1. Introduction
Wheat is one of the most important and widely distributed crops in the world, with the highest yield and sown area. About one-third of the world’s population feeds on it [
1]. It is mainly sown in the temperate zone of the northern hemisphere, which accounts for more than 90% of global wheat production [
2]. China, Russia, and the United States are the major wheat producers, accounting for about fifty percent of the global output [
3]. Under the pressures of climate change, urban expansion, and geopolitical conflicts, the sown area of winter wheat is changing at different spatial and temporal scales [
4,
5,
6]. The resulting food supply crisis and the sharp rise in international wheat prices pose a massive threat to the regional and global economy and food security. Aside from its socioeconomic function, as one of the largest agricultural ecosystems in the world, wheat plays an essential role in the water cycle, carbon budget, and soil biochemistry [
7,
8,
9]. The timely and accurate monitoring of wheat sowing information is important to global food security, the social economy, and the environment.
Remote sensing-based crop mapping has been studied for several decades over the world. These studies use various remote sensing images and classification approaches based on crop-specific signatures to map crops. Some studies directly use the spectral bands, vegetation index (VI) values, or a combination thereof during the crop phenological period as the primary inputs for rule-based classification such as decision trees [
10,
11,
12]. Shape features (e.g., curve slope, the second derivative, curve amplitude) and phenological metrics (e.g., start of the season, end of the season, season length, fastest growth, peak growth, fastest drying) extracted from the VI temporal patterns by Fourier transforms, curve-fitting functions, Whitkett filters, logistic/sigmoid functions, or a combination thereof are widely used for supervised and unsupervised classification methods [
13,
14,
15]. Texture is a kind of context information often used in crop classification. Commonly used algorithms for texture feature extraction include the gray level concurrence matrix (GLCM), Markov, the Kalman filter, the Gabor filter, wavelet transform, etc. These methods can be used to process optical and synthetic aperture radar (SAR) imagery either directly or through improvements [
16]. A common way to classify crops is by fusing the texture features of an SAR image with the spectral VI features of an optical image [
17]. Although the efficiency of texture features for different remote sensing data and different application scenarios is still quite uncertain, many studies have indicated that the addition of texture information indeed improves the classification accuracy to a certain extent [
18]. Image segmentation is another way to utilize context information and reduce the noise in crop classification. Some studies use object-based classification methods to extract a crop’s sown area based on segmented objects [
19]. Although the object-based approach can reduce the salt-and-pepper noise in the classification maps [
20], the classification accuracy is greatly affected by the segmentation accuracy. The segmentation error may lead to totally wrong classification results. To avoid this problem, some studies use superpixel segmentation to generate over-segmented objects, which can suppress noise and improve classification accuracy [
21].
Classification is the most applied method for crop mapping. The decision tree classifier relies on a lot of manual interpretation and analyses of the VI, spectral bands, or other temporal patterns of different land cover types, from which the detailed rules for the extraction of target crops are established [
22]. This process is often inseparable from professional knowledge and experience and requires a lot of human labor. When this set of rules is applied to the cross-time and cross-space tasks, the original rules may be invalid because of the skewing of feature curves resulting from the environmental changes such as precipitation, drought, farmland management, cloud-related noises, etc. Therefore, new rules must be established repeatedly. Random forests (RF), support vector machines (SVM), spectral angle mapping (SAM), and the maximum likelihood classifier (MLC) are the most commonly used supervised classifiers [
23,
24,
25]. Supervised classification often requires many training samples to train the classifier. The training samples are generally obtained by fieldwork and visual interpretation, bringing a big workload and limiting the spatio-temporal transferability of the supervised methods. At the same time, the collected samples in a given year cannot be used for another year’s classification. This is mainly due to changes in the planting structure and the surface landscape across years, so the training samples must be collected repeatedly, resulting in low cross-year repeatability and the high cost of human labor. K-means, the iterative self-organizing data analysis techniques algorithm (ISODATA), fuzzy C-means (FCM), and change vector analysis (CVA) are unsupervised classification methods that are commonly used [
26,
27,
28]. Although it is not necessary to train the classifier using many training samples for unsupervised methods, much post-classification work is unavoidable in order to obtain qualified results.
