due to the specific SMILES form used.
Figure 1 shows the same three molecules after projecting into the latent space of an RNN to RNN autoencoder. The different SMILES representation of the molecules end up being projected to very different areas of the latent space, although some clustering can be observed. The latent space thus also contains information about the specific SMILES string and not only the molecule it represents which has also previously been noted [
2,
6]. One way of solving this challenge could be to use special engineered networks and graph based approaches [
9] for molecular generation.
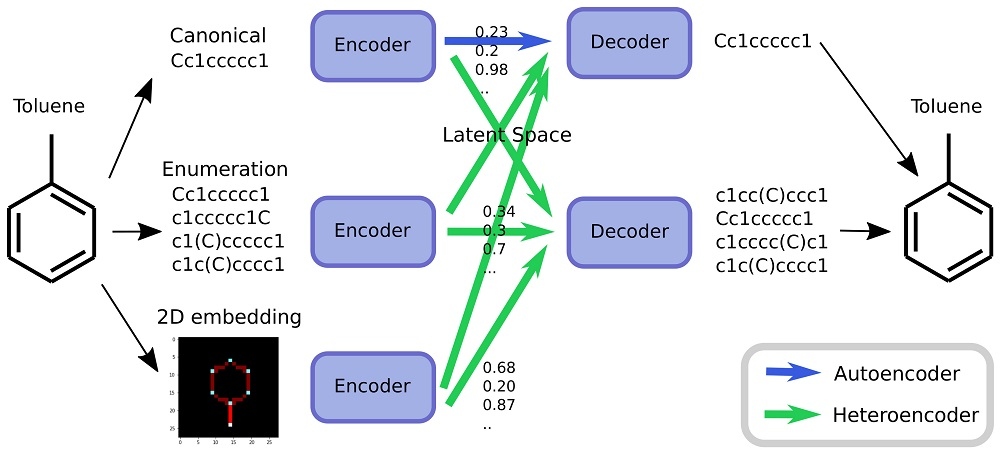
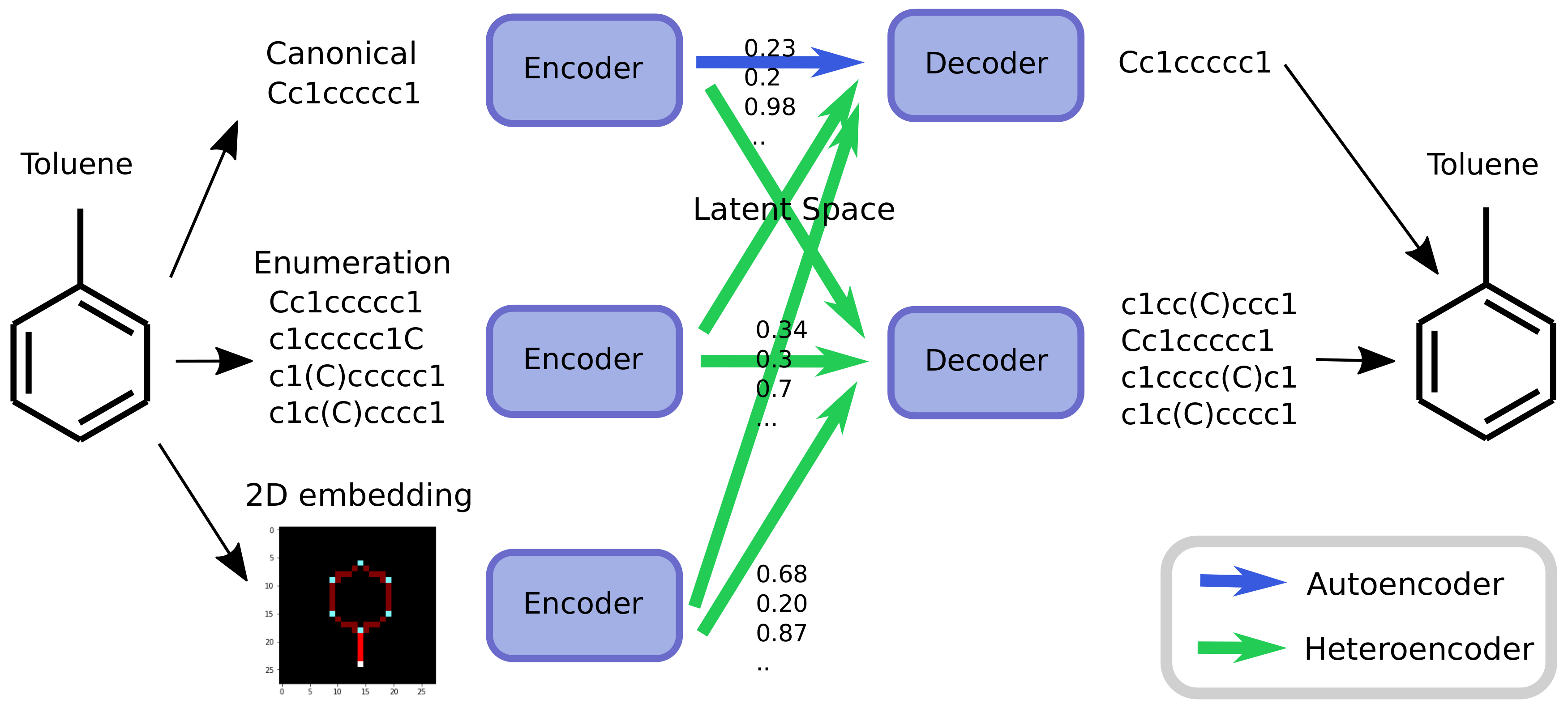
As an alternative to engineering the outcome, it is here suggested that it is possible to use SMILES enumeration or chemception image embedding [
10] to create chemical heteroencoders. The concept is illustrated in
Figure 2. By translating from one format or representation of the molecule to the other, the encoder–decoder network is forced to identify the latent information behind both representations. This should in principle lead to a more chemically relevant latent space, independent of the representations or canonicalization used.
Here, the choice of representation and enumeration is explored for both training the encoder or decoder and the latent space similarity to SMILES and scaffold based metrics calculated. Moreover, it is tested if these changes influence the properties of the decoder when used for de novo design of molecules. Furthermore, an optimized and expanded heteroencoder architectures trained on ChEMBL23 datasets are used to encode latent vectors for subsequent use as input to QSAR models of five different molecular datasets.
3. Discussion
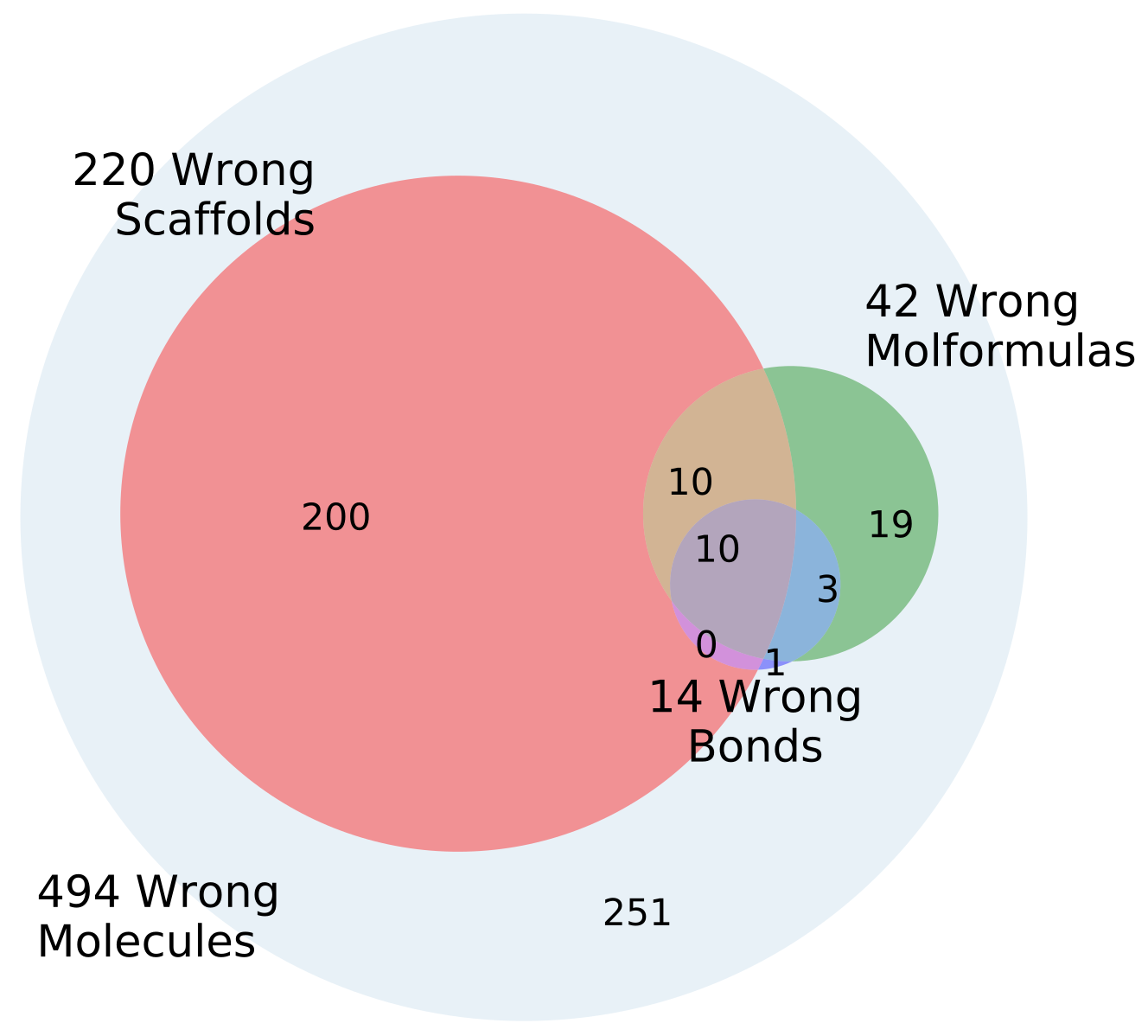
