
Urban Air Quality Assessment by Fusing Spatial and Temporal Data from Multiple Study Sources Using Refined Estimation Methods



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
- The air quality monitoring data, which span the time period from 28 February 2013 to 28 February 2014 with a time granularity of one hour, were collected by the air quality monitoring stations in Beijing. The data include the monitoring station ID, monitoring station name, longitude and latitude, collection time, PM2.5 index, PM10 index, NO2 index, and so on, where PM2.5 is the estimation target of this study model (As shown in Figure 1). And PM2.5 index, PM10 index, and NO2 index are calculated by hourly average values.
- For meteorological monitoring data, the data span the time period from 28 February 2013 to 28 February 2014, with a time granularity of one hour. The data include information on temperature (°C), pressure (hPa), humidity (%), wind speed (km/h), wind direction (°), and description of weather conditions (rain, snow, clear, etc.). Temperature, pressure, humidity, and wind speed are calculated by hourly average values. Because the urban environmental protection department in the construction of air quality monitoring stations, will be equipped with meteorological characteristics monitoring equipment. Therefore, the meteorological Monitoring site is consistent with the air quality monitoring site.
- The vehicle track data, which are the location data recorded by the vehicle GPS of the cab, span from 1 May 2013 to 31 July 2013 with a time granularity of 10 s. The data include the vehicle number, UTC time, geographic coordinates (longitude, latitude), direction (unit: degree), speed (unit: m/s), passenger status (0/1), and other information, containing 3500 cab travel routes covering Beijing. The information was available for all areas of Beijing. The higher the traffic congestion level was, the higher the tailpipe emissions [36,37]. We calculated the traffic congestion level to estimate the impact of tailpipe emissions on air quality. The calculation of the traffic congestion factor is based on the traffic congestion evaluation method adopted by the Beijing Municipal Administration 2011 of Quality and Technical Supervision in 2009 [38].
- Urban road network, including vector layers of national roads, provincial roads, urban roads, urban ramps, line roads, and rural roads in Beijing.