In both supervised and unsupervised classifications, the classification accuracy is greatly affected by the similarity measures. The similarity between two samples is often estimated by the distance measures and similarity measures [
29,
30]. The algorithm used to calculate the distance and similarity even determines whether the classification is correct or not. Euclidean distance (ED) is a commonly used definition that refers to the actual distance between two points in n-dimensional space or the natural length of a vector. It is widely used to measure the distance between two vectors to represent their similarity [
31]. ED is easily affected by the vector dimension and the correlation of characteristic parameters. Spectral angle cosine distance (SAD) [
32] evaluates the similarity of two vectors by calculating the cosine of their included angle, representing the relative difference in direction. SAD would consider the samples (1,10,100) and (10,100,1000) to be pretty similar, but obviously, the two samples are pretty different. Different measures have their own characteristics and advantages, and understanding these measures can help us deal with or optimize the problems encountered in these fields. The current crop classification research mainly focuses on feature engineering and classification algorithm, but there are few investigations and analyses on distance and similarity measures.
Over the past ten years, remote sensing images of various spectral, spatial, and temporal resolutions have been used to identify specific crops using the spectral bands, time-series VI values, phenological metrics, or a combination of several features. Optical satellite images are primarily used [
33,
34,
35], including the medium-resolution imagery (e.g., Terra MODIS, Aqua MODIS, NOAA/AVHRR, SPOT-VEGETATION), high-resolution images such as Landsat, ASTER NDVI, Sentinel-2 (S2), SPOT, and very high-resolution images (e.g., Gaofen-1 WFV, IKONOS, Worldview III). SAR imagery such as Sentinel-1 (S1), Radarsat-2, TerraSAR-X, and Gaofen-3 have also been used in crop classification and mapping studies [
36,
37], but far from the level that optical images have been used. Previous studies [
38,
39,
40,
41,
42] show that the supervised classifiers and rule-based decision trees at the pixel-level are the primarily used methods for mapping winter wheat mainly based on optical remote sensing images and training samples by fieldwork and visual interpretation.
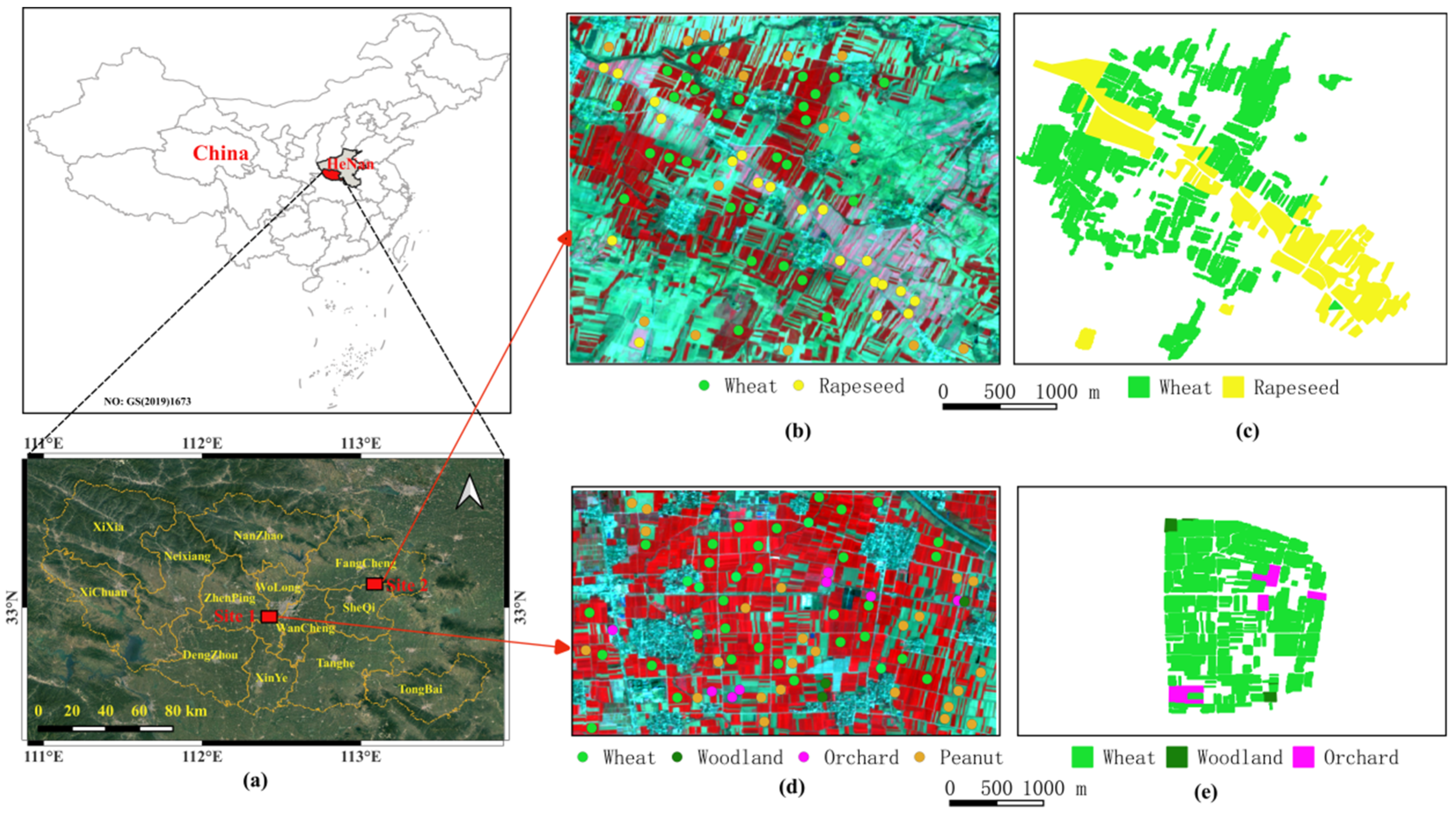