Changing the representations used for training autoencoders (here called heteroencoders) have a marked influence on the properties and organization of the latent space. Although a perfect correlation to the standard fingerprint similarity is not wanted or expected, it is more reassuring that the dependence to the SMILES sequences is at a similar level to the fingerprint based similarity, than the situation where the correlation to the SMILES sequence is much larger than the correlation to the fingerprint metric. The greater balance between the two correlations strongly indicates that the latent space is just as relevant for the molecular scaffold as it is to the SMILES sequence in itself.
The dataset used in the first part of this study was of a limited size and molecular complexity (only eight atoms). Additionally, as the dataset is fully enumerated, the same graph structures are very likely present in both training and test set, which could be the basis of the excellent reconstructions of the test sets. The model could in principle memorize all graph structures instead of learning the rules behind the graph scaffolds, and then simply assign a specific sequence of atoms to the memorized graph. Even though the dataset was somewhat simple, the models trained on enumerated data may have struggled because of a low neural network fitting capacity. This indeed seems to be the case as the 2-layer enum2enum model has much lower final loss (
Table 1) and also much better reconstruction statistics when reconstructing (
Table 1) and sampling the molecules (
Table 2) than the single layer enum2enum model. There is a rough correlation between the SMILES validity rate and the molecule reconstruction error rat. However, with heteroencoders, the molecule reconstruction error rate becomes a more relevant term to measure than the SMILES validity rate, as the former can become high, while the SMILES validity error rate is still low.
Models employed in other studies are more complex with larger and multiple layers [
1,
2,
3,
9,
10,
12]. The heteroencoder concept was thus further expanded to also handle ChEMBL datasets. The expansion of the networks to two layers in both the encoder and decoder, use of bidirectional layers in the encoder and a larger number of LSTM cells allowed to fit the larger molecules, although the uncertainty in the reconstruction of the molecule is still present (c.f.