- POI data record the distribution of geographic entities in urban space and can accurately reflect local urban spatial functions and social activity attributes. The data were derived from the Baidu Map API, totaling 380,000 POI points in Beijing, including geographic coordinates (longitude and latitude), names, detailed street addresses, and other information. The data were rendered by density to generate a POI density distribution map of Beijing. The urban POI data provide the distribution of different kinds of geographic entities in urban space, which is highly correlated with social activities and can reflect the distribution of people’s activities and the pattern of urban spatial functions.
- The land use type data were derived from the FROM-GLC-seg global land use raster image (available online: http://data.ess.tsinghua.edu.cn/ (accessed on 1 December 2019)) produced by the Earth System Science Research Center of Tsinghua University with a resolution of 30 m × 30 m, including farmland, forest, grassland, shrub, water body, human-made surface, bare land, and other types. Land use data reflect forest, shrub, and other vegetation types. This information has an important impact on air quality.
- Remote sensing image data were derived from the remote sensing satellite images of Google Maps. The data are from the 2013 Beijing remote sensing image, and the resolution is 30 m × 30 m. Remote sensing data can reflect forest, shrub, and other vegetation coverage. This information has an important impact on air quality.
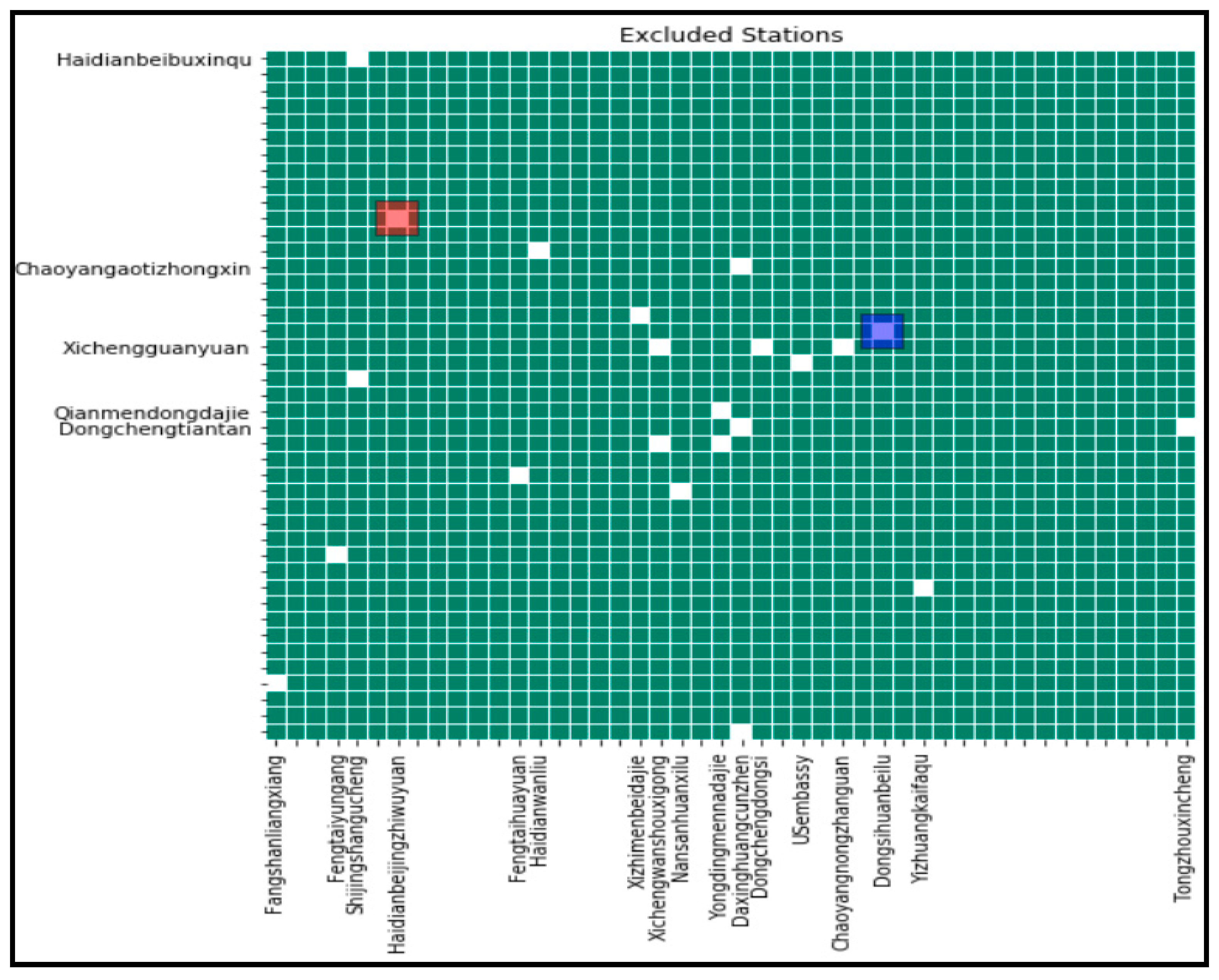
2.2. Spatio-Temporal Data Preprocessing
- (1)
- Space unit setting
- (2)
- Spatio-temporal data normalization
- (3)
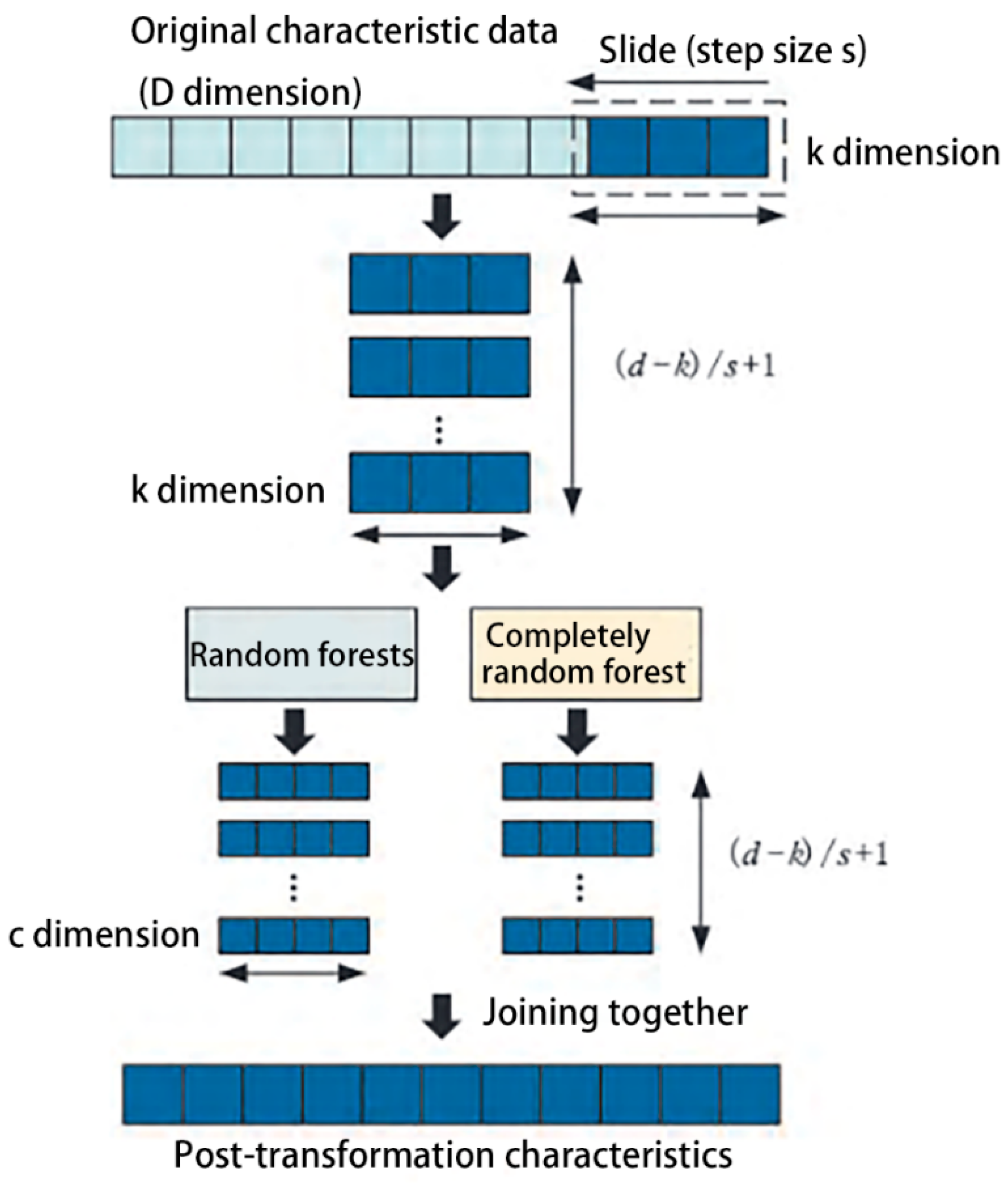
- Spatio-temporal feature scanning model
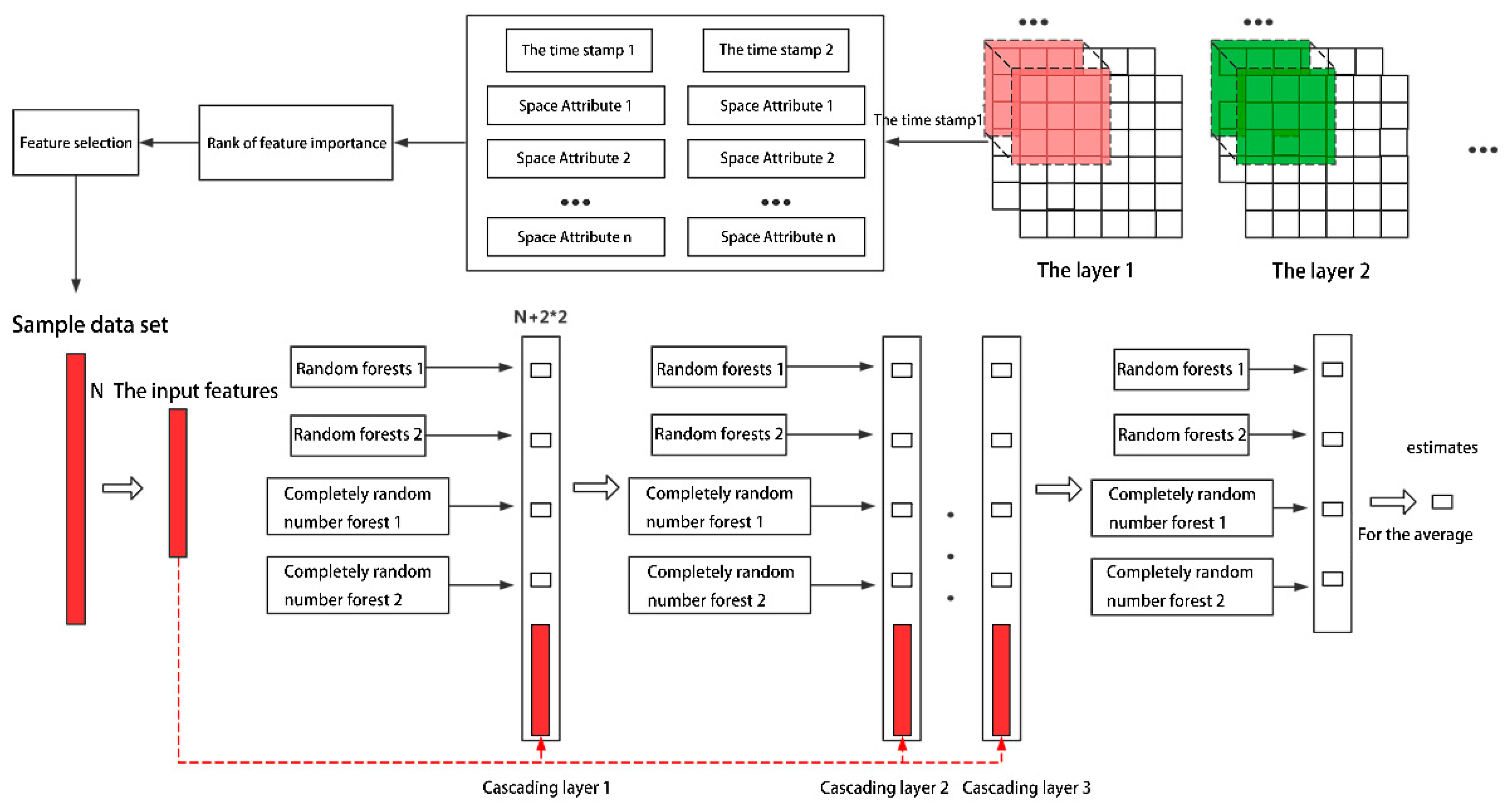
2.3. A Refined Urban Air Quality Estimation Method Integrating Multisource Spatio-Temporal Data
- (1)
- Feature Screening
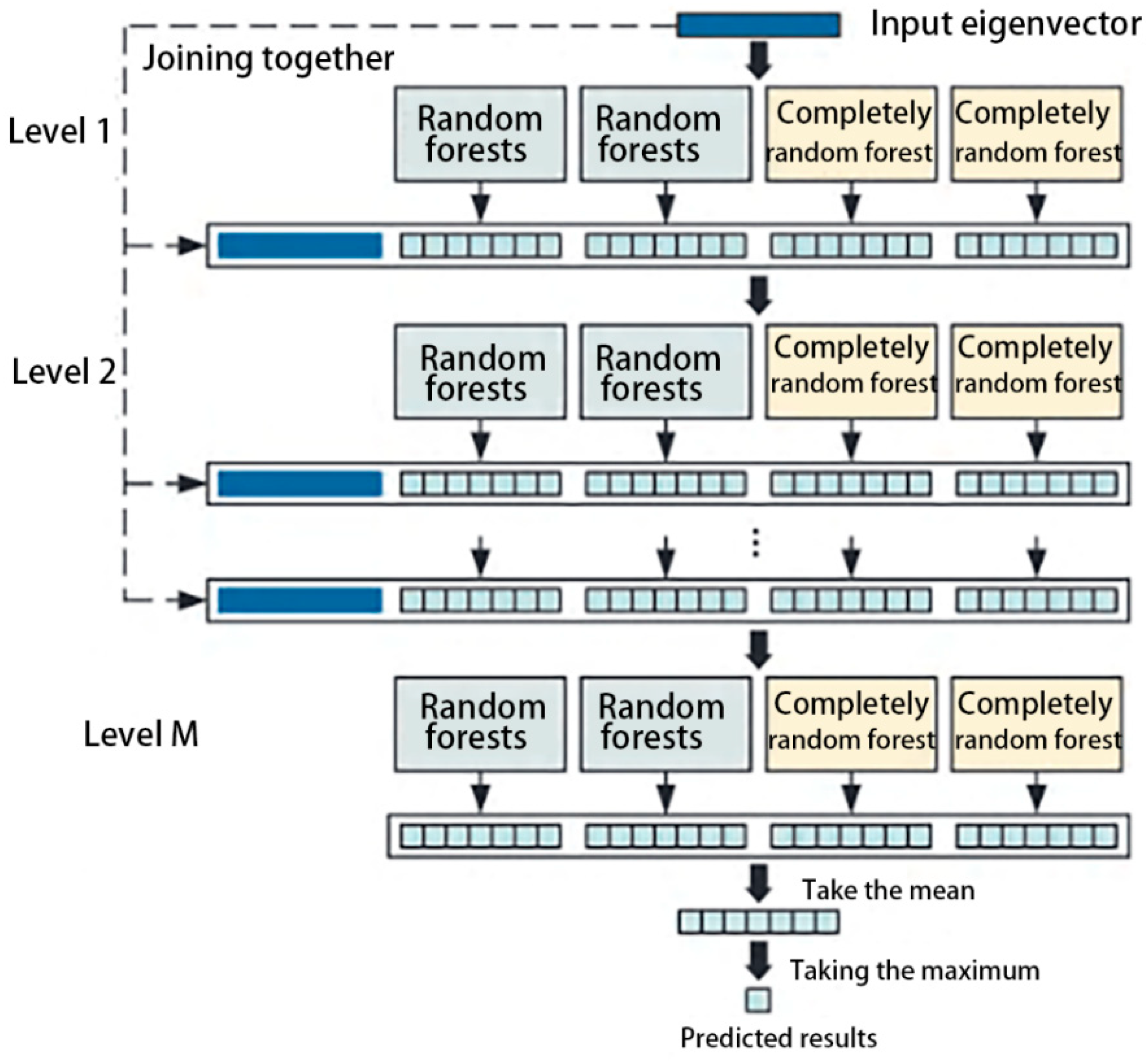
- (2)
- Multigrained cascade forest algorithm
- (3)
- Model calibration and implementation
- a.
- Model parameter calibration
- b.
- Algorithm implementation
3. Results
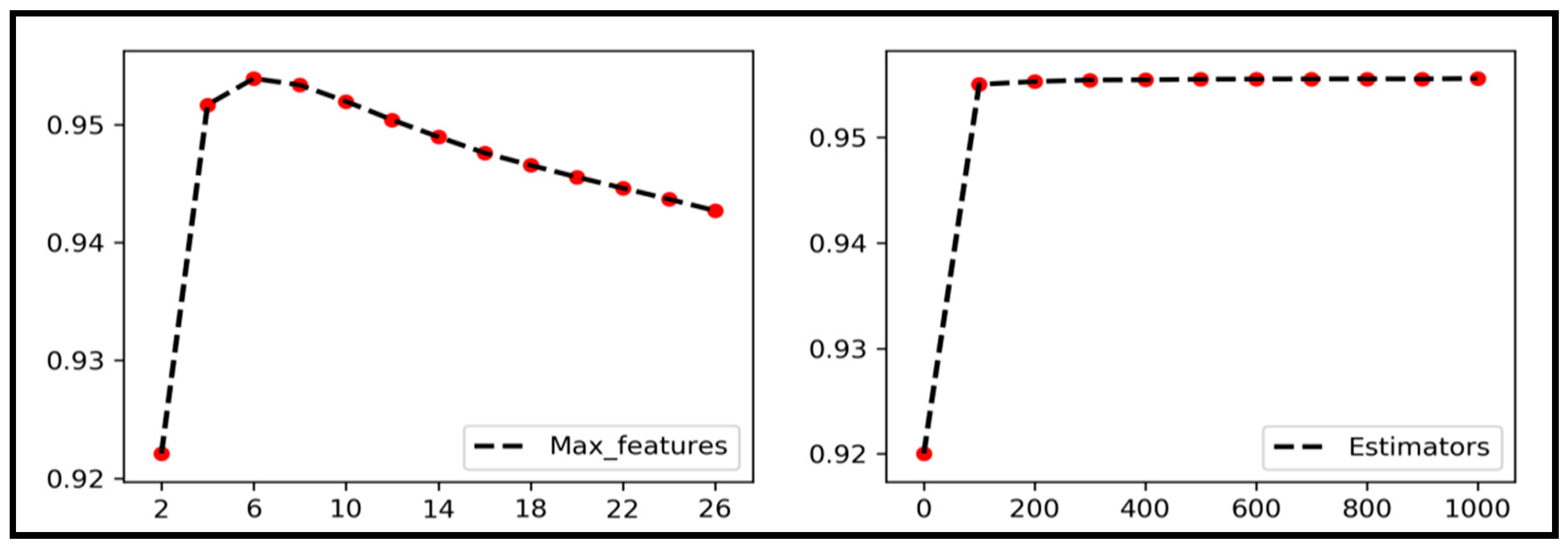
3.1. Parameter Optimization Results
- (1)
- Maximum number of features involved in judgement when dividing attributes (m)