In this study, two study sites were selected in Nanyang city in Henan Province because Henan Province is China’s largest wheat producer, accounting for about a quarter of the country’s wheat production. Automatic winter wheat mapping using satellite remote sensing data remains a challenge in Henan due to the heterogeneous and fragmentary agricultural landscape, a high probability of cloudy weather over a year, and the similar phenology patterns of winter wheat to those of other vegetation classes and other crops. In response to these problems, we developed an automatic object-based approach to map winter wheat in the study areas.
3. Methodology
We developed an automatic object-based approach to map winter wheat in the study areas (
Figure 2). First, image segmentation was conducted based on the fusion of optical and SAR imagery to obtain the homogeneous spatial objects. Then, an automatic classification approach was introduced into winter wheat mapping. The proposed similarity measures were evaluated by comparing them with the commonly used measures. Finally, the effectiveness of optical images, SAR images, as well as SAR–optical image fusion in winter wheat classification was systematically studied and analyzed.
3.1. Remote Sensing Images and Preprocessing
The COPERNICUS/S2_SR collection available on Google Earth Engine (GEE) is used in this study. Each scene contains 12 spectral bands representing surface reflectance (SR) scaled by 10,000 with a spatial resolution of 10 m, 20 m or 60 m. In addition, three QA bands are present, with one (QA60) being a bitmask band with cloud mask information. The S2 images needed for this study were preprocessed using the following steps (
Figure 3): (1) Image selection. The COPERNICUS/S2_SR collection was screened by setting the study time interval (i.e., 1 October 2019 to 1 July 2020) and the study areas, and ten spectral bands were selected for use (
Table 2); (2) Pansharpening. The bands with spatial resolutions of 20 m and 60 m were processed by pansharpening to obtain a consistent spatial resolution of 10 m (
Figure 4); (3) Cloud removal. The COPERNICUS/S2_CLOUD_PROBABILITY data collection was used to remove clouds from each scene. We found that it is not consistently efficient to use the QA60 band to remove clouds, similar to how most studies were carried out. The use of COPERNICUS/S2_CLOUD_PROBABILITY data allowed us to obtain images with a much better quality; (4) Temporal linear interpolation. This was performed by using two adjacent image values before and after the data holes. Through interpolation, data holes at specific phenological dates caused by cloud removal were filled to obtain continuous image profiles; (5) VI calculation. Five spectral vegetation indexes (i.e., NDVI, mNDWI, LSWI, EVI, and BSI) were calculated and added to the S2 spectral bands. The calculation formulas of VIs from S2 imagery are shown in
Table 3; (6) Temporal medium value filter. A 15-day equal-interval image dataset (namely, S2_15DAY) of ten spectral bands and five VIs was obtained by medium value filtering in the time dimension, which was ready to be used (
Table 2).