Table 3). It is likely that even more complex architectures with three LSTM layers or a further enlargement of the number of LSTM cells would be needed to lower the molecule reconstruction error further.
The image to sequence model seems to be an outlier in comparison with the SMILES based models, in the respect that the latent space don’t show much correlation with neither the SMILES sequence to be decoded or the molecular graph. However, the model produces a very low percentage of invalid SMILES and also has a low error rate with respect to molecule reconstruction, but is also decoding to canonical SMILES which is an easier task than decoding to enumerated SMILES. The various other tests showed no big difference or benefit when compared to the much simpler use of different SMILES representations. However, the success of the image to SMILES model to transcode between the image and the SMILES representation illustrates that the concept is not limited to SMILES based models. Other types of presenting molecules to neural networks, such as graph convolutional approaches for molecules [
13,
14] would also be worth exploring for the encoder network. The heteroencoder architecture may be useful for architectural experiments with large unlabeled datasets to find better architectures and suitable deep learning feature extractions for training on molecules. The identified architectures and trained weights may be useful for transfer learning in for example QSAR modeling.
The failure of the image to SMILES heteroencoder to produce significantly better latent representation fits with the observation that the latent space is mostly influenced by the decoding procedure, not the encoding procedure. The various encoders, whether based on images, canonical SMILES or trained on enumerated SMILES, seem to learn to recognize the molecules anyway and create a latent space that is best suitable for recreation of the decoders form. It thus seems that using enumeration techniques or other molecular representation for the decoder will influence the latent space the most.