- (2)
- Number of base learners and the number of decision trees they contain (k)
- (3)
- Number of cascade layers (n)
3.2. Model Performance Evaluation
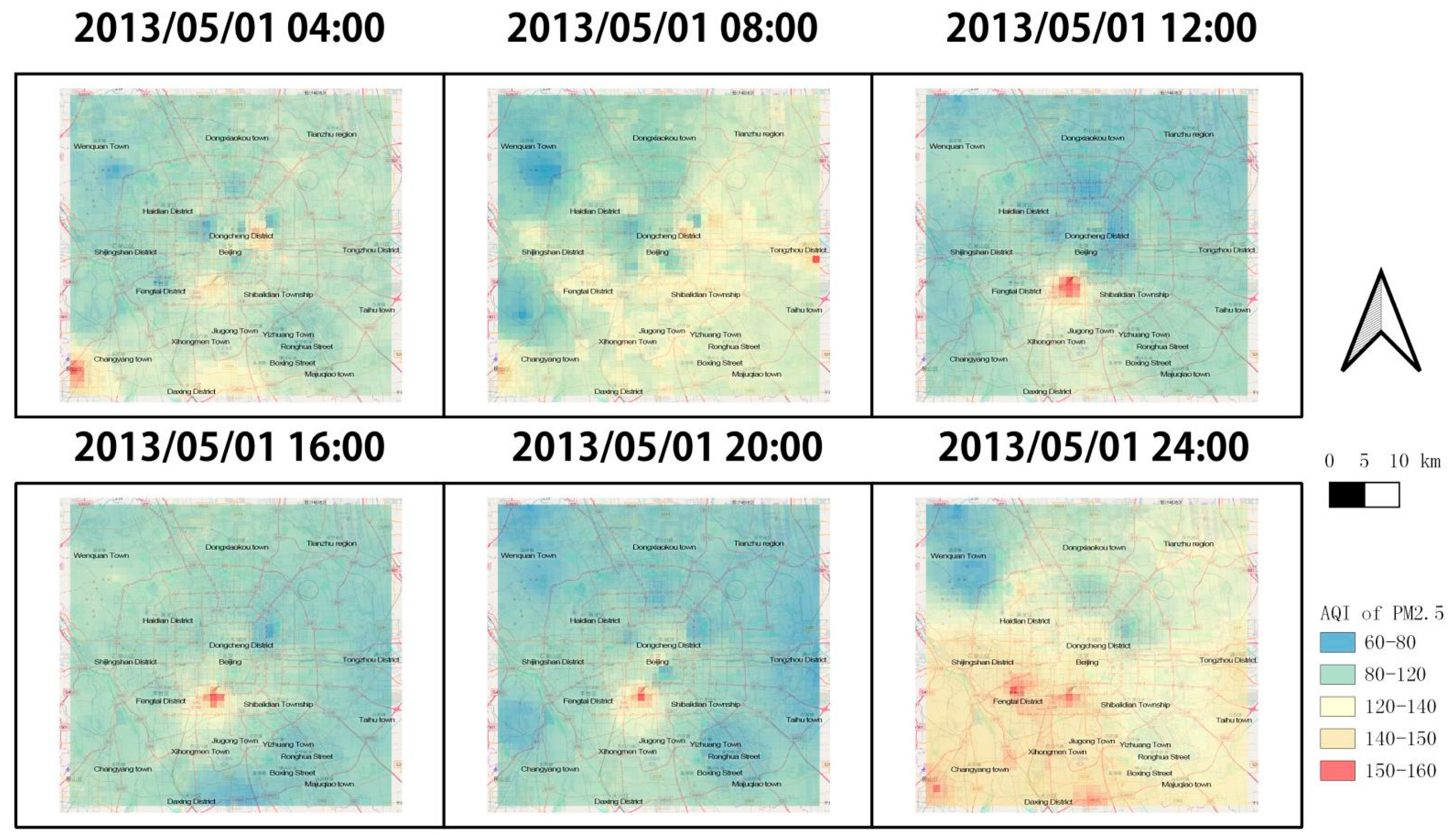
3.3. Real-Time Estimation of Effects
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Greenbaum, D.S.; Bachmann, D.; Krewski, D.; Samet, J.M.; White, R.; Wyzga, R.E. Particulate Air Pollution Standards and Morbidity and Mortality: Case Study. Am. Ournal Epidemiol. 2001, 154 (Suppl. S12), S78–S90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiménez-Guerrero, P.; Pérez, C.; Jorba, O.; Baldasano, J.M. Contribution of Saharan dust in an integrated air quality system and its on-line assessment. Geophys. Res. Lett. 2008, 35, 183–199. [Google Scholar] [CrossRef] [Green Version]
- Millman, A.; Tang, D.; Perera, F.P. Air pollution threatens the health of children in China. Pediatrics 2008, 122, 620–628. [Google Scholar] [CrossRef] [Green Version]
- Arnold, R.; Dennis, R.L. Testing CMAQ chemistry sensitivities in base case and emissions control runs at SEARCH and SOS99 surface sites in the southeastern US. Atmos. Environ. 2006, 40, 5027–5040. [Google Scholar] [CrossRef]
- Martin, R.V. Satellite Remote Sensing of Surface Air Quality. Atmos. Environ. 2008, 42, 7823–7843. [Google Scholar] [CrossRef]
- Wu, L.; Bocquet, M. Optimal redistribution of the background ozone monitoring stations over France. Atmos. Environ. 2011, 45, 772–783. [Google Scholar] [CrossRef] [Green Version]
- Austin, E.; Coull, B.A.; Zanobetti, A.; Koutrakis, P. A framework to spatially cluster air pollution monitoring sites in US based on the PM2.5 composition. Environ. Int. 2013, 59, 244–254. [Google Scholar] [CrossRef]
- Goodsite, M.E.; Hertel, O.; Johnson, M.S.; Jørgensen, N.R. Urban air quality: Sources and concentrations. Air Pollut. Sources Stat. Health Eff. 2021, 193–214. [Google Scholar] [CrossRef]
- Jorquera, H.; Montoya, L.D.; Rojas, N.Y. Urban air pollution. In Urban Climates in Latin America; Springer: Cham, Switzerland, 2019; pp. 137–165. [Google Scholar]
- Seo, J.; Park, D.-S.R.; Kim, J.Y.; Youn, D. Effects of meteorology and emissions on urban air quality: A quantitative statistical approach to long-term records (1999–2016) in Seoul, South Korea. Atmos. Chem. Phys. 2018, 18, 16121–16137. [Google Scholar] [CrossRef] [Green Version]