The Sentinel-1 mission provides data from a dual-polarization C-band SAR instrument at 5.405GHz. The COPERNICUS/S1_GRD collection available on GEE was used in this study. Each scene contains two polarization bands, VV+VH (VV: single co-polarization, vertical transmit/vertical receive; VH: dual-band cross-polarization, vertical transmit/horizontal receive), and also includes an additional angle band that contains the approximate incidence angle from ellipsoid in degrees at every point. Each scene was preprocessed with the Sentinel-1 toolbox using the following steps to derive the backscatter coefficient in each pixel: orbit file application, border noise removal, thermal noise removal, radiometric calibration, and terrain correction using SRTM 30 DEM and ASTER DEM. The final terrain-corrected values are resampled to a resolution of 10 m and converted to decibels via log scaling (10*log10(x)). The COPERNICUS/S1_GRD collection was selected according to the time range (1 October 2019 to 1 July 2020) and the study areas, and VV, VH, and VH/VV polarization bands were chosen to be used. A multitemporal GAMMA filtering with a kernel of 5 × 5 was applied to remove speckle noise for each scene [
43]. A 15-day equal-interval dataset of three polarization bands was obtained by the mean value filter in the time dimension. The VH/VV band was derived by the ratio of VH and VV polarization bands. Then, the GLCM algorithm was applied to the dataset and derived seven texture parameters for each image pixel. As a result, a 15-day dataset (namely, S1_15DAY) consisting of three polarization bands (i.e., VV, VH, VH/VV) and seven texture bands (
Table 2) was ready to be used.
3.2. SNIC Segmentation with a Fusion of S1 and S2 Imagery
The purpose of superpixel segmentation was to obtain spatial objects with high homogeneity that remain stable throughout the whole phenological period of winter wheat. The derived spatial objects were used for generating the object-level TPP for each land cover and for the object-based winter wheat classification. We used a fusion of optical and SAR imagery for SNIC segmentation. Two median composite images (i.e., S2_202003, S1_202003) respectively derived from all S2 images and S1 images sensed in March 2020 were fused (i.e., S1S2_202003) to implement the segmentation for several reasons: (1) The magnitude of winter wheat temporal pattern in March is significantly higher than that of any other land covers. During this period, wheat is most distinguishable from other land cover types; (2) The greenness of other vegetation types in March is lower than in April, so the vegetation disturbance to winter wheat extraction is minor. At the same time, the vegetation signals of the vegetation-related mixed pixels in remote sensing images are weak, so they have less interference in land cover classification; (3) The medium value filter can significantly reduce image noise to improve the accuracy of the segmentation results especially for SAR images. The example images of the S1 sensor in both sites are displayed in
Figure 5 to demonstrate the effects of the temporal median filtering for reducing the speckle noise in SAR imagery.
For the purpose of segmentation, ten spectral and polarization bands of the fused image S1S2_202003 were used for segmentation, including B2, B3, B4, B5, B8, B11, B12, VV, VH, and VH/VV (
Table 4). Band names of the S2 imagery bands used in image segmentation are reported in
Table 2. The segmentation with several other inputs was taken into consideration for the purpose of comparison. Furthermore, to evaluate the effect of texture information on SAR image segmentation, we extracted seven texture parameters with the GLCM algorithm and obtained the image S1_202003_GLCM, and compared its segmentation result with that of other inputs.