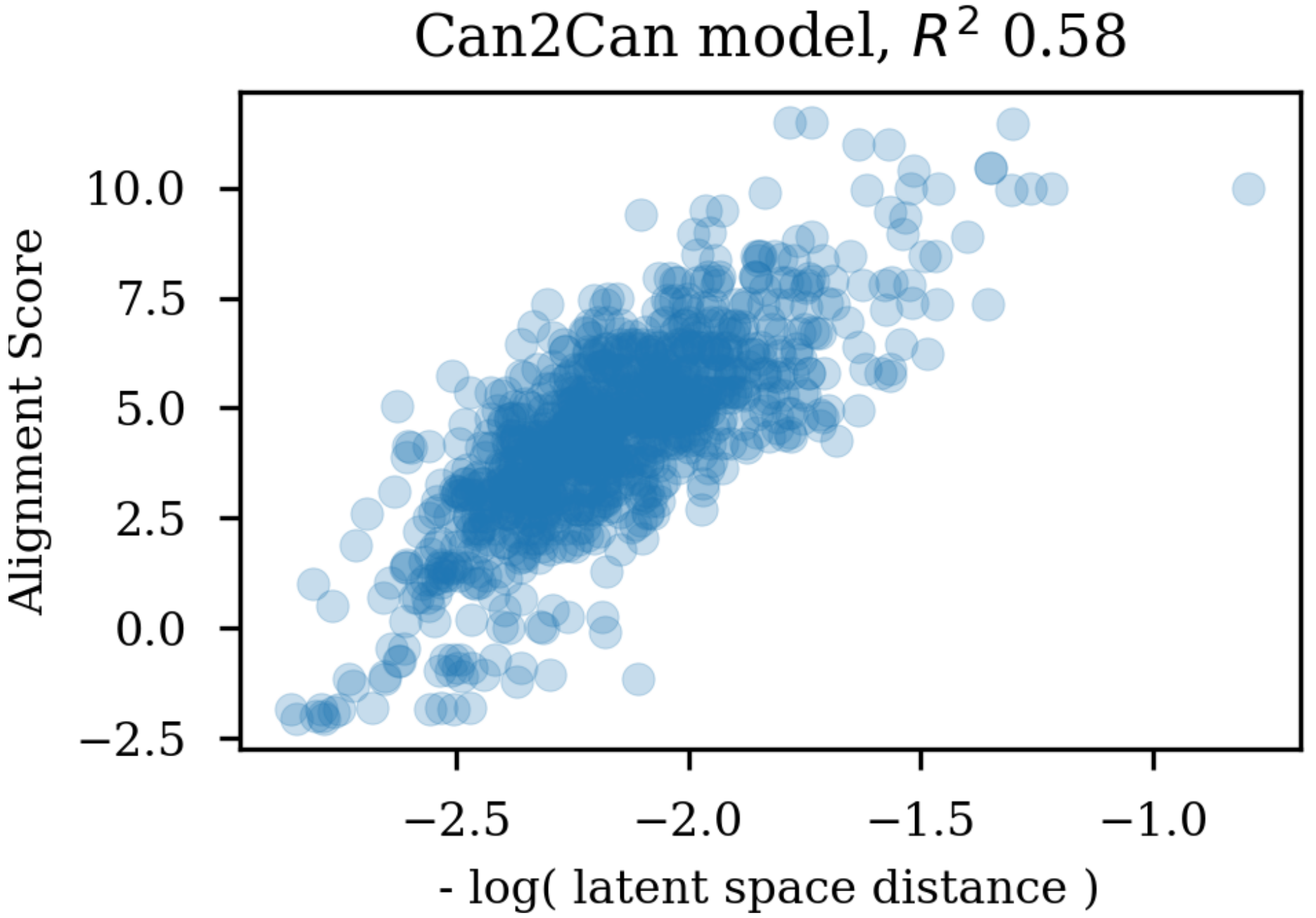
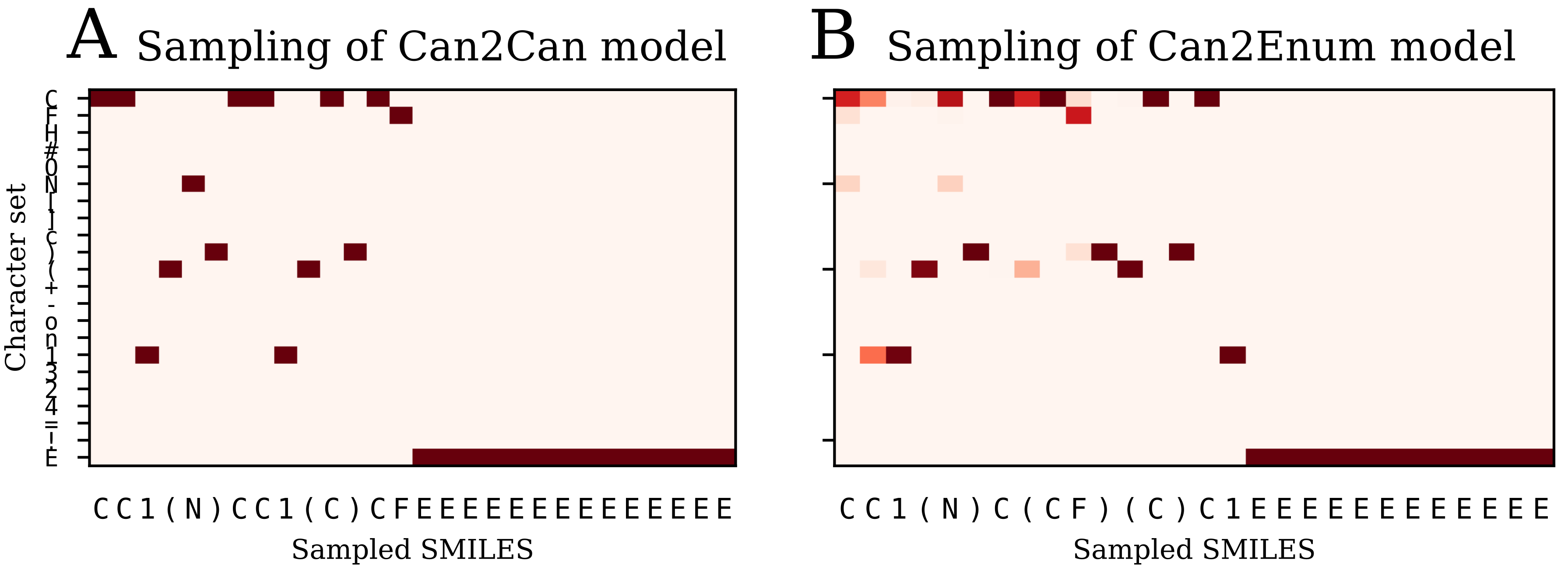
Training autoencoders on enumerated or different data further seems to improve the latent space with respect to its relevance for QSAR modelling. This is encouraging as it suggests that the encoded vectors are not only relevant for reconstruction of the molecular scaffold in itself, but additionally capture the variations underlying biological as well as physico-chemical properties of the molecules. It seem that already the encoder independence of the SMILES form for the enum2can leads to a more smooth latent space (c.f.
Figure 9 panel A), which increases the relevance for QSAR modelling. This is in contrast to the results in
Table 1, where a less skewed correlation to the decoded SMILES serialization in the encoder part is forced by training on enumerated data in the output, which however only leads to marginal gains in QSAR model performance.
The improvement seems quite marked and larger than what other studies have found. Winter et al. also used the heteroencoder approach in parallel to our work and found improvements for QSAR modelling [
15]. However, the improvements over baseline models were not as marked as in our results. The differences in network architectures (our use of bidirectional layers, LSTM vs. GRUs and batch normalization as example) and maybe also the choice of training data (Drug like molecules of ChEMBL) could be possible explanations. Future benchmarking on common datasets will likely show the way to the best network architecture and what unlabelled datasets to use for specific tasks.
On the other hand, the solubility dataset we used have previously been carefully modelled with chosen features and topological descriptors, resulting in a R
2 of 0.92 and a standard deviation of prediction of the test set of 0.6 [
16]. Likewise, a carefully crafted QSAR model of BCF obtained a R
2 of 0.73 and an RMSE of 0.69 [
17], which is on par with our model using the can2enum derived latent vectors. However, a later benchmark showed better performance for the CORAL software for prediction of BCF (R
2: 0.76, RMSE: 0.64) [
18], suggesting that further improvements are possible.
Thus, the QSAR models based on heteroencoder derived latent vectors seem to almost match the performance of highly optimized QSAR models from selected features (c.f.