- Hsieh, H.P.; Lin, S.D.; Zheng, Y. Inferring Air Quality for Station Location Recommendation Based on Urban Big Data. In Proceedings of the 21th SIGKDD conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 437–446. [Google Scholar]
- Li, T.; Shen, H.; Zeng, C.; Yuan, Q.; Zhang, L. Point-surface fusion of station measurements and satellite observations for mapping PM2.5 distribution in China: Methods and assessment. Atmos. Environ. 2017, 152, 477–489. [Google Scholar] [CrossRef] [Green Version]
- Gurram, S.; Stuart, A.L.; Pinjari, A.R. Agent-based modeling to estimate exposures to urban air pollution from transportation: Exposure disparities and impacts of high-resolution data. Comput. Environ. Urban Syst. 2019, 75, 22–34. [Google Scholar] [CrossRef]
- Shad, R.; Mesgari, M.S.; Abkar, A.; Shad, A. Predicting air pollution using fuzzy genetic linear membership kriging in GIS. Comput. Environ. Urban Syst. 2009, 33, 472–481. [Google Scholar] [CrossRef]
- Zou, B.; Pu, Q.; Bilal, M.; Weng, Q.; Zhai, L.; Nichol, J.E. High-Resolution Satellite Mapping of Fine Particulates Based on Geographically Weighted Regression. In IEEE Geoscience & Remote Sensing Letters; IEEE: Piscataway, NJ, USA, 2016; Volume 13, pp. 495–499. [Google Scholar]
- You, W.; Zang, Z.; Zhang, L.; Li, Y.; Pan, X.; Wang, W. National-Scale Estimates of Ground-Level PM2.5 Concentration in China Using Geographically Weighted Regression Based on 3 km Resolution MODIS AOD. Remote Sens. 2016, 8, 184. [Google Scholar] [CrossRef] [Green Version]
- Feizizadeh, B.; Blaschke, T. Examining urban heat island relations to land use and air pollution: Multiple endmember spectral mixture analysis for thermal remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1749–1756. [Google Scholar] [CrossRef]
- Hu, X.; Waller, L.A.; Lyapustin, A.; Wang, Y.; Al-Hamdan, M.Z.; Crosson, W.L.; Estes, M.G., Jr.; Estes, S.M.; Quattrochi, D.A.; Puttaswamy, S.J.; et al. Estimating ground-level PM2.5 concentrations in the Southeastern United States using MAIAC AOD retrievals and a two-stage model. Remote Sens. Environ. 2014, 140, 220–232. [Google Scholar] [CrossRef]
- Lee, H.J.; Liu, Y.; Coull, B.A.; Schwartz, J.; Koutrakis, P. A novel calibration approach of MODIS AOD data to predict PM2.5 concentrations. Atmos. Chem. Phys. 2011, 11, 9769–9795. [Google Scholar] [CrossRef] [Green Version]