GEE provides three segmentation algorithms, namely G-means, K-means, and SNIC. SNIC is a kind of superpixel clustering algorithm that outputs a band of cluster IDs and the per-cluster averages for each of the input bands [
44], which is represented by “ee.Algorithms.Image.Segmentation.SNIC (image, size, compactness, connectivity, neighborhoodSize, seeds)” on GEE. SNIC has been proven effective and efficient in several studies [
45]. We applied the SNIC algorithm using the configuration as ee.Algorithms.Image.Segmentation.SNIC (S1S2_202003, 20, 2, 8, 256, seedGrid (20, ‘hex’)). The information on the inputs for the SNIC algorithm is listed in
Table 4. Finally, a raster image was exported, representing the mean values of each input band for each spatial object.
The boundary vector of the spatial objects will be used to process S1_15DAY and S2_15DAY datasets to obtain object-level datasets (namely S1_15DAY_object and S2_15DAY_object). The resulting datasets (i.e., S1_15DAY_object and S2_15DAY_object) represent the mean values of each object for each temporal image, which will be used for the following object-based analysis.
3.3. Generation of Object-Based Temporal Phenology Patterns
The TPP of each land cover type at a 15-day interval during the winter wheat phenology period (1 October 2019 to 1 July 2020) was established based on the ground samples, and the S1_15DAY_object and S2_15DAY_object images were established by the temporal median filtering (
Figure 6). The S1_15DAY_object and S2_15DAY_object are object-level images generated by the SNIC segmentation. The neighborhood information introduced by the segmented objects reduces the influence of noise on pixels and improves the representativity of TPP for each land cover type. The two winter wheat curves (i.e., WW
1 and WW
2) in
Figure 6 are respectively derived from the two study sites in this study. Two curves of winter wheat have similar overall trends but some small differences. These differences are likely caused by the combined effects of the geographical location, agricultural management, and remote sensing imaging mechanism. The differences in TPPs between winter wheat and other land cover types provide the fundamental basis for winter wheat extraction and mapping.
Figure 6 shows that the NDVI temporal pattern of wheat is significantly different from that of other land cover types at each phenological stage. During the sowing period (October to November), the NDVI value of wheat is the lowest and lower than that of most other land types (NDVI< 0.25); then, it increases rapidly (December–January) and enters a fast-growing period (February–April). The NDVI value is significantly higher than all other land types in the fast-growing period. In early May, wheat begins maturing, and the NDVI value decreases rapidly (May-June) to the minimum value after harvesting, lower than all other land types. During the whole growth period, the NDVI temporal pattern of winter wheat has a significant difference in both shape and magnitude from other land cover types, which indicates that the NDVI trajectory could be practical for distinguishing winter wheat from other land cover types.
Unsown farmland is the second primary agricultural land use type besides wheat and is set aside for sowing peanuts. Since the sowing time of peanuts is in late April, unsown peanut land shows the characteristics of bare land for most of the time during the phenological period of winter wheat and it shows the features of peanut crops only after the wheat harvest. Therefore, in the whole wheat phenology period, the NDVI patterns of unsown peanut land and built-up land are pretty similar, and they are both significantly different from the wheat’s NDVI pattern. Vegetation types during the phenological period of wheat include evergreen woodland, deciduous woodland, orchard, and flowers. In the whole wheat phenological period, NDVI patterns of various vegetation types are pretty similar in shape and remain relatively stable. However, the NDVI values are much lower than that of winter wheat during February–April, and remain at a high value after wheat harvesting, which makes them significantly different from winter wheat. Water-related land cover types in farming areas are very complex. In addition to the general waterbodies, there are also paddy fields, fishponds, and lotus ponds. They are generally small in area and can easily form mixed pixels in the remote sensing image with surrounding objects. Additionally, vegetation growth and eutrophication cause the variation of waters NDVI pattern during the wheat phenological period. However, in general, water-related land cover types mainly display water characteristics, and the NDVI value is much lower than crops, which can be easily distinguished from the wheat.