Table 4), and it may rather be the ECFP4 and can2can model derived latent vectors that are mediocre for the tested type of QSAR tasks. Furthermore, the ECFP fingerprints and auto-/heteroencoder derived latent vectors are of different dimension and nature. The fingerprints are 1024-dimensional, but binary, where the latent vectors are 256-dimensional and real valued. To make sure that the improvements were not due to different optima of the model hyper parameters for the different data, the neural network architectures for the QSAR models were optimized based on the ECFP4 fingerprint input. Some improvement of the fingerprint based models were observed, but reusing the ECFP4 hyper parameters for the latent vector based modelling still resulted in a large improvement in model performance for these input types. Further tuning of the hyper parameters of the models based on the latent vectors could likely further increase the performance to some degree (not tested). On the other hand, the denser dimensionality (256 < 1024) could help protect against over fitting and make the choice of hyper parameters less critical for these models. Either way, the use of heteroencoder derived latent vectors seem to be the better choice.
Feature generation for a dataset of chemical structures using the ChEMBL trained auto-/ heteroencoders described in the publication is publicly available and hosted on the open sciende data repository (OSDR) platform [
19], where it is possible to encode molecular datasets into the latent vector space for subsequent uses, such as in QSAR modelling.
The increased relevance of the latent space with respect to bioactivity and physico-chemical properties are likely to increase the relevance and quality of the de novo generated libraries where the neighborhood of as example lead compounds are sampled on purpose. However, the use of enumeration for training the decoder comes at the cost of greater uncertainty in the decoding, at a marginal improvement to the relevance of the latent space for QSAR modelling when compared to the enum2can model. On the other hand, the greater uncertainty and “creativity” in decoding could be beneficial and further help in creating more diversity in the generated libraries, but if this is the case has yet to be investigated. The choice of enumeration for decoder and/or encoder will thus likely depend on the intended use-cases.
4. Materials and Methods
4.1. Datasets
4.1.1. GDB-8
The GDB-8 dataset [
20,
21] was downloaded and split randomly into a train and test set using a 0.9 to 0.1 ratio.
4.1.2. ChEMBL23
Structures were extracted from the ChEMBL23 database [
22] and validated using in-house rules at Science Data Software LLC (Rockville, MD, USA) (salts were stripped, solvents removed, charges neutralized and stereo information removed). The maximum available length of the canonical SMILES string allowed for a molecule was 100 characters. In addition, 10,000 molecules were selected randomly for the held out test set. From the remainder of the 1.2 million molecules, a training set of 400,000 molecules and a validation set of 300,000 molecules was randomly selected for use during training procedures.
4.1.3. QSAR Datasets
Five experimental datasets were used, spanning physico-chemical properties as well as bioactivity. Four datasets (IGC50, BCF, MP, LD50) for QSAR modeling were downloaded from the EPA Toxicity Estimation Software Tool [
23] webpage [
24] and used as is without any additional standardization. The solubility was obtained from the supplementary information of [
16]. The parsed dataset is availble for download [
25]. Information of the datasets are shown in
Table 5.
Datasets from EPA’s TEST suite were already split into train/test sets in a 75/25% ratio and were used accordingly. Molecules for the solubility dataset were obtained by resolving CAS numbers from the supporting info [
16] and the dataset was randomly split using the same ratio as the other QSAR datasets.
4.2. 1D and 2D Vectorization
SMILES were enumerated and vectorized with one-hot encoding as previously described [
8]. In addition, 2D vectorization was done similar to the vectorization used in Chemception networks [
10] with the following modifications: a PCA with three principal components was calculated on atomic properties from the mendeleev python package [
29] (dipole_polarizability, electron_affinity, electronegativity, vdw_radius, atomic_volume, softness and hardness). The PCA scores were normalized with min-max scaling to be between zero and one to create the atom type encoding. PCA and scaling were performed with the Scikit-Learn python package [
30]. RDKit [
11] was used to compute 2D coordinates and extract information about atom type and bond order. The normalized PCA scores of the atom types were used to encode the first three layers and the bond order was used to encode the forth layer. A fifth layer was used to encode the RDKit aromaticity perception. The 2D coordinates of the RDKit molecule were rotated randomly up to
180° around the center of coordinates before discretization into numpy [
31] floating point arrays.
4.3. Neural Network Modeling for GDB-8 Dataset
Sequence to Sequence RNN models were constructed using Keras v. 2.1.1 [
32] and Tensorflow v. 1.4 [
33]. The overall architecture follows the encoder -> code layer -> decoder scheme shown in
Figure 2 with a detailed scheme in the
Supplementary Information Figure S1.
The first layer consisted of 64 LSTM cells [
5] used in batch mode. The final internal memory (C) and hidden (H) states were concatenated and used as input to a dense layer (the code layer) of 64 neurons with the rectified linear unit activation function (ReLU) [
34]. Two separate dense layers with ReLU activation functions were used to decode the code layer outputs into the initial C and H states for the RNN based decoder. The decoder consisted of a single layer of 64 LSTM cells trained with teacher forcing [
35] in batch mode. The output from the LSTM cells was connected to a Dense layer with a softmax activation function matching the dimensions of the character set. A two-layer model was also constructed by increasing the number of LSTM cells to 128 and the number of LSTM layers to two in both the encoder and decoder. Accordingly, four separate dense networks were used to decode the code layer into the initial C and H states for the two LSTM layers in the decoder.