- Han, W.; Ling, T.; Chen, Y. A new algorithm for aerosol retrieval using H-1 CCD and MODIS NDVI data over urban areas. In Proceedings of the Geoscience & Remote Sensing Symposium, Beijing, China, 10–15 July 2016. [Google Scholar]
- Xiang, J.; Li, R.; Wang, G.; Qie, G.; Wang, Q.; Xu, L.; Zhang, M.; Tang, M. Modeling Urban PM2.5 Concentration by Combining Regression Models and Spectral Unmixing Analysis in a Region of East China. Water Air Soil Pollut. 2017, 228, 250. [Google Scholar] [CrossRef]
- Huang, B.; Wu, B.; Barry, M. Geographically and Temporally Weighted Regression for Modeling Spatio-Temporal Variation in House Prices; Taylor & Francis, Inc.: Oxfordshire, UK, 2010; Volume 24, pp. 383–401. [Google Scholar]
- Chu, H.J.; Huang, B.; Lin, C.Y. Modeling the spatio-temporal heterogeneity in the PM10-PM2.5 relationship. Atmos. Environ. 2015, 102, 176–182. [Google Scholar] [CrossRef]
- He, Q.; Bo, H. Satellite-based mapping of daily high-resolution ground PM2.5 in China via space-time regression modeling. Remote Sens. Environ. 2018, 206, 72–83. [Google Scholar] [CrossRef]
- Zou, B.; Chen, J.; Zhai, L.; Fang, X.; Zheng, Z. Satellite Based Mapping of Ground PM2.5 Concentration Using Generalized Additive Modeling. Remote Sens. 2016, 9, 1. [Google Scholar] [CrossRef] [Green Version]
- Zou, B.; Zheng, Z.; Wan, N.; Qiu, Y.; Wilson, J.G. An optimized spatial proximity model for fine particulate matter air pollution exposure assessment in areas of sparse monitoring. Int. Ournal Geogr. Inf. Sci. 2015, 30, 727–747. [Google Scholar] [CrossRef]
- Kovács, A.; Leelőssy, Á.; Tettamanti, T.; Esztergár-Kiss, D.; Mészáros, R.; Lagzi, I. Coupling traffic originated urban air pollution estimation with an atmospheric chemistry model. Urban Clim. 2021, 37, 100868. [Google Scholar] [CrossRef]
- Harrison, R.M.; Van Vu, T.; Jafar, H.; Shi, Z. More mileage in reducing urban air pollution from road traffic. Environ. Int. 2021, 149, 106329. [Google Scholar] [CrossRef] [PubMed]
- Borck, R.; Schrauth, P. Population density and urban air quality. Reg. Sci. Urban Econ. 2021, 86, 103596. [Google Scholar] [CrossRef]
- Ma, Y.; Li, J.; Guo, R. Application of data fusion based on deep belief network in air quality monitoring. Procedia Comput. Sci. 2021, 183, 254–260. [Google Scholar] [CrossRef]