In general, VH, VV, and VH/VV bands display different temporal patterns (
Figure 6). The reason for this lies in the complex imaging mechanism of SAR sensors, as well as the complex scattering mechanism of various land features that changes with time. The VV temporal phenology pattern of winter wheat has significant differences to all the other land cover types in in terms of curve shape over the whole period and curve magnitude at several phenological stages (i.e., March–May), and these differences could be very helpful for distinguishing winter wheat from all the other land covers. In contrast, although the VH pattern of winter wheat is distinguishable from various vegetation types (e.g., evergreen and deciduous woodland) over the whole period, it is very similar to water-related objects and unsown peanut farming lands, which will probably lead to the failure to distinguish winter wheat from these two kinds of land cover types. The VH/VV temporal phenology pattern of winter wheat displays significant overall differences from most of the other land covers but displays quite a similar curve shape with that of the winter rapeseed, indicating its’ disadvantage for distinguishing winter wheat from winter rapeseed.
3.4. Improved Similarity Measures
The TPPs of various land cover types tell us that different land features often have a similar shape or magnitude of TPP, which change with the bands and features. Similarly, due to the difference in climate, farming styles, weather conditions, and feature selection, the same land cover often has a different shape or magnitude of TPP, which probably leads to the errors in classification results. According to the analysis in
Section 3.3, we believe that the accuracy of winter wheat extraction can be improved by using a combination of the shape similarity and the distance difference between TPPs over the phenological period. ED and SAD are two commonly used measures to evaluate the similarity of two feature vectors in the classification. Given two spectral feature vectors
and
, the ED is calculated by:
The cosine similarity
between the two vectors can be calculated by:
where
is the angle between two feature vectors. Then, SAD can be calculated by:
The size of ED is affected by the vector dimension, the range is not fixed, and the meaning is vague. ED reflects the absolute difference in distance between two vectors but ignores their shape similarity. In contrast, always remains ‘1’ when two vectors are in the same direction, ‘0’ when they are orthogonal, and ‘−1’ when they are opposite, regardless of the dimension and magnitude of the vectors. That is, SAD reflects the relative difference in vector directions, which focuses on the shape similarity but ignores their difference in absolute distance.
To avoid the disadvantages of a single measure, we built a composite distance measure ESD by fusing ED and SAD using the formula:
where ED represents the Euclidean distance of two temporal patterns, and SAD reflects the shape difference between two temporal patterns.
Moreover, we introduce a new similarity measure DSF by fusing a difference factor (
) and a similarity factor (
),
where
represents the relative deviation of two vectors to evaluate the distance difference and
is a factor used to assess the shape similarity of two vectors [
46]. The DSF measure considers both the shape and distance metrics of vectors and is expected to improve the classification accuracy.
3.5. Object-Based Winter Wheat Mapping
The purpose of this step is to automatically identify winter wheat objects from the segmented spatial objects using the OTSU algorithm based on TPPs derived from S2_15DAY_object and S1_15DAY_object images. In the OTSU algorithm, the DSF was taken as the similarity measure between TPPs, and the distance measure ED, the shape measure SAD as well as the composite measure ESD were taken into the comparison. The OTSU algorithm was used to find the optimal decision-making threshold automatically. Specifically, first, the TPP of winter wheat obtained in
Section 3.3 was used as the reference pattern. Then, the DSF measure between the reference pattern and the TPP of each segmentation object was calculated. Finally, the OTSU algorithm was applied to automatically find an optimal threshold to distinguish winter wheat objects from the others.