The networks were trained with mini-batches of 256 sequences for 300 epochs using the categorical cross entropy loss function and the Adam optimizer [
36] with an initial learning rate of 0.05. The two layer model was trained with an initial learning rate of 0.01. The loss was followed on the test set and the learning rate lowered by a factor of two when no improvement in the test set loss had been observed for 5 epochs.
After training in batch mode, three models were created from the parts of the full model. A decoder model from the initial input to the output of the cdoe layer. A model to calculate the initial states of the LSTM cells in the decoder, given the output of the code layer. Lastly, a stateful decoder model was constructed by creating a model with the exact same architecture as the decoder in the full model, except the LSTM cells were used in stateful mode and the input vector reduced to a size of one in the sequence dimension. After creation of the stateful model, the weights for the networks were copied from corresponding parts of the trained full model.
The image to sequence model CNN encoder was built from three different Inception-like modules [
37] similar to the Chemception modelsChemception networks [
10]. The architecture is shown schematically in the
Supplementary Information Figure S2. The first module consisted of a tower with a
2D convolutional layer (Conv2D) followed by a
Conv2D, a tower with a
Conv2D layer followed by a
Conv2D layer and a tower with just a single
Conv2D layer. The outputs from the towers were concatenated and sent to the next module.
The standard inception module was constructed with a tower of Conv2D layer followed by a Conv2D layer, a tower with a Conv2D layer followed by a Conv2D layer, an extra tower of a Conv2D layer followed by a Conv2D but with only half the number of kernels and a tower with a Maxpooling layer followed by a Conv2D layer. All strides were . The outputs from the four towers were concatenated and sent to the next module.
The inception reduction modules were similar to the standard module, except they had no tower and used a stride of .
A standard inception module was stacked with a reduction inception module three times, giving 7 inception modules in total including the initial one. The number of kernels was set to 32.
The outputs from the last inception module were flattened and followed by a dropout layer with a dropout rate of 0.2. Lastly the output was connected to the code layer consisting of a dense layer with the ReLU activation function. The decoder part was constructed similar to the sequence to sequence models described above with one layer LSTM cells. The image to sequence model was trained similar to the sequence to sequence models for 200 epochs.
The models are named after the training data in a encoder2decoder naming scheme. “Can” is training data with canonical SMILES, where “Enum” designates that the input or output was enumerated during the training. “Img” shows that the data was the 2D image embedding.
4.4. Similarity Metrics
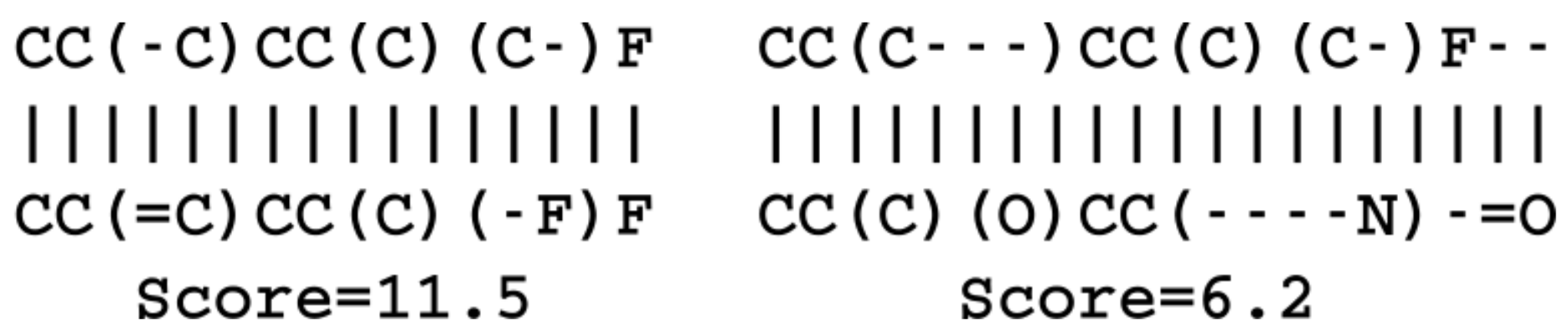
SMILES strings sequence similarities were calculated as the alignment score reported by the pairwise global alignment algorithm of the Biopython package [
38]. The match score was set to 1, the mismatch to
, the gap opening to
and the gap extension to
. The fingerprint similarity metric was calculated on basis of circular Morgan fingerprints with a radius of 2 as implemented in the RDKit library [
11]. The fingerprints were hashed to 2048 bits and the similarity calculated with the RDKit packages FingerprintSimilarity function. The latent space similarity between two molecules was calculated as the negative logarithm to the Euclidean distance of the vector coordinates.