- Yu, Z. Methodologies for Cross-Domain Data Fusion: An Overview. IEEE Trans. Big Data 2015, 1, 16–34. [Google Scholar]
- Liu, J.; Li, T.; Xie, P.; Du, S.; Teng, F.; Yang, X. Urban big data fusion based on deep learning: An overview. Inf. Fusion 2020, 53, 123–133. [Google Scholar] [CrossRef]
- Zheng, Y.; Yi, X.; Li, M.; Li, R.; Shan, Z.; Chang, E.; Li, T. Forecasting Fine-Grained Air Quality Based on Big Data: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015. [Google Scholar]
- Zheng, Y.; Chen, X.; Jin, Q.; Chen, Y.; Qu, X.; Liu, X.; Chang, E.; Ma, W.; Rui, Y.; Sun, W. A Cloud-Based Knowledge Discovery System for Monitoring Fine-Grained Air Quality. MSR-TR-2014-40. Tech. Rep.. 2014, Volume 1, p. 40. Available online: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/UAir20Demo.pdf (accessed on 3 April 2022).
- Zheng, Y.; Liu, F.; Hsieh, H.P. U-Air: When urban air quality inference meets big data: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. In Proceedings of the 19th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2013), Chicago, IL, USA, 11–14 August 2013. [Google Scholar]
- Masiol, M.; Harrison, R.M. Aircraft engine exhaust emissions and other airport-related contributions to ambient air pollution: A review. Atmos. Environ. 2014, 95, 409–455. [Google Scholar] [CrossRef] [Green Version]
- Burr, M.; Karani, G.; Davies, B.; Holmes, B.; Williams, K. Effects on respiratory health of a reduction in air pollution from vehicle exhaust emissions. Occup. Environ. Med. 2004, 61, 212. [Google Scholar] [CrossRef] [Green Version]
- Su, F.; Dong, H.; Jia, L.; Sun, X. On urban road traffic state evaluation index system and method. Mod. Phys. Lett. B 2017, 31, 1650428. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. VSURF: An R Package for Variable Selection Using Random Forests. R J. 2015, 7, 19–33. [Google Scholar] [CrossRef] [Green Version]
- Kuras, M.B. Robustness of Random Forest-based gene selection methods. BMC Bioinform. 2014, 15, 8. [Google Scholar] [CrossRef] [Green Version]
- Podgorelec, V.; Kokol, P.; Stiglic, B.; Rozman, I. Decision Trees: An Overview and Their Use in Medicine. J. Med. Syst. 2002, 26, 445–463. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.H.; Feng, J. Deep Forest: Towards an Alternative to Deep Neural Networks. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3553–3559. [Google Scholar]