5. Discussion
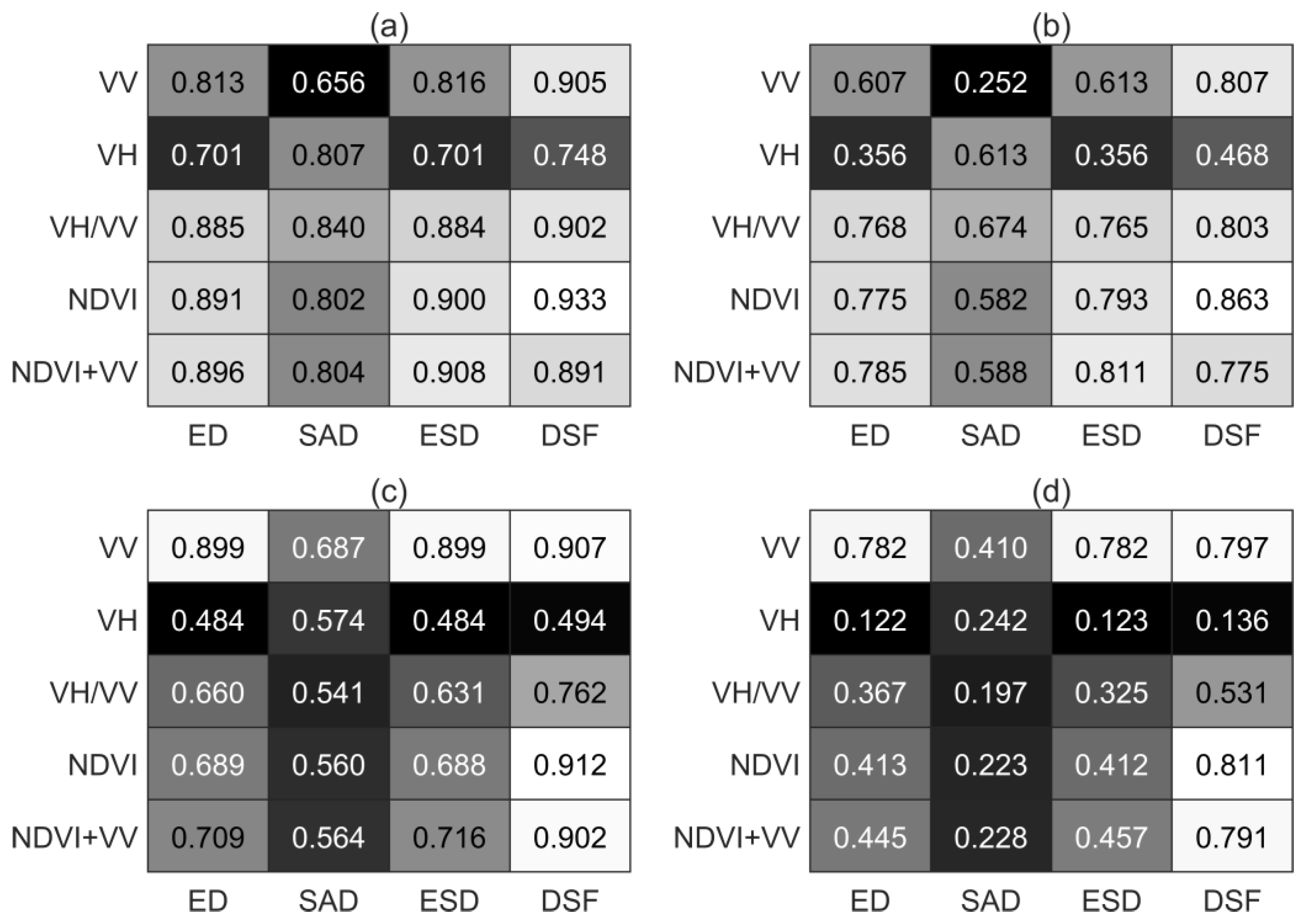
A new similarity measure (DSF) is introduced and achieves the best classification accuracy in all feature bands (e.g., NDVI, VV, VH/VV, NDVI + VV) and in both study sites. The new measure considers both distance difference and shape similarity, which can better describe the detailed differences between TPPs of land covers, thus obtaining better classification results. Generally speaking, different land covers often have different TPPs while the same land covers have the same TPPs. However, due to complicated biological and abiotic factors, the TPPs of specific ground objects often have unpredictable nonlinear distortion, resulting in the phenomena characterized by the ‘same object with a different spectrum’ and a ‘different object with the same spectrum’, which makes feature extraction and image interpretation difficult. Broad metrics may lead to a false alarm of target objects and thus result in overestimates, while strict metrics may lead to omissions of target objects, thus resulting in underestimates. Existing similarity measures have their advantages, and some focus on the distance difference while some focus on the shape similarity. Using a single measure to evaluate the correlation of two TPPs often results in great uncertainty in classification results. In particular, in large-scale areas, the differences in climate, soil, and topography lead to great variability in the TPPs of surface objects. Using a single distance or shape measure will inevitably lead to great deviation between the predicted results and the actual surface features.