4.5. Enumeration Challenge
The encoder was used to calculate the latent space of the test set, followed by a dimensionality reduction with standard principal components analysis (PCA) as implemented in the Scikit-Learn package [
30]. Three molecules were converted to different SMILES strings with SMILES enumeration [
8]. The latent space coordinates of the non-canonical SMILES were calculated with the encoder and transformed and projected onto the visualization of the principal components from the PCA analysis.
4.6. Error Analysis of Output
The percentage of invalid SMILES was quantified as the number of produced SMILES which could not be validated as molecules by RDKit. Subsequently the equality of the input and output RDKit molecules was checked. The similarity of the scaffold was checked by comparing the generalized murcko scaffolds [
39] including side-chains. The atom equivalence was checked by comparing the molecular sum formulas. The number and nature of bonds was compared via a “bond sum formula” by counting the number of single, double, triple and aromatic bonds.
4.7. Multinomial Sampling of Decoder
Multinomial sampling was implemented as previously described [
12]. The sampling temperature was kept at 1.0.
4.8. Neural Network Modelling for the ChEMBL Dataset
The overall steps for producing the QSAR models is illustrated in
Figure 12. The sequence to sequence autoencoder used for encoding the ChEMBL data and encoding of vectors for QSAR modelling was programmed in Python 3.6.1 [
40] using Keras version 2.1.5 [
32] with the tensorflow backend [
33]. A detailed scheme of the network is available in the
Supplementary Information Figure S3. The encoder consisted of two bidirectional layers of 128 CuDNNLSTM cells in each one-way layer. The final C and H states were concatenated and passed as input to a dense layer with 256 neurons using the ReLU [
34] activation function (the code layer). The output from the dense layer were decoded by four parallel dense layers with the ReLU activation function, whose outputs were used to set the initial C and H states of the decoder LSTM layers. The decoder itself consisted of two unidirectional layers of 256 CuDNNLSTM cells each. The decoder was trained under teacher forcing as described for the simpler networks above. Every non-linear activation was followed by Batch Normalization. No additional regularization was used. Furthermore, 400,000 random structures from the CheMBL23 training set were pre-enumerated 50-times for each SMILES string. The new 20 million pairs were shuffled and used in both a canonical to enumerated and an enumerated to canonical setting and trained until model convergence. The same 400,000 canonical SMILES were also used to train an auto encoder from canonical to canonical SMILES. For the enumerated to enumerated training setting 50 pairs (when possible) of different SMILES strings were created for each molecule of the training set. The network was trained using mini-batches of 256 one-hot encoded SMILES strings, using the Adam optimizer with an initial learning rate of 0.005. The training was monitored and controlled by three callbacks. One callback monitored the loss of the validation set and lowered the learning rate by a factor two when no improvement had been observed for two epochs (ReduceLROnPlateu). Another Callback stopped training when no improvement in the validation set loss had been observed for five epochs (EarlyStopping), and the last callback saved the model if the validation loss has improved (CheckPoint). Models typically converged after approximately 40 epochs, which usually took about six hours on a NVIDIA GTX 1080 Ti equipped server.
4.9. QSAR Modelling
Subsequent QSAR modelling was performed using the machine learning capabilities of the Open Science Data Repository [
41]. An initial search for hyper parameters was performed after converting the molecules into ECPF4 fingerprints (radius 2, 1024 bits). The hyper parameter search for a neural network was performed using Tree of Parzen Estimators (TPE) algorithm [
42] as implemented in Hyperopt [
43] with the search space bounds listed in
Table 6. The performance on each dataset was optimized using 3-fold cross validation on the training set. The performance of the model with the final hyperparameters were subsequently tested on the held-out test set using an ensemble of 10 models build during 10-fold cross validation during training. The auto-/heteroencoders trained on the ChEMBL23 molecules were subsequently used to encode the QSAR datasets into vectors using the output from the code layer. The vectors were used as input to the QSAR models. The same hyper parameters were used as identified for the ECFP4 based models, with no further attempt to optimize the hyper parameters of the feed forward neural networks using the auto-/heteroencoder encoded molecules.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}