- Fischer, M.M.; Wang, J. Spatial Data Analysis. Annu. Rev. Public Health 2013, 37, 47. [Google Scholar]
- Zeng, Q.; Chen, L.; Zhu, H.; Wang, Z.; Wang, X.; Zhang, L.; Gu, T.; Zhu, G.; Zhang, Y. Satellite-Based Estimation of Hourly PM2.5 Concentrations Using a Vertical-Humidity Correction Method from Himawari-AOD in Hebei. Sensors 2018, 18, 3456. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gressent, A.; Malherbe, L.; Colette, A.; Rollin, H.; Scimia, R. Data fusion for air quality mapping using low-cost sensor observations: Feasibility and added-value. Environ. Int. 2020, 143, 105965. [Google Scholar] [CrossRef] [PubMed]
- Hasenfratz, D.; Saukh, O.; Sturzenegger, S.; Thiele, L. Participatory Air Pollution Monitoring Using Smartphones. Mob. Sens. 2012, 1, 1–5. [Google Scholar]
- Zhang, Y.; Bocquet, M.; Mallet, V.; Seigneur, C.; Baklanov, A. Real-time air quality forecasting, part II: State of the science, current research needs, and future prospects. Atmos. Environ. 2012, 60, 656–676. [Google Scholar] [CrossRef]
- Tunno, B.; Shields, K.N.; Lioy, P.; Chu, N.; Kadane, J.B.; Parmanto, B.; Pramana, G.; Zora, J.; Davidson, C.; Holguin, F.; et al. Understanding intra-neighborhood patterns in PM2.5 and PM10 using mobile monitoring in Braddock, PA. Environ. Health A Glob. Access Sci. Source 2012, 11, 76. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Li, K.; Tian, L.; Piedrahita, R.; Yun, X.; Mansat, O.; Lv, Q.; Dick, R.P.; Hannigan, M.; Shang, L. MAQS: A personalized mobile sensing system for indoor air quality monitoring. In Proceedings of the 13th International Conference on Ubiquitous Computing (UBICOMP 2011), Beijing, China, 17–21 September 2011; pp. 271–280. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Description | Number of Features |
|---|---|---|
| Time Factor | Hours, seasons, days of the week | 3 |
| Previous AQI | AQI of PM2.5 in the last hour | 1 |
| Meteorological characteristics of the current moment | Temperature (°C), pressure (hPa), humidity (%), and wind speed (km/h) | 4 |
| Meteorological characteristics of the previous moment | Temperature (°C), pressure (hPa), humidity (%), and wind speed (km/h) | 4 |
| Traffic Congestion Factor | Current hour and previous hour spatial 3 × 3 neighbourhood congestion level | 2 × 9 |