Although some composite measures have been expected to solve the above problems, few of them are widely accepted and used. The reason for this is that these measures are only a simple addition or multiplication between existing single measures, lacking scientific explanation and sufficient practical proof. These measures may achieve good results in small specific test areas, but the generalization performance in time and space often cannot stand the test. In addition, the generalization ability of these similarity measures to different sensors, features, and bands is also a great challenge to their performance. Their performance varies with the input bands and features. When the TPPs of the same land cover type extracted from different sensors or different bands have considerable nonlinear variations, a qualified similarity measurement should be able to identify it and assign a consistent attribute label for it. If this is not practical, finding an optimal and robust similarity measure for each commonly used feature or band (e.g., NDVI, EVI, VV, VH) may be a good alternative. This issue will be further studied in our future work.
The SNIC segmentation adopted in this study is a kind of superpixel clustering segmentation algorithm, which has a simple principle and high time efficiency. The algorithm generally divides a large surface feature into several spatial objects with high homogeneity. It avoids including different surrounding parts across the boundary to ensure the consistent category attribute for each object and significantly reduces the segmentation error. In this study, the SNIC segmentation with the fusion of the S2 optical image and the S1 SAR image achieves satisfactory segmentation results, which provided highly homogenous spatial objects and perfect details. Most of the adjacent crops of different species in small areas or thin strip plots are well separated, indicating that the combined use of optical and SAR imagery has improved the separability of land covers. Although the SNIC algorithm does not need to input the optimal segmentation scale, it needs to determine the density of seed points, that is, the sampling interval of seed points. In this study, we use three sampling intervals (i.e., 10, 20, and 30 pixels) to generate seed points and implement the experiments under the three conditions. Finally, we find that the optimal sampling interval of seed points is 20 pixels. In this case, the segmentation algorithm not only derives the spatial objects with high homogeneity and consistent boundaries with actual ground features but also provides fine ground details. The object-based approach may not show significant advantages over pixel-level classification in small study areas, but it can provide an excellent solution to the problems caused by highly heterogeneous surfaces, mixed pixels, and image noise to significantly improve the accuracy and consistency of large scale classification.
This study found that different spectral or VI bands displayed different performances for land cover classification. These findings demonstrate that the ability of remote sensing to distinguish land cover types varies with bands. NDVI has more potent universality and shows excellent capability for distinguishing various land cover types. The NDVI band achieves the best overall classification accuracy, although it is very close to that of the NDVI + VV band. Surprisingly, the VV polarization of SAR imagery has produced impressive results over various land cover types that are very close to those of the NDVI band. The better performance of VV polarization in comparison with VH is because wheat plants have dominant vertical structure so that the VV-polarized backscattered energy is stronger than that from the VH-polarized signals [
47]. As the growing season continues, the vertical structure of wheat plants changes greatly, and wheat shows a unique temporal phenology curve that is different from other land covers, which is beneficial to winter wheat identification [
48]. In addition, VV polarization achieves such good winter wheat maps partly because of the speckle noise reduction by image segmentation. Based on segmented spatial objects, VV polarization displays outstanding capability in distinguishing winter wheat from other easily confused crops. This is very important for crop mapping with multitemporal remote sensing. Because of the cloudy weather, optical imagery may be unavailable during the crop growth period, which harms the temporal-phenology-based classification. In this case, SAR imagery is expected to provide trusted alternatives. Due to the complexity of the land surface composition and the mechanism for remote sensing imaging, a single band or feature is prone to failure when trying to solve all problems in most cases. Although the commonly used bands or features can be used as alternatives, they can only possibly produce the second-best classification results. Exploring the dominant bands or features for specific land cover types and using them for image interpretation would potentially improve the land cover and land use classifications in nature.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