| POI Category | Number of each POI category in the spatial 3 × 3 neighbourhood | 5 × 9 |
| Surface vegetation type | Number of each vegetation type in the spatial 3 × 3 neighbourhood | 6 × 9 |
| Features | Description | Number of Features |
|---|---|---|
| Time Factor | Hours, seasons, days of the week | 3 |
| Previous AQI | AQI of PM2.5 in the last hour | 1 |
| Current moment meteorological characteristics | Temperature (°C), pressure (hPa), humidity (%), and wind speed (km/h) | 4 |
| Meteorological characteristics of the previous moment | Temperature (°C), pressure (hPa), humidity (%), and wind speed (km/h) | 4 |
| Traffic Congestion Factor | Current hour and previous hour spatial 3 × 3 neighbourhood congestion averages | 2 |
| POI Category | Average of the number of POI categories in the current and previous hour spatial 3 × 3 neighbourhoods | 5 |
| Surface vegetation type | Mean values of the number of vegetation types in each spatial 3 × 3 neighbourhood at the current hour and the previous hour | 6 |
| Algorithm | R_CV2 | R2_Test | RMSE |
|---|---|---|---|
| ANN | 0.931 | 0.934 | 23.01 |
| RF | 0.993 | 0.955 | 18.96 |
| CF | 0.999 | 0.961 | 17.47 |
| Models | p | e |
|---|---|---|
| FFA | 0.749 | 23.7 |
| CF | 0.926 | 10.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Wang, J.; Wang, H.; Jin, T. Urban Air Quality Assessment by Fusing Spatial and Temporal Data from Multiple Study Sources Using Refined Estimation Methods. ISPRS Int. J. Geo-Inf. 2022, 11, 330. https://doi.org/10.3390/ijgi11060330
Chen L, Wang J, Wang H, Jin T. Urban Air Quality Assessment by Fusing Spatial and Temporal Data from Multiple Study Sources Using Refined Estimation Methods. ISPRS International Journal of Geo-Information. 2022; 11(6):330. https://doi.org/10.3390/ijgi11060330
Chicago/Turabian StyleChen, Lirong, Junyi Wang, Hui Wang, and Tiancheng Jin. 2022. "Urban Air Quality Assessment by Fusing Spatial and Temporal Data from Multiple Study Sources Using Refined Estimation Methods" ISPRS International Journal of Geo-Information 11, no. 6: 330. https://doi.org/10.3390/ijgi11060330
APA StyleChen, L., Wang, J., Wang, H., & Jin, T. (2022). Urban Air Quality Assessment by Fusing Spatial and Temporal Data from Multiple Study Sources Using Refined Estimation Methods. ISPRS International Journal of Geo-Information, 11(6), 330. https://doi.org/10.3390/ijgi11060